Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
BigQuery × ML × troccoを用いた VoC分析のためのデータ基盤構築
Search
tkkihr2548
December 07, 2023
280
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
BigQuery × ML × troccoを用いた VoC分析のためのデータ基盤構築
「年末恒例データ利活用分科会フルオープンLT大会、Looker Japan User Group もジョインしたよ」向け資料
tkkihr2548
December 07, 2023
More Decks by tkkihr2548
See All by tkkihr2548
DataOps Night特別編 Snowflake Summit 2026 Recap - いま知っておきたい Context と Memory in Snowflake Summit 2026
lana2548
1
180
Snowflakeのパフォーマンスチューニングってこんな感じ ~Snowflake Unconference #4~
lana2548
0
210
Snowflake女子会#3 Snowpipeの良さを5分で語るよ
lana2548
0
920
Featured
See All Featured
What's in a price? How to price your products and services
michaelherold
247
13k
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
The Curious Case for Waylosing
cassininazir
1
420
Optimizing for Happiness
mojombo
378
71k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
260
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
870
Design in an AI World
tapps
1
260
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
230
Abbi's Birthday
coloredviolet
3
8.5k
Transcript
BigQuery × MLを用いた VoC分析のためのデータ基盤構築 for Jagu'e'r LT大会 1 株式会社primeNumber 庵原
崚生
BigQuery × ML × troccoを用いた VoC分析のためのデータ基盤構築 for Jagu'e'r LT大会 2
株式会社primeNumber 庵原 崚生
