Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Kafka Connect:Iceberg Sink Connectorを使ってみる
Search
システム開発部広報委員会
PRO
March 06, 2024
Programming
40
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Kafka Connect:Iceberg Sink Connectorを使ってみる
Open Table Format Study Group Tokyo Meetup #2
https://otfsg-tokyo.connpass.com/event/301158/
システム開発部広報委員会
PRO
March 06, 2024
More Decks by システム開発部広報委員会
See All by システム開発部広報委員会
Rancherで実現した、クラウドに頼らない低コストな次世 代データレイク
microaddevelopers
PRO
0
20
オンプレ環境でIcebergを運用して分かったテーブルメンテナンスの重要性
microaddevelopers
PRO
0
27
徹底比較!LonghornとCephのアーキテクチャ&パフォーマンス
microaddevelopers
PRO
0
260
マイクロアドでの Hive → Iceberg 移行事例紹介
microaddevelopers
PRO
1
130
Rancher × Hashicorp Vault で 実現する秘密情報管理
microaddevelopers
PRO
1
65
大規模システムを支える実践的インフラ基盤の開発と運用
microaddevelopers
PRO
0
93
マイクロアドのData LakehouseとIcebergテーブルの最適化について
microaddevelopers
PRO
1
44
広告配信システムにおけるデータ基盤移行の事例紹介
microaddevelopers
PRO
0
17
3rd Party Cookie 規制後の広告配信技術
microaddevelopers
PRO
0
16
Other Decks in Programming
See All in Programming
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
150
React本体のコードリーディング
