Agenda
- 데이터 분석의 위한 사전 지식
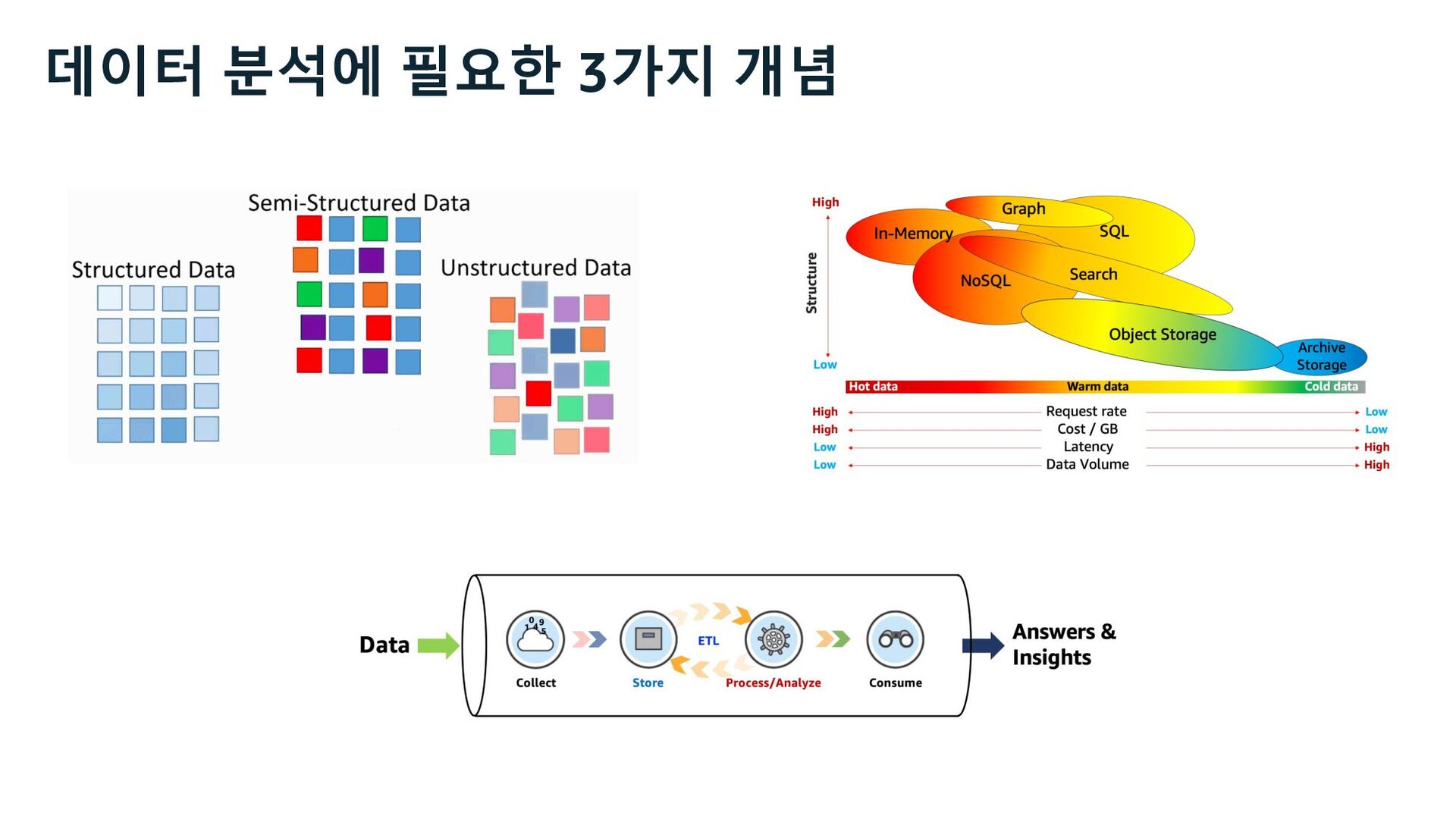
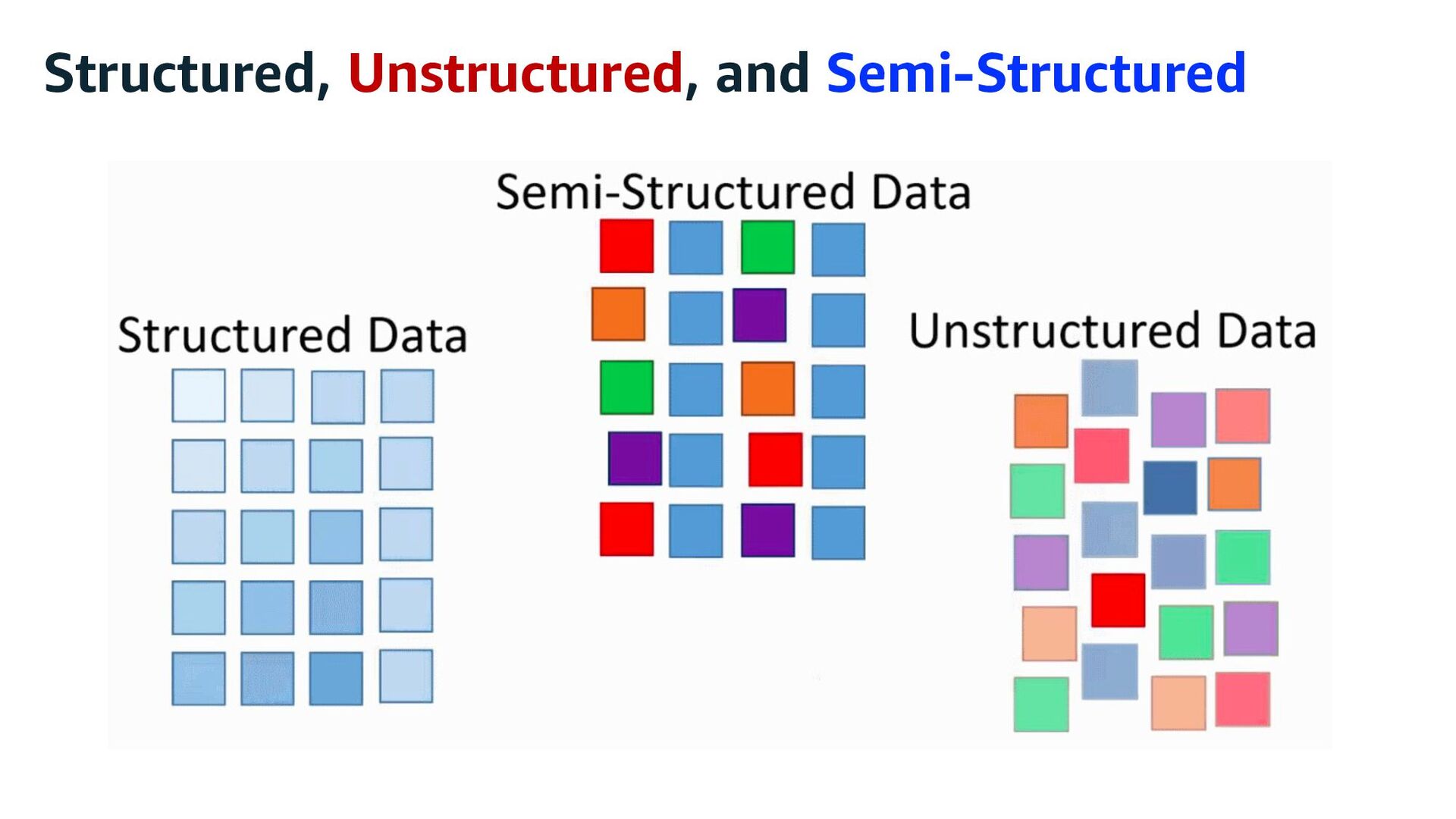
- 데이터 구조
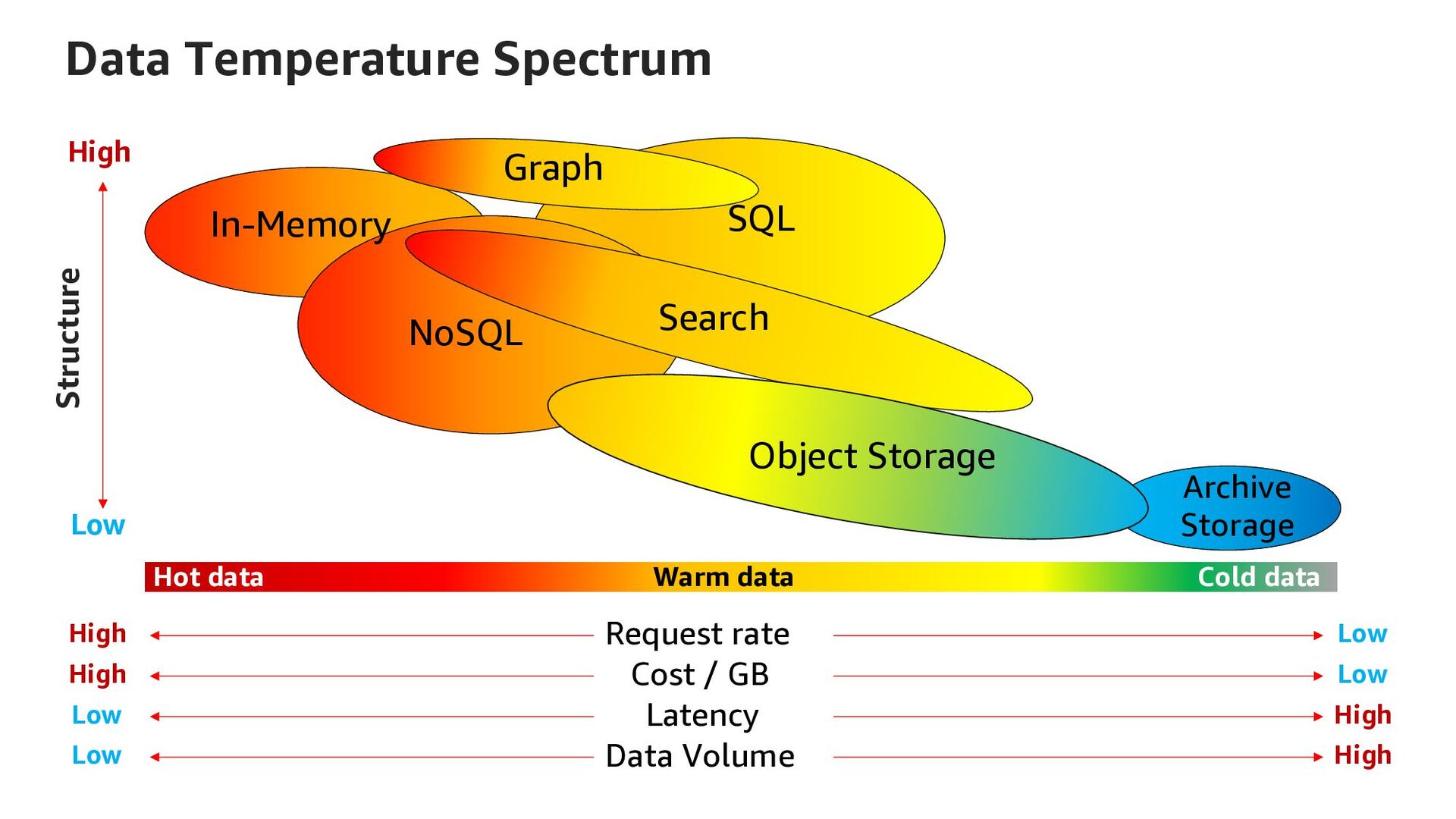
- 데이터 온도 스펙트럼
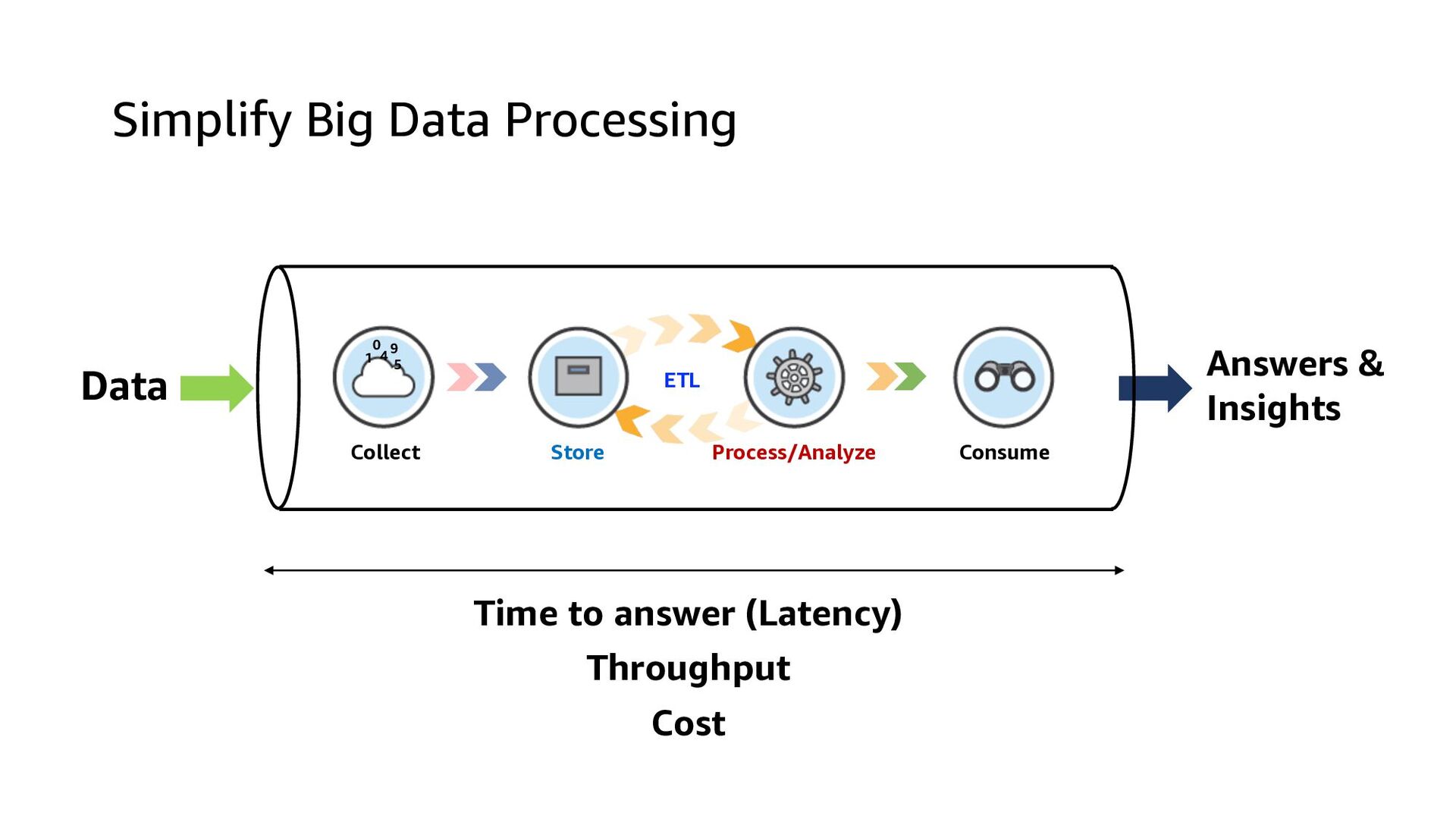
- 데이터 파이프라인
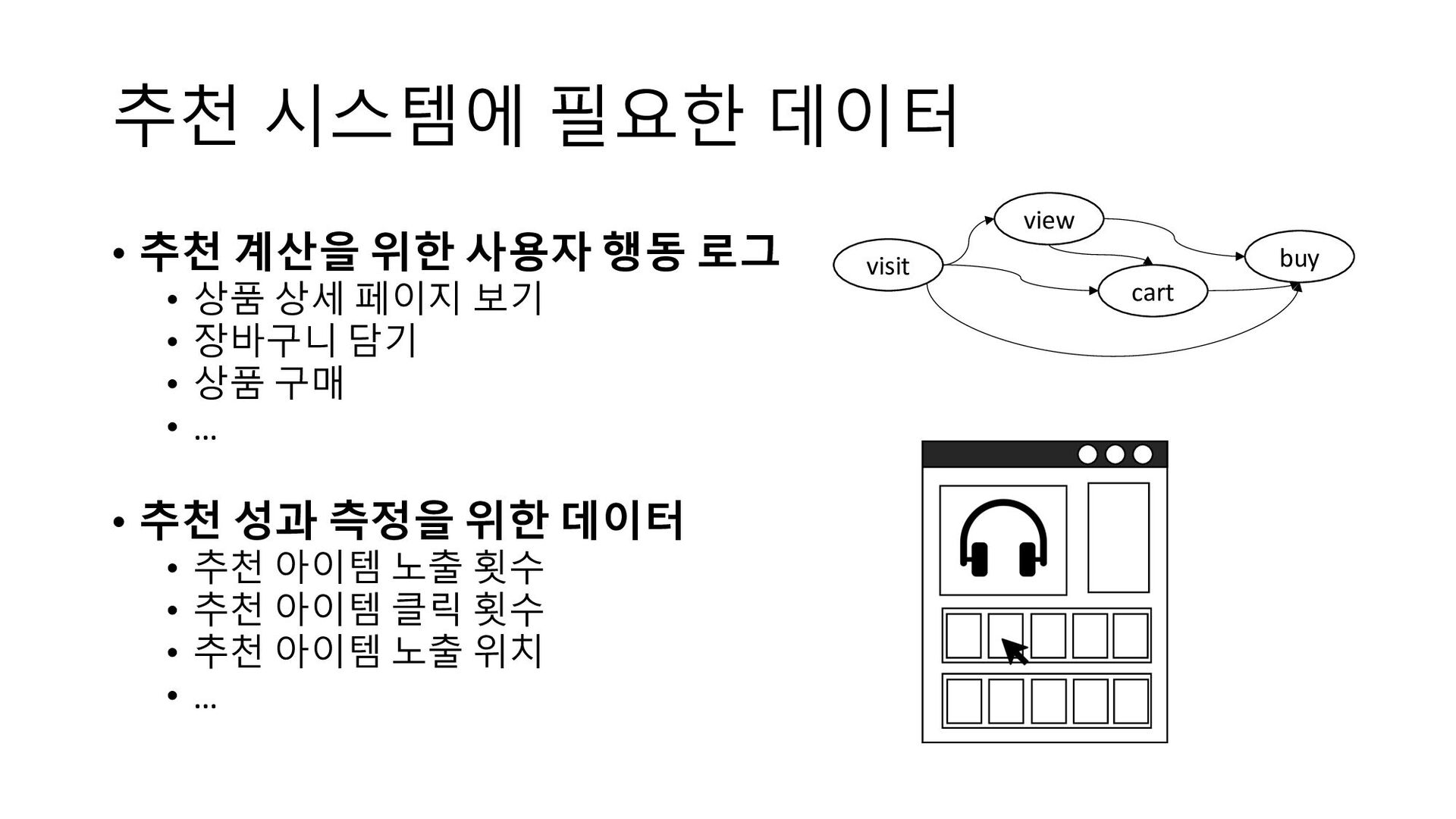
- 추천 시스템 구축을 위해 필요한 데이터
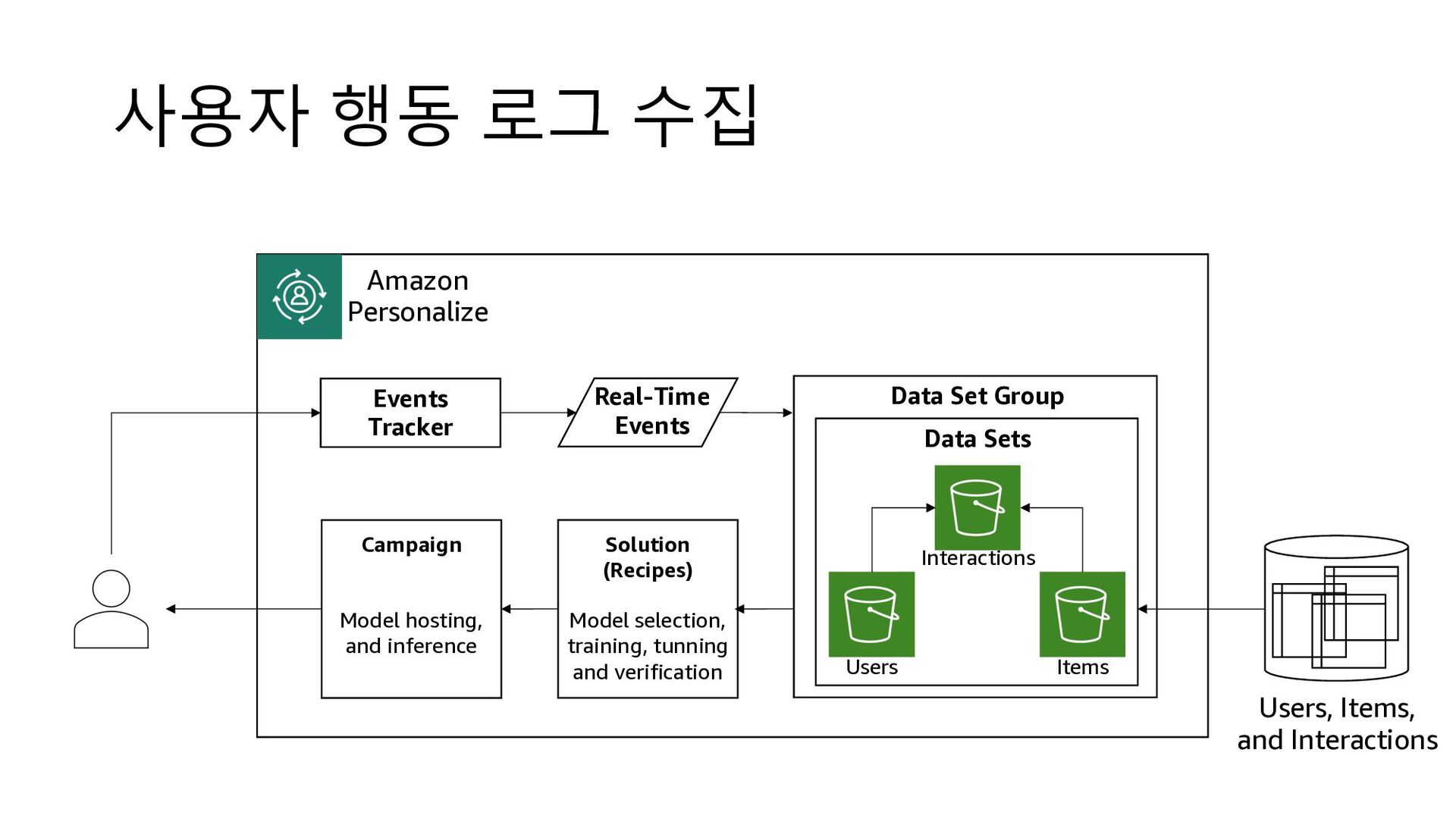
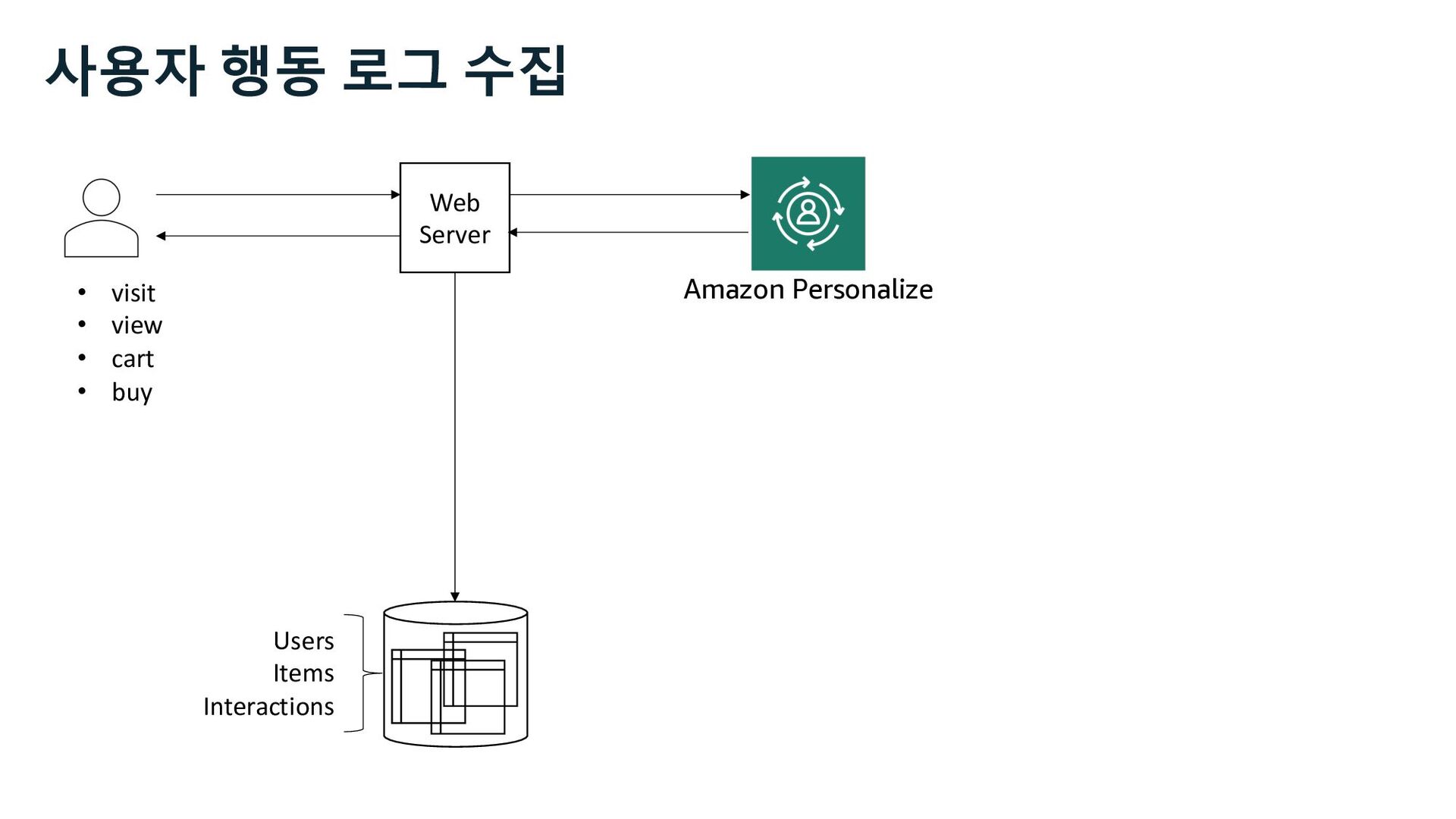
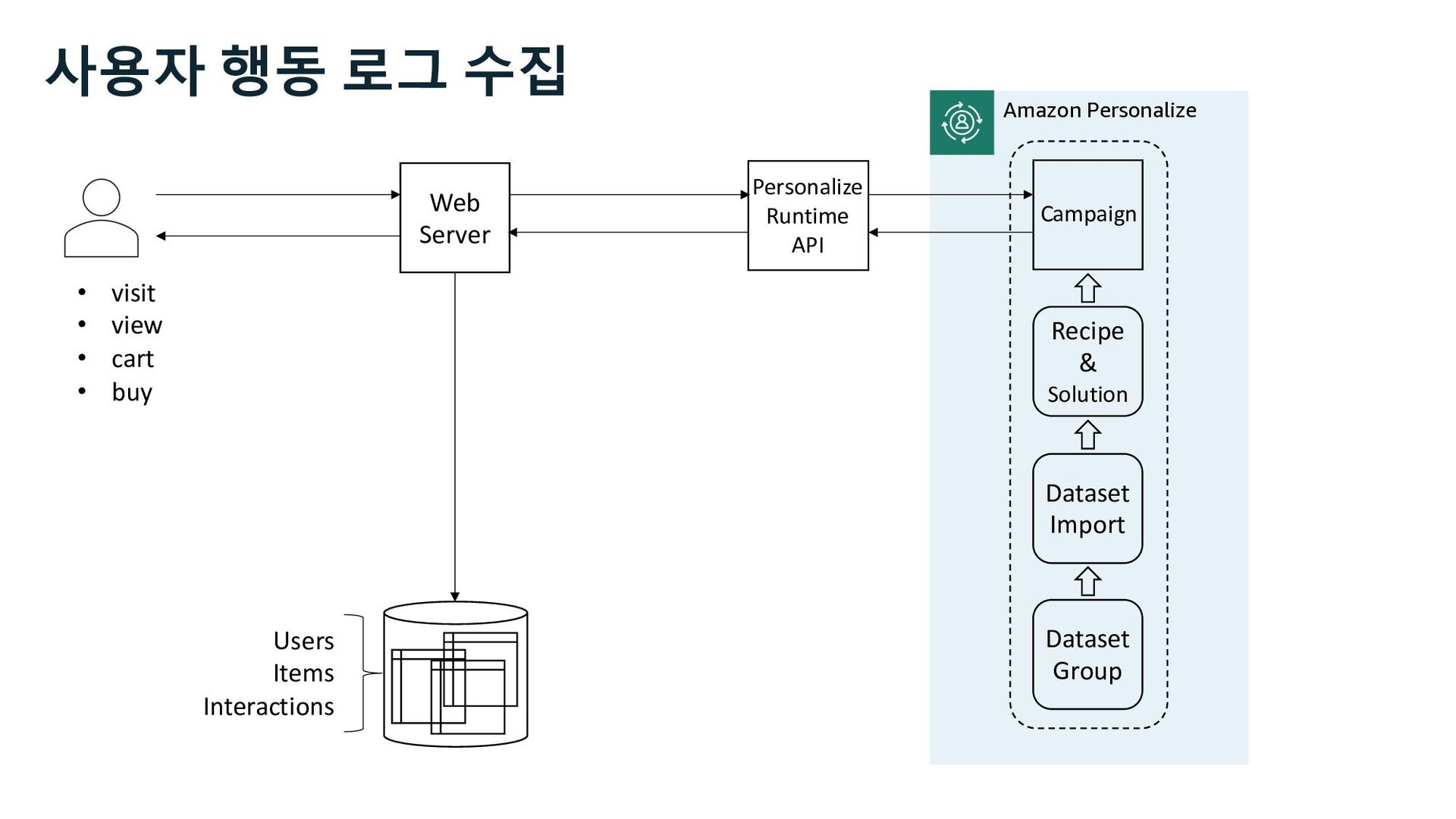
- 사용자 행동 로그
- 추천성과분석지표
- 사용자 행동 로그 수집을 위한 데이터 분석 아키텍처
- 추천 성과 분석을 위한 데이터 분석 시스템 확장
- Lesson Learned
• 데이터 온도 스펙트럼 • 데이터 파이프라인 • 추천 시스템 구축을 위해 필요한 데이터 • 사용자 행동 로그 • 추천 성과 분석 지표 • 사용자 행동 로그 수집을 위한 데이터 분석 아키텍처 • 추천 성과 분석을 위한 데이터 분석 시스템 확장 • Lesson Learned
Request rate Low High Cost / GB Low High Latency Low High Data Volume Low In-Memory SQL NoSQL Search Object Storage Archive Storage Graph Data Temperature Spectrum
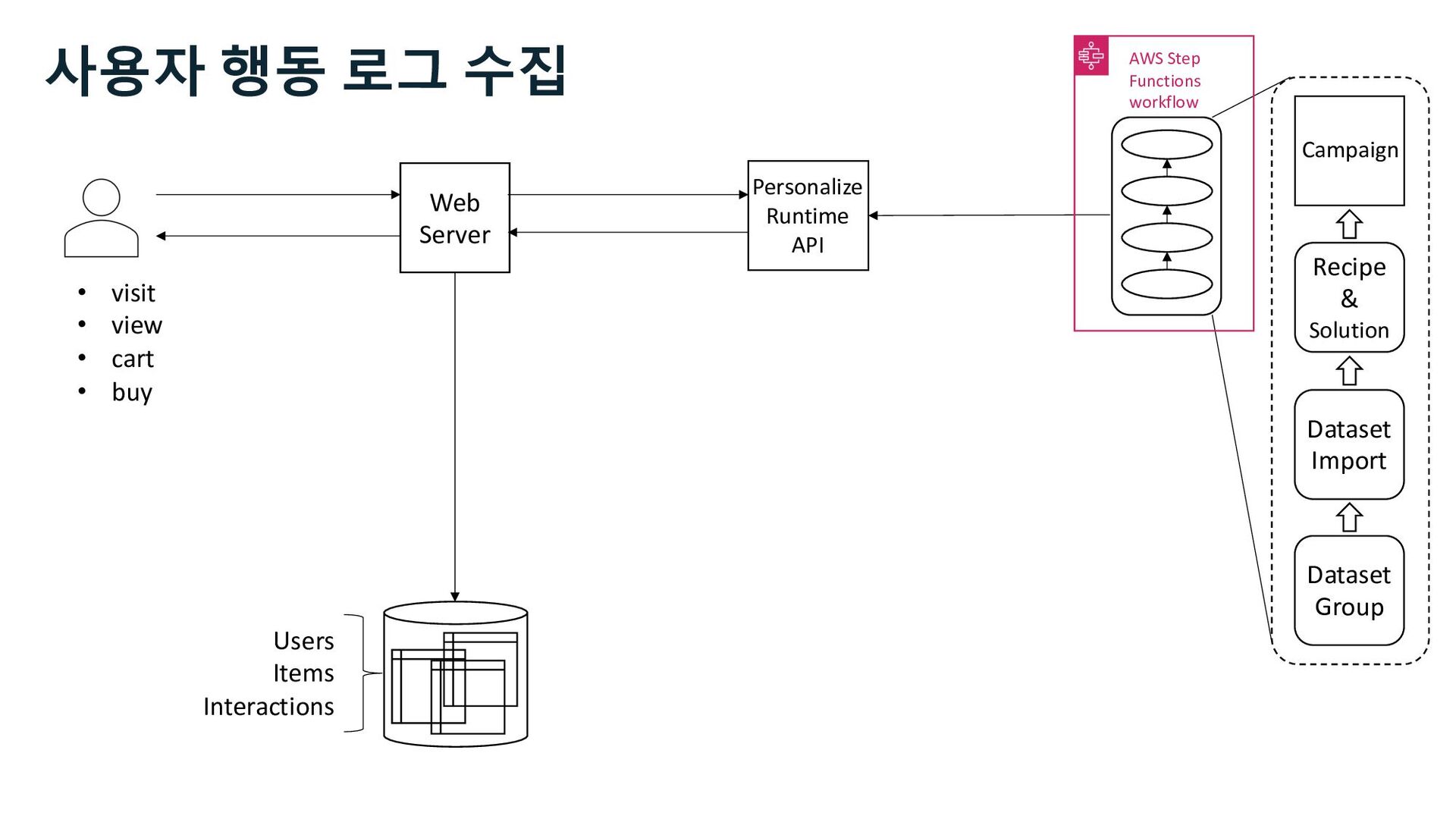
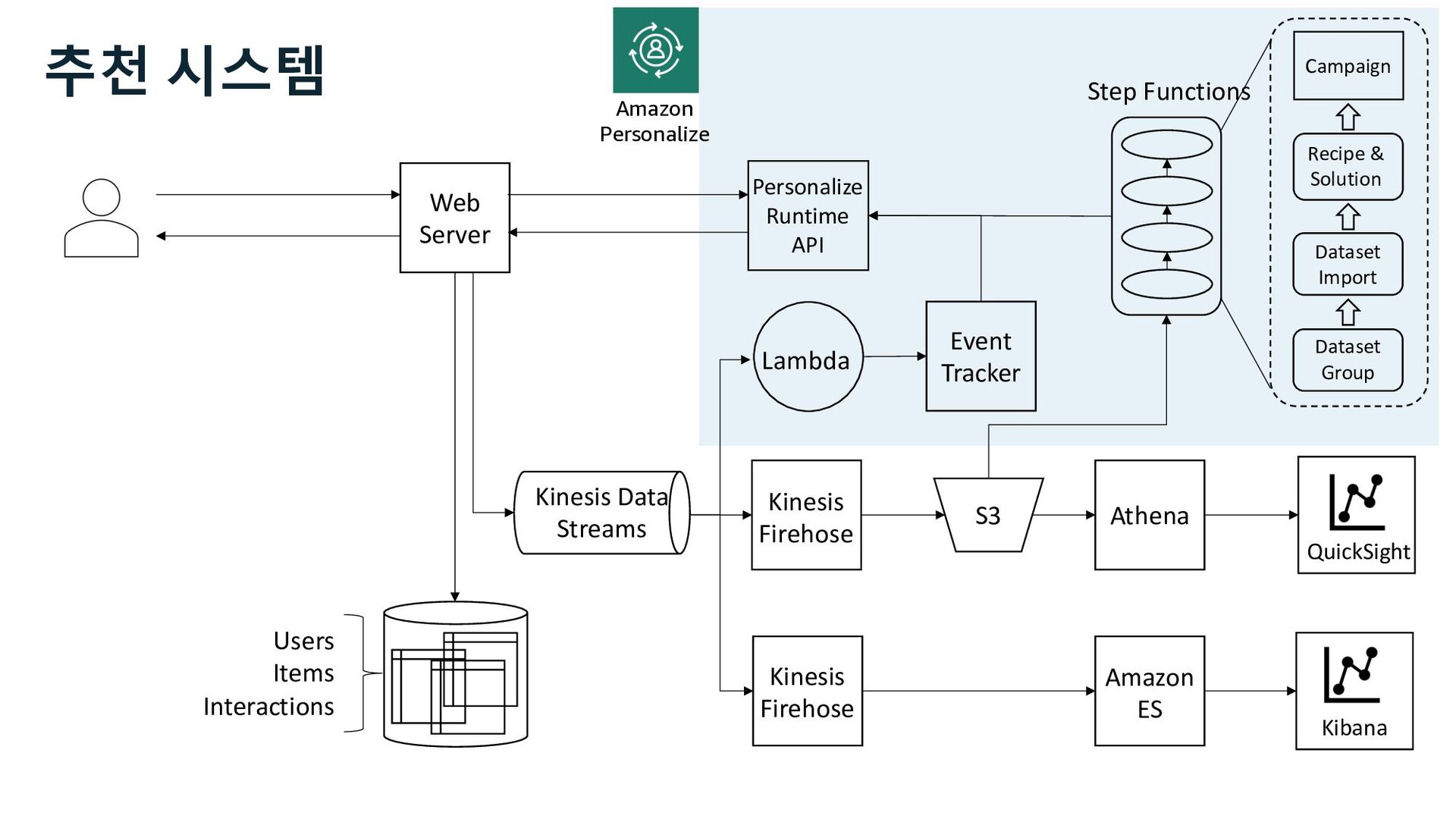
Solution (Recipes) Model selection, training, tunning and verification Campaign Model hosting, and inference Events Tracker Data Sets Users, Items, and Interactions Real-Time Events Amazon Personalize
