Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Iceberg で Amazon Athena をデータウェアハウスぽく使おう
Search
Niino
June 14, 2024
8.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Iceberg で Amazon Athena をデータウェアハウスぽく使おう
2024/6/12「クラメソおおさか IT 勉強会 Midosuji Tech #1」で登壇した内容です。
Niino
June 14, 2024
More Decks by Niino
See All by Niino
祝!Iceberg祭開幕!re:Invent 2024データレイク関連アップデート10分総ざらい
kniino
4
1.1k
Amazon Personalizeの レコメンドシステム構築、実際何するの? 〜大体10分で具体的なイメージをつかむ〜
kniino
1
950
〜小さく始めて大きく育てる〜データ分析基盤の開発から活用まで
kniino
1
3.4k
20分で大体わかる! AWS Glue Data Qualityによる データ品質検査
kniino
0
31k
ダッシュボードもコード管理!Amazon QuickSightで考えるBIOps
kniino
0
3.3k
Featured
See All Featured
Making Projects Easy
brettharned
120
6.7k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
720
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Context Engineering - Making Every Token Count
addyosmani
9
1k
The agentic SEO stack - context over prompts
schlessera
0
850
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
How GitHub (no longer) Works
holman
316
150k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
970
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Transcript
Iceberg で Amazon Athena を データウェアハウスぽく使おう クラメソおおさか IT 勉強会 Midosuji
Tech #1 「クラメソエンジニアが語る AWS 使いこなしテク」 niino 1
⾃⼰紹介 niino(@kniino1234) • データアナリティクス事業本部 インテグレーション部 機械学習チーム ◦ 2023 Japan AWS
Top Engineer(Analytics) • 最近の⾼い買い物︓ベース • 奈良県出⾝ ⼤阪オフィス所属 この辺の出身
3 今日話すこと • Icebergとは • データレイクとデータウェアハウス • テーブルフォーマットとは • Athenaで使うIceberg
• スキーマ(Schema Evolution) • パーティション
4 Icebergとは
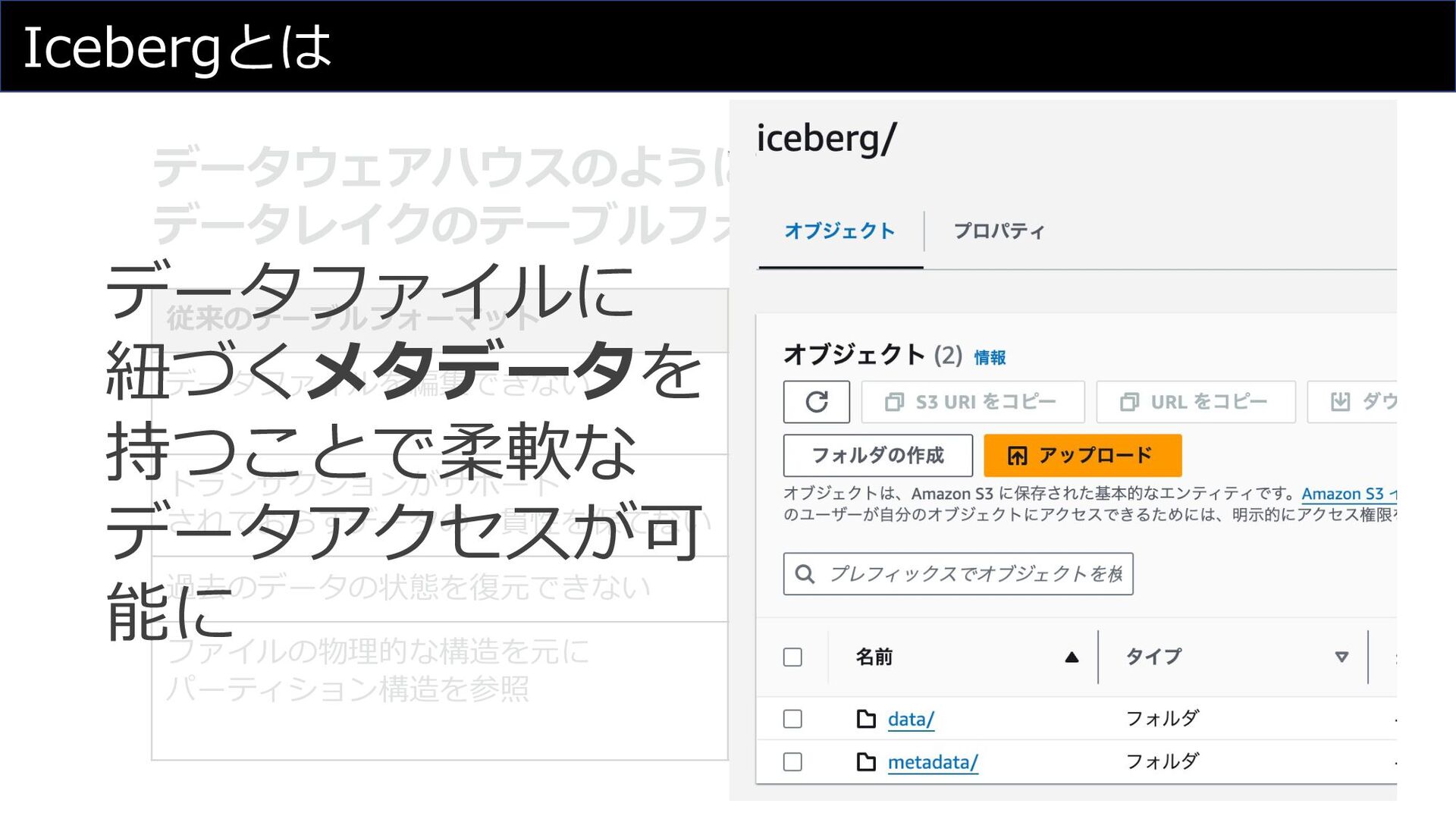
