Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Cross-Sentence Grammatical Error Correction(pap...
Search
Shota Koyama
September 28, 2019
210
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Cross-Sentence Grammatical Error Correction(paper reading slnp2019)
Shota Koyama
September 28, 2019
More Decks by Shota Koyama
See All by Shota Koyama
BPE-Dropout: Simple and Effective Subword Regularization
nymwa
0
390
Featured
See All Featured
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
380
HDC tutorial
michielstock
2
750
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
First, design no harm
axbom
PRO
2
1.2k
GitHub's CSS Performance
jonrohan
1033
470k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Discover your Explorer Soul
emna__ayadi
2
1.2k
How to Ace a Technical Interview
jacobian
281
24k
Designing Experiences People Love
moore
143
24k
Transcript
Cross-Sentence Grammatical Error Correction Shamil Chollampatt, Weiqi Wang, Hwee Tou
Ng ACL 2019 最先端 NLP 勉強会 2019 2019/09/28 読む人:古山翔太 (東工大岡崎研 B4) 1
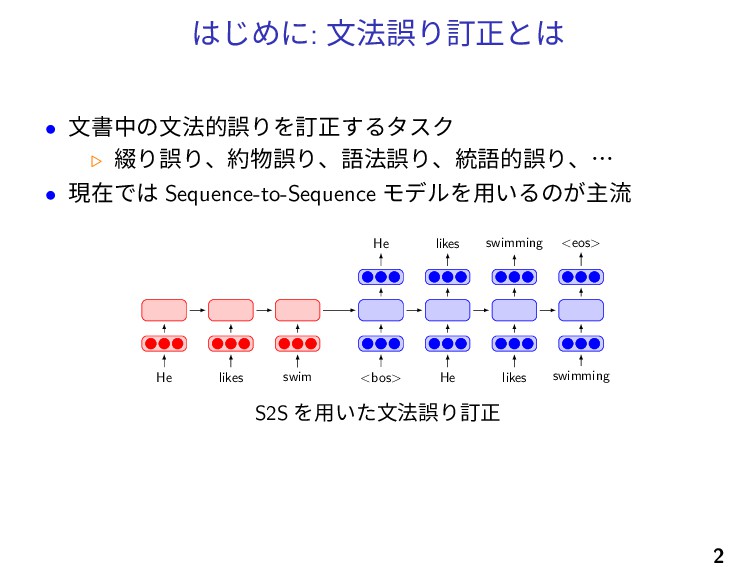
はじめに: 文法誤り訂正とは • 文書中の文法的誤りを訂正するタスク ▷ 綴り誤り、約物誤り、語法誤り、統語的誤り、⋯ • 現在では Sequence-to-Sequence モデルを用いるのが主流
He likes swim He <bos> likes He swimming likes <eos> swimming S2S を用いた文法誤り訂正 2
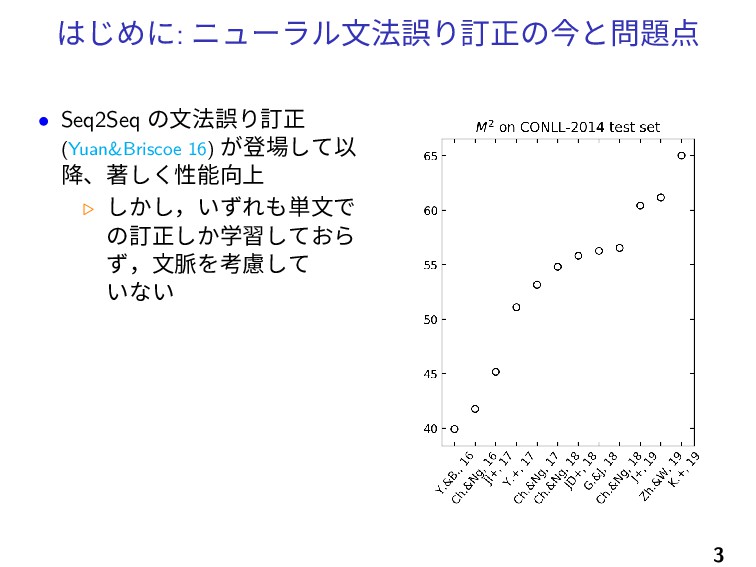
はじめに: ニューラル文法誤り訂正の今と問題点 • Seq2Seq の文法誤り訂正 (Yuan&Briscoe 16) が登場して以 降、著しく性能向上 ▷
しかし,いずれも単文で の訂正しか学習しておら ず,文脈を考慮して いない 3
はじめに: 文脈を考慮した文法誤り訂正 • しかし NUCLE コーパスには 文脈を考慮しないと訂正でき ない誤りが存在している • OUT
OF CONTEXT (´・_・) 4
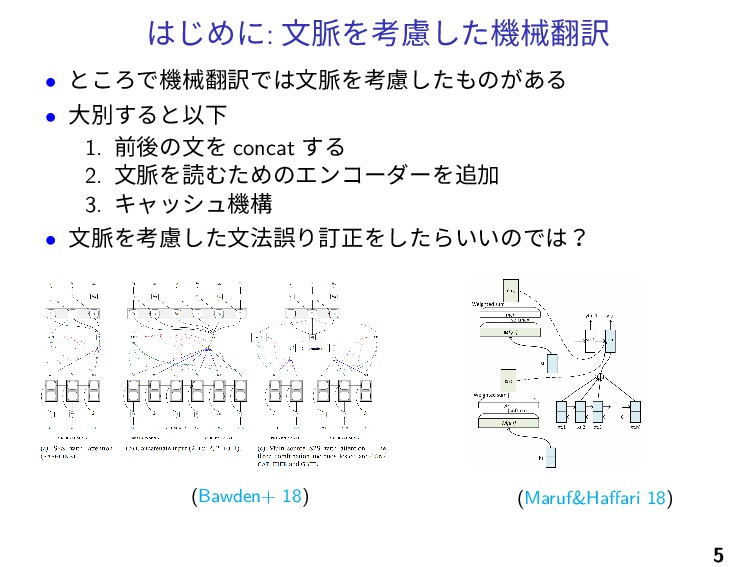
はじめに: 文脈を考慮した機械翻訳 • ところで機械翻訳では文脈を考慮したものがある • 大別すると以下 1. 前後の文を concat する
2. 文脈を読むためのエンコーダーを追加 3. キャッシュ機構 • 文脈を考慮した文法誤り訂正をしたらいいのでは? (Bawden+ 18) (Maruf&Haffari 18) 5
概略 • 問題点 ▷ 既存の文法誤り訂正の手法は文脈を考慮した訂正を行ってい ない ▷ そのため,文脈に依存した文法誤りを検出することがで きない •
提案手法 ▷ 既存のエンコーダーデコーダーモデルに,訂正する文の前の 数文から補助アテンションを得る仕組み追加する • 結果 ▷ CoNLL-2014 共有タスクで M2 スコアが上昇 (F0.5 = 57.30) 6
Cross-Sentense Context を利用した 文法誤り訂正モデル 7
