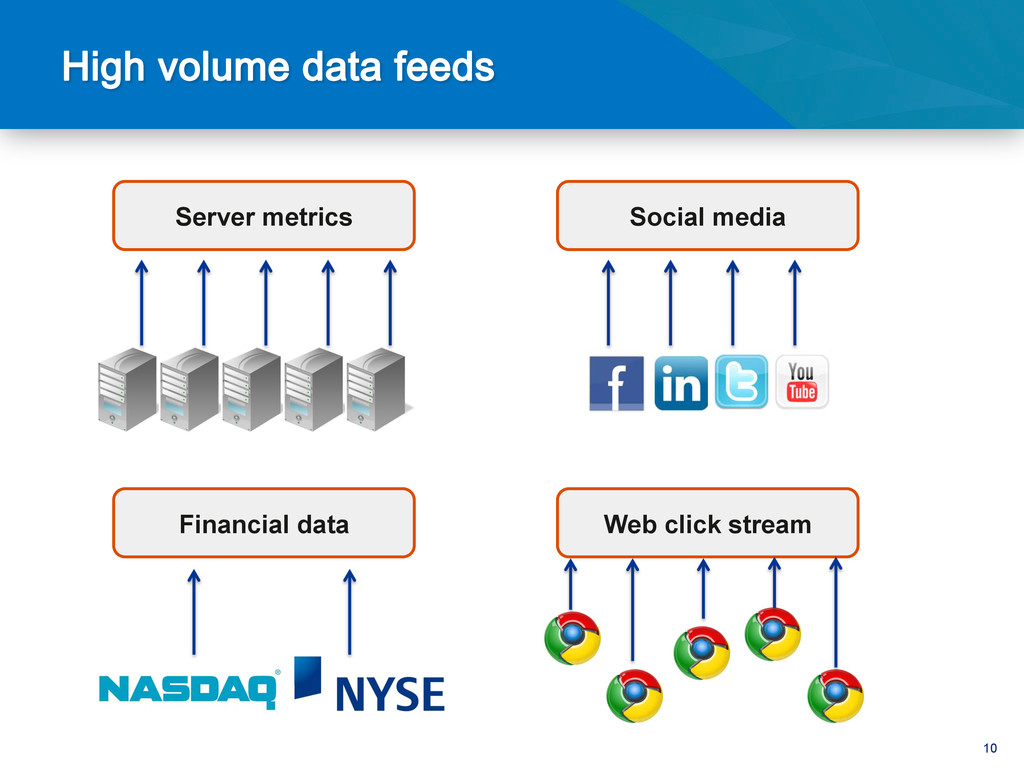
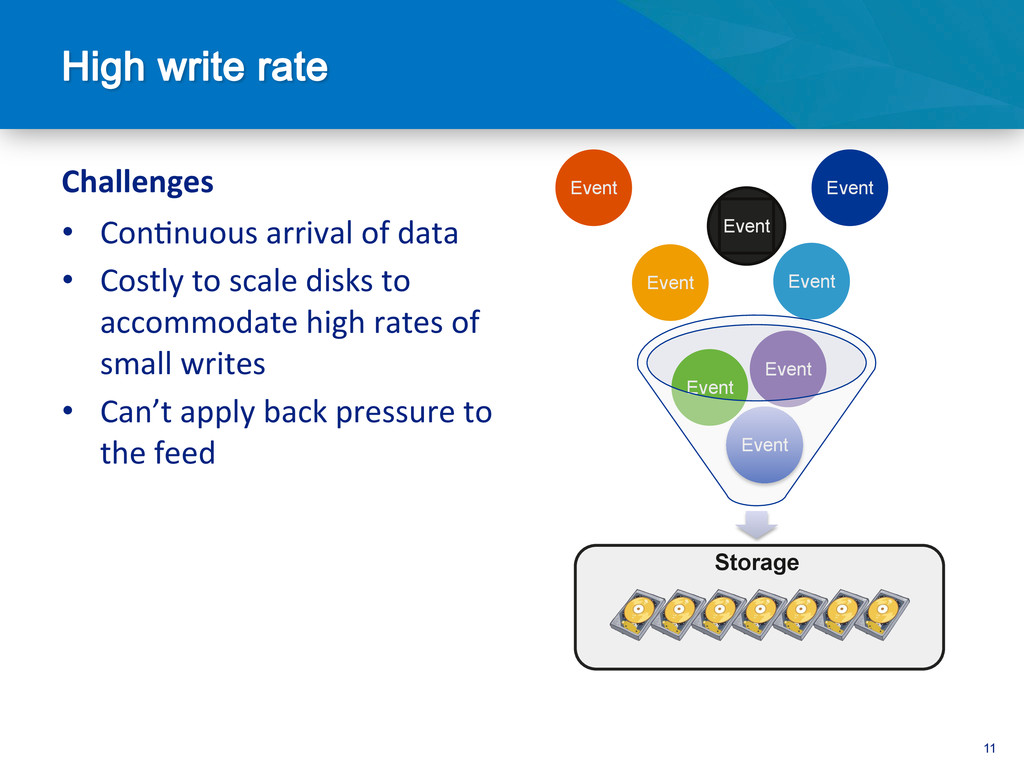
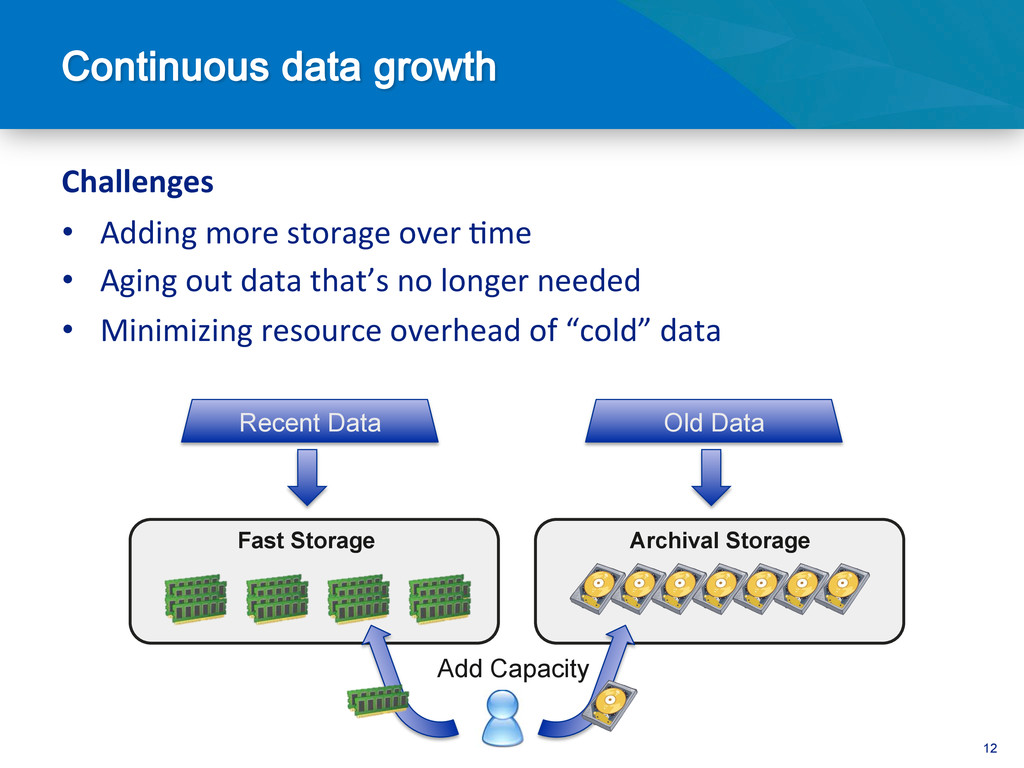