Icebergとは データウェアハウスのように使える データレイクのテーブルフォーマット
6 データレイクとデータウェアハウス
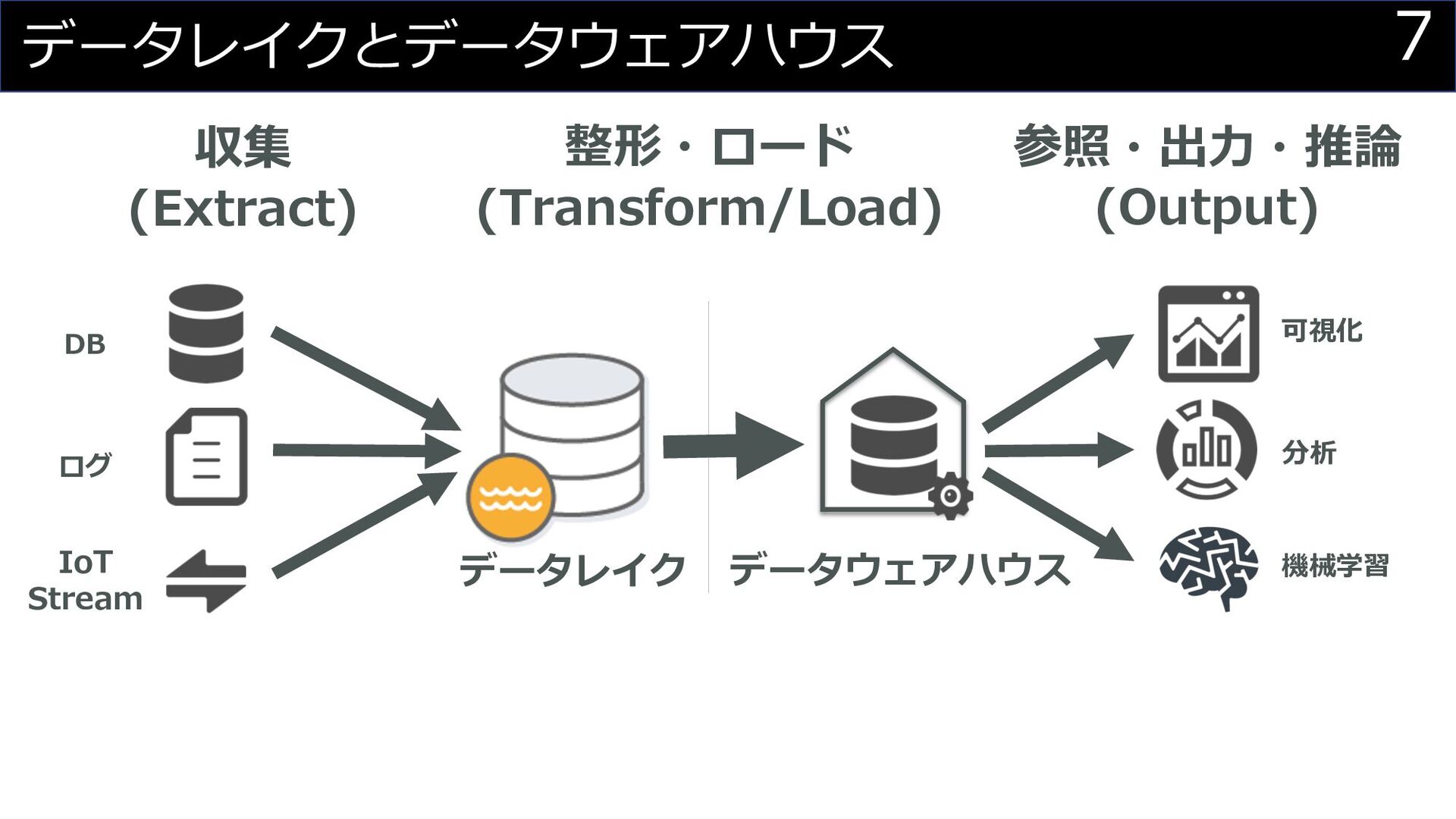
DB ログ IoT Stream データレイク 収集 (Extract) 整形・ロード (Transform/Load) 参照・出⼒・推論
(Output) 可視化 分析 機械学習 データウェアハウス データレイクとデータウェアハウス 7
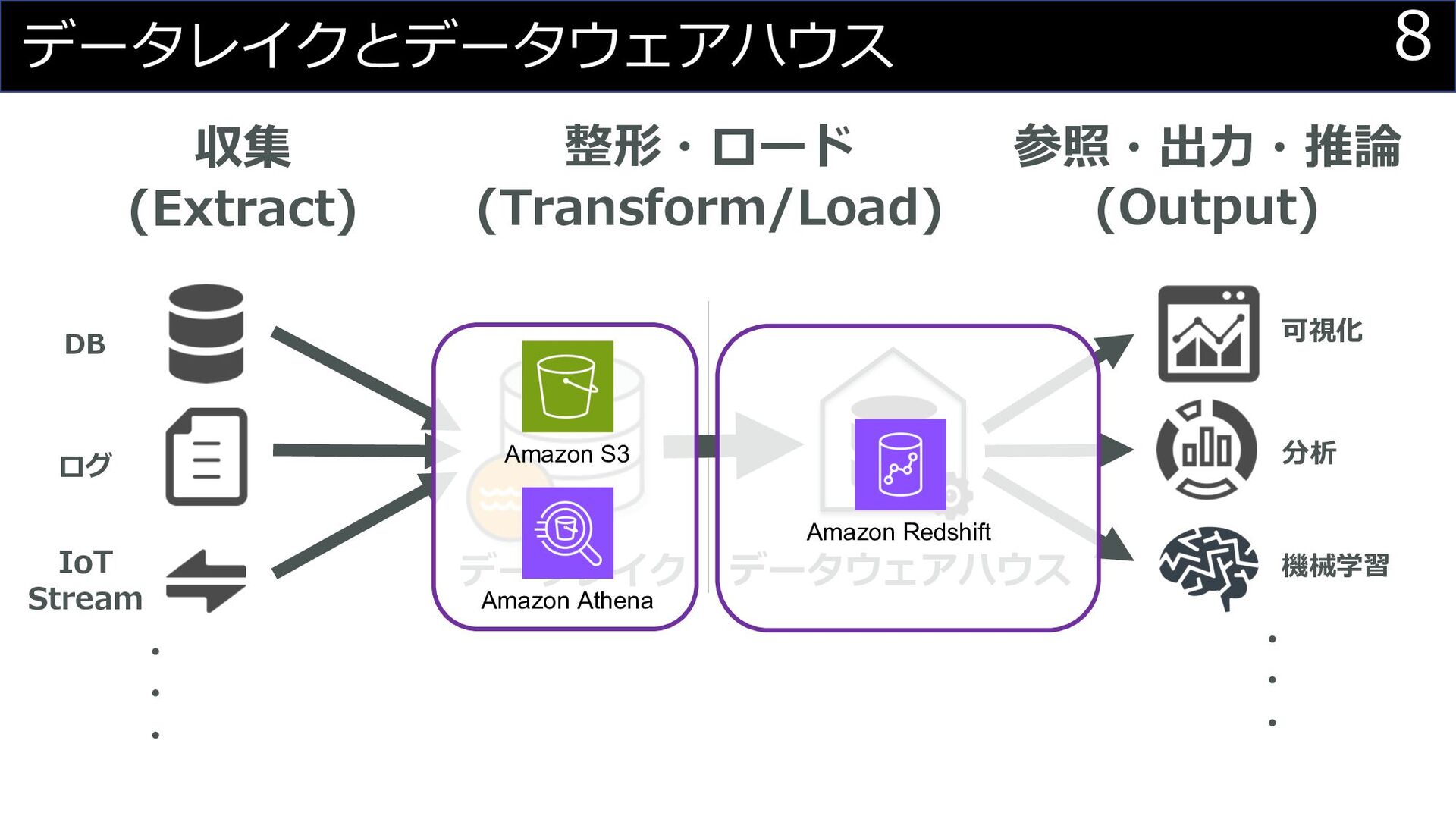
DB ログ IoT Stream データレイク 収集 (Extract) 整形・ロード (Transform/Load) 参照・出⼒・推論
(Output) 可視化 分析 機械学習 データウェアハウス ・ ・ ・ ・ ・ ・ データレイクとデータウェアハウス 8 Amazon Redshift Amazon Athena Amazon S3
9 テーブルフォーマットとは
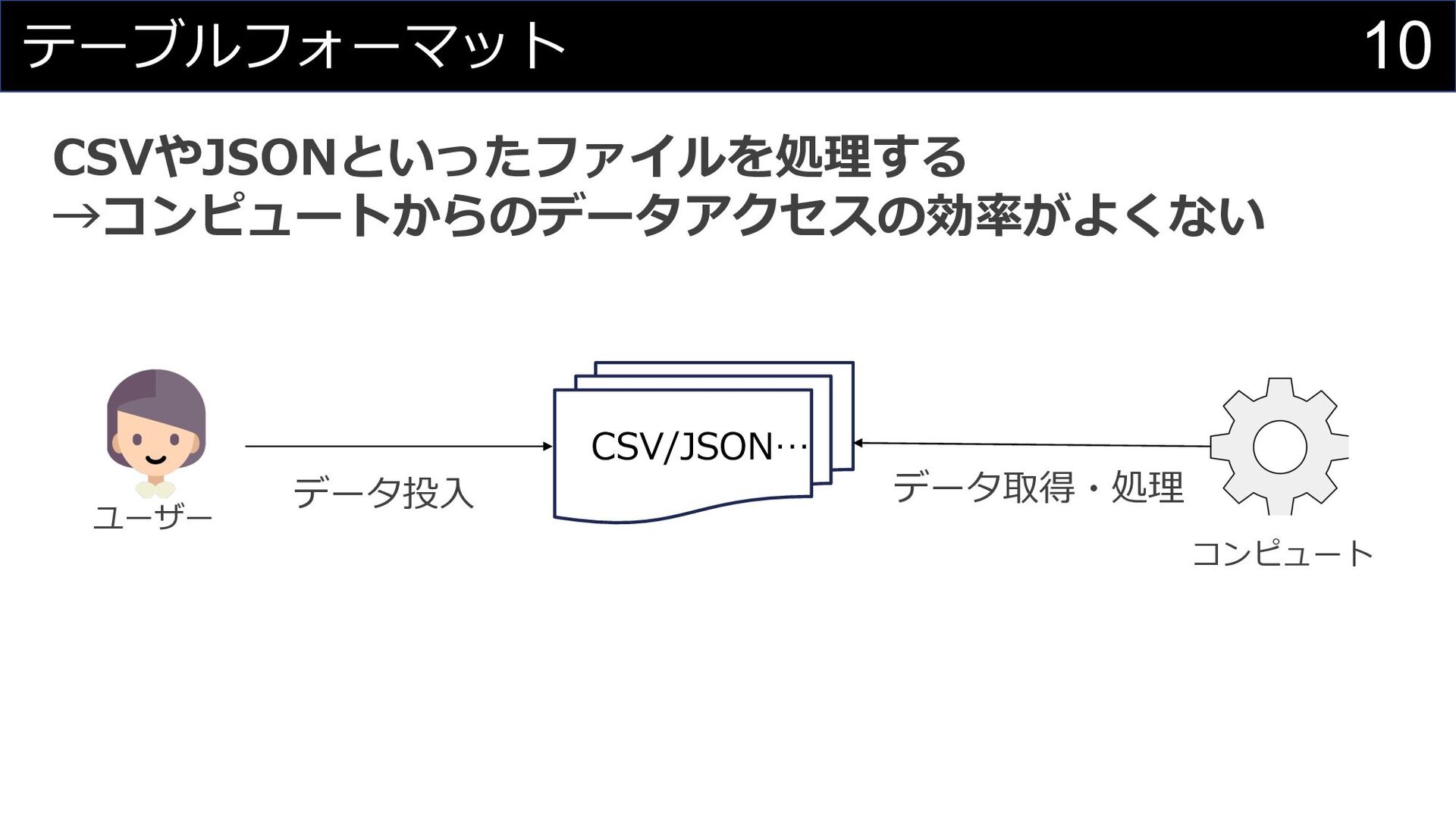
10 テーブルフォーマット データ投⼊ データ取得・処理 CSV/JSON… ユーザー コンピュート CSVやJSONといったファイルを処理する →コンピュートからのデータアクセスの効率がよくない
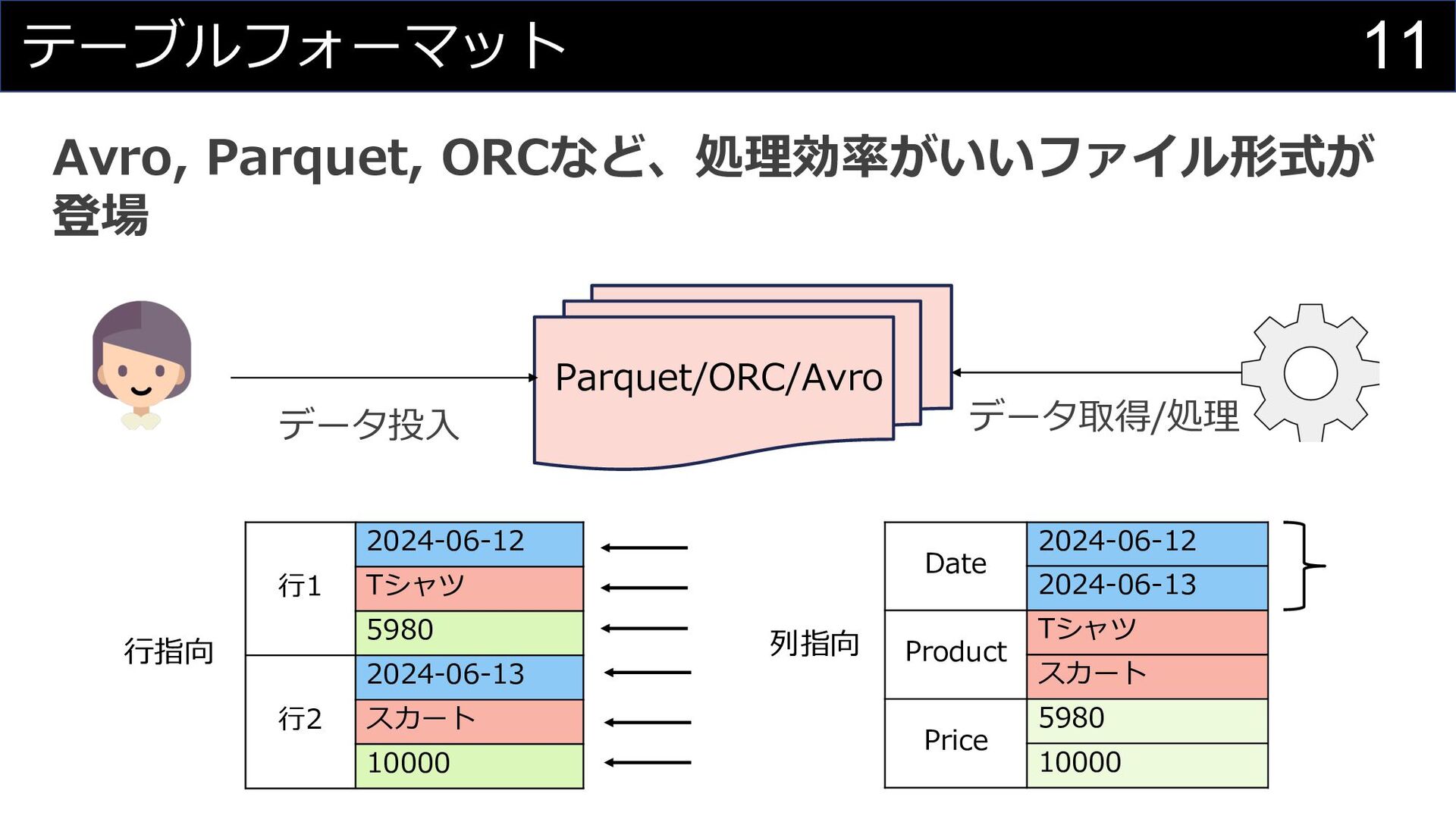
11 テーブルフォーマット データ投⼊ データ取得/処理 Parquet/ORC/Avro Avro, Parquet, ORCなど、処理効率がいいファイル形式が 登場 ⾏1
