Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
BPE-Dropout: Simple and Effective Subword Regul...
Search
Shota Koyama
September 23, 2020
390
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
BPE-Dropout: Simple and Effective Subword Regularization
Shota Koyama
September 23, 2020
More Decks by Shota Koyama
See All by Shota Koyama
Cross-Sentence Grammatical Error Correction(paper reading slnp2019)
nymwa
0
210
Featured
See All Featured
Code Review Best Practice
trishagee
74
20k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
620
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.7k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Odyssey Design
rkendrick25
PRO
2
730
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
410
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
How to Ace a Technical Interview
jacobian
281
24k
Thoughts on Productivity
jonyablonski
76
5.3k
The Spectacular Lies of Maps
axbom
PRO
1
870
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Transcript
BPE-Dropout: Simple and Effective Subword Regularization Ivan Provilkov, Dmitrii Emelianenko,
Elena Voita (ACL 2020) 最先端 NLP 勉強会 2020(2020/09/25) 読む人: 古山翔太(東工大岡崎研 M1) 1
概要 • 新しいサブワード正則化手法 BPE-Dropout を提案 ▷ 確率的に BPE のマージを dropout
• 貢献 ▷ シンプル & 効果的なサブワード正則化 ▷ BPE に比べ BLEU が~2.3 ポイント向上 ▷ embedding の質の向上や綴り誤りへの頑健性を確認 2
背景 (1): BPE • 各単語をまず文字単位に分解して, 規則に従ってマージしていく ▷ 語彙サイズ抑えめで低頻度語を扱える ▷ 系列が長くなりすぎない
