level, monitoring allows you to gain visibility into a system, which is a core requirement for judging service health and diagnosing your service when things go wrong. 最も基本的なレベルでは、モニタリングによってシ ステムを可視化することができます。これは、サー ビスの健全性を判断し、問題が発生した場合に サービスを診断するための中核的な要件です。 https://sre.google/workbook/monitoring/
we fix the underlying issue, and services return to their normal operating conditions. Unless we have some formalized process of learning from these incidents in place, they may recur ad infinitum. Left unchecked, incidents can multiply in complexity or even cascade, overwhelming a system and its operators and ultimately impacting our users. Therefore, postmortems are an essential tool for SRE. インシデントが発生すると、根本的な問題が解決され、サー ビスは通常の動作状態に戻ります。 これらの事件から学ぶ ための何らかの正式なプロセスを整備しない限り、事件は 無限に繰り返される可能性があります。 チェックを怠ると、 インシデントが複雑化したり連鎖的に発生したりして、シス テムとそのオペレーターに負担をかけ、最終的にはユー ザーに影響を与える可能性があります。 したがって、事後 分析は SRE にとって不可欠なツールです。 https://sre.google/workbook/monitoring/
to spend time on long-term engineering project work instead of operational work. Because the term operational work may be misinterpreted, we use a specific word: toil. SRE では、運用作業ではなく、長期的なエン ジニアリング プロジェクト作業に時間を費や したいと考えています。 