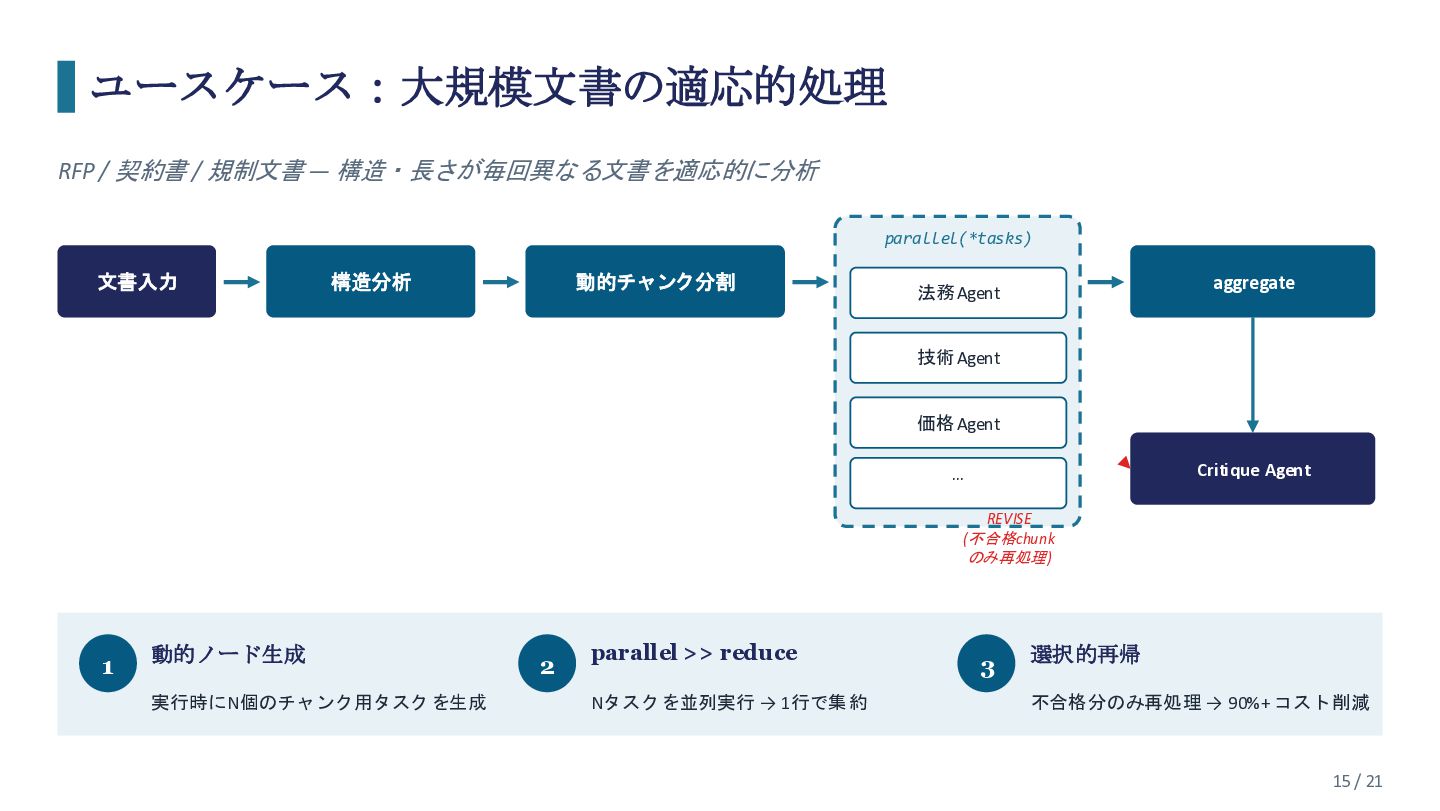
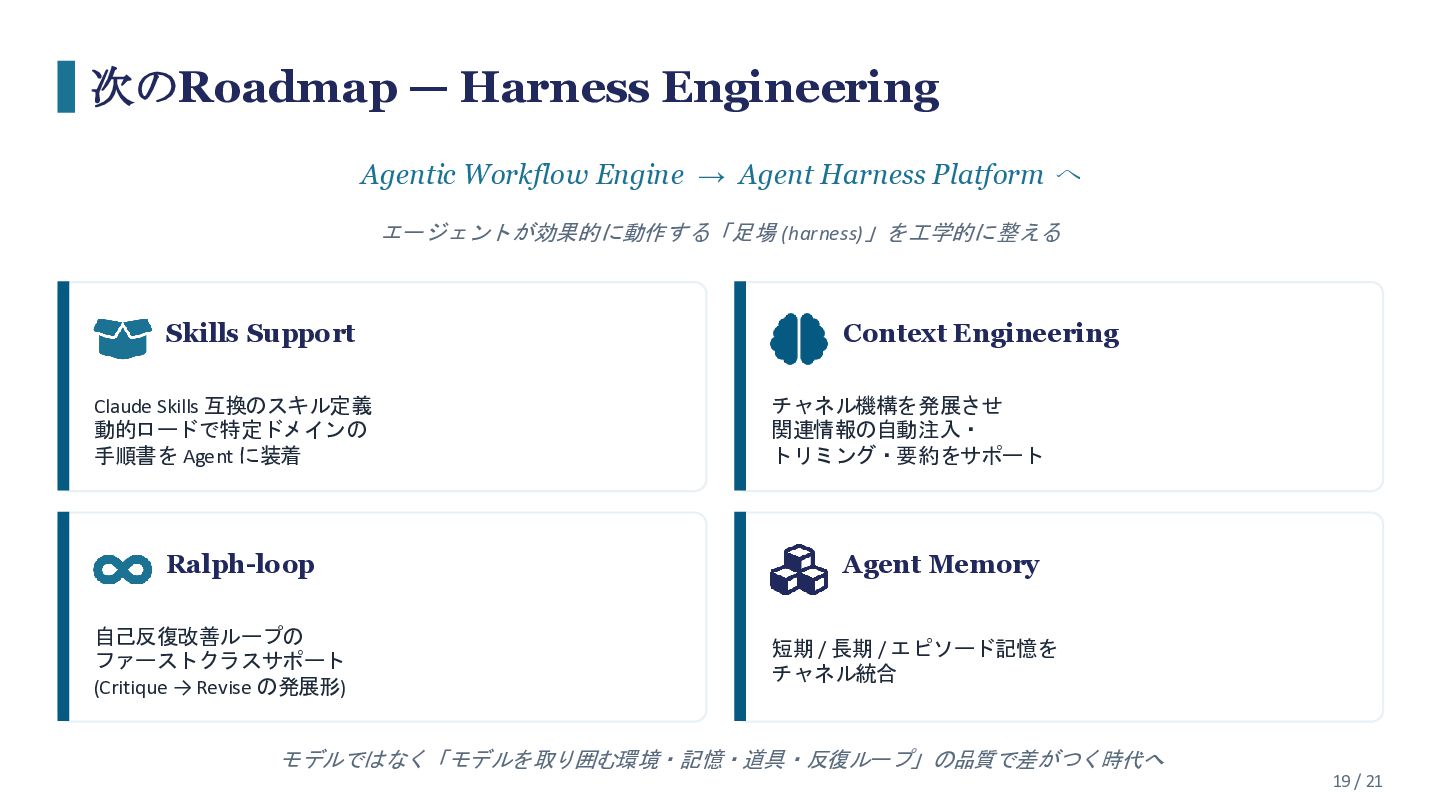
AIエージェントの実用化が進む中、「エージェントにどう仕事をさせるか」だけでなく「複数のエージェントをどう協調させるか」が新たな課題となっています。 