Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Jigsaw-ACRC-7th-place
Search
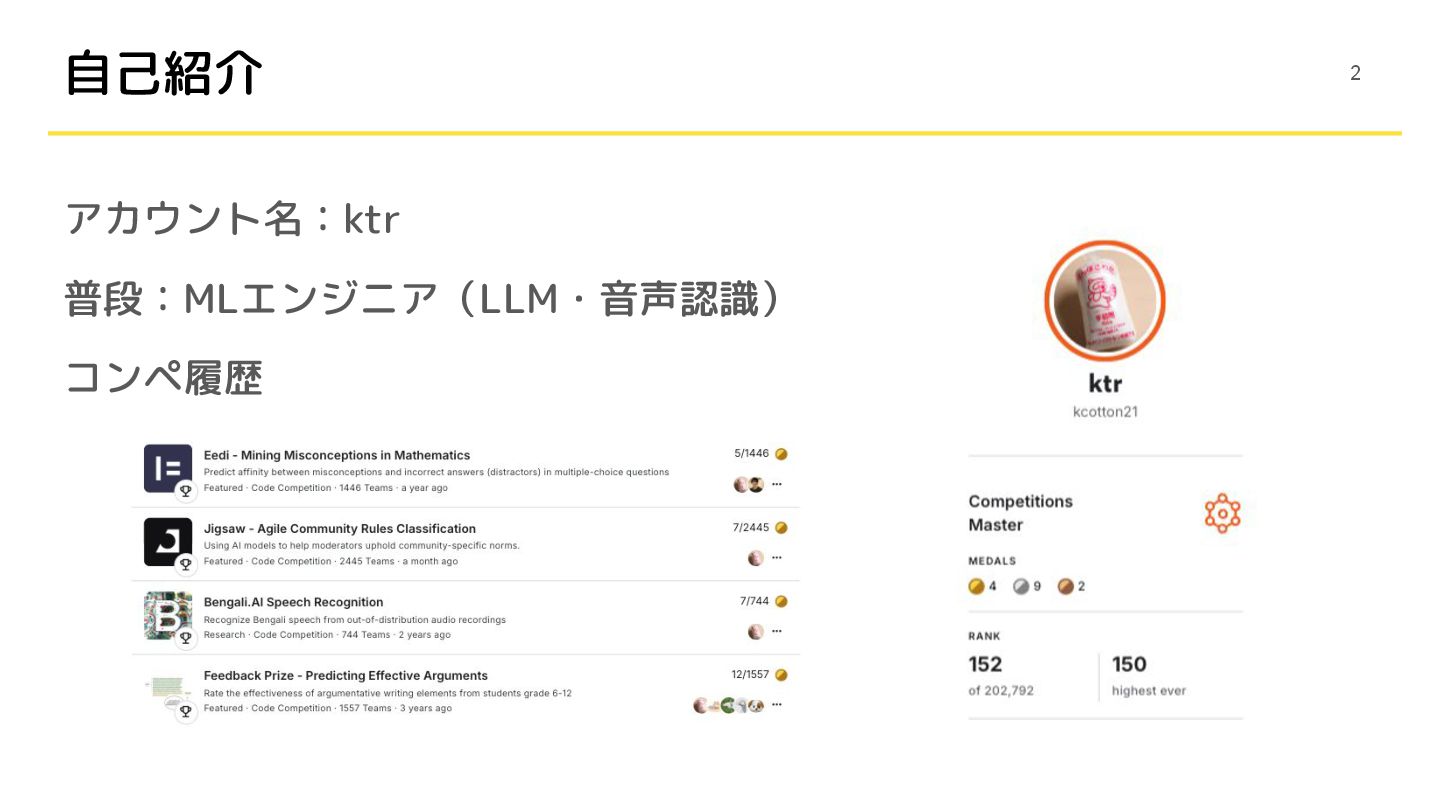
ktr
November 26, 2025
400
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Jigsaw-ACRC-7th-place
ktr
November 26, 2025
More Decks by ktr
See All by ktr
atma cup #17 振り返り会
ktrw1011
0
330
Quora With BERT
ktrw1011
0
2.1k
APTOS_2019_Blindness_Detection_96th_Solution
ktrw1011
0
830
Featured
See All Featured
Context Engineering - Making Every Token Count
addyosmani
9
