Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
大規模システムを支える実践的インフラ基盤の開発と運用
Search
システム開発部広報委員会
PRO
December 22, 2025
93
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
大規模システムを支える実践的インフラ基盤の開発と運用
2025/12/22
豊橋技術科学大学B3ソフトウェア設計論 特別講義
システム開発部広報委員会
PRO
December 22, 2025
More Decks by システム開発部広報委員会
See All by システム開発部広報委員会
Rancherで実現した、クラウドに頼らない低コストな次世 代データレイク
microaddevelopers
PRO
0
20
オンプレ環境でIcebergを運用して分かったテーブルメンテナンスの重要性
microaddevelopers
PRO
0
27
徹底比較!LonghornとCephのアーキテクチャ&パフォーマンス
microaddevelopers
PRO
0
260
マイクロアドでの Hive → Iceberg 移行事例紹介
microaddevelopers
PRO
1
130
Rancher × Hashicorp Vault で 実現する秘密情報管理
microaddevelopers
PRO
1
65
マイクロアドのData LakehouseとIcebergテーブルの最適化について
microaddevelopers
PRO
1
44
広告配信システムにおけるデータ基盤移行の事例紹介
microaddevelopers
PRO
0
17
3rd Party Cookie 規制後の広告配信技術
microaddevelopers
PRO
0
16
Kafka Connect:Iceberg Sink Connectorを使ってみる
microaddevelopers
PRO
1
40
Featured
See All Featured
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
430
Raft: Consensus for Rubyists
vanstee
141
7.6k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
Color Theory Basics | Prateek | Gurzu
gurzu
0
400
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Exploring anti-patterns in Rails
aemeredith
3
450
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
BBQ
matthewcrist
89
10k
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
GitHub's CSS Performance
jonrohan
1033
470k
Transcript
豊橋技術科学大学 B3 ソフトウェア設計論 特別講義 大規模システムを支える 実践的インフラ基盤の開発と運用 齊藤 大貴 株式会社マイクロアド システム開発部
プラットフォームエンジニアリングユニット
アウトライン • 自己紹介・会社紹介・チーム紹介 • インフラ基盤の規模感 • サーバ管理 • 運用監視 •
ネットワークの冗長化 • ストレージ技術 • そして Kubernetes へ • プラットフォームエンジニアリング • まとめ 2
自己紹介・会社概要・チーム紹介 3
自己紹介 名前 齊藤 大貴(さいとう だいき) 出身高専 都立産業技術高専 出身研究室 計算機システム性能工学研究室(佐藤研) 現在
株式会社マイクロアド システム開発部 プラットフォームエンジニアリングユニット( 10名) 趣味 カラオケ、ウォーキング 4
会社概要 設立 2007年7月 市場区分 東証グロース市場 本社所在地 東京都渋谷区 拠点数 日本7拠点/海外3ヵ国 社員数
400名(連結・2025年6月末時点) 平均年齢 31歳 5
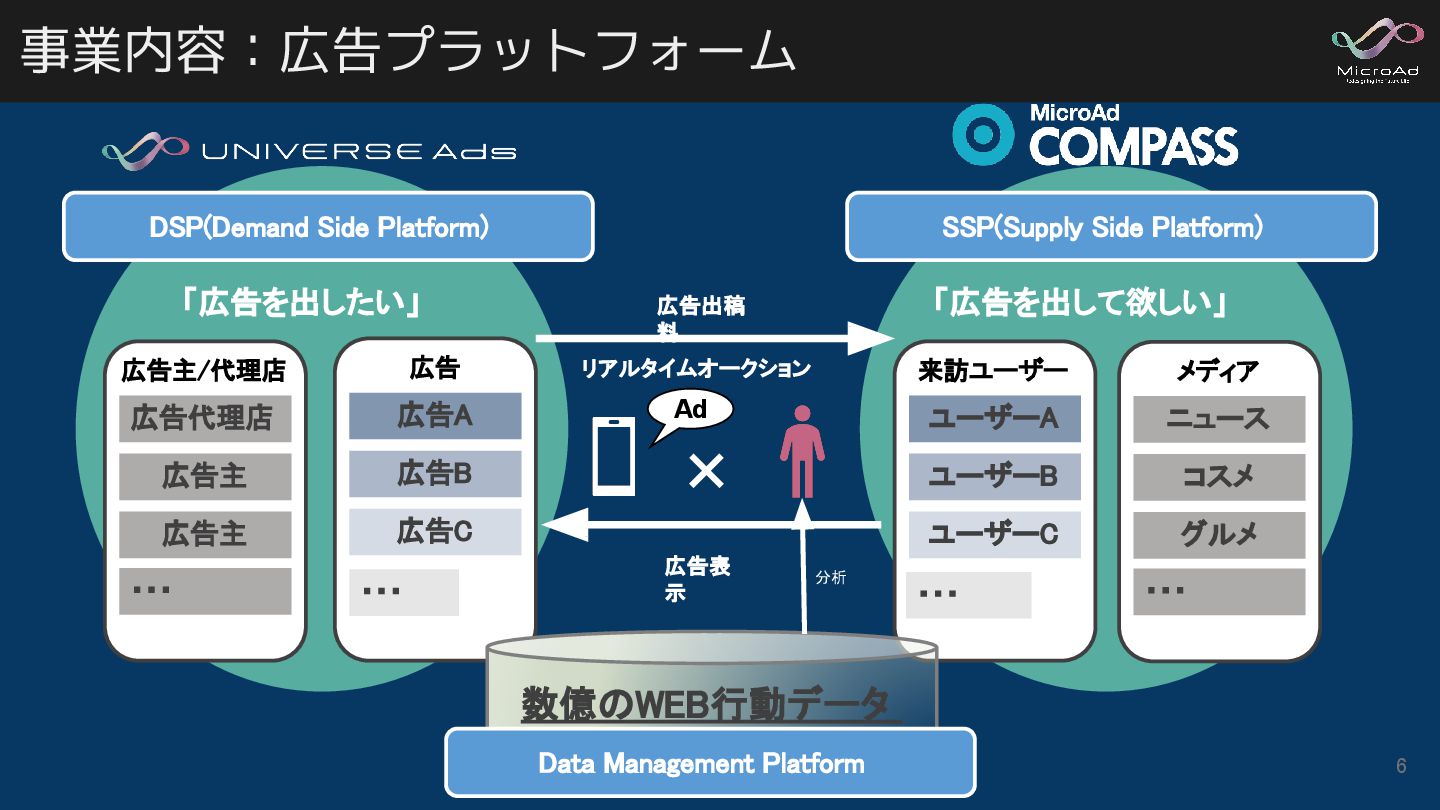
事業内容:広告プラットフォーム DSP(Demand Side Platform) SSP(Supply Side Platform) 「広告を出したい」
「広告を出して欲しい」 広告主/代理店 広告代理店 広告主 広告主 ・・・ 広告 広告A 広告B 広告C ・・・ 来訪ユーザー ユーザーA ユーザーB ユーザーC ・・・ メディア ニュース コスメ グルメ ・・・ Ad 広告出稿 料 広告表 示 ✕ リアルタイムオークション 数億のWEB行動データ Data Management Platform 分析 6
数字で見るシステム ▪ レスポンス : 0.05秒 ▪ オークション数 : 150億回 / 日 ▪
データ処理量 : 10TB / 日 ▪ ユニークブラウザ: 4億件 ▪ 携帯端末データ : 3,000万件 ... 7
We Are Hiring!! 8 オンプレ×Google Cloud な大規模データプラットフォームの開発・運用を 一緒に挑戦してみたい人を募集しています! https://recruit.microad.co.jp/ 公式アカウント
@microad_dev もよろしくお願いします。
プラットフォームエンジニアリングユニット(PEU) チーム体制 現在10名(マネージャ2名、エンジニア8名)で、6つの技術領域を担当 少人数で広範囲のインフラを運用している 担当領域 • DevSecOps (監視基盤, 構成管理, CI/CD基盤)
• データ基盤 (Hadoop, MySQL, Spark, Trino) • ストレージ・仮想化基盤 (K8s, OpenStack, Ceph) • 配信・管理画面 (RTB基盤) • ネットワーク・OS領域 (L3 NW, OS) • クラウド管理領域 (GoogleCloud, AWS) 9
インフラ基盤の規模感 10
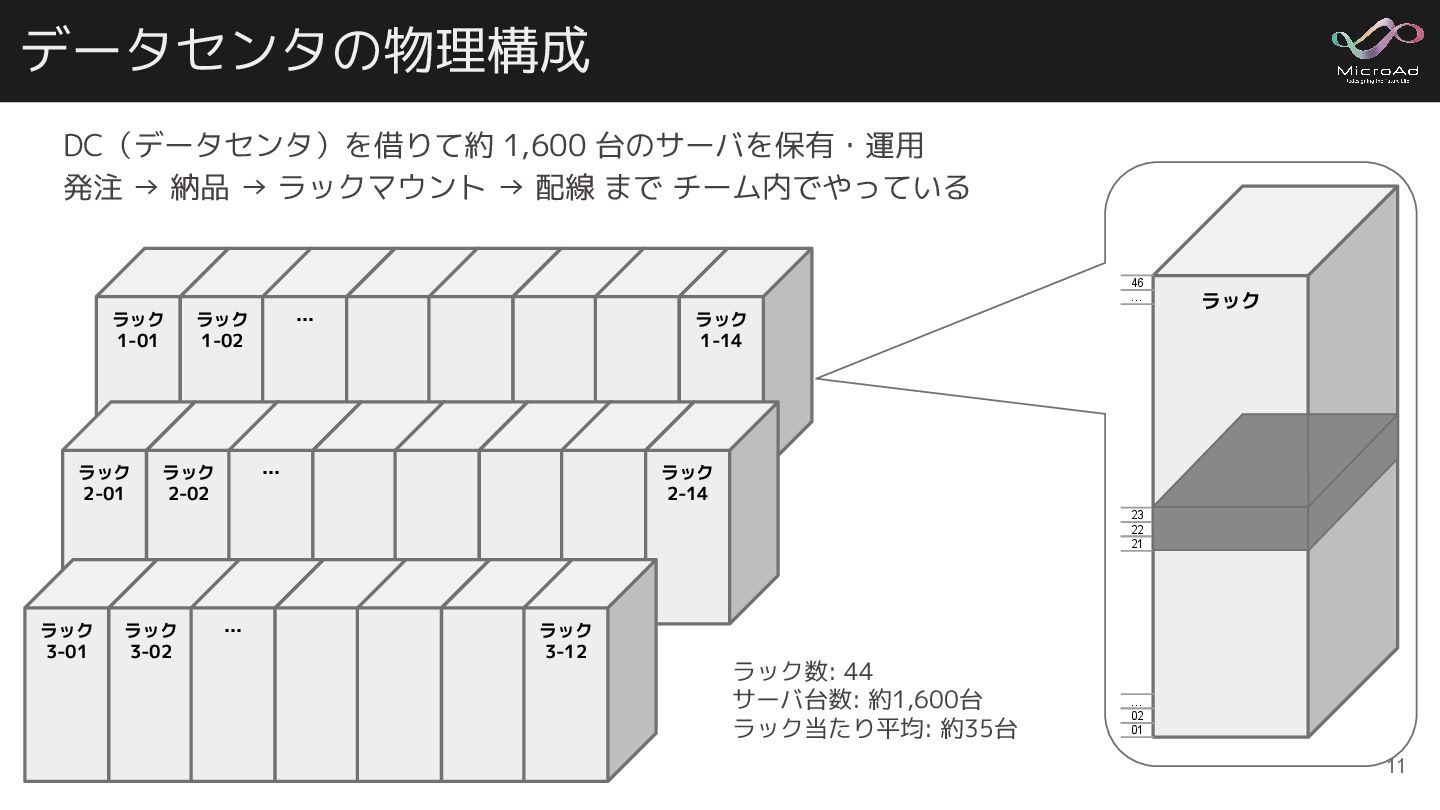
DC(データセンタ)を借りて約 1,600 台のサーバを保有・運用 発注 → 納品 → ラックマウント → 配線
まで チーム内でやっている ラック 1-01 ラック 1-02 … ラック 1-14 ラック 2-01 ラック 2-02 … ラック 2-14 データセンタの物理構成 ラック 3-01 ラック 3-02 … ラック 3-12 ラック数: 44 サーバ台数: 約1,600台 ラック当たり平均: 約35台 ラック 22 23 21 02 … 01 … 46 11
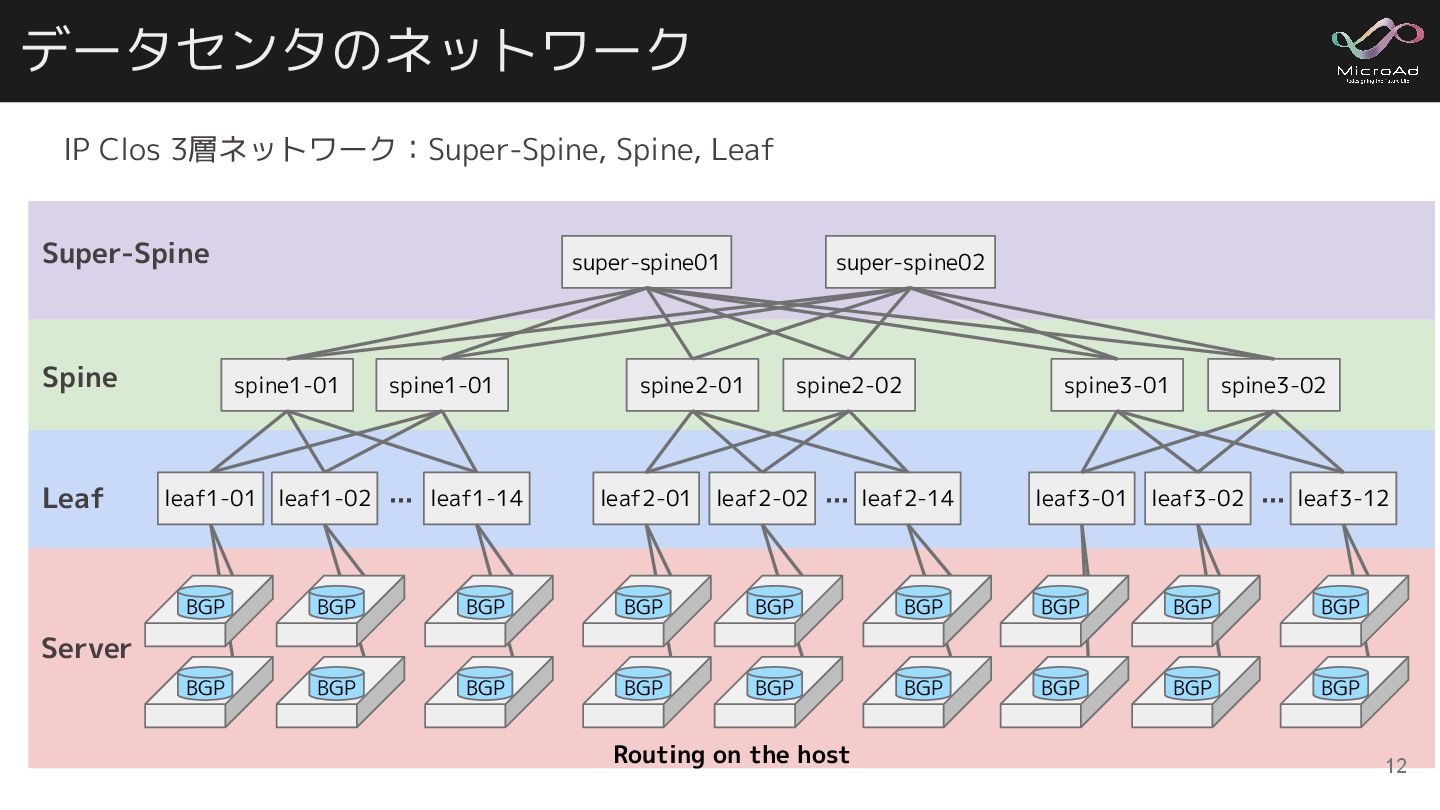
Routing on the host データセンタのネットワーク spine1-01 spine1-01 spine2-01 super-spine01 spine2-02
leaf2-02 leaf2-14 leaf2-01 leaf1-02 leaf1-14 leaf1-01 … super-spine02 spine3-01 spine3-02 … leaf3-02 leaf3-12 leaf3-01 … BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP IP Clos 3層ネットワーク:Super-Spine, Spine, Leaf Super-Spine Spine Leaf Server 12
Routing on the host データセンタのネットワーク spine1-01 spine1-01 spine2-01 super-spine01 spine2-02
leaf2-02 leaf2-14 leaf2-01 leaf1-02 leaf1-14 leaf1-01 … super-spine02 spine3-01 spine3-02 … leaf2-02 leaf2-14 leaf2-01 … BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP BGP IP Clos 3層ネットワーク:Super-Spine, Spine, Leaf Super-Spine Spine Leaf Server IP Clos を採用した理由 • ネットワークの拡張性 ◦ Spineを増設 → 通信帯域の増速 ◦ Leafを増設 → サーバ収容ポートの増加 • BGPによるトラフィックコントロールのしやすさ ◦ メンテナンス時にトラフィックを迂回できる • ベンダーロックインの回避 ◦ 様々なベンダーの様々な機器を利用でき 用途により最善なものを選べる 13
