analysis of the morphological complexity of Malayalam language”. In: International Conference on Text, Speech and Dialogue pp 71-78. 2. Kurian, Cini, Balakrishnan Kannan, “Speech recognition of Malayalam numbers”. In: 2009 world congress on nature & biological inspired computing(NaBIC) 3. Mohammed, Anuj, Nair K.N , “HMM/ANN hybrid model for continuous Malayalam speech recognition”. In: Procedia Engineering, Volume 30, pp: 616-622 4. Manohar Kavya,, Jayan A.R , Rajan Rajeev, , “Syllable Subword Tokens for Open Vocabulary Speech Recognition in Malayalam”. In: NSURL 2022, pages 1-7, Trento, Italy. 5. Radford, Alec, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. "Robust speech recognition via large-scale weak supervision." In International Conference on Machine Learning, pp. 28492-28518. PMLR, 2023. 6. S. Gandhi, P. Von Platen, and A. M. Rush, “Esb: A benchmark for multi-domain end-to-end speech recognition,”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Hybrid ASR for Malayalam Kavya et.al [4] proposed a](https://files.speakerdeck.com/presentations/0a521722451a482d8770fe21f99d0f3e/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fine tuning architecture 1. Whisper [5] Whisper is a Transformer](https://files.speakerdeck.com/presentations/0a521722451a482d8770fe21f99d0f3e/slide_15.jpg){kind=link}