high_g_engineer
0
110
人間の目はかわらない、だからJPEGは30年もつ
yuzneri
12
17k
Foundation Models frameworkで画像分析
ryodeveloper
1
160
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
420
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
1.1k
ここ半年くらいでAIに作らせたR用ツール
eitsupi
0
330
自動化したのに回らないテスト運用の壁ーAI時代の品質責任と生産性
mfunaki
0
110
全PRの83%がAIレビューだけでマージできるようになった開発組織はその後どうなったか
athug
0
620
AI時代のPHPer生存戦略 ~「言語、もうなんでもよくない?」に本気で向き合う~
vivion
0
210
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.8k
FDEが実現するAI駆動経営の現在地
gonta
2
240
Featured
See All Featured
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
230
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
880
How to make the Groovebox
asonas
2
2.3k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.6k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.7k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Product Roadmaps are Hard
iamctodd
55
12k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
760
Transcript
Kafka Connect Iceberg Sink Connectorを使ってみる 2024/3/1 OTFSG Tokyo Meetup #2
株式会社マイクロアド 永富 安和 ( @yassan168 ) #otfsg_tokyo
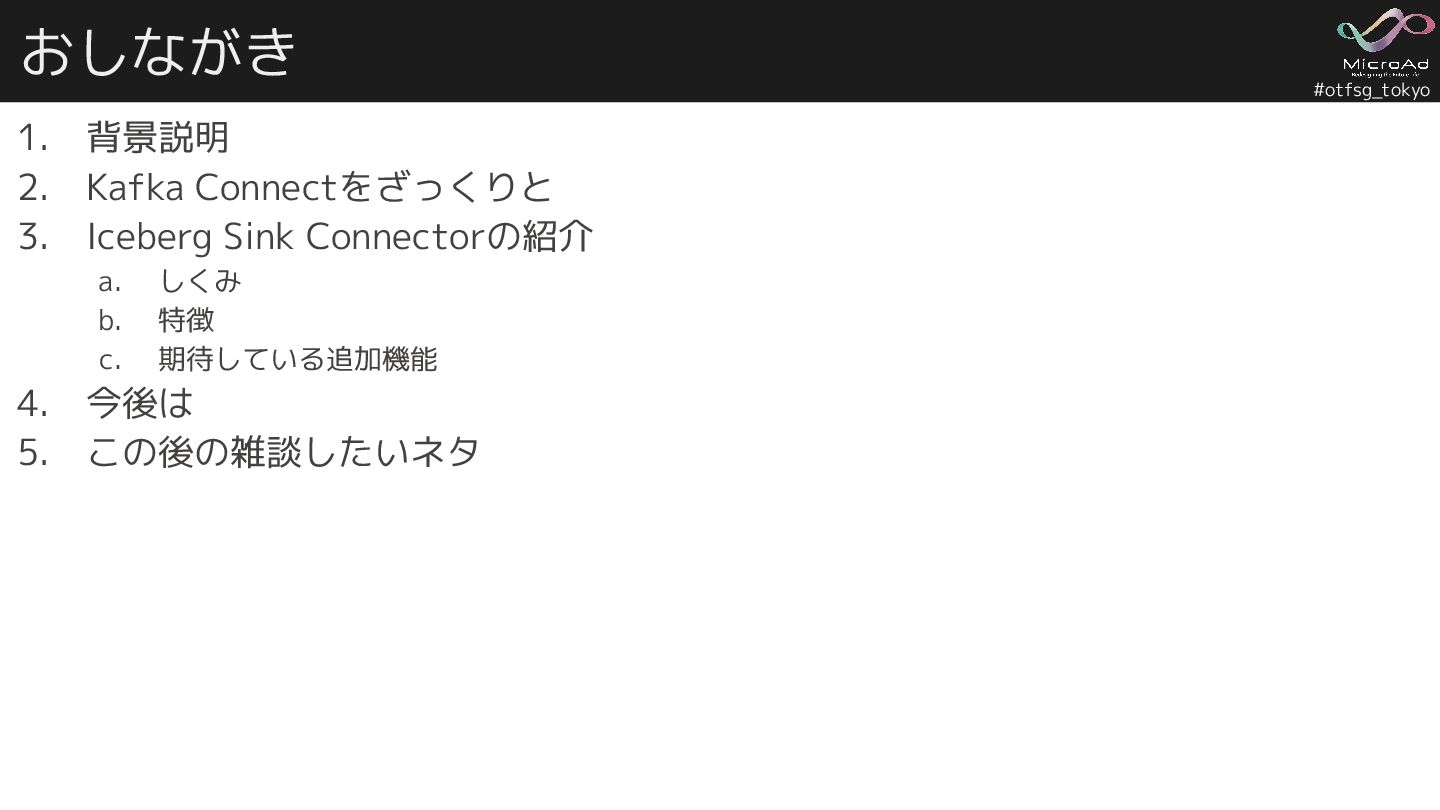
#otfsg_tokyo おしながき 1. 背景説明 2. Kafka Connectをざっくりと 3. Iceberg Sink
Connectorの紹介 a. しくみ b. 特徴 c. 期待している追加機能 4. 今後は 5. この後の雑談したいネタ
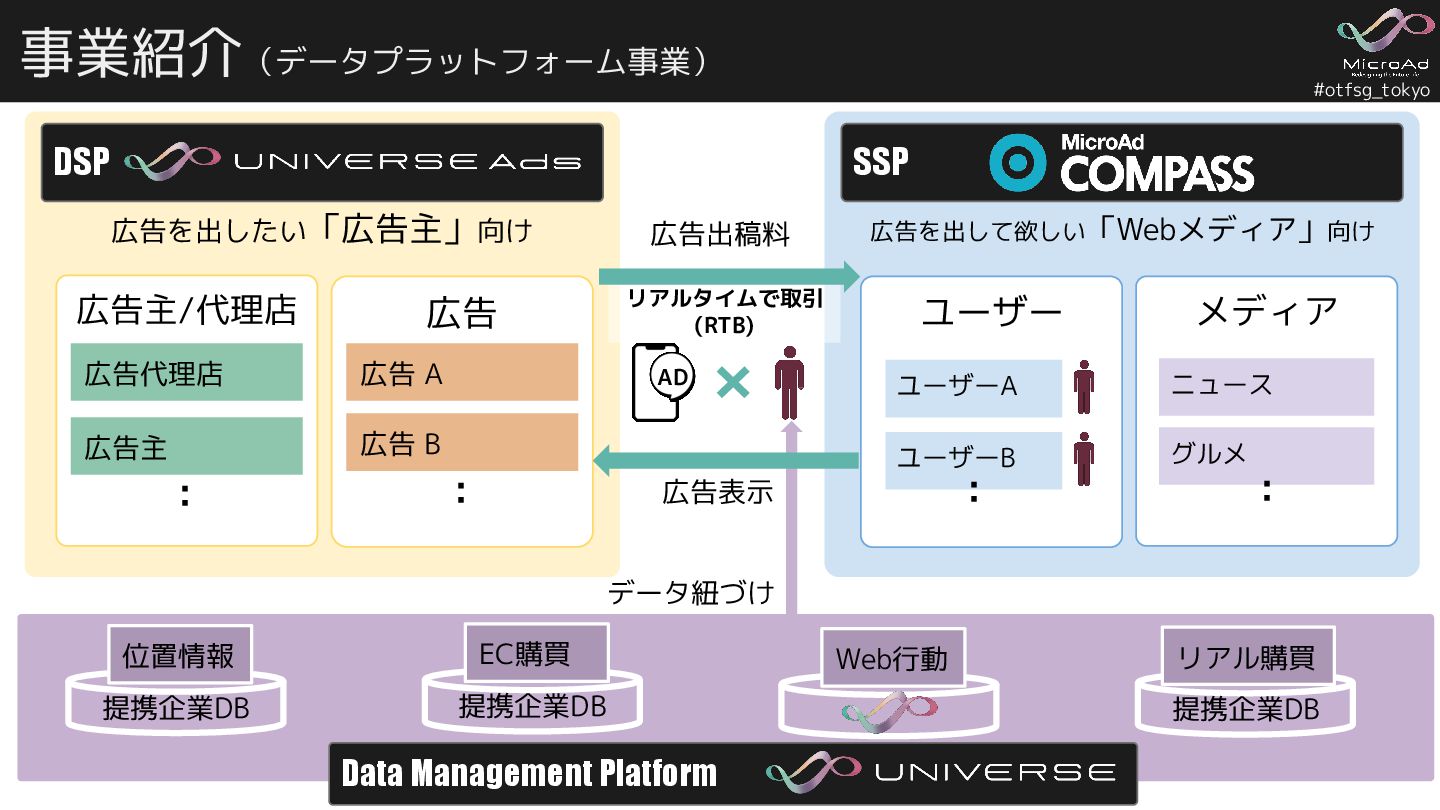
#otfsg_tokyo 事業紹介(データプラットフォーム事業) 6 広告を出したい「広告主」向け DSP SSP 広告を出して欲しい「Webメディア」向け 広告 メディア ユーザー
ユーザーB 広告主/代理店 リアルタイムで取引 (RTB) 広告出稿料 広告表示 広告代理店 広告主 : 広告 A 広告 B : AD ユーザーA : ニュース グルメ : Data Management Platform 提携企業DB 位置情報 データ紐づけ 提携企業DB EC購買 Web行動 提携企業DB リアル購買
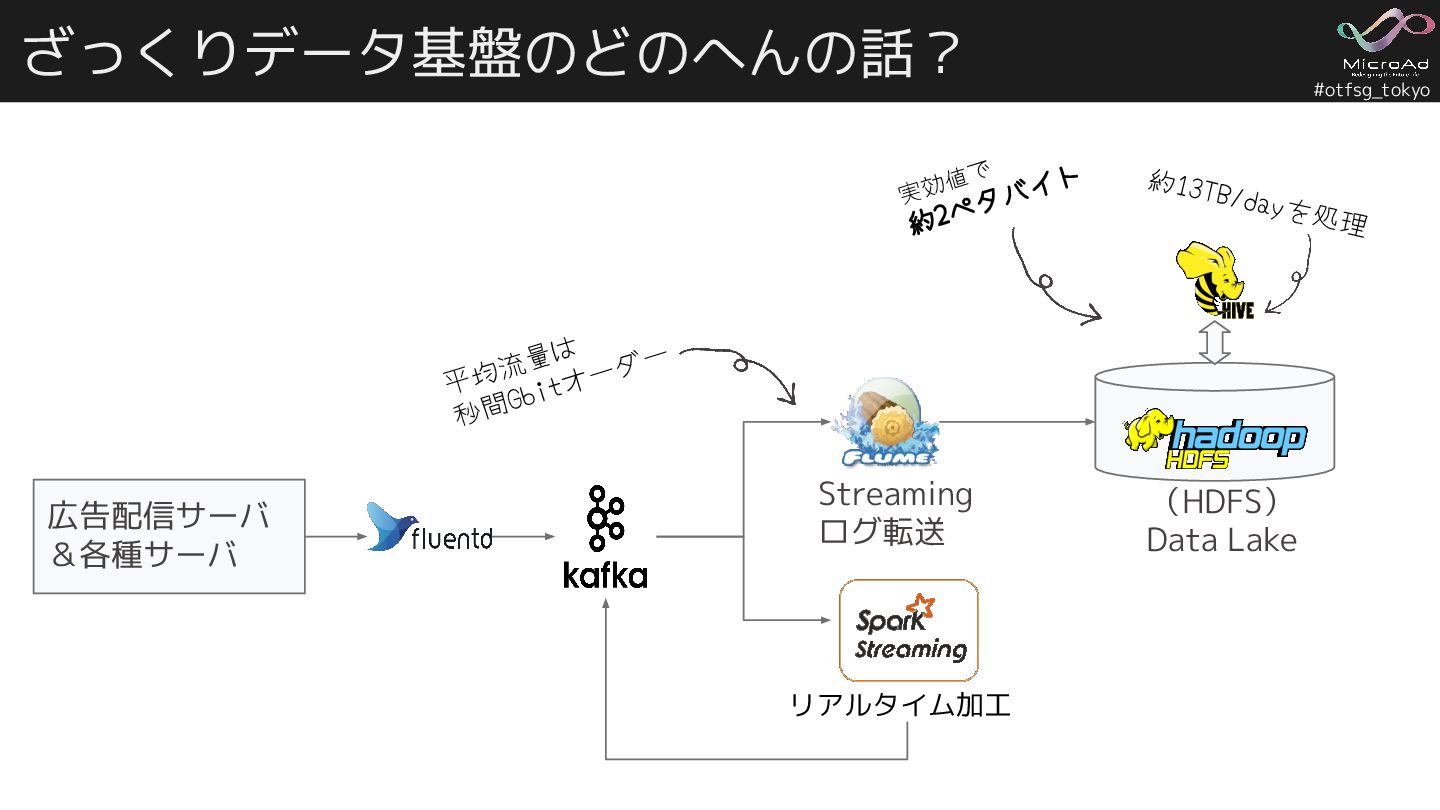
#otfsg_tokyo ざっくりデータ基盤のどのへんの話? 広告配信サーバ &各種サーバ (HDFS) Data Lake Streaming ログ転送 リアルタイム加工
約13TB/dayを処理 実効値で 約2ペタバイト 平均流量は 秒間Gbitオーダー
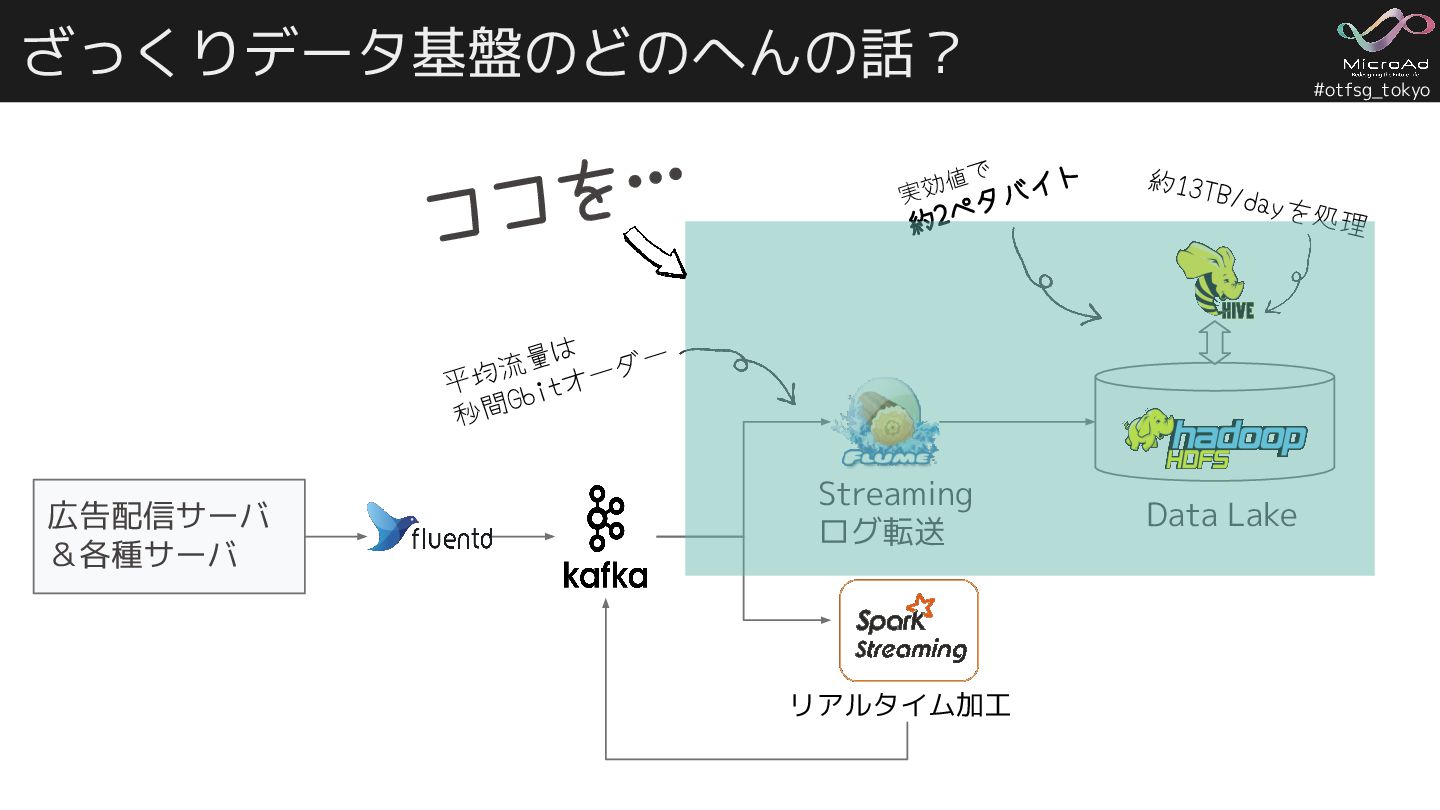
#otfsg_tokyo ざっくりデータ基盤のどのへんの話? 広告配信サーバ &各種サーバ Data Lake Streaming ログ転送 リアルタイム加工 約13TB/dayを処理
実効値で 約2ペタバイト 平均流量は 秒間Gbitオーダー ココを…
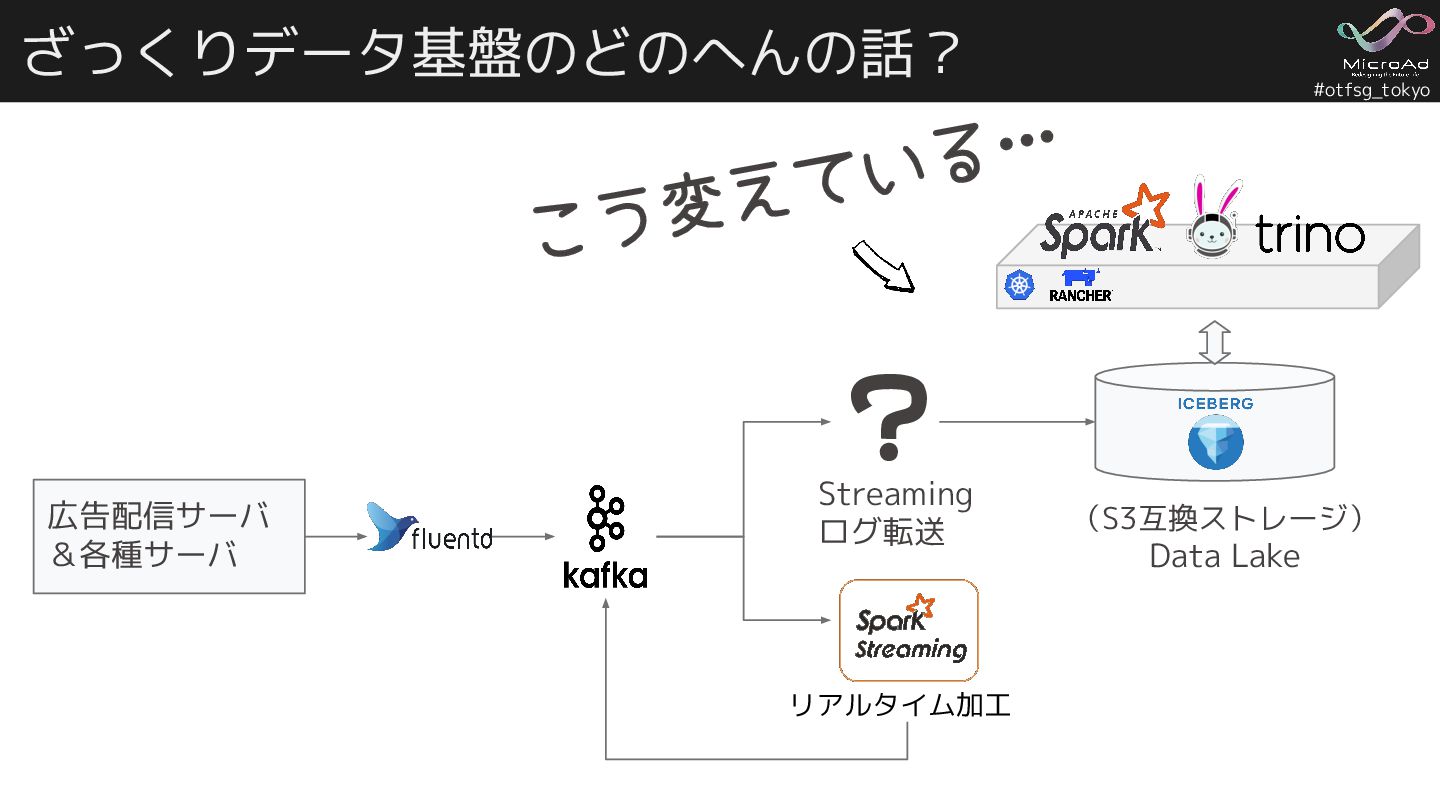
#otfsg_tokyo ざっくりデータ基盤のどのへんの話? 広告配信サーバ &各種サーバ (S3互換ストレージ) Data Lake Streaming ログ転送 リアルタイム加工
こう変えている… ?
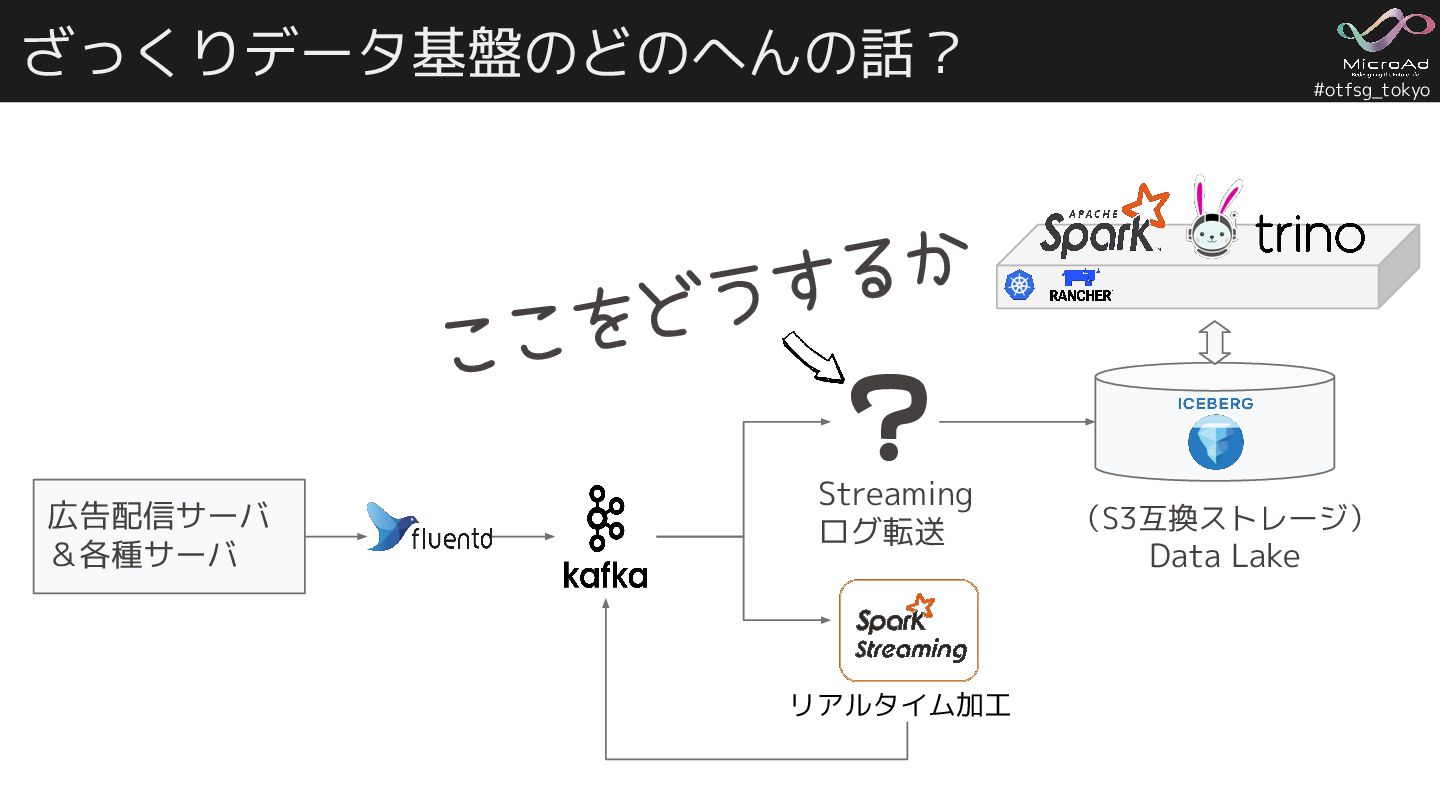
#otfsg_tokyo ざっくりデータ基盤のどのへんの話? 広告配信サーバ &各種サーバ (S3互換ストレージ) Data Lake Streaming ログ転送 リアルタイム加工
ここをどうするか ?
