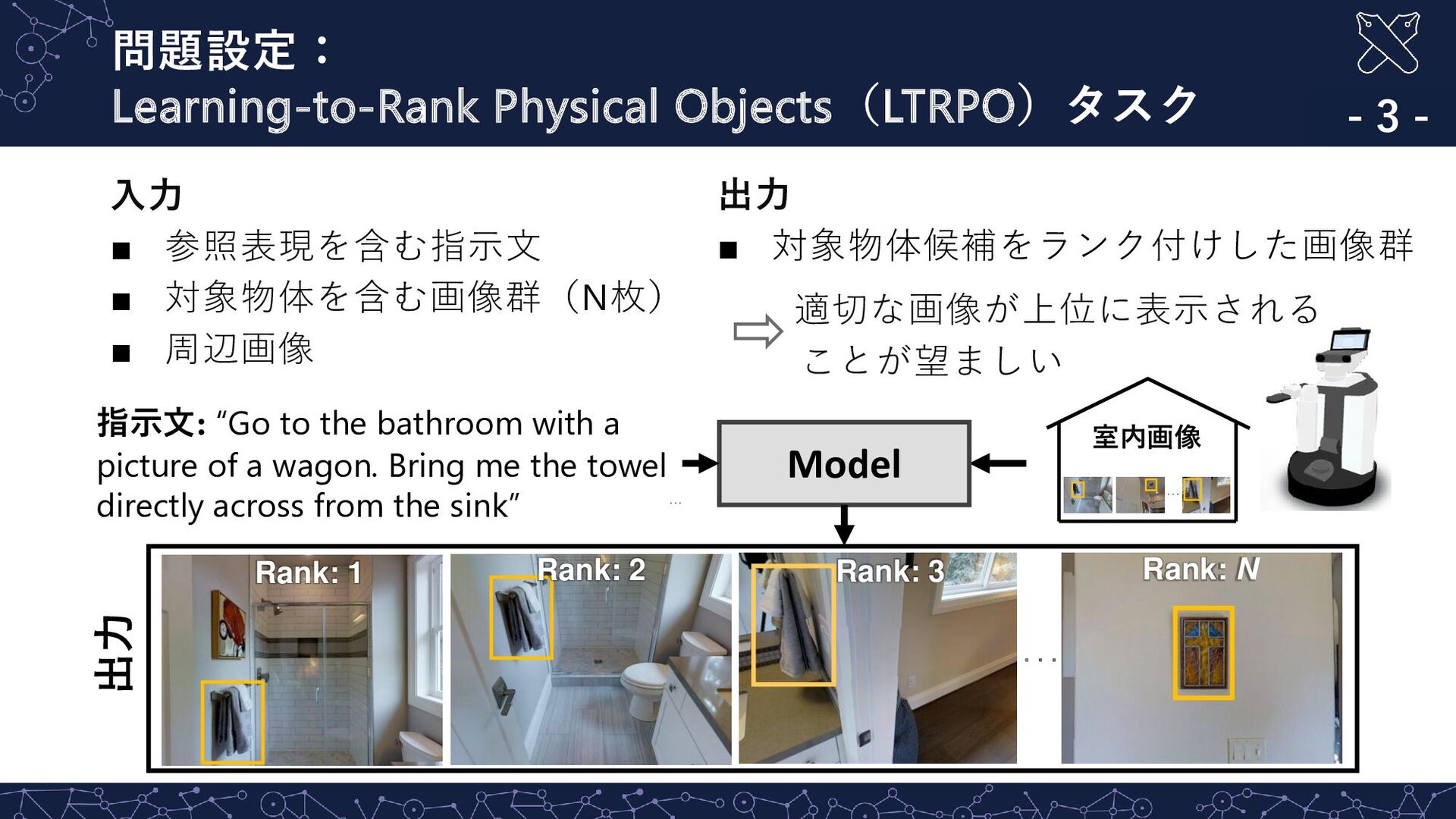
▪ 対象物体を含む画像群(N枚) ▪ 周辺画像 指示文: “Go to the bathroom with a picture of a wagon. Bring me the towel directly across from the sink” ・・・ Model Rank: N Rank: 3 Rank: 2 ・・・ 室内画像 Rank: 1 出力 出力 ▪ 対象物体候補をランク付けした画像群 適切な画像が上位に表示される ことが望ましい ・・・