2024-06-12 Tシャツ 5980 ⾏2 2024-06-13 スカート 10000 Date 2024-06-12 2024-06-13 Product Tシャツ スカート Price 5980 10000 ⾏指向 列指向
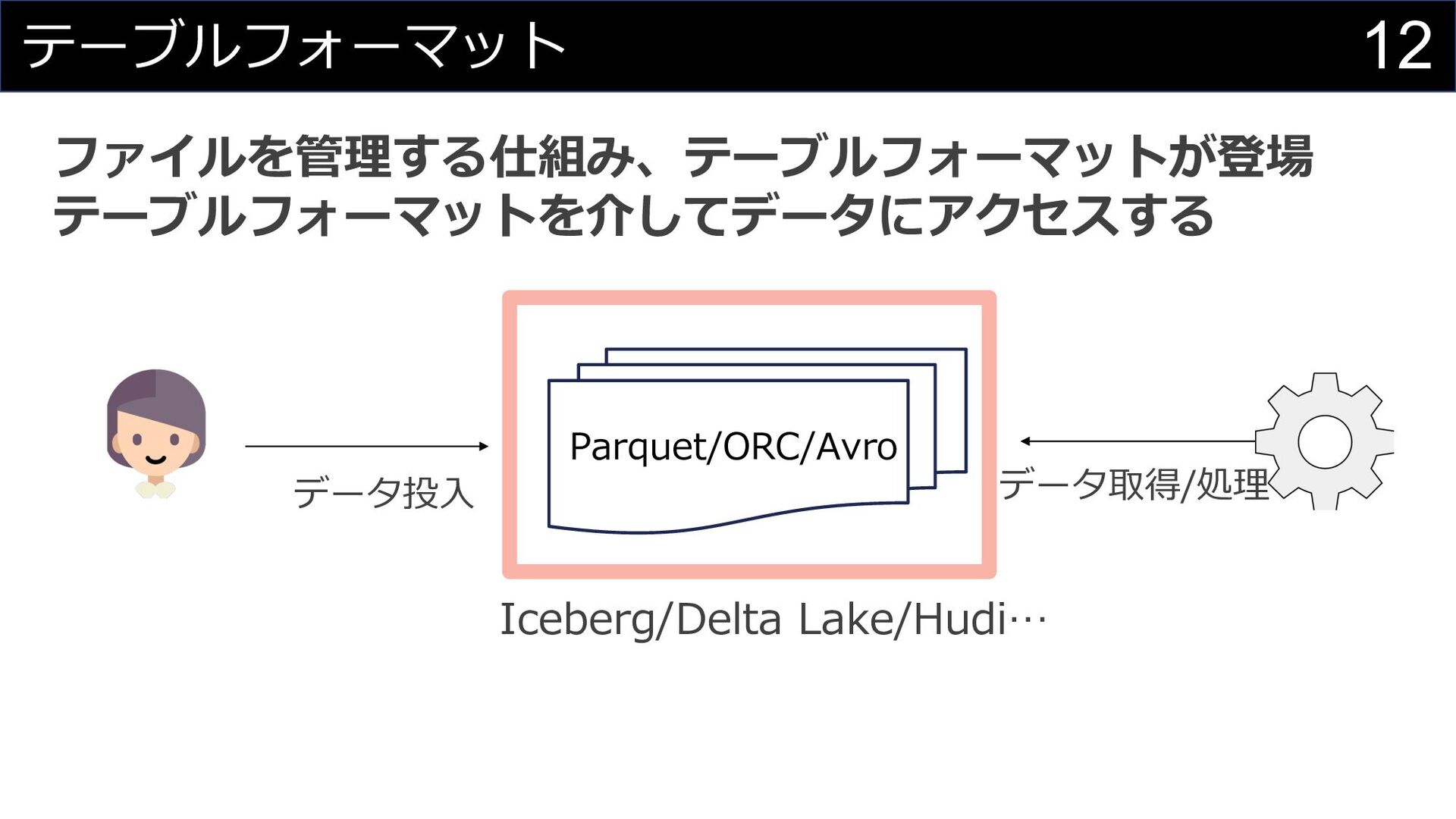
12 テーブルフォーマット データ投⼊ データ取得/処理 Parquet/ORC/Avro ファイルを管理する仕組み、テーブルフォーマットが登場 テーブルフォーマットを介してデータにアクセスする Iceberg/Delta Lake/Hudi…
Icebergとは データウェアハウスのように使える データレイクのテーブルフォーマット 従来のテーブルフォーマット Iceberg データファイルを編集できない UPDATE/DELETE/MERGEによる データの編集・削除が可能 トランザクションがサポート されておらずデータの⼀貫性を保てない
ACIDトランザクションによる 同時アクセス時の整合性を担保 過去のデータの状態を復元できない テーブルのタイムトラベル機能 ファイルの物理的な構造を元に パーティション構造を参照 メタデータを元にパーティション構造 を把握する、より精度の⾼い パーティショニング
Icebergとは データウェアハウスのように使える データレイクのテーブルフォーマット 従来のテーブルフォーマット Iceberg データファイルを編集できない UPDATE/DELETE/MERGEによる データの編集・削除が可能 トランザクションがサポート されておらずデータの⼀貫性を保てない