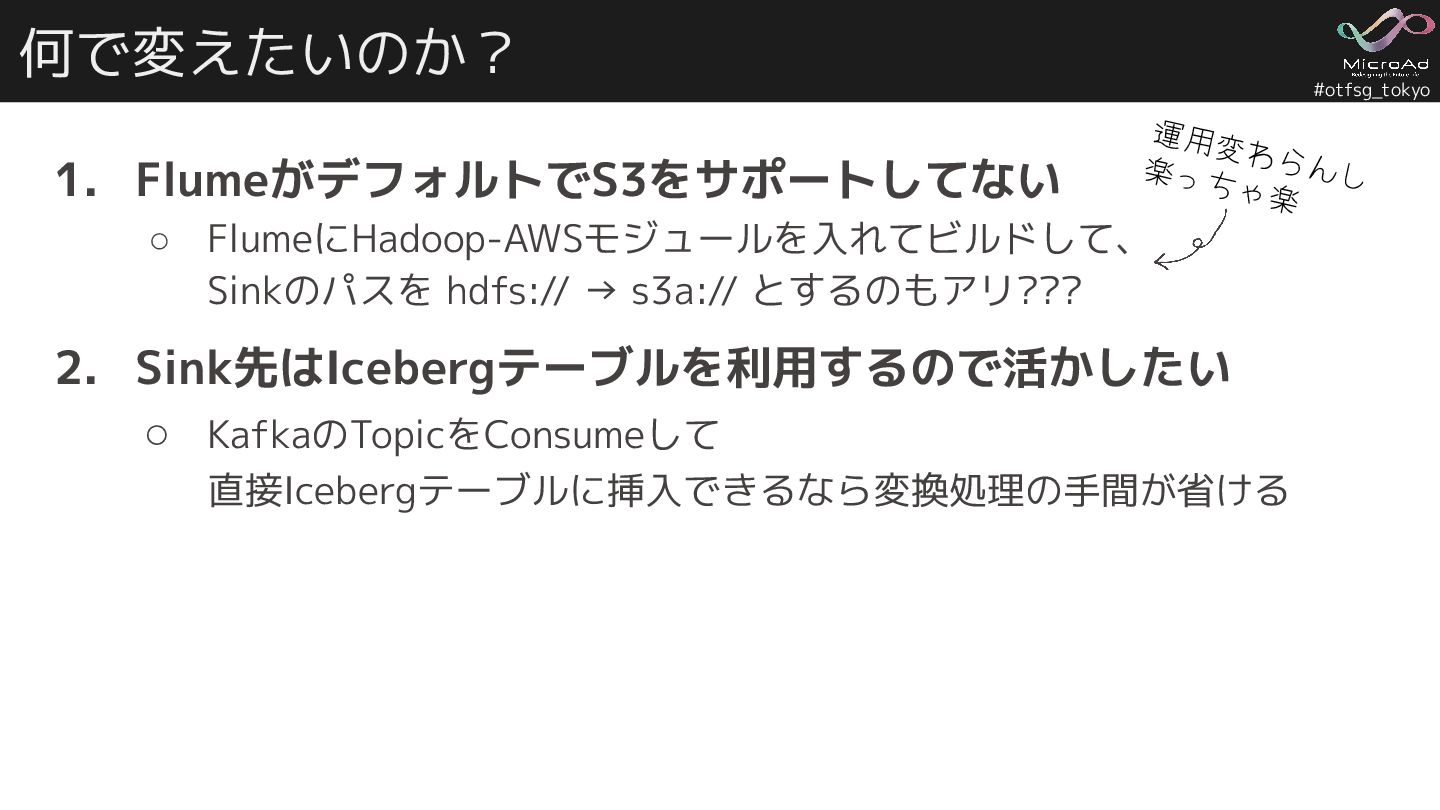
#otfsg_tokyo 何で変えたいのか? 1. FlumeがデフォルトでS3をサポートしてない ◦ FlumeにHadoop-AWSモジュールを入れてビルドして、 Sinkのパスを hdfs:// → s3a://
とするのもアリ??? 2. Sink先はIcebergテーブルを利用するので活かしたい ◦ KafkaのTopicをConsumeして 直接Icebergテーブルに挿入できるなら変換処理の手間が省ける 運用変わらんし 楽っちゃ楽
#otfsg_tokyo Streamingログ転送に求める事 1. メッセージのデータ型のJSONをデシリアライズ 2. 日時の文字列カラムをパースしてSinkするパスに変換 3. ネストしたデータ構造をフラット化 4. デイリーでローテーションしてるTopic(topic.20240102)を
1つのSinkとして扱いたい 5. (出来れば)Icebergテーブルに直接レコードを挿入 6. 可能な限り必要になるコンポーネントは少なく
#otfsg_tokyo Streamingログ転送に求める事 1. メッセージのデータ型のJSONをデシリアライズ 2. 日時の文字列カラムをパースしてSinkするパスに変換 🙌 直接Icebergテーブルに挿入するので考慮不要 3. ネストしたデータ構造をフラット化
4. デイリーでローテーションしてるTopic(topic.20240102)を 1つのSinkとして扱いたい 5. (出来れば)Icebergテーブルに直接レコードを挿入 6. 可能な限り必要になるコンポーネントは少なく
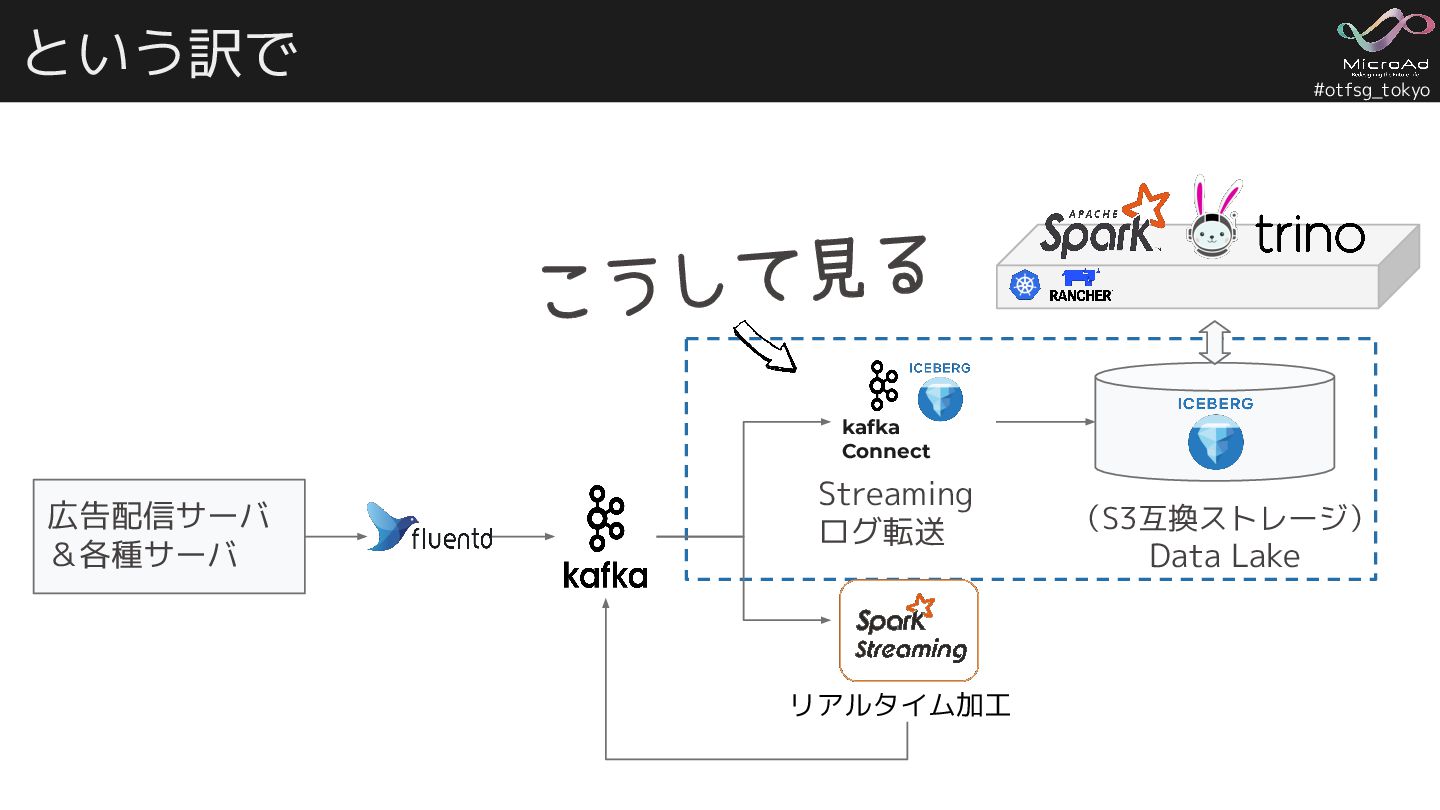
#otfsg_tokyo という訳で 広告配信サーバ &各種サーバ (S3互換ストレージ) Data Lake Streaming ログ転送 リアルタイム加工
こうして見る kafka Connect
#otfsg_tokyo そもそもKafka Connectとは Kafka Connectとは、Apache Kafkaの一部(Confluent製品だと誤解してた) で、 データパイプラインを実行・管理するラインタイム。 Kafka Connectは、プラグインを組み合わせて複雑なデータパイプラインを構築します。
パイプラインを定義するためのプラグインをコネクタプラグインと呼びます。 コネクタプラグインには以下の種類があります。 • 外部システムからKafkaにデータをImportする Source Connector • Kafkaから外部システムにデータをExportする Sink Connector • Kafka Connectと外部システム間でデータを変換する Converter • Kafka Connectを流れるデータを変換する Transformation • 条件付きで変換を適用する Predicate 設定変更や操作などはREST APIで行えるので自動化と相性が良い。
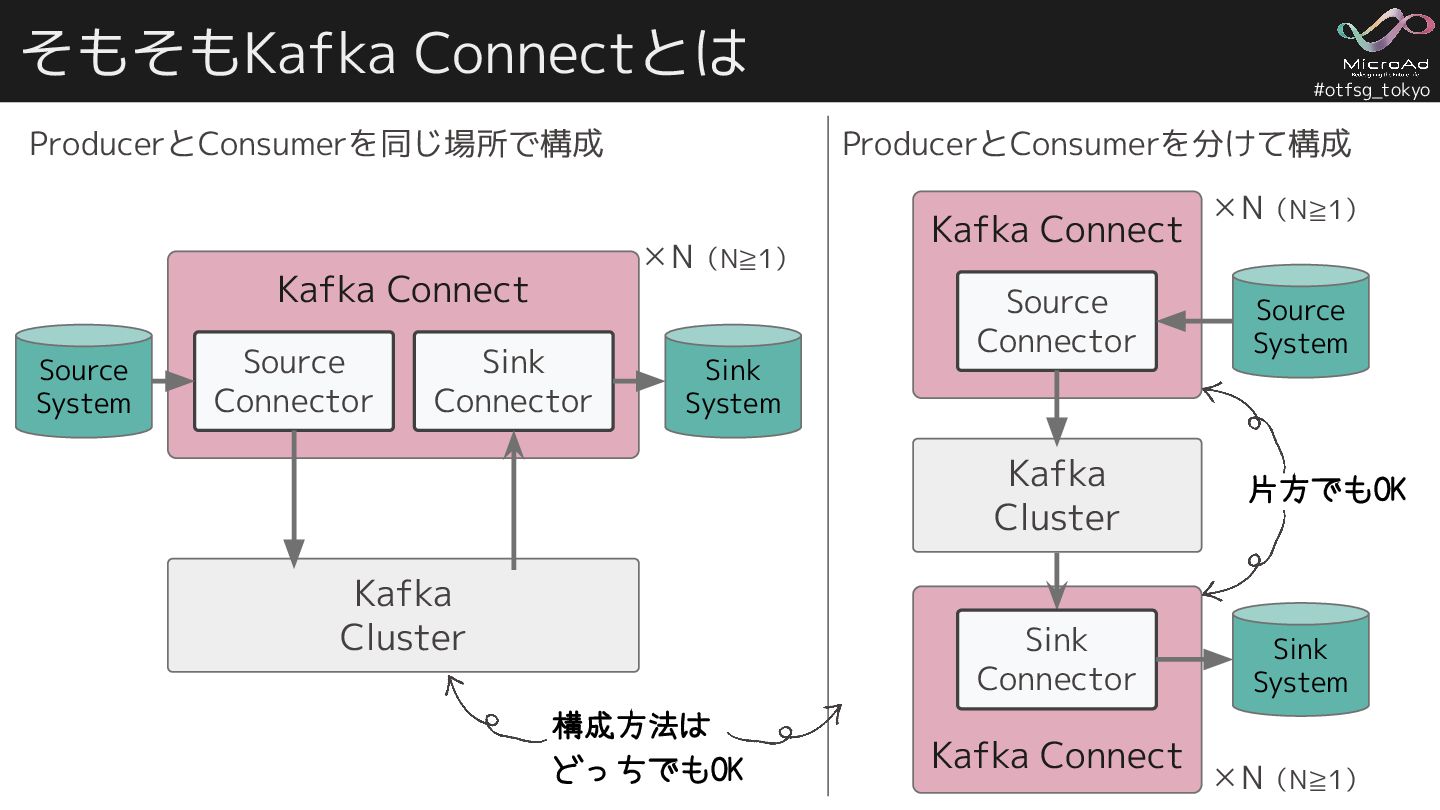
#otfsg_tokyo Kafka Connect Kafka Connect そもそもKafka Connectとは Sink System Kafka
Cluster Source System Source Connector Sink Connector 構成方法は どっちでもOK Kafka Connect Kafka Cluster Source System Source Connector Sink System Sink Connector 片方でもOK ProducerとConsumerを同じ場所で構成 ProducerとConsumerを分けて構成 ✕N(N≧1) ✕N(N≧1) ✕N(N≧1)