マイクロアドで使用しているサーバ & NW 機器(一部) 3U 8ノード 汎用サーバ Supermicro MicroCloud[3] 2U
4ノード 汎用サーバ DELL PowerEdge C6520[2] [1] Dell製品ページ, https://www.dell.com/en-us/shop/dell-poweredge-servers/poweredge-r6525-rack-server/spd/poweredge-r6525/pe_r6525_13783_vi_vp [2] Dell製品ページ, https://www.dell.com/support/product-details/ja-jp/product/poweredge-c6520/overview [3] Supermicro製品ページ, https://www.supermicro.com/en/products/system/microcloud/3u/sys-531mc-h8tnr [4] Dell製品ページ, https://www.dell.com/support/product-details/en-us/product/networking-s5248f-on/resources/manuals 1U 1ノード 汎用サーバ DELL PowerEdge 6525[1] 1U L3 Switch DELL PowerSwitch[4] 14
サーバ管理 15
1,000台以上のサーバをどう管理するか サーバを構築したことってありますか? • USBメモリにOSイメージ(Ubuntu, CentOS, Windows...)を入れる • → BIOSの起動順序をUSBに変える •
→ 起動してOSをインストールする • → パッケージ管理ツール(apt, dnf, yum...)を使ってミドルウェアを入れる • → 設定ファイルを書く → ミドルウェアを起動する これを手作業で1,000台...やりません! ではどうするか ベアメタル管理ツールとIaCツールを活用する💪 16
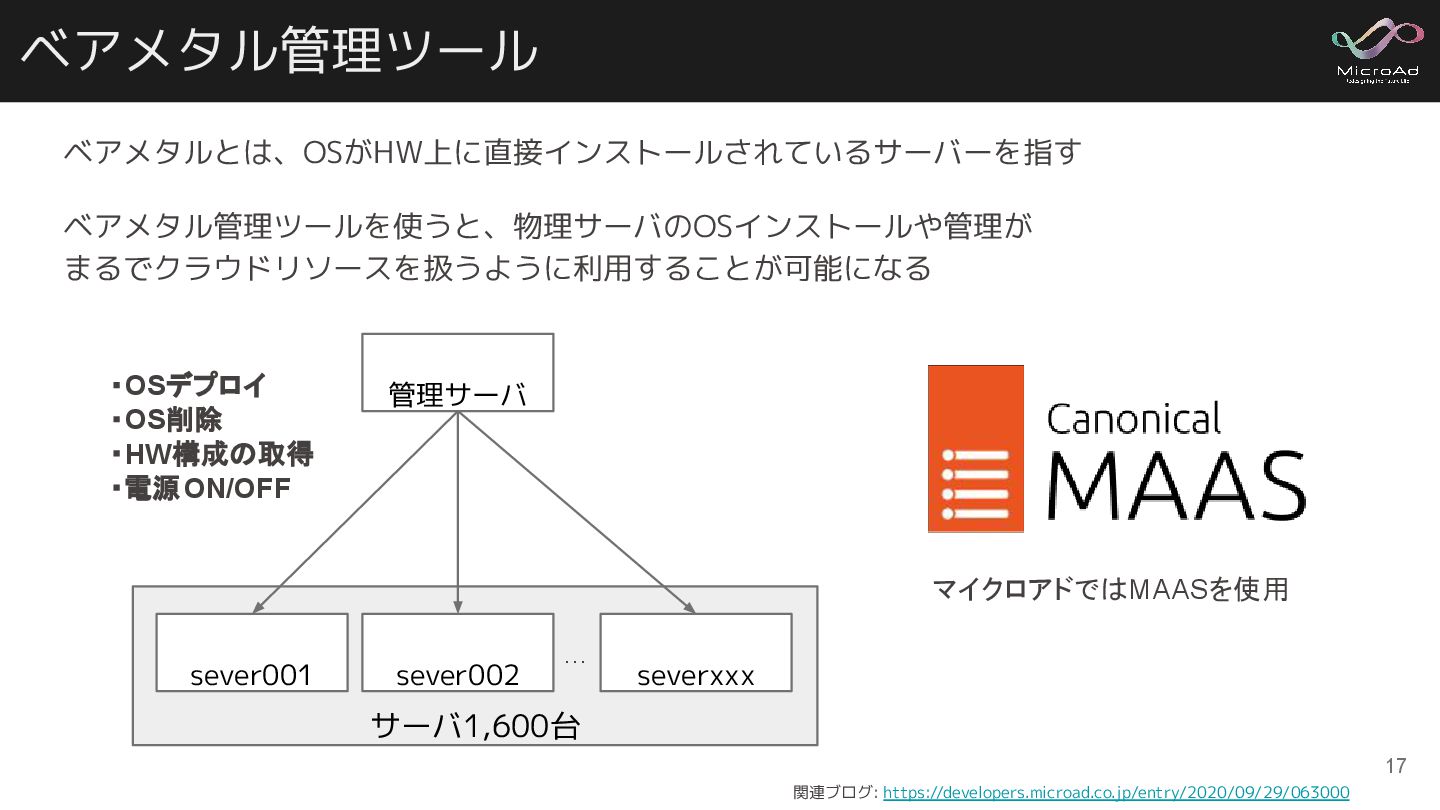
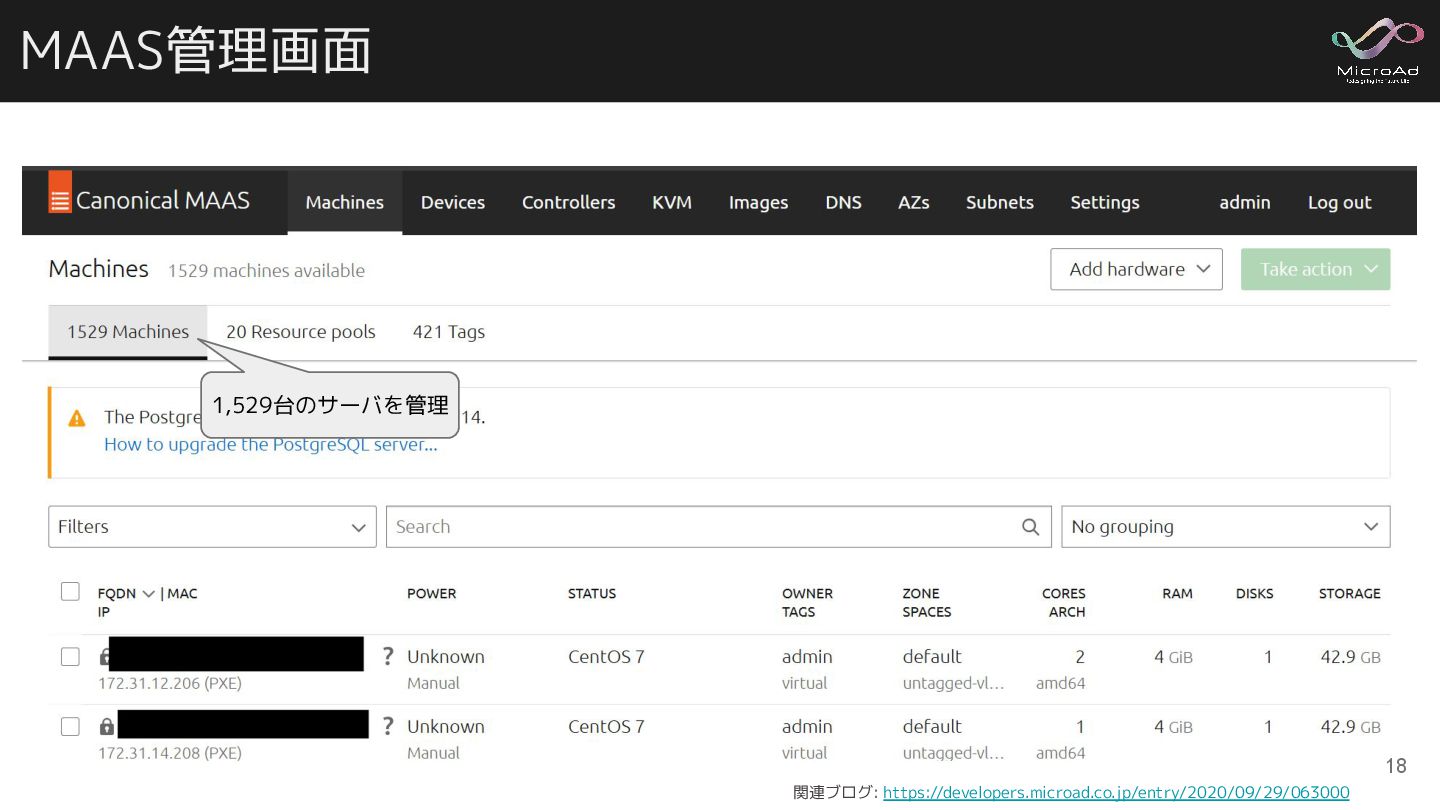
ベアメタル管理ツール ベアメタルとは、OSがHW上に直接インストールされているサーバーを指す ベアメタル管理ツールを使うと、物理サーバのOSインストールや管理が まるでクラウドリソースを扱うように利用することが可能になる 関連ブログ: https://developers.microad.co.jp/entry/2020/09/29/063000 サーバ1,600台 … severxxx sever002
sever001 ・OSデプロイ ・OS削除 ・HW構成の取得 ・電源ON/OFF 管理サーバ マイクロアドではMAASを使用 17
MAAS管理画面 関連ブログ: https://developers.microad.co.jp/entry/2020/09/29/063000 1,529台のサーバを管理 18
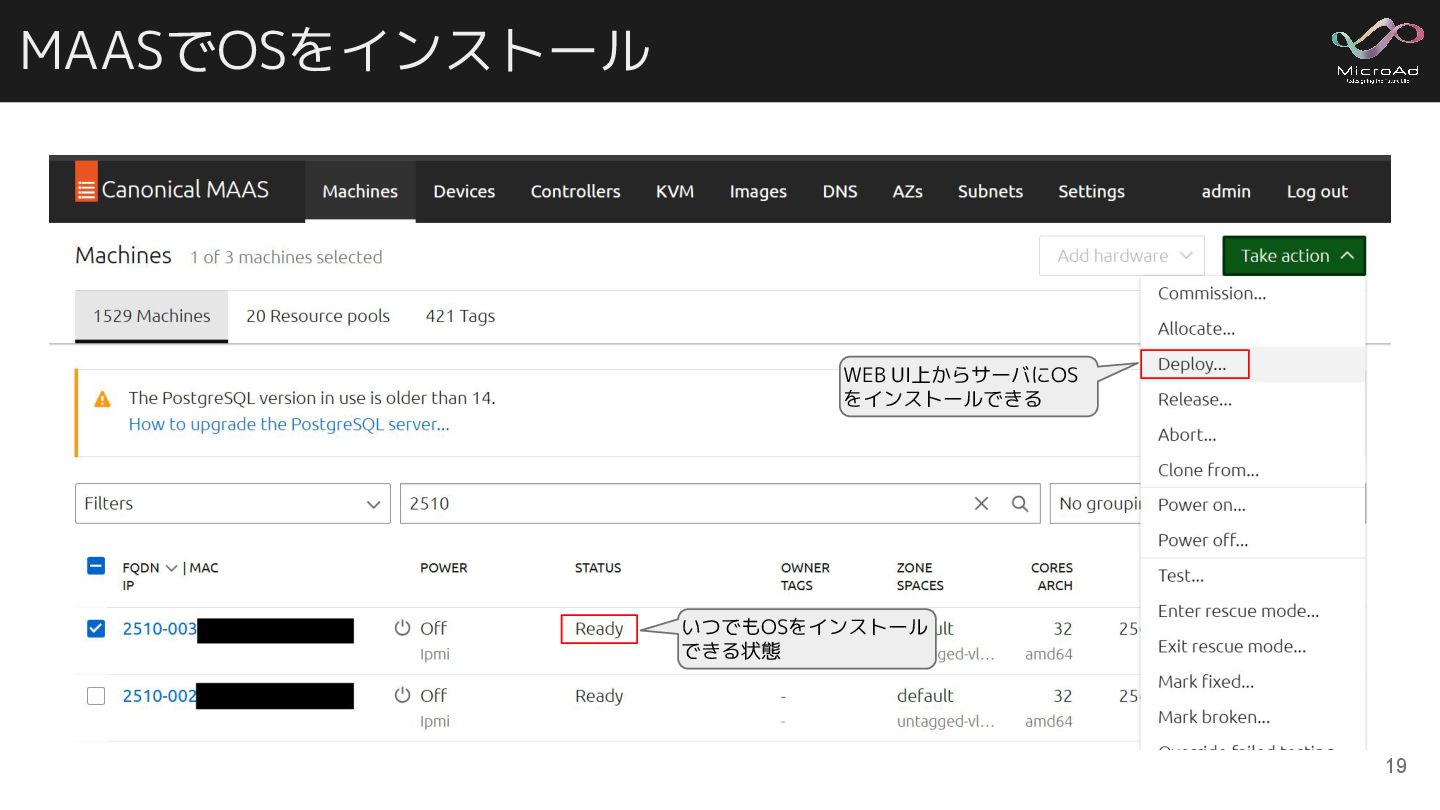
MAASでOSをインストール WEB UI上からサーバにOS をインストールできる いつでもOSをインストール できる状態 19
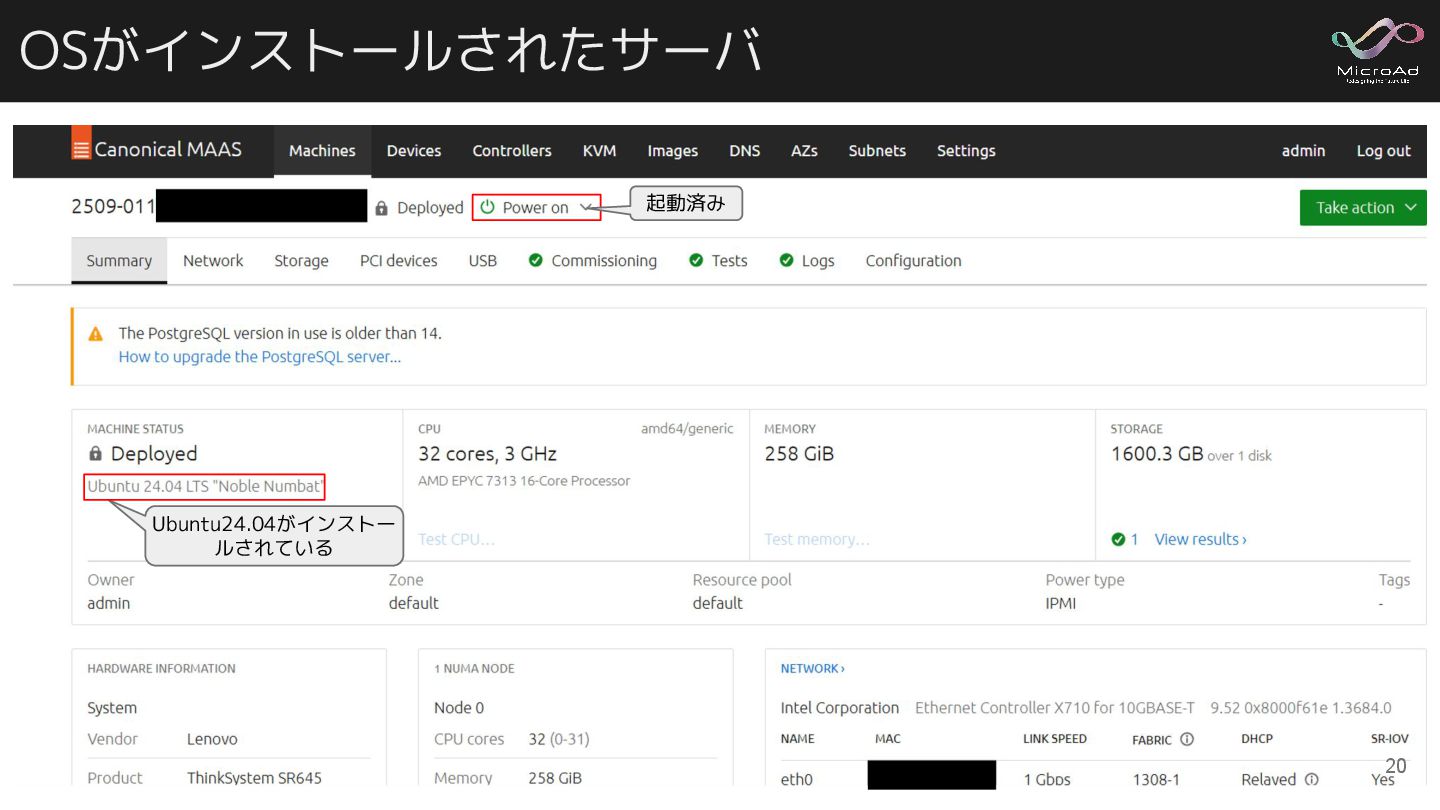
OSがインストールされたサーバ Ubuntu24.04がインストー ルされている 起動済み 20
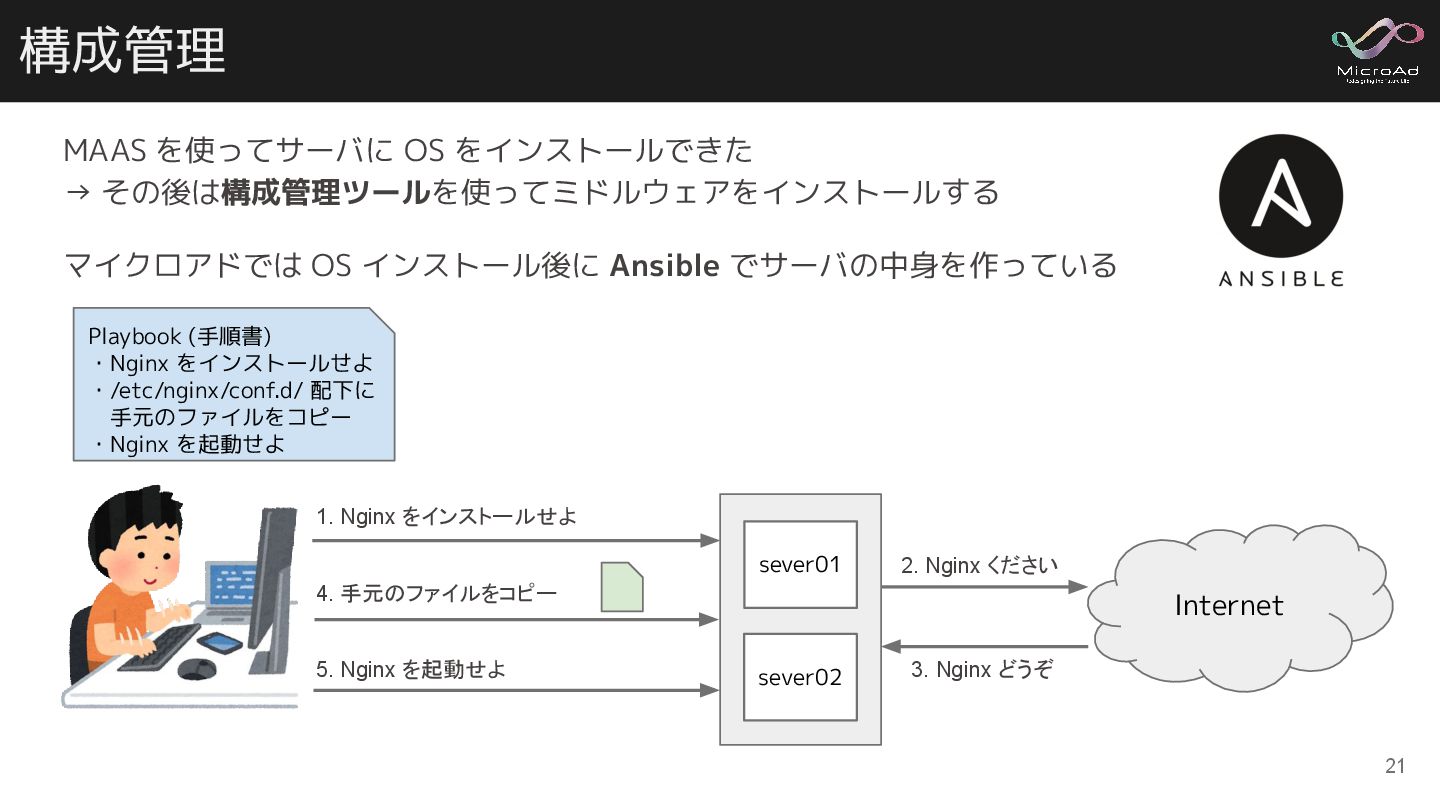
構成管理 MAAS を使ってサーバに OS をインストールできた → その後は構成管理ツールを使ってミドルウェアをインストールする マイクロアドでは OS インストール後に
Ansible でサーバの中身を作っている Playbook (手順書) ・Nginx をインストールせよ ・/etc/nginx/conf.d/ 配下に 手元のファイルをコピー ・Nginx を起動せよ 1. Nginx をインストールせよ 4. 手元のファイルをコピー 5. Nginx を起動せよ Internet 2. Nginx ください 3. Nginx どうぞ sever01 sever02 21
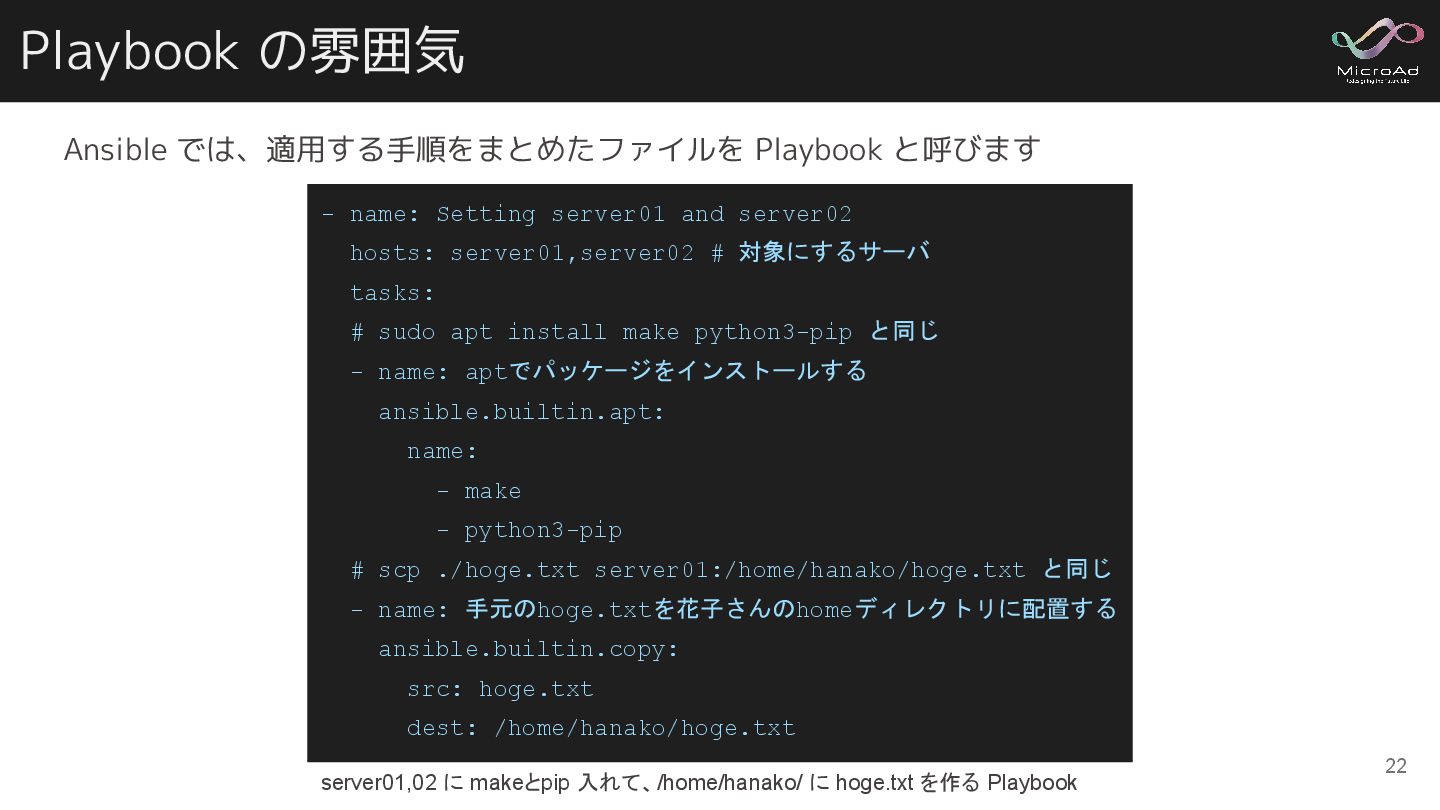
Playbook の雰囲気 Ansible では、適用する手順をまとめたファイルを Playbook と呼びます - name: Setting server01
and server02 hosts: server01,server02 # 対象にするサーバ tasks: # sudo apt install make python3-pip と同じ - name: aptでパッケージをインストールする ansible.builtin.apt: name: - make - python3-pip # scp ./hoge.txt server01:/home/hanako/hoge.txt と同じ - name: 手元のhoge.txtを花子さんのhomeディレクトリに配置する ansible.builtin.copy: src: hoge.txt dest: /home/hanako/hoge.txt server01,02 に makeとpip 入れて、/home/hanako/ に hoge.txt を作る Playbook 22
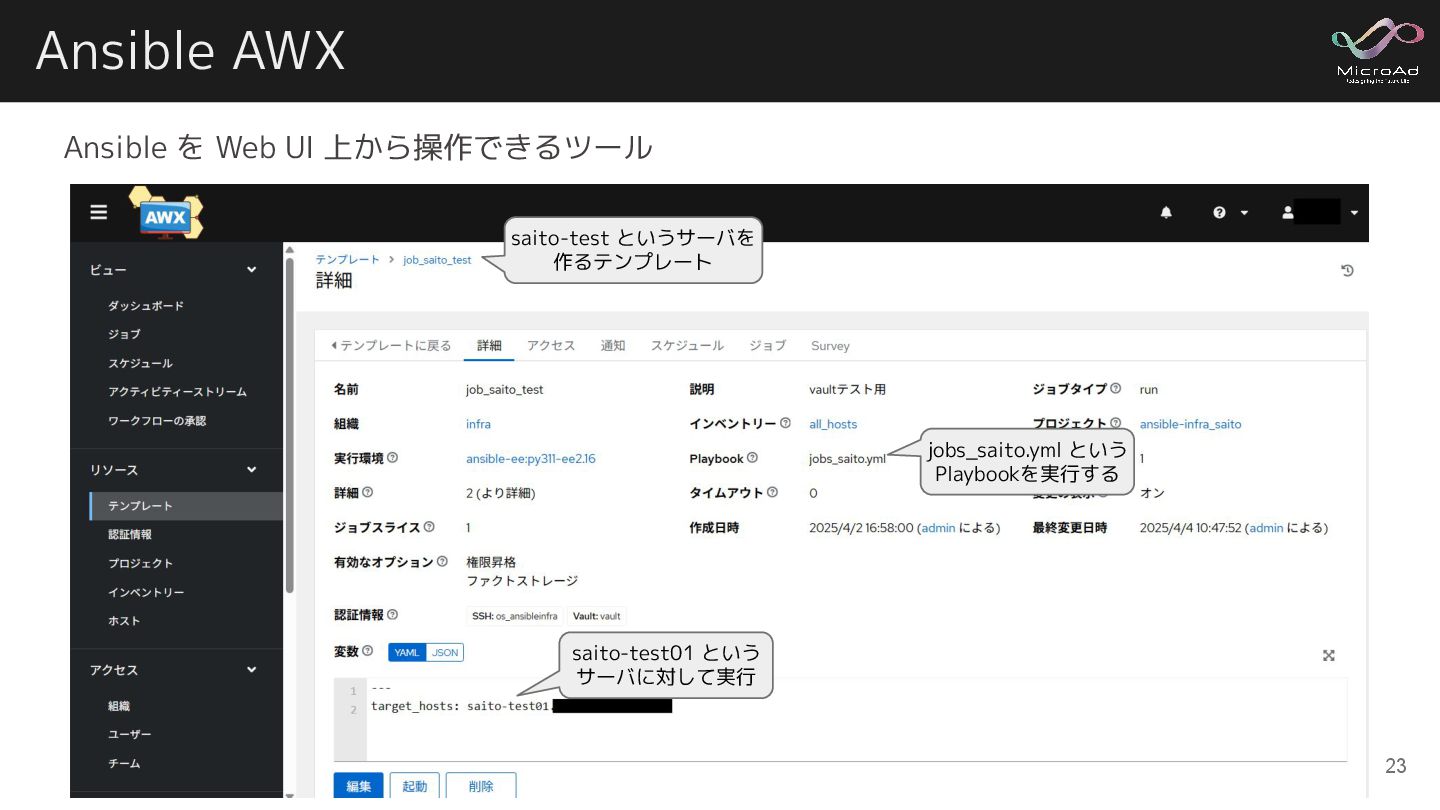
Ansible AWX Ansible を Web UI 上から操作できるツール saito-test というサーバを 作るテンプレート
jobs_saito.yml という Playbookを実行する saito-test01 という サーバに対して実行 23
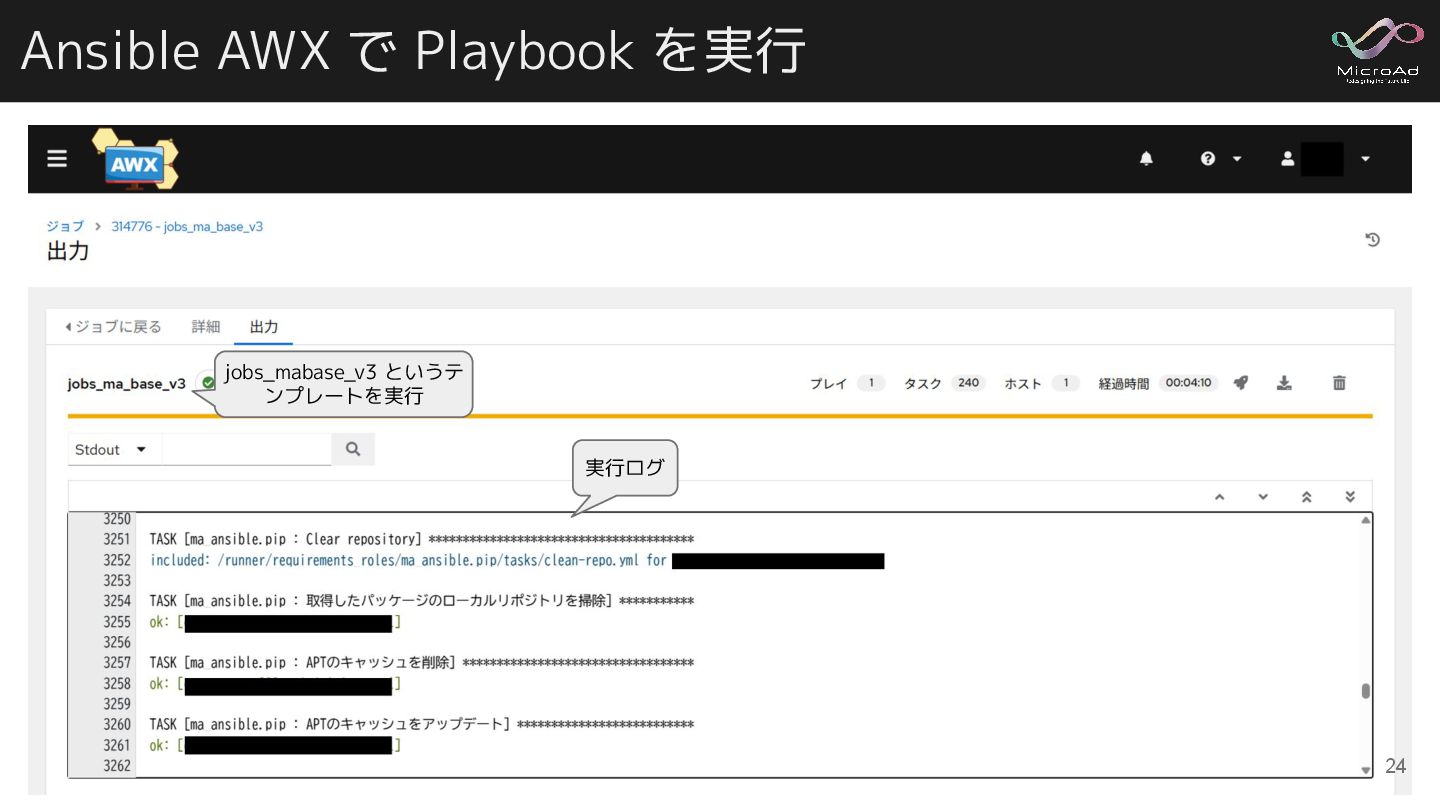
Ansible AWX で Playbook を実行 jobs_mabase_v3 というテ ンプレートを実行 実行ログ 24
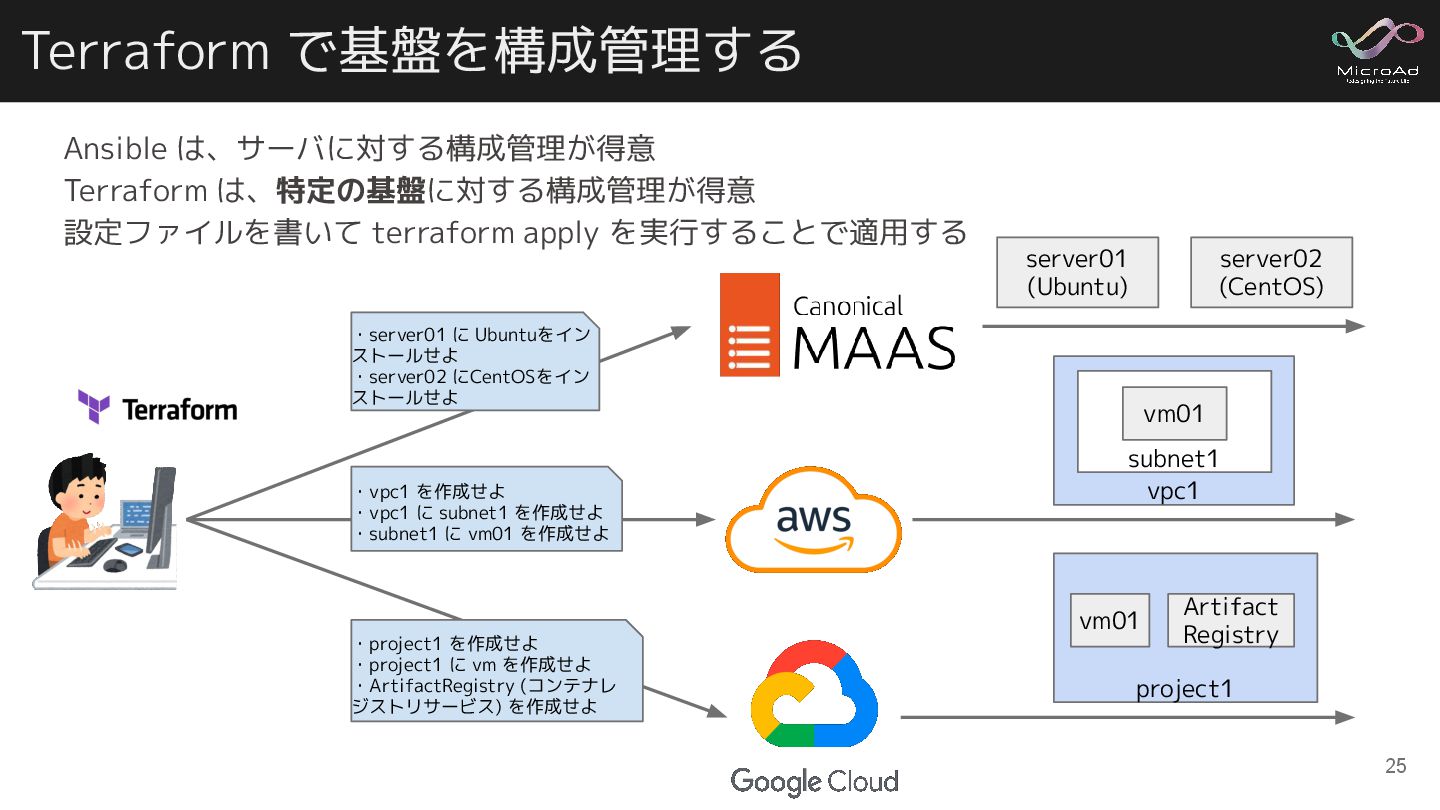
Ansible は、サーバに対する構成管理が得意 Terraform は、特定の基盤に対する構成管理が得意 設定ファイルを書いて terraform apply を実行することで適用する Terraform で基盤を構成管理する
server01 (Ubuntu) server02 (CentOS) ・server01 に Ubuntuをイン ストールせよ ・server02 にCentOSをイン ストールせよ vpc1 subnet1 vm01 project1 vm01 Artifact Registry ・vpc1 を作成せよ ・vpc1 に subnet1 を作成せよ ・subnet1 に vm01 を作成せよ ・project1 を作成せよ ・project1 に vm を作成せよ ・ArtifactRegistry (コンテナレ ジストリサービス) を作成せよ 25
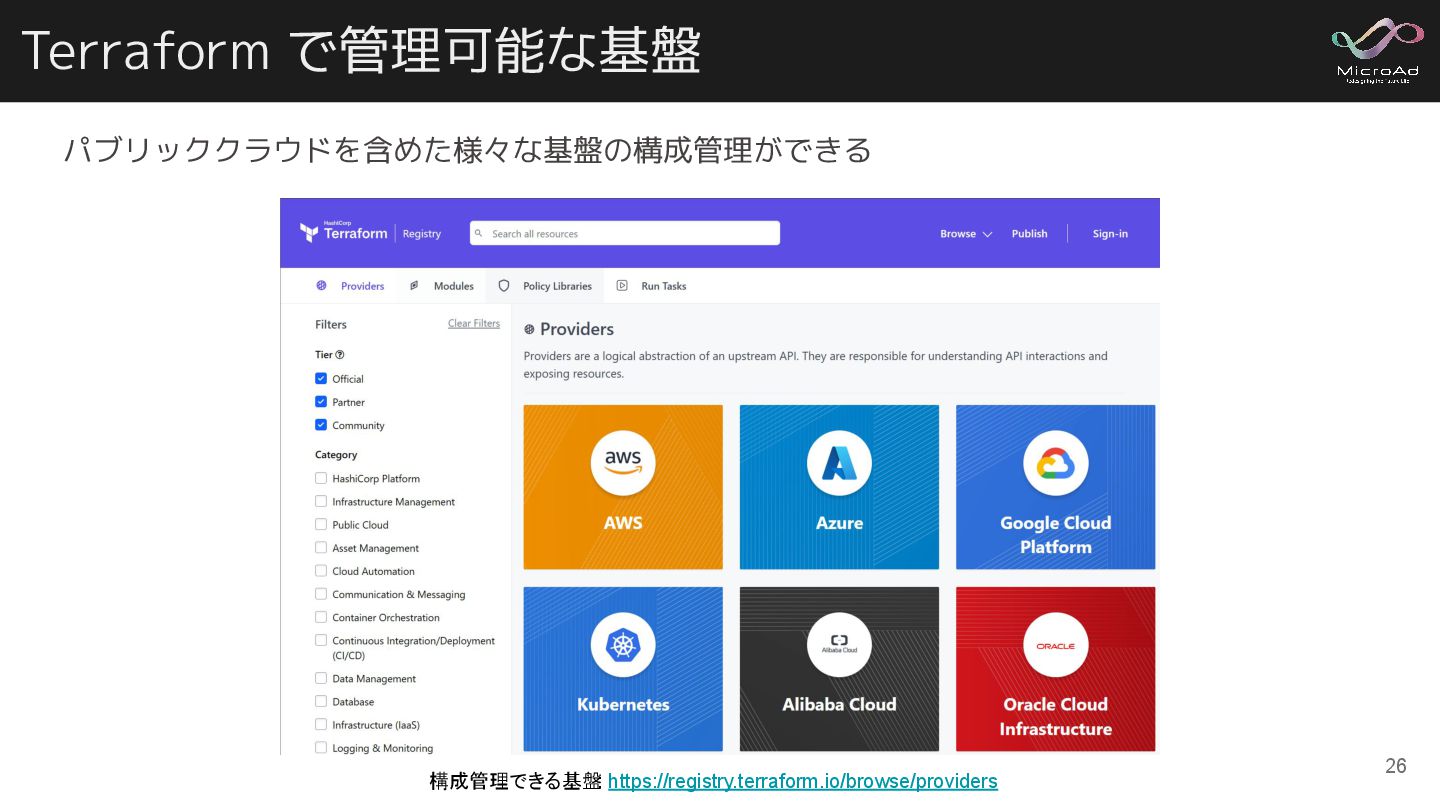
Terraform で管理可能な基盤 パブリッククラウドを含めた様々な基盤の構成管理ができる 構成管理できる基盤 : https://registry.terraform.io/browse/providers 26
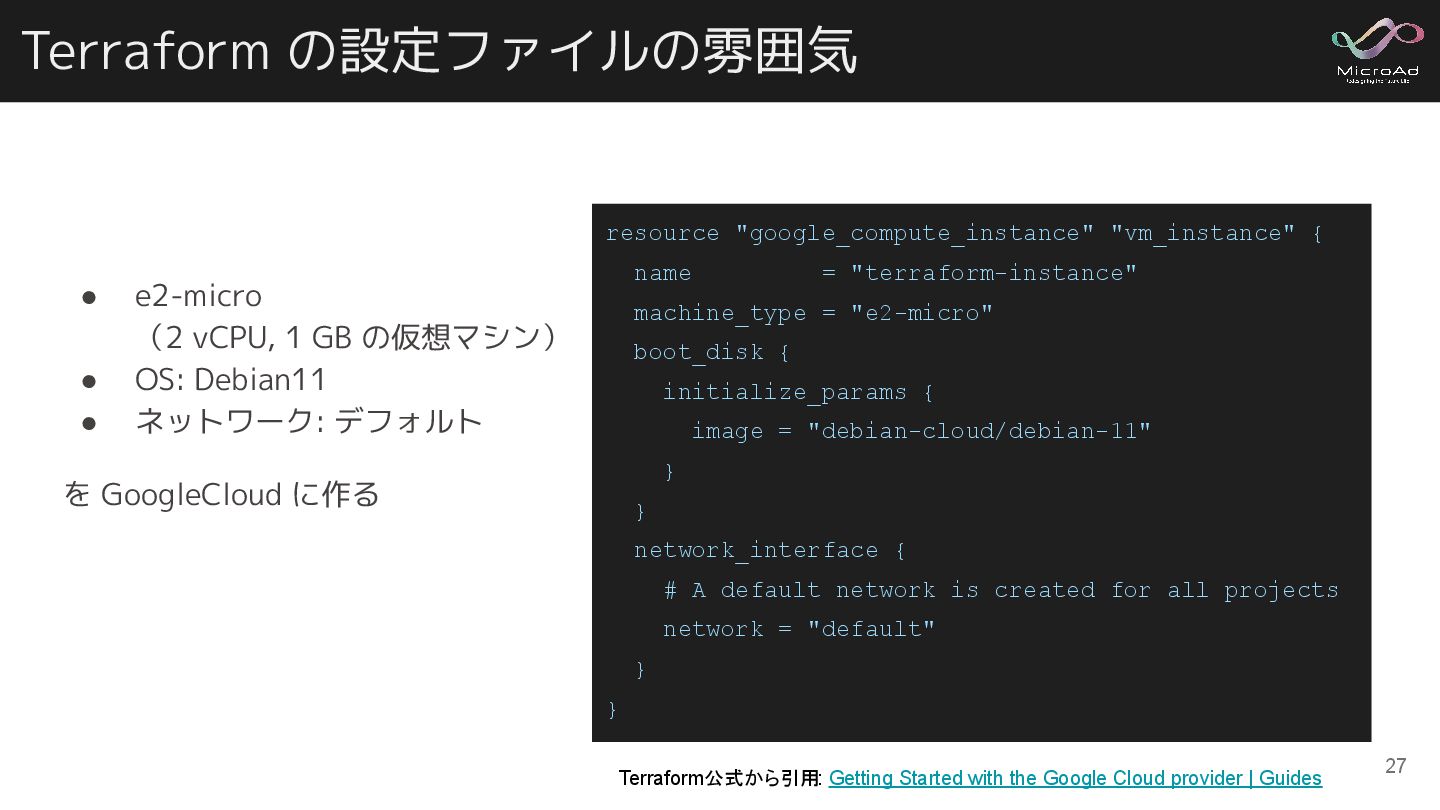
Terraform の設定ファイルの雰囲気 • e2-micro (2 vCPU, 1 GB の仮想マシン) •
