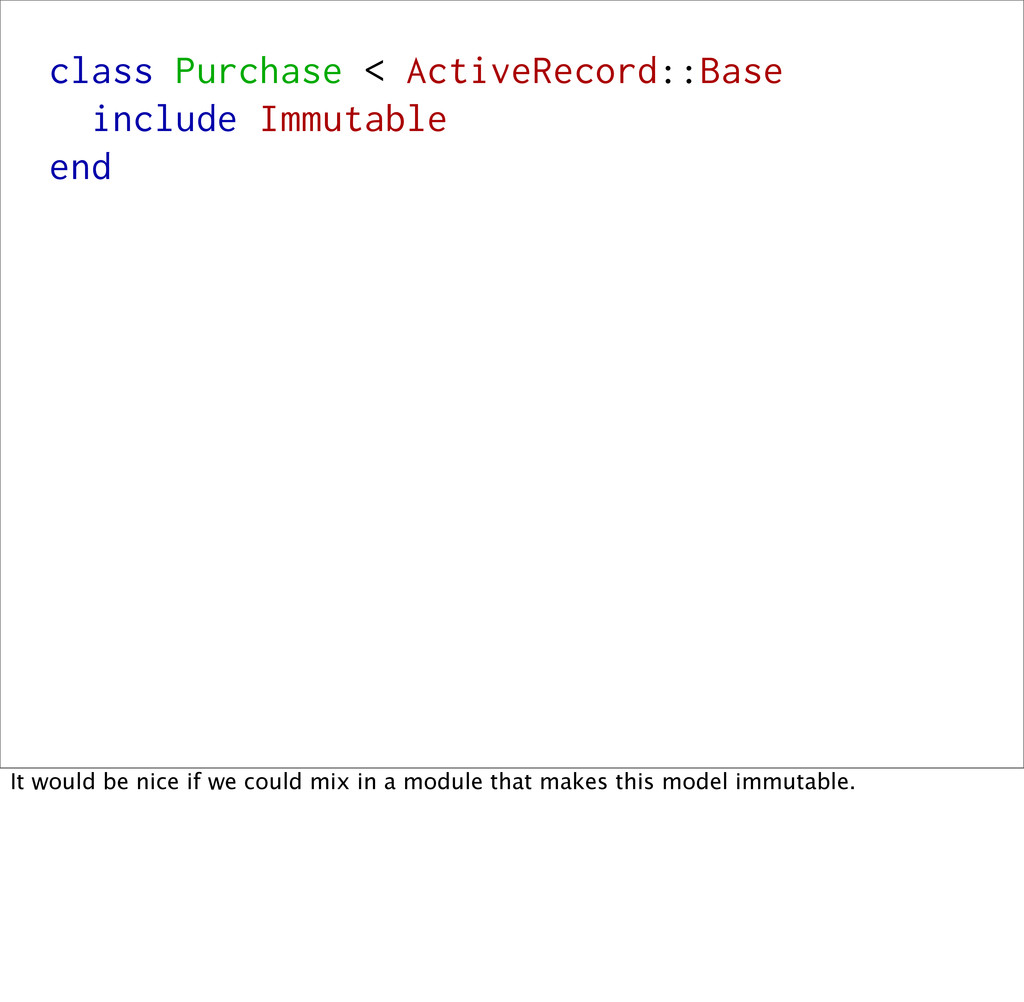
Ruby, an immutable object would be one that can't me modified after it's created. Obviously, a program that doesn't change anything isn't particularly useful, but in small pockets, immutability can be a tool for helping you reason about and structure your code. I'm going to tell you some stories of bad code (full of mutable state) that I've written that came back to bite me, and some stories of good code that I've written in an immutable style and how it paid off.
# t.integer :item_id end Let's pretend you're running an online store, and you record all of your purchases in a purchase table. You probably never want to update the data in this table. If you were to come in and change the value of the "price" column, it wouldn't actually change how much you charged the users credit card. When you're recording data that reflects events that have happened outside of your application (in a 3rd party or in the "real world"), you often want this data to be immutable.
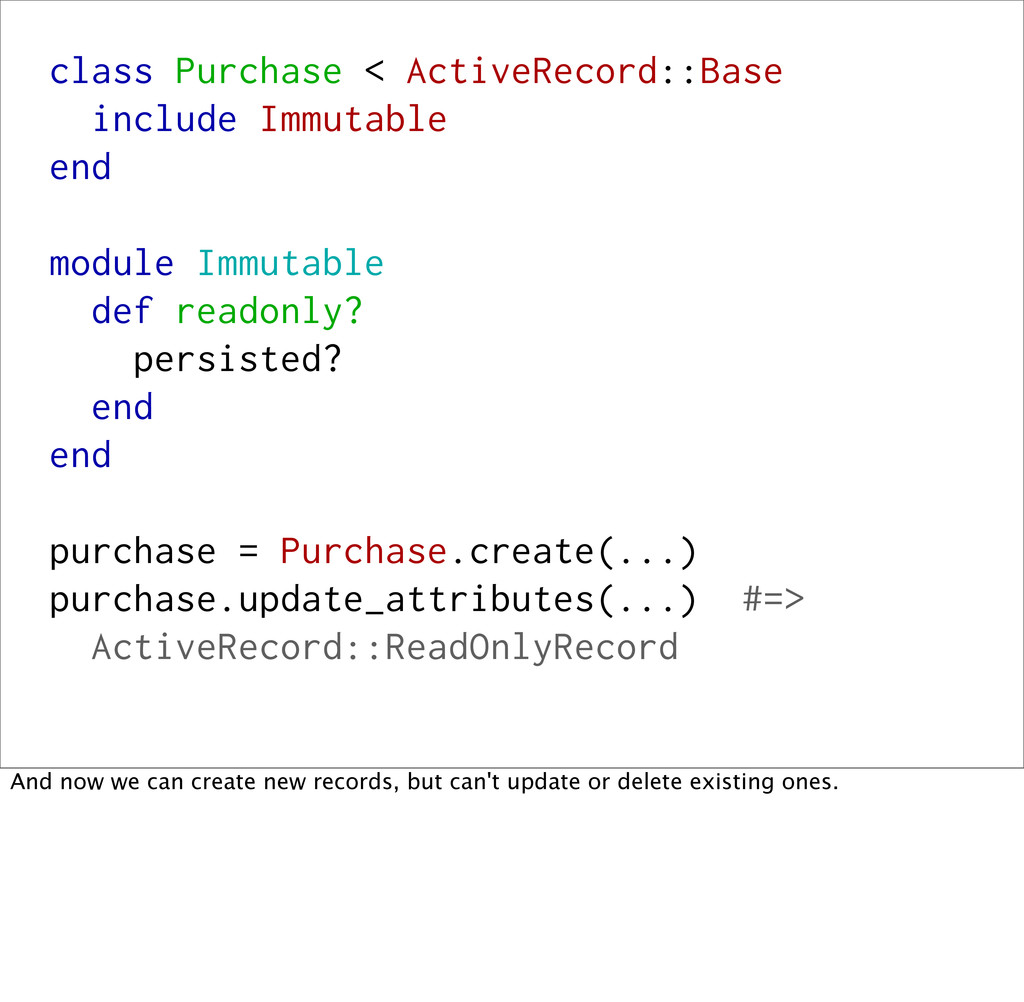
readonly? persisted? end end purchase = Purchase.create(...) purchase.update_attributes(...) #=> ActiveRecord::ReadOnlyRecord And now we can create new records, but can't update or delete existing ones.
FROM app; You could even go as far as giving your application a special user in the database and removing the ability to modify or delete your immutable tables at the database level.
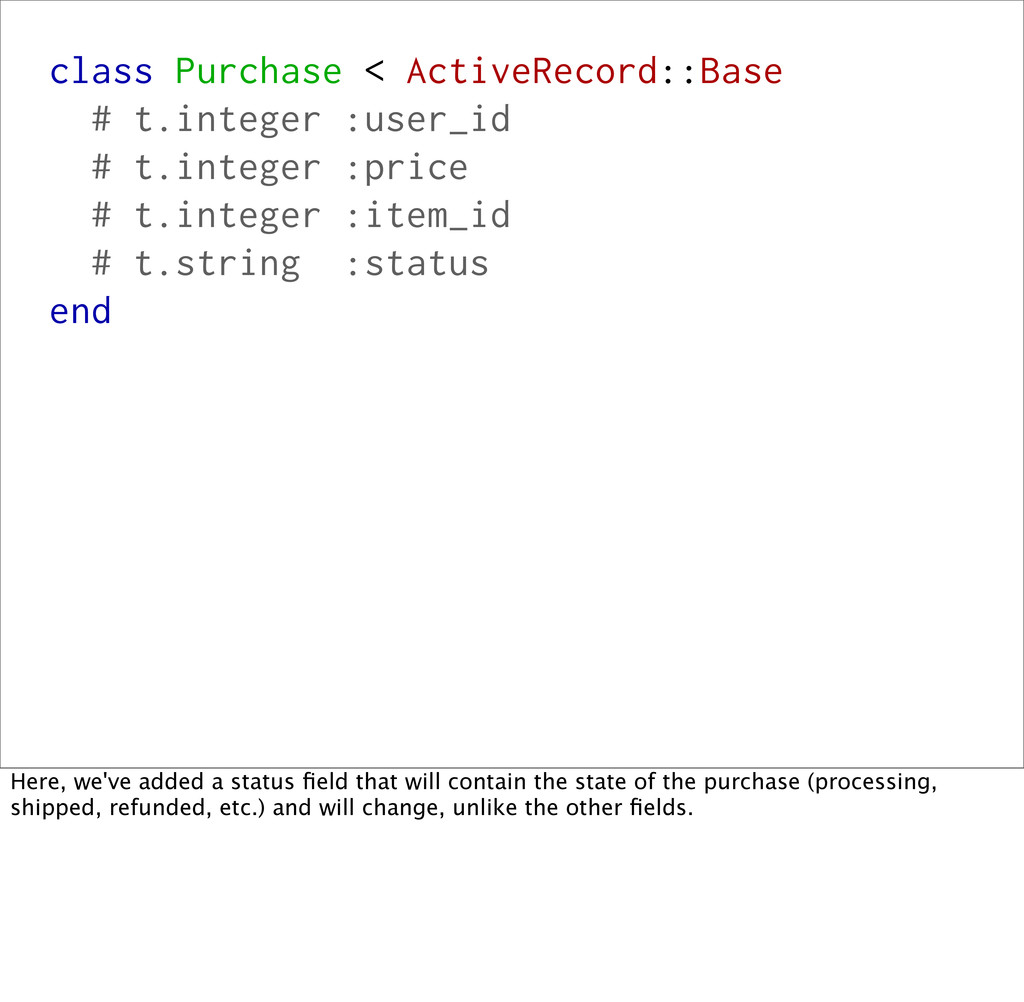
# t.integer :item_id # t.string :status end Here, we've added a status field that will contain the state of the purchase (processing, shipped, refunded, etc.) and will change, unlike the other fields.
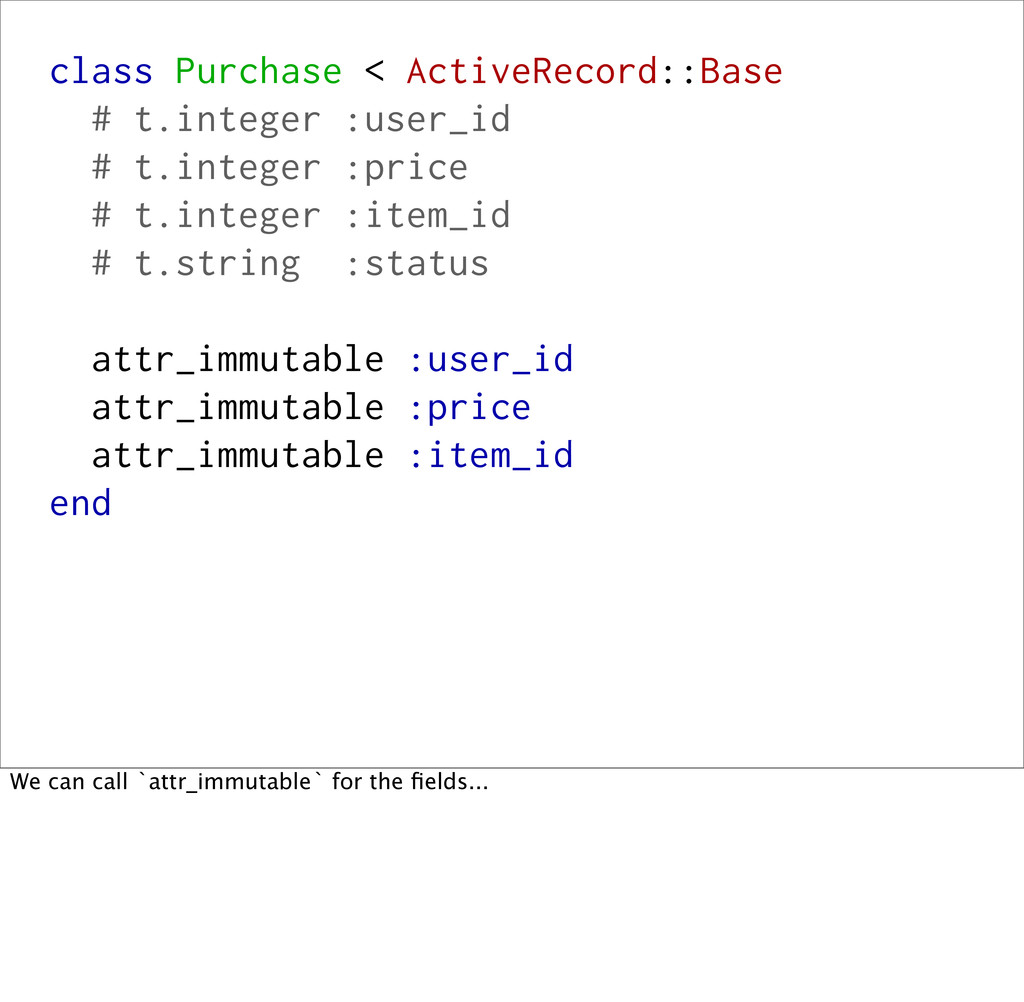
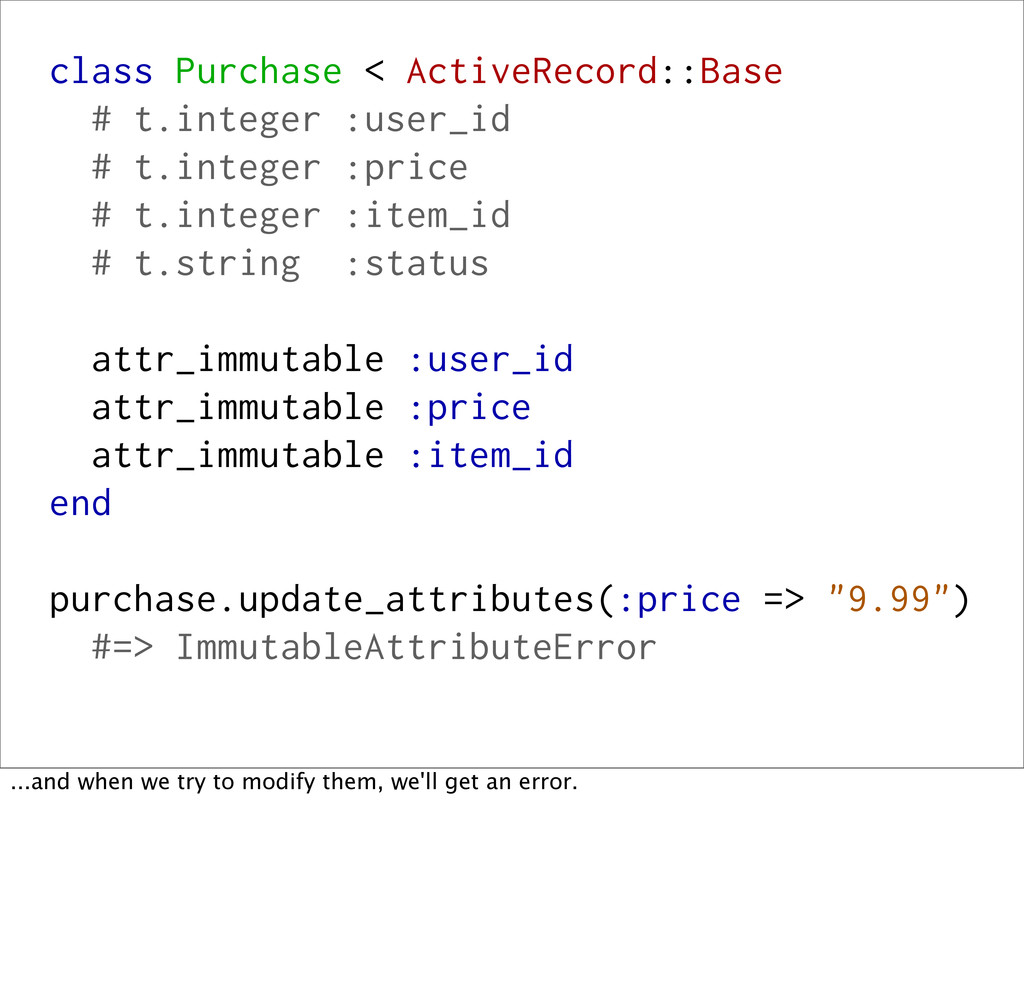
# t.integer :item_id # t.string :status attr_immutable :user_id attr_immutable :price attr_immutable :item_id end We can call `attr_immutable` for the fields...
# t.integer :item_id # t.string :status attr_immutable :user_id attr_immutable :price attr_immutable :item_id end purchase.update_attributes(:price => "9.99") #=> ImmutableAttributeError ...and when we try to modify them, we'll get an error.