自己紹介 Self - Introduction
©primeNumber Inc. 庵原 崚生(いはら たかき) WHO AM I? 株式会社primeNumber Data
Engineer ←入社時の写真 あれから5kgほど痩せました。 人生初LT、緊張してます。 最近Google Cloud Professional Data Engineerを 取得してウッキウキです。 1
今日話すこと Today’s Topic
今日話すこと (9割フィクションです。) LLM、流行ってきてんな。 この前(夏)にBigQueryからPaLM2使える様になったらしい やん。 データあるし、自分なんかおもろいことやってや。 お客様 僕
今日話すこと (9割フィクションです。) LLM、流行ってきてんな。 この前(夏)にBigQueryからPaLM2使える様になったらしい やん。 データあるし、自分なんかおもろいことやってや。 はい!!喜んでぇ!!! お客様 僕
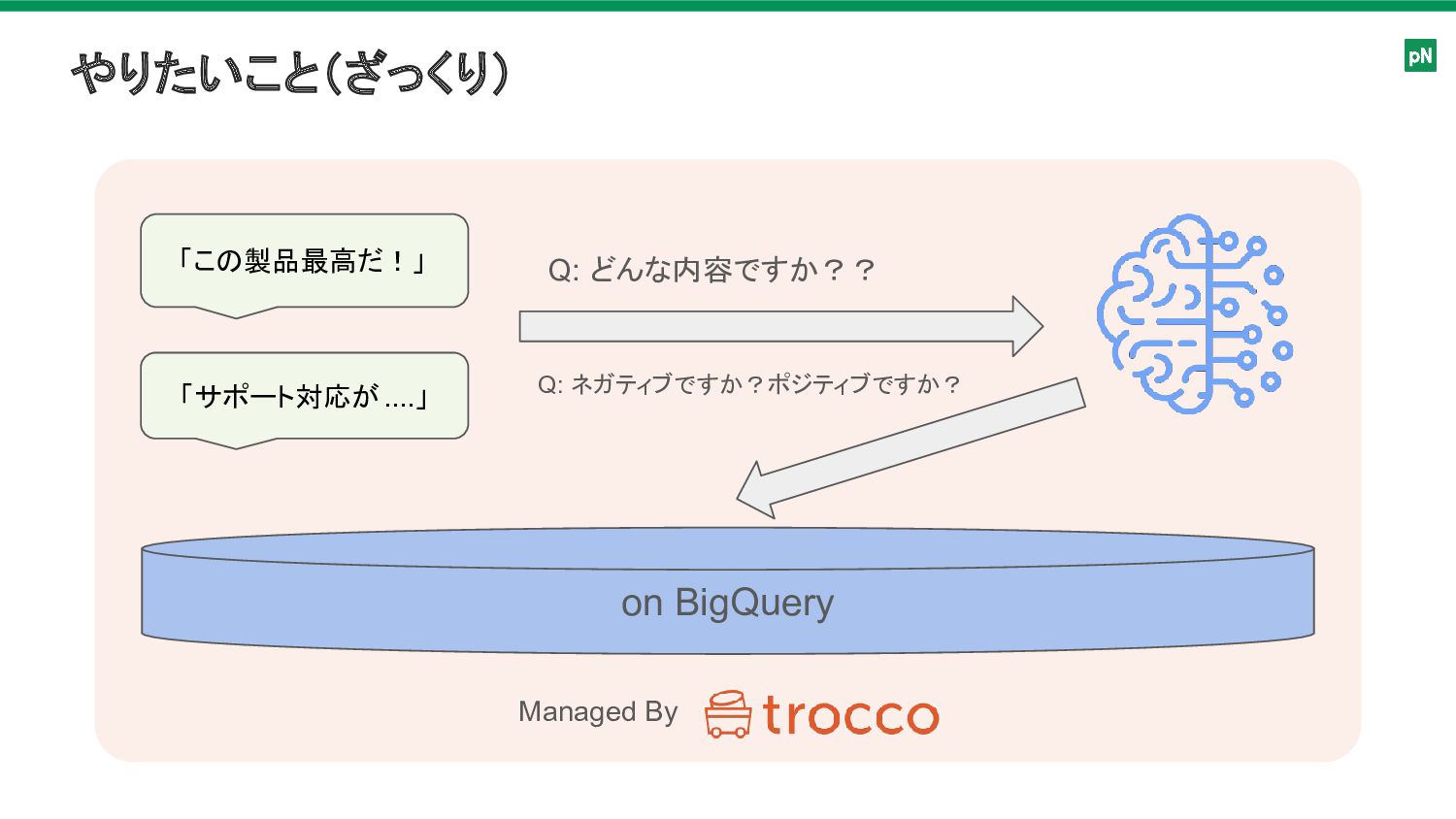
やりたいこと(ざっくり) 「この製品最高だ!」 「サポート対応が....」 Q: どんな内容ですか?? Q: ネガティブですか?ポジティブですか? on BigQuery Managed
By
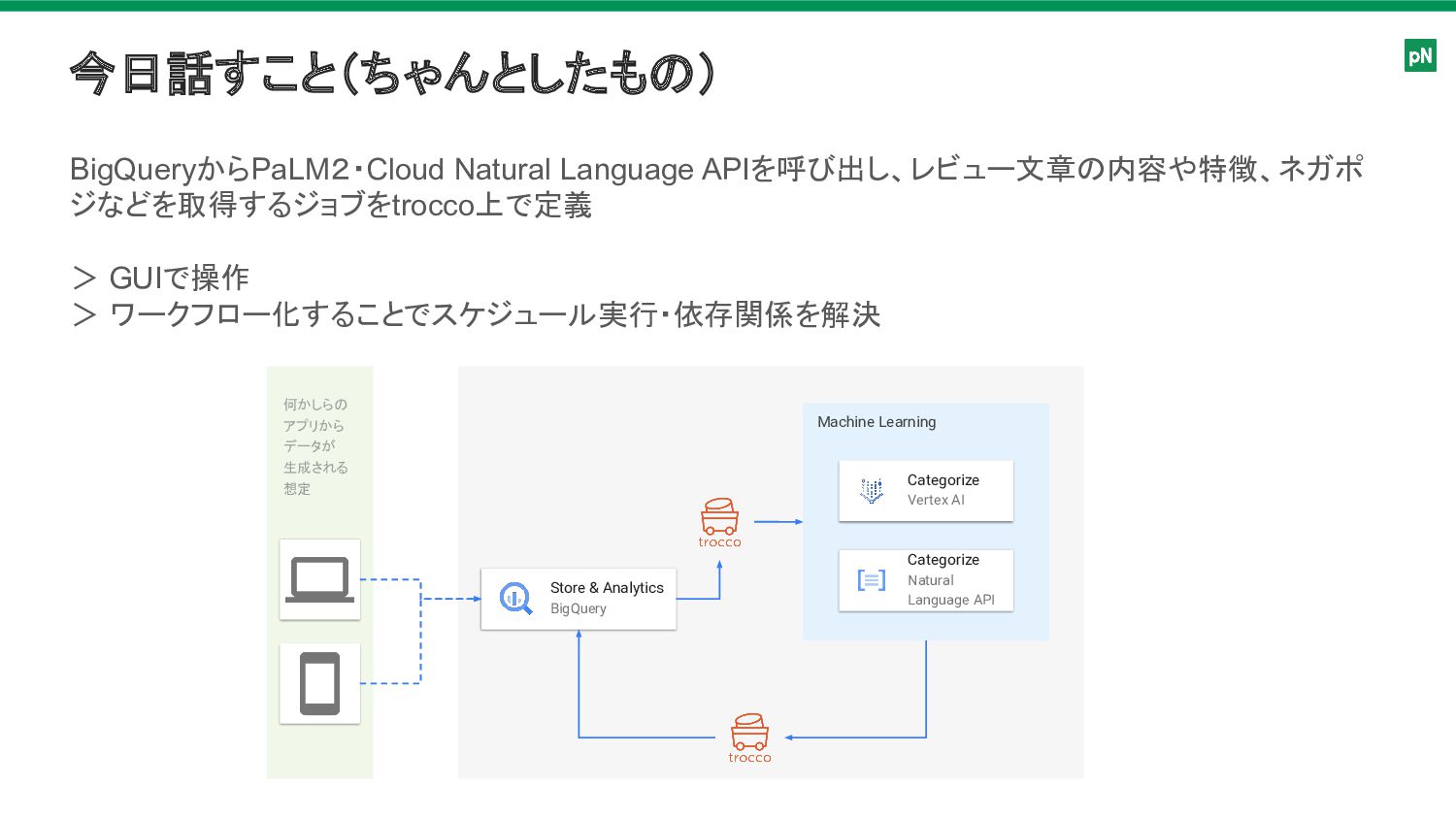