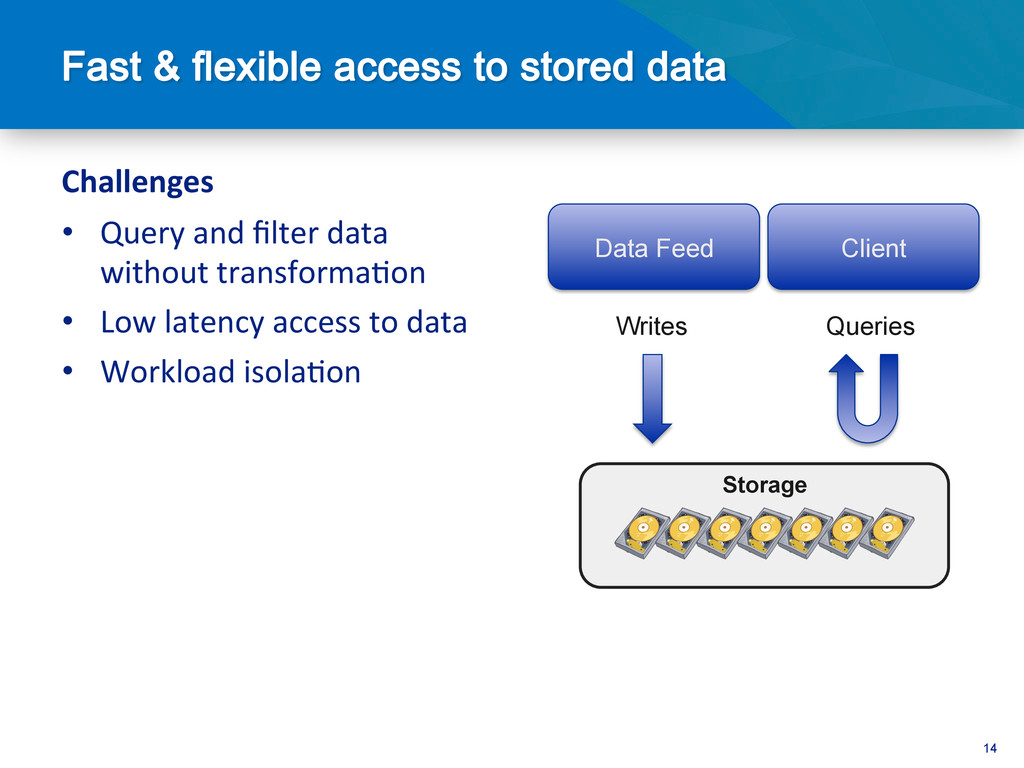
Ingesting large streams of data such as server logs, telemetry data, stock market data, or social media status updates