OS: Debian11 • ネットワーク: デフォルト を GoogleCloud に作る resource "google_compute_instance" "vm_instance" { name = "terraform-instance" machine_type = "e2-micro" boot_disk { initialize_params { image = "debian-cloud/debian-11" } } network_interface { # A default network is created for all projects network = "default" } } Terraform公式から引用: Getting Started with the Google Cloud provider | Guides 27
IaC(Infrastructure as Code) 構成管理ツールを使ってインフラ構築をコード化することを IaC という スピード 手動構築と比べて圧倒的な 速さでインフラリソースを 展開できる
コードを実行するだけで環 境が完成する 一貫性 誰がいつ実行しても全く同 じ環境が再現される 人為的な設定ミスや環境間 の差異を排除できる 可視性と管理 インフラの状態がコードと して残るため、 変更履歴の追跡が容易にな り透明性が向上する 28
運用監視 29
これだけ HW があると... ラック 1-01 ラック 1-02 … ラック 1-14
ラック 2-01 ラック 2-02 … ラック 2-14 ラック 3-01 ラック 3-02 … ラック 3-12 これだけ多くの HW があると頻繁に故障します 故障があるとデータセンタ(DC)に駆けつけて修理・ 交換します ※ HW故障でDCに駆けつけるインフラ エンジニアのイラスト (Geminiで生成) 30
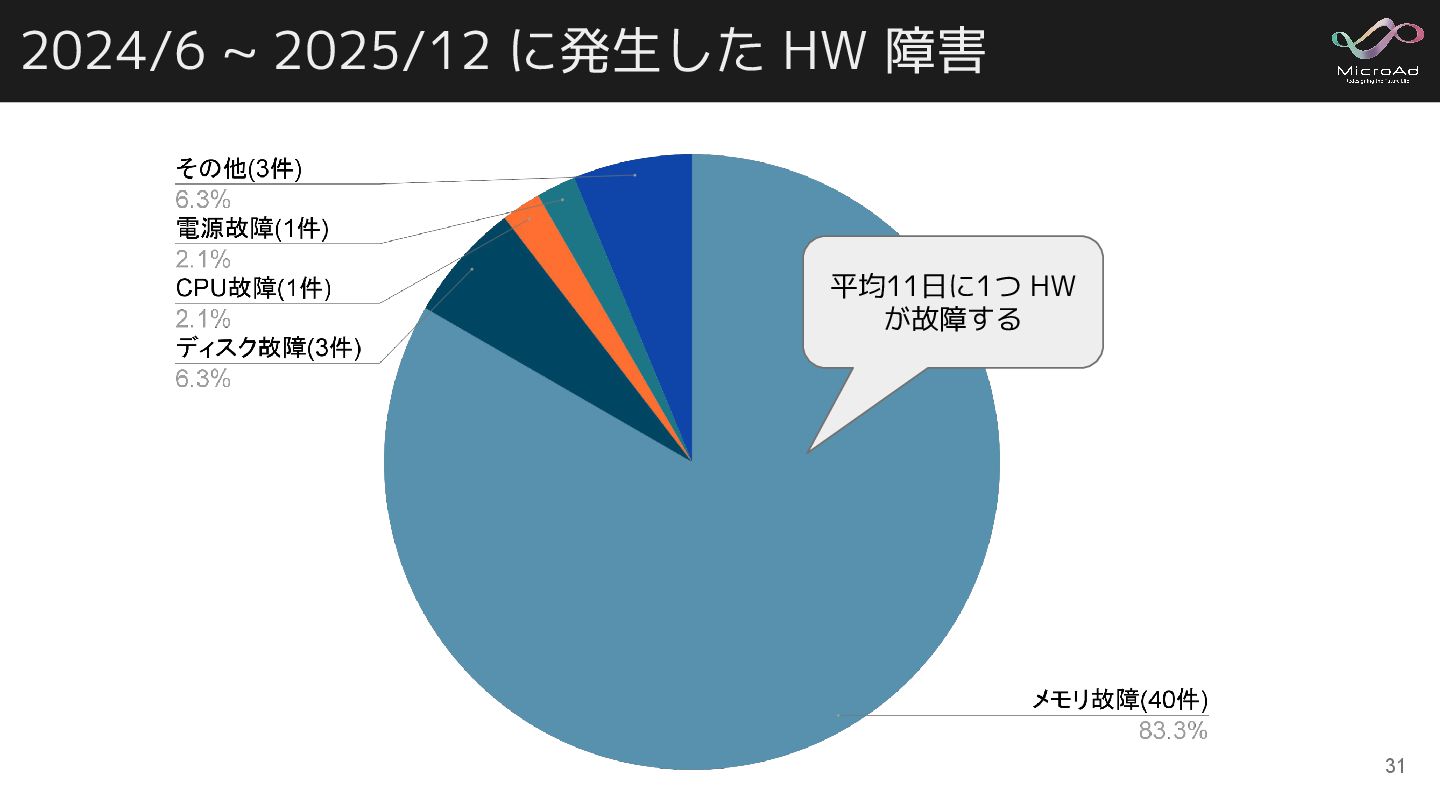
2024/6 ~ 2025/12 に発生した HW 障害 平均11日に1つ HW が故障する 31
ソフトウェア起因の障害 ケース1:リリースに伴うエラー(設計ミス:API の不整合など) • アプリ間でHTTPヘッダの受け渡しがうまくいかない ケース2:外部のシステムに影響された障害 • 提携企業のシステムからのリクエスト数増によるサーバダウン ケース3:設定ミス •
入札価格を間違えて超低価格にしたことで落札が大量発生 32
Q: 故障をどうやって知るか? アプローチA: 定期的にDCに行きサーバを目視で巡回確認 • 変なランプが点灯していないか?異音がしていないか? アプローチB: コマンドによる個別確認 • Ping確認
→ SSHログイン → ログ確認 → 10人で1,000台以上のサーバに対応するのは人員リソース的に不可能 • また、障害検知の見落としや、エンジニアの疲弊・モチベーション低下につながります ではどうするか... 運用監視基盤を作る💪 33
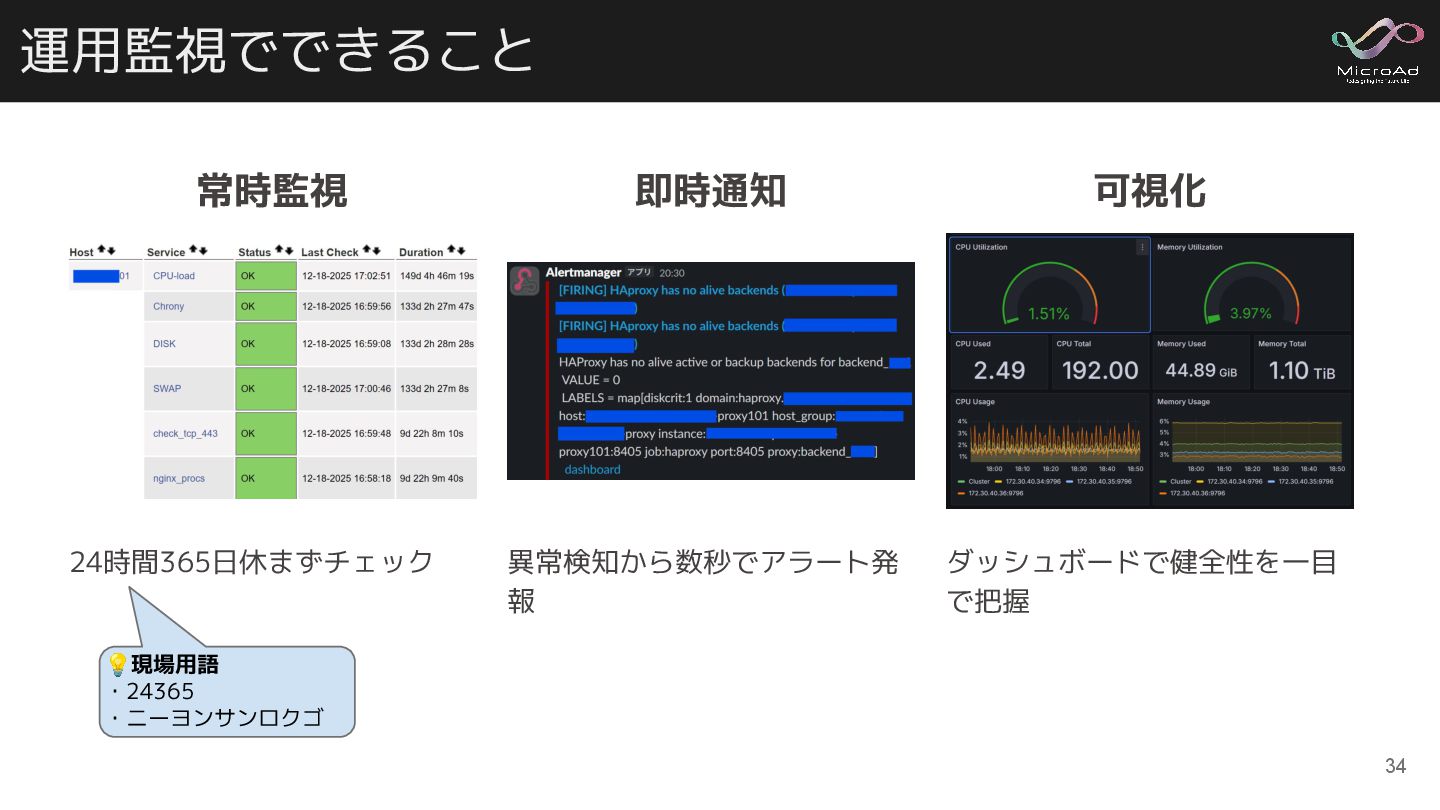
運用監視でできること 常時監視 24時間365日休まずチェック 即時通知 異常検知から数秒でアラート発 報 可視化 ダッシュボードで健全性を一目 で把握 💡現場用語
・24365 ・ニーヨンサンロクゴ 34
内部監視と外形監視 内部監視:ネットワークの内側からアクセスしシステムを監視すること • メトリクスを使って障害を検出する • ディスクのひっ迫、CPU・メモリ使用量の異常な上昇 外形監視:ネットワークの外側からアクセスし接続状況を監視すること • Ping や
cURL で疎通確認して障害を検出する • 外部から見た時にシステムに障害が発生したことが分かる 35
マイクロアドで使用しているツール 内部監視 外部監視 ロギング 可視化 用途に合わせて様々なツールを使い分けている 36
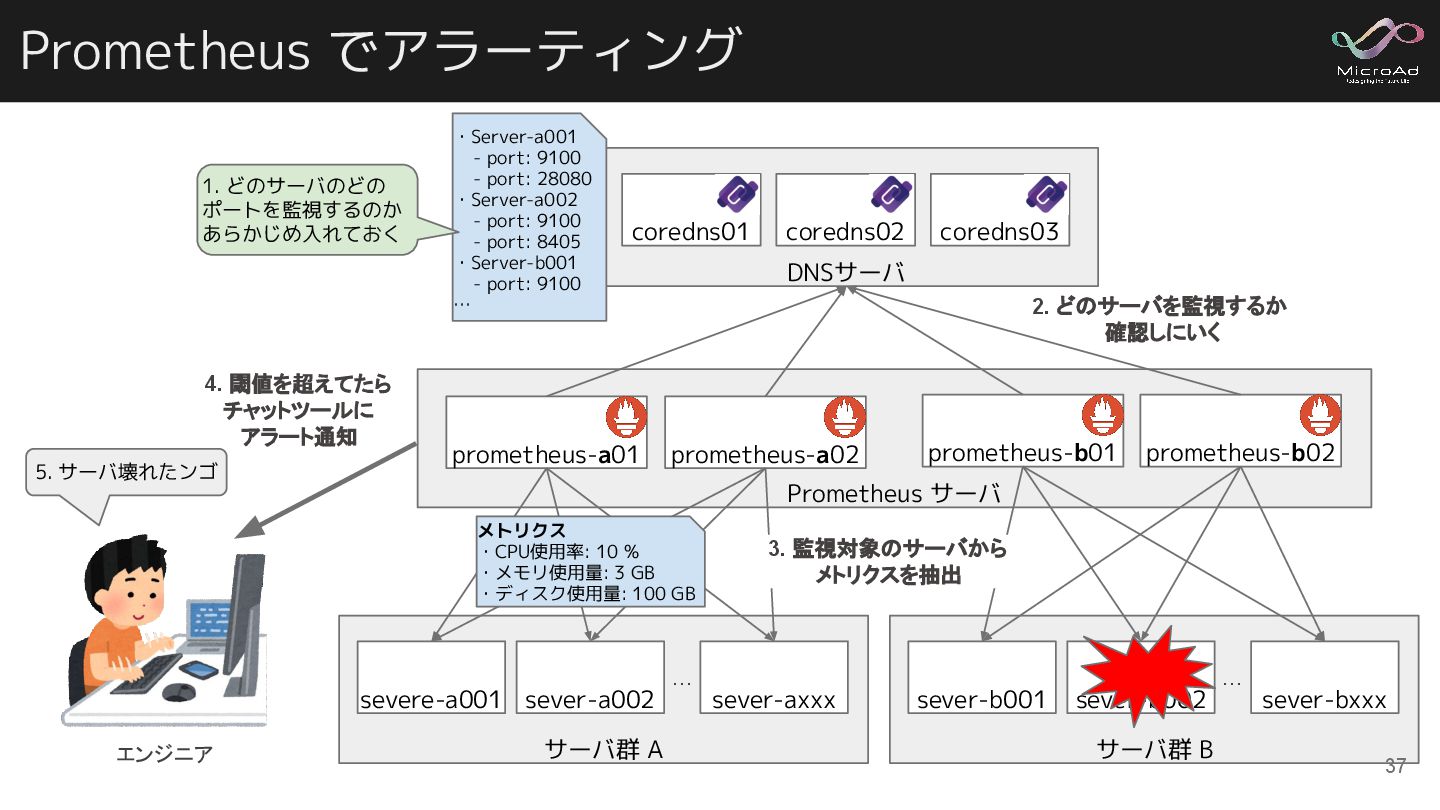
DNSサーバ Prometheus でアラーティング coredns01 coredns02 Prometheus サーバ coredns03 サーバ群 A
… prometheus-a01 sever-axxx sever-a002 severe-a001 prometheus-b01 prometheus-b02 サーバ群 B prometheus-a02 … sever-bxxx sever-b002 sever-b001 4. 閾値を超えてたら チャットツールに アラート通知 エンジニア 2. どのサーバを監視するか 確認しにいく ・Server-a001 - port: 9100 - port: 28080 ・Server-a002 - port: 9100 - port: 8405 ・Server-b001 - port: 9100 … 1. どのサーバのどの ポートを監視するのか あらかじめ入れておく 5. サーバ壊れたンゴ 3. 監視対象のサーバから メトリクスを抽出 メトリクス ・CPU使用率: 10 % ・メモリ使用量: 3 GB ・ディスク使用量: 100 GB 37
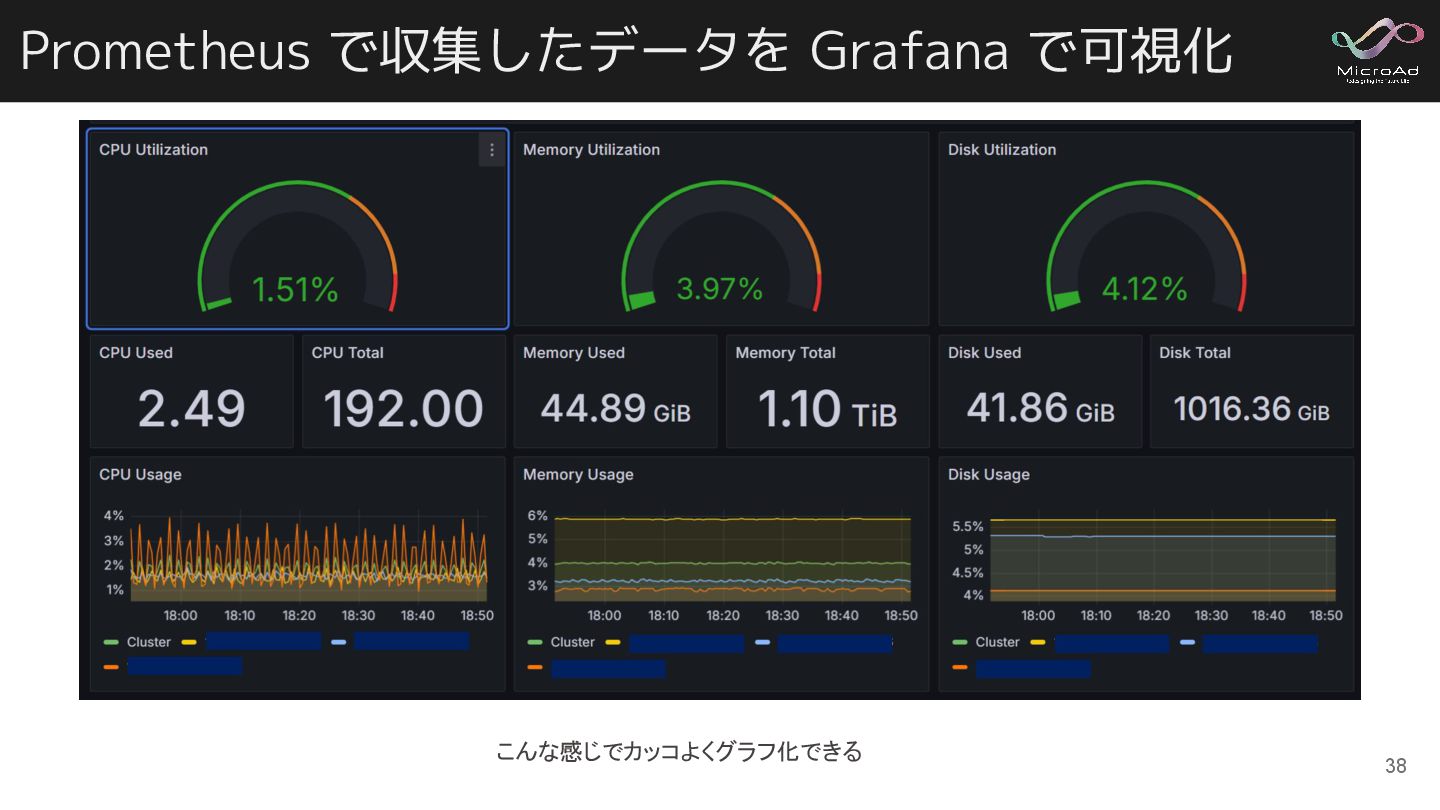
Prometheus で収集したデータを Grafana で可視化 こんな感じでカッコよくグラフ化できる 38
運用監視の先へ(発展) 運用監視を包括する概念で「オブザーバビリティ」があります オブザーバビリティは、障害や性能劣化が起きたときに勘や経験に頼らず事実ベースで原因を説 明し素早く直すことを目的としている なぜ必要か:システムが複雑化し、事前に想定した監視だけでは原因を特定できなくなったため 実現方法 • データ収集 • 可視化・分析
• アクション(運用) 観点 従来の運用監視 オブザーバビリティ 目的 異常に気づく 原因を理解・説明する 使うデータ 主にメトリクス メトリクス, ログ, トレース 位置づけ ・壊れたことは分かる ・壊れた原因は分からない ・壊れた原因を突き止める ・再発防止につながる 39
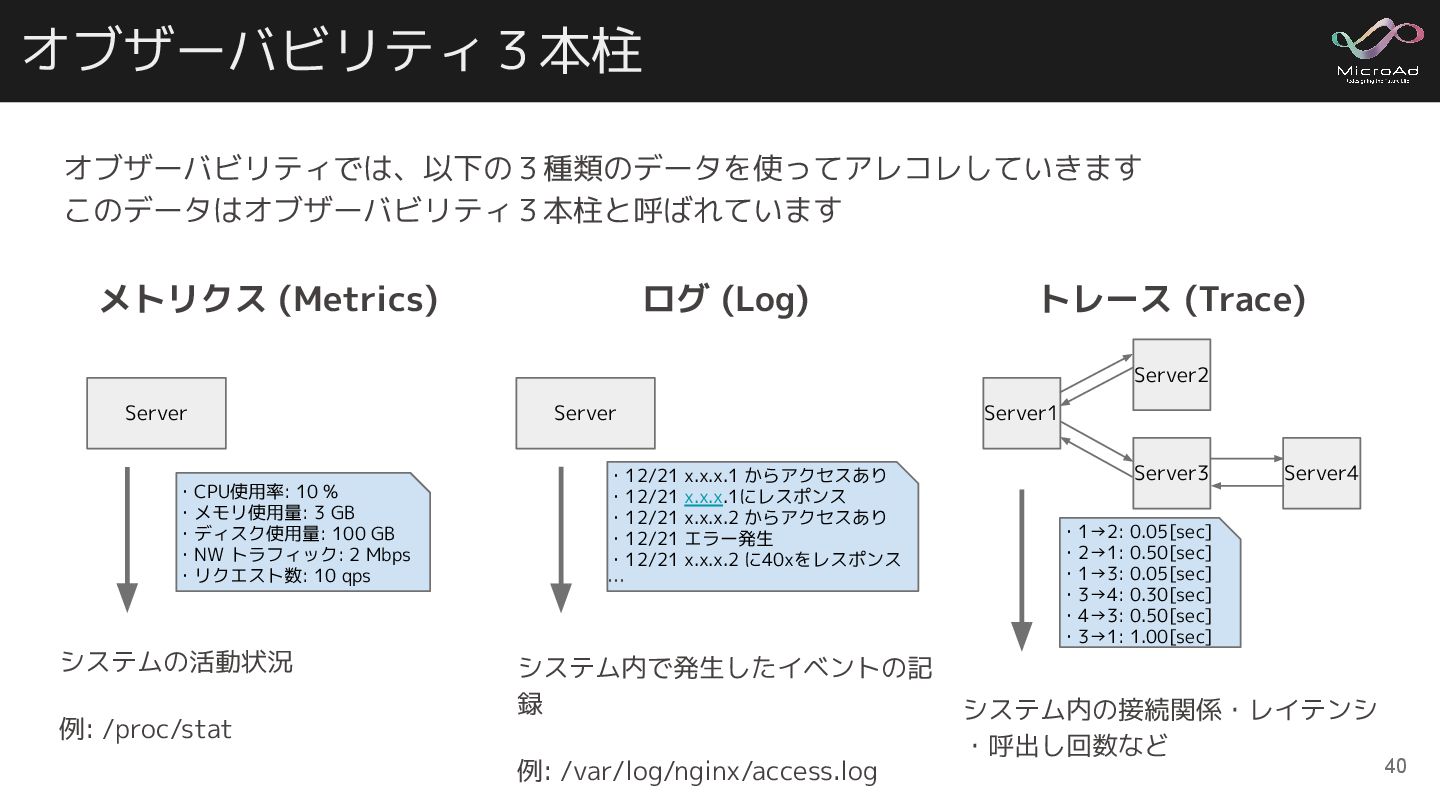
メトリクス (Metrics) システムの活動状況 例: /proc/stat オブザーバビリティ3本柱 ログ (Log) システム内で発生したイベントの記 録
例: /var/log/nginx/access.log トレース (Trace) システム内の接続関係・レイテンシ ・呼出し回数など Server ・CPU使用率: 10 % ・メモリ使用量: 3 GB ・ディスク使用量: 100 GB ・NW トラフィック: 2 Mbps ・リクエスト数: 10 qps Server ・12/21 x.x.x.1 からアクセスあり ・12/21 x.x.x.1にレスポンス ・12/21 x.x.x.2 からアクセスあり ・12/21 エラー発生 ・12/21 x.x.x.2 に40xをレスポンス … Server1 Server2 Server3 Server4 ・1→2: 0.05[sec] ・2→1: 0.50[sec] ・1→3: 0.05[sec] ・3→4: 0.30[sec] ・4→3: 0.50[sec] ・3→1: 1.00[sec] オブザーバビリティでは、以下の3種類のデータを使ってアレコレしていきます このデータはオブザーバビリティ3本柱と呼ばれています 40
ネットワーク冗長化 41
サーバは簡単に壊れるがシステムを止めたくない... ラック 1-01 ラック 1-02 … ラック 1-14 ラック 2-01
ラック 2-02 … ラック 2-14 ラック 3-01 ラック 3-02 … ラック 3-12 これだけ多くの HW があると頻繁に故障します 故障があるとデータセンタ(DC)に駆けつけて修理・ 交換します ※ HW故障でDCに駆けつけるインフラ エンジニアのイラスト (Geminiで生成) サーバが故障してもシステムを止めないように するにはどうすればよいか? ネットワークの冗長化 ストレージの冗長化 42
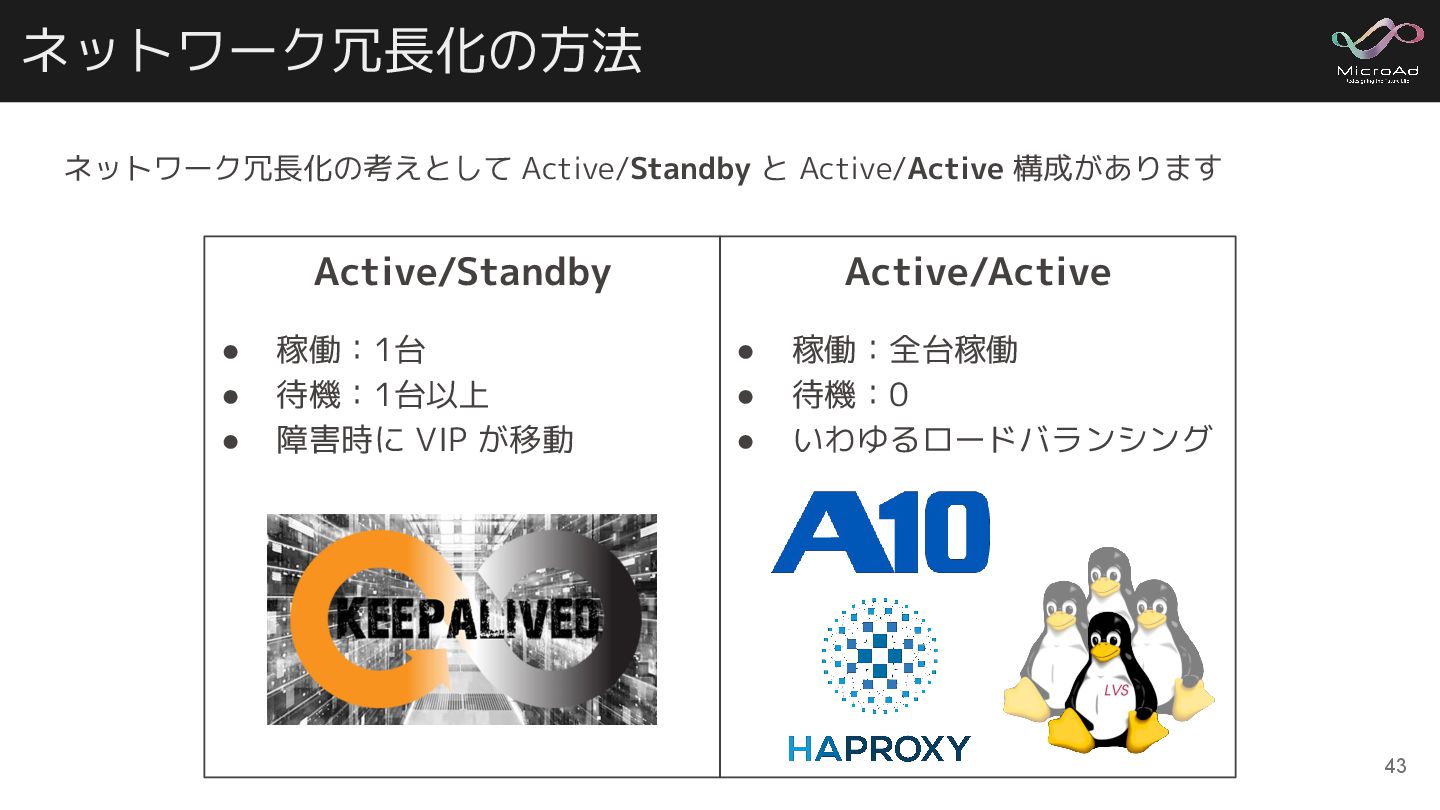
ネットワーク冗長化の方法 ネットワーク冗長化の考えとして Active/Standby と Active/Active 構成があります Active/Standby • 稼働:1台 •
待機:1台以上 • 障害時に VIP が移動 Active/Active • 稼働:全台稼働 • 待機:0 • いわゆるロードバランシング 43
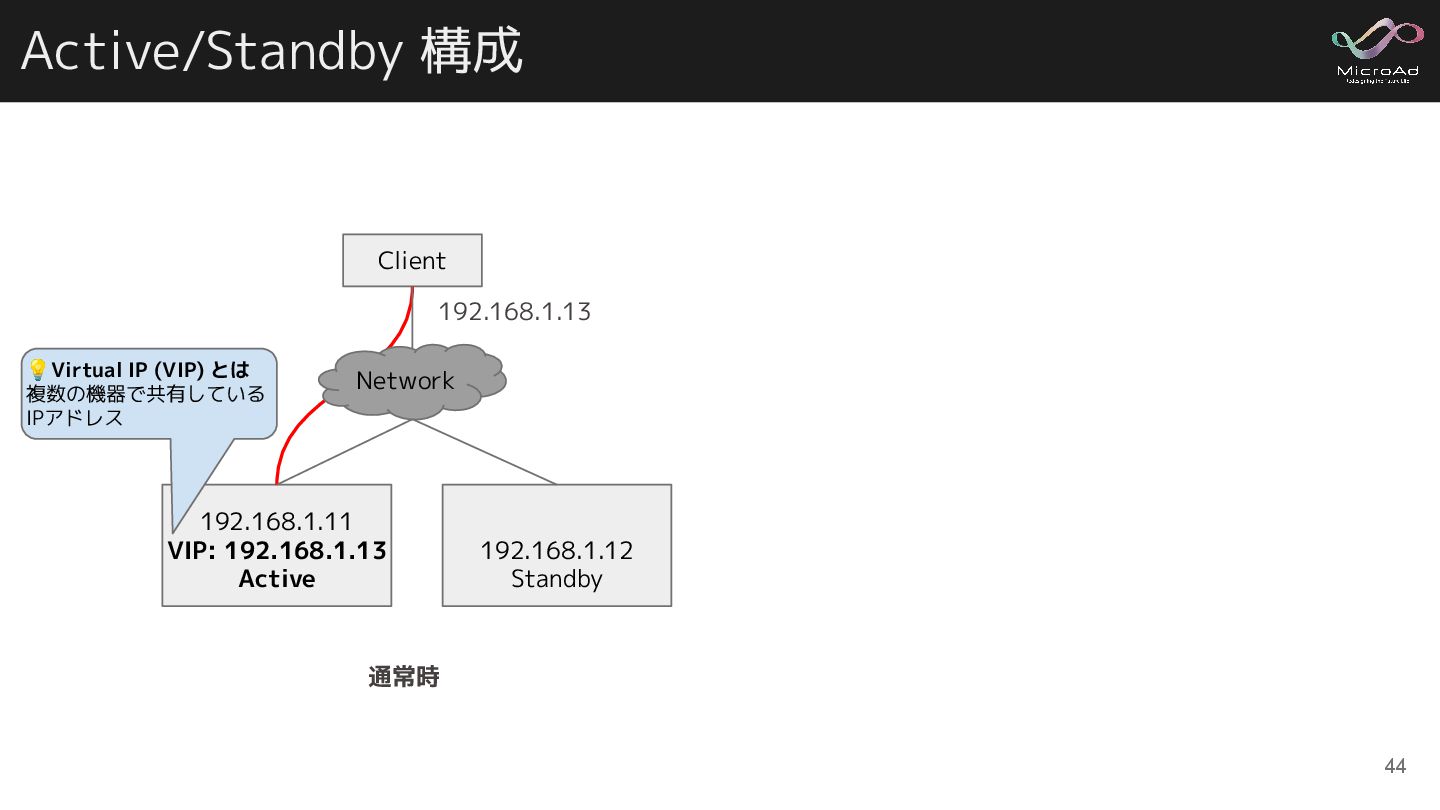
Active/Standby 構成 Client 192.168.1.11 VIP: 192.168.1.13 Active 192.168.1.12 Standby 通常時
192.168.1.13 Network 💡Virtual IP (VIP) とは 複数の機器で共有している IPアドレス 44
