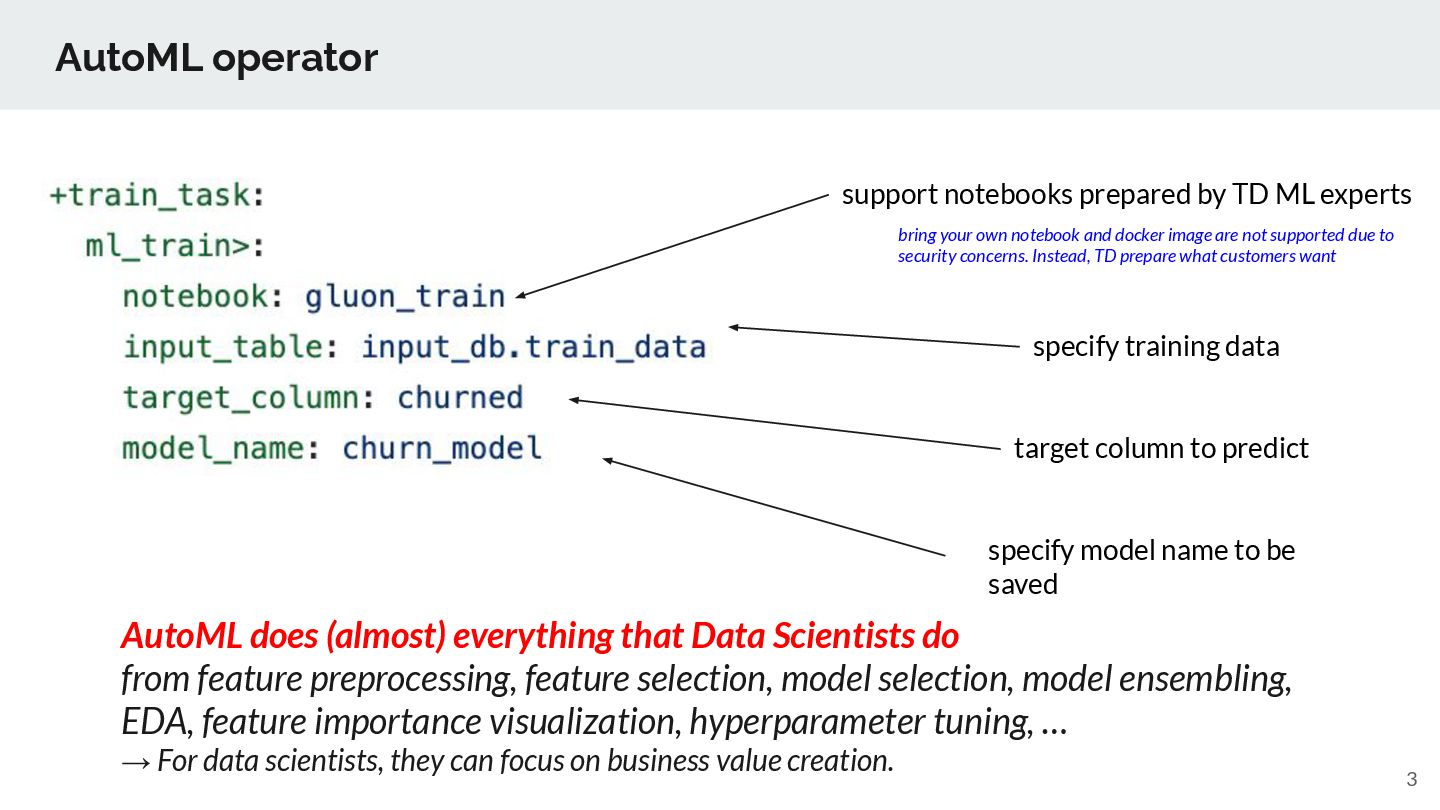
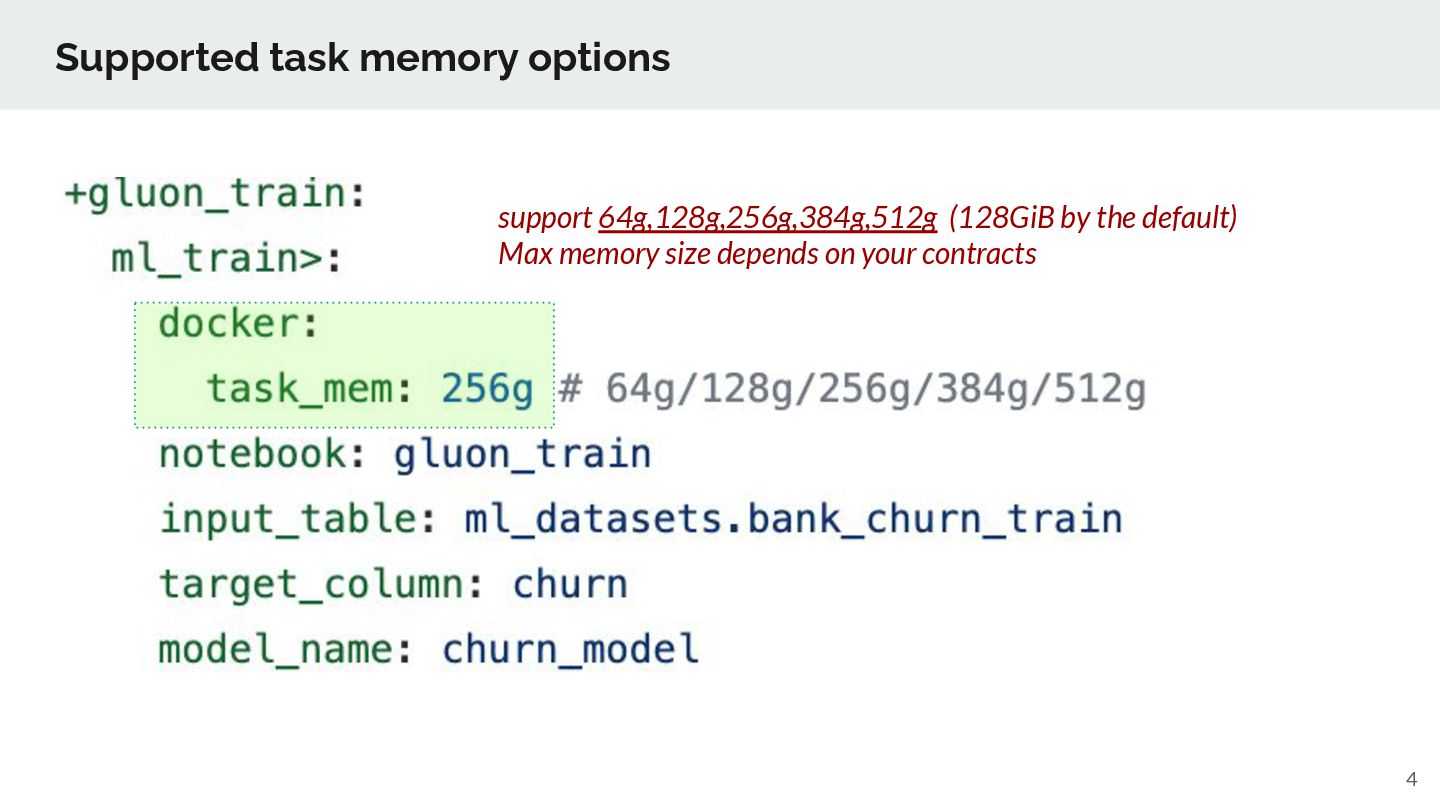
specify training data specify model name to be saved target column to predict AutoML does (almost) everything that Data Scientists do from feature preprocessing, feature selection, model selection, model ensembling, EDA, feature importance visualization, hyperparameter tuning, … → For data scientists, they can focus on business value creation. bring your own notebook and docker image are not supported due to security concerns. Instead, TD prepare what customers want
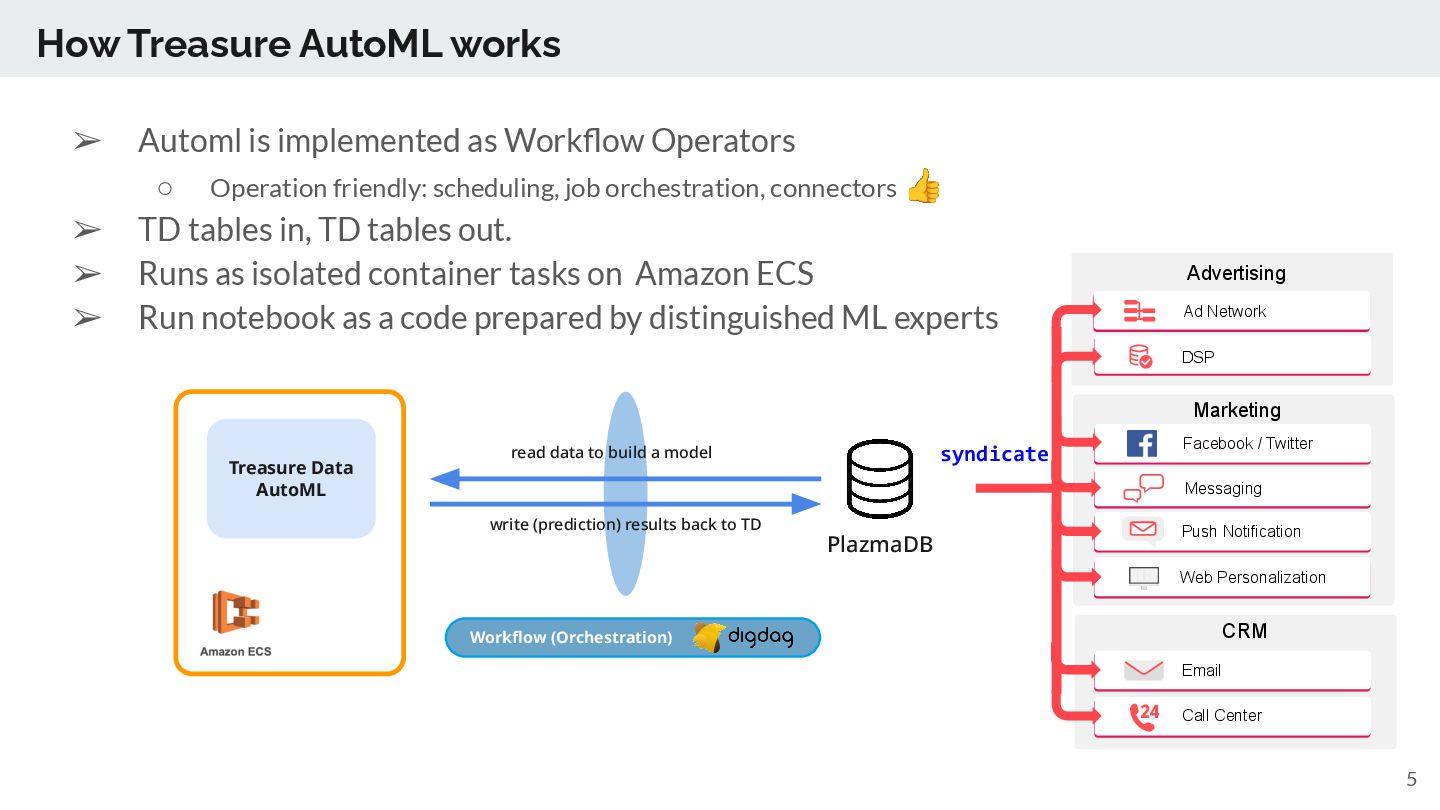
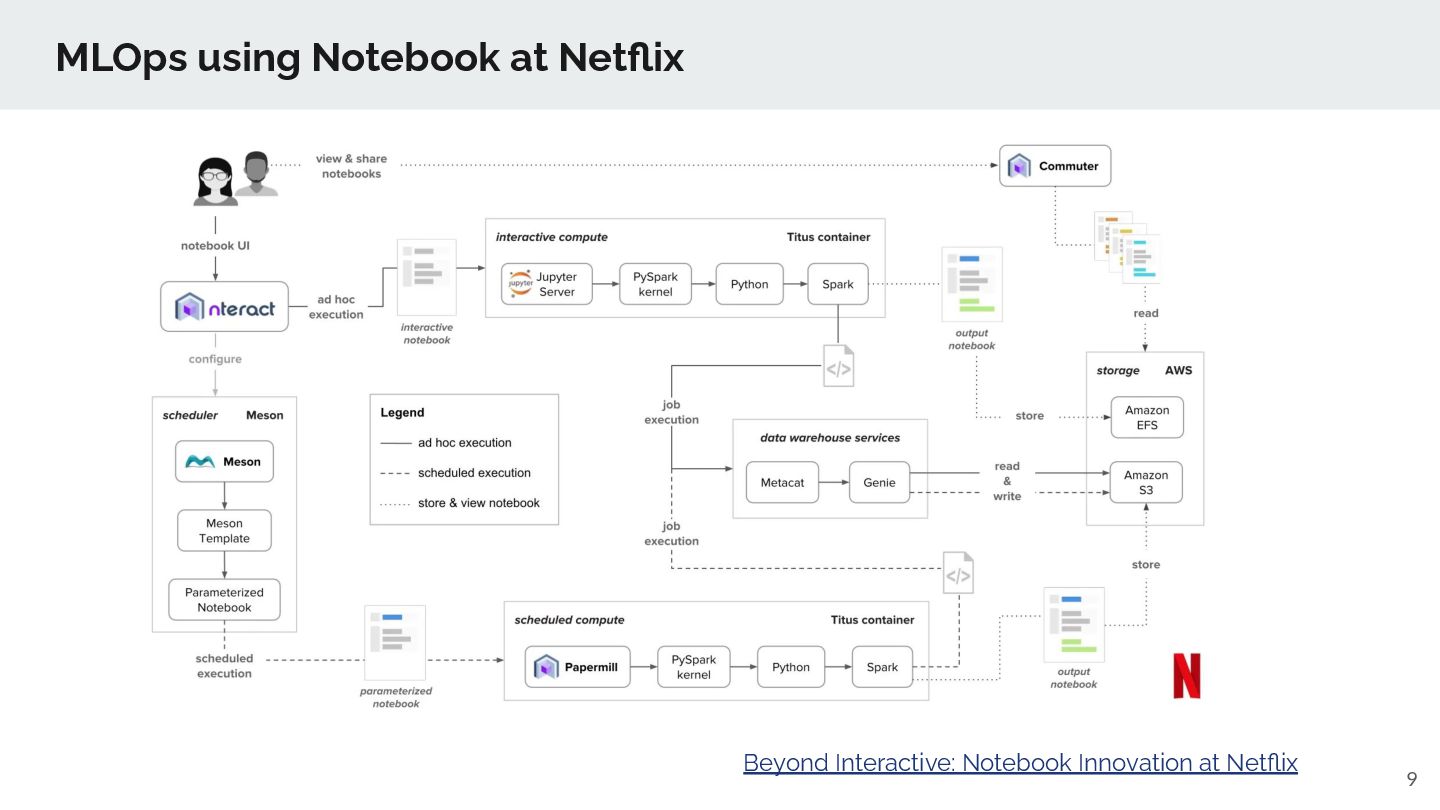