{kind=link}
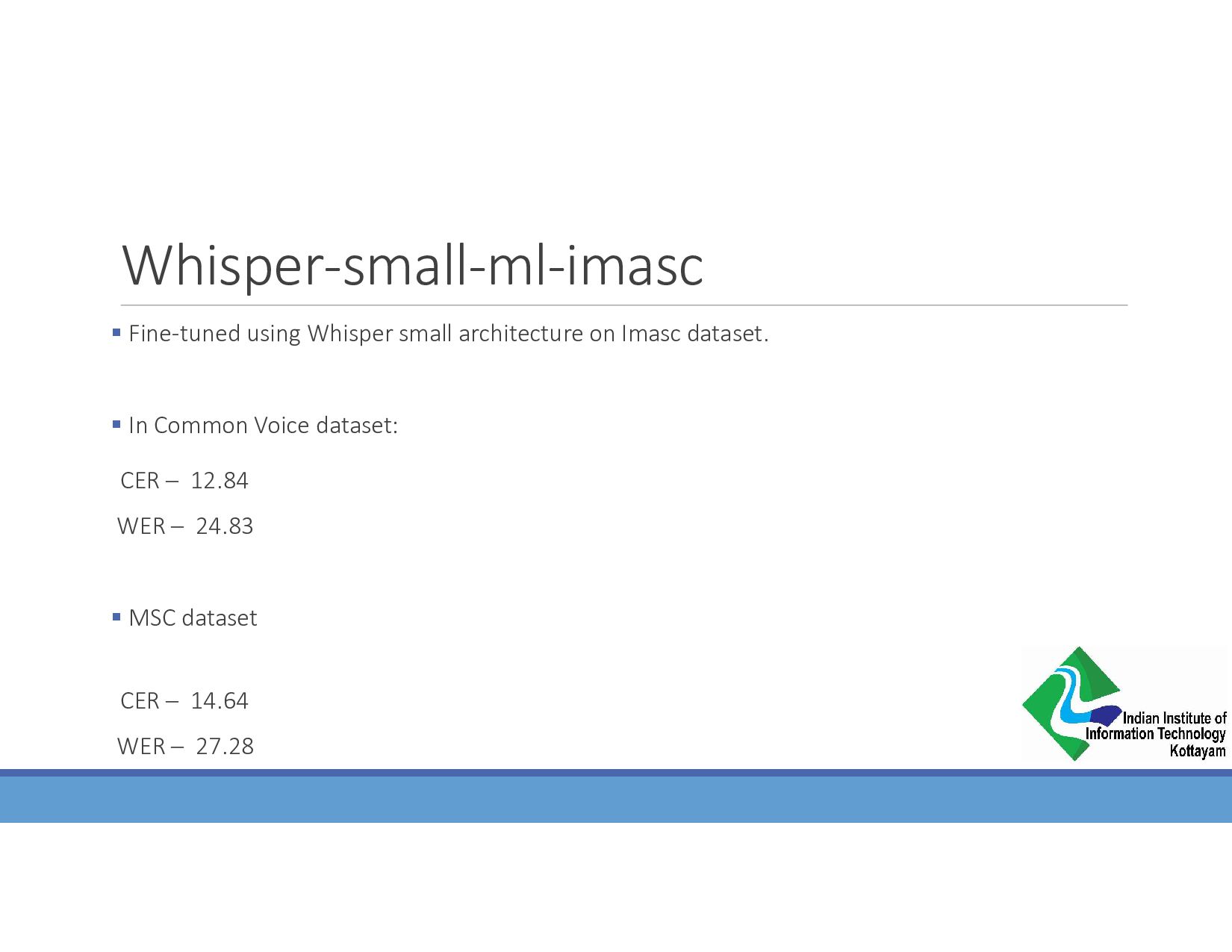{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Methodology According to Max et al. [8], the support for](https://files.speakerdeck.com/presentations/0a521722451a482d8770fe21f99d0f3e/slide_21.jpg){kind=link}