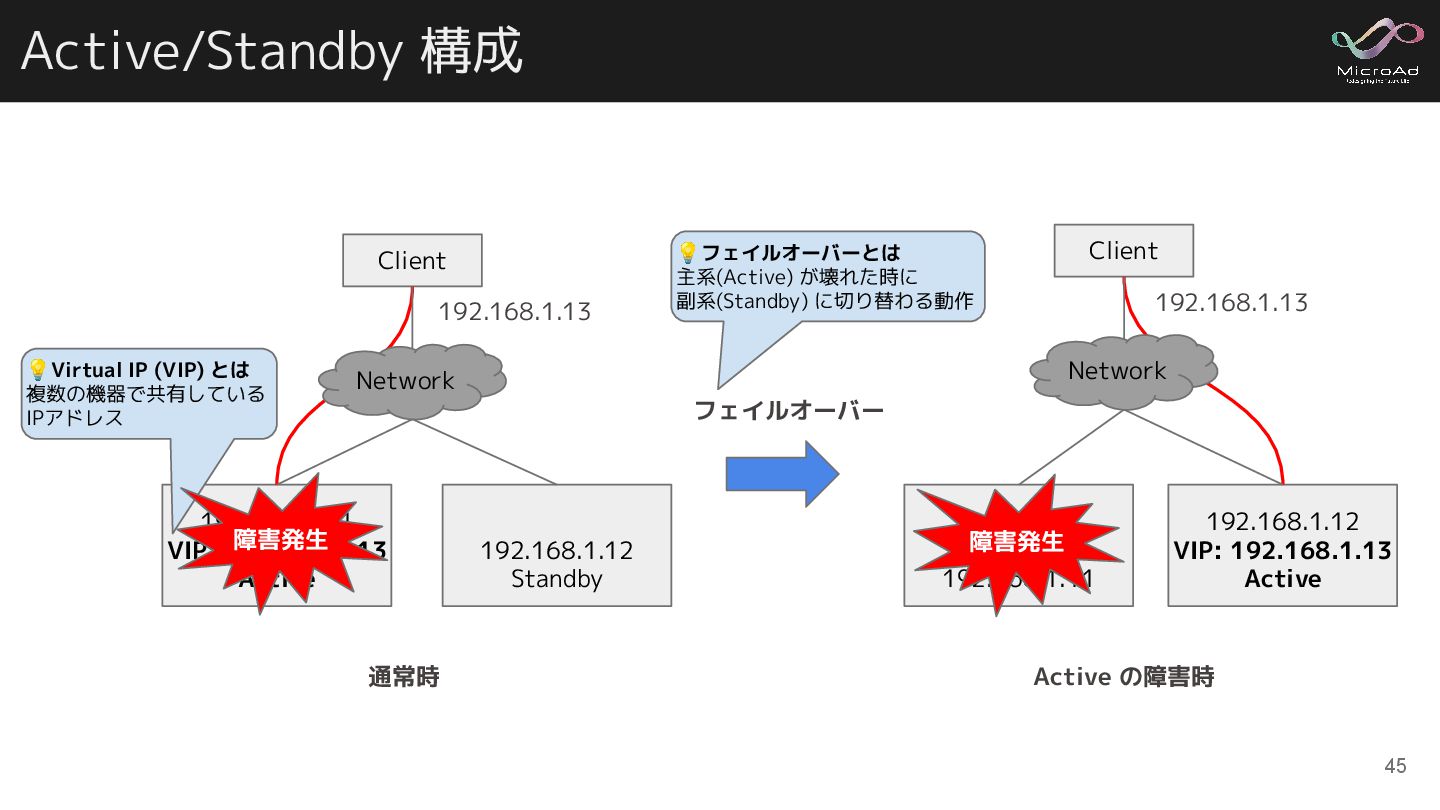
Active/Standby 構成 Client 192.168.1.11 VIP: 192.168.1.13 Active 192.168.1.12 Standby 通常時
192.168.1.13 Network Active の障害時 Client 192.168.1.11 192.168.1.12 VIP: 192.168.1.13 Active 障害発生 192.168.1.13 Network フェイルオーバー 💡フェイルオーバーとは 主系(Active) が壊れた時に 副系(Standby) に切り替わる動作 💡Virtual IP (VIP) とは 複数の機器で共有している IPアドレス 45 障害発生
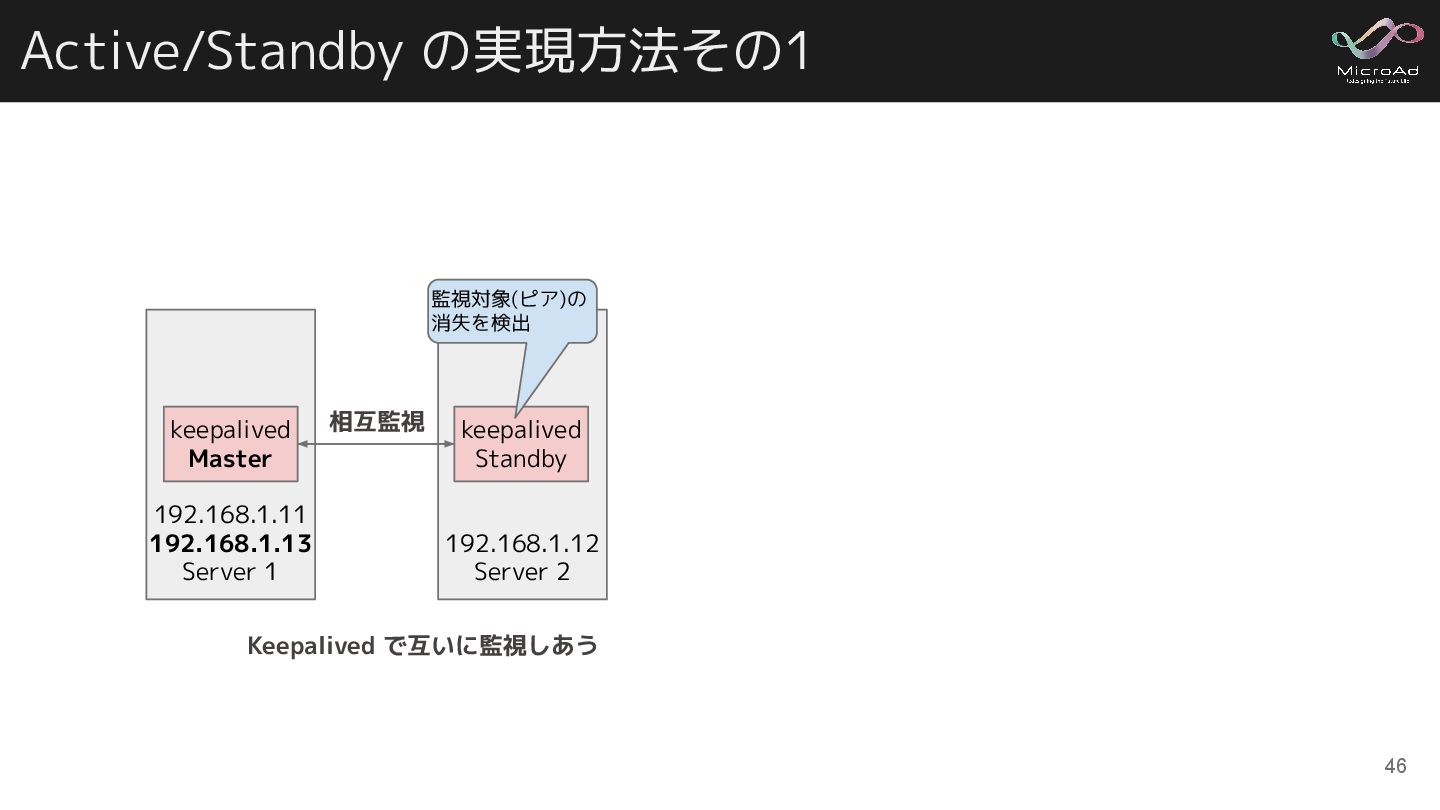
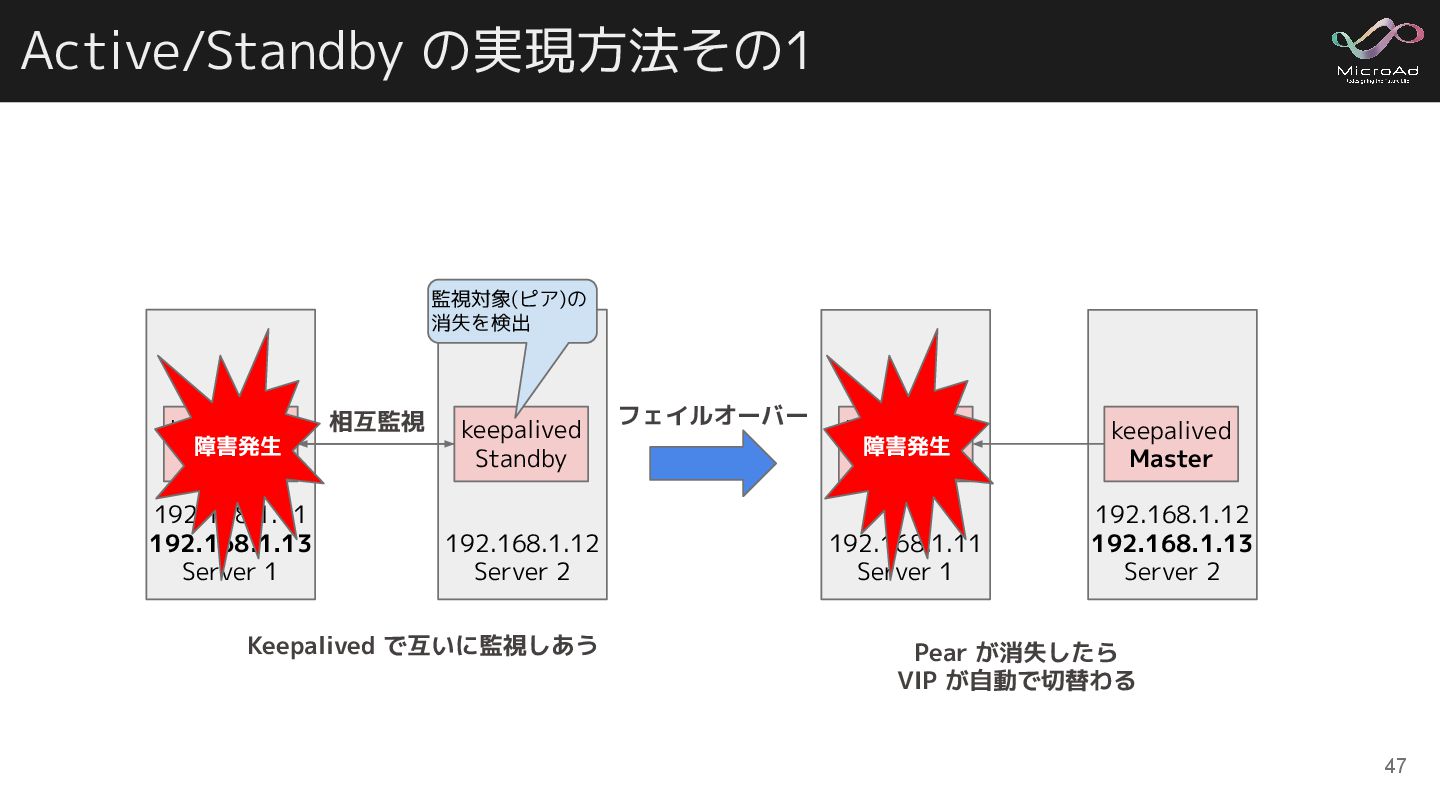
Active/Standby の実現方法その1 192.168.1.11 192.168.1.13 Server 1 192.168.1.12 Server 2 keepalived
Master keepalived Standby Keepalived で互いに監視しあう 相互監視 監視対象(ピア)の 消失を検出 46
Active/Standby の実現方法その1 192.168.1.11 192.168.1.13 Server 1 192.168.1.12 Server 2 keepalived
Master keepalived Standby Keepalived で互いに監視しあう 相互監視 監視対象(ピア)の 消失を検出 障害発生 192.168.1.11 Server 1 192.168.1.12 192.168.1.13 Server 2 keepalived Standby keepalived Master フェイルオーバー Pear が消失したら VIP が自動で切替わる 障害発生 47 障害発生
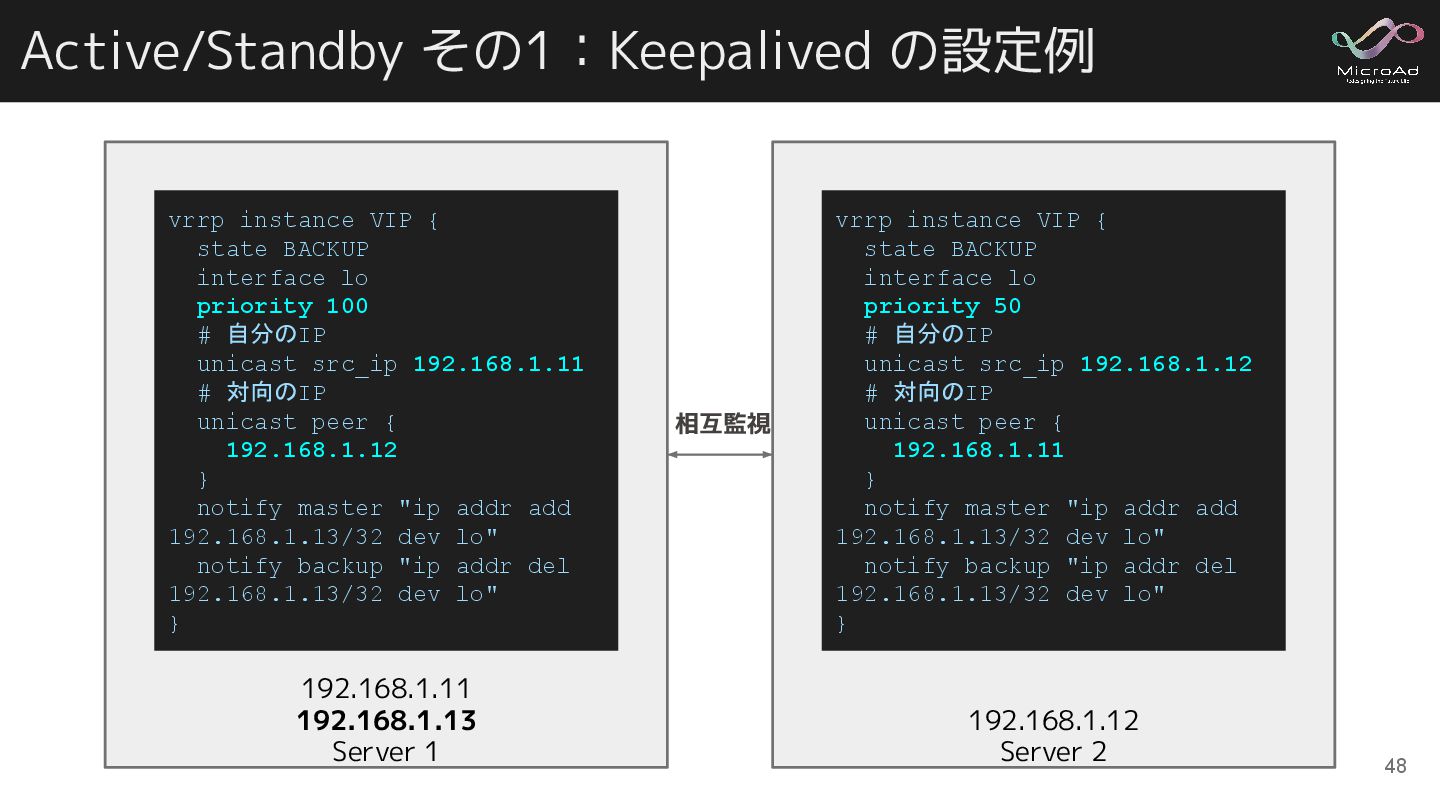
192.168.1.11 192.168.1.13 Server 1 192.168.1.12 Server 2 Active/Standby その1:Keepalived の設定例
vrrp_instance VIP { state BACKUP interface lo priority 50 # 自分のIP unicast_src_ip 192.168.1.12 # 対向のIP unicast_peer { 192.168.1.11 } notify_master "ip addr add 192.168.1.13/32 dev lo" notify_backup "ip addr del 192.168.1.13/32 dev lo" } vrrp_instance VIP { state BACKUP interface lo priority 100 # 自分のIP unicast_src_ip 192.168.1.11 # 対向のIP unicast_peer { 192.168.1.12 } notify_master "ip addr add 192.168.1.13/32 dev lo" notify_backup "ip addr del 192.168.1.13/32 dev lo" } 相互監視 48
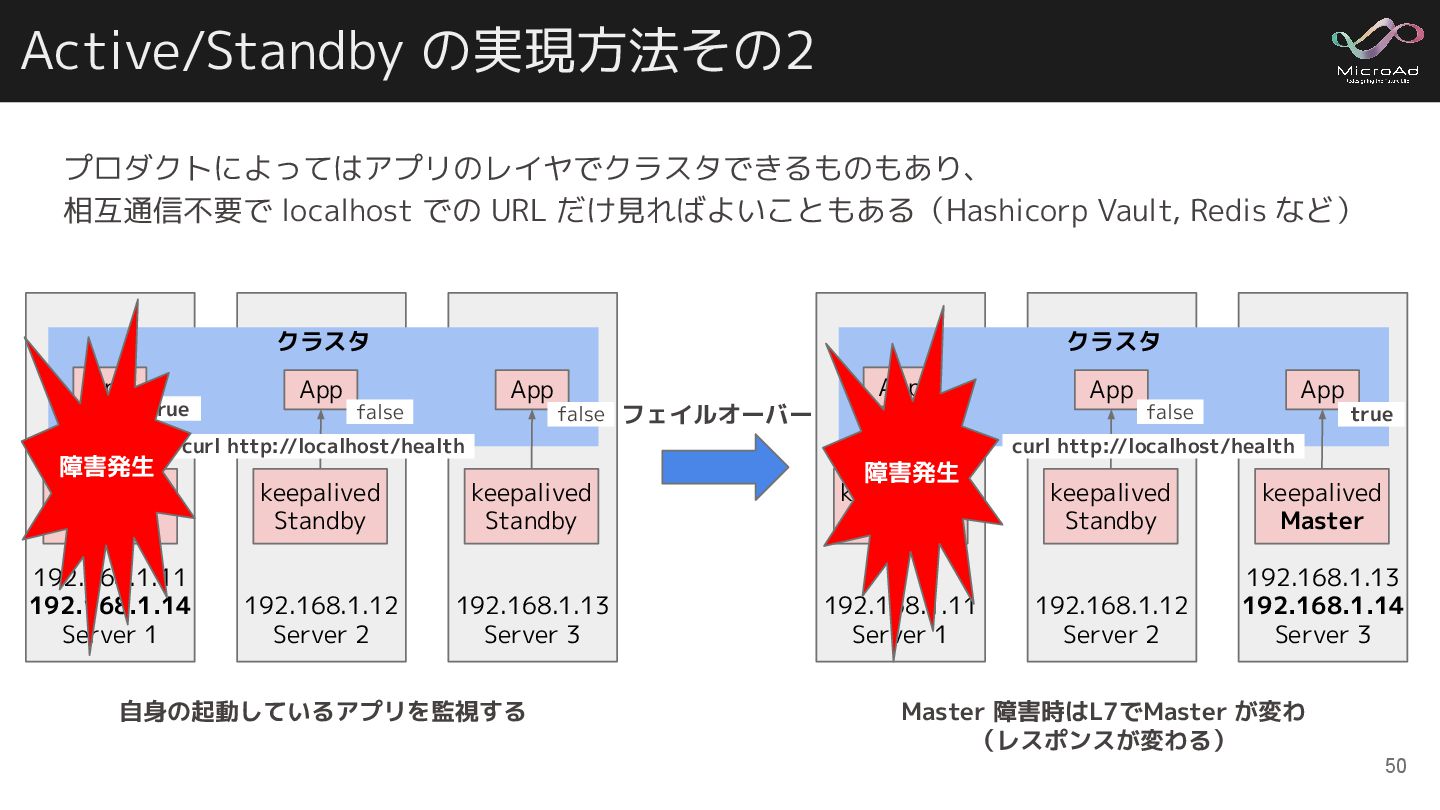
Active/Standby の実現方法その2 192.168.1.11 192.168.1.14 Server 1 192.168.1.12 Server 2 keepalived
Master keepalived Standby 自身の起動しているアプリを監視する プロダクトによってはアプリのレイヤでクラスタできるものもあり、 相互通信不要で localhost での URL だけ見ればよいこともある(Hashicorp Vault, Redis など) 192.168.1.13 Server 3 keepalived Standby クラスタ App App App curl http://localhost/health true false false 49
Active/Standby の実現方法その2 192.168.1.11 192.168.1.14 Server 1 192.168.1.12 Server 2 keepalived
Master keepalived Standby 自身の起動しているアプリを監視する プロダクトによってはアプリのレイヤでクラスタできるものもあり、 相互通信不要で localhost での URL だけ見ればよいこともある(Hashicorp Vault, Redis など) 192.168.1.13 Server 3 keepalived Standby クラスタ App App App curl http://localhost/health true false false 192.168.1.11 Server 1 192.168.1.12 Server 2 keepalived Master keepalived Standby Master 障害時はL7でMaster が変わ (レスポンスが変わる) 192.168.1.13 192.168.1.14 Server 3 keepalived Master クラスタ App App App curl http://localhost/health false true 障害発生 フェイルオーバー 50 障害発生
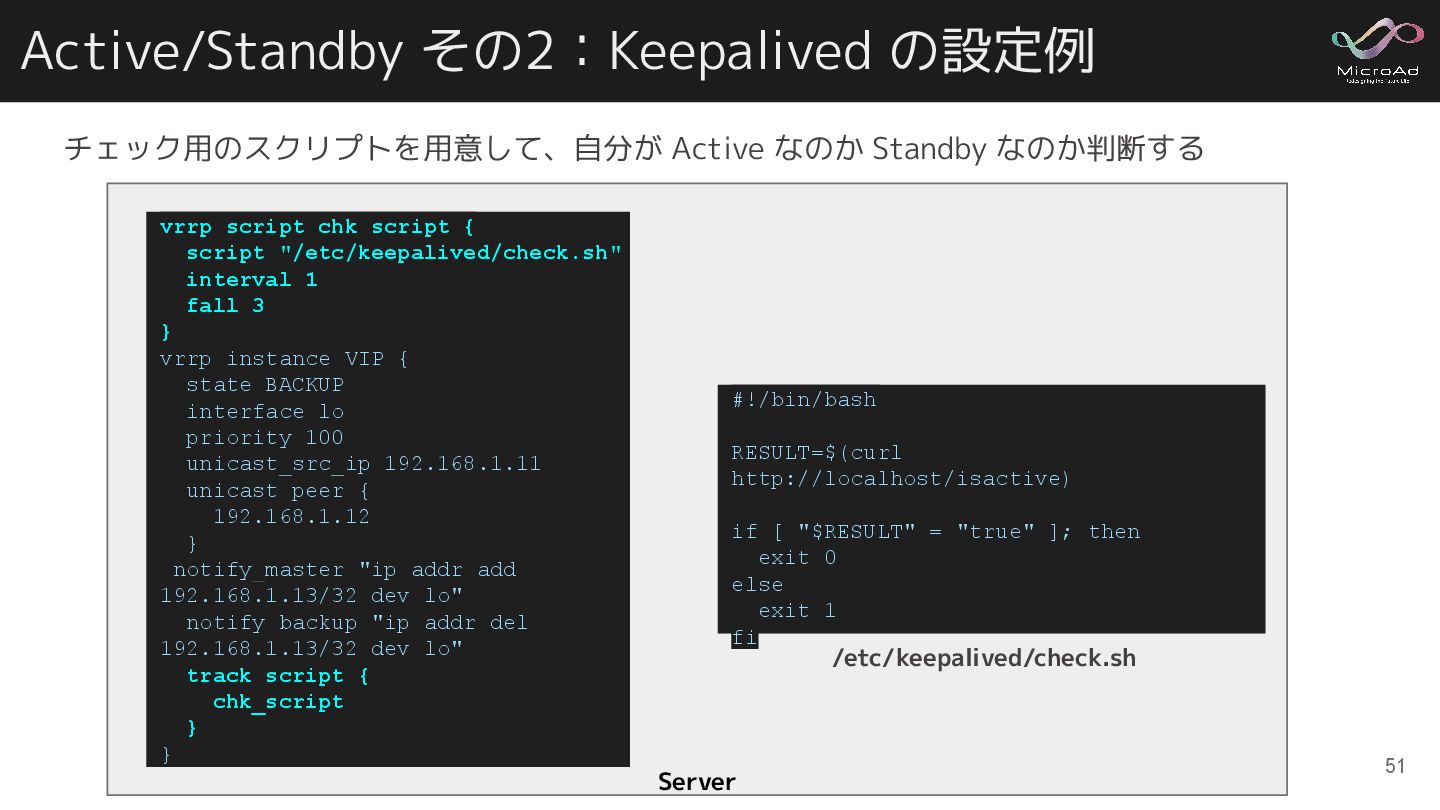
Active/Standby その2:Keepalived の設定例 Server vrrp_script chk_script { script "/etc/keepalived/check.sh" interval
1 fall 3 } vrrp_instance VIP { state BACKUP interface lo priority 100 unicast_src_ip 192.168.1.11 unicast_peer { 192.168.1.12 } notify_master "ip addr add 192.168.1.13/32 dev lo" notify_backup "ip addr del 192.168.1.13/32 dev lo" track_script { chk_script } } #!/bin/bash RESULT=$(curl http://localhost/isactive) if [ "$RESULT" = "true" ]; then exit 0 else exit 1 fi /etc/keepalived/check.sh チェック用のスクリプトを用意して、自分が Active なのか Standby なのか判断する 51
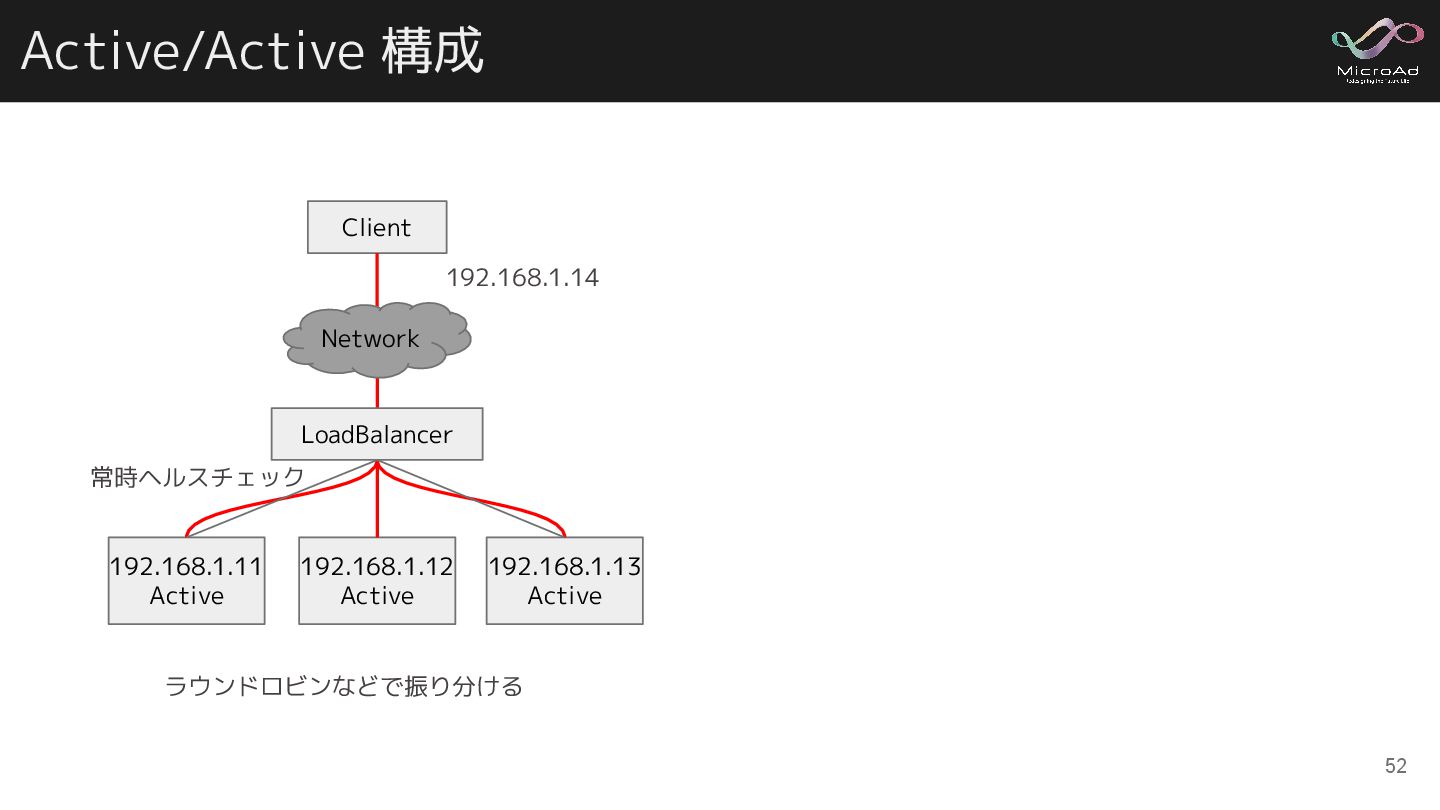
Active/Active 構成 192.168.1.11 Active 192.168.1.12 Active Client 192.168.1.13 Active 192.168.1.14
ラウンドロビンなどで振り分ける LoadBalancer Network 常時ヘルスチェック 52
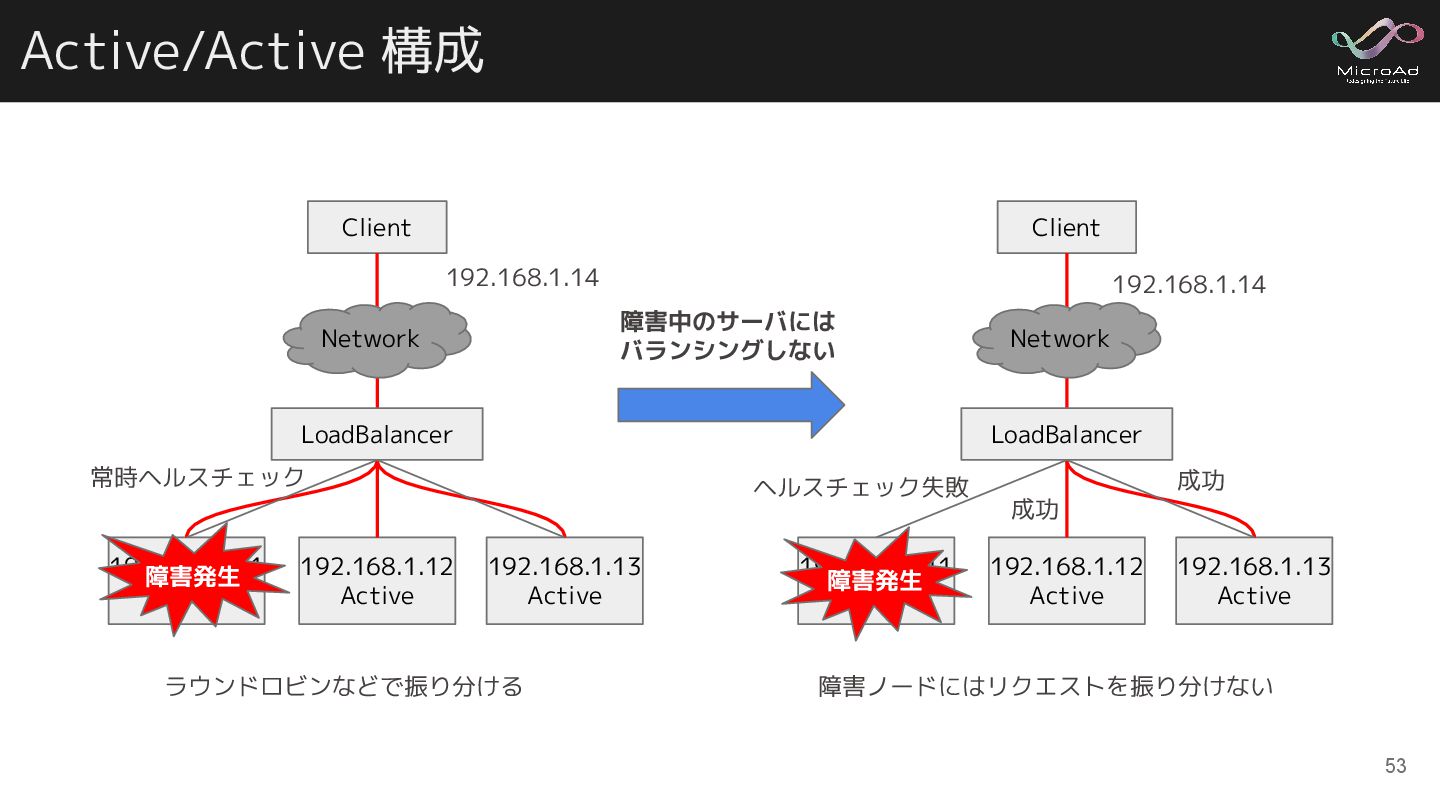
Active/Active 構成 192.168.1.11 Active 192.168.1.12 Active Client 192.168.1.13 Active 192.168.1.14
ラウンドロビンなどで振り分ける LoadBalancer Network 常時ヘルスチェック 障害ノードにはリクエストを振り分けない 192.168.1.11 Active 192.168.1.12 Active Client 192.168.1.13 Active ヘルスチェック失敗 障害発生 192.168.1.14 LoadBalancer Network 障害中のサーバには バランシングしない 成功 成功 53 障害発生
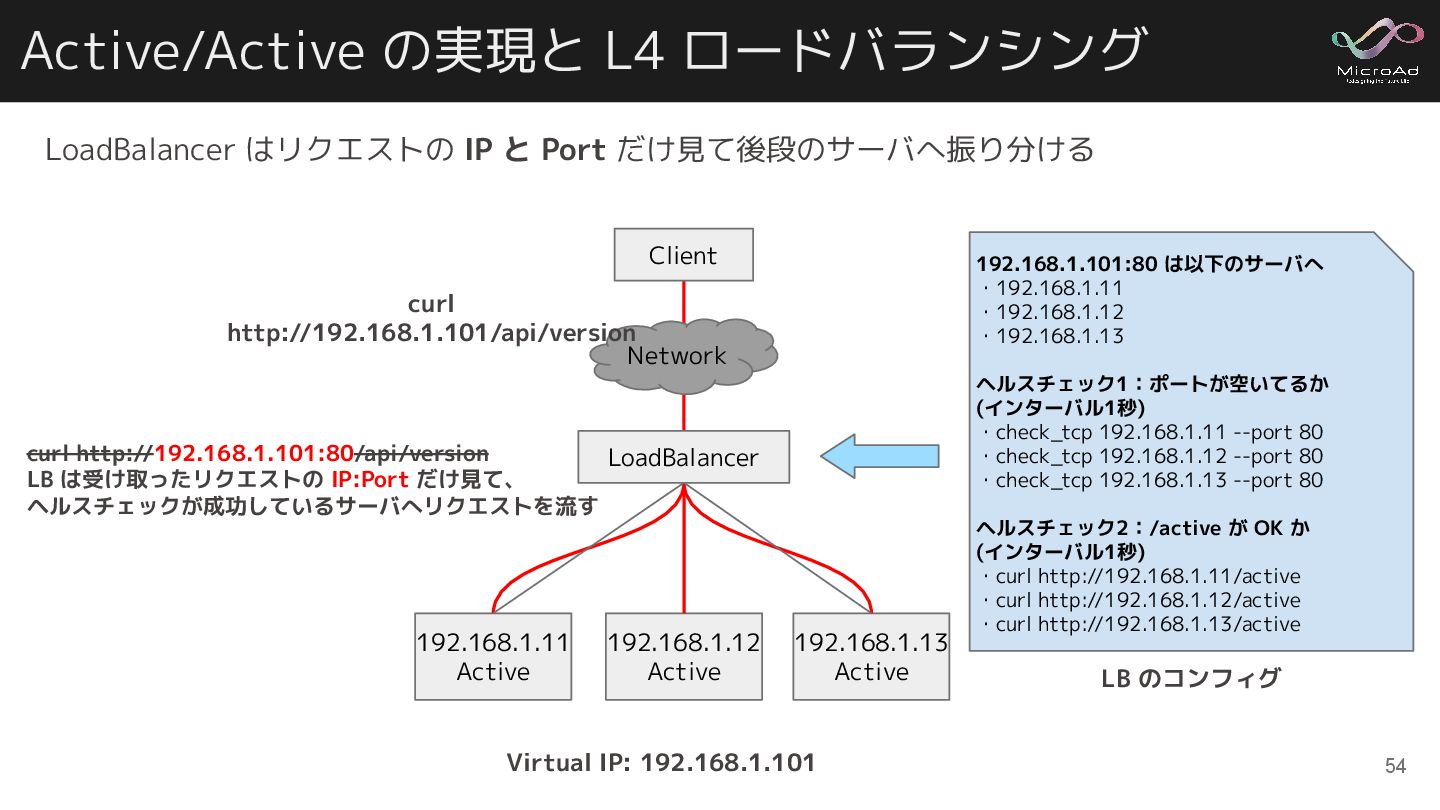