ACIDトランザクションによる 同時アクセス時の整合性を担保 過去のデータの状態を復元できない テーブルのタイムトラベル機能 ファイルの物理的な構造を元に パーティション構造を参照 メタデータを元にパーティション構造 を把握する、より精度の⾼い パーティショニング データファイルに 紐づくメタデータを 持つことで柔軟な データアクセスが可 能に
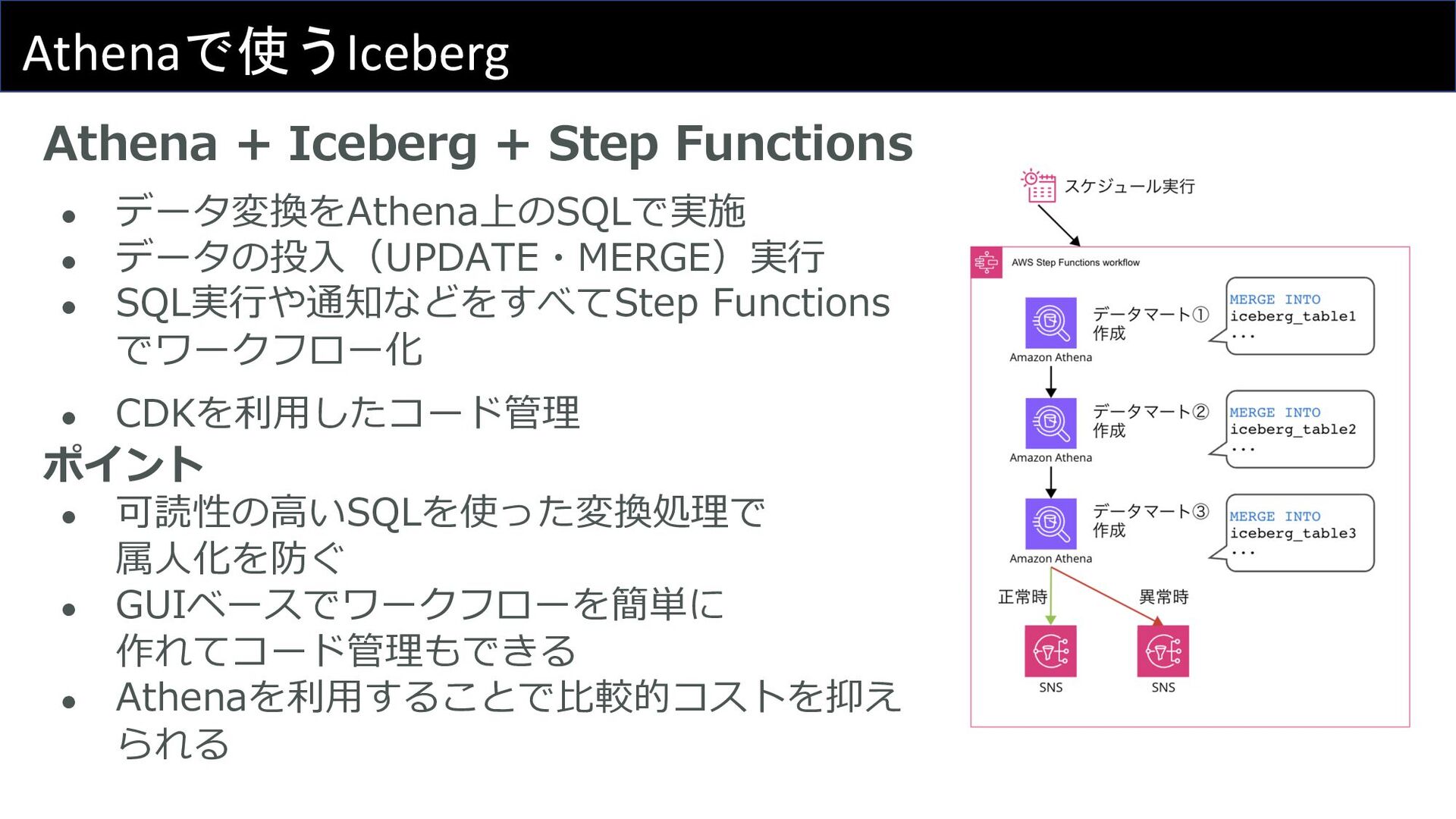
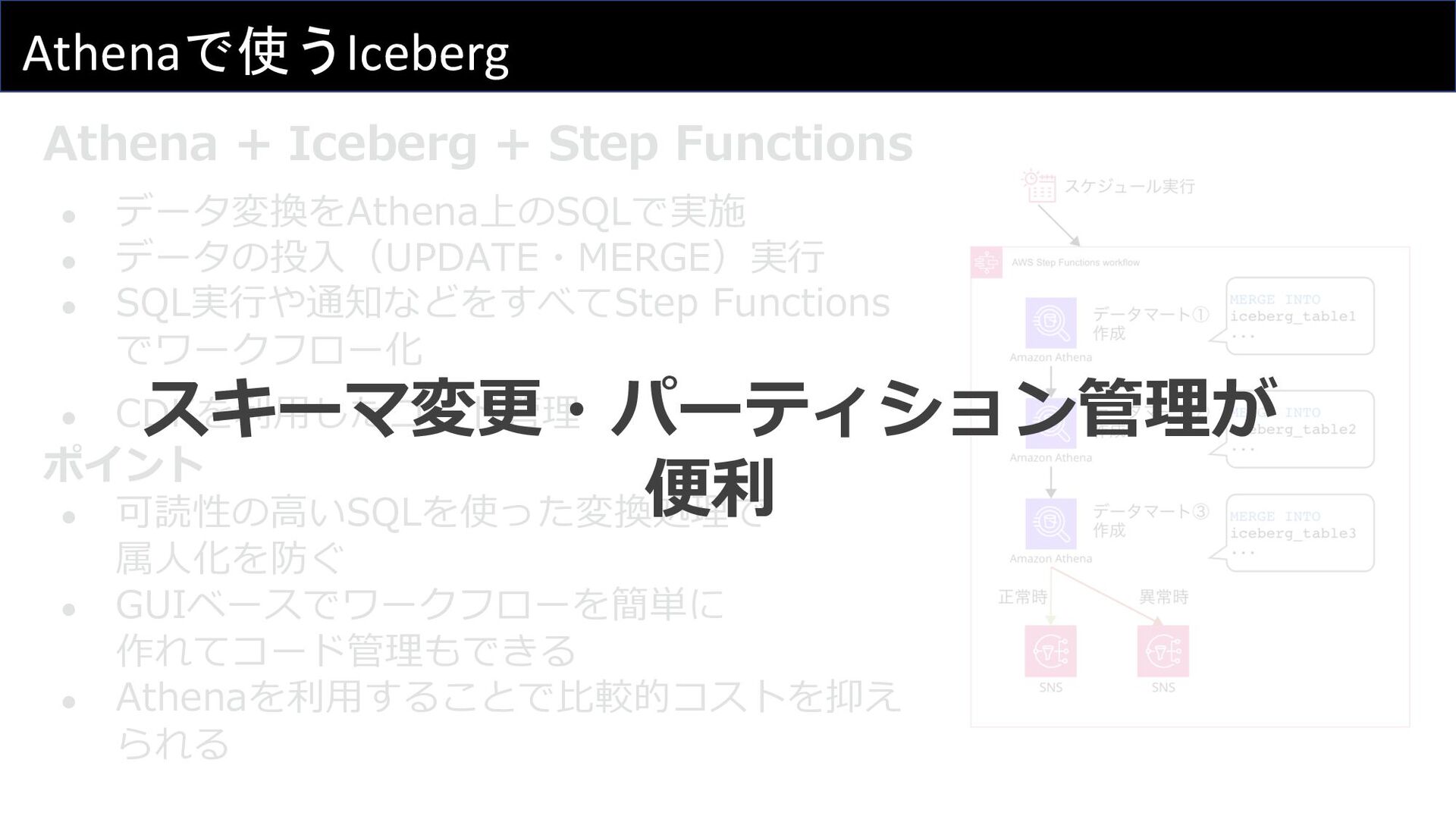
Athenaで使うIceberg Athena + Iceberg + Step Functions • データ変換をAthena上のSQLで実施 •
データの投⼊(UPDATE・MERGE)実⾏ • SQL実⾏や通知などをすべてStep Functions でワークフロー化 • CDKを利⽤したコード管理 ポイント • 可読性の⾼いSQLを使った変換処理で 属⼈化を防ぐ • GUIベースでワークフローを簡単に 作れてコード管理もできる • Athenaを利⽤することで⽐較的コストを抑え られる
Athenaで使うIceberg Athena + Iceberg + Step Functions • データ変換をAthena上のSQLで実施 •
データの投⼊(UPDATE・MERGE)実⾏ • SQL実⾏や通知などをすべてStep Functions でワークフロー化 • CDKを利⽤したコード管理 ポイント • 可読性の⾼いSQLを使った変換処理で 属⼈化を防ぐ • GUIベースでワークフローを簡単に 作れてコード管理もできる • Athenaを利⽤することで⽐較的コストを抑え られる スキーマ変更・パーティション管理が 便利
スキーマ
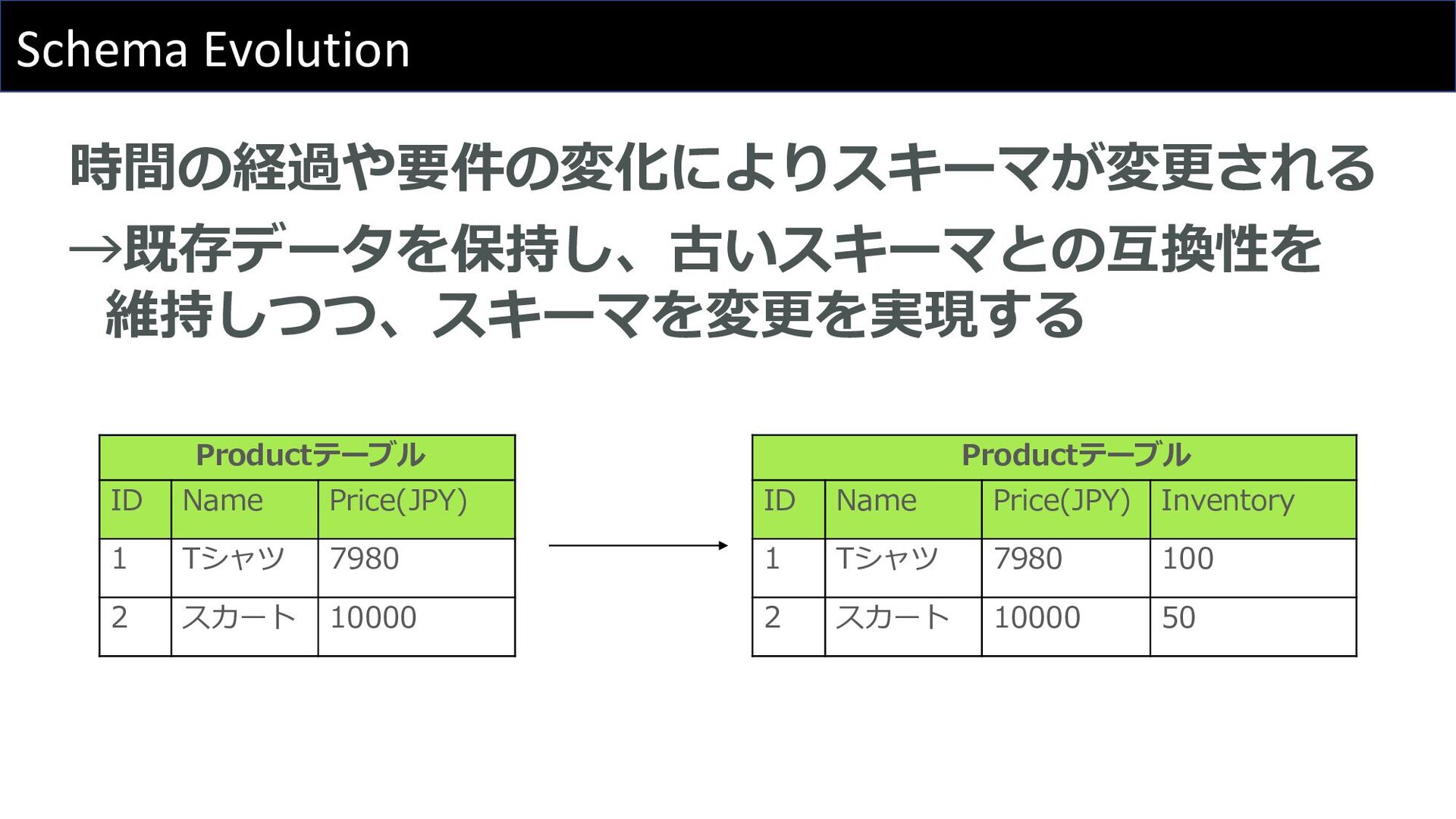