data to build a model Workflow (Orchestration) write (prediction) results back to TD Advertising Marketing CRM Ad Network DSP Email Messaging Push Notification Facebook / Twitter Call Center Web Personalization syndicate ➢ Automl is implemented as Workflow Operators ◦ Operation friendly: scheduling, job orchestration, connectors 👍 ➢ TD tables in, TD tables out. ➢ Runs as isolated container tasks on Amazon ECS ➢ Run notebook as a code prepared by distinguished ML experts
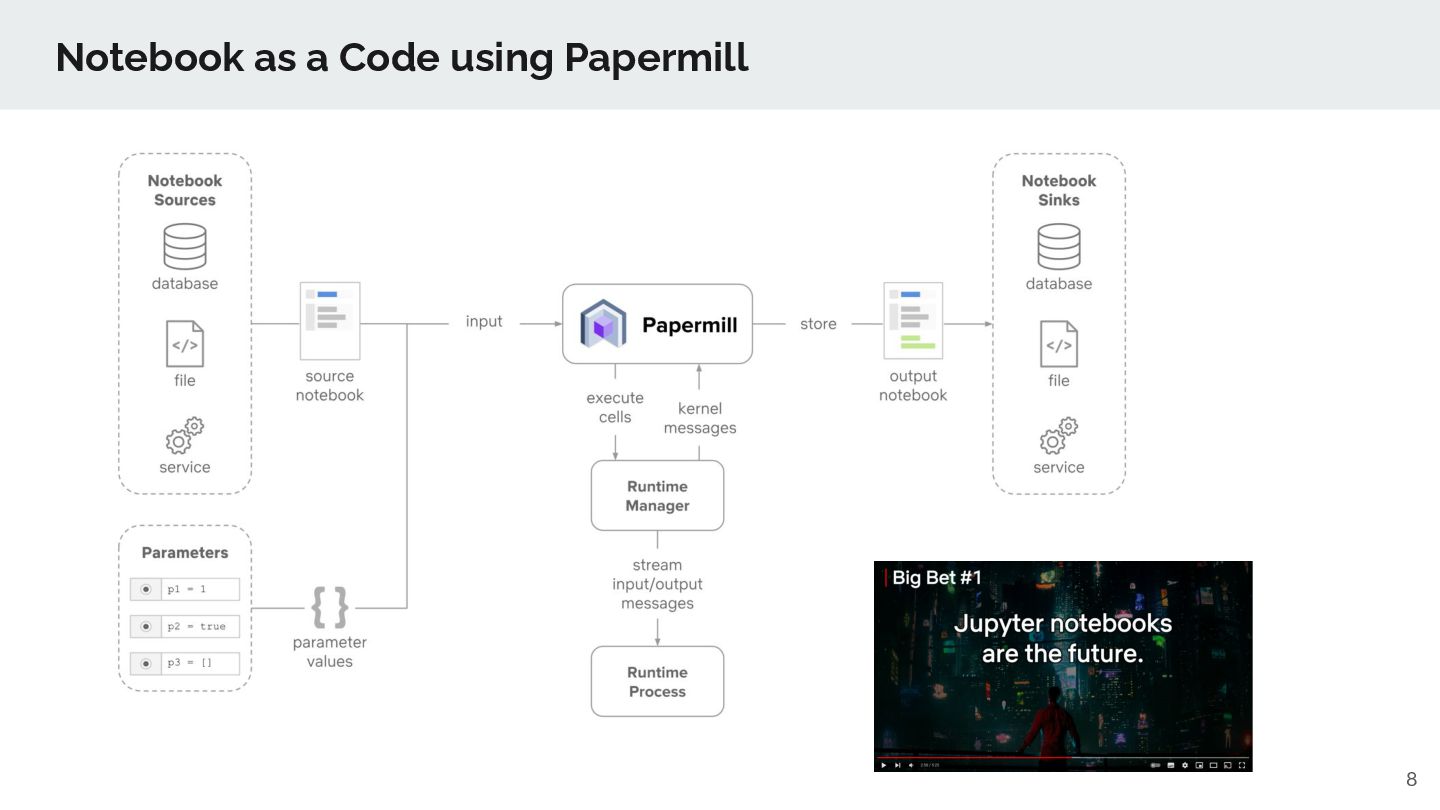
output, explanatory text, and rich visualization in a single document. In notebooks, code is written in blocks called "cells" (starting with In[n]), and codes are executed sequentially in each cell. Future reading: Beyond Interactive: Notebook Innovation at Netflix Notebook as a Code