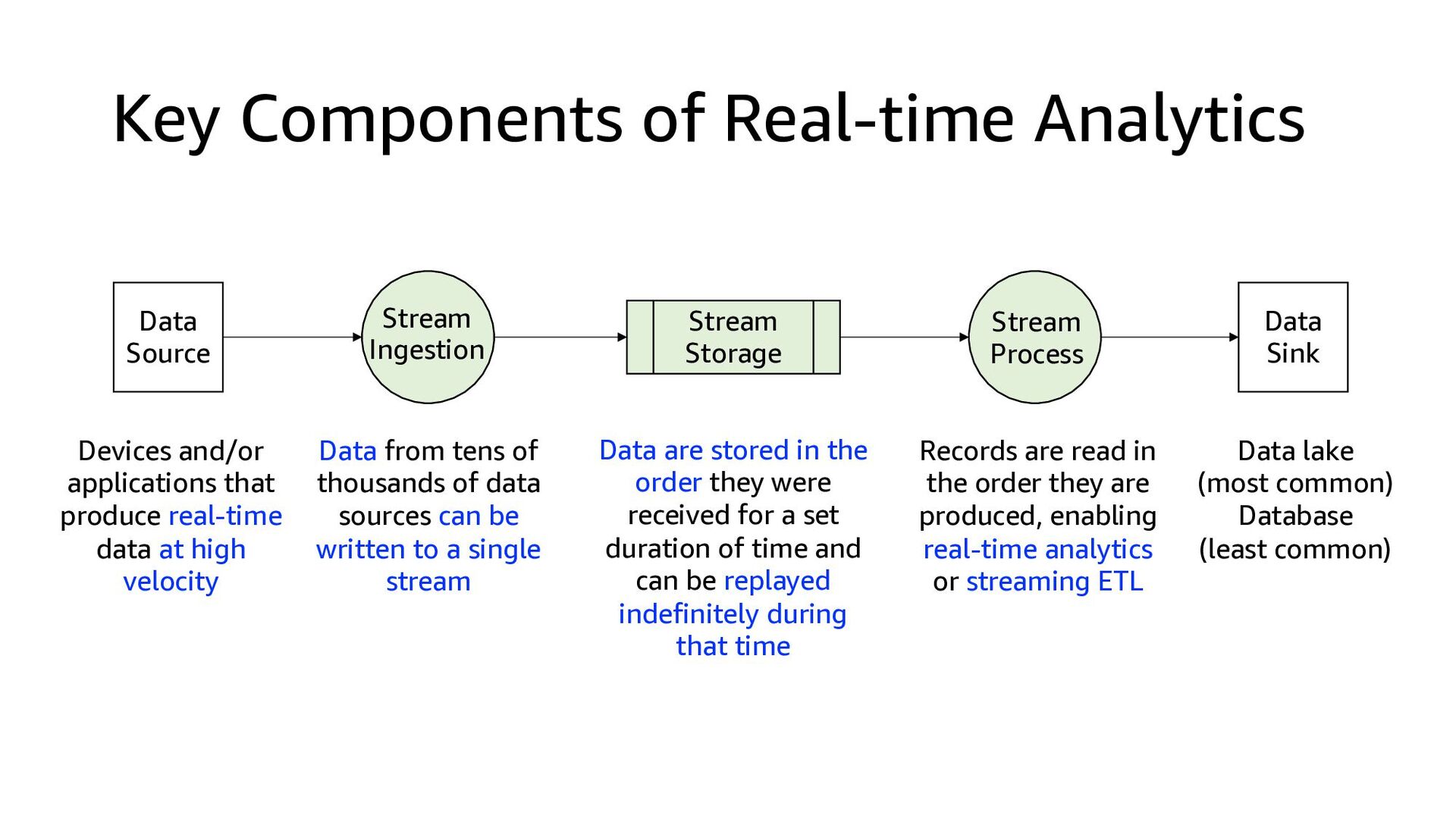
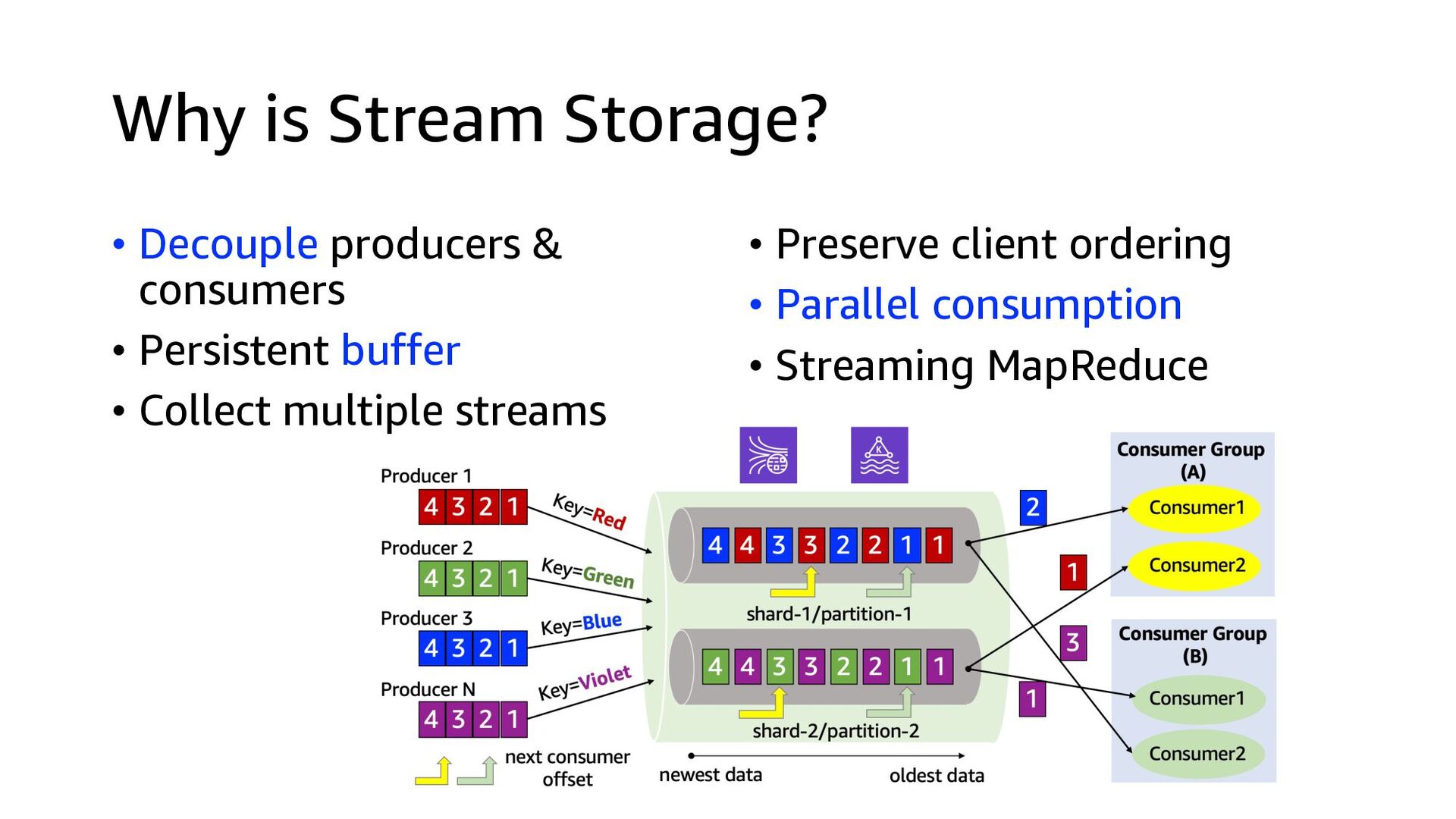
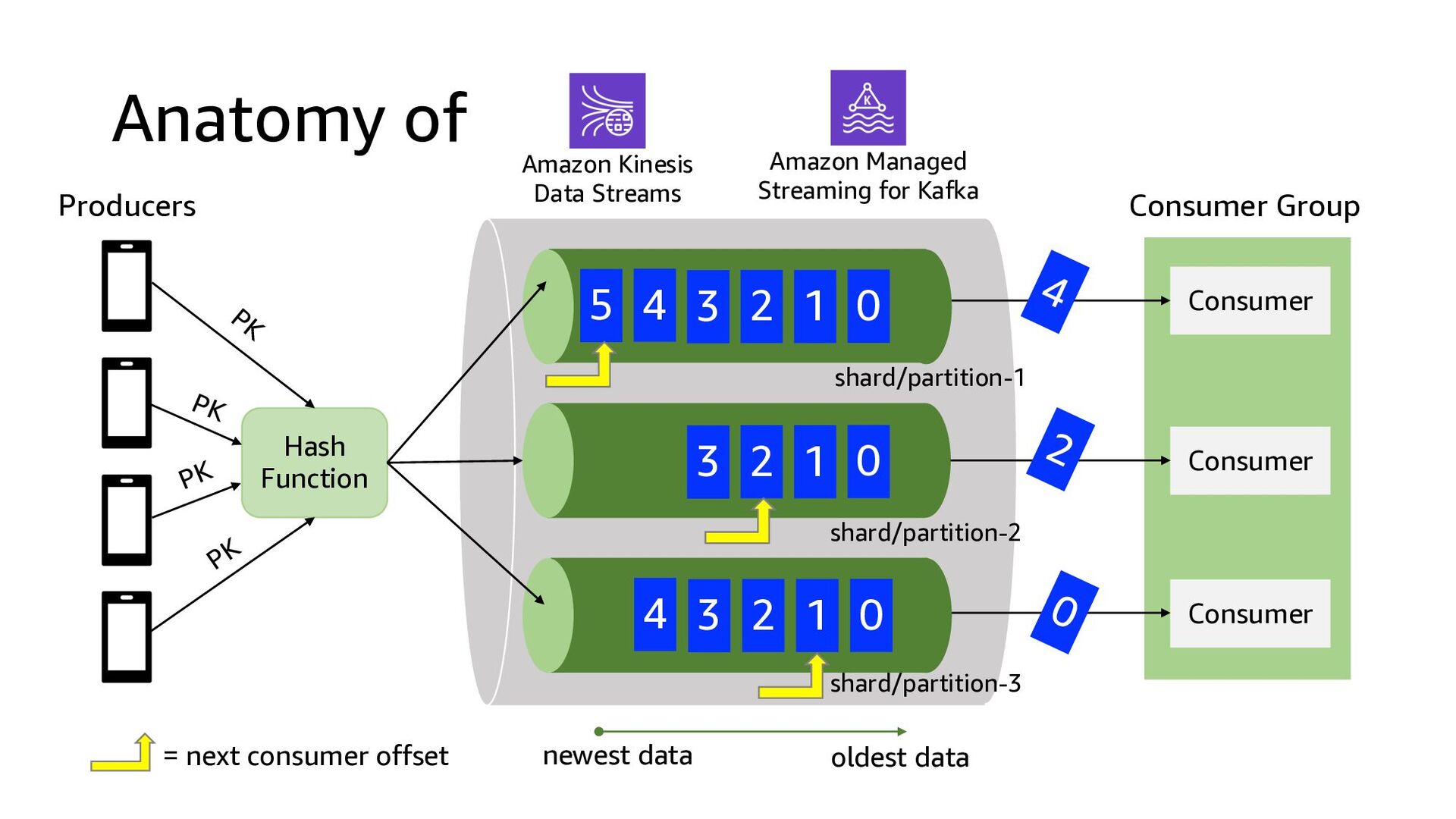
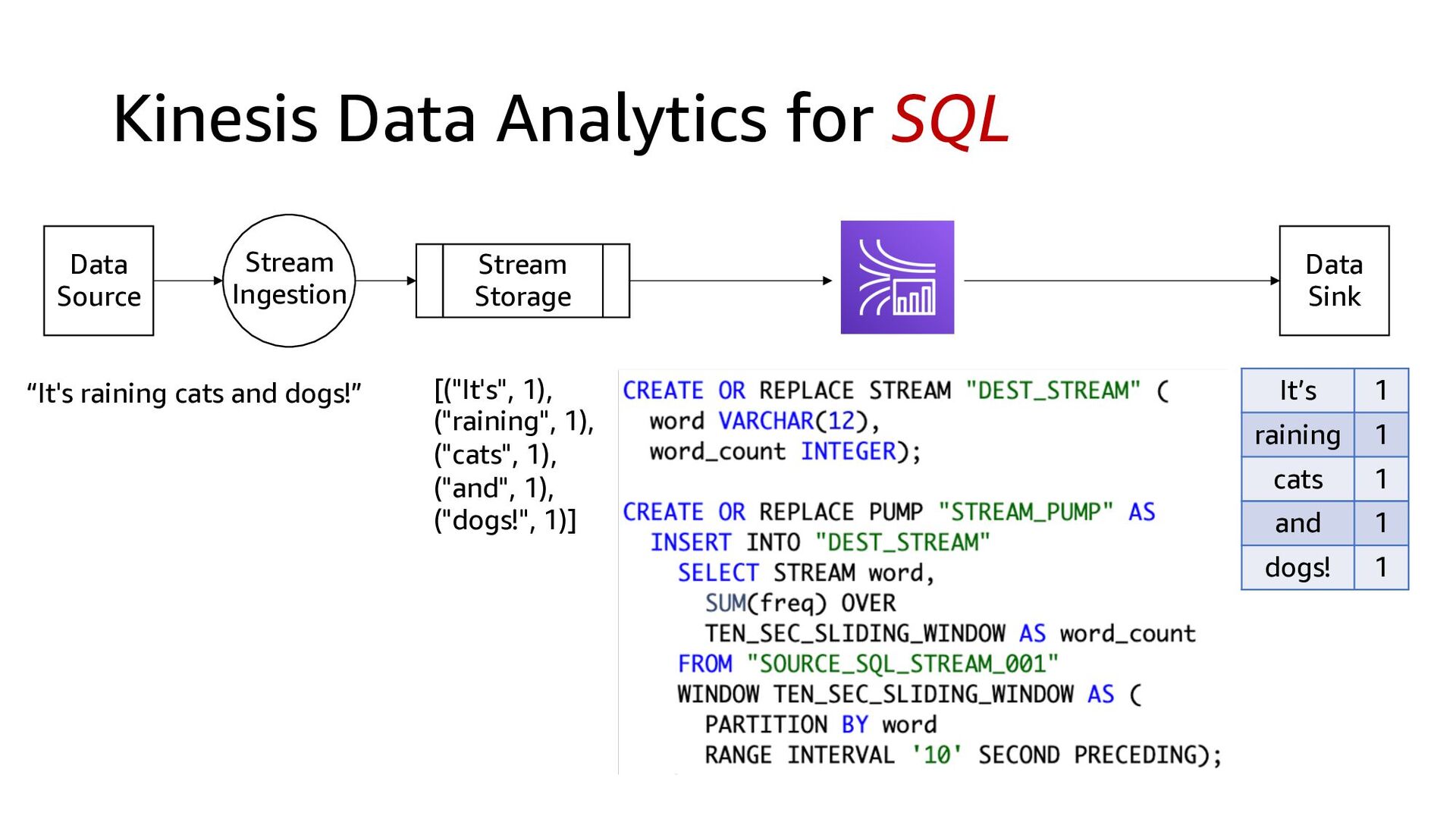
Process Stream Ingestion Data Sink Devices and/or applications that produce real-time data at high velocity Data from tens of thousands of data sources can be written to a single stream Data are stored in the order they were received for a set duration of time and can be replayed indefinitely during that time Records are read in the order they are produced, enabling real-time analytics or streaming ETL Data lake (most common) Database (least common)
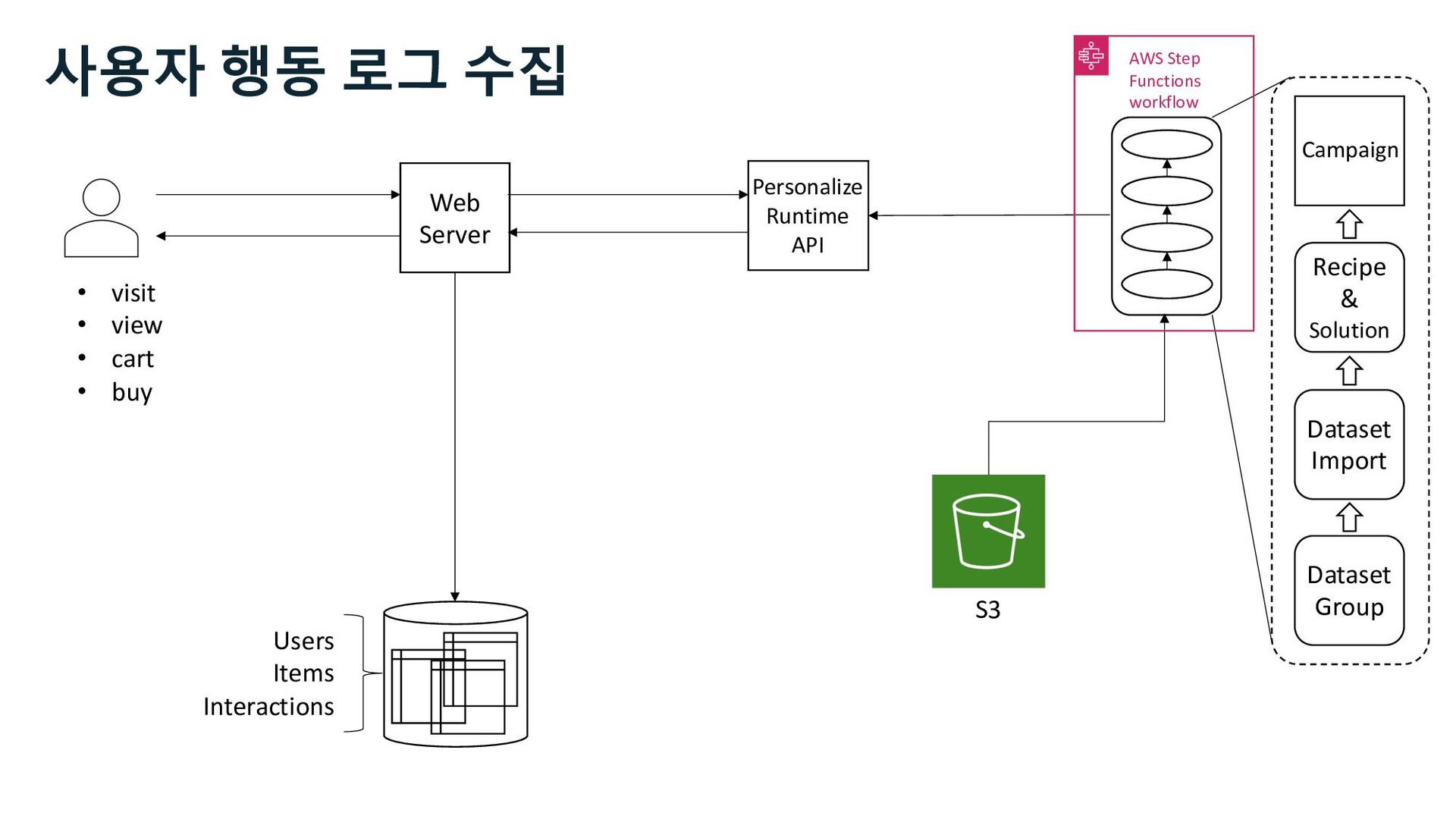
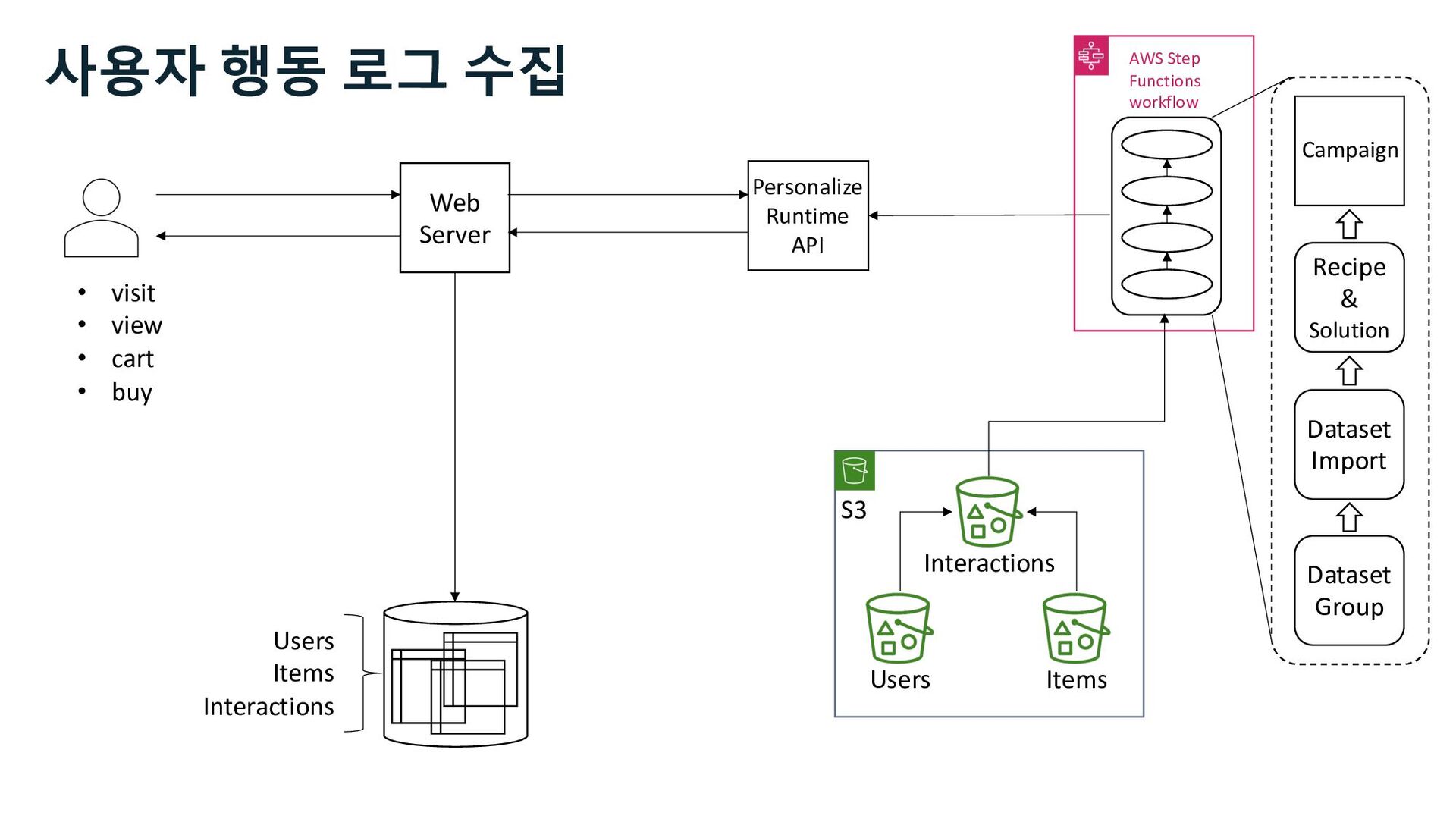
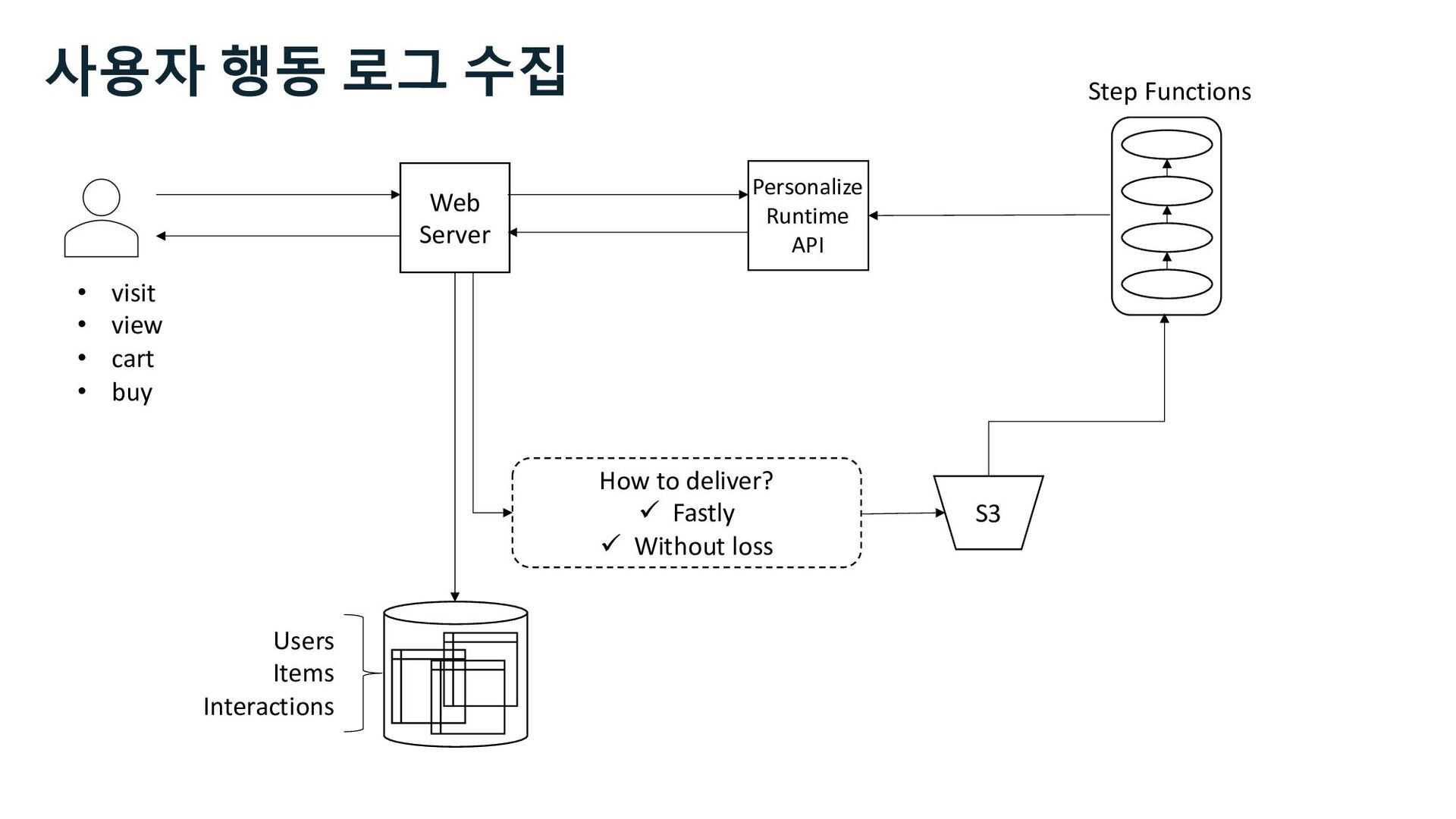
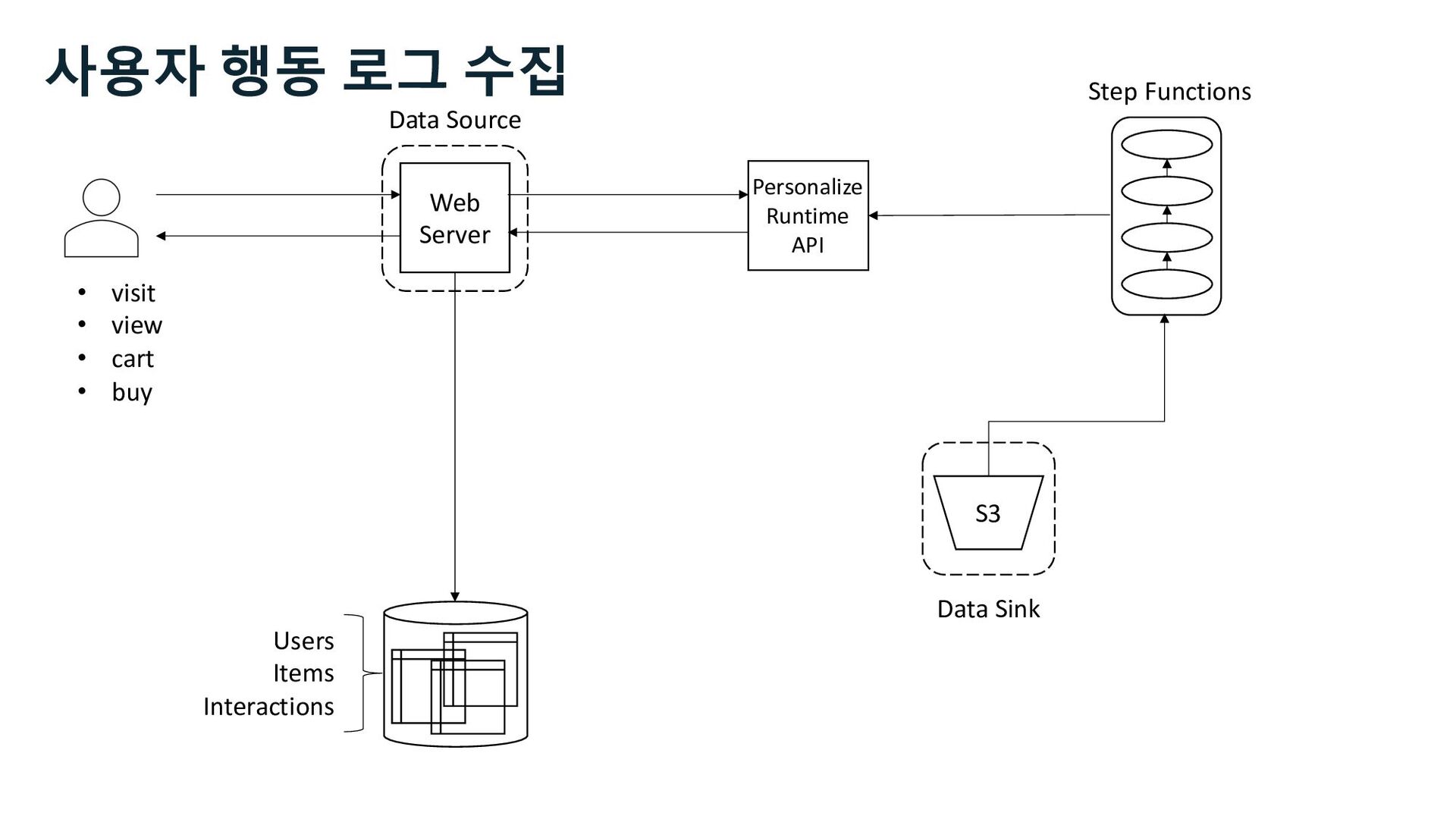
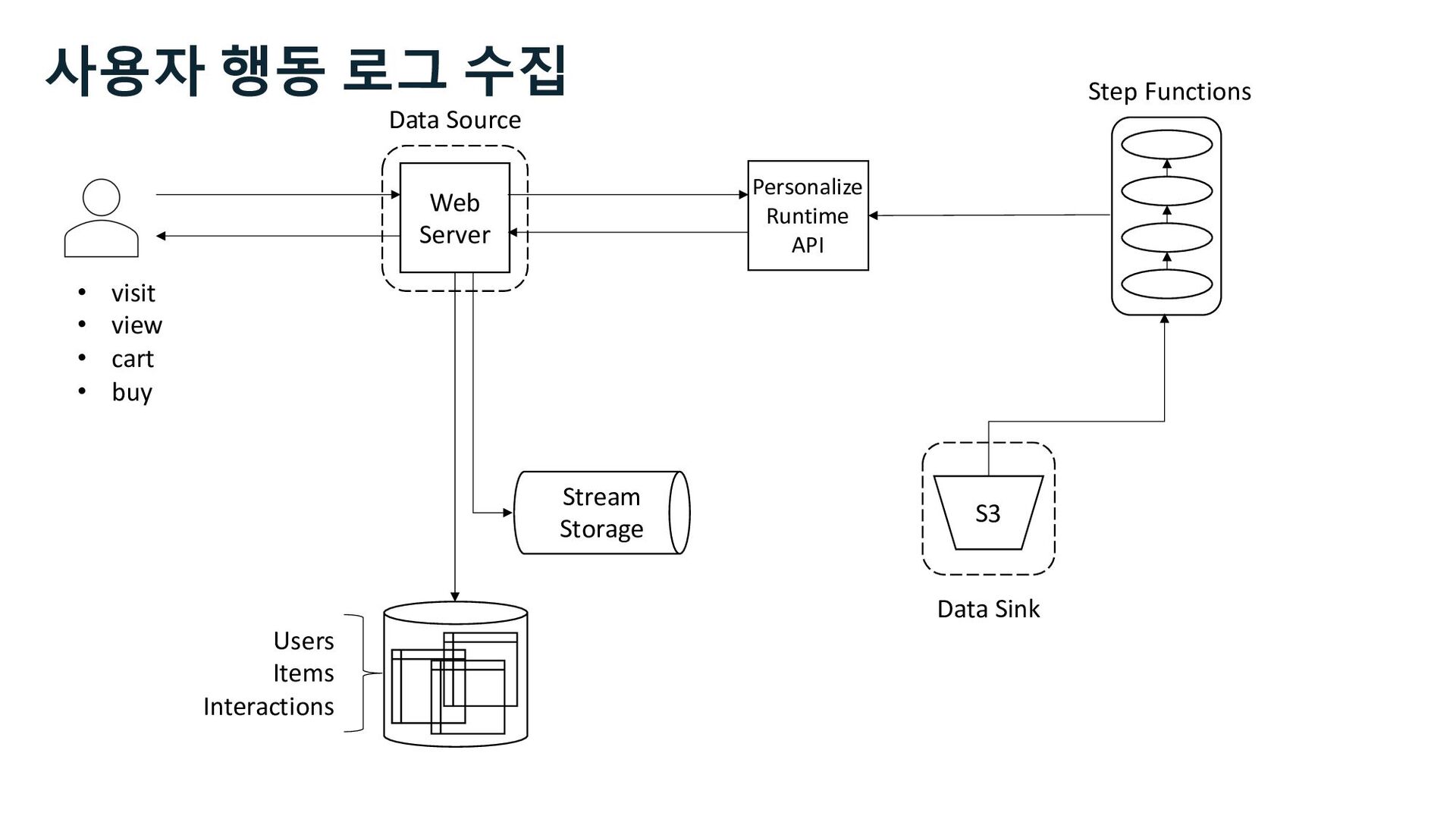
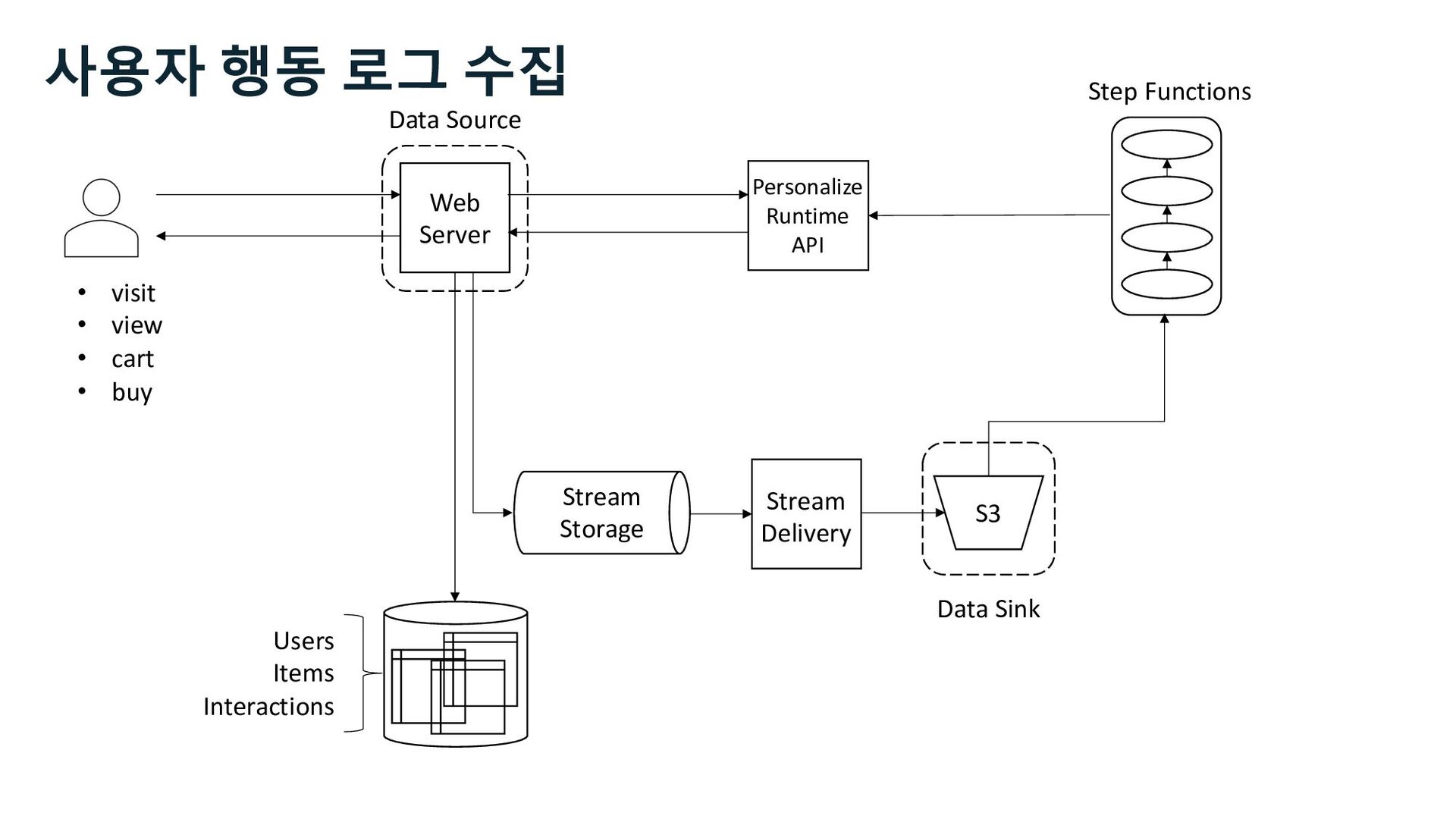
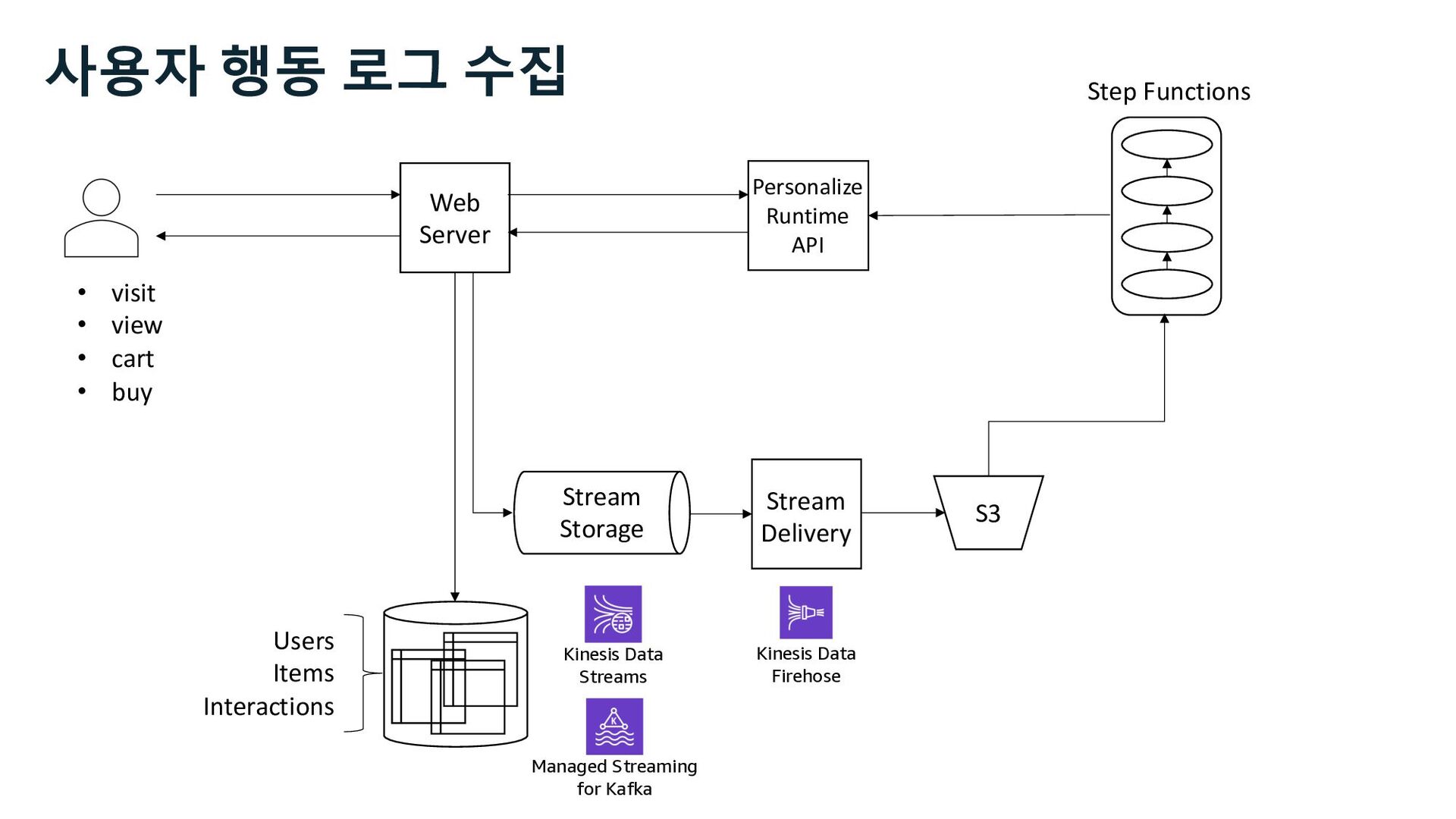
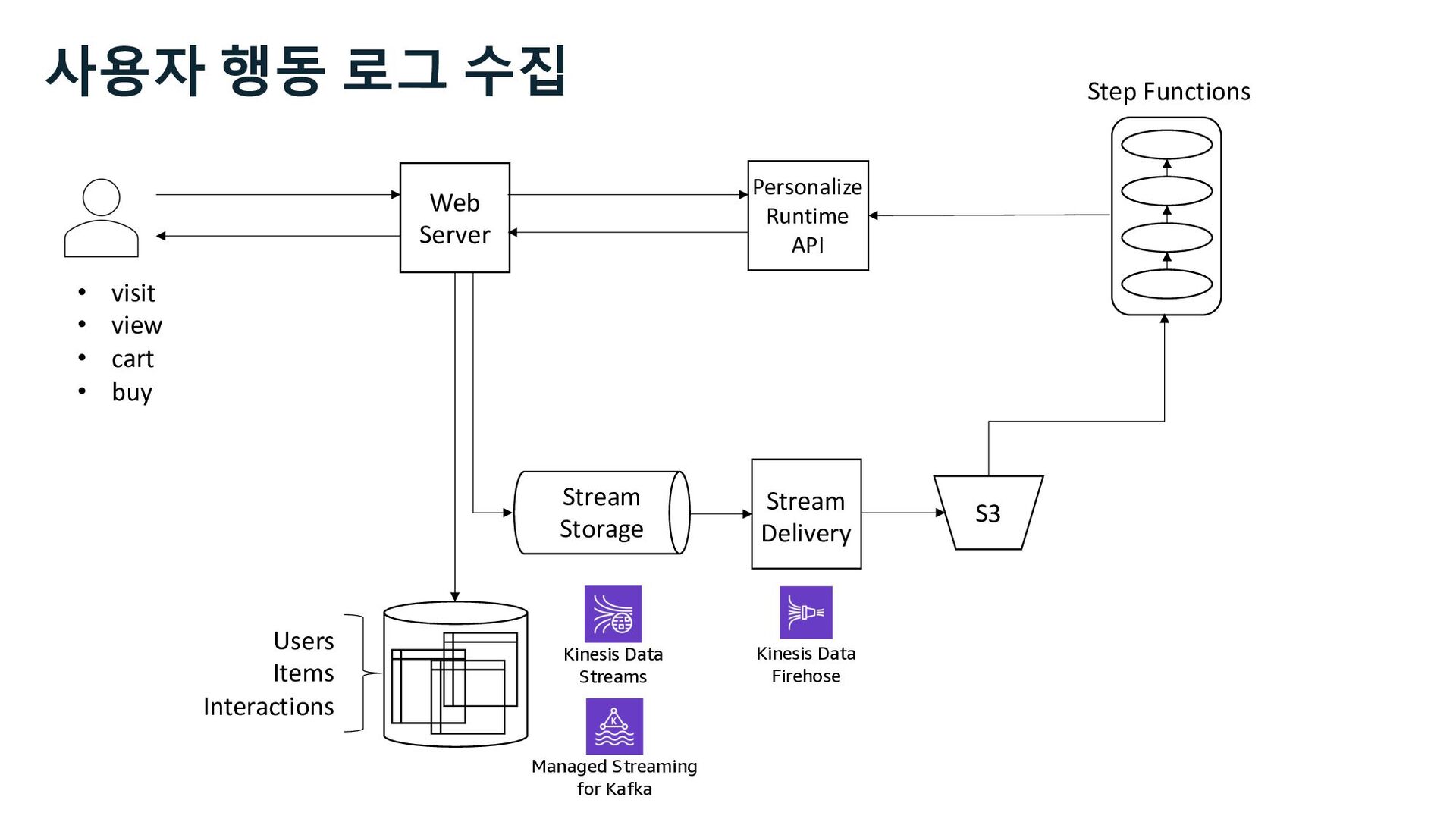
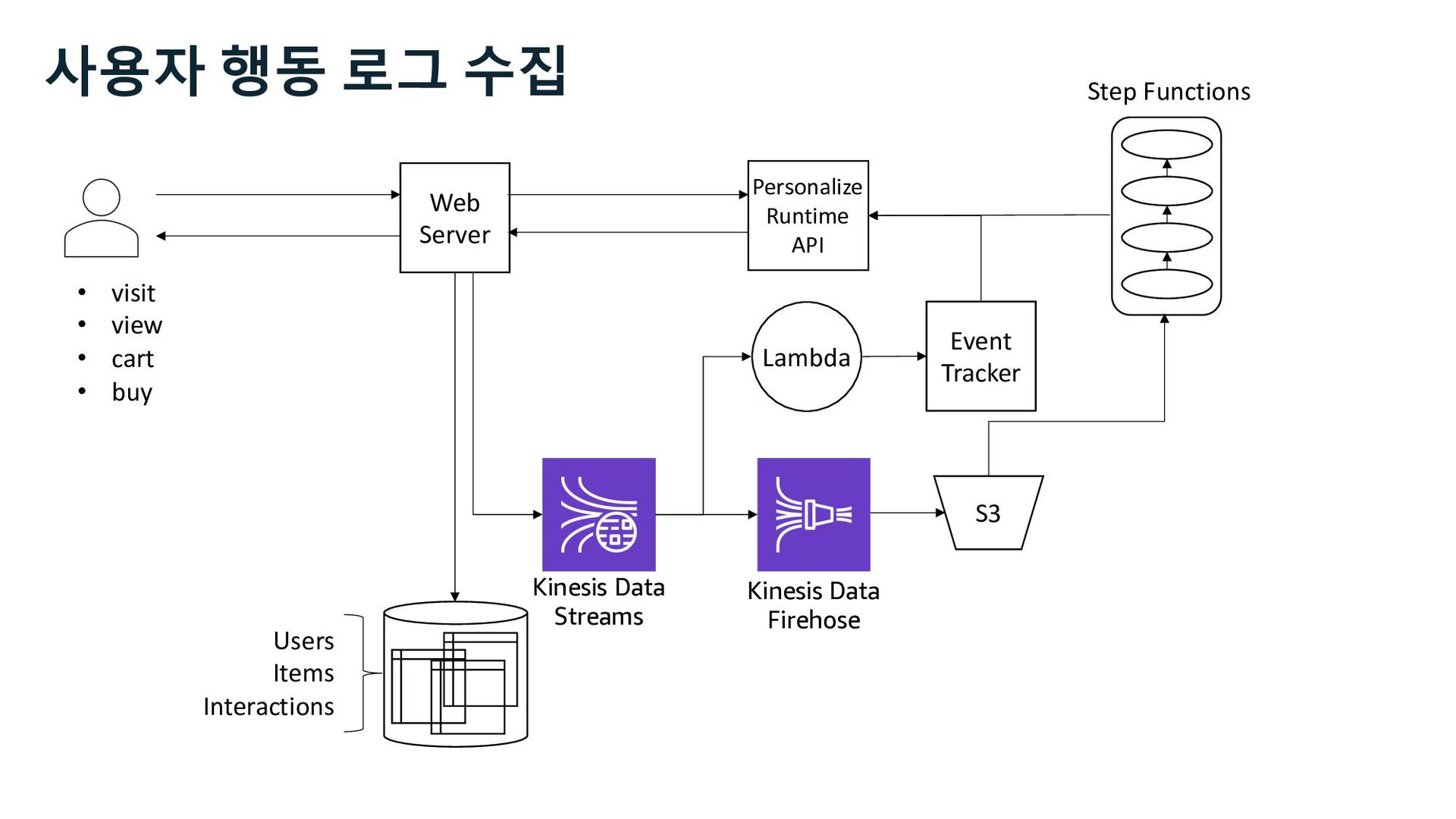
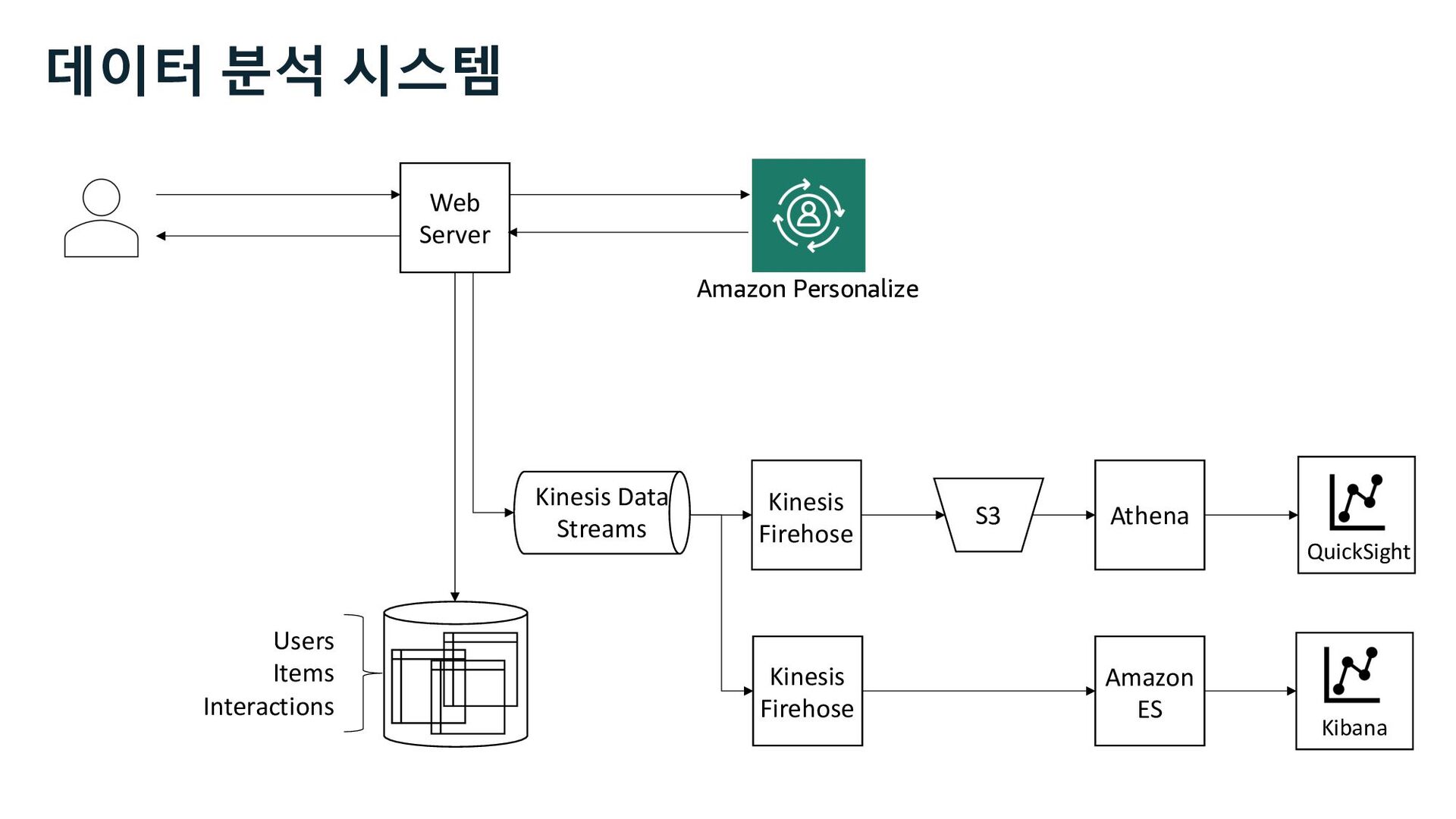