• 機械翻訳などの生成タスクにおいて, de-facto standard しかし... • 各単語は決定的に分割される ▷ 形態論的特徴 (語形・形態素など) を活かせていないかも... • unrelated = un + related など • 低頻度語の分割がうまいこといってるのか謎 3
背景 (2): Sentencepiece • 複数の分割候補を言語モデルを用いてサンプリングする • 複数の分割を考慮すると,分割の曖昧性やノイズに頑健に ▷ サブワード正則化 •
翻訳で BPE より高性能 しかし... • ユニグラム言語モデルからサブワードの確率を計算・EM 法,ビ タビ法による探索 ▷ BPE と比べて大変 4
提案手法: BPE-Dropout(1) • まずは普通の BPE 1. 現在の分割で可能なマージを列 挙 (図の”-”) 2.
学習コーパスで最頻なペアをマ ージ ▷ ”-” がなくなったら終了 5
提案手法: BPE-Dropout(2) • BPE-dropout 1. 現在の分割で可能なマージを列 挙 (図の”-”) 2. 列挙したマージ操作を確率
p で 削除(図の” ”) 3. 学習コーパスで最頻なペアをマ ージ ▷ ”-” がなくなったら終了 6
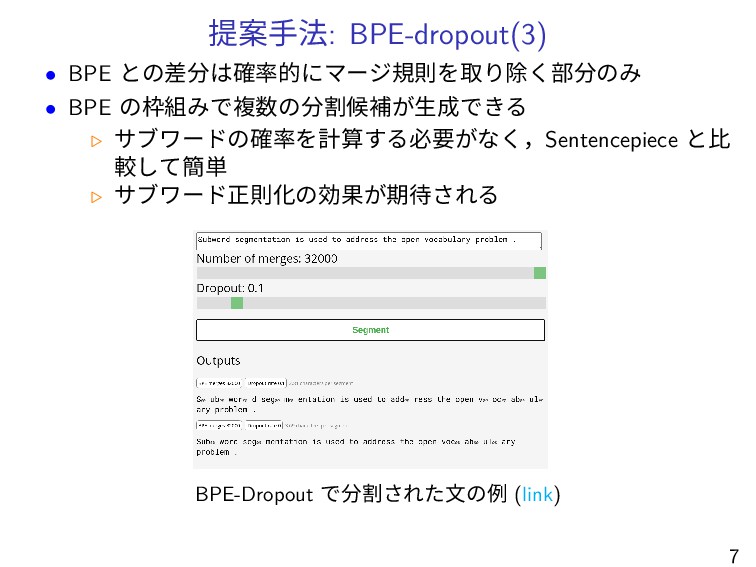
提案手法: BPE-dropout(3) • BPE との差分は確率的にマージ規則を取り除く部分のみ • BPE の枠組みで複数の分割候補が生成できる ▷ サブワードの確率を計算する必要がなく,Sentencepiece
と比 較して簡単 ▷ サブワード正則化の効果が期待される BPE-Dropout で分割された文の例 (link) 7
実験設定 • タスク: NMT • モデル: Transformer base • ベースライン