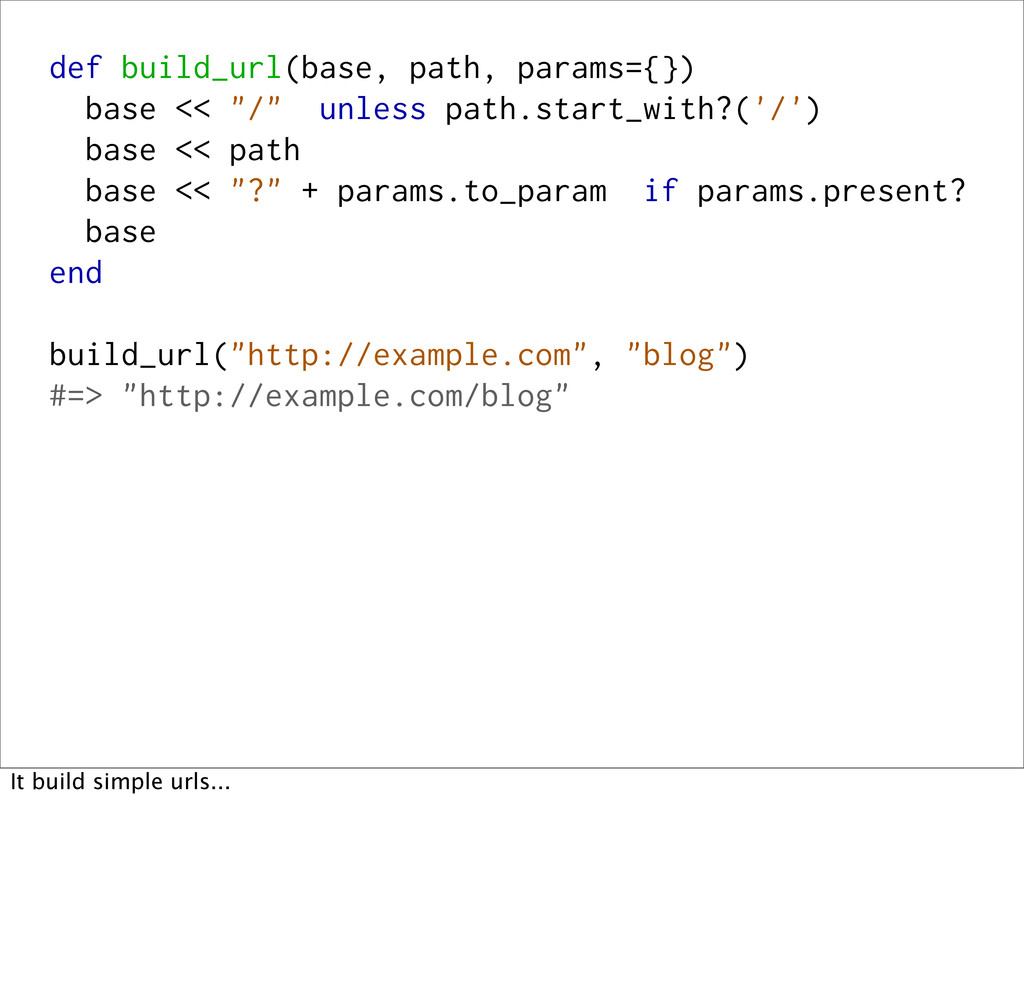
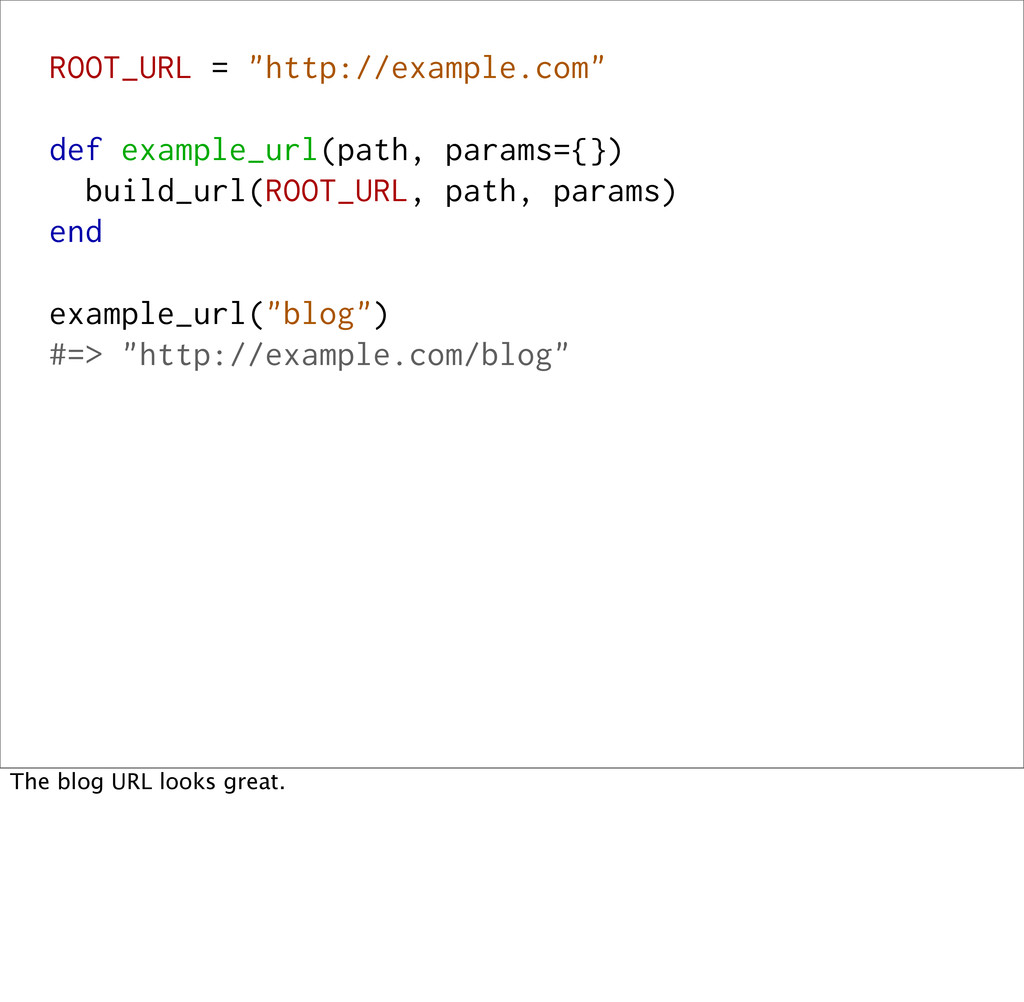
<< path base << "?" + params.to_param if params.present? base end Let's pretend you have a `build_url` method that takes a domain name, a path, and some optional query params, and will build a full URL out of them.
<< path base << "?" + params.to_param if params.present? base end build_url("http://example.com", "blog") #=> "http://example.com/blog" It build simple urls...
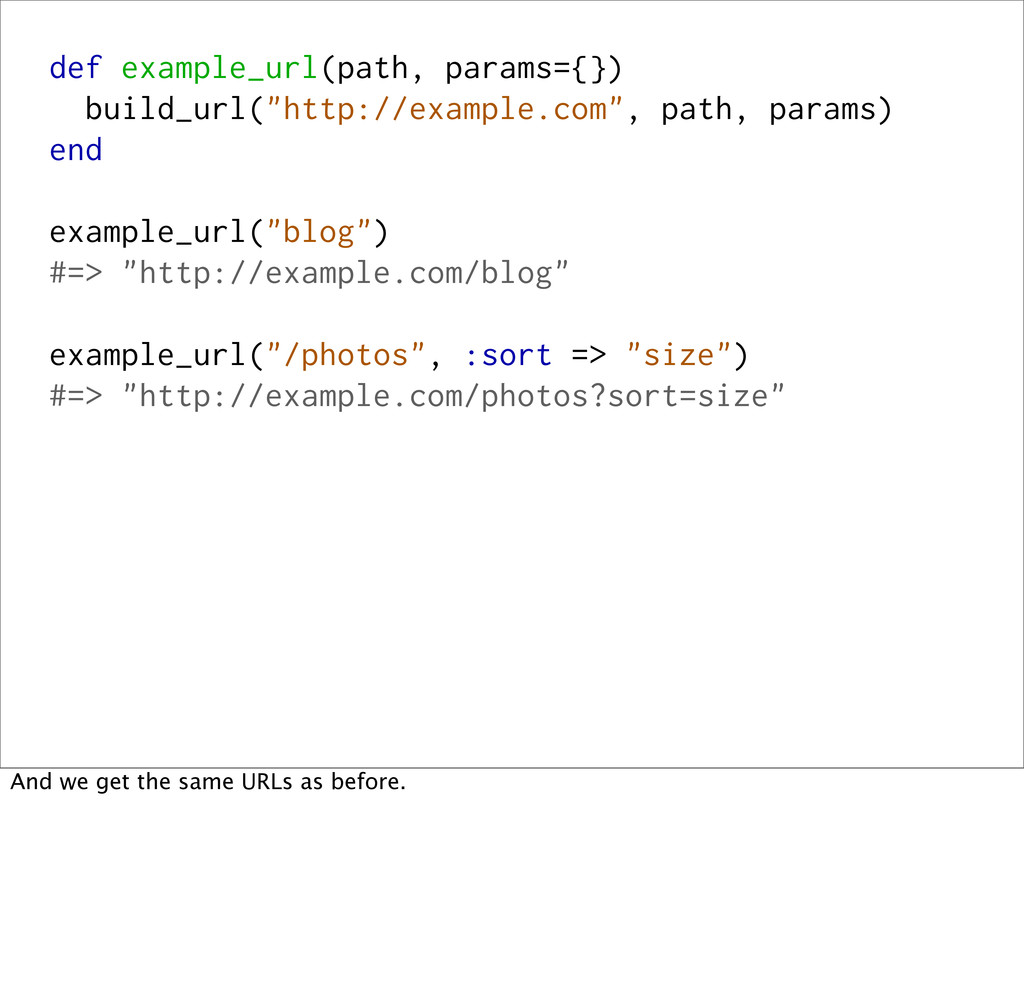
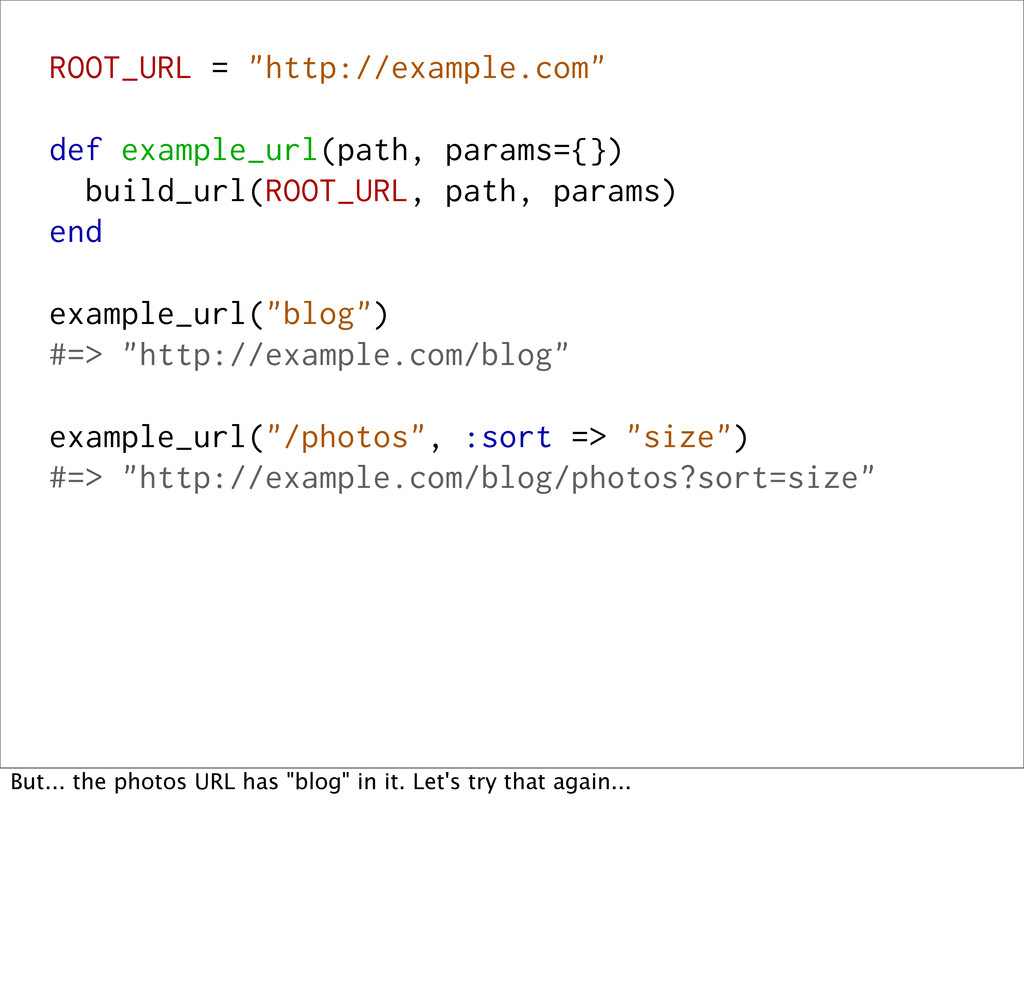
<< path base << "?" + params.to_param if params.present? base end build_url("http://example.com", "blog") #=> "http://example.com/blog" build_url("http://example.com", "/photos", :sort => "size") #=> "http://example.com/photos?sort=size" ...and ones that are a little more complex.
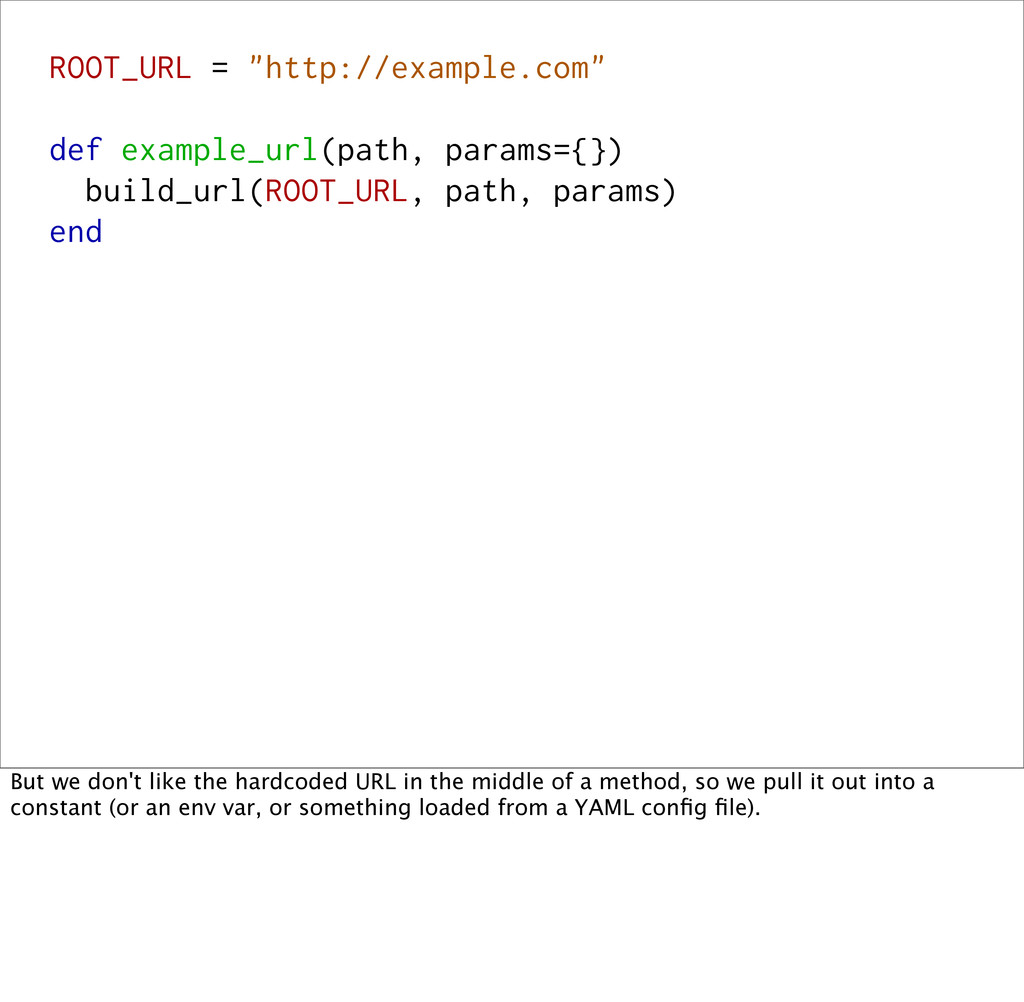
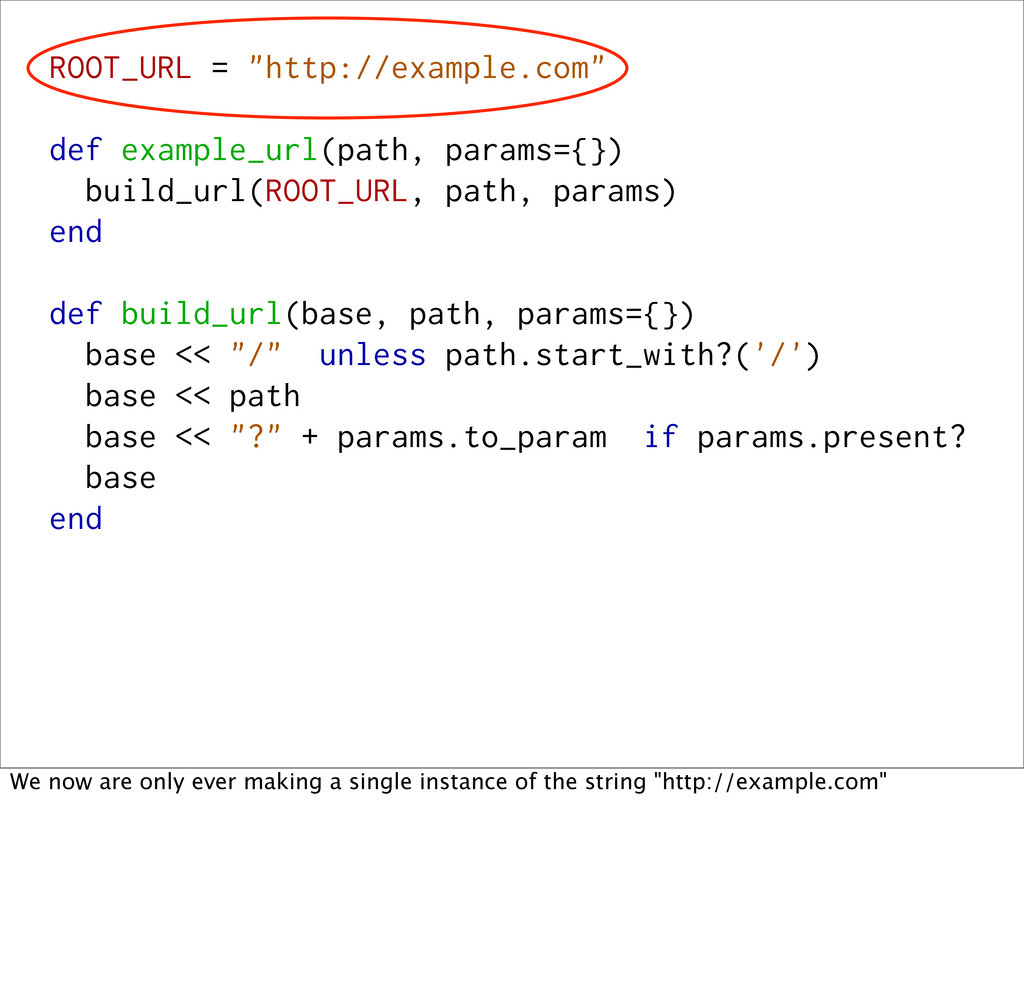
But we don't like the hardcoded URL in the middle of a method, so we pull it out into a constant (or an env var, or something loaded from a YAML config file).
