Rimworld) - Matlab -> Excel -> PL/SQL -> Delphi -> Python - Apaixonado pela área de Dados - Engenheiro de Dados especializado em ML - Python Brasil: Segunda participação, Primeira palestra 3 Matheus Queiroz
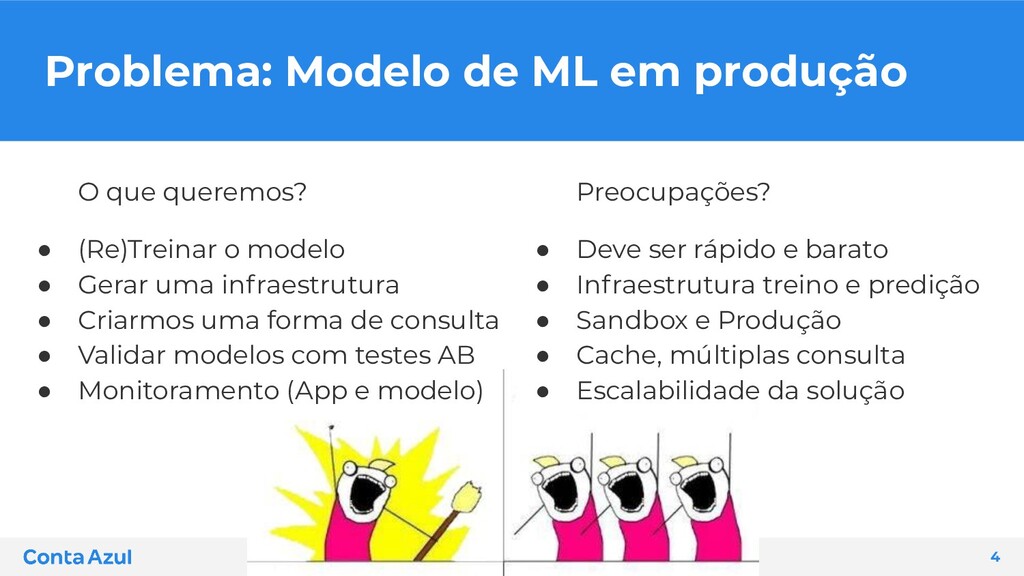
ser rápido e barato • Infraestrutura treino e predição • Sandbox e Produção • Cache, múltiplas consulta • Escalabilidade