S3 Stream Delivery Users Items Interactions Step Functions Kinesis Data Streams Managed Streaming for Kafka Kinesis Data Firehose Personalize Runtime API 사용자 행동 로그 수집 Stream Storage
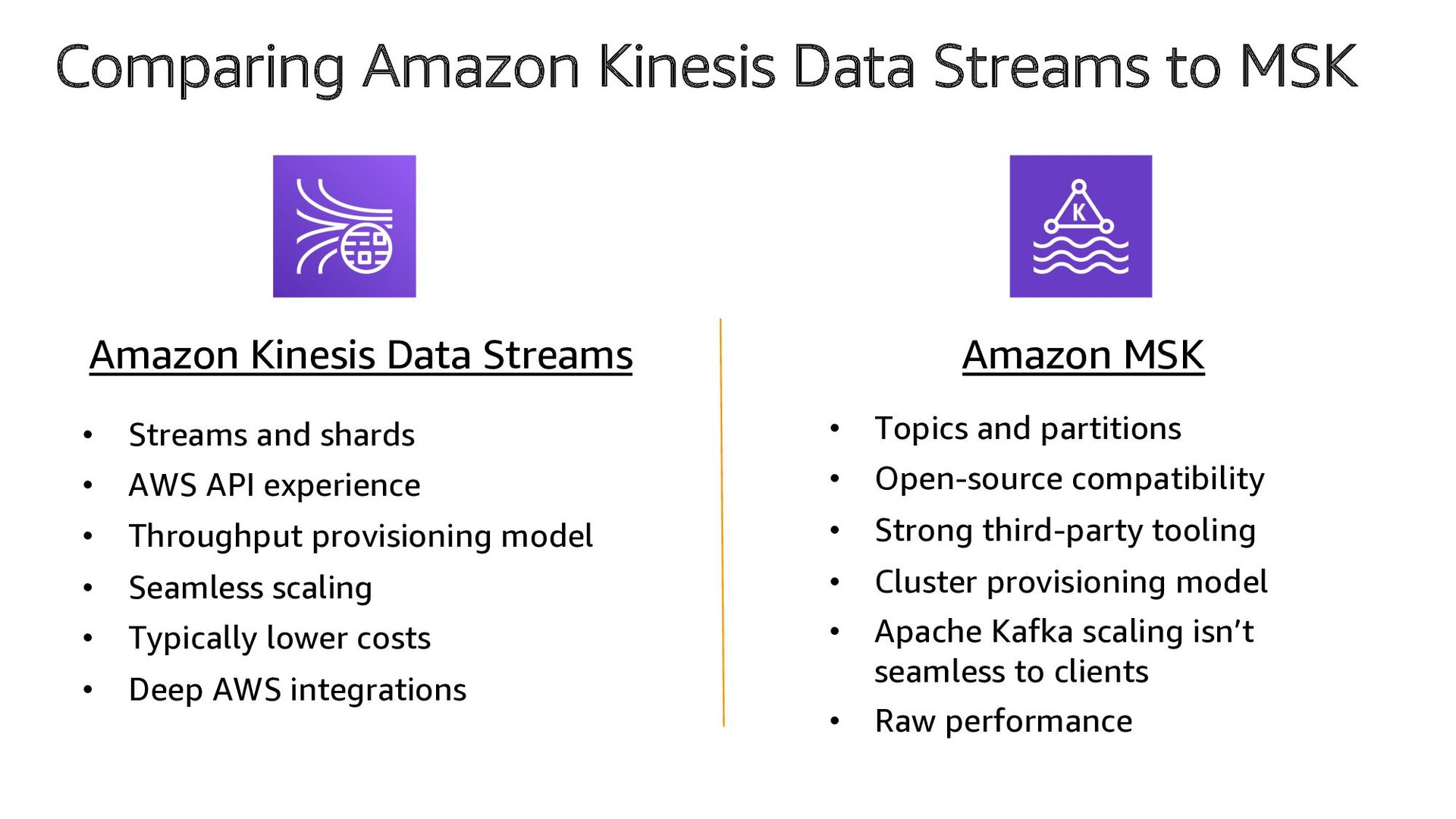
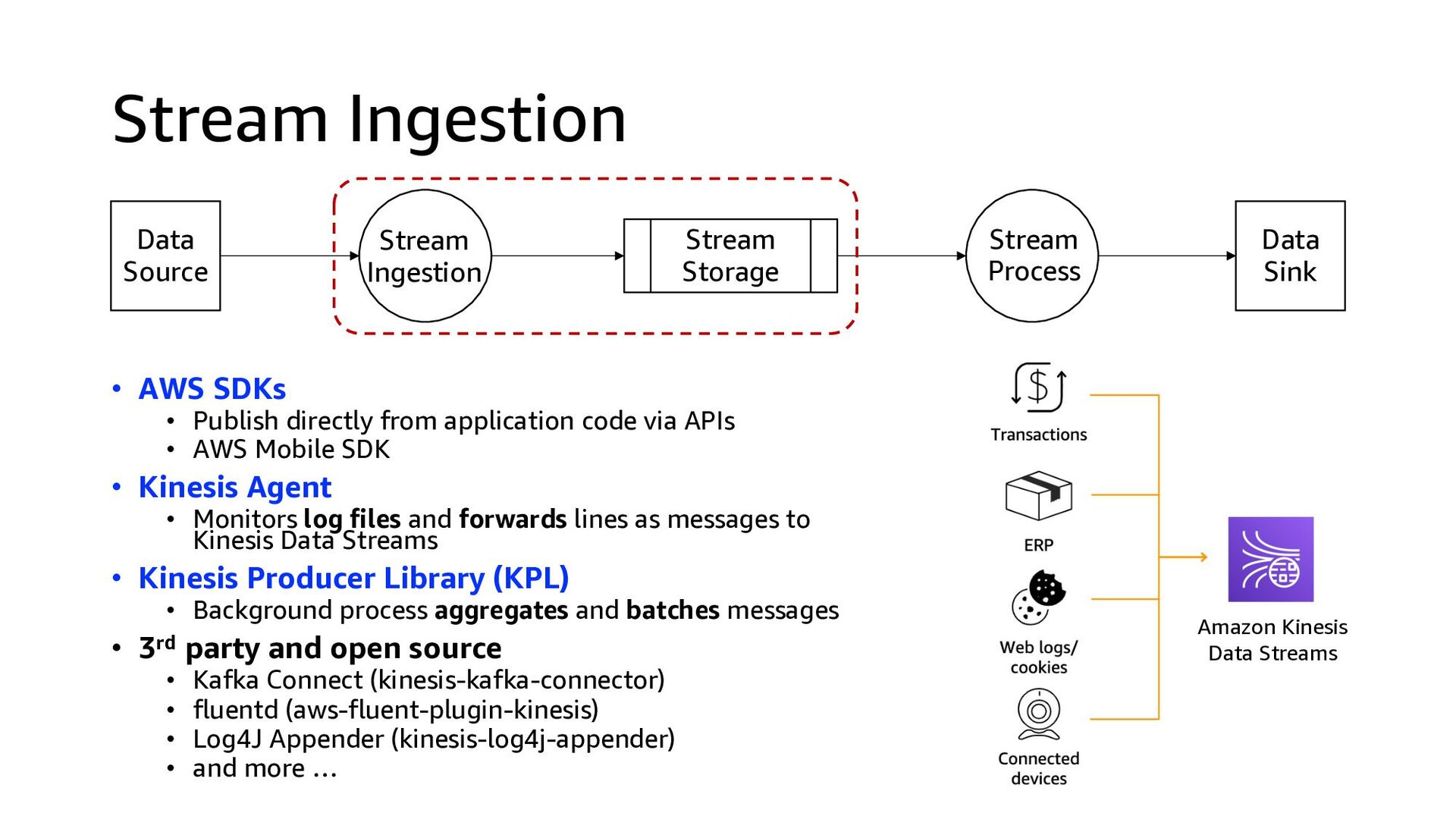
code via APIs • AWS Mobile SDK • Kinesis Agent • Monitors log files and forwards lines as messages to Kinesis Data Streams • Kinesis Producer Library (KPL) • Background process aggregates and batches messages • 3rd party and open source • Kafka Connect (kinesis-kafka-connector) • fluentd (aws-fluent-plugin-kinesis) • Log4J Appender (kinesis-log4j-appender) • and more … Data Source Stream Storage Stream Process Stream Ingestion Data Sink Amazon Kinesis Data Streams
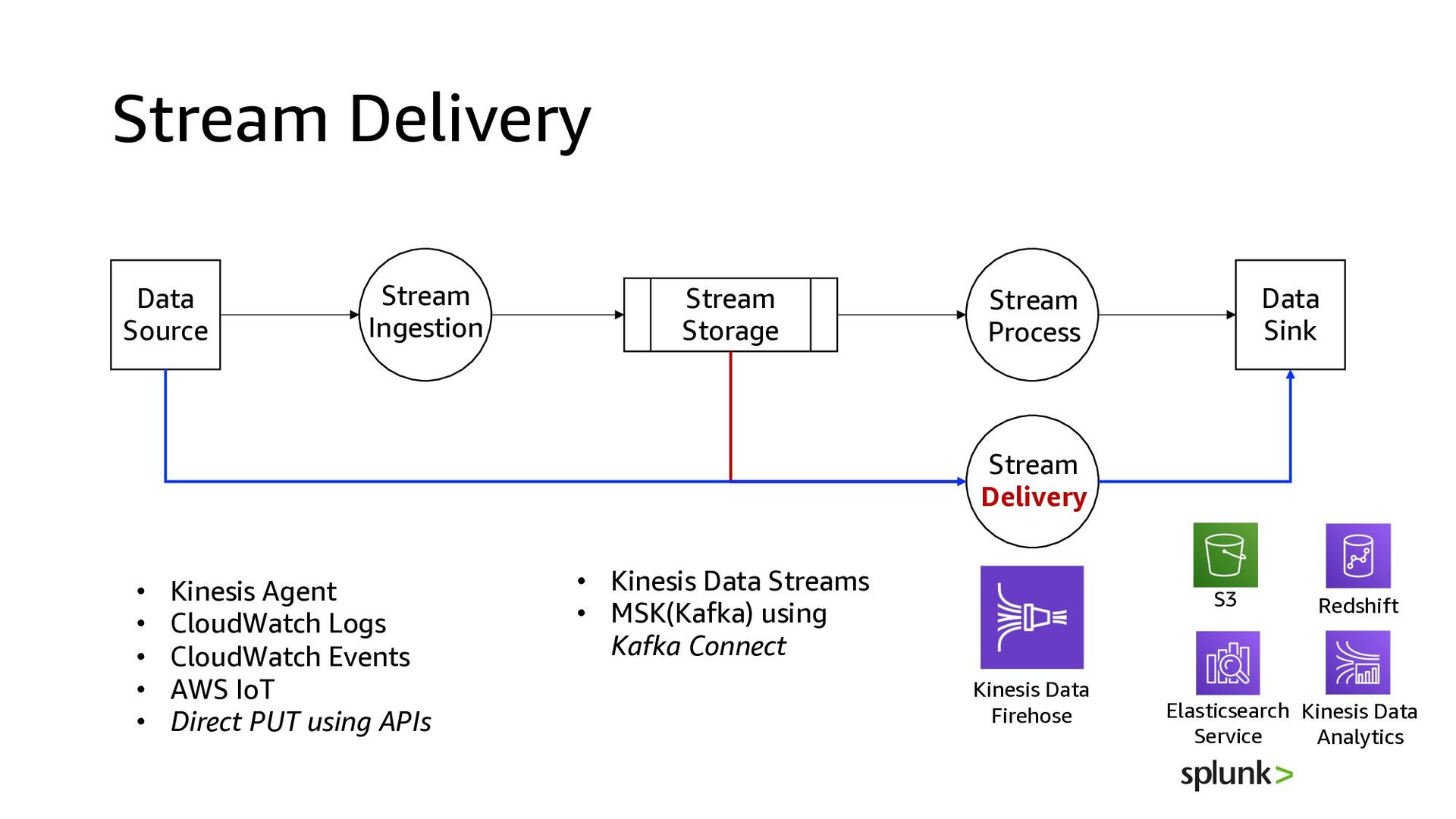
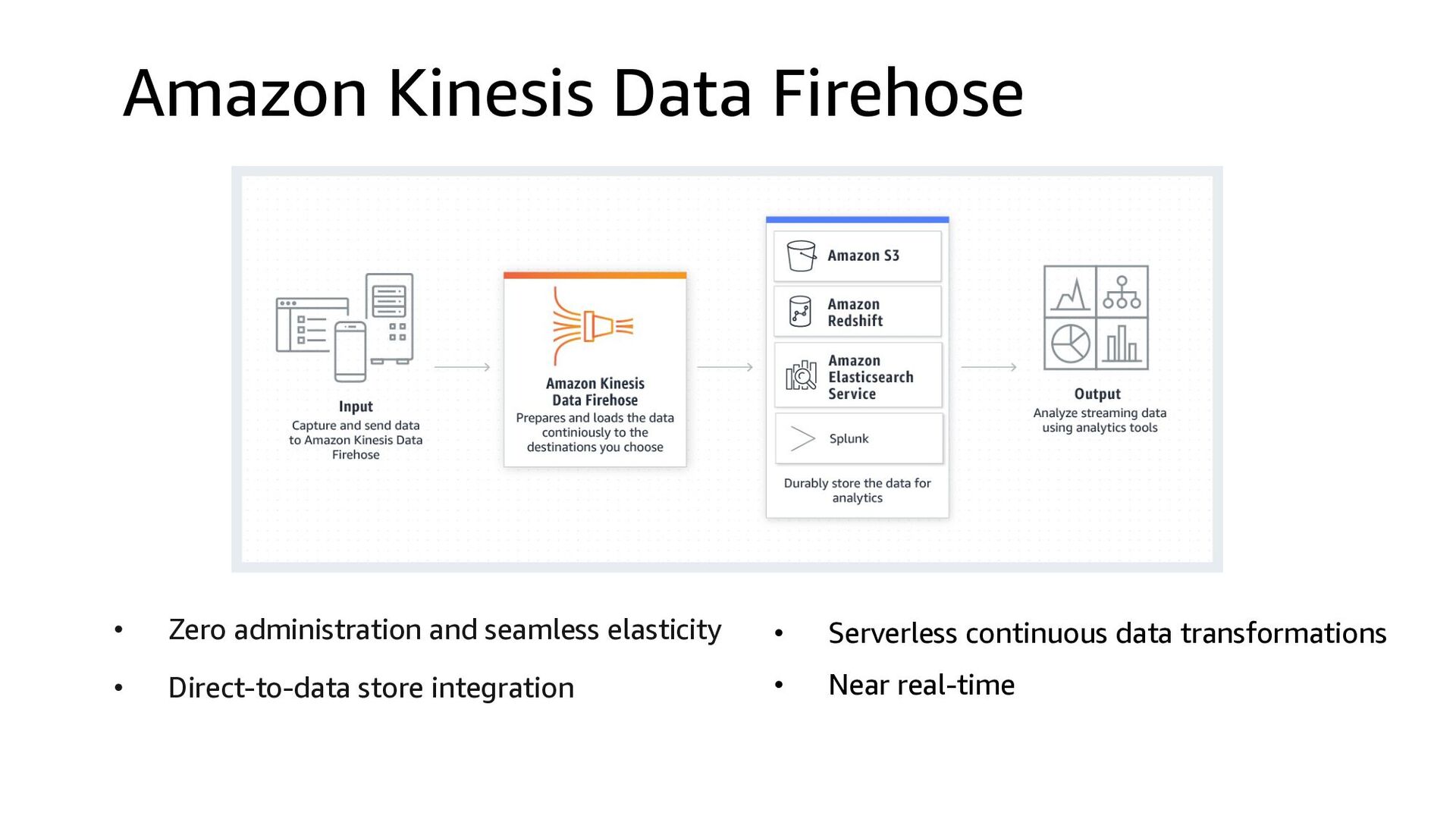
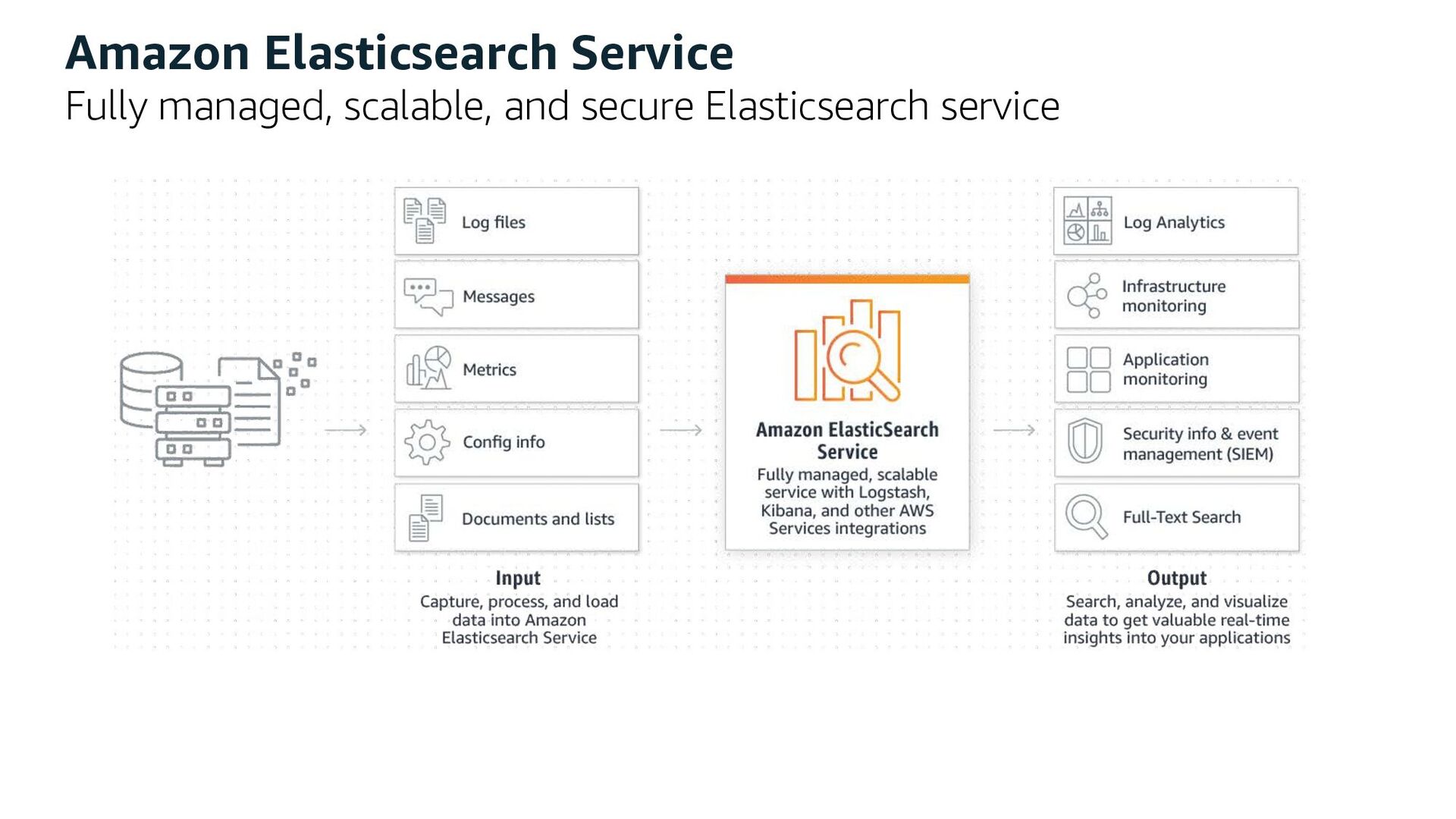
Process Stream Ingestion Data Sink Stream Delivery Kinesis Data Firehose • Kinesis Agent • CloudWatch Logs • CloudWatch Events • AWS IoT • Direct PUT using APIs • Kinesis Data Streams • MSK(Kafka) using Kafka Connect Kinesis Data Analytics S3