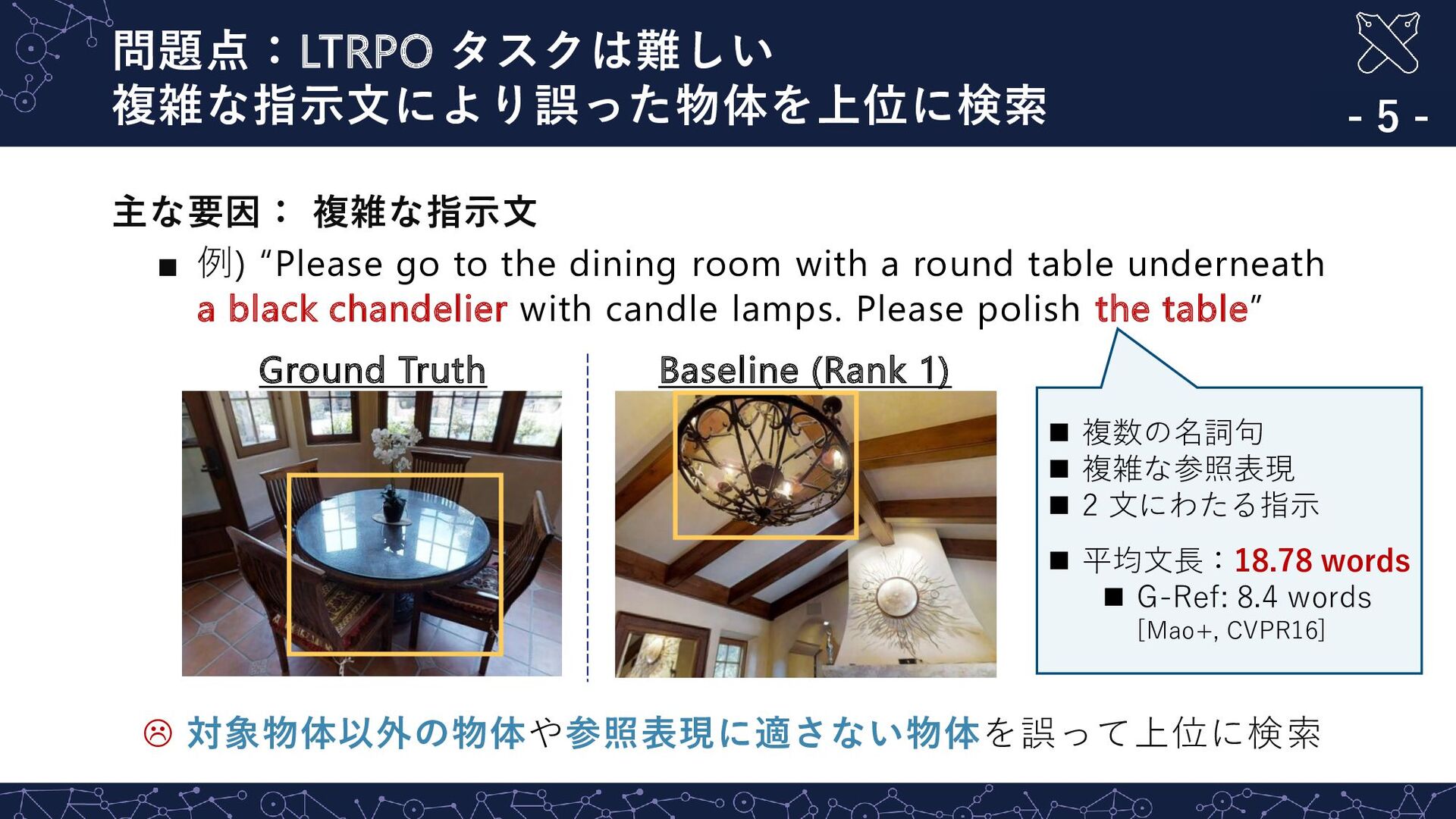
with a round table underneath a black chandelier with candle lamps. Please polish the table” 対象物体以外の物体や参照表現に適さない物体を誤って上位に検索 問題点:LTRPO タスクは難しい 複雑な指示文により誤った物体を上位に検索 - 5 - Ground Truth