complexity of binary search is 'log n' whereas the complexity of a sequential search is 'n'. In a binary search, each time we proceed, we have to deal with only half of the elements of the array compared to the previous one. So the search is faster.
it remembers its caller and hence knows where to return to when the function has to return. Recursion makes use of system stack for storing the return addresses of the function calls. Every recursive function has its equivalent iterative (non-recursive) function. Even when such equivalent iterative procedures are written, explicit stack is to be used.
Data structure. He has been told to use one of the following Methods a. Insertion b. Selection c. Exchange d. Linear Now Ram says a Method from the above can not be used to sort. Which is the method?
selection we can perform selection sort, and using exchange we can perform bubble sort. But no sorting method is possible using linear method; Linear is a searching method
full binary tree. By the method of elimination: Full binary tree contains odd number of nodes. So there cannot be a full binary tree with 8 or 14 nodes. With 13 nodes, you can form a complete binary tree but not a full binary tree. Full and complete binary trees are different All full binary trees are complete binary trees but not vice versa
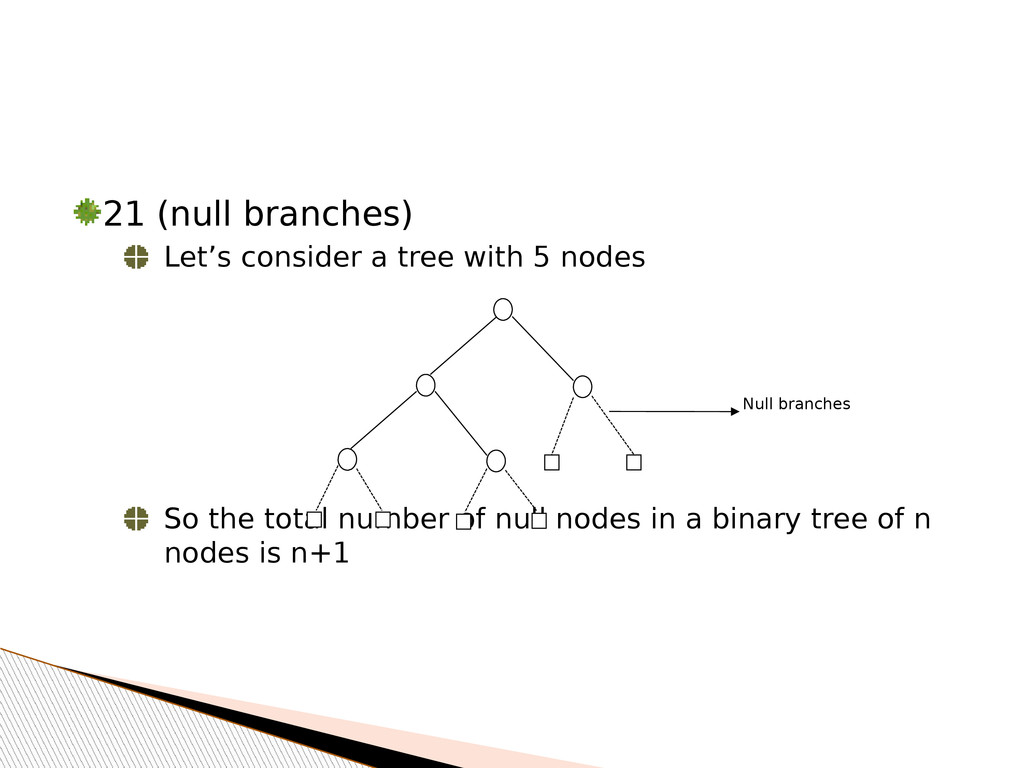
tree if and only if: Each non leaf node has exactly two child nodes All leaf nodes have identical path length It is called full since all possible node slots are occupied A B C D E F G
satisfies the following conditions: Level 0 to h-1 represent a full binary tree of height h-1 One or more nodes in level h-1 may have 0, or 1 child nodes A B C D E F G H I J K
You are presented with a linked list, which may have a "loop" in it. That is, an element of the linked list may incorrectly point to a previously encountered element, which can cause an infinite loop when traversing the list. Devise an algorithm to detect whether a loop exists in a linked list. How does your answer change if you cannot change the structure of the list elements?
element of the list. You could then traverse the list, starting at the head and tagging each element as you encounter it. If you ever encountered an element that was already tagged, you would know that you had already visited it and that there existed a loop in the linked list. What if you are not allowed to alter the structure of the elements of the linked list?
