Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Snowflakeのパフォーマンスチューニングってこんな感じ ~Snowflake Uncon...
Search
tkkihr2548
January 21, 2025
Technology
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Snowflakeのパフォーマンスチューニングってこんな感じ ~Snowflake Unconference #4~
tkkihr2548
January 21, 2025
More Decks by tkkihr2548
See All by tkkihr2548
DataOps Night特別編 Snowflake Summit 2026 Recap - いま知っておきたい Context と Memory in Snowflake Summit 2026
lana2548
1
180
Snowflake女子会#3 Snowpipeの良さを5分で語るよ
lana2548
0
920
BigQuery × ML × troccoを用いた VoC分析のためのデータ基盤構築
lana2548
0
280
Other Decks in Technology
See All in Technology
product engineering with qa
nealle
0
150
ポストモーテム! DDoSからサイトは守れた。 でもビジネスは守れなかった。
bengo4com
0
480
『AIに負けない』より『AIと遊ぶ』」〜ワクワクが最強のテスト・QA学習戦略_公開用
odan611
1
450
プロンプト_きのこカンファレンス2026_LT
yurufuwahealer
0
140
SRE Lounge Hiroshimaへの招待
grimoh
0
290
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
1
550
“ID沼入口” - 基本とセキュリティから始める、考え続けるためのID管理技術勉強会 告知&イントロ
ritou
0
420
生成AIの活用/high_school2026
okana2ki
0
110
Baseline対応のDOMの型定義を作った
uhyo
3
710
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
1.8k
組織における AI-DLC 実践
askul
0
320
Text-to-SQLをAgentCoreで実現し、生成されるSQLの精度を定量的に評価する
yakumo
2
620
Featured
See All Featured
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
340
Thoughts on Productivity
jonyablonski
76
5.2k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.5k
Mind Mapping
helmedeiros
PRO
1
280
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
The Mindset for Success: Future Career Progression
greggifford
PRO
0
380
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
640
Building the Perfect Custom Keyboard
takai
2
810
Transcript
Snowflakeの パフォーマンスチューニングってこんな感じ ~Snowflake Unconference #4~ 2025.1 株式会社primeNumber 庵原 崚生
目次 2 1. 自己紹介 2. ちょっと会社紹介 3. Snowflakeで実際に行ったパフォーマンスチューニン グの話 4.
第一次改善!! 5. 第二次改善!! 6. まとめ
3 自己紹介
4 庵原 崚生(いはら たかき) 株式会社primeNumber プロフェッショナル本部 シニアデータエンジニア Webアプリケーションエンジニア → primeNumber1人目のデータエンジニア
• 今年で3kg痩せた • ポケポケ5連勝チャレンジ勝てない • ジークアクスしか勝たん
5 ちょっと会社紹介
会社概要 6 株式会社primeNumber 代表取締役CEO 田邊 雄樹 2015年11月 約100名 約34億円 東京都品川区上大崎3丁目1番1号
JR東急目黒ビル5F 会社名 代表 創業 メンバー数 累計調達額 オフィス © primeNumber Inc.
7 © primeNumber Inc. あらゆるデータを、 ビジネスの力に変える。 人とAIが共存する時代に。 知の源泉となるデータを、 誰もがすばやく、自由に使えるように。 primeNumberは、テクノロジーの力で
データ活用における不自由をなくし、 あらゆるデータを、ビジネスの力に変えていく。 そして、それまでの常識や産業の枠を超えて、 さまざまな人や企業、技術、アイデアとつながり、 まだない価値を共に生み出していく。 私たちは、人とデータの開かれた関係を築くことで、 人の創造力を解放し、 世界中のビジネスと社会全体の可能性を拡げます。 VISION
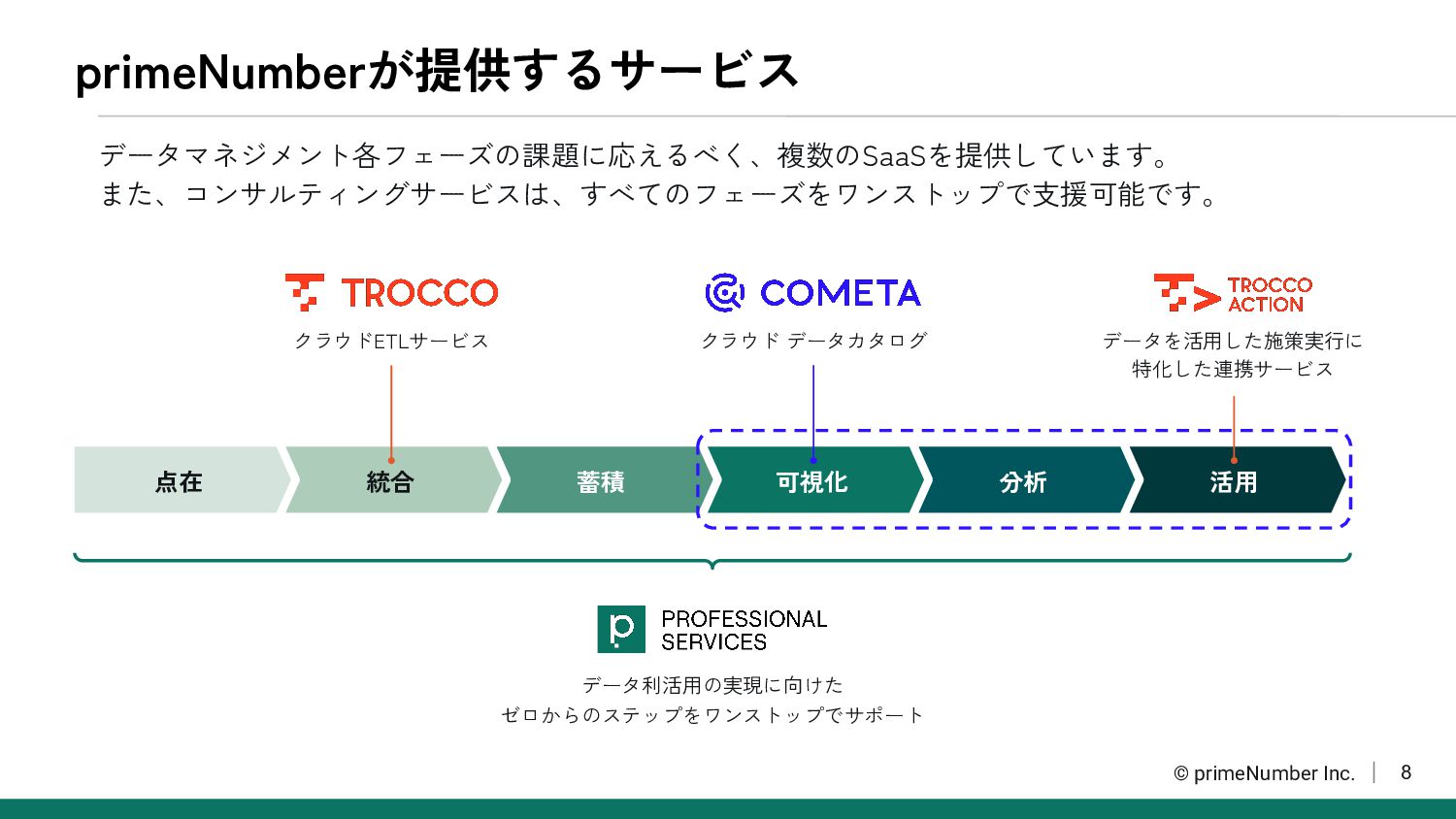
8 primeNumberが提供するサービス データマネジメント各フェーズの課題に応えるべく、複数のSaaSを提供しています。 また、コンサルティングサービスは、すべてのフェーズをワンストップで支援可能です。 © primeNumber Inc. 活用 分析 可視化
蓄積 統合 点在 データ利活用の実現に向けた ゼロからのステップをワンストップでサポート クラウドETLサービス データを活用した施策実行に 特化した連携サービス クラウド データカタログ
9 Snowflakeで実際に行った パフォーマンスチューニングの話
10 はじめに みなさん、パフォーマンスチューニングってしたことありますか?
