Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
EMアルゴリズム from Machine Learning - A Probabilisti...
Search
Kenya Hondoh
December 12, 2017
Science
0
5.2k
EMアルゴリズム from Machine Learning - A Probabilistic Perspective
輪読資料
Kenya Hondoh
December 12, 2017
Tweet
Share
Other Decks in Science
See All in Science
データベース15: ビッグデータ時代のデータベース
trycycle
PRO
0
440
白金鉱業Vol.21【初学者向け発表枠】身近な例から学ぶ数理最適化の基礎 / Learning the Basics of Mathematical Optimization Through Everyday Examples
brainpadpr
1
600
NDCG is NOT All I Need
statditto
2
2.8k
次代のデータサイエンティストへ~スキルチェックリスト、タスクリスト更新~
datascientistsociety
PRO
2
28k
蔵本モデルが解き明かす同期と相転移の秘密 〜拍手のリズムはなぜ揃うのか?〜
syotasasaki593876
1
210
データから見る勝敗の法則 / The principle of victory discovered by science (open lecture in NSSU)
konakalab
1
270
データマイニング - コミュニティ発見
trycycle
PRO
0
210
【論文紹介】Is CLIP ideal? No. Can we fix it?Yes! 第65回 コンピュータビジョン勉強会@関東
shun6211
5
2.3k
データベース05: SQL(2/3) 結合質問
trycycle
PRO
0
880
SpatialRDDパッケージによる空間回帰不連続デザイン
saltcooky12
0
160
[Paper Introduction] From Bytes to Ideas: Language Modeling with Autoregressive U-Nets
haruumiomoto
0
200
baseballrによるMLBデータの抽出と階層ベイズモデルによる打率の推定 / TokyoR118
dropout009
2
800
Featured
See All Featured
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
0
180
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
359
30k
The Invisible Side of Design
smashingmag
302
51k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
It's Worth the Effort
3n
188
29k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
310
Art, The Web, and Tiny UX
lynnandtonic
304
21k
How to Ace a Technical Interview
jacobian
281
24k
From π to Pie charts
rasagy
0
130
Paper Plane
katiecoart
PRO
0
46k
How To Speak Unicorn (iThemes Webinar)
marktimemedia
1
380
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.2k
Transcript
Machine Learning A Probabilistic Perspective Chapter.11 Mixture models and the
EM algorithm pp.348 – pp.359 発表者: M1 本藤拳也 2017/12/22 1
11.4 EMアルゴリズム • データに欠損値や潜在変数が含まれるとき, 最尤法やMAP推定を行うのは困難になる • 例えば,それ以外のパラメータ推定手法として勾配法 ベースのものがある 例)負の対数尤度(negative log
likelihood)の局所最小値を 計算する勾配法 NLL =−≜ 1 log (|) 問題点: 制約が多く計算困難なことが多い 分散共分散行列が正定値行列,重みの和が1,など 2 (11.16)
11.4 EMアルゴリズム • 制約が多い場合,EMアルゴリズム(EM法)を使うほう がよりシンプルな場合がある EM法…expectation maximization algorithm • シンプルな反復法のアルゴリズム
• 以下の2つのステップを交互に繰り返す E step:既知のパラメータを基に,欠損値を予測 M step:予測した値を基に,パラメータを更新 3
11.4.1 基本的なアイデア 潜在変数を含むときの対数尤度 を観測データとする. を潜在変数(or欠損値)とする. 次の対数尤度を最大化することが,EM法のゴールである. = =1 log
= =1 log ( , |) この対数尤度は,logの内側にΣが入っており,最適化が困 難である. 4 (11.17)
11.4.1 基本的なアイデア EM法は次のようにしてこの問題を避ける. 完全データ対数尤度(complete data log likelihood)を次のよう に定義する ≜
=1 log , は定義上不明なのでこのままでは計算できない. そこで,完全データ対数尤度の期待値を次のように定義 する: , −1 = E[ ()|, −1] ここで,は反復回数である.は補助関数と呼ばれる. 5 (11.18) (11.19)
11.4.1 基本的なアイデア , −1 = E[ ()|, −1] E stepでは,Q関数を−1,
をもとに計算する. E stepのゴールは, , −1 の中の最尤推定が 関係する項を計算することである.この項のことを, 期待十分統計量という. M stepでは,Q関数を最大化するを求める: = arg max (, −1) 次のように書き換えれば,MAP推定になる: = arg max (, −1) + log () 6 (11.20) (11.21)
11.4.1 基本的なアイデア 余談: EMアルゴリズムの反復計算では,観測データの対数尤 度は単調に増加する.もし計算中に下がることがあれ ば,それは数式かコードにバグがあることを示す. ➡図らずしも便利なデバッグツールになる 次に具体例として,混合ガウスモデル(GMM)のフィッ ティングを行うEM法をみていく. 7
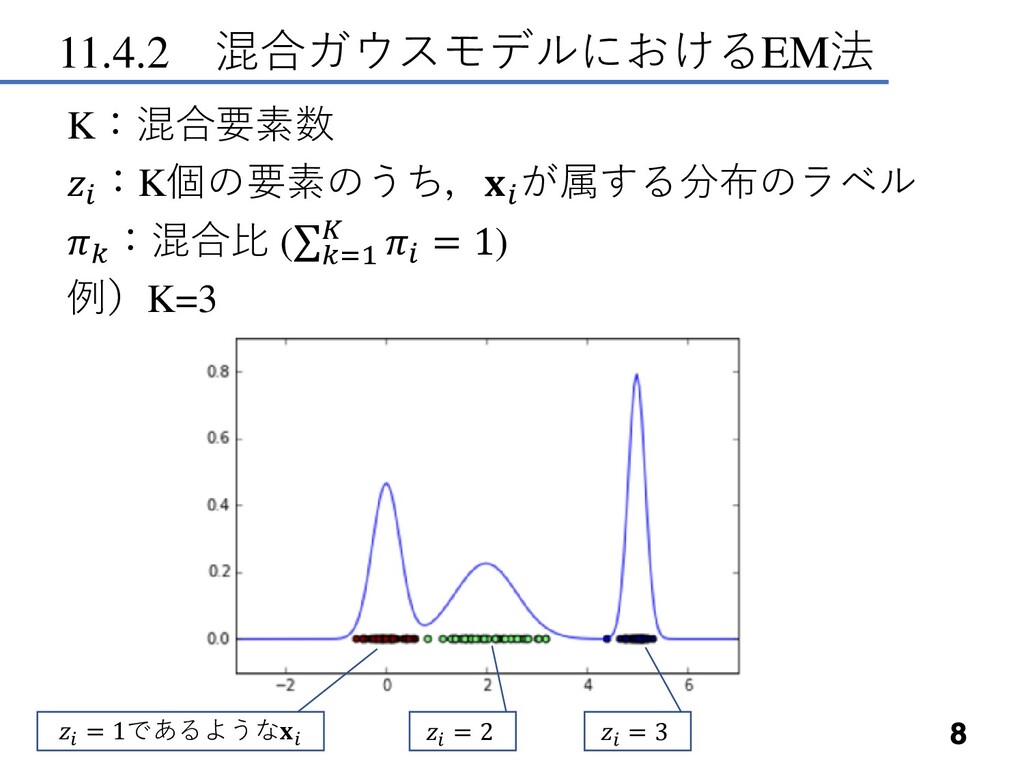
11.4.2 混合ガウスモデルにおけるEM法 8 K:混合要素数 :K個の要素のうち, が属する分布のラベル :混合比 (σ=1 = 1)
例)K=3 = 1であるような = 2 = 3
11.4.2 混合ガウスモデルにおけるEM法 9 このとき,完全データ対数尤度は ≜ ( = | , −1)を負荷率(responsibility)という.
