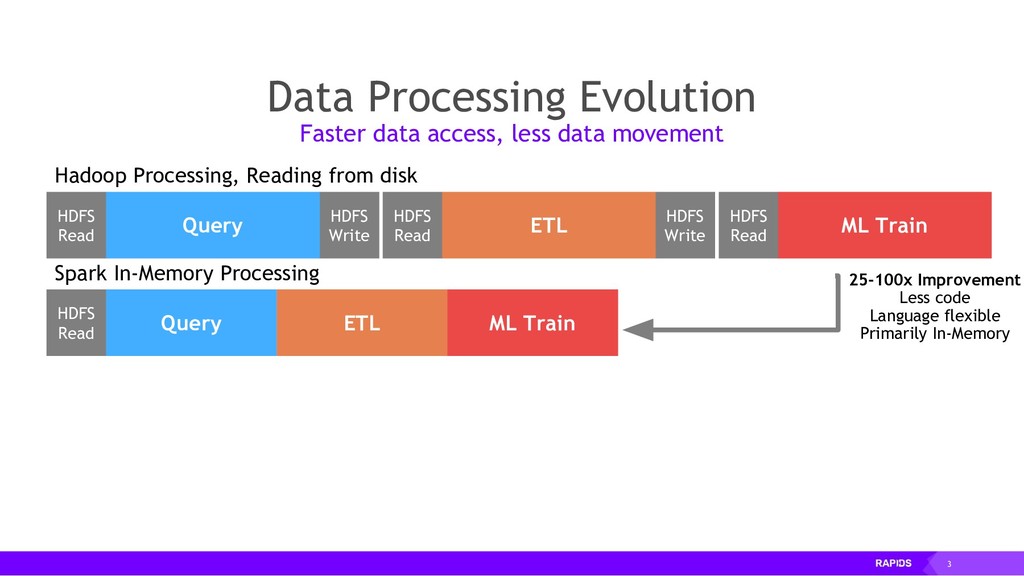
As the community of data science engineers approaches problems of increasing volume, there is a prescient concern over the timeliness of their solutions. Python has become the lingua franca for constructing simple case studies that communicate domain-specific intuition; therein, codifying a procedure to (1) build a model that apparently works on a small subset of data, (2) use conventional methods to scale that solution to a large cluster of variable size, (3) realize