Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
DMMTVにおけるデータ蓄積とモデル改善
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
nadare
June 04, 2024
480
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
DMMTVにおけるデータ蓄積とモデル改善
「【DMM.com × Databricks】機械学習モデルの評価と改善」における発表資料です
https://dmm.connpass.com/event/313388/
nadare
June 04, 2024
More Decks by nadare
See All by nadare
軽量音声認識OSS Parapper
nadare881
0
78
DMMのあちこちをパーソナライズする推薦システム
nadare881
3
1.7k
atmaCup#15と実世界のレコメンドの比較(の一例)
nadare881
1
1.1k
embeddingを用いた分析・検索・推薦の技術
nadare881
0
4.2k
Featured
See All Featured
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1.1k
Code Review Best Practice
trishagee
74
20k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
310
Mind Mapping
helmedeiros
PRO
1
290
DBのスキルで生き残る技術 - AI時代におけるテーブル設計の勘所
soudai
PRO
67
56k
For a Future-Friendly Web
brad_frost
183
10k
How to Talk to Developers About Accessibility
jct
2
460
Being A Developer After 40
akosma
91
590k
GraphQLとの向き合い方2022年版
quramy
50
15k
WENDY [Excerpt]
tessaabrams
11
39k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Transcript
© DMM © DMM CONFIDENTIAL DMM TVにおける 定性評価とモデル改善 【DMM.com ×
Databricks】機械学習モデルの評価と改善 合同会社DMM.com レコメンドGrowthチーム 金子剛士 2024/05/30
© DMM 自己紹介 金子 剛士 (nadare) 2022年10月に合同会社DMM.comに入社 複数サービスでのレコメンドエンジン作成を担当 Kaggle Competitions Master
最近の趣味はVRChatのBarでお酒を飲むこと 副業で開発しているAIボイチェン(Paravo)でバ美肉し ウィスキーを片手におしゃべりが楽しい 2 #dmm_databricks
© DMM 概要 深層学習モデルはブラックボックス故、想定外の挙動により意図せぬ結果がでることがありま す。 DMM TVはDMM内では新しいサービスで、これまで十分にデータが蓄積されてきたサービスへ の導入と異なり、十分な検証データの無い状態でのレコメンド導入を行いました。そのため、 データの分析とモデルの改善のサイクルを回して改善を行いました。 今回はデータの蓄積と観察によってレコメンドを改善できた事例を3つほど紹介します。
3 #dmm_databricks
© DMM 1.たまたま出現したペアの強化による悪循環 レコメンド導入最初期 一部センシティブなマイナーコンテンツがレコメンド上位にくるように マイナー作品なのになぜレコメンド上位に? 4 #dmm_databricks