11 はじめに みなさん、パフォーマンスチューニングってしたことありますか? → 今日はその実例をお話しします
12 まず一般論のお話 SnowflakeをはじめとするOLAP系のパフォーマンスについての一般論 • 大規模データの集計・分析 ◦ 列指向データベース • 一括書き込み・読み込み ◦
バッチ処理 • 更新処理 ◦ レコードベースでの頻繁な書 き換え・削除 ◦ 高度な行単位更新 • 行指向の検索 ◦ 単一レコードの検索
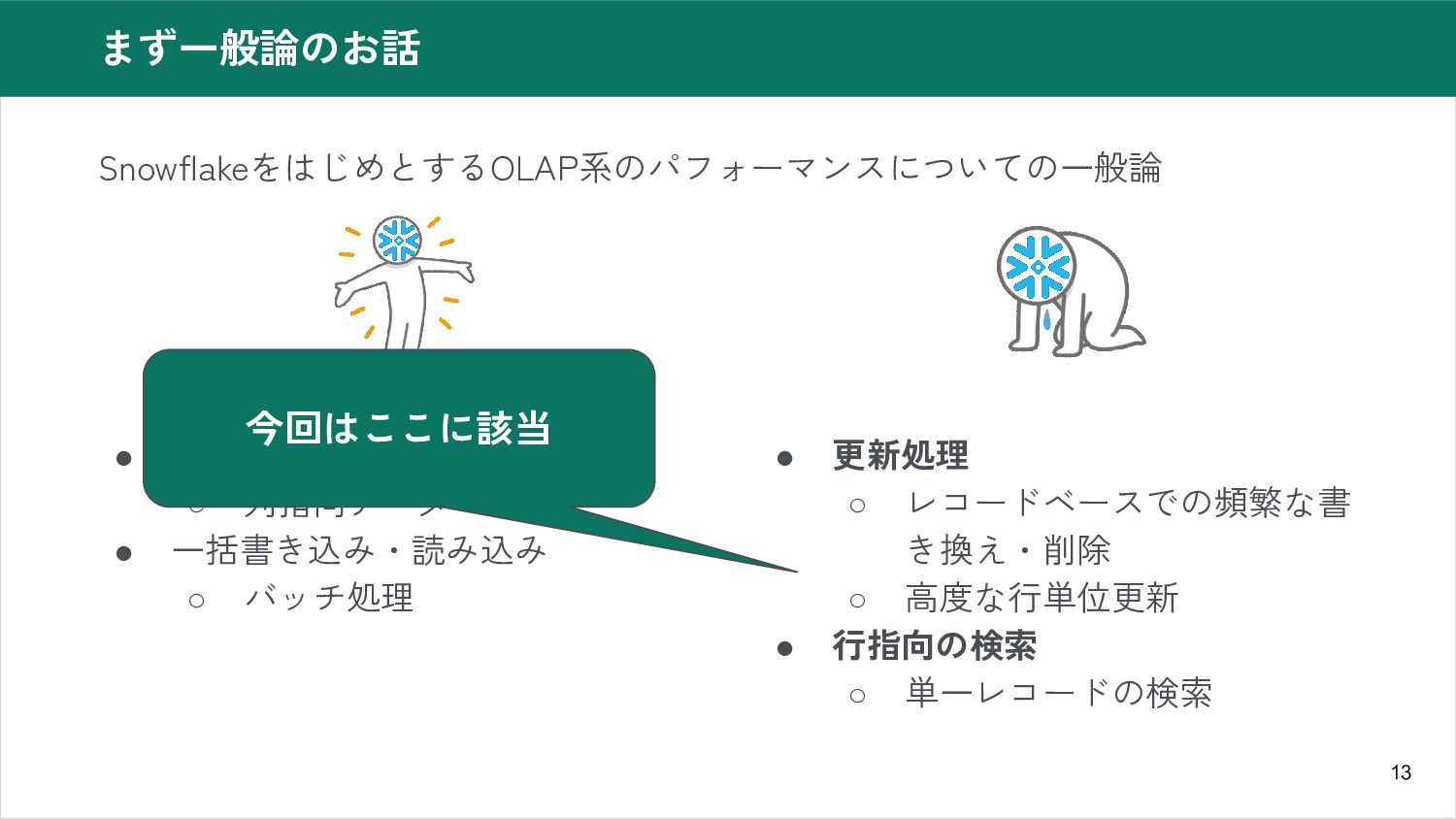
13 まず一般論のお話 SnowflakeをはじめとするOLAP系のパフォーマンスについての一般論 • 大規模データの集計・分析 ◦ 列指向データベース • 一括書き込み・読み込み ◦
バッチ処理 • 更新処理 ◦ レコードベースでの頻繁な書 き換え・削除 ◦ 高度な行単位更新 • 行指向の検索 ◦ 単一レコードの検索 今回はここに該当
14 今回の敵 諸事情で詳しい内容はお話しできないですが、、、 • 約120億行のテーブルに対するデータの更新処理(UPDATE) ◦ 1秒単位のログデータ • 事前にマスタデータとの結合 ◦
1.3億行 • Warehouse XSサイズを用いて7時間経っても処理が終わらなかった
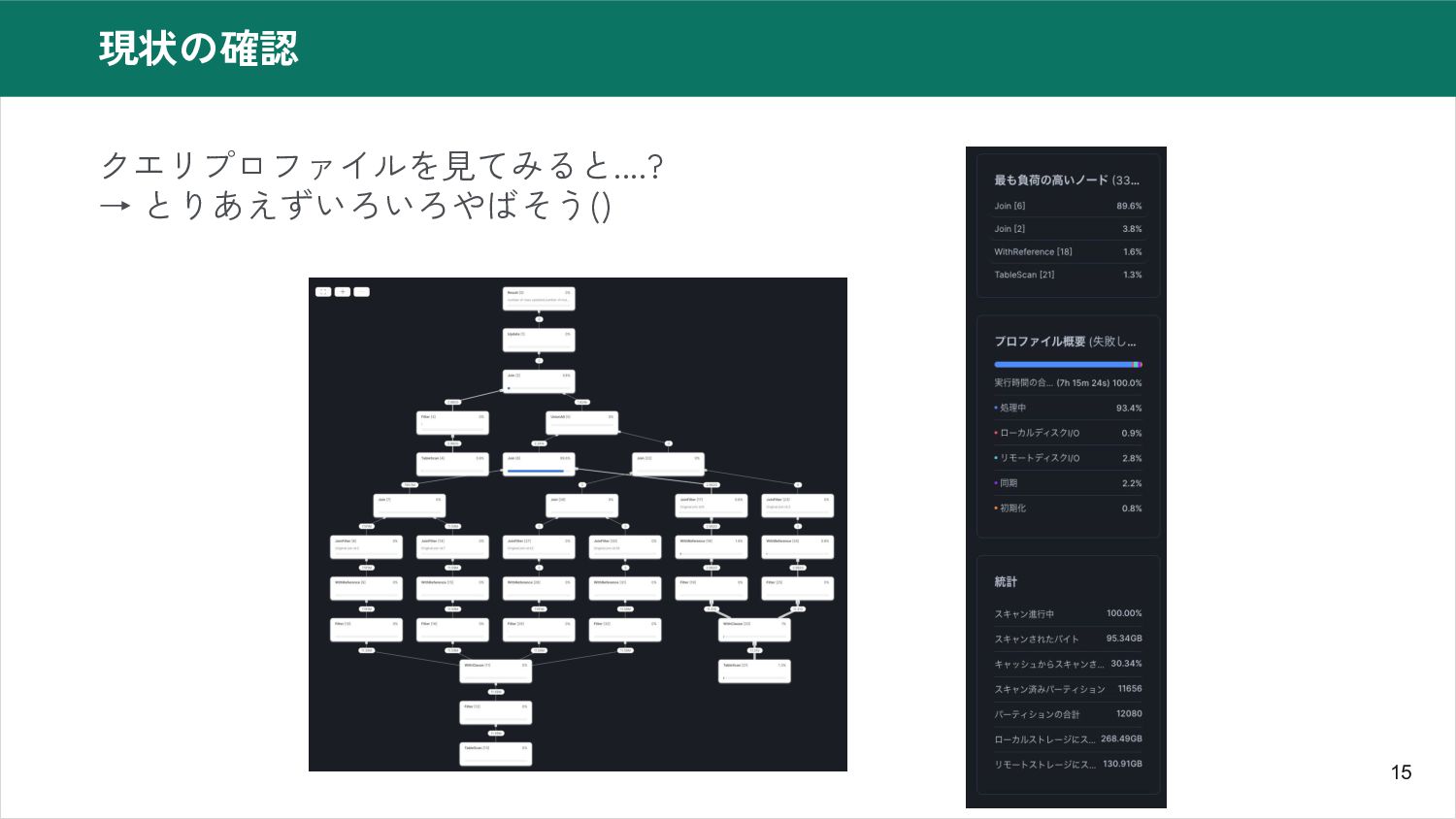
15 現状の確認 クエリプロファイルを見てみると....? → とりあえずいろいろやばそう()
16 第一次改善!!
