4 • Masked Language Model : 単語の穴埋めクイズ ◦ my dog is hairy → my dog is [MASK] ◦ [MASK] トークンを当てる • Next Sentence Prediction : 隣接文クイズ ◦ [CLS] Sentence A [SEP] Sentence B [SEP] ◦ Sentence A と Sentence B が意味のある繋がりとなっているか当てる 事前学習 : 大規模コーパスで汎用的な言語表現を獲得
Sincere : 純粋な質問文 ▪ What is AI based on? (AIは何に基づいていますか?) ◦ Insincere : 主義主張が含まれたり、道徳的に不適切な質問 ▪ 'Why do so many idiots ask so many idiotic questions about that idiotic President Trump, on Quora?' (どうして多くのバカげた人がバカげたトランプ大統領についてバカげた質問をする の?) 9
= ξ x ηk ◦ ベースの学習率を2e-5、ξ=0.95 として段階的に下げる ◦ [2e-5, 0.95 x 2e-5, (0.95)^2 x 2e-5, …..] 15 [1] How to Fine-Tune BERT for Text Classification? ( https://arxiv.org/pdf/1905.05583.pdf)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
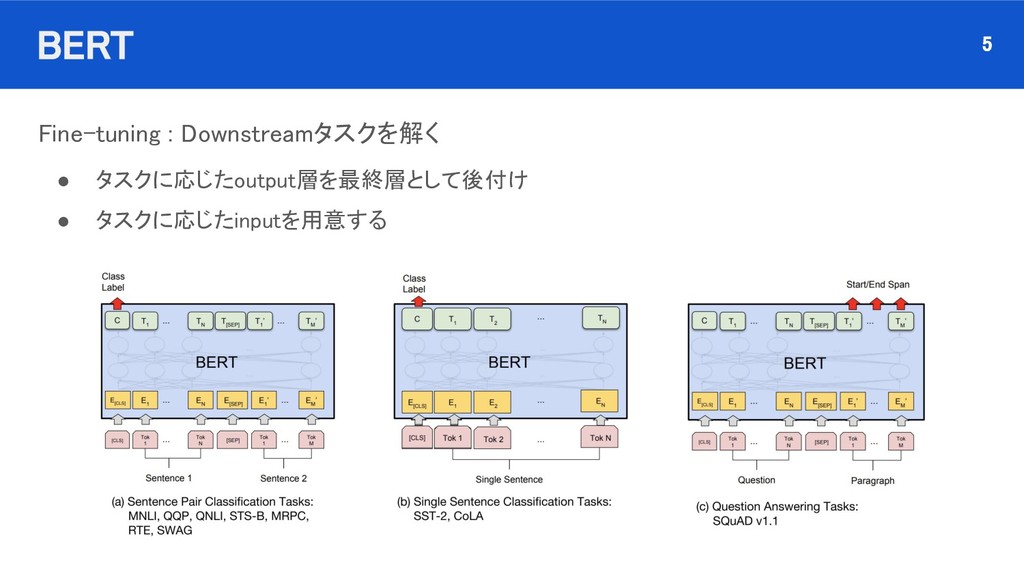
![BERT Fine-tuning Classification [CLS]トークンを文章の先頭に付加して、[CLS]トークンの最終出力を全結合層にinputして分類タスク として解く 12](https://files.speakerdeck.com/presentations/36a1fdbbbd5c4042857f83a6542fe401/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
![Experiment 2 • 層ごとに学習率を変える [1] ◦ 下層は経験的に汎用的な表現を獲得していると考えられているので、それを忘却しない ように学習率を下げる ◦ ηk-1](https://files.speakerdeck.com/presentations/36a1fdbbbd5c4042857f83a6542fe401/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![所感 ② • リソース ◦ モデルのみで418MB、1batch 512シーケンスだと合計1237MB [2] ▪](https://files.speakerdeck.com/presentations/36a1fdbbbd5c4042857f83a6542fe401/slide_18.jpg){kind=link}
{kind=link}