データ が要素に含まれる確率に相当する
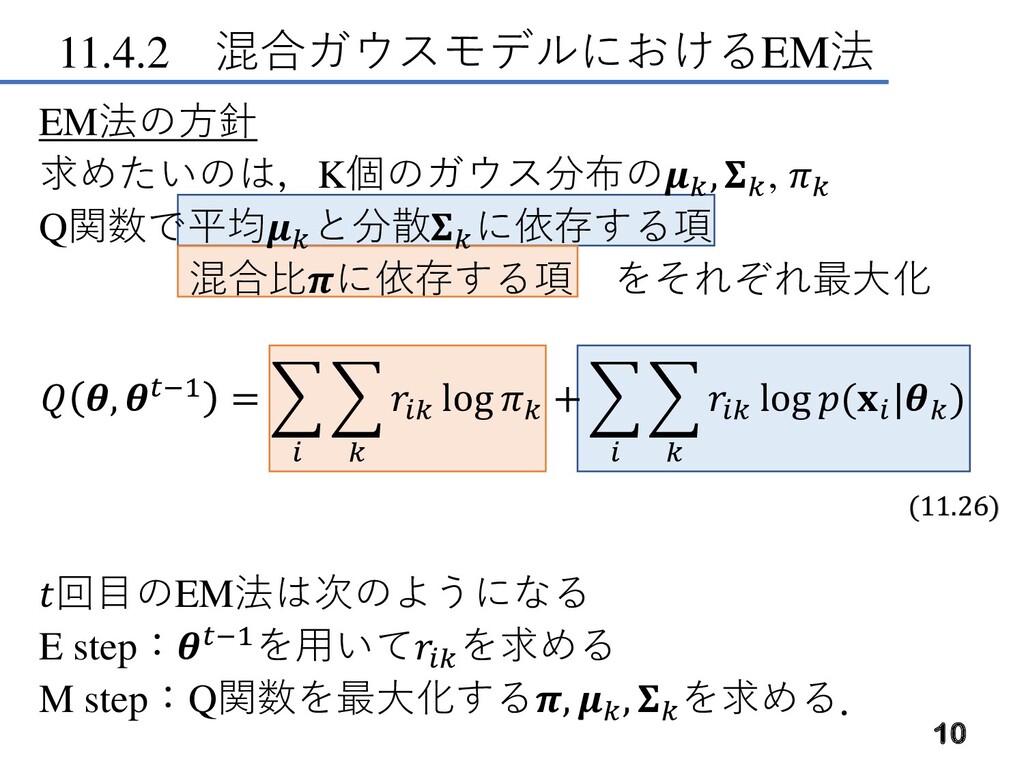
11.4.2 混合ガウスモデルにおけるEM法 10 EM法の方針 求めたいのは,K個のガウス分布の , , Q関数で平均 と分散 に依存する項
混合比に依存する項 をそれぞれ最大化 , −1 = log + log ( | ) 回目のEM法は次のようになる E step:−1を用いて を求める M step:Q関数を最大化する, , を求める. (11.26)
11.4.2 混合ガウスモデルにおけるEM法 11 , −1 = log +
log ( | ) E step:t-1回目のパラメータ−1を用いて を求める = ( | −1) σ ′ ′ ( | ′ −1) (11.27)
11.4.2 混合ガウスモデルにおけるEM法 12 , −1 = log +
log ( | ) M step:E stepで求めたパラメータを基にQ関数最大化 に関する最大化 は自明に = 1 σ = σ σ log の最大化(subject to Σ = 1) ➡ラグランジュ法 = log − ( − 1) = − = 0 = − 1 = 0 (11.28)
11.4.2 混合ガウスモデルにおけるEM法 13 , −1 = log +
log ( | ) M step:E stepで求めたパラメータを基にQ関数最大化 , に関する最大化 , = log ( | ) = − 1 2 log + − −1 − ➡ = σ , = σ − − = σ − (11.30) (11.29) (11.31) (11.32)
11.4.2 混合ガウスモデルにおけるEM法 14 EM法で推定されたパラメータ = 1 = = σ
, = σ − − = σ − 直感的な意味: クラスタkの平均は,データ点 の重み(kに属する確率) つきの標本平均 クラスタkの分散は,標本共分散行列と同じ
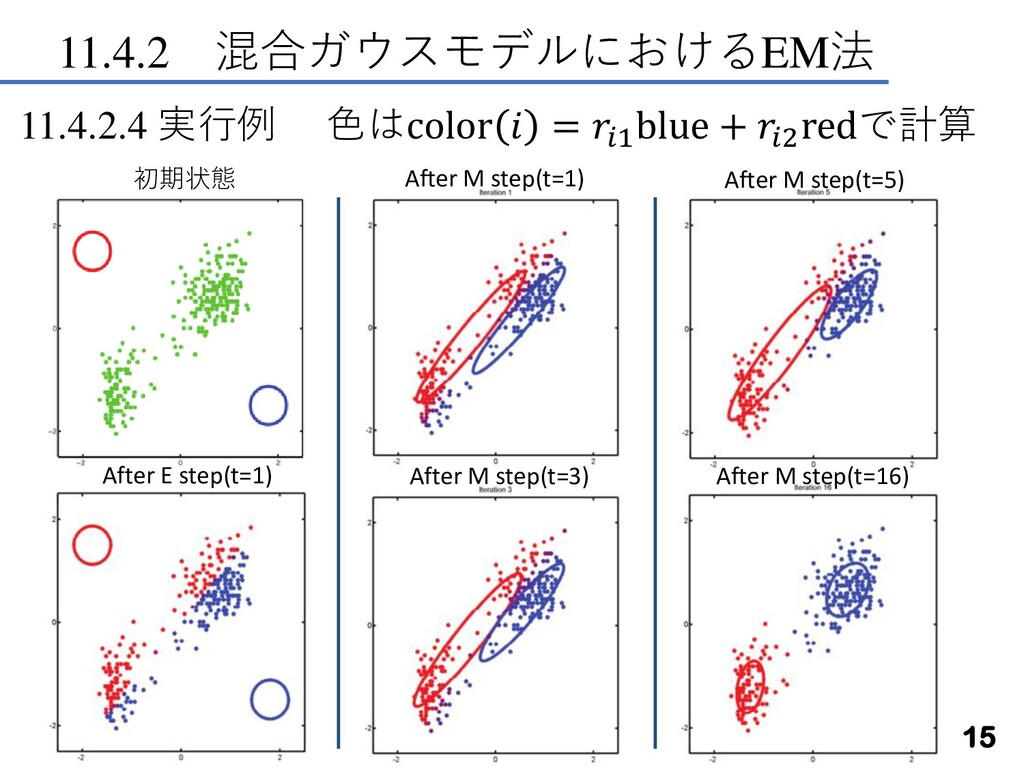
11.4.2 混合ガウスモデルにおけるEM法 15 11.4.2.4 実行例 色はcolor = 1 blue +