da solução O que queremos? • (Re)Treinar o modelo • Gerar uma infraestrutura • Criarmos uma forma de consulta • Validar modelos com testes AB • Monitoramento (App e modelo)
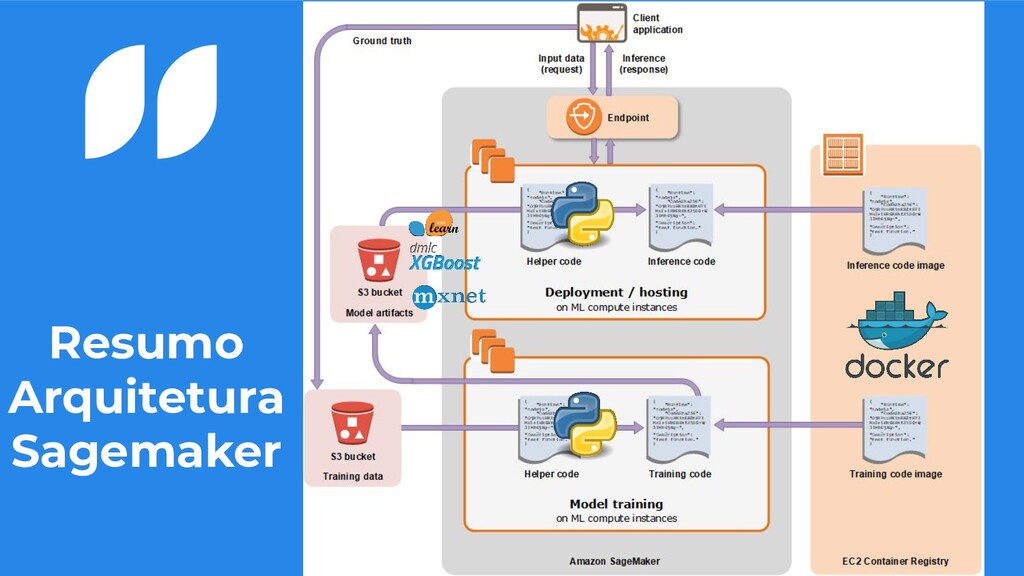
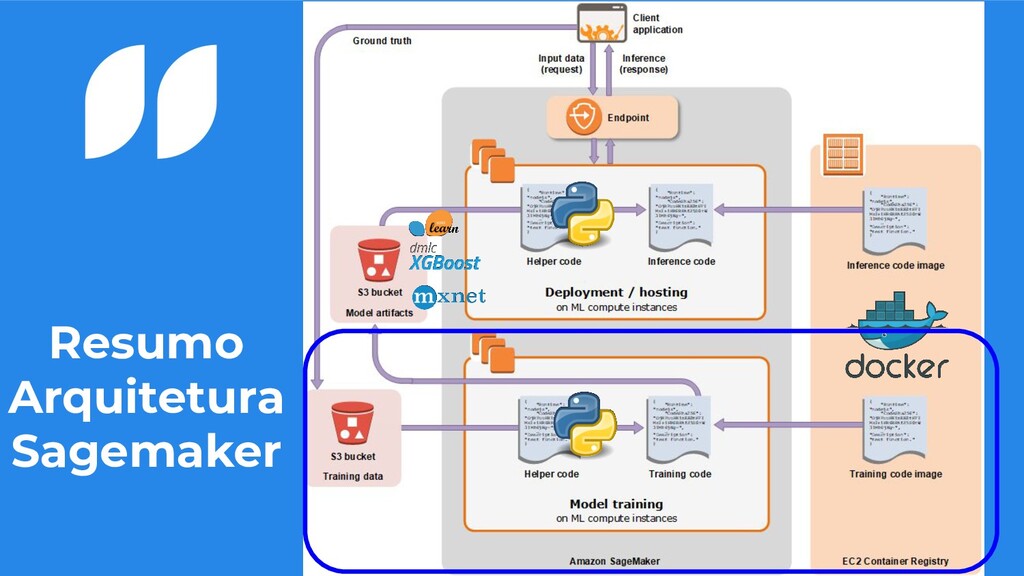
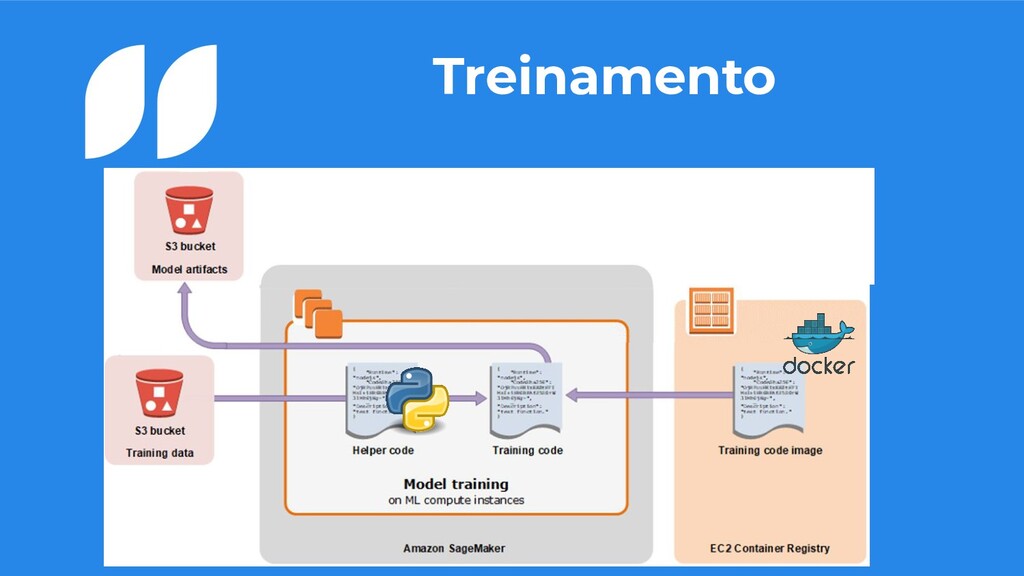
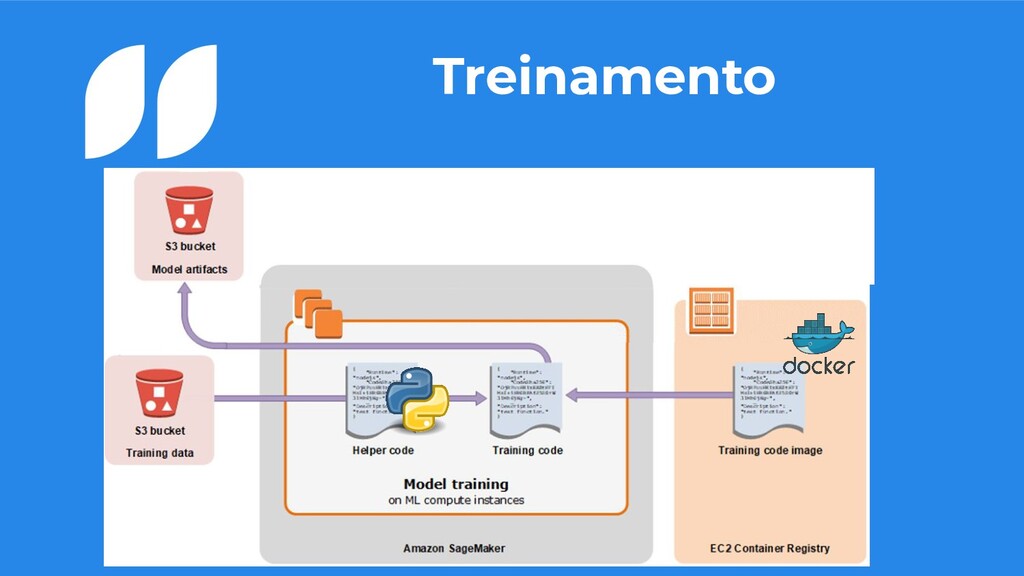