17 第一次改善、の前に いろいろ前提 • 私が関与したクエリではなかった ◦ 作成・レビューは別の方が実施 ◦ そのため処理の背景はめっちゃざっくり +
詳細は何もわかっていない • もしかしたら無駄な処理があるので、そもそも根本から改善できる? ◦ パフォーマンスチューニングにおいては「無駄を省く」が前提 ◦ 作成した担当の方がめっちゃしっかりした方なので、「要件は間違って いないだろう!!!」という絶大な信頼のもの、パフォーマンスだけを みることに
18 第一次改善 クエリプロファイル右側・統計情報から攻めてみる 気になった点 • 「スキャン済みパーティション」「パーティションの合 計」がほぼ一緒の値 ◦ パーティションプルーニング(剪定)が行われてい ない
• 「ローカルストレージにスピルしたバイト数」「リモート ストレージにスピルしたバイト数」が存在する & デカすぎ る ◦ 扱っているデータ量が多すぎる 解決策 • とりあえずクラスタリングキーを設定してプルーニングを 発生させ、データ量を減らそう
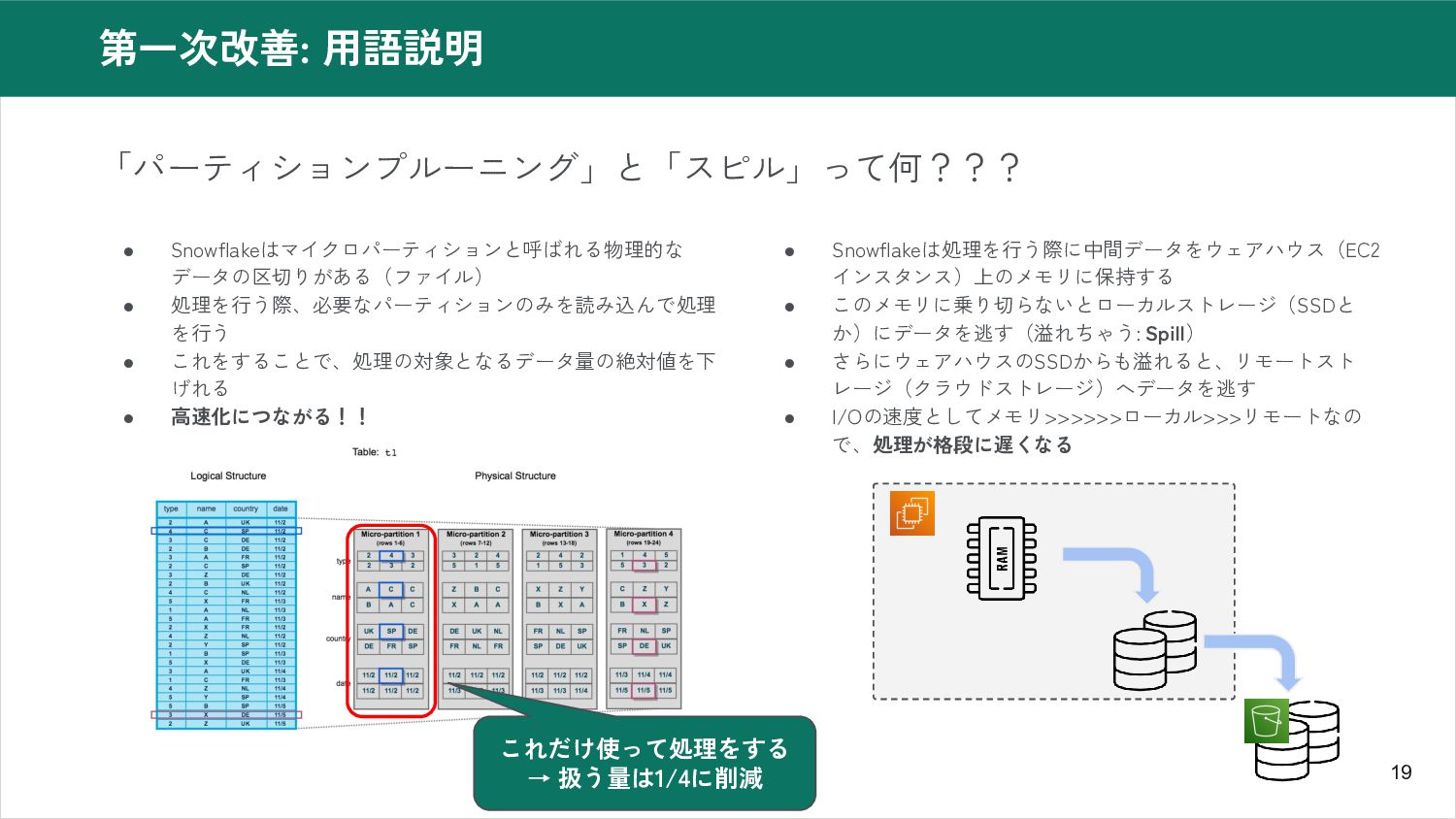
19 第一次改善: 用語説明 「パーティションプルーニング」と「スピル」って何??? • Snowflakeはマイクロパーティションと呼ばれる物理的な データの区切りがある(ファイル) • 処理を行う際、必要なパーティションのみを読み込んで処理 を行う
• これをすることで、処理の対象となるデータ量の絶対値を下 げれる • 高速化につながる!! • Snowflakeは処理を行う際に中間データをウェアハウス(EC2 インスタンス)上のメモリに保持する • このメモリに乗り切らないとローカルストレージ(SSDと か)にデータを逃す(溢れちゃう: Spill) • さらにウェアハウスのSSDからも溢れると、リモートスト レージ(クラウドストレージ)へデータを逃す • I/Oの速度としてメモリ>>>>>>ローカル>>>リモートなの で、処理が格段に遅くなる これだけ使って処理をする → 扱う量は1/4に削減