2 redで計算 初期状態 After E step(t=1) After M step(t=1) After M step(t=3) After M step(t=5) After M step(t=16)
11.4.2.5 K-meansアルゴリズム K-meansアルゴリズムとは,混合ガウスモデルのパラ メータをEM法で推定する方法の変種である K-meansでは,次のパラメータを固定する = 2 , = 1
そして,クラスタ平均 と,データ点がどのクラスタ に属するかについての(潜在)変数 を更新していく. 16
11.4.2.5 K-meansアルゴリズム E stepは次のように書き換えられる. = = , ≈ I k
= zi ∗ zi ∗ = arg max = , つまり,データ点 は,ただ1つのクラスタのみに属 するように変更する. 純粋なEM法では,データ点 がK個のどのクラスタに 属するかは確率的だったのに対して,K-meansでは唯 一つのクラスタを割り当てる.このようなEMをhard EMという. 17 (11.34)
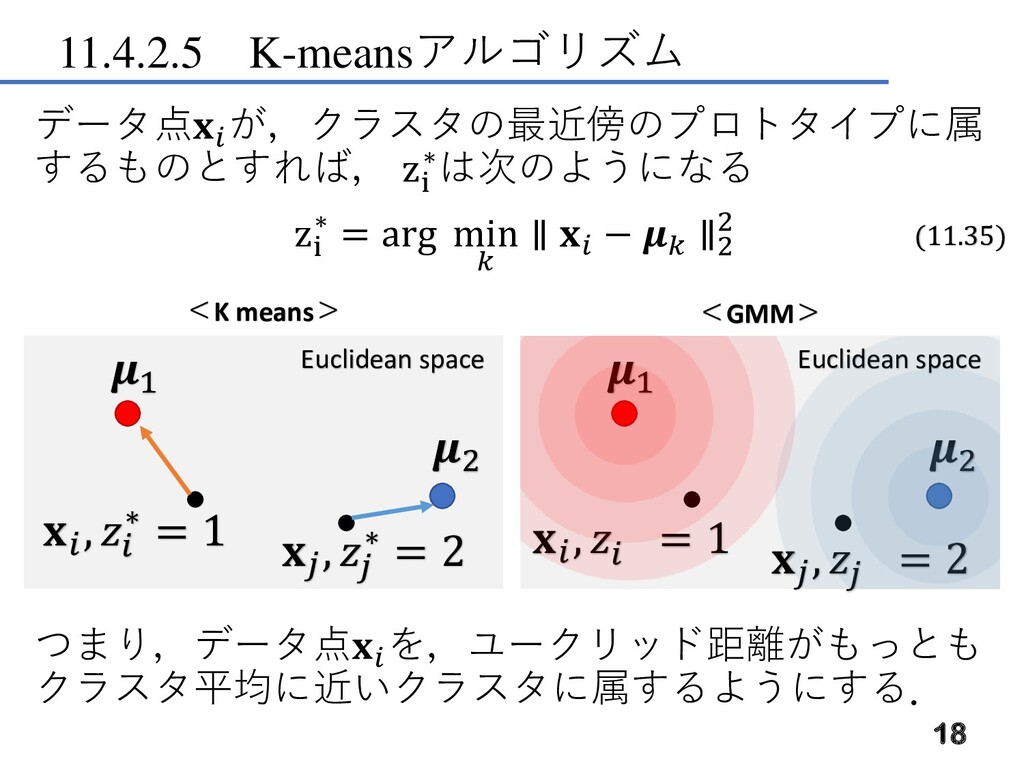
11.4.2.5 K-meansアルゴリズム データ点 が,クラスタの最近傍のプロトタイプに属 するものとすれば, zi ∗は次のようになる zi ∗ =
arg min ∥ − ∥2 2 つまり,データ点 を,ユークリッド距離がもっとも クラスタ平均に近いクラスタに属するようにする. 18 1 2 , ∗ = 1 Euclidean space , ∗ = 2 1 2 , = 1 Euclidean space , = 2 <K means> <GMM> (11.35)
11.4.2.5 K-meansアルゴリズム D次元ユークリッド空間でN個のデータをK個のクラ スタに分配するのは()時間かかるが,工夫をす ることで高速化ができる(Elkan 2003) さて,M stepは,純粋なEM法と同じようにクラスタk の平均 の計算をする.
