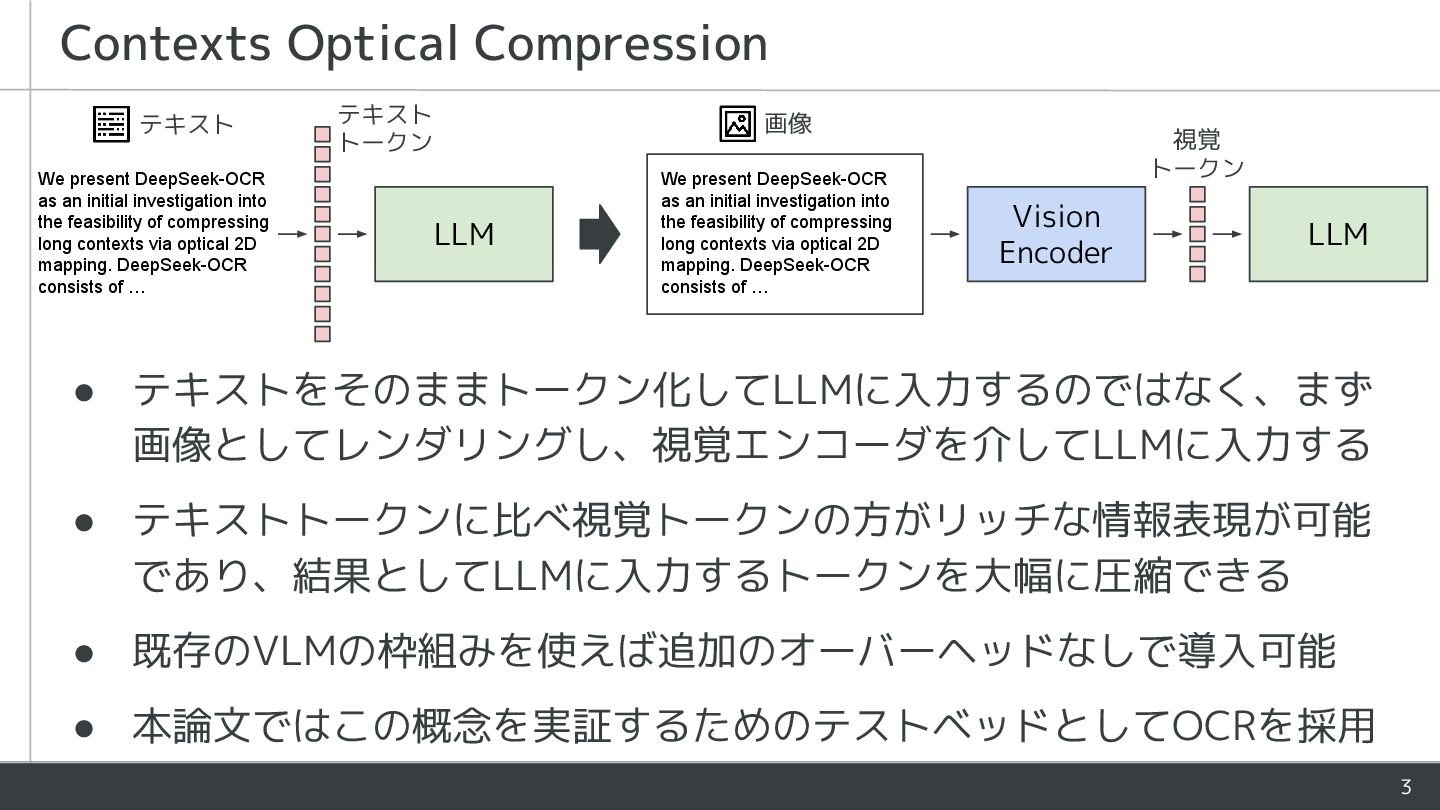
investigation into the feasibility of compressing long contexts via optical 2D mapping. DeepSeek-OCR consists of … LLM We present DeepSeek-OCR as an initial investigation into the feasibility of compressing long contexts via optical 2D mapping. DeepSeek-OCR consists of … LLM Vision Encoder テキスト 画像 テキスト トークン 視覚 トークン • テキストをそのままトークン化してLLMに入力するのではなく、まず 画像としてレンダリングし、視覚エンコーダを介してLLMに入力する • テキストトークンに比べ視覚トークンの方がリッチな情報表現が可能 であり、結果としてLLMに入力するトークンを大幅に圧縮できる • 既存のVLMの枠組みを使えば追加のオーバーヘッドなしで導入可能 • 本論文ではこの概念を実証するためのテストベッドとしてOCRを採用
a Vision Transformer for any Aspect Ratio and Resolution,” NurIPS, 2023. [2] A. Kirillov et al., “Segment Anything,” arXiv, 2023. [3] Y. Li et al., “Exploring Plain Vision Transformer Backbones for Object Detection,” arXiv, 2022. [4] P. Rust et al., “Language Modelling with Pixels,” ICLR, 2023. 参考文献
{kind=link}
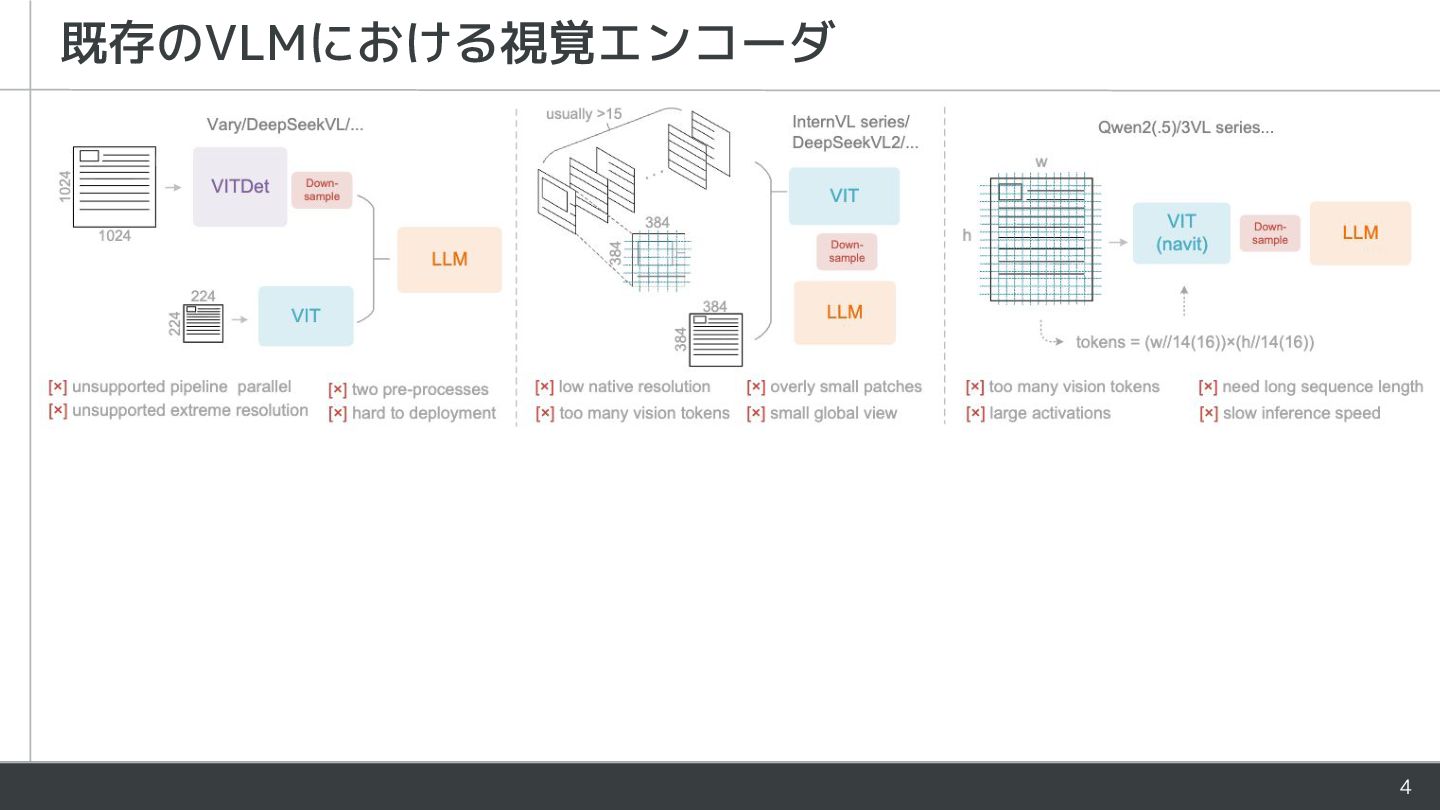
![2 • 中国のDeepSeekから10/20に論文と共にリリースされたOCRモデル • OCRと謳っているが、LLMの入力をテキストから画像に変えることで 大幅なコンテキスト圧縮が可能であることを示すのが本当の狙い DeepSeek-OCR [paper] [code] •](https://files.speakerdeck.com/presentations/fdccd374c66840e3a25cc29ca3f19051/slide_1.jpg){kind=link}
