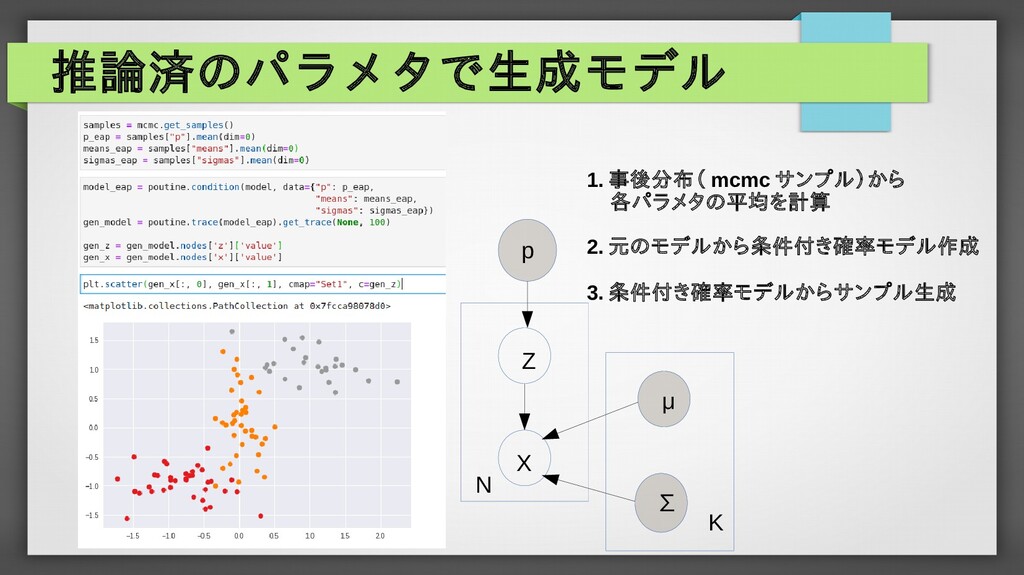
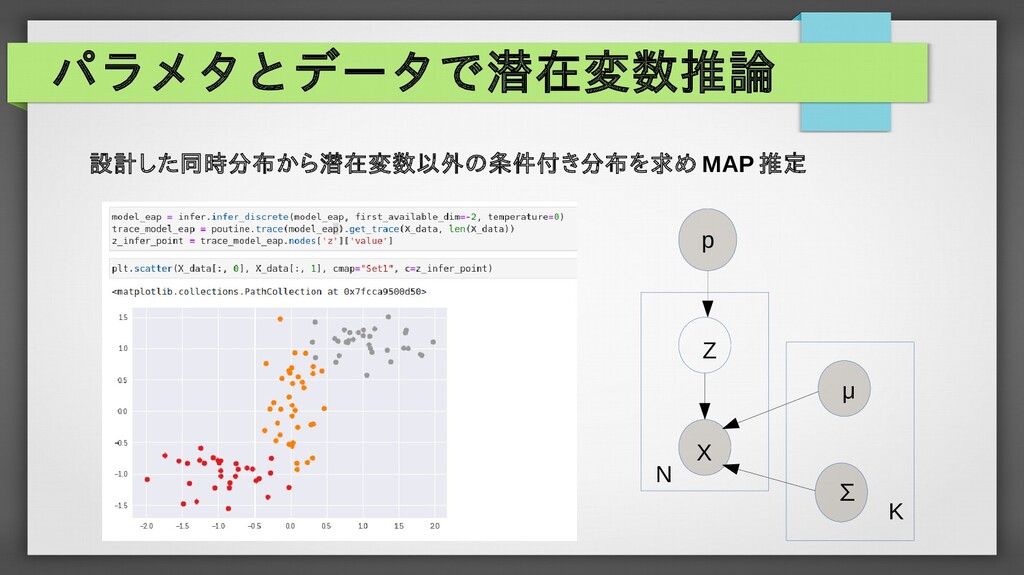
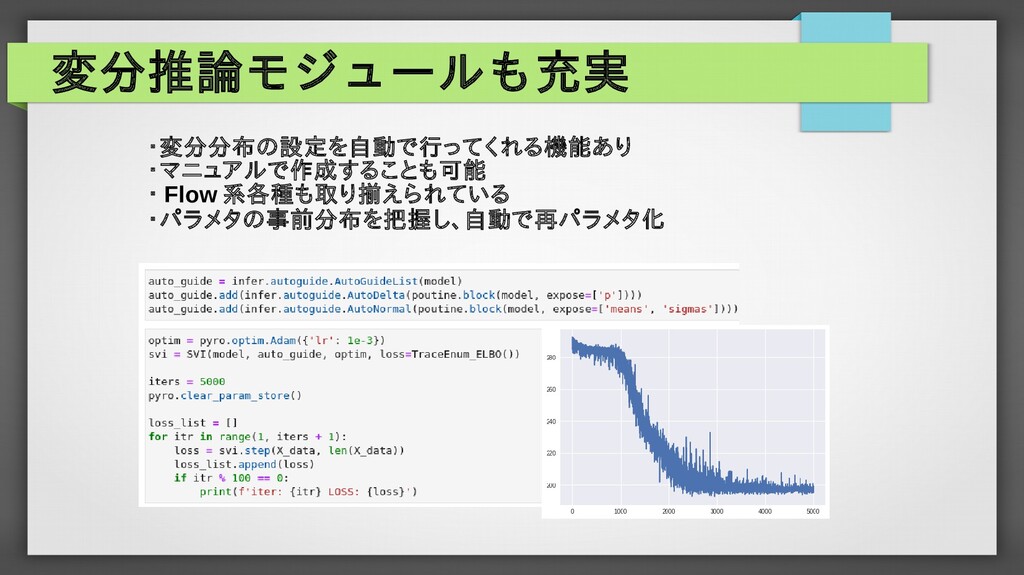
p( X ,Y ,W )=p(X) p(W ) p(Y|X ,W ) p(Y ,W|X)=p(W ) p(Y|X ,W ) p(W )=N (W|μ ,Σ) p(Y ,W|X)= p( X ,Y ,W ) p(X) =p(W ) p(Y|X ,W ) p(Y|X ,W )=N (Y|f (W , X),σ) X Y W μ ∑ σ N p(W|( X ,Y )N )= p(W ,(X ,Y )N ) p(( X ,Y)N ) 1.予測したい変数を取り巻く確率変数の関係性を整理 2.各変数、パラメータに確率分布を設定(具体的な同時分布が形成) 3.