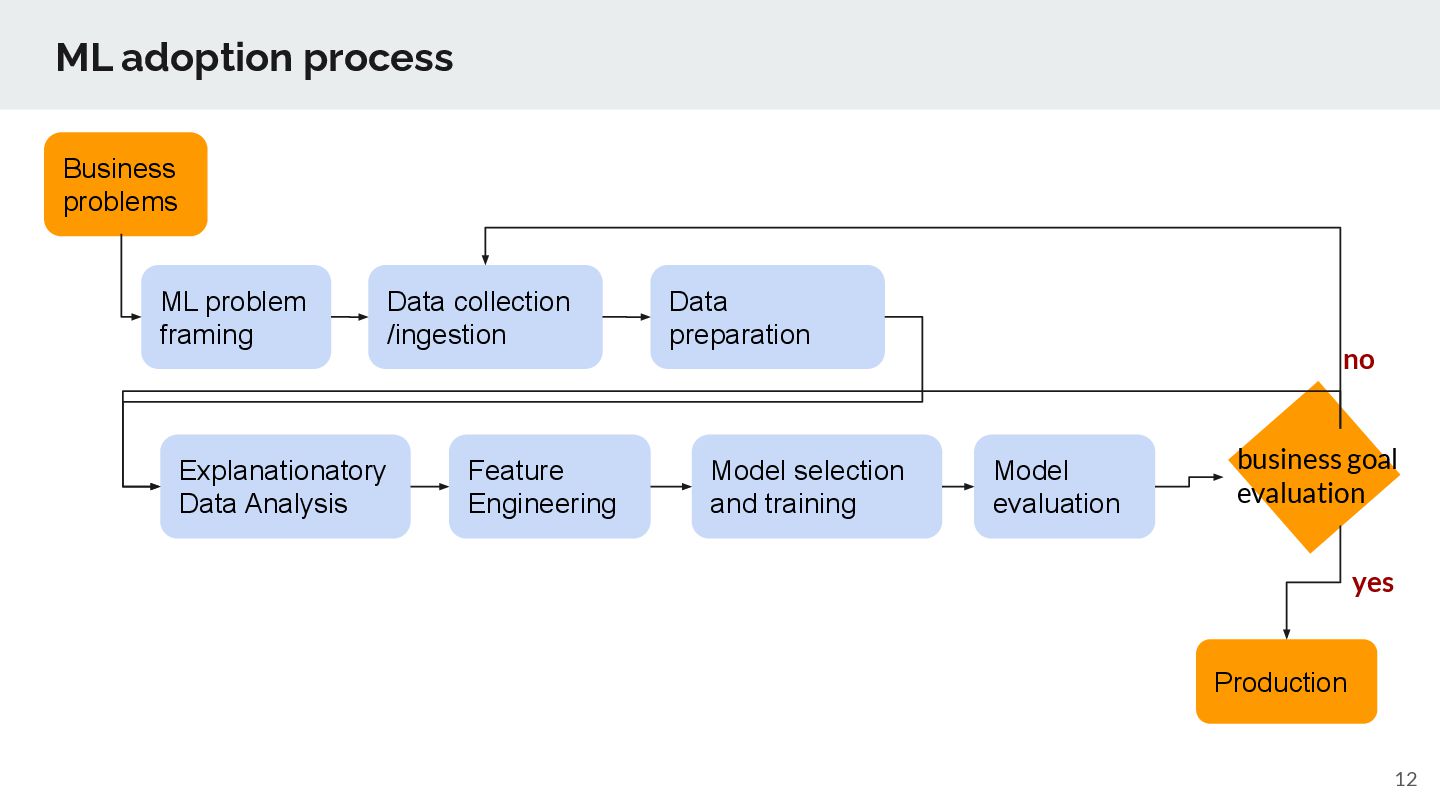
collection /ingestion Data preparation Explanationatory Data Analysis Feature Engineering Model selection and training Production business goal evaluation Model evaluation yes no
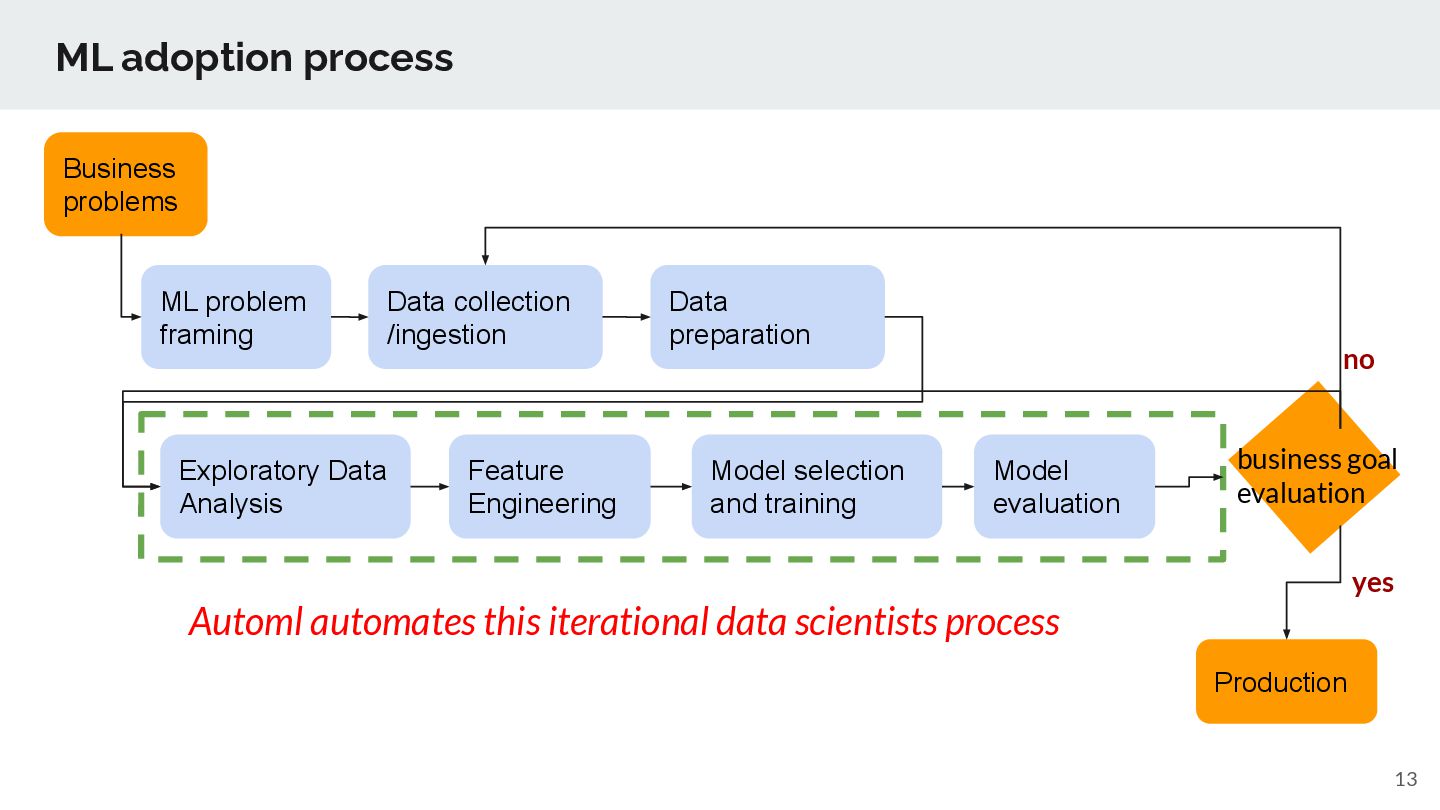
collection /ingestion Data preparation Exploratory Data Analysis Feature Engineering Model selection and training Production business goal evaluation Model evaluation yes Automl automates this iterational data scientists process no
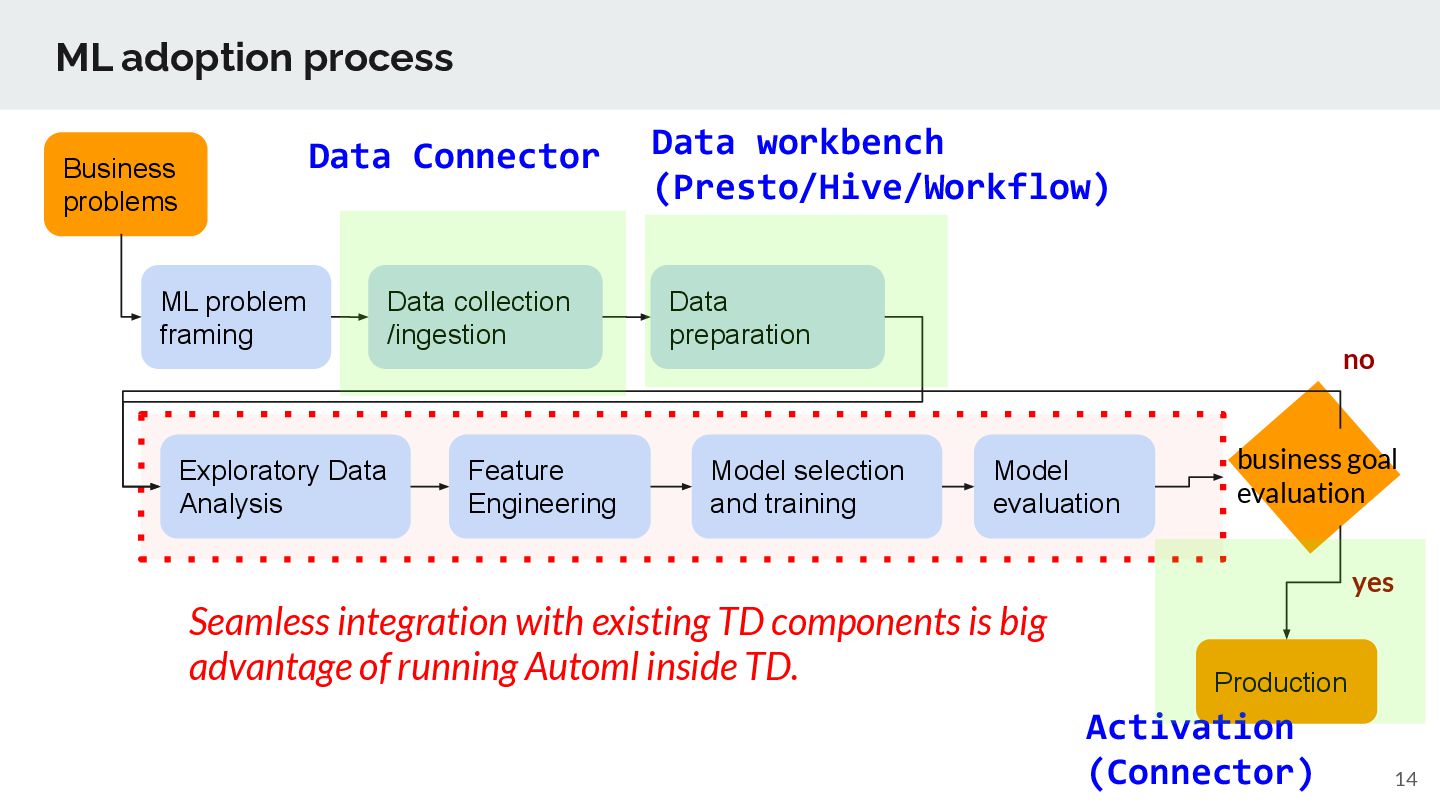
collection /ingestion Data preparation Exploratory Data Analysis Feature Engineering Model selection and training Production business goal evaluation Model