1k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
390
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Distributed Sagas: A Protocol for Coordinating Microservices
caitiem20
333
23k
So, you think you're a good person
axbom
PRO
2
2.1k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
630
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
600
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Accessibility Awareness
sabderemane
1
150
Transcript
7th place solution MAP, Jigsaw, Code Golf 振り返り会 by 関東kaggler会
(2025/11/27) Jigsaw - Agile Community Rules Classification
自己紹介 アカウント名:ktr 普段:MLエンジニア(LLM・音声認識) コンペ履歴 2
アジェンダ • ソリューションの紹介 • ソリューションにいたるまで 3
ソリューションの紹介 4
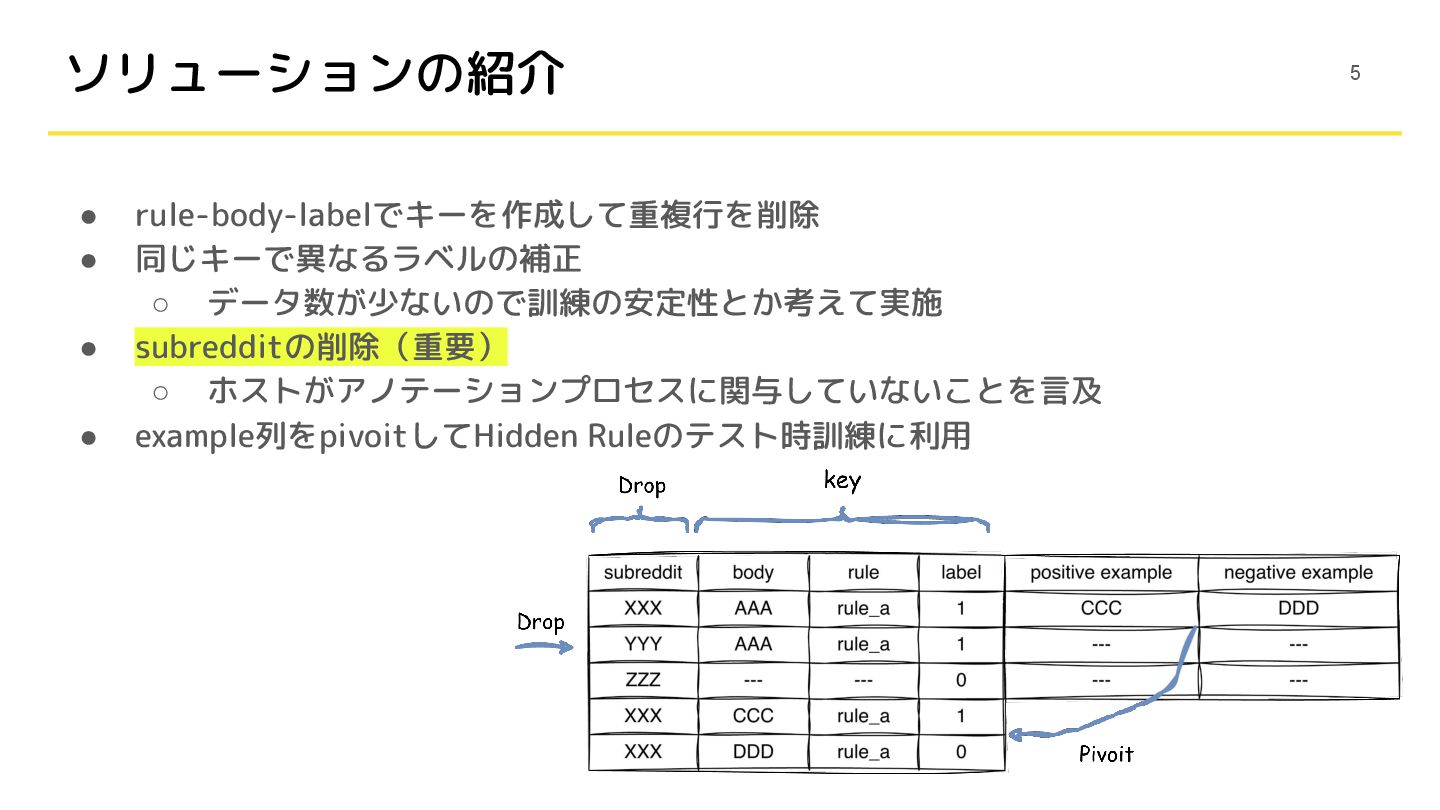
• rule-body-labelでキーを作成して重複行を削除 • 同じキーで異なるラベルの補正 ◦ データ数が少ないので訓練の安定性とか考えて実施 • subredditの削除(重要) ◦ ホストがアノテーションプロセスに関与していないことを言及
• example列をpivoitしてHidden Ruleのテスト時訓練に利用 ソリューションの紹介 5
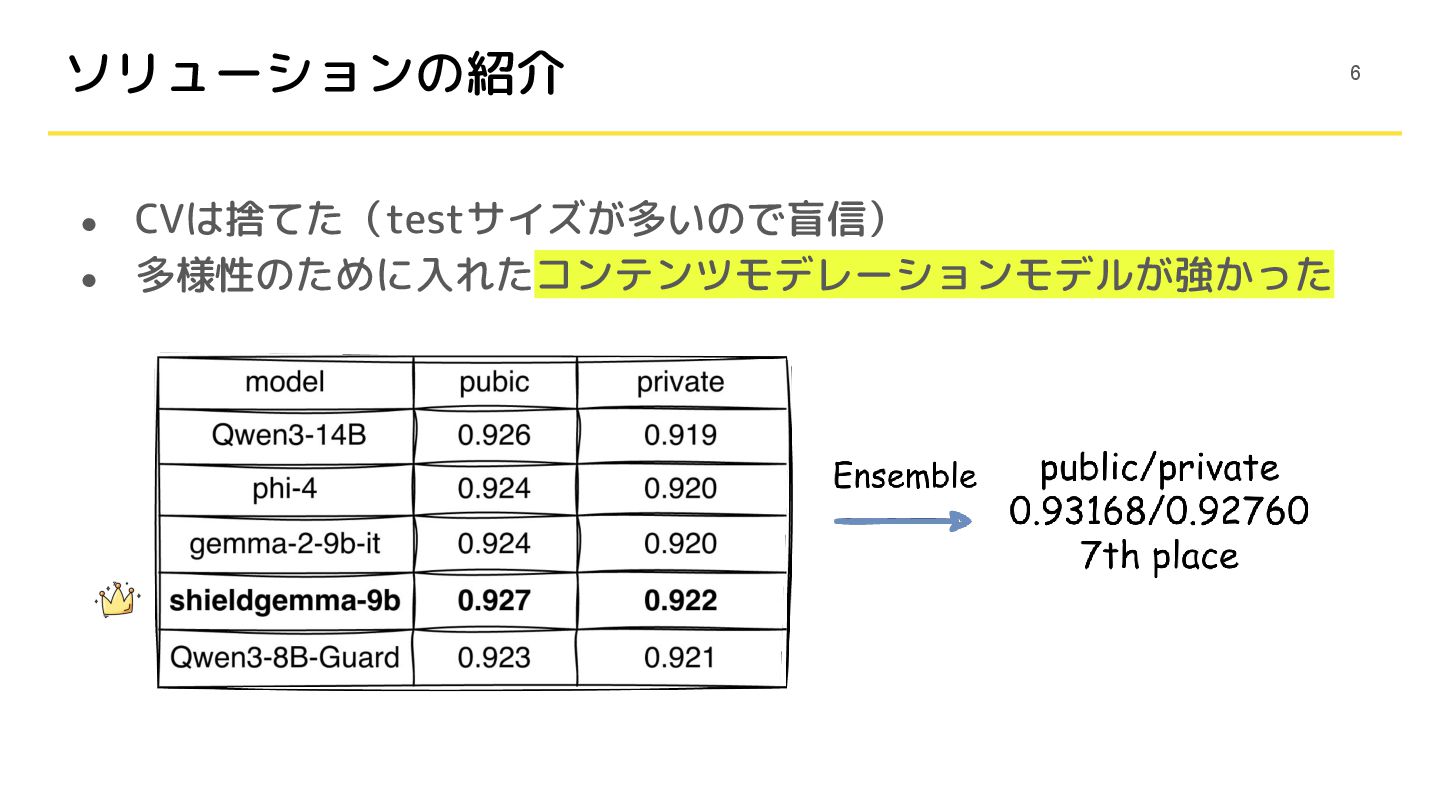
• CVは捨てた(testサイズが多いので盲信) • 多様性のために入れたコンテンツモデレーションモデルが強かった ソリューションの紹介 6
ソリューションにいたるまで 7