本セッションでは、エージェント協調のための次世代ワークフローエンジン「Graflow」の設計思想と、実際のAIエージェント構築事例についてお話しします。 Graflowは、Pythonの演算子(>> で逐次、| で並列)という直感的なDSLでワークフローを定義し、動的タスク生成・Human-in-the-Loop・分散スケーリング・OpenTelemetryによるFull Observabilityを備えたOSSワークフローエンジンです。 「Developer Experience」と「本番運用の堅牢性」の両立を目指し、未踏アドバンスト事業の支援を受けて開発しました。 既存のワークフローエンジン(Airflow等)やAIフレームワーク(LangGraph等)との違い、Graflow上でのマルチエージェント構築の具体例についてお話しします。
プロジェクトサイト: https://github.com/GraflowAI/graflow
{kind=link}
{kind=link}
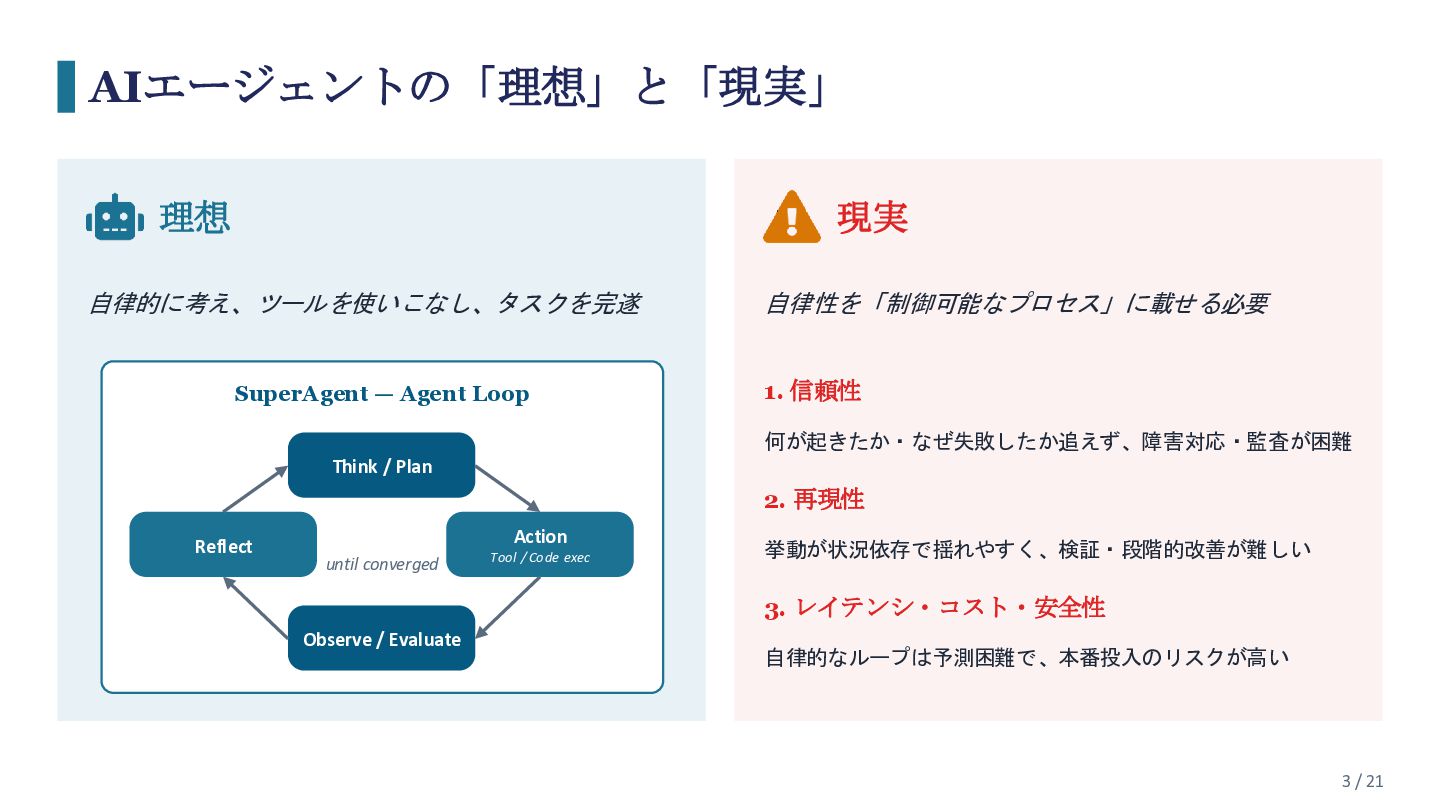{kind=link}
{kind=link}
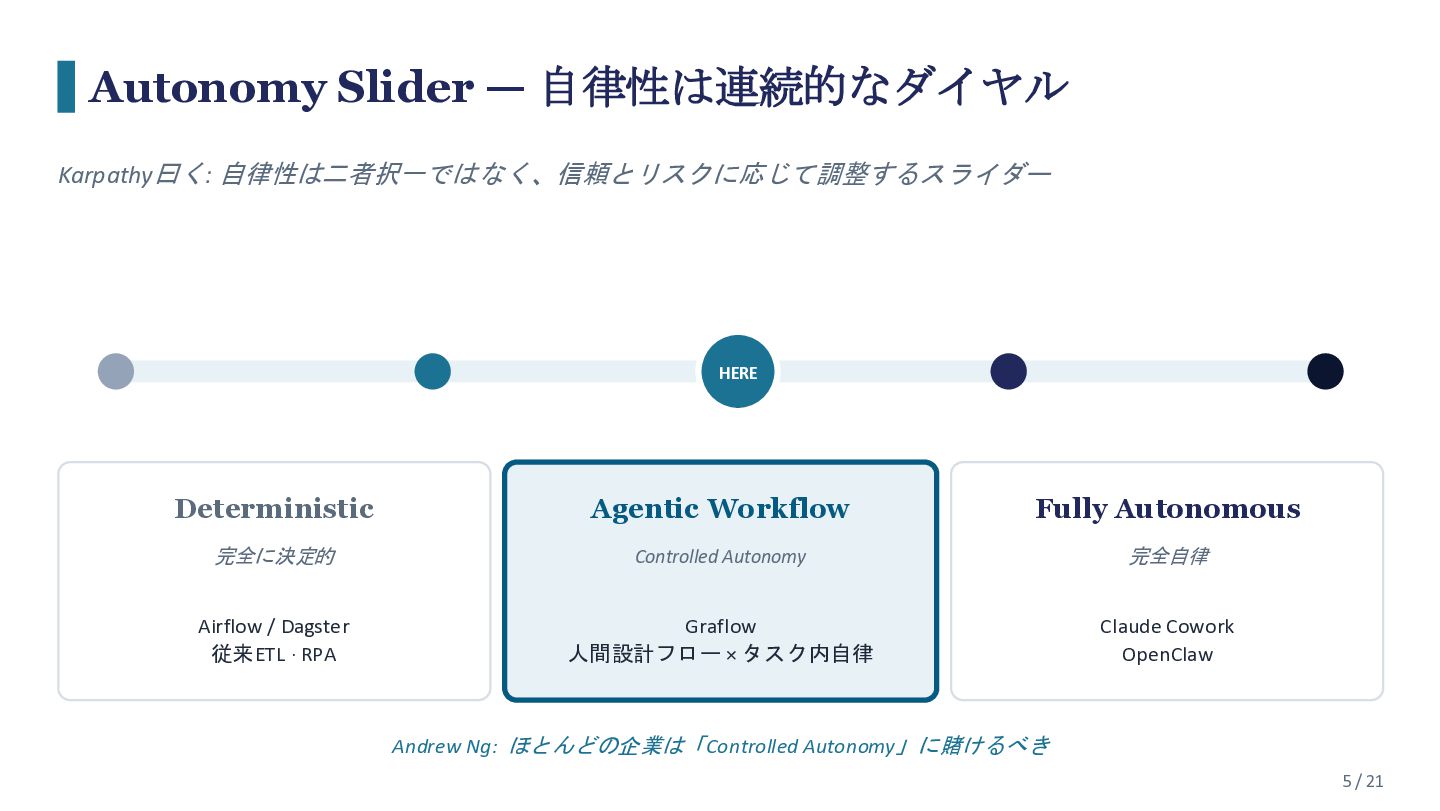{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