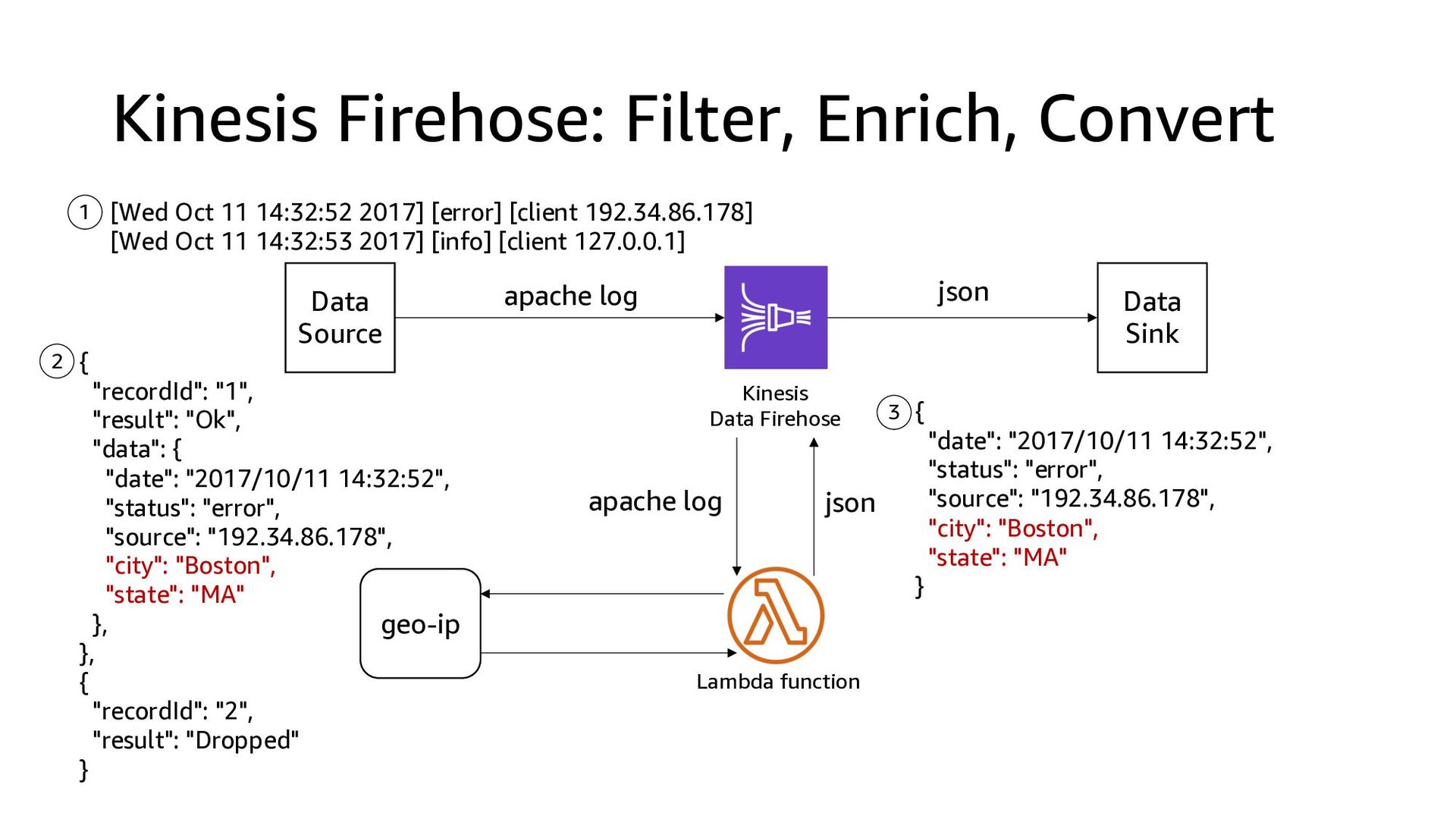
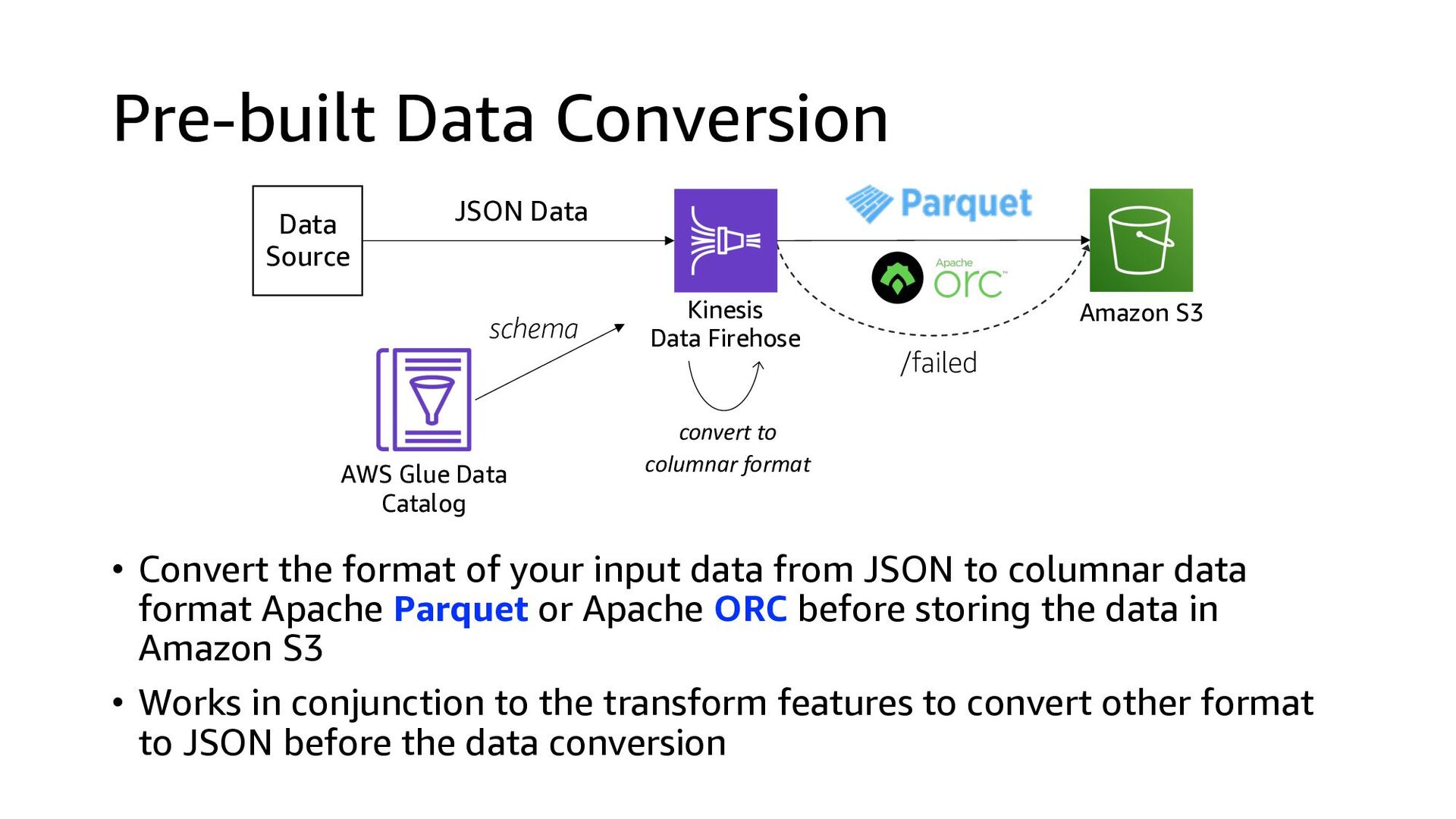
schema AWS Glue Data Catalog Amazon S3 • Convert the format of your input data from JSON to columnar data format Apache Parquet or Apache ORC before storing the data in Amazon S3 • Works in conjunction to the transform features to convert other format to JSON before the data conversion convert to columnar format /failed
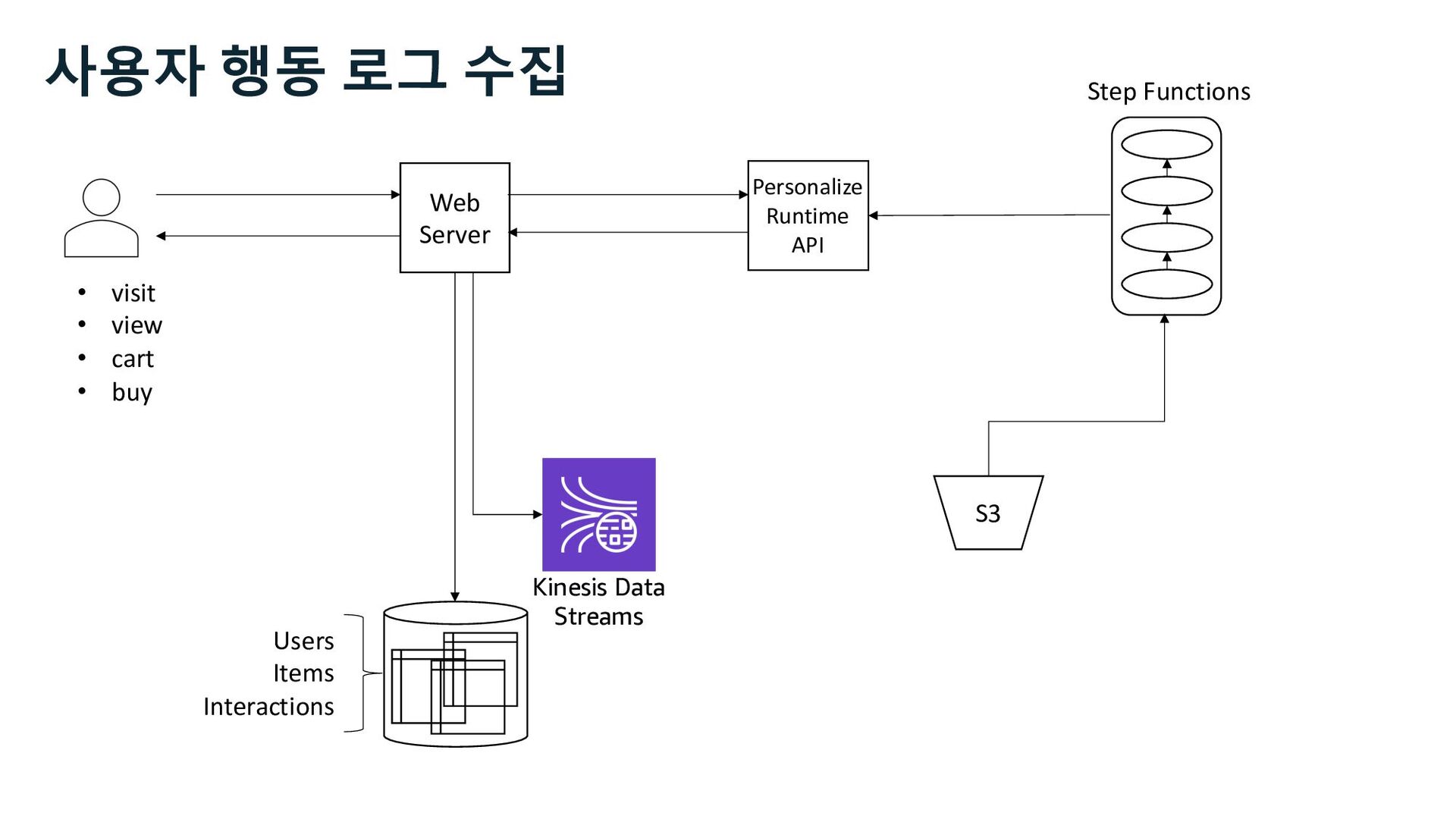
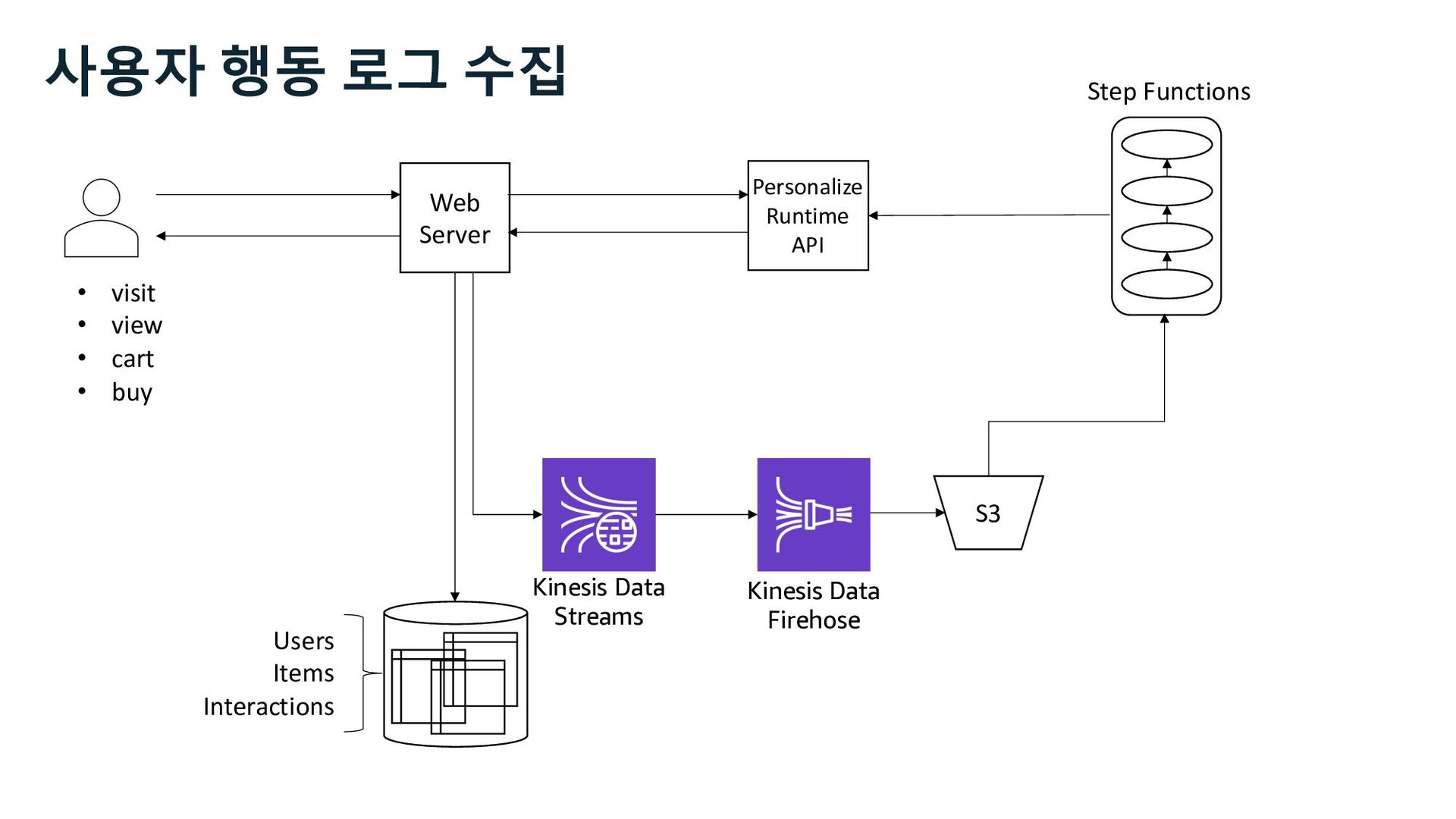
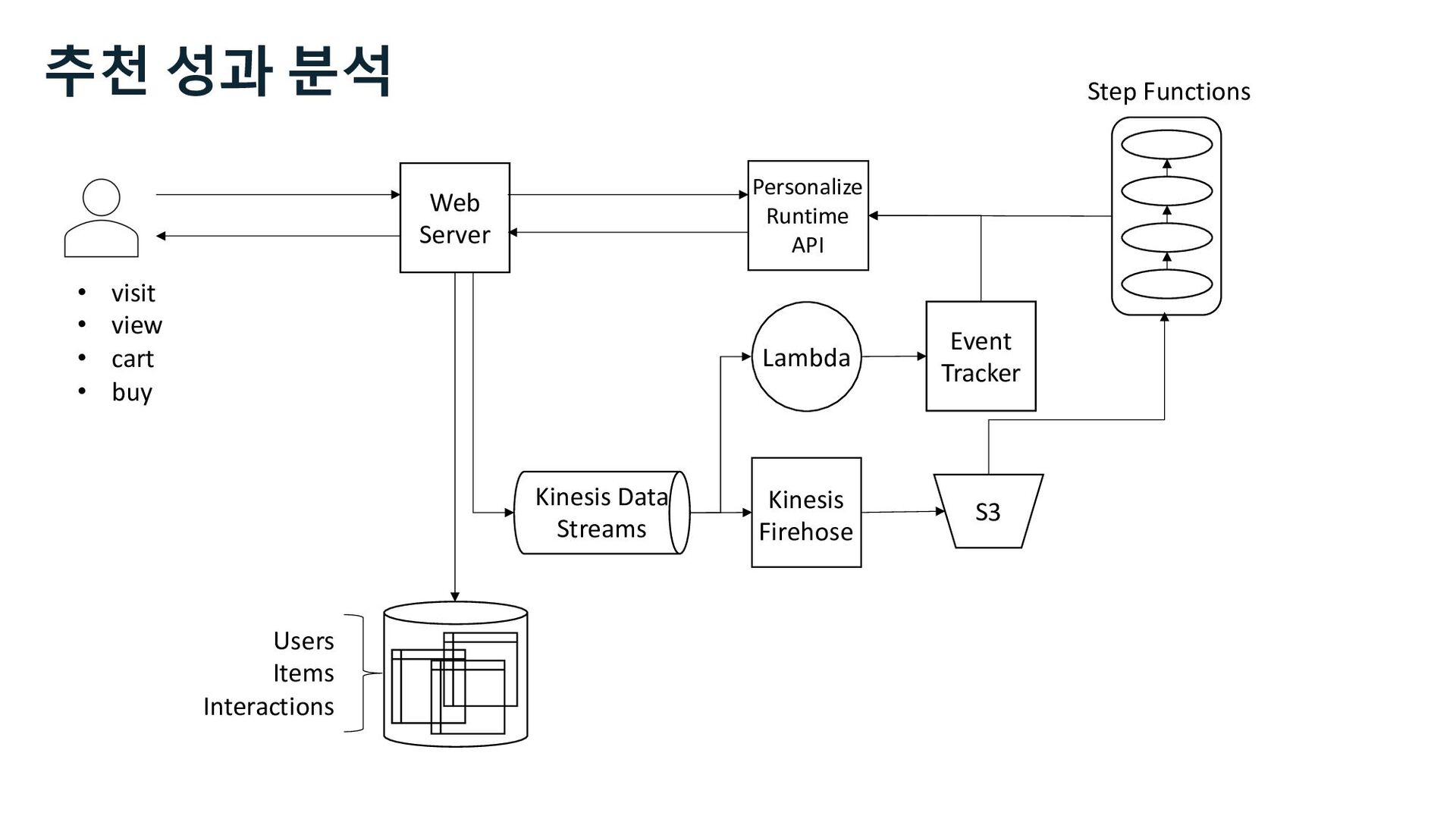
S3 Stream Delivery Users Items Interactions Step Functions Personalize Runtime API Kinesis Data Streams Managed Streaming for Kafka Kinesis Data Firehose 사용자 행동 로그 수집 Stream Storage
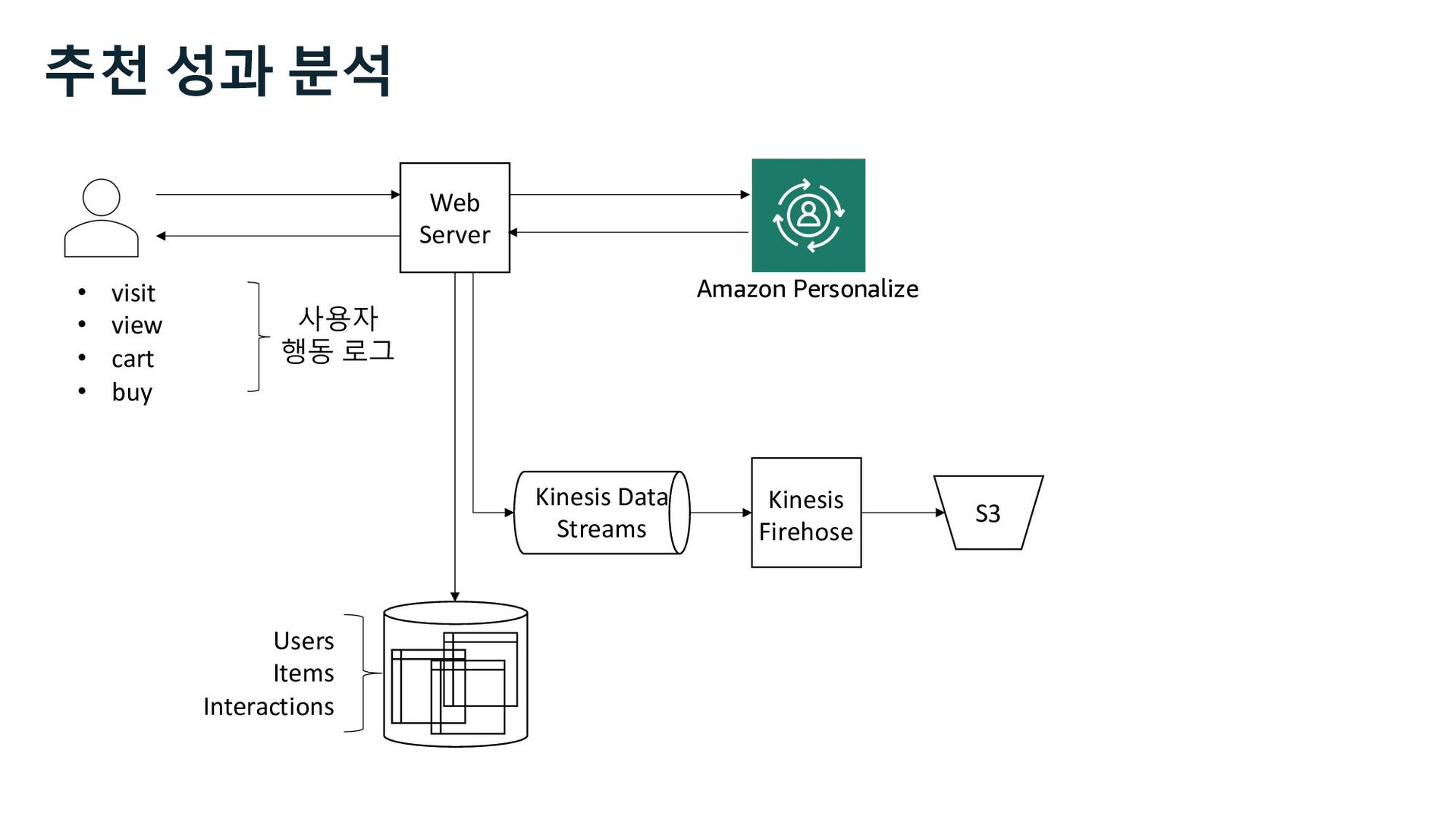
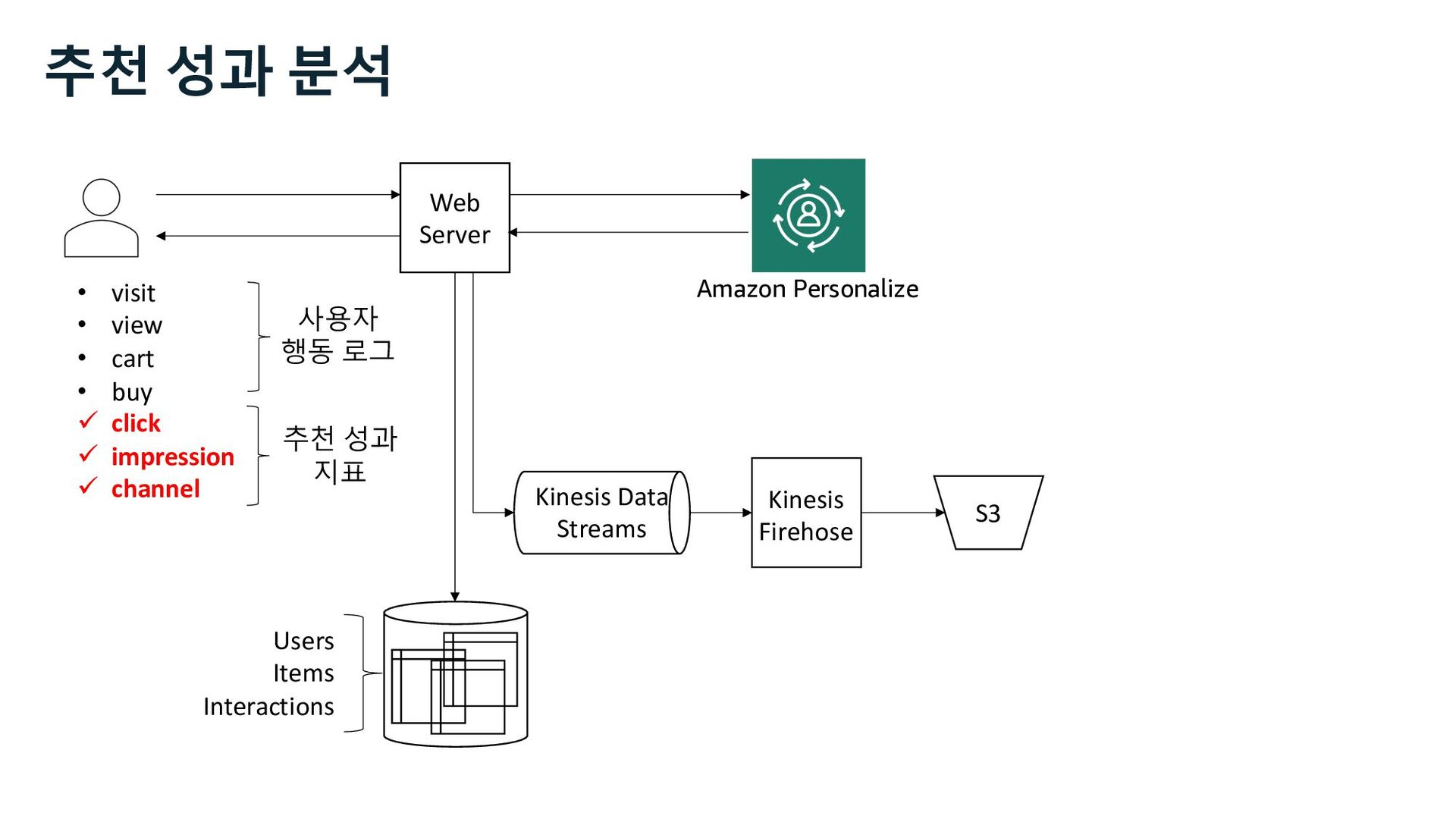
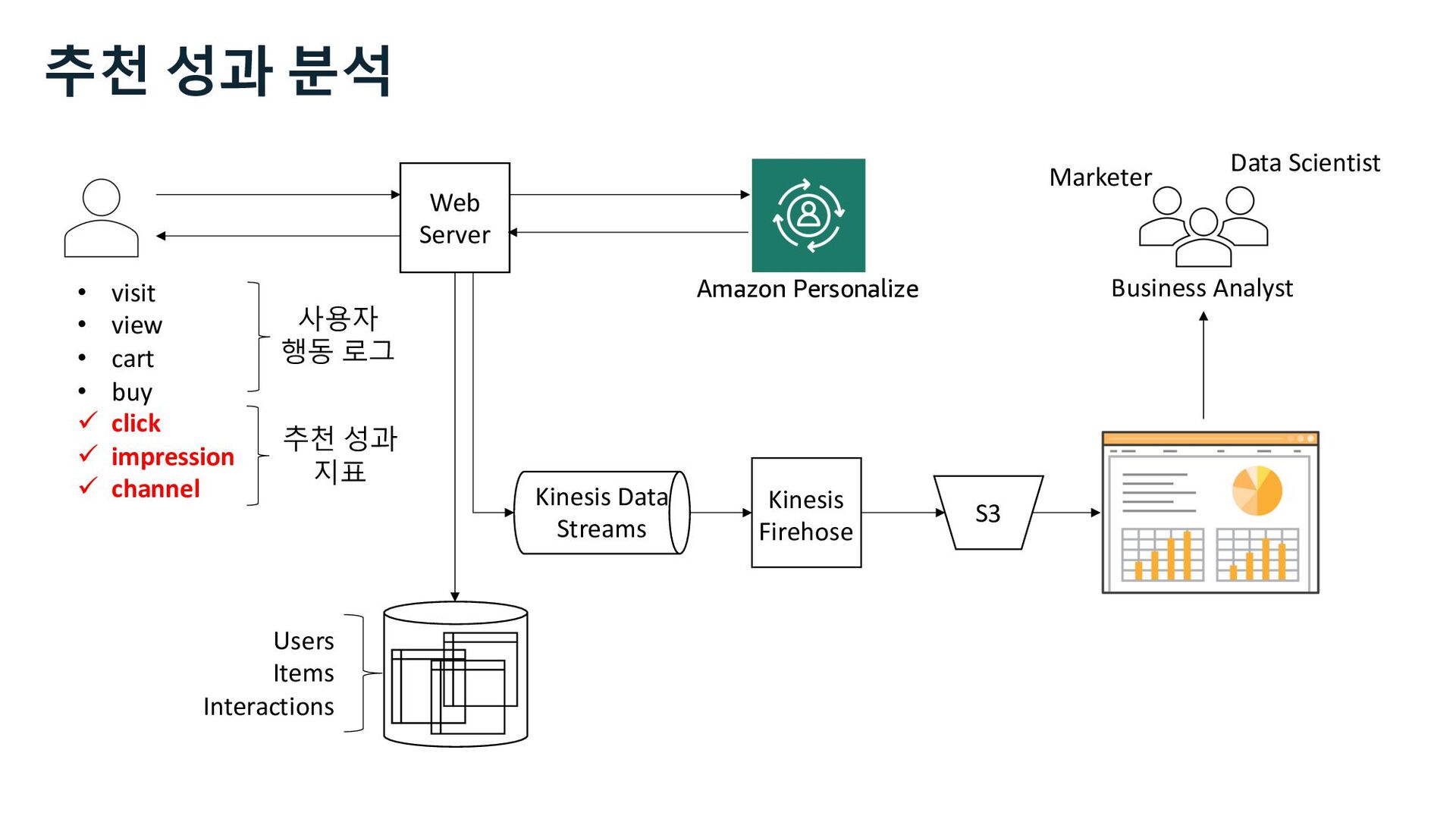
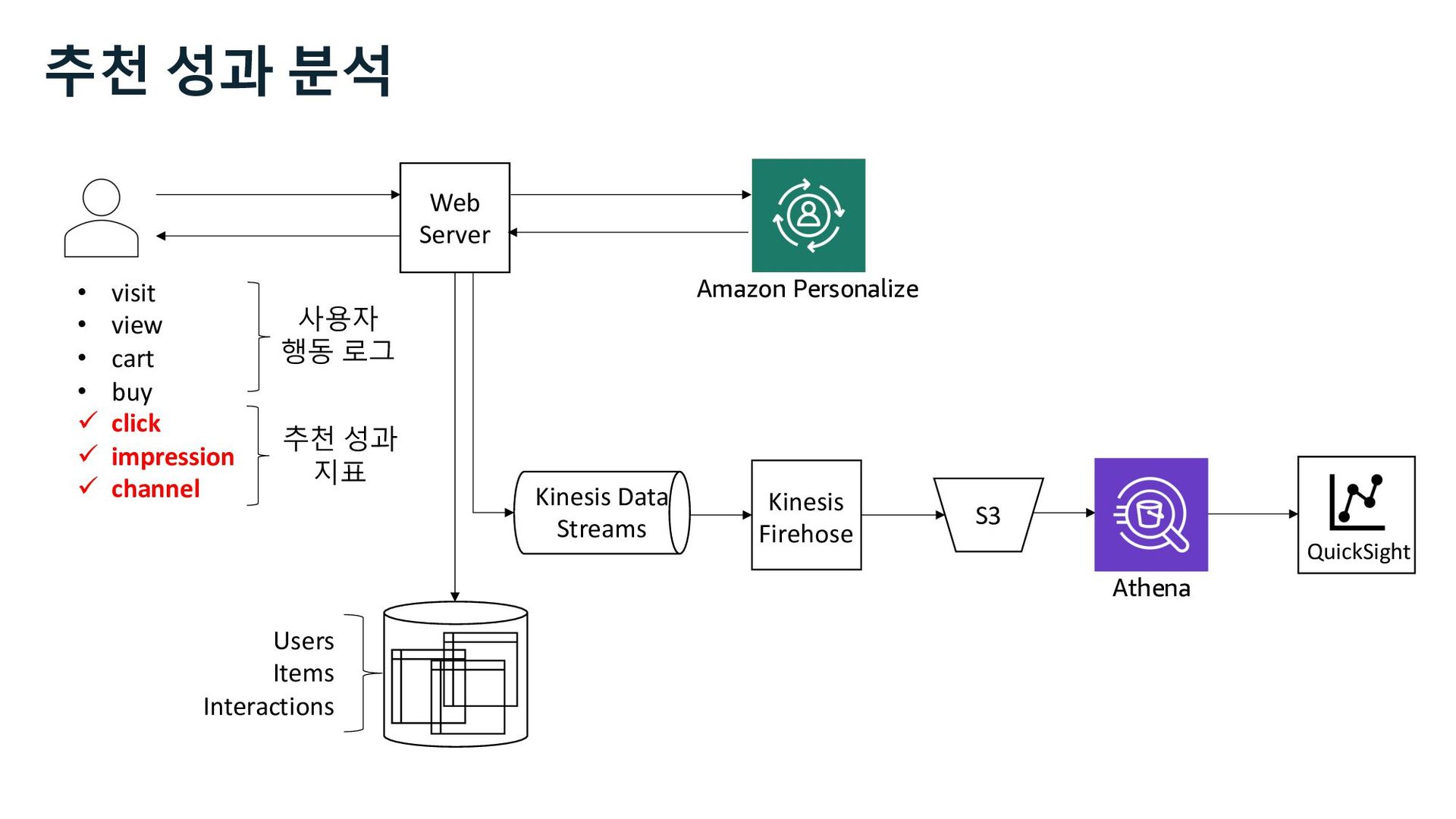
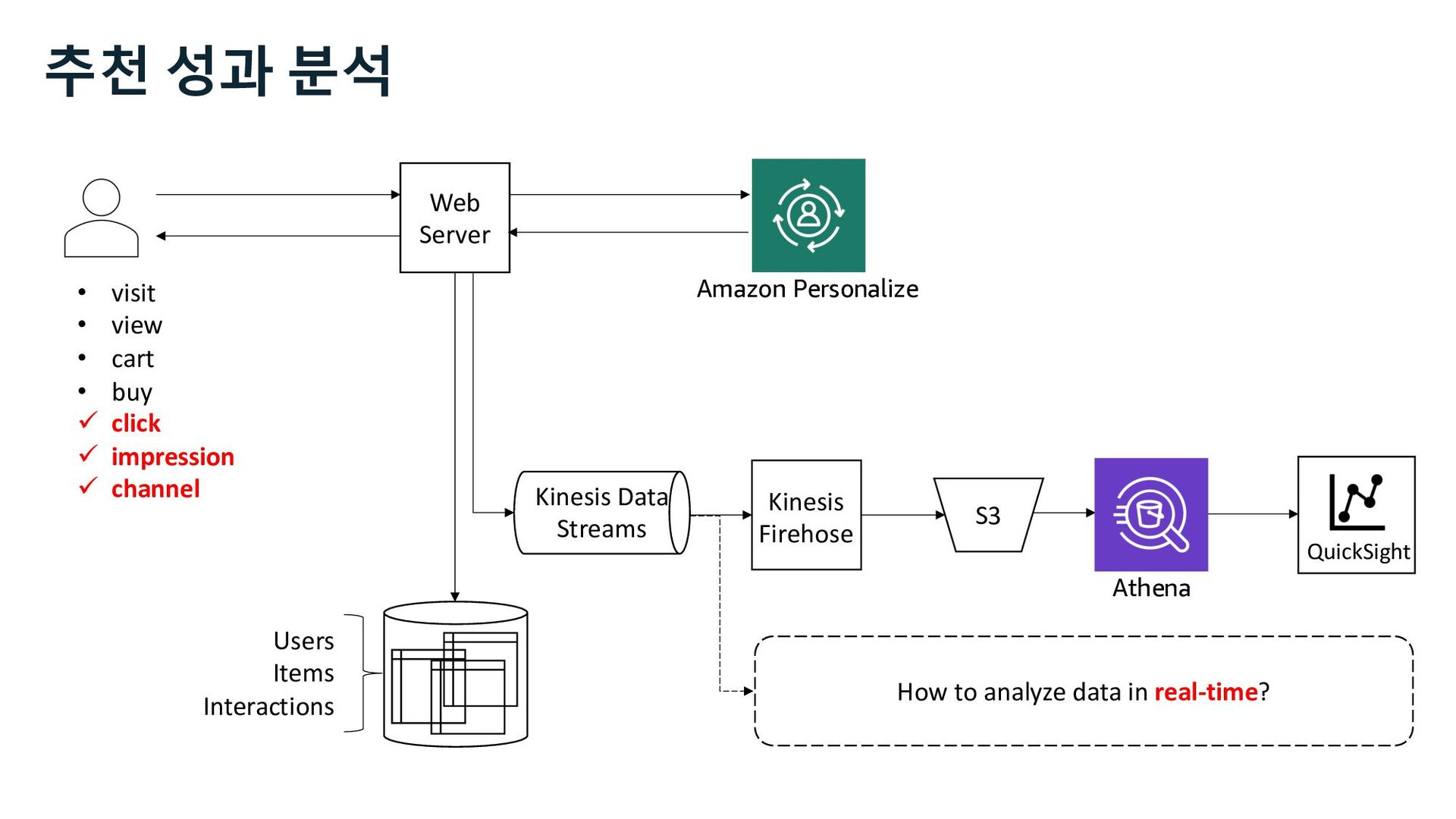
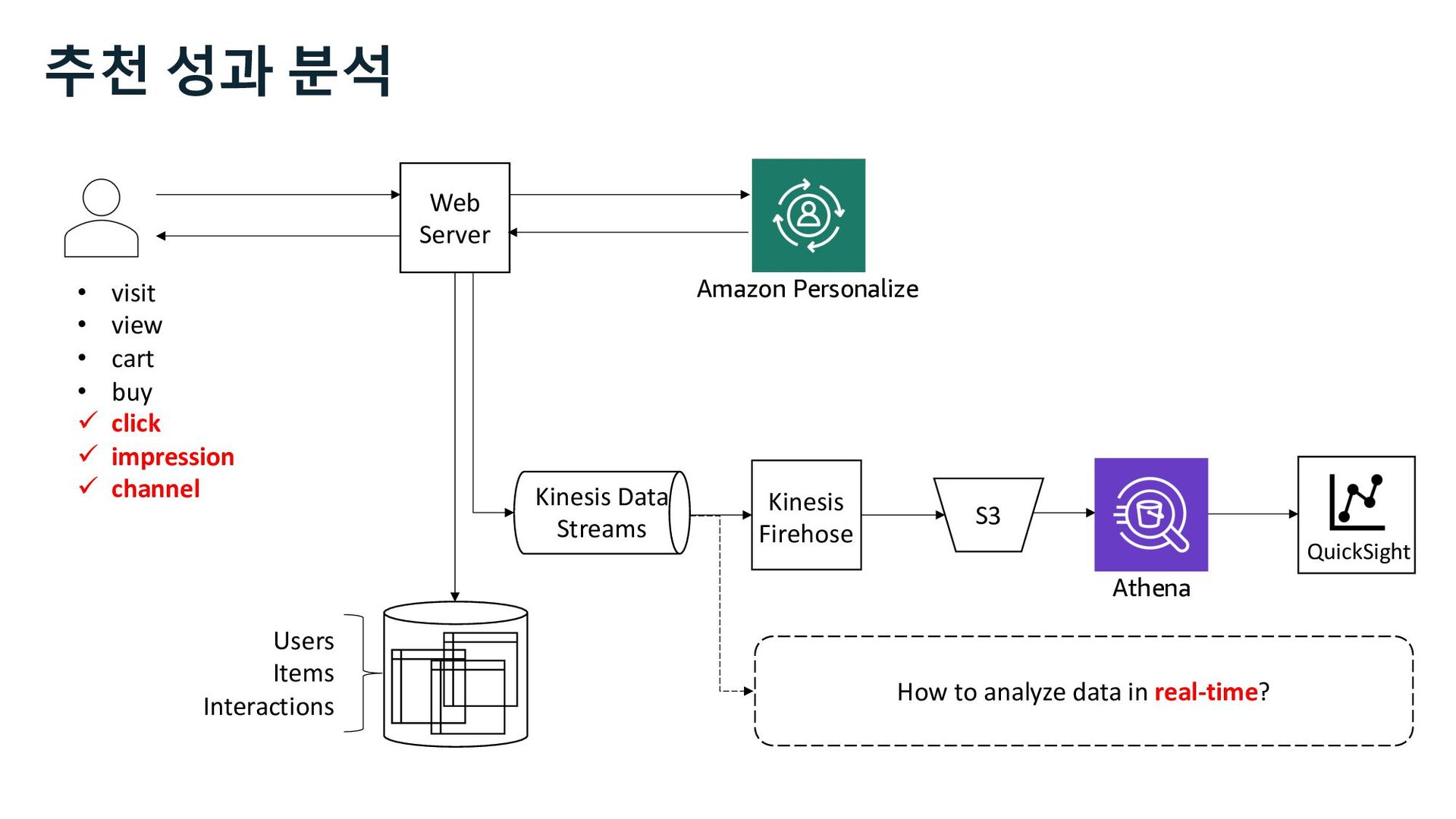
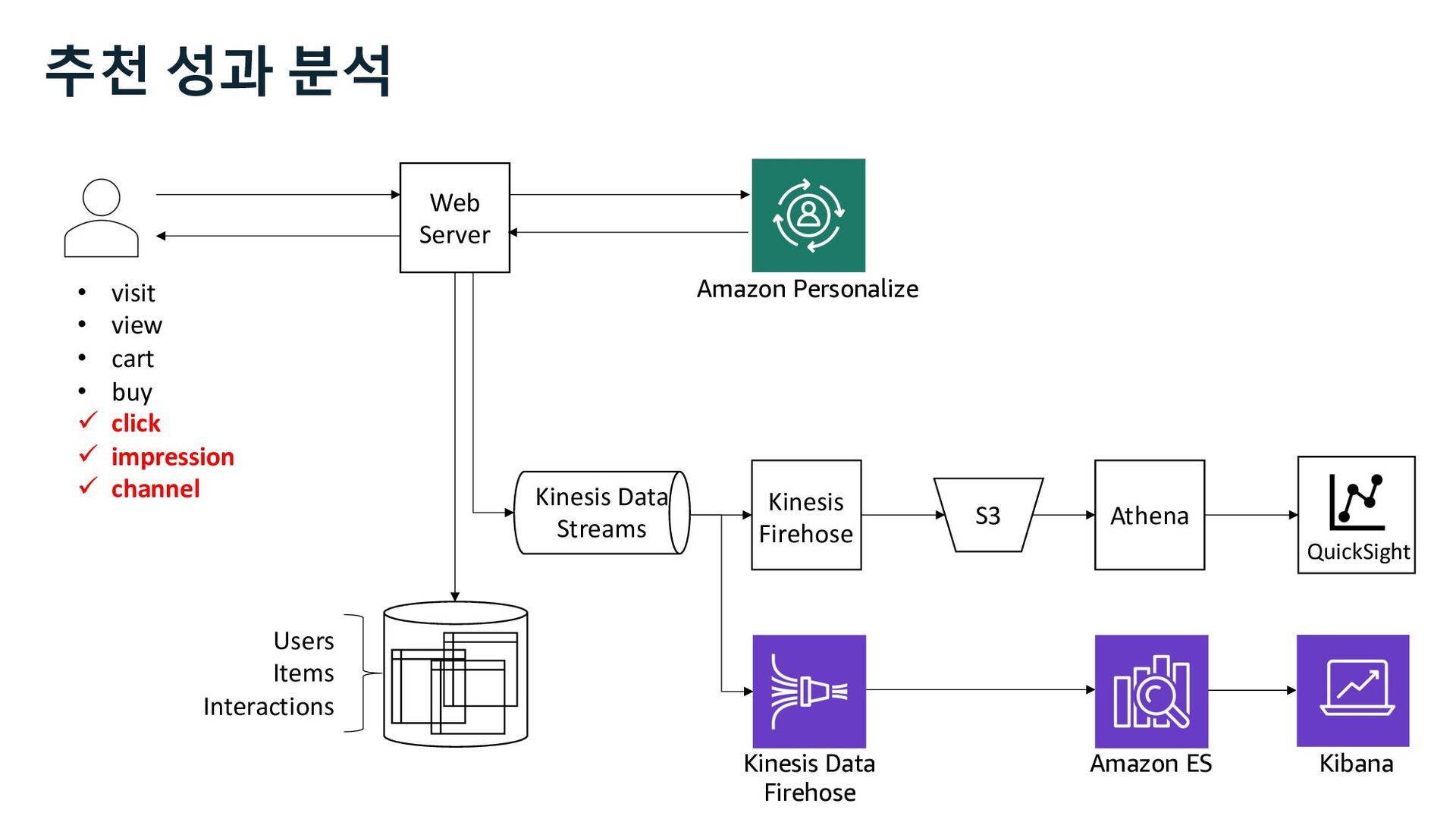
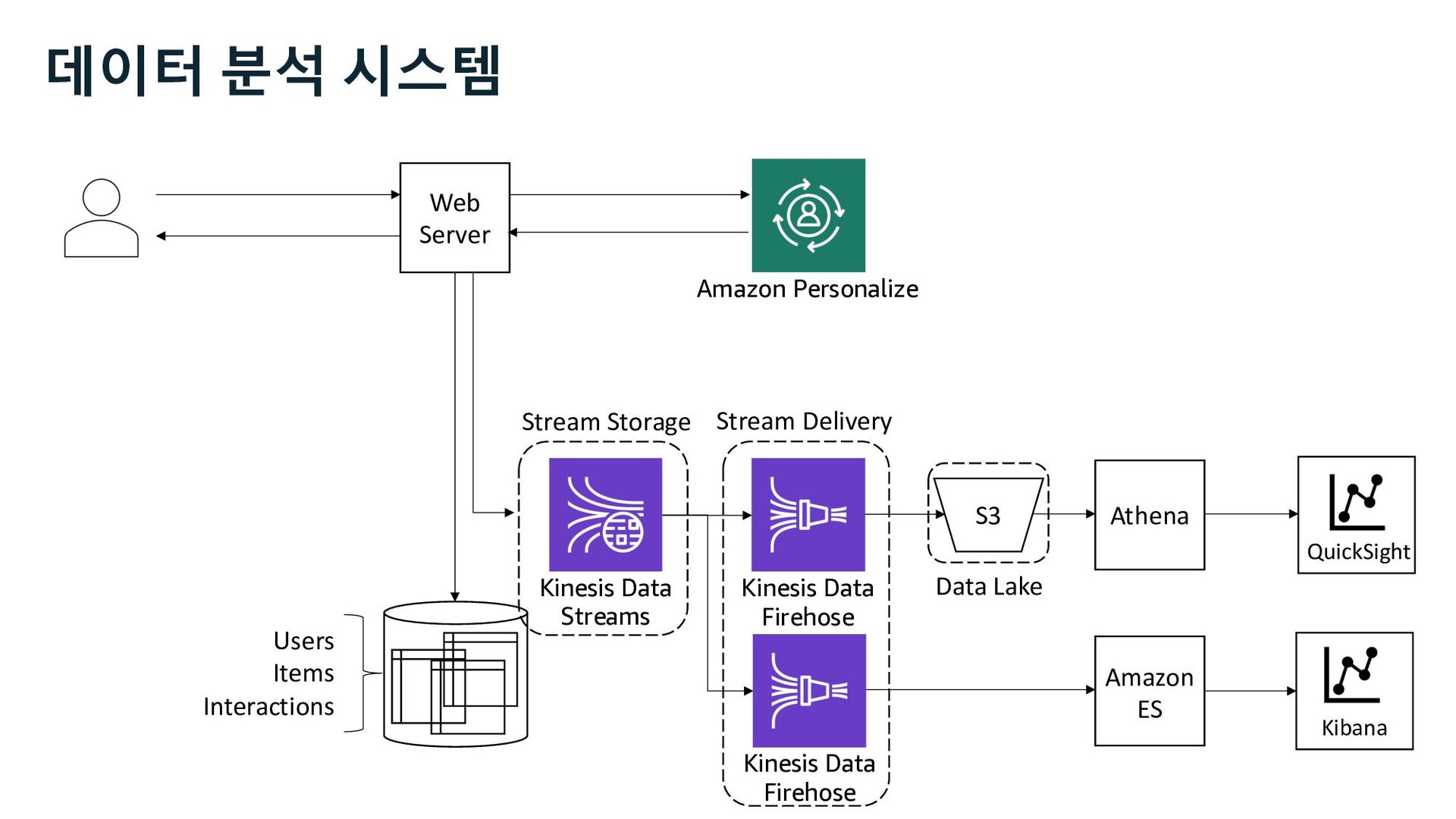
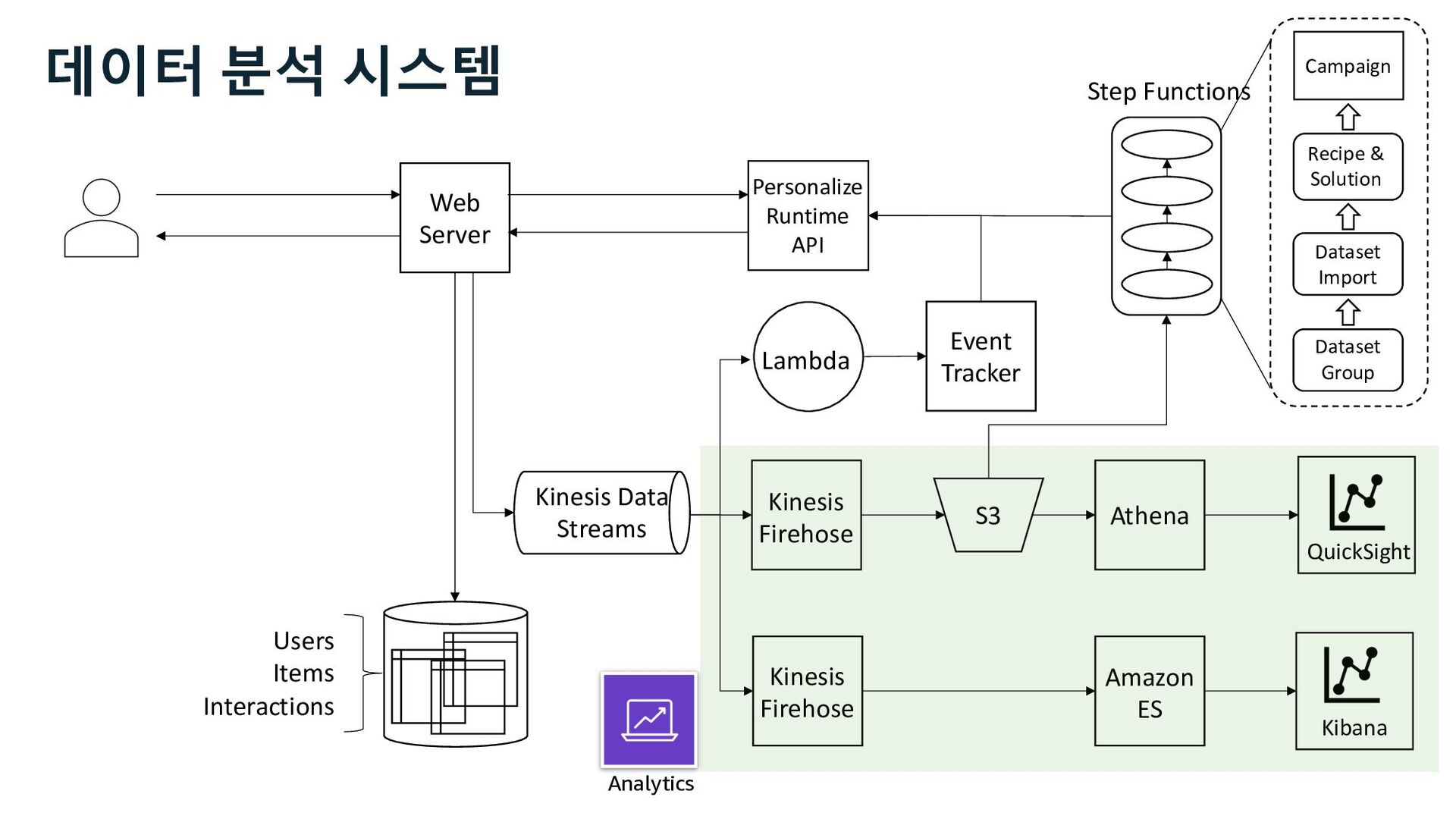