Baseline (Rank 1) ◼ 複数の名詞句 ◼ 複雑な参照表現 ◼ 2 文にわたる指示 ◼ 平均文長:18.78 words ◼ G-Ref: 8.4 words [Mao+, CVPR16]
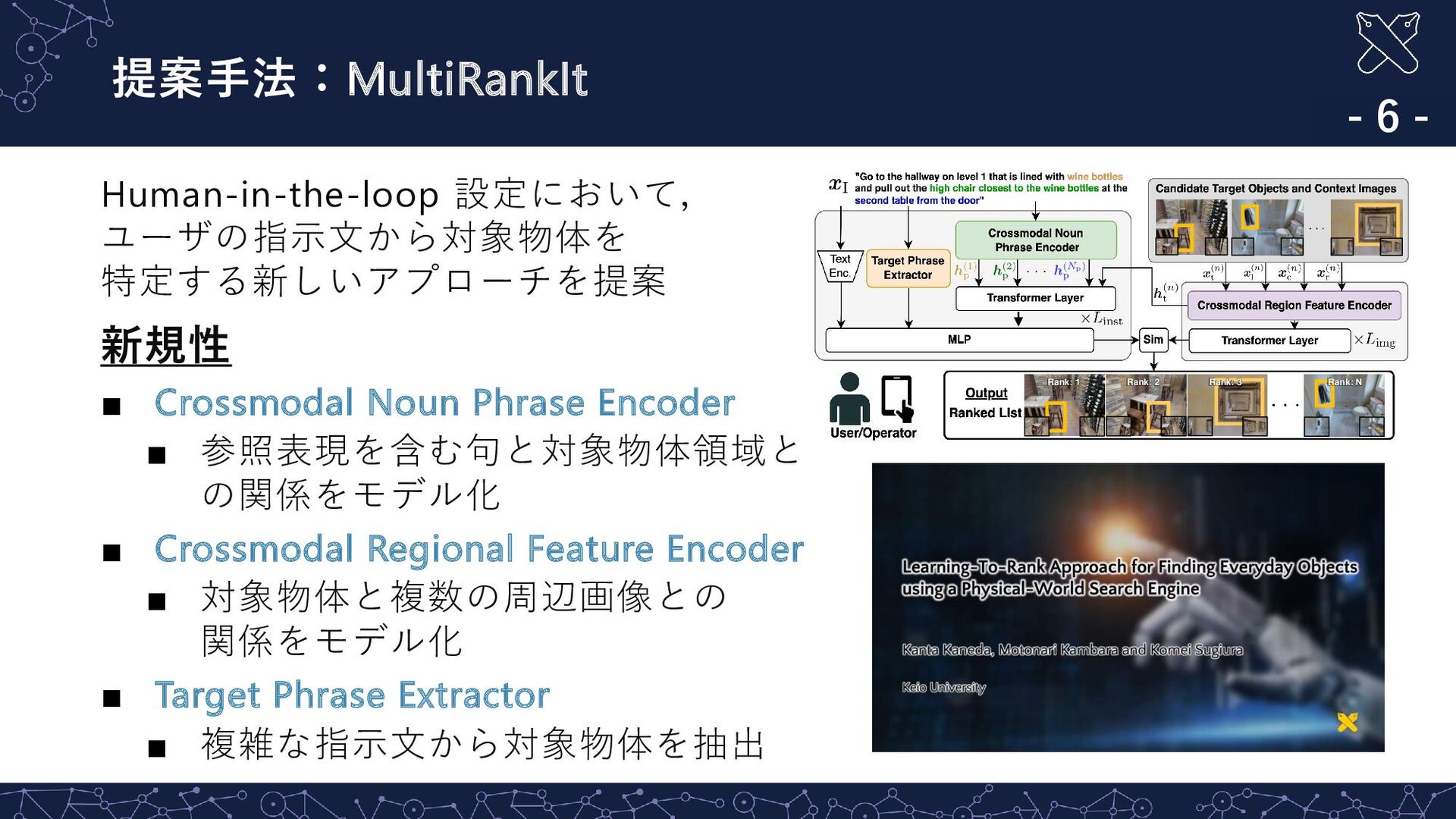
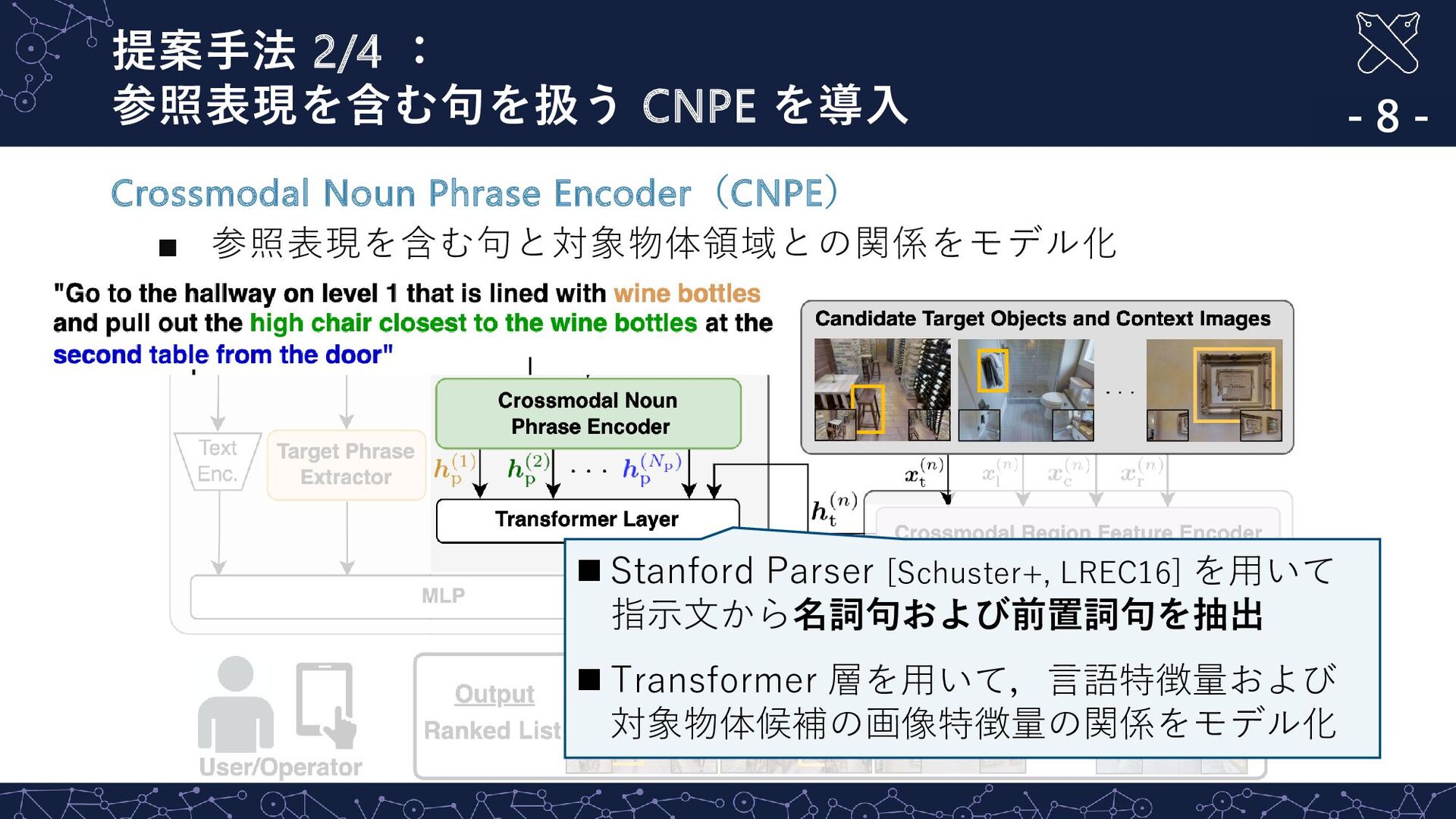
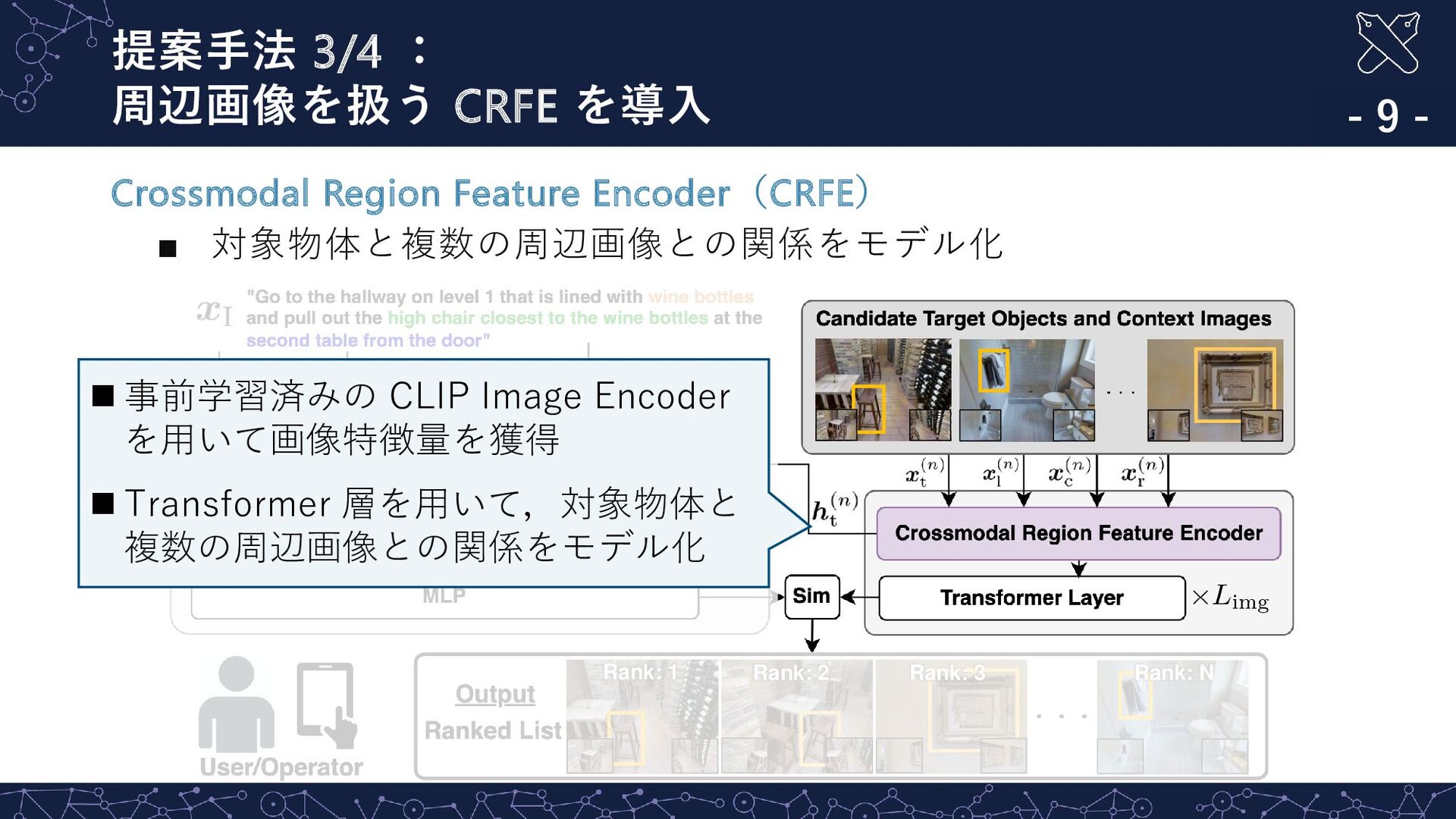