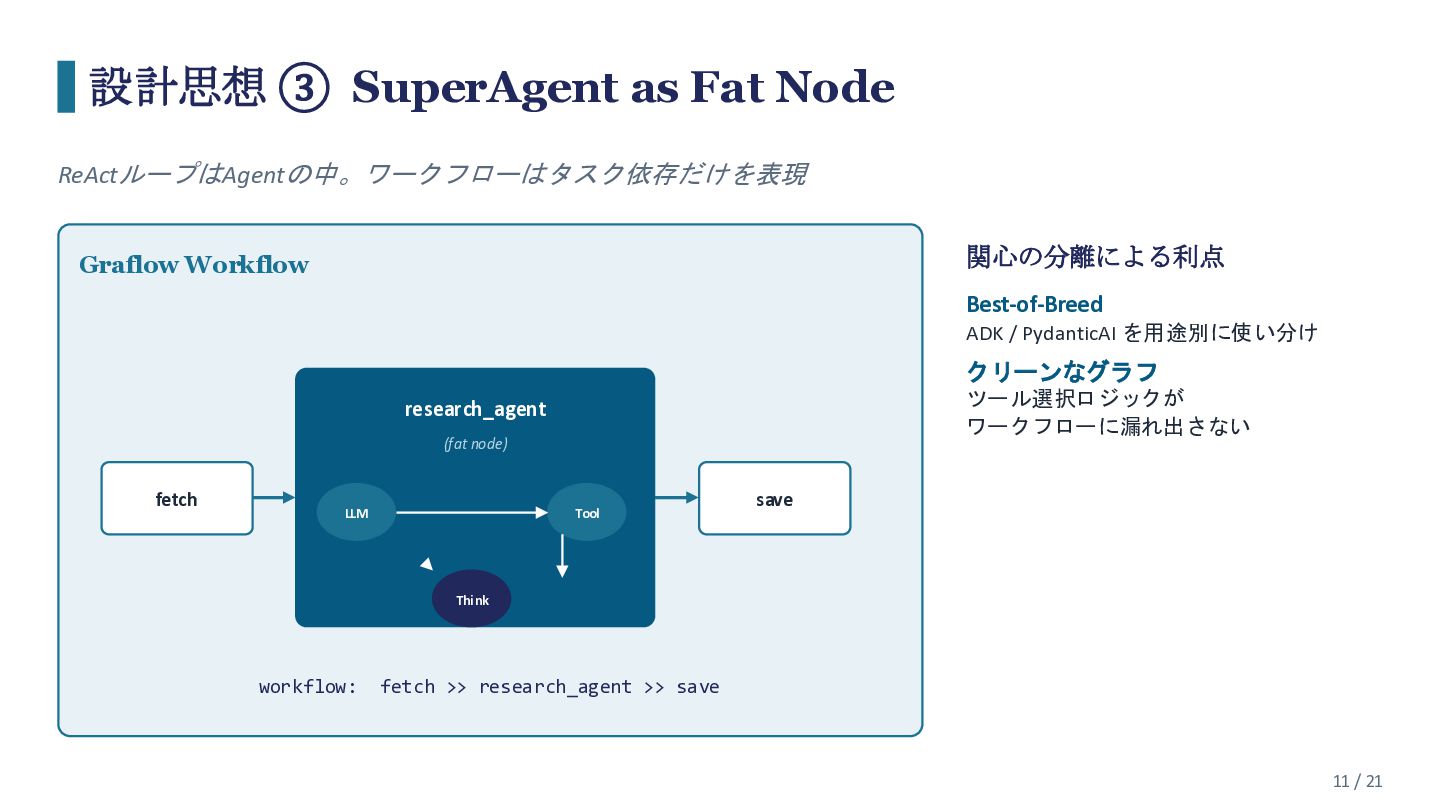{kind=link}
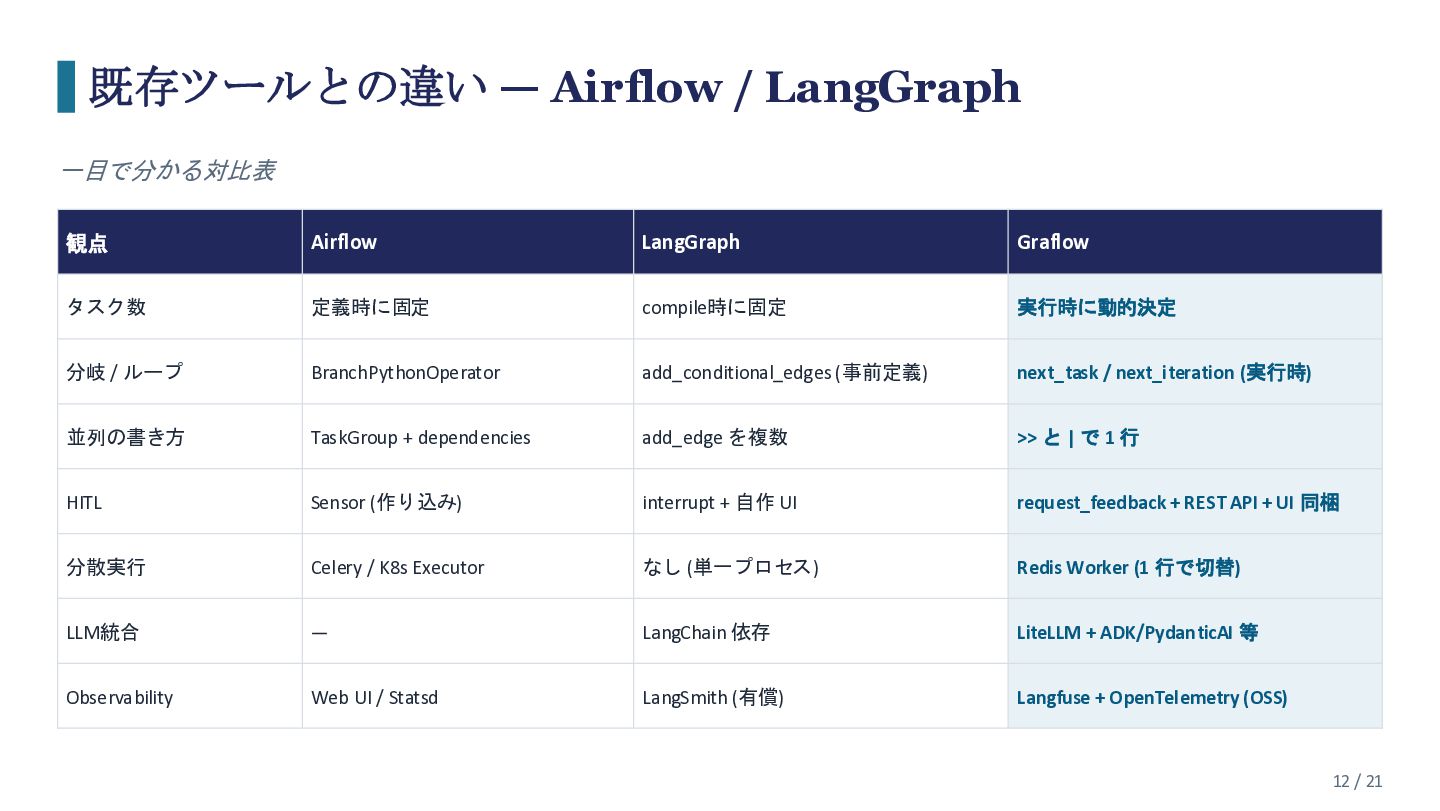{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}