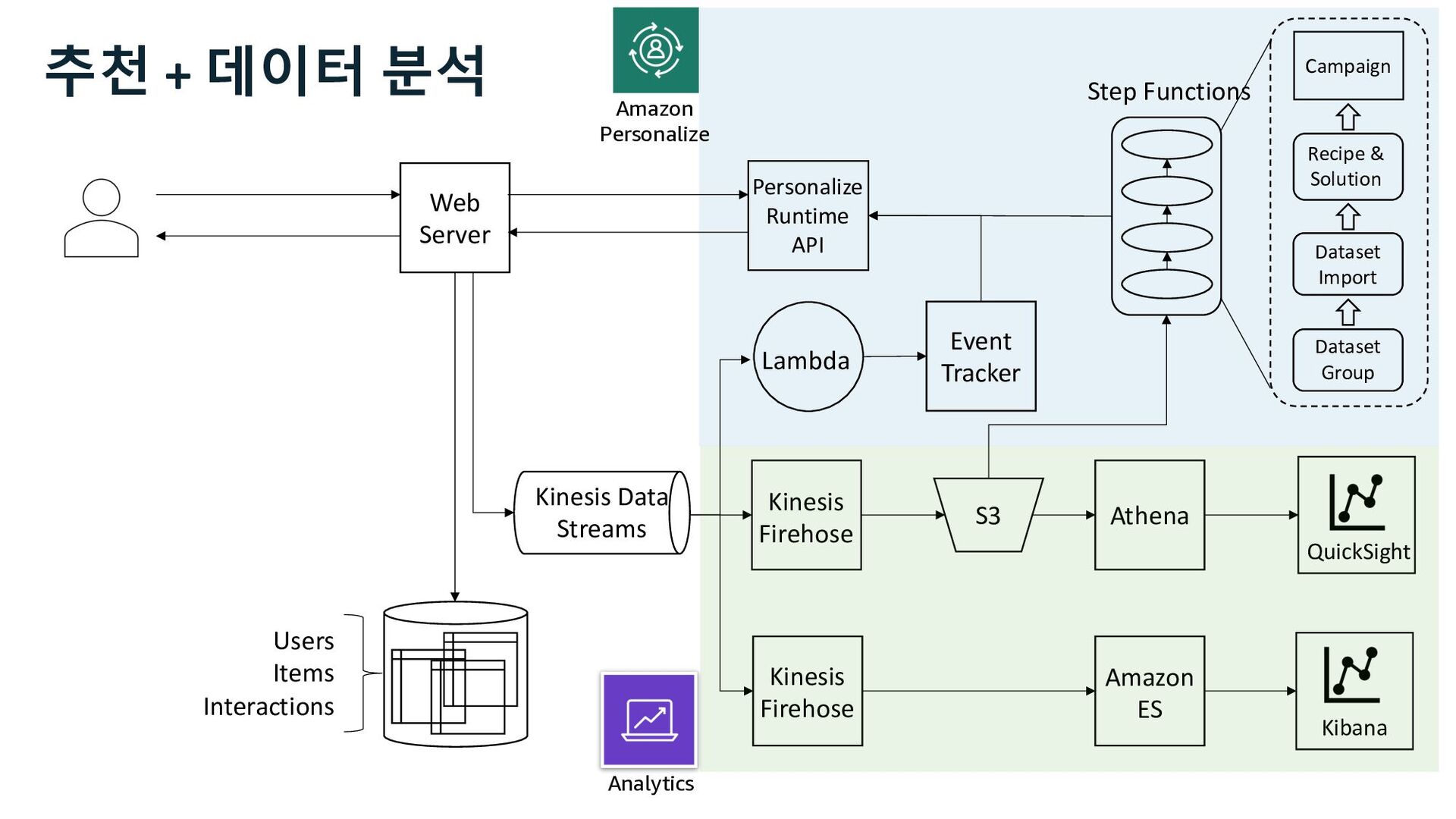
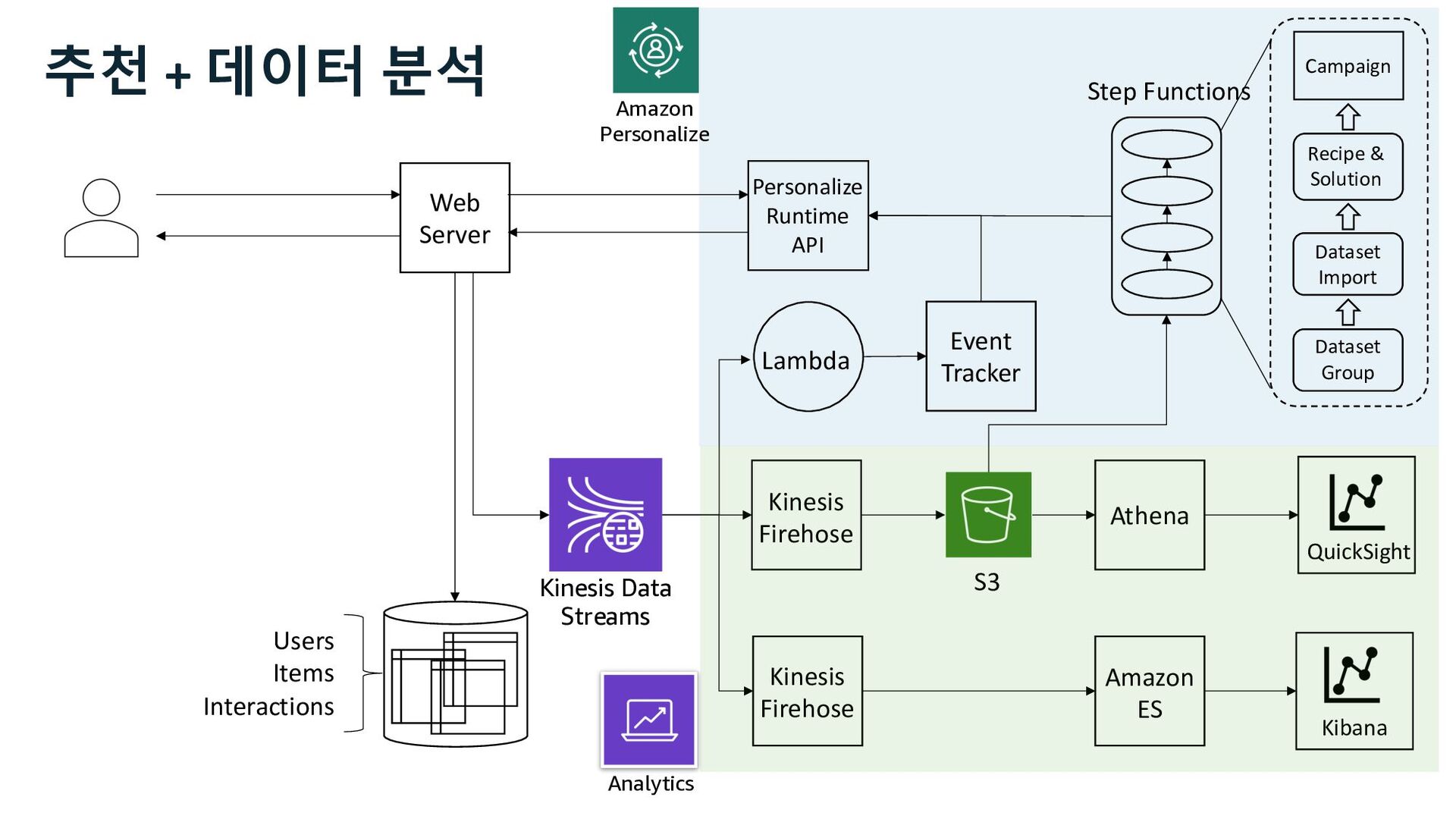
ü impression ü channel Web Server S3 Kinesis Firehose Users Items Interactions Amazon Personalize Marketer Data Scientist Business Analyst 사용자 행동 로그 추천 성과 분석 추천 성과 지표 Kinesis Data Streams
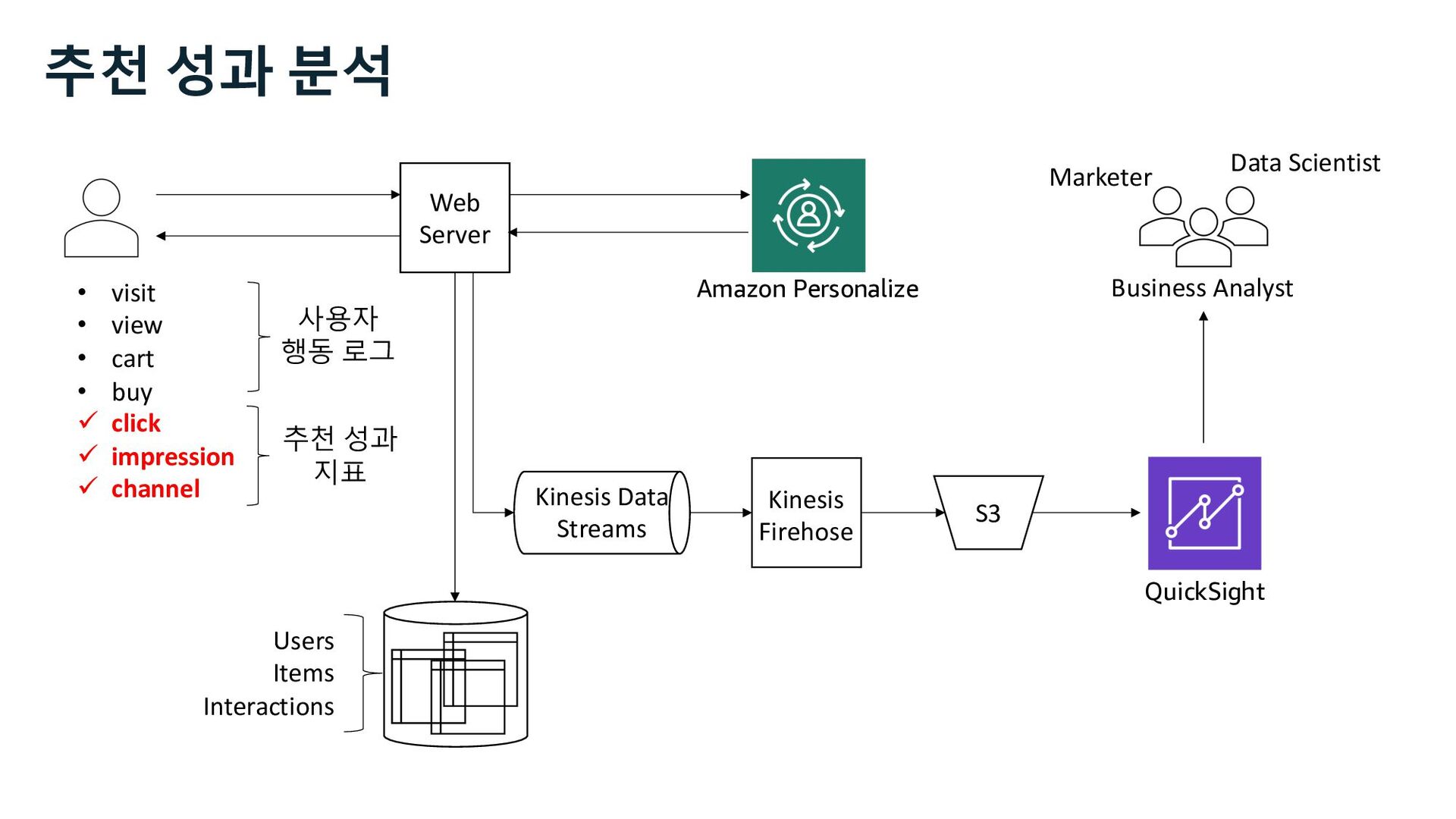
ü impression ü channel Web Server S3 Kinesis Firehose Users Items Interactions Amazon Personalize Marketer Data Scientist Business Analyst QuickSight 사용자 행동 로그 추천 성과 지표 추천 성과 분석 Kinesis Data Streams
SETS Retail Data Ops Data Marketing Data ANALYSES DASHBOARDS & STORIES Amazon QuickSight Fast BI Service with Pay-per-Session Pricing and ML Insights for everyone
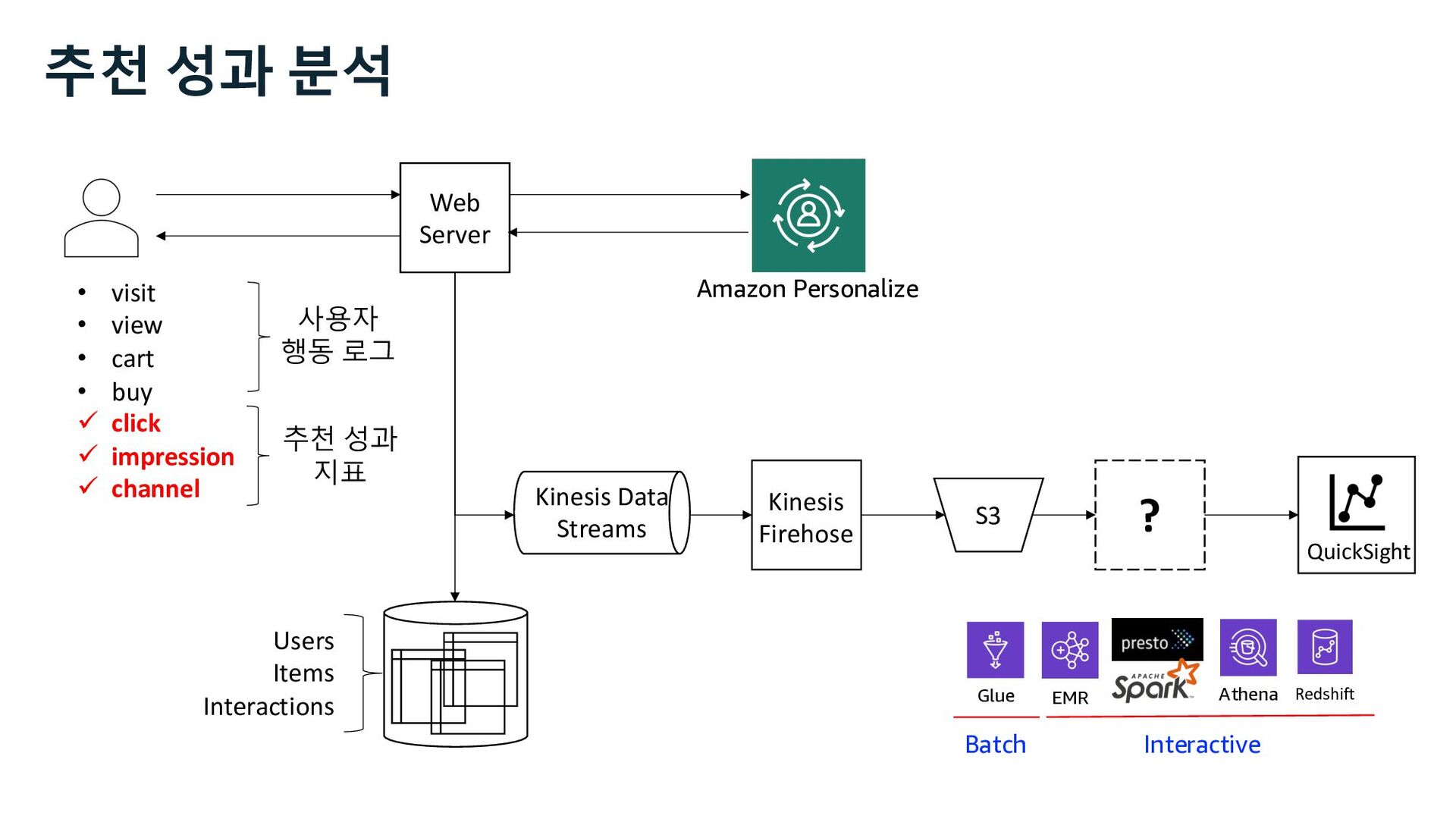
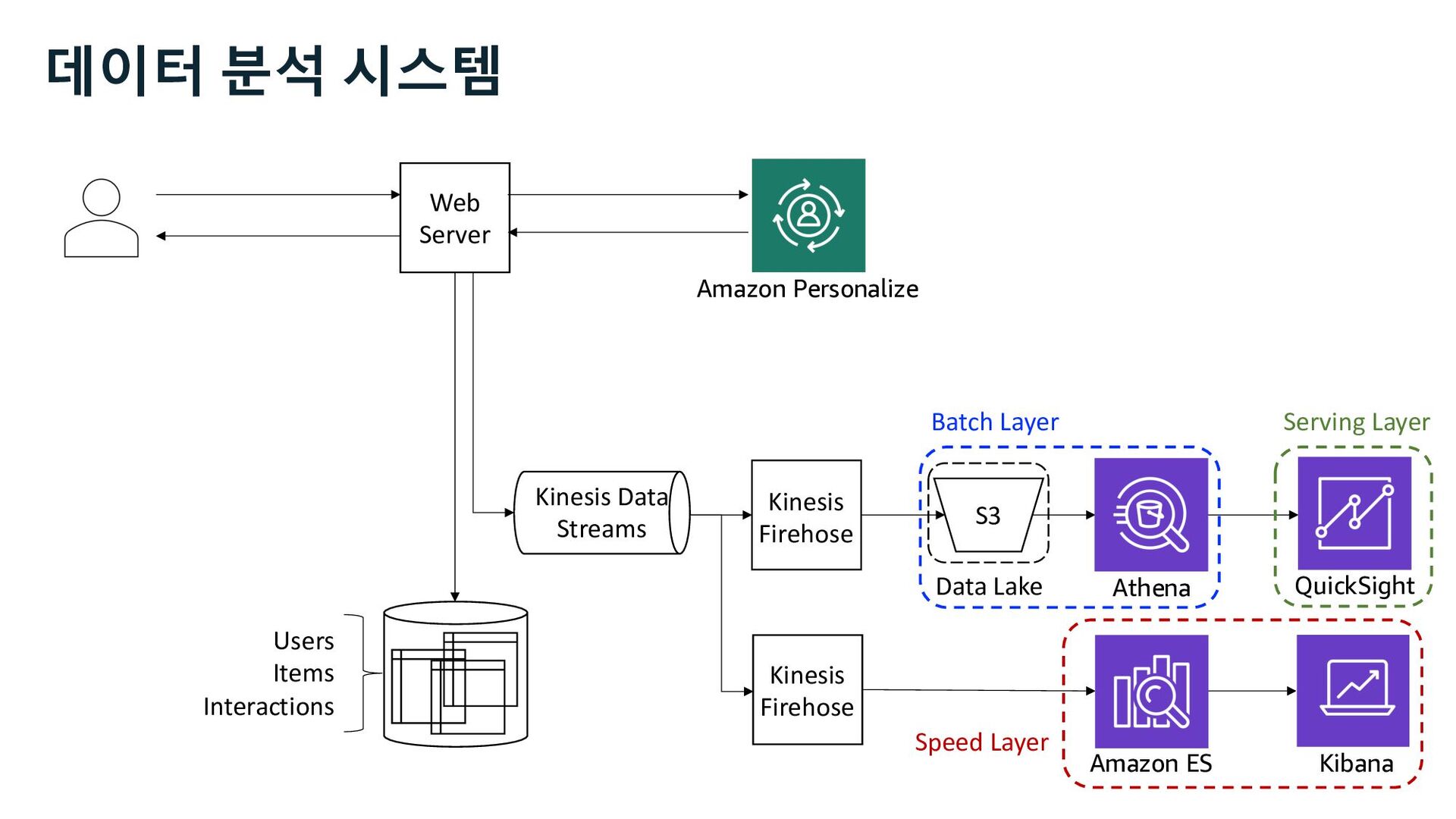
Glue Athena EMR Redshift Batch Interactive Amazon Personalize • visit • view • cart • buy ü click ü impression ü channel 사용자 행동 로그 추천 성과 지표 추천 성과 분석 Kinesis Data Streams
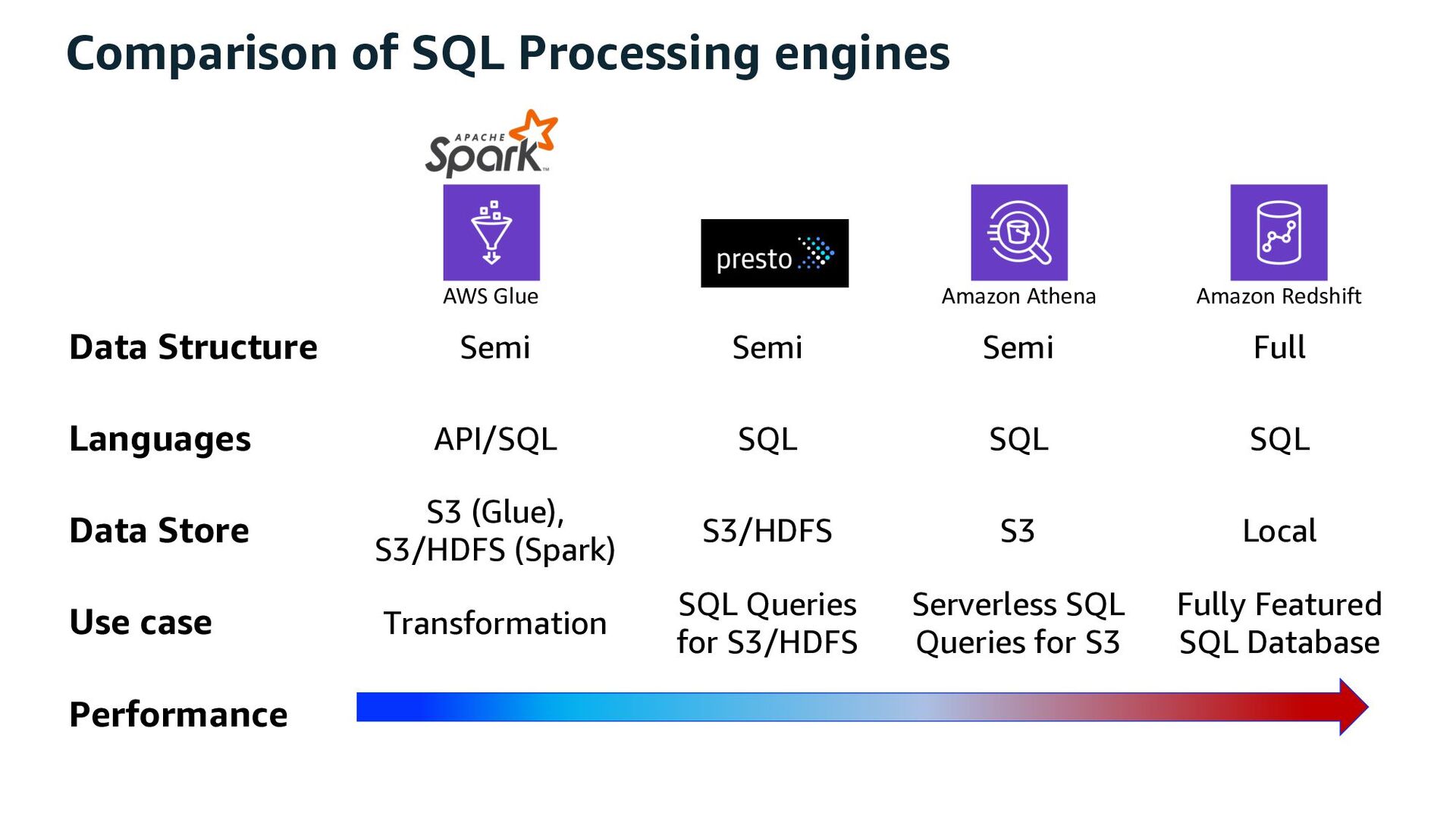