Active/Active の実現と L4 ロードバランシング 192.168.1.11 Active 192.168.1.12 Active 192.168.1.13 Active
Virtual IP: 192.168.1.101 LoadBalancer 192.168.1.101:80 は以下のサーバへ ・192.168.1.11 ・192.168.1.12 ・192.168.1.13 ヘルスチェック1:ポートが空いてるか (インターバル1秒) ・check_tcp 192.168.1.11 --port 80 ・check_tcp 192.168.1.12 --port 80 ・check_tcp 192.168.1.13 --port 80 ヘルスチェック2:/active が OK か (インターバル1秒) ・curl http://192.168.1.11/active ・curl http://192.168.1.12/active ・curl http://192.168.1.13/active Client Network curl http://192.168.1.101/api/version curl http://192.168.1.101:80/api/version LB は受け取ったリクエストの IP:Port だけ見て、 ヘルスチェックが成功しているサーバへリクエストを流す LB のコンフィグ LoadBalancer はリクエストの IP と Port だけ見て後段のサーバへ振り分ける 54
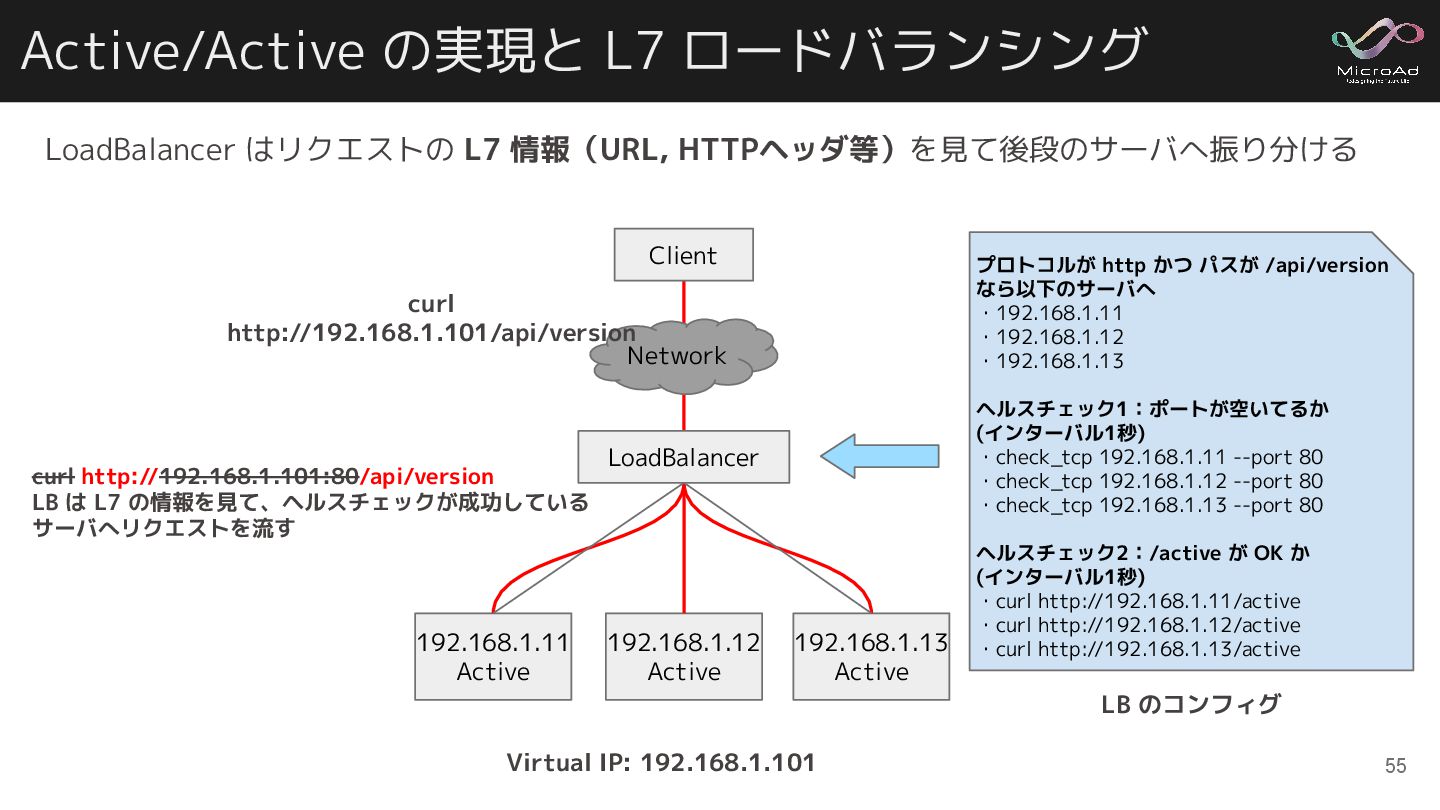
Active/Active の実現と L7 ロードバランシング 192.168.1.11 Active 192.168.1.12 Active 192.168.1.13 Active
Virtual IP: 192.168.1.101 LoadBalancer プロトコルが http かつ パスが /api/version なら以下のサーバへ ・192.168.1.11 ・192.168.1.12 ・192.168.1.13 ヘルスチェック1:ポートが空いてるか (インターバル1秒) ・check_tcp 192.168.1.11 --port 80 ・check_tcp 192.168.1.12 --port 80 ・check_tcp 192.168.1.13 --port 80 ヘルスチェック2:/active が OK か (インターバル1秒) ・curl http://192.168.1.11/active ・curl http://192.168.1.12/active ・curl http://192.168.1.13/active Client Network curl http://192.168.1.101/api/version curl http://192.168.1.101:80/api/version LB は L7 の情報を見て、ヘルスチェックが成功している サーバへリクエストを流す LB のコンフィグ LoadBalancer はリクエストの L7 情報(URL, HTTPヘッダ等)を見て後段のサーバへ振り分ける 55
ストレージ技術 56
サーバは簡単に壊れるがシステムを止めたくない... ラック 1-01 ラック 1-02 … ラック 1-14 ラック 2-01
ラック 2-02 … ラック 2-14 ラック 3-01 ラック 3-02 … ラック 3-12 これだけ多くの HW があると頻繁に故障します 故障があるとデータセンタ(DC)に駆けつけて修理・ 交換します ※ HW故障でDCに駆けつけるインフラ エンジニアのイラスト (Geminiで生成) サーバが故障してもシステムを止めないように するにはどうすればよいか? ネットワークの冗長化 ストレージの冗長化 57
ストレージの種類 ブロックストレージ: ブロックデバイスをネットワーク越しに提供 • プロトコル: FIber Channel, iSCSI • OSS実装:
open-iscsi, Ceph RBD, ファイルストレージ: ファイルシステムネットワーク越しに提供(今日はここを説明します) • 代表プロトコル: NFS, SMB • OSS実装: nfs-server, GlusterFS, CephFS オブジェクトストレージ: データを保存する領域とアップロード/ダウンロードのAPIを提供 • 代表 API: S3, Swift • OSS実装: OpenStack Swift, Ceph RGW • パブリッククラウド: AWS S3, Google Cloud GCS 58
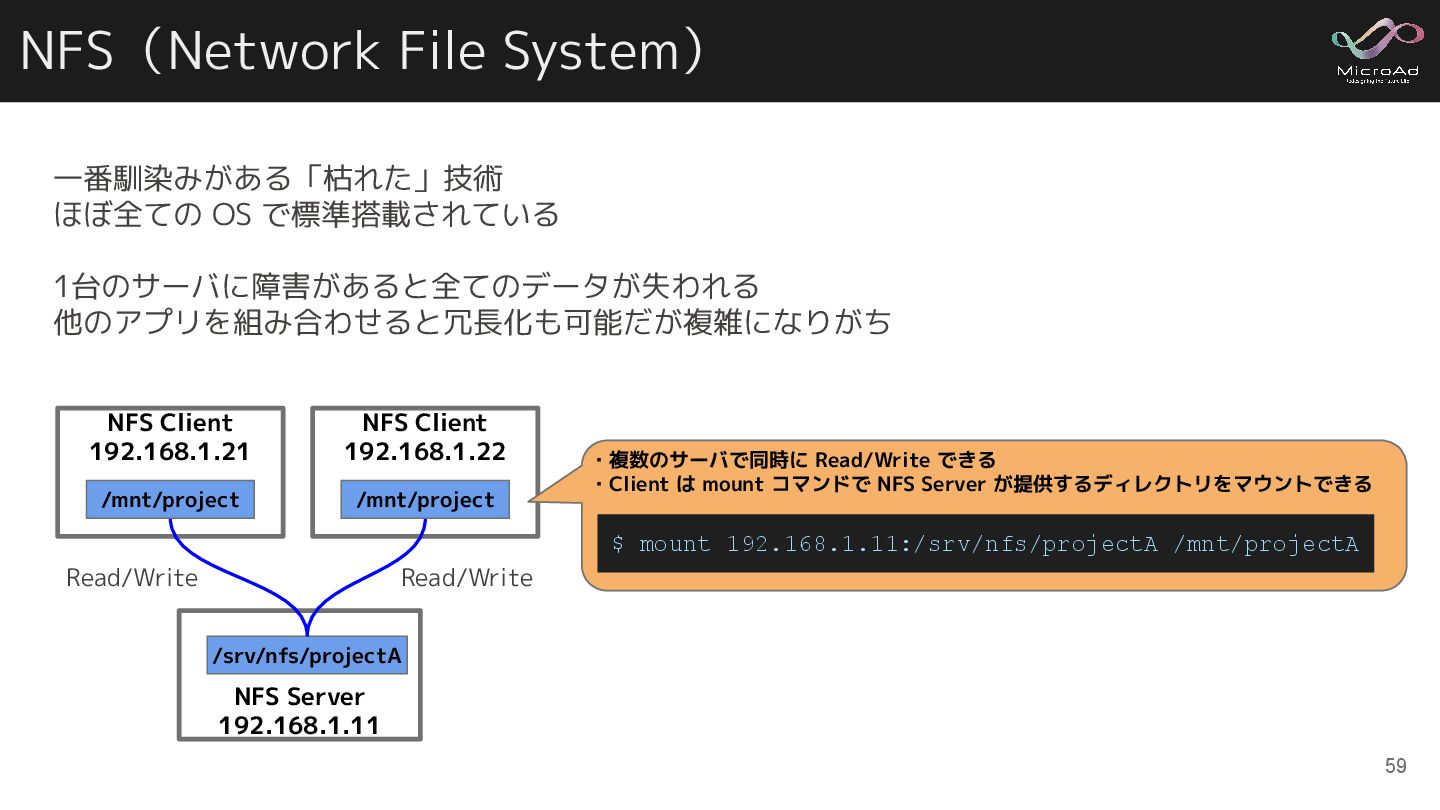
NFS(Network File System) 一番馴染みがある「枯れた」技術 ほぼ全ての OS で標準搭載されている 1台のサーバに障害があると全てのデータが失われる 他のアプリを組み合わせると冗長化も可能だが複雑になりがち NFS
Server 192.168.1.11 /srv/nfs/projectA NFS Client 192.168.1.21 /mnt/project NFS Client 192.168.1.22 /mnt/project Read/Write Read/Write ・複数のサーバで同時に Read/Write できる ・Client は mount コマンドで NFS Server が提供するディレクトリをマウントできる $ mount 192.168.1.11:/srv/nfs/projectA /mnt/projectA 59
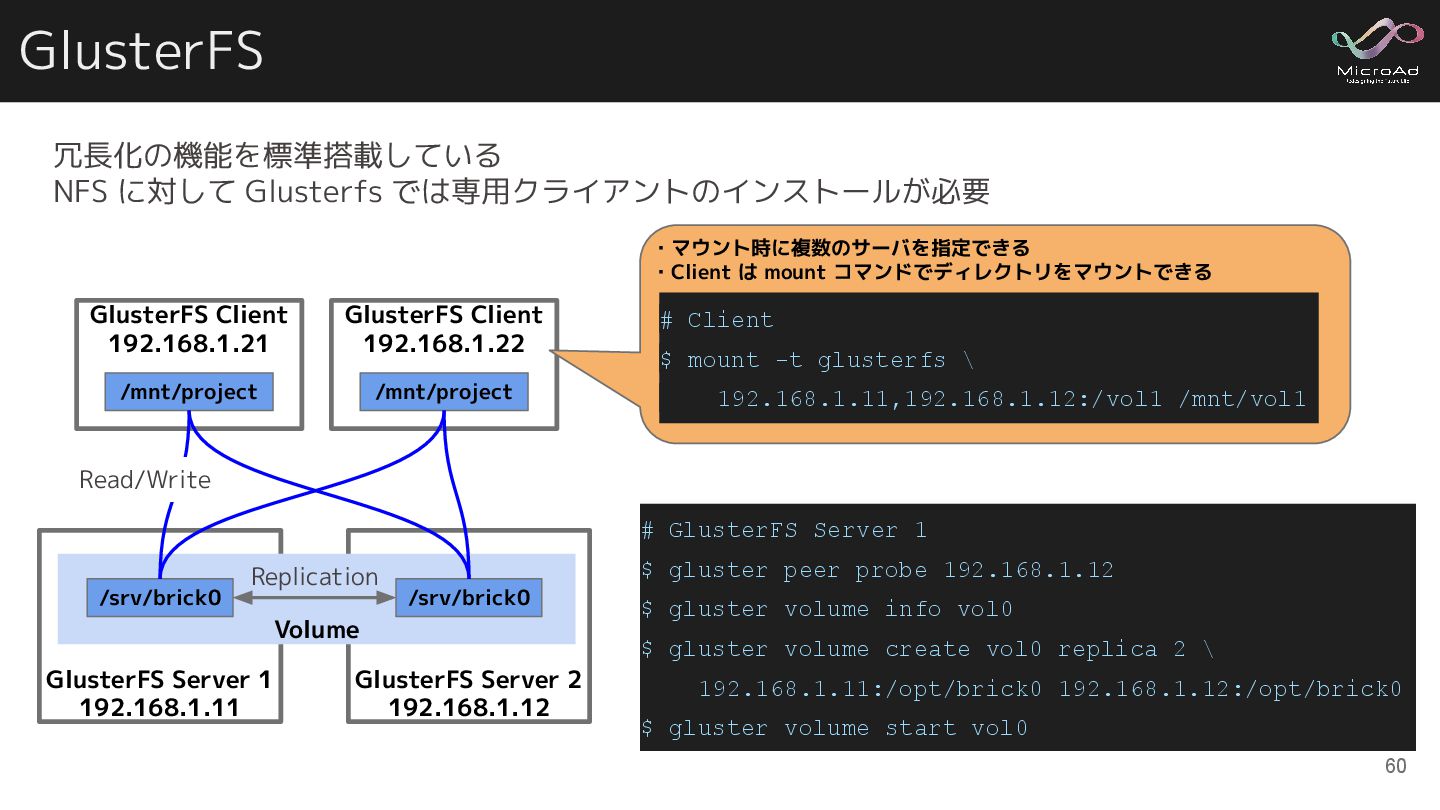
GlusterFS 冗長化の機能を標準搭載している NFS に対して Glusterfs では専用クライアントのインストールが必要 GlusterFS Server 1 192.168.1.11
GlusterFS Client 192.168.1.21 /mnt/project GlusterFS Client 192.168.1.22 /mnt/project GlusterFS Server 2 192.168.1.12 # GlusterFS Server 1 $ gluster peer probe 192.168.1.12 $ gluster volume info vol0 $ gluster volume create vol0 replica 2 \ 192.168.1.11:/opt/brick0 192.168.1.12:/opt/brick0 $ gluster volume start vol0 Volume /srv/brick0 /srv/brick0 Replication Read/Write ・マウント時に複数のサーバを指定できる ・Client は mount コマンドでディレクトリをマウントできる # Client $ mount -t glusterfs \ 192.168.1.11,192.168.1.12:/vol1 /mnt/vol1 60
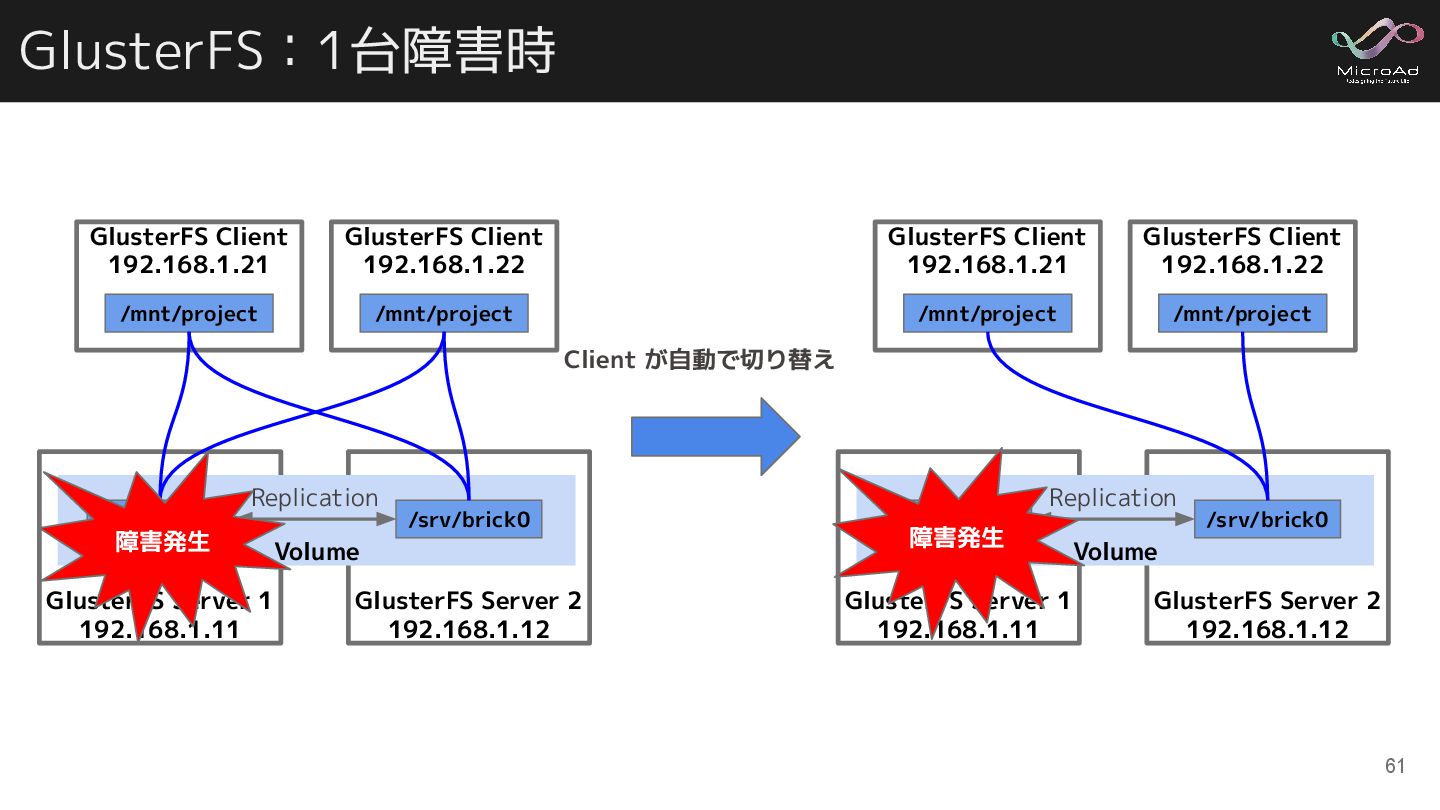
GlusterFS:1台障害時 GlusterFS Server 1 192.168.1.11 GlusterFS Client 192.168.1.21 /mnt/project GlusterFS
Client 192.168.1.22 /mnt/project GlusterFS Server 2 192.168.1.12 Volume /srv/brick0 /srv/brick0 Replication GlusterFS Server 1 192.168.1.11 GlusterFS Client 192.168.1.21 /mnt/project GlusterFS Client 192.168.1.22 /mnt/project GlusterFS Server 2 192.168.1.12 Volume /srv/brick0 /srv/brick0 Replication 障害発生 Client が自動で切り替え 61 障害発生
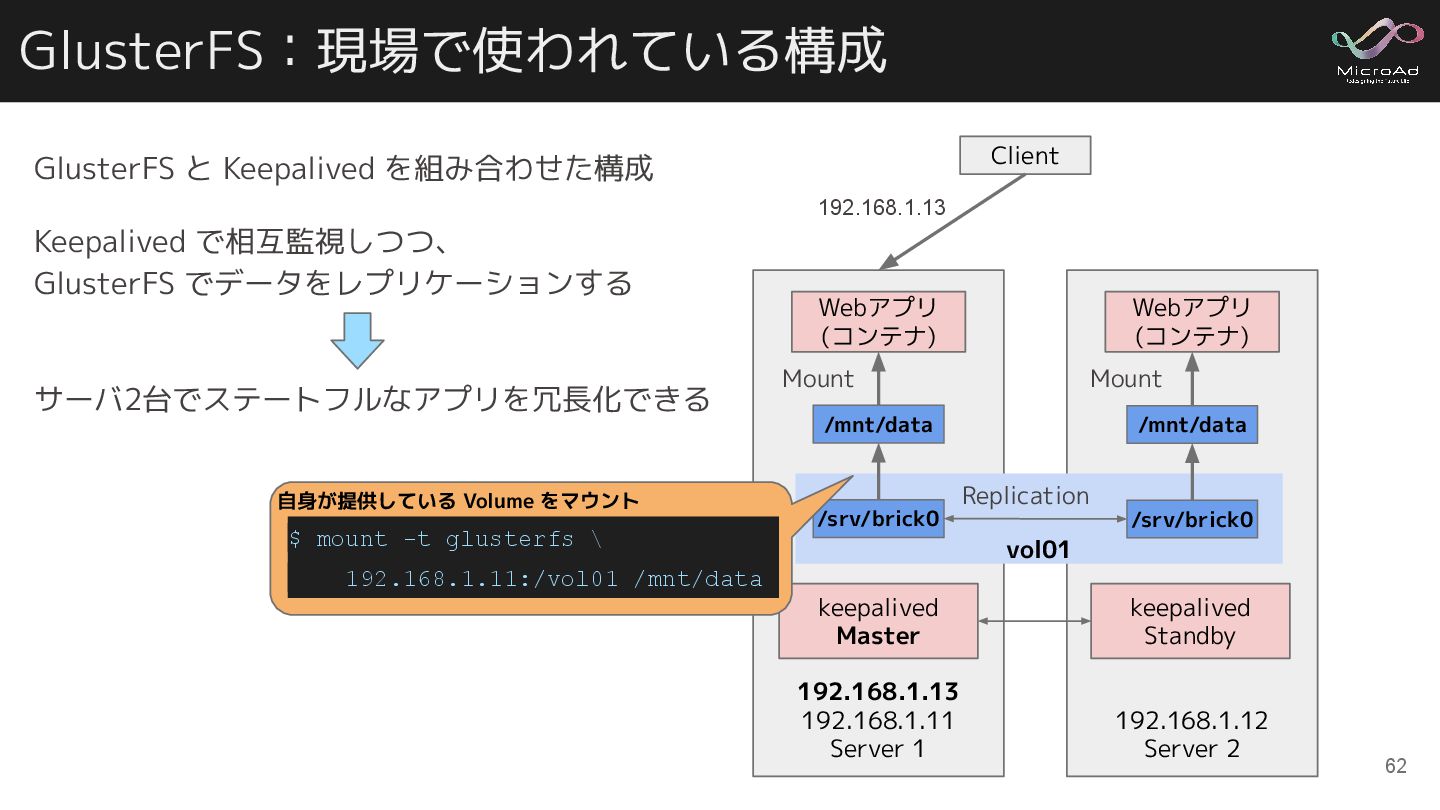
GlusterFS:現場で使われている構成 192.168.1.13 192.168.1.11 Server 1 192.168.1.12 Server 2 Webアプリ (コンテナ)
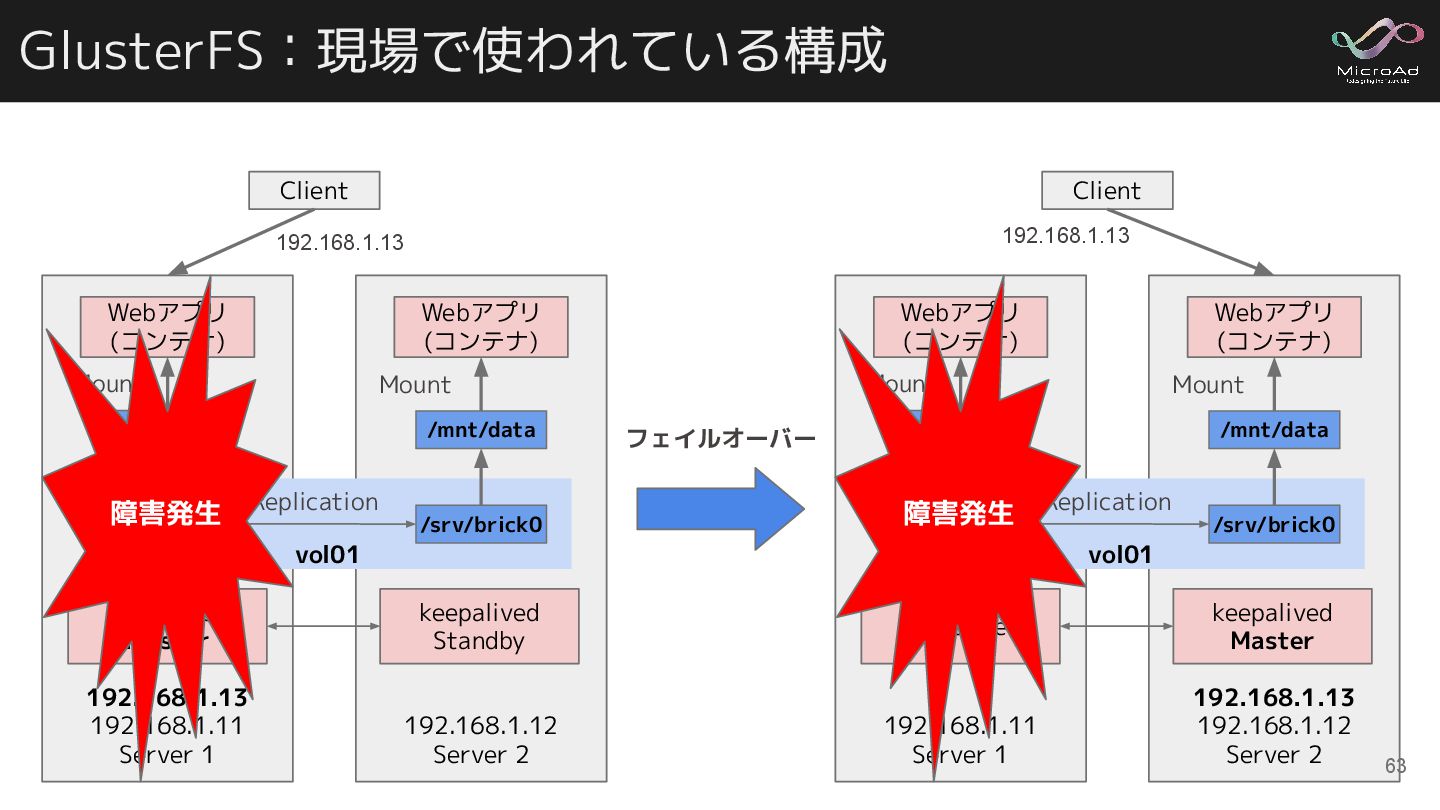
