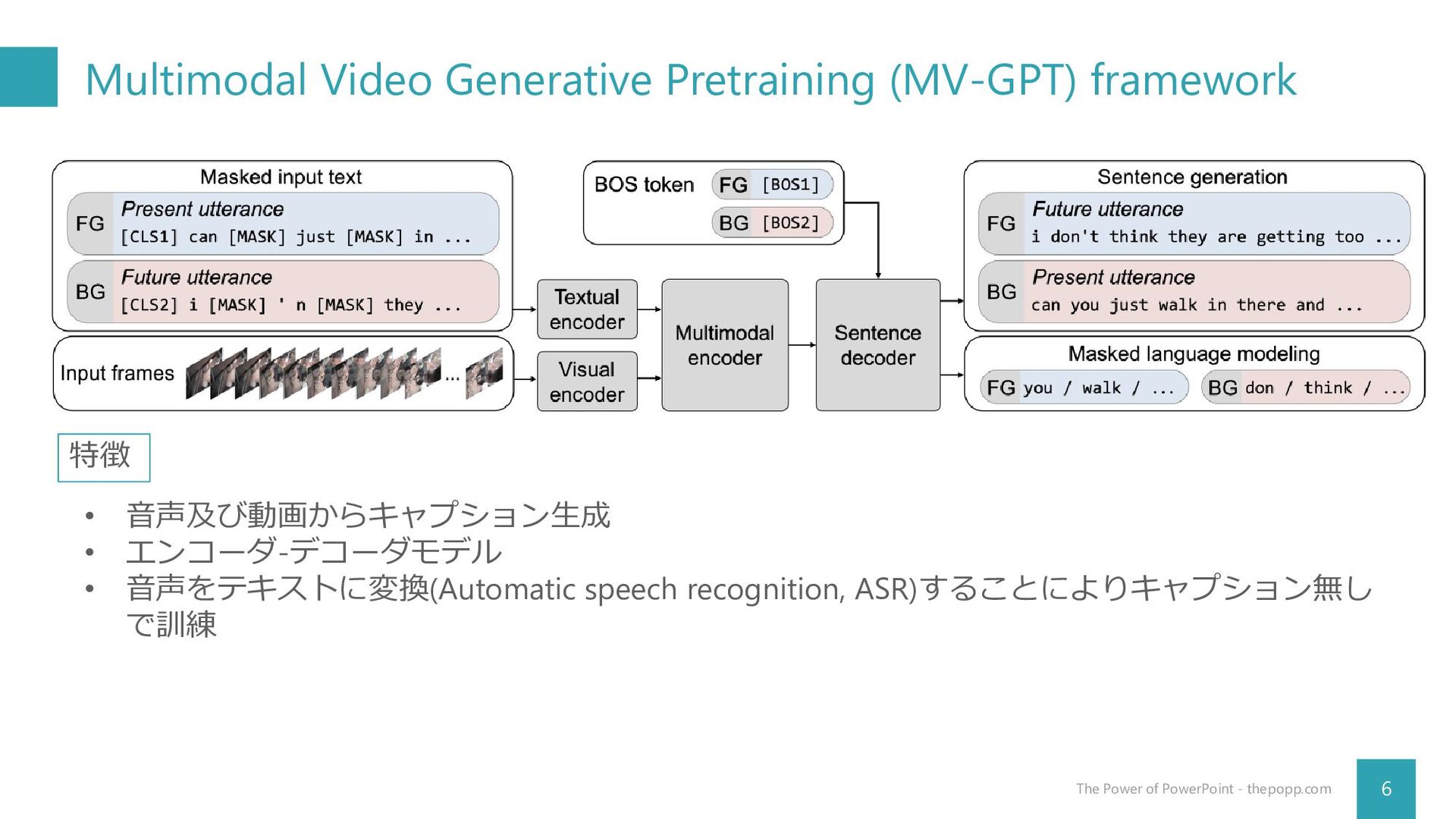
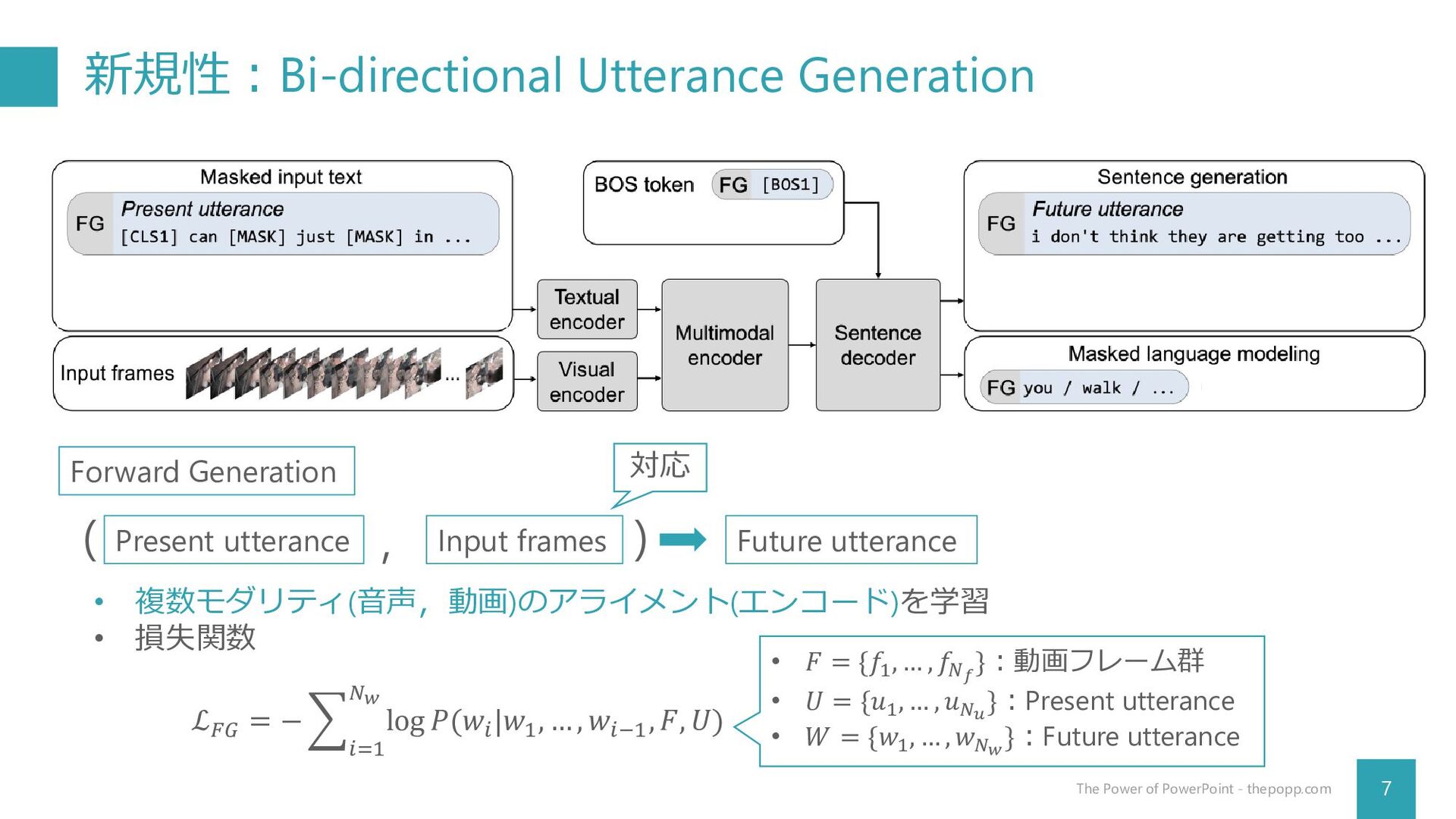
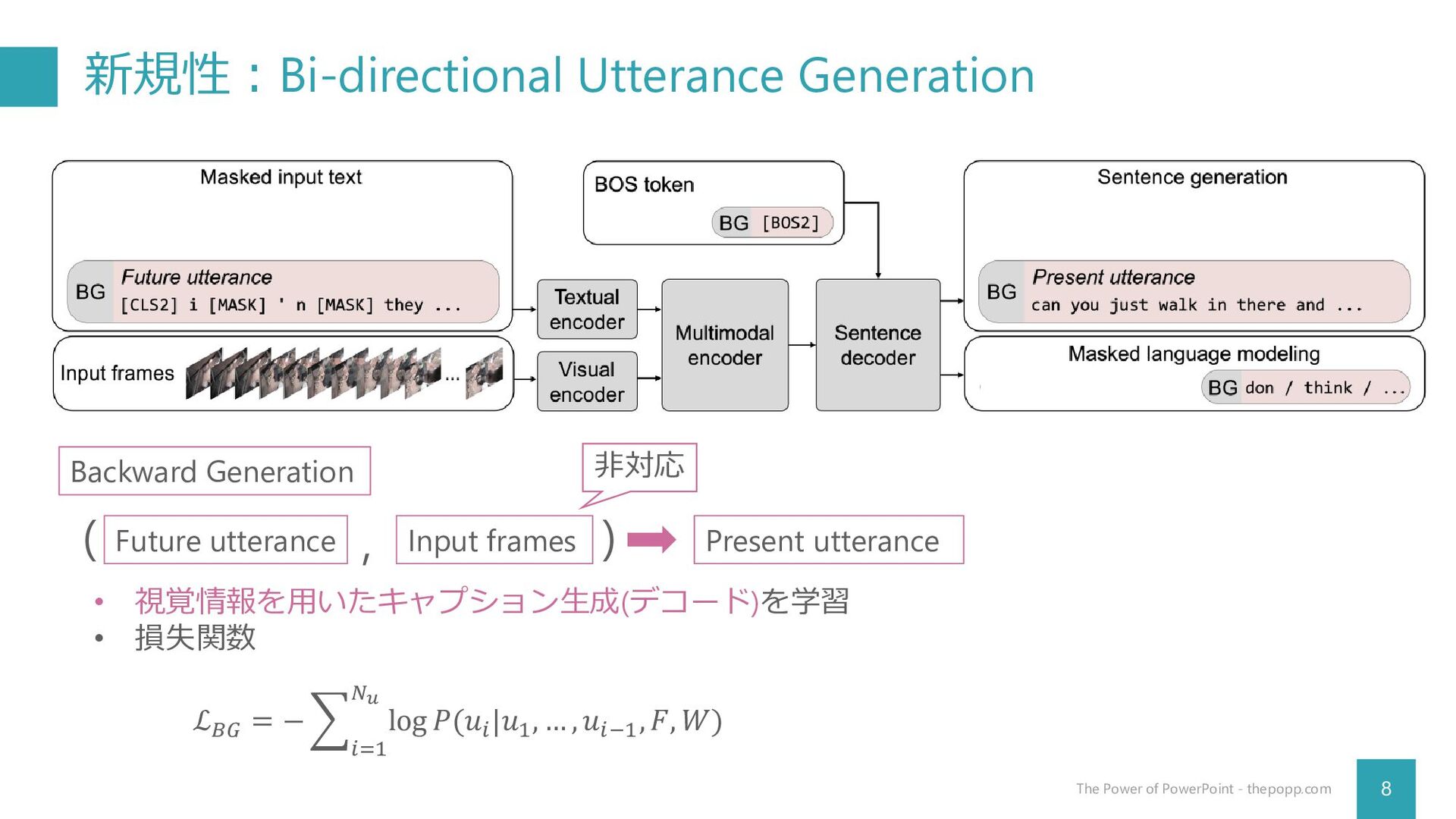
Arsha Nagrani, Anurag Arnab, Cordelia Schmid Google Research CVPR 2022 杉浦孔明研究室 神原元就 Seo, P. H., Nagrani, A., Arnab, A., & Schmid, C. (2022). End-to-end generative pretraining for multimodal video captioning. In CVPR (pp. 17959-17968).