evaluation yes Seamless integration with existing TD components is big advantage of running Automl inside TD. no Data Connector Activation (Connector) Data workbench (Presto/Hive/Workflow)
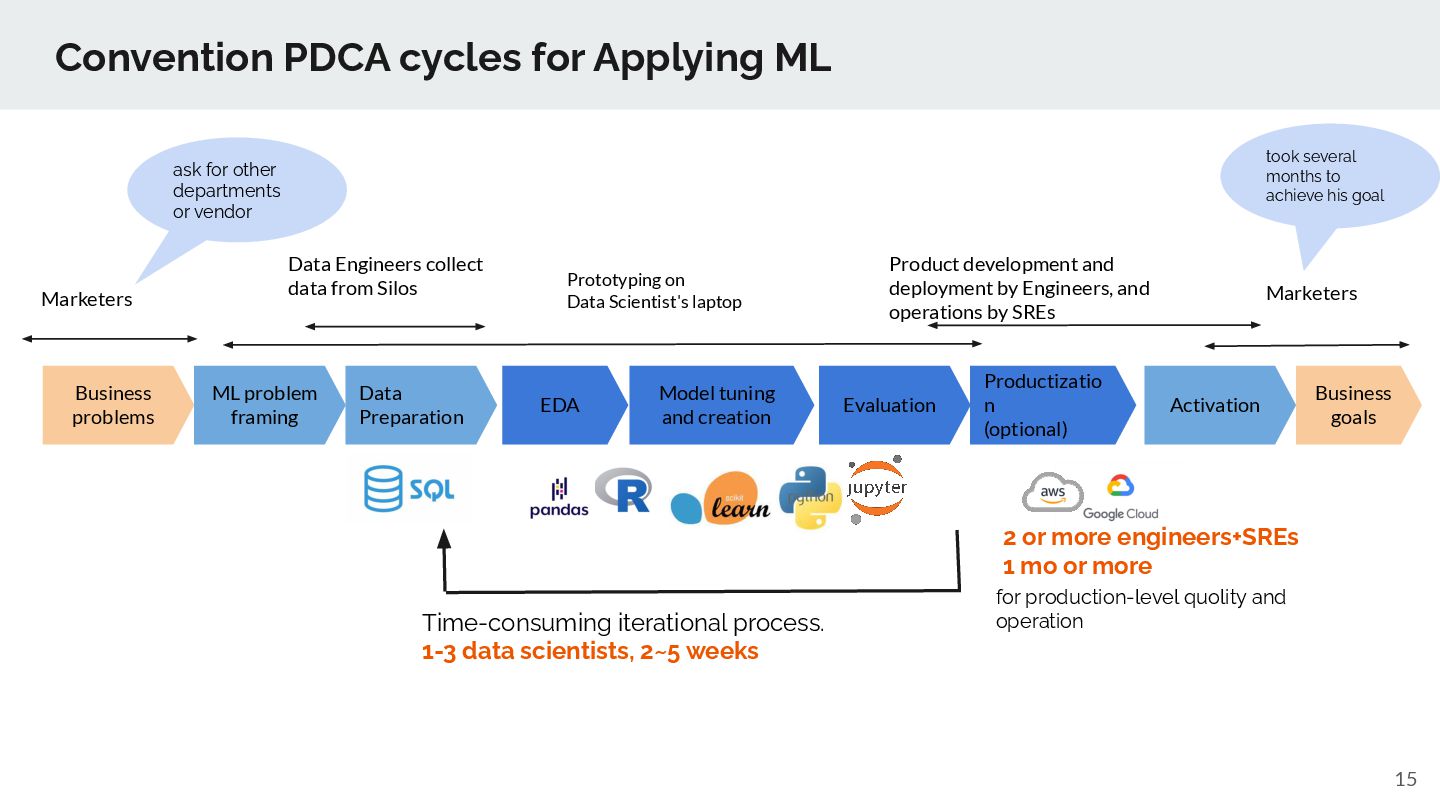
EDA Data Preparation Model tuning and creation Evaluation Productizatio n (optional) Activation Prototyping on Data Scientist's laptop Marketers Business problems Business goals Data Engineers collect data from Silos Product development and deployment by Engineers, and operations by SREs Marketers Time-consuming iterational process. 1-3 data scientists, 2~5 weeks 2 or more engineers+SREs 1 mo or more for production-level quolity and operation ask for other departments or vendor took several months to achieve his goal