Full Languages API/SQL SQL SQL SQL Data Store S3 (Glue), S3/HDFS (Spark) S3/HDFS S3 Local Use case Transformation SQL Queries for S3/HDFS Serverless SQL Queries for S3 Fully Featured SQL Database Performance AWS Glue Amazon Athena Amazon Redshift
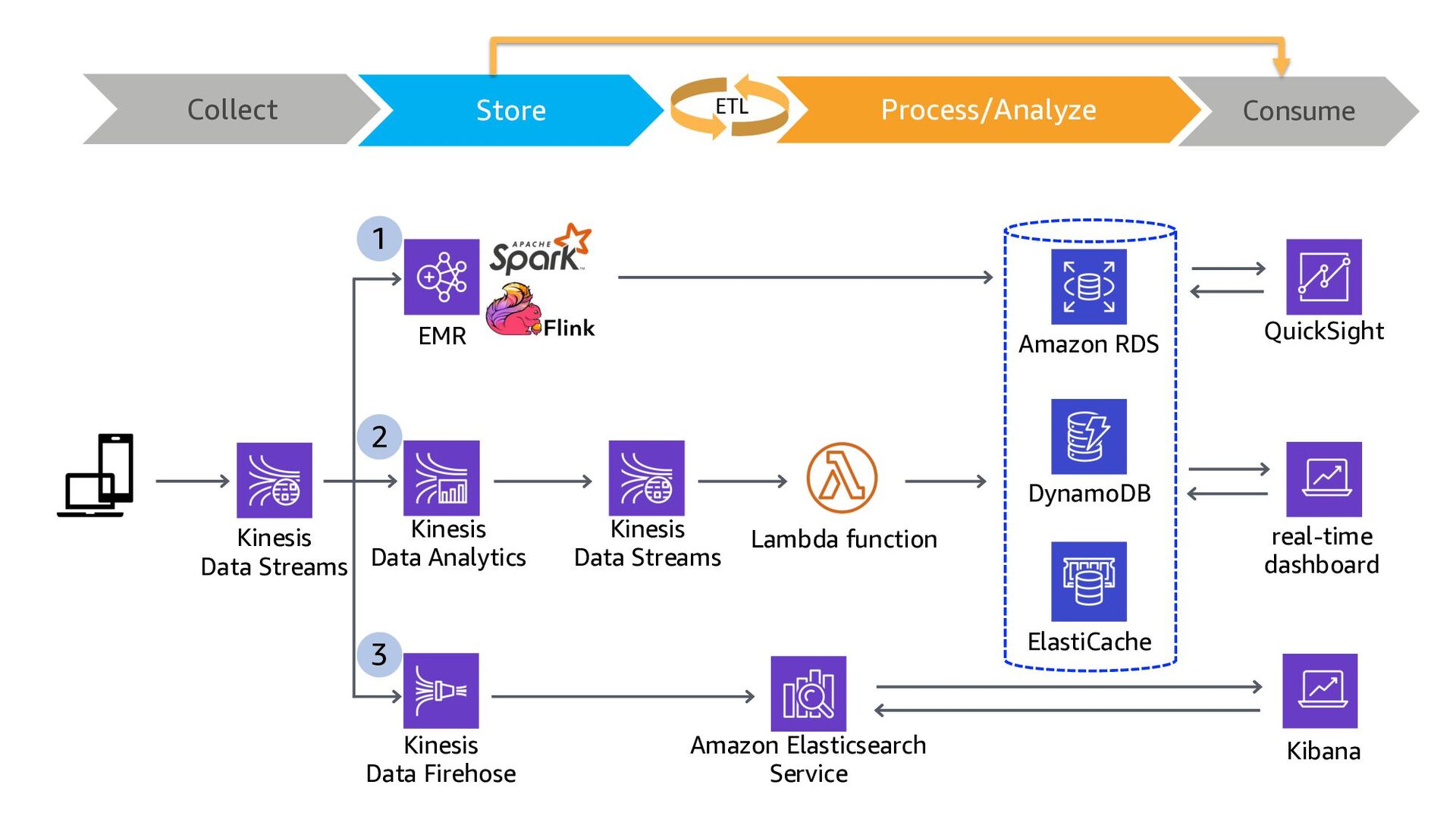
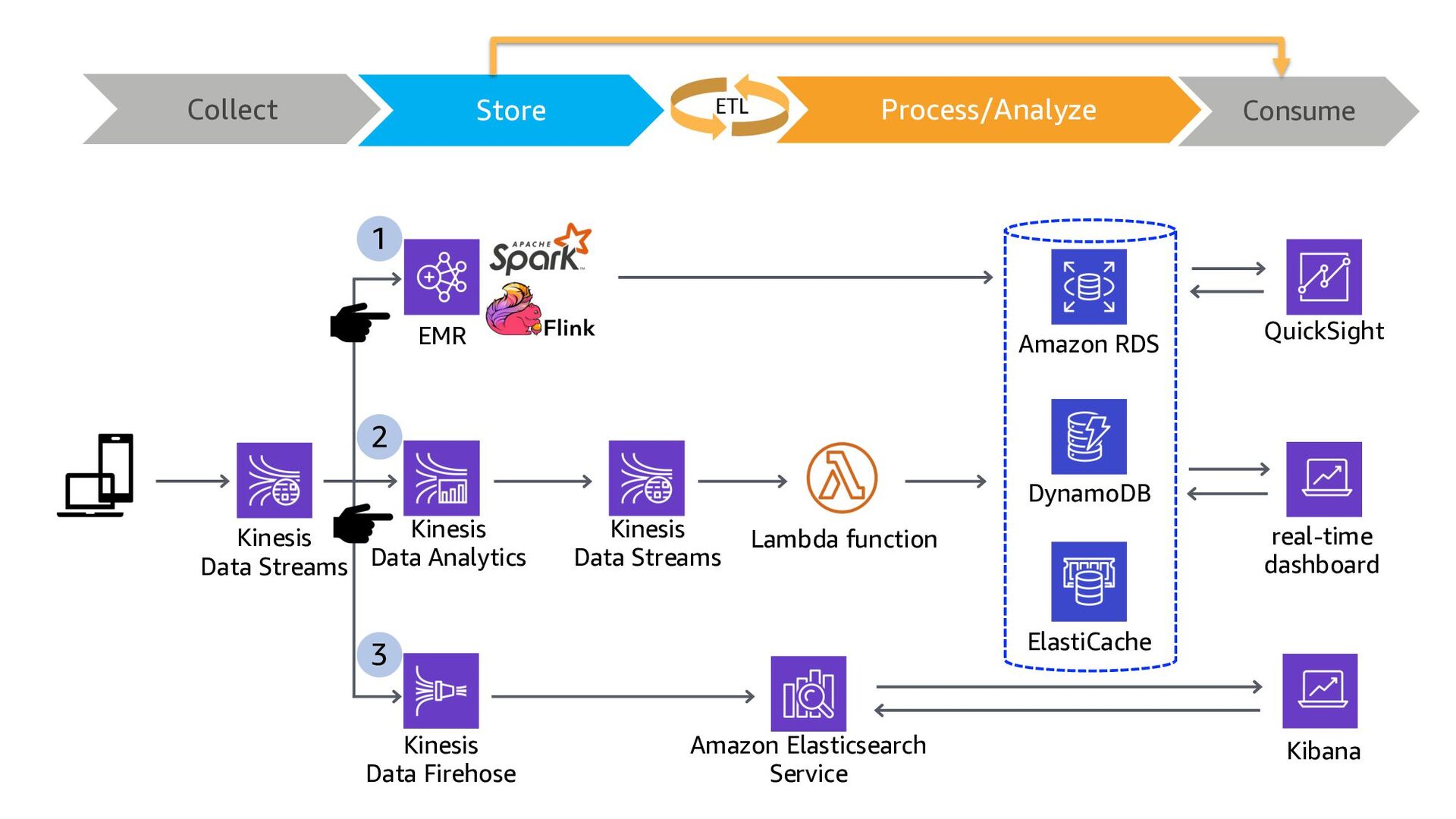
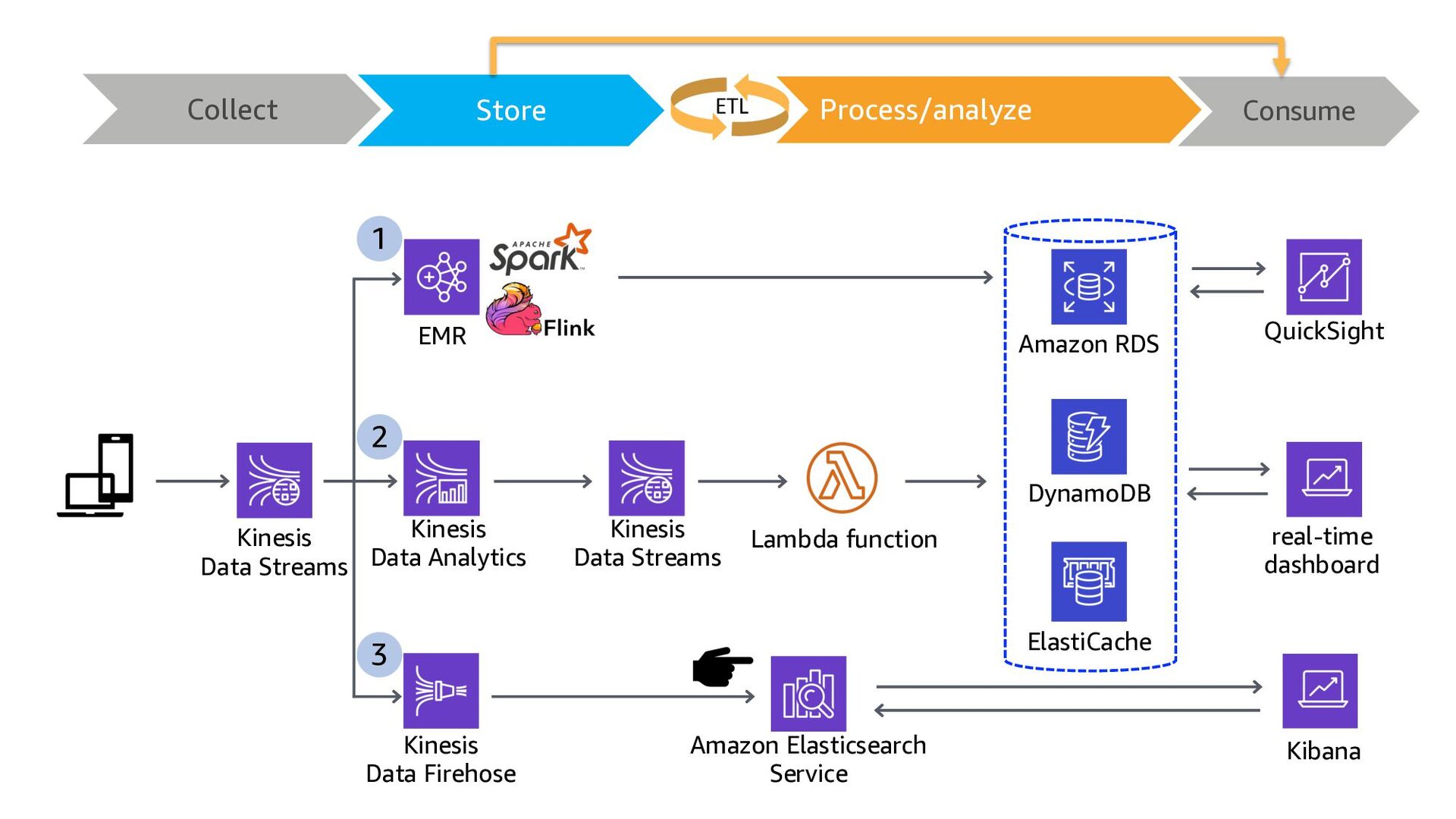
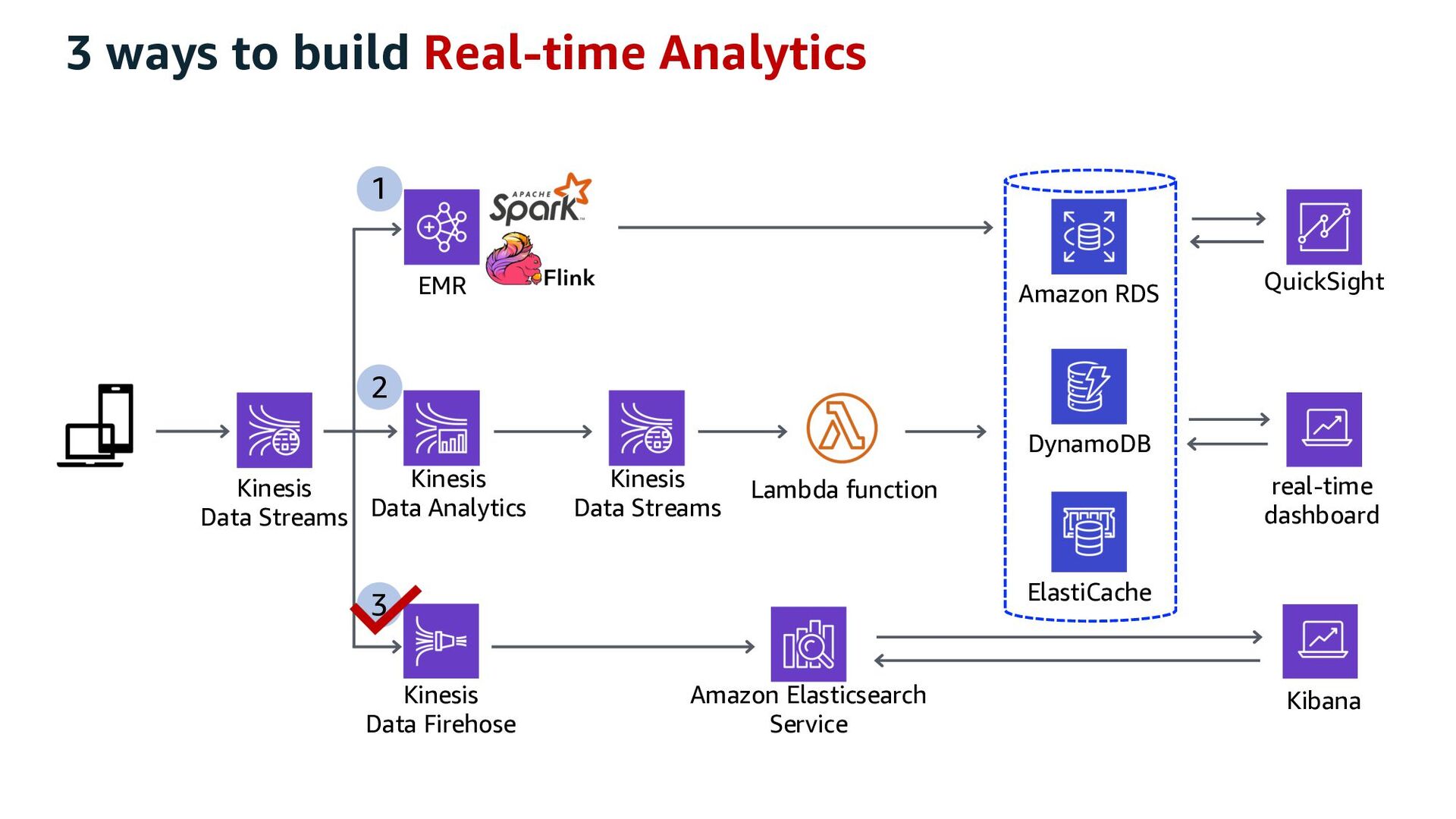
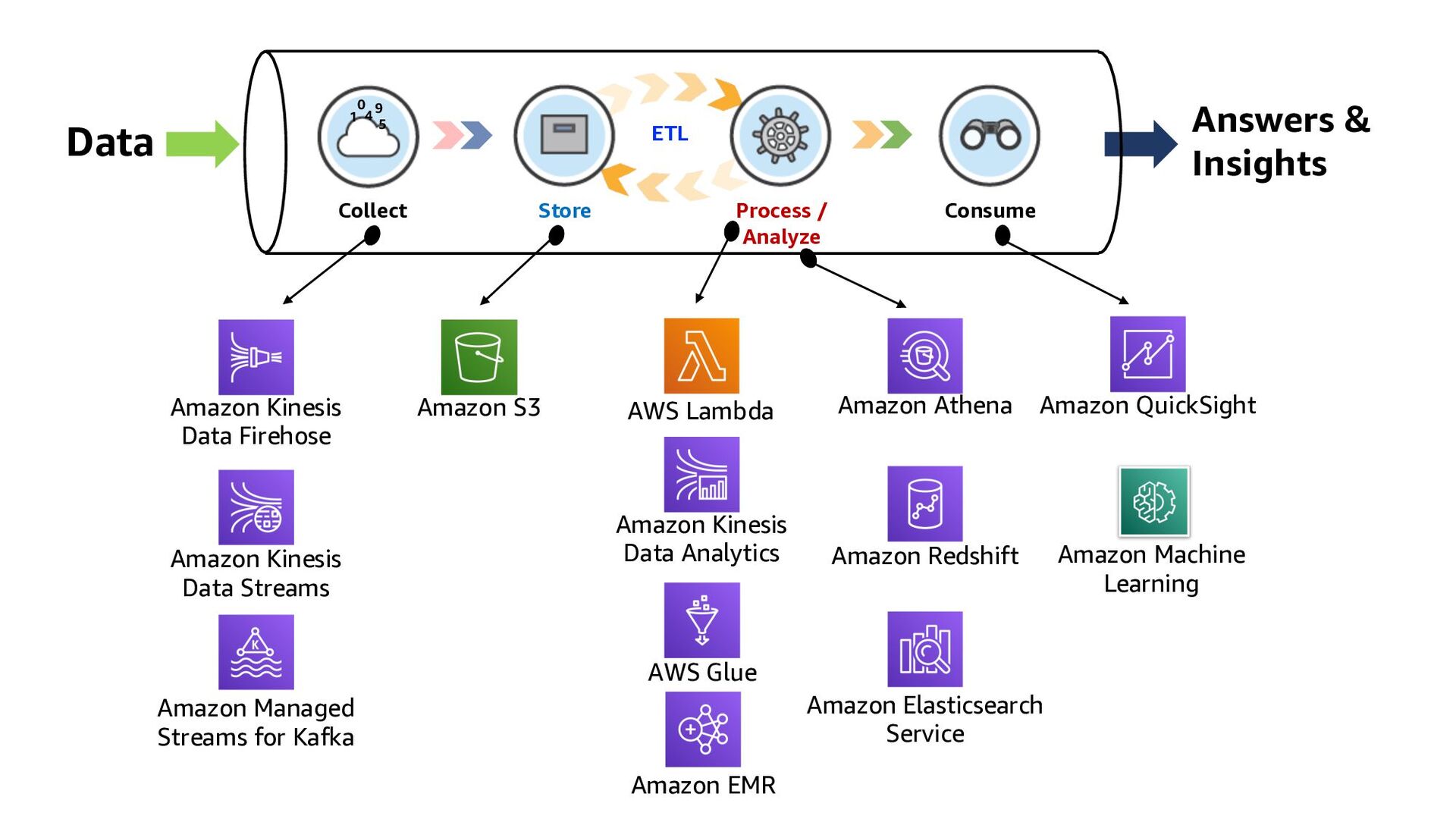
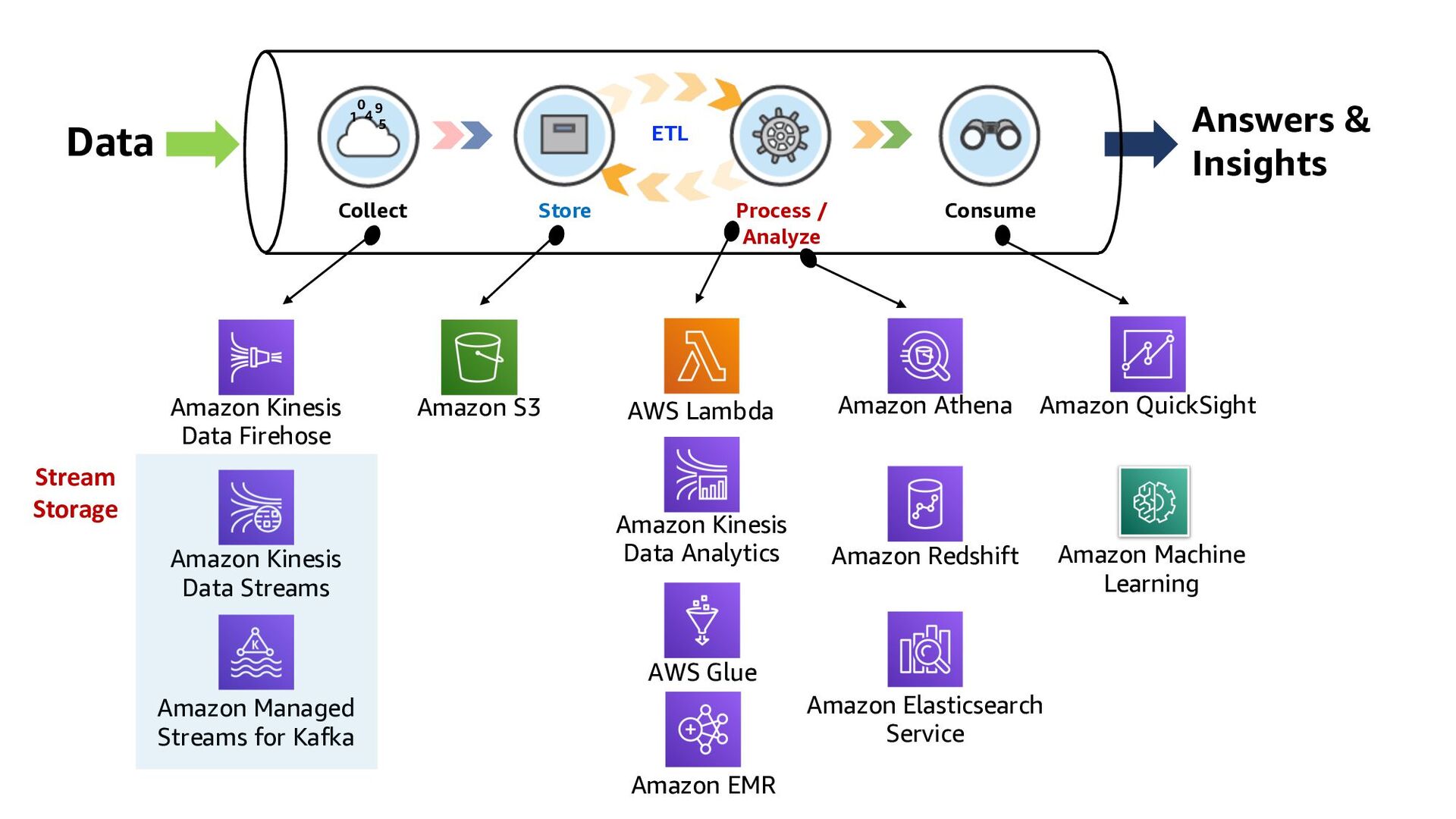
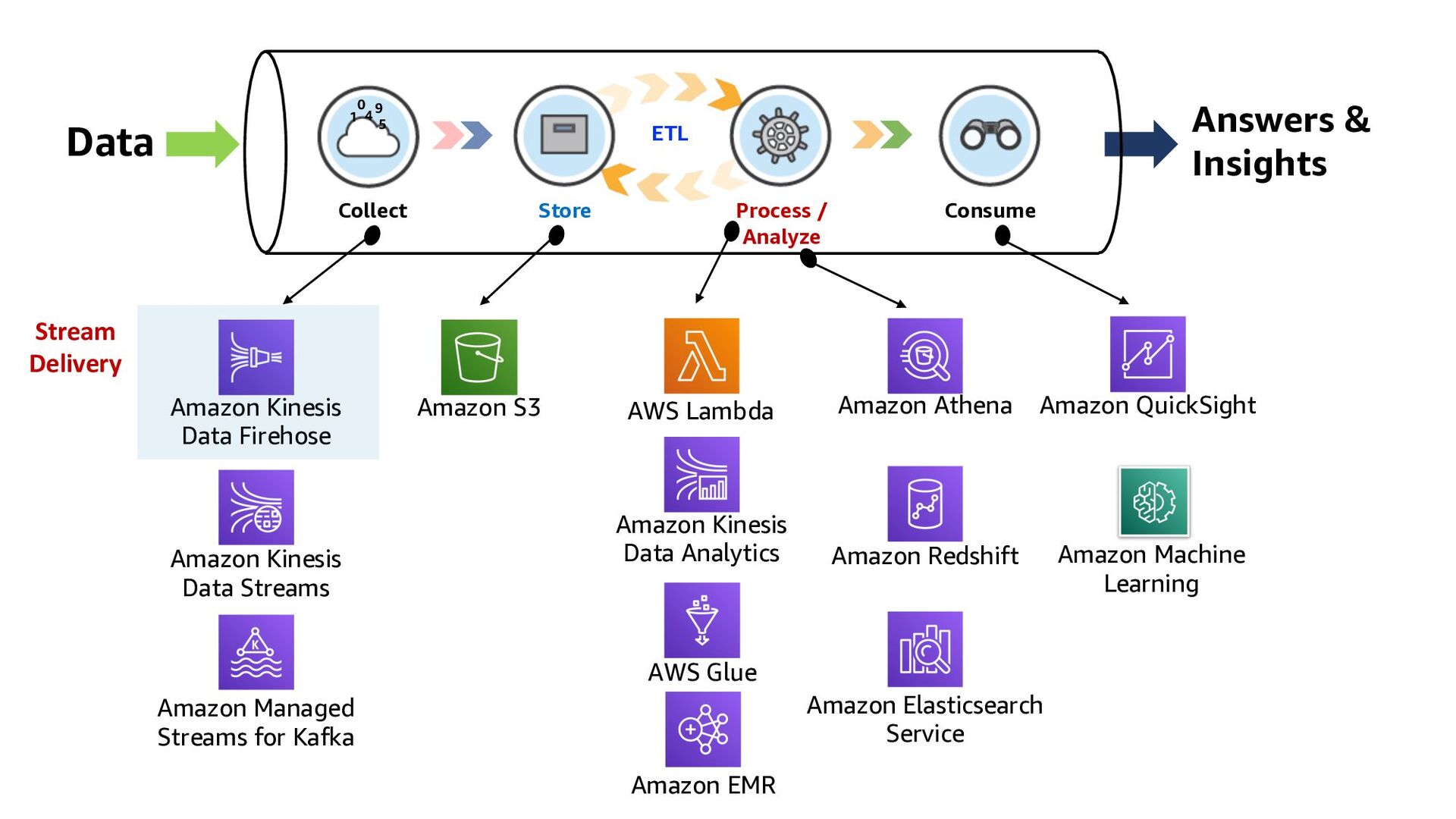
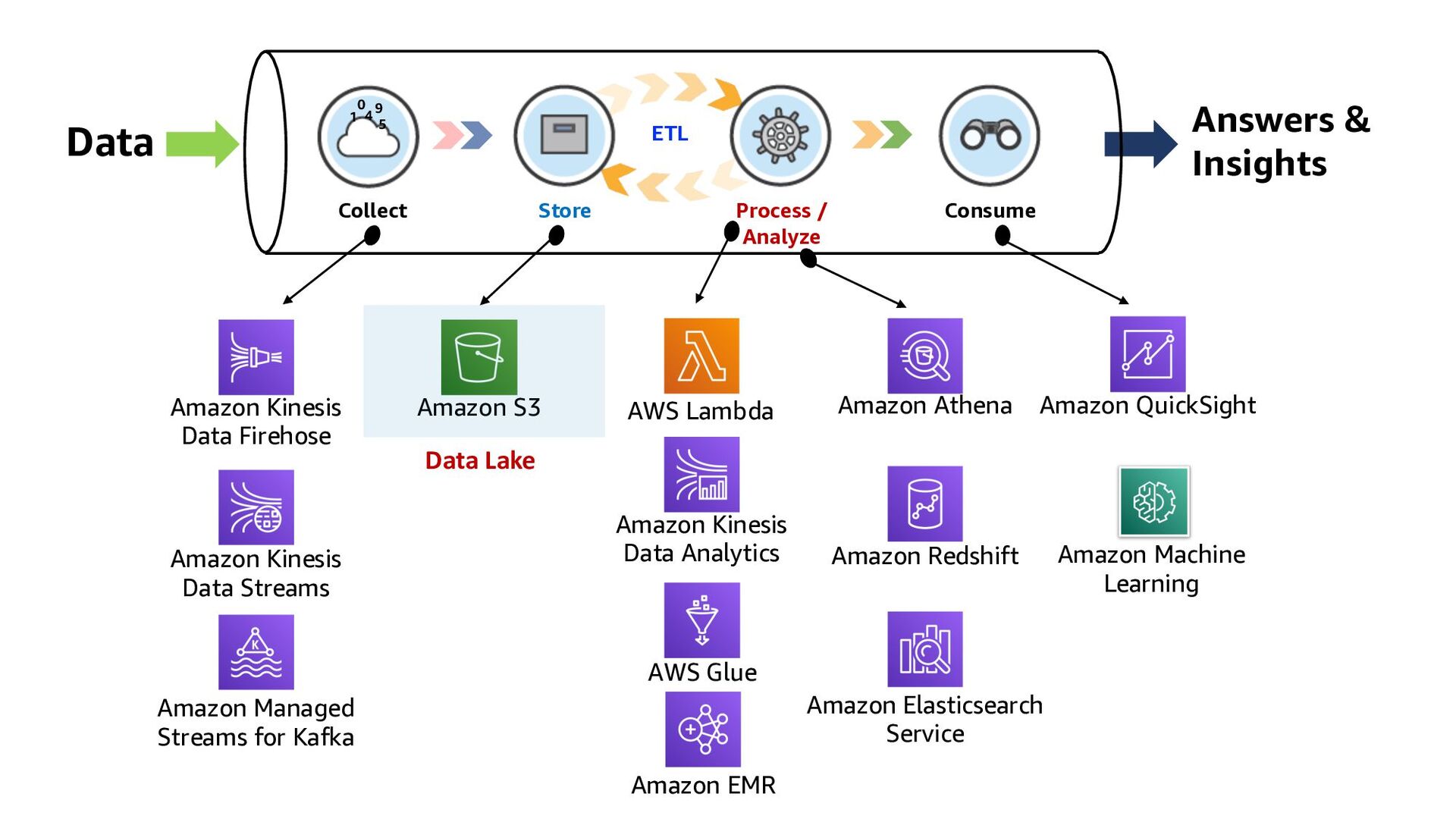
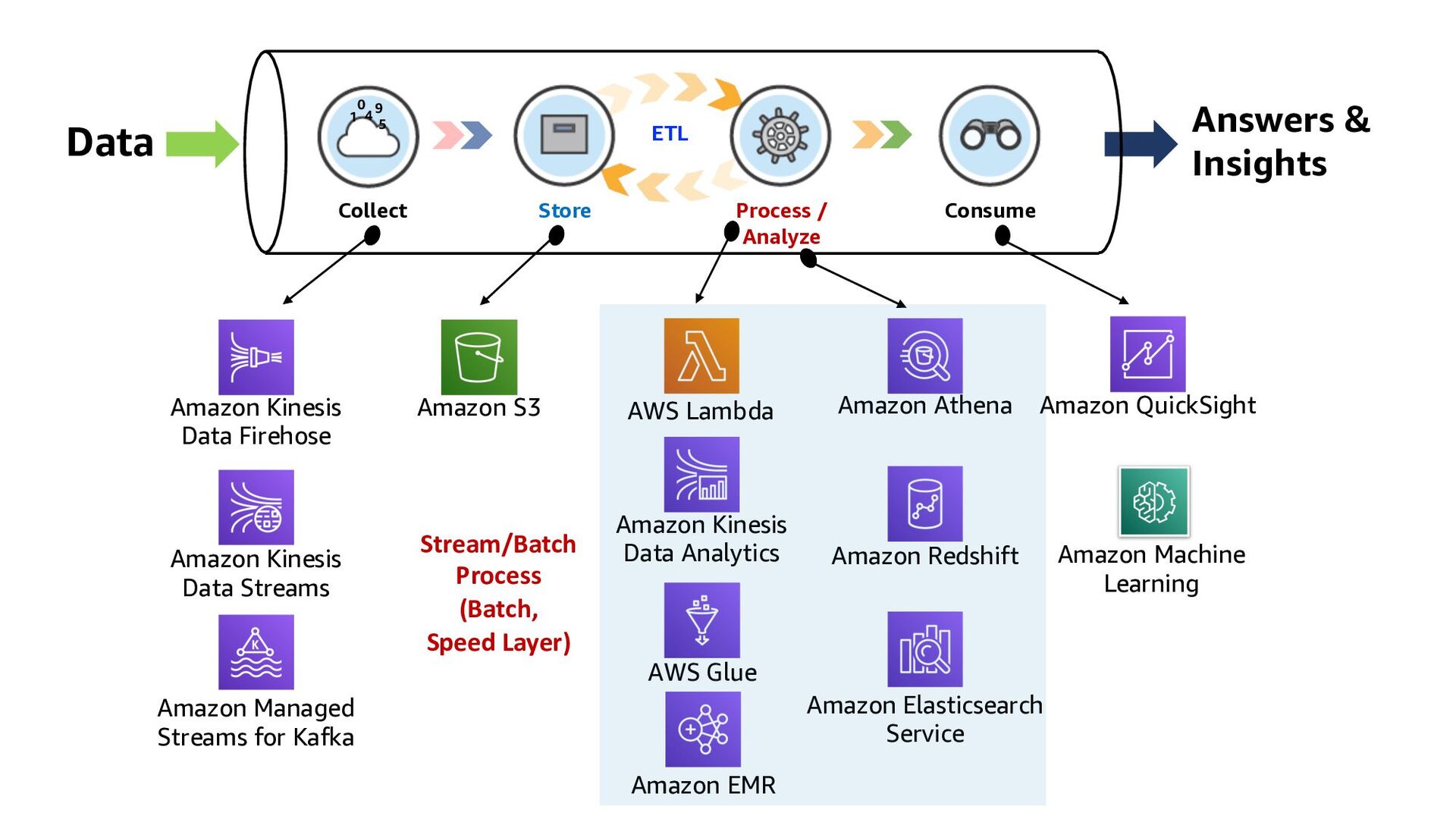
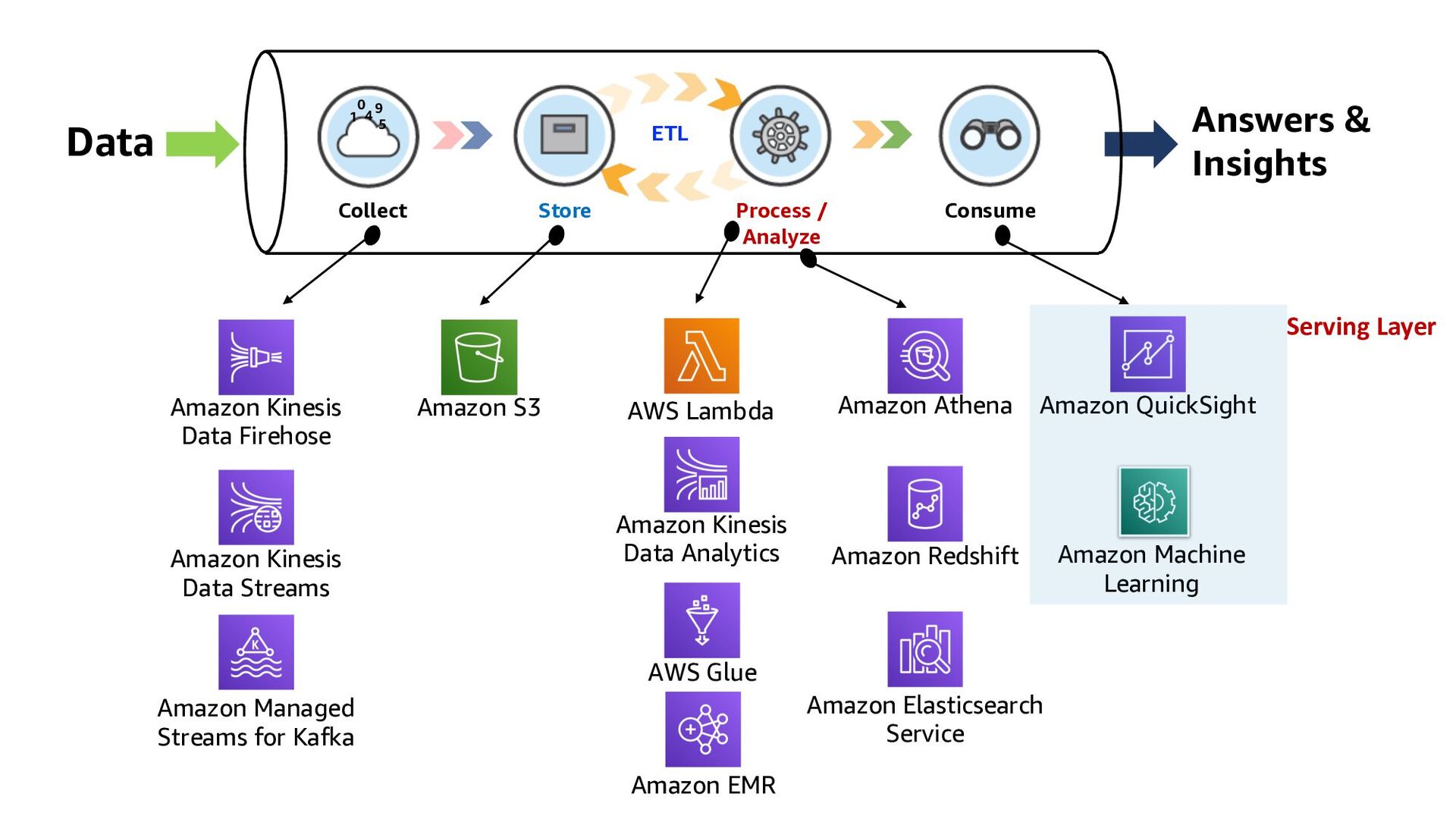
ElastiCache Kinesis Data Analytics Lambda function QuickSight Amazon RDS Kinesis Data Streams DynamoDB 1 2 3 Kinesis Data Firehose Collect Store Consume Process/Analyze ETL
ElastiCache Kinesis Data Analytics Lambda function QuickSight Amazon RDS Kinesis Data Streams DynamoDB 1 2 3 Kinesis Data Firehose Collect Store Consume Process/Analyze ETL
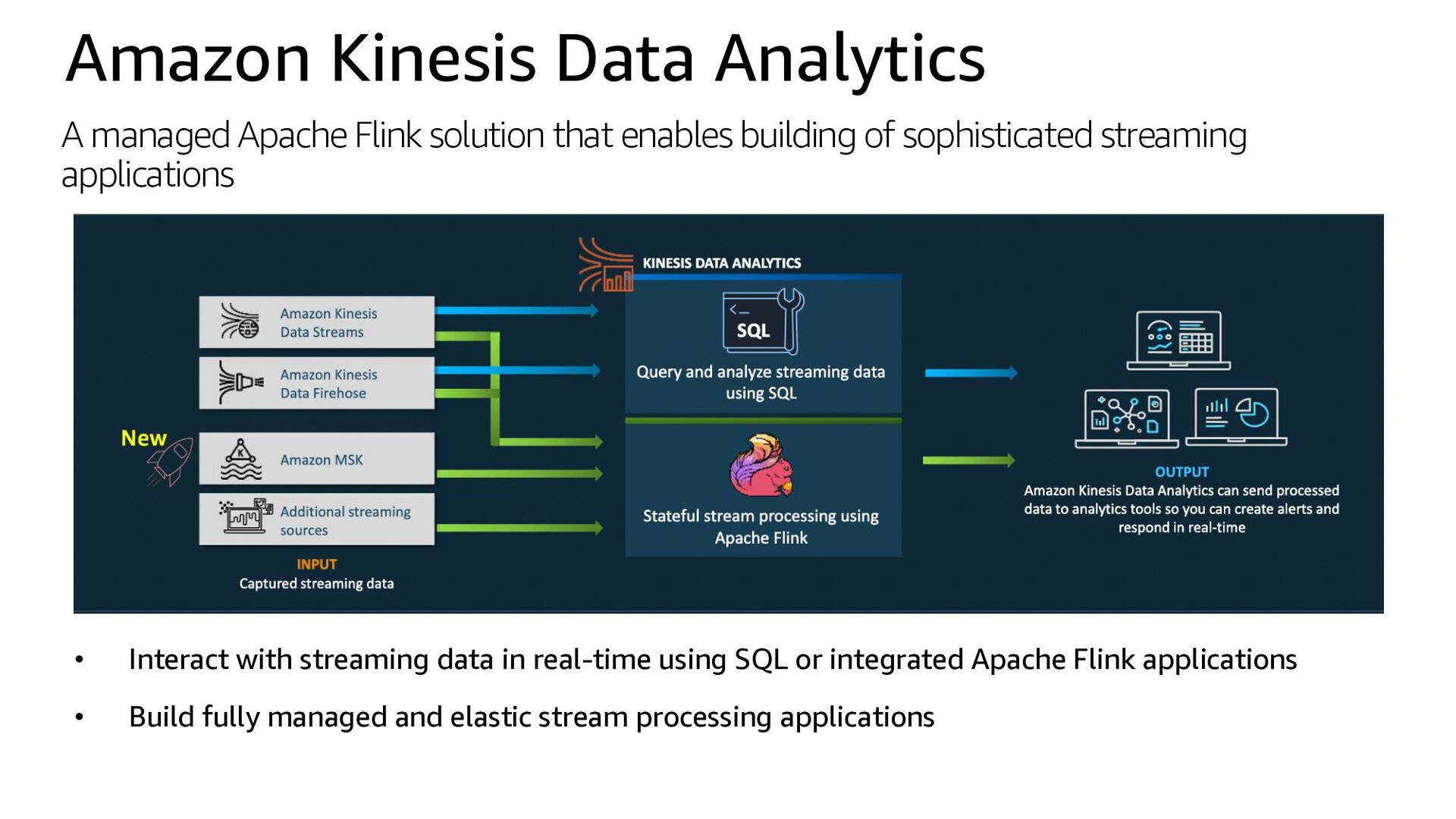
integrated Apache Flink applications • Build fully managed and elastic stream processing applications Amazon Kinesis Data Analytics A managed Apache Flink solution that enables building of sophisticated streaming applications
