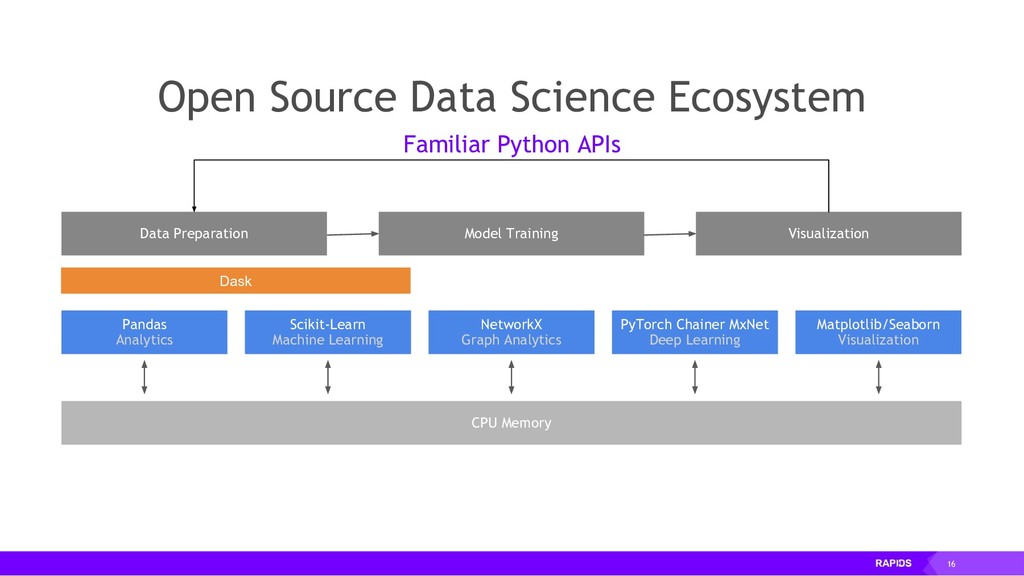
The Python data science stack is composed of a rich set of powerful libraries that work wonderfully well together, providing coherent, beautiful, Pythonic APIs that let the Data Scientist think less about programming and more about the data. However, many of these libraries are largely single_threaded (e.g., Pandas, Scikit-Learn), and as data workflows grow larger, they quickly run up against this limitation. RAPIDS is a suite of open-source libraries that provide APIs nearly identical to existing popular Python libraries. By leveraging the massively parallel processing capabilities of GPUs, RAPIDS libraries can provide speedups of 50x or more over their purely-CPU counterparts. cuDF is a GPU DataFrame library following the Pandas API. cuML is a GPU Machine Learning library following the Scikit-Learn API. cuGraph is a GPU Graph Analytics library with an API inspired by NetworkX. This talk will provide an overview of the RAPIDS ecosystem, with a focus on the cuDF library, its features and design. We'll show how cuDF combines the use of Numba, Cython, modern C++, CUDA, and Apache Arrow to build a highly performant DataFrame library that is also highly interoperable with other libraries in the PyData ecosystem. We'll show examples of workflows using cuDF both on a single GPU, and across multiple GPUs in conjunction with the Dask library. We'll also share some performance results, best practices, tips, and tricks.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![23 GPU-Accelerated ETL In [1]: import cudf In [2]: cudf.set_allocator(pool=True)](https://files.speakerdeck.com/presentations/b4abeaf3cf80412199f0a899a58bc915/slide_22.jpg){kind=link}
![24 GPU-Accelerated ETL In [1]: import cudf In [2]: cudf.set_allocator(pool=True)](https://files.speakerdeck.com/presentations/b4abeaf3cf80412199f0a899a58bc915/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANK YOU Ashwin Srinath and Keith Kraus @keithjkraus [email protected] [email protected]](https://files.speakerdeck.com/presentations/b4abeaf3cf80412199f0a899a58bc915/slide_45.jpg){kind=link}