um S3 • Precisamos de uma imagem docker para o treinamento do nosso modelo • Podemos colocar um script e/ou requirements que irá auxiliar o realizamento do nosso treino • Ao final nosso modelo será salvo no S3 compactado no formato tar.gz 7
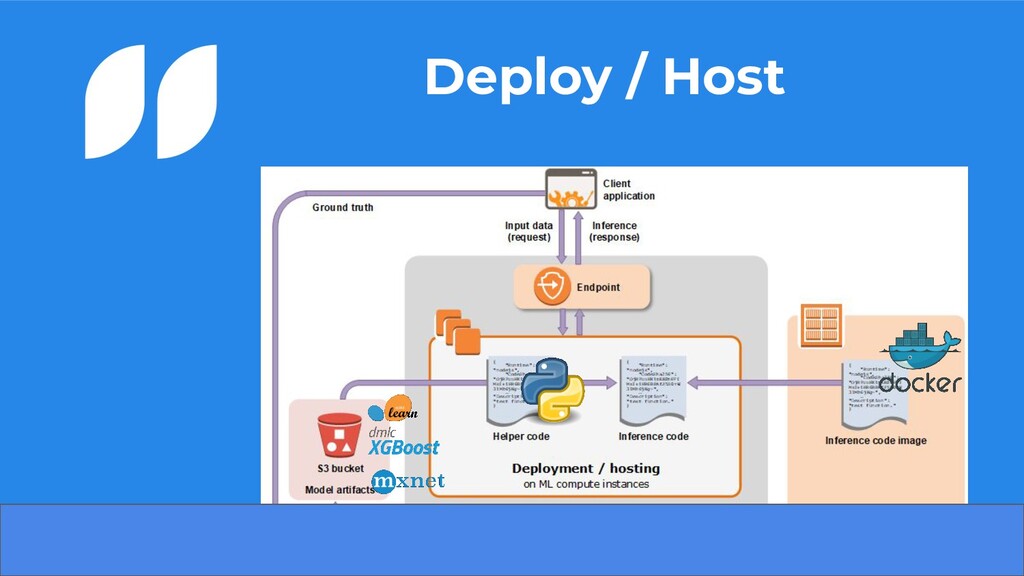
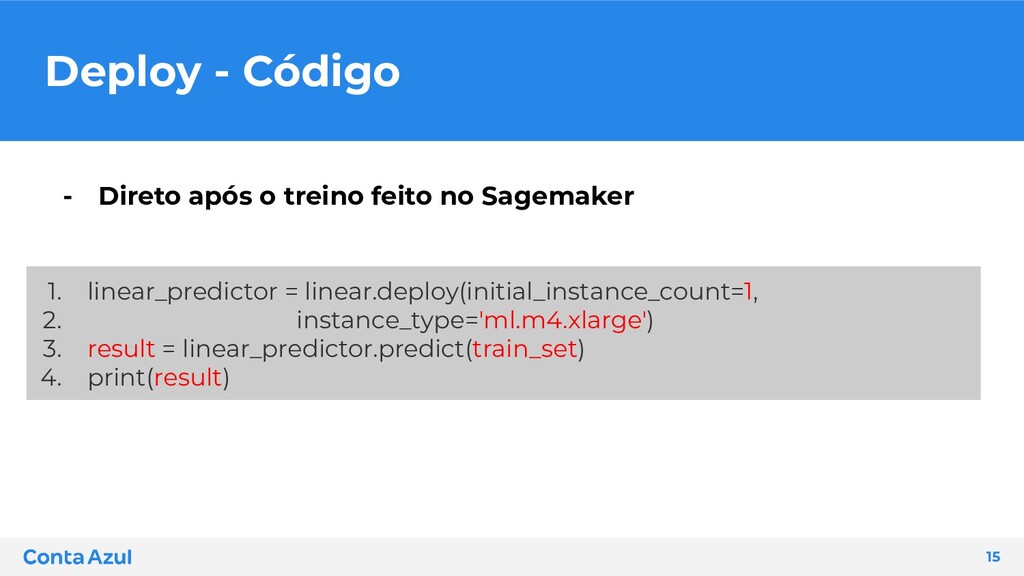
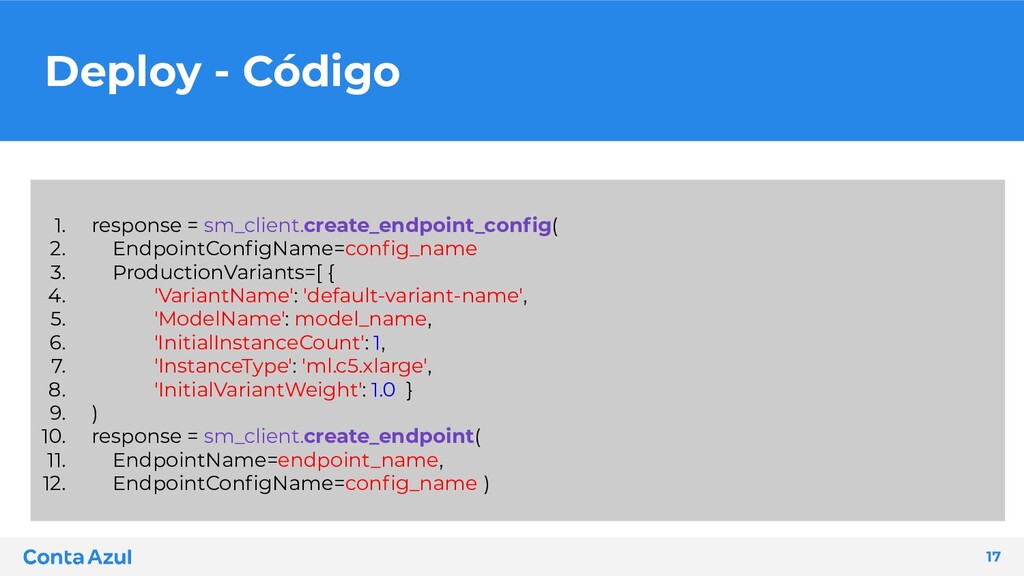
