This slide deck was used to introduce to the audience the concept of Data Science as well as introducing Amazon Sagemaker as a tool for building, training, and deploying ML models.
The meetup also includes a Demo and a hands-on activity.
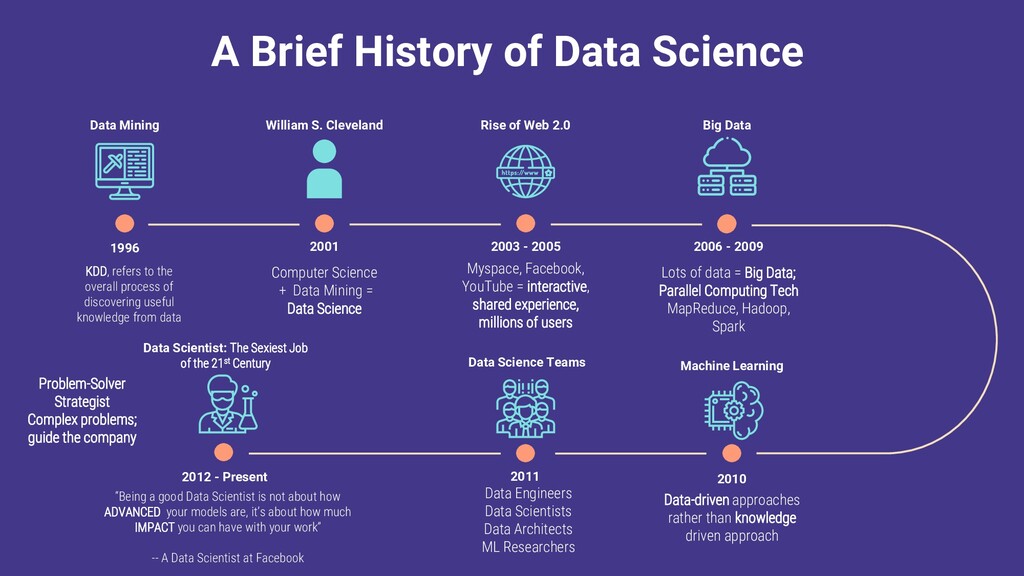
the overall process of discovering useful knowledge from data Data Mining 2001 William S. Cleveland Computer Science + Data Mining = Data Science Rise of Web 2.0 2003 - 2005 Myspace, Facebook, YouTube = interactive, shared experience, millions of users Big Data 2006 - 2009 Lots of data = Big Data; Parallel Computing Tech MapReduce, Hadoop, Spark Machine Learning 2010 Data-driven approaches rather than knowledge driven approach Data Science Teams Data Engineers Data Scientists Data Architects ML Researchers 2011 Data Scientist: The Sexiest Job of the 21st Century 2012 - Present Problem-Solver Strategist Complex problems; guide the company “Being a good Data Scientist is not about how ADVANCED your models are, it’s about how much IMPACT you can have with your work” -- A Data Scientist at Facebook
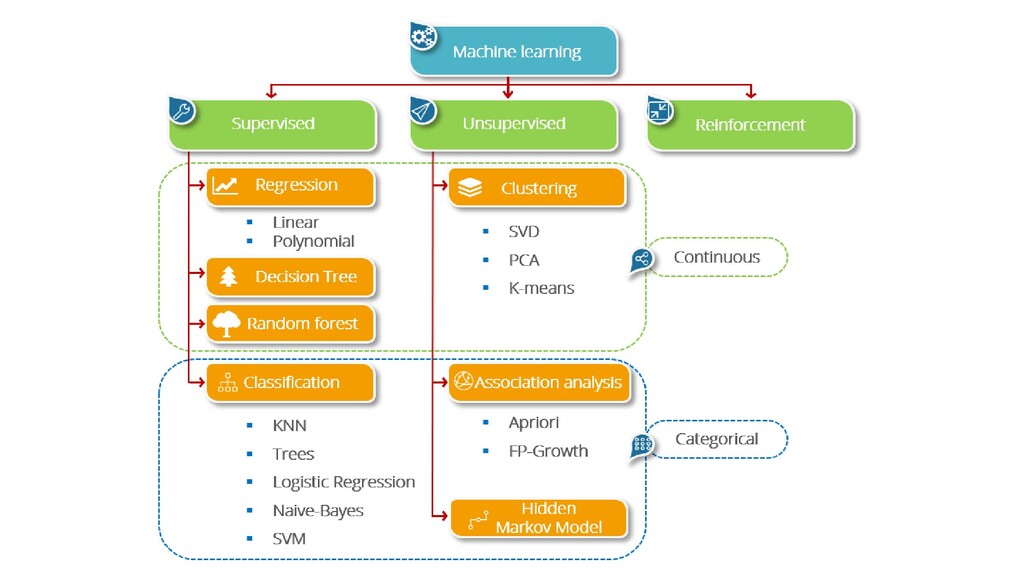
program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.“ A subfield of artificial intelligence. • goal is to enable computers to learn on their own. • A machine’s learning algorithm enables it to identify patterns in observed data, build models that explain the world, and predict things without having explicit pre- programmed rules and models
• consider the learning is guided by a teacher • dataset acts as a teacher and its role is to train the model or the machine • can start making a prediction or decision when new data is given to it. • Unsupervised Learning – I am self sufficient in learning • learns through observation and finds structures in the data • automatically finds patterns and relationships in the dataset by creating clusters in it • what it cannot do is add labels to the cluster, like it cannot say this a group of apples or mangoes, but it will separate all the apples from mangoes • Reinforcement Learning – My life My rules! (Hit & Trial) • it is the ability of an agent to interact with the environment and find out what is the best outcome. It follows the concept of hit and trial method • agent is rewarded or penalized with a point for a correct or a wrong answer, and on the basis of the positive reward points gained the model trains itself