requiers a storage layer that's capable of keeping up with a high volume of writes. In this session, we will cover how MongoDB's scale out architecture and fast write performance make it a perfect fit for storing and processing such large volume data feeds.
Promotion Information
{kind=link}
{kind=link}
{kind=link}
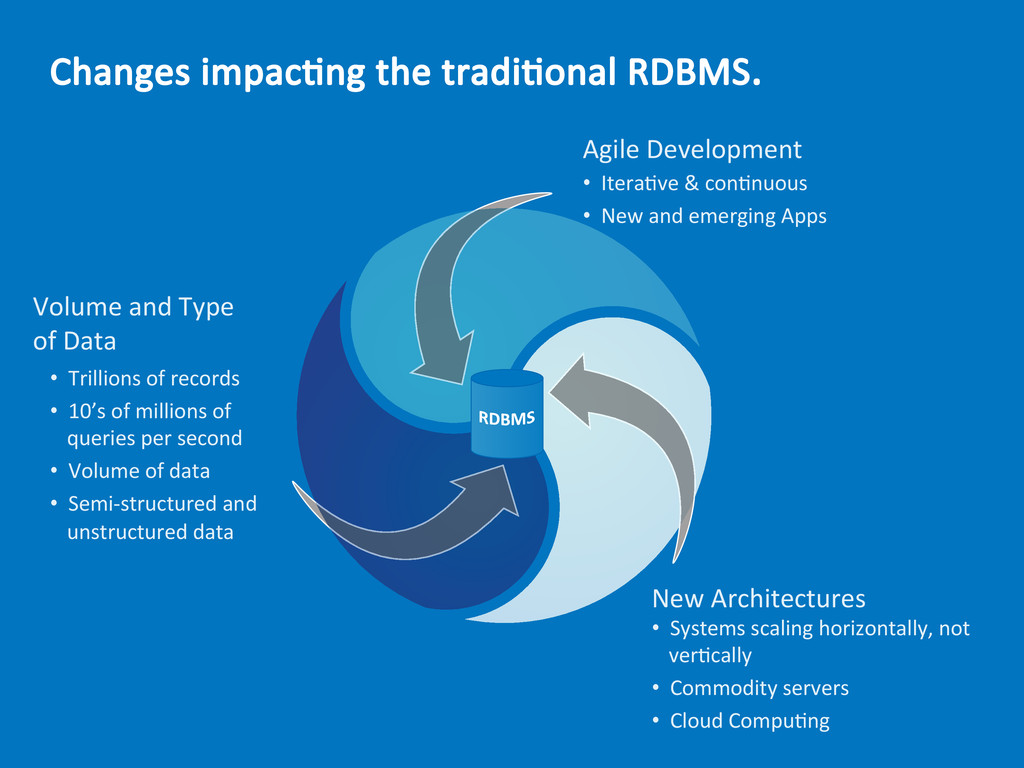{kind=link}
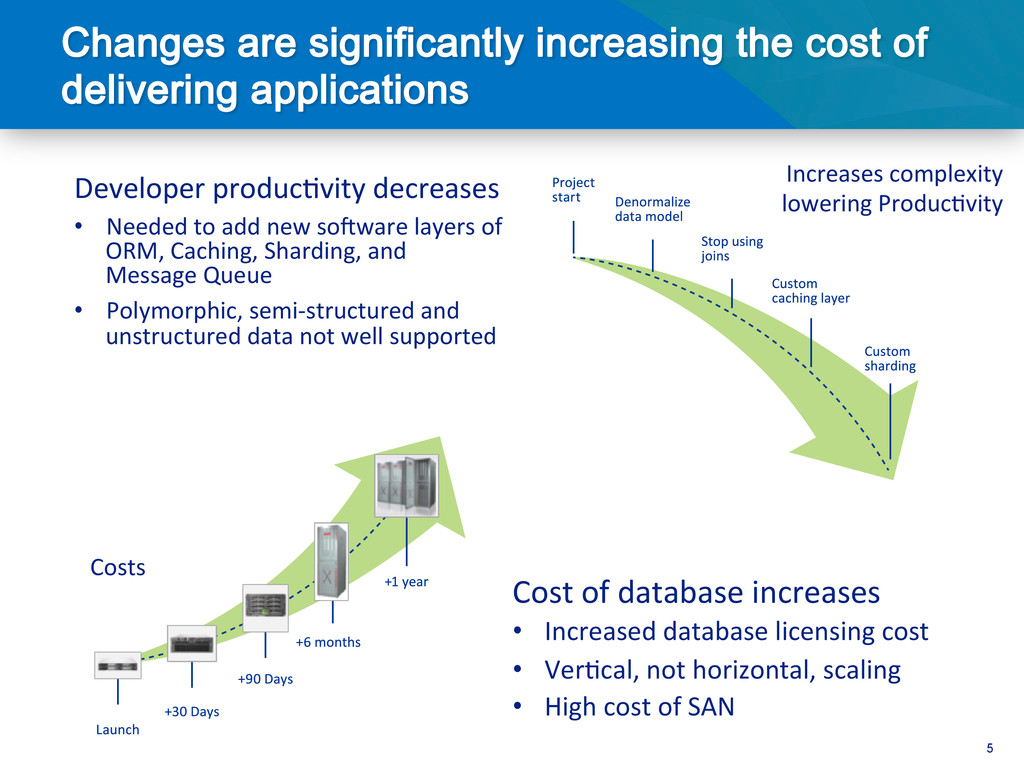{kind=link}
