datatech-jp Casual Talks #8で発表した「SQLのASTからモデル類似率を計算してみた」のスライドです。
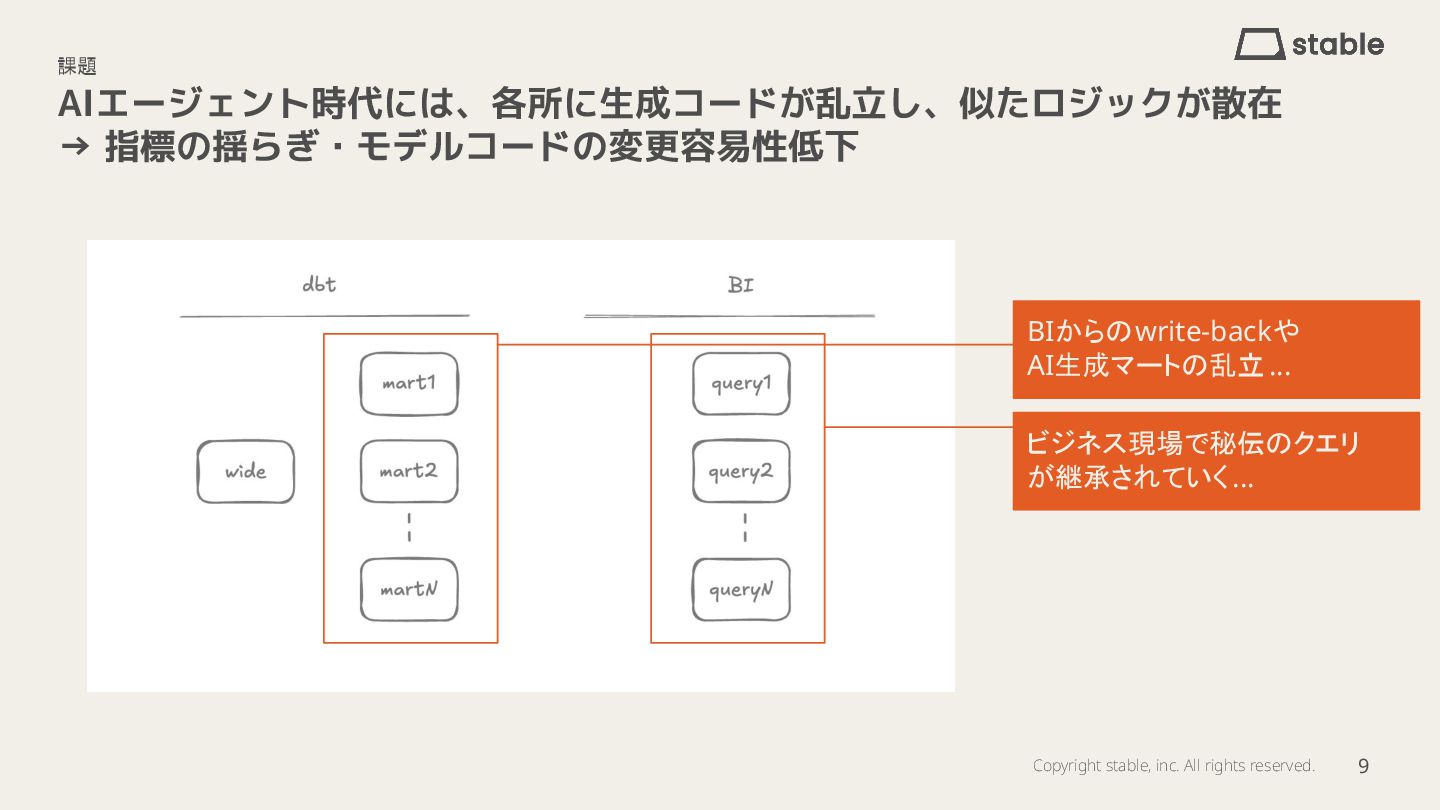
AIエージェント時代では、各所に生成コードが乱立し、似たロジックが散在することで指標の揺らぎやモデルコードの変更容易性低下が課題となります。
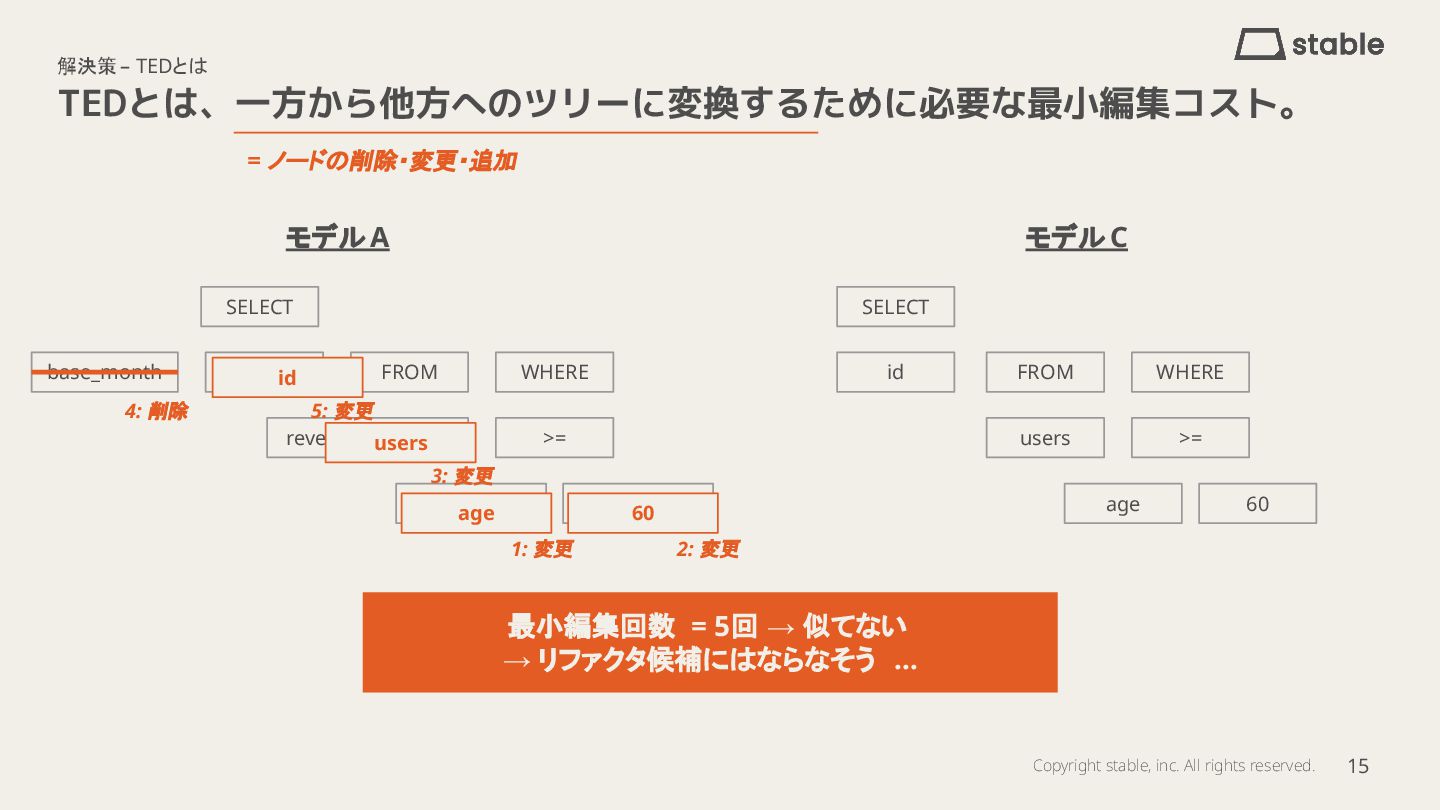
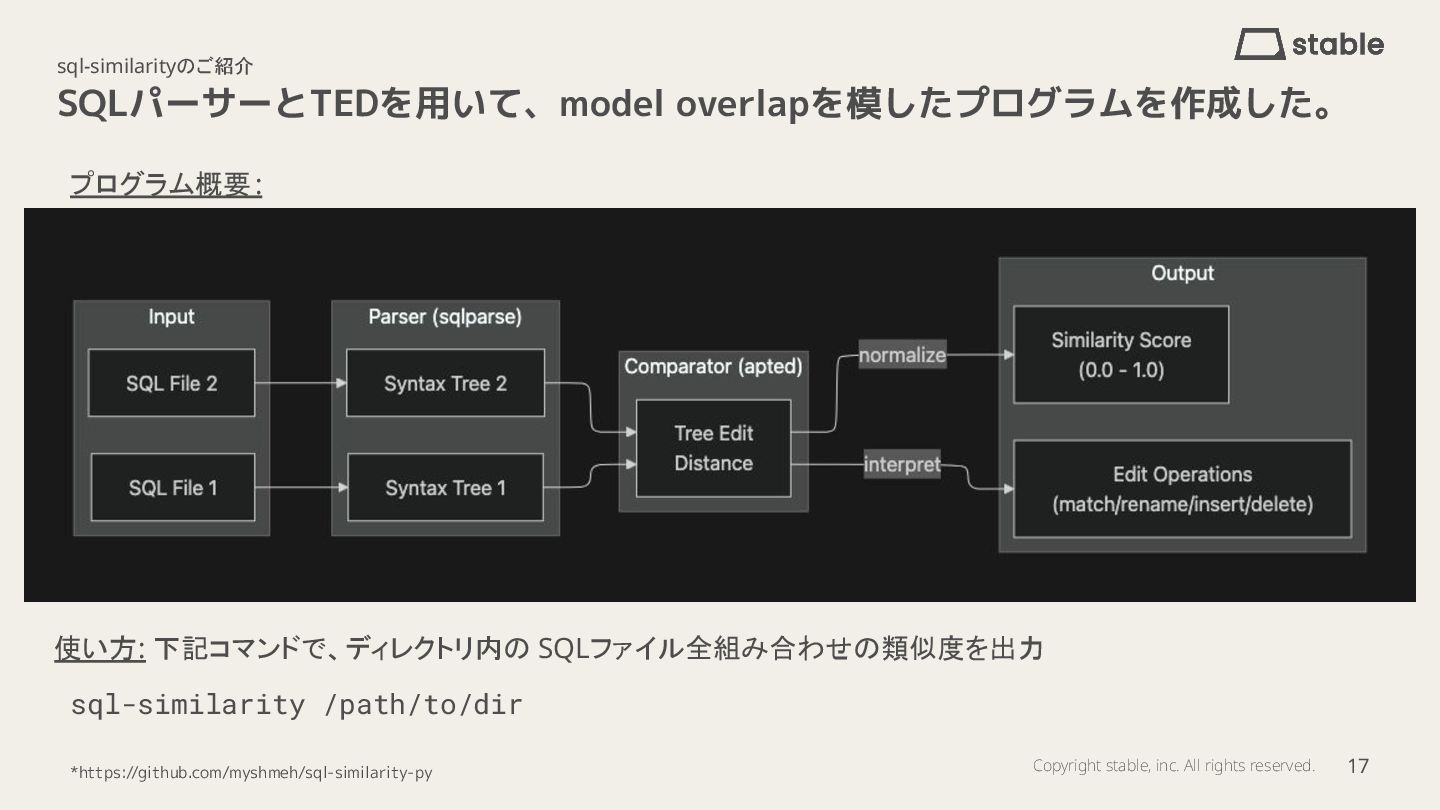
本発表では、dbt