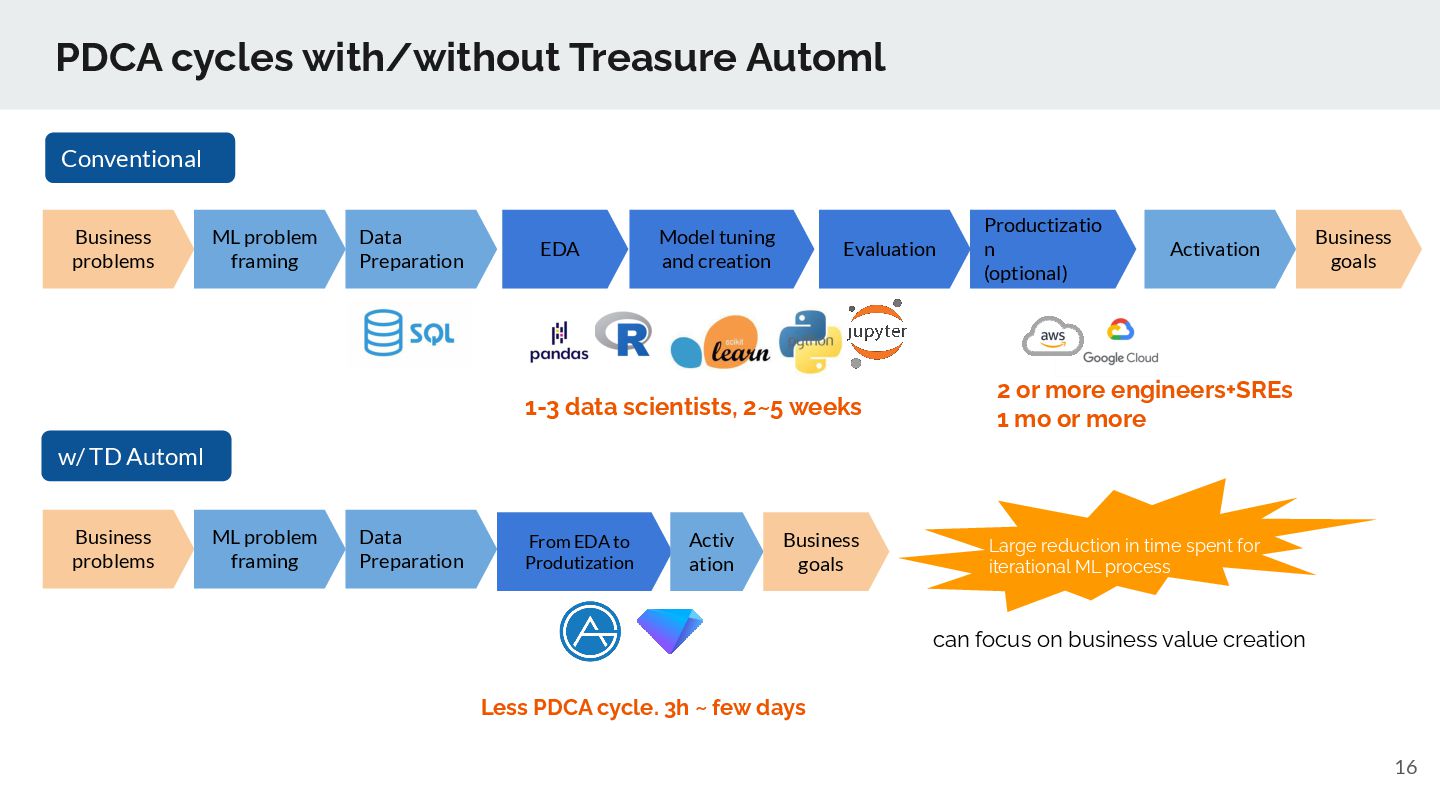
Data Preparation Model tuning and creation Evaluation Productizatio n (optional) Activation Business problems Business goals ML problem framing Data Preparation Business problems From EDA to Produtization Activ ation Business goals w/ TD Automl Conventional can focus on business value creation Less PDCA cycle. 3h ~ few days 2 or more engineers+SREs 1 mo or more 1-3 data scientists, 2~5 weeks Large reduction in time spent for iterational ML process
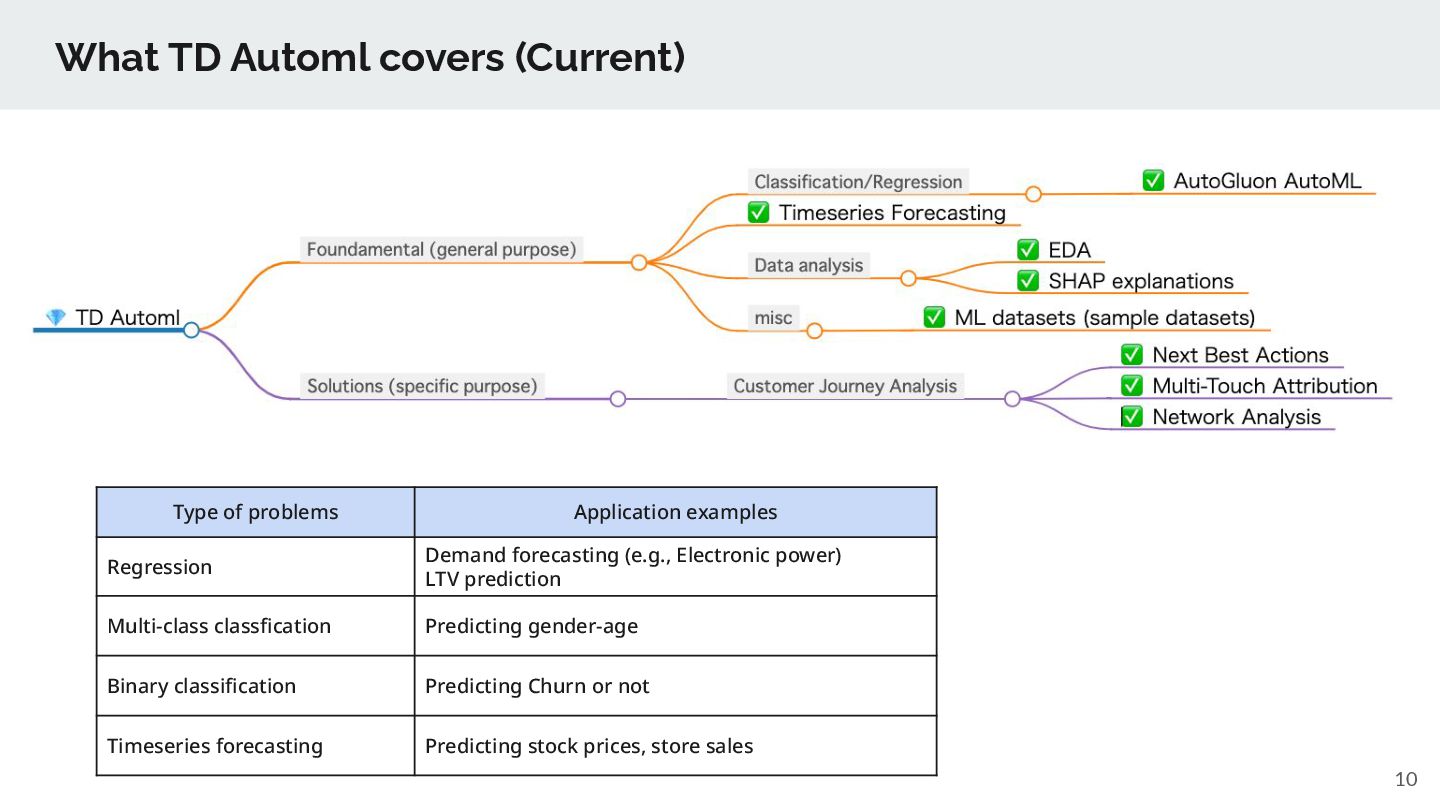
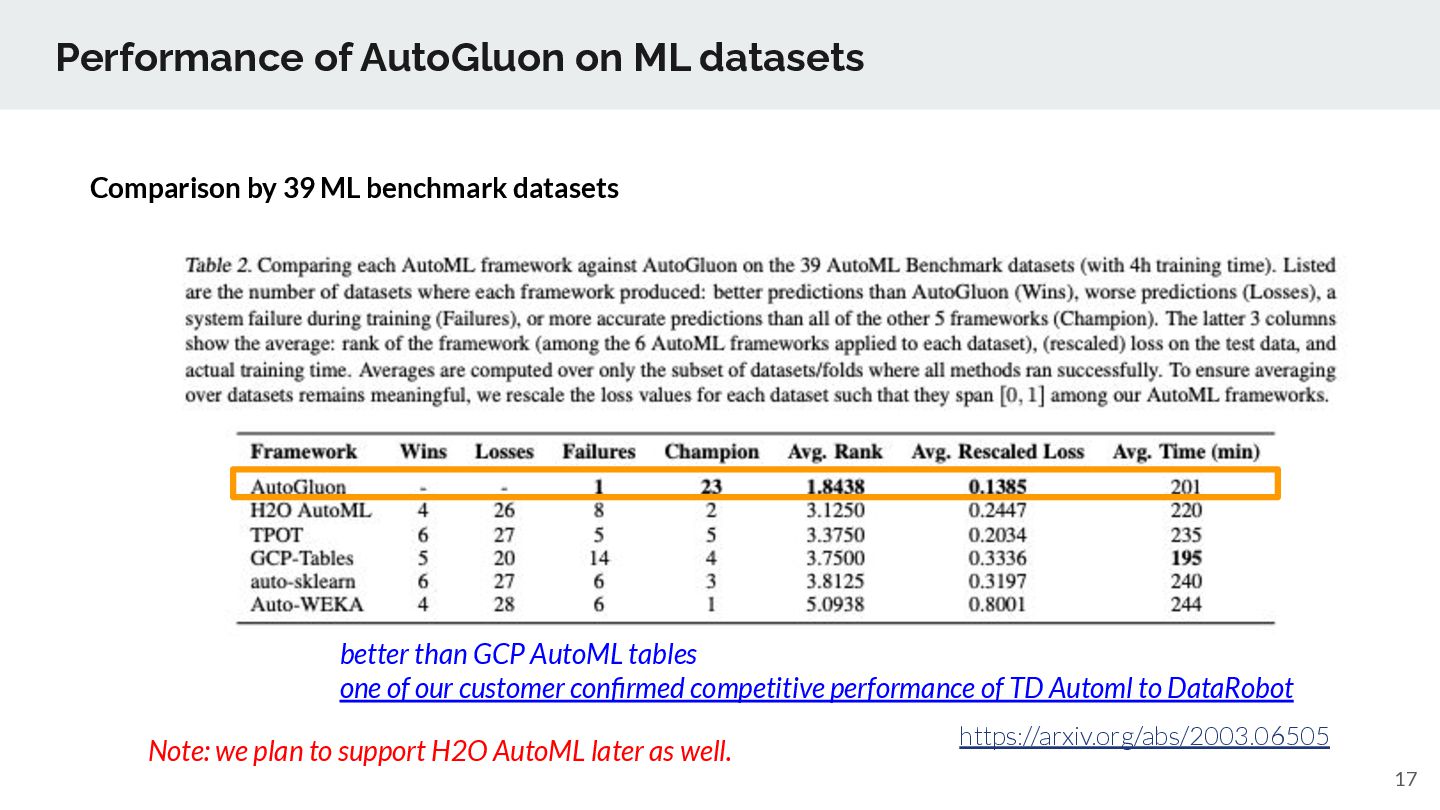
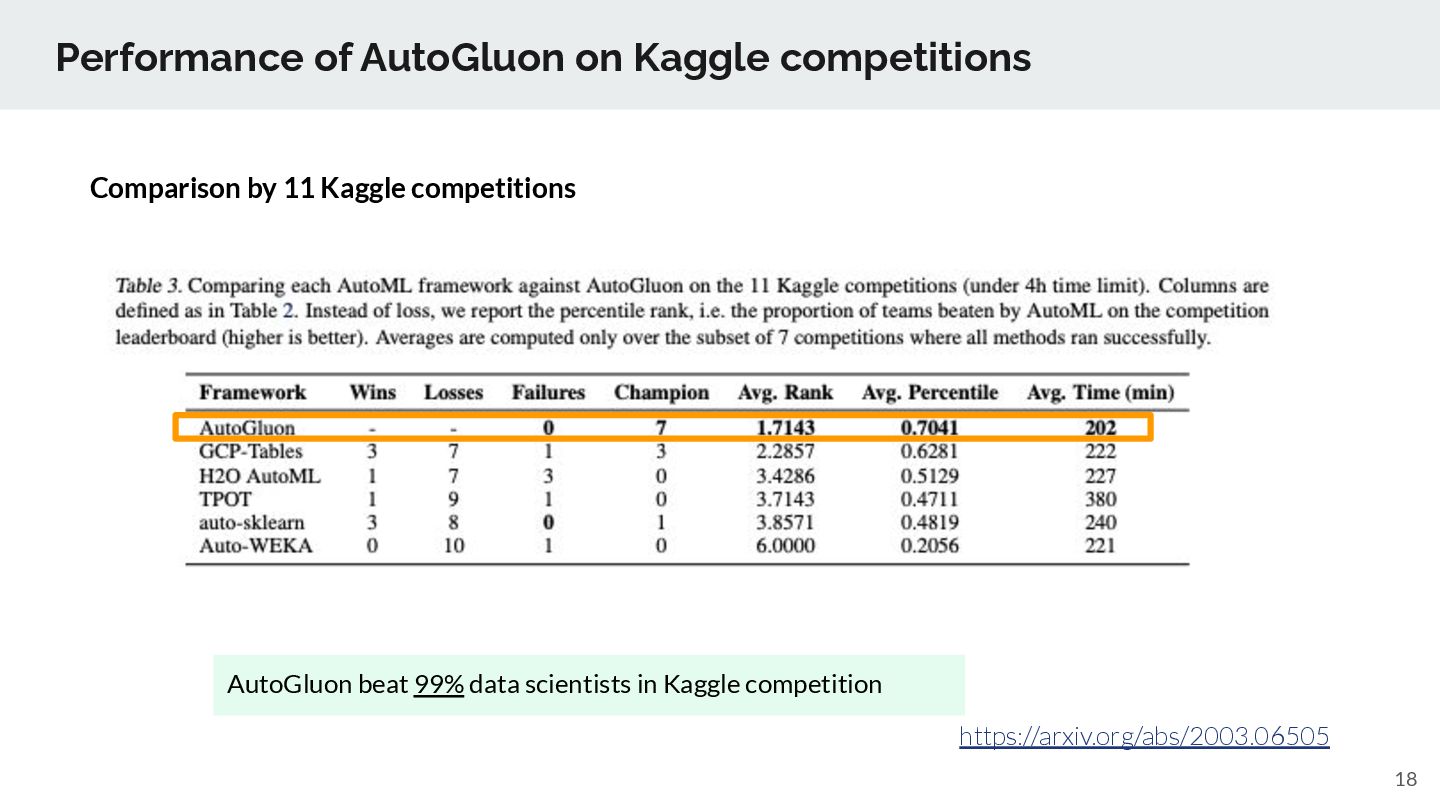
