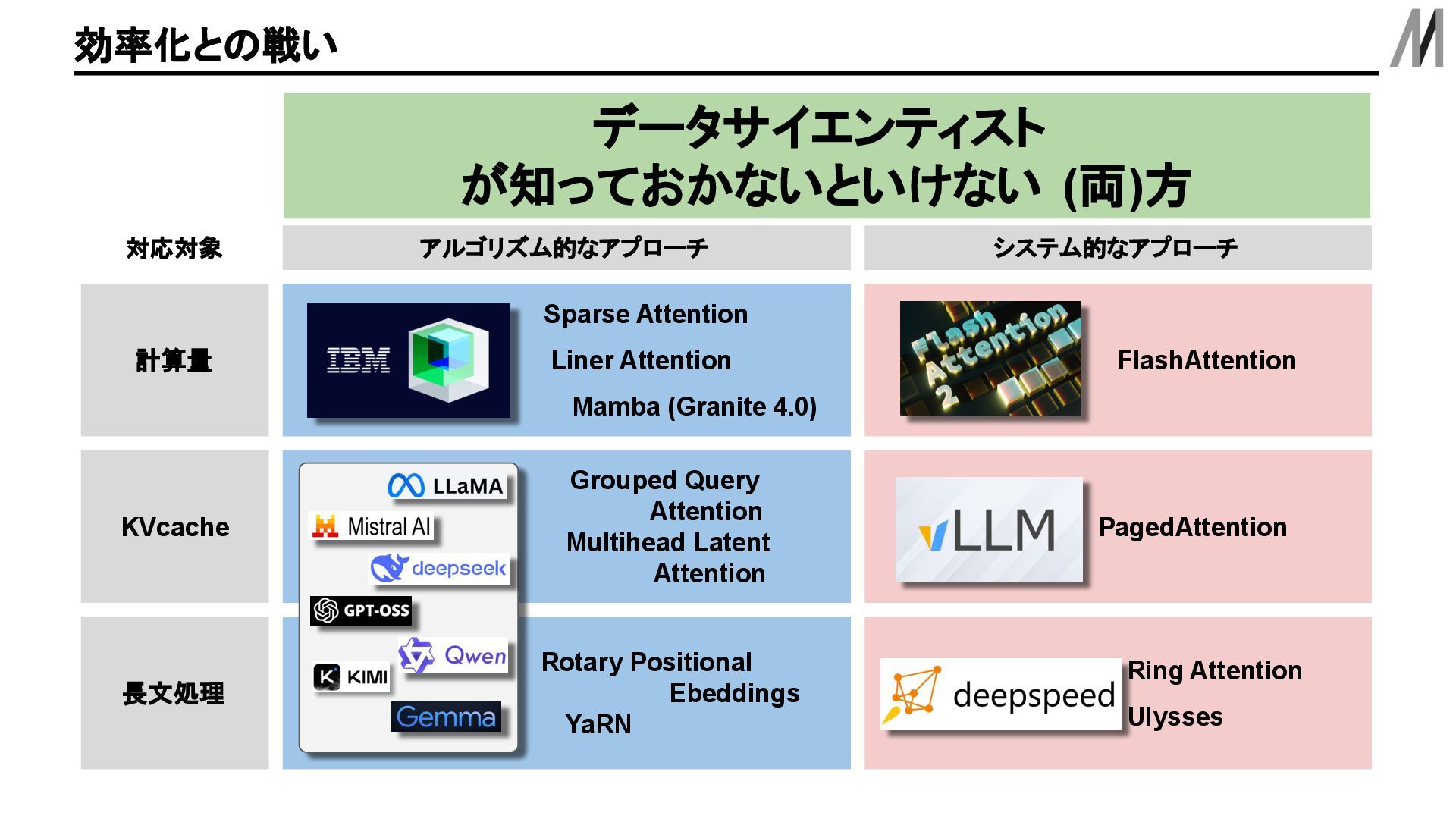
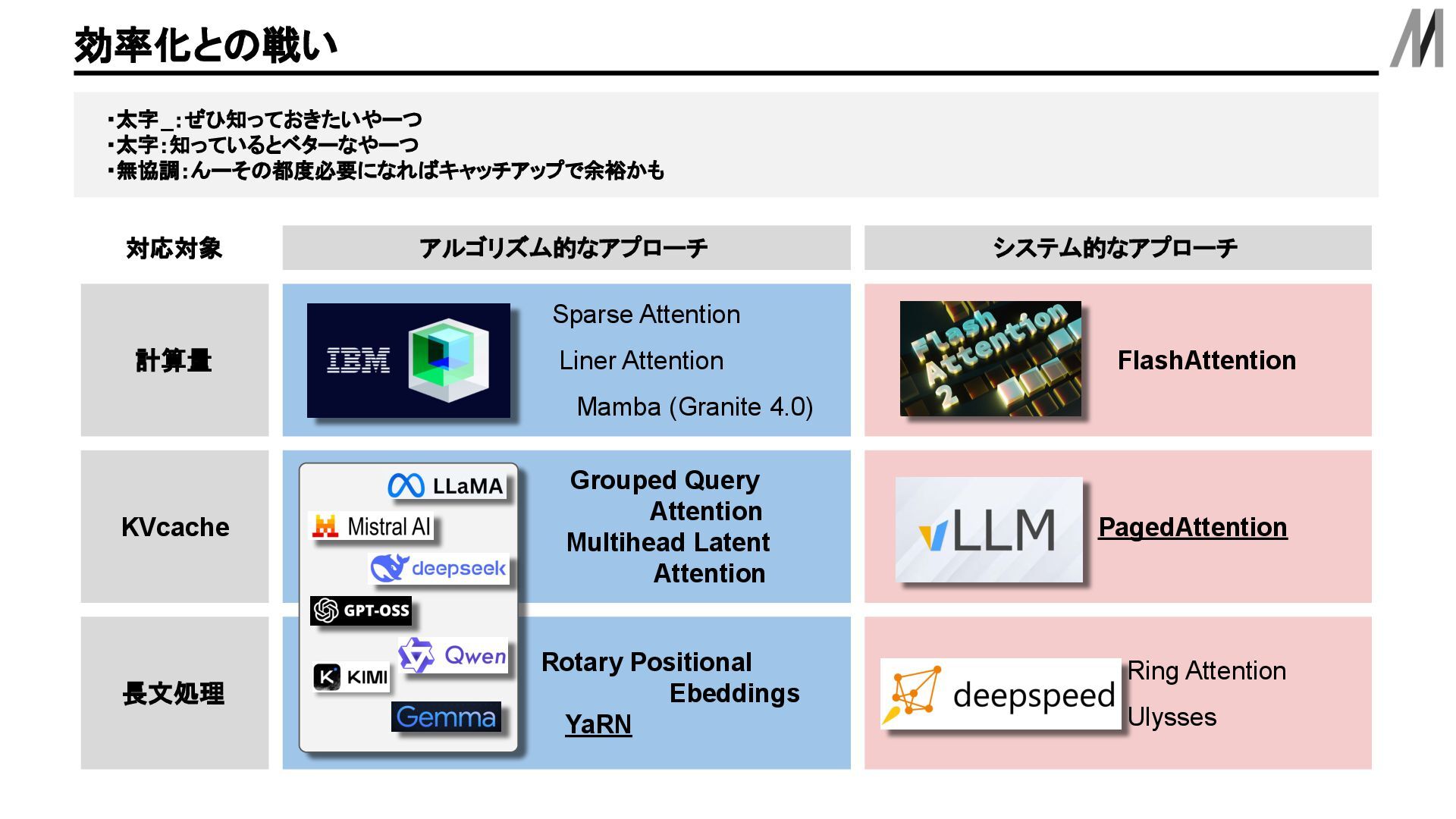
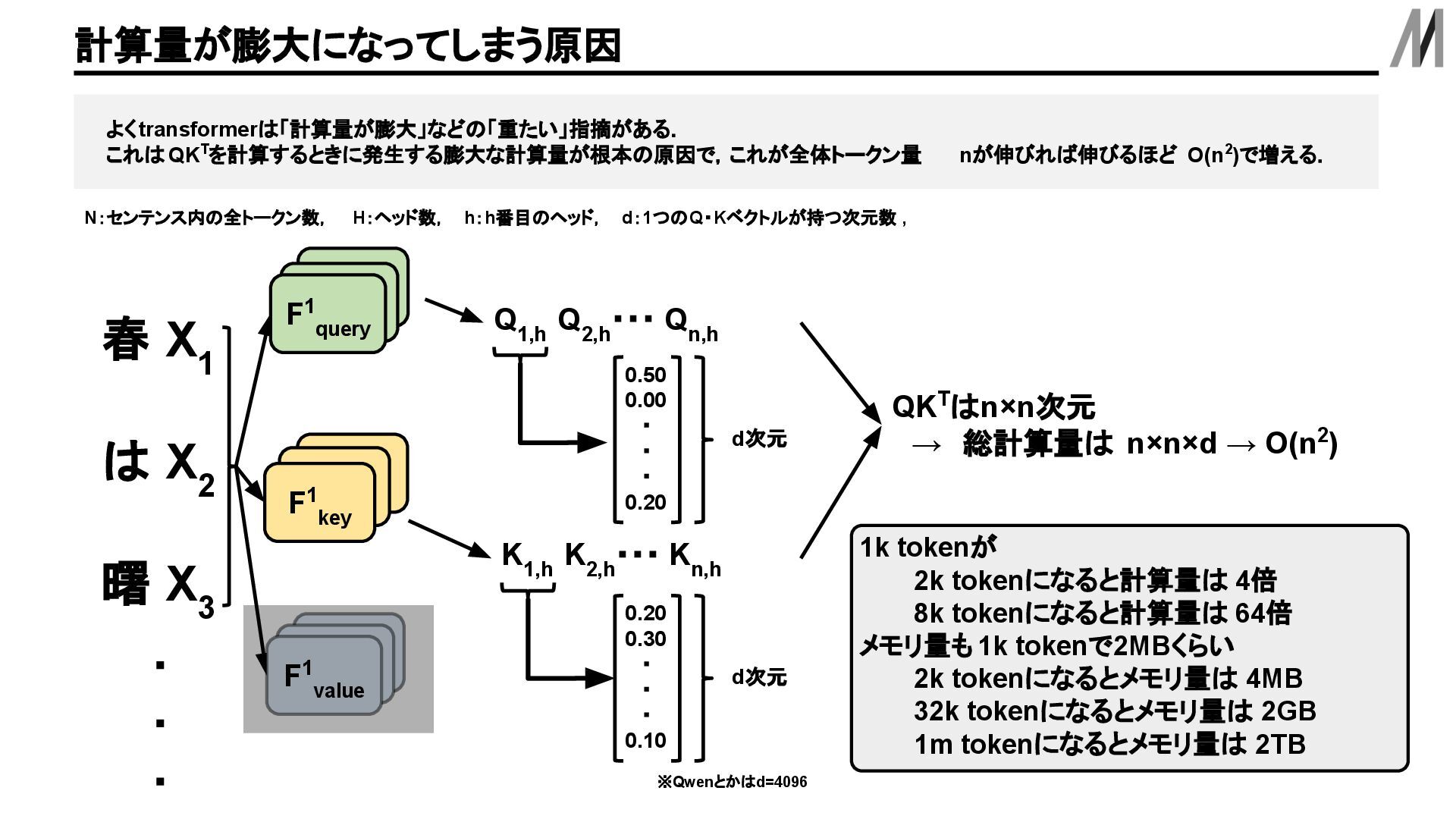
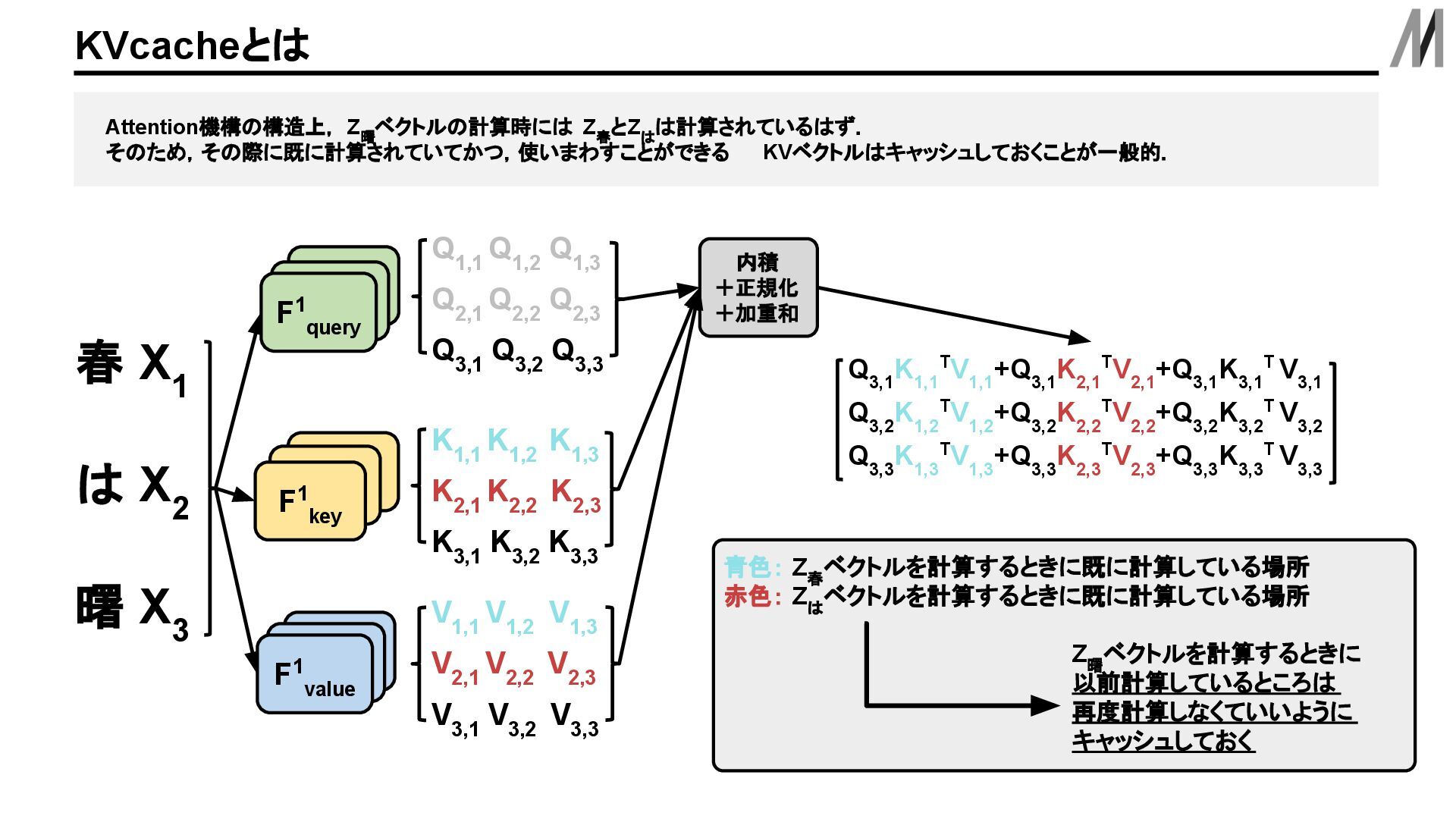