Client keepalived Master keepalived Standby 192.168.1.13 vol01 /srv/brick0 Replication /srv/brick0 /mnt/data /mnt/data 自身が提供している Volume をマウント $ mount -t glusterfs \ 192.168.1.11:/vol01 /mnt/data Webアプリ (コンテナ) Mount Mount GlusterFS と Keepalived を組み合わせた構成 Keepalived で相互監視しつつ、 GlusterFS でデータをレプリケーションする サーバ2台でステートフルなアプリを冗長化できる 62
GlusterFS:現場で使われている構成 192.168.1.13 192.168.1.11 Server 1 192.168.1.12 Server 2 Webアプリ (コンテナ)
Client keepalived Master keepalived Standby 192.168.1.13 vol01 /srv/brick0 Replication /srv/brick0 /mnt/data /mnt/data Webアプリ (コンテナ) Mount Mount 192.168.1.11 Server 1 192.168.1.13 192.168.1.12 Server 2 Webアプリ (コンテナ) Client keepalived keepalived Master 192.168.1.13 vol01 /srv/brick0 Replication /srv/brick0 /mnt/data /mnt/data Webアプリ (コンテナ) Mount Mount フェイルオーバー 障害発生 63 障害発生
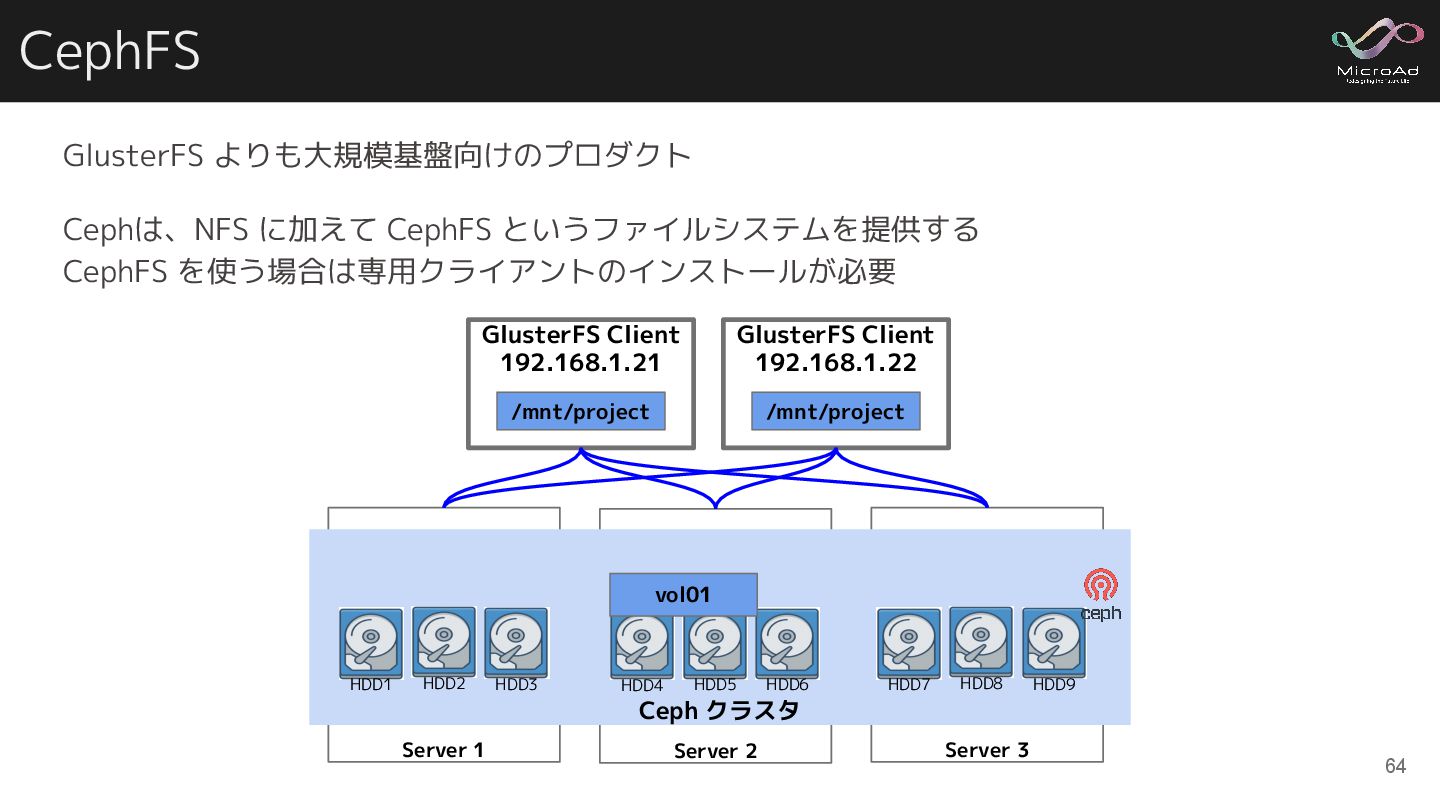
CephFS Server 1 Server 2 Server 3 Ceph クラスタ HDD1
HDD2 HDD3 HDD4 HDD5 HDD6 HDD7 HDD8 HDD9 vol01 GlusterFS よりも大規模基盤向けのプロダクト Cephは、NFS に加えて CephFS というファイルシステムを提供する CephFS を使う場合は専用クライアントのインストールが必要 GlusterFS Client 192.168.1.21 /mnt/project GlusterFS Client 192.168.1.22 /mnt/project 64
CephFS:FailureDomain 設定なし node 1 HDD1 HDD2 HDD3 node 2 HDD4
HDD5 HDD6 node 3 HDD7 HDD8 HDD9 障害発生 PG Replica1 Replica2 Replica3 ホスト分布 PG0 HDD 1 HDD 2 HDD 3 node 1 PG1 HDD 2 HDD 3 HDD 4 node 1, 2 PG2 HDD 3 HDD 4 HDD 5 node 1, 2 PG3 HDD 4 HDD 5 HDD 6 node 2 PG4 HDD 5 HDD 6 HDD 7 node 2, 3 PG5 HDD 6 HDD 7 HDD 8 node 2, 3 PG6 HDD 7 HDD 8 HDD 9 node 3 PG7 HDD 8 HDD 9 HDD 1 node 3, 1 PG0 PG1 PG2 PG3 PG4 PG5 PG6 PG7 Pool FailureDomain を設定しない と、同じサーバでグループを 作ることがある データが破損 障害発生 65
CephFS:FailureDomain = Host PG Replica1 Replica2 Replica3 ホスト分布 PG0 HDD
1 HDD 4 HDD 7 node 1, 2, 3 PG1 HDD 2 HDD 5 HDD 8 node 1, 2, 3 PG2 HDD 3 HDD 6 HDD 9 node 1, 2, 3 PG3 HDD 1 HDD 5 HDD 9 node 1, 2, 3 PG4 HDD 2 HDD 6 HDD 7 node 1, 2, 3 PG5 HDD 3 HDD 4 HDD 8 node 1, 2, 3 PG6 HDD 1 HDD 6 HDD 8 node 1, 2, 3 PG7 HDD 2 HDD 4 HDD 9 node 1, 2, 3 node 1 HDD1 HDD2 HDD3 node 2 HDD4 HDD5 HDD6 node 3 HDD7 HDD8 HDD9 PG0 PG1 PG2 PG3 PG4 PG5 PG6 PG7 Pool FailureDomain を設定する と同じグループのHDDを散 らしてくれる データの破損はなし 障害発生 障害発生 66
CephFS:その他 の FailureDomain • ラック:そのラック内のサーバが全て壊れてもOK(電源障害など) • データセンタ:そのデータセンタ内のサーバ全てが壊れてもOK(大規模災害など) 67
そして Kubernetes へ 68
とはいえ、インフラ周りを覚えるのは大変 ここまでで • ネットワークの冗長化には、Keepalived, HAProxy • ストレージ技術には、GlusterFS, Ceph といった技術があることが分かりました とはいえ、これらの技術を全て理解するのはなかなか大変
インフラに明るくなくてもしっかりネットワークやストレージを冗長化して堅牢なシステムが作 りたい! Kubernetes を活用する💪 69
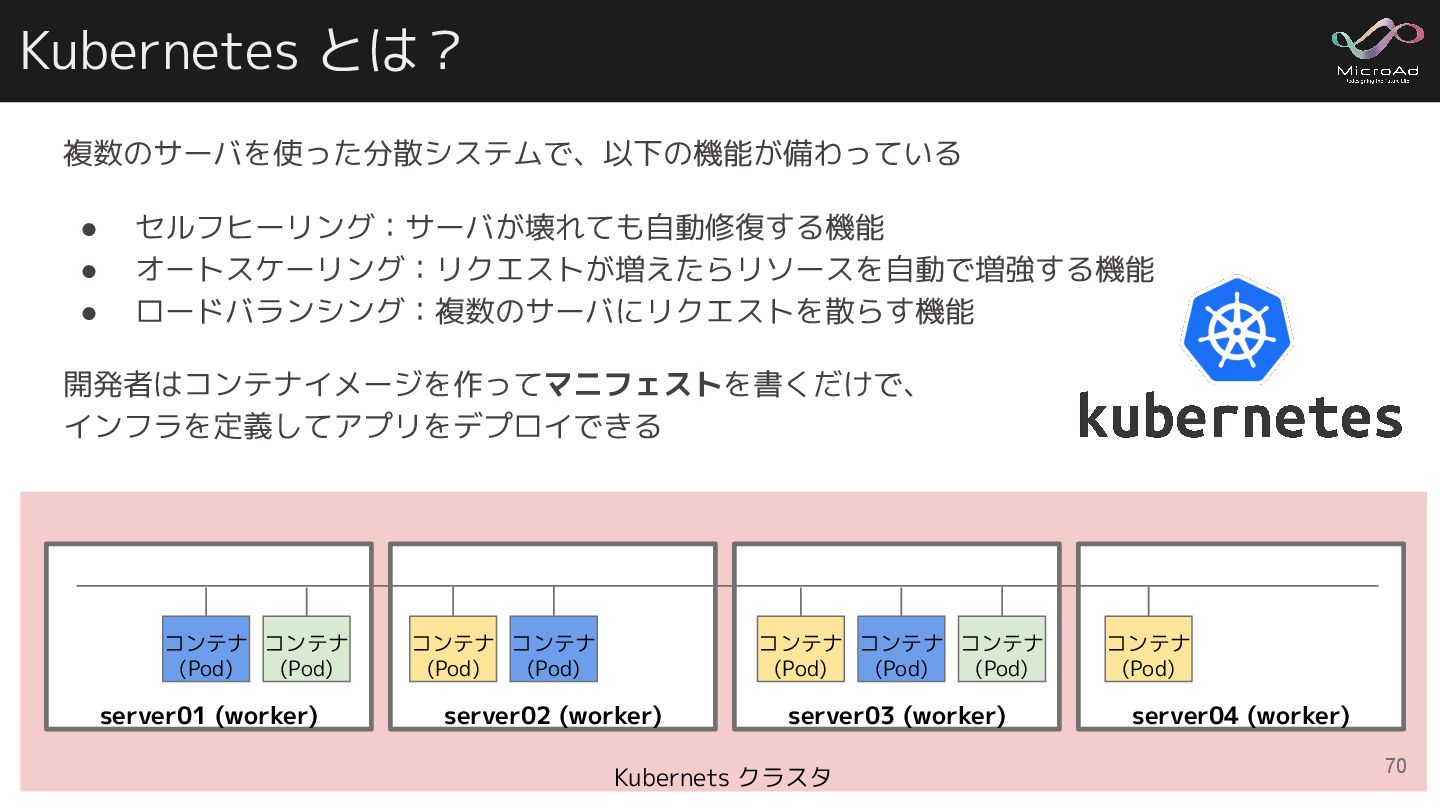
Kubernetes とは? 複数のサーバを使った分散システムで、以下の機能が備わっている • セルフヒーリング:サーバが壊れても自動修復する機能 • オートスケーリング:リクエストが増えたらリソースを自動で増強する機能 • ロードバランシング:複数のサーバにリクエストを散らす機能 開発者はコンテナイメージを作ってマニフェストを書くだけで、
インフラを定義してアプリをデプロイできる Kubernets クラスタ server02 (worker) コンテナ (Pod) コンテナ (Pod) server01 (worker) コンテナ (Pod) コンテナ (Pod) server03 (worker) コンテナ (Pod) コンテナ (Pod) コンテナ (Pod) server04 (worker) コンテナ (Pod) 70
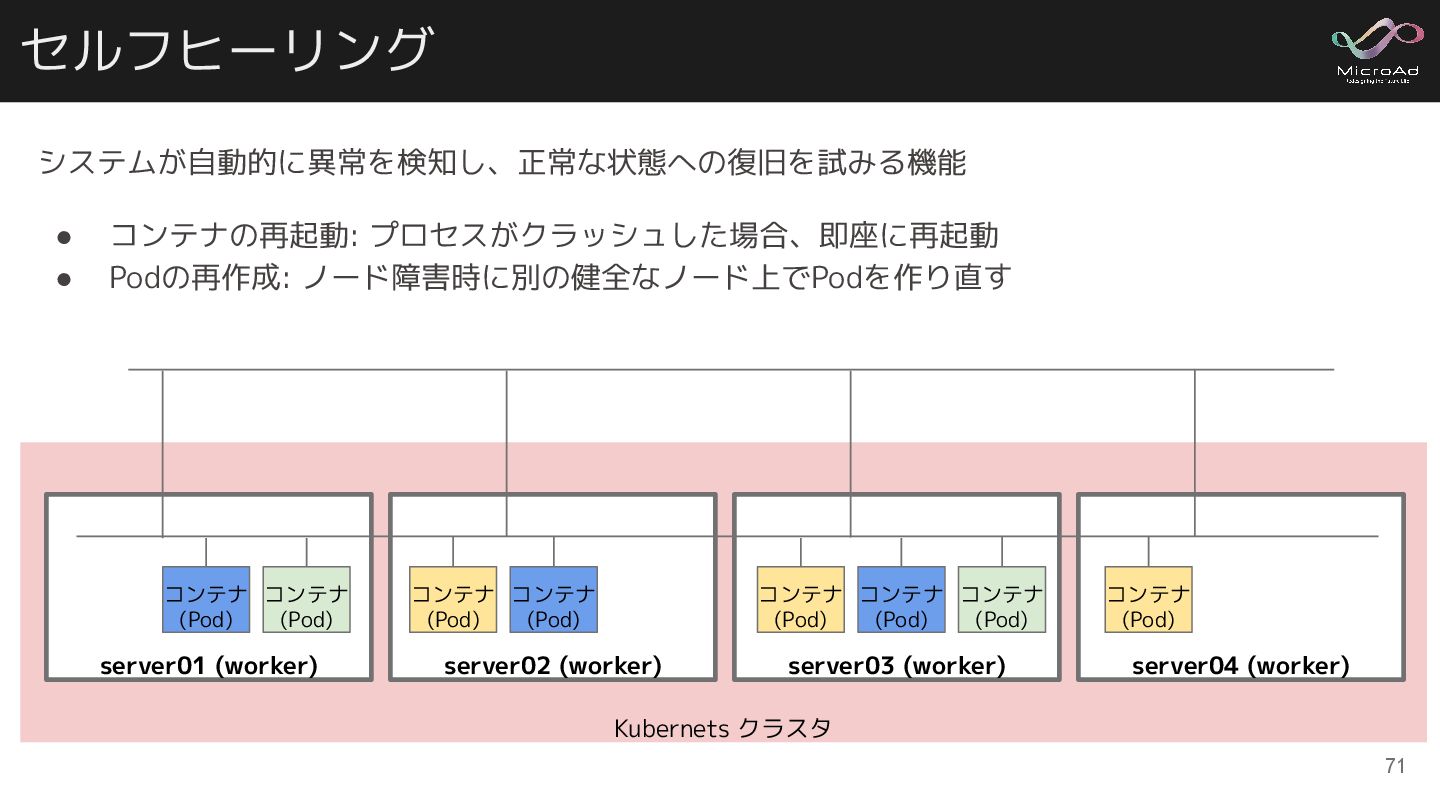
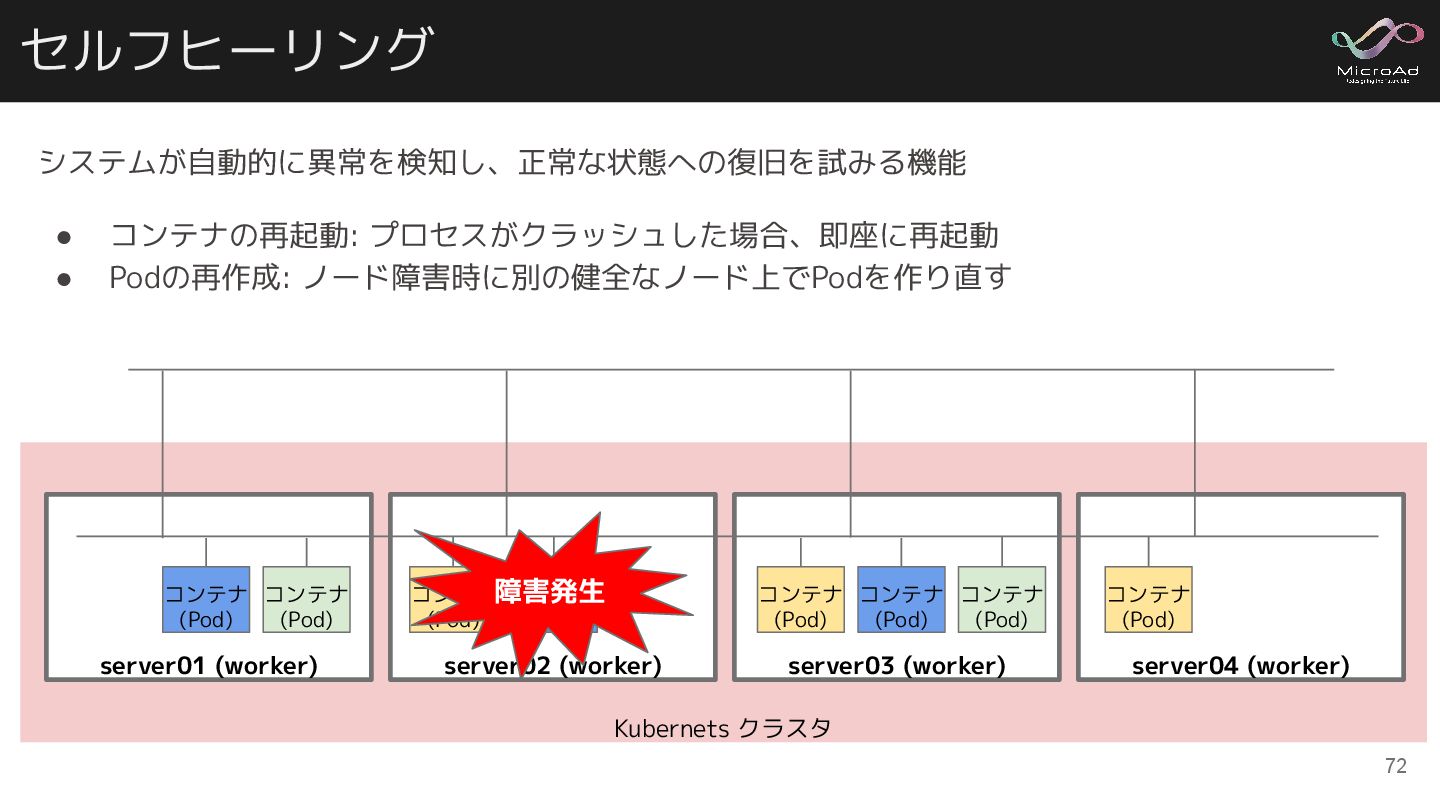
システムが自動的に異常を検知し、正常な状態への復旧を試みる機能 • コンテナの再起動: プロセスがクラッシュした場合、即座に再起動 • Podの再作成: ノード障害時に別の健全なノード上でPodを作り直す Kubernets クラスタ セルフヒーリング
server02 (worker) コンテナ (Pod) コンテナ (Pod) server01 (worker) コンテナ (Pod) コンテナ (Pod) server03 (worker) コンテナ (Pod) コンテナ (Pod) コンテナ (Pod) server04 (worker) コンテナ (Pod) 71
システムが自動的に異常を検知し、正常な状態への復旧を試みる機能 • コンテナの再起動: プロセスがクラッシュした場合、即座に再起動 • Podの再作成: ノード障害時に別の健全なノード上でPodを作り直す Kubernets クラスタ セルフヒーリング
server02 (worker) コンテナ (Pod) コンテナ (Pod) server01 (worker) コンテナ (Pod) コンテナ (Pod) server03 (worker) コンテナ (Pod) コンテナ (Pod) コンテナ (Pod) server04 (worker) コンテナ (Pod) 障害発生 72
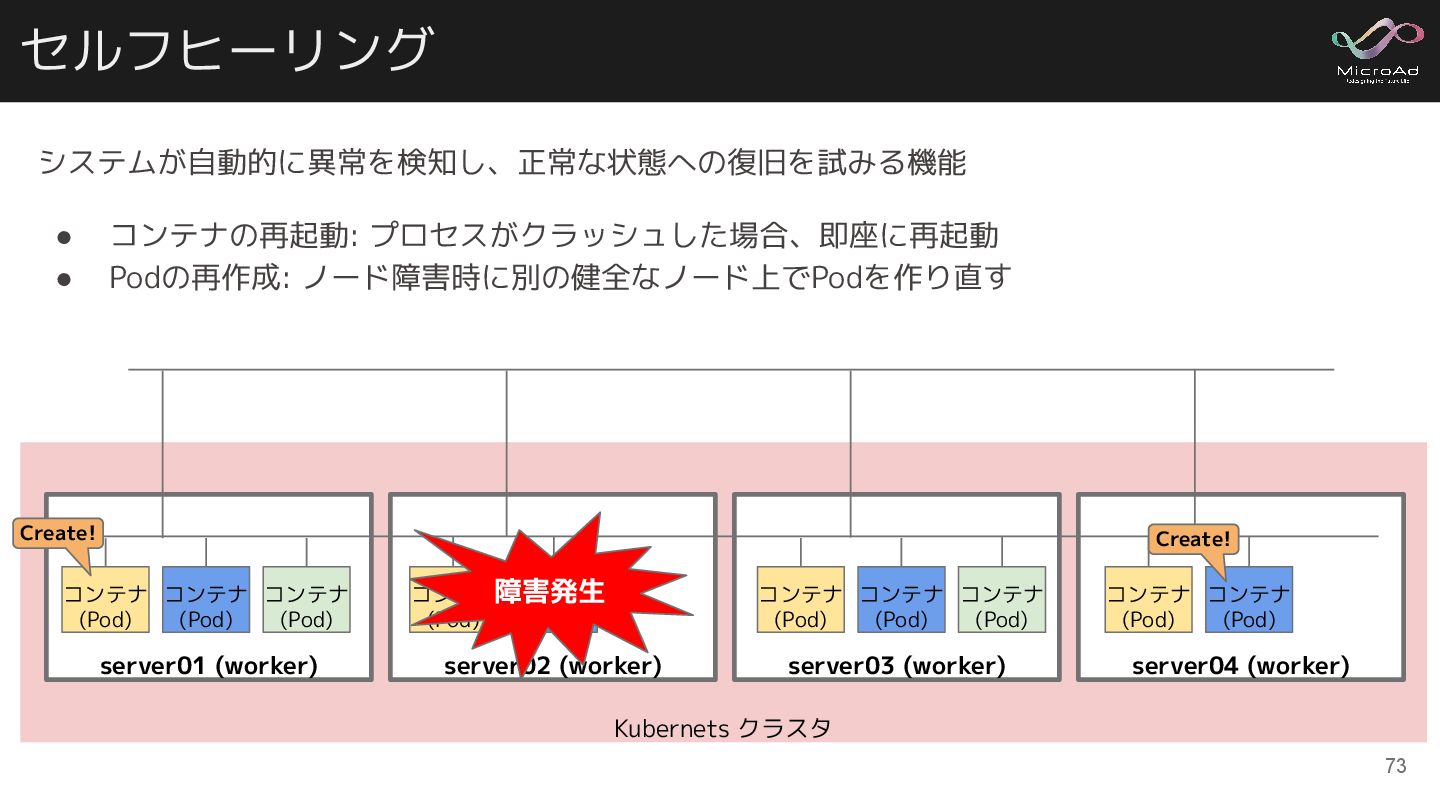
システムが自動的に異常を検知し、正常な状態への復旧を試みる機能 • コンテナの再起動: プロセスがクラッシュした場合、即座に再起動 • Podの再作成: ノード障害時に別の健全なノード上でPodを作り直す Kubernets クラスタ セルフヒーリング
