Slides for the presentations given at:
- STARTUP LISBOA, on December 7th, 2016: https://www.meetup.com/Lisbon-Open-Data-Meetup/events/235879313/
- Porto's TensorFlow Dev Summit Viewing Party, on February 15th 2017, organised by GDG Porto: https://www.nei-isep.org/2017/02/tensorflow-dev-summit-viewing-party-porto/
Abstract:
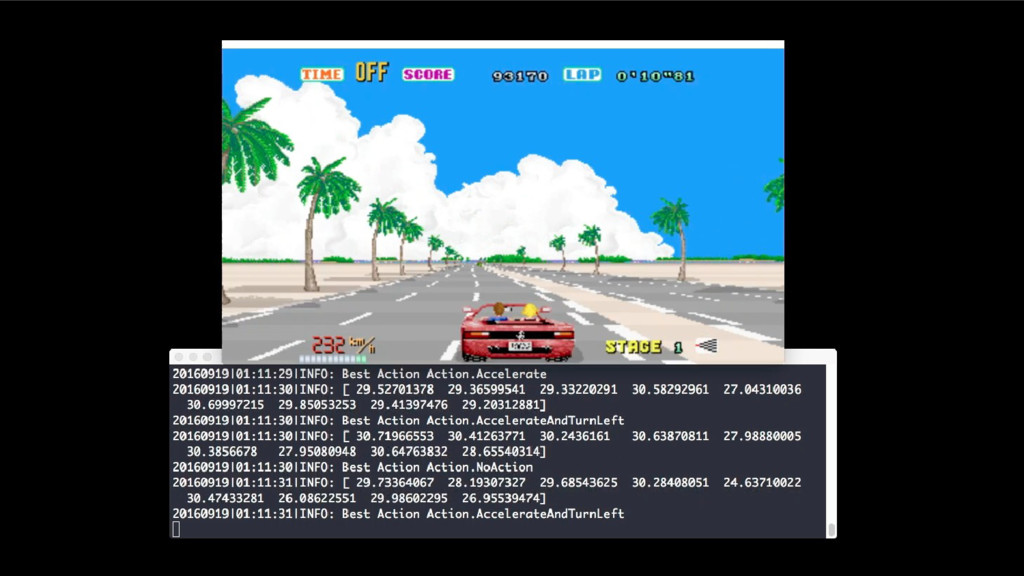
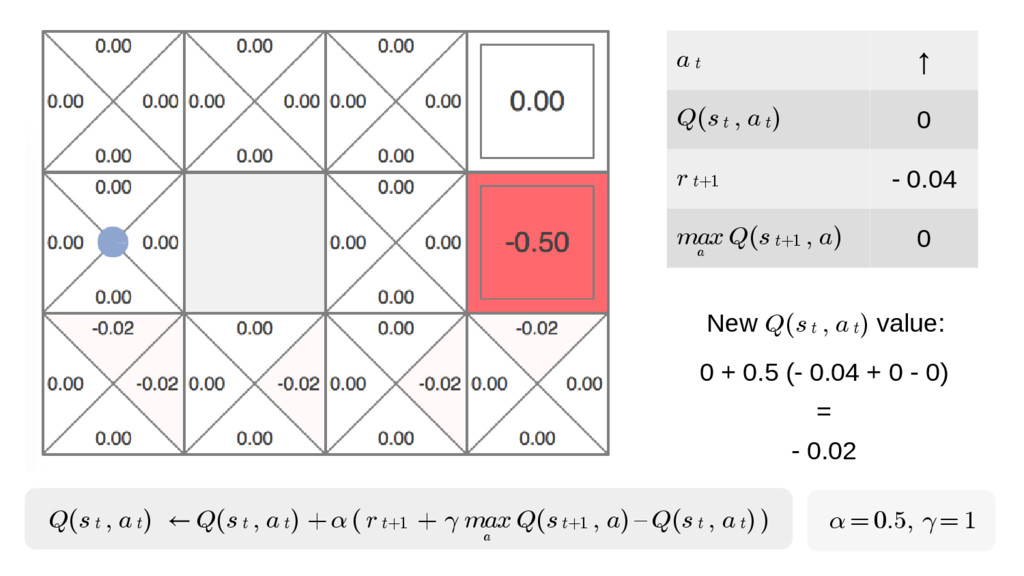
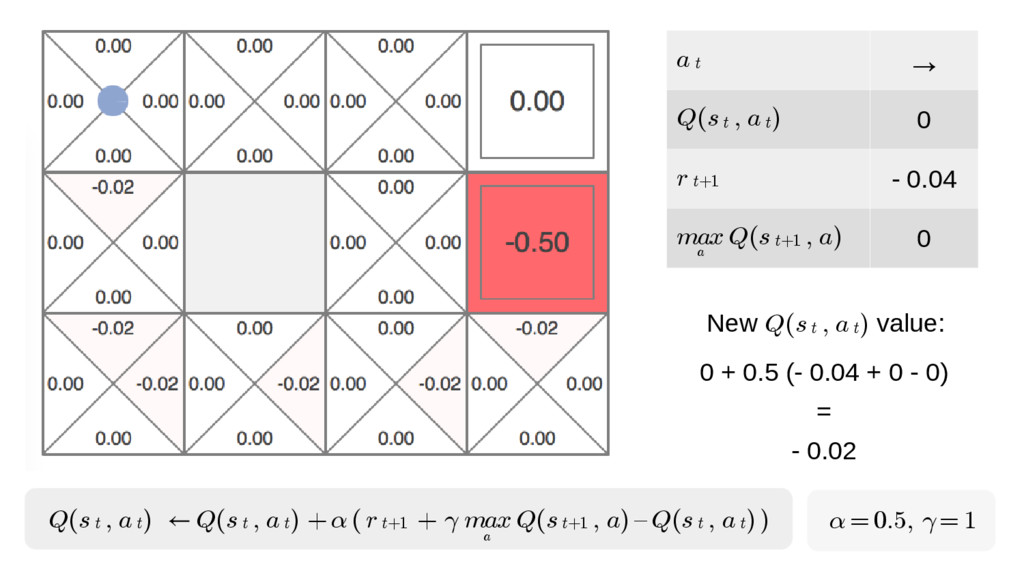
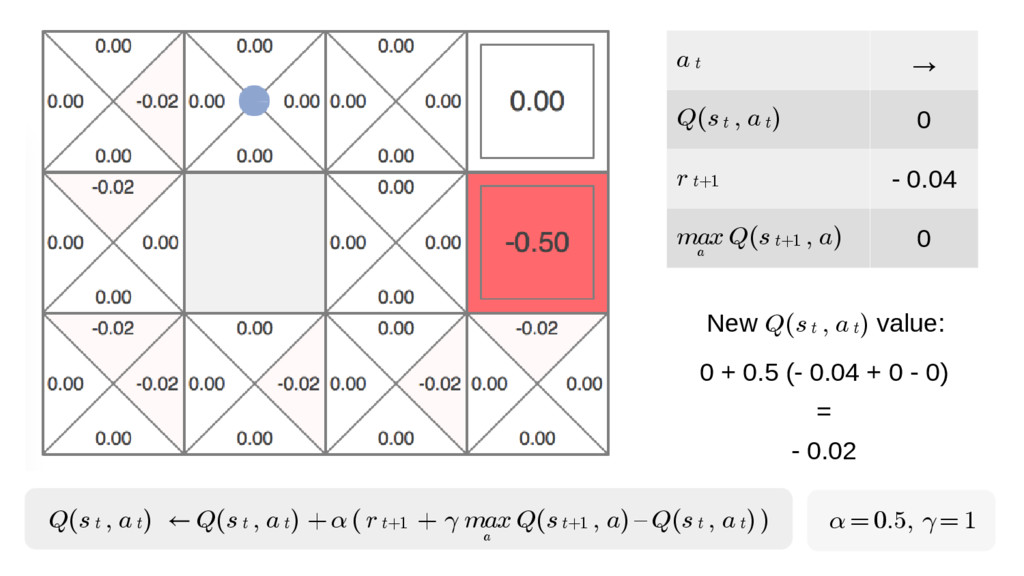
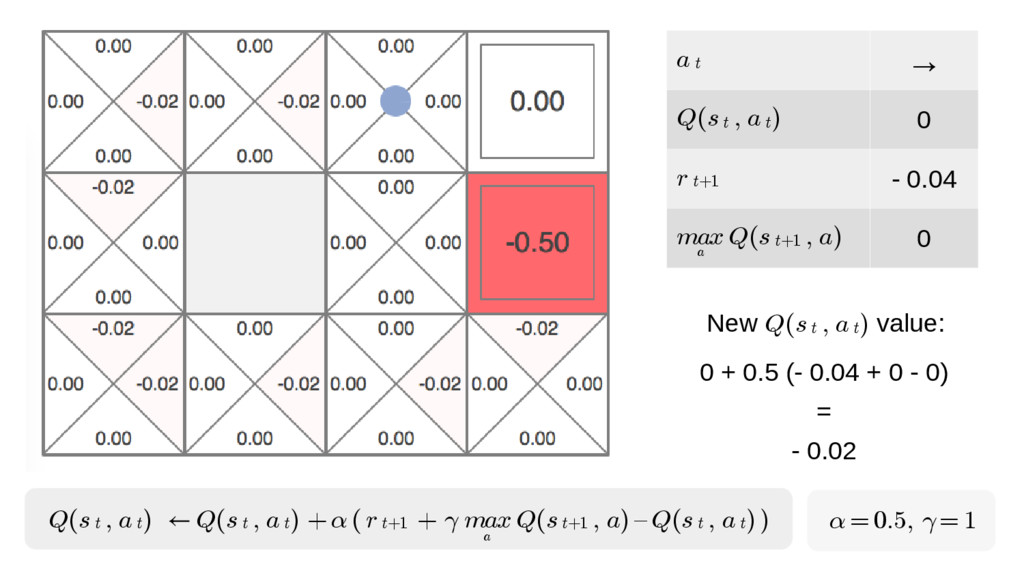
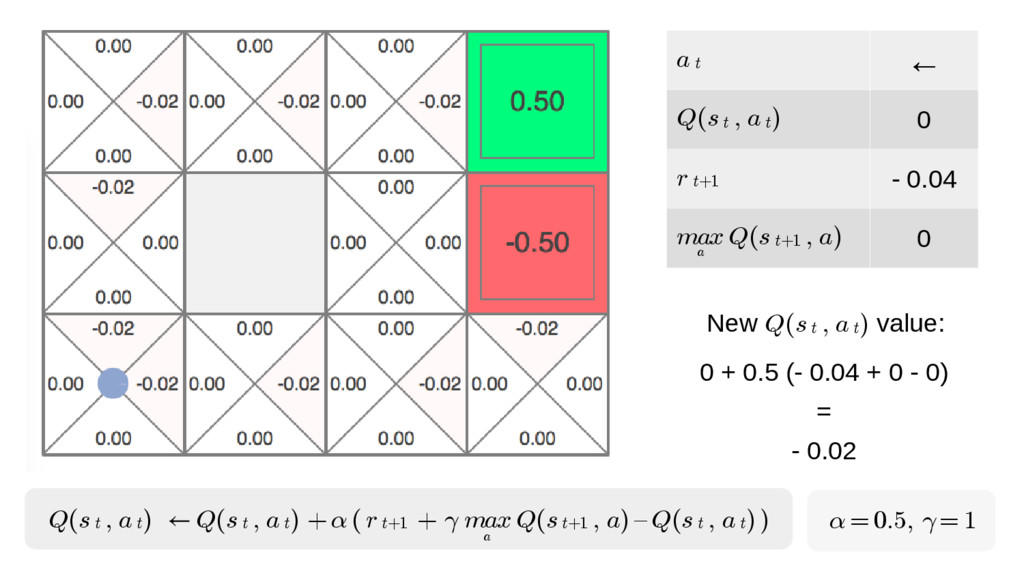
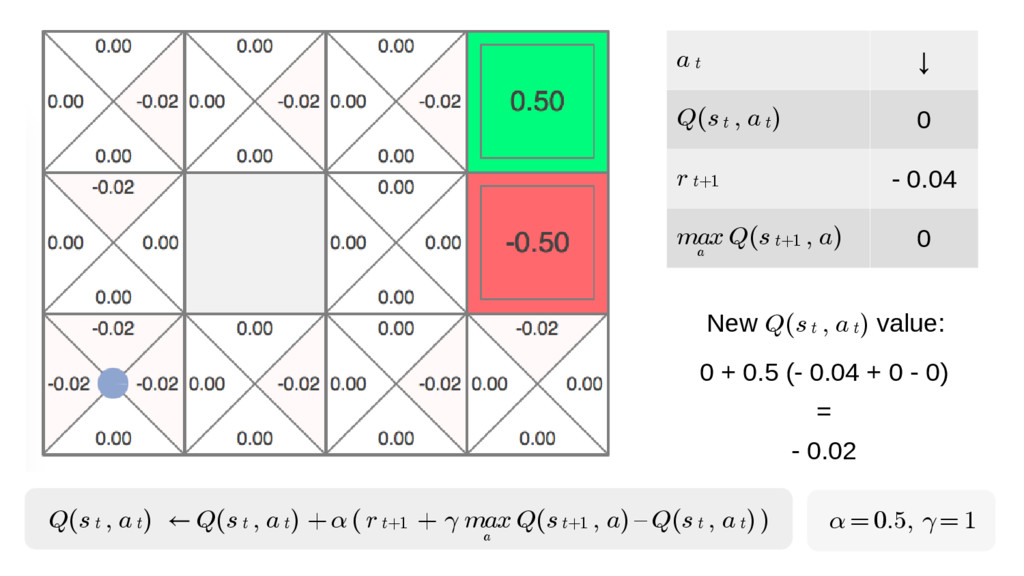
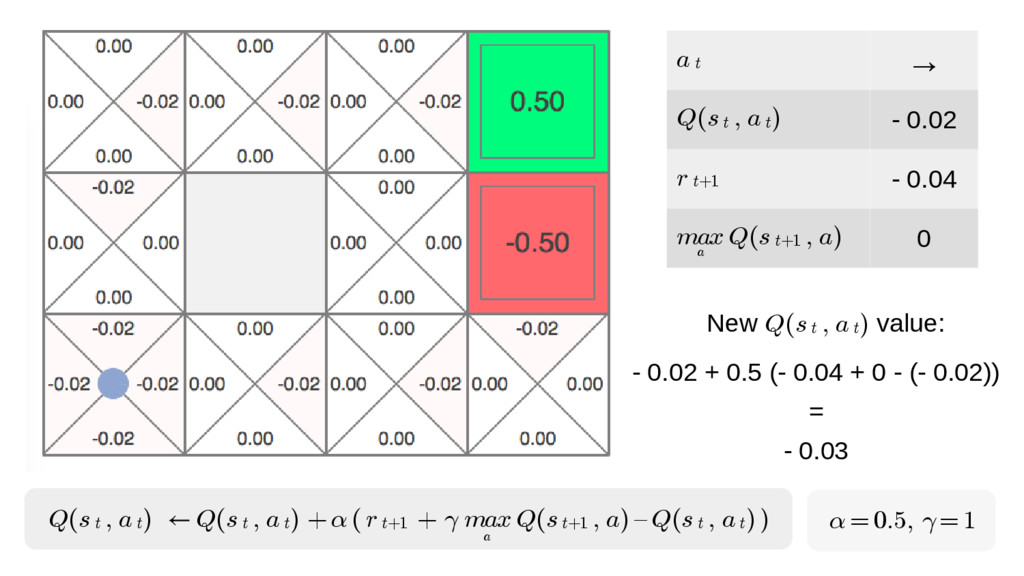
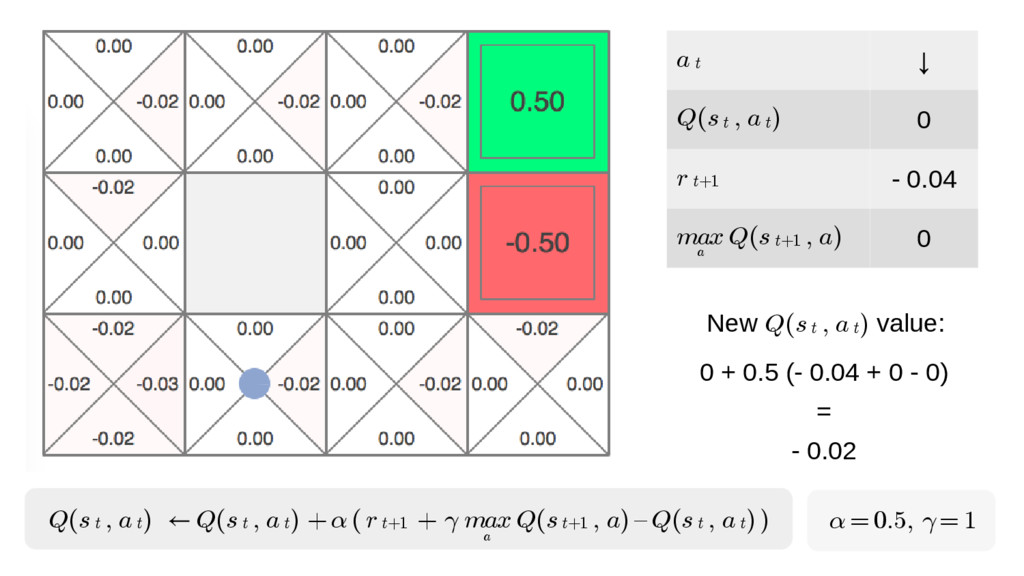
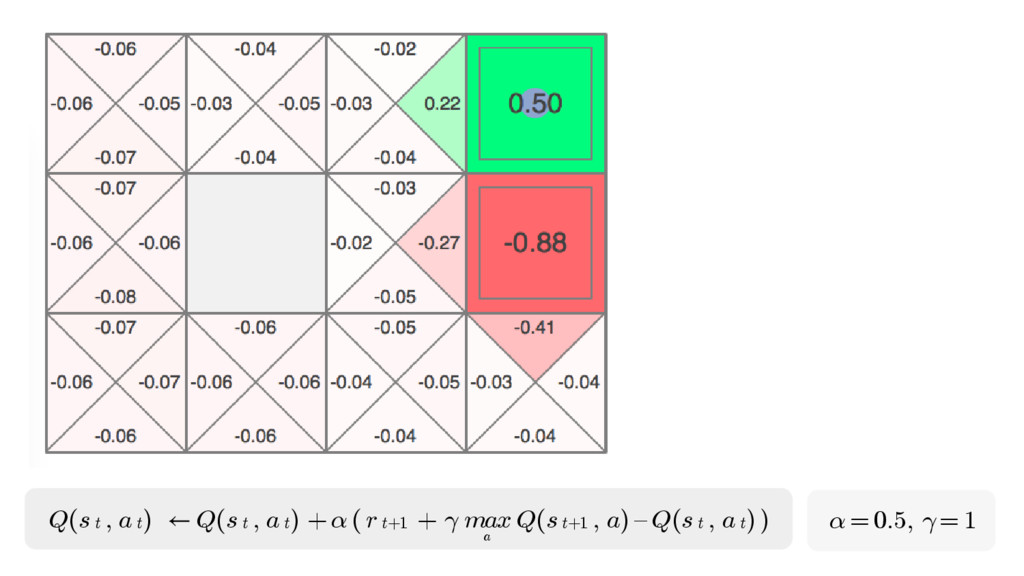
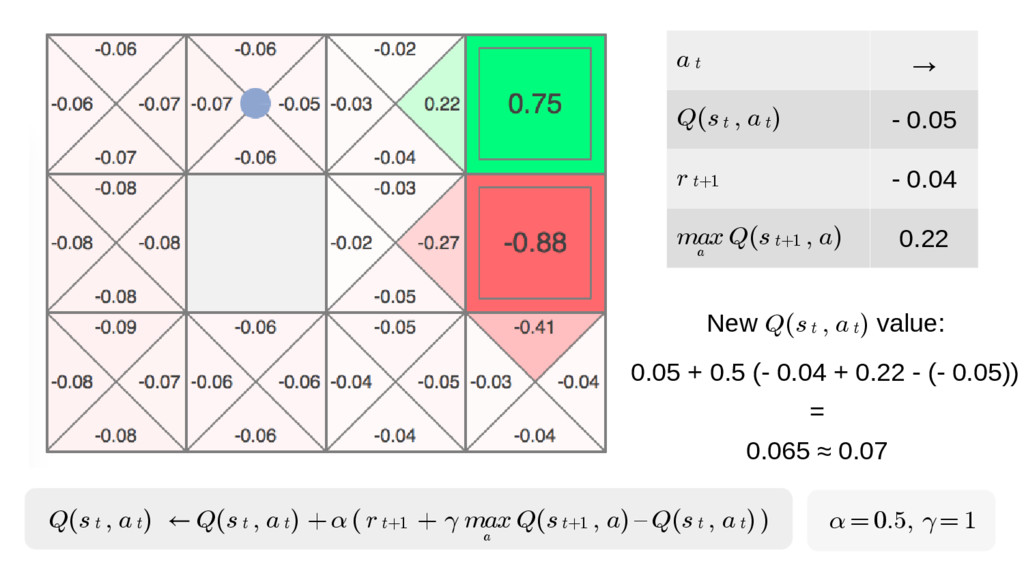
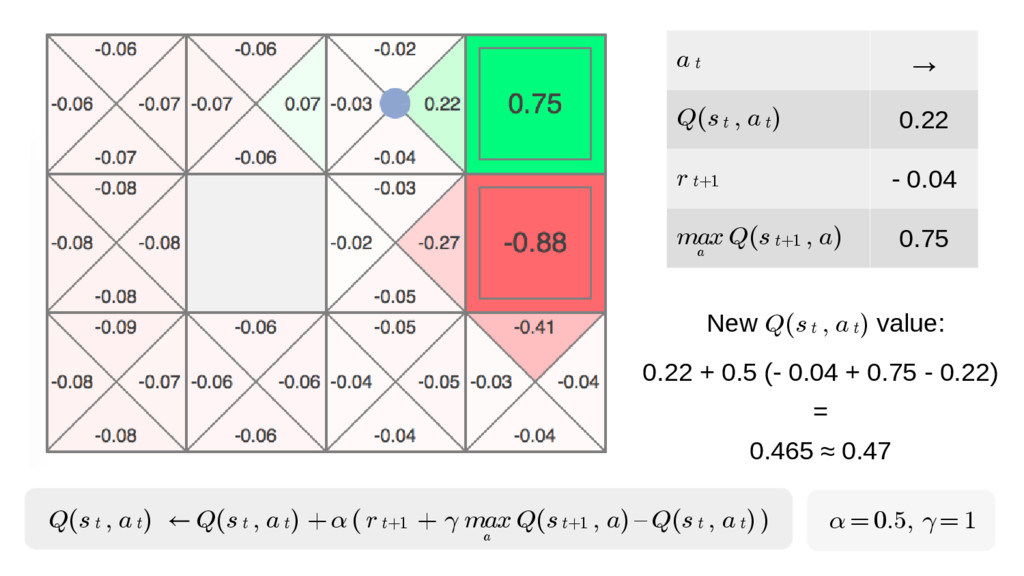
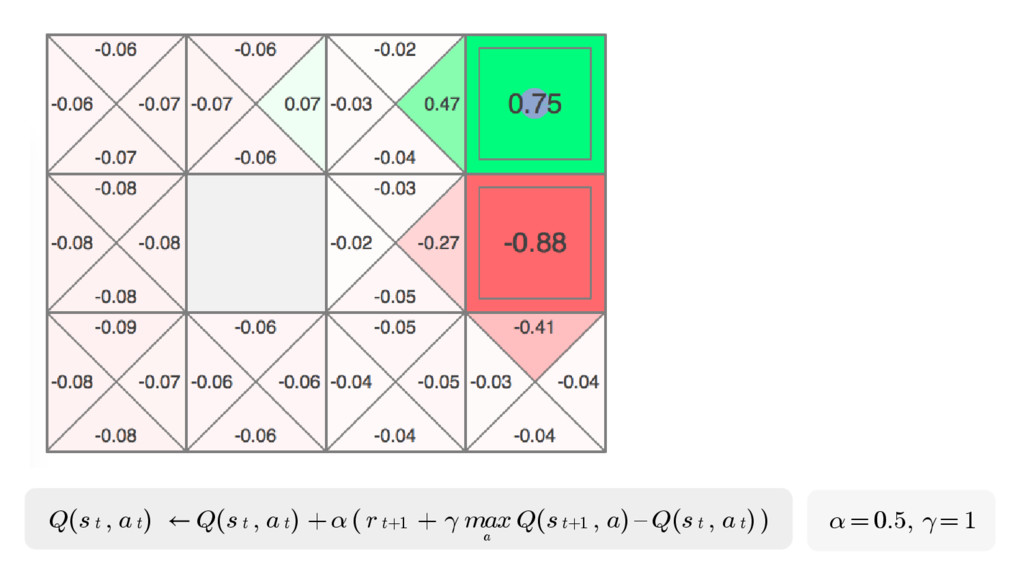
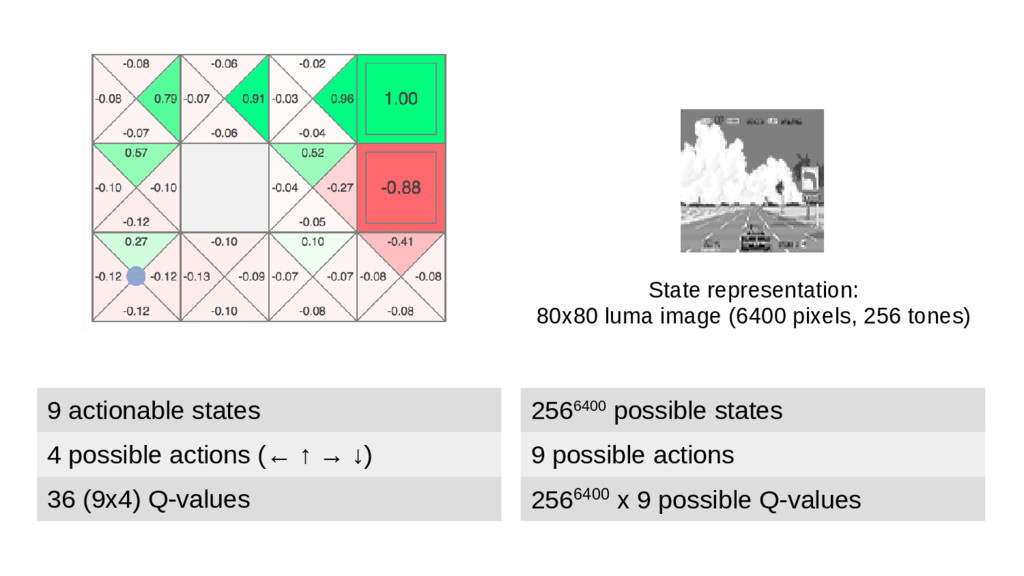
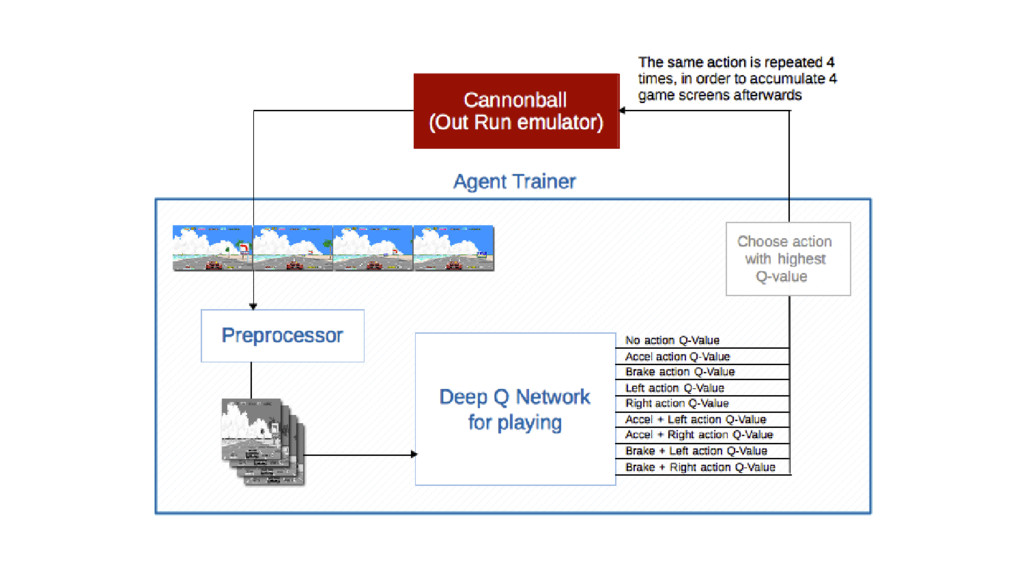
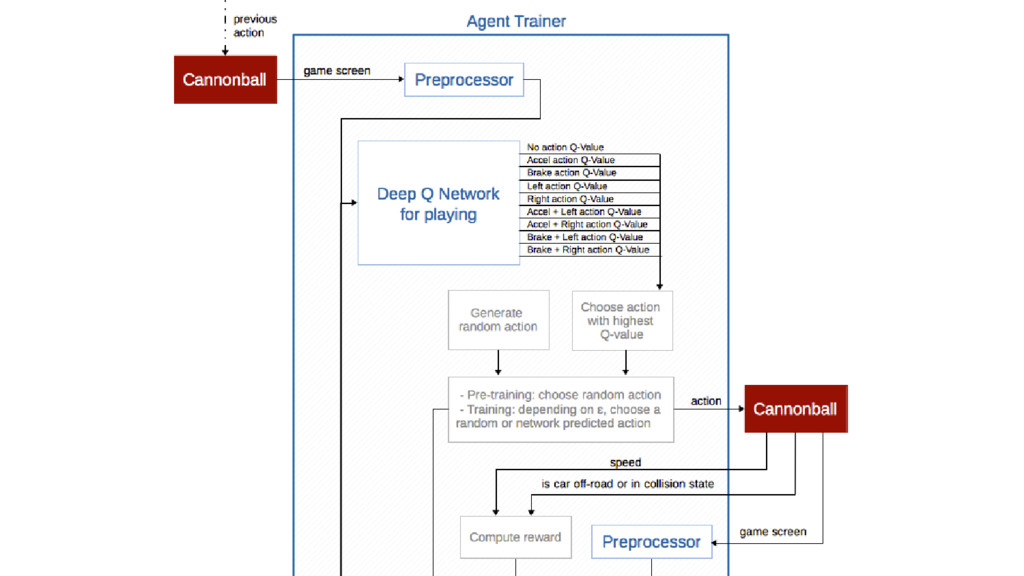
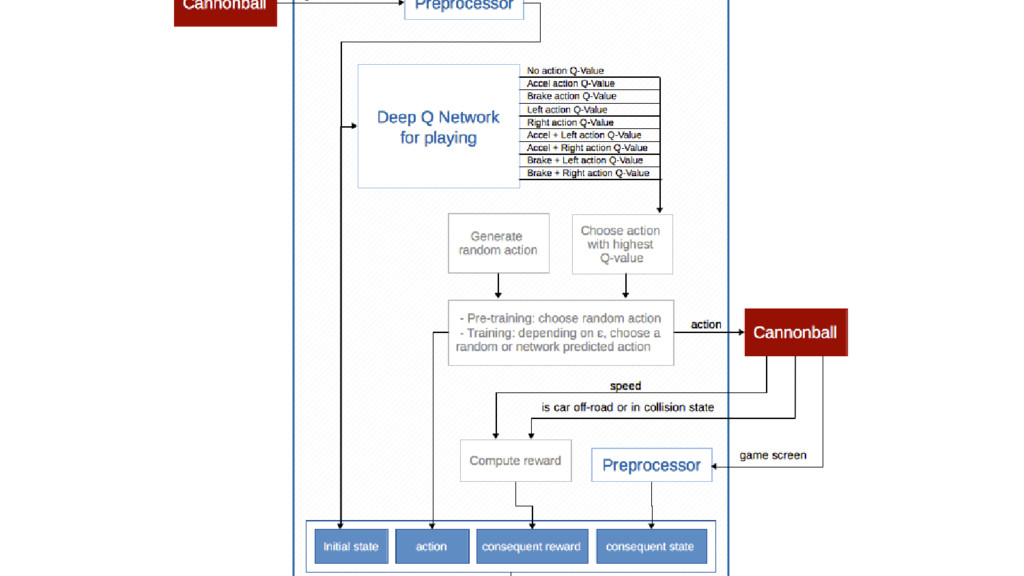
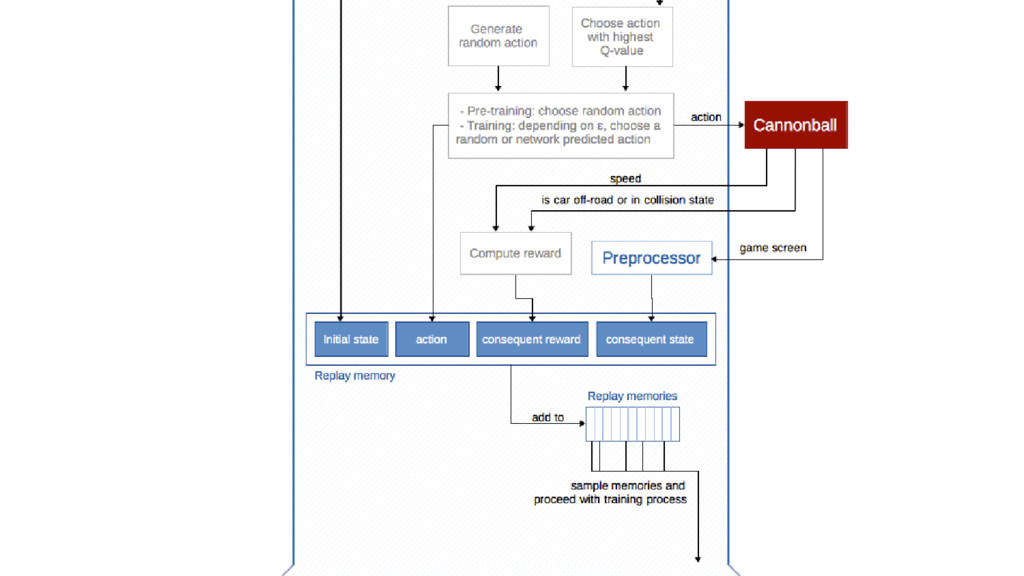
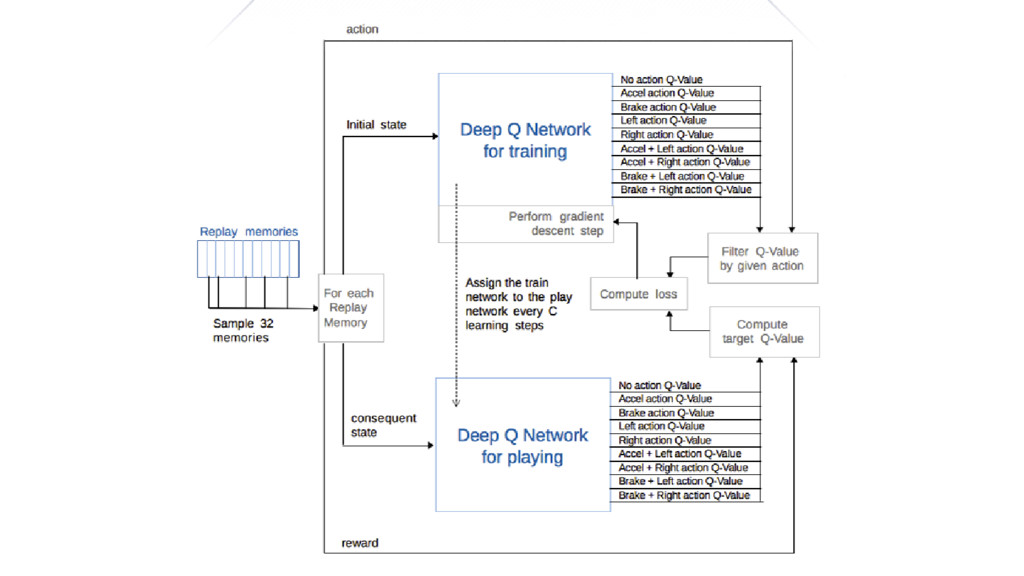
We will go through the inner workings of Deep Q-learning, a deep reinforcement learning algorithm implemented by a Python/Tensorflow agent to play "Out Run", an arcade racing game. This algorithm was previously developed and used by DeepMind to play 49 different Atari games.
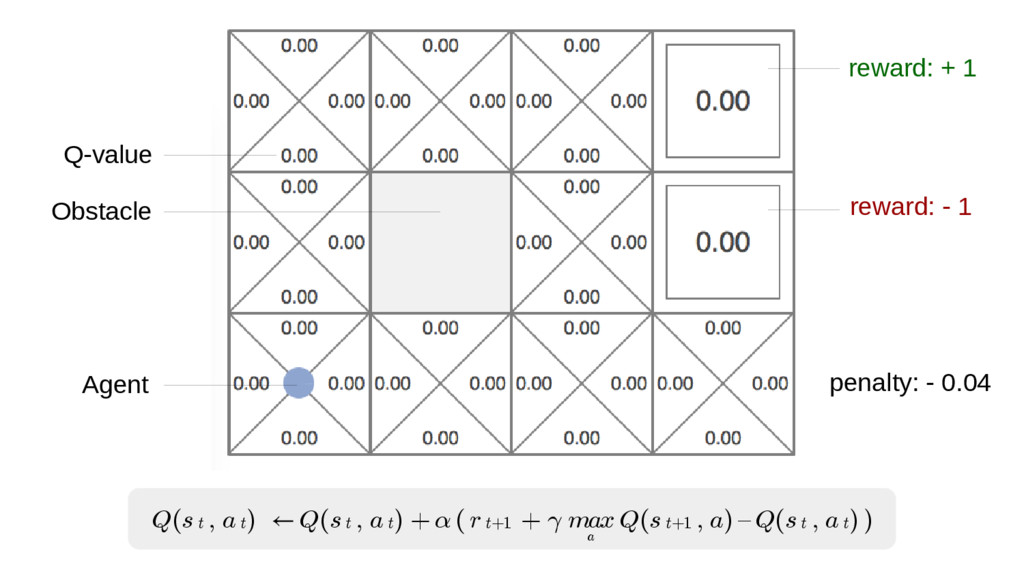
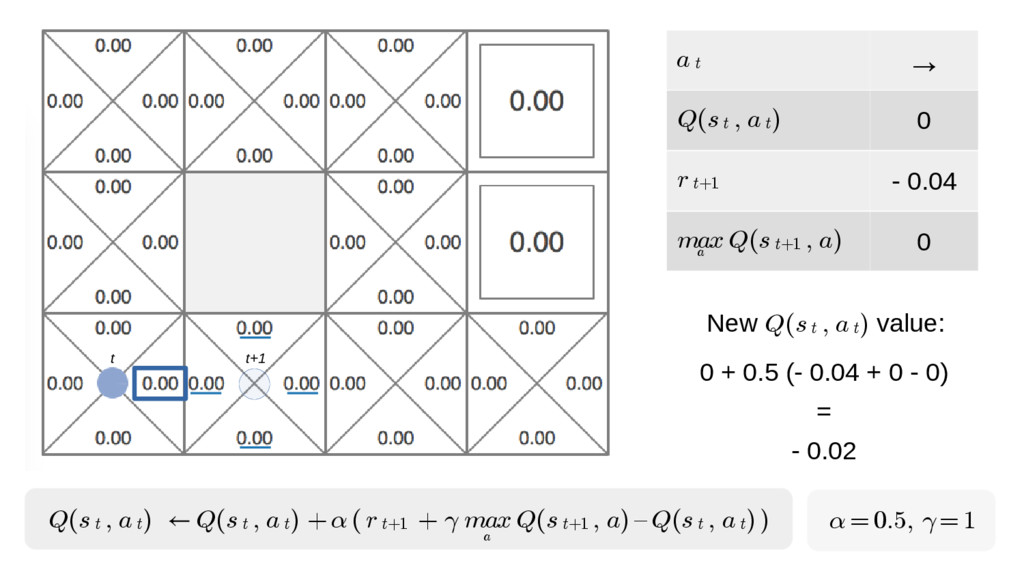
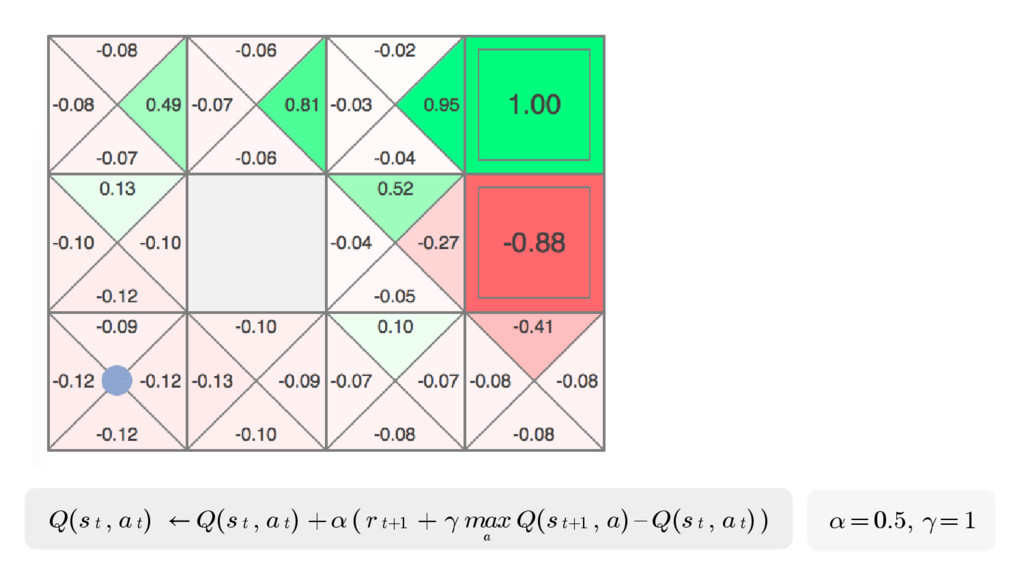
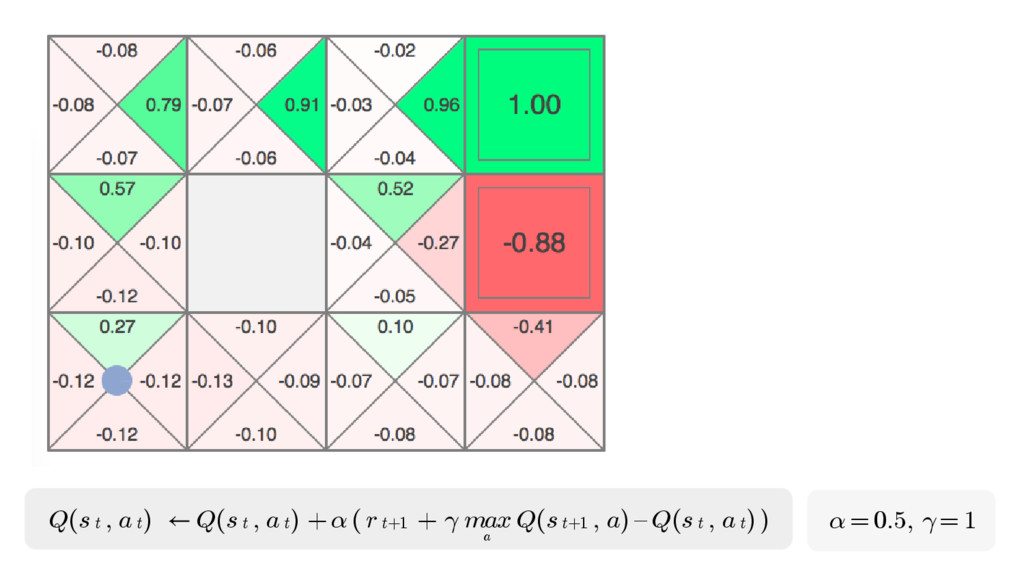
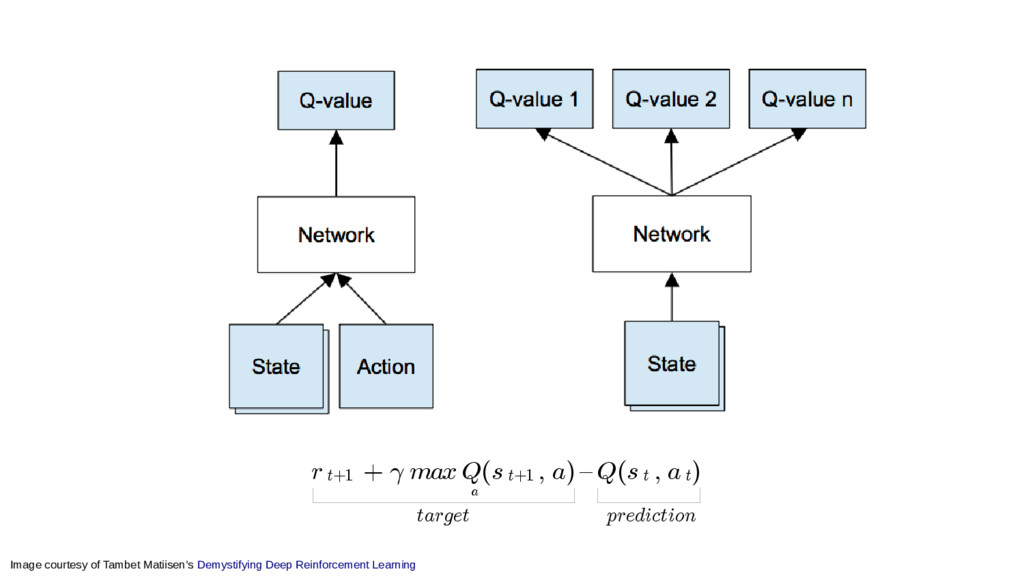
In particular, we will dive into Q-learning and to how it interconnects with Neural Networks and other concepts to create an autonomous agent capable of playing a game, only by having access to its screens, score (lives, speed, etc) and controls.
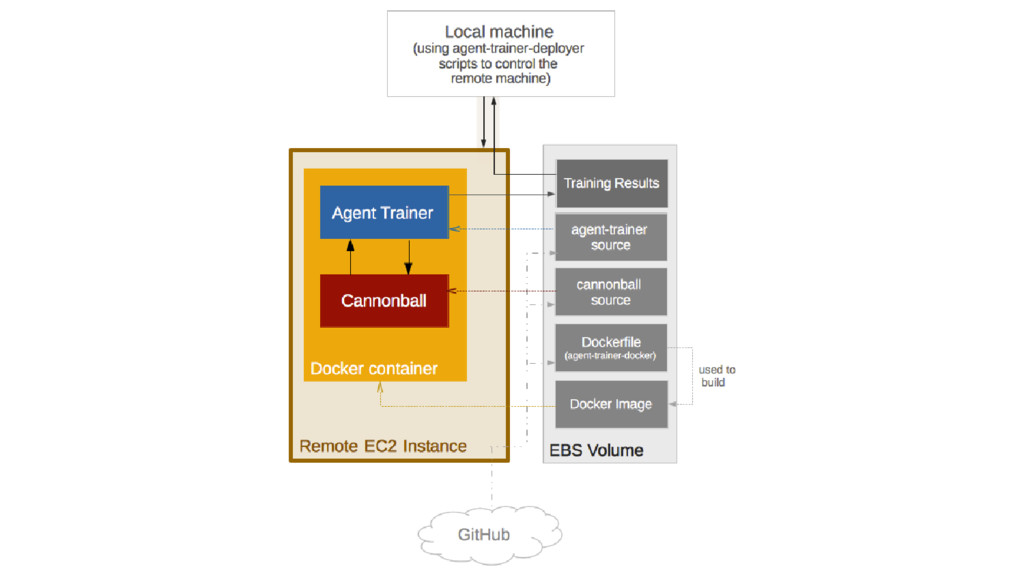
This presentation builds upon a blog article about the aforementioned Python/Tensorflow agent. Source code, AWS EC2 GPU instance deployment scripts and blog article are available here: https://lopespm.github.io/machine_learning/2016/10/06/deep-reinforcement-learning-racing-game.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
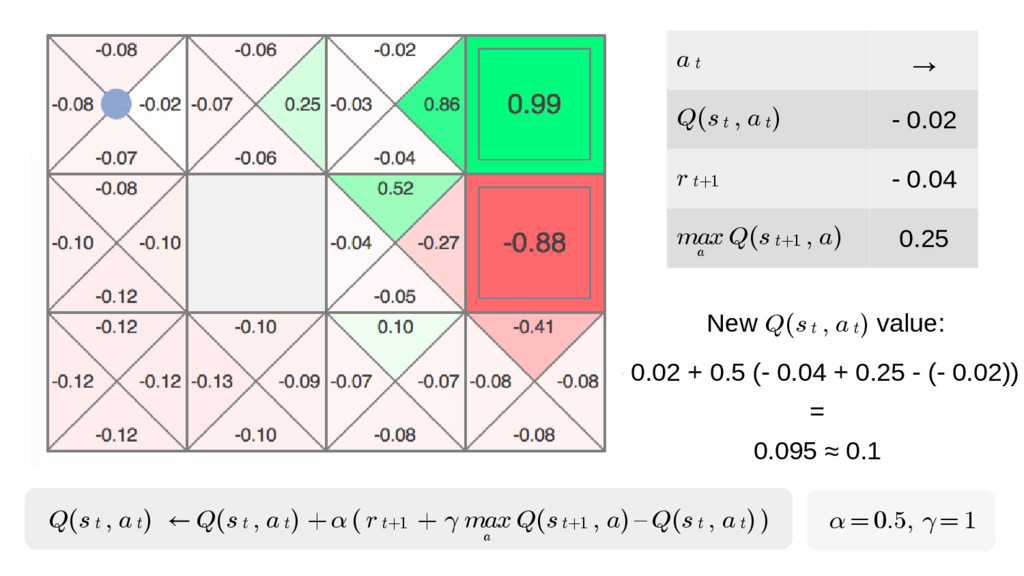{kind=link}
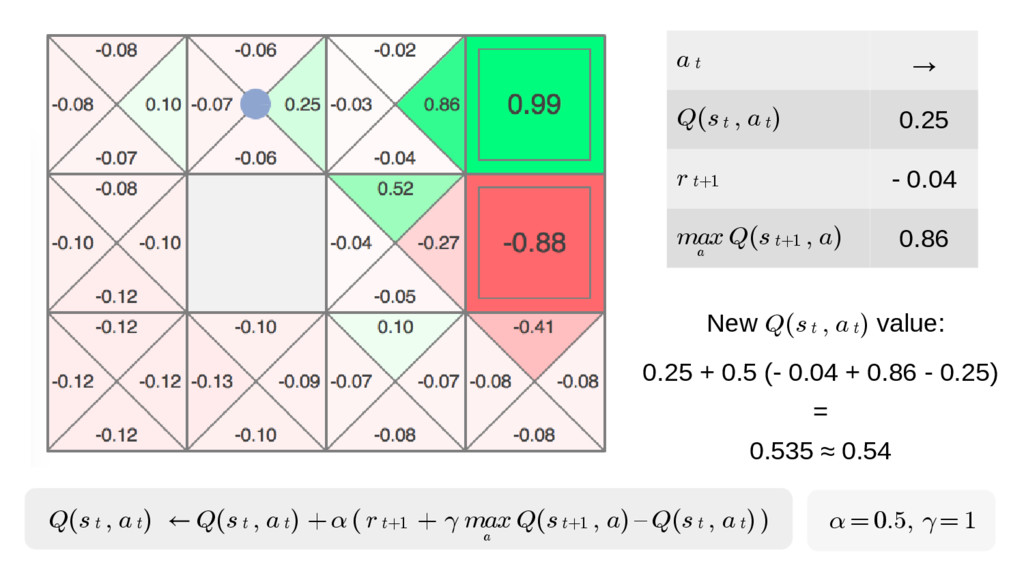{kind=link}
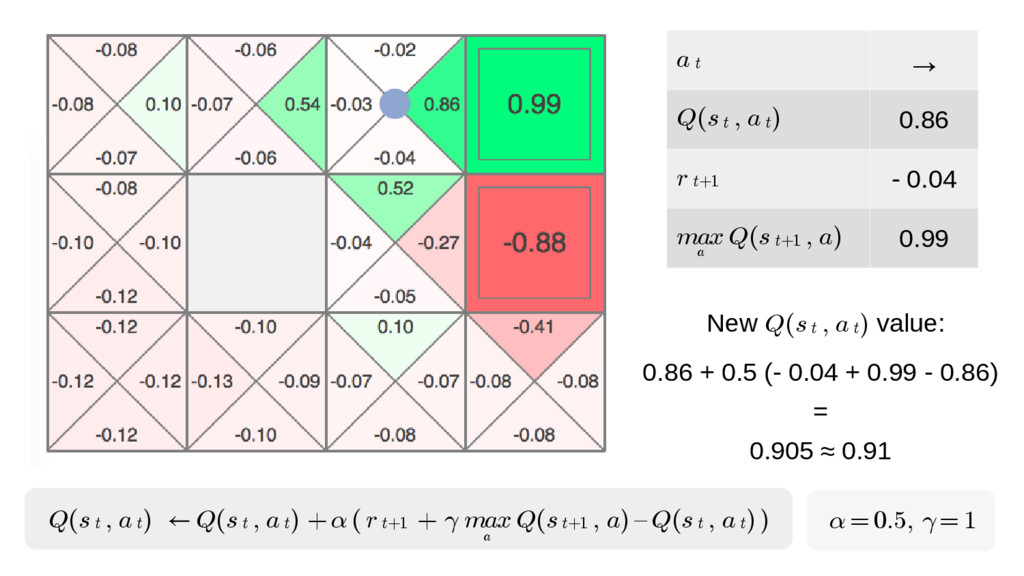{kind=link}
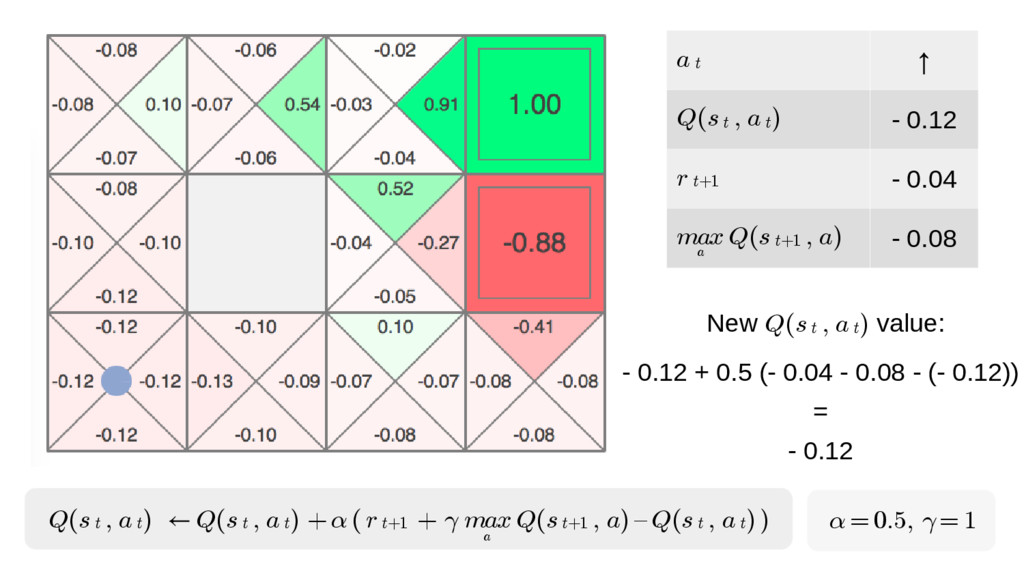{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}