tomatoes in a pan and the put them on a plate” “Add oil to a pan and spread it well so as to fry the bacon” “Cook bacon until crispy, then drain on paper towel” YouCook2データセット [Zho+, AAAI18] 動画へのキャプション付与 • 高コスト • 主観的 ラベル(キャプション)なし動画を用いた クロスモーダルキャプション生成 Vision & Language分野における課題
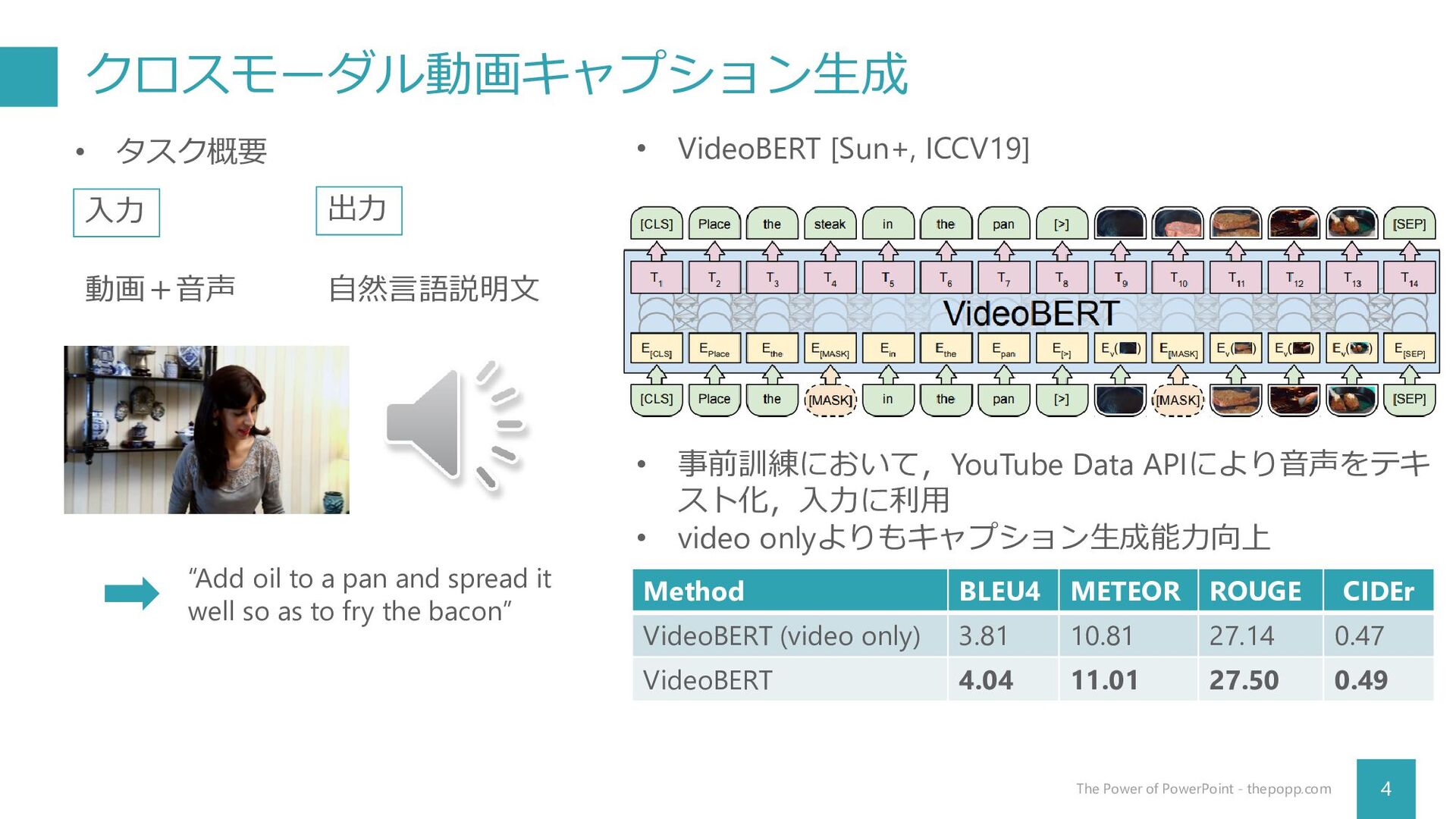
出力 自然言語説明文 • タスク概要 “Add oil to a pan and spread it well so as to fry the bacon” • VideoBERT [Sun+, ICCV19] • 事前訓練において,YouTube Data APIにより音声をテキ スト化,入力に利用 • video onlyよりもキャプション生成能力向上 Method BLEU4 METEOR ROUGE CIDEr