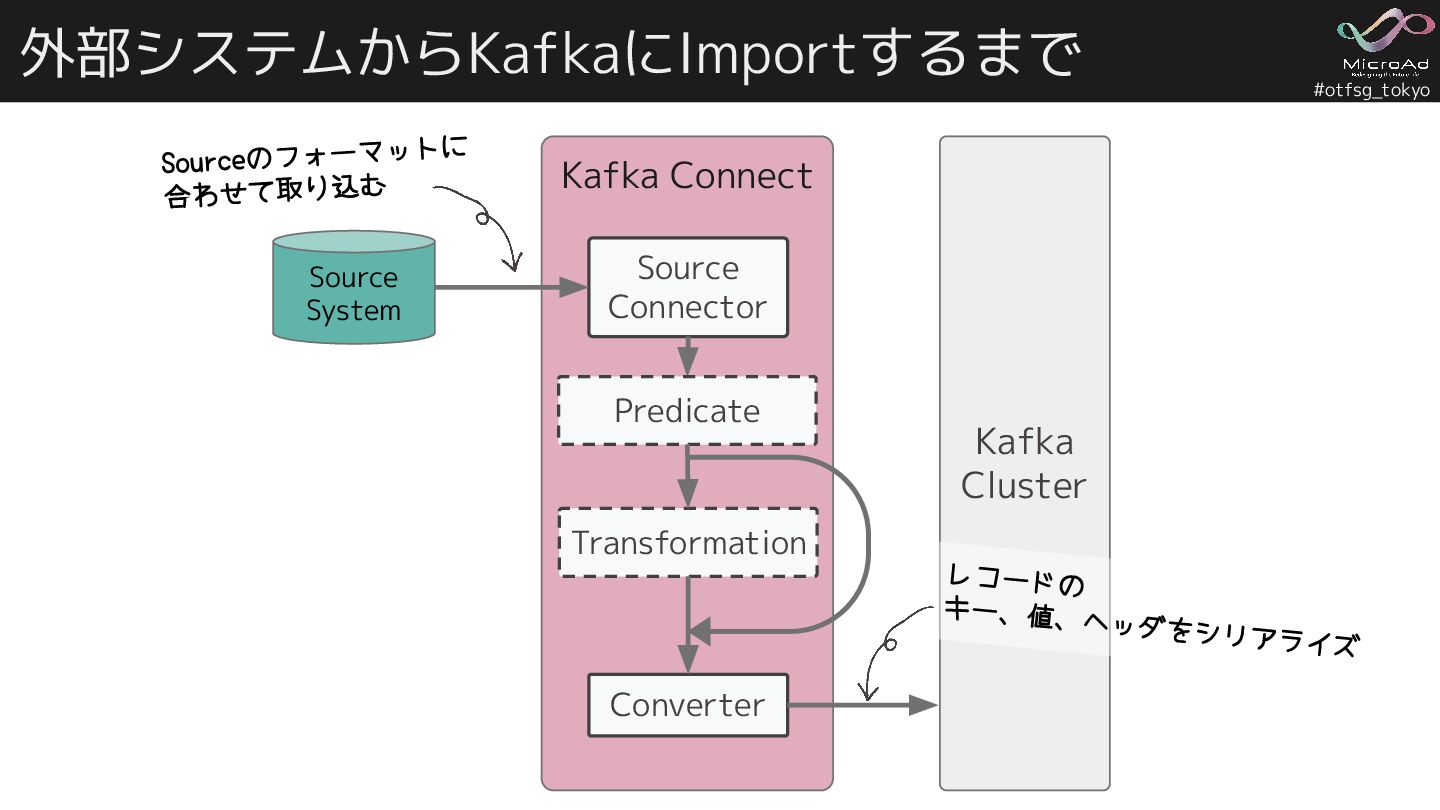
#otfsg_tokyo Kafka Connect 外部システムからKafkaにImportするまで Kafka Cluster Source System Source Connector
Transformation Converter レコードの キー、値、ヘッダをシリアライズ Sourceのフォーマットに 合わせて取り込む Predicate
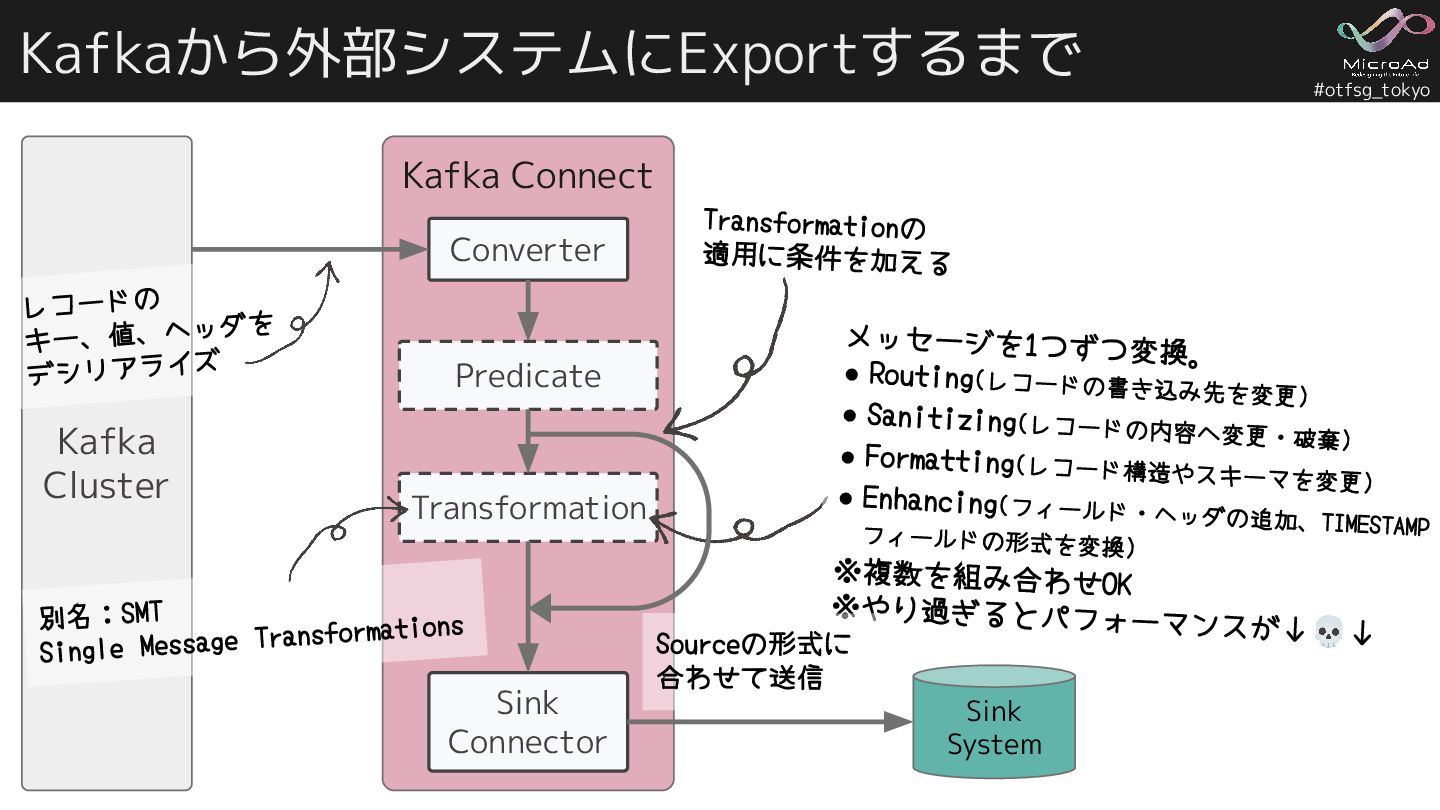
#otfsg_tokyo Kafka Connect Kafkaから外部システムにExportするまで Sink System Kafka Cluster Sink Connector
Transformation Converter レコードの キー、値、ヘッダを デシリアライズ 別名:SMT Single Message Transformations メッセージを1つずつ変換。 • Routing(レコードの書き込み先を変更) • Sanitizing(レコードの内容へ変更・破棄) • Formatting(レコード構造やスキーマを変更) • Enhancing(フィールド・ヘッダの追加、TIMESTAMP フィールドの形式を変換) ※複数を組み合わせOK ※やり過ぎるとパフォーマンスが↓💀↓ Predicate Transformationの 適用に条件を加える Sourceの形式に 合わせて送信
#otfsg_tokyo 続きは、、 以下のパックマンフロッグ本がとても参考になります(日本語版欲しいなぁ。。。) Kafka Connect: Build and Run Data Pipelines
https://developers.redhat.com/e-books/kafka-connect-build-and-run-data-pipelines
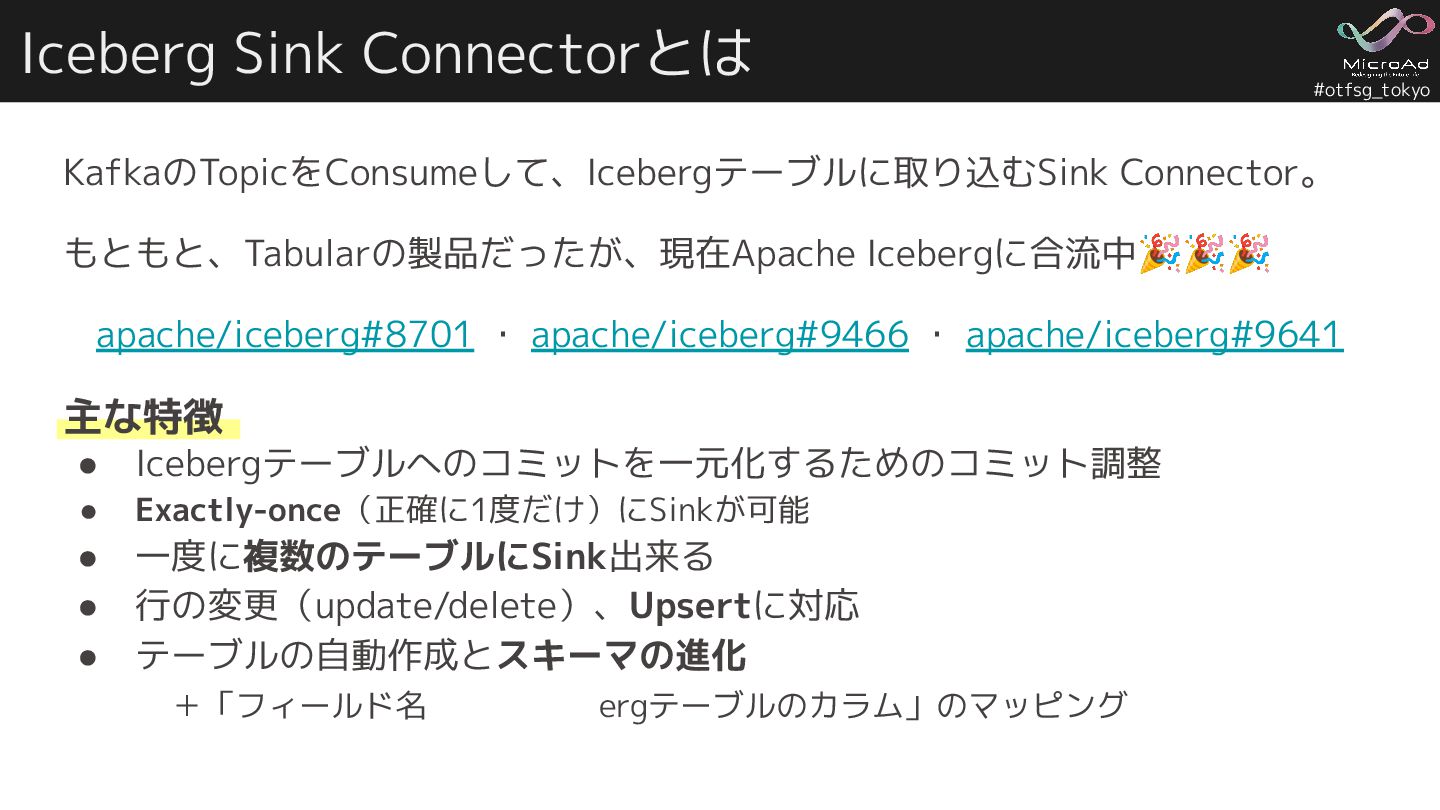
#otfsg_tokyo Iceberg Sink Connectorとは KafkaのTopicをConsumeして、Icebergテーブルに取り込むSink Connector。 もともと、Tabularの製品だったが、現在Apache Icebergに合流中🎉🎉🎉 apache/iceberg#8701 ・
apache/iceberg#9466 ・ apache/iceberg#9641 主な特徴 • Icebergテーブルへのコミットを一元化するためのコミット調整 • Exactly-once(正確に1度だけ)にSinkが可能 • 一度に複数のテーブルにSink出来る • 行の変更(update/delete)、Upsertに対応 • テーブルの自動作成とスキーマの進化 +「フィールド名」と「Icebergテーブルのカラム」のマッピング
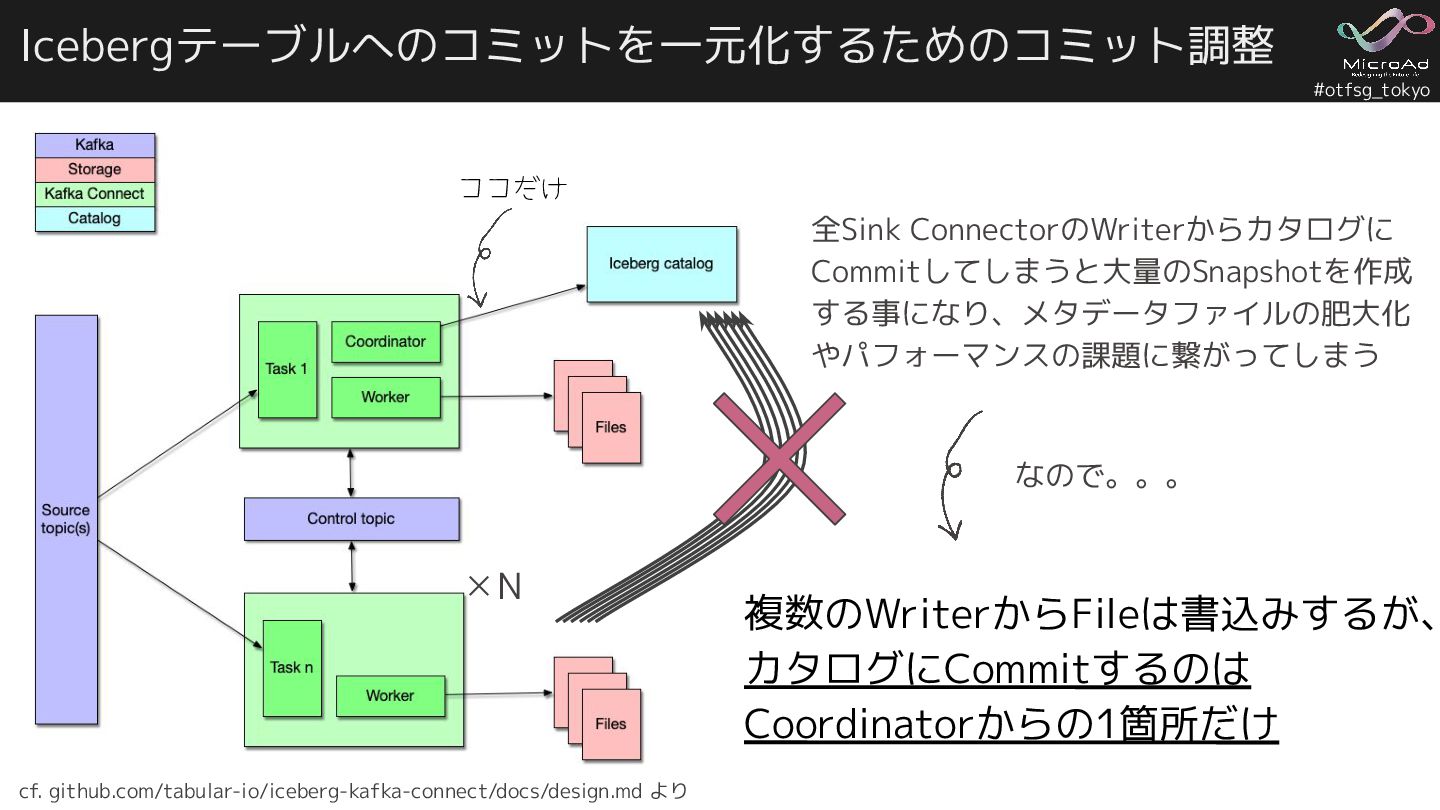
#otfsg_tokyo Icebergテーブルへのコミットを一元化するためのコミット調整 全Sink ConnectorのWriterからカタログに Commitしてしまうと大量のSnapshotを作成 する事になり、メタデータファイルの肥大化 やパフォーマンスの課題に繋がってしまう 複数のWriterからFileは書込みするが、 カタログにCommitするのは Coordinatorからの1箇所だけ
