Zisserman. "WhisperX: Time-accurate speech transcription of long-form audio." In: Interspeech conference (2023). 8. Gopinath, Deepa P., and Vrinda V. Nair. "IMaSC--ICFOSS Malayalam Speech Corpus." arXiv preprint arXiv:2211.12796 (2022). 9. Benoy Kurian et al., In: https://github.com/kurianbenoy/whisper_normalizer 10. Dinesh S Akshay, Thottingal Santhosh et al., In: https://github.com/libindic/normalizer 11. Kunchukuttan Anoop et al., In: https://github.com/anoopkunchukuttan/indic_nlp_library 12. S. wen Yang, P.-H. Chi, Y.-S. Chuang, C.-I. J. Lai, K. Lakhotia, Y. Y.Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Lin, T.-H. Huang, W.-C. Tseng, K. tik Lee, D.-R. Liu, Z. Huang, S. Dong, S.-W. Li, S. Watanabe, A. Mohamed, and H. yi Lee, “SUPERB: Speech Processing Universal PERformance Benchmark,” in Proc. Interspeech 2021, pp. 1194–1198, 2021
{kind=link}
{kind=link}
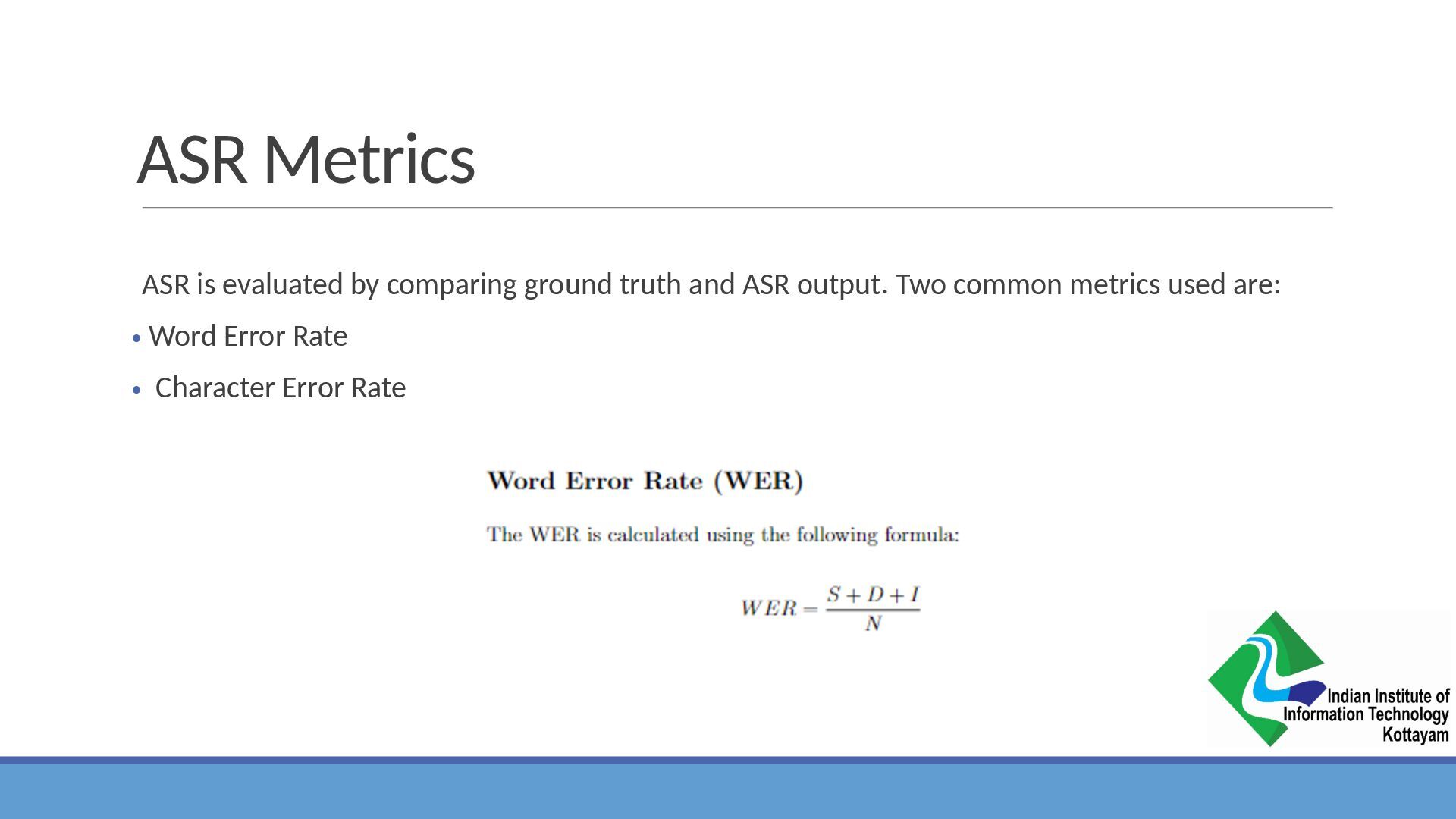{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
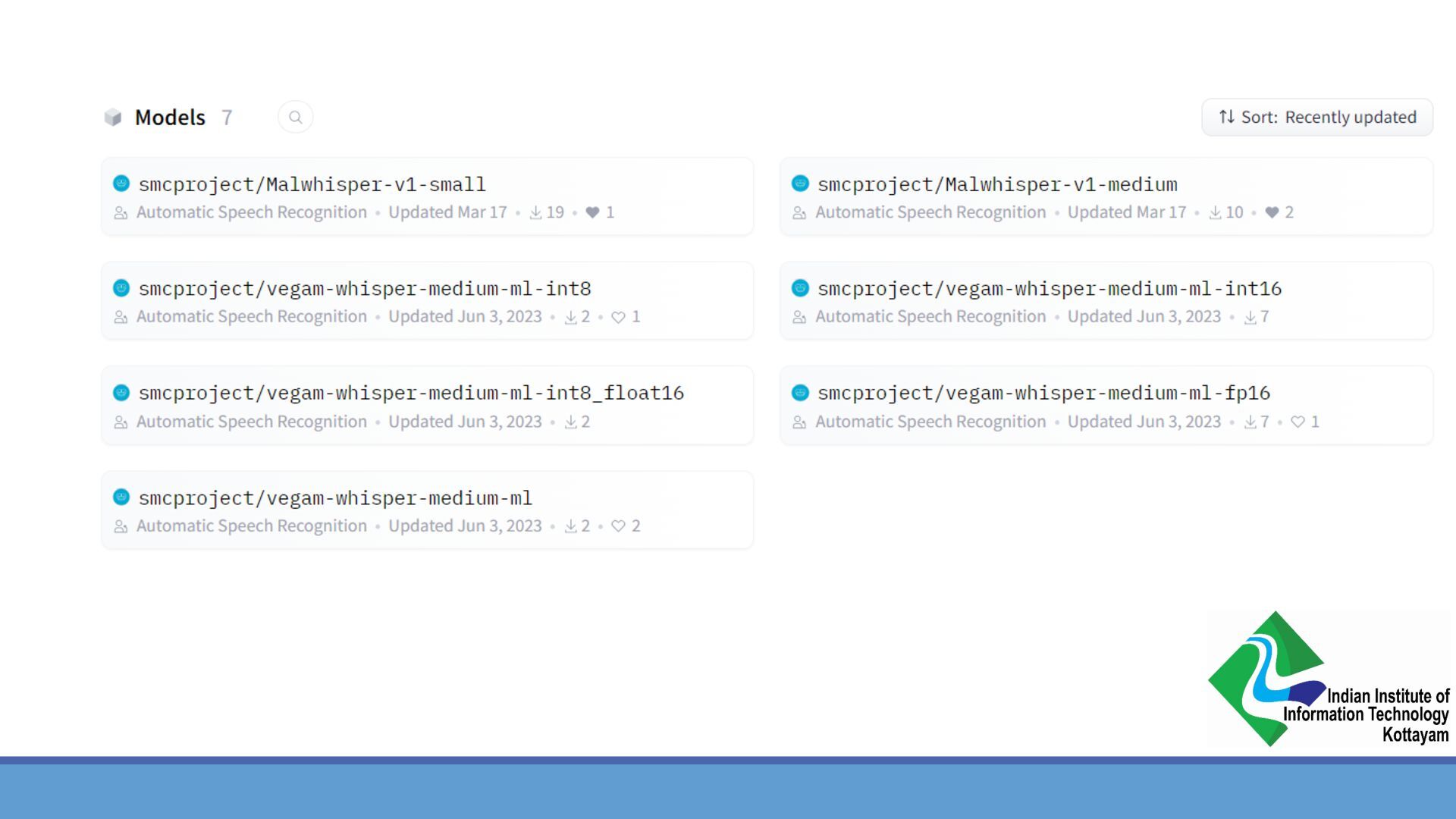{kind=link}
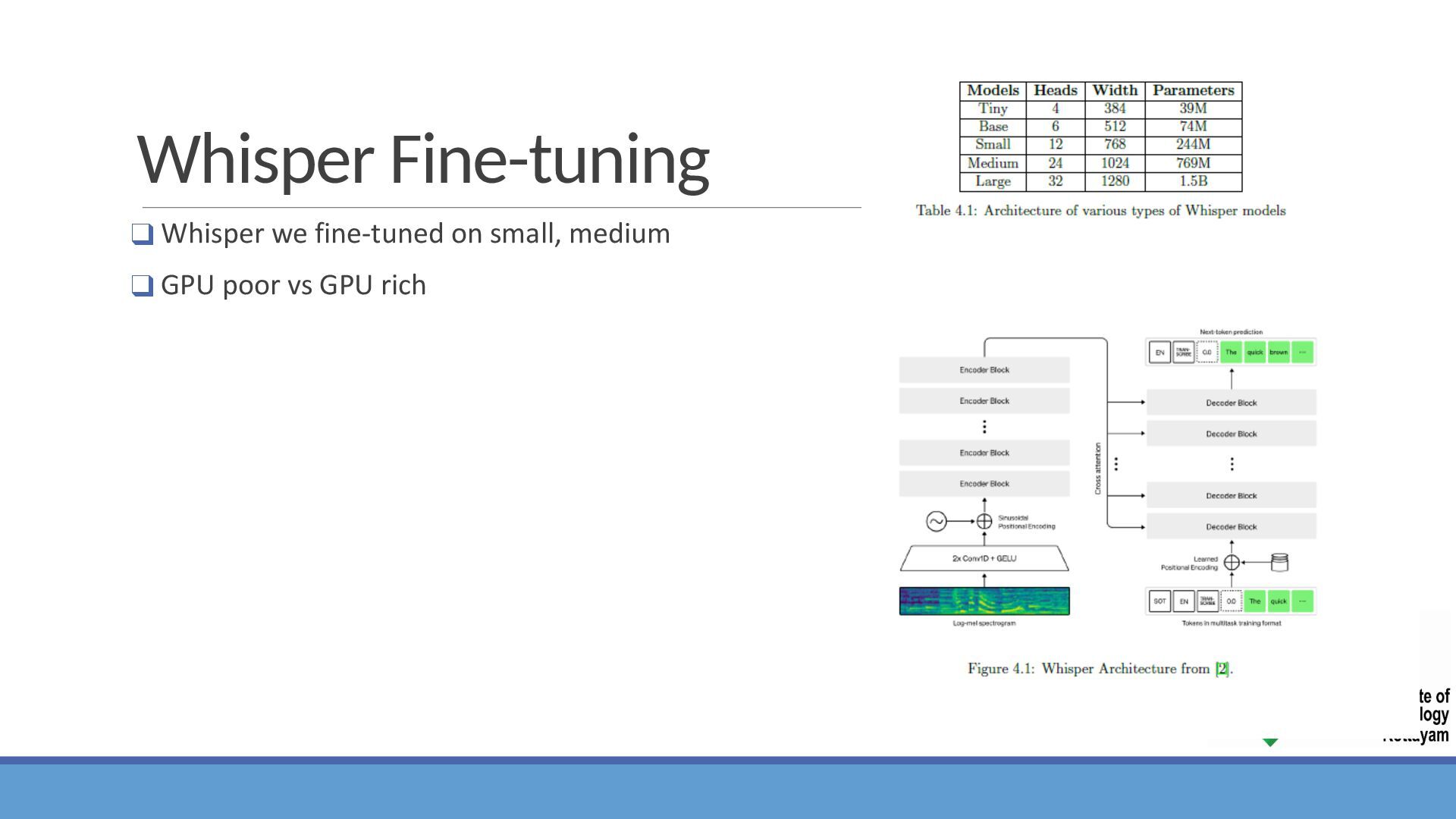{kind=link}
{kind=link}
{kind=link}
{kind=link}