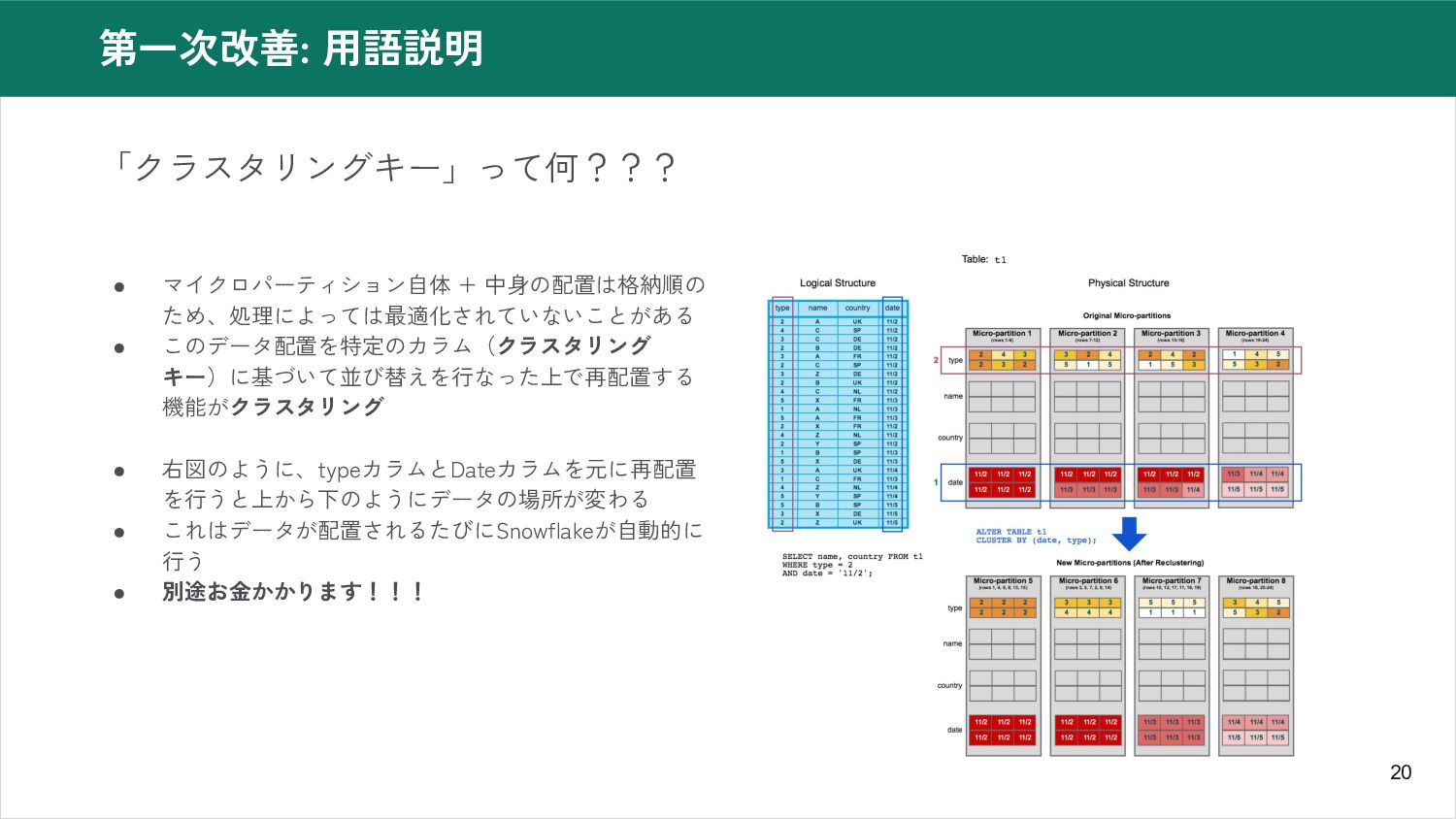
20 第一次改善: 用語説明 「クラスタリングキー」って何??? • マイクロパーティション自体 + 中身の配置は格納順の ため、処理によっては最適化されていないことがある •
このデータ配置を特定のカラム(クラスタリング キー)に基づいて並び替えを行なった上で再配置する 機能がクラスタリング • 右図のように、typeカラムとDateカラムを元に再配置 を行うと上から下のようにデータの場所が変わる • これはデータが配置されるたびにSnowflakeが自動的に 行う • 別途お金かかります!!!
21 第一次改善: データ配置の確認 データ量を減らす→効果的にプルーニングを発生させる→クラスタリングキーを付与する!! 現状のデータ配置を確認する → SYSTEM$CLUSTERING_INFORMATIONというシステム関数を使う 詳しい話は避けるのですが... • 「average_overlaps」「average_depth」の値が大きい
◦ 小さい方が良いパラメーター ◦ 取得するパーティション数が増える • 「partition_depth_histogram」の分布が歪になっている ◦ 512 / 1024が多い 要は??? →パフォーマンスが悪い!!!
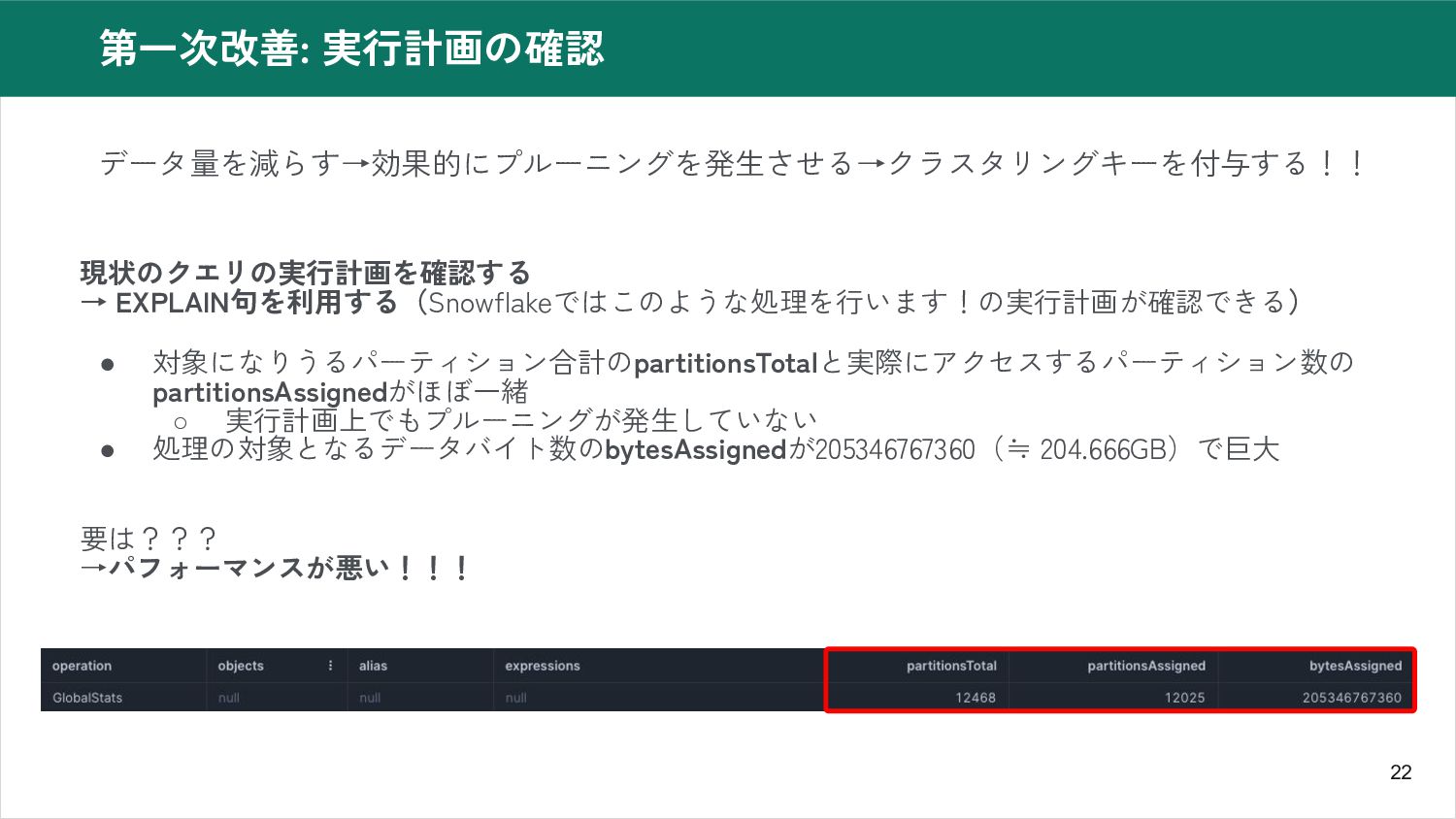
22 第一次改善: 実行計画の確認 データ量を減らす→効果的にプルーニングを発生させる→クラスタリングキーを付与する!! 現状のクエリの実行計画を確認する → EXPLAIN句を利用する(Snowflakeではこのような処理を行います!の実行計画が確認できる) • 対象になりうるパーティション合計のpartitionsTotalと実際にアクセスするパーティション数の partitionsAssignedがほぼ一緒
◦ 実行計画上でもプルーニングが発生していない • 処理の対象となるデータバイト数のbytesAssignedが205346767360(≒ 204.666GB)で巨大 要は??? →パフォーマンスが悪い!!!