that the subset wasn't representative, requiring that (4) a new model be used, back to (1), and on it repeats until satisfaction is achieved. This procedure standardizes missteps and friction, whilst instilling within the community the notion that Python is not performant enough to address the great many problems ahead.
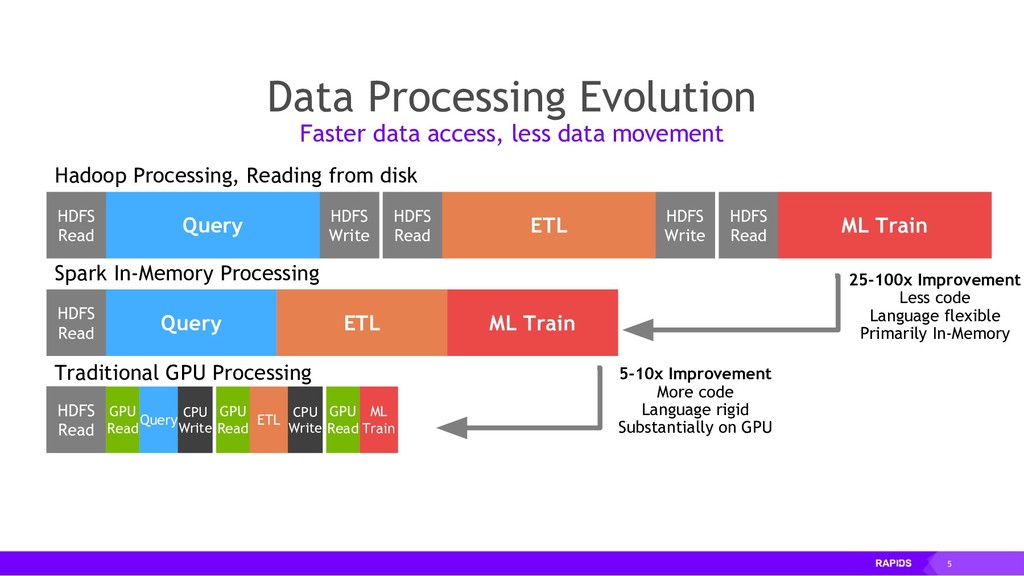
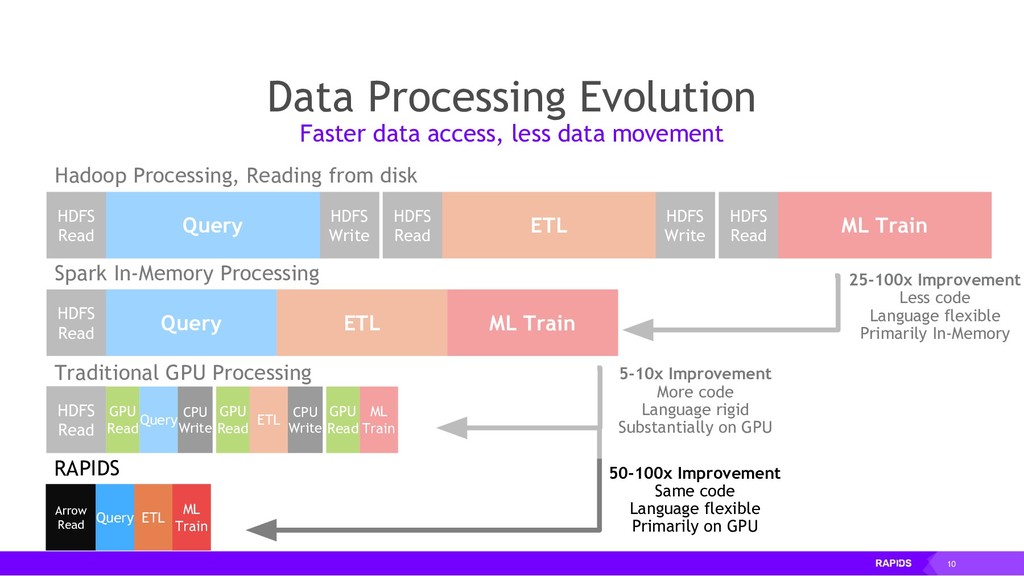
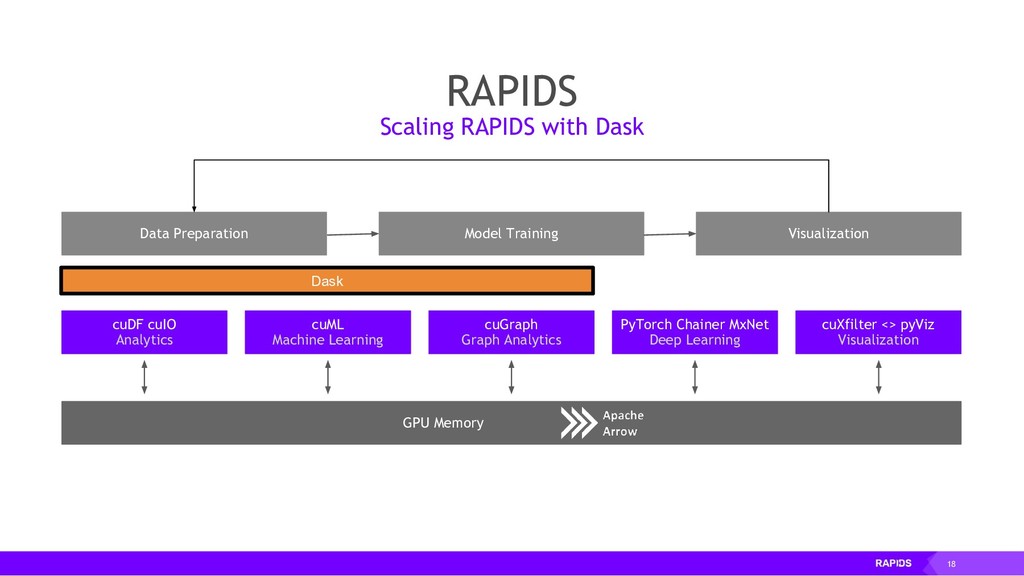
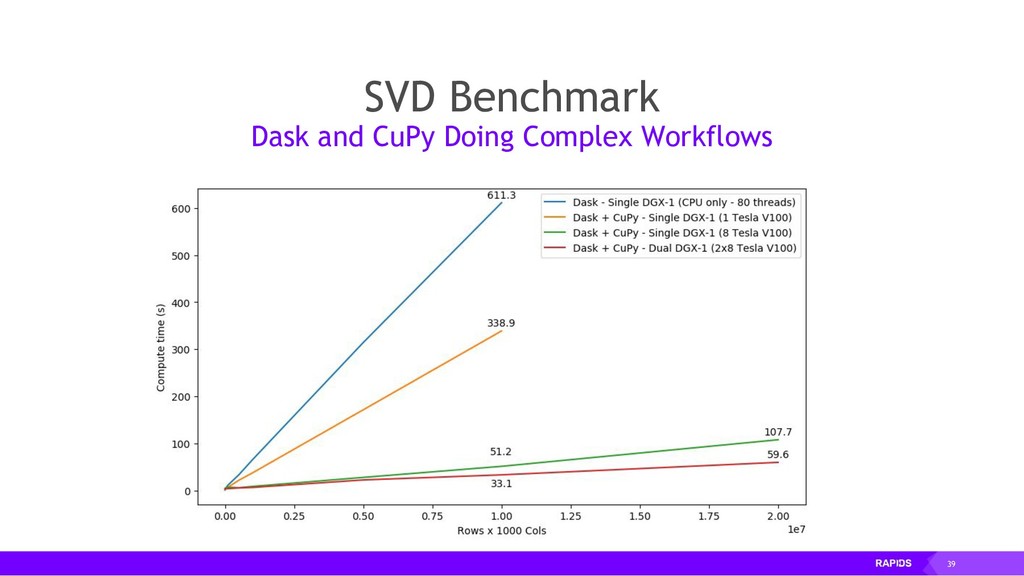