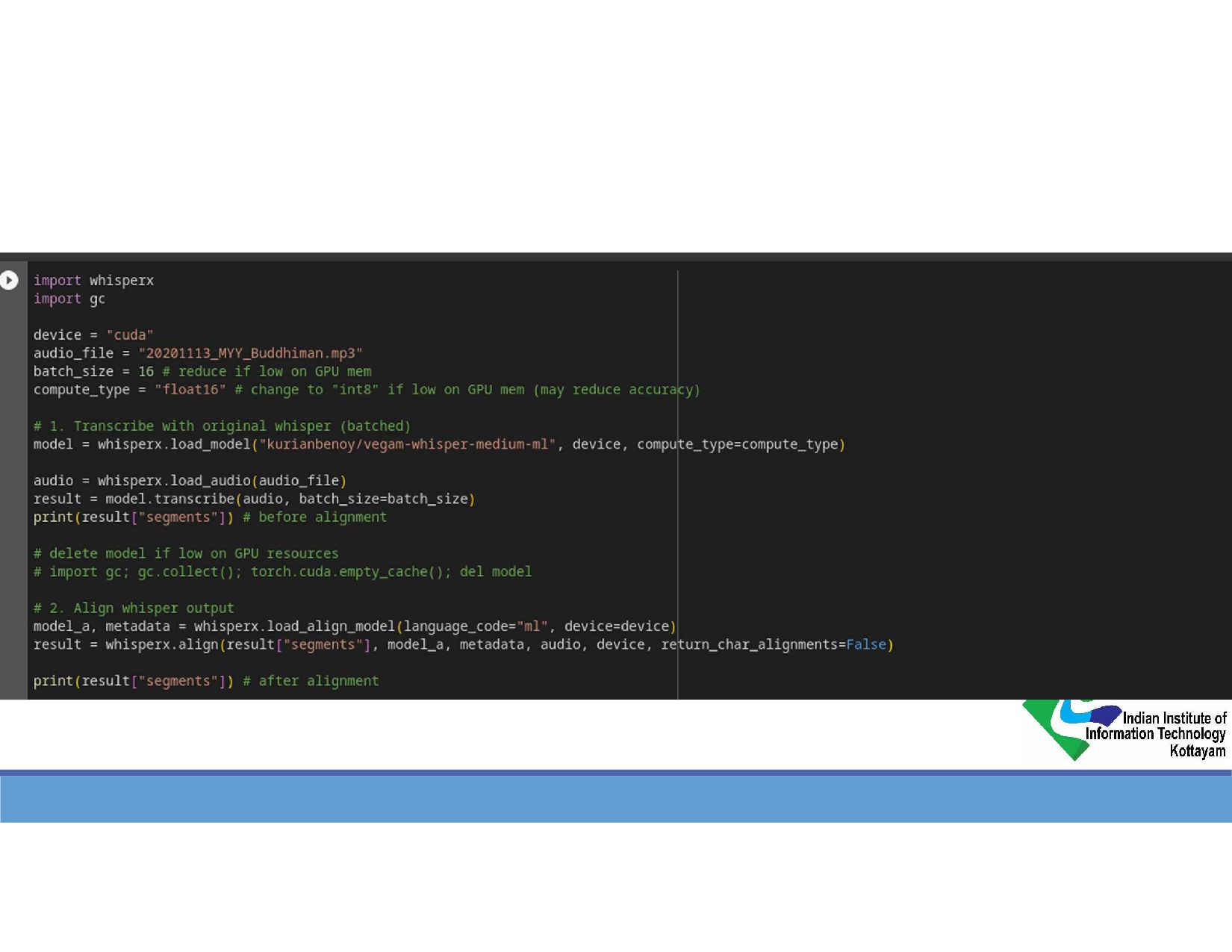{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
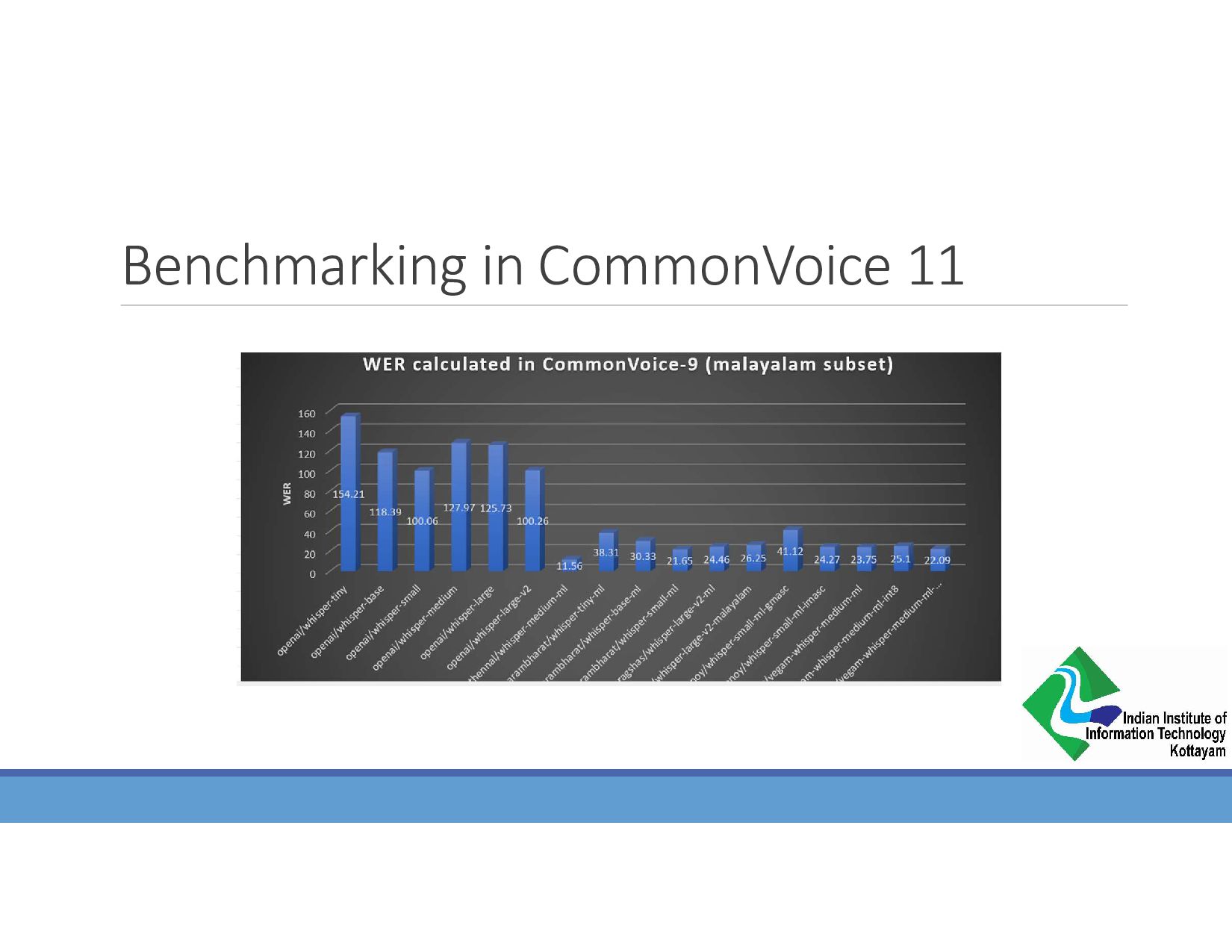{kind=link}
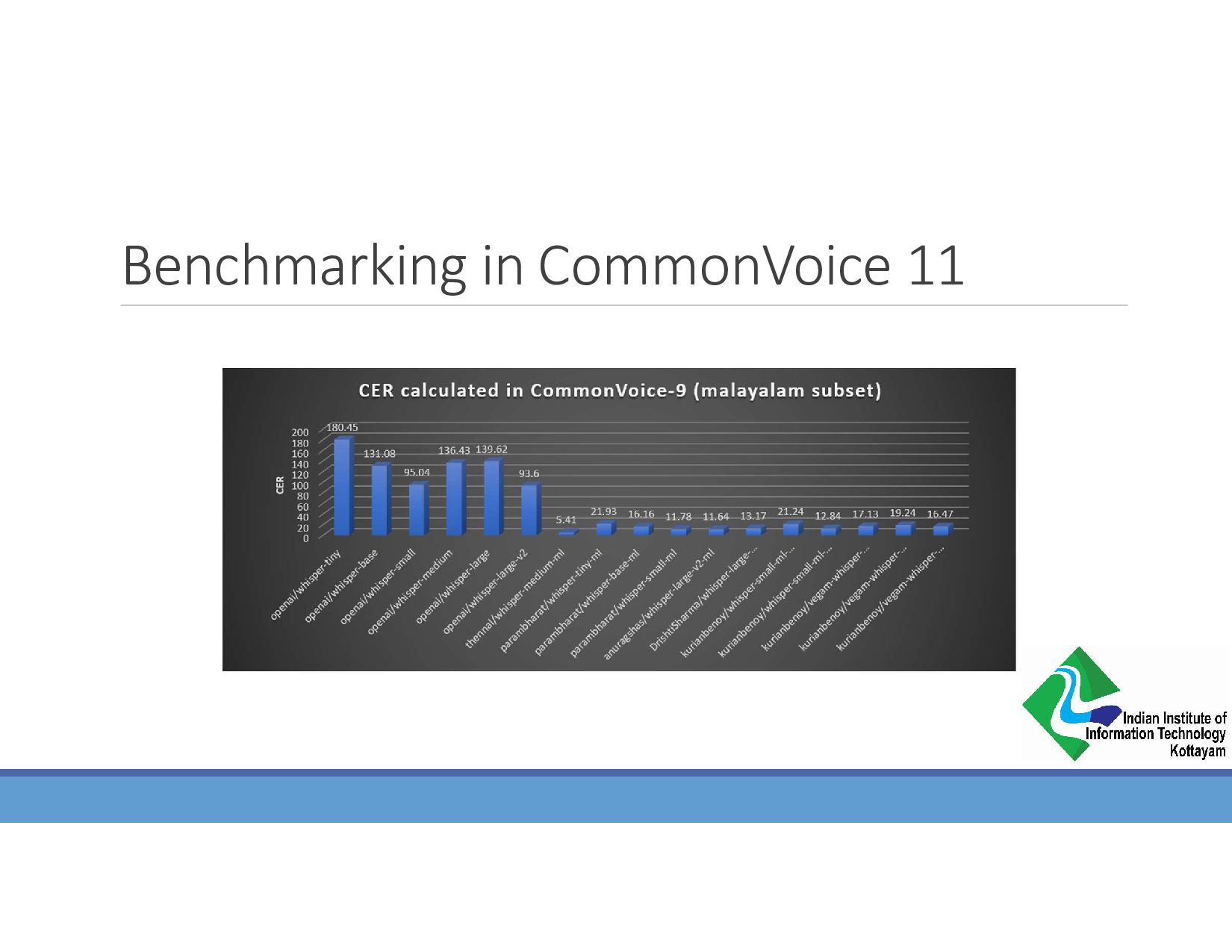{kind=link}
{kind=link}
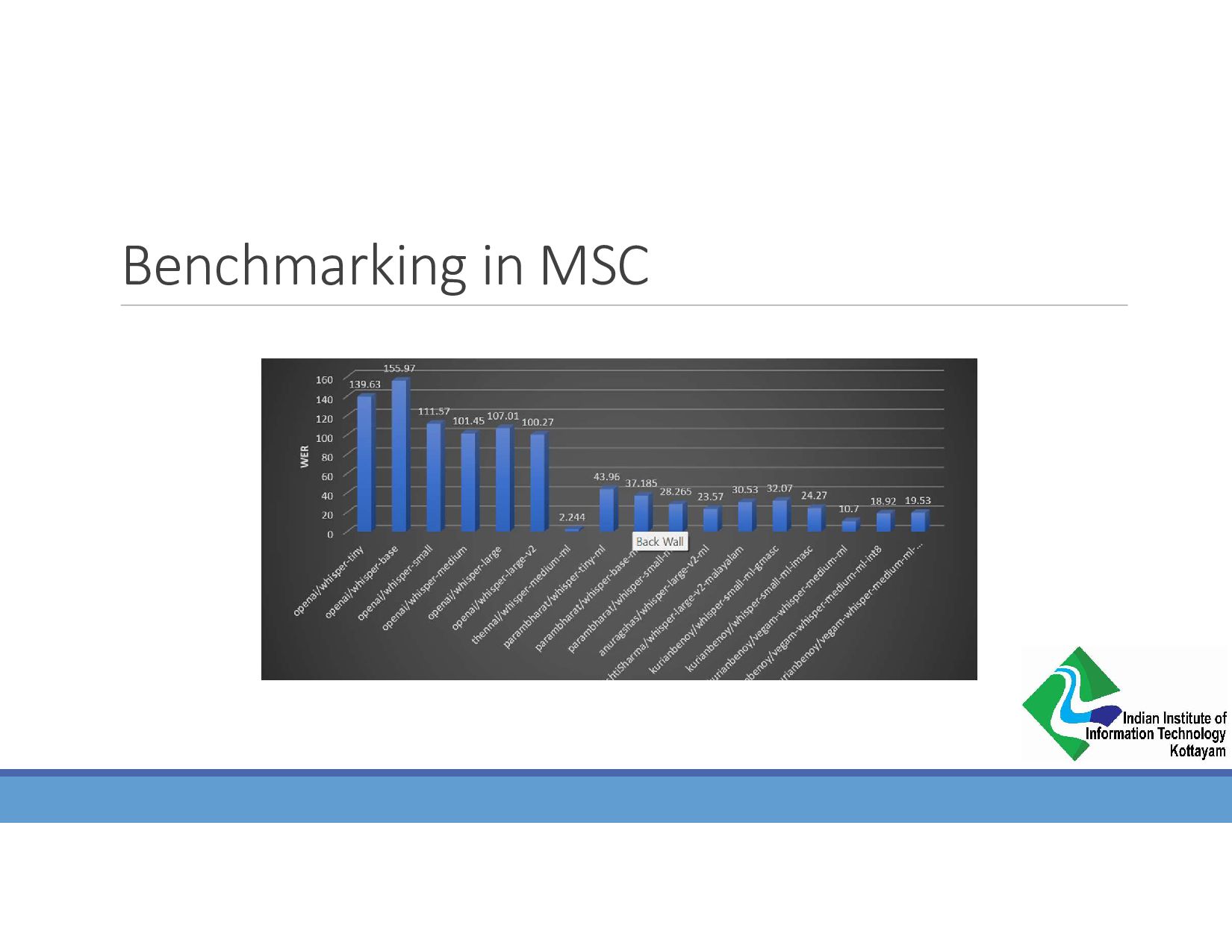{kind=link}
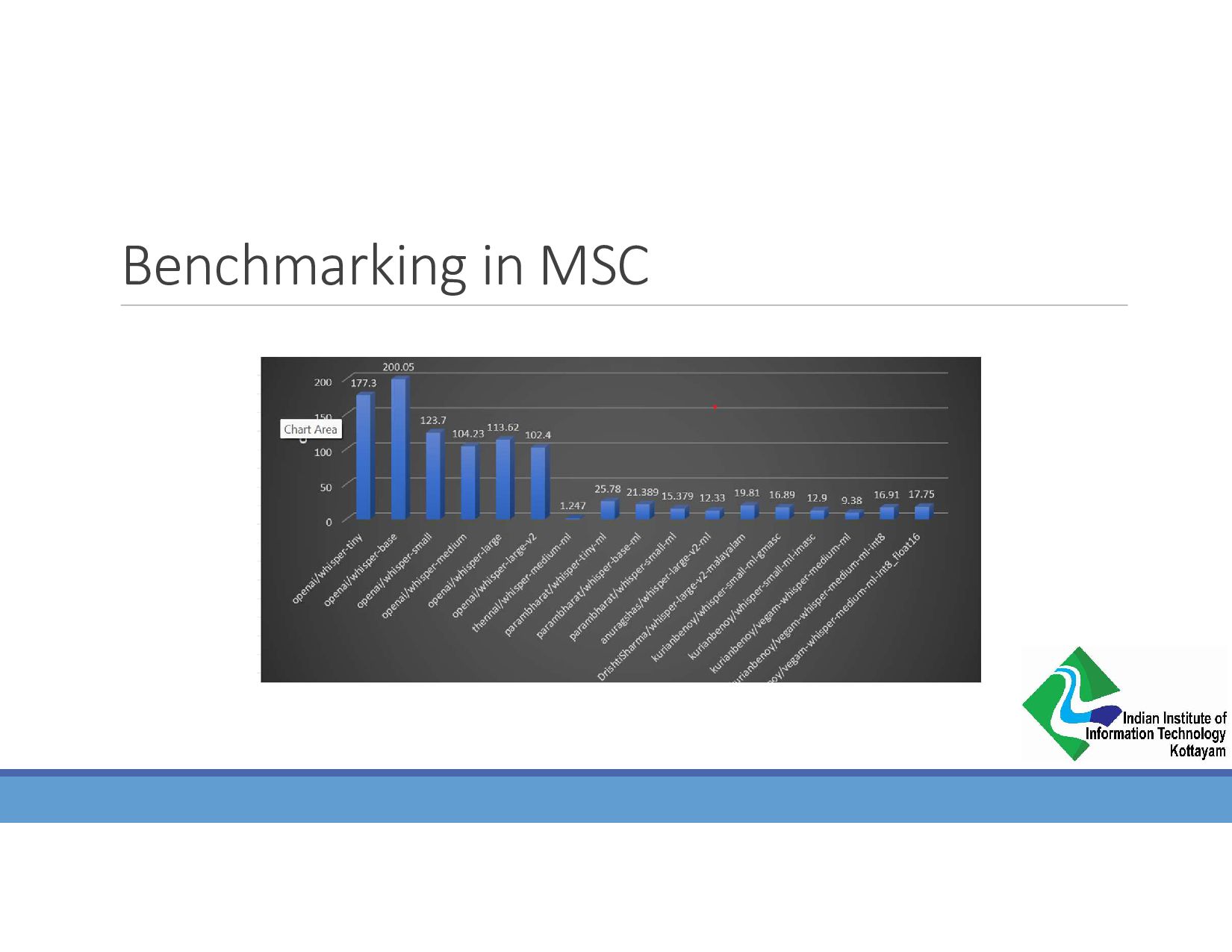{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}