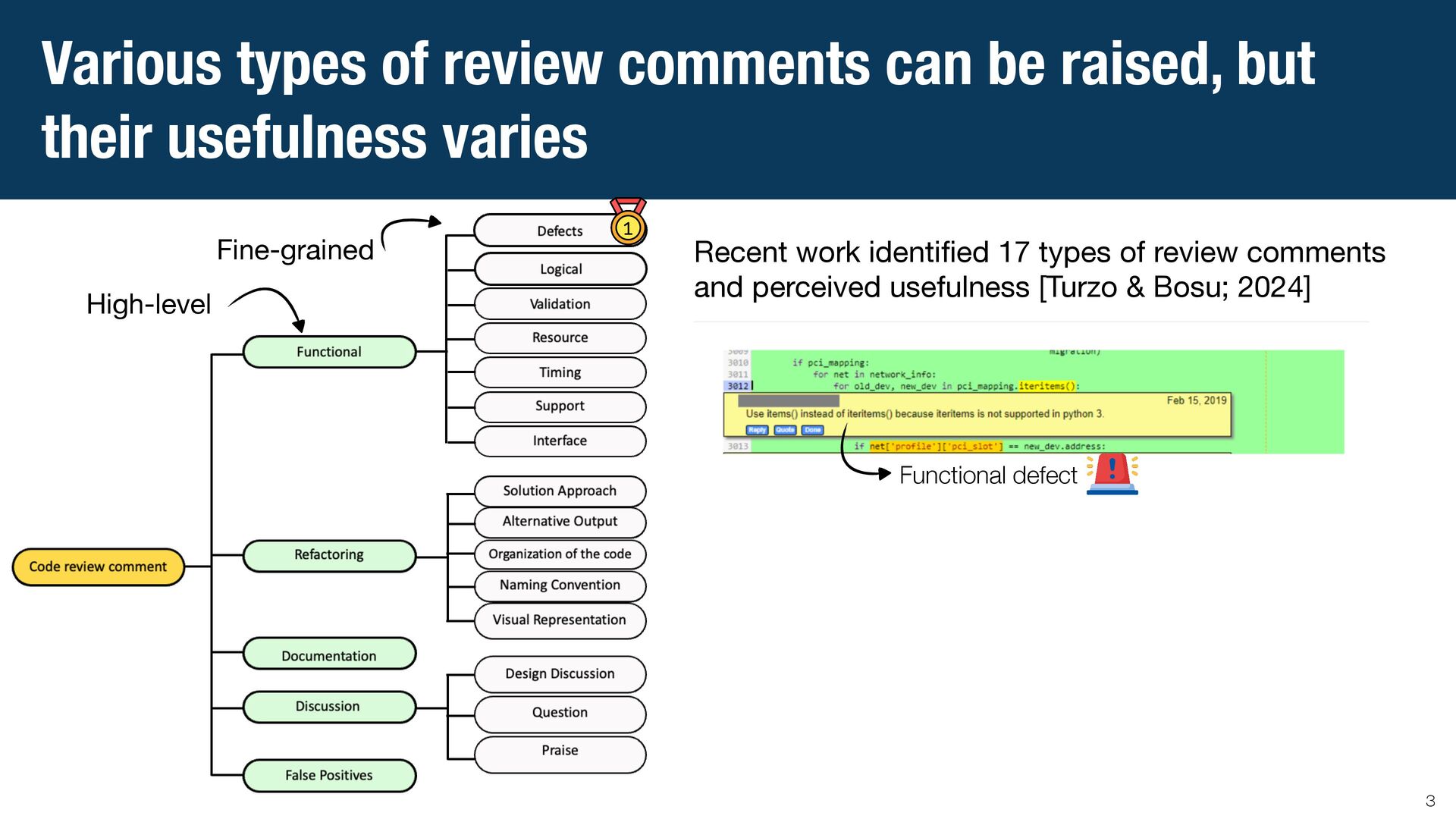
Code review is a crucial practice in software development. As code review nowadays is lightweight, various issues can be identified, and sometimes, they can be trivial. Research has investigated automated approaches to classify review comments to gauge the effectiveness of code reviews. However, previous studies have primarily relied on supervised machine learning, which requires extensive manual annotation to train the models effectively. To address this limitation, we explore the potential of using Large Language Models (LLMs) to classify code review comments. We assess the performance of LLMs to classify 17 categories of code review comments. Our results show that LLMs can classify code review comments, outperforming the state-of-the-art approach using a trained deep learning model. In particular, LLMs achieve better accuracy in classifying the five most useful categories, which the state-of-the-art approach struggles with due to low training examples. Rather than relying solely on a specific small training data distribution, our results show that LLMs provide balanced performance across high- and low-frequency categories. These results suggest that the LLMs could offer a scalable solution for code review analytics to improve the effectiveness of the code review process.