ML benchmark datasets https://arxiv.org/abs/2003.06505 Note: we plan to support H2O AutoML later as well. better than GCP AutoML tables one of our customer confirmed competitive performance of TD Automl to DataRobot
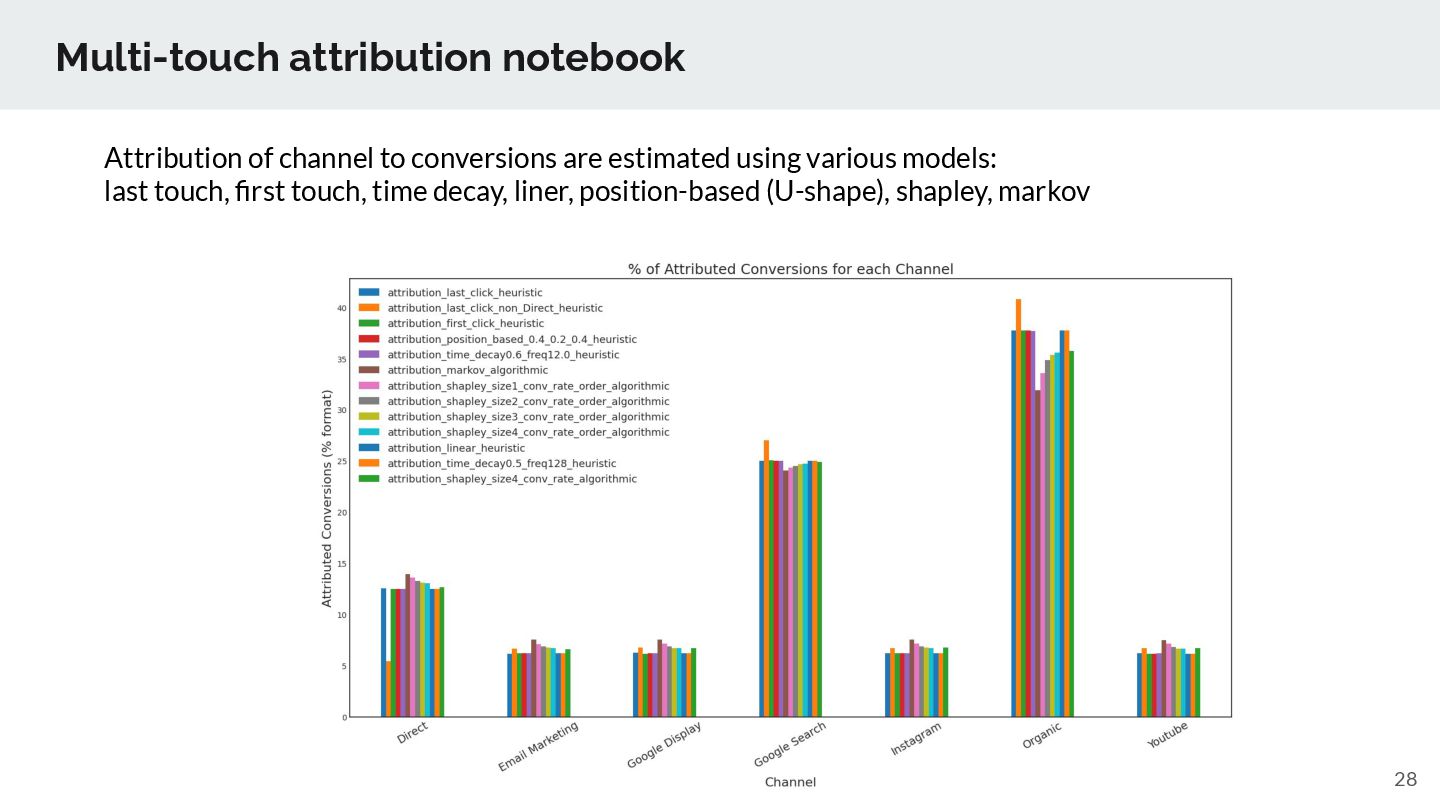
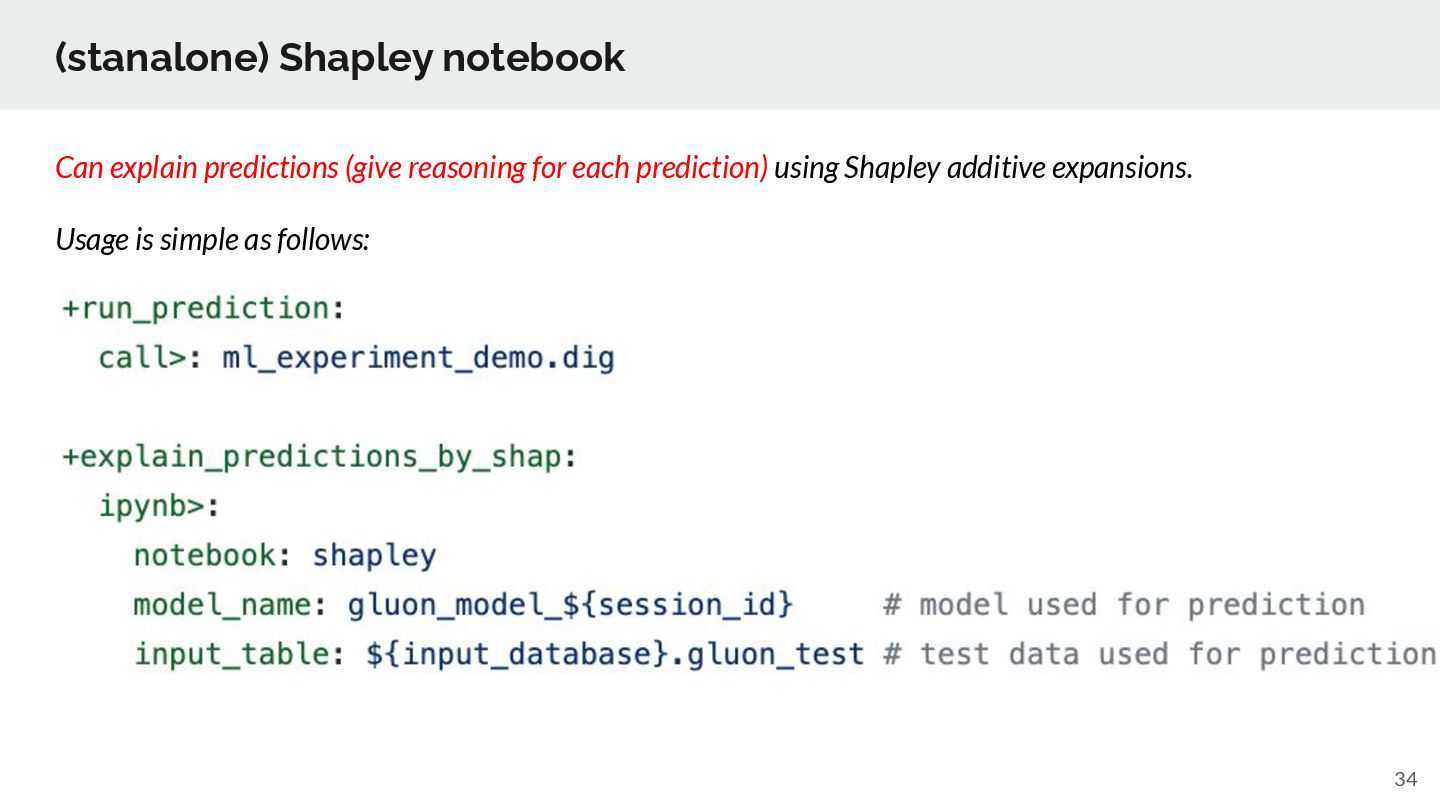
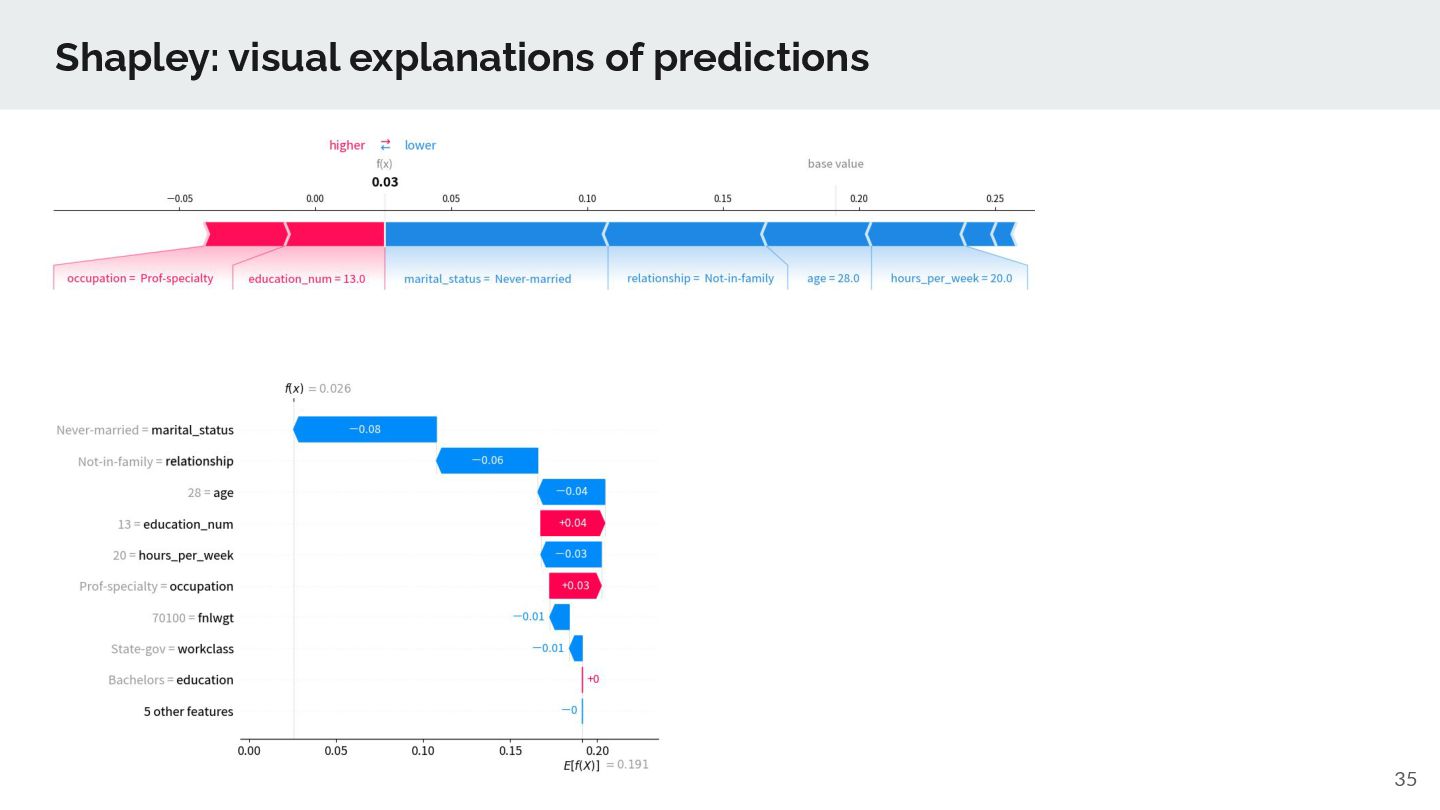
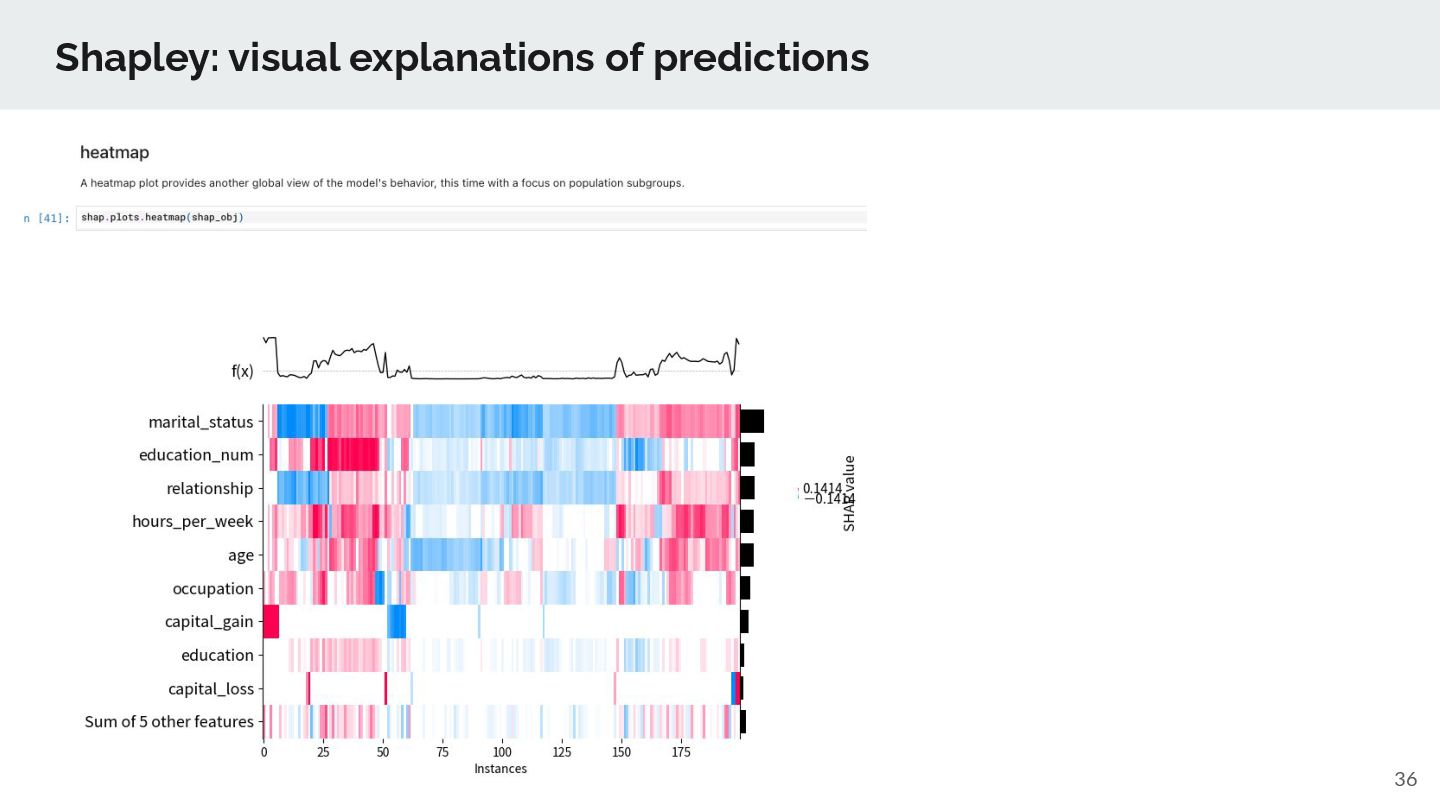
Apply bug fixes and workarounds for underlying OSS libraries (SHAP, autogluon) and bundling the best of knowledge of us for EDA, model explanation (XAI) steps ➢ We’ll extend AutoGluon for feature engineering (e.g., adding holiday features, identity feature elimination), supported new models (e.g. tabnet), applies bug fixes. ➢ We plan to support other supervised learning options