✕N なので。。。 ココだけ cf. github.com/tabular-io/iceberg-kafka-connect/docs/design.md より
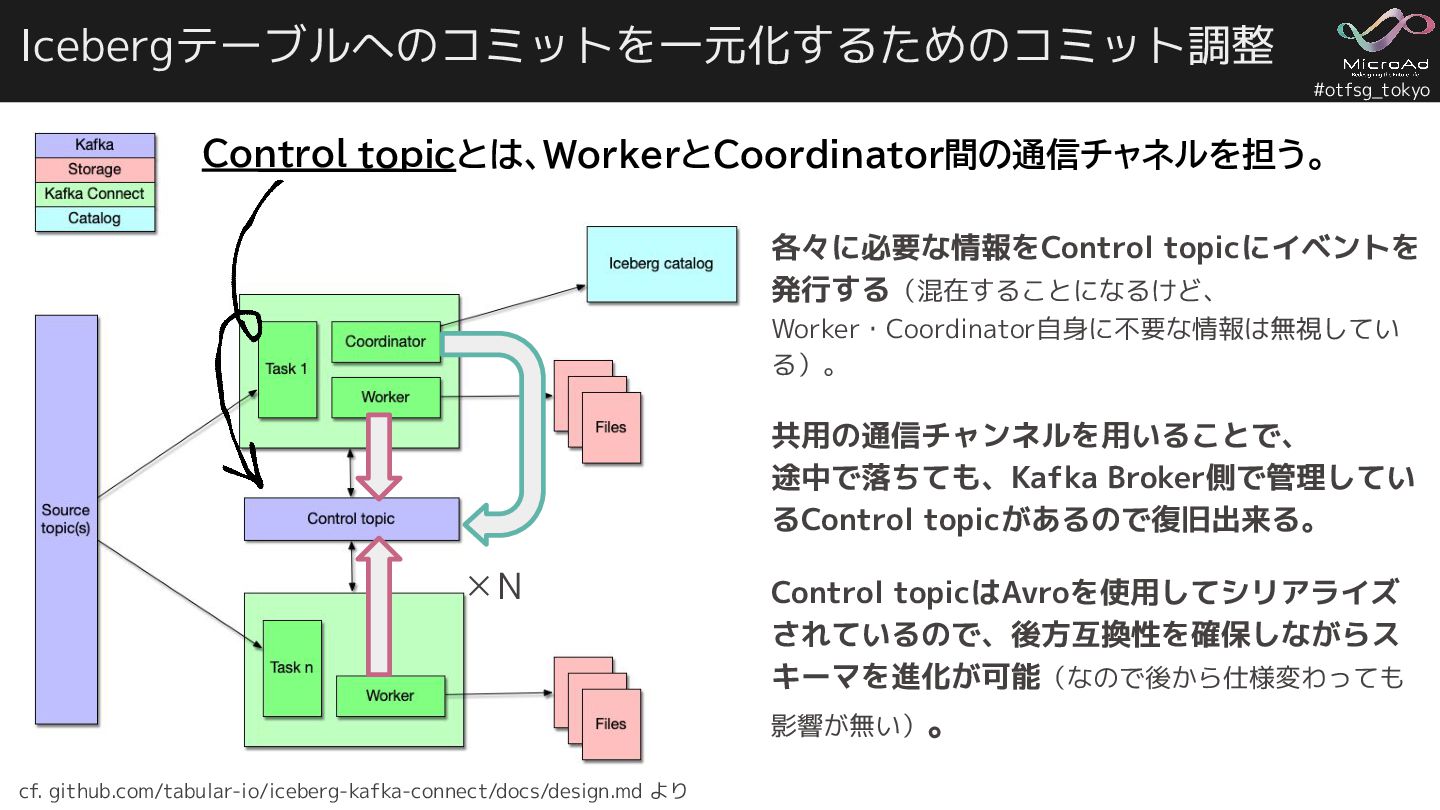
#otfsg_tokyo Icebergテーブルへのコミットを一元化するためのコミット調整 各々に必要な情報をControl topicにイベントを 発行する(混在することになるけど、 Worker・Coordinator自身に不要な情報は無視してい る)。 共用の通信チャンネルを用いることで、 途中で落ちても、Kafka Broker側で管理してい
るControl topicがあるので復旧出来る。 Control topicはAvroを使用してシリアライズ されているので、後方互換性を確保しながらス キーマを進化が可能(なので後から仕様変わっても 影響が無い)。 Control topicとは、WorkerとCoordinator間の通信チャネルを担う。 ✕N cf. github.com/tabular-io/iceberg-kafka-connect/docs/design.md より
#otfsg_tokyo Iceberg Sink Connectorのコミットプロセス Iceberg Sink Connectorのコミットプロセスは以下の順で実行されます。 1. コミットタイマー(iceberg.control.commit.interval-ms) の初期化とチェック
2. コミットプロセスの開始 3. Workerによるデータファイルの準備 4. Coordinatorによるコミットの実行 5. Snapshotプロパティの設定 a. Control topicのoffset、UUID、完全に処理されたTimestamp VTTS (Valid-Through Timestamp)
#otfsg_tokyo Exactly-once(正確に1度だけ)にSinkが可能 Workerは、Kafkaトランザクション内でデータファイルのイベントを送信し、 Source TopicのOffsetをコミットすることで、これを保証します。 Coordinatorは、Control topicのConsumerがコミットされたイベントのみを読み込む ように設定し、Control topicのOffsetをIcebergコミットデータの一部として保存する ことで、これを保証しています。
• Sinkが管理するConsumer GroupのSource topicのOffsetは、 Control topicに正常に書き込まれたデータファイルイベントに対応する • OffsetはSnapshotメタデータに保存されるため、 Control topicのOffsetはIceberg Snapshotに対応する
#otfsg_tokyo これってつまり、運用上の注意点でもある Source TopicのOffsetは、以下の2つの異なるConsumer Groupに保存することになる • Sink管理Consumer Group (iceberg.control.group-idで指定しているやつ) ◦
Exactly-OnceでSinkする為に使用 • Kafka Connect管理Consumer Group(デフォルト名:connect-[コネクタ名]) ◦ Sink管理Consumer Groupが見つからない場合のフォールバック用 なので、(障害などの場合など) Offsetをリセットしたい場合は、両方のConsumer Groupのリセットが必要