Schema Evolution 時間の経過や要件の変化によりスキーマが変更される →既存データを保持し、古いスキーマとの互換性を 維持しつつ、スキーマを変更を実現する Productテーブル ID Name Price(JPY) 1
Tシャツ 7980 2 スカート 10000 Productテーブル ID Name Price(JPY) Inventory 1 Tシャツ 7980 100 2 スカート 10000 50
Schema Evolution Icebergでのスキーマ変更はメタデータファイルの変更のみ テーブル再作成、データ再ロードの必要なし • Add(新しい列追加) • Drop(既存の列削除) • Rename(列名変更)
• Update(データ型を拡張) • Reorder(列の順序変更) ALTER TABLE iceberg_table ADD COLUMNS (new_column string) ALTER TABLE iceberg_table DROP COLUMN price ALTER TABLE iceberg_table CHANGE COLUMN old_column new_column string FIRST
パーティション
Partition Evolution クエリパターンの傾向の変化により、パーティション 変更が必要になるケース ⽉ごとに 分析すれば⼗分 ⽇ごとの傾向の 変化が⾒たい…
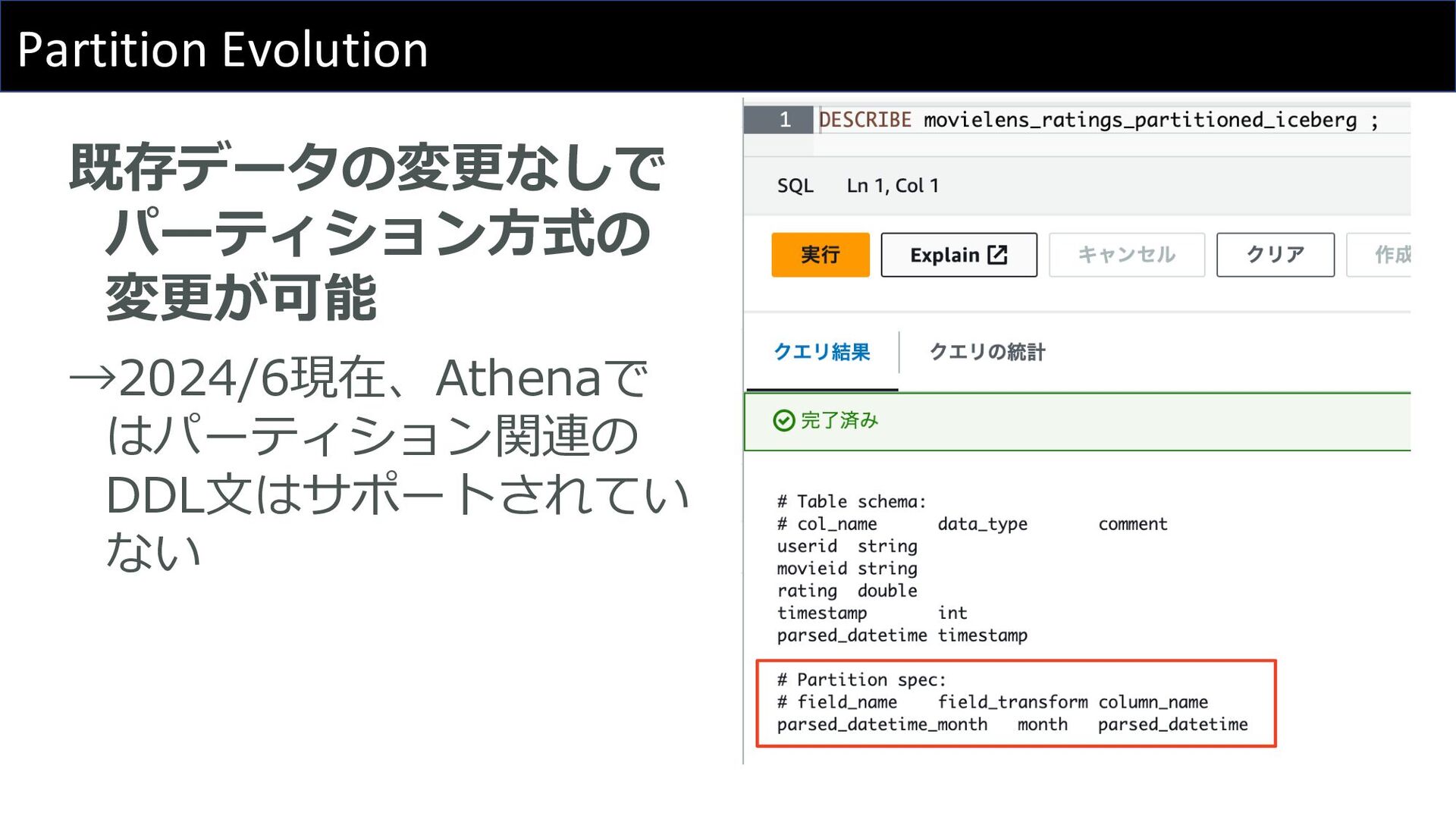
Partition Evolution 既存データの変更なしで パーティション⽅式の 変更が可能 →2024/6現在、Athenaで はパーティション関連の DDL⽂はサポートされてい ない