今日話すこと(ちゃんとしたもの) 何かしらの アプリから データが 生成される 想定 Store & Analytics BigQuery
Machine Learning Categorize Vertex AI Categorize Natural Language API BigQueryからPaLM2・Cloud Natural Language APIを呼び出し、レビュー文章の内容や特徴、ネガポ ジなどを取得するジョブをtrocco上で定義 > GUIで操作 > ワークフロー化することでスケジュール実行・依存関係を解決
サービス紹介 Service introduction
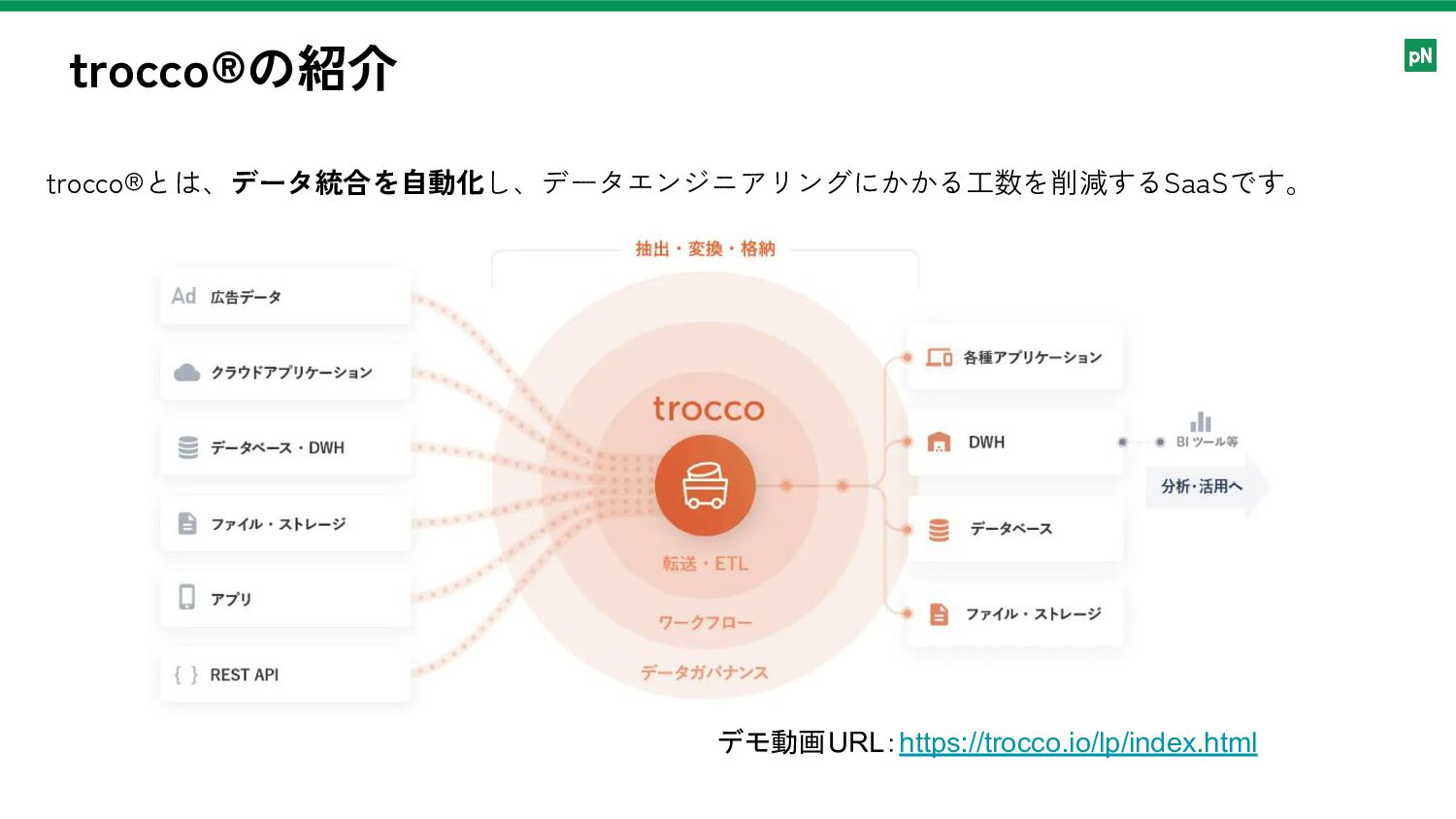
trocco®の紹介 デモ動画URL:https://trocco.io/lp/index.html trocco®とは、データ統合を自動化し、データエンジニアリングにかかる工数を削減するSaaSです。
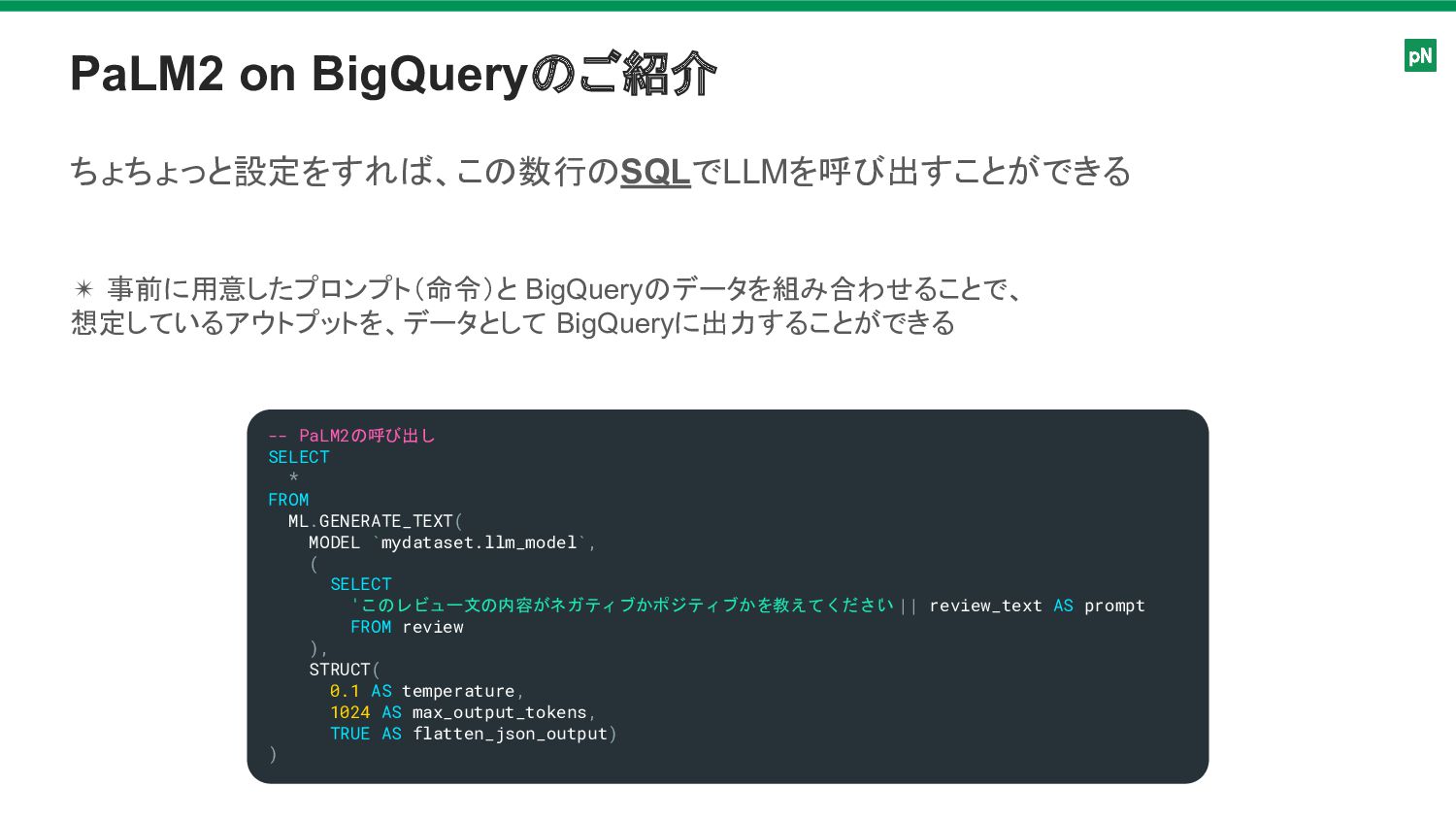
PaLM2 on BigQueryのご紹介 -- PaLM2の呼び出し SELECT * FROM ML.GENERATE_TEXT( MODEL
`mydataset.llm_model`, ( SELECT 'このレビュー文の内容がネガティブかポジティブかを教えてください ' || review_text AS prompt FROM review ), STRUCT( 0.1 AS temperature, 1024 AS max_output_tokens, TRUE AS flatten_json_output) ) ちょちょっと設定をすれば、この数行のSQLでLLMを呼び出すことができる ✴ 事前に用意したプロンプト(命令)と BigQueryのデータを組み合わせることで、 想定しているアウトプットを、データとして BigQueryに出力することができる
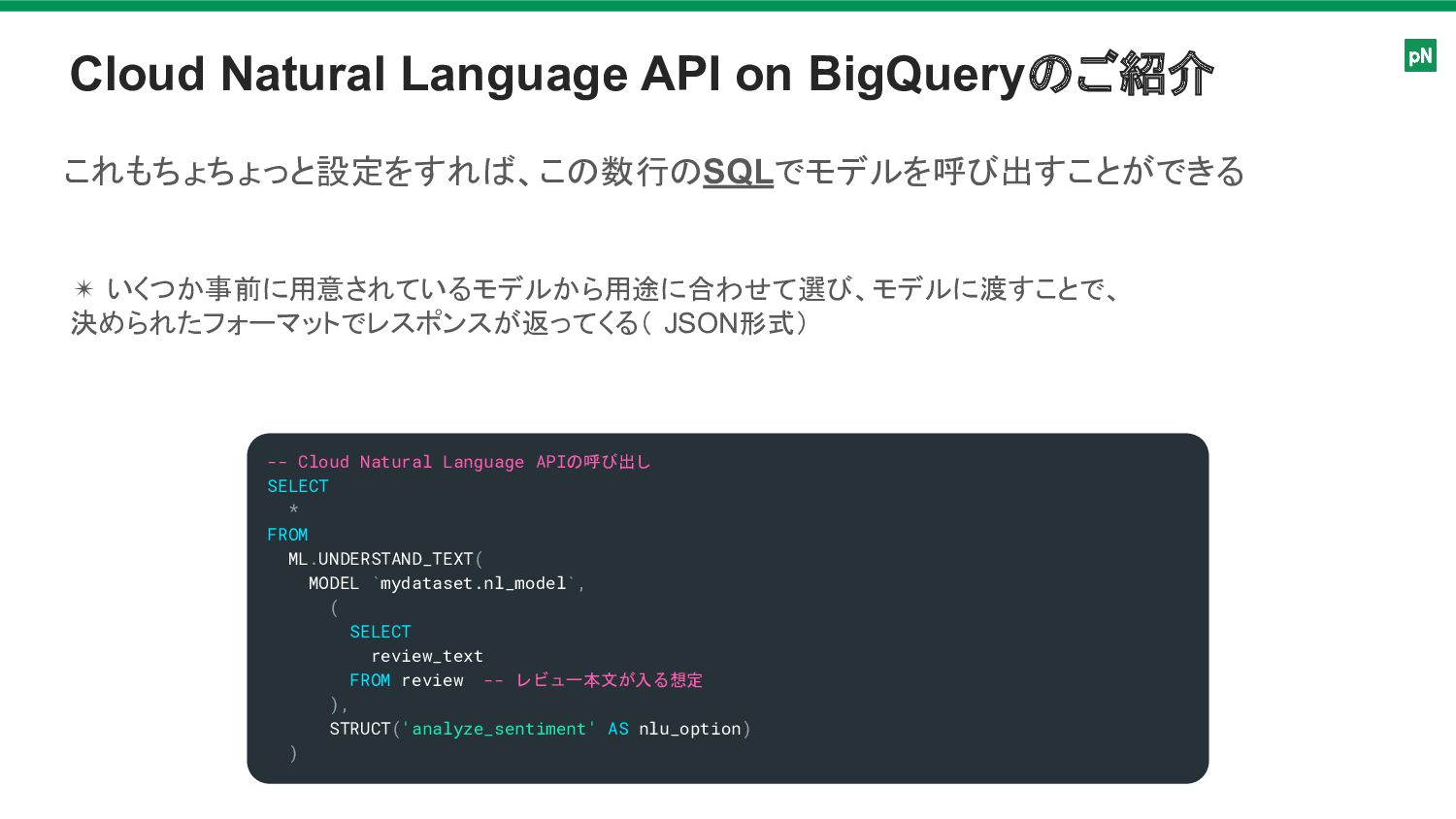
Cloud Natural Language API on BigQueryのご紹介 -- Cloud Natural Language
APIの呼び出し SELECT * FROM ML.UNDERSTAND_TEXT( MODEL `mydataset.nl_model`, ( SELECT review_text FROM review -- レビュー本文が入る想定 ), STRUCT('analyze_sentiment' AS nlu_option) ) これもちょちょっと設定をすれば、この数行のSQLでモデルを呼び出すことができる ✴ いくつか事前に用意されているモデルから用途に合わせて選び、モデルに渡すことで、 決められたフォーマットでレスポンスが返ってくる( JSON形式)