E stepでデータ点 が属するクラスタを求めたので, これをもとに新たなクラスタの中心を計算する: = 1 := 19 (11.36)
11.4.2.5 K-meansアルゴリズム Algorithm 11.1はK-meansの疑似コードを示す. 20
11.4.2.6 ベクトル量子化 Introduction K-meansは正確なEMアルゴリズムではなく,尤度を最大 化することができない. これは,損失関数を近似的に最小化する貪欲アルゴリズム と解釈できる.そして,この貪欲アルゴリズムはデータ圧 縮と関連がある. データ圧縮 実数値ベクトル
∈ ℝに対し,不可逆圧縮を行うことを 考える.単純なアプローチとして知られるのが,ベクトル 量子化である. 離散的なシンボル ∈ {1, … , }に対し, をK個のプロト タイプ に割り当てることを考える. 21
11.4.2.6 ベクトル量子化 ・データベクトル ∈ ℝ ・シンボル ∈ 1, … ,
・シンボルKのプロトタイプ ∈ ℝ (codebook) データベクトルは,もっともユークリッド距離が近い プロトタイプにエンコードされる.すなわち, encode = arg min ∥ − ∥2 プロトタイプの定め方によって,圧縮後のデータの品 質は変わってくる.つまり,適切にプロトタイプ を 設定する必要がある. 22 (11.37)
11.4.2.6 ベクトル量子化 そこで,プロトタイプがどれだけ適切であるかを評価 するコスト関数として,再構成誤差(reconstruction error)を導入する. , , ≜ 1
=1 ∥ − decode encode ∥2 = 1 ∥ − ∥2 where decode() = . 式(11.38)は元データと圧縮後の誤差である.K-means は,この誤差関数を最小化する反復法であると考える ことができる. 23 (11.38)
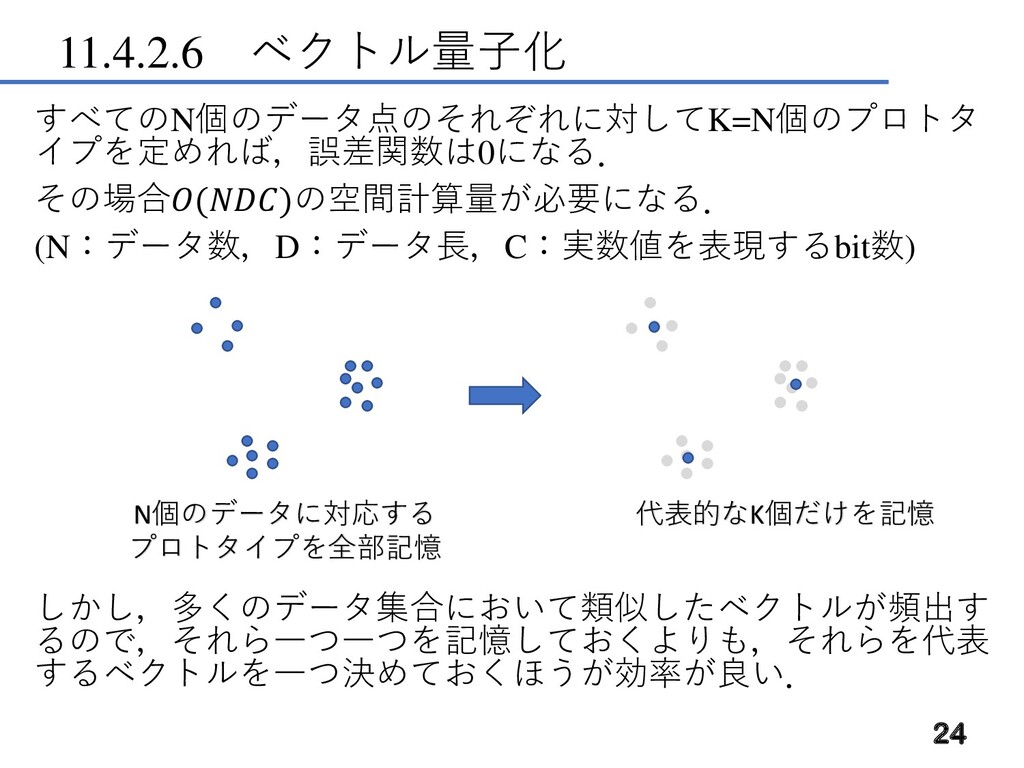
11.4.2.6 ベクトル量子化 すべてのN個のデータ点のそれぞれに対してK=N個のプロトタ イプを定めれば,誤差関数は0になる. その場合()の空間計算量が必要になる. (N:データ数,D:データ長,C:実数値を表現するbit数) しかし,多くのデータ集合において類似したベクトルが頻出す るので,それら一つ一つを記憶しておくよりも,それらを代表 するベクトルを一つ決めておくほうが効率が良い. 24
N個のデータに対応する プロトタイプを全部記憶 代表的なK個だけを記憶
11.4.2.6 ベクトル量子化 ベクトル量子化の空間計算量 このように,頻出する類似ベクトルに対してK個の代 表点を定めることで空間計算量を log2 + に削減することができる. ( log2