ElastiCache Kinesis Data Analytics Lambda function QuickSight Amazon RDS Kinesis Data Streams DynamoDB 1 2 3 Kinesis Data Firehose Collect Store Consume Process/analyze ETL
ElastiCache Kinesis Data Analytics Lambda function QuickSight Amazon RDS Kinesis Data Streams DynamoDB 1 2 3 Kinesis Data Firehose 3 ways to build Real-time Analytics
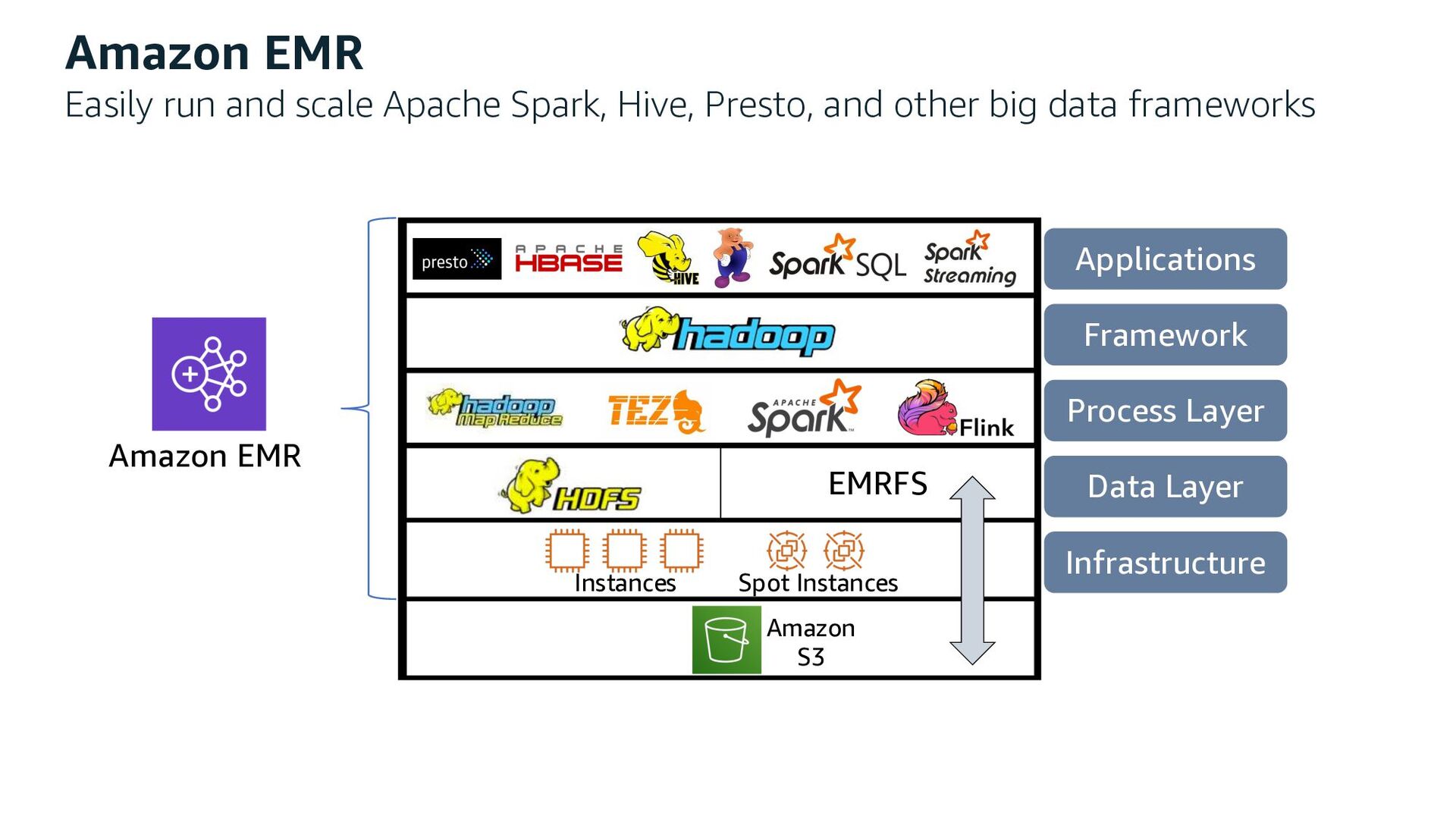
by big data frameworks (Spark, Hive, Presto, etc.) • Decouple storage and compute • No need to run compute clusters for storage (unlike HDFS) • Can run transient Amazon EMR clusters with Amazon EC2 Spot Instances • Multiple & heterogeneous analysis clusters and services can use the same data • Designed for 99.999999999% durability • No need to pay for data replication within a region • Secure: SSL, client/server-side encryption at rest • Low cost
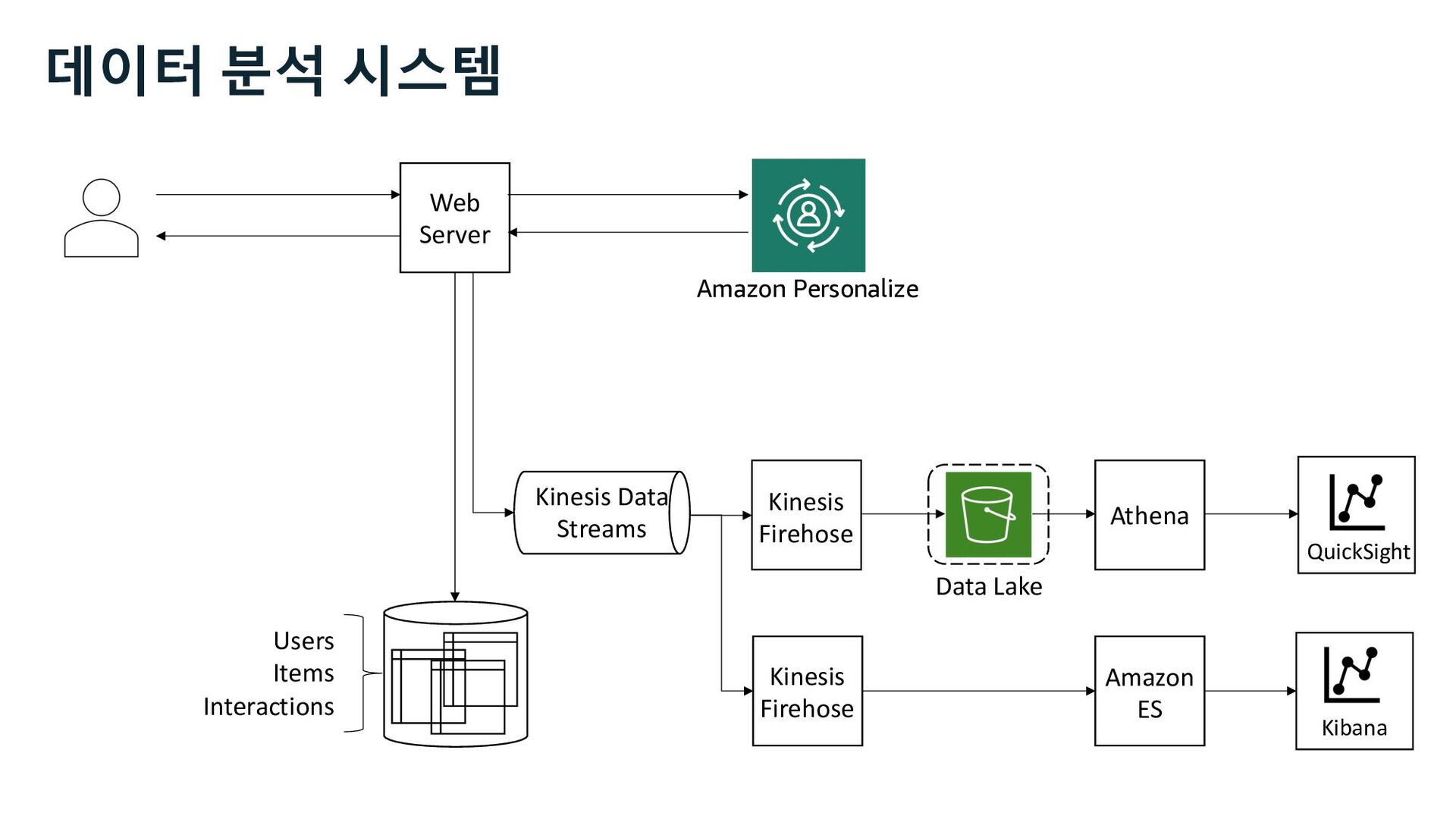
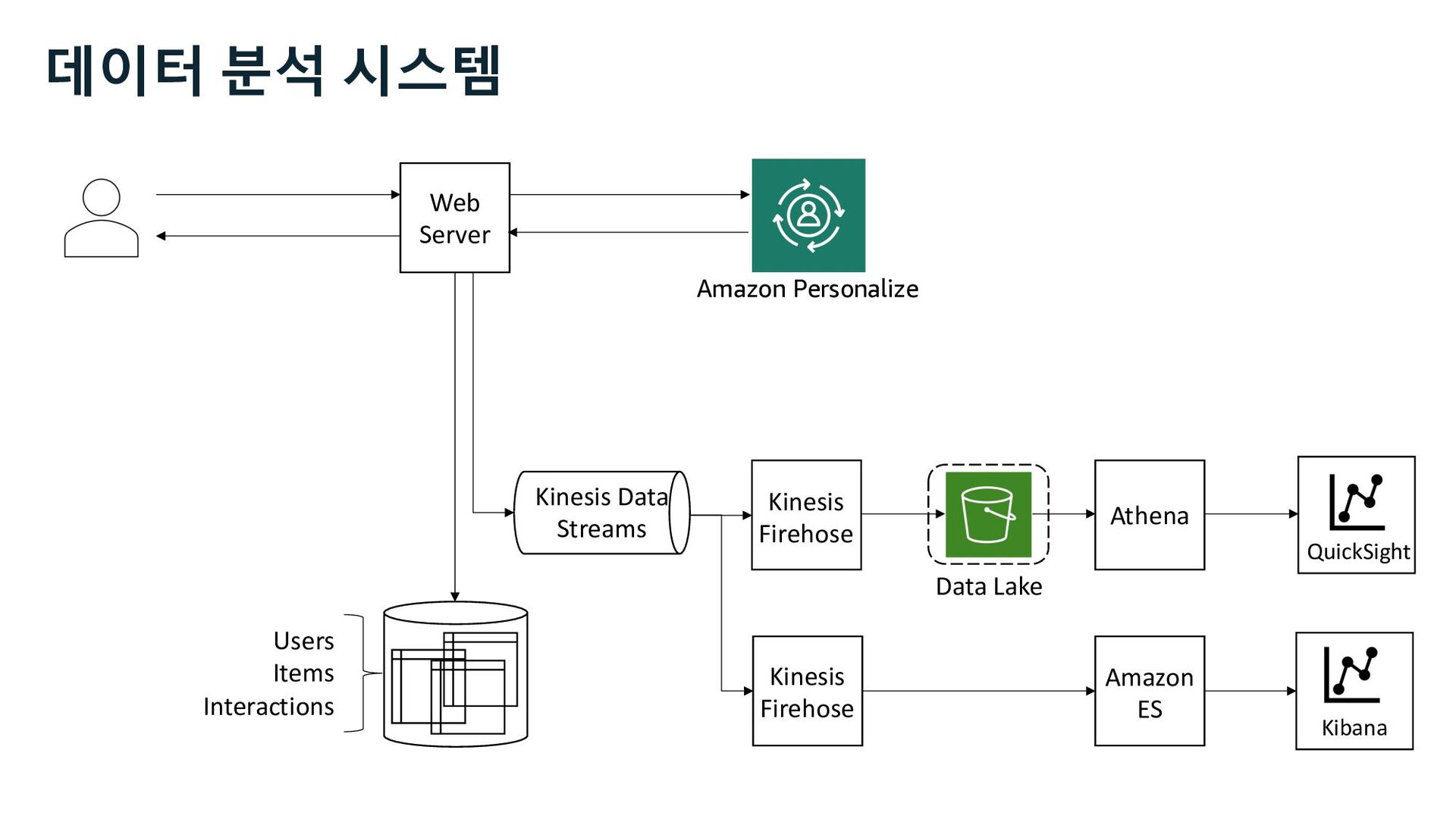
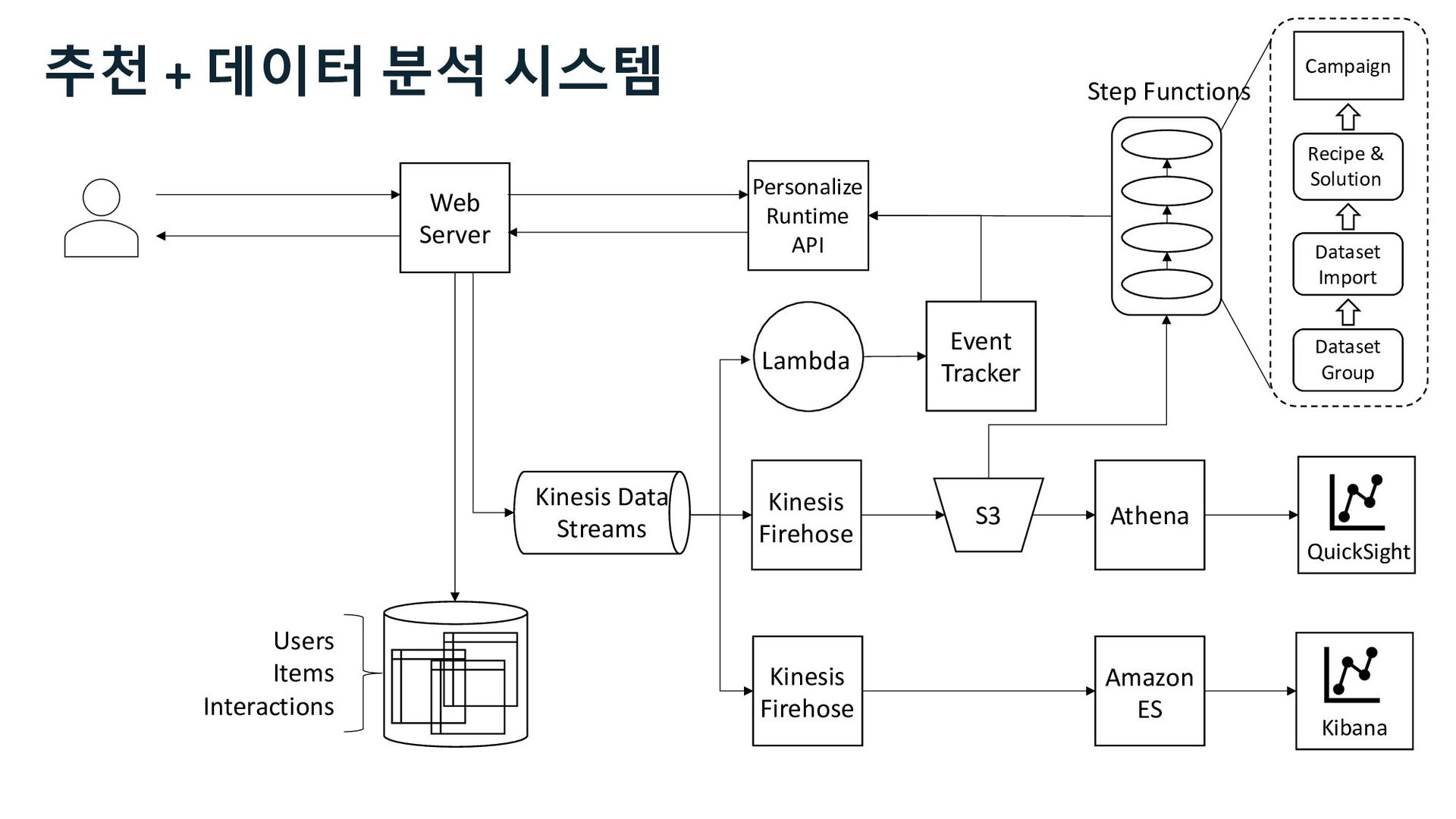