#otfsg_tokyo 一度に複数のテーブルにSink出来る もちろん、そのままレコードをテーブルに書き込み出来ますが、 以下の様に複数のテーブルへSinkも出来る。 • Multi-table fan-out, Static routing ◦
指定したフィールドの値に応じて、指定するテーブルに書き込む。 その他のレコードはスキップ。 • Multi-table fan-out, Dynamic routing ◦ 指定したフィールドの値を名前とするテーブルにレコードを書き込む。 テーブルが無いならレコードはスキップ。
#otfsg_tokyo 行の変更(update/delete)、Upsertに対応 ⚠行レベルの更新と削除に対応出来るIcebergテーブルがIceberg v2形式が必要 行の変更 iceberg.tables.cdc-fieldで指定したフィールドの値に応じて、 Icebergテーブルへの操作を変更する。 • I :追加操作(append)として機能
• D:等価削除操作(equality delete)として機能 • U:等価削除操作に続いて追加操作を行うことで、更新として機能 Upsertモード iceberg.tables.upsert-mode-enabled=true とする事で すべての受信レコードが「更新」として扱われ、各レコードに対して、等しい削除が実 行され、その後に追加されます。
#otfsg_tokyo テーブルの自動作成とスキーマの進化 メッセージは、Icebergスキーマに最も適合するようにIcebergレコードに変換される。 フィールドは Icebergの名前マッピングと一致するようにマッピングされる。 もし、フィールドの名前マッピングが定義されていない場合は、Iceberg スキーマの フィールド名が使用されます。 流れとしては、、 Source側のSchema(Avro、JSON、Protobuf)
→ Connect側で型変換 → Icebergテーブルのスキーマと比較 → 差分があれば、Icebergテーブルをスキーマ進化して追従させる。
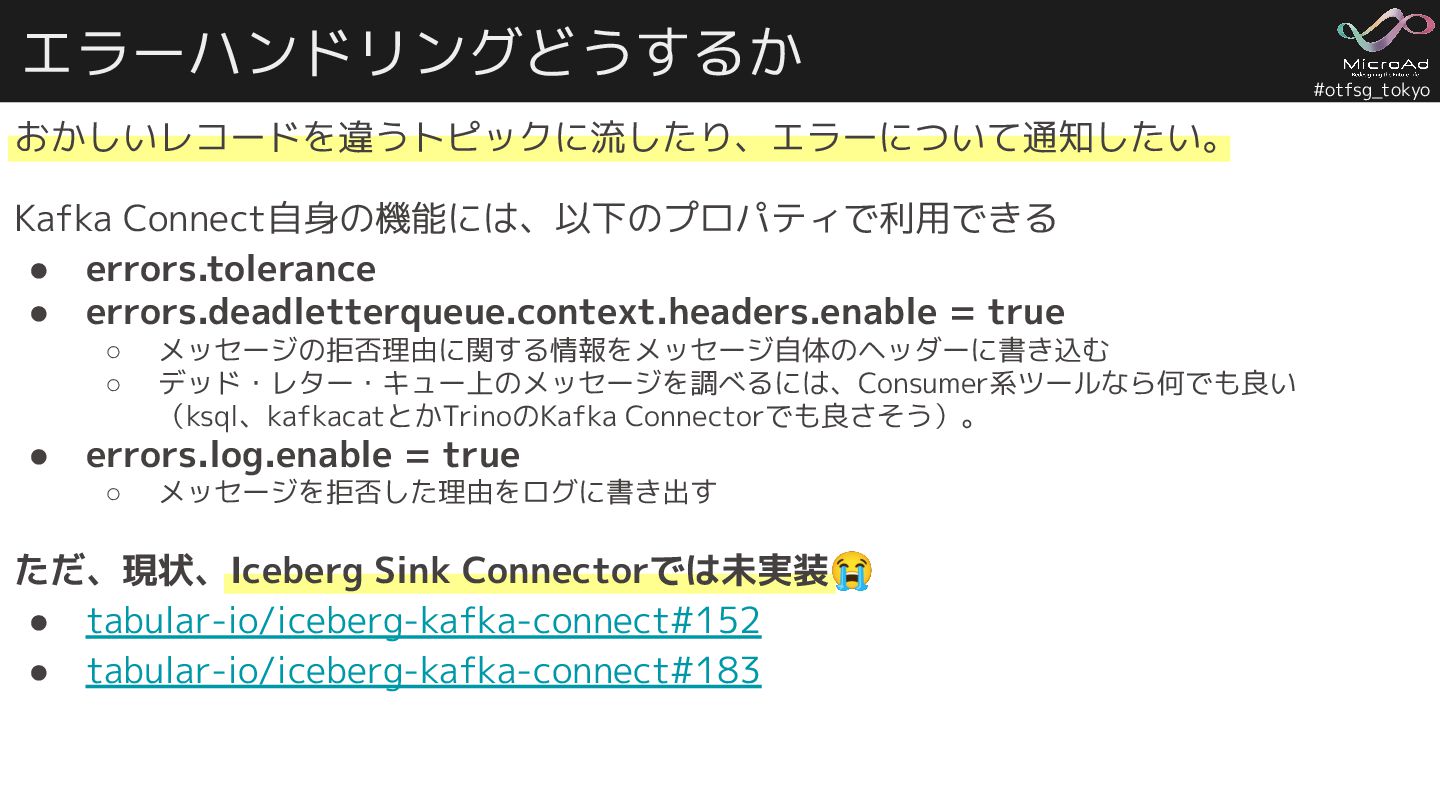
#otfsg_tokyo エラーハンドリングどうするか おかしいレコードを違うトピックに流したり、エラーについて通知したい。 Kafka Connect自身の機能には、以下のプロパティで利用できる • errors.tolerance • errors.deadletterqueue.context.headers.enable =
true ◦ メッセージの拒否理由に関する情報をメッセージ自体のヘッダーに書き込む ◦ デッド・レター・キュー上のメッセージを調べるには、Consumer系ツールなら何でも良い (ksql、kafkacatとかTrinoのKafka Connectorでも良さそう)。 • errors.log.enable = true ◦ メッセージを拒否した理由をログに書き出す ただ、現状、Iceberg Sink Connectorでは未実装😭 • tabular-io/iceberg-kafka-connect#152 • tabular-io/iceberg-kafka-connect#183
#otfsg_tokyo 今後は、、 • ネストしたJSONスキーマのフラット化(純粋にはIceberg Sink Connectorとは違うけど) • スキーマ進化がどの程度まで柔軟にいけるのか確認 ◦ 追加くらいしか試せてない(ネストしたフィールド側の追加とかは?)