server02 (worker) コンテナ (Pod) コンテナ (Pod) server01 (worker) コンテナ (Pod) コンテナ (Pod) server03 (worker) コンテナ (Pod) コンテナ (Pod) コンテナ (Pod) server04 (worker) コンテナ (Pod) 障害発生 コンテナ (Pod) コンテナ (Pod) Create! Create! 73
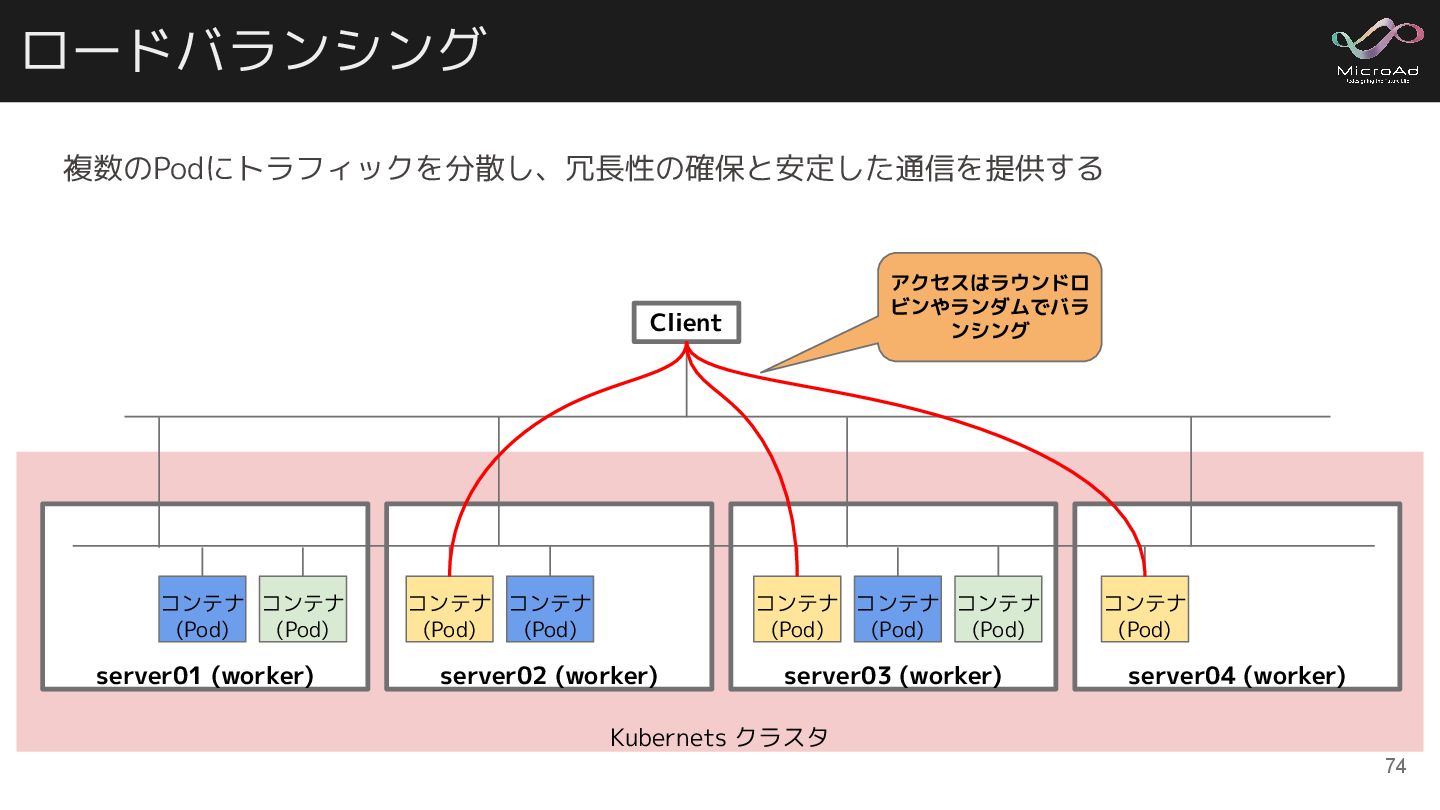
ロードバランシング 複数のPodにトラフィックを分散し、冗長性の確保と安定した通信を提供する Kubernets クラスタ server02 (worker) コンテナ (Pod) コンテナ (Pod)
server01 (worker) コンテナ (Pod) コンテナ (Pod) server03 (worker) コンテナ (Pod) コンテナ (Pod) コンテナ (Pod) server04 (worker) コンテナ (Pod) Client アクセスはラウンドロ ビンやランダムでバラ ンシング 74
オートスケーリング Kubernets クラスタ server02 (worker) コンテナ (Pod) コンテナ (Pod) server01
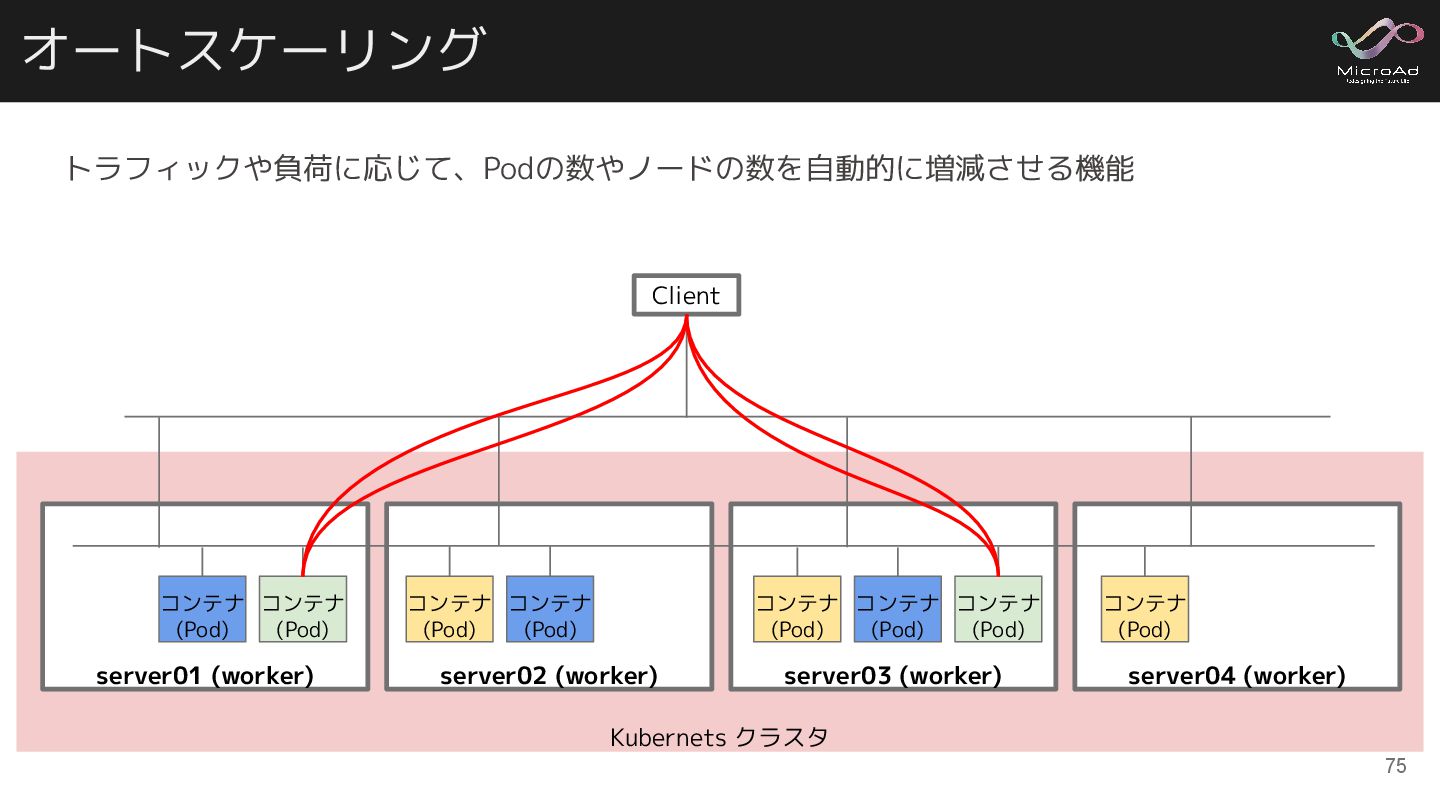
(worker) コンテナ (Pod) コンテナ (Pod) server03 (worker) コンテナ (Pod) コンテナ (Pod) コンテナ (Pod) server04 (worker) コンテナ (Pod) Client トラフィックや負荷に応じて、Podの数やノードの数を自動的に増減させる機能 75
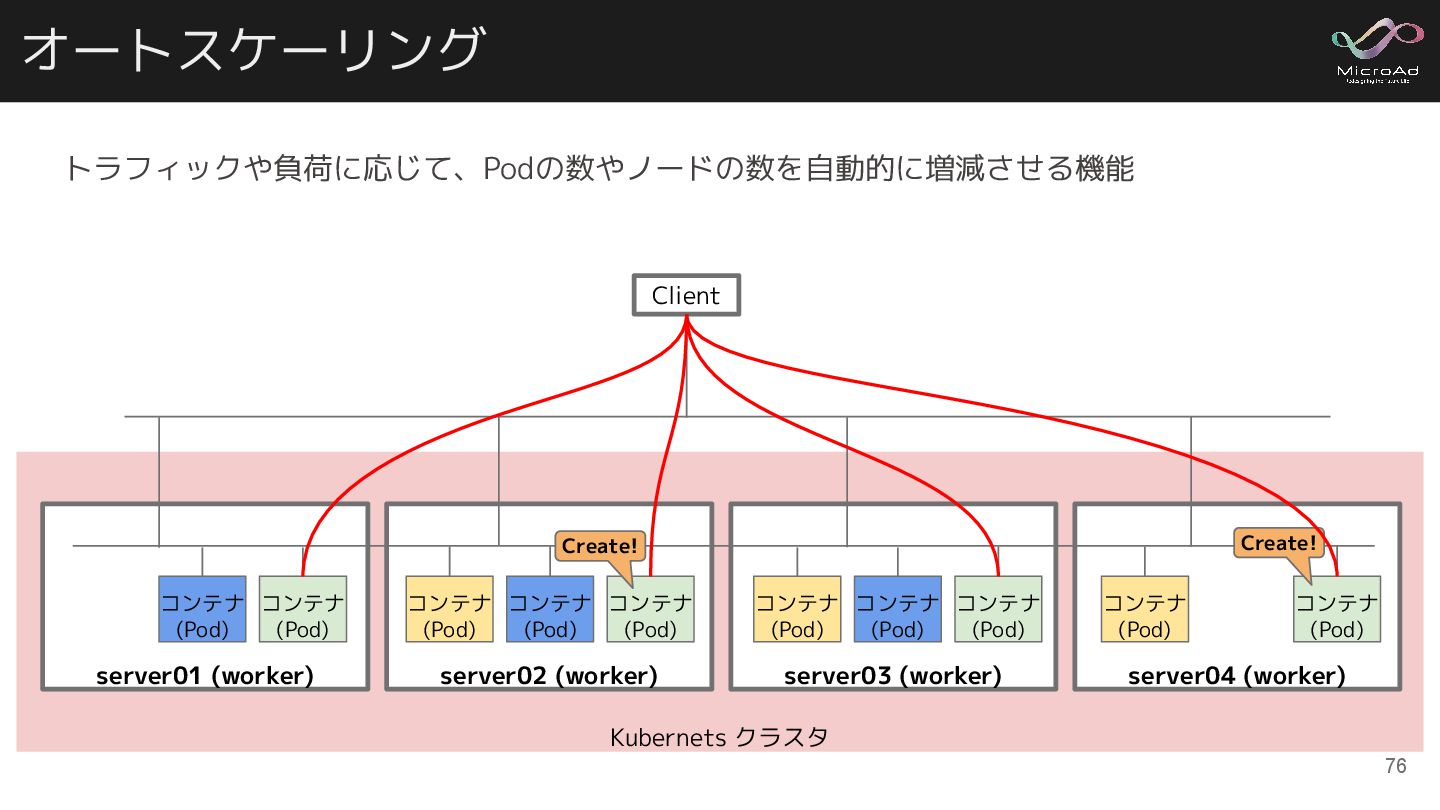
オートスケーリング Kubernets クラスタ server02 (worker) コンテナ (Pod) コンテナ (Pod) server01
(worker) コンテナ (Pod) コンテナ (Pod) server03 (worker) コンテナ (Pod) コンテナ (Pod) コンテナ (Pod) server04 (worker) コンテナ (Pod) Client コンテナ (Pod) コンテナ (Pod) Create! Create! トラフィックや負荷に応じて、Podの数やノードの数を自動的に増減させる機能 76
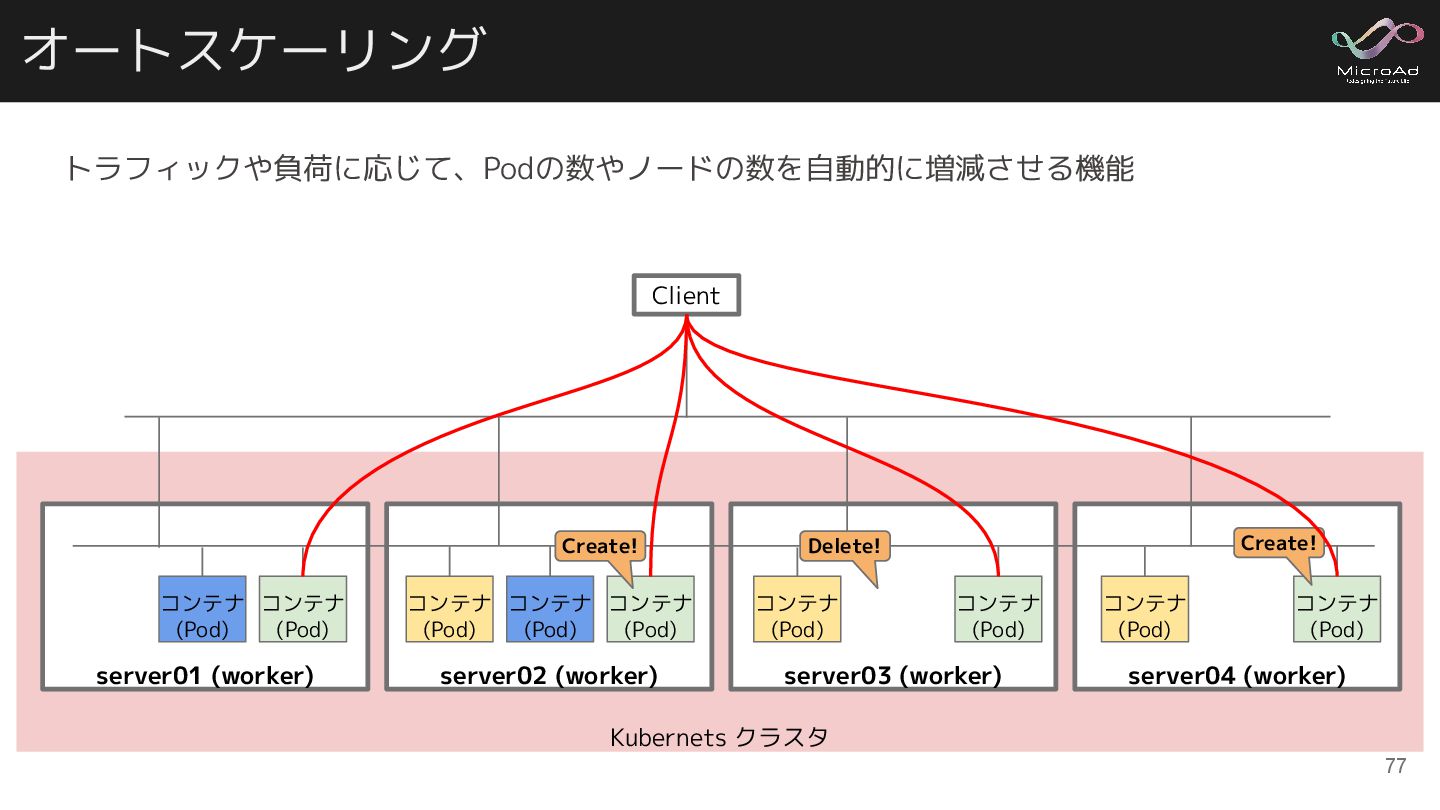
オートスケーリング Kubernets クラスタ server02 (worker) コンテナ (Pod) コンテナ (Pod) server01
(worker) コンテナ (Pod) コンテナ (Pod) server03 (worker) コンテナ (Pod) コンテナ (Pod) server04 (worker) コンテナ (Pod) Client コンテナ (Pod) コンテナ (Pod) Create! Create! トラフィックや負荷に応じて、Podの数やノードの数を自動的に増減させる機能 Delete! 77
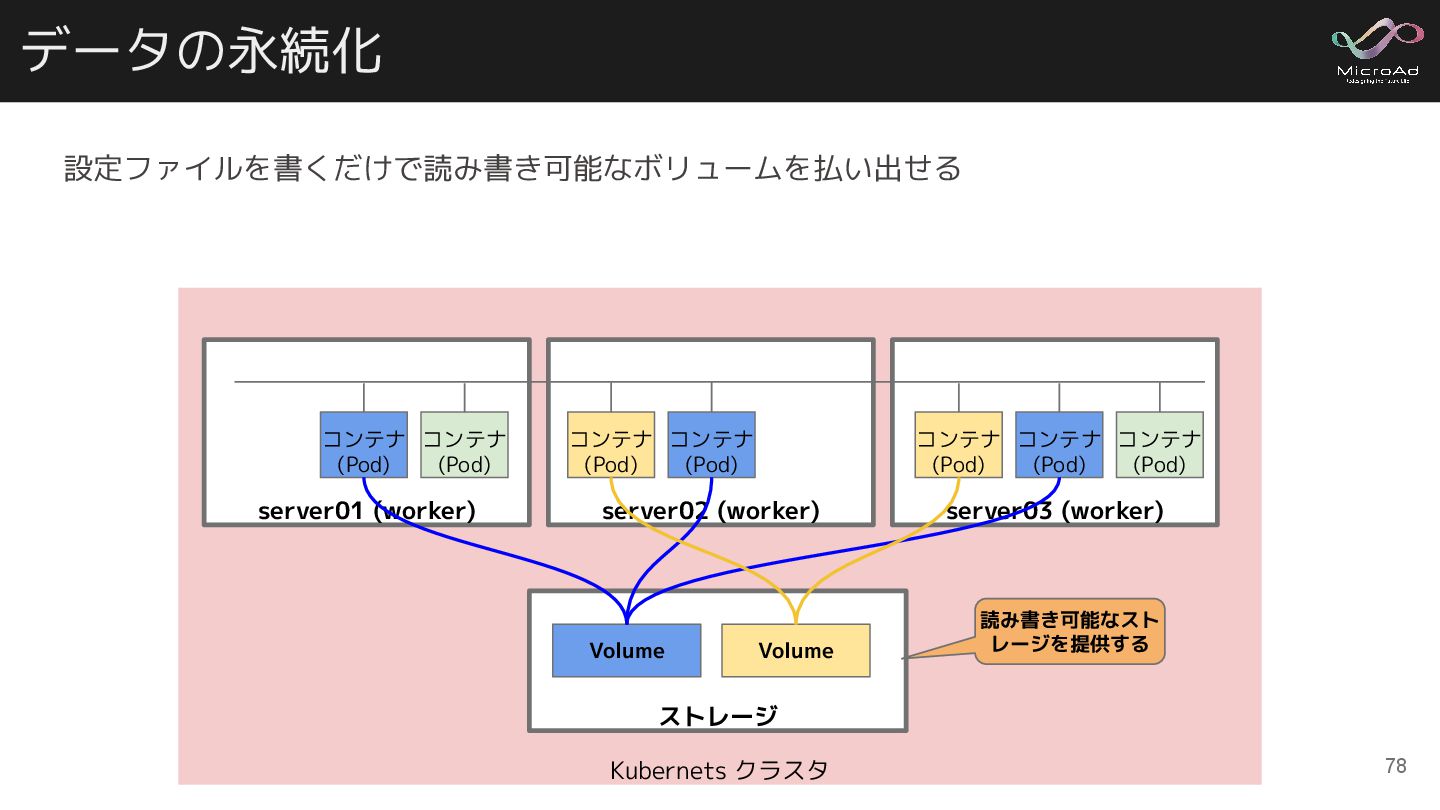
データの永続化 Kubernets クラスタ server02 (worker) コンテナ (Pod) コンテナ (Pod) server01
(worker) コンテナ (Pod) コンテナ (Pod) server03 (worker) コンテナ (Pod) コンテナ (Pod) コンテナ (Pod) ストレージ Volume Volume 読み書き可能なスト レージを提供する 設定ファイルを書くだけで読み書き可能なボリュームを払い出せる 78
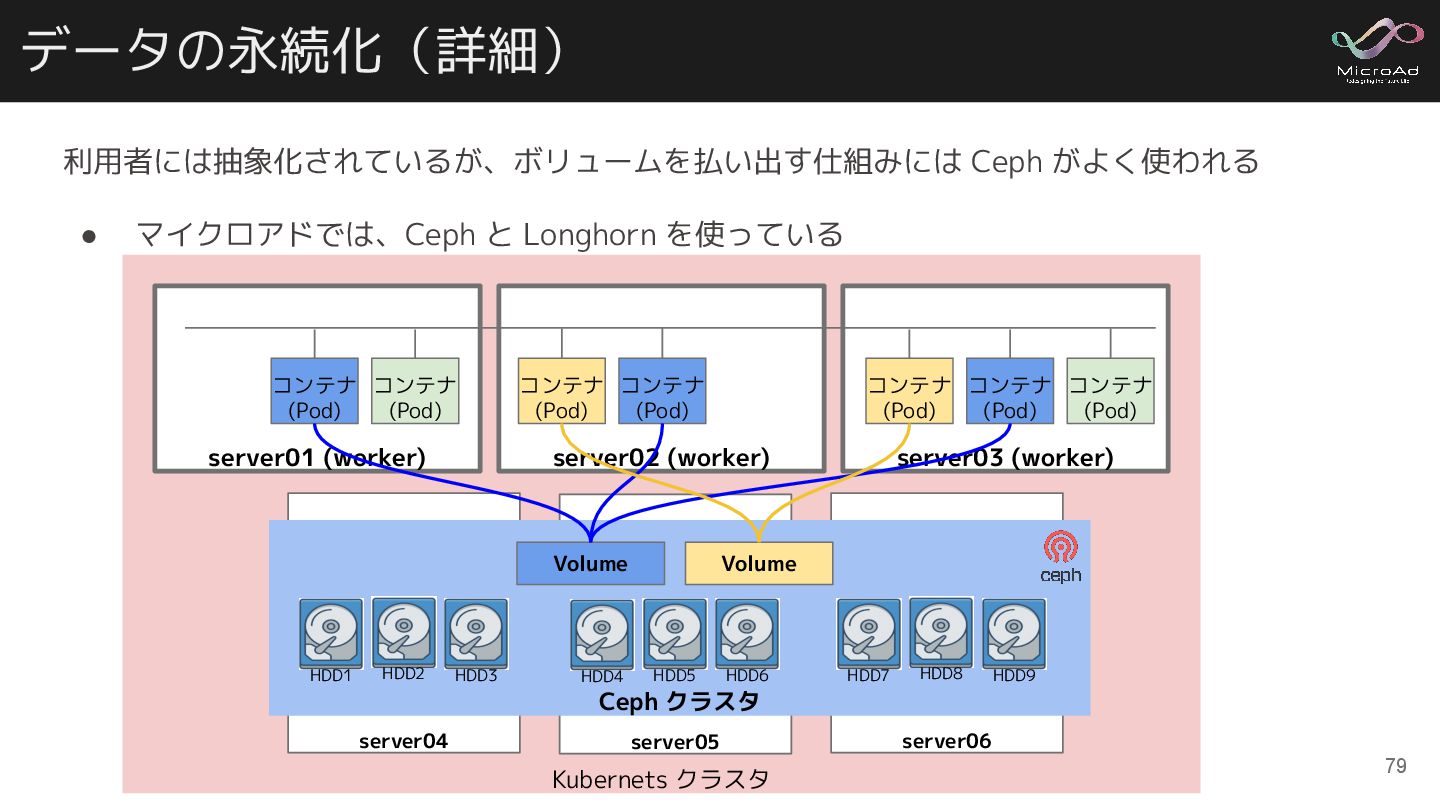
データの永続化(詳細) Kubernets クラスタ server02 (worker) コンテナ (Pod) コンテナ (Pod) server01
(worker) コンテナ (Pod) コンテナ (Pod) server03 (worker) コンテナ (Pod) コンテナ (Pod) コンテナ (Pod) 利用者には抽象化されているが、ボリュームを払い出す仕組みには Ceph がよく使われる • マイクロアドでは、Ceph と Longhorn を使っている server04 server05 server06 Ceph クラスタ HDD1 HDD2 HDD3 HDD4 HDD5 HDD6 HDD7 HDD8 HDD9 Volume Volume 79
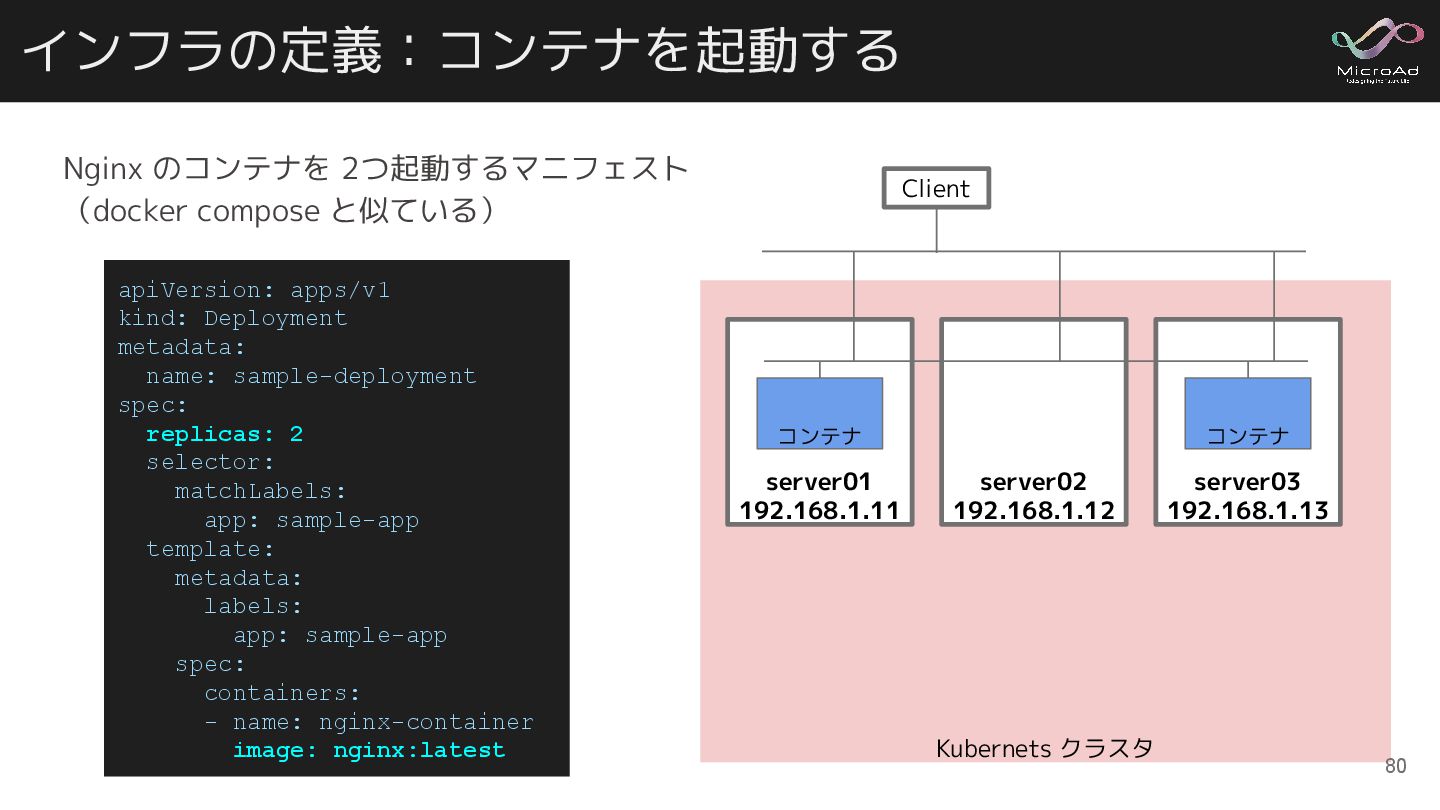
インフラの定義:コンテナを起動する Nginx のコンテナを 2つ起動するマニフェスト (docker compose と似ている) apiVersion: apps/v1 kind:
Deployment metadata: name: sample-deployment spec: replicas: 2 selector: matchLabels: app: sample-app template: metadata: labels: app: sample-app spec: containers: - name: nginx-container image: nginx:latest Kubernets クラスタ :80 :80 Client server01 192.168.1.11 コンテナ server02 192.168.1.12 server03 192.168.1.13 コンテナ 80
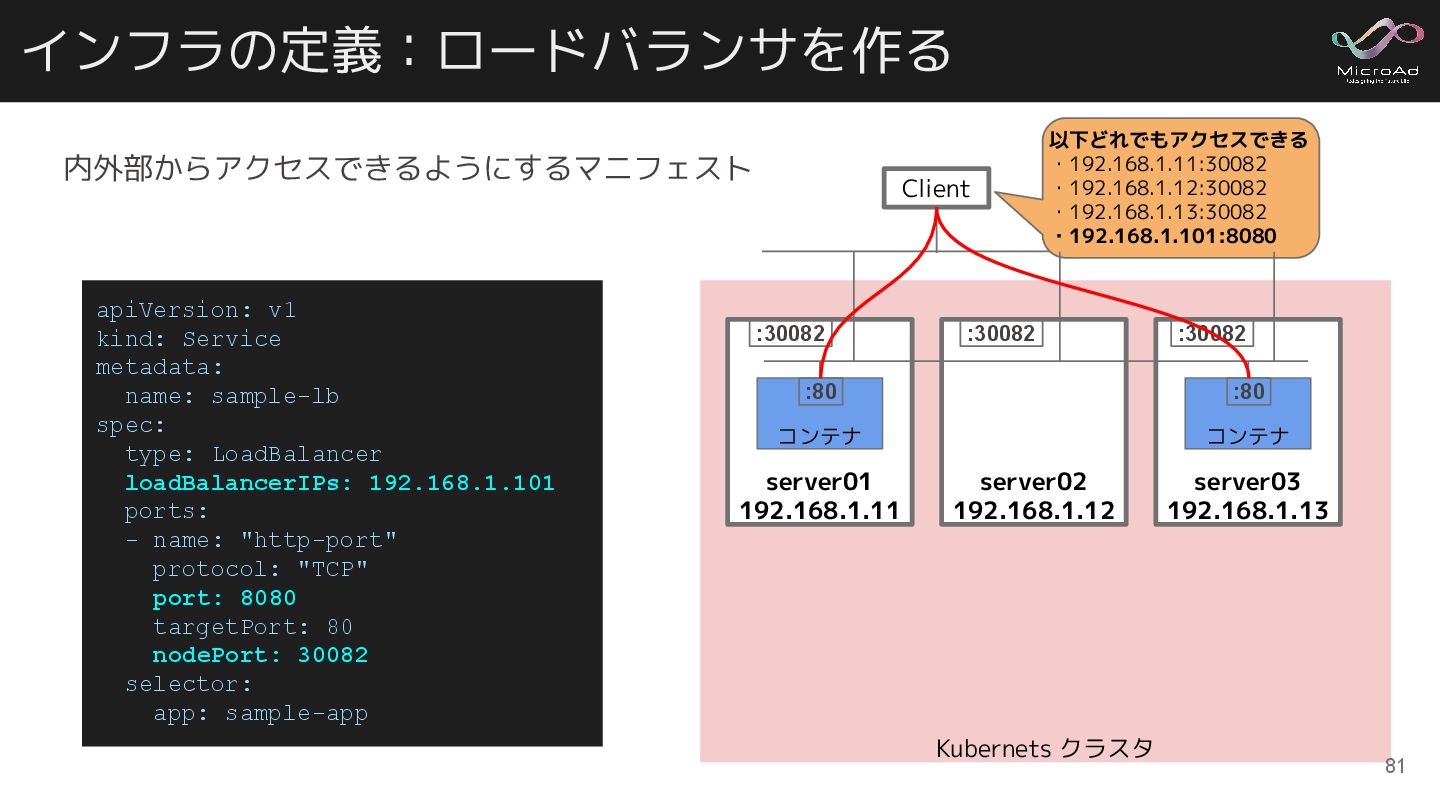
インフラの定義:ロードバランサを作る apiVersion: v1 kind: Service metadata: name: sample-lb spec: type:
LoadBalancer loadBalancerIPs: 192.168.1.101 ports: - name: "http-port" protocol: "TCP" port: 8080 targetPort: 80 nodePort: 30082 selector: app: sample-app 内外部からアクセスできるようにするマニフェスト Kubernets クラスタ :80 :80 :30082 :30082 :30082 Client 以下どれでもアクセスできる ・192.168.1.11:30082 ・192.168.1.12:30082 ・192.168.1.13:30082 ・192.168.1.101:8080 server01 192.168.1.11 コンテナ server02 192.168.1.12 server03 192.168.1.13 コンテナ :80 :80 :30082 :30082 :30082 81
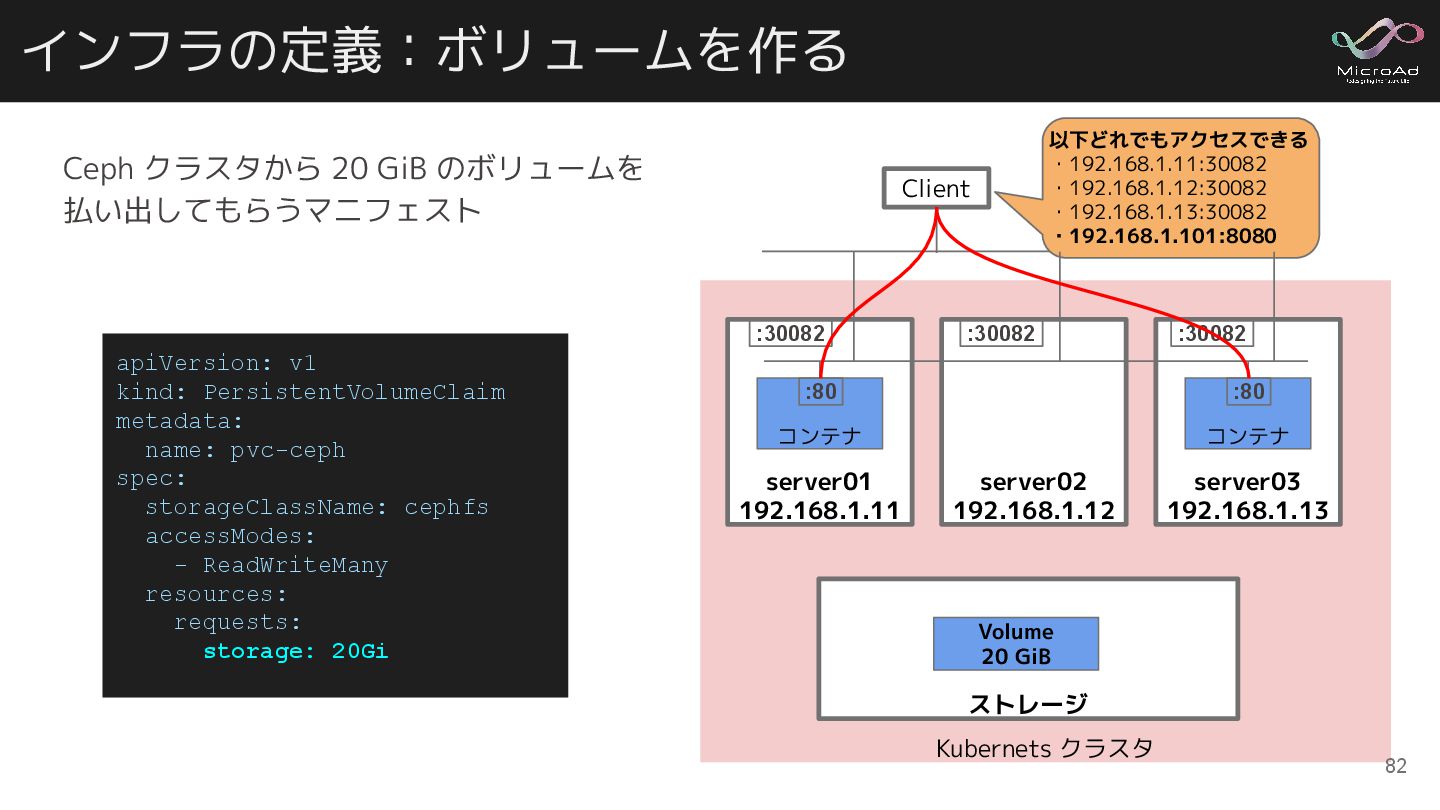
インフラの定義:ボリュームを作る Ceph クラスタから 20 GiB のボリュームを 払い出してもらうマニフェスト apiVersion: v1 kind:
PersistentVolumeClaim metadata: name: pvc-ceph spec: storageClassName: cephfs accessModes: - ReadWriteMany resources: requests: storage: 20Gi Kubernets クラスタ ストレージ Volume 20 GiB :80 :80 :30082 :30082 :30082 Client 以下どれでもアクセスできる ・192.168.1.11:30082 ・192.168.1.12:30082 ・192.168.1.13:30082 ・192.168.1.101:8080 server01 192.168.1.11 コンテナ server02 192.168.1.12 server03 192.168.1.13 コンテナ :80 :80 :30082 :30082 :30082 82
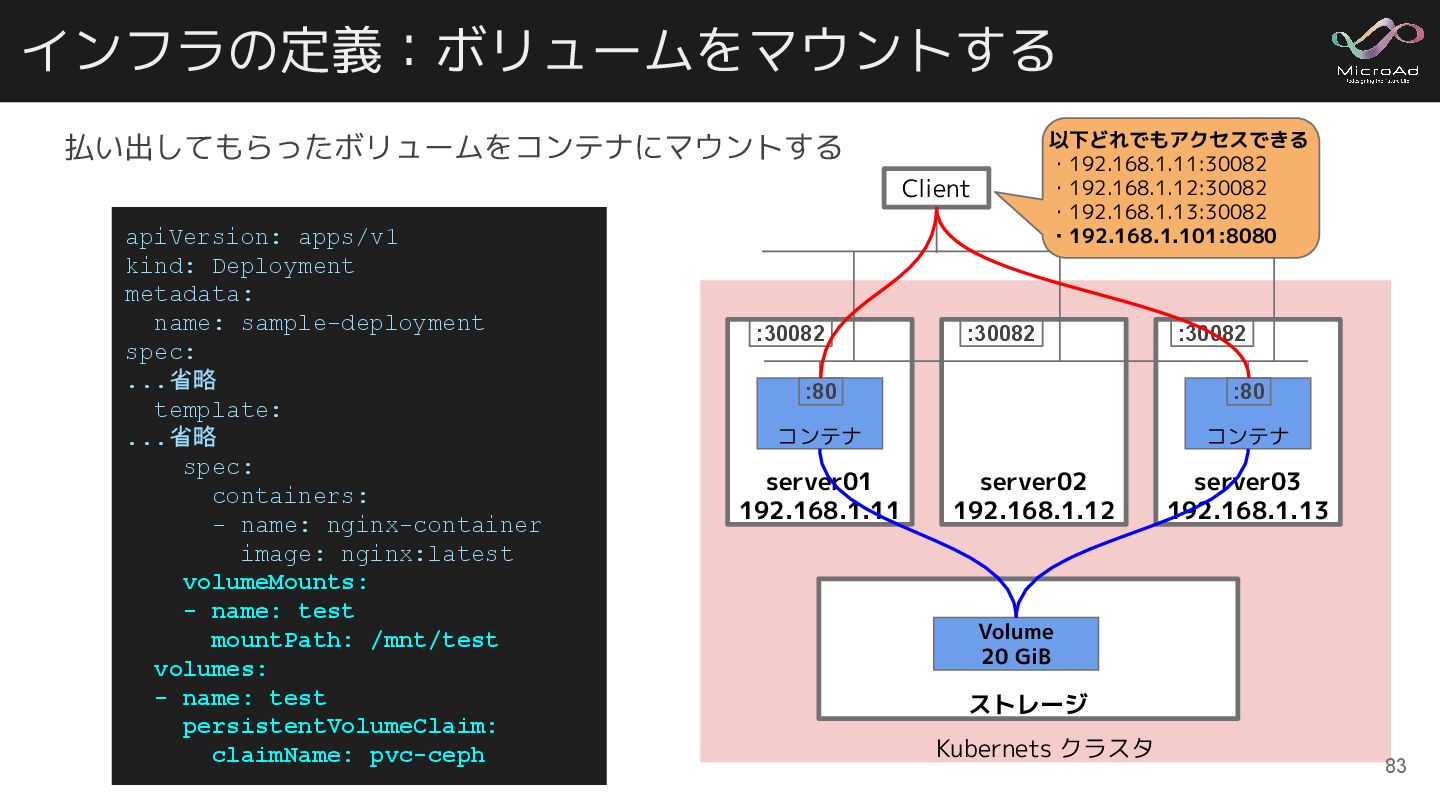
インフラの定義:ボリュームをマウントする apiVersion: apps/v1 kind: Deployment metadata: name: sample-deployment spec: ...省略