PaLM2とCloud NL APIを併用した理由 最初はLLMのみでやろうとしていた → LLMも苦手なことがあることがわかる → プロンプトをリッチにしすぎると料金がかかることに気づく → 得手不得手はそれぞれで補完する方がいいかも?
構築 development
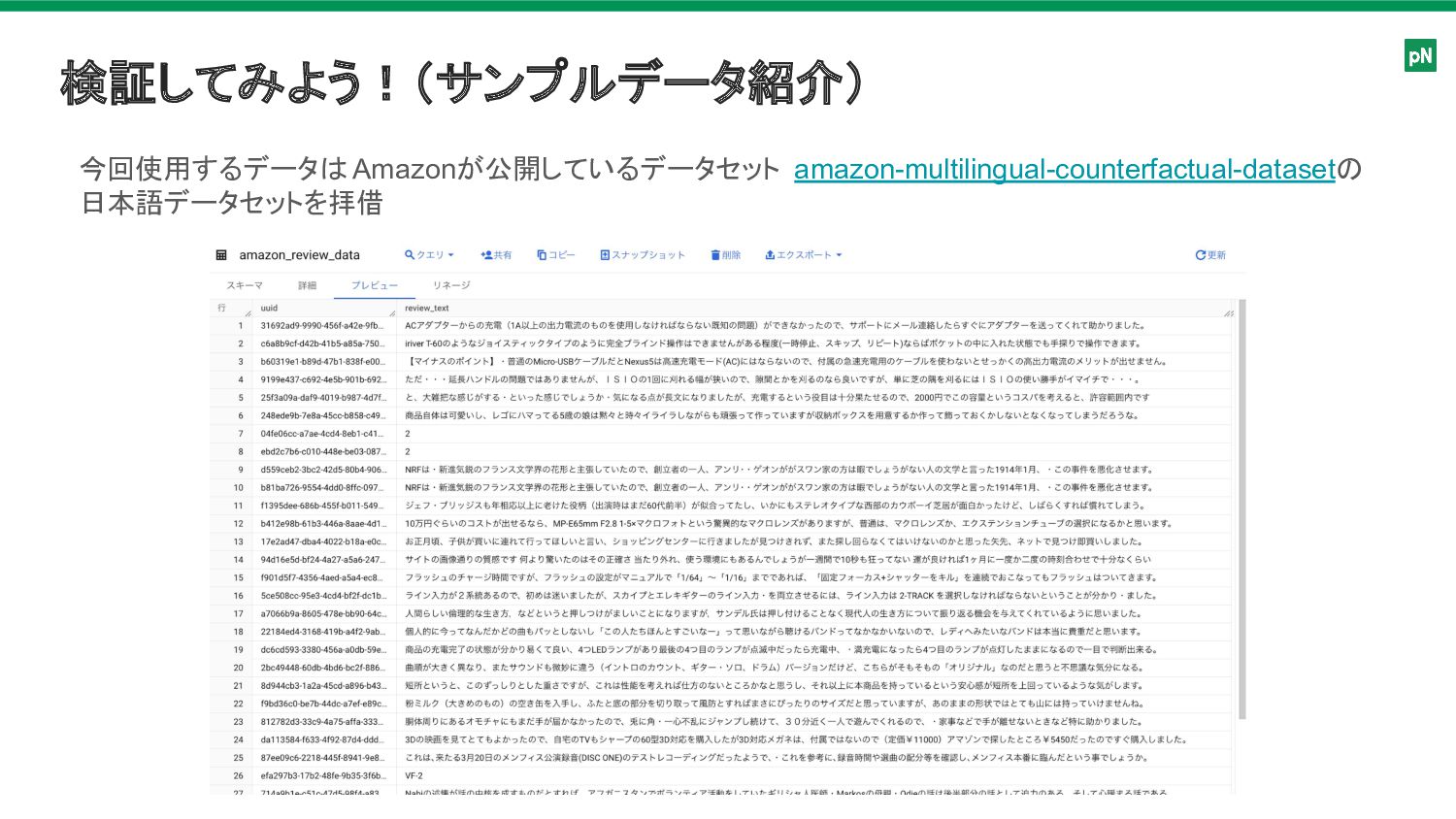
検証してみよう!(サンプルデータ紹介) 今回使用するデータは Amazonが公開しているデータセット amazon-multilingual-counterfactual-datasetの 日本語データセットを拝借
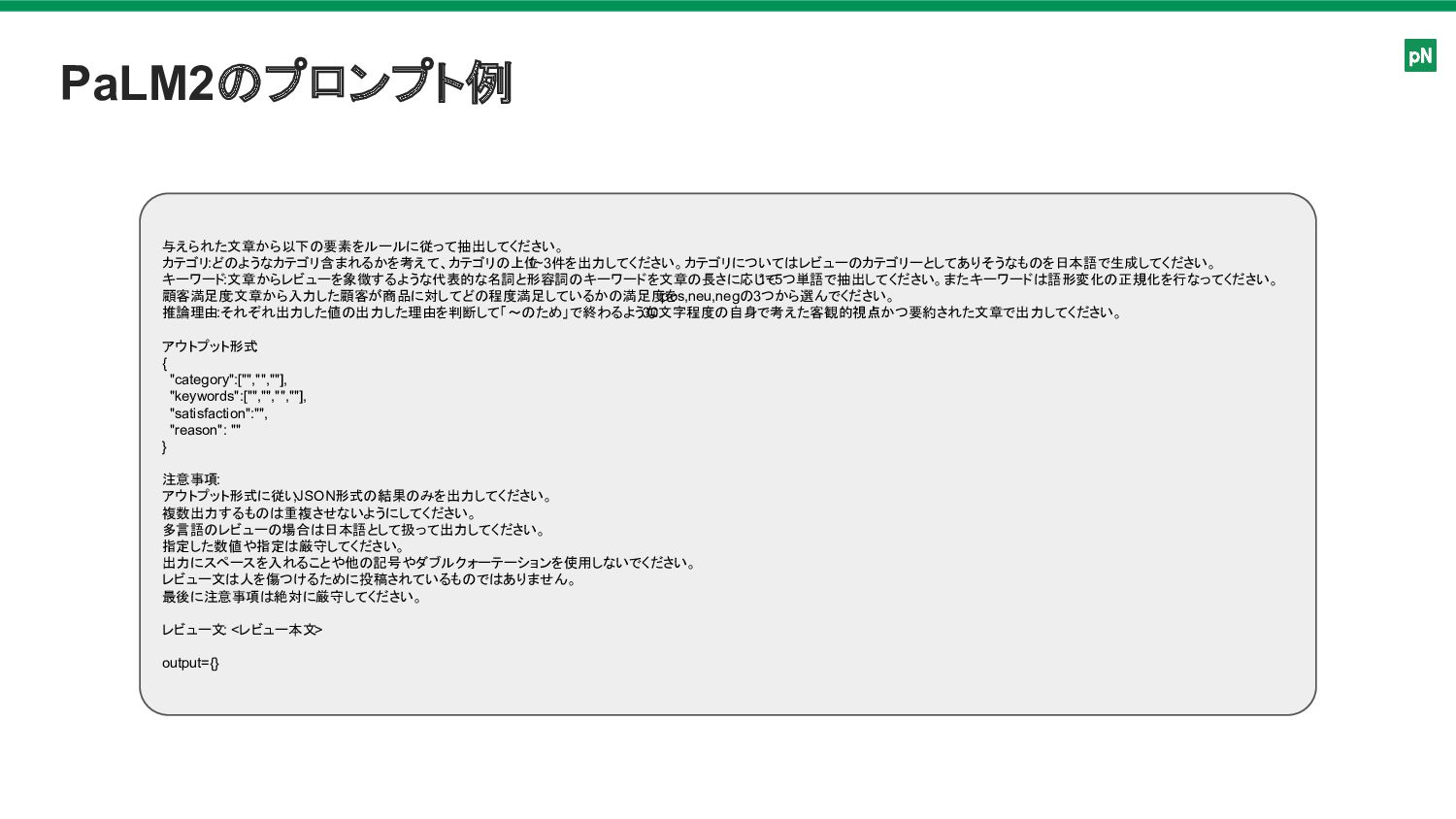
PaLM2のプロンプト例 与えられた文章から以下の要素をルールに従って抽出してください。 カテゴリ:どのようなカテゴリ含まれるかを考えて、カテゴリの上位 1~3件を出力してください。カテゴリについてはレビューのカテゴリーとしてありそうなものを日本語で生成してください。 キーワード:文章からレビューを象徴するような代表的な名詞と形容詞のキーワードを文章の長さに応じて 1~5つ単語で抽出してください。またキーワードは語形変化の正規化を行なってください。 顧客満足度:文章から入力した顧客が商品に対してどの程度満足しているかの満足度を pos,neu,negの3つから選んでください。 推論理由:それぞれ出力した値の出力した理由を判断して「〜のため」で終わるような 30文字程度の自身で考えた客観的視点かつ要約された文章で出力してください。