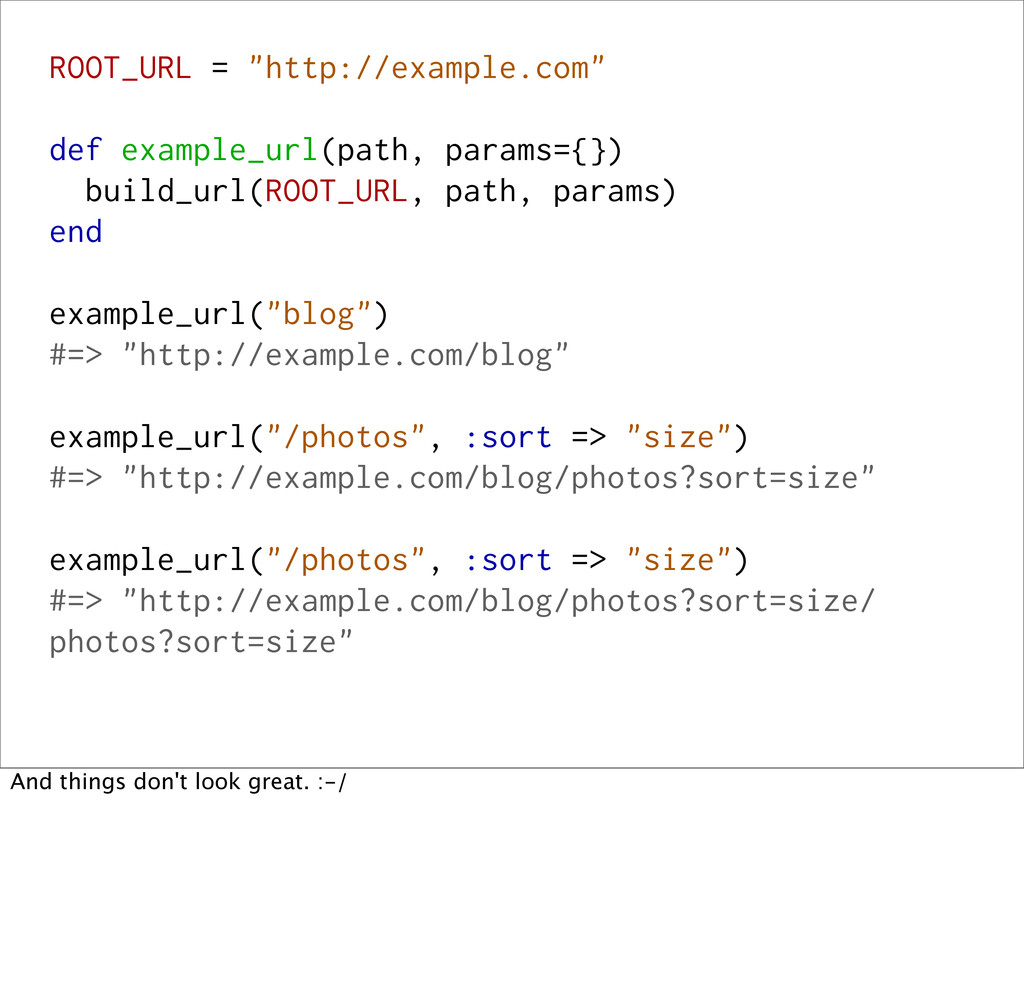
example_url("blog") #=> "http://example.com/blog" example_url("/photos", :sort => "size") #=> "http://example.com/blog/photos?sort=size" But... the photos URL has "blog" in it. Let's try that again...
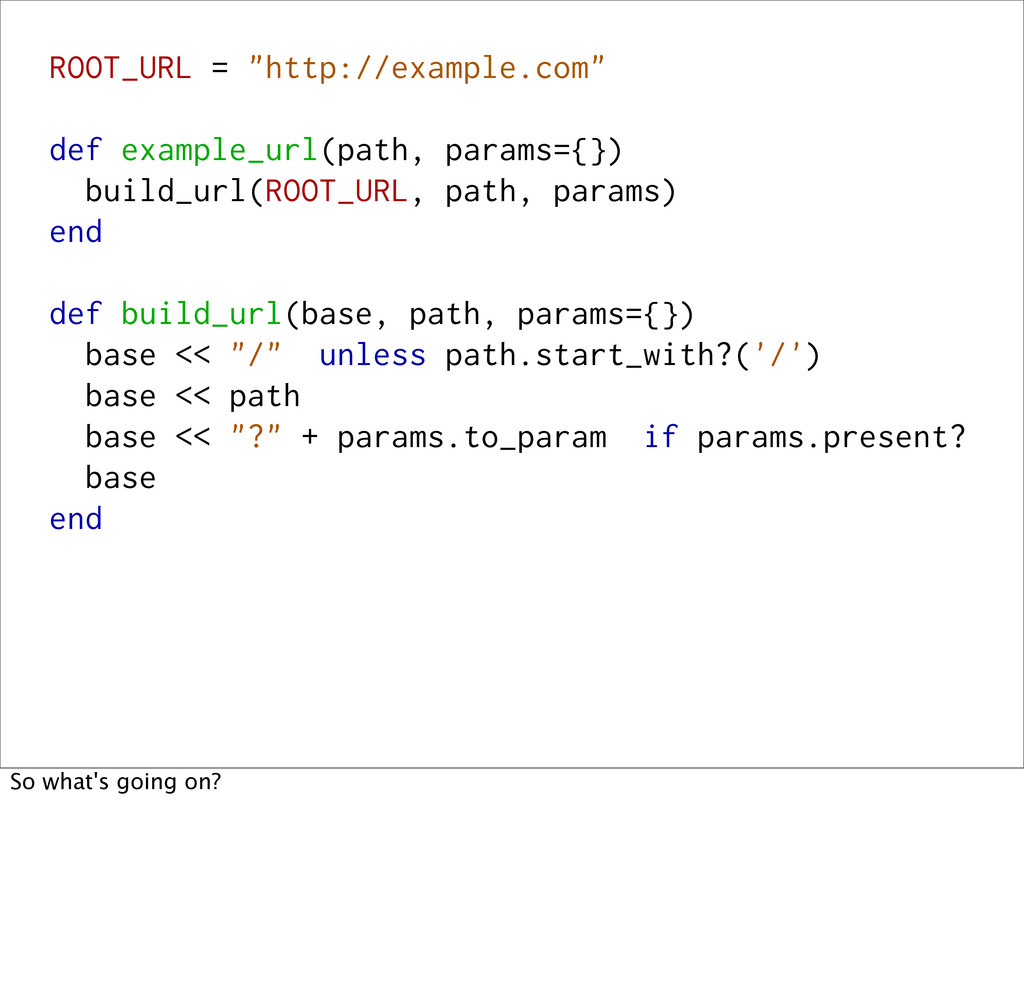
def build_url(base, path, params={}) base << "/" unless path.start_with?('/') base << path base << "?" + params.to_param if params.present? base end So what's going on?
def build_url(base, path, params={}) base << "/" unless path.start_with?('/') base << path base << "?" + params.to_param if params.present? base end We now are only ever making a single instance of the string "http://example.com"
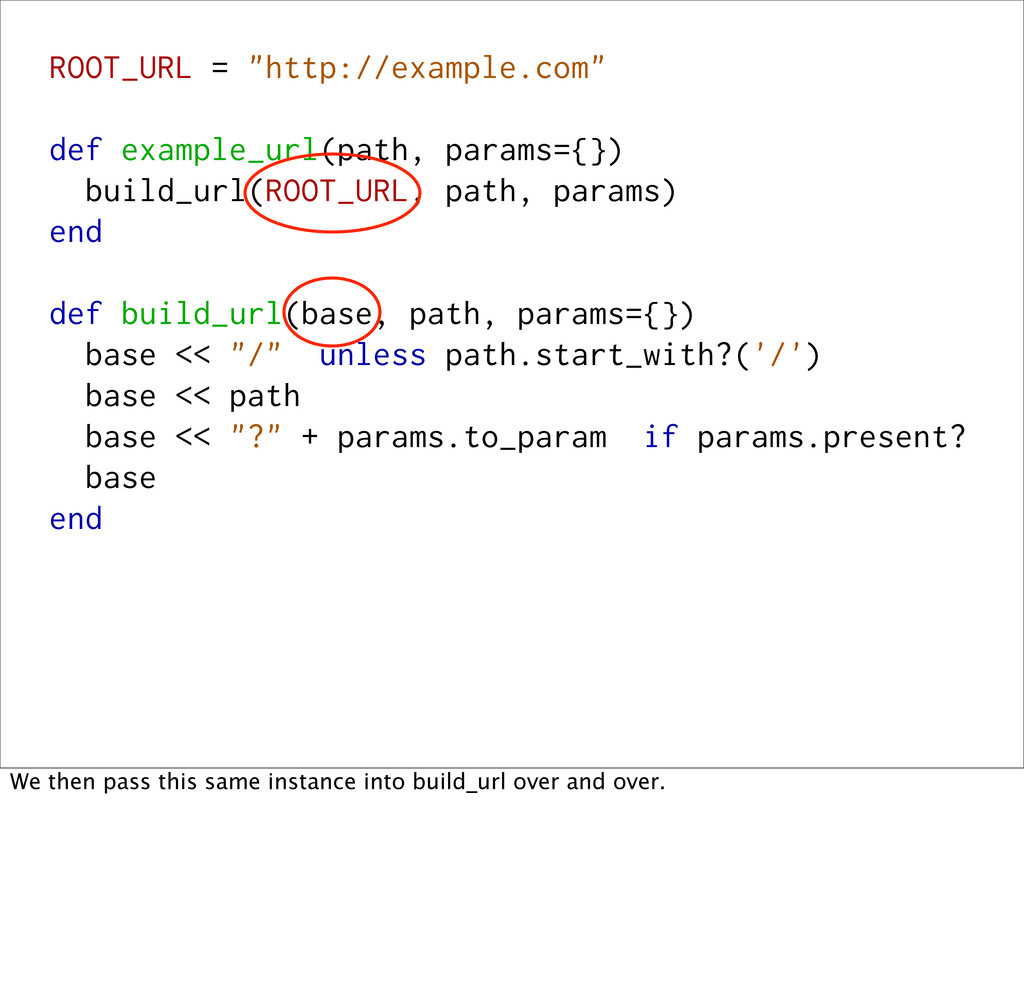
def build_url(base, path, params={}) base << "/" unless path.start_with?('/') base << path base << "?" + params.to_param if params.present? base end We then pass this same instance into build_url over and over.
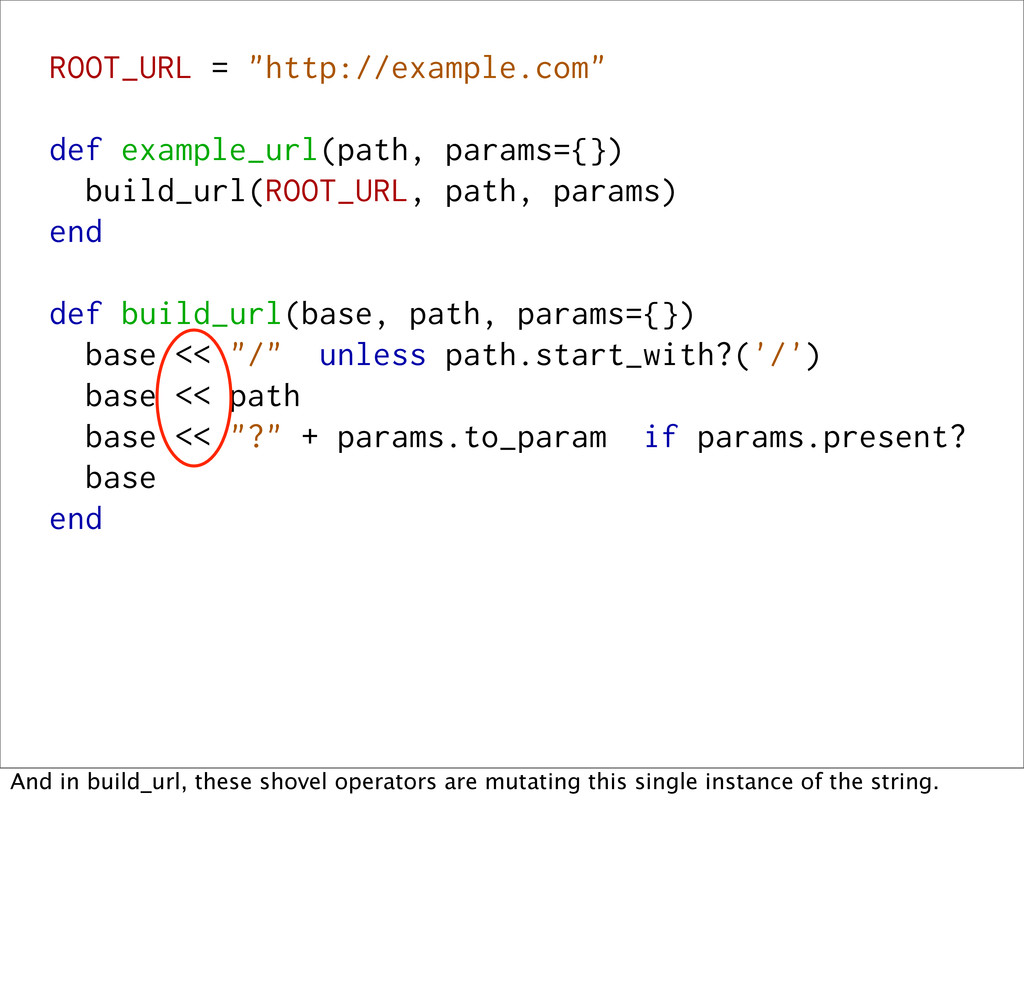
def build_url(base, path, params={}) base << "/" unless path.start_with?('/') base << path base << "?" + params.to_param if params.present? base end And in build_url, these shovel operators are mutating this single instance of the string.
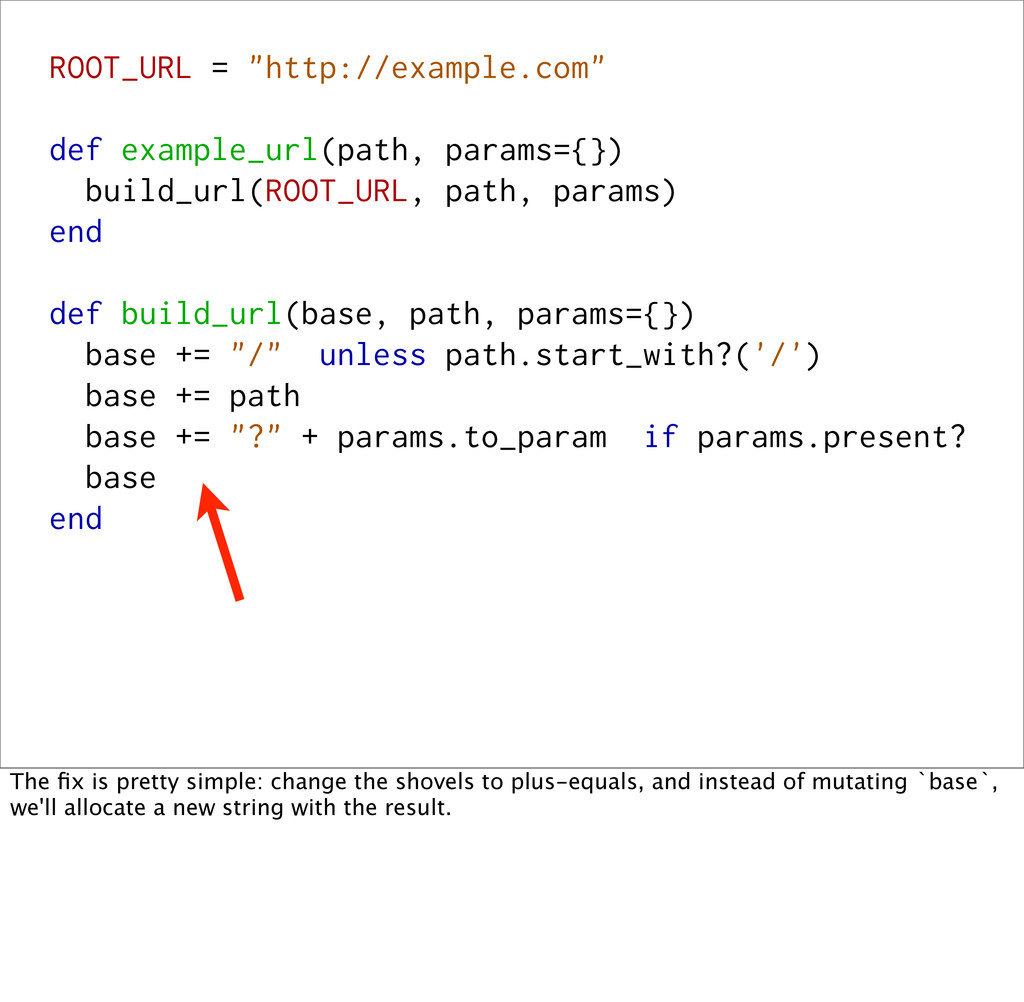
def build_url(base, path, params={}) base += "/" unless path.start_with?('/') base += path base += "?" + params.to_param if params.present? base end The fix is pretty simple: change the shovels to plus-equals, and instead of mutating `base`, we'll allocate a new string with the result.