such as H2O automl, custom Automl implementation. ➢ TD Automl goes beyond Supervised learning ◦ support Clustering, Timeseries forecasting, Recommendation, Causal Analysis ◦ support ML-based solution notebooks such as PII data masking, Timeseries forecasting, Text-analysis, Next-best action solutions
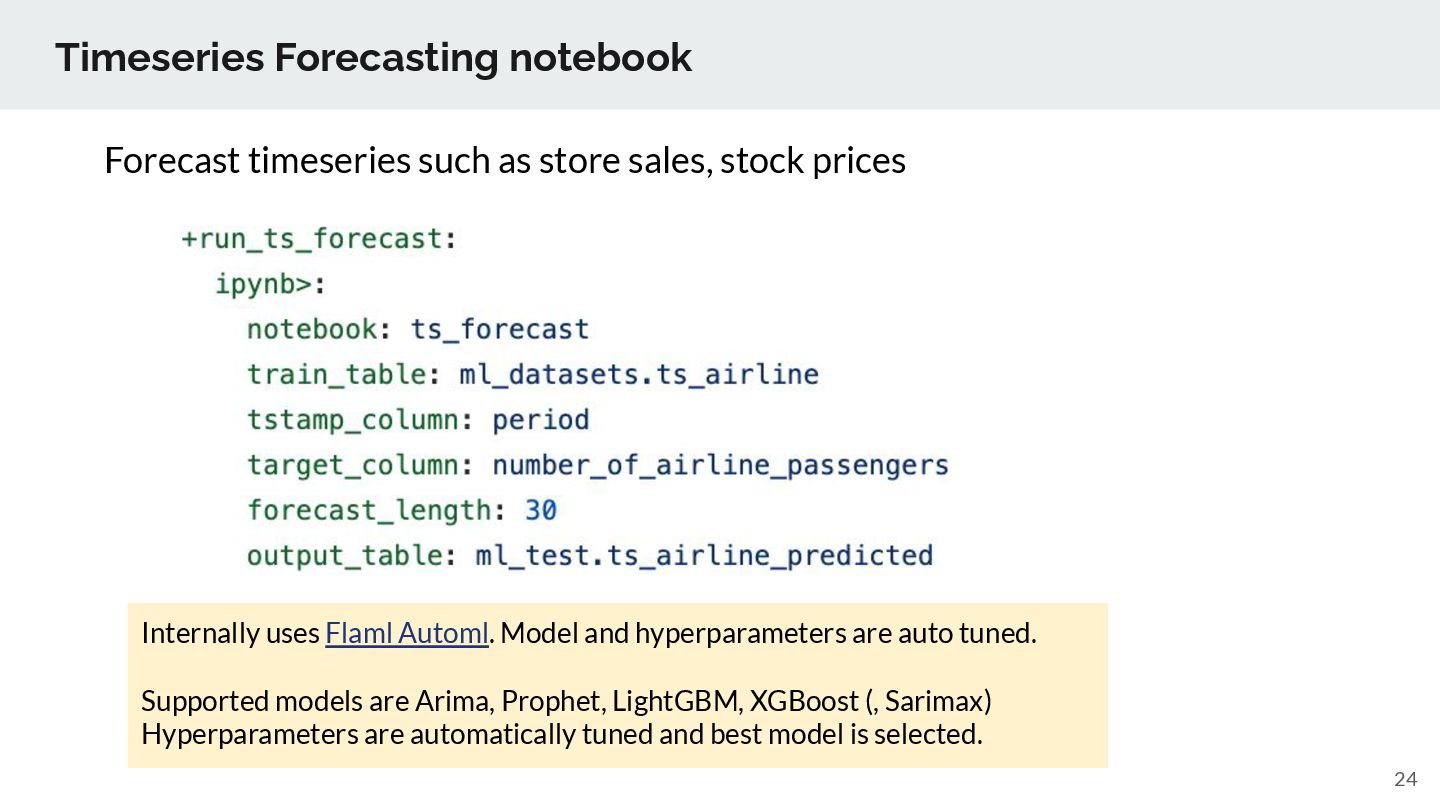
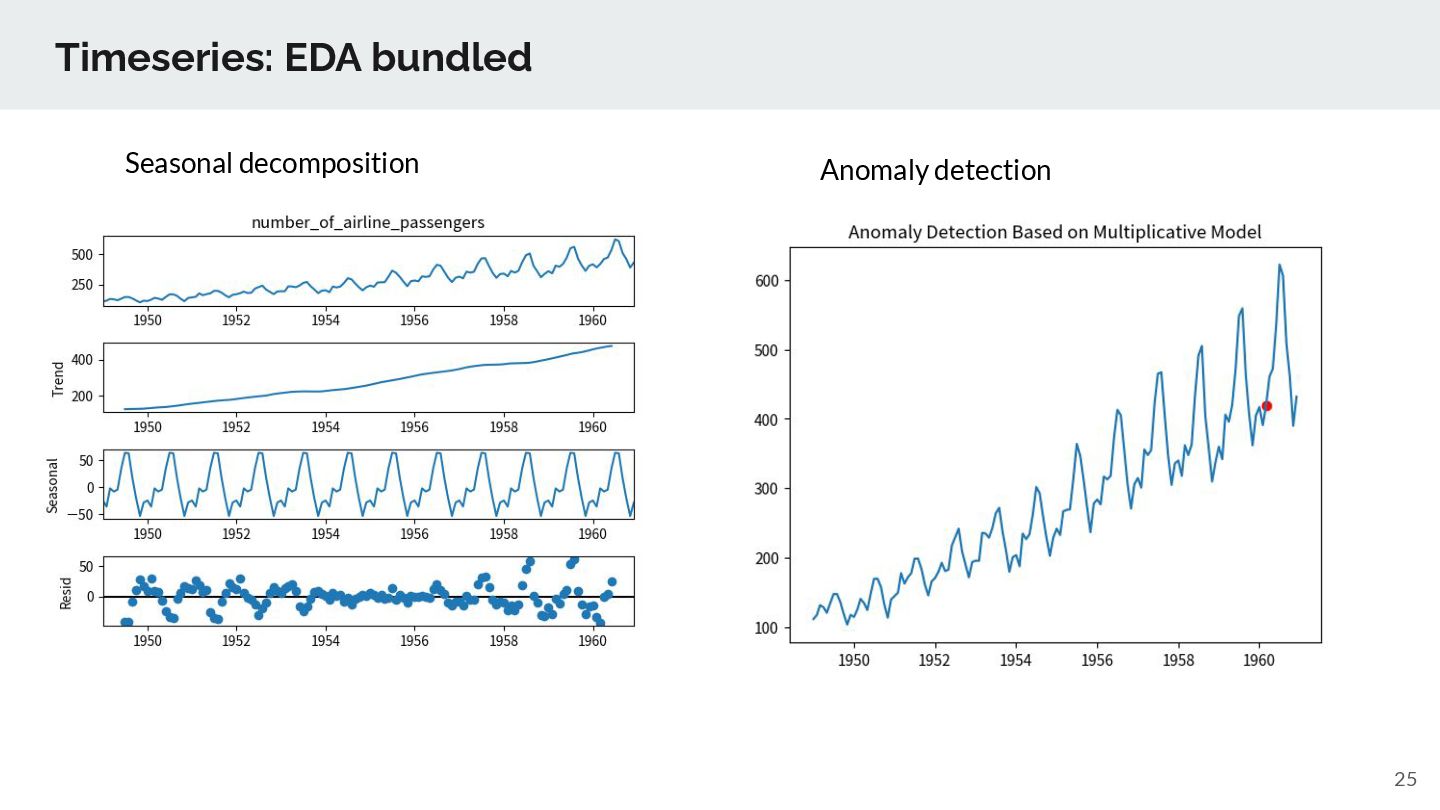
hyperparameters are auto tuned. Supported models are Arima, Prophet, LightGBM, XGBoost (, Sarimax) Hyperparameters are automatically tuned and best model is selected. Forecast timeseries such as store sales, stock prices
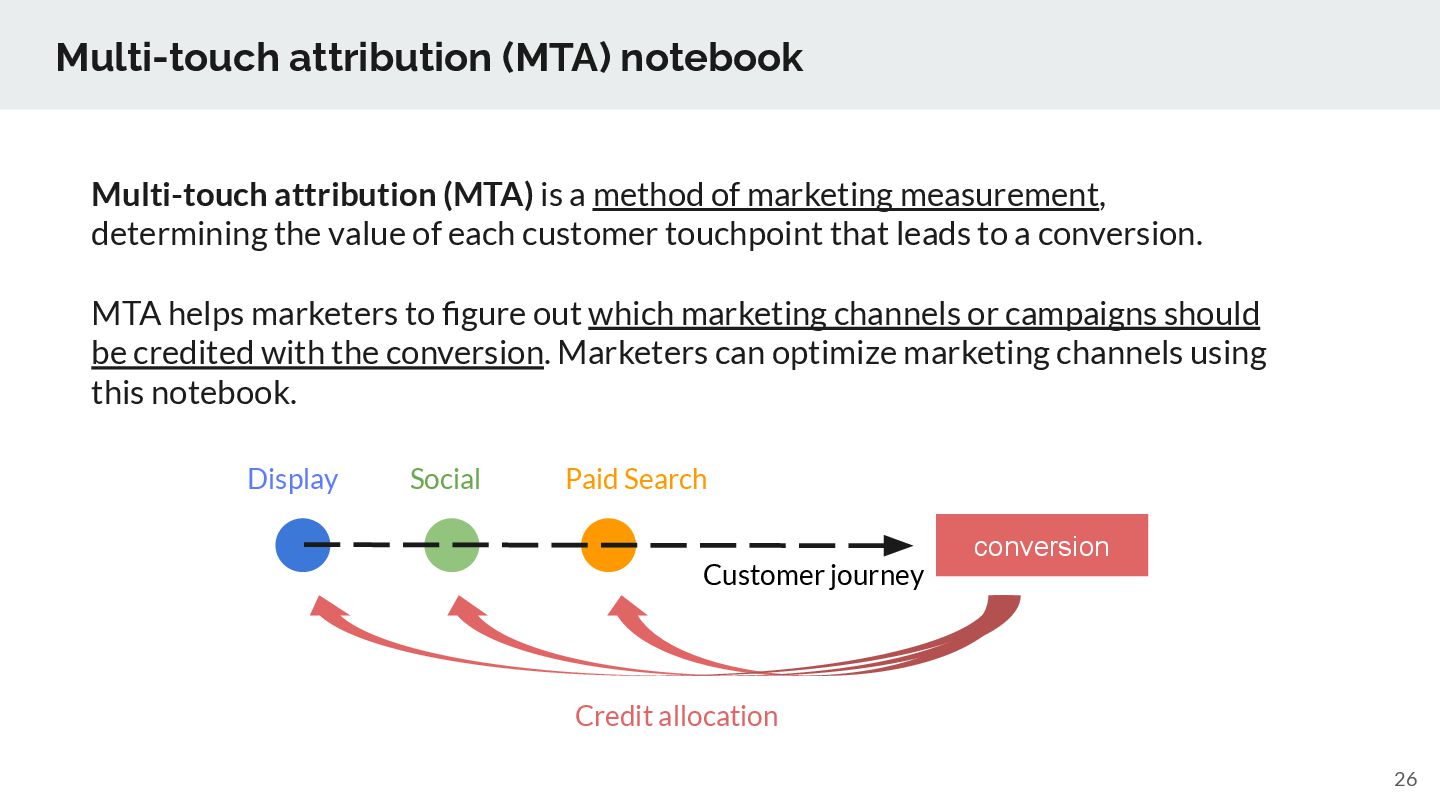