運用作業という用語 は誤解される可能性があるため、「労苦」とい う特定の用語を使用します。 https://sre.google/sre-book/eliminating-toil/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
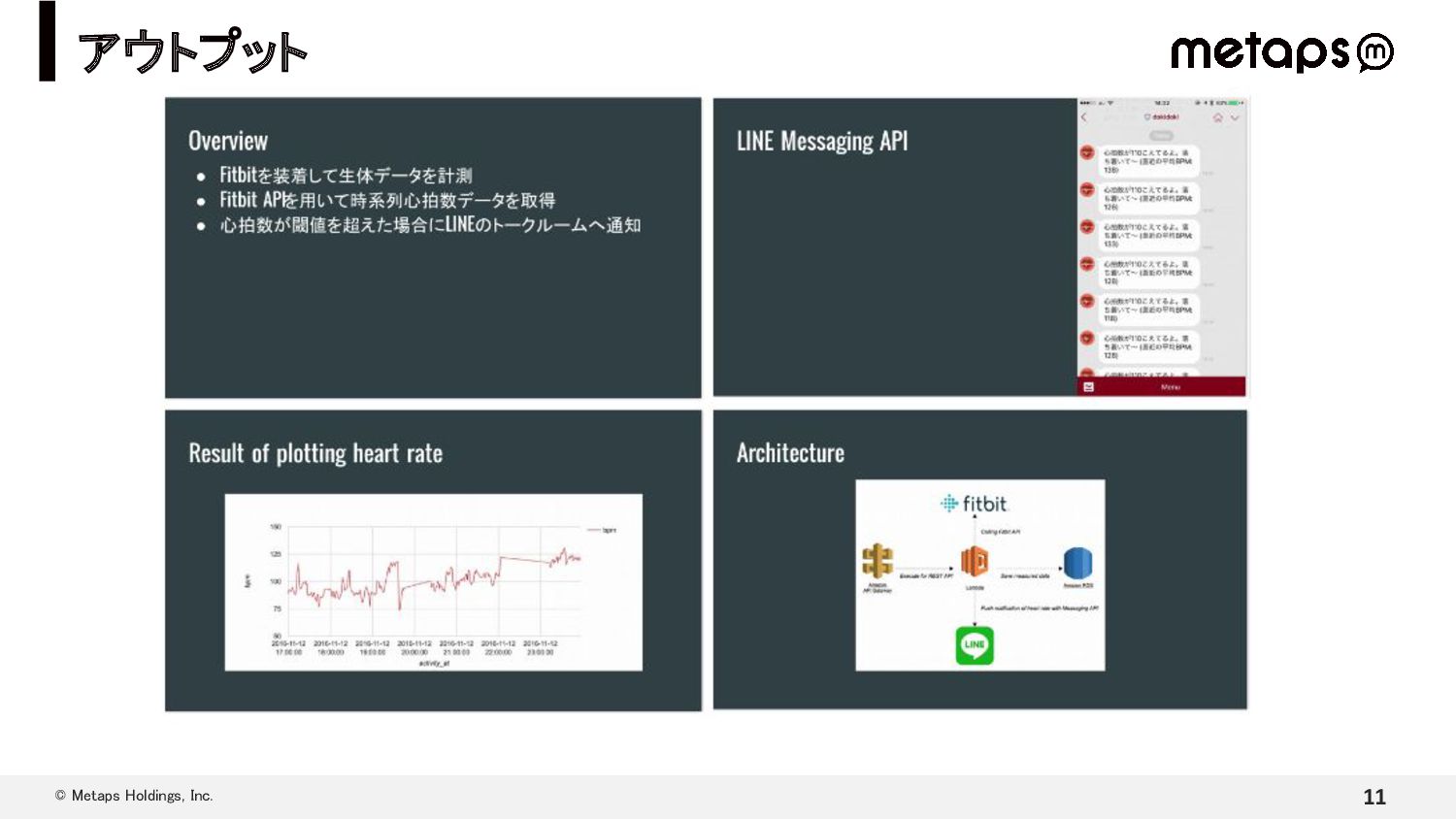{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