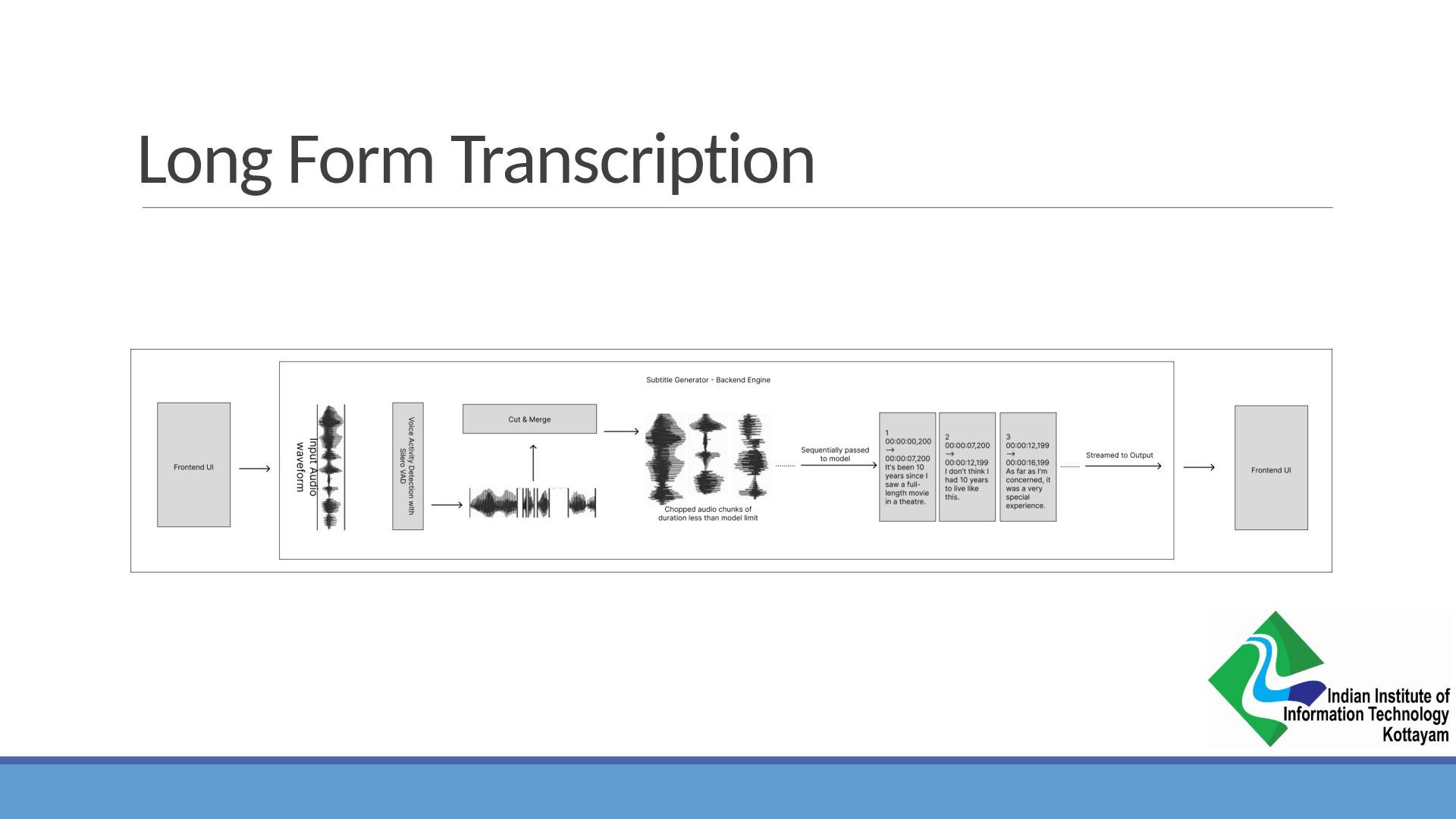{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
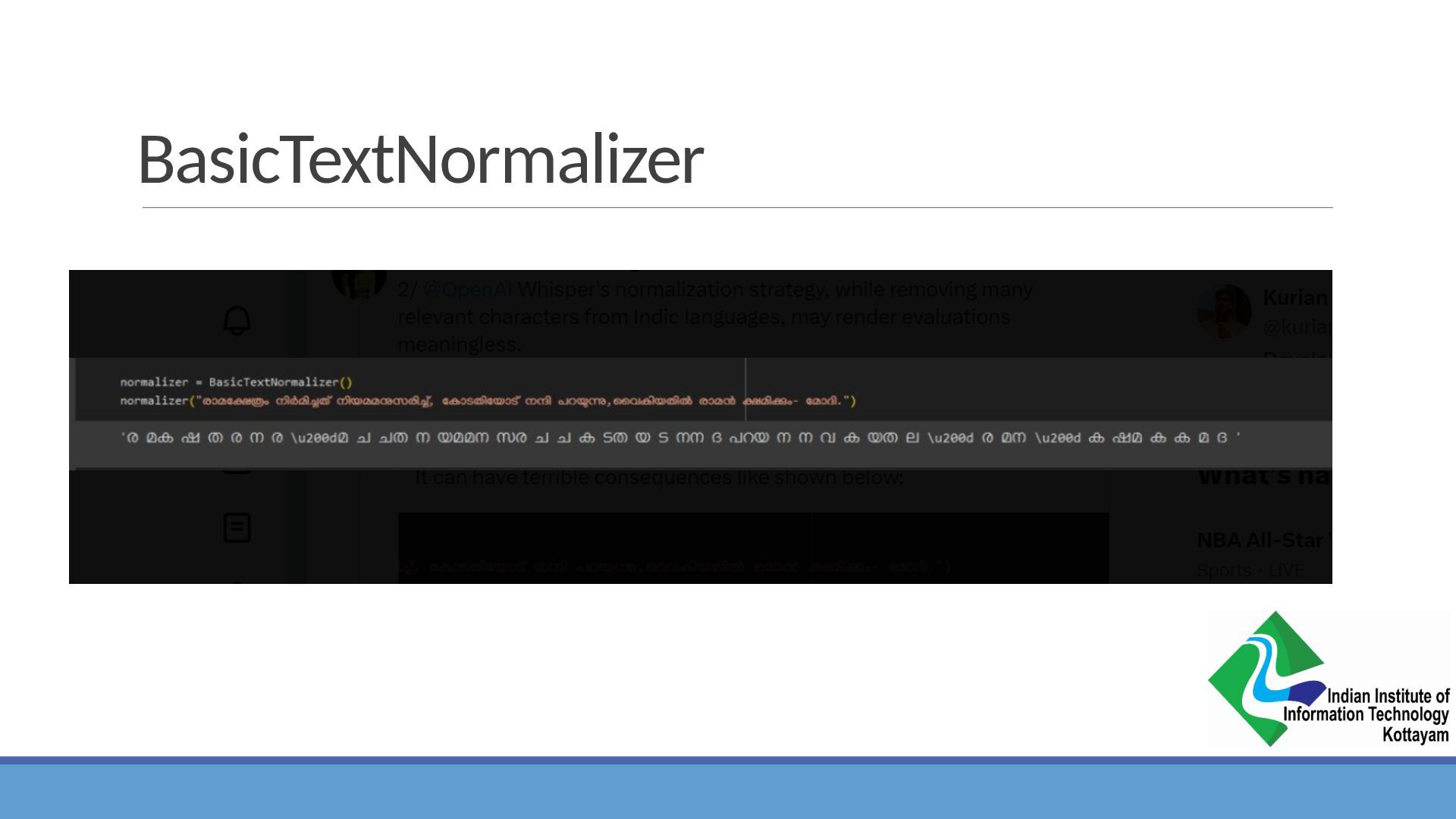
![Whisper_normalizer[9] package](https://files.speakerdeck.com/presentations/cc724a25e8094c89951e575348142ffb/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}