Enter RAPIDS, a platform for accelerating integrated data science. By binding efficient low-level implementations in CUDA C/C++ to Python, and by using Dask's elastic scaling model, a data scientist may now employ a two-step procedure that is many times faster than conventional methods: (1) construct a prototypical solution based on a small subset of data, and (2) deploy the same code on a large cluster of variable size, repeating until the right features are engineered.
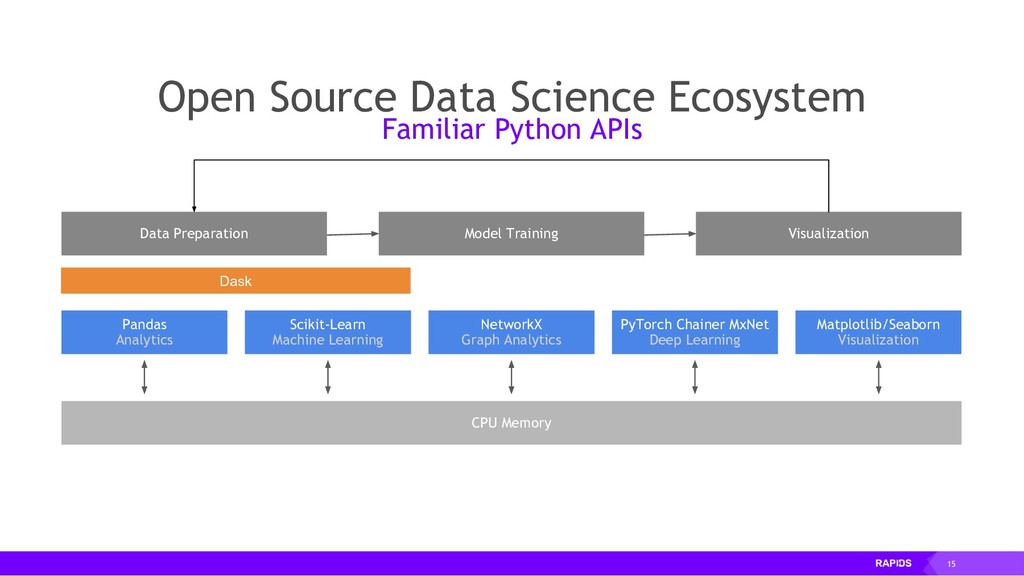