© DMM 1.たまたま出現したペアの強化による悪循環 新着棚に出ていた目につくマイナー作品が異常なFBを受けていた 1. データが少ない作品についての学習 メジャー作品 色々なユーザーの例から類似アイテムを学習 マイナー作品 たまたま一緒に視聴されたメジャー商品を類似商品と学習
→大抵は一定以下の頻度しか出ていない作品は除去すると除ける 2. 間違ったレコメンドの学習の加速 目を引くマイナー作品が新着でトップにでる →ものめずらしさでクリックされ、類似アイテムとしての学習が強化 →さらにレコメンド上位に表示され、クリックが加速 5 #dmm_databricks
© DMM 1.たまたま出現したペアの強化による悪循環 導入初期の念入りなチェック - 導入後数日~数週はユーザーをサンプルして履歴とレコメンド結果を比較 - 定期的に実施で違和感に気づいた レコメンドモデル自体の改善 -
メタデータの追加、人気度を考慮したペナルティにより偶然を減らす - 学習のepoch数を減らし、間違ったペアの学習回数を減らす 表示コンテンツの改善 - データが少ない初期ほどノイズを拾いやすい - 新着・特集などの表示コンテンツに気を付け、良質なFBをモデルに与える 6 #dmm_databricks
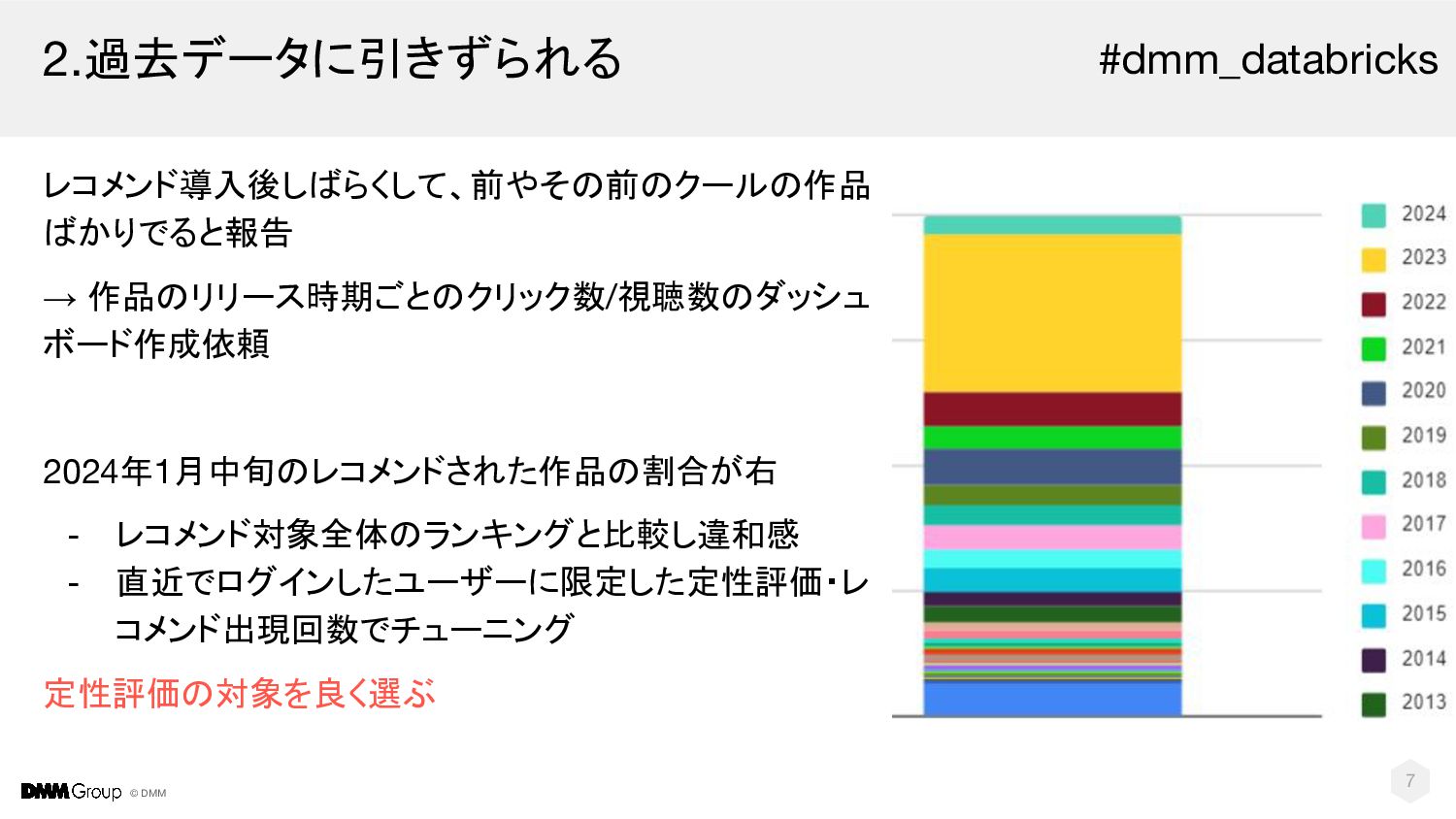
© DMM 2.過去データに引きずられる レコメンド導入後しばらくして、前やその前のクールの作品 ばかりでると報告 → 作品のリリース時期ごとのクリック数/視聴数のダッシュ ボード作成依頼 2024年1月中旬のレコメンドされた作品の割合が右 -
レコメンド対象全体のランキングと比較し違和感 - 直近でログインしたユーザーに限定した定性評価・レ コメンド出現回数でチューニング 定性評価の対象を良く選ぶ 7 #dmm_databricks
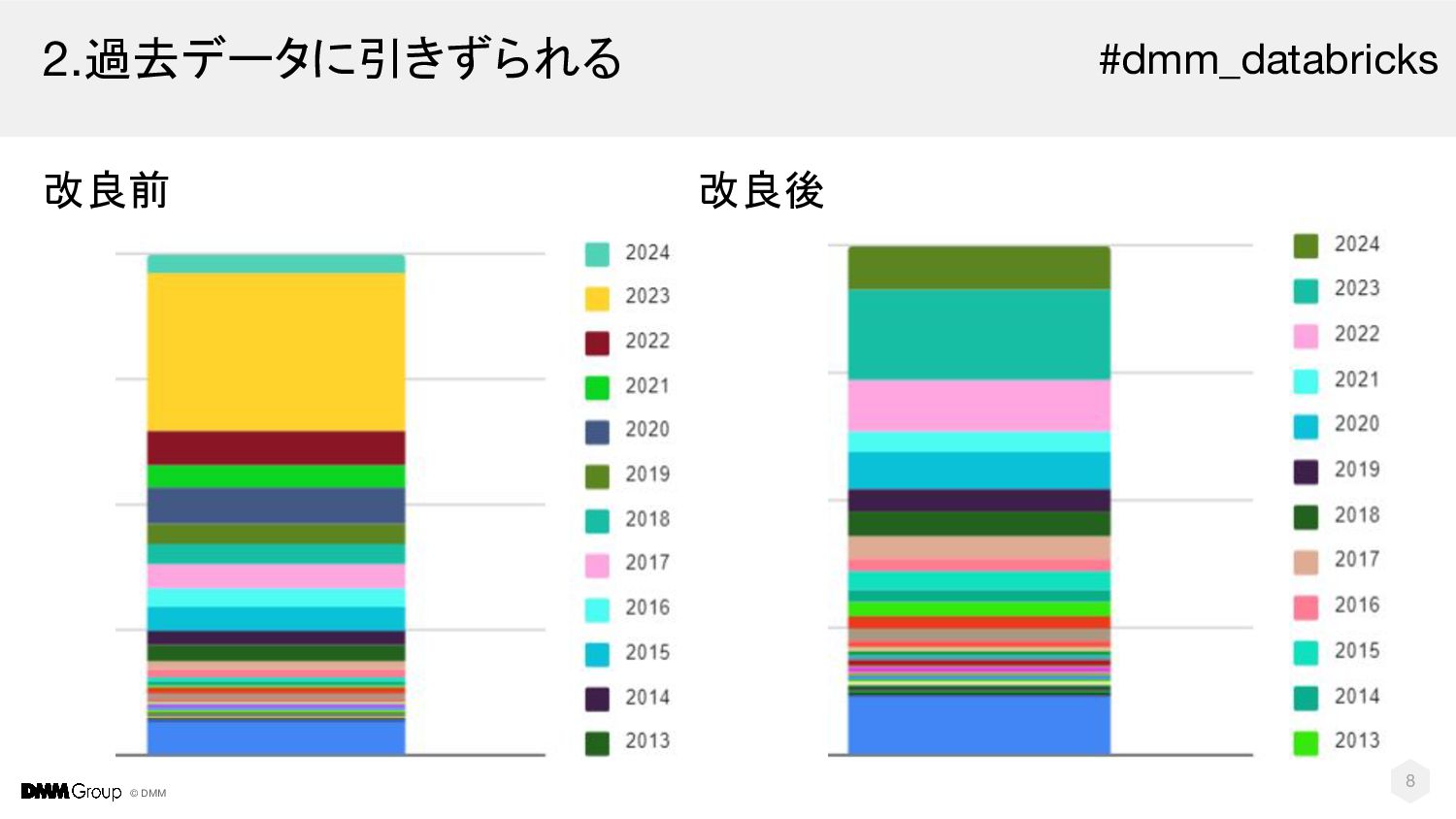
© DMM 2.過去データに引きずられる 改良前 改良後 8 #dmm_databricks