観測データによるパラメータの事後分布を計算(紙とペン or MCMC or 変分推論) = ∏ i=1 N p(W , X i ,Y i ) ∫ W ∏ i=1 N p(W , X i ,Y i )dW = p(W )∏ i=1 N p(Y i |X i ,W ) ∫ W p(W )∏ i=1 N p(Y i |X i ,W )dW
p( X ,Y ,W )=p(X) p(W ) p(Y|X ,W ) p(Y ,W|X)=p(W ) p(Y|X ,W ) p(W )=N (W|μ ,Σ) p(Y ,W|X)= p( X ,Y ,W ) p(X) =p(W ) p(Y|X ,W ) p(Y|X ,W )=N (Y|f (W , X),σ) X Y W μ ∑ σ N p(W|( X ,Y )N )= p(W ,(X ,Y )N ) p(( X ,Y)N ) 1.予測したい変数を取り巻く確率変数の関係性を整理 2.各変数、パラメータに確率分布を設定(具体的な同時分布が形成) 3.観測データによるパラメータの事後分布を計算(紙とペン or MCMC or 変分推論) = ∏ i=1 N p(W , X i ,Y i ) ∫ W ∏ i=1 N p(W , X i ,Y i )dW = p(W )∏ i=1 N p(Y i |X i ,W ) ∫ W p(W )∏ i=1 N p(Y i |X i ,W )dW この領域を PPL が対応
p( X ,Y ,W )=p(X) p(W ) p(Y|X ,W ) p(Y ,W|X)=p(W ) p(Y|X ,W ) p(W )=N (W|μ ,Σ) p(Y ,W|X)= p( X ,Y ,W ) p(X) =p(W ) p(Y|X ,W ) p(Y|X ,W )=N (Y|f (W , X),σ) X Y W μ ∑ σ N p(W|( X ,Y )N )= p(W ,(X ,Y )N ) p(( X ,Y)N ) 1.予測したい変数を取り巻く確率変数の関係性を整理 2.各変数、パラメータに確率分布を設定(具体的な同時分布が形成) 3.