The paper has been accepted at the 2025 IEEE International Conference on Source Code Analysis & Manipulation (SCAM)
![Patanamon (Pick) Thongtanunam [email protected] http://patanamon.com Exploring the Potential of Large](https://files.speakerdeck.com/presentations/a992f5fb4c4e40e1b172f7502755eb99/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
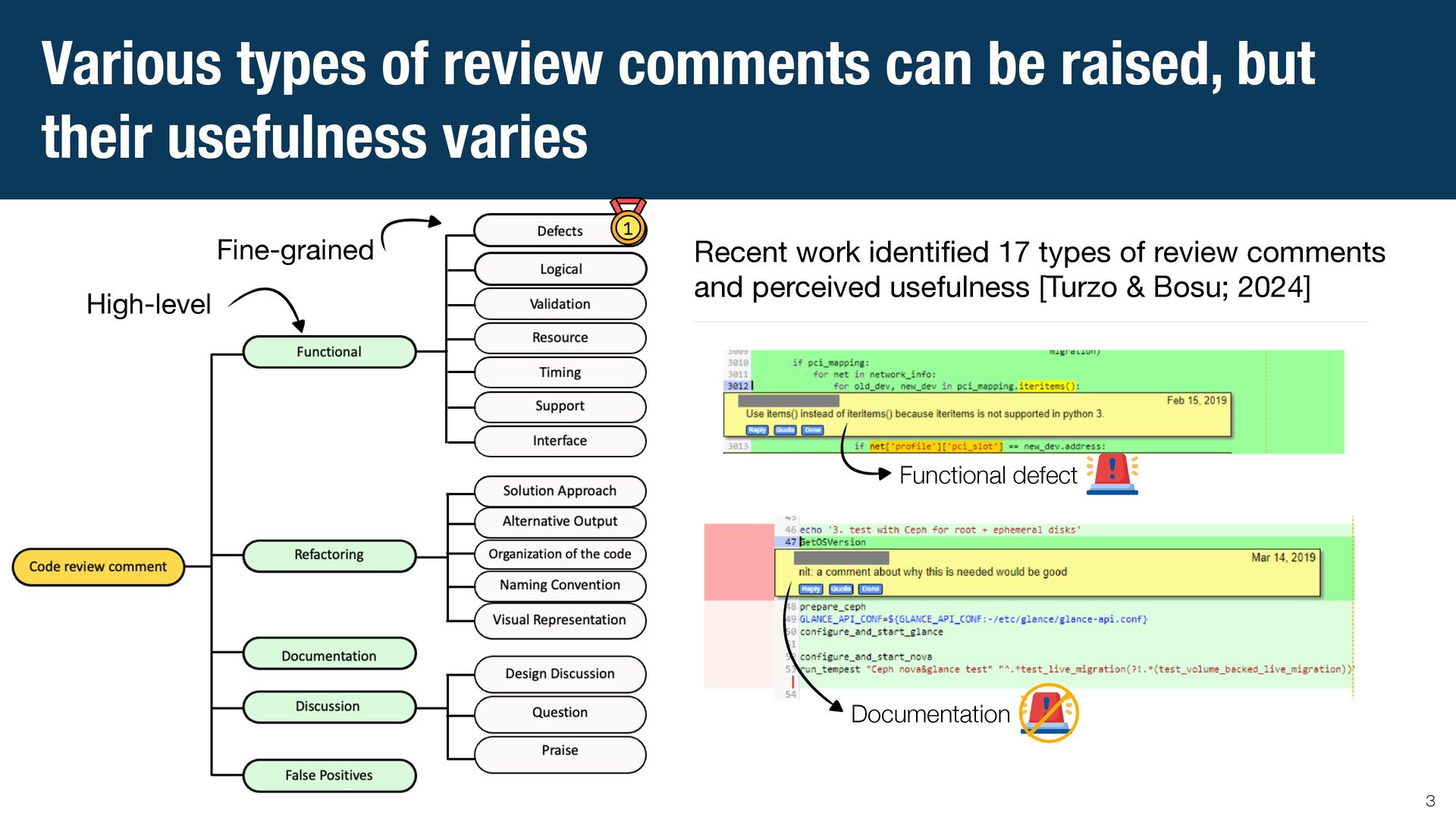{kind=link}
{kind=link}
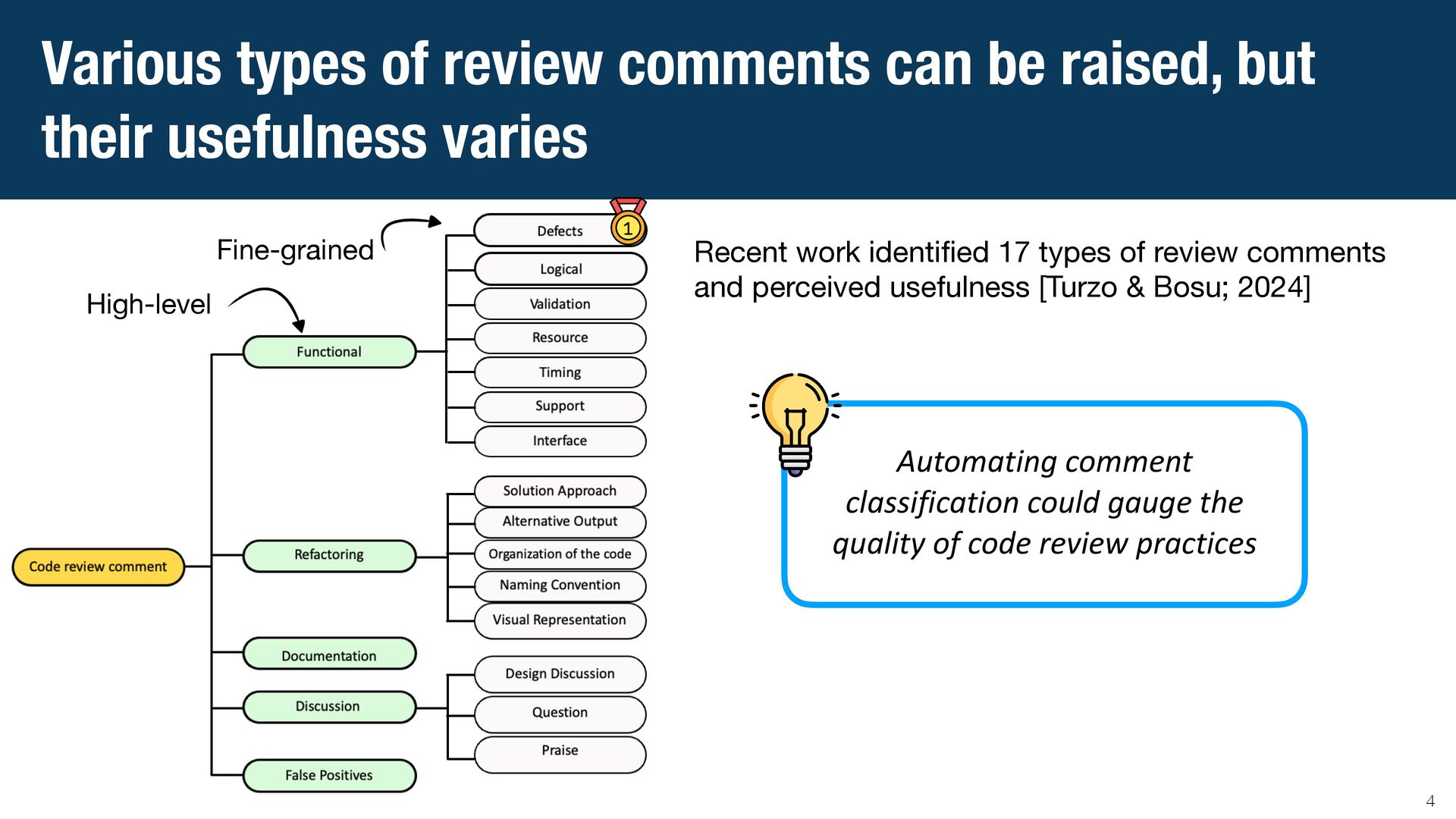{kind=link}