文脈を組み込んだ翻訳モデル • 文法誤り訂正は誤り文から修正文への翻訳タスク • 標準的な文レベルの翻訳モデル P(Tk|Sk, Θ) = |Tk| i=1
P(tk,i|Tk,<i, Sk, Θ) (1) • ソース文書の文脈を考慮した翻訳モデル P(Tk|Sk, Θ) = |Tk| i=1 P(tk,i|Tk,<i, Sk, Sdoc, Θ) (2) • 簡単のため,Sdoc = Sk−2, Sk−1 (前の 2 文) とする 8
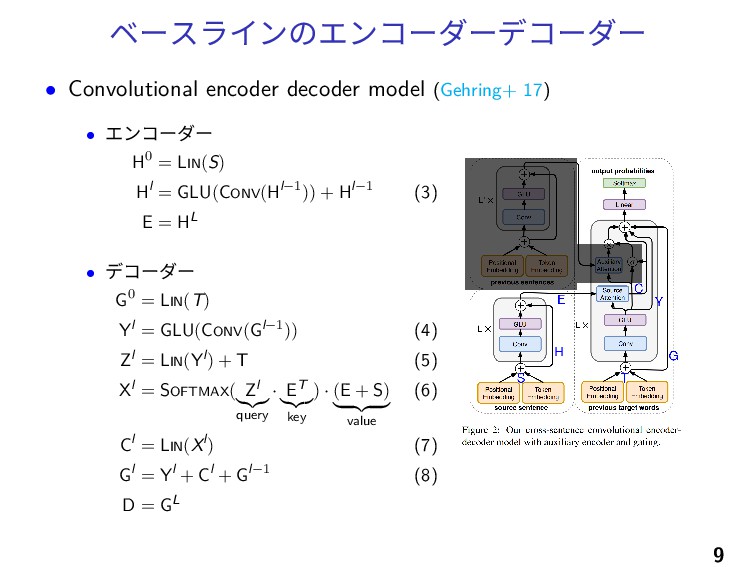
ベースラインのエンコーダーデコーダー • Convolutional encoder decoder model (Gehring+ 17) • エンコーダー
H0 = LIN(S) Hl = GLU(CONV(Hl−1)) + Hl−1 (3) E = HL • デコーダー G0 = LIN(T) Yl = GLU(CONV(Gl−1)) (4) Zl = LIN(Yl) + T (5) Xl = SOFTMAX( Zl query · ET key ) · (E + S) value (6) Cl = LIN(Xl) (7) Gl = Yl + Cl + Gl−1 (8) D = GL 9
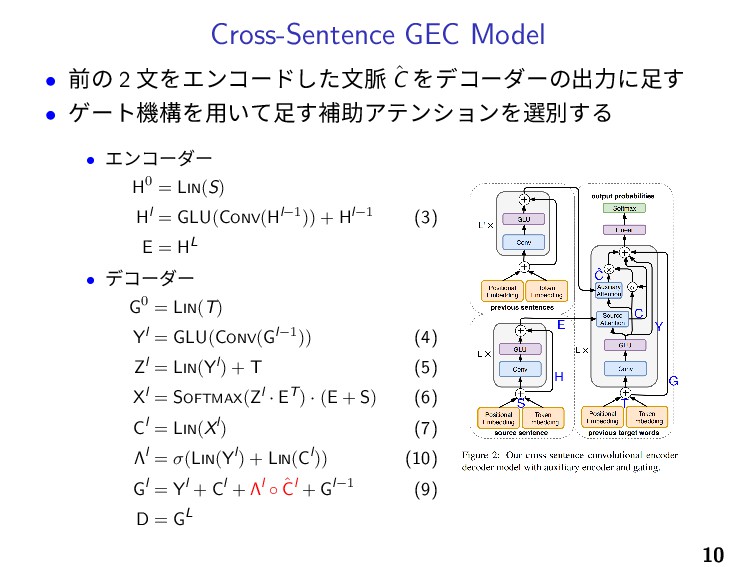
Cross-Sentence GEC Model • 前の 2 文をエンコードした文脈 ˆ C をデコーダーの出力に足す
• ゲート機構を用いて足す補助アテンションを選別する • エンコーダー H0 = LIN(S) Hl = GLU(CONV(Hl−1)) + Hl−1 (3) E = HL • デコーダー G0 = LIN(T) Yl = GLU(CONV(Gl−1)) (4) Zl = LIN(Yl) + T (5) Xl = SOFTMAX(Zl · ET) · (E + S) (6) Cl = LIN(Xl) (7) Λl = σ(LIN(Yl) + LIN(Cl)) (10) Gl = Yl + Cl + Λl ◦ ˆ Cl + Gl−1 (9) D = GL 10
実験 11