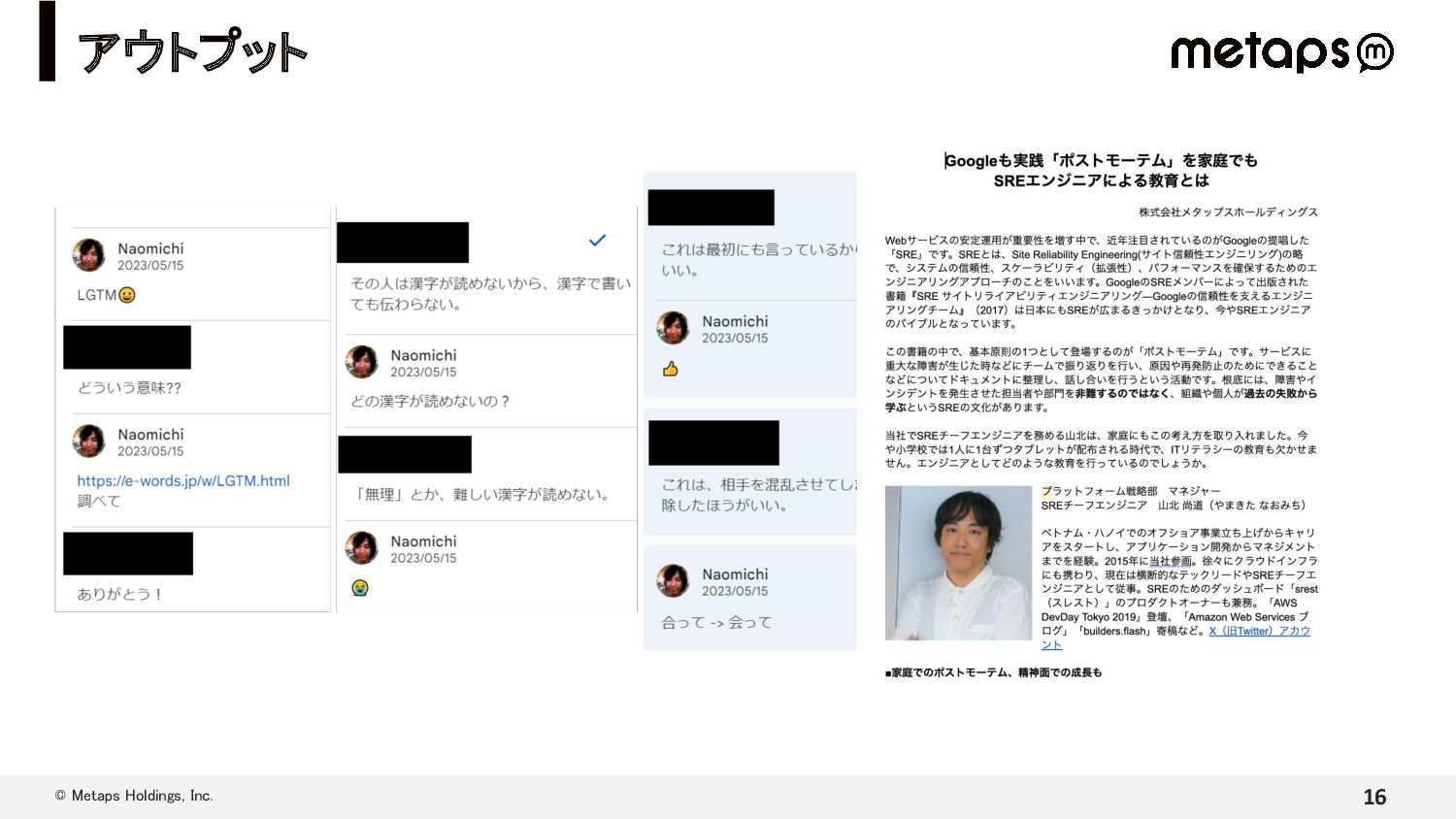{kind=link}
{kind=link}
{kind=link}
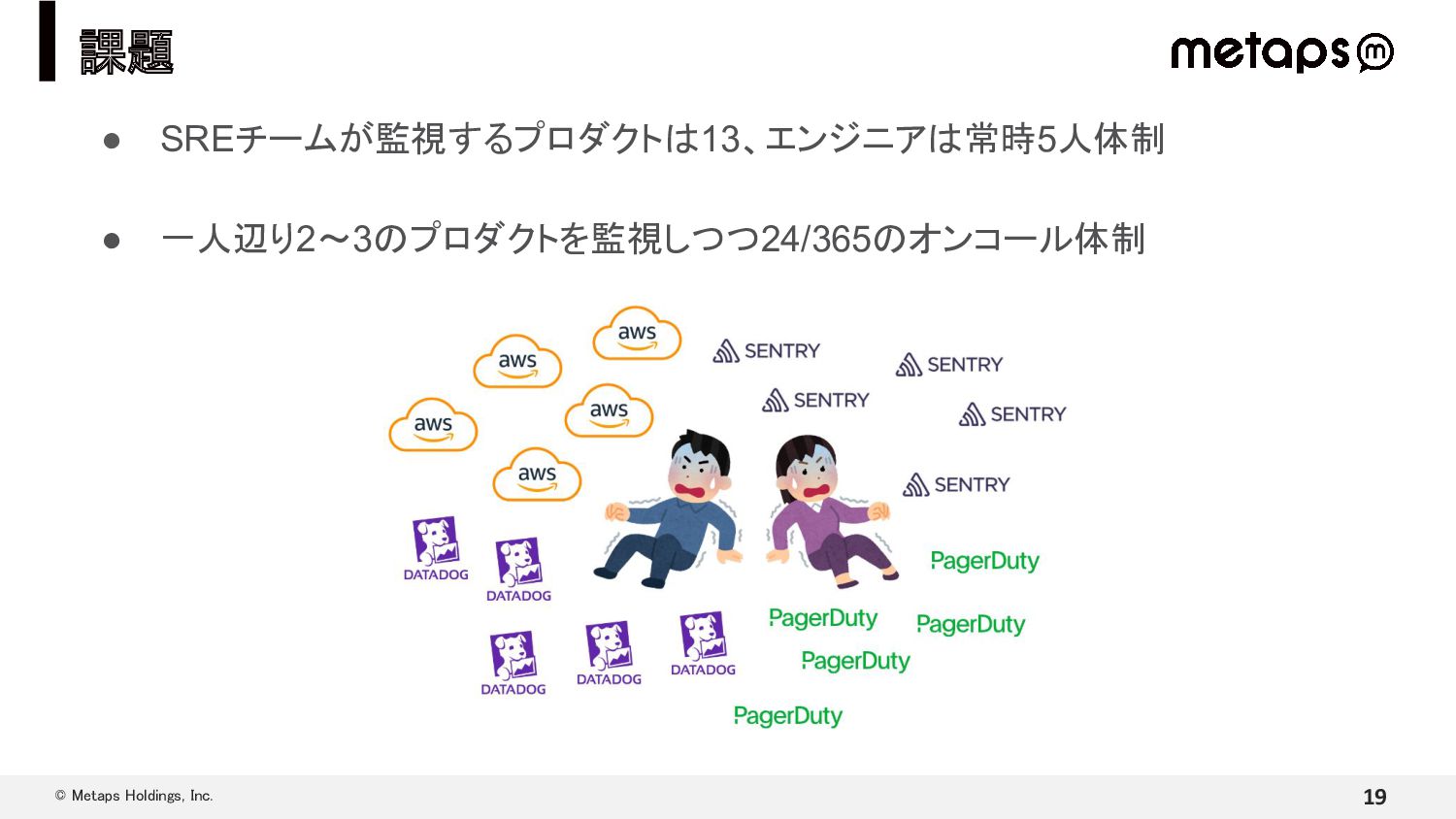{kind=link}
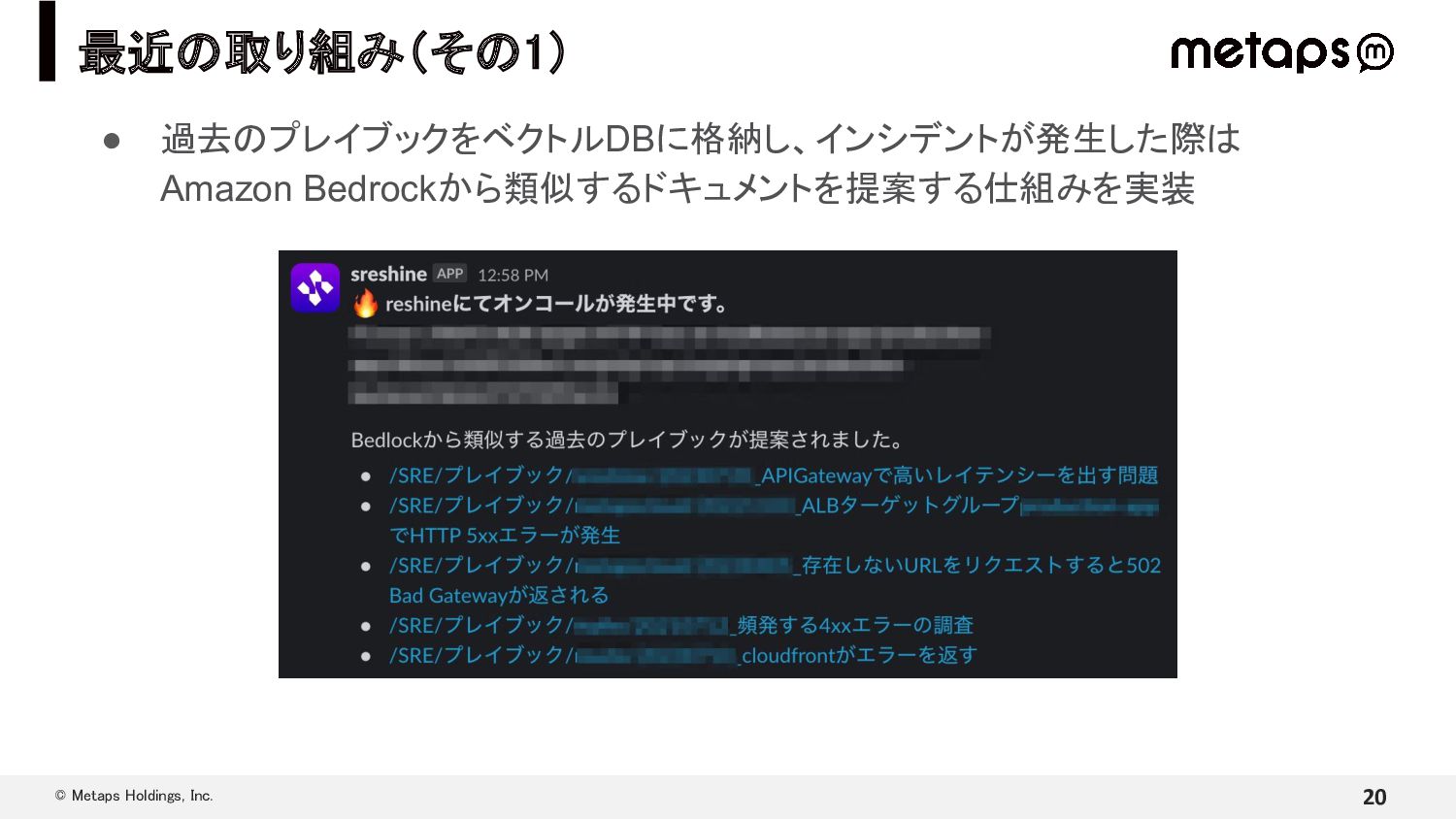{kind=link}
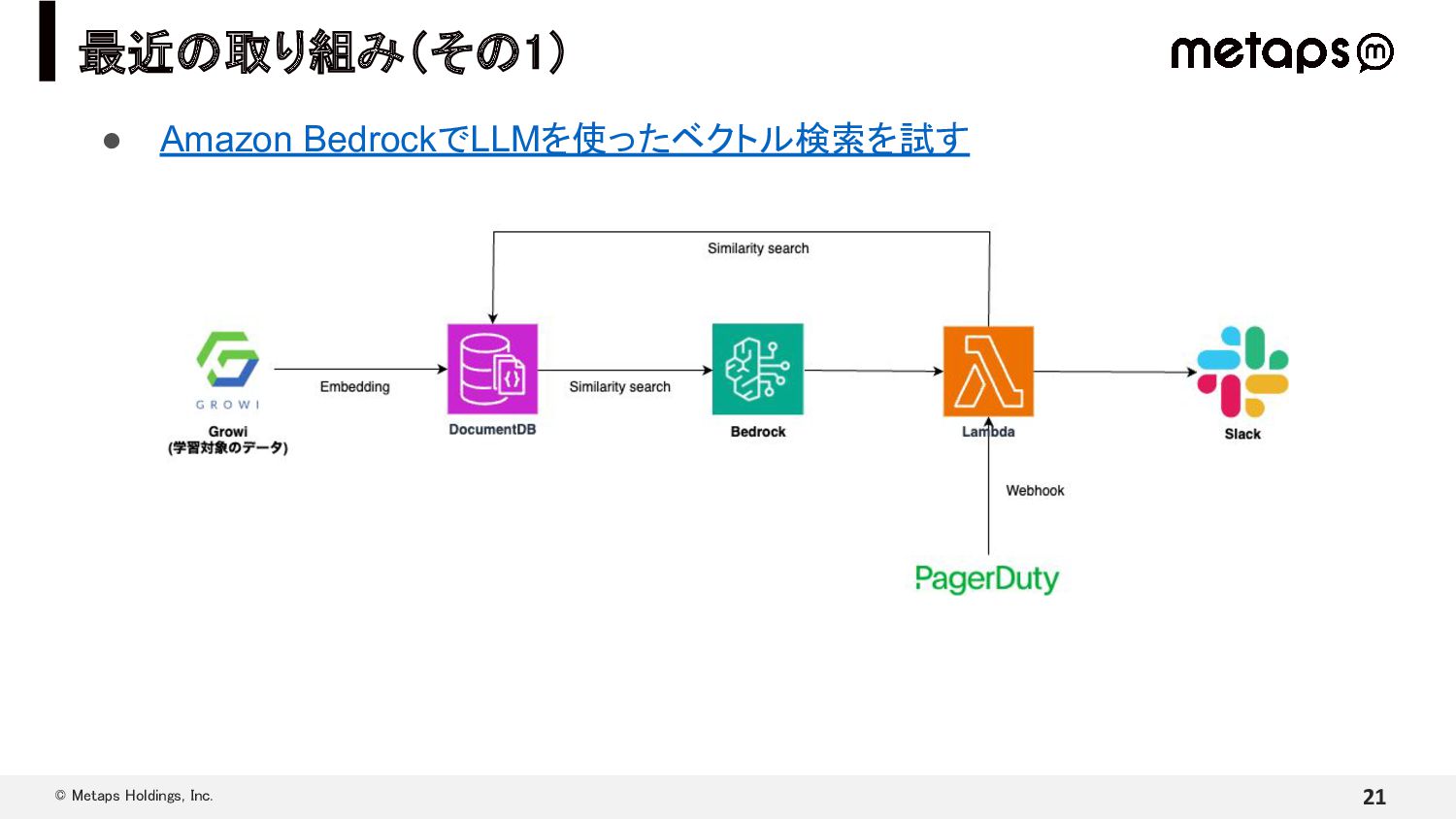{kind=link}
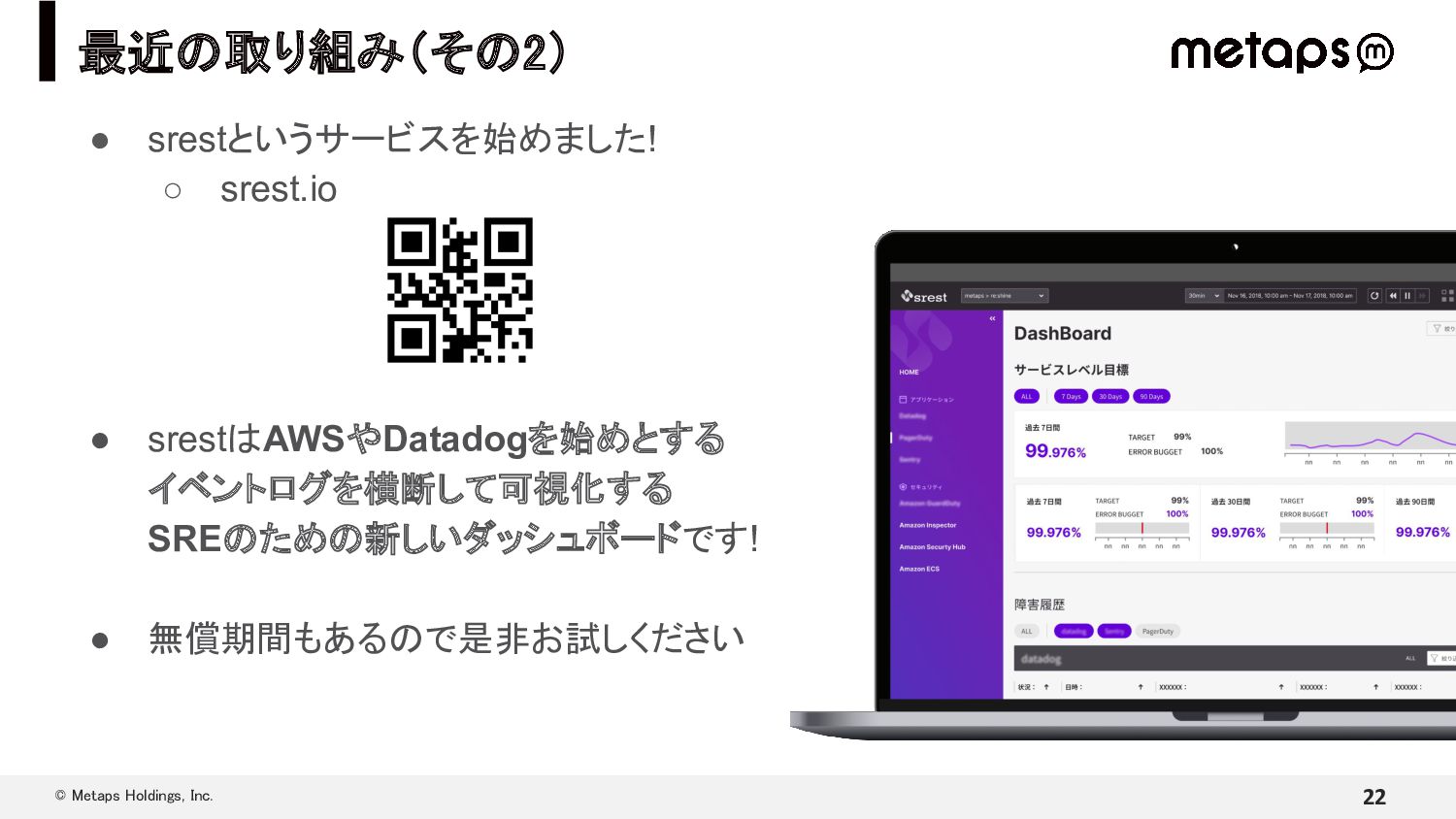{kind=link}
{kind=link}