{kind=link}
{kind=link}
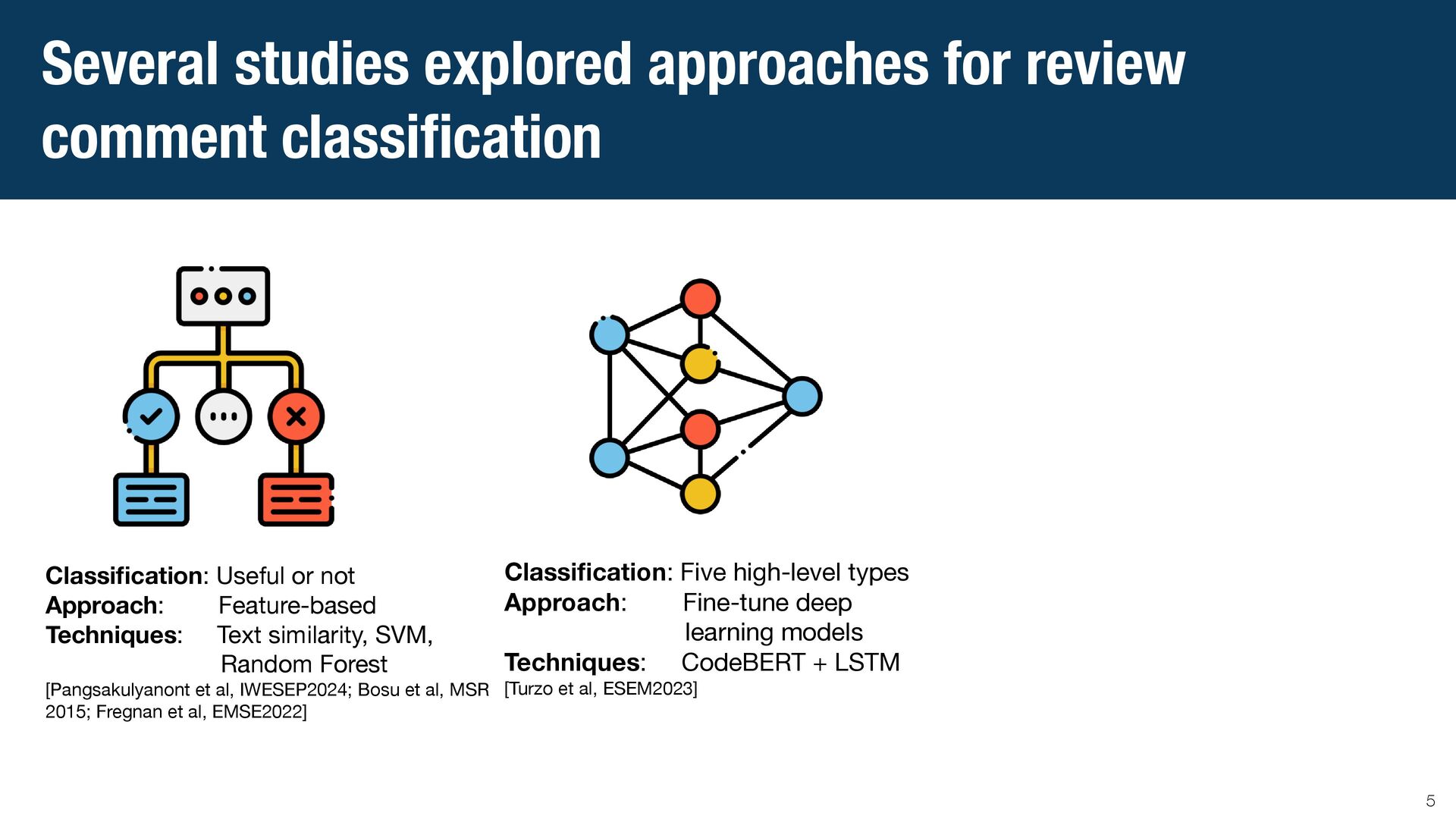{kind=link}
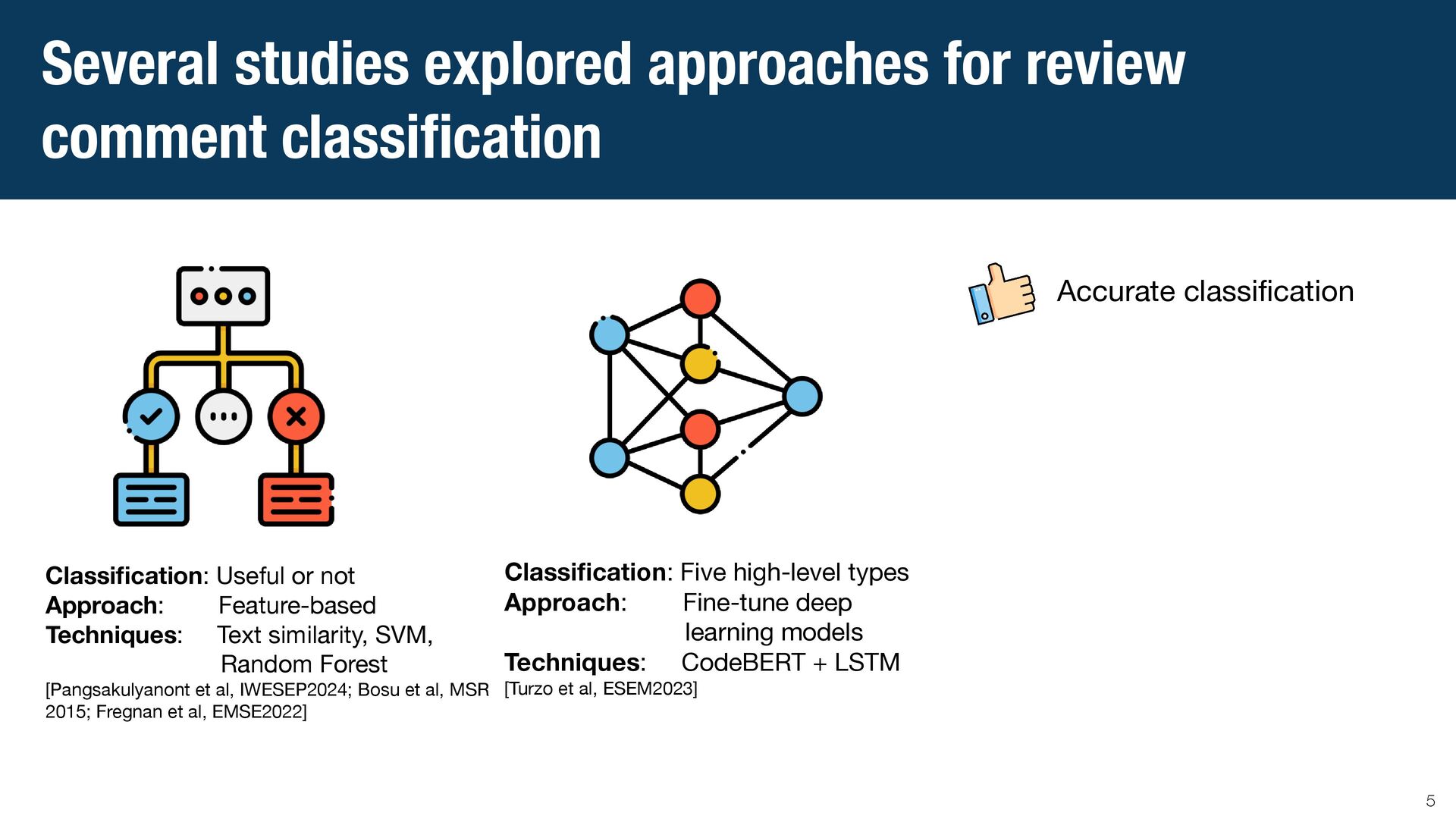{kind=link}