実験設定 • データ ▷ 訓練データ:Lang-8 Leaner Corpora V2.0 と NUCLE
• どちらも文書からなり,文脈を利用可能 ▷ 検証データ:NUCLE の subset ▷ テストデータ:CoNLL-2013,CoNLL-2014,FCE • どちらも文書からなり,文脈を考慮できているか評価可 能 • M2 スコアで評価 12
実験設定 • モデル ▷ ベースライン (BASELINE) • ConvS2S (Gehring+ 17)
• ソース文の単語毎ドロップアウト (Junczys-Dowmunt+ 18b) • 単語ベクトルの事前学習 (Chollampatt&Ng 18a) ▷ Wikipedia • デコーダーの事前学習 (Chollampatt&Ng 18b) ▷ Common Crawl • ラベル平滑化 (ϵls = 0.1) ▷ 提案手法 (CROSENT) • ベースラインに補助エンコーダーを追加 13
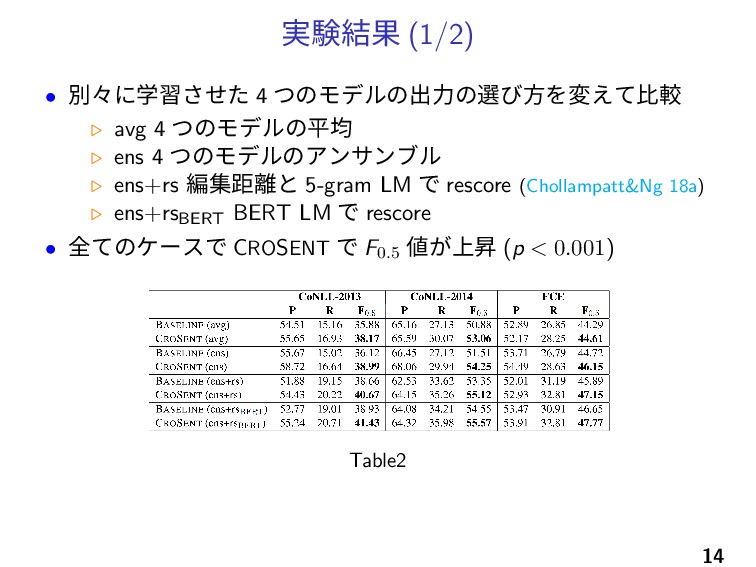
実験結果 (1/2) • 別々に学習させた 4 つのモデルの出力の選び方を変えて比較 ▷ avg 4 つのモデルの平均
▷ ens 4 つのモデルのアンサンブル ▷ ens+rs 編集距離と 5-gram LM で rescore (Chollampatt&Ng 18a) ▷ ens+rsBERT BERT LM で rescore • 全てのケースで CROSENT で F0.5 値が上昇 (p < 0.001) Table2 14
実験結果 (2/2) • 他の手法との比較 ▷ 出力の品質評価をした手 法 (Chollampatt&Ng 18b) と
のアンサンブルで F0.5 が 上昇 ▷ 同じデータセットを用い た他の手法より良い1 ▷ データセットを増やした ものに迫る結果でとても 良いと思います Table3 1今では 61.15(Zhao+ 19) などの方が良い 15
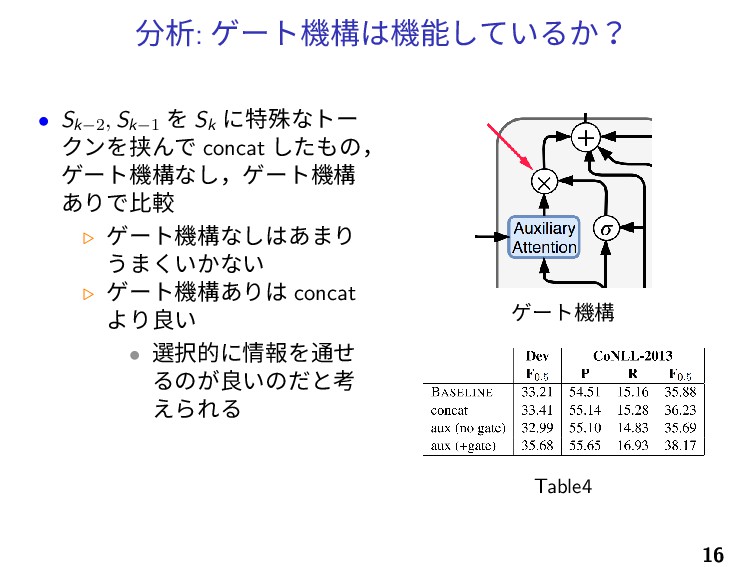
分析: ゲート機構は機能しているか? • Sk−2, Sk−1 を Sk に特殊なトー クンを挟んで concat