VideoBERT (video only) 3.81 10.81 27.14 0.47 VideoBERT 4.04 11.01 27.50 0.49
by considering the whole host of nature and nurture influences, we can take a broader view of mental health … Ground truth A man in a brown blazer discussing mental health MV-GPT w/o pretrain A man in a blue shirt is talking MV-GPT A man in a suit is talking about mental health YouCook2における定性的結果 Ground truth Spread mustard on the bread MV-GPT w/o pretrain Flip the sandwiches MV-GPT Spread the sauce on the bread
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
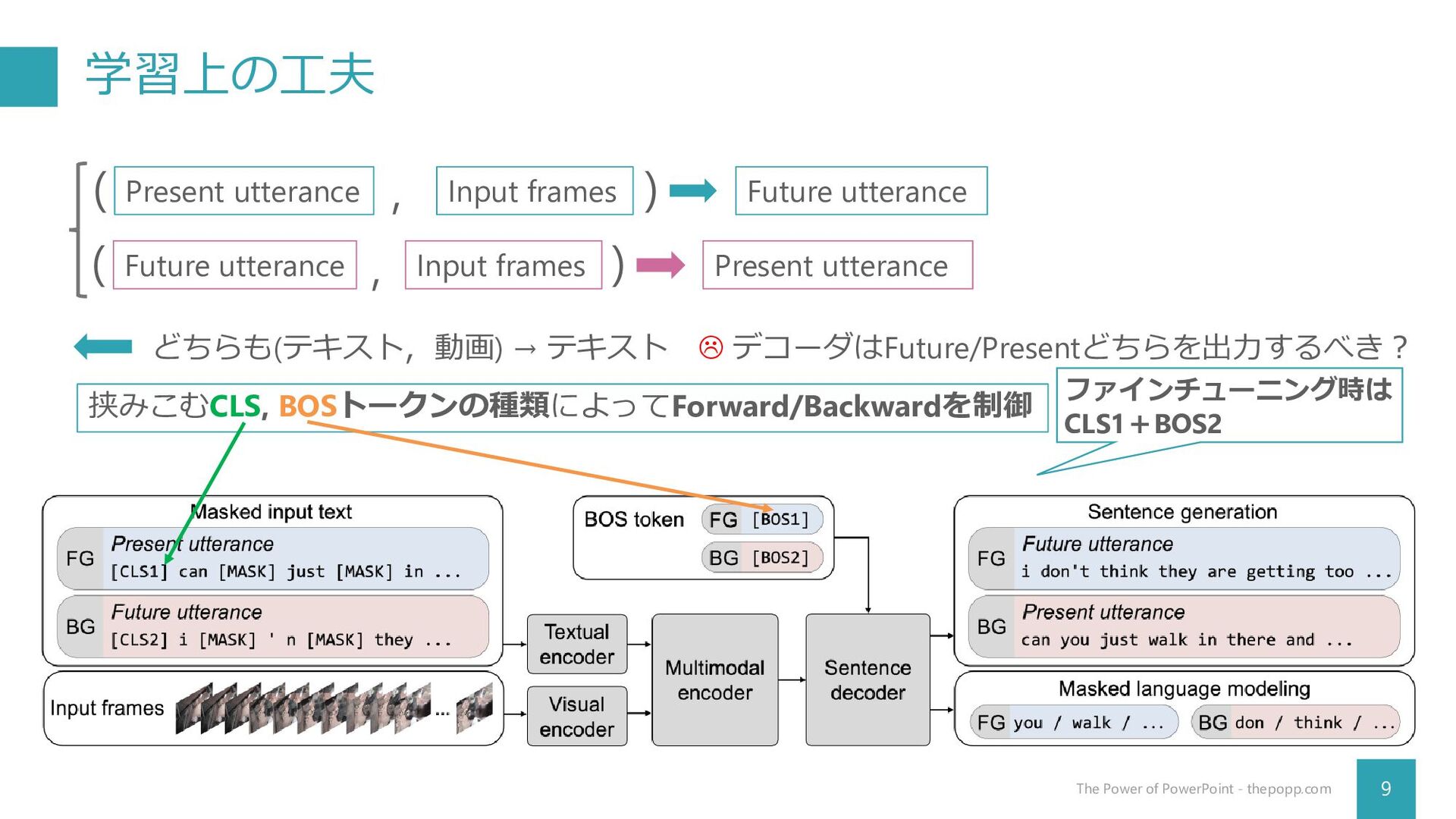{kind=link}
{kind=link}
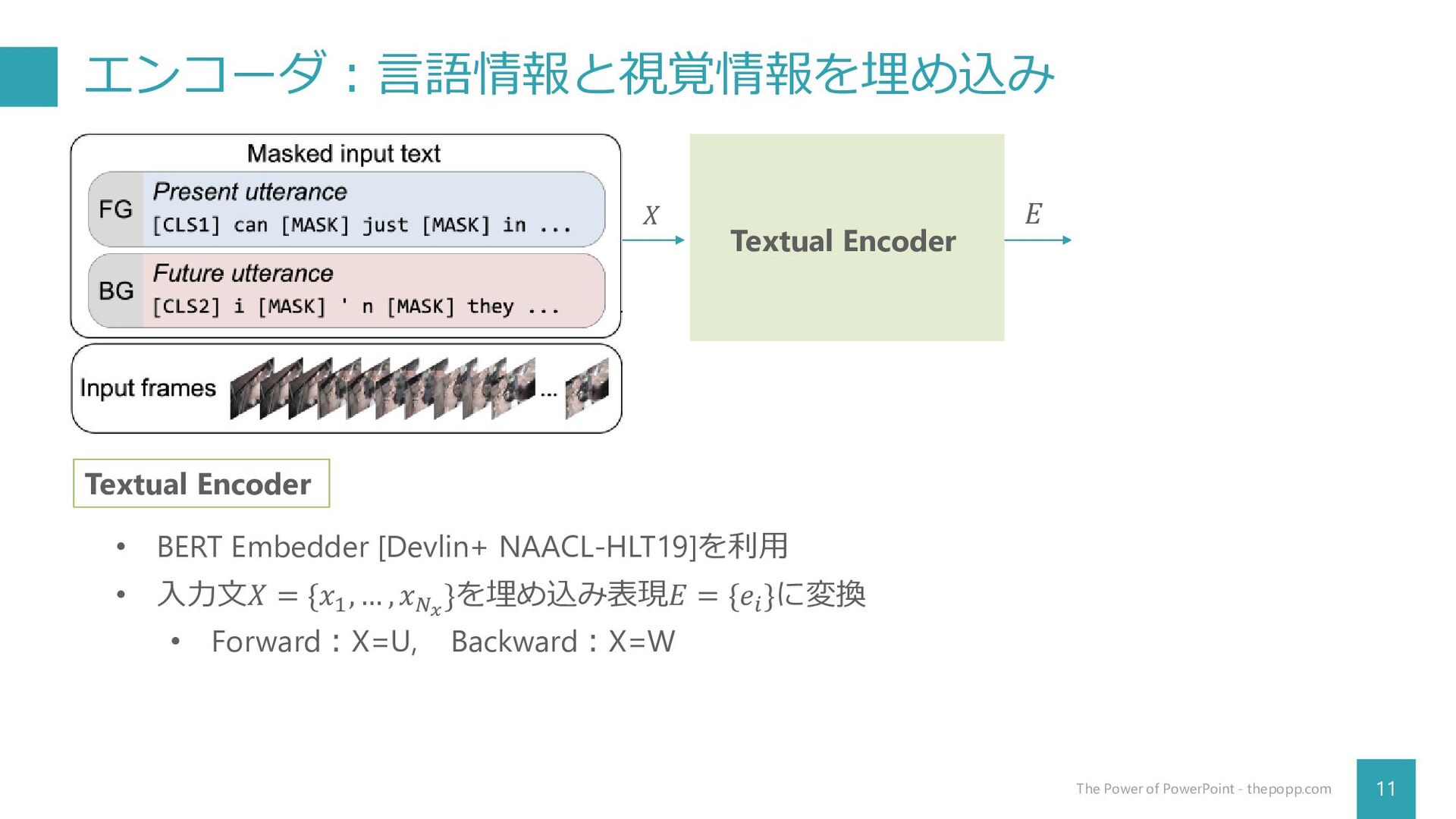{kind=link}
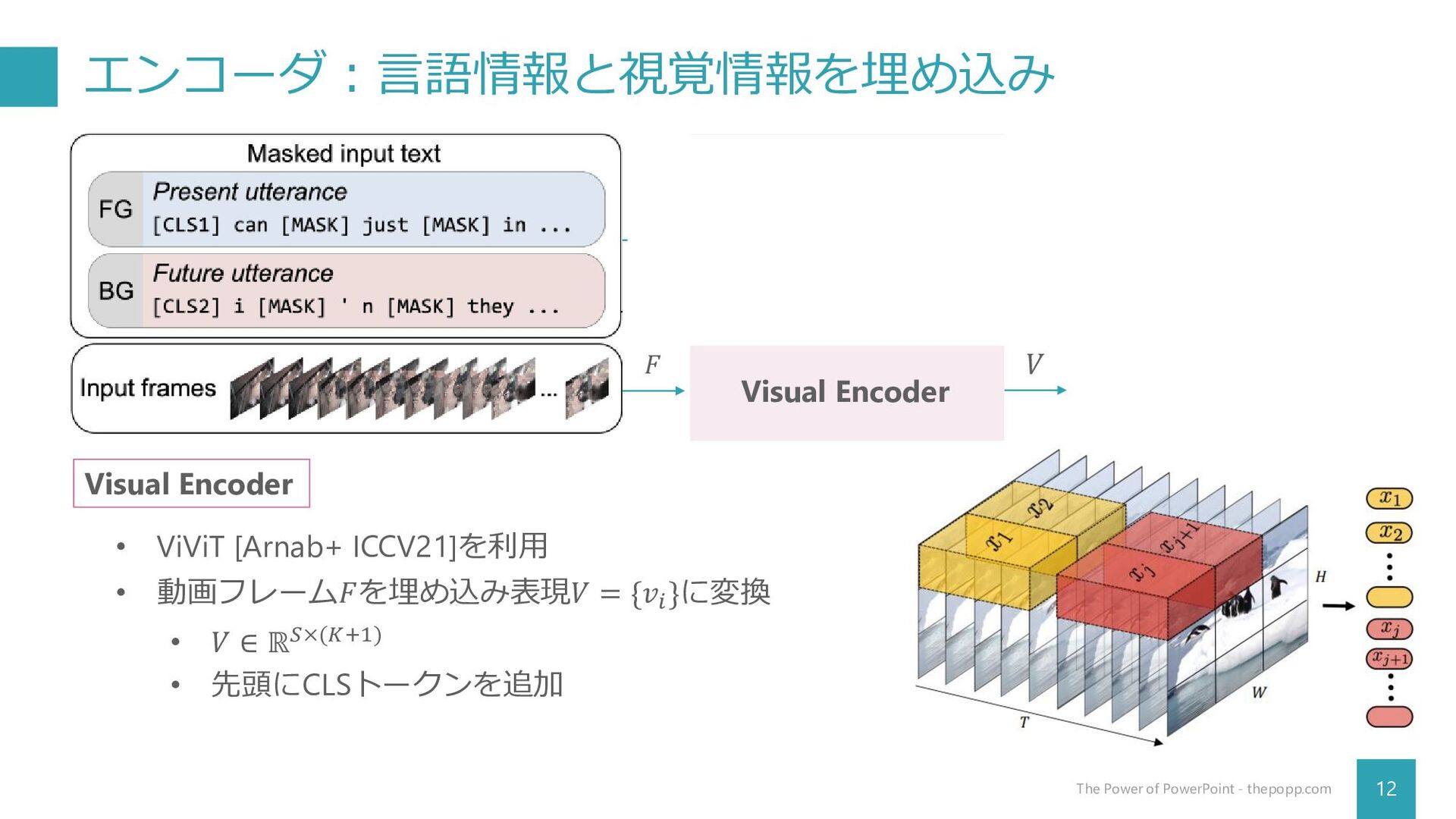{kind=link}
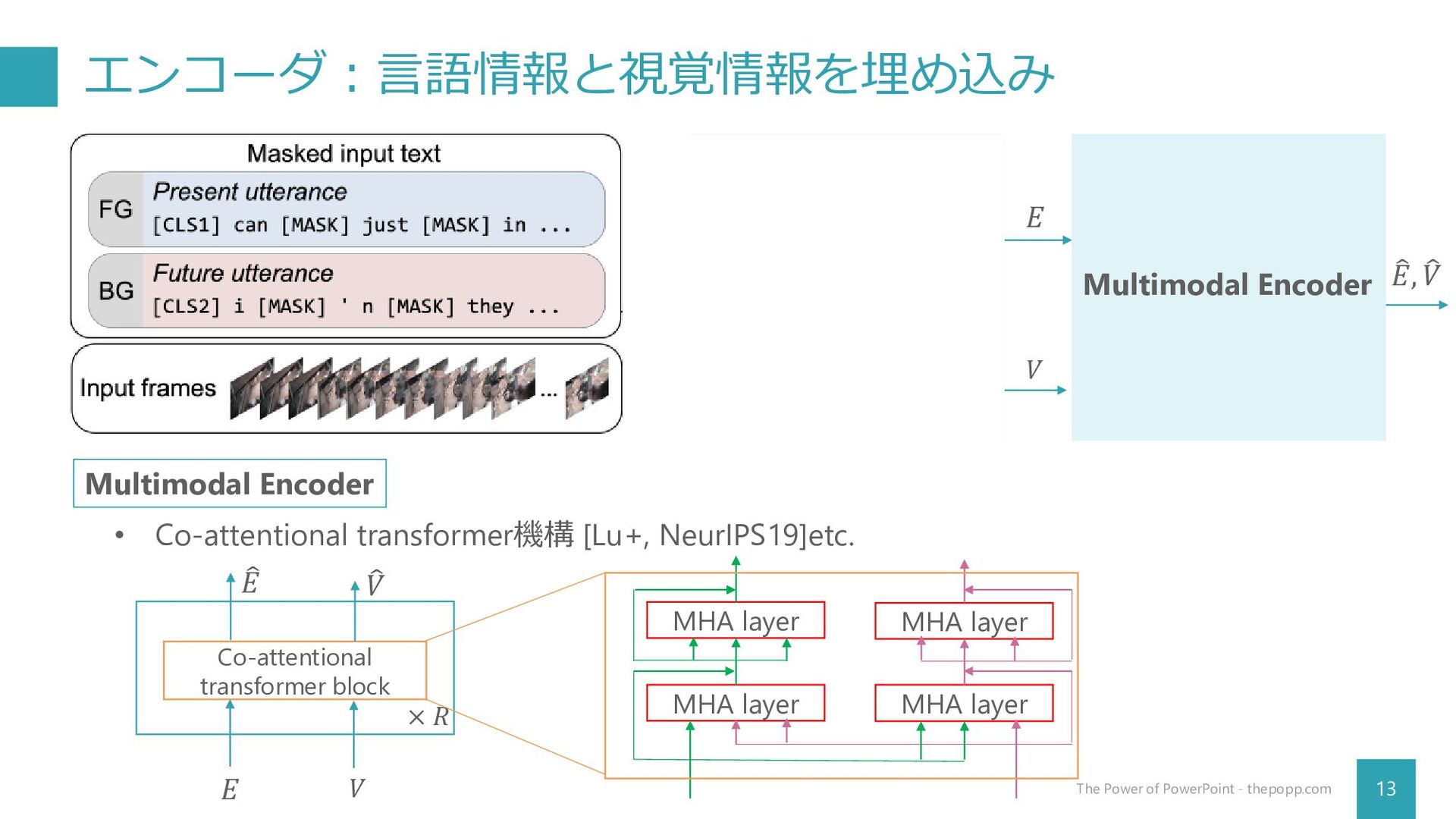{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}