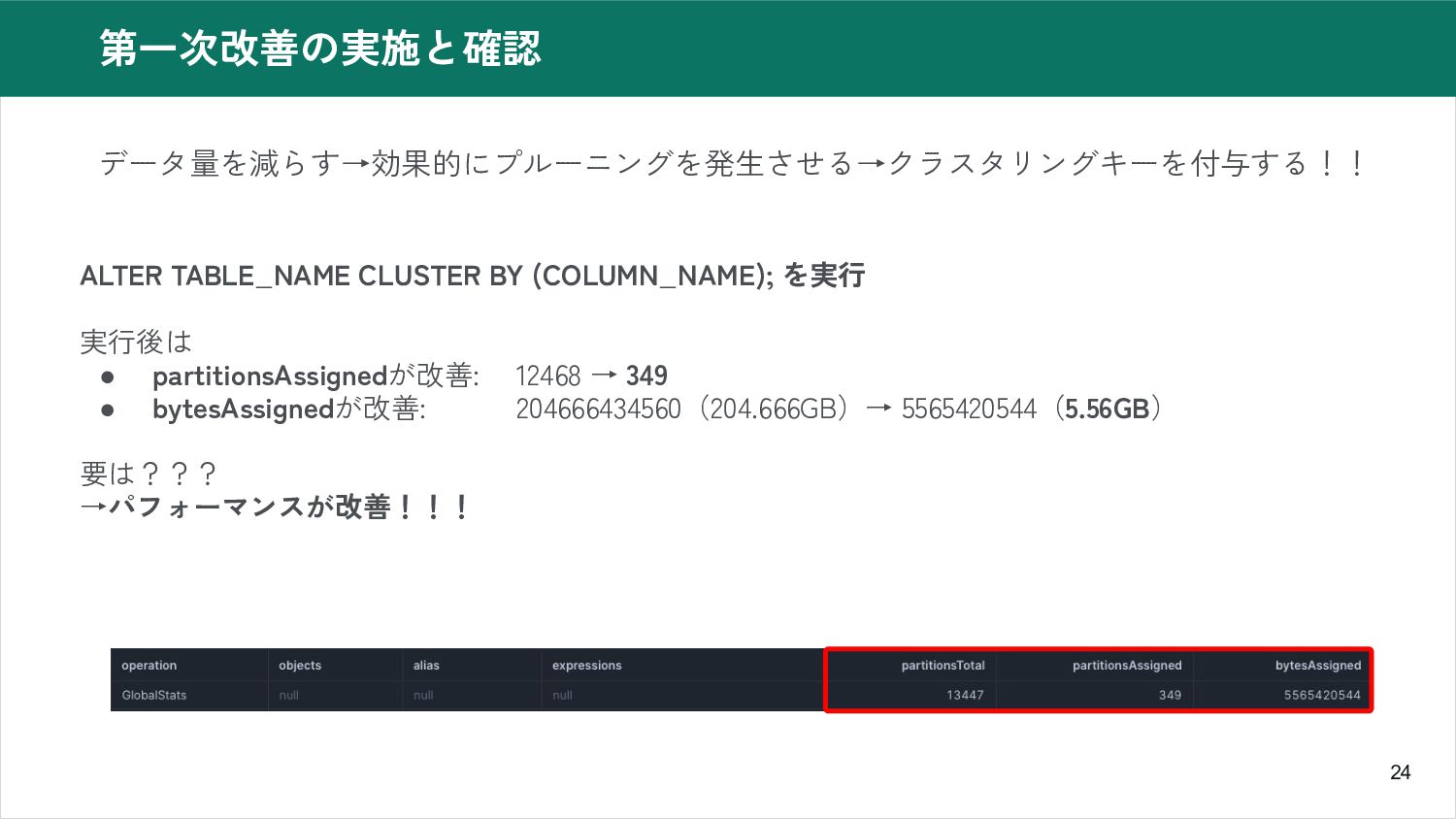
23 第一次改善の実施と確認 データ量を減らす→効果的にプルーニングを発生させる→クラスタリングキーを付与する!! ALTER TABLE_NAME CLUSTER BY (COLUMN_NAME); を実行 実行後は
• 「average_overlaps」「average_depth」が大きく改善 ◦ average_overlaps: 489.6288 → 0.5147 ◦ average_depth: 325.4582 → 1.3208 • 「partition_depth_histogram」の分布綺麗になった ◦ 最大でも9 要は??? →パフォーマンスが改善!
24 第一次改善の実施と確認 データ量を減らす→効果的にプルーニングを発生させる→クラスタリングキーを付与する!! ALTER TABLE_NAME CLUSTER BY (COLUMN_NAME); を実行 実行後は
• partitionsAssignedが改善: 12468 → 349 • bytesAssignedが改善: 204666434560(204.666GB)→ 5565420544(5.56GB) 要は??? →パフォーマンスが改善!!!
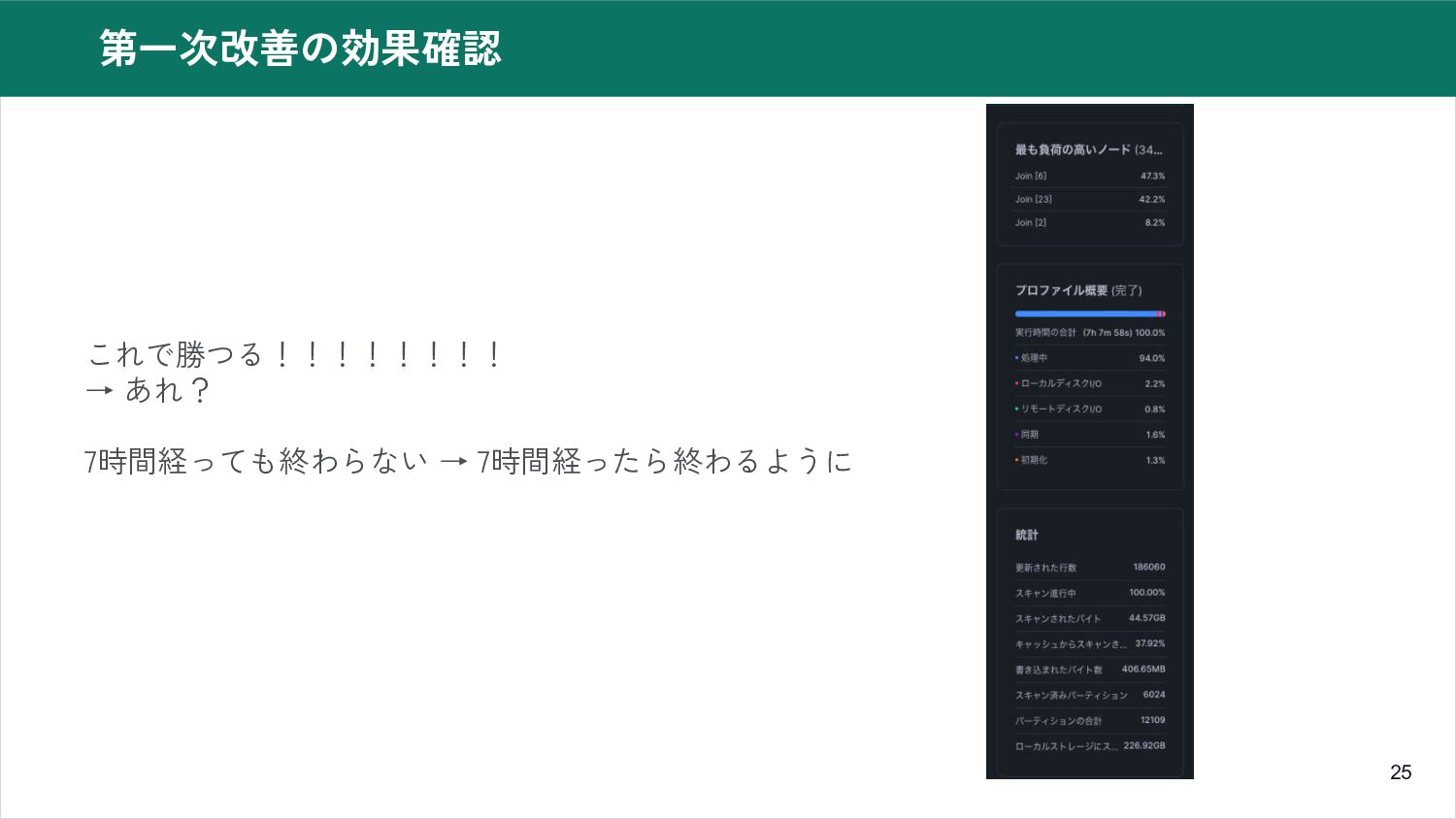
25 第一次改善の効果確認 これで勝つる!!!!!!!! → あれ? 7時間経っても終わらない → 7時間経ったら終わるように
26 第二次改善!!