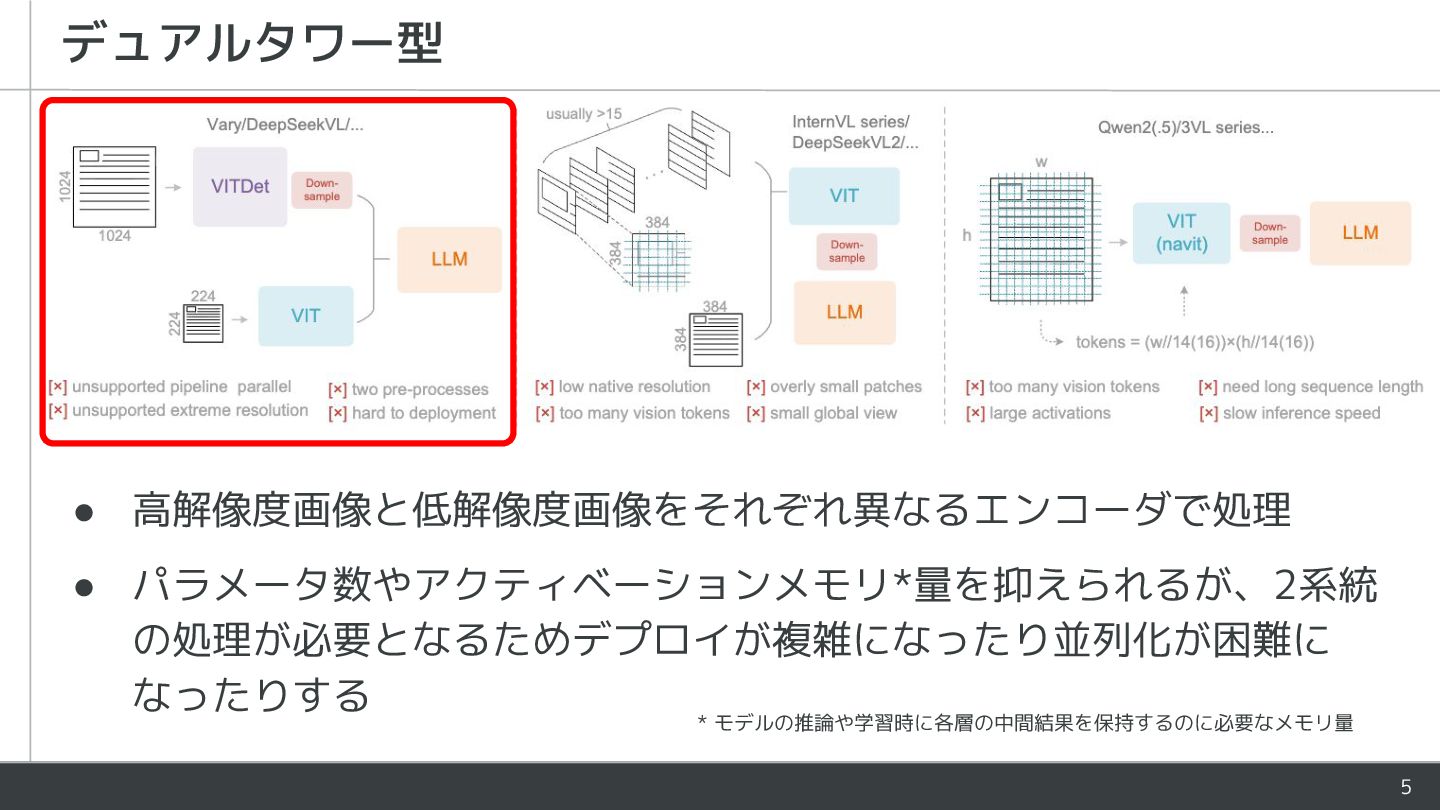
{kind=link}
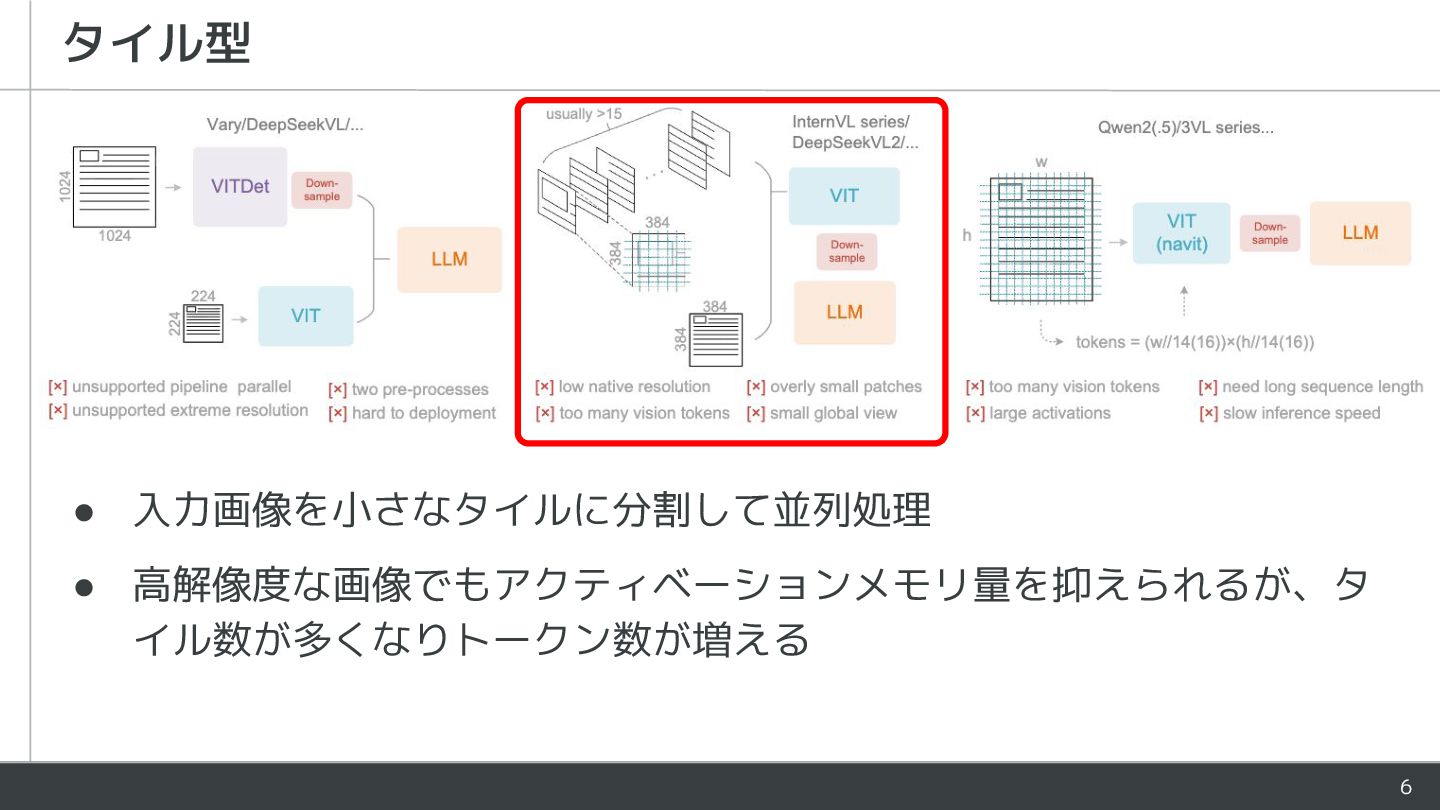
{kind=link}
{kind=link}
{kind=link}
![7 適応型 • NaViT [1] を用いることで、リサイズやタイル分割をせずに入力画像 をそのまま処理 • 多様な解像度の画像を扱えるが、高解像度画像だとアクティベーショ ンメモリの肥大化や極めて長いトークン処理の必要性が生じる](https://files.speakerdeck.com/presentations/fdccd374c66840e3a25cc29ca3f19051/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