template: ...省略 spec: containers: - name: nginx-container image: nginx:latest volumeMounts: - name: test mountPath: /mnt/test volumes: - name: test persistentVolumeClaim: claimName: pvc-ceph Kubernets クラスタ ストレージ Volume 20 GiB server01 192.168.1.11 コンテナ server02 192.168.1.12 server03 192.168.1.13 コンテナ :80 :80 :30082 :30082 :30082 Client 以下どれでもアクセスできる ・192.168.1.11:30082 ・192.168.1.12:30082 ・192.168.1.13:30082 ・192.168.1.101:8080 払い出してもらったボリュームをコンテナにマウントする 83
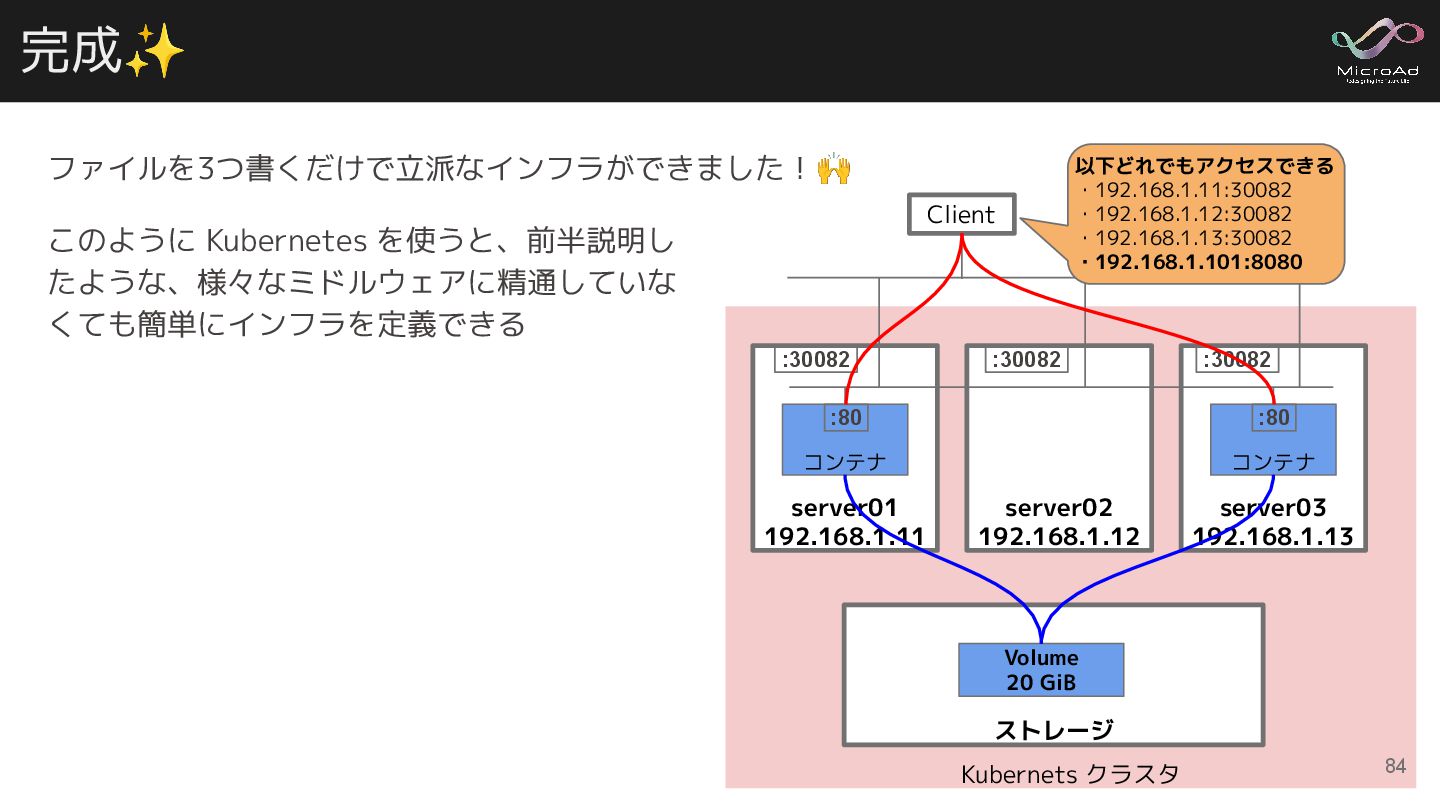
完成✨ Kubernets クラスタ ストレージ Volume 20 GiB server01 192.168.1.11 コンテナ
server02 192.168.1.12 server03 192.168.1.13 コンテナ :80 :80 :30082 :30082 :30082 Client 以下どれでもアクセスできる ・192.168.1.11:30082 ・192.168.1.12:30082 ・192.168.1.13:30082 ・192.168.1.101:8080 このように Kubernetes を使うと、前半説明し たような、様々なミドルウェアに精通していな くても簡単にインフラを定義できる ファイルを3つ書くだけで立派なインフラができました!🙌 84
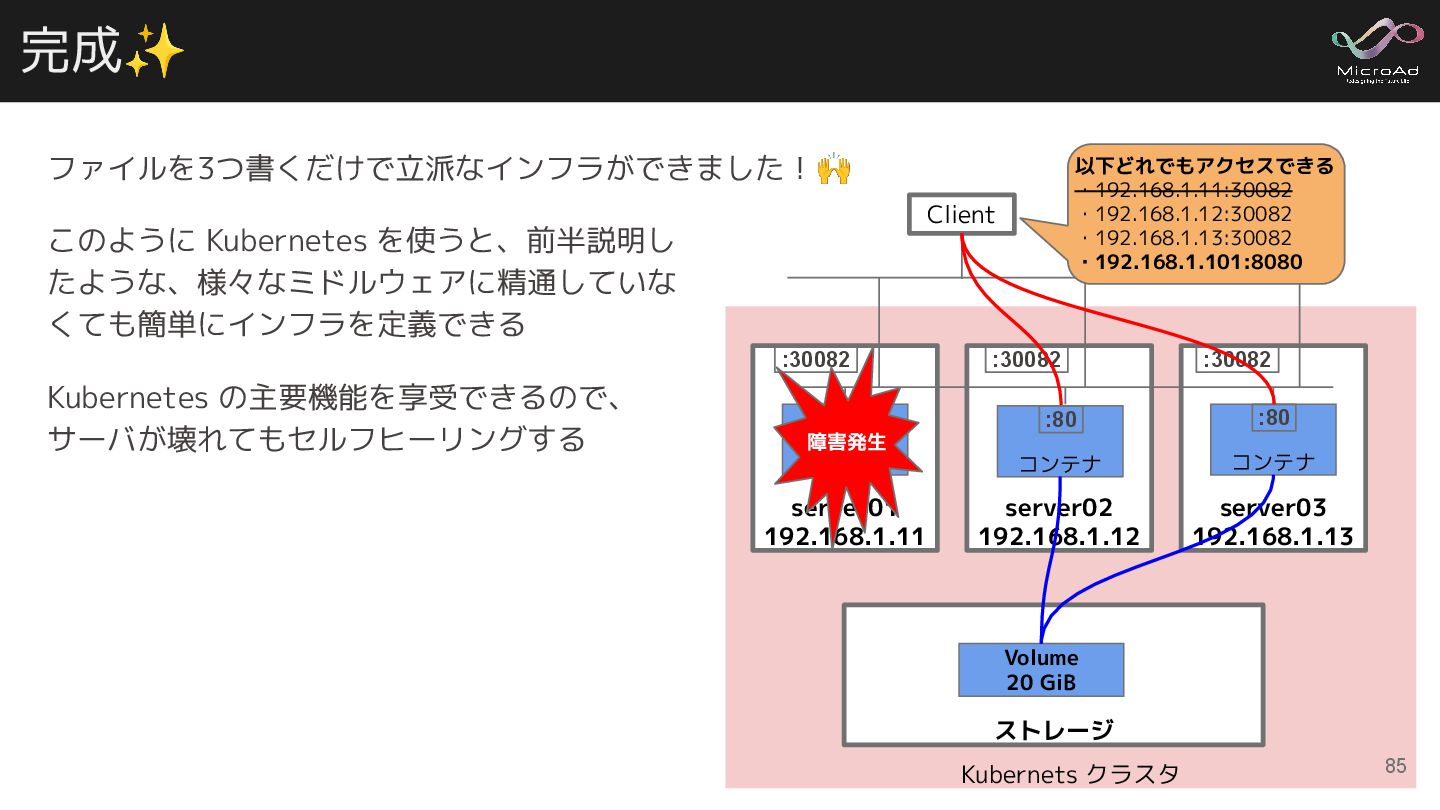
完成✨ Kubernets クラスタ ストレージ Volume 20 GiB server01 192.168.1.11 コンテナ
server02 192.168.1.12 server03 192.168.1.13 コンテナ :80 :80 :30082 :30082 :30082 Client 以下どれでもアクセスできる ・192.168.1.11:30082 ・192.168.1.12:30082 ・192.168.1.13:30082 ・192.168.1.101:8080 このように Kubernetes を使うと、前半説明し たような、様々なミドルウェアに精通していな くても簡単にインフラを定義できる Kubernetes の主要機能を享受できるので、 サーバが壊れてもセルフヒーリングする ファイルを3つ書くだけで立派なインフラができました!🙌 障害発生 コンテナ :80 85
マネージド Kubernetes 実は Kubernetes 自体を構築することは大変... とりあえずお試しで使ってみたい方は パブリッククラウドが提供しているマネージド Kubernetes がおススメです https://www.reddit.com/r/kubernetes/comments/1i5gcc9/i_created_my_first_vanilla_kubernetes_cluster_i/
Kubernetes クラスタを1日かけて作って喜んでいる人 86
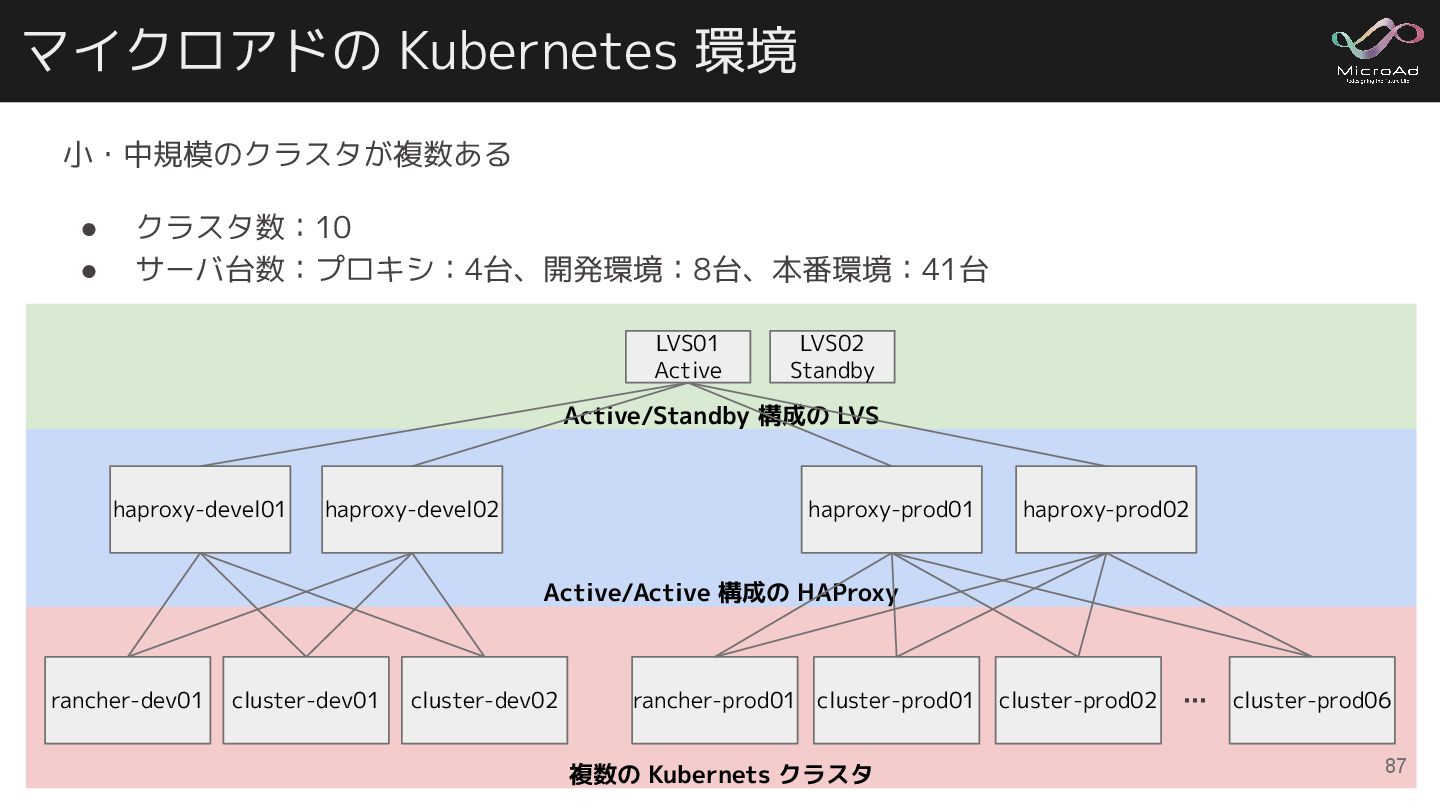
Active/Standby 構成の LVS Active/Active 構成の HAProxy 複数の Kubernets クラスタ マイクロアドの
Kubernetes 環境 haproxy-devel01 haproxy-devel02 haproxy-prod01 LVS01 Active haproxy-prod02 LVS02 Standby cluster-prod01 cluster-prod02 rancher-prod01 cluster-prod06 cluster-dev01 cluster-dev02 rancher-dev01 … 小・中規模のクラスタが複数ある • クラスタ数:10 • サーバ台数:プロキシ:4台、開発環境:8台、本番環境:41台 87
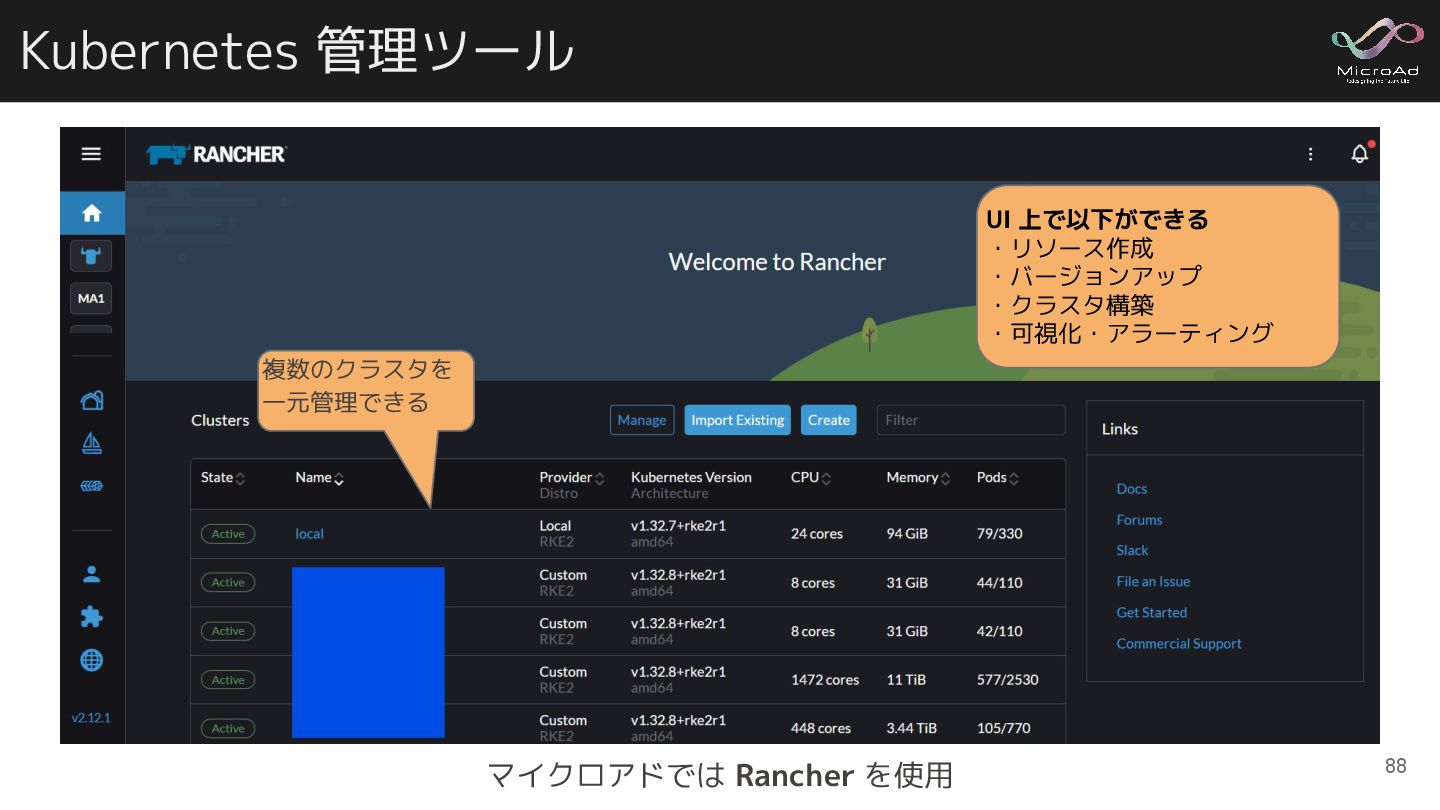
Kubernetes 管理ツール マイクロアドでは Rancher を使用 複数のクラスタを 一元管理できる UI 上で以下ができる ・リソース作成
・バージョンアップ ・クラスタ構築 ・可視化・アラーティング 88
プラットフォームエンジニアリング 89
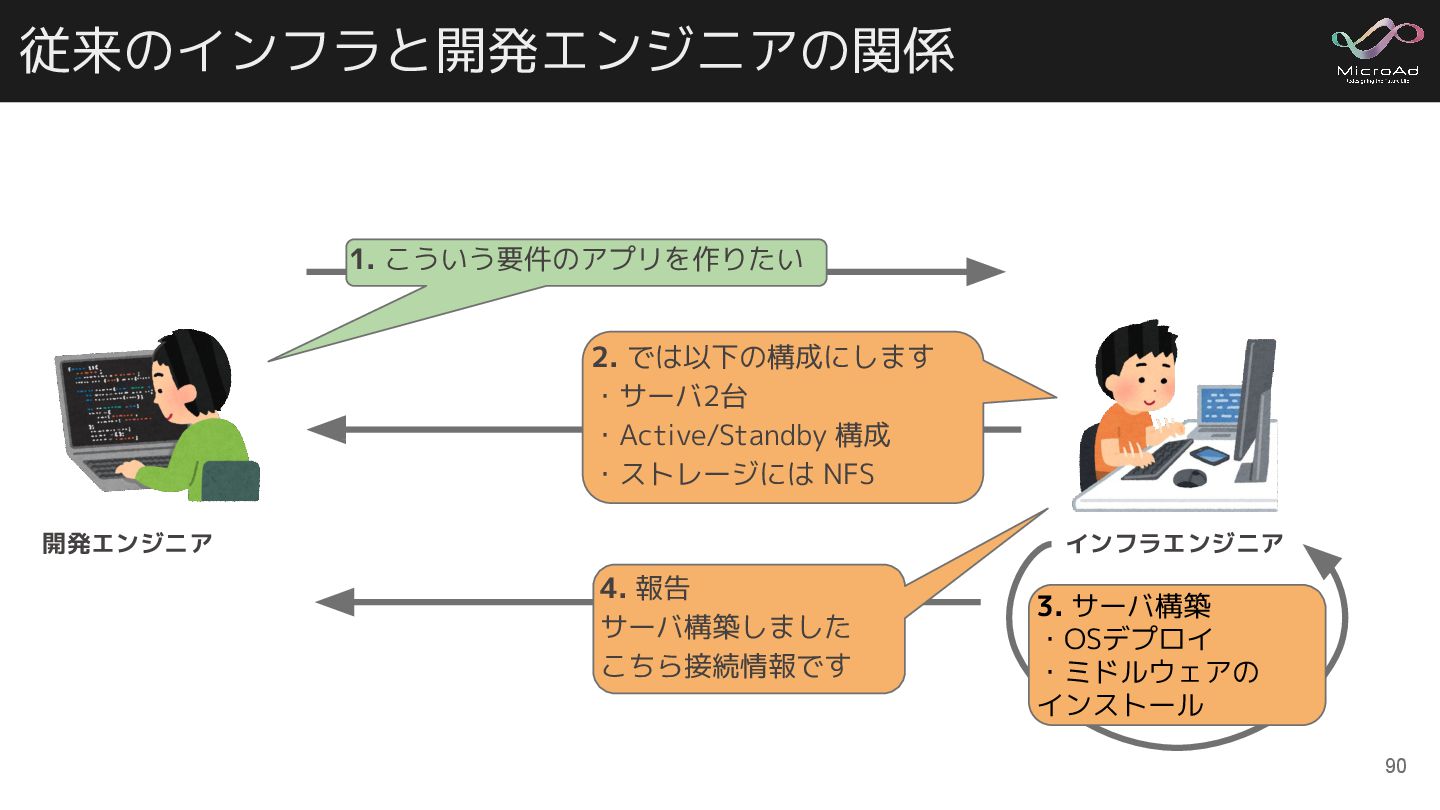
従来のインフラと開発エンジニアの関係 開発エンジニア インフラエンジニア 1. こういう要件のアプリを作りたい 2. では以下の構成にします ・サーバ2台 ・Active/Standby 構成
・ストレージには NFS 3. サーバ構築 ・OSデプロイ ・ミドルウェアの インストール 4. 報告 サーバ構築しました こちら接続情報です 90
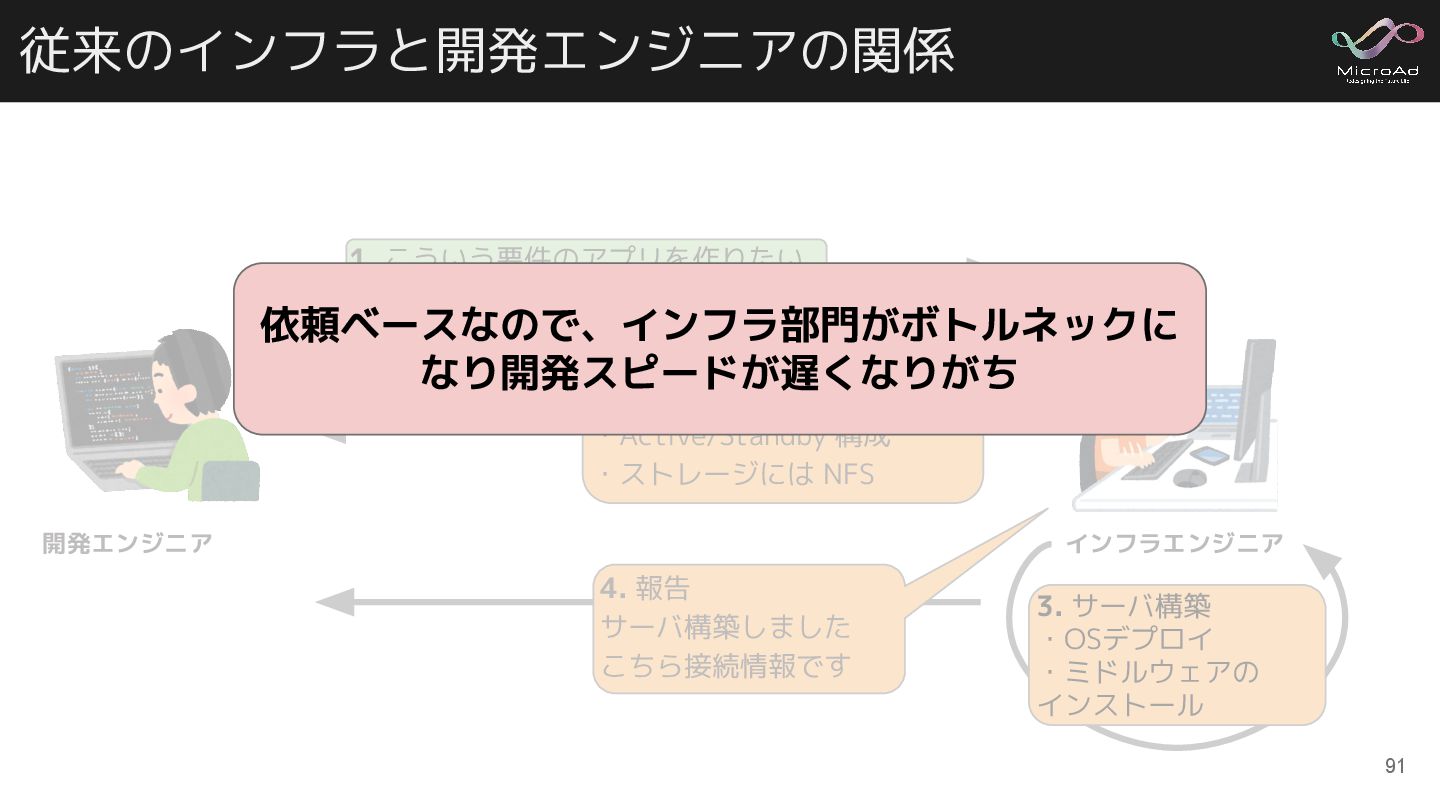
従来のインフラと開発エンジニアの関係 開発エンジニア インフラエンジニア 1. こういう要件のアプリを作りたい 2. では以下の構成にします ・サーバ2台 ・Active/Standby 構成
・ストレージには NFS 3. サーバ構築 ・OSデプロイ ・ミドルウェアの インストール 4. 報告 サーバ構築しました こちら接続情報です 依頼ベースなので、インフラ部門がボトルネックに なり開発スピードが遅くなりがち 91
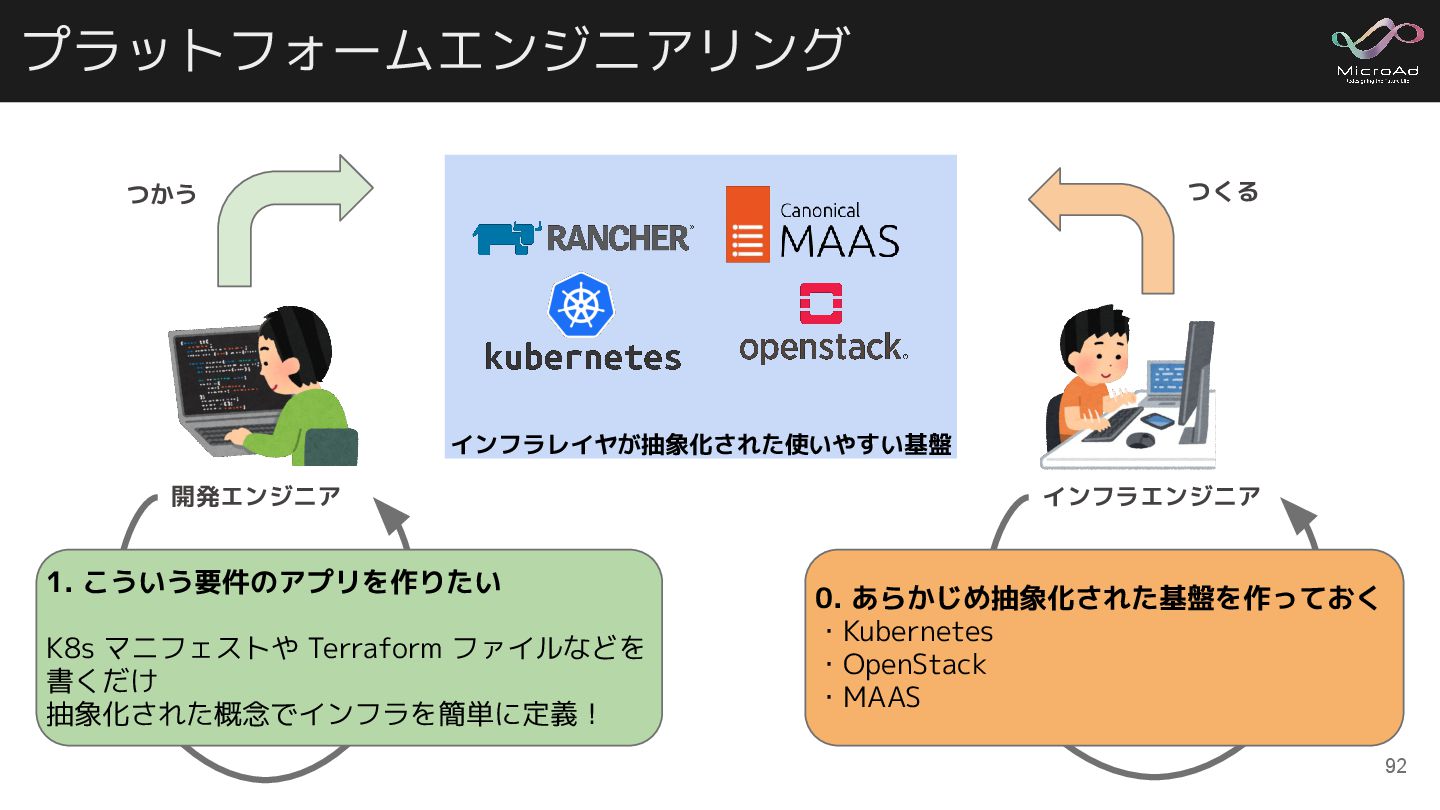
プラットフォームエンジニアリング 開発エンジニア インフラエンジニア 1. こういう要件のアプリを作りたい K8s マニフェストや Terraform ファイルなどを 書くだけ
抽象化された概念でインフラを簡単に定義! つかう つくる インフラレイヤが抽象化された使いやすい基盤 0. あらかじめ抽象化された基盤を作っておく ・Kubernetes ・OpenStack ・MAAS 92
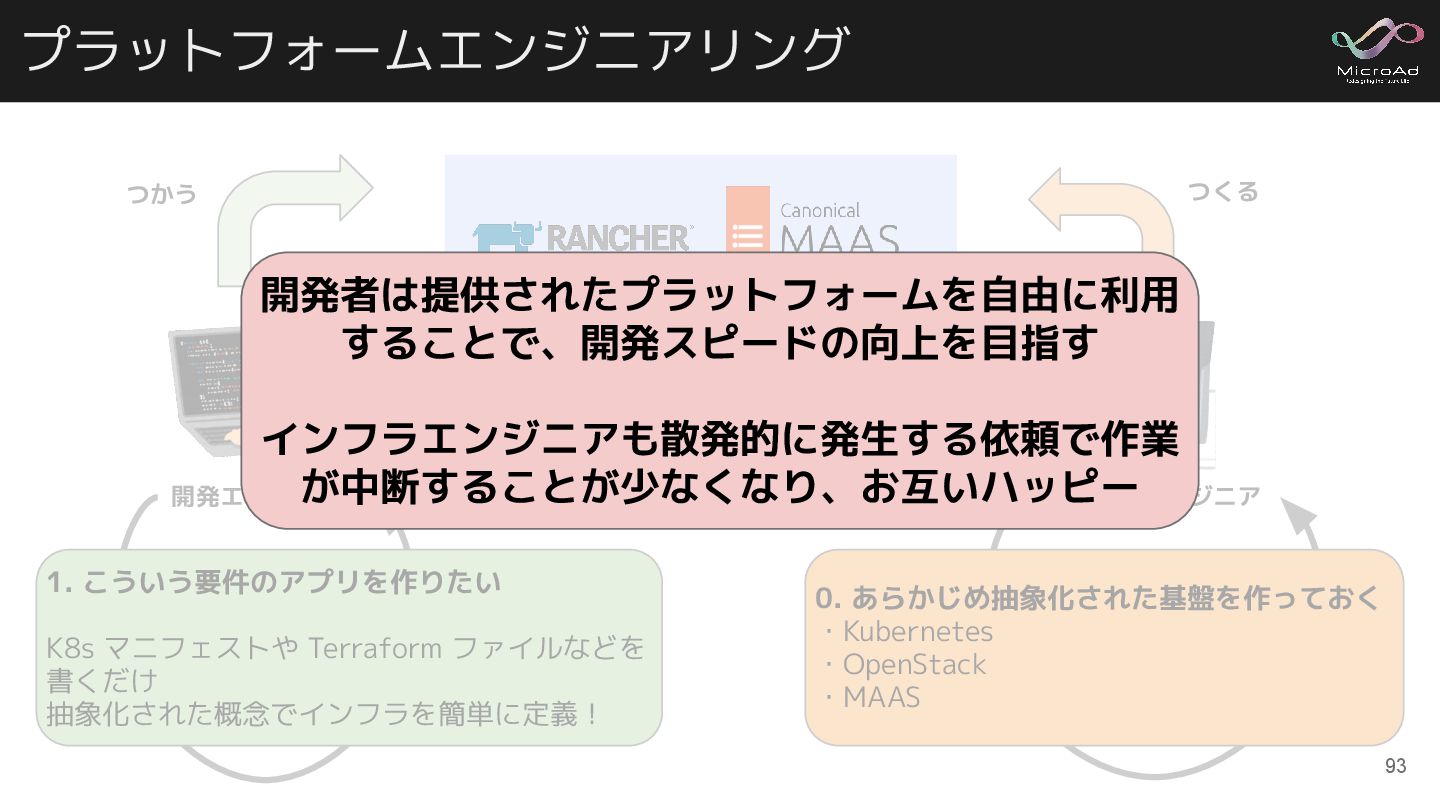
プラットフォームエンジニアリング 抽象化された使いやすいインフラ基盤 開発エンジニア インフラエンジニア 0. あらかじめ抽象化された基盤を作っておく ・Kubernetes ・OpenStack ・MAAS 1.
こういう要件のアプリを作りたい K8s マニフェストや Terraform ファイルなどを 書くだけ 抽象化された概念でインフラを簡単に定義! つかう つくる 開発者は提供されたプラットフォームを自由に利用 することで、開発スピードの向上を目指す インフラエンジニアも散発的に発生する依頼で作業 が中断することが少なくなり、お互いハッピー 93
まとめ 94
現場で働いてみて 現場では、冗長化が大事 • システムを止めると顧客からの信頼に関わる • エンジニアのリソース削減(夜間・休日などに急な対応が発生しない仕組みづくり) ◦ システムの停止を最小限にすることで、 エンジニアも最小のリソースで運用をすることが可能になる オンプレの楽しさ
• L0(物理設計)から L7 アプリまで自身が関わって理想とする状況を作ることができる • マイクロアドの場合、サーバが大量にあり自由に使える(一人で十数台使って検証できる) 泥臭い部分もある • 深夜土日にアラートがなることもある → 誰かしらが対応 • 古い Active/Standby 構成のシステムでは、内部では人力で切り替えてる場合がある • 誰かしらいつでも DC に駆けつけられる必要がある → メンバー全員で旅行とかはできない 95
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![マイクロアドで使用しているサーバ & NW 機器(一部) 3U 8ノード 汎用サーバ Supermicro MicroCloud[3] 2U](https://files.speakerdeck.com/presentations/7ef7325e7cc741809be9be606dc5fdb0/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}