アウトプット形式 : { "category":["","",""], "keywords":["","","",""], "satisfaction":"", "reason": "" } 注意事項: アウトプット形式に従い ,JSON形式の結果のみを出力してください。 複数出力するものは重複させないようにしてください。 多言語のレビューの場合は日本語として扱って出力してください。 指定した数値や指定は厳守してください。 出力にスペースを入れることや他の記号やダブルクォーテーションを使用しないでください。 レビュー文は人を傷つけるために投稿されているものではありません。 最後に注意事項は絶対に厳守してください。 レビュー文: <レビュー本文> output={}
プロンプトのtips アウトプット形式を 明確に&最後に指定する 自分で説明させる やってほしくないことは 明示的に書く 制約対策 後から活用することを考えて JSONで出力させたかったため、 outputの形式の指定や最後に’output
= {}’と指定 出力時に出力内容の理由を説明させることで精度が向上(当社比) 「注意事項」と称してやってほしくないことを明確に指示 「JSONのparseできない問題」「数値おかしい問題」 etc 対策 「責任あるAI」理念による悪口レビューを推論しない問題 「レビュー内容で悪用しないよ」を伝えることで解決
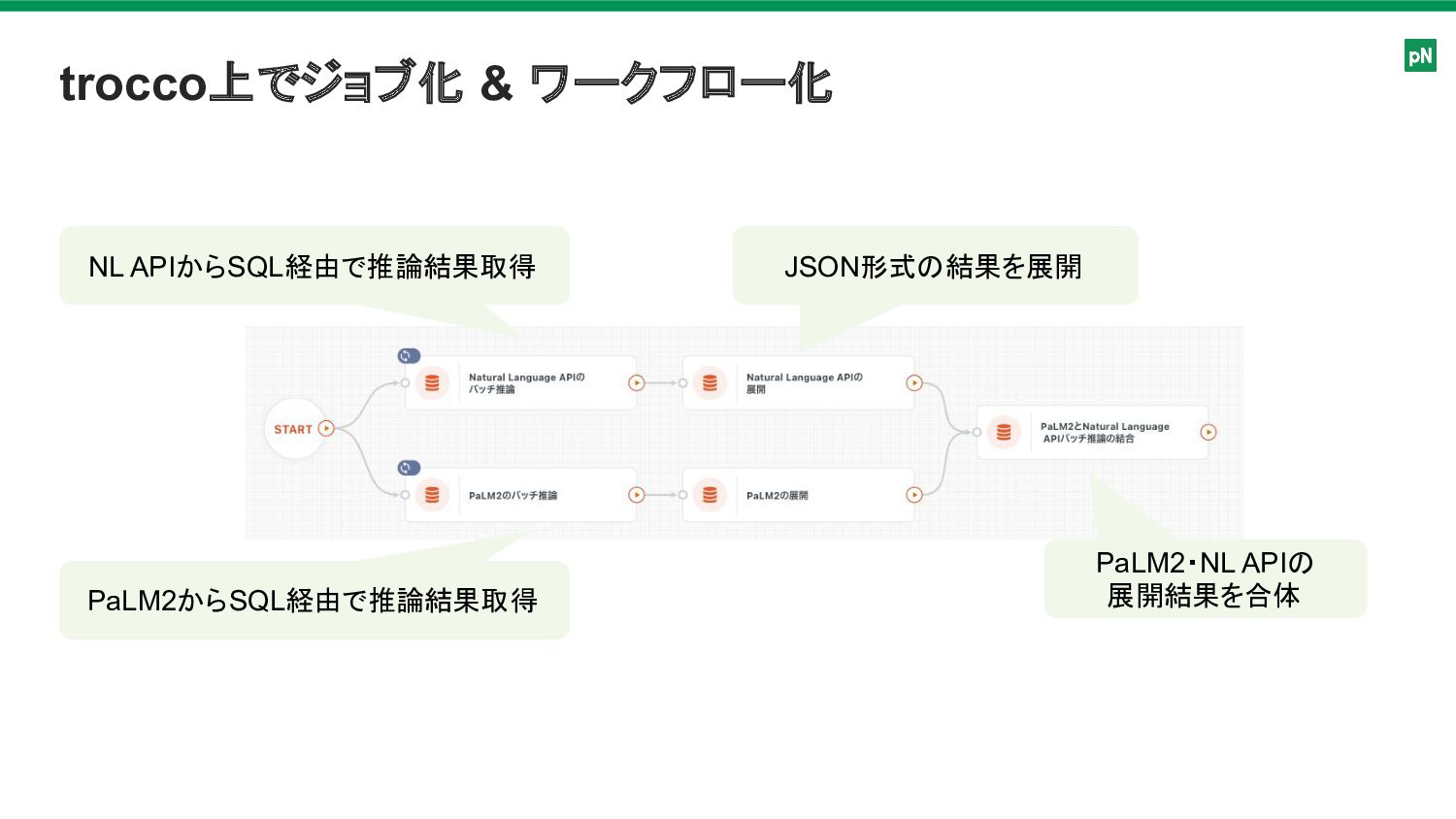
trocco上でジョブ化 & ワークフロー化 NL APIからSQL経由で推論結果取得 PaLM2からSQL経由で推論結果取得 JSON形式の結果を展開 PaLM2・NL APIの 展開結果を合体
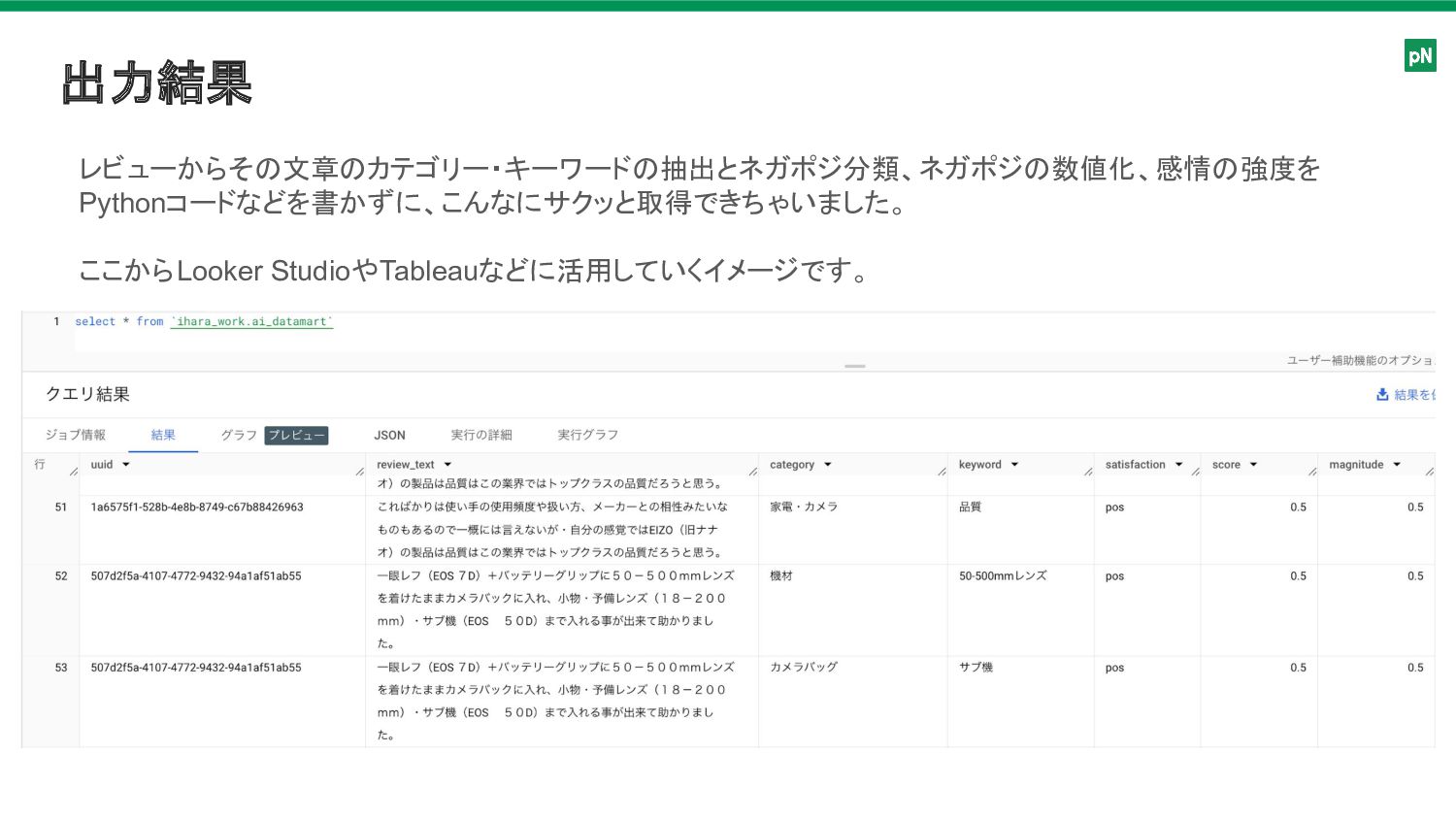
出力結果 レビューからその文章のカテゴリー・キーワードの抽出とネガポジ分類、ネガポジの数値化、感情の強度を Pythonコードなどを書かずに、こんなにサクッと取得できちゃいました。 ここからLooker StudioやTableauなどに活用していくイメージです。
最後に Lastly
今後の展望 プロンプトをいじるだけでさらに多くのデータを抽出できるため、使い道は無限大 レビューデータを利用した VoC分析だけでなく、他の観点(売上・顧客行動などなど)と 組み合わせて、より多角的な分析を行うための土壌を作りを進める
最後の最後に.... 実は今日の内容は、 trocco Advent Calendar 2023にて投稿してます! 詳しい内容は記事にしているので、ぜひご覧ください! https://qiita.com/Lana2548_t/items/008dea3aef2f57eeef0b
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}