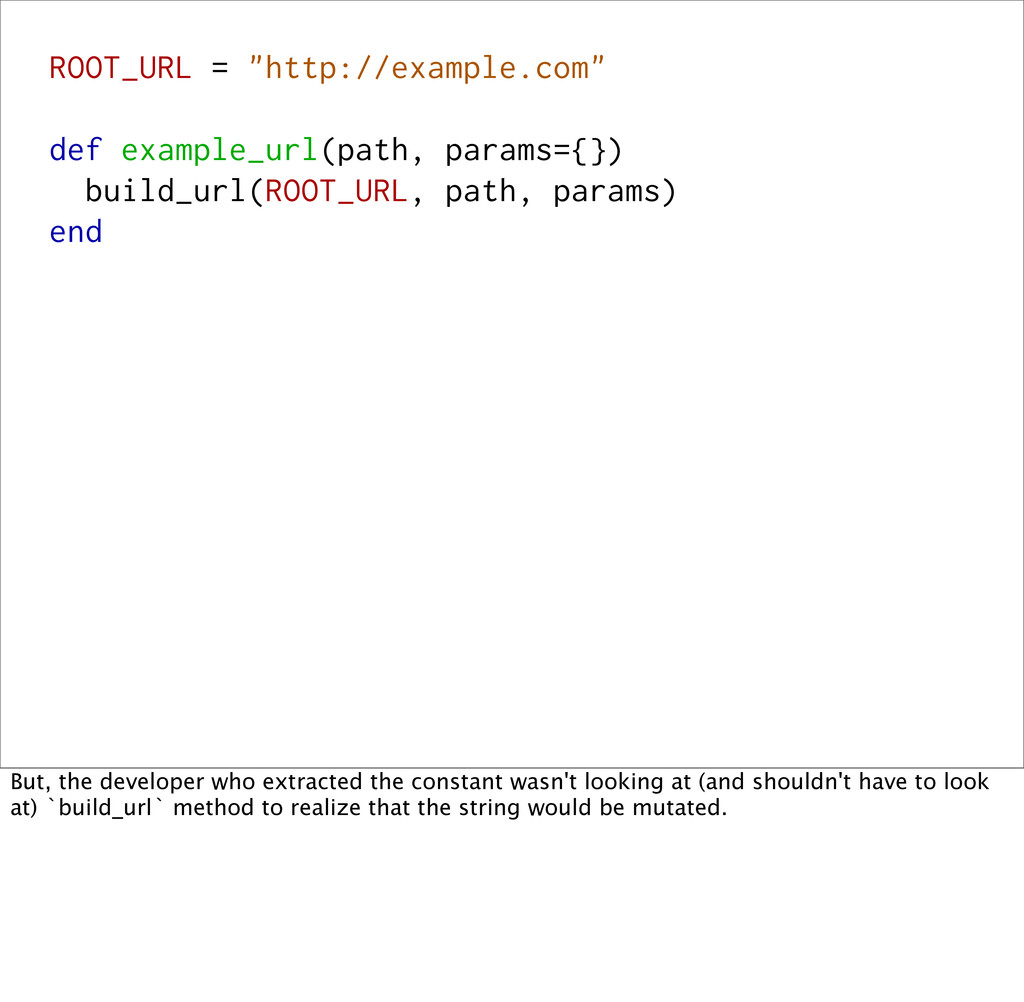
But, the developer who extracted the constant wasn't looking at (and shouldn't have to look at) `build_url` method to realize that the string would be mutated.
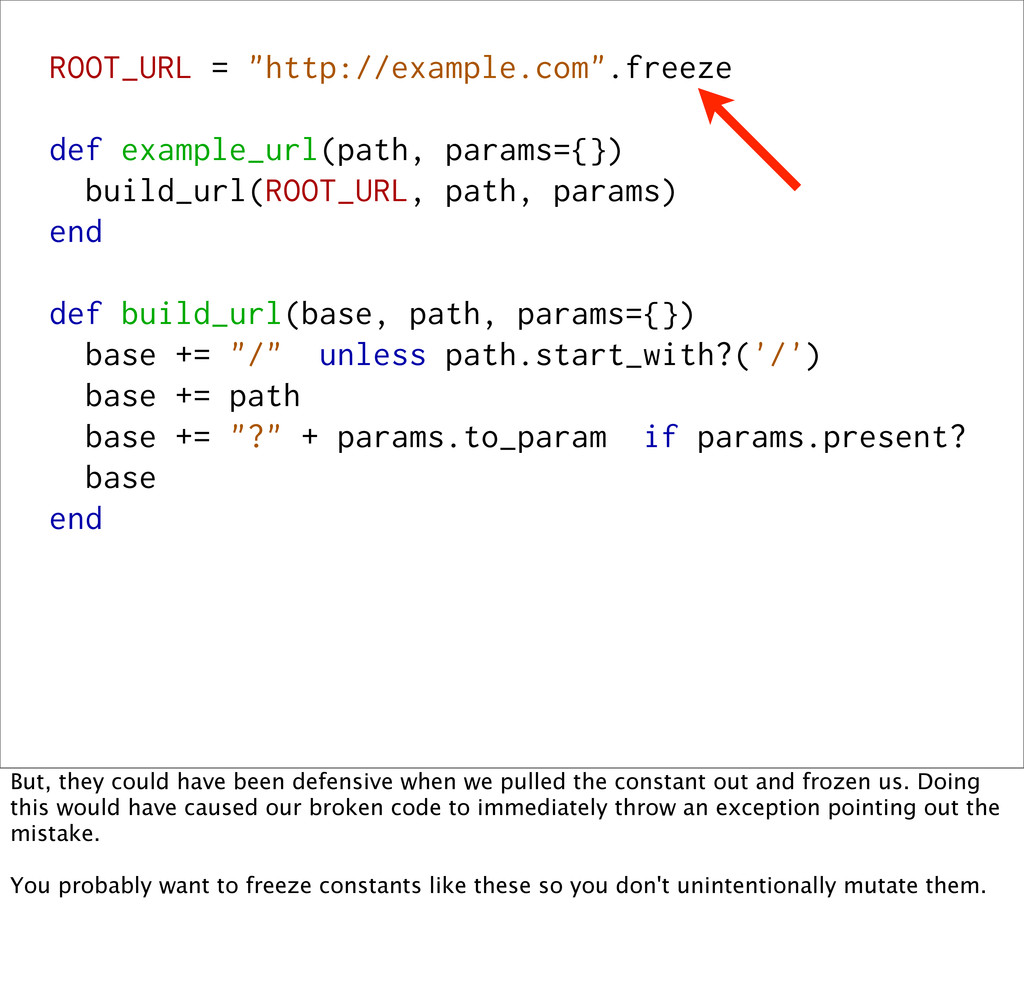
def build_url(base, path, params={}) base += "/" unless path.start_with?('/') base += path base += "?" + params.to_param if params.present? base end But, they could have been defensive when we pulled the constant out and frozen us. Doing this would have caused our broken code to immediately throw an exception pointing out the mistake. You probably want to freeze constants like these so you don't unintentionally mutate them.
freeze the instance variables, collection elements, etc. of the object you freeze. There's an ice_nine gem that adds a `deep_freeze` method that will recursively freeze all of these things.
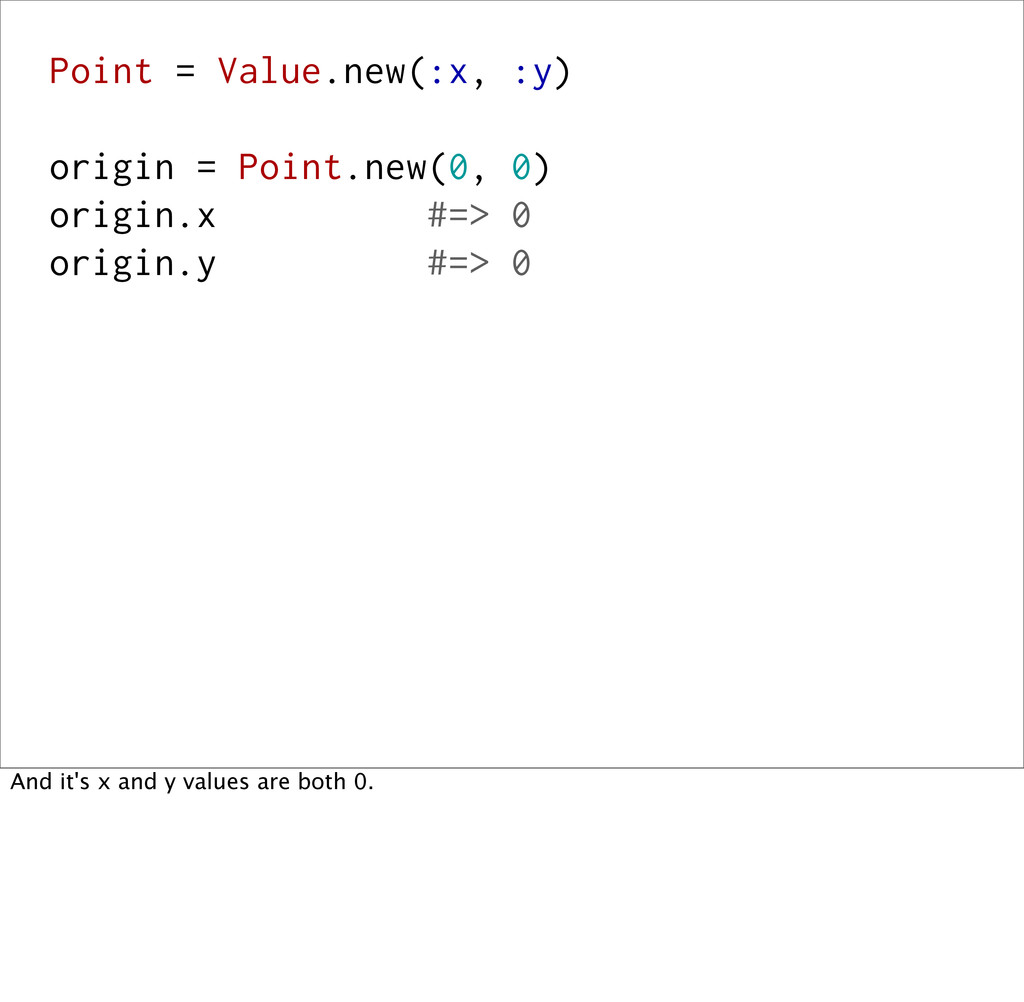
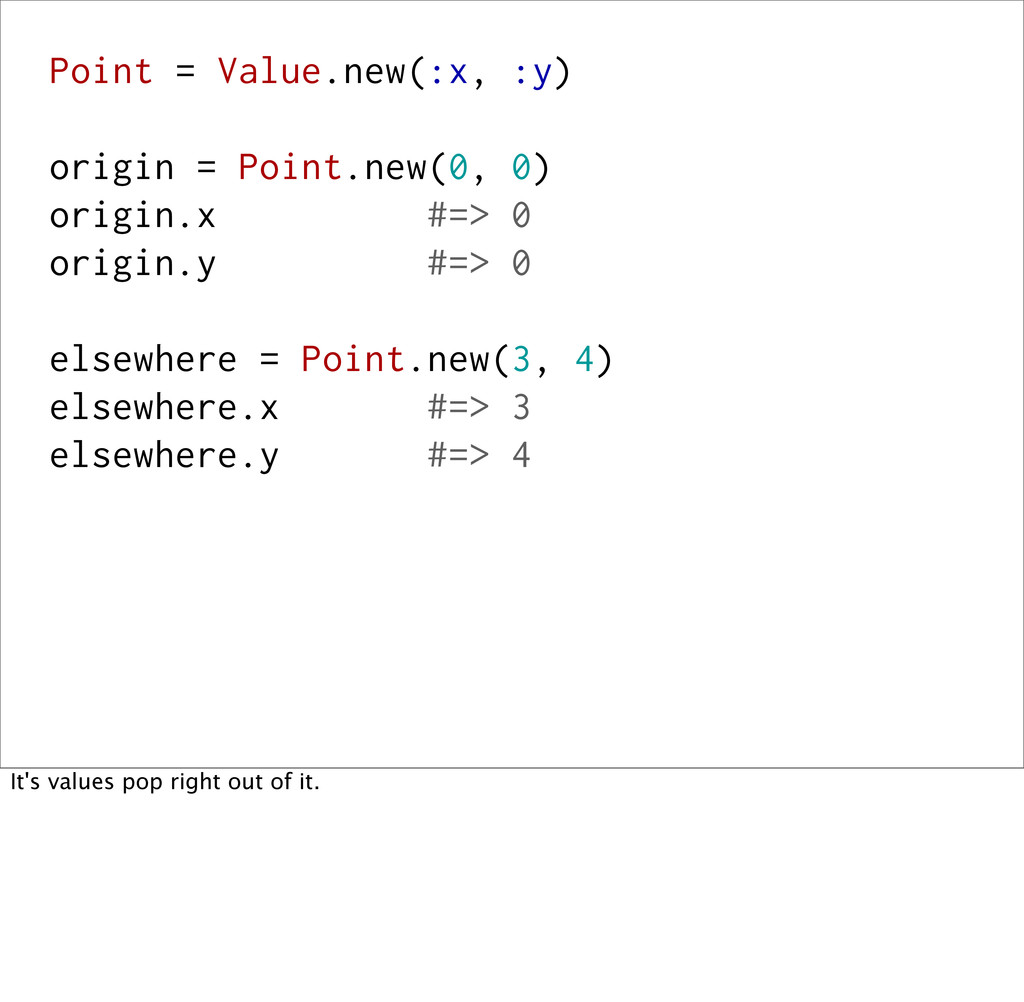
the data inside of them, rather than some external identity. So, ActiveRecord objects are not values, because even if two distinct AR objects contain the same data, they aren't equal. Their `id`s are what determine their identity. Values are also immutable. You work with values (like numbers and time) every day in Ruby, but you aren't limited to the value objects that Ruby provides you.
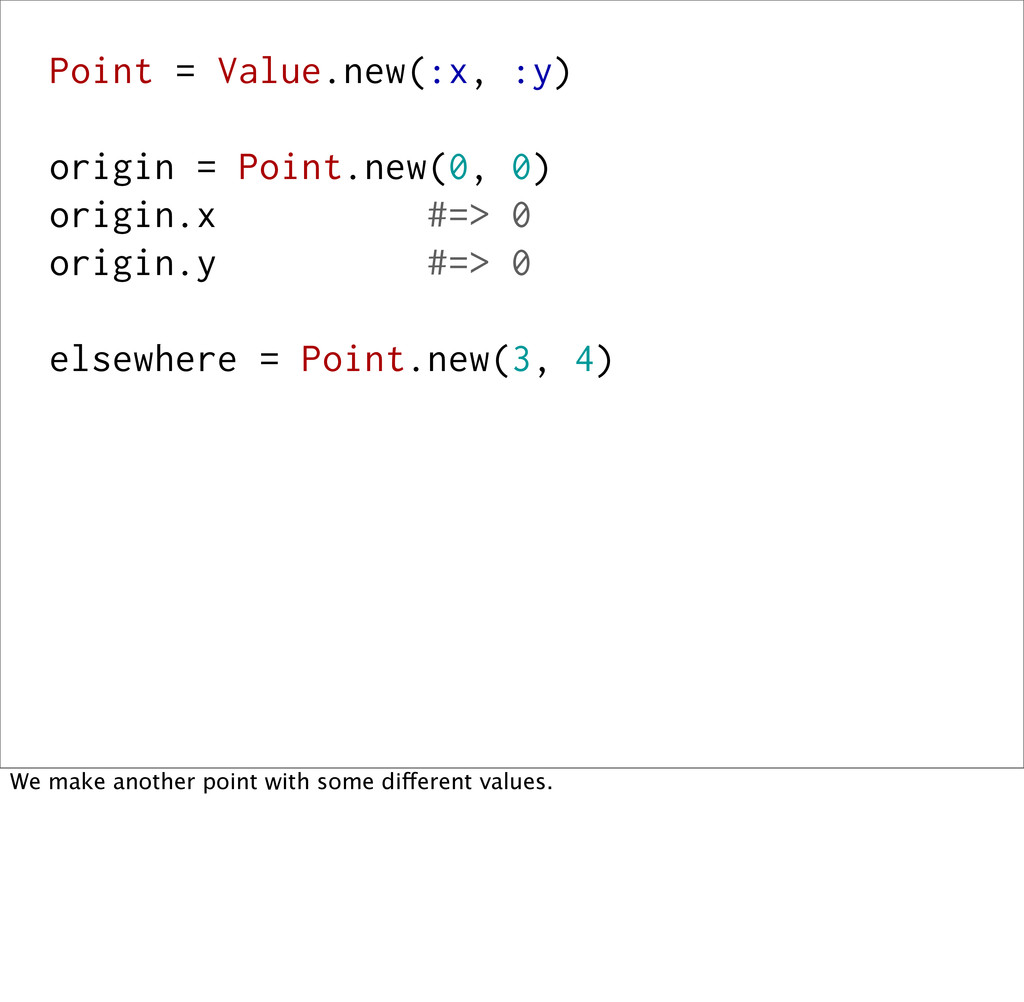
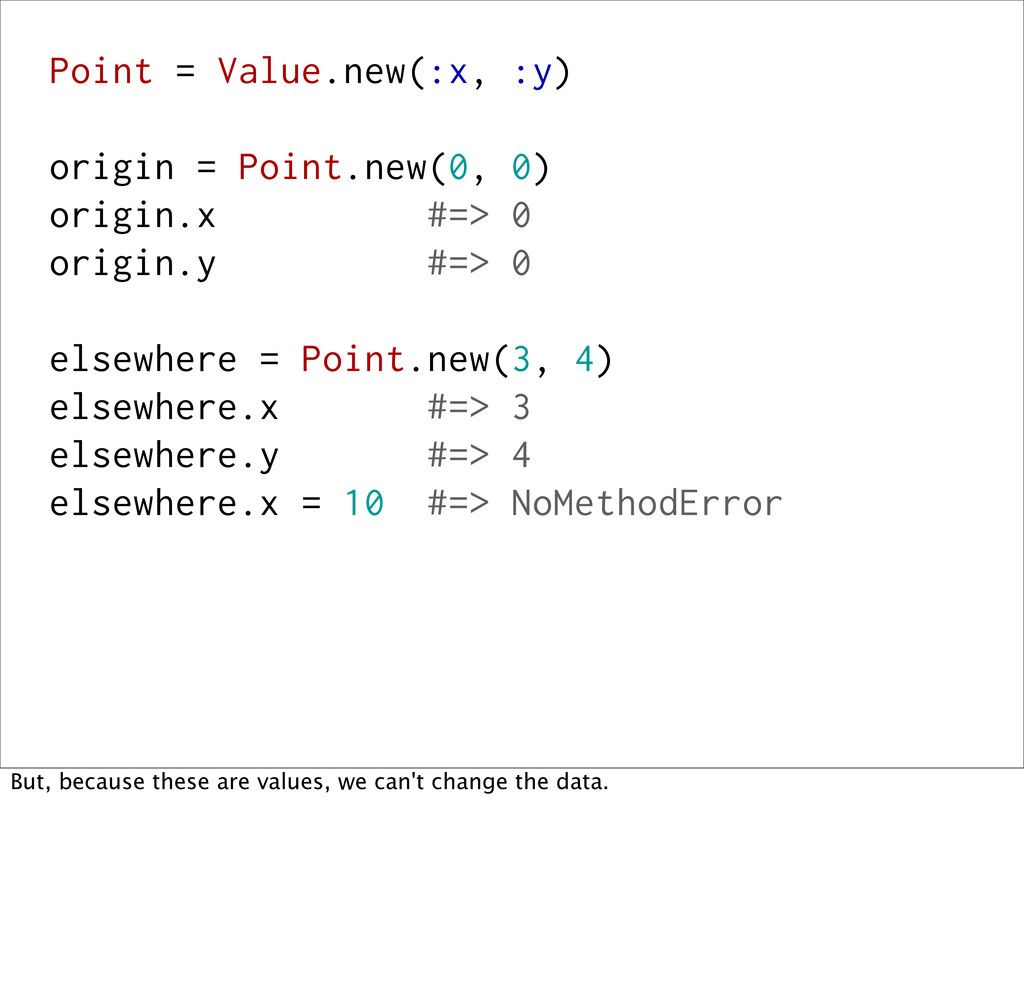
0 origin.y #=> 0 elsewhere = Point.new(3, 4) elsewhere.x #=> 3 elsewhere.y #=> 4 elsewhere.x = 10 #=> NoMethodError elsewhere == Point.new(3, 4) #=> true And, the equality is based off of the data inside of it, not any kind of external identity (e.g. object_id). And, once you determine that two values are identical, you know they'll always be.