ソリューションにいたるまで 1. デカいモデルは絶対につよいはず 2. 合成・外部データをうまく扱った人が勝つ 3. とにかくモデルを積む(アンサンブル) 8
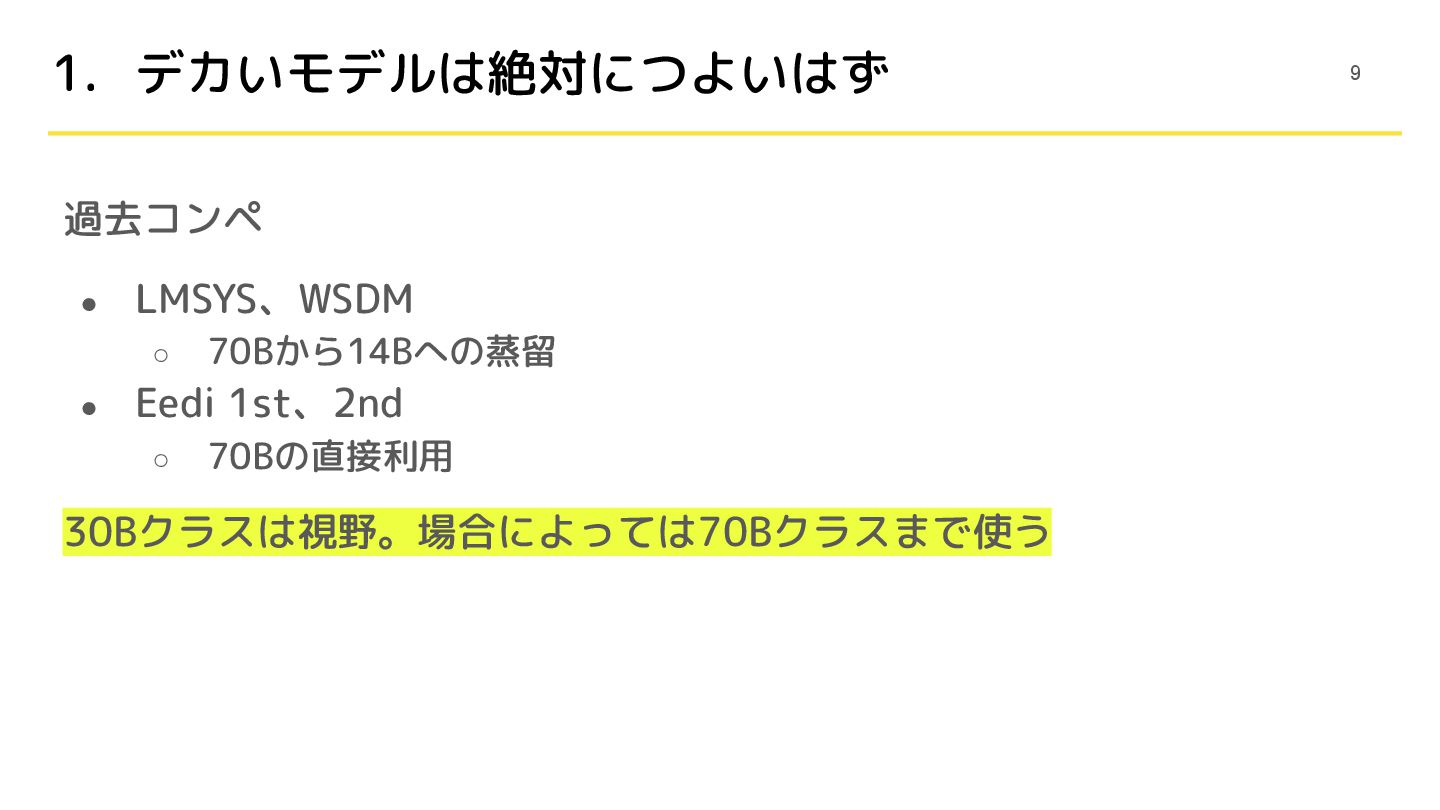
1. デカいモデルは絶対につよいはず 過去コンペ • LMSYS、WSDM ◦ 70Bから14Bへの蒸留 • Eedi 1st、2nd
◦ 70Bの直接利用 30Bクラスは視野。場合によっては70Bクラスまで使う 9
1. デカいモデルは絶対につよいはず 今回のタスクではNotebook(T4x2)で訓練+推論まで行う必要がある • 訓練:14BくらいまでシングルGPUで可能 ◦ QLoRA+unslothを利用してT4x2で並列実行 • 推論:vllm T4x2で14Bを量子化なしで実行
◦ LoRAアダプターのマージなしでOK 10
2. 合成・外部データをうまく扱った人が勝つ 過去コンペ • LMSYS、WSDM ◦ 外部データで事前学習 => コンペデータで学習 •
Eedi ◦ Claude (1st)、Qwen2.5 72B (4th)を使って合成データ作成 11