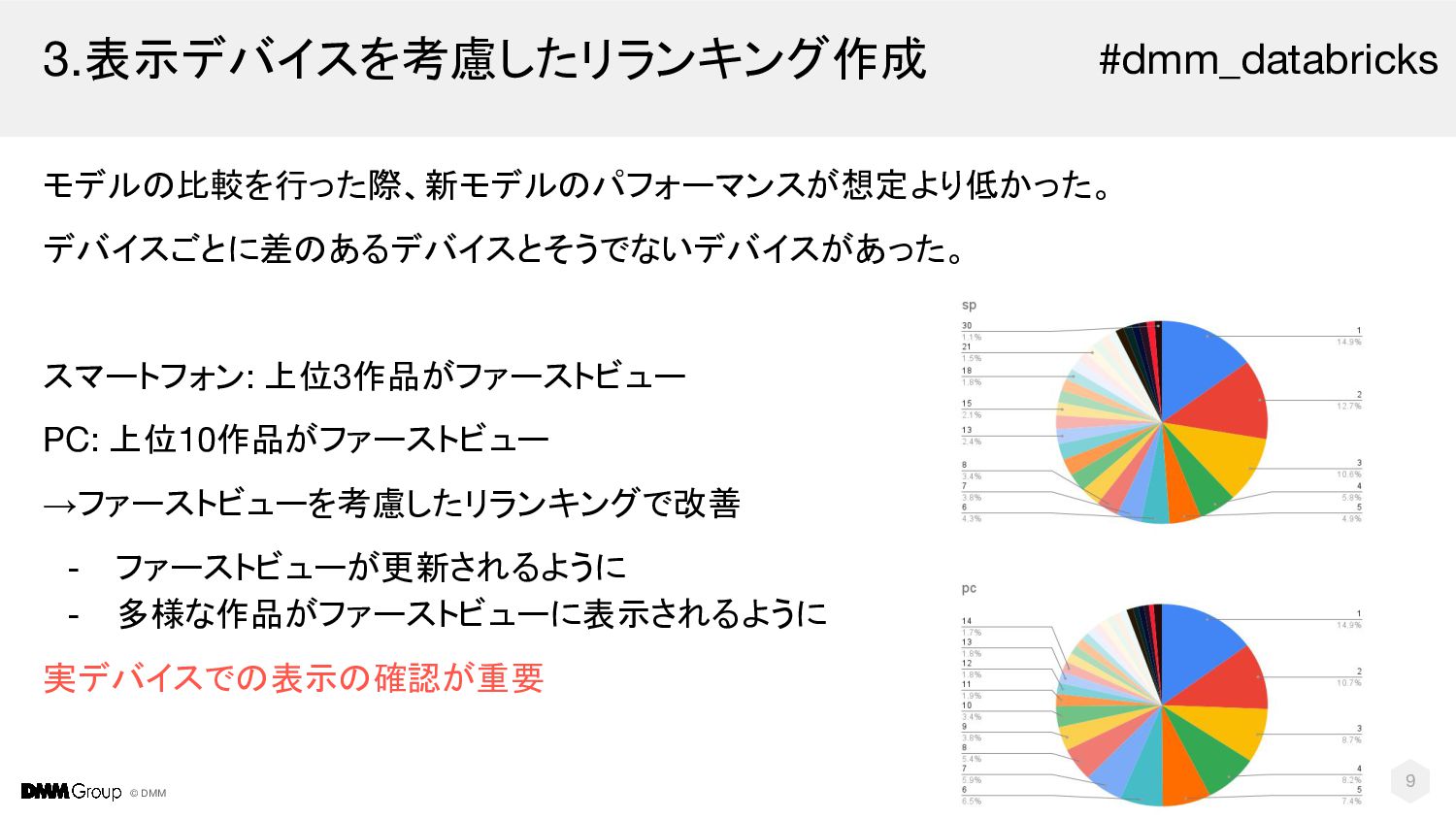
© DMM 3.表示デバイスを考慮したリランキング作成 モデルの比較を行った際、新モデルのパフォーマンスが想定より低かった。 デバイスごとに差のあるデバイスとそうでないデバイスがあった。 スマートフォン: 上位3作品がファーストビュー PC: 上位10作品がファーストビュー →ファーストビューを考慮したリランキングで改善
- ファーストビューが更新されるように - 多様な作品がファーストビューに表示されるように 実デバイスでの表示の確認が重要 9 #dmm_databricks
© DMM オフライン定性評価のコツ 過去のレコメンド結果やユーザーの視聴履歴・クリック履歴はBQに保存されていて jupyter notebookからBQを叩いて可視化・モデルの比較ができる u2i 視聴・クリック履歴と推薦結果を比較 直近1日でログインがあったユーザー、登録したばかりのユーザー、復帰ユーザーなど様々条 件を用意して、ランダムに表示
全体で推薦された合計をランキングにして、トレンドに沿っているか確認 i2i ジャンル・累計視聴数ごとにサンプリングしてi2iを確認 →結果をインタラクティブに確認できる仕組みの導入は大事 10 #dmm_databricks
© DMM まとめ DMM TVのレコメンド改善における、データの観測とそれに基づく改善の事例について紹介しま した。 生成AIでは結果をインタラクティブに確認することが重要で BQ + notebookやスプレッドシートで可視化を行うほか
gradioやTensorBoard、W&B等のツールの活用も有効です。 より細かいチューニングの内容や、他事業における改善の例もありますので 懇親会時に是非意見交換できればと思います。 11 #dmm_databricks
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}