観測データによるパラメータの事後分布を計算(紙とペン or MCMC or 変分推論) = ∏ i=1 N p(W , X i ,Y i ) ∫ W ∏ i=1 N p(W , X i ,Y i )dW = p(W )∏ i=1 N p(Y i |X i ,W ) ∫ W p(W )∏ i=1 N p(Y i |X i ,W )dW
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
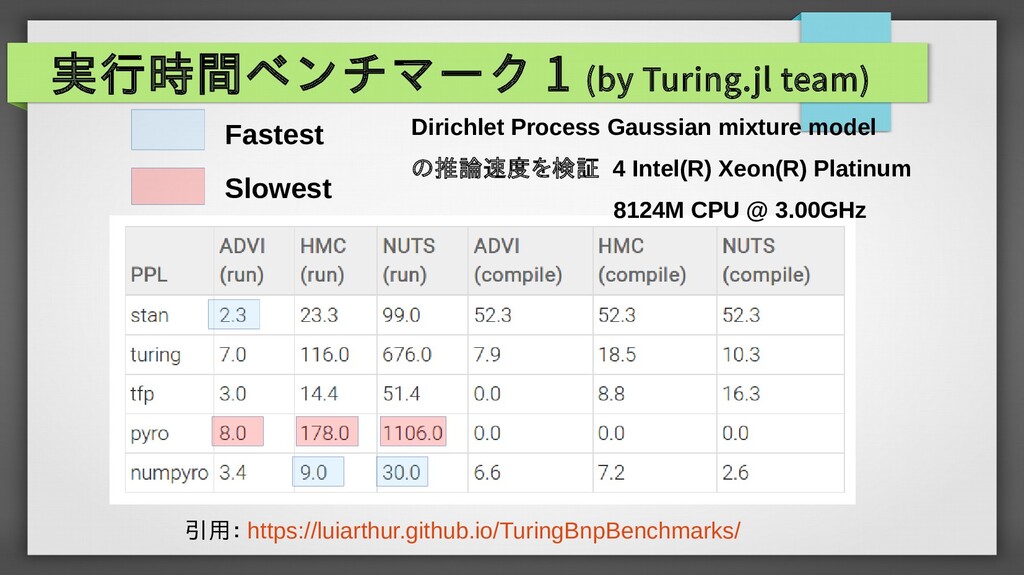{kind=link}
{kind=link}
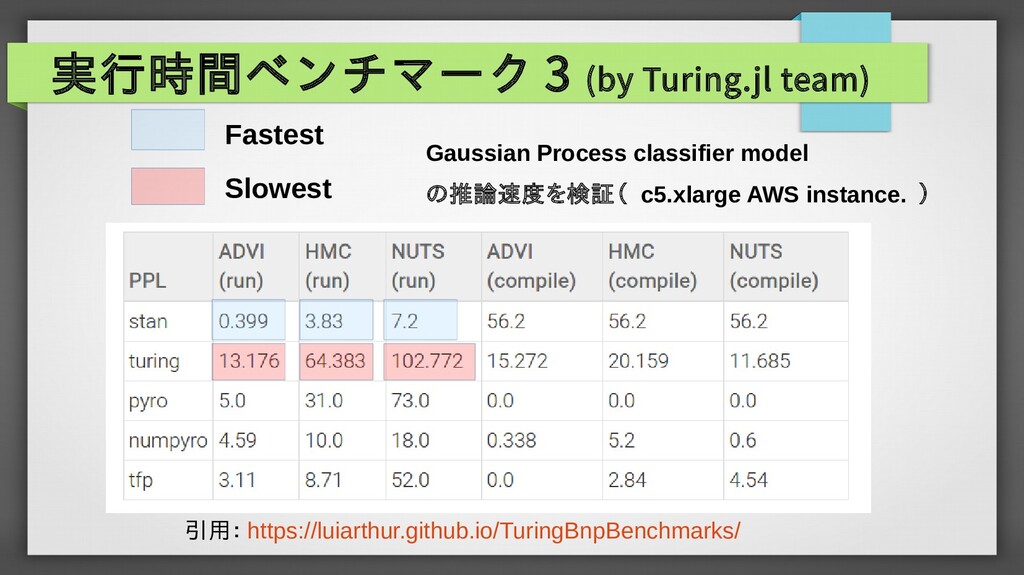{kind=link}
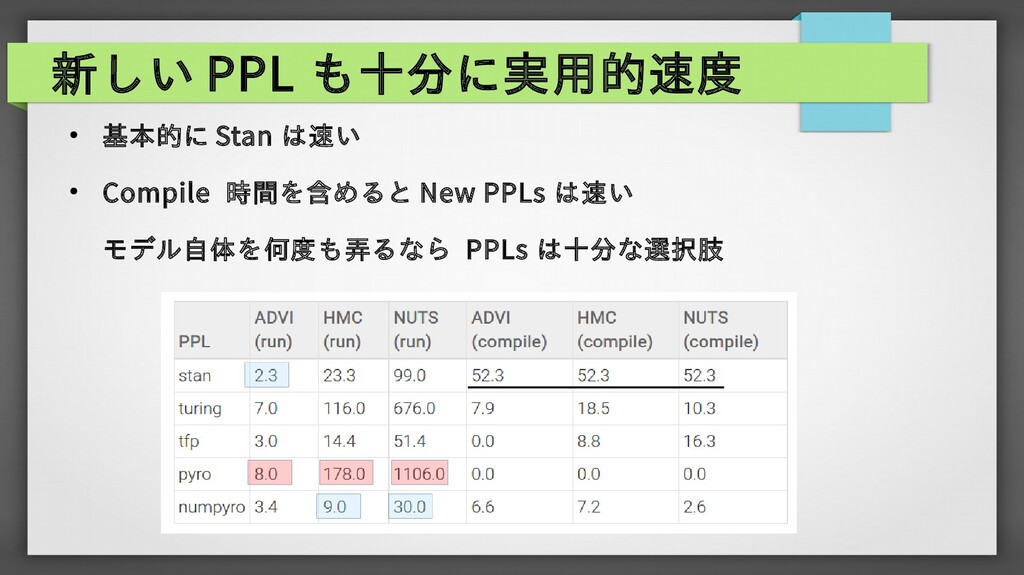{kind=link}
{kind=link}
{kind=link}
{kind=link}
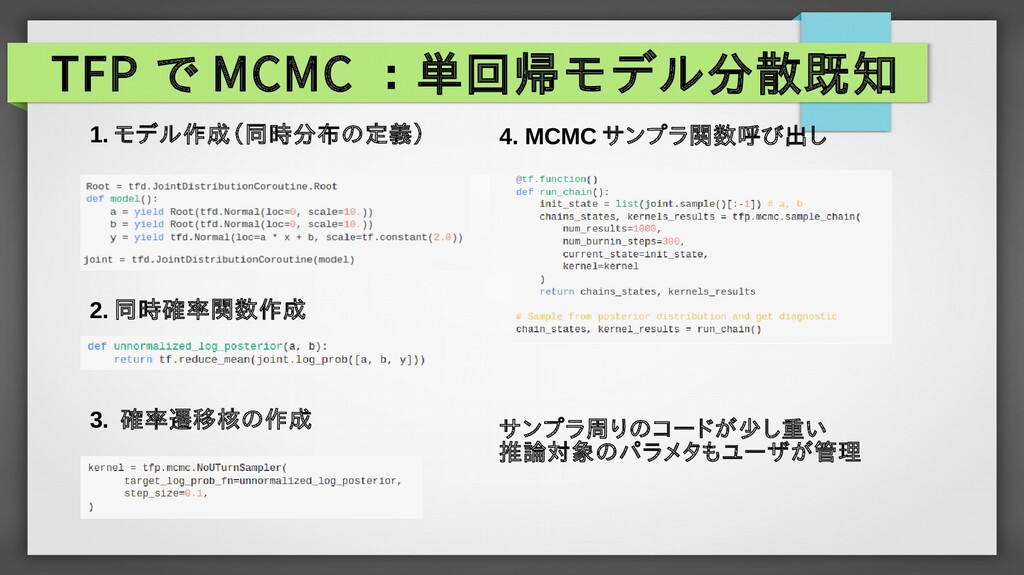{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}