two pointers ptr1 and ptr2. b) Set ptr1 and ptr2 to the head of the linked list. c) Traverse the linked list with ptr1 moving twice as fast as ptr2 (for every two elements that ptr1 advances within the list, advance ptr2 by one element). d) Stop when ptr1 reaches the end of the list, or when ptr1 = ptr2. e) If ptr1 and ptr2 are ever equal, then there must be a loop in the linked list. If the linked list has no loops, ptr1 should reach the end of the linked list ahead of ptr2
the end in the LL. First, just keep on incrementing the first pointer (ptr1) till the number of increments cross n (which is 6 in this case) STEP 1 : 1(ptr1,ptr2) -> 2 -> 3 -> 4 -> 5 -> 6 -> 7 -> 8 -> 9 -> 10 STEP 2 : 1(ptr2) -> 2 -> 3 -> 4 -> 5 -> 6(ptr1) -> 7 -> 8 -> 9 -> 10 Now, start the second pointer (ptr2) and keep on incrementing it till the first pointer (ptr1) reaches the end of the LL. STEP 3 : 1 -> 2 -> 3 -> 4(ptr2) -> 5 -> 6 -> 7 -> 8 -> 9 -> 10 (ptr1) So here you have the 6th node from the end pointed to by ptr2!
node** headReference, struct node* newNode) { // Special case for the head end if (*headReference == NULL || (*headReference)->data >= newNode->data) { newNode->next = *headReference; The solution is to iterate down the list looking for the correct place to insert the new node. That could be the end of the list, or a point just before a node which is larger than the new node. Let us assume the memory for the new node has already been allocated and a pointer to that memory is being passed to this function.
before which the insertion is to happen! struct node* current = *headReference; while (current->next!=NULL && current->next->data < newNode->data) { current = current->next; } newNode->next = current->next; current->next = newNode; } }
head) { struct node* current = head; if (current == NULL) return; // do nothing if the list is empty // Compare current node with next node while(current->next!=NULL) { As the linked list is sorted, we can start from the beginning of the list and compare adjacent nodes. When adjacent nodes are the same, remove the second one. There's a tricky case where the node after the next node needs to be noted before the deletion.
of one is NULL, return false return 0; else return ((T1->element == T2->element) && CheckIdentical(T1->left, T2-i>left) && CheckIdentical(T1->right, T2->right)); // if element of both tree are same and left and right tree is also same then both trees are same }
nodes and we need a pointer to connect them. It is not possible to use ordinary pointers for this. So we use void pointer. Void pointer is capable of storing pointer to any type of data (eg., integer or character) as it is a generic pointer type.
tree, if the maximum level is i, then, upto the (i-1)th level should be complete. At level i, the number of nodes can be less than or equal to 2^i. If the number of nodes is less than 2^i, then the nodes in that level should be completely filled, only from left to right The property of an ascending heap is that, the root is the lowest and given any other node i, that node should be less than its left child and its right child. In a descending heap, the root should be the highest and given any other node i, that node should be greater than its left child and right child.
Once the heap is created, the root has the highest value. Now we need to sort the elements in ascending order. The root can not be exchanged with the nth element so that the item in the nth position is sorted. Now, sort the remaining (n-1) elements. This can be achieved by reconstructing the heap for (n-1) elements.
int flag; for(j = 1; j < n; j++) { flag = 0; for(i = 0; i < (n - j); i++) { if(a[i] >= a[i + 1]) { //Swap a[i], a[i+1] flag = 1; } } if(flag==0)break; } } To improvise this basic algorithm, keep track of whether a particular pass results in any swap or not. If not, you can break out without wasting more cycles.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Bubble sort algorithm void bubble_sort(int a[], int n) { int](https://files.speakerdeck.com/presentations/09daded015140130fcf11231381d5b8c/slide_99.jpg){kind=link}
![void bubble_sort(int a[], int n) { int i, j, temp;](https://files.speakerdeck.com/presentations/09daded015140130fcf11231381d5b8c/slide_100.jpg){kind=link}
![Selection Sort Algorithm void selection_sort(int a[], int n) { int](https://files.speakerdeck.com/presentations/09daded015140130fcf11231381d5b8c/slide_101.jpg){kind=link}
![Quick Sort Algorithm int partition(int a[], int low, int high)](https://files.speakerdeck.com/presentations/09daded015140130fcf11231381d5b8c/slide_102.jpg){kind=link}
![void quicksort(int a[], int low, int high) { int j;](https://files.speakerdeck.com/presentations/09daded015140130fcf11231381d5b8c/slide_103.jpg){kind=link}
![Insertion Sort Algorithm void insertion_sort(int a[], int n) { int](https://files.speakerdeck.com/presentations/09daded015140130fcf11231381d5b8c/slide_104.jpg){kind=link}