)は,N個のデータ点をK個のプロトタイプ に割り当てるために生じる ()は,D次元のK個のプロトタイプ(ベクトル)を 保持するために生じる 一般に log2 + のうち, log2 の項が支 配的なので,エンコードレートを(log2 )で見積も ることが多い. 25
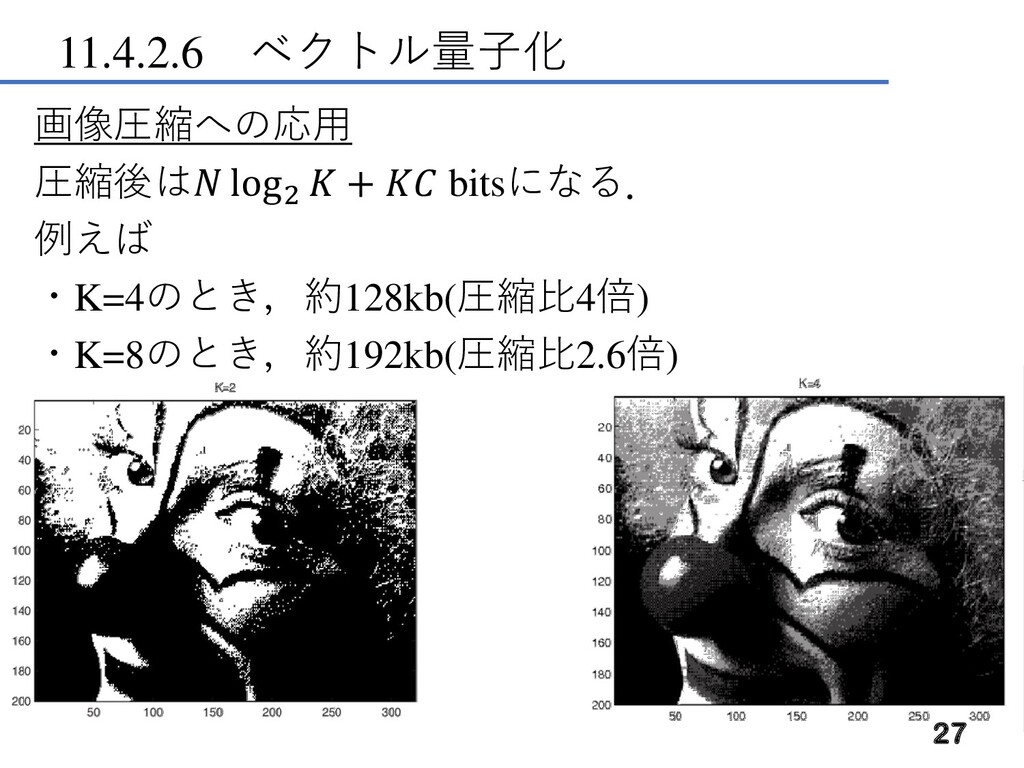
11.4.2.6 ベクトル量子化 画像圧縮への応用 N=200×320=64,000 pixel,グレースケール(D=1) 色強度[0,255](C=8)の画像は, = 512,000 bitsで表現できる K=2
K=4 26
11.4.2.6 ベクトル量子化 画像圧縮への応用 圧縮後は log2 + bitsになる. 例えば ・K=4のとき,約128kb(圧縮比4倍) ・K=8のとき,約192kb(圧縮比2.6倍)
27
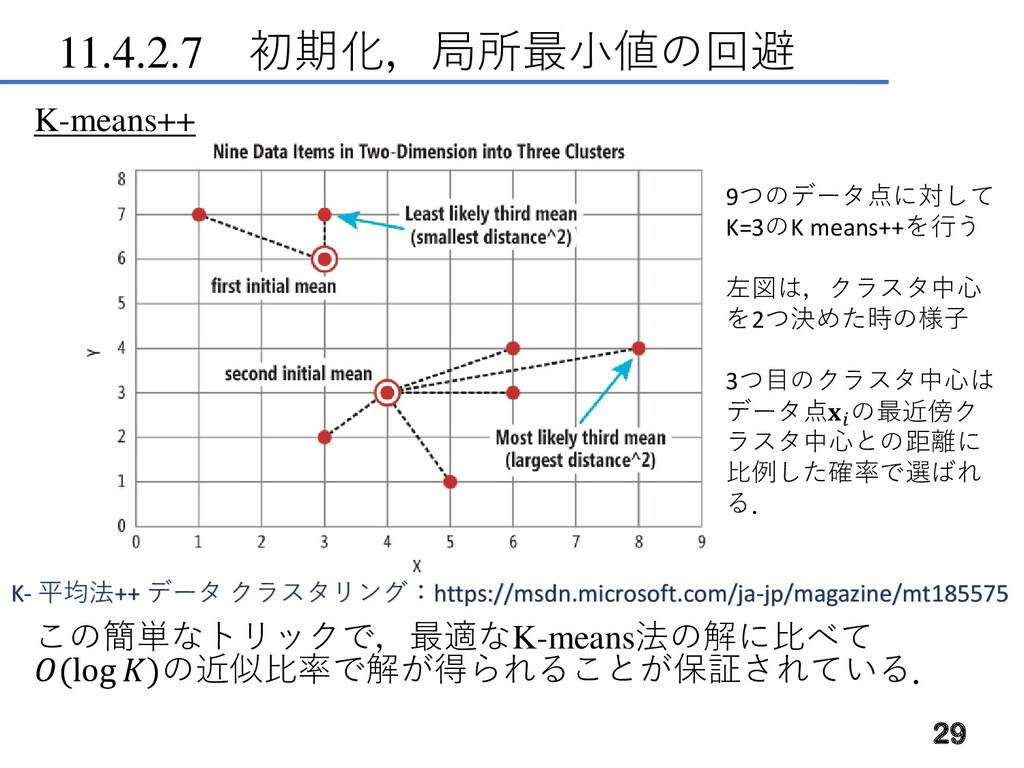
11.4.2.7 初期化,局所最小値の回避 初期化 K-meansもEM法も初期化が必要で,K個のプロトタイ プ点をランダムに決めるのが一般的である. K-means++ 初期プロトタイプ点を「データ点全体を覆う」ように 逐次的に選ぶ方法もある. この方法では,まず最初に初期値を一様ランダムに選 ぶ.次に選ぶデータ点は,前に選んだクラスター中心
との二乗距離に比例した確率で選ぶ.この方法は,最 長距離法もしくはK-means++と呼ばれる. 28
11.4.2.7 初期化,局所最小値の回避 K-means++ この簡単なトリックで,最適なK-means法の解に比べて (log )の近似比率で解が得られることが保証されている. 29 K- 平均法++ データ
クラスタリング:https://msdn.microsoft.com/ja-jp/magazine/mt185575 9つのデータ点に対して K=3のK means++を行う 左図は,クラスタ中心 を2つ決めた時の様子 3つ目のクラスタ中心は データ点 の最近傍ク ラスタ中心との距離に 比例した確率で選ばれ る.
11.4.2.7 初期化,局所最小値の回避 音声認識とEM 音声認識で一般的に知られているヒューリスティック として,GMMを「成長させる」というものがある. ①混合比に基づいてクラスタにスコアを与える ②各反復で,最も高いスコアを持つクラスタを二分する ③二分したクラスタの重心を求め,それぞれに元のスコアの半 分を割り当てる ④新たなクラスタのスコアが小さすぎたり,分散が小さい場合
は破棄する ①~④を,所望のクラスタ数が得られるまで行う 30