▷ BPE ▷ Sentencepiece • ハイパーパラメータは Kudo+ 18 に準拠 • dropout 確率 ▷ 訓練時: 0.1 ▷ 推論時: 0 8
データセット • 上 2 段が low-resource • 下 2 段が
high-resource • Zh, Ja は文のままで分割 ▷ En, Fr 等とトークン数の増加率を合わせるため p = 0.6 9
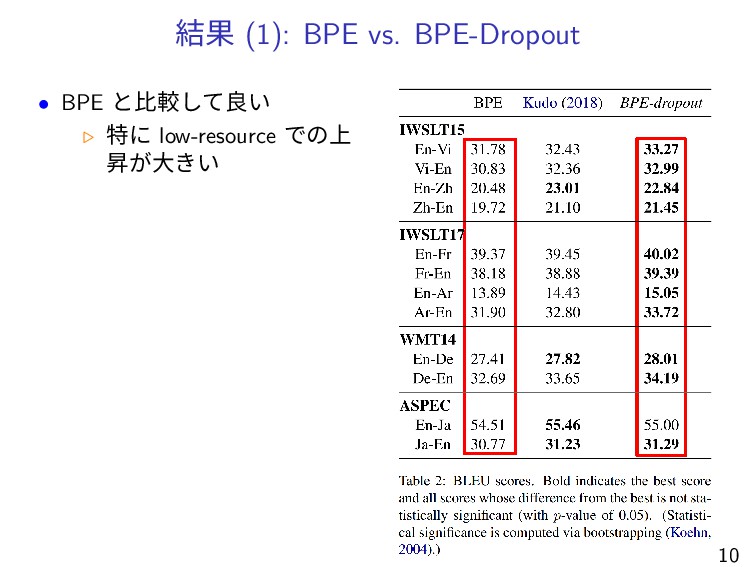
結果 (1): BPE vs. BPE-Dropout • BPE と比較して良い ▷ 特に
low-resource での上 昇が大きい 10
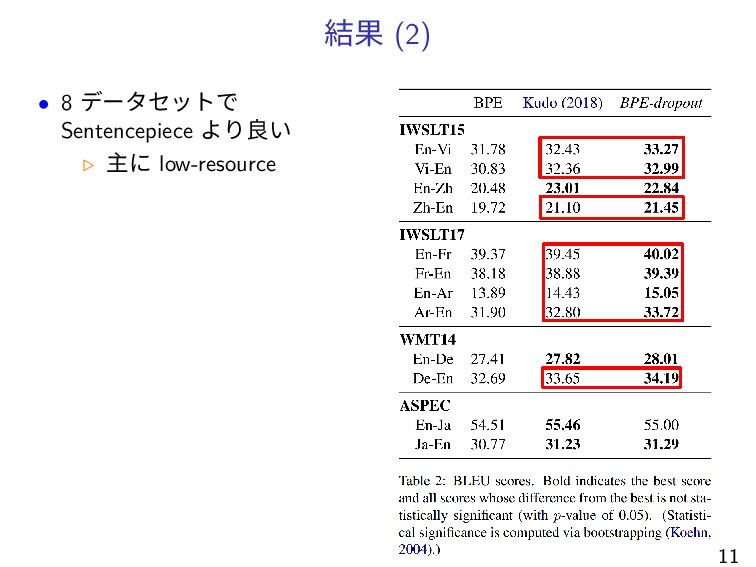
結果 (2) • 8 データセットで Sentencepiece より良い ▷ 主に low-resource
11
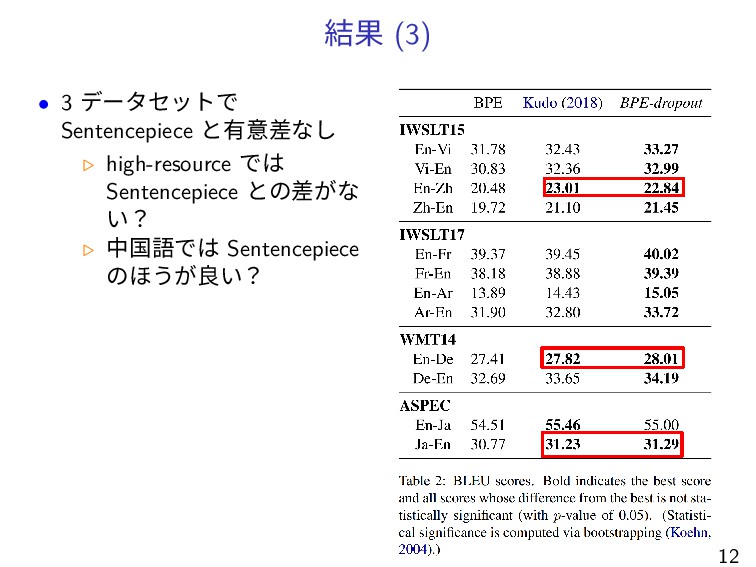
結果 (3) • 3 データセットで Sentencepiece と有意差なし ▷ high-resource では
Sentencepiece との差がな い? ▷ 中国語では Sentencepiece のほうが良い? 12
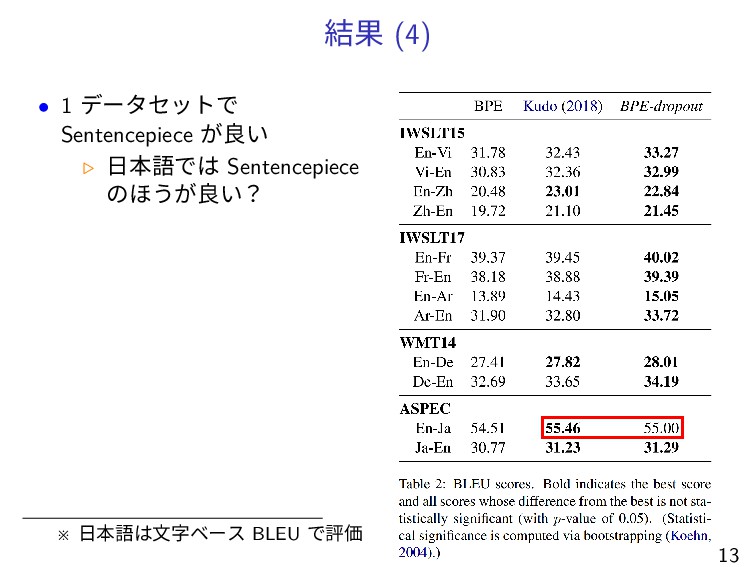
結果 (4) • 1 データセットで Sentencepiece が良い ▷ 日本語では Sentencepiece
のほうが良い? ※ 日本語は文字ベース BLEU で評価 13
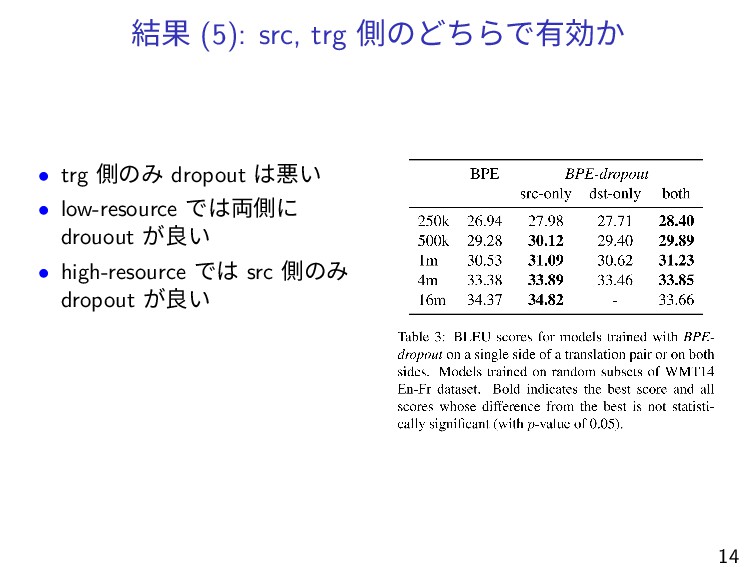