したもの, ゲート機構なし,ゲート機構 ありで比較 ▷ ゲート機構なしはあまり うまくいかない ▷ ゲート機構ありは concat より良い • 選択的に情報を通せ るのが良いのだと考 えられる ゲート機構 Table4 16
分析: 文脈が必要な誤りを訂正できているか? • simple Wikipedia の 795 文に人 工的に時制の誤り (1090
個) を 入れて実験 ▷ Sk−2, Sk−1 には誤りが入ら ないようにする ▷ CROSENT は文脈が必要な 誤りを訂正できる 人工的な誤りの例 Table5 17
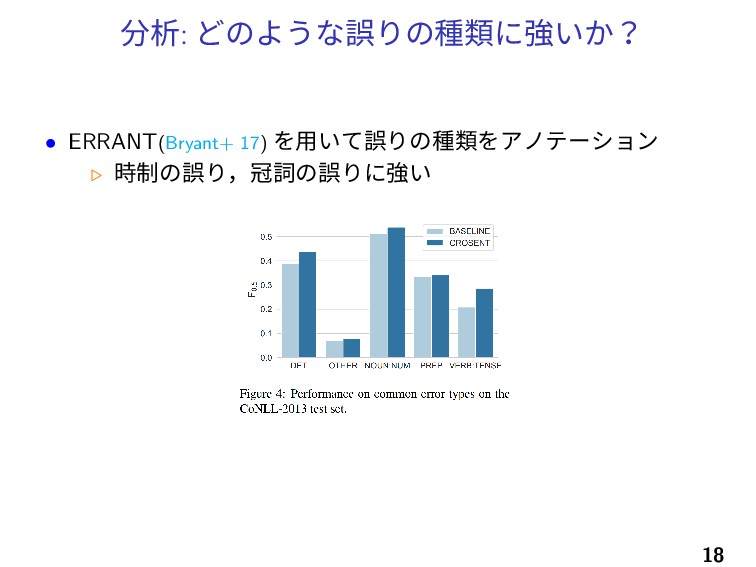
分析: どのような誤りの種類に強いか? • ERRANT(Bryant+ 17) を用いて誤りの種類をアノテーション ▷ 時制の誤り,冠詞の誤りに強い 18
分析: 補助アテンションを欲しているのは誰だ? • 補助アテンションと一様分布の KL 距 離を見て,過去の文脈のどの語にア テンションがかかっているかを見た ▷ CoNLL
13 テストセットで実験 • 名詞にかかっていることが 多い • 同じ名詞が連続した文に現 れがちなためと考えられる ▷ 一様分布との平均 KL 距離が大き いアテンションを張る品詞 • 名詞・固有名詞は過去の文 の同じ語にかかる • 動詞・冠詞は訂正に文脈が 必要なためかかっている 19
まとめと感想 • 前 2 文の補助アテンションを得るエンコーダーを追加して,文脈 を必要とする動詞の時制や冠詞の誤りの訂正を行えるようにした ▷ ゲート機構が大事 ▷ 同じデータセットに限れば当時の
SOTA • 動詞の時制と冠詞の一致だけしか見てないのはなぜ? ▷ 代名詞の誤りや接続詞の誤りに効いてるのだろうか ▷ 名詞で性数格の一致が必要な言語もある • 名詞のアテンションが前の文の同じ名詞にかかるのはわかる ▷ 果たしてそれだけなんだろうか ▷ 形容詞や前置詞の誤りへの寄与とかありそうに思う ▷ 名詞変化の多い言語とかだと違う挙動をしそう • Chollampatt さん,ConvS2S 好きすぎなのでは? 20
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}