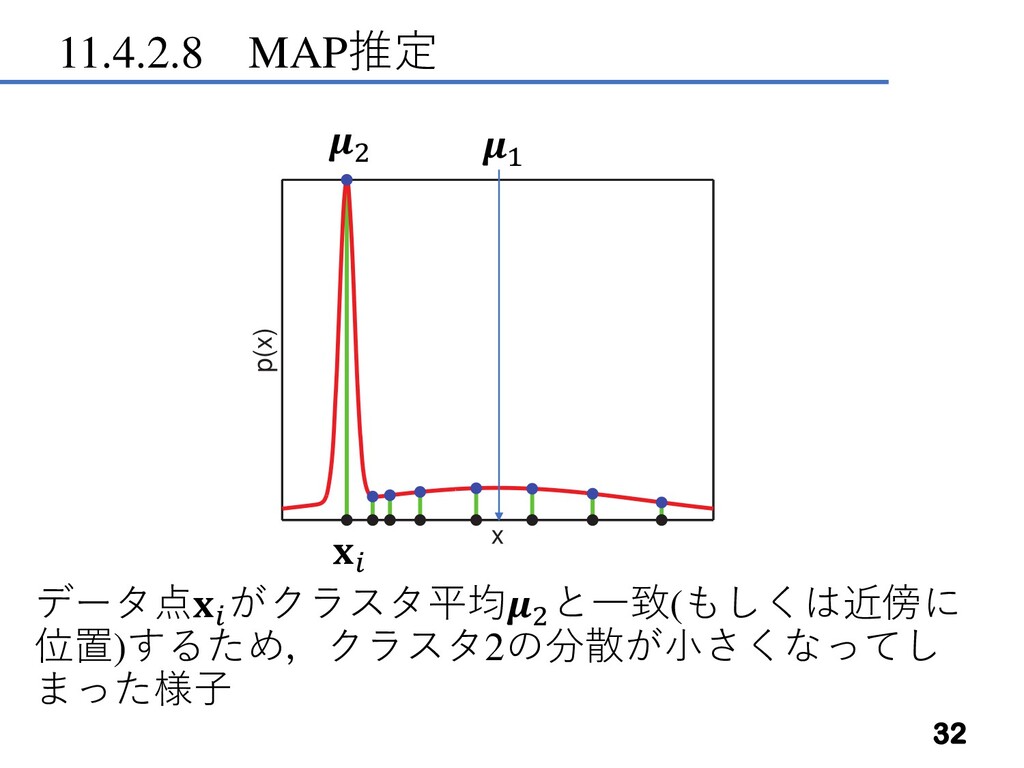
11.4.2.8 MAP推定 最尤推定は多くの場合過学習する. これはGMMの場合,特に深刻な問題となる. 次の例を考えるとわかりやすい. = 2, = 2とする.あるデータ点1 だけが,クラスタ2
に 割り当てられているとする.このデータ点の尤度への寄与は 1 2 , 2 2 = 1 22 2 0 1 = 2 ,すなわち2 = 0となり尤度は発散する. これを”collapsing variance problem”(※ 分散収縮問題)という. ※私がつけた訳語 collapse…(風船などが)しぼむ,収縮する 31 2 1 (11.39)
11.4.2.8 MAP推定 データ点 がクラスタ平均2 と一致(もしくは近傍に 位置)するため,クラスタ2の分散が小さくなってし まった様子 32 2 1
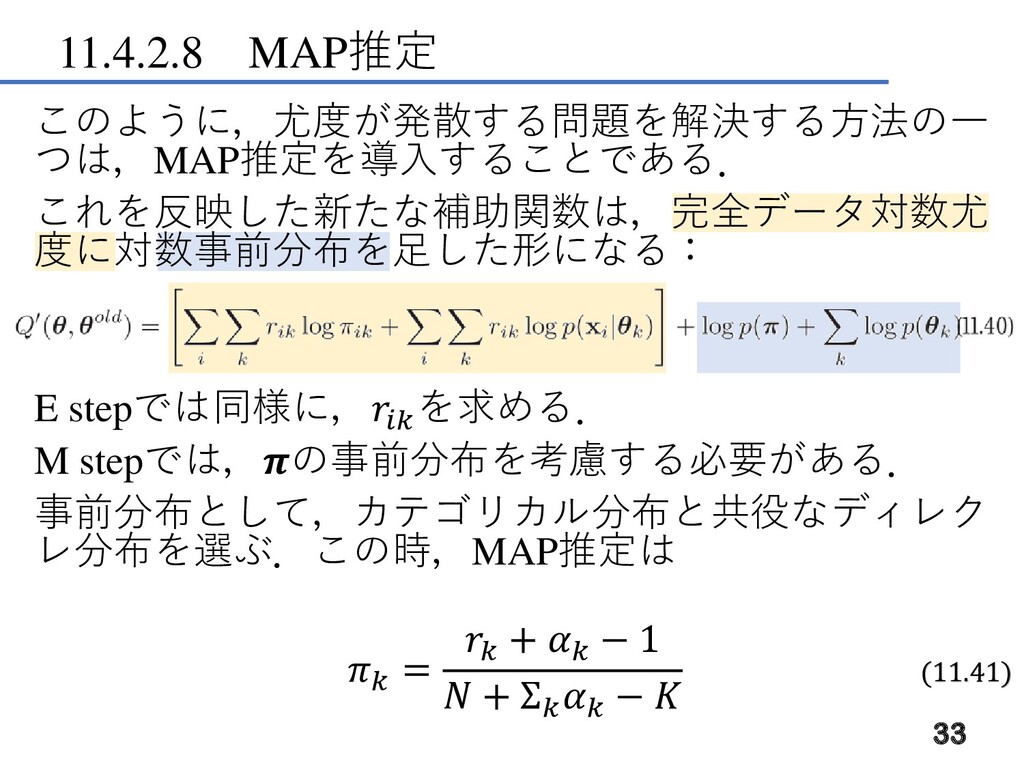
11.4.2.8 MAP推定 このように,尤度が発散する問題を解決する方法の一 つは,MAP推定を導入することである. これを反映した新たな補助関数は,完全データ対数尤 度に対数事前分布を足した形になる: E stepでは同様に, を求める. M
stepでは,の事前分布を考慮する必要がある. 事前分布として,カテゴリカル分布と共役なディレク レ分布を選ぶ.この時,MAP推定は = + − 1 + Σ − 33 (11.41)
11.4.2.8 MAP推定 = + − 1 + Σ − ここで,
= 1とすれば事前分布は一様分布となり, もとのEMアルゴリズムと同様になる. パラメータの事前分布( )は,クラス条件付き密度 の形式に依存する. 34 (11.41)
11.4.2.8 MAP推定 簡単のため,共役事前分布を以下の形式で記述する , = NIW( , |0 , 0
, 0 , 0 ) NIW…natural inverse Wishart 分布 MAP推定結果は次のようになる ෝ = ത +00 +0 , ത ≜ σ , = 0++ 0 0+ ത −0 ത −0 0+++2 , ≜ σ − ത − ത 35 (11.43) (11.44) (11.46) (11.47)
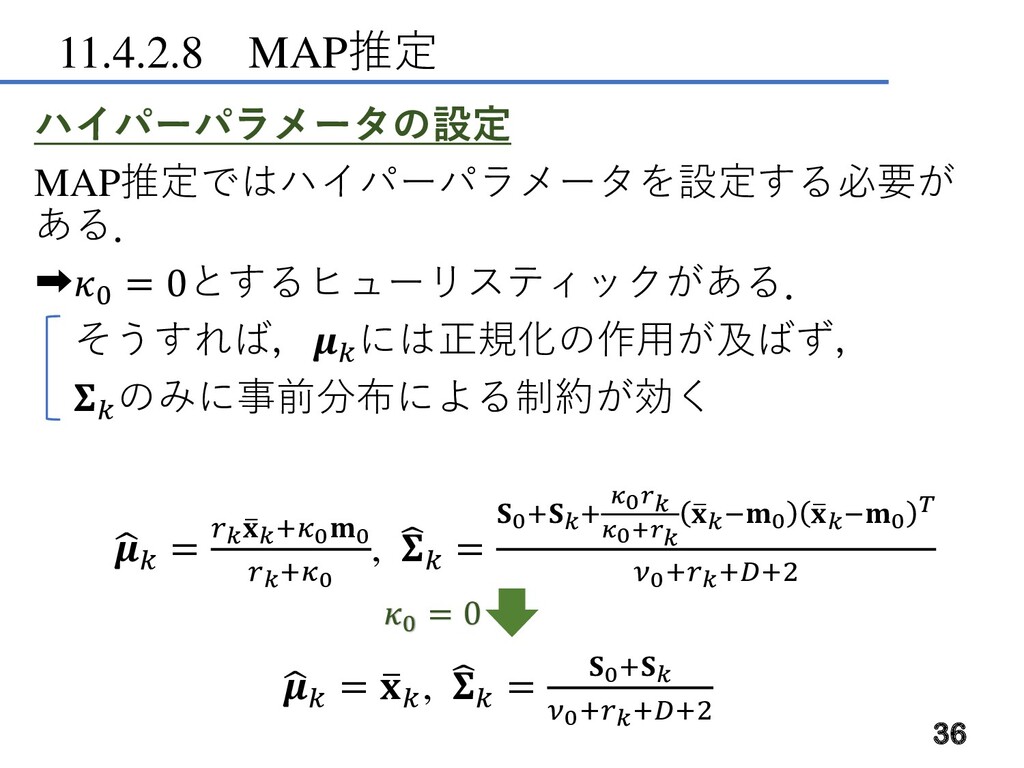
11.4.2.8 MAP推定 ハイパーパラメータの設定 MAP推定ではハイパーパラメータを設定する必要が ある. ➡0 = 0とするヒューリスティックがある. そうすれば, には正規化の作用が及ばず,