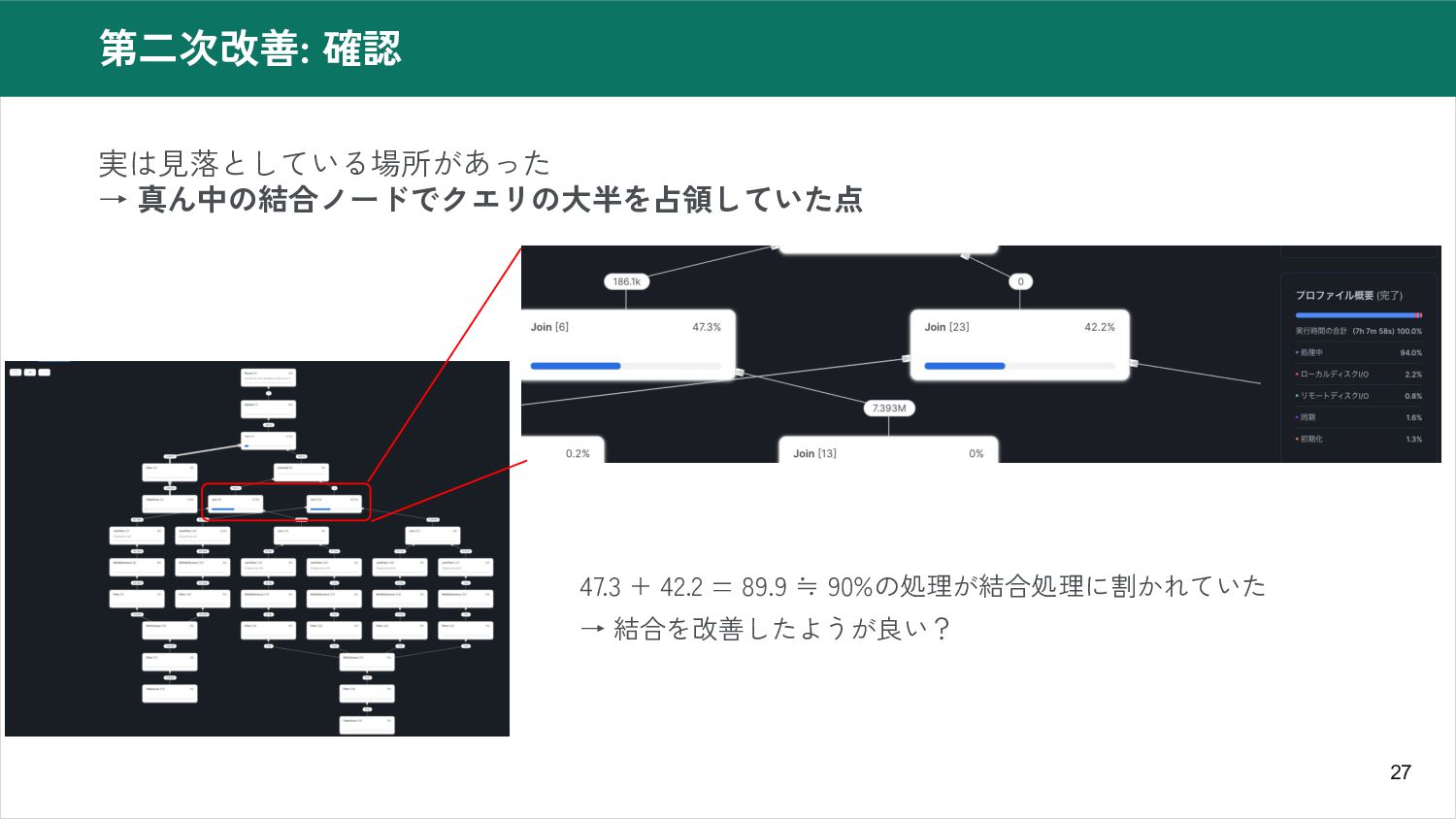
27 第二次改善: 確認 実は見落としている場所があった → 真ん中の結合ノードでクエリの大半を占領していた点 47.3 + 42.2 =
89.9 ≒ 90%の処理が結合処理に割かれていた → 結合を改善したようが良い?
28 第二次改善: 結合方法の非効率部分の特定 また実行計画くんに助けを求める 上で何度も出している実行計画の中には、結合を行う際にどのような結合を 行うのか?を明記してくれている 今回の場合は右の通り、全て「Inner Join」になっている → ここでCartesian
joinと書かれている場合は真っ先にそこを改善する → Cross Joinと同義のため、1万行のテーブルと1万行のテーブルをjoinす ると中間テーブルとして、1億行のテーブルが作成されてしまい、それ こそスピルが発生してしまう(カルテシアン積で伝わる方がいれば、そ れです) けど今回は発生していないっぽいので、SQLを眺めてみる