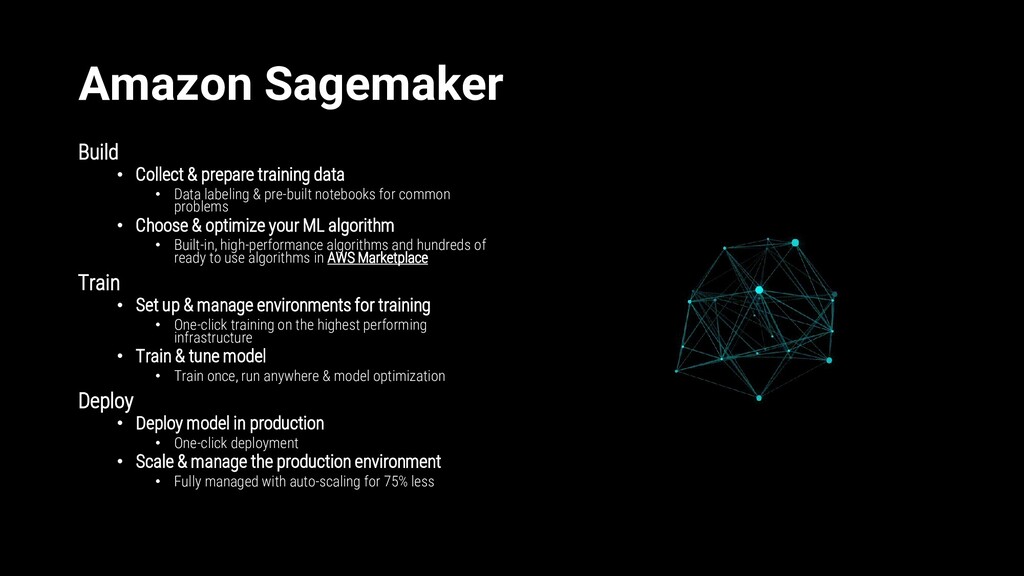
Data labeling & pre-built notebooks for common problems • Choose & optimize your ML algorithm • Built-in, high-performance algorithms and hundreds of ready to use algorithms in AWS Marketplace Train • Set up & manage environments for training • One-click training on the highest performing infrastructure • Train & tune model • Train once, run anywhere & model optimization Deploy • Deploy model in production • One-click deployment • Scale & manage the production environment • Fully managed with auto-scaling for 75% less
the tone of that text is positive, negative, or neutral Common Use Cases: Track Customer Sentiment vs. Time Determine Which Customer Segments Have the Strongest Opinions Planning Product Improvements Determine the Most Effective Communication Channels Prioritize Customer Service Issues
either classification or regression problems Input Data: x is a high-dimensional vector y is a numeric label algorithm learns a linear function, or, for classification problems, a linear threshold function, and maps a vector x to an approximation of the label y
of the gradient boosted trees algorithm a supervised learning algorithm that attempts to accurately predict a target variable by combining an ensemble of estimates from a set of simpler, weaker models Famous for its flexibility and ability to robustly handle a variety of data types widely used in data science competitions like Kaggle
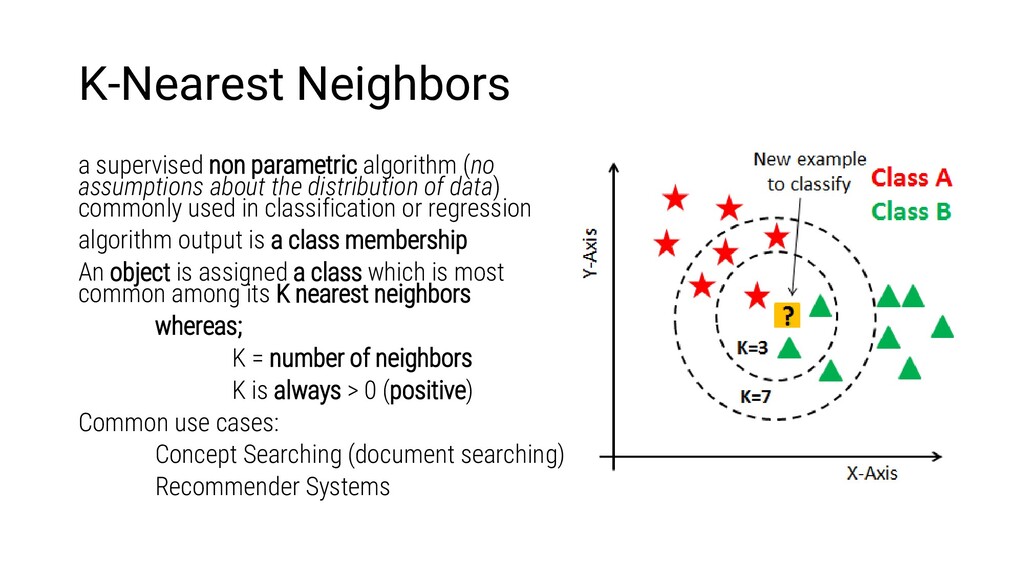
the distribution of data) commonly used in classification or regression algorithm output is a class membership An object is assigned a class which is most common among its K nearest neighbors whereas; K = number of neighbors K is always > 0 (positive) Common use cases: Concept Searching (document searching) Recommender Systems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}