のみに事前分布による制約が効く ෝ = ത +00 +0 , = 0++ 0 0+ ത −0 ത −0 0+++2 ෝ = ത , = 0+ 0+++2 36 0 = 0
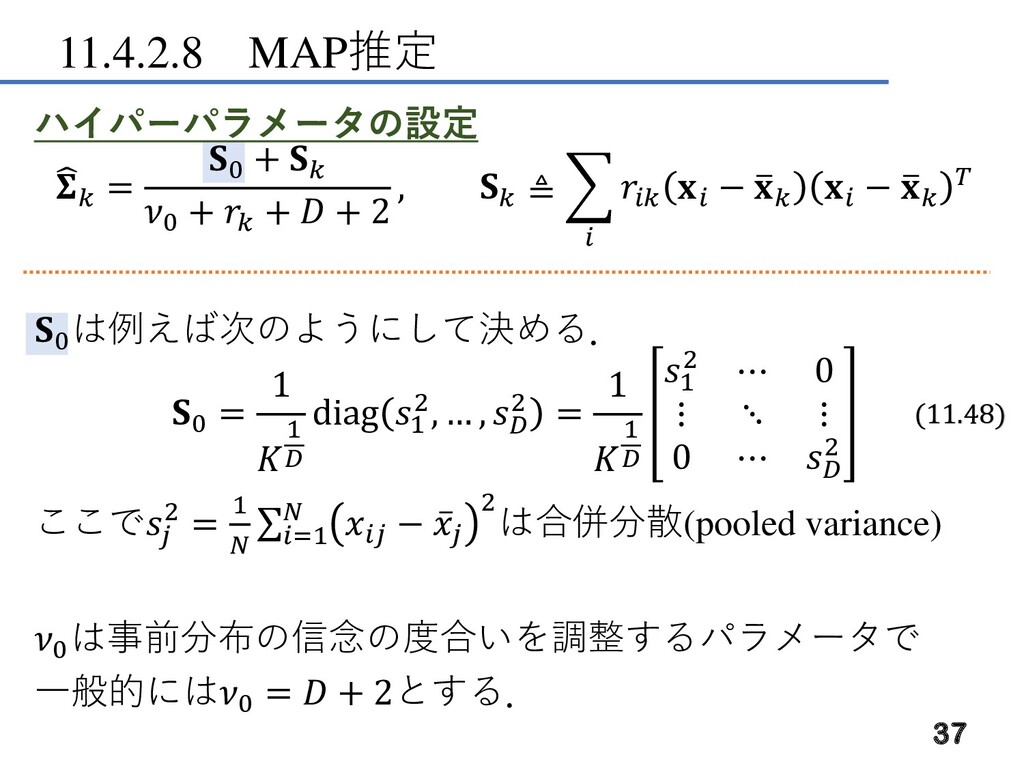
11.4.2.8 MAP推定 ハイパーパラメータの設定 = 0 + 0 + +
+ 2 , ≜ − ത − ത 0 は例えば次のようにして決める. 0 = 1 1 diag 1 2, … , 2 = 1 1 1 2 ⋯ 0 ⋮ ⋱ ⋮ 0 ⋯ 2 ここで 2 = 1 σ=1 − ҧ 2は合併分散(pooled variance) 0 は事前分布の信念の度合いを調整するパラメータで 一般的には0 = + 2とする. 37 (11.48)
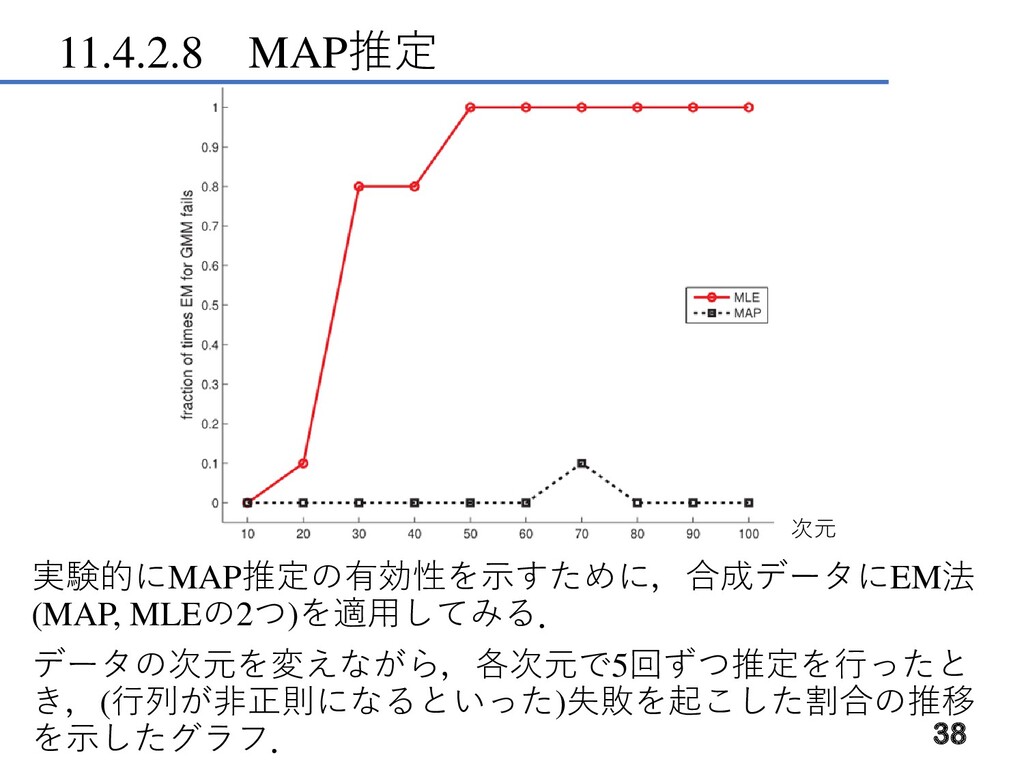
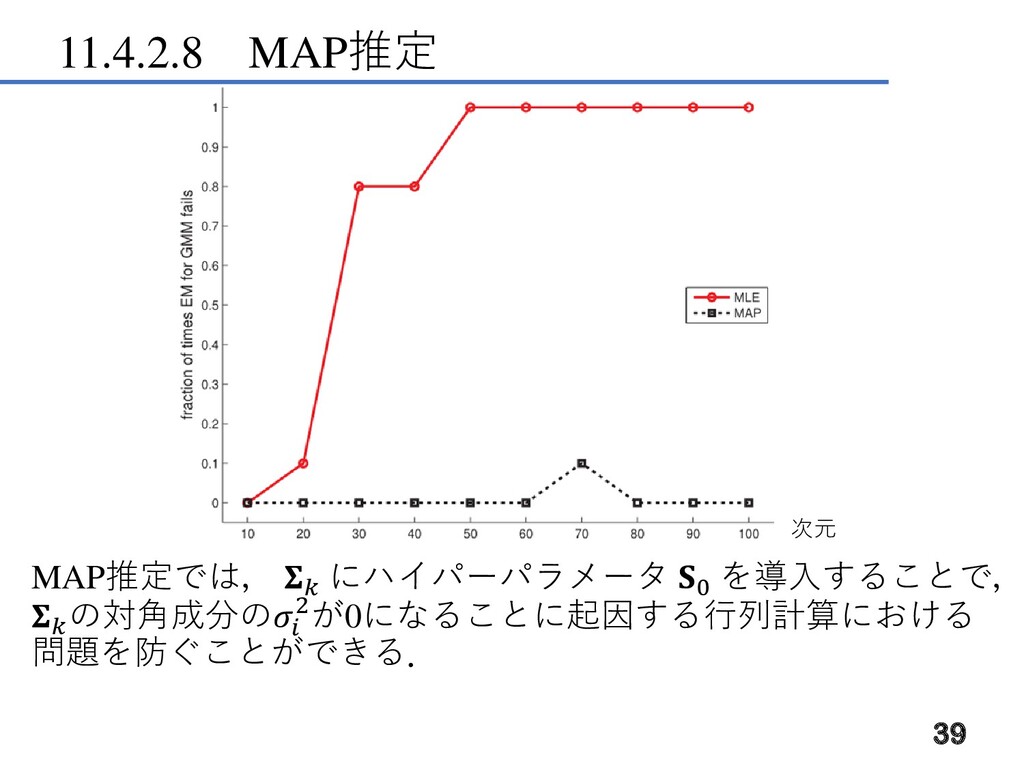
11.4.2.8 MAP推定 実験的にMAP推定の有効性を示すために,合成データにEM法 (MAP, MLEの2つ)を適用してみる. データの次元を変えながら,各次元で5回ずつ推定を行ったと き,(行列が非正則になるといった)失敗を起こした割合の推移 を示したグラフ. 38 次元
11.4.2.8 MAP推定 MAP推定では, にハイパーパラメータ 0 を導入することで, の対角成分の 2が0になることに起因する行列計算における 問題を防ぐことができる. 39
次元
11.4.3 混合エキスパートモデルのEM法 混合エキスパートモデルのフィッティングは,EM法を そのまま適用することでできる. , = =1 =1
log[ ( | , 2)] , ≜ = ( = | , ) ∝ ( | , 2 ) E stepは, を, に置き換える以外は同じである. 40 (11.49) (11.50) (11.51)
11.4.3 混合エキスパートモデルのEM法 , = =1 =1 log[ (
| , 2)] M stepでは,(, )を , 2, に関して最大化する モデルkに対する目的関数は: , = =1 − 1 2 − 2 これは重みつき最小二乗法と考えることができる. が小さいとき,モデルのパラメータ推定の際に データ点の誤差の寄与が小さくなることを示している 41 (11.52)
11.4.3 混合エキスパートモデルのEM法 , = =1 − 1 2 (
− ) この目的関数を最小化する はMLEの結果より = −1 , where k = diag(:,k ) 分散に関するMLE結果は 2 = σ =1 − 2 σ =1 42 (11.54) (11.53)
11.4.3 混合エキスパートモデルのEM法 , ≜ = ( = | , )