*(scale) Point.new(x * scale, y * scale) end end Point.new(1, 2) * 3 #=> "(3, 6)" Value objects can have "behavior", in the form of convenience methods. These methods can't modify the internal state of the object though.
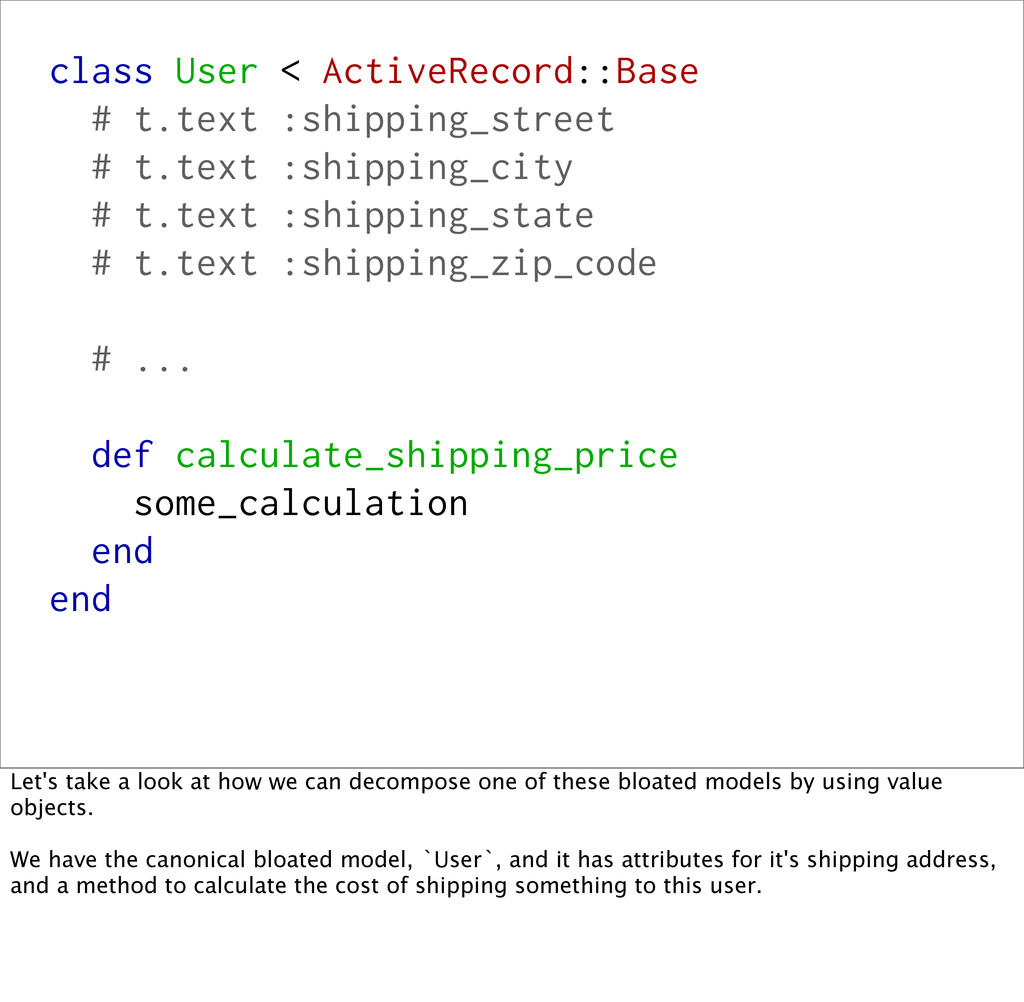
is something we hear in Rails-land all the time. Having logic in your models is definitely better than having logic in your controllers, but now there's a proliferation of apps with "god objects" that have thousands of lines of code and hundreds of methods. (It's often your `User` class, or some other central model central to your domain). Value objects are a natural way to pull logic out of your bloated models.
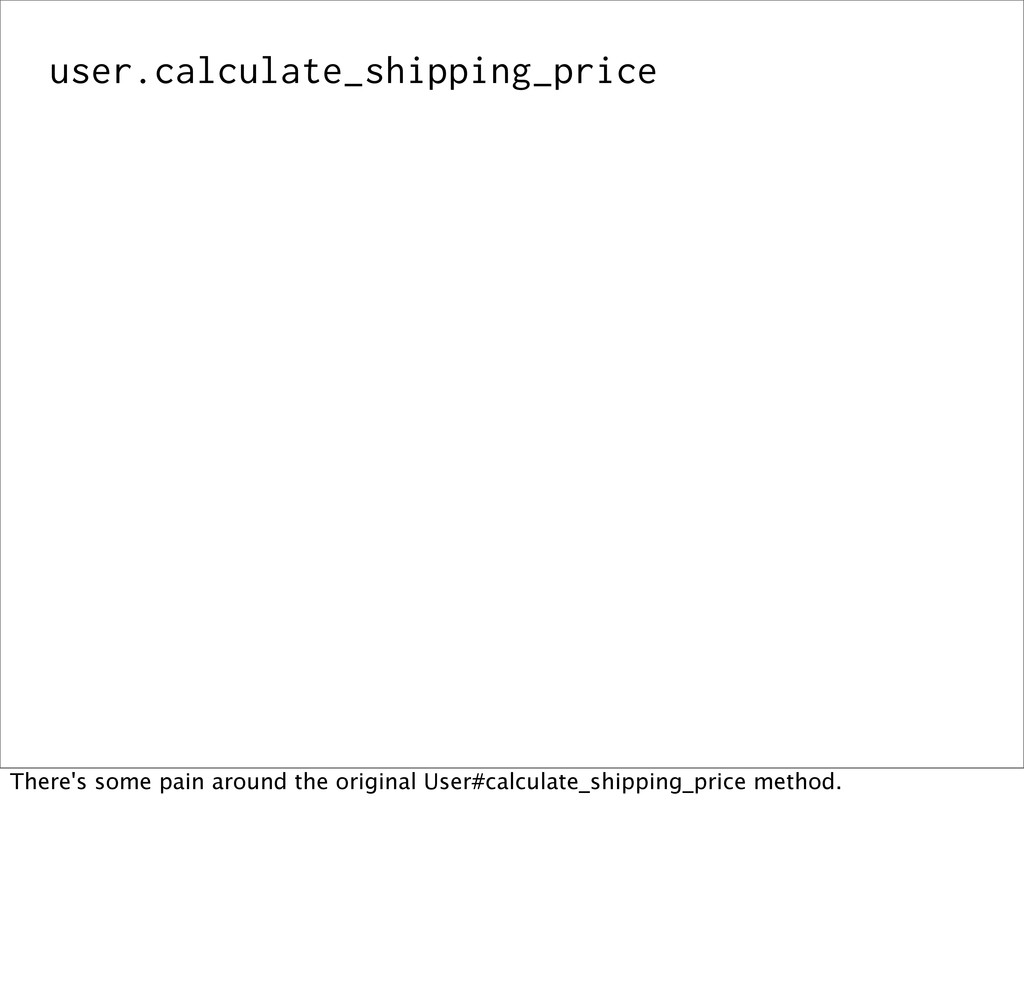
# t.text :shipping_state # t.text :shipping_zip_code # ... def calculate_shipping_price some_calculation end end Let's take a look at how we can decompose one of these bloated models by using value objects. We have the canonical bloated model, `User`, and it has attributes for it's shipping address, and a method to calculate the cost of shipping something to this user.
=> [ ["shipping_street", "street"], ["shipping_city", "city"], ["shipping_state", "state"], ["shipping_zip_code", "zip_code"] ] end We used ActiveRecord's composed_of helper to map our database fields to the value object's fields.
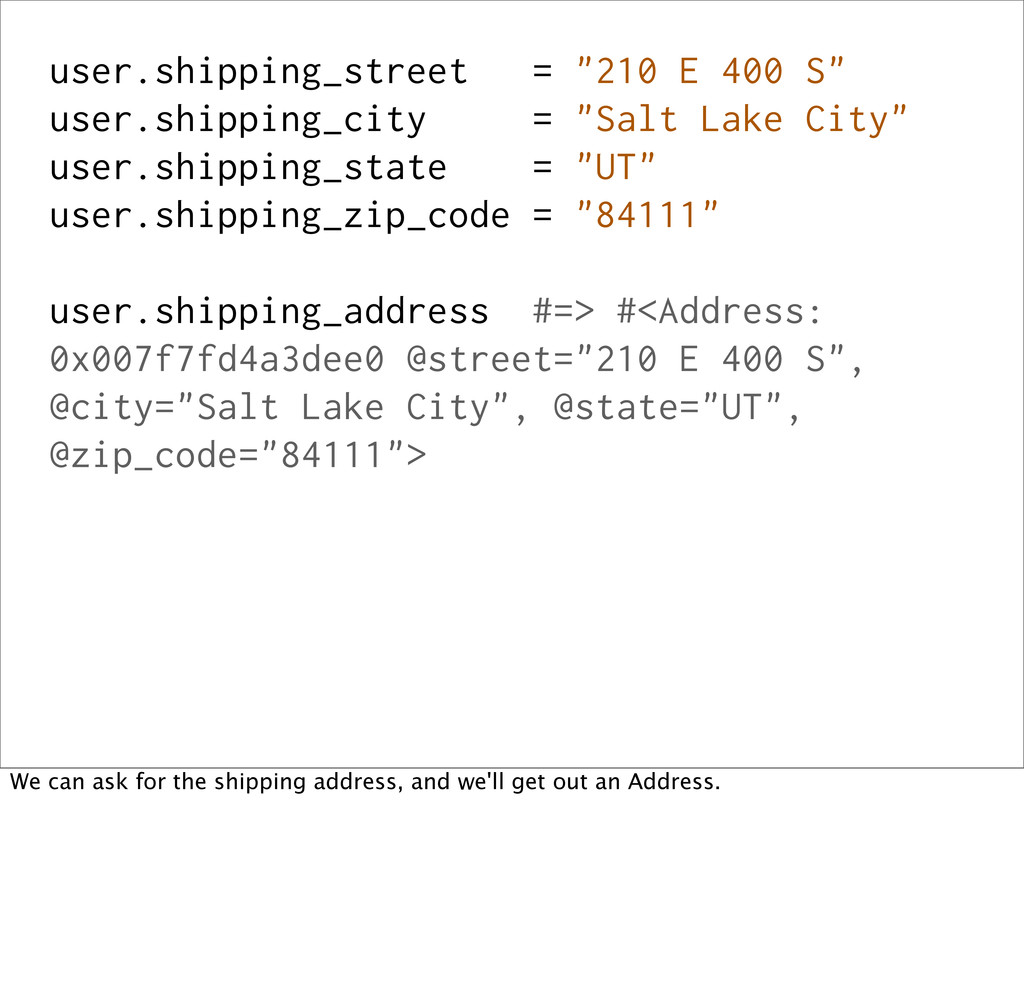
City" user.shipping_state = "UT" user.shipping_zip_code = "84111" Now, when the fields are assigned to (from a form, or as it comes out of the database)...
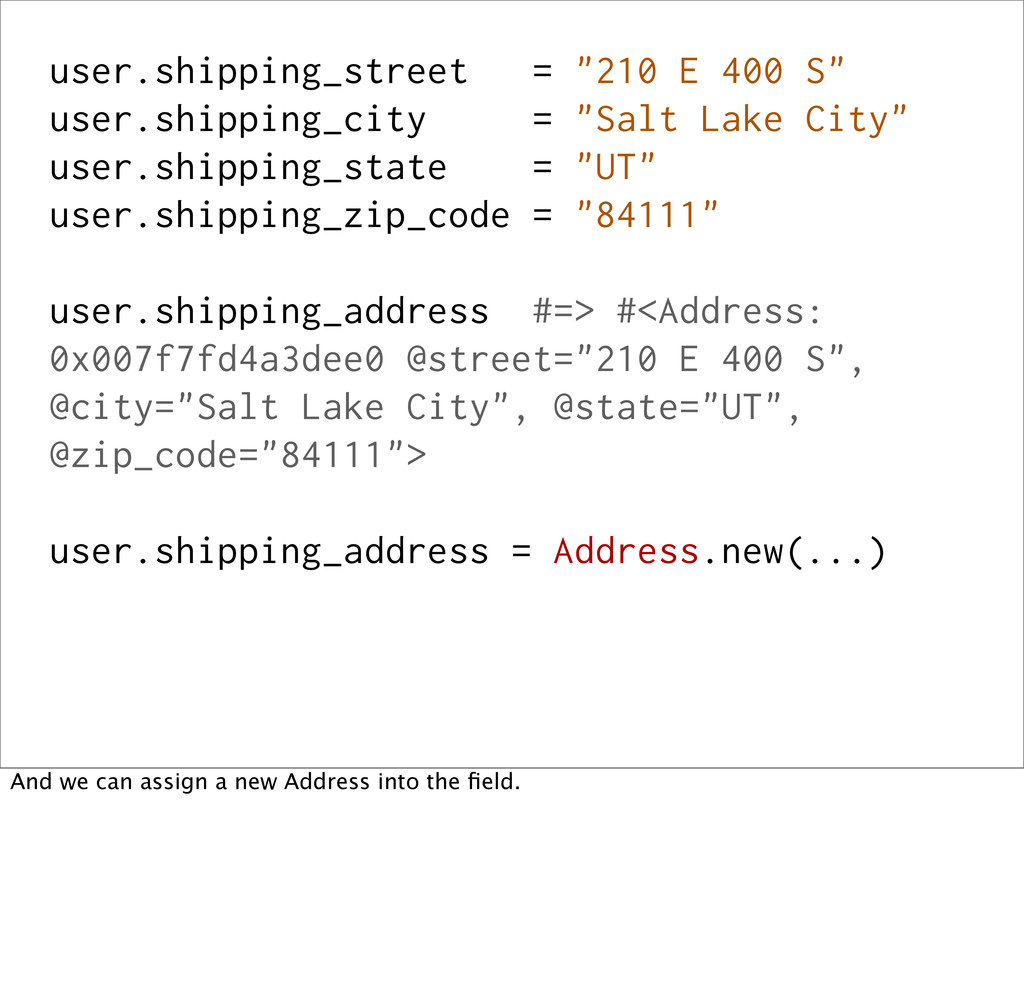
City" user.shipping_state = "UT" user.shipping_zip_code = "84111" user.shipping_address #=> #<Address: 0x007f7fd4a3dee0 @street="210 E 400 S", @city="Salt Lake City", @state="UT", @zip_code="84111"> We can ask for the shipping address, and we'll get out an Address.
City" user.shipping_state = "UT" user.shipping_zip_code = "84111" user.shipping_address #=> #<Address: 0x007f7fd4a3dee0 @street="210 E 400 S", @city="Salt Lake City", @state="UT", @zip_code="84111"> user.shipping_address = Address.new(...) And we can assign a new Address into the field.