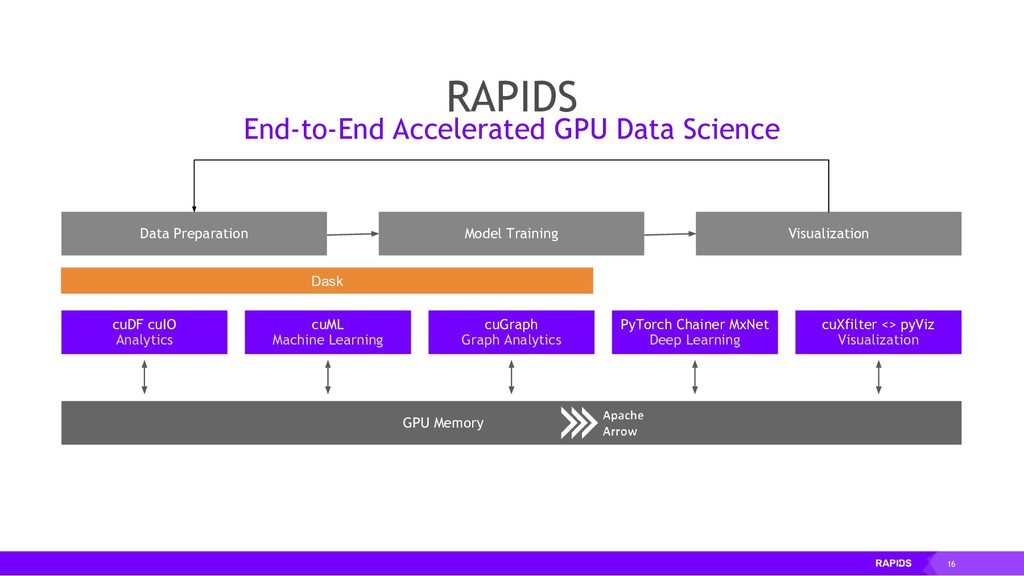
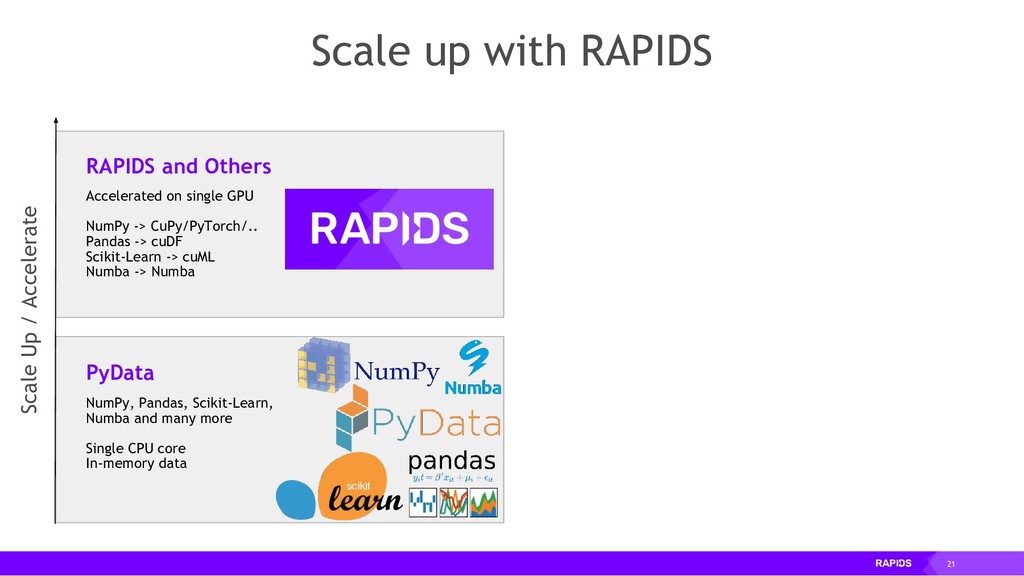
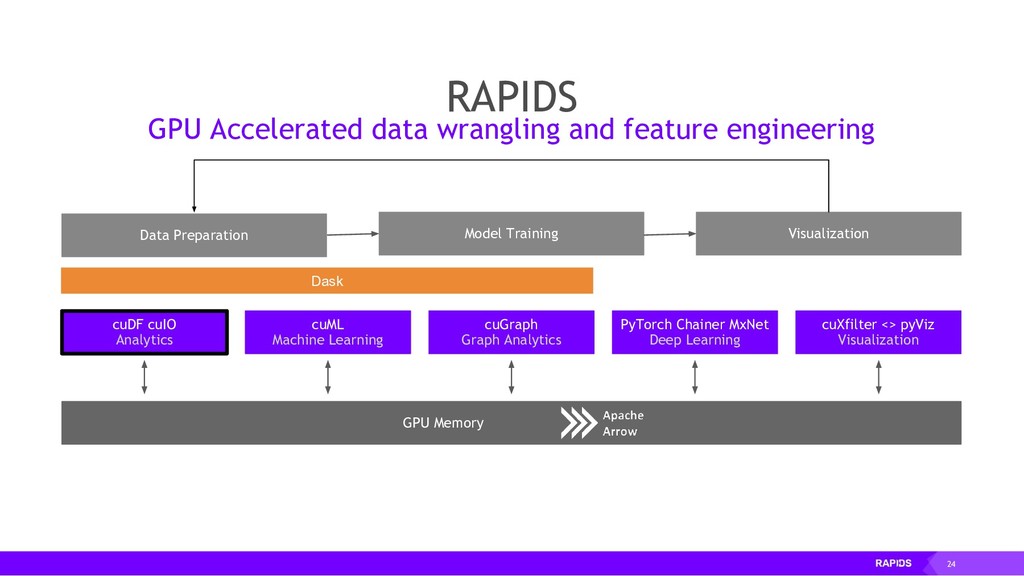
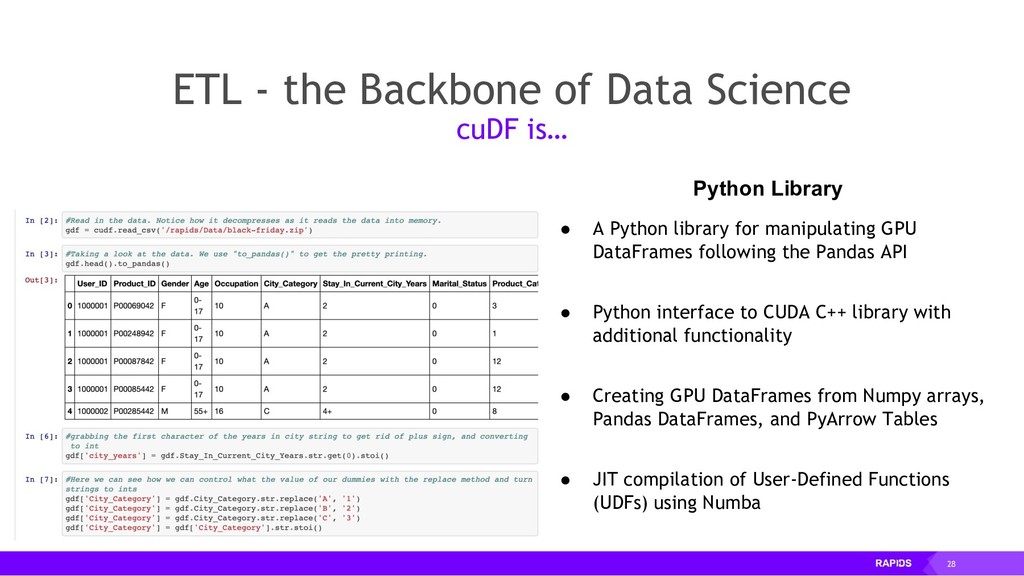
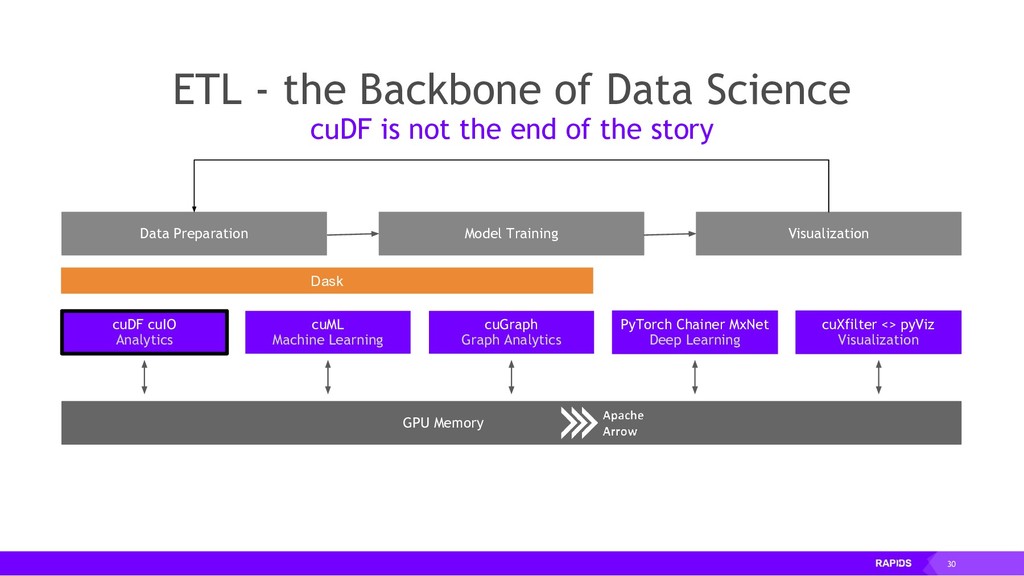
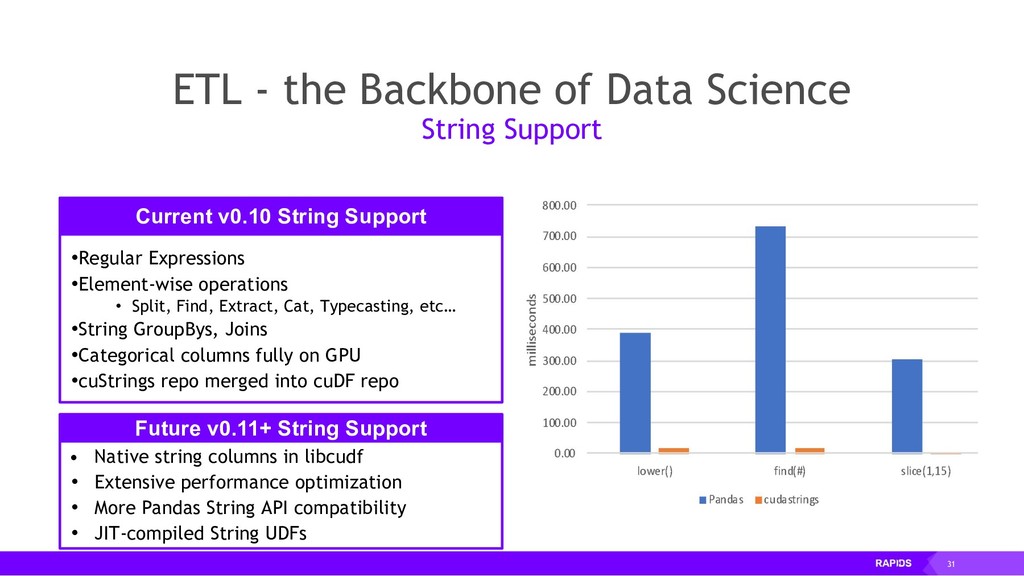
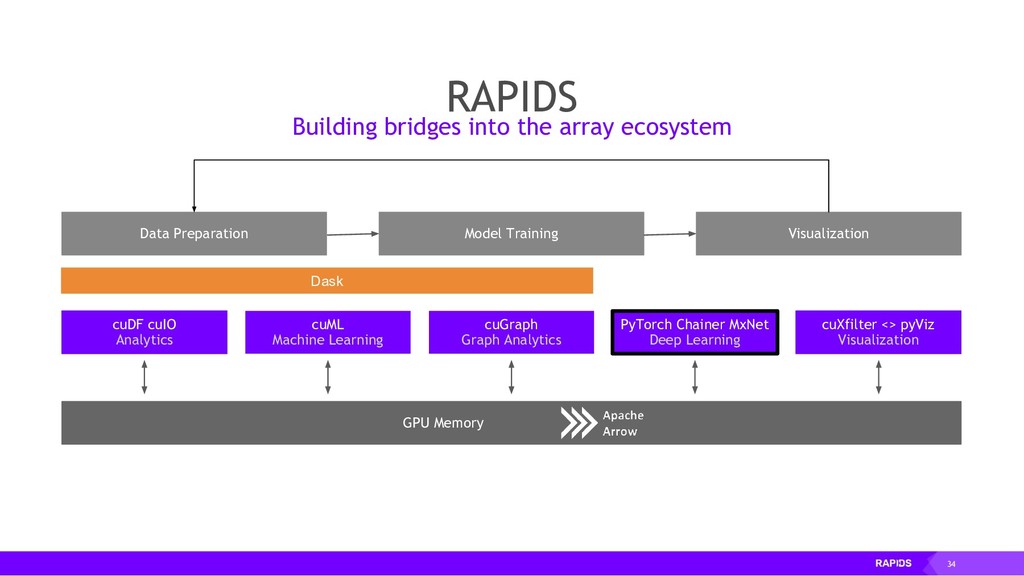
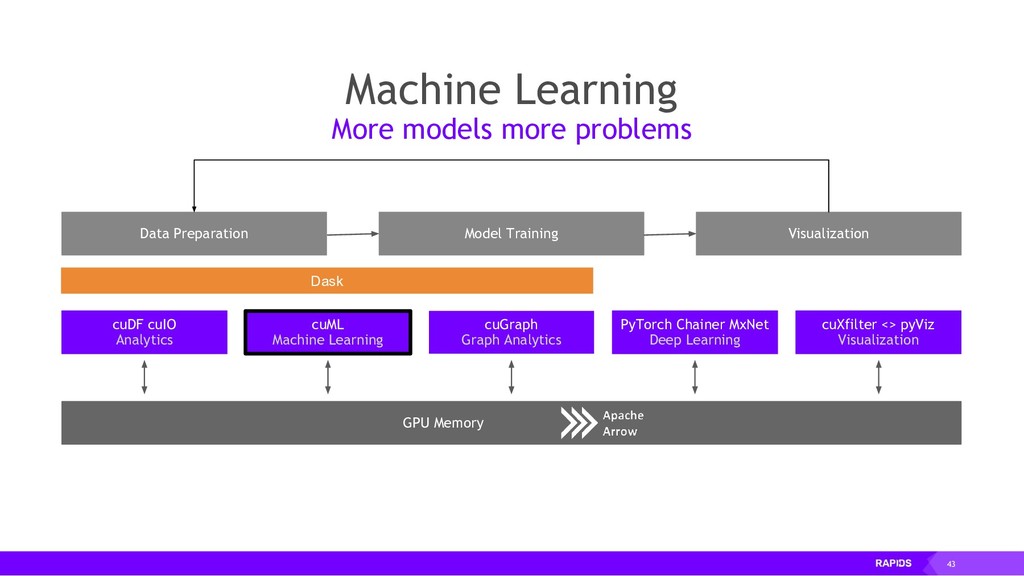
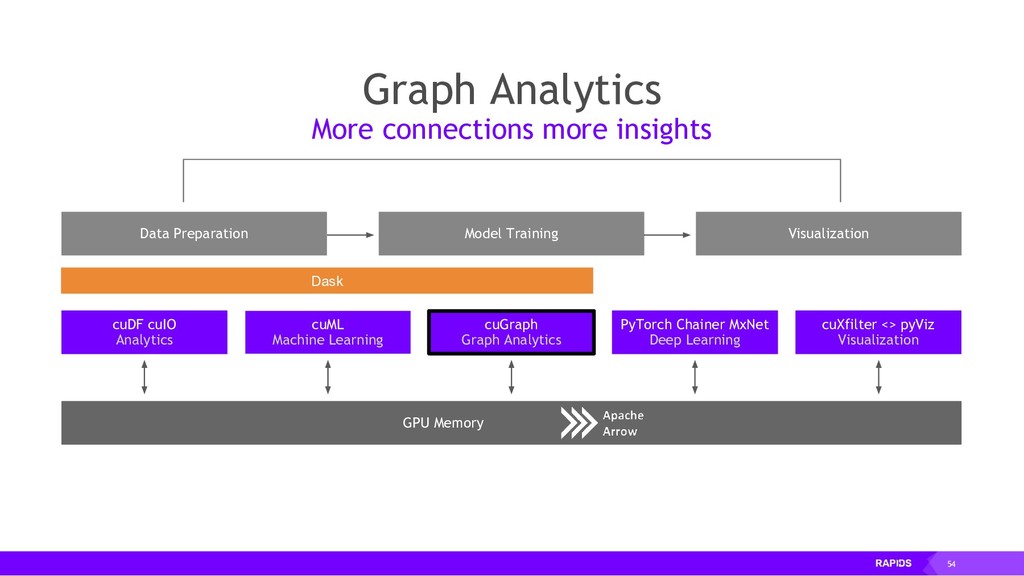
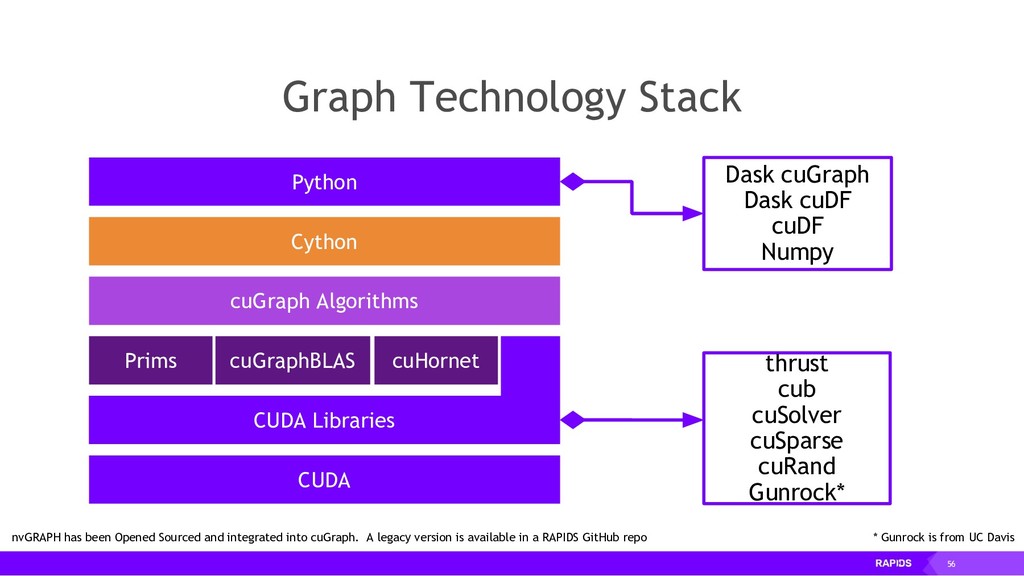
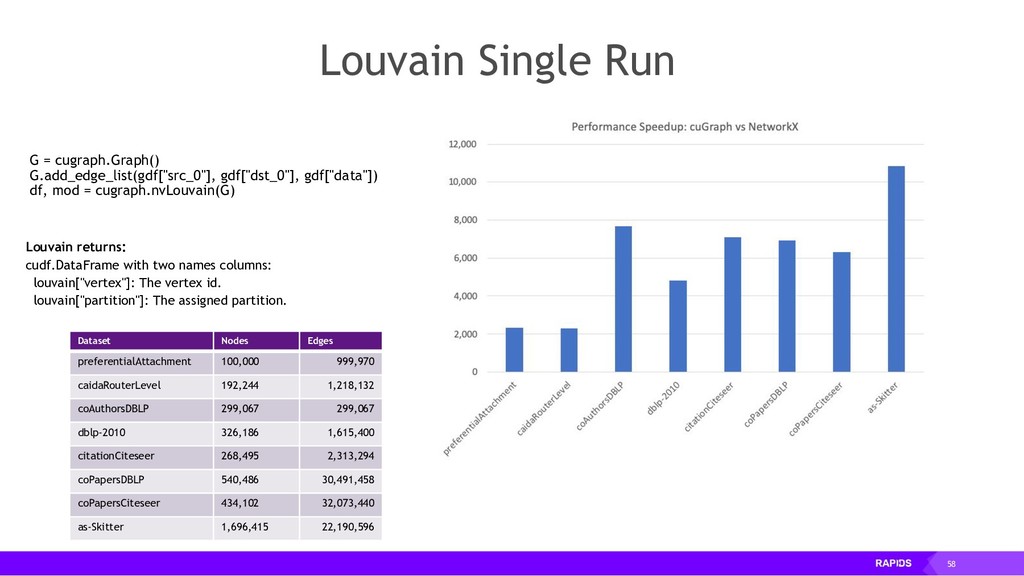
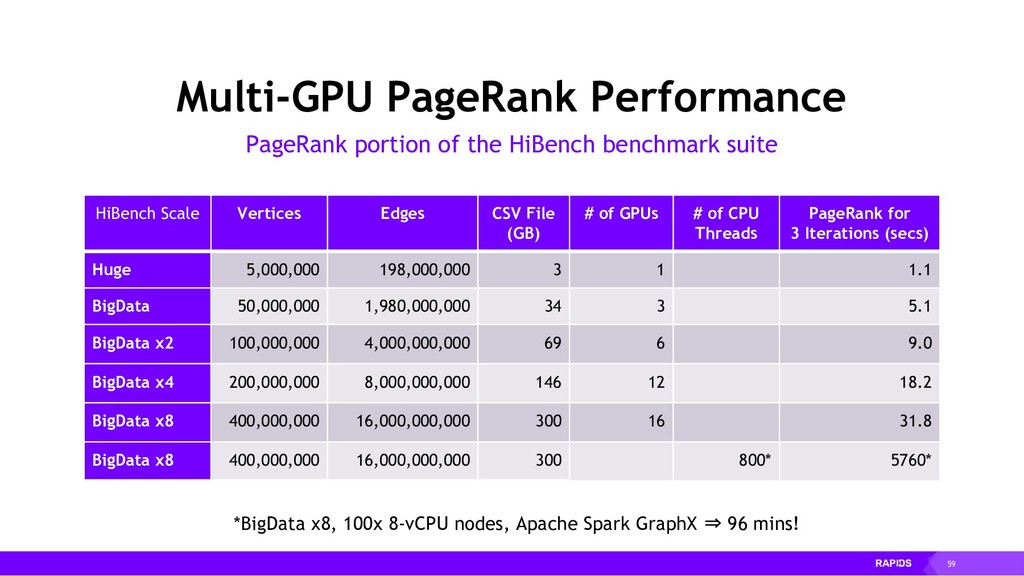