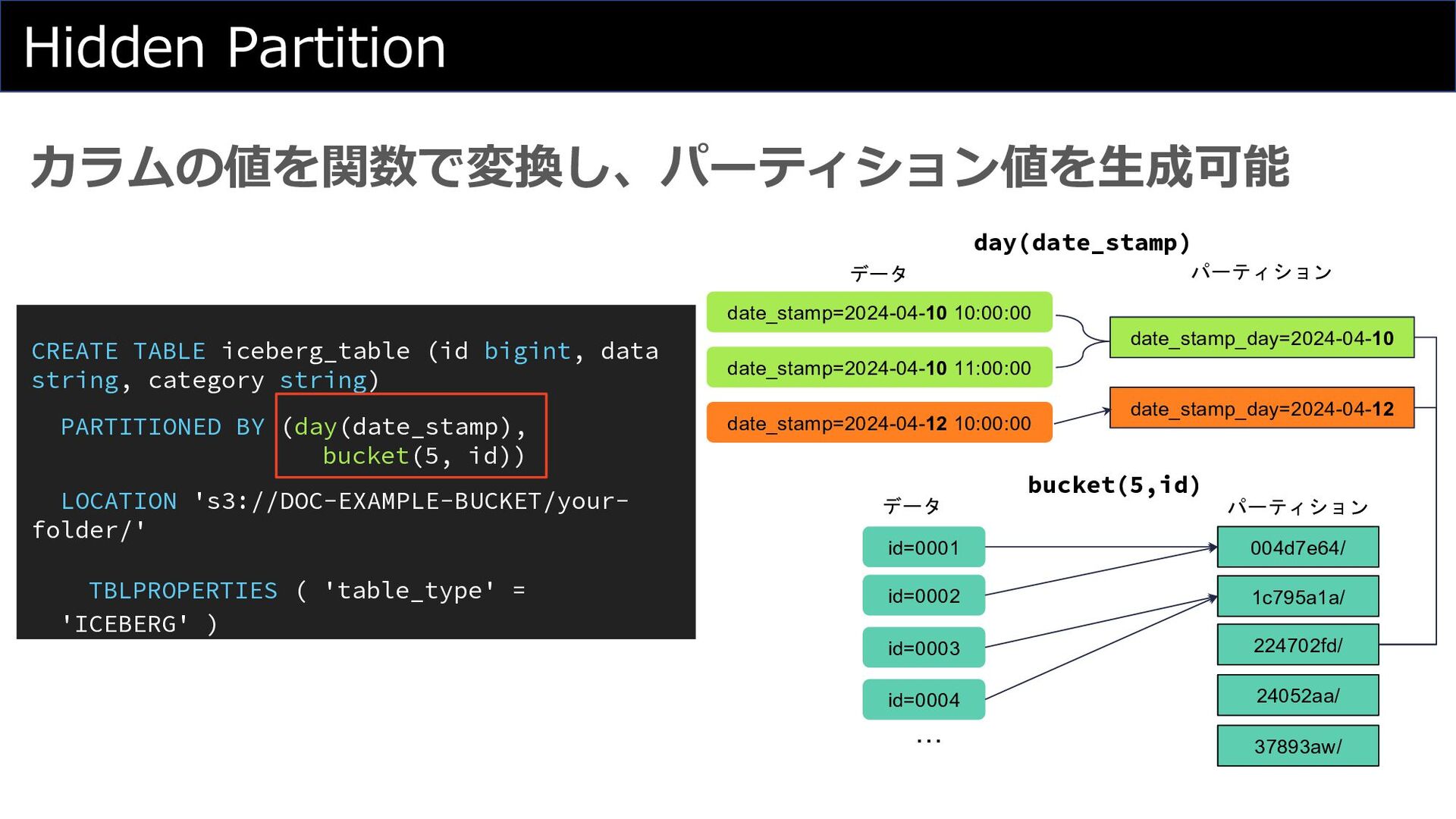
Hidden Partition カラムの値を関数で変換し、パーティション値を⽣成可能 CREATE TABLE iceberg_table (id bigint, data string,
category string) PARTITIONED BY (day(date_stamp), bucket(5, id)) LOCATION 's3://DOC-EXAMPLE-BUCKET/your- folder/' TBLPROPERTIES ( 'table_type' = 'ICEBERG' ) date_stamp=2024-04-10 10:00:00 date_stamp=2024-04-10 11:00:00 date_stamp=2024-04-12 10:00:00 date_stamp_day=2024-04-10 date_stamp_day=2024-04-12 データ パーティション 004d7e64/ id=0001 id=0002 パーティション 1c795a1a/ 224702fd/ 24052aa/ 37893aw/ id=0003 id=0004 … day(date_stamp) bucket(5,id) データ
Athenaで利⽤可能なHidden Partitionの関数 関数 機能 例 year(timestamp) 年部分でパーティション化 2024 month(timestamp) ⽉部分でパーティション化