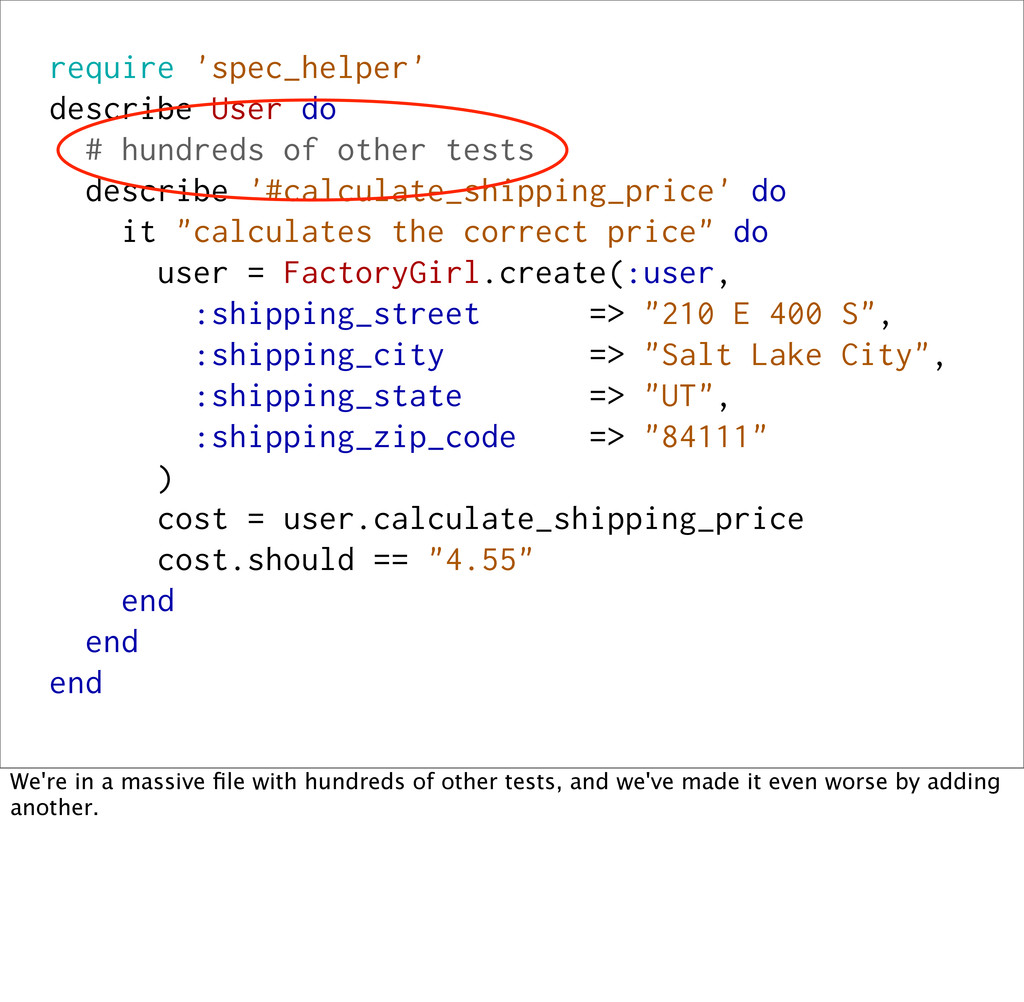
describe '#calculate_shipping_price' do it "calculates the correct price" do user = FactoryGirl.create(:user, :shipping_street => "210 E 400 S", :shipping_city => "Salt Lake City", :shipping_state => "UT", :shipping_zip_code => "84111" ) cost = user.calculate_shipping_price cost.should == "4.55" end end end Testing the version of the method that lives on `User` isn't _too_ difficult, but there are a few unpleasantries.
describe '#calculate_shipping_price' do it "calculates the correct price" do user = FactoryGirl.create(:user, :shipping_street => "210 E 400 S", :shipping_city => "Salt Lake City", :shipping_state => "UT", :shipping_zip_code => "84111" ) cost = user.calculate_shipping_price cost.should == "4.55" end end end We have to include spec_helper, which is going to fire up an entire rails environment and make our test slow to start.
describe '#calculate_shipping_price' do it "calculates the correct price" do user = FactoryGirl.create(:user, :shipping_street => "210 E 400 S", :shipping_city => "Salt Lake City", :shipping_state => "UT", :shipping_zip_code => "84111" ) cost = user.calculate_shipping_price cost.should == "4.55" end end end We're in a massive file with hundreds of other tests, and we've made it even worse by adding another.
describe '#calculate_shipping_price' do it "calculates the correct price" do user = FactoryGirl.create(:user, :shipping_street => "210 E 400 S", :shipping_city => "Salt Lake City", :shipping_state => "UT", :shipping_zip_code => "84111" ) cost = user.calculate_shipping_price cost.should == "4.55" end end end We have to use FactoryGirl to build up a model, and we have to talk to the database to save it.
price for here" do address = Address.new( :street => "489 Elizabeth Street", :city => "Melbourne", :state => "VIC", :postal_code => "3000" ) cost = address.calculate_price cost.should == "4.55" end end end If we have a separate `Shipping` class, then the tests become a lot nicer. There are no dependencies on external libraries, no special factories, and we end up with both a class and test quite that are small and isolated.
be able to calculate shipping costs for domain models besides `User`, again, the 2nd version is incredibly easy to extend, but to make the 1st work, we'd probably have to extract some sort of `Shippable` module that gets mixed into both `User` and `Business` and is not at all straightforward to test.
you decided you needed to have different shipping prices for different items, you could move the `calculate_shipping_price` to the items, and have the method take an `Address`. And this change is fairly non-invasive because we're passing around value objects rather then full blown models.
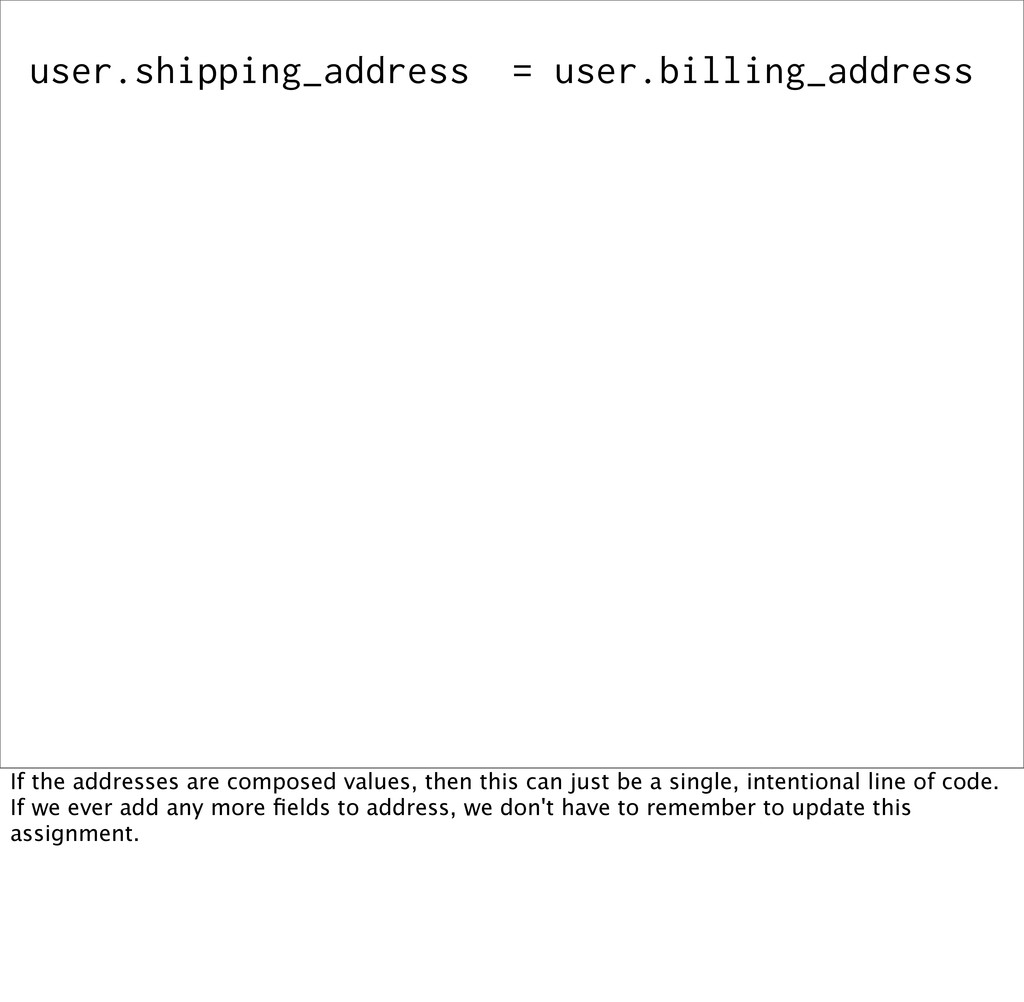
= user.billing_zip_code One more example of change that the value-based version is resilient to. Let's think about how we would implement the "my shipping address is the same as my billing address" check box. It's pretty ugly to have to assign each of the address fields individually, and we ever add a new field to the addresses, it's unlikely that we'd remember to come update this code.
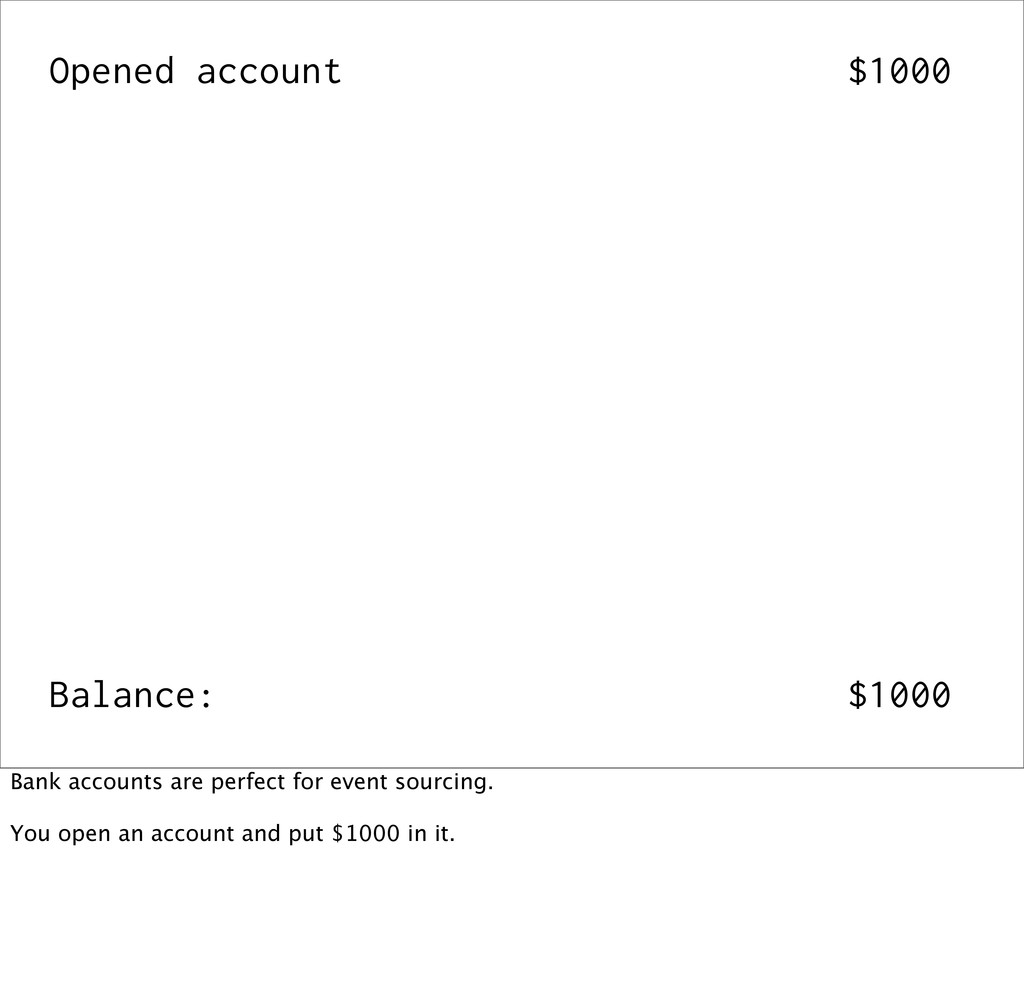
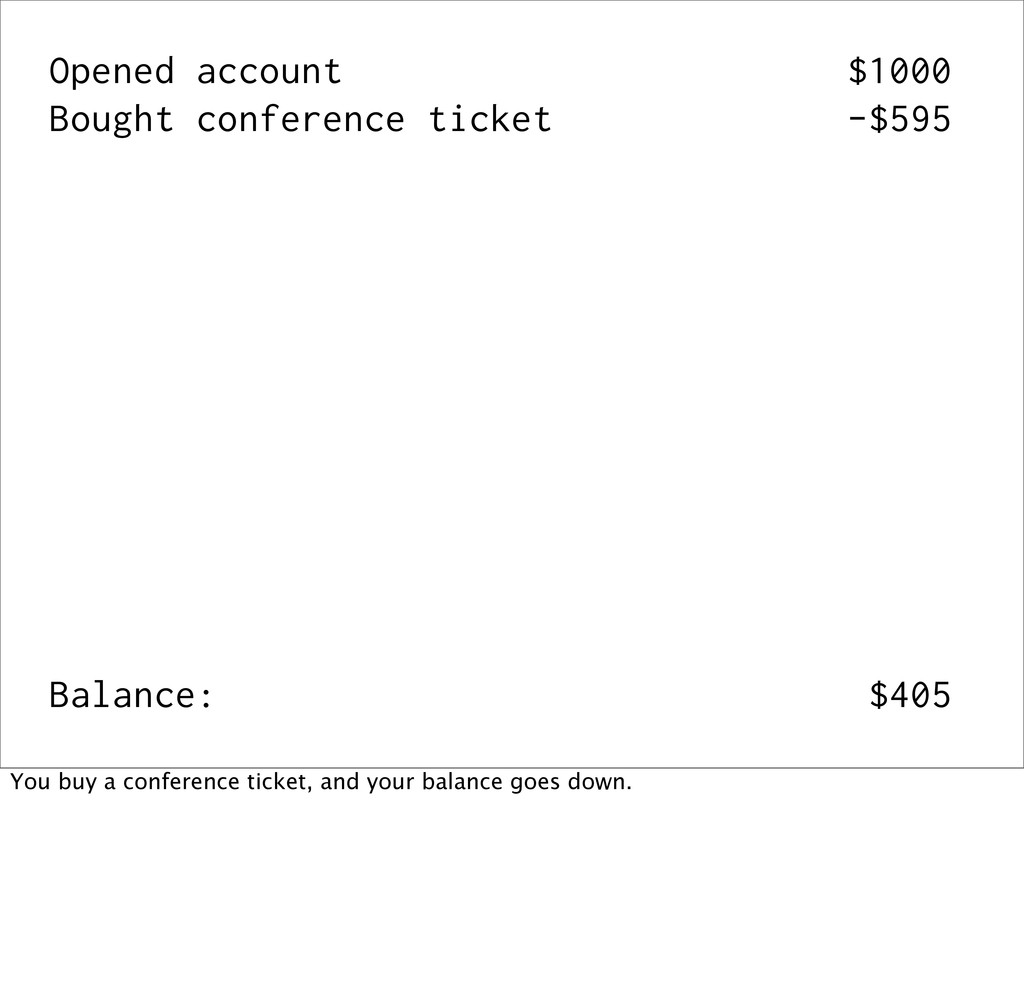
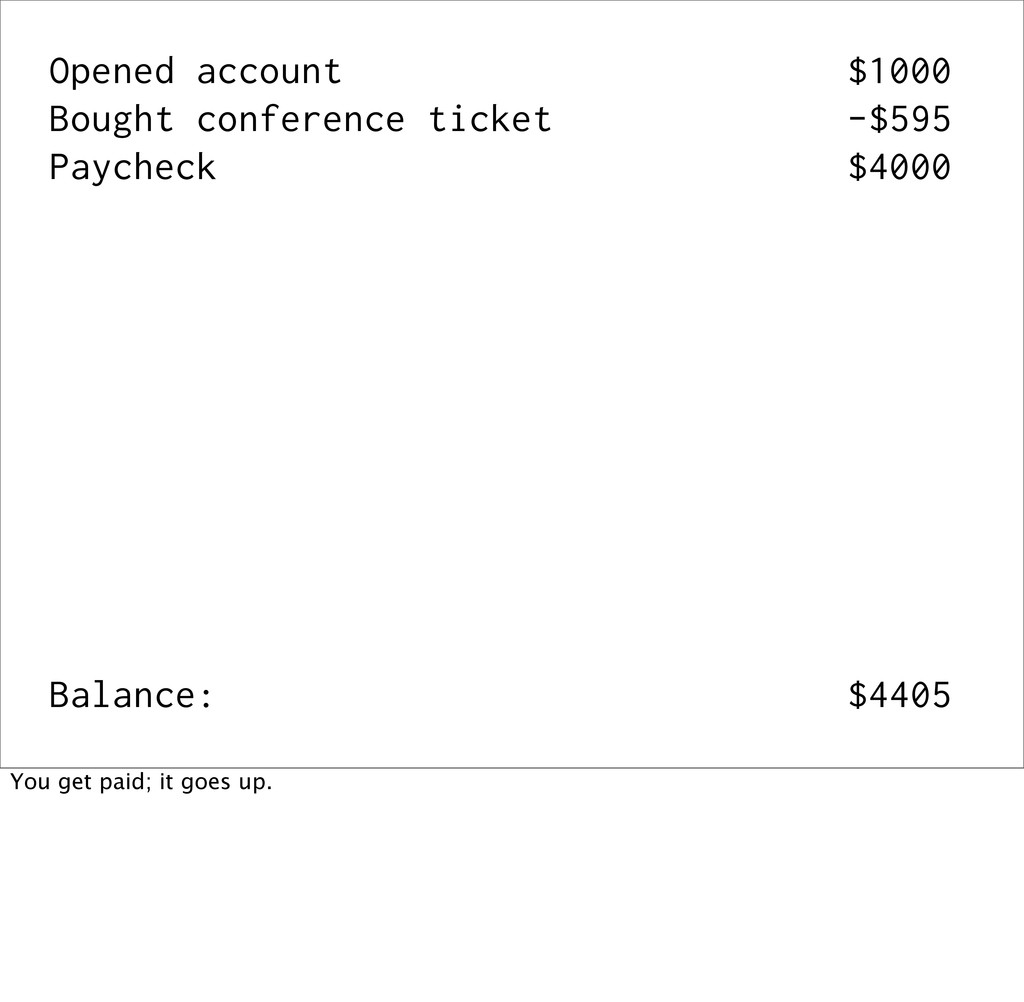
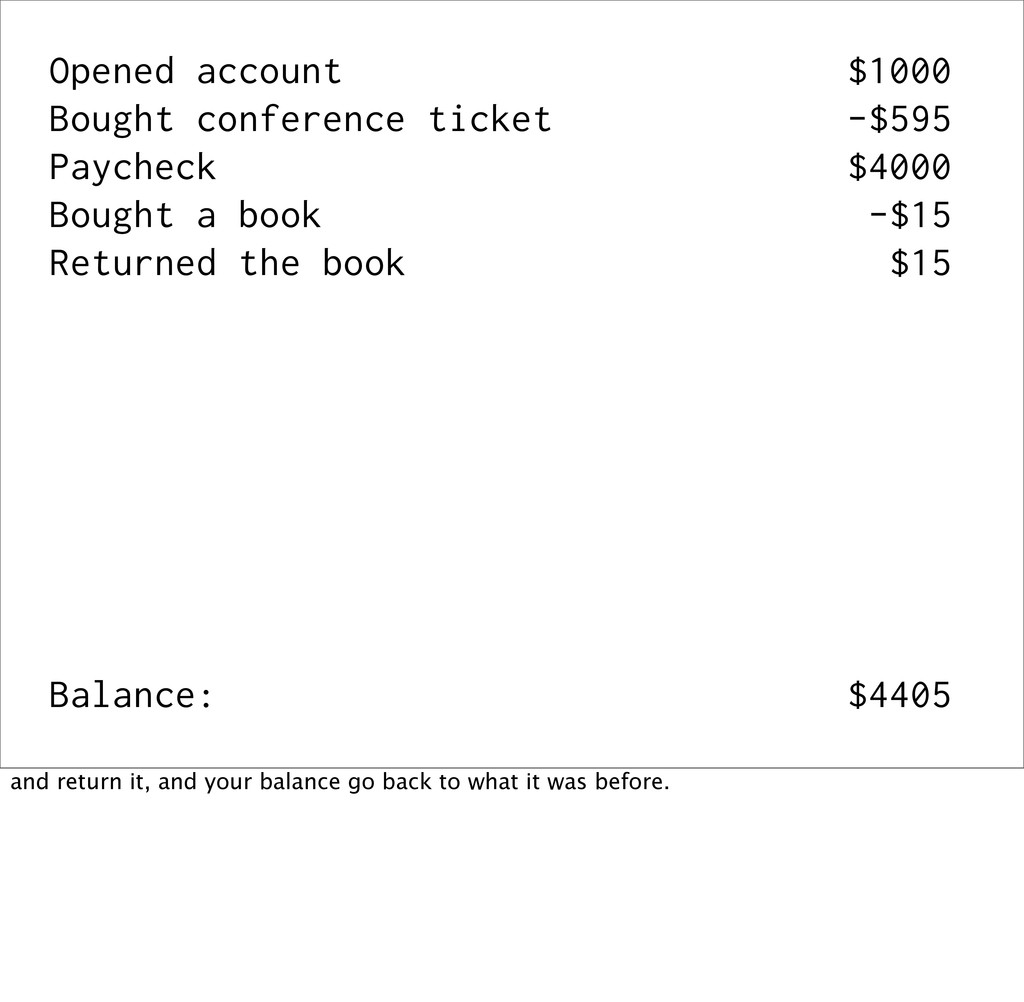
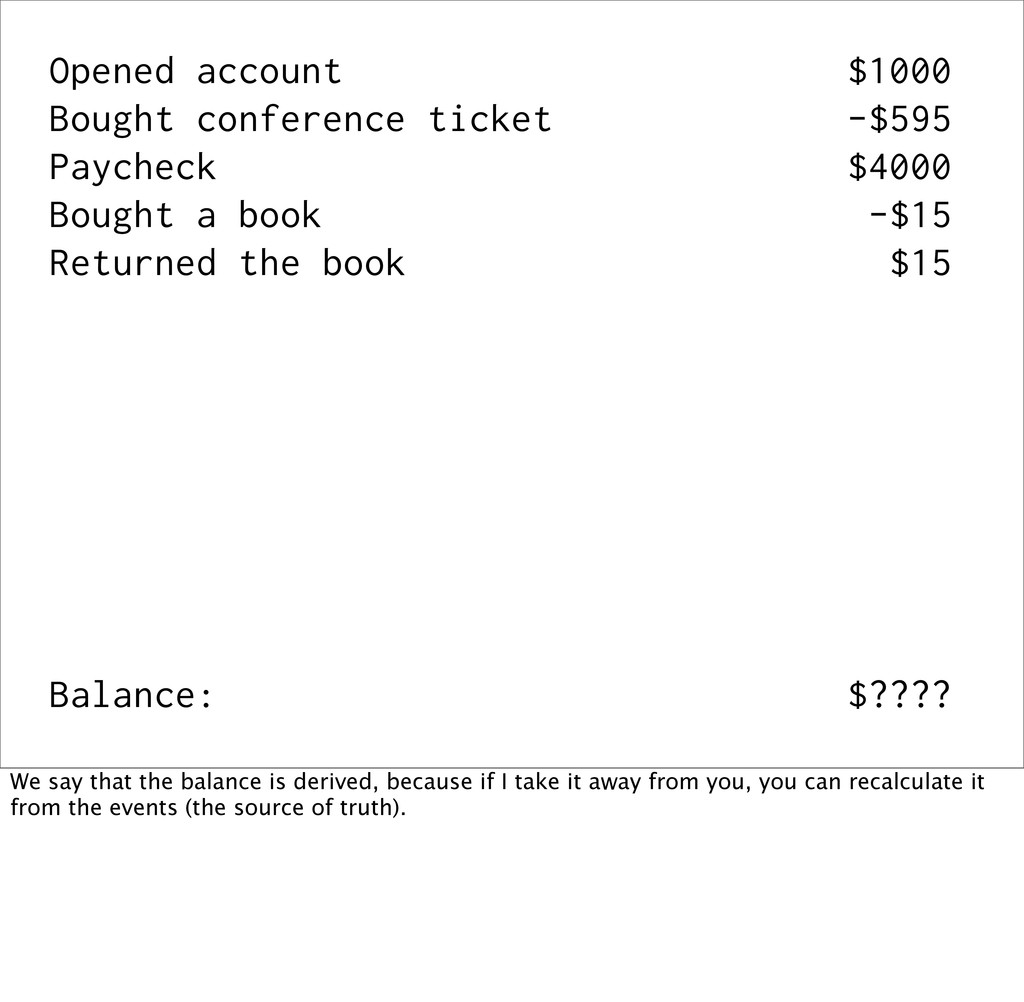
events Event sourcing is when you capture all changes to an application's state as a sequence of immutable events. This is best explained with an example...