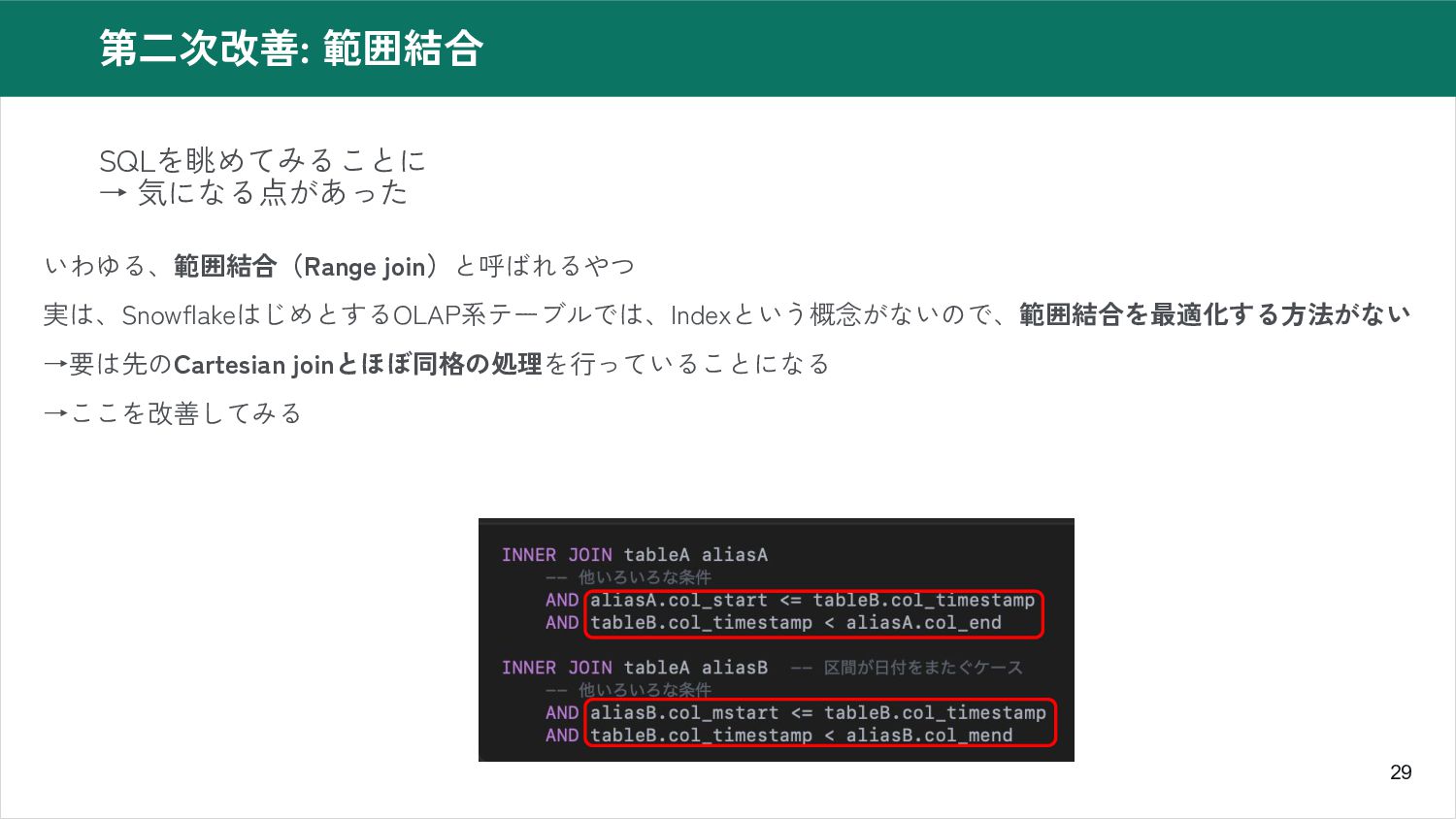
29 第二次改善: 範囲結合 SQLを眺めてみることに → 気になる点があった いわゆる、範囲結合(Range join)と呼ばれるやつ 実は、SnowflakeはじめとするOLAP系テーブルでは、Indexという概念がないので、範囲結合を最適化する方法がない →要は先のCartesian
joinとほぼ同格の処理を行っていることになる →ここを改善してみる
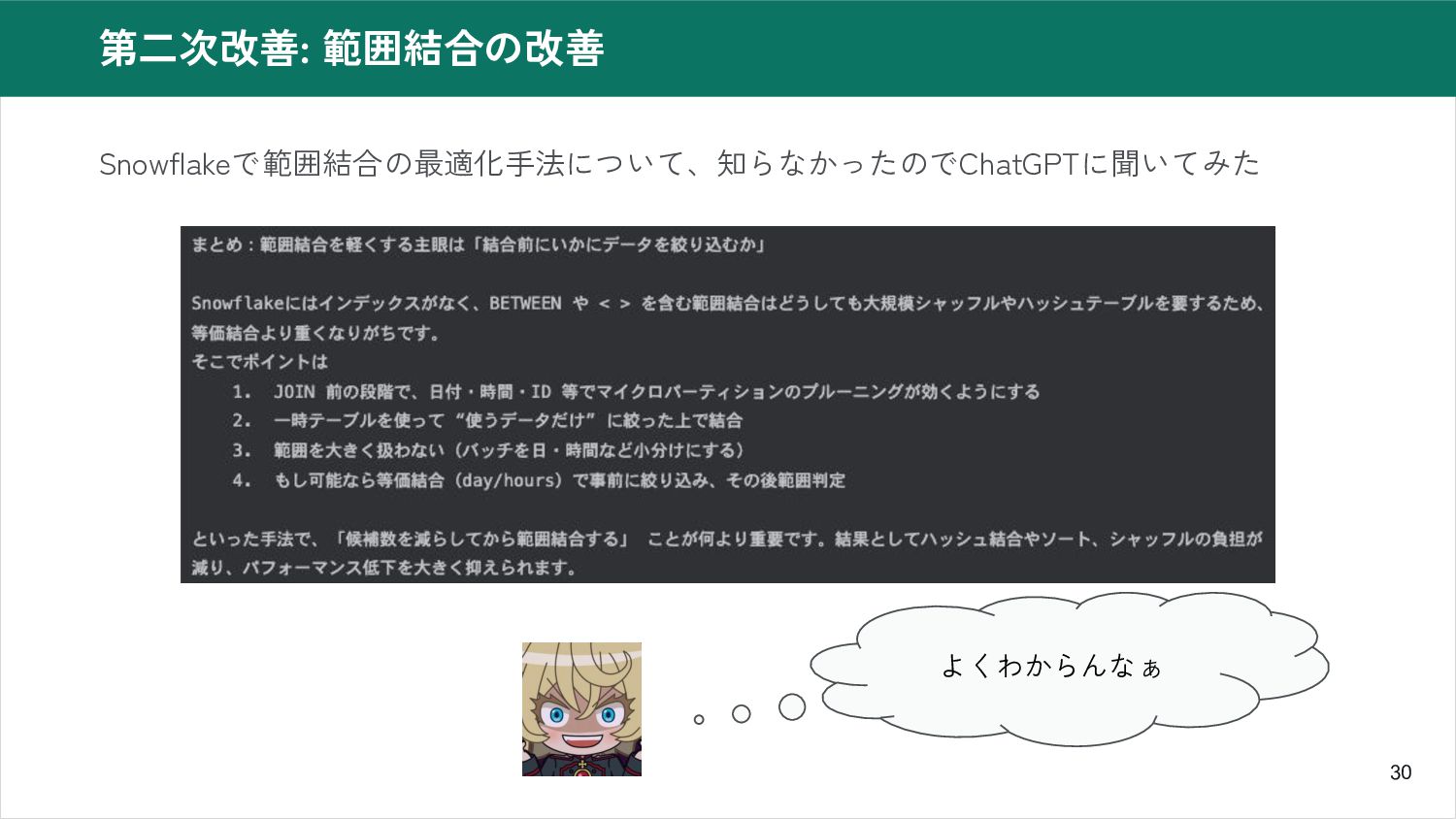
30 第二次改善: 範囲結合の改善 Snowflakeで範囲結合の最適化手法について、知らなかったのでChatGPTに聞いてみた よくわからんなぁ
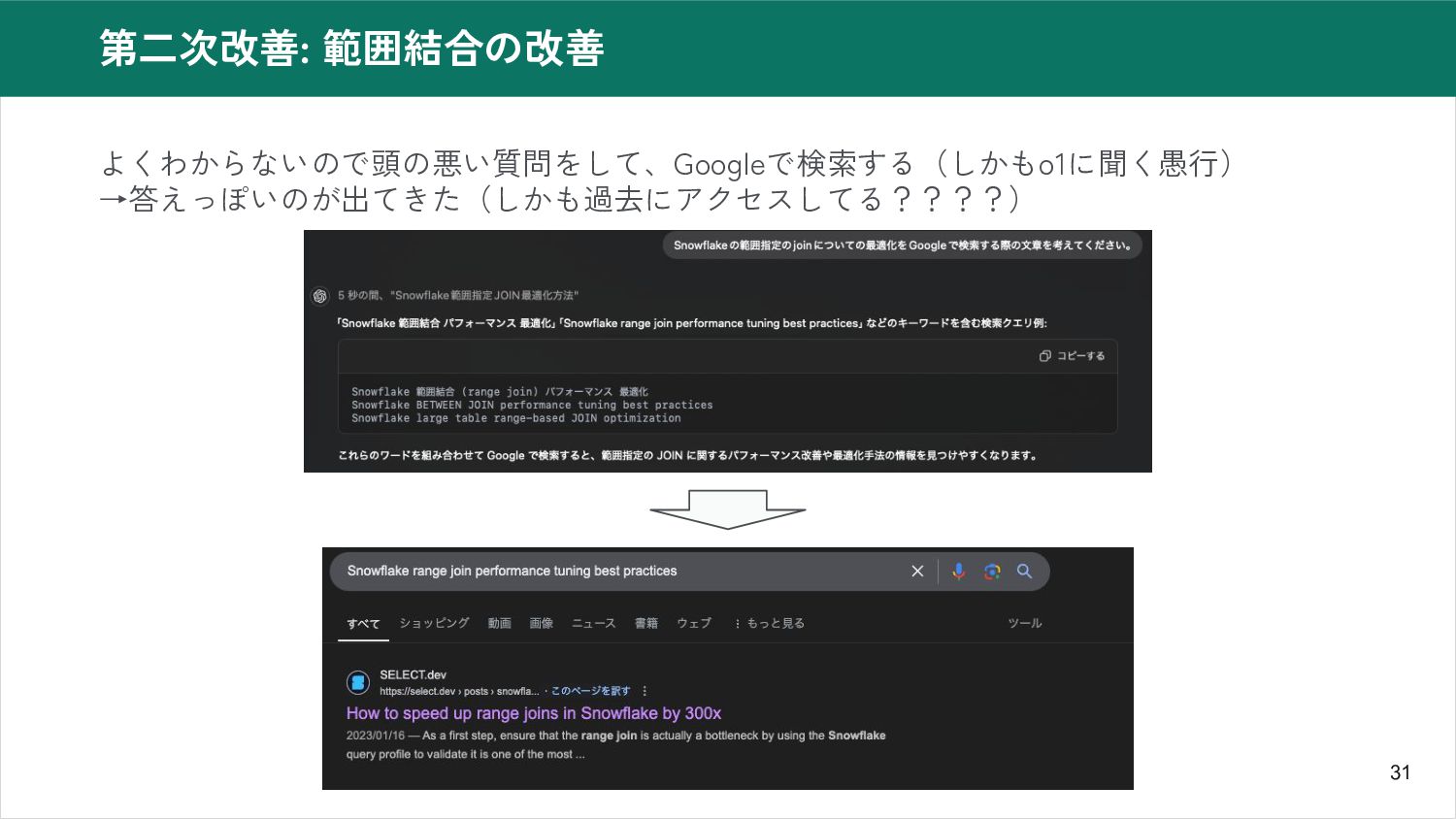
31 第二次改善: 範囲結合の改善 よくわからないので頭の悪い質問をして、Googleで検索する(しかもo1に聞く愚行) →答えっぽいのが出てきた(しかも過去にアクセスしてる????)