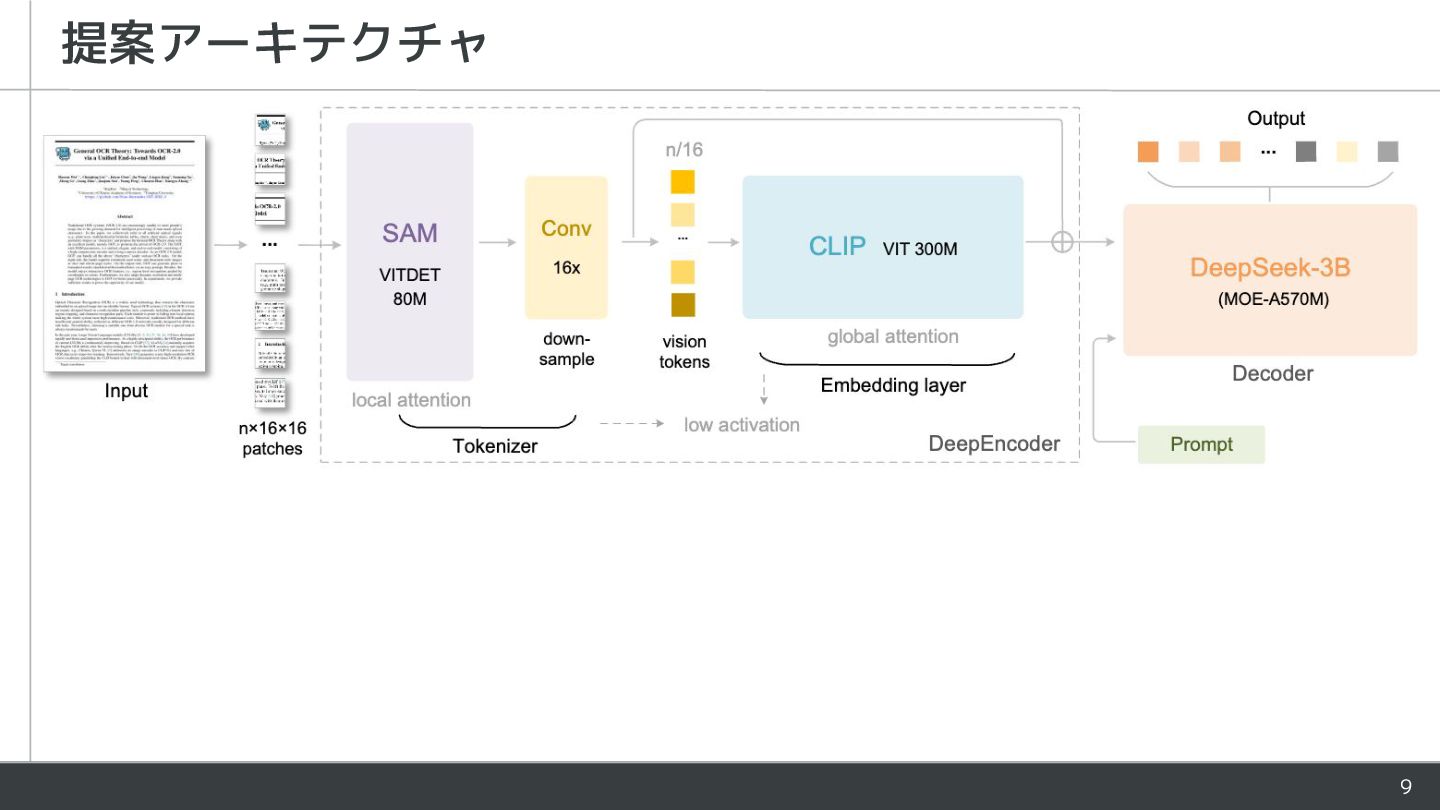
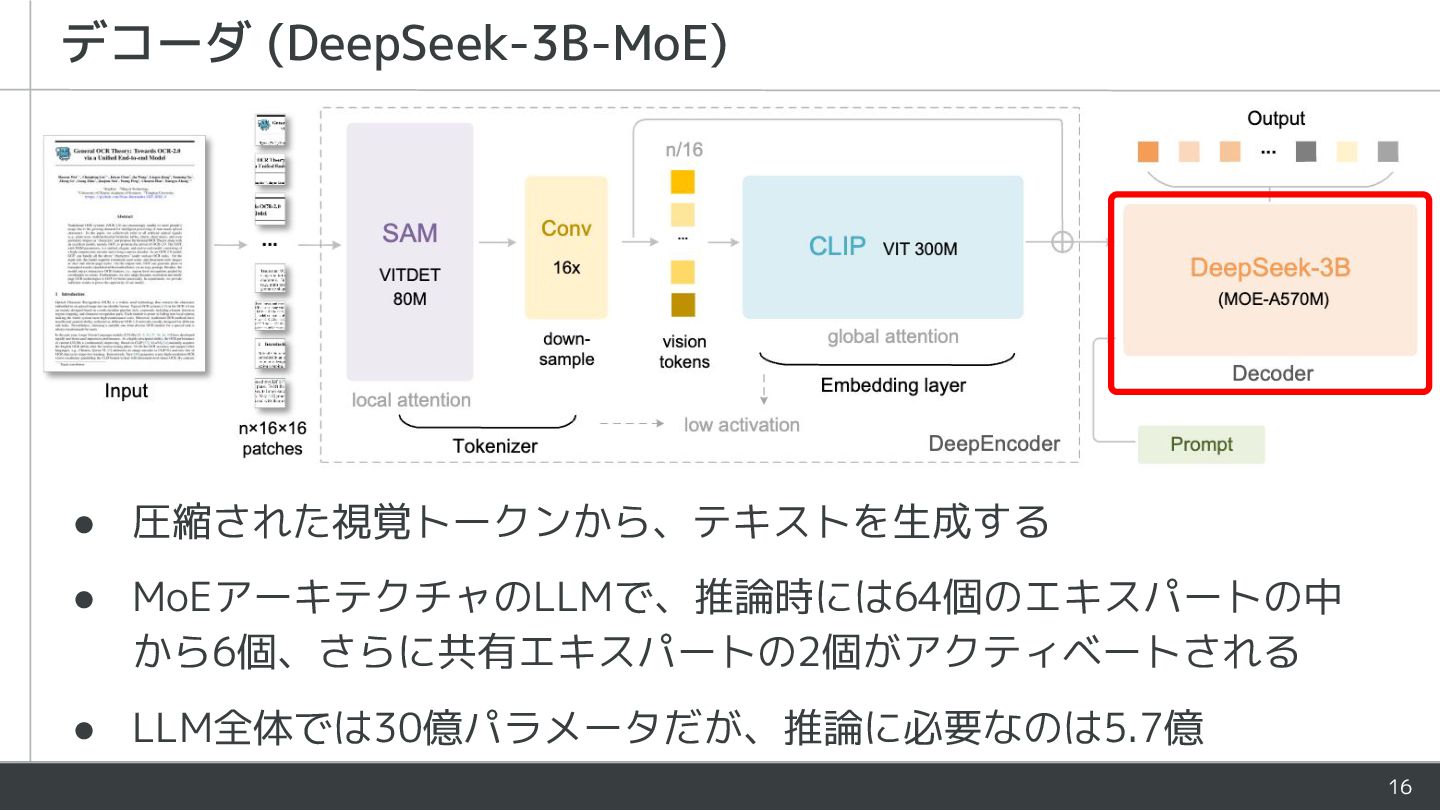
![10 エンコーダ (DeepEncoder) • SAM [2] のバックボーン (ViTDet [3]) で特徴を抽出し、2層のCNN](https://files.speakerdeck.com/presentations/fdccd374c66840e3a25cc29ca3f19051/slide_9.jpg){kind=link}
![• SAM [2] のバックボーン (ViTDet [3]) で特徴を抽出し、2層のCNN でダウンサンプルして視覚トークンを得る • 