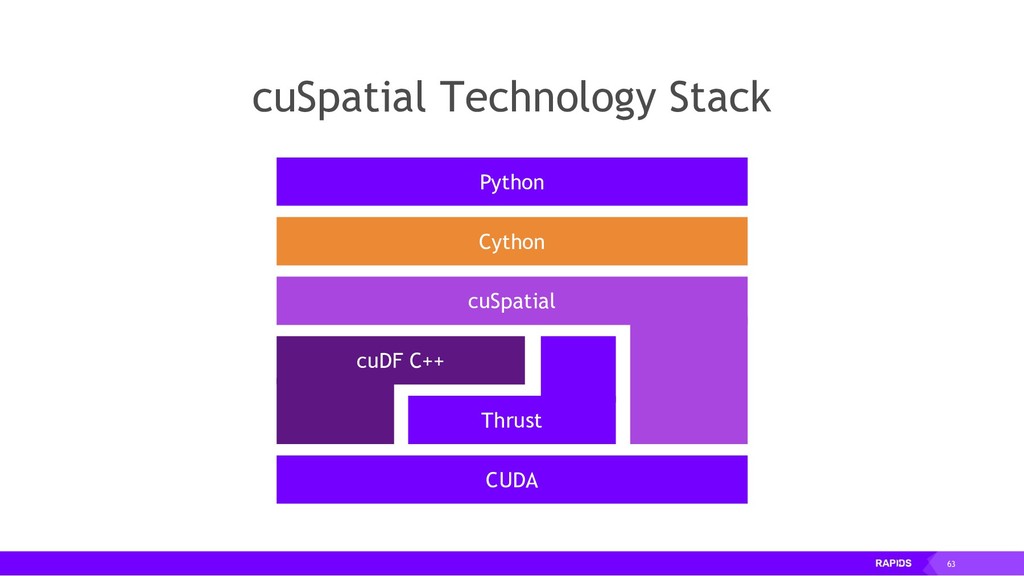
RAPIDS is a collection of open-source libraries fostered by Nvidia, and based on years of accelerated analytics experience. RAPIDS leverages low-level implementations in CUDA, optimizing for massive parallelism, high-bandwidth, and maintaining a focused user-friendly Python interface. Chiefly, we concern ourselves with API parity with respect to Pandas and Scikit-Learn; meaning, a data scientist that knows Pandas and Scikit-Learn will have an easy time getting up to speed