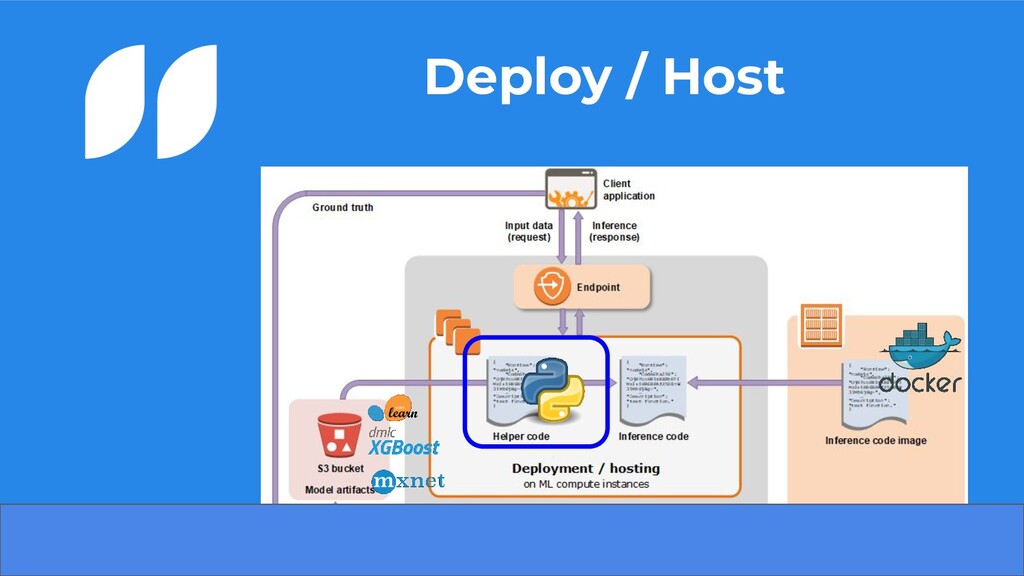
compactado no formato tar.gz • Definimos qual imagem iremos utilizar para hospedar nosso modelo • Podemos definir um script e/ou requirements que irá tratar nossos dados no sagemaker • Configuramos como iremos querer ter nosso endpoint no ar ◦ Seleção do modelo, podendo ser mais que um para testes AB 14
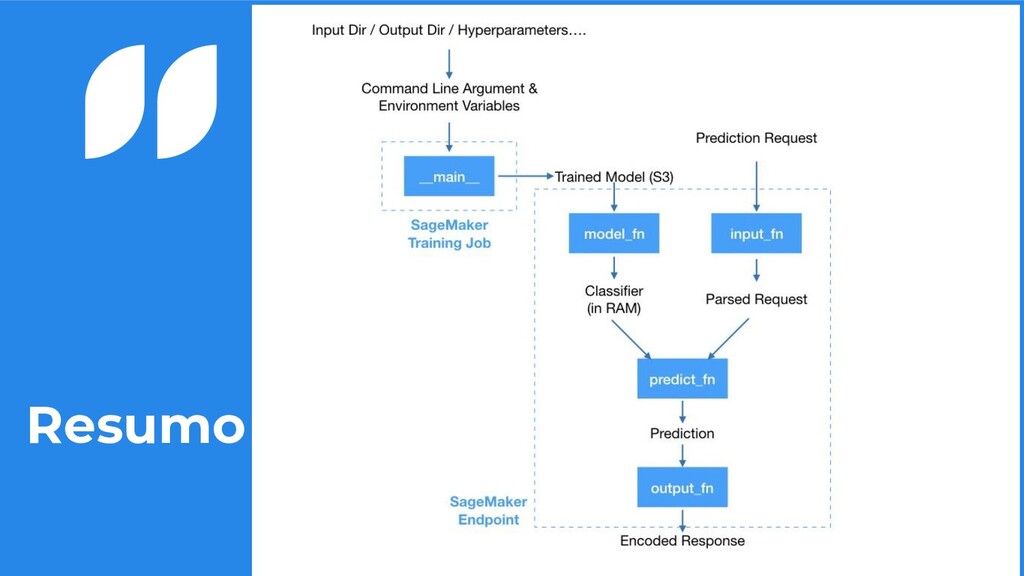