混合比の推定は,の推定に置き換えられ,目的関 数は次のようになる = log , これは,多項ロジスティック回帰の対数尤度と同等で ある.よって多項ロジスティック回帰と同様にを推 定することができる. 43 (11.55)
11.4.3 潜在変数つきDGMのEM法 混合エキスパートモデルにおけるEM法のアイデアを 一般化することで,DGM(有向グラフィカルモデル)の MLE, MAP推定ができる. このとき,EM法は次のようになる. E step:潜在変数を予測する M
step:予測した潜在変数をもとにMLE計算 表記を簡単にするために,条件付き確率分布(CPD)は 表形式とする.確率表は次のように計算できる , , = ෑ =1 () ෑ =1 I(=,, =) 44 (11.56)
11.4.3 潜在変数つきDGMのEM法 完全データ対数尤度は log (|) = =1 =1
() =1 log where = σ =1 I( = , , = ) この期待値は E log = ഥ log where ഥ = σ =1 E[I( = , , = )] = σ ( = , , = | ) 45 (11.57) (11.58) (11.59)
11.4.3 潜在変数つきDGMのEM法 ഥ = ( = , , =
| ) family marginal という ഥ は十分統計量の期待値で,E stepの出力である M stepは, መ = ഥ σ ′ ഥ ′ この結果はσ = 1という制約のもとラグランジュ法で 導かれる. ഥ に疑似的な観測回数(=ハイパーパラメータ)を加えれ ば,ディレクレ分布を事前分布としたMAP推定に変更す ることができる. 46 (11.59) (11.60)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![11.4.1 基本的なアイデア , −1 = E[ ()|, −1] E stepでは,Q関数を−1,](https://files.speakerdeck.com/presentations/0bf3f3abf9044ff9be9f752d8028ff0d/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
の画像は, = 512,000 bitsで表現できる K=2](https://files.speakerdeck.com/presentations/0bf3f3abf9044ff9be9f752d8028ff0d/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}