32 第二次改善: How to speed up range joins in Snowflake
by 300x を読み解く (実は以前読んだことあるのにすっかり忘れていた) 詳しい内容はぜひ記事を見て欲しいが、要はSnowflakeにおける範囲結合のパフォーマンス低下 についての原因 + 改善策が書かれていた ここでは「ビン化」と呼ばれる手法でパフォーマンス改善を行う方法を解説している
33 第二次改善: ビン化とは? ChatGPT要約の要約 • Equi-join(等価結合)条件の追加 ◦ 範囲条件に加えて、同じ「時刻単位」や「区切り番号(bin)」で等価結合をかける。 ◦ Snowflakeは等価結合をハッシュ結合で最適化しやすく、中間データが劇的に減る。
• Bin(任意の区間幅)を使った汎用的なアプローチ ◦ “1時間” のような固定時間ではなく、汎用的なビン(たとえば2秒ごと、30秒ごとなど)を作り、各 行に「bin番号」を付与する。 ◦ 範囲が広いほど多くのbinに展開されるが、大半のクエリ時間が短ければ実際には爆発的に増えな い。 ◦ bin同士の「等価結合」で先に絞ってから、最終的に「実際の開始時刻・終了時刻に対する範囲条 件」を適用するとで高速化が図れる。
34 第二次改善: ビン化の手順 手順 1. ビンにする範囲を決定する • 範囲結合する際の、時間範囲(end_time - start_time)を計算して、パーセンタイルを計算する
2. 範囲に基づいて、ビンを作成する • 今回は1800秒(30分)ごとにビンを作成 • 等価評価→範囲評価(1週間分)が等価評価→範囲評価(1800秒分)に削減 ◦ 1週間→30分は範囲を0.02%分まで削減できる 3. 等価条件にビン同士の条件を追加 4. ついでの改善もここでしちゃう • メモリSpillが気になっていたので、CTE → 一時テーブル(TEMPORARY TABLE)に変更 • UNION ALLを使っていたので改善 ◦ JOINが2回必要になっていたため ※ ビン化の詳しい手順については、若干複雑だったので割愛しています。ぜひ記事をご覧ください!
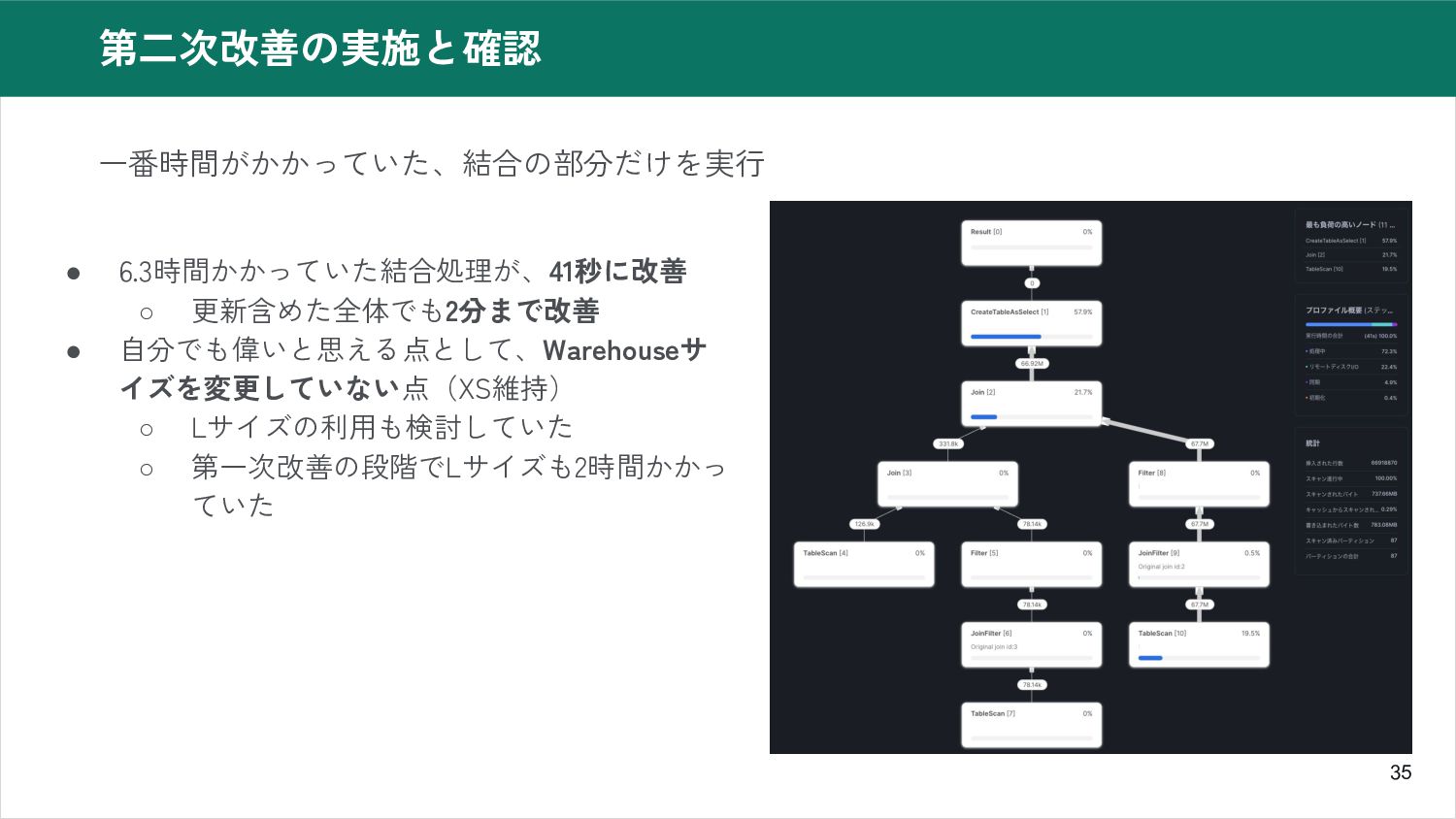
35 第二次改善の実施と確認 一番時間がかかっていた、結合の部分だけを実行 • 6.3時間かかっていた結合処理が、41秒に改善 ◦ 更新含めた全体でも2分まで改善 • 自分でも偉いと思える点として、Warehouseサ イズを変更していない点(XS維持)
◦ Lサイズの利用も検討していた ◦ 第一次改善の段階でLサイズも2時間かかっ ていた
36 まとめ
37 まとめ • 以下をやればパフォーマンス系は大体解決できそう 1. 実行履歴・実行計画をまず見ながら、明らかにヤバそうなところやボトルネックに なっている点を探す 2. +αでSQL・Snowflakeのアンチパターンを総合して戦う 3.
改善して、結果を見る 4. 1 ~ 3を繰り返す 5. 上がダメならWarehouseサイズを変える 6. それでもダメならそもそものパイプライン・テーブル設計を変える • パフォーマンス改善は泥臭い ◦ 何が原因か?に様々な要因が絡むので、紐解くのが大変 • やってる時は楽しい ◦ エンジニア垂涎の一瞬を楽しんでいる気分 ◦ 効果が大きければ大きいほど楽しい
38 参考資料 • How to speed up range joins in
Snowflake by 300x • Snowflake の Adaptive Join Decisions • SnowflakeのALTER TABLEで100万溶かした顔になった ◦ 今日公開の記事 ◦ クラスタリングキーを貼る際の教訓 • ChatGPTくん
Thank you!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}