2024-06 day(timestamp) ⽇付部分でパーティション化 2024-06-12 hours(timestamp) 時間部分でパーティション化 2024-06-12-19 bucket(n, カラム) 指定した(n)数のバケットに パーティションを分割 buket(5,id)では、idの値ごと に5つのバケットに分散 truncate(n, カラム) 指定した(n)⽂字⽬の値で パーティション化 truncate(1,id)では、idの1⽂字 ⽬でパーティション化
まとめ
Icebergとは データウェアハウスのように使える データレイクのテーブルフォーマット 従来のテーブルフォーマット Iceberg データファイルを編集できない UPDATE/DELETE/MERGEによる データの編集・削除が可能 トランザクションがサポート されておらずデータの⼀貫性を保てない
ACIDトランザクションによる 同時アクセス時の整合性を担保 過去のデータの状態を復元できない テーブルのタイムトラベル機能 ファイルの物理的な構造を元に パーティション構造を参照 メタデータを元にパーティション構造 を把握する、より精度の⾼い パーティショニング
まとめ l Icebergを使ってデータウェアハウスでも提供され ている操作をデータレイクにも実⾏できる l スキーマ変更のクエリが使える l Hidden Partitionで新たにカラムを作成すること なくパーティション値を⽣成できる
参考 l Evolution - Apache Iceberg l What is Schema
Evolution? | Dremio l ALTER TABLE ADD PARTITION - Amazon Athena l AWSにおける Hudi/Iceberg/Delta Lake の 使 いどころと違いについて
29
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}