method of marketing measurement, determining the value of each customer touchpoint that leads to a conversion. MTA helps marketers to figure out which marketing channels or campaigns should be credited with the conversion. Marketers can optimize marketing channels using this notebook. conversion Customer journey Social Display Paid Search Credit allocation
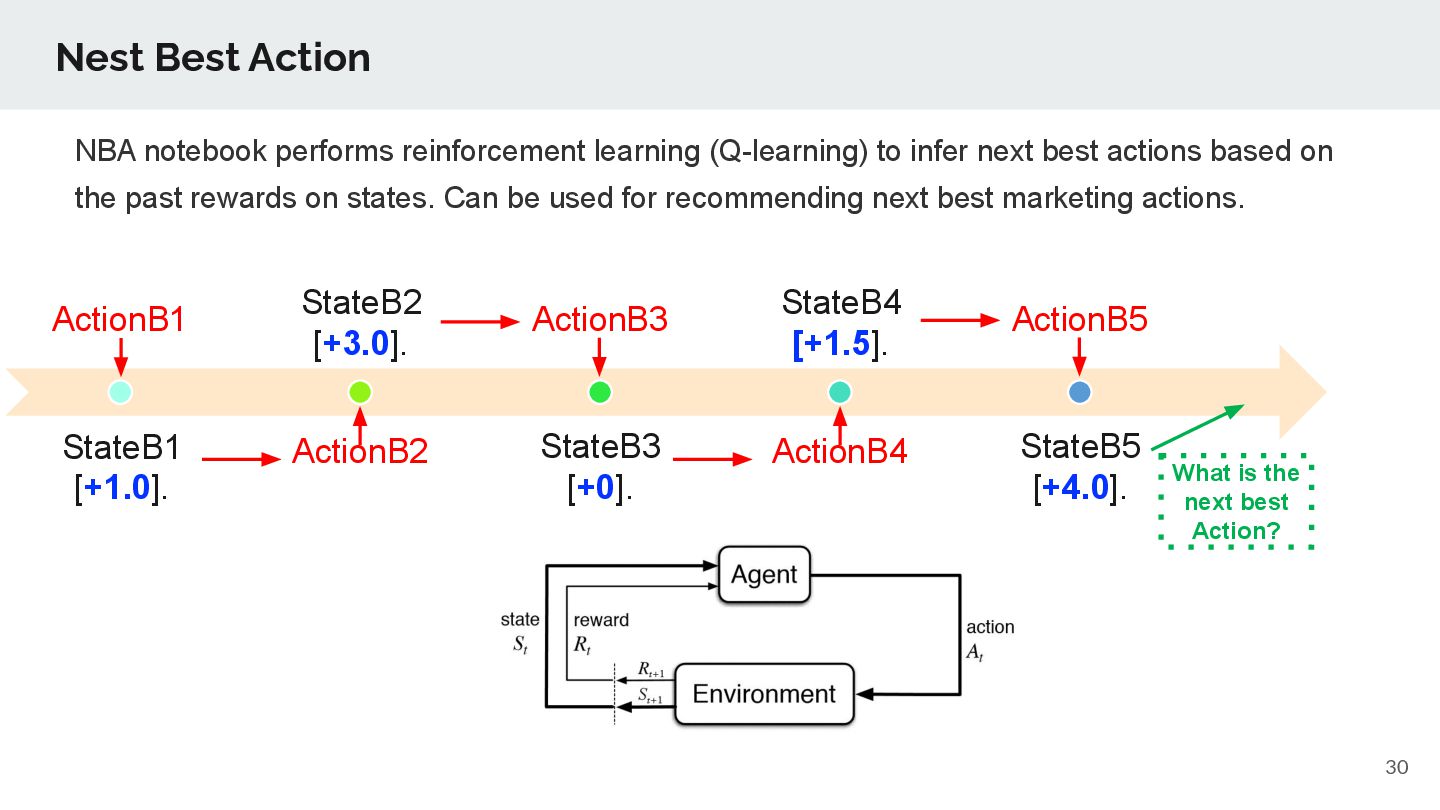
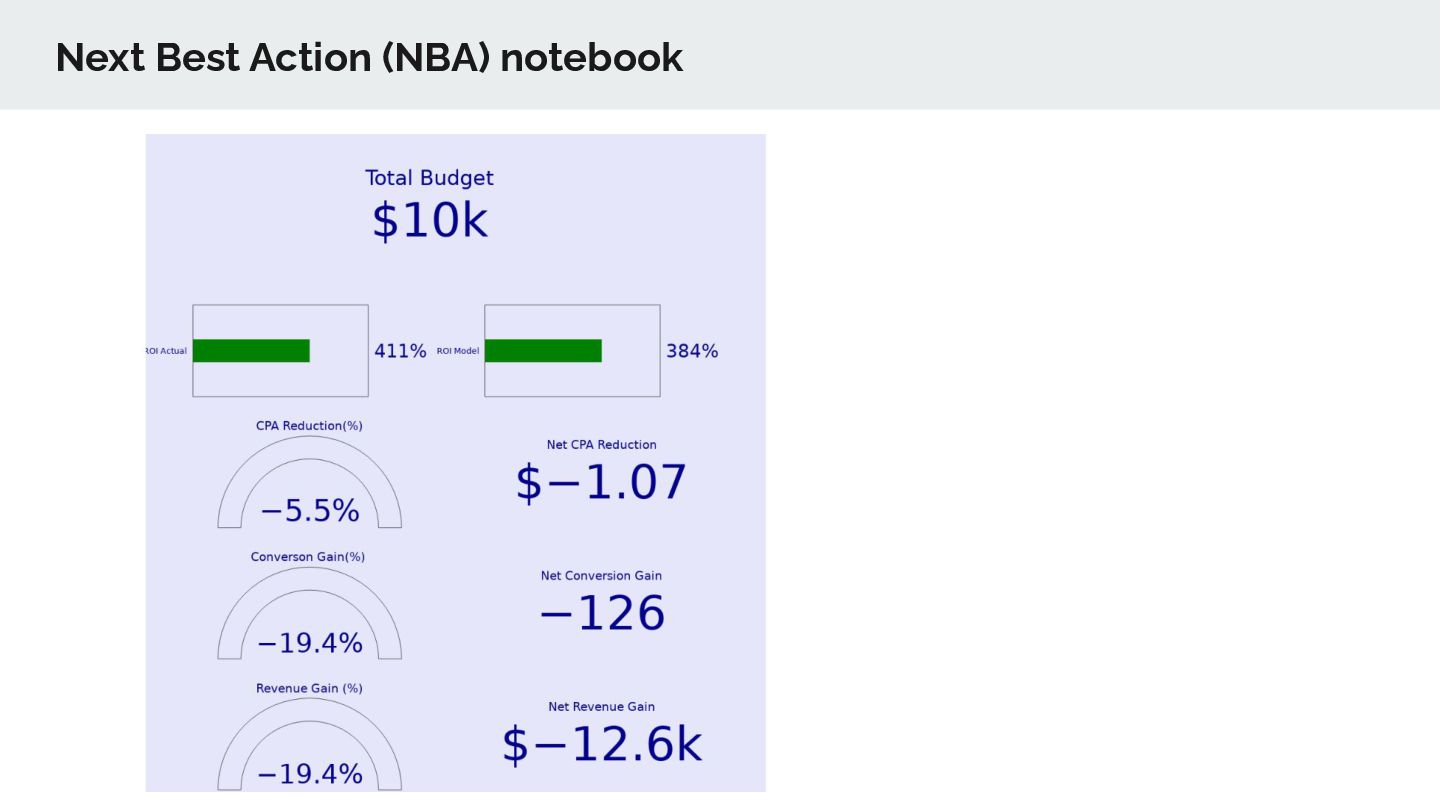
actions based on the past rewards on states. Can be used for recommending next best marketing actions. 30 ActionB1 ActionB2 ActionB3 ActionB4 ActionB5 StateB1 [+1.0]. StateB3 [+0]. StateB5 [+4.0]. StateB2 [+3.0]. StateB4 [+1.5]. What is the next best Action? Nest Best Action
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}