QuickSight Event Tracker Lambda Step Functions Kinesis Firehose Dataset Group Dataset Import Recipe & Solution Campaign Amazon ES Personalize Runtime API 추천 + 데이터 분석 시스템 Kinesis Data Streams
QuickSight Event Tracker Lambda Step Functions Kinesis Firehose Dataset Group Dataset Import Recipe & Solution Campaign Amazon ES Analytics Personalize Runtime API 데이터 분석 시스템 Kinesis Data Streams
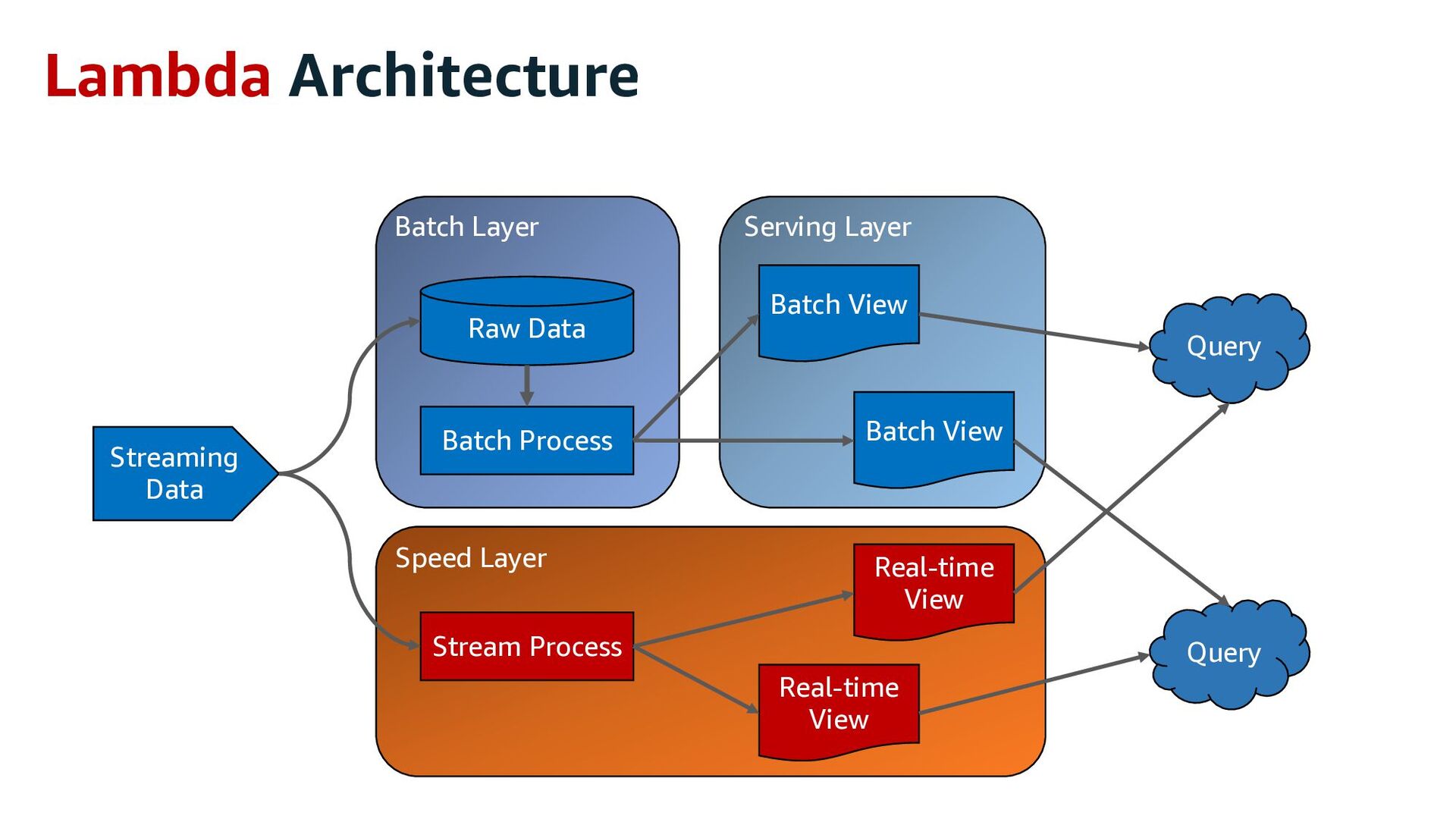
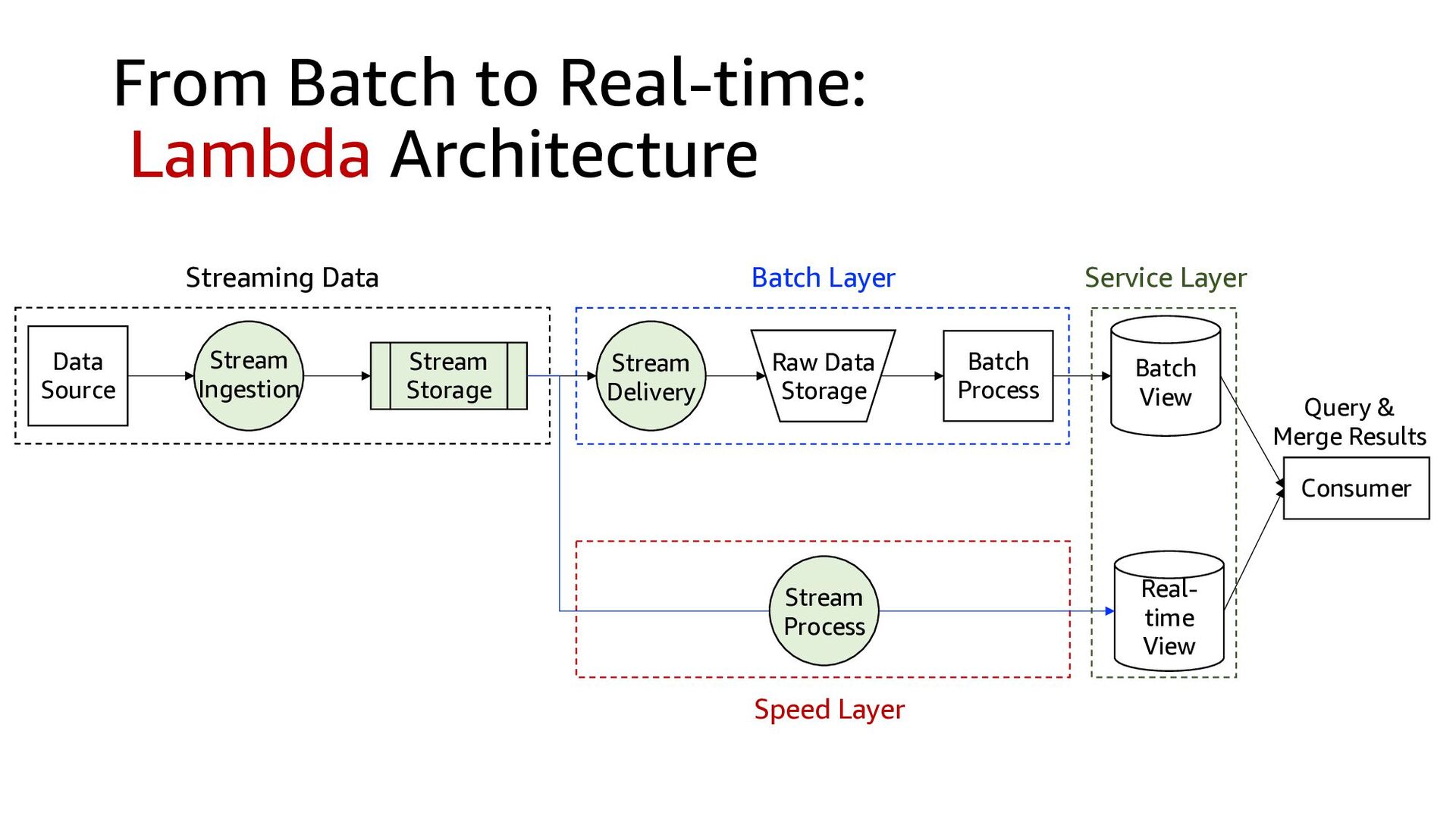
Speed Layer Batch Layer Batch Process Batch View Real- time View Consumer Query & Merge Results Service Layer Stream Ingestion Raw Data Storage Streaming Data Stream Delivery Stream Process
→ Store → Process → Store → Analyze → Answers • Use the right tool for the job - Data structure, latency, throughput, access patterns • Leverage managed and serverless services - Scalable/elastic, available, reliable, secure, no/low admin • Use log-centric design patterns - Immutable logs (data lake), materialized views • Be cost-conscious - Big data ≠ Big cost • Working backwards - Design from consume to collect
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}