LLM を用いて複雑な指示文から対象物体を特定 - 7 - Target Phrase Extractor(TPE) ▪ LLM を用いて複雑な指示文から対象物体を特定 ◼ ChatGPT を用いて指示文から対象物体を特定 ◼ プロンプト:“<指示文>. Extract the portion of the above instruction that indicates the target object. Please enclose the information with #. Output the information only.“ ◼ 出力:#high chair#
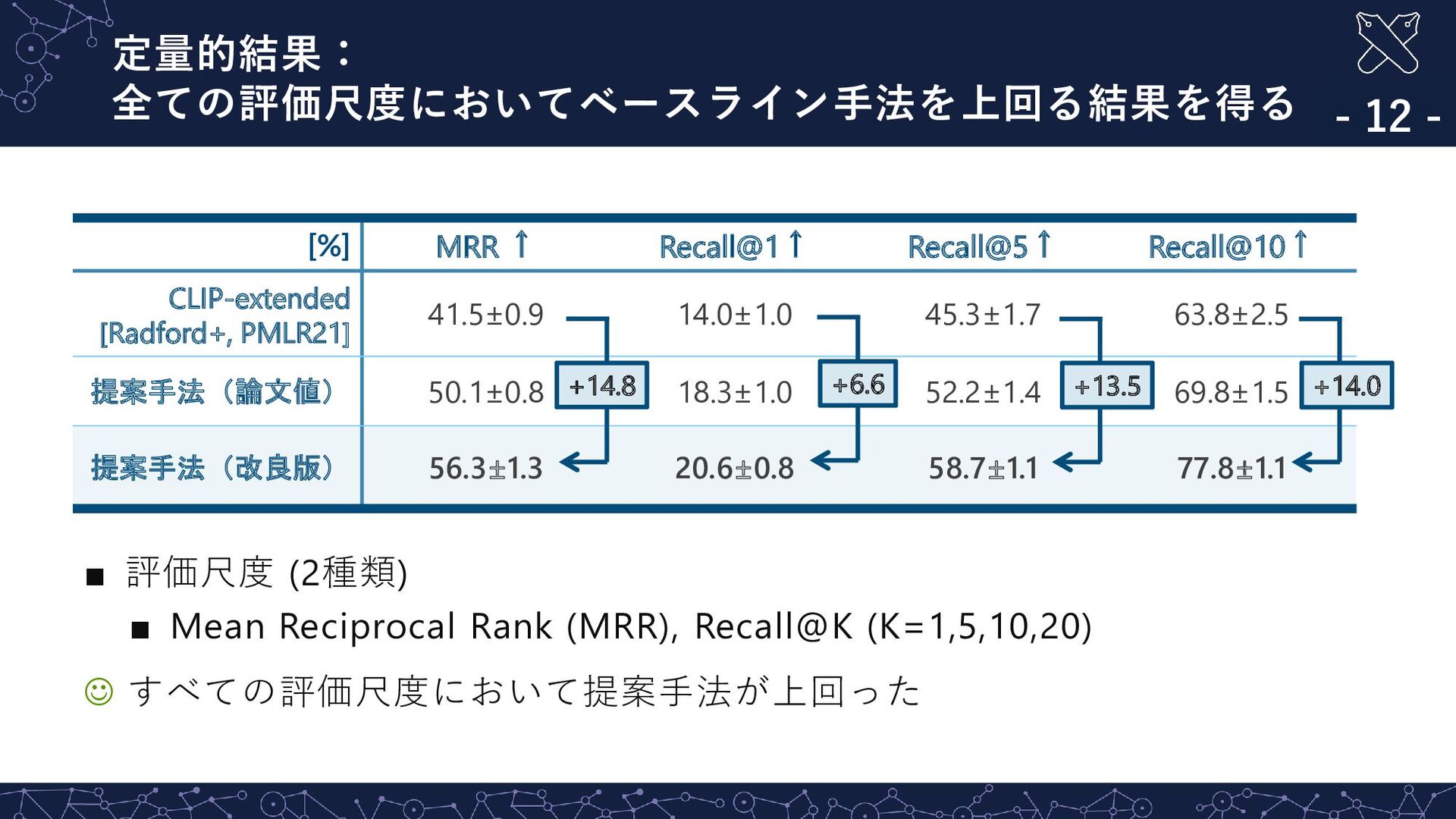
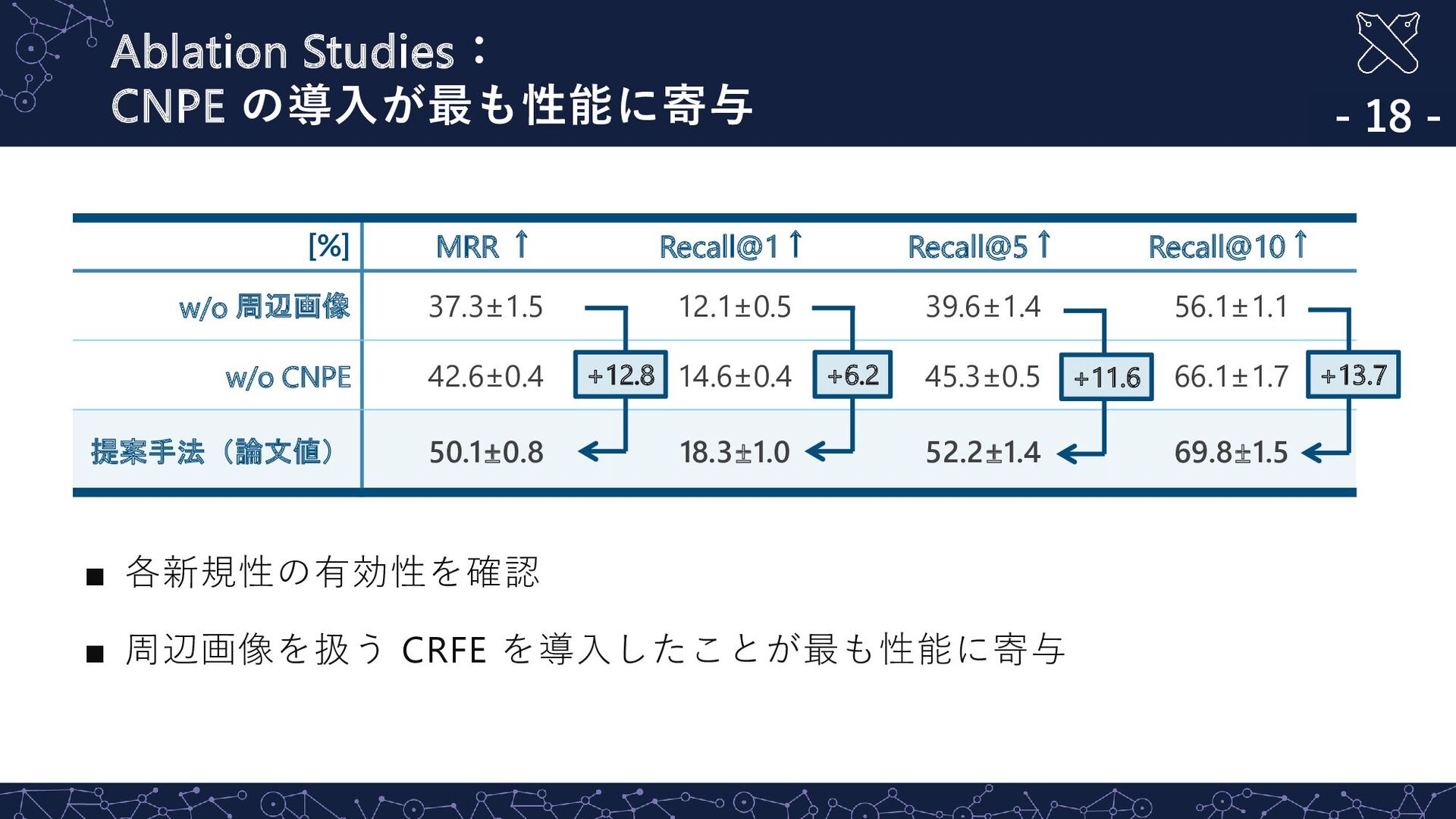
Truth Rank: 2 Rank: 3 Rank: 4 Rank: 5 Rank: 6 指示文:”Go to the hallway on level 1 that is lined with wine bottles and pull out the high chair closest to the wine bottles at the second table from the door” 指示文:”Go to the hallway on level 1 that is lined with wine bottles and pull out the high chair closest to the wine bottles at the second table from the door” ☺ 参照表現を含む句と対象物体領域との関係をモデル化する CNPE の 導入により,複雑な参照表現を含む指示文に対して適切な画像を検索
1 … 指示文:”Go to the bathroom with a picture of a wagon and bring me the towel directly across from the sink” Ground Truth Rank: 2 Rank: 3 Rank: 4 Rank: 5 Rank: 6
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}