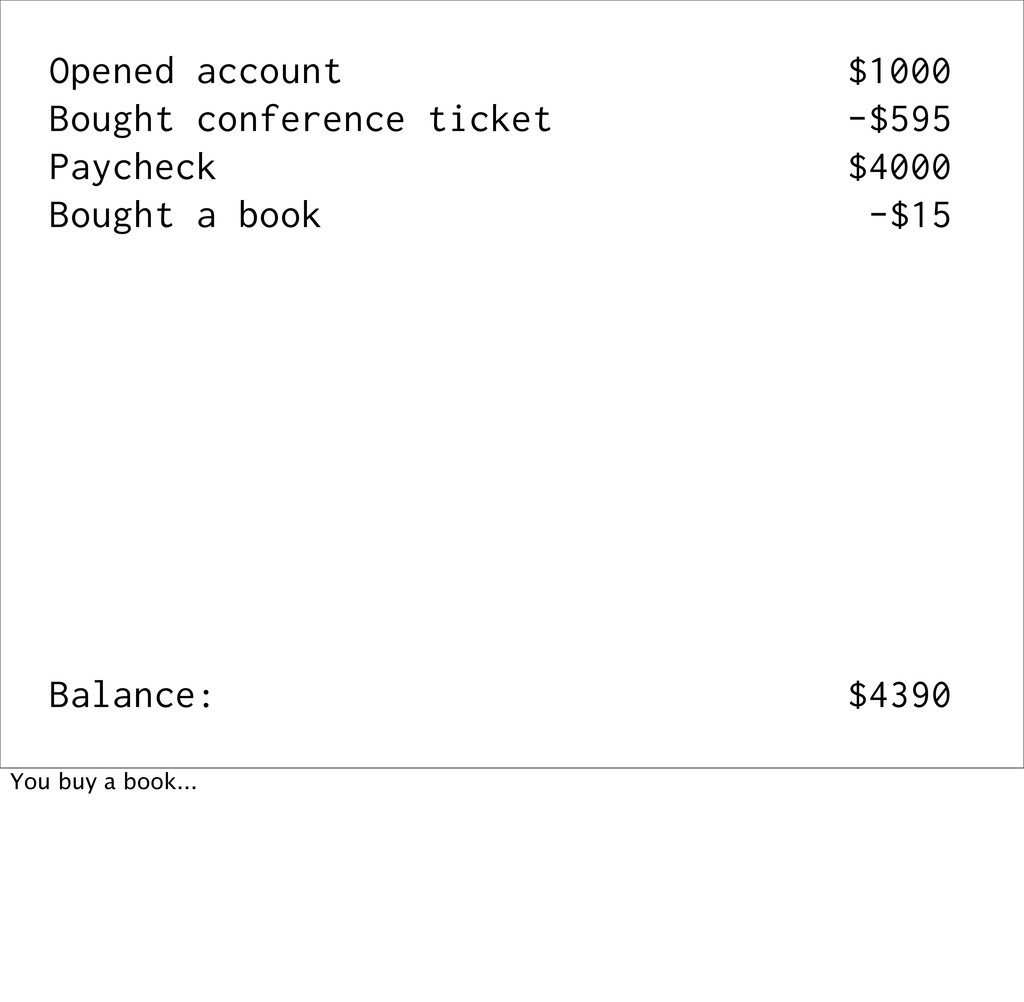
a book -$15 Returned the book $15 Balance: $???? We say that the balance is derived, because if I take it away from you, you can recalculate it from the events (the source of truth).
be replayed. If there's an error, the banks programmers could grab the event log and replay it up until the point in time where the error occurred, and they'd have the system in the exact state it was in in production.
startup, we built a family tree feature, and we decided to event source all of the modifications to the family trees on our site. This turned out to be a really good decision.
a fancy pants graph database, but we didn't trust it (and our administration of it) to not lose our data. We stored the event log in Postgres and the resulting application state in the graph database. If the graph database ever went kaput, we would still have a canonical version of the data in reliable storage.
back into Postgres, and rather than having to do a complicated ETL to get the data out of the graph DB and into Postgres, we changed our code to write the computed data into Postgres. We then replayed the entire event log, and our Postgres DB then held all of our data, in the most recent state.
and modifications of a field can be made in just one table" So that we won't have to make updates in more than one place. Well... if you're not making updates, then you'll never have to do it in more than one place, and thus normalization isn't necessary.
let you declare variable as const or final, Ruby will gladly let you reach inside objects and change their instance variables, reassign constants, and even unfreeze frozen objects.
interesting, I have some pointers to things you can read or watch or explore to learn more. (This link in the bottom right takes you to a page that has links to everything I'm about to mention.
Immutability is central to all of them, and they make you jump through hoops to change state. You might find this impractical for your day to day programming, but learning at least one of them will help you understand immutability more deeply and
Database as a Value Persistent Data Structures and Managed References http://goo.gl/Esa7r Rich Hickey is the creator of Clojure, and he has a handful of really good talks centered around immutability.
an interesting idea on how to structure functional/immutable code and imperative/mutable code in an application together, and he explores this idea in depth in "Boundaries".
When you "modify" one of them, you actually get a new copy of the data and the original version remains unchanged. "Persistent" here shouldn't be confused with the term that means a database writes to disk, but rather it means that it sticks around.
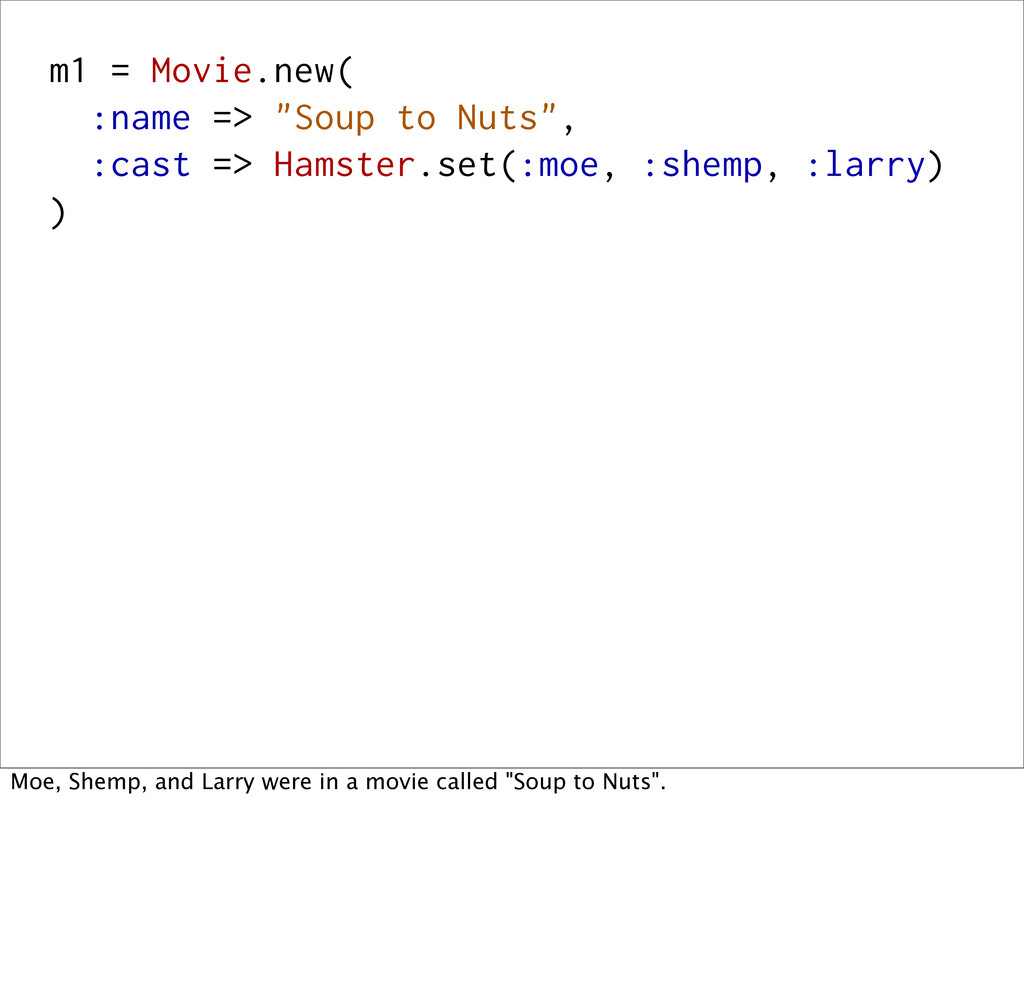
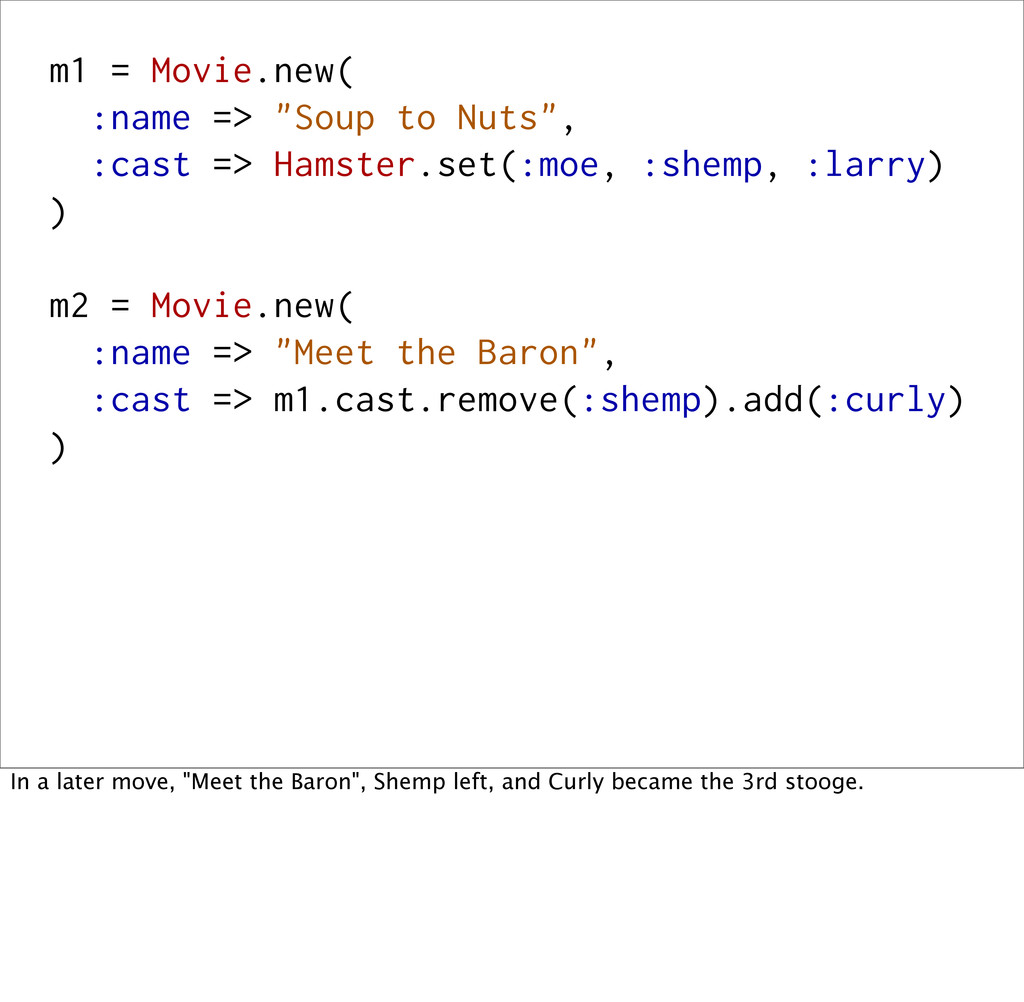
Hamster.set(:moe, :shemp, :larry) ) m2 = Movie.new( :name => "Meet the Baron", :cast => m1.cast.remove(:shemp).add(:curly) ) In a later move, "Meet the Baron", Shemp left, and Curly became the 3rd stooge.
Hamster.set(:moe, :shemp, :larry) ) m2 = Movie.new( :name => "Meet the Baron", :cast => m1.cast.remove(:shemp).add(:curly) ) m3 = Movie.new( :name => "Gold Raiders", :cast => m2.cast.remove(:curly).add(:shemp) ) And then in "Gold Raiders", Shemp came back, and Curly was out again.
m3.cast #=> {:moe, :larry, :shemp} If we had been using mutable data structures, these cast lists would've clobbered each other when they were shared between the movies.