{kind=link}
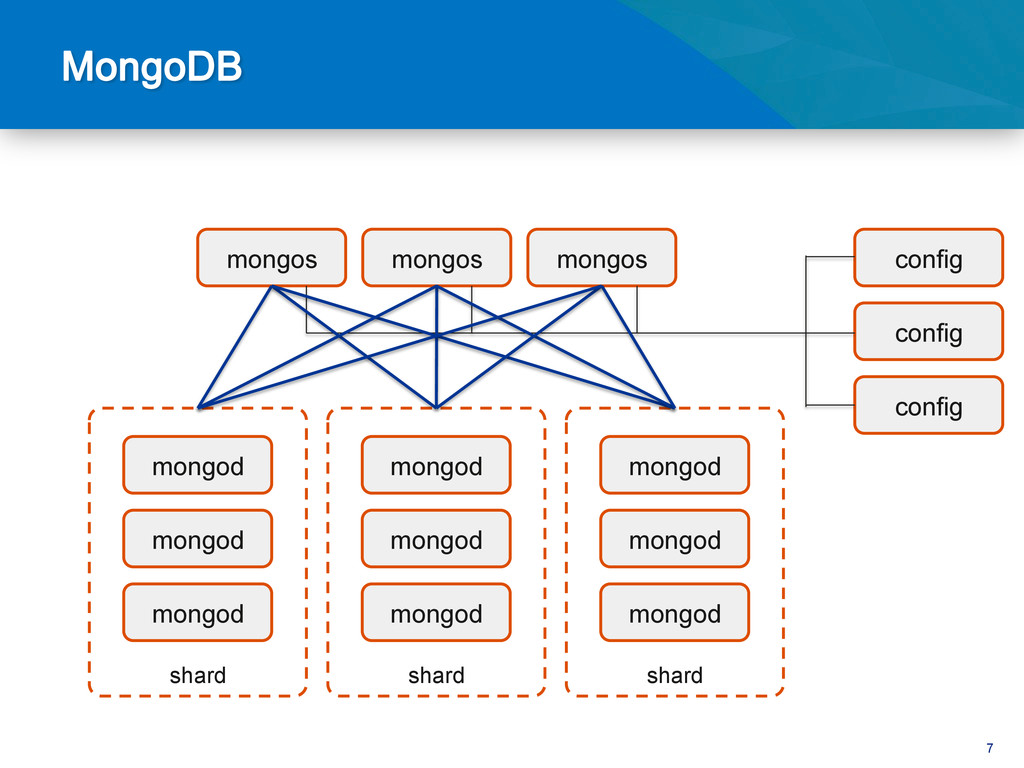{kind=link}
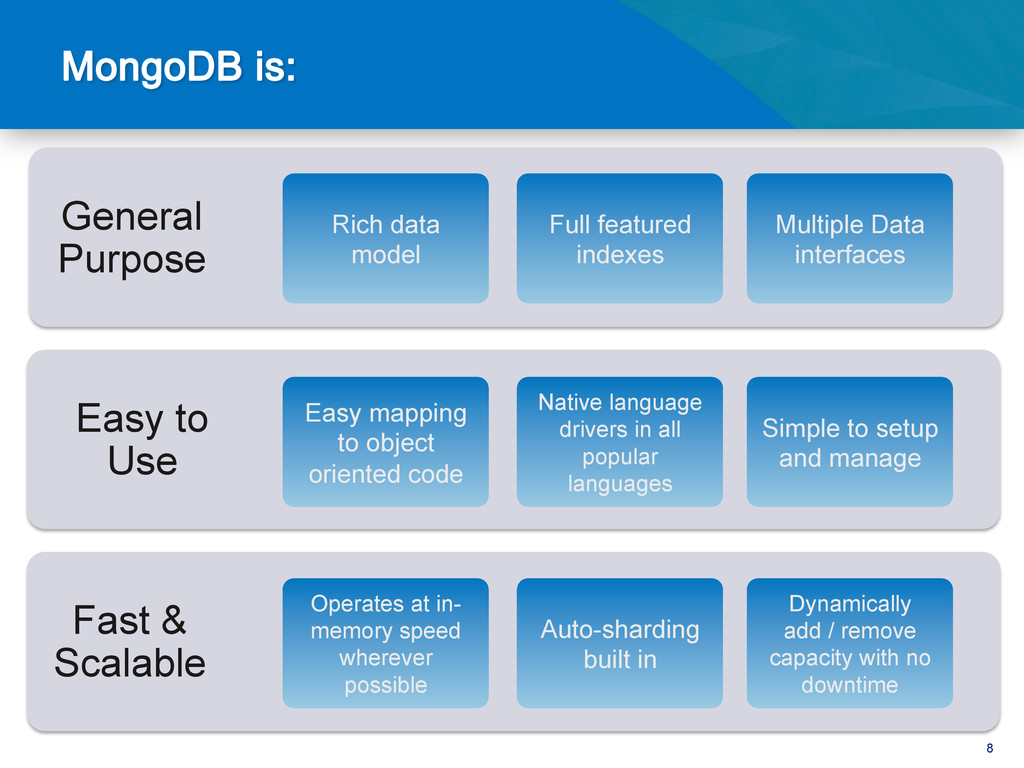{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