with RAPIDS. RAPIDS maintains and contributes to many libraries, including cuDF, a GPU DataFrame library with Pandas parity; cuML, a GPU machine learning library with Scikit-Learn parity; cuGRAPH, a GPU graph library with NetworkX parity; cuXFilter, a GPU cross-filter library, a browser-based cross-filtering solution for visualizing feature data in-memory; and Dask-cuDF, a library for distributed CUDA DataFrame objects. RAPIDS also contributes to libraries for elastic compute and machine learning: Dask, XGBoost, with many more to come.
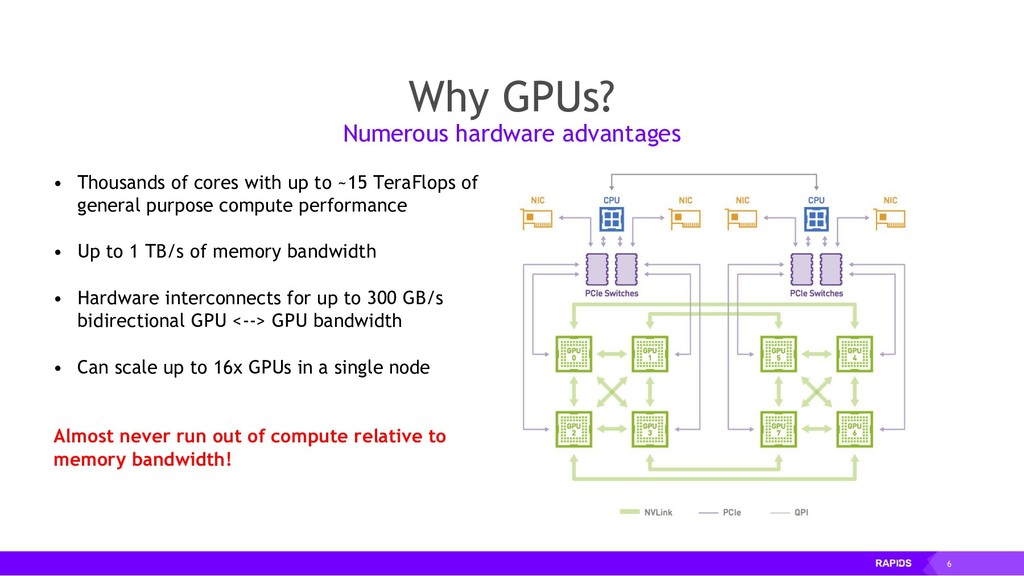
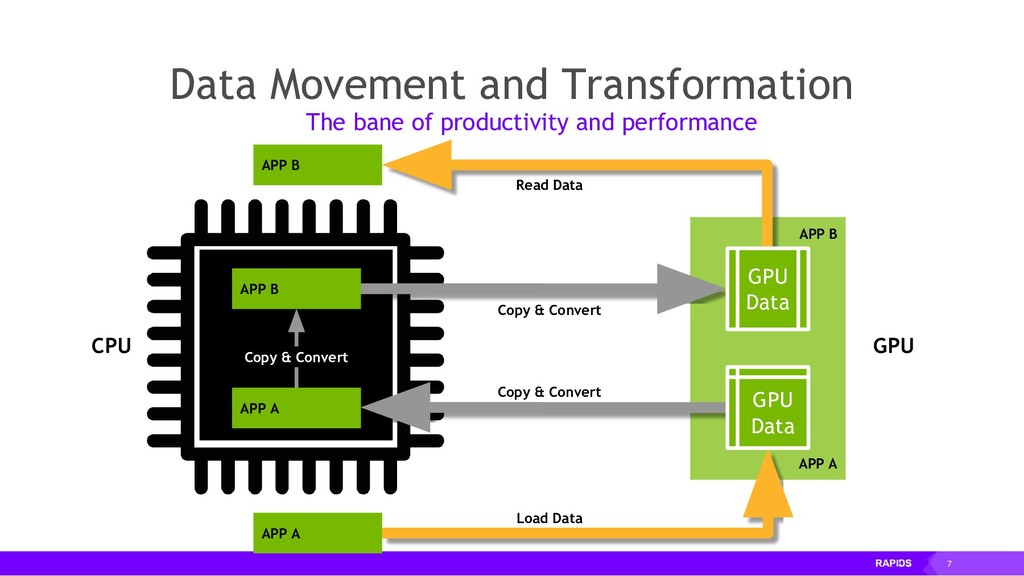
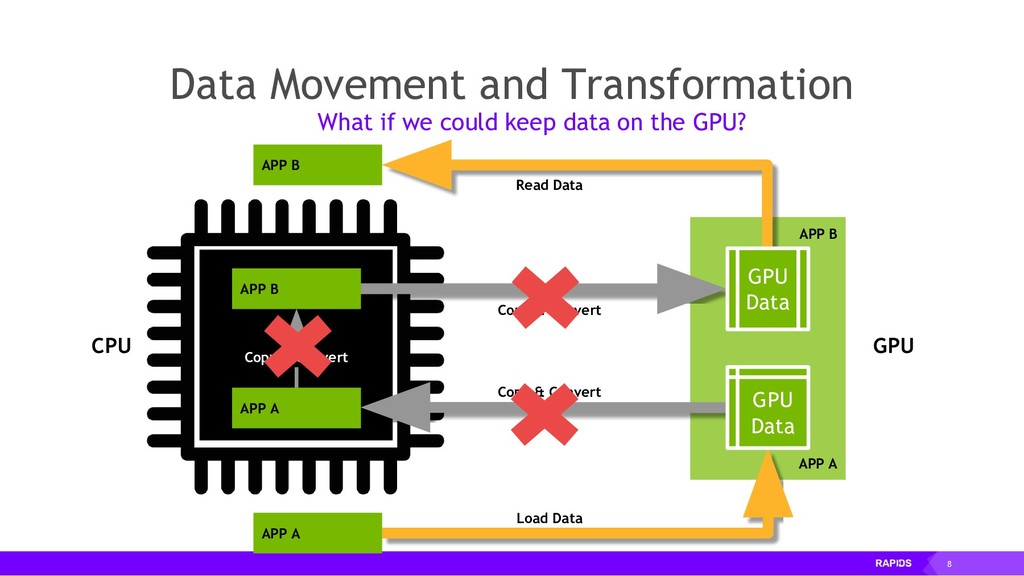
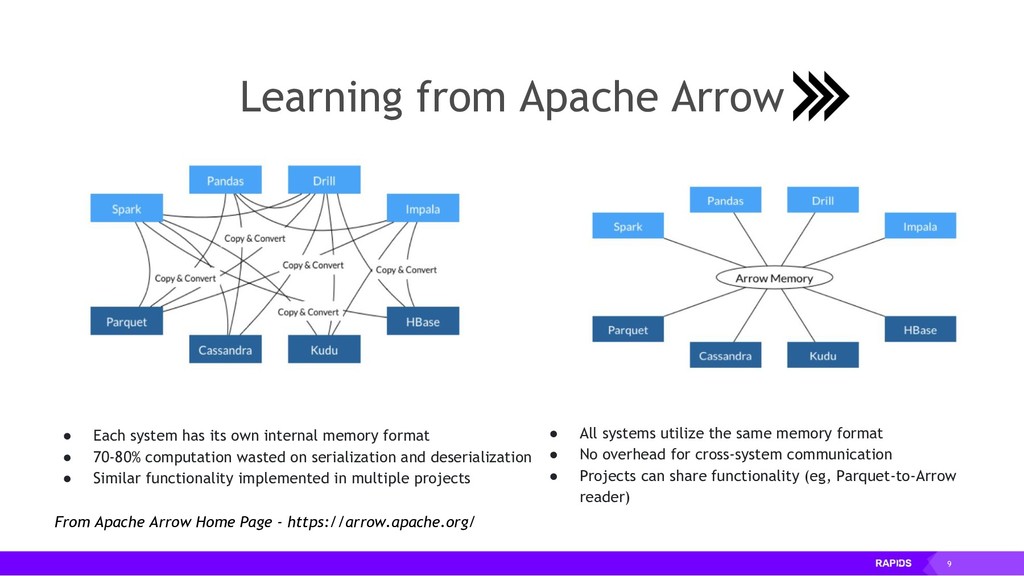
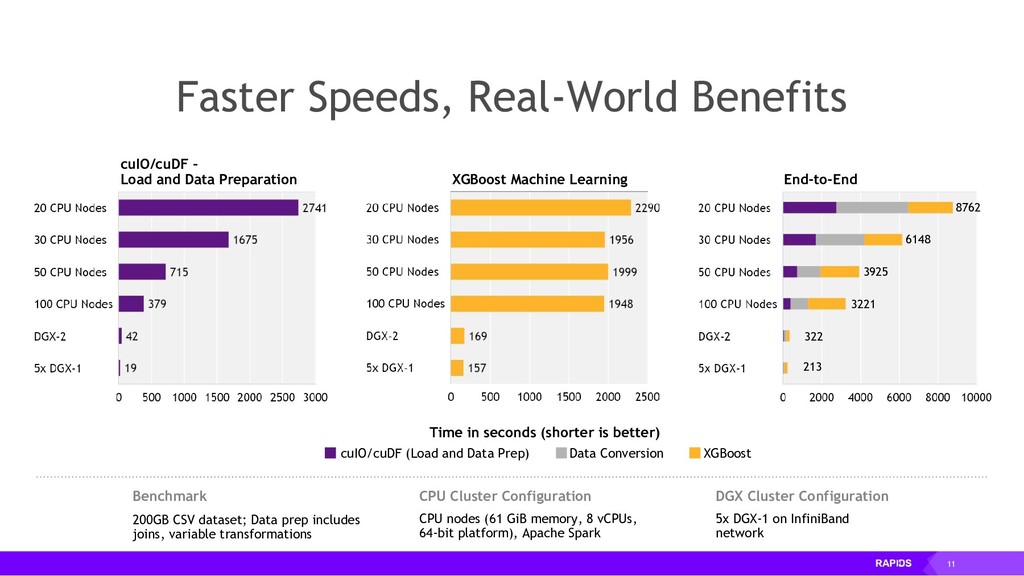
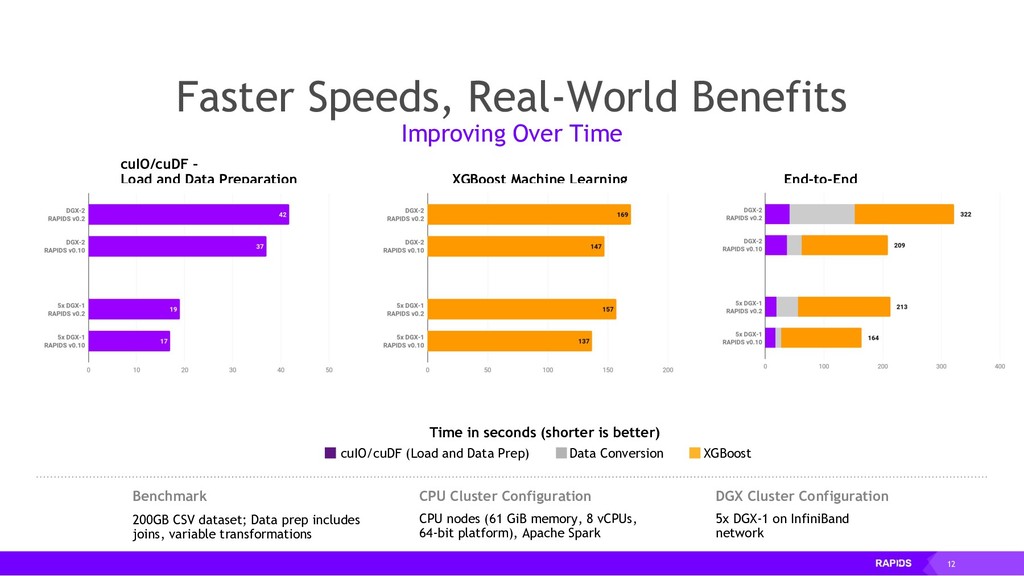
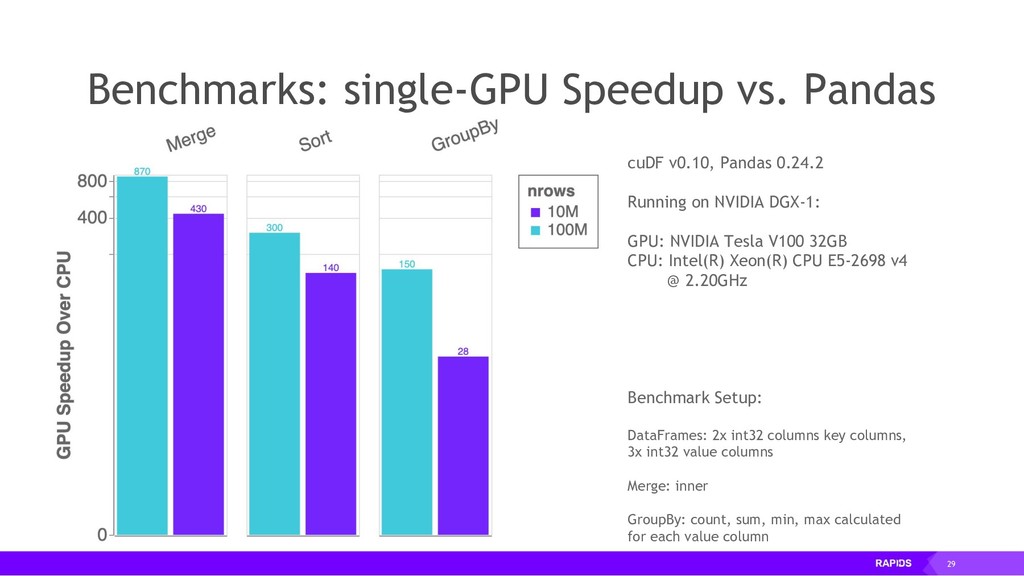
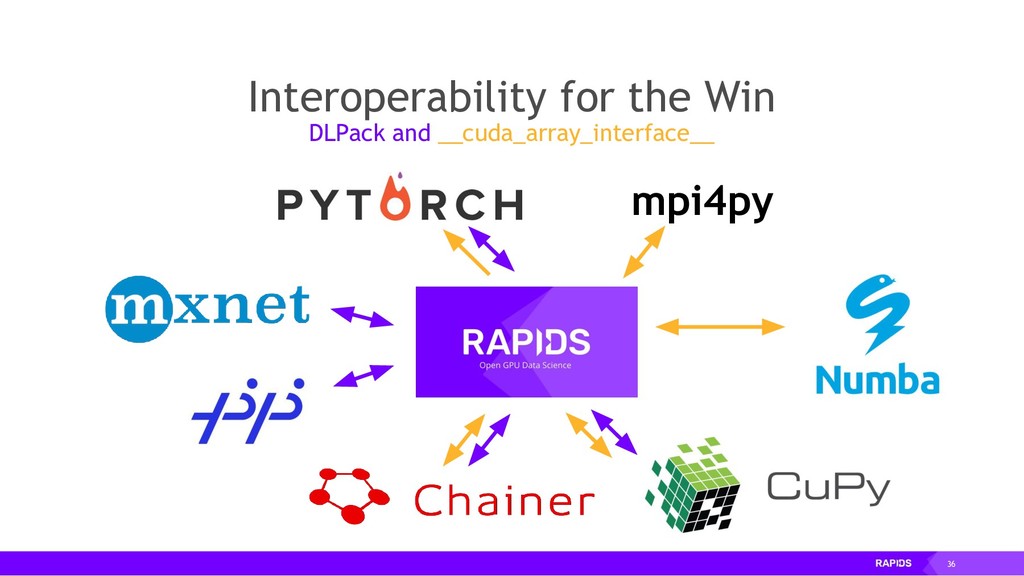
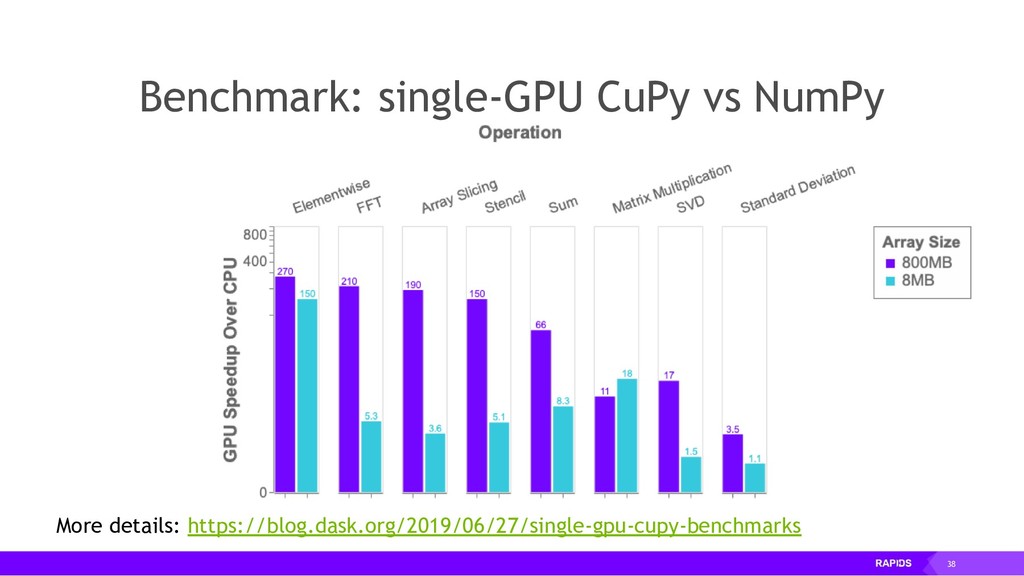
By accelerating the entire ecosystem with CUDA, RAPIDS benefits from incredible acceleration over state-of-the-art CPU implementations and conventional methods. Even better, RAPIDS is committed to the community with its API-parity approach, and with its Apache Arrow compliance. This eliminates inefficient glue-code, and makes it easier for the RAPIDS ecosystem to interoperate with other external libraries.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU Keith Kraus @keithjkraus [email protected]](https://files.speakerdeck.com/presentations/d0d215d0925b41e3809dadd57a70f95b/slide_82.jpg){kind=link}