Fusionで実装検討中のmodel_overlap機能のアプローチを予想し、SQLのAST(抽象構文木)とTree Edit Distance(TED)を用いてモデル間の類似度を計算する手法を自前実装した所感をお話ししています。
内容
- 課題:AI生成コードの乱立による類似ロジックの散在
- 解決策:TEDによるASTベースの類似度検出
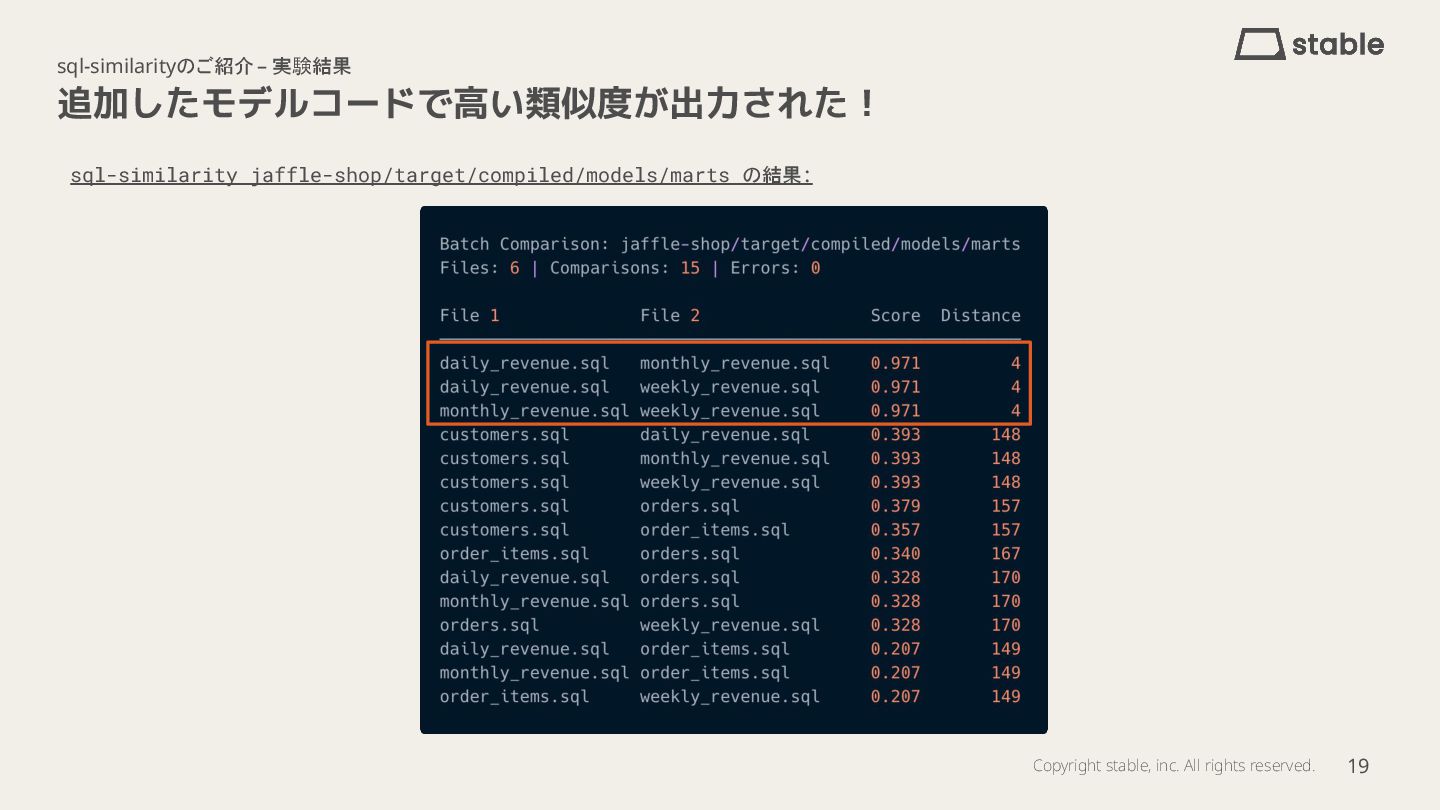
- sql-similarityツールの紹介と実験結果
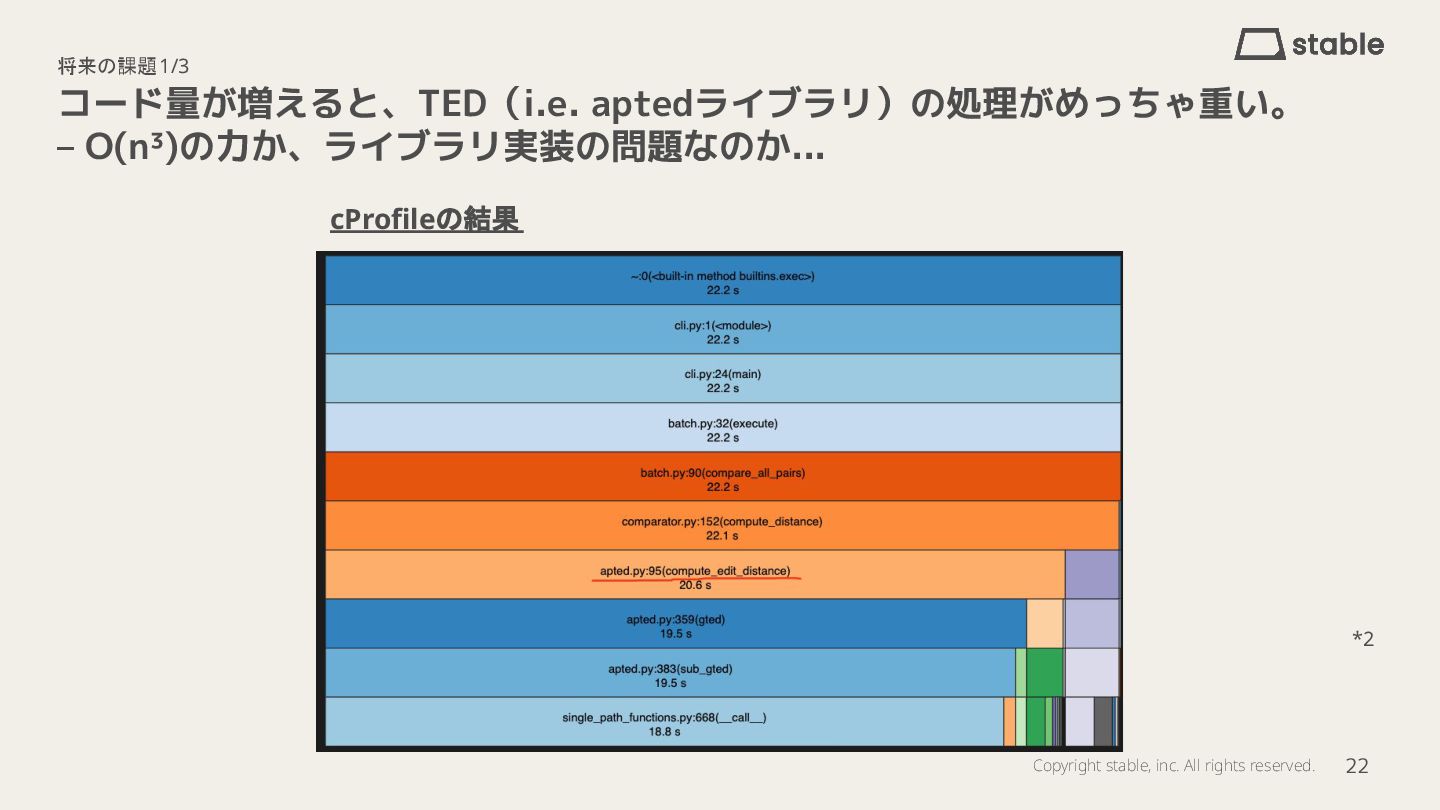
- 将来の課題:パフォーマンス、指標としての妥当性、粒度の検討
関連リンク
- sql-similarity: https://github.com/myshmeh/sql-similarity-py
- Zenn記事もあります
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}