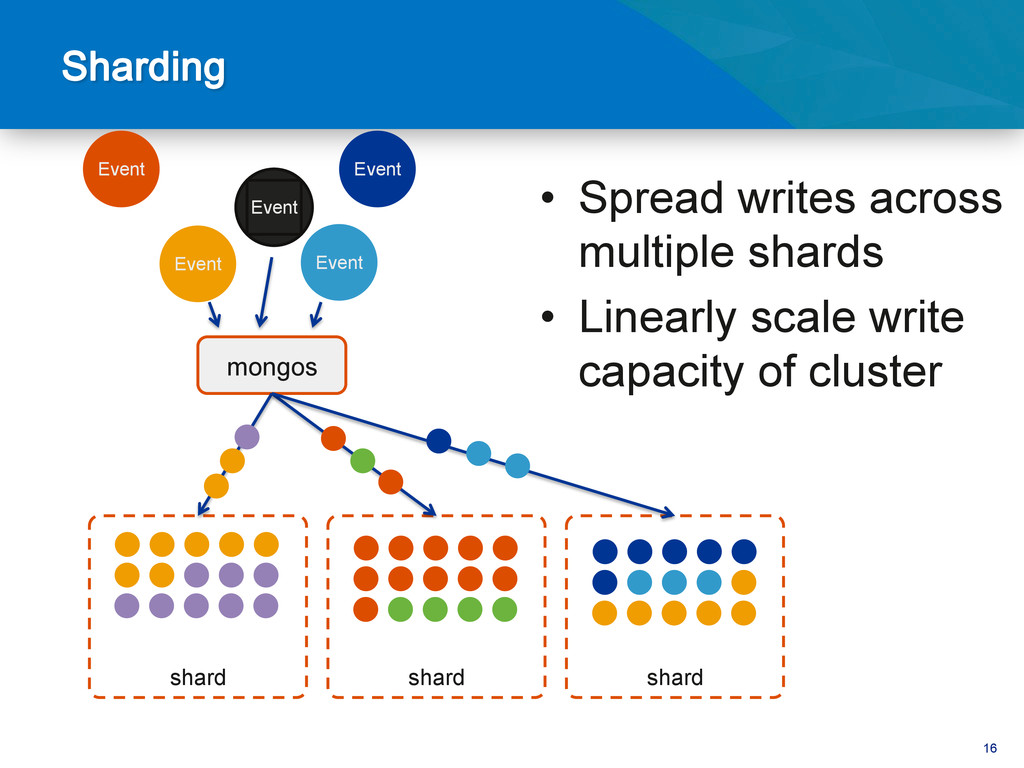{kind=link}
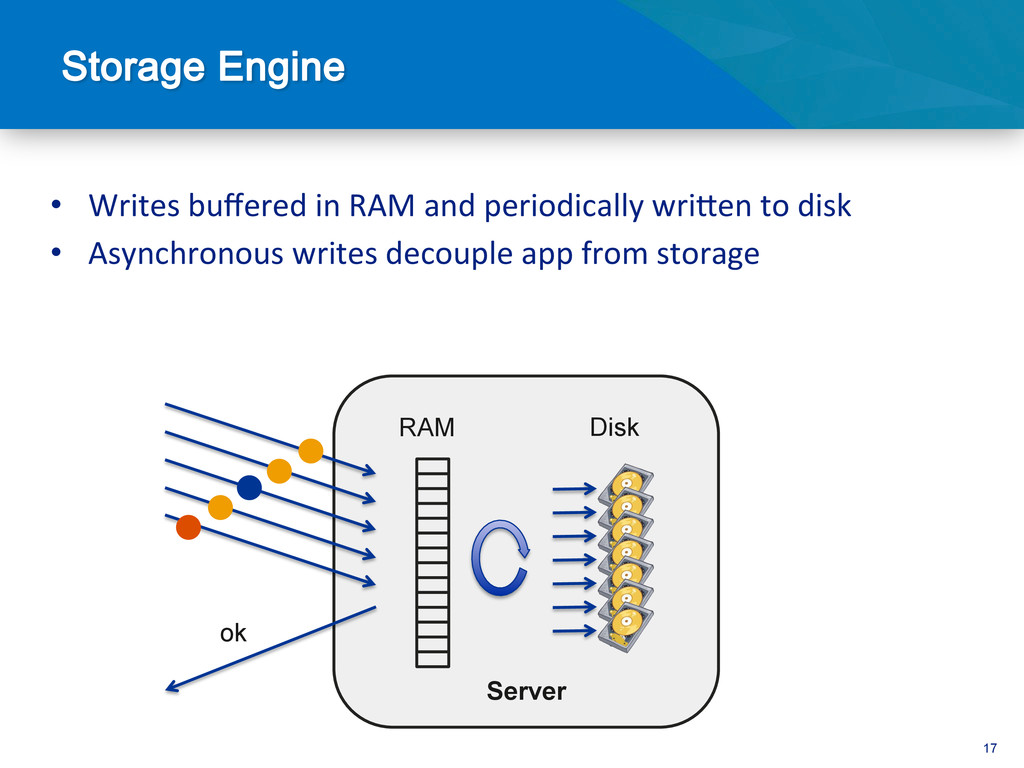{kind=link}