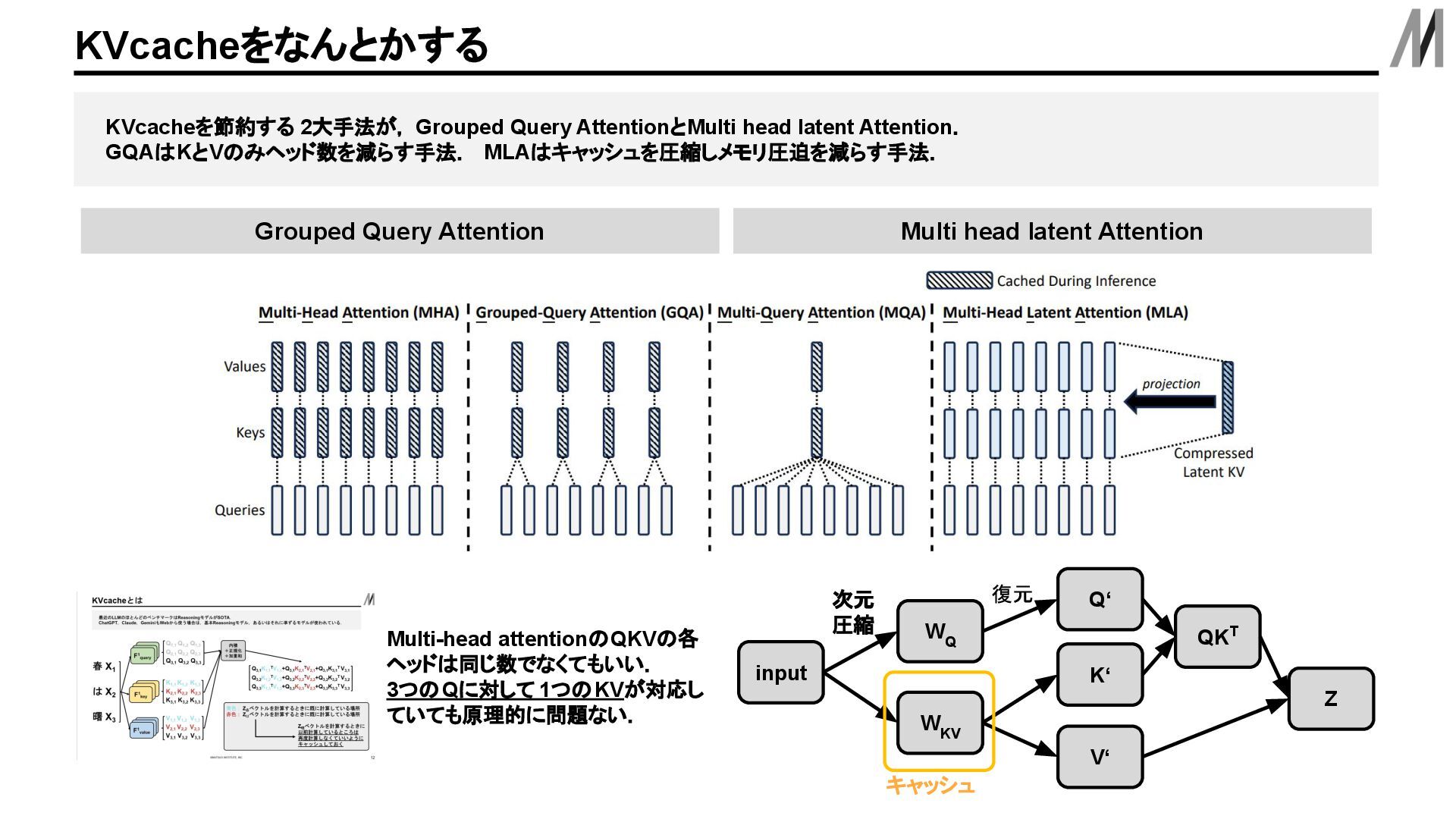
KVベクトルはキャッシュしておくことが一般的. KVcacheとは は X 2 春 X 1 曙 X 3 内積 +正規化 +加重和 Q 1,1 Q 1,2 Q 1,3 Q 2,1 Q 2,2 Q 2,3 Q 3,1 Q 3,2 Q 3,3 F query F1 query F1 query F key F key F1 key F query F1 query F1 value K 1,1 K 1,2 K 1,3 K 2,1 K 2,2 K 2,3 K 3,1 K 3,2 K 3,3 V 1,1 V 1,2 V 1,3 V 2,1 V 2,2 V 2,3 V 3,1 V 3,2 V 3,3 Q 3,1 K 1,1 TV 1,1 +Q 3,1 K 2,1 TV 2,1 +Q 3,1 K 3,1 T V 3,1 Q 3,2 K 1,2 TV 1,2 +Q 3,2 K 2,2 TV 2,2 +Q 3,2 K 3,2 T V 3,2 Q 3,3 K 1,3 TV 1,3 +Q 3,3 K 2,3 TV 2,3 +Q 3,3 K 3,3 T V 3,3 青色: Z 春 ベクトルを計算するときに既に計算している場所 赤色: Z は ベクトルを計算するときに既に計算している場所 Z 曙 ベクトルを計算するときに 以前計算しているところは 再度計算しなくていいように キャッシュしておく
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}