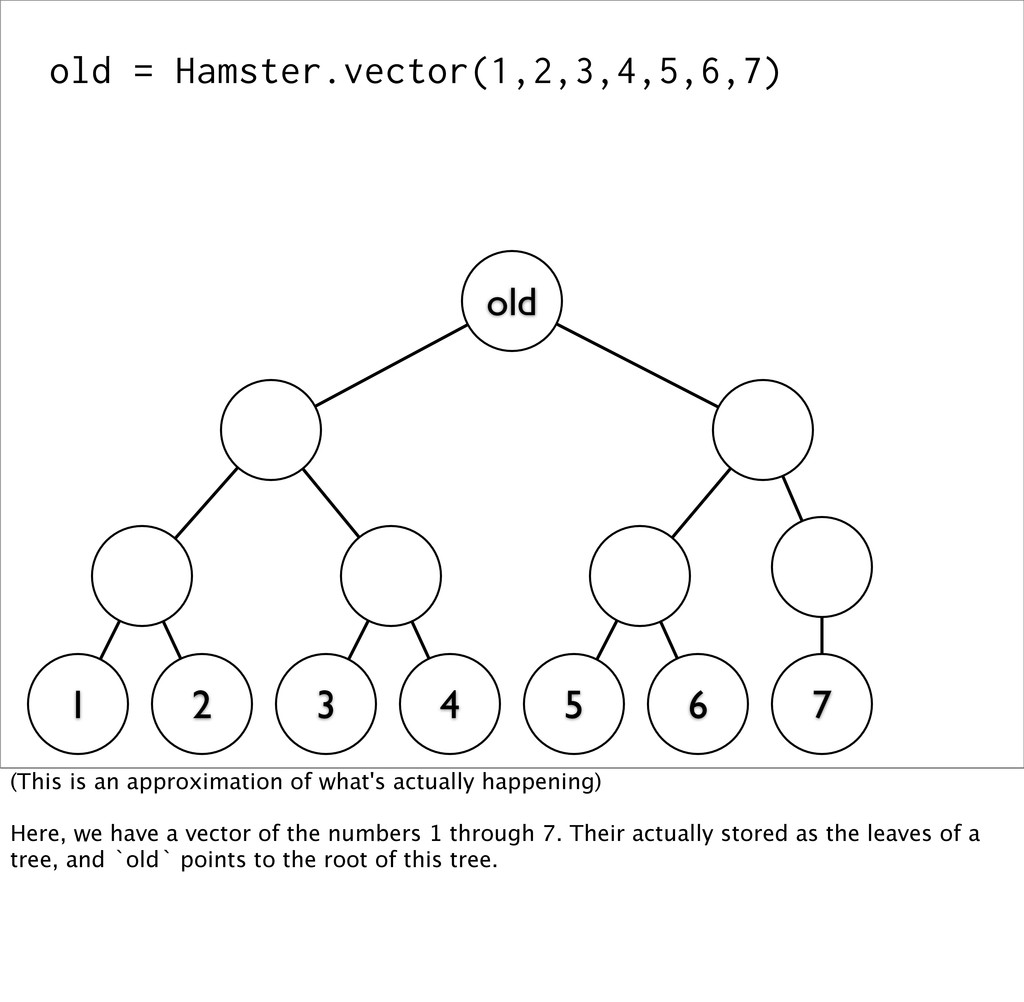
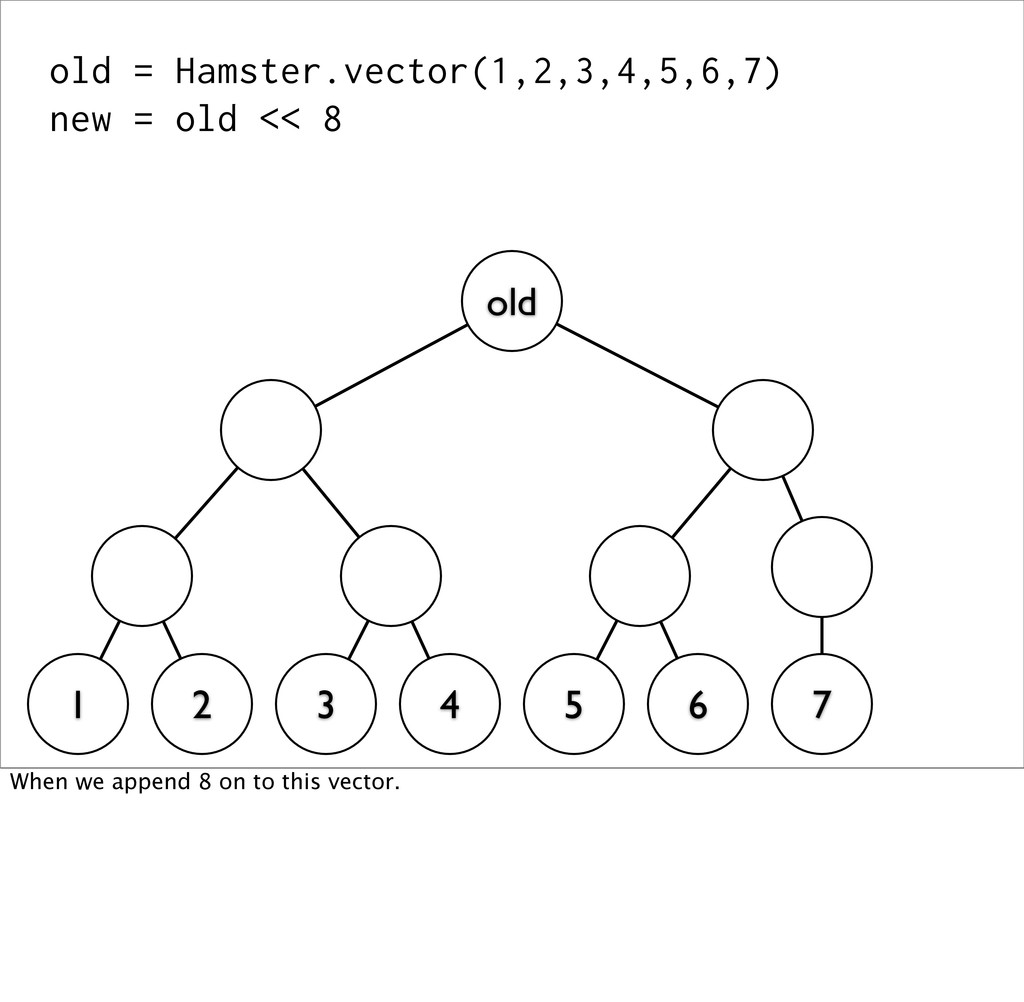
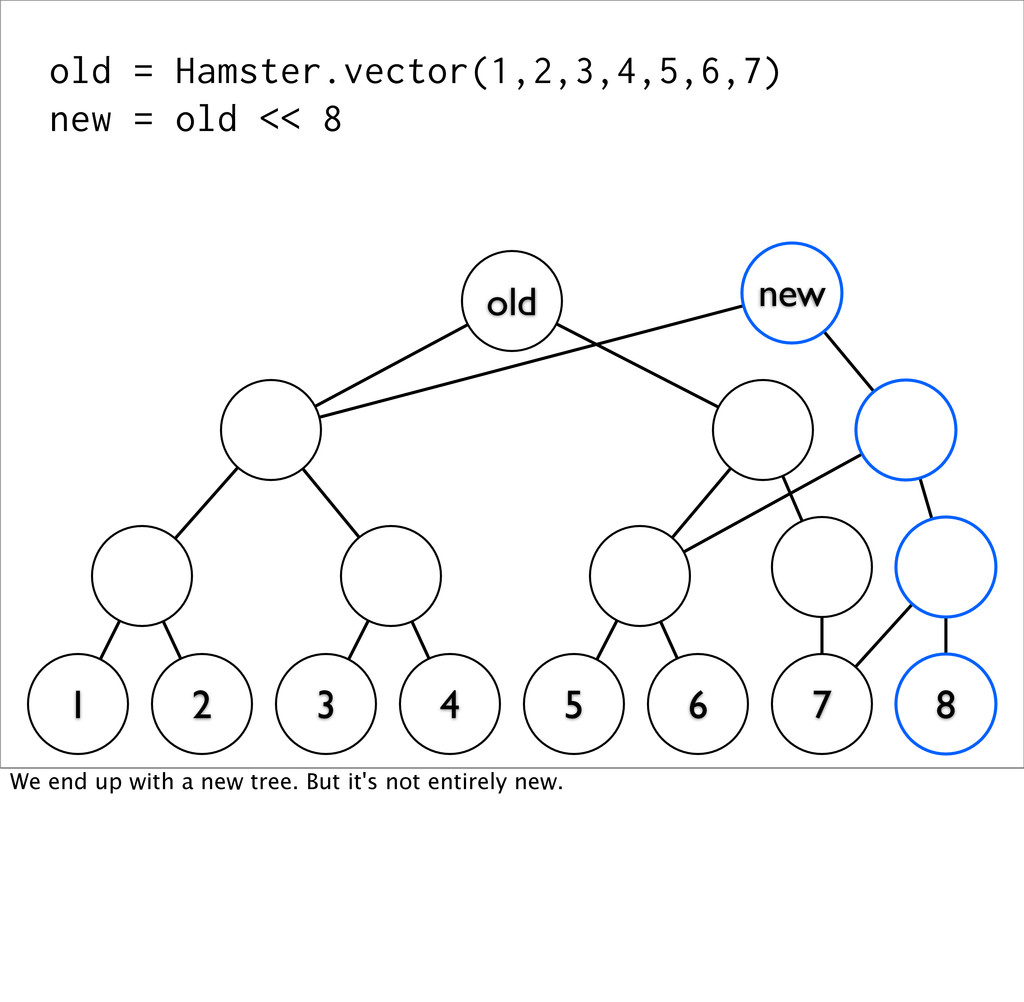
old (This is an approximation of what's actually happening) Here, we have a vector of the numbers 1 through 7. Their actually stored as the leaves of a tree, and `old` points to the root of this tree.
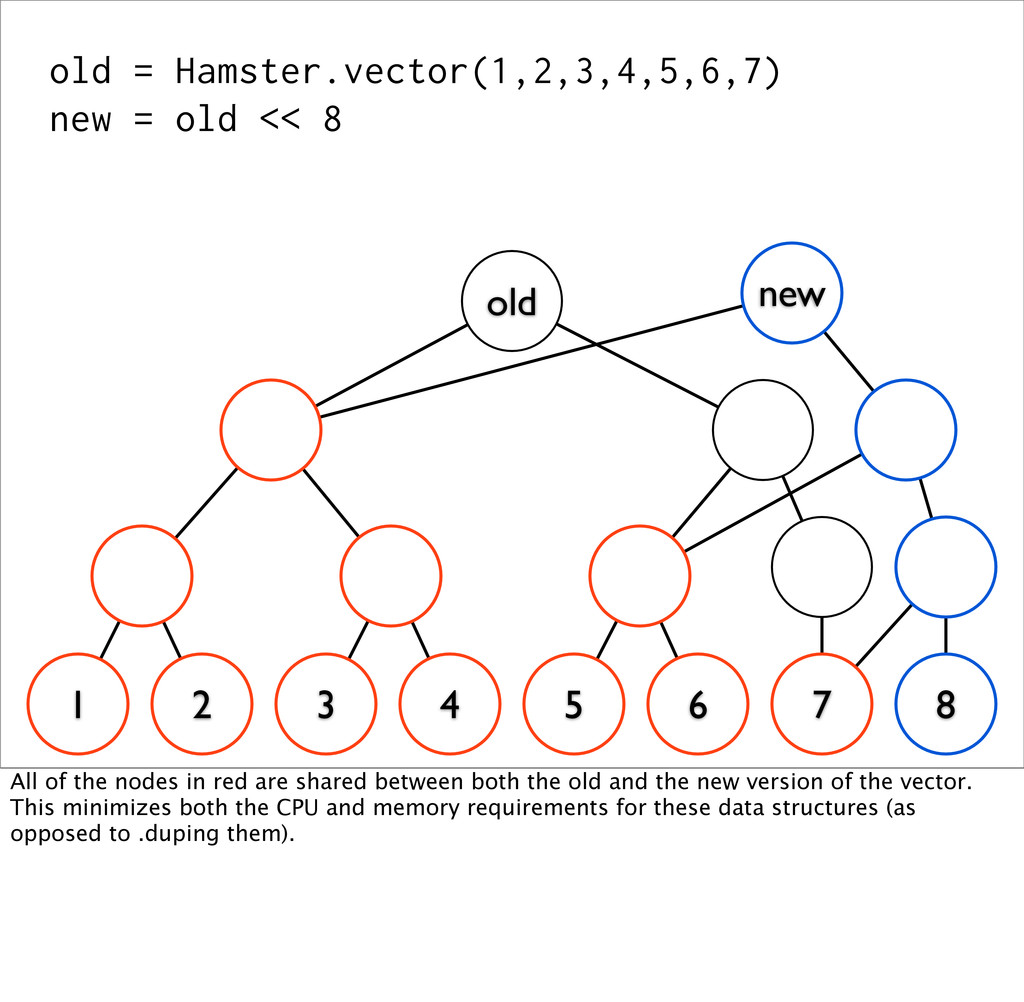
3 4 5 6 7 8 old new All of the nodes in red are shared between both the old and the new version of the vector. This minimizes both the CPU and memory requirements for these data structures (as opposed to .duping them).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![user.calculate_shipping_price vs. user.address.calculate_shipping_price user.addresses[2].calculate_shipping_price Let's say a user had multiple](https://files.speakerdeck.com/presentations/482415e0928d013062891e5646d94223/slide_61.jpg){kind=link}
![user.calculate_shipping_price vs. user.address.calculate_shipping_price user.addresses[2].calculate_shipping_price business.address.calculate_shipping_price Or, if we want to](https://files.speakerdeck.com/presentations/482415e0928d013062891e5646d94223/slide_62.jpg){kind=link}
![user.calculate_shipping_price vs. user.address.calculate_shipping_price user.addresses[2].calculate_shipping_price business.address.calculate_shipping_price item.calculate_shipping(user.address) item.calculate_shipping(user.addresses[2]) item.calculate_shipping(business.address) And if](https://files.speakerdeck.com/presentations/482415e0928d013062891e5646d94223/slide_63.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
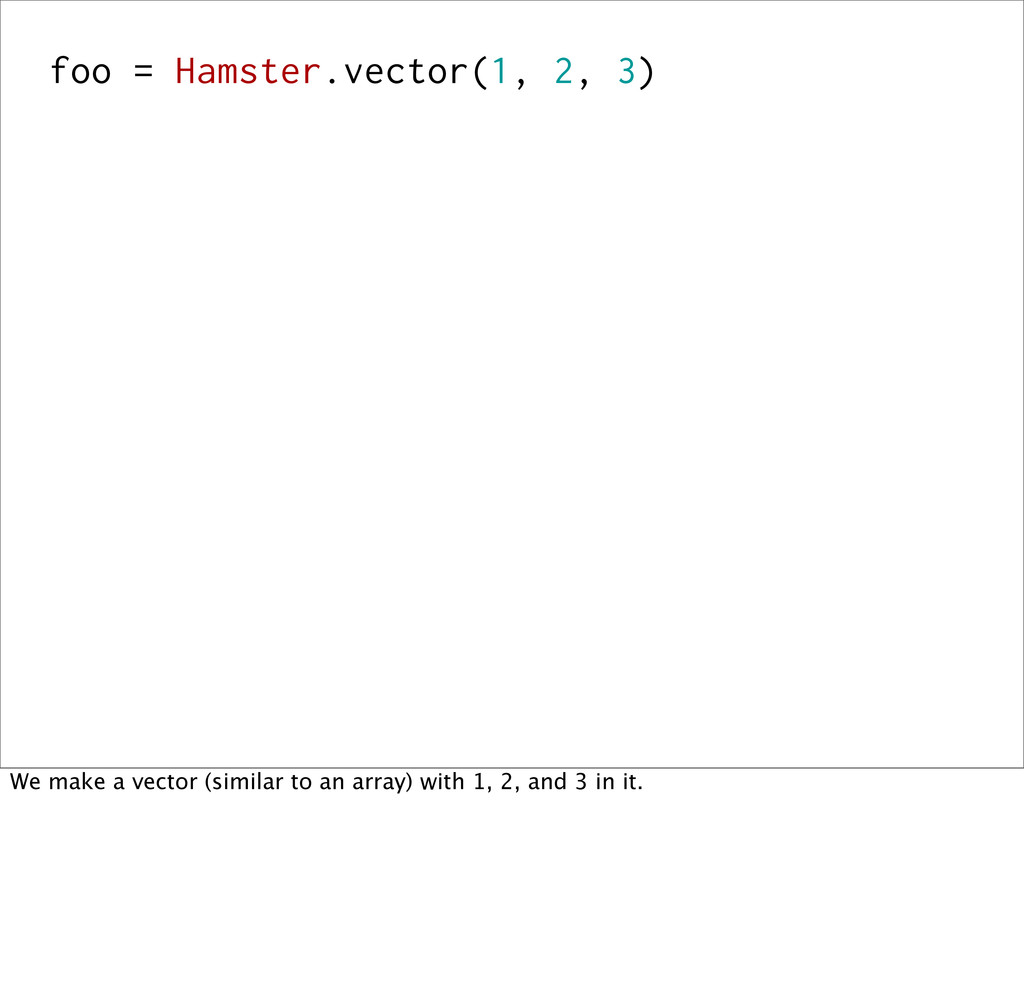
![foo = Hamster.vector(1, 2, 3) foo #=> [1, 2, 3]](https://files.speakerdeck.com/presentations/482415e0928d013062891e5646d94223/slide_114.jpg){kind=link}
![foo = Hamster.vector(1, 2, 3) foo #=> [1, 2, 3]](https://files.speakerdeck.com/presentations/482415e0928d013062891e5646d94223/slide_115.jpg){kind=link}
![foo = Hamster.vector(1, 2, 3) foo #=> [1, 2, 3]](https://files.speakerdeck.com/presentations/482415e0928d013062891e5646d94223/slide_116.jpg){kind=link}
![foo = Hamster.vector(1, 2, 3) foo #=> [1, 2, 3]](https://files.speakerdeck.com/presentations/482415e0928d013062891e5646d94223/slide_117.jpg){kind=link}
![foo = Hamster.vector(1, 2, 3) foo #=> [1, 2, 3]](https://files.speakerdeck.com/presentations/482415e0928d013062891e5646d94223/slide_118.jpg){kind=link}
![foo = Hamster.vector(1, 2, 3) foo #=> [1, 2, 3]](https://files.speakerdeck.com/presentations/482415e0928d013062891e5646d94223/slide_119.jpg){kind=link}
![foo = Hamster.vector(1, 2, 3) foo #=> [1, 2, 3]](https://files.speakerdeck.com/presentations/482415e0928d013062891e5646d94223/slide_120.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}