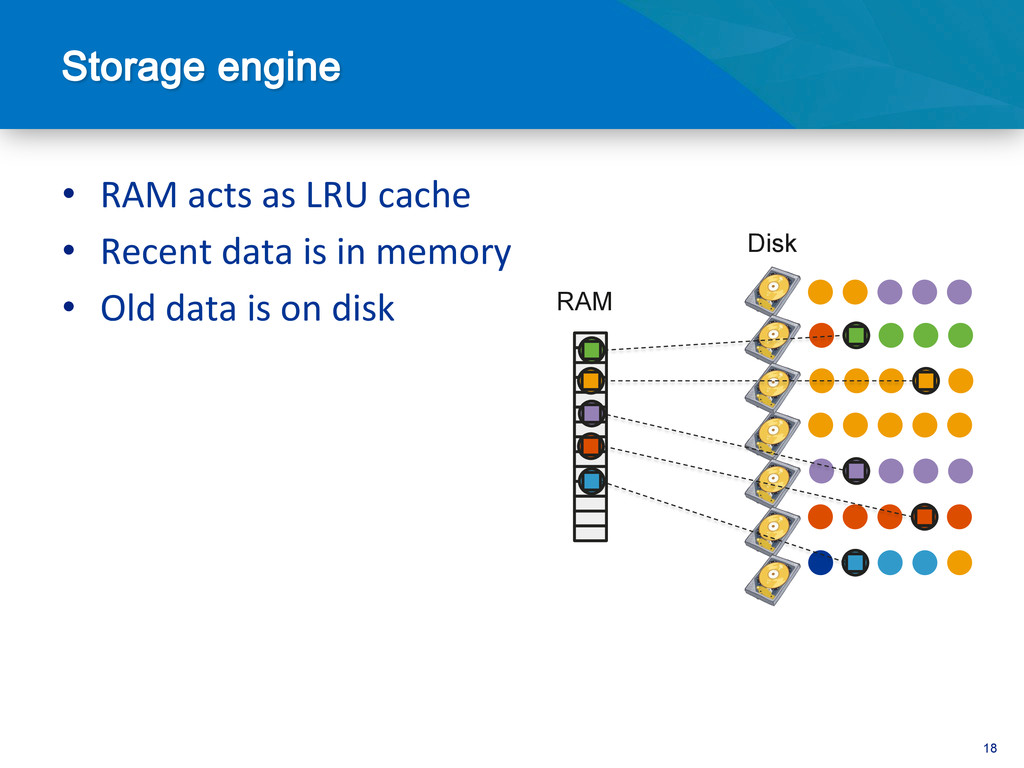{kind=link}
{kind=link}
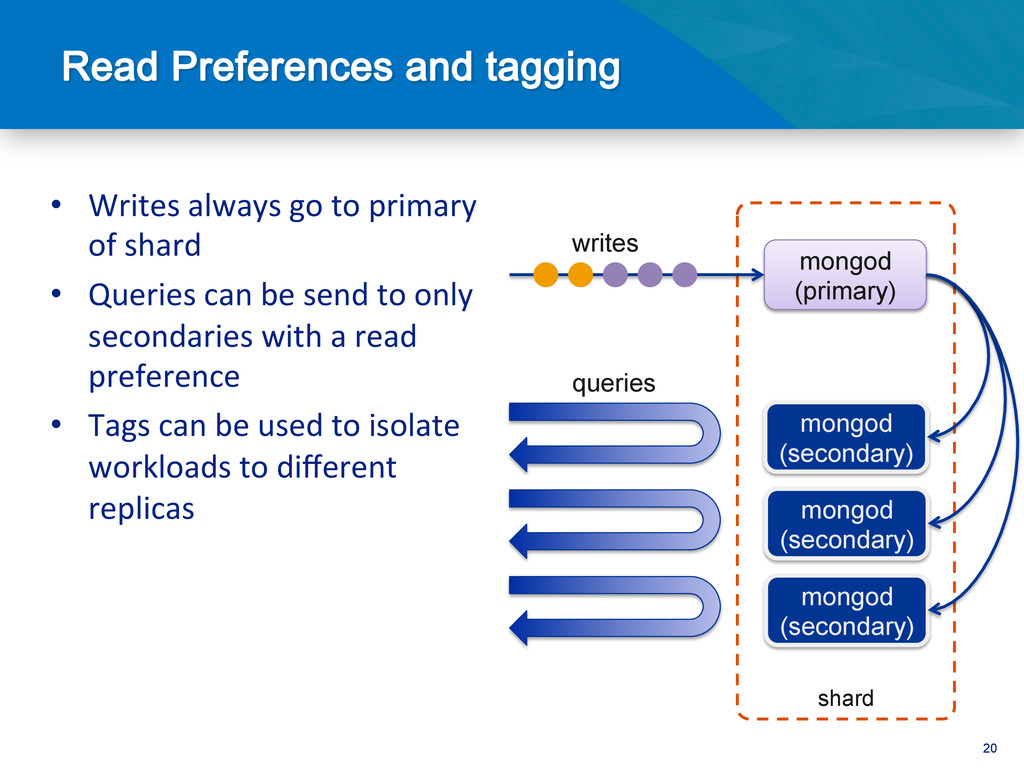{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}