結果 (5): src, trg 側のどちらで有効か • trg 側のみ dropout は悪い
• low-resource では両側に drouout が良い • high-resource では src 側のみ dropout が良い 14
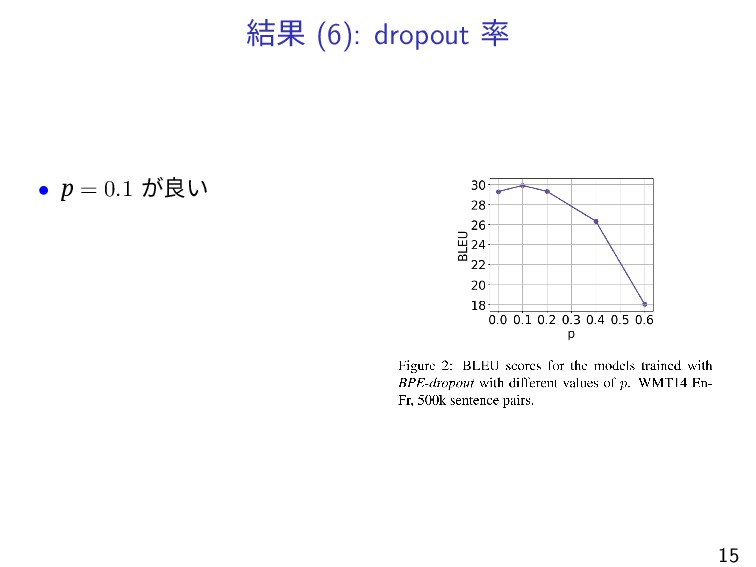
結果 (6): dropout 率 • p = 0.1 が良い 15
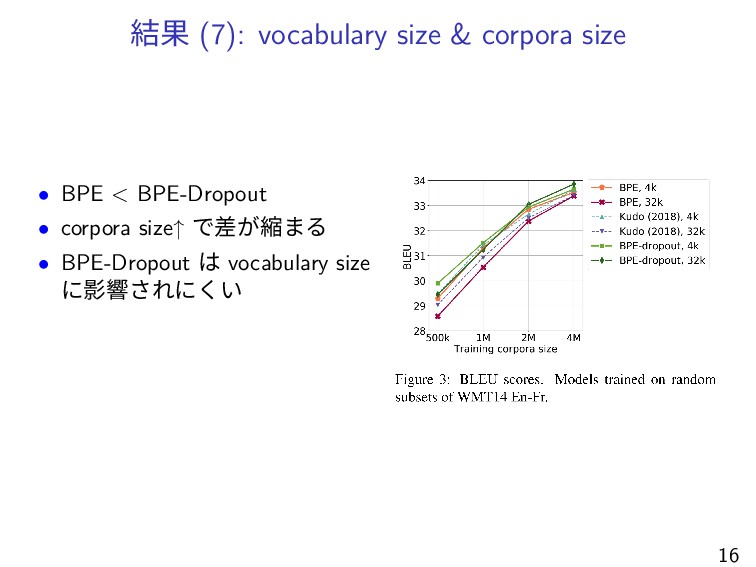
結果 (7): vocabulary size & corpora size • BPE <
BPE-Dropout • corpora size↑ で差が縮まる • BPE-Dropout は vocabulary size に影響されにくい 16
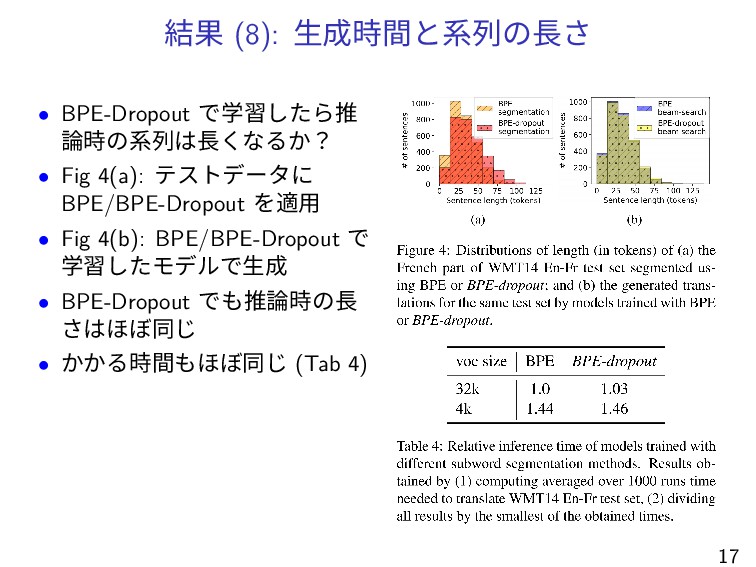
結果 (8): 生成時間と系列の長さ • BPE-Dropout で学習したら推 論時の系列は長くなるか? • Fig 4(a):
テストデータに BPE/BPE-Dropout を適用 • Fig 4(b): BPE/BPE-Dropout で 学習したモデルで生成 • BPE-Dropout でも推論時の長 さはほぼ同じ • かかる時間もほぼ同じ (Tab 4) 17
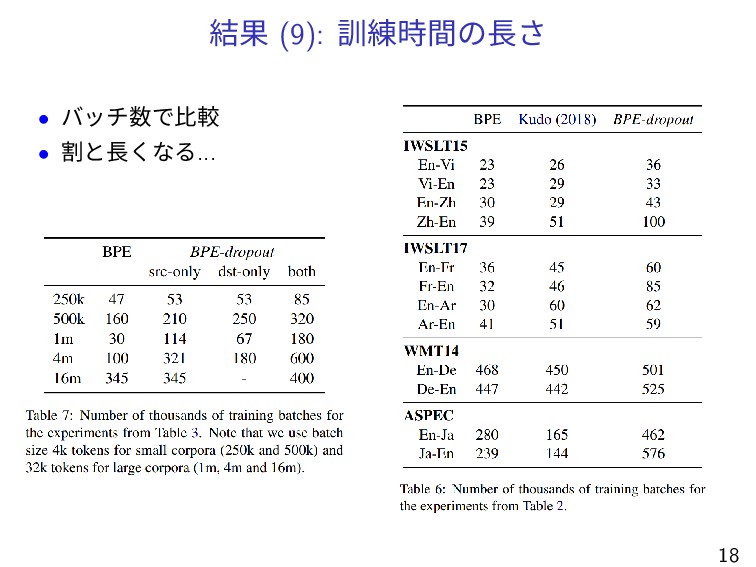
結果 (9): 訓練時間の長さ • バッチ数で比較 • 割と長くなる... 18
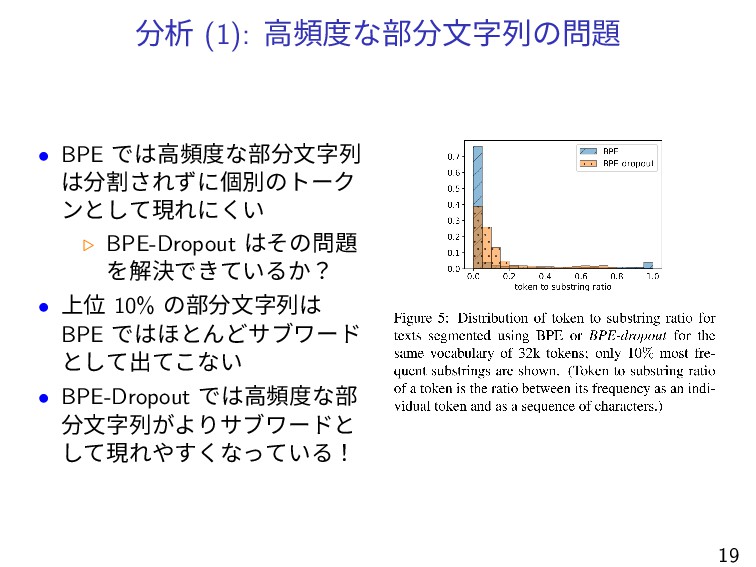