2. 合成・外部データをうまく扱った人が勝つ • ProbingでRuleは判明したので、labelを指定してBodyさえ合成すれ ば良い状況 • 実験してみても改善しない+スコアの大きな変動がほとんどなかった アイディアを捨てた • コンテキストがなさすぎる?有用なモデルは大抵セーフガードが入って
いてToxicなデータを生成しづらい? 12
3. とにかくモデルを積む(アンサンブル) 過去コンペ • CommonLit Readability Prize 2nd(19モデル) • Jigsaw
Rate Severity of Toxic Comments 1th (15モデル) ◦ 壮大なソリューションのモデル欄 合成がうまくいかないのでこちらを重点的にやることに 13
3. とにかくモデルを積む(アンサンブル) • 8 -14Bモデルまでをsweepして実験 • 30モデルくらいためした • unslothの動作+チャットテンプレート+vllmのモデル対応とか地味 な動作検証がコンペ時間の大半だった
14
3. とにかくモデルを積む(アンサンブル) • ベースライン:llama3.1 8b(public:0.920) • これより後にリリースされた同程度サイズのモデルで、このスコアを 超えるモデルはほとんど存在しなかった ◦ GLM-4-9B:0.919、Falcon-3-10b-it:0.914
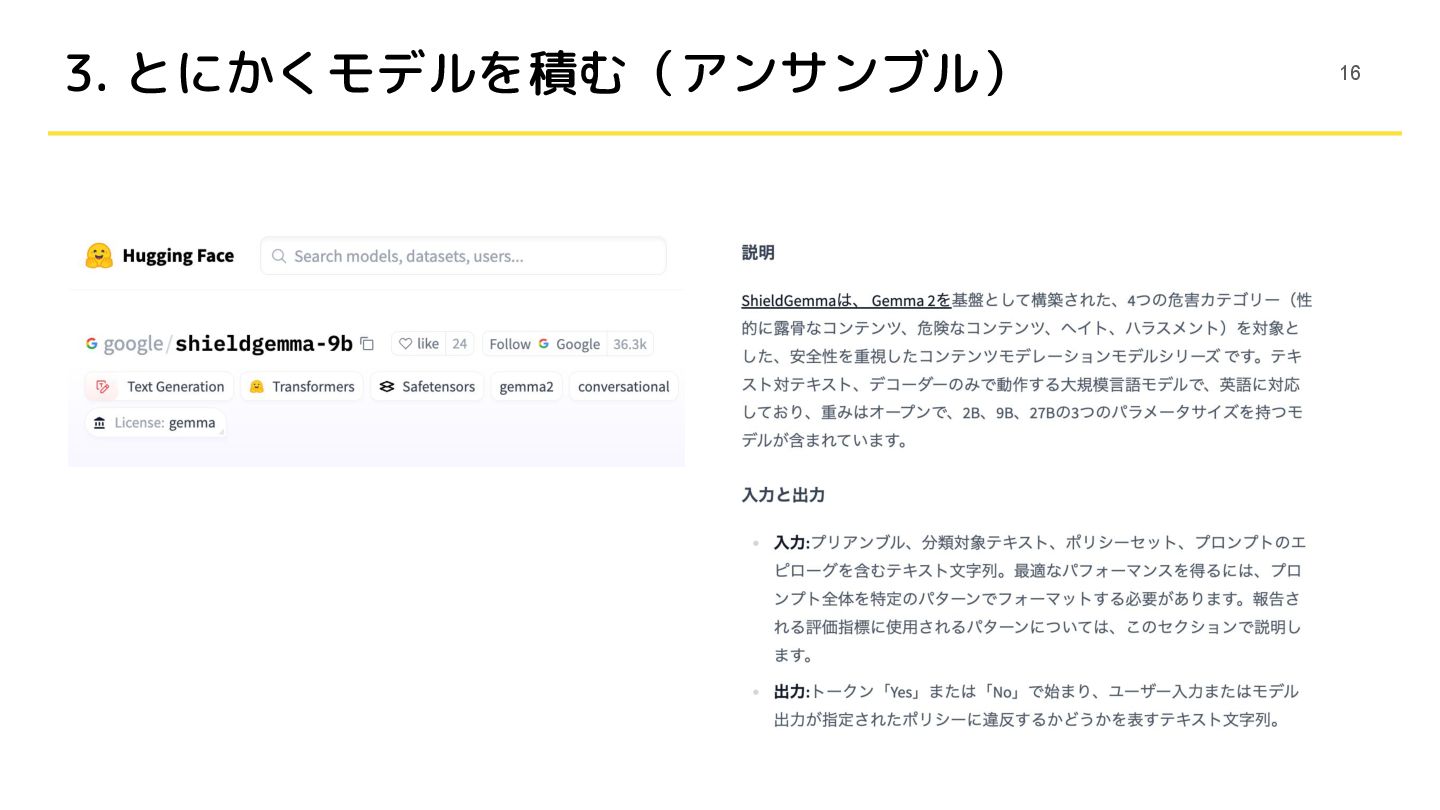
• gemma-2-9b-itがモデルサイズに対して強い(0.924) • shieldgemma-9bが最もパフォーマンスがよかった(0.927) ◦ コンテンツモデレーションタスクで学習した派生モデル ◦ Qwen(Guard)でも同様の傾向だった 15
3. とにかくモデルを積む(アンサンブル) 16
まとめ • 過去の動向とかを考えてやることを3つに絞ってやってた ◦ タスクの本質的(OODへの対応)的な部分にリーチした感覚はない ◦ 他チーム:Triplet Lossで多様性だすとかの独創的なアプローチ • 金圏ボーダーのスコア差は0.00082。振り返るとアンサンブルのゴ
リ押し+CVの盲信で運の要素も大きかった印象 17
ありがとうございました🤗 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}