• Schema Registryの無しでどれくらいつらみがあるのか体験 ◦ そもそもSchema Registryなに使うか問題 ▪ ConfulentのSchema Registory? AivenのKarapace? • 大きめの流量のTopicをConsumeしてどうなるか確認してみたい ◦ メタデータまわりの状況 ◦ Icebergテーブルの最適化(CompactionやSnapshotのExpireの頻度とか)どうするか • Iceberg Sink Connectorの設定の管理&反映まわりをGitのPRベースの運用に 落とし込む対応の検討
#otfsg_tokyo この辺をこの後、雑談したい。 • Kafka または、Kafka ConnectをKubernetesで運用するのしんどない? ◦ 構成要素が単純(特にKafka Connect)なので、Kubernetesと相性は良さそう ◦
ただ、KubernetesのアップデートやOperatorのアップデートに引きずられるけど、そこをどうする か? • Sink Connectorサーバ1台あたり、どれくらいさばけるのか? ◦ 何Topicくらいまで面倒見られそうか • Schema Registory無しじゃだめ? ◦ Iceberg Sink Connector側でTopicのスキーマ変更を検知してIcebergテーブルをスキーマ進化するな ら不要? ◦ Graceful Shutdown出来るなら、設定変更に伴うKafka Connectの再起動はズグだし
いかがだったでしょうか。。。
#otfsg_tokyo そんな貴方にDocker Composeな検証環境あります。 実際に触って試したい場合は、以下をどうぞ。 https://github.com/Wuerike/kafka-iceberg-streaming KakaとKafka ConnectをRedpandaを使って構成しています(UIがあるのでむっちゃ便利)。 UIからTopicやConnectorの状況や設定の変更も可能。 ストレージにはMinIOを使い、IcebergカタログはRESTカタログを用いています。 Jupyter
NotebookとセットになったSpark&Icebergもあるので、 NotebookからブラウザからIcebergテーブルの操作も可能。 Kafka に流すデータは、Benthosを使って生成。 GolangのライブラリのfakerをベースにBenthos固有のBloblangってのを使うと ダミーデータを生成してデータをPublish出来るので非常に便利。
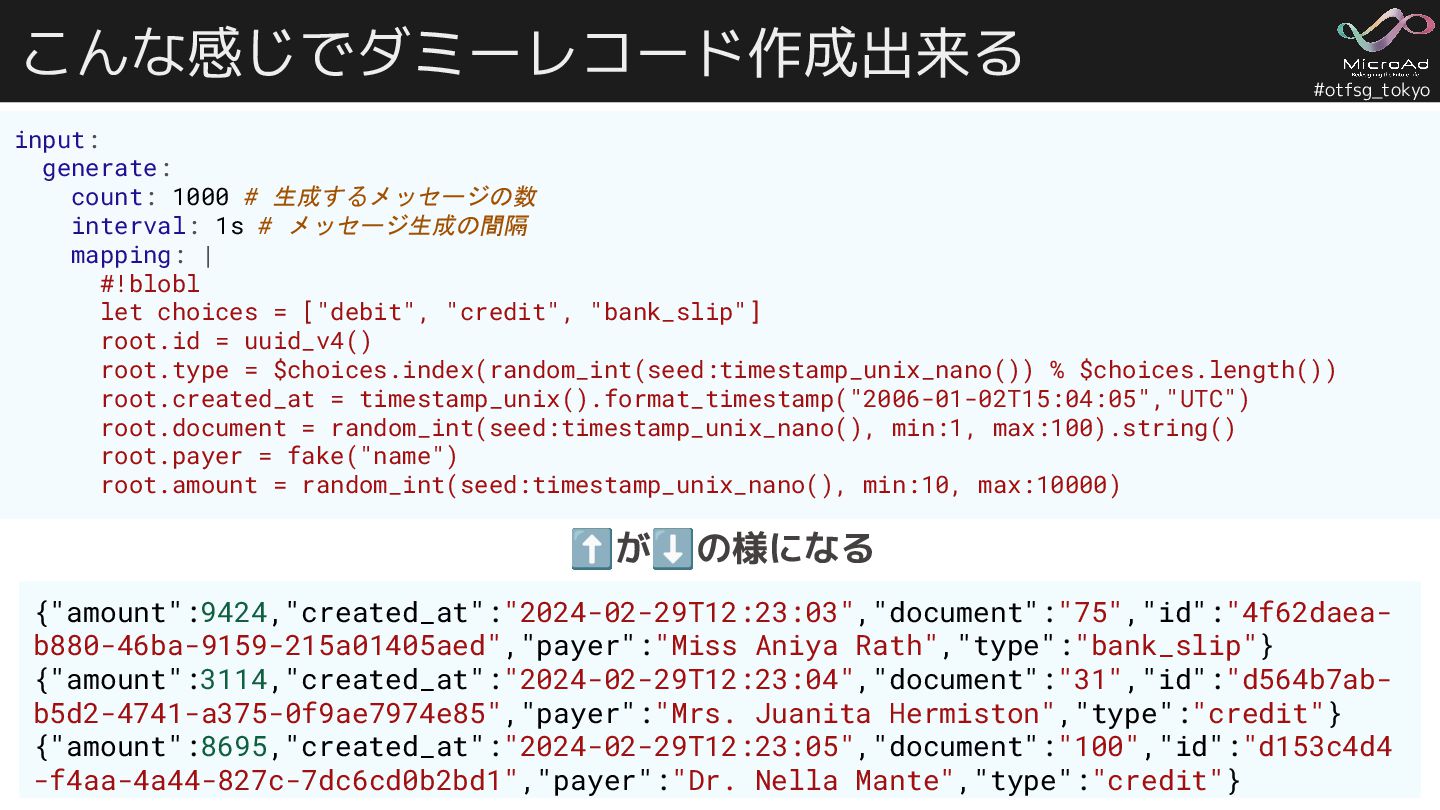
#otfsg_tokyo こんな感じでダミーレコード作成出来る input: generate: count: 1000 # 生成するメッセージの数 interval: 1s
# メッセージ生成の間隔 mapping: | #!blobl let choices = ["debit", "credit", "bank_slip"] root.id = uuid_v4() root.type = $choices.index(random_int(seed:timestamp_unix_nano()) % $choices.length()) root.created_at = timestamp_unix().format_timestamp("2006-01-02T15:04:05","UTC") root.document = random_int(seed:timestamp_unix_nano(), min:1, max:100).string() root.payer = fake("name") root.amount = random_int(seed:timestamp_unix_nano(), min:10, max:10000) ⬆が⬇の様になる {"amount":9424,"created_at":"2024-02-29T12:23:03","document":"75","id":"4f62daea- b880-46ba-9159-215a01405aed","payer":"Miss Aniya Rath","type":"bank_slip"} {"amount":3114,"created_at":"2024-02-29T12:23:04","document":"31","id":"d564b7ab- b5d2-4741-a375-0f9ae7974e85","payer":"Mrs. Juanita Hermiston","type":"credit"} {"amount":8695,"created_at":"2024-02-29T12:23:05","document":"100","id":"d153c4d4 -f4aa-4a44-827c-7dc6cd0b2bd1","payer":"Dr. Nella Mante","type":"credit"}
補足
#otfsg_tokyo • Kafka Connect自身に関する情報 ◦ Kafka Connect Deep Dive –
Converters and Serialization Explained | Confluent https://www.confluent.io/ja-jp/blog/kafka-connect-deep-dive-converters-serialization-explained/ ◦ Kafka Connect Deep Dive – Error Handling and Dead Letter Queues | Confluent https://www.confluent.io/blog/kafka-connect-deep-dive-error-handling-dead-letter-queues ◦ Iceberg Sink Connectorのドキュメント https://github.com/tabular-io/iceberg-kafka-connect/tree/main/docs ◦ Iceberg Sink Connector向けのSMTのドキュメント https://github.com/tabular-io/iceberg-kafka-connect/blob/main/kafka-connect-transforms • 検証環境に関連する情報 ◦ faker:https://pkg.go.dev/github.com/go-faker/faker/v4 ◦ Benthosで生成出来るダミーデータ仕様 https://www.benthos.dev/docs/guides/bloblang/functions/#fake
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}