分析 (1): 高頻度な部分文字列の問題 • BPE では高頻度な部分文字列 は分割されずに個別のトーク ンとして現れにくい ▷ BPE-Dropout
はその問題 を解決できているか? • 上位 10% の部分文字列は BPE ではほとんどサブワード として出てこない • BPE-Dropout では高頻度な部 分文字列がよりサブワードと して現れやすくなっている! 19
分析 (2): embedding の質 • embedding を SVD で可視化 (→)
▷ BPE では頻度によるバイ アスが起こる ▷ BPE-Dropout では解消 • BPE-Dropout では部分文字列 を共有した embedding が近傍 に来やすい 20
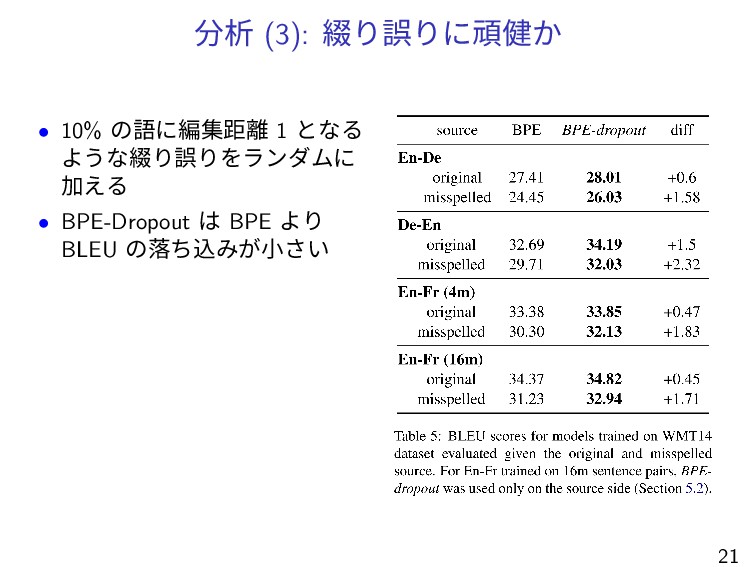
分析 (3): 綴り誤りに頑健か • 10% の語に編集距離 1 となる ような綴り誤りをランダムに 加える
• BPE-Dropout は BPE より BLEU の落ち込みが小さい 21
まとめ • サブワード正則化手法 BPE-Dropout を提案 • 既存手法よりシンプル & 性能の向上に寄与 •
embedding の質が向上 & 綴り誤りに頑健 22
実装 • subword-nmt ▷ subword-nmt apply-bpe --dropout 0.1 • sentencepiece(に実装されている
BPE) ▷ sp.encode("hoge", enable_sampling = True, alpha = 0.1) 23
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}