視覚トークンをCLIPエンコーダに入力し、CLIPによる画像とテキス](https://files.speakerdeck.com/presentations/fdccd374c66840e3a25cc29ca3f19051/slide_10.jpg){kind=link}
![• SAM [2] のバックボーン (ViTDet [3]) で特徴を抽出し、2層のCNN でダウンサンプルして視覚トークンを得る • 視覚トークンをCLIPエンコーダに入力し、CLIPによる画像とテキス](https://files.speakerdeck.com/presentations/fdccd374c66840e3a25cc29ca3f19051/slide_11.jpg){kind=link}
![• SAM [2] のバックボーン (ViTDet [3]) で特徴を抽出し、2層のCNN でダウンサンプルして視覚トークンを得る • 視覚トークンをCLIPエンコーダに入力し、CLIPによる画像とテキス](https://files.speakerdeck.com/presentations/fdccd374c66840e3a25cc29ca3f19051/slide_12.jpg){kind=link}
![• SAM [2] のバックボーン (ViTDet [3]) で特徴を抽出し、2層のCNN でダウンサンプルして視覚トークンを得る • 視覚トークンをCLIPエンコーダに入力し、CLIPによる画像とテキス](https://files.speakerdeck.com/presentations/fdccd374c66840e3a25cc29ca3f19051/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
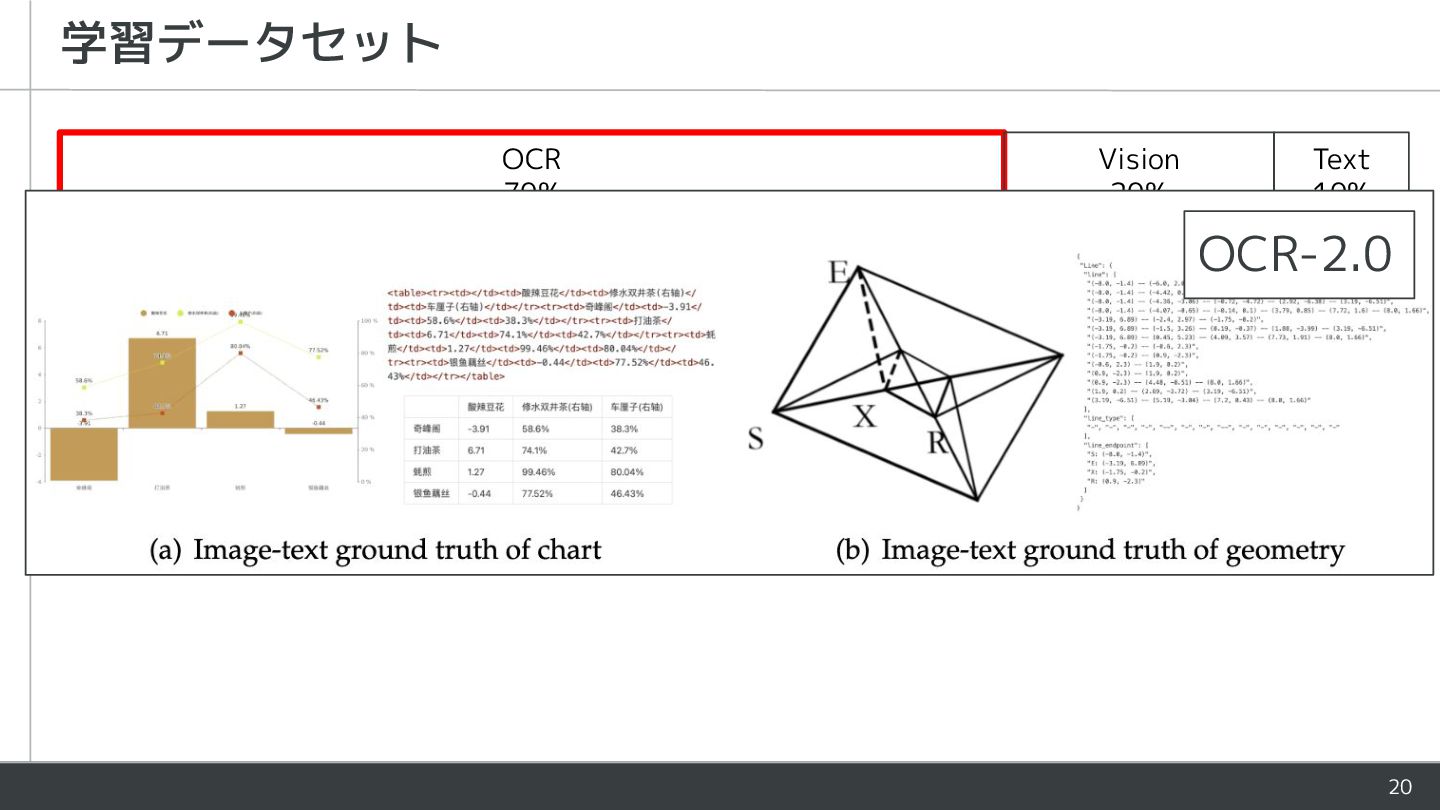{kind=link}
{kind=link}
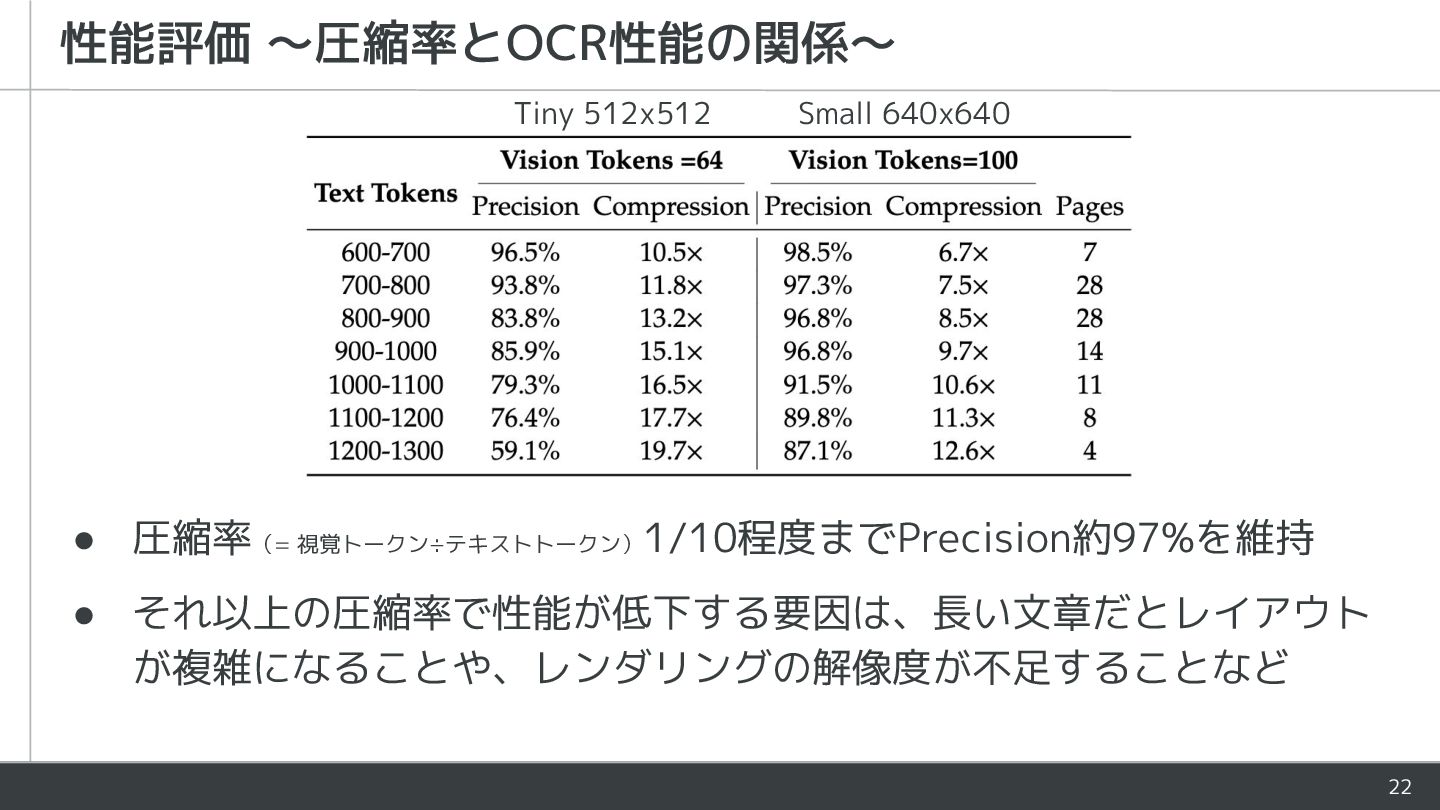{kind=link}
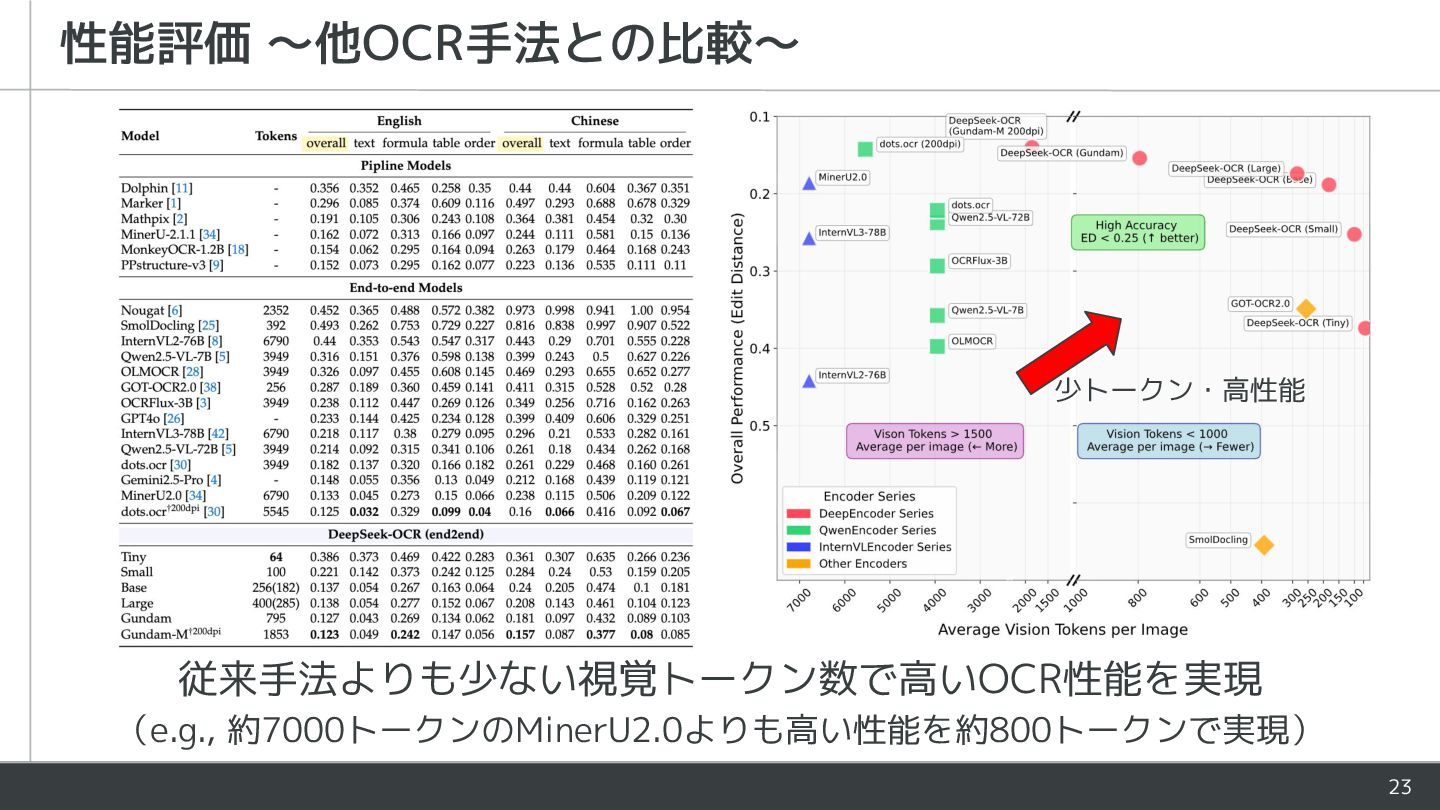{kind=link}
{kind=link}
{kind=link}
![26 [1] M. Dehghani et al., “Patch n’ Pack: NaViT,](https://files.speakerdeck.com/presentations/fdccd374c66840e3a25cc29ca3f19051/slide_25.jpg){kind=link}