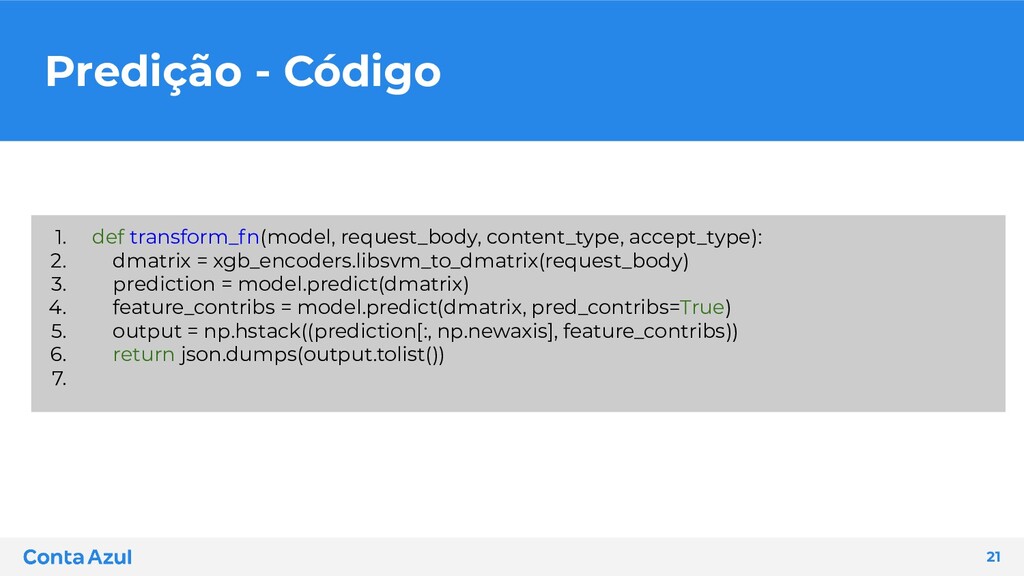
nos containers disponibilizados da AWS: • model_fn: carrega seu modelo dentro da sua imagem • input_fn: recebe o request para passar os dados para predição • predict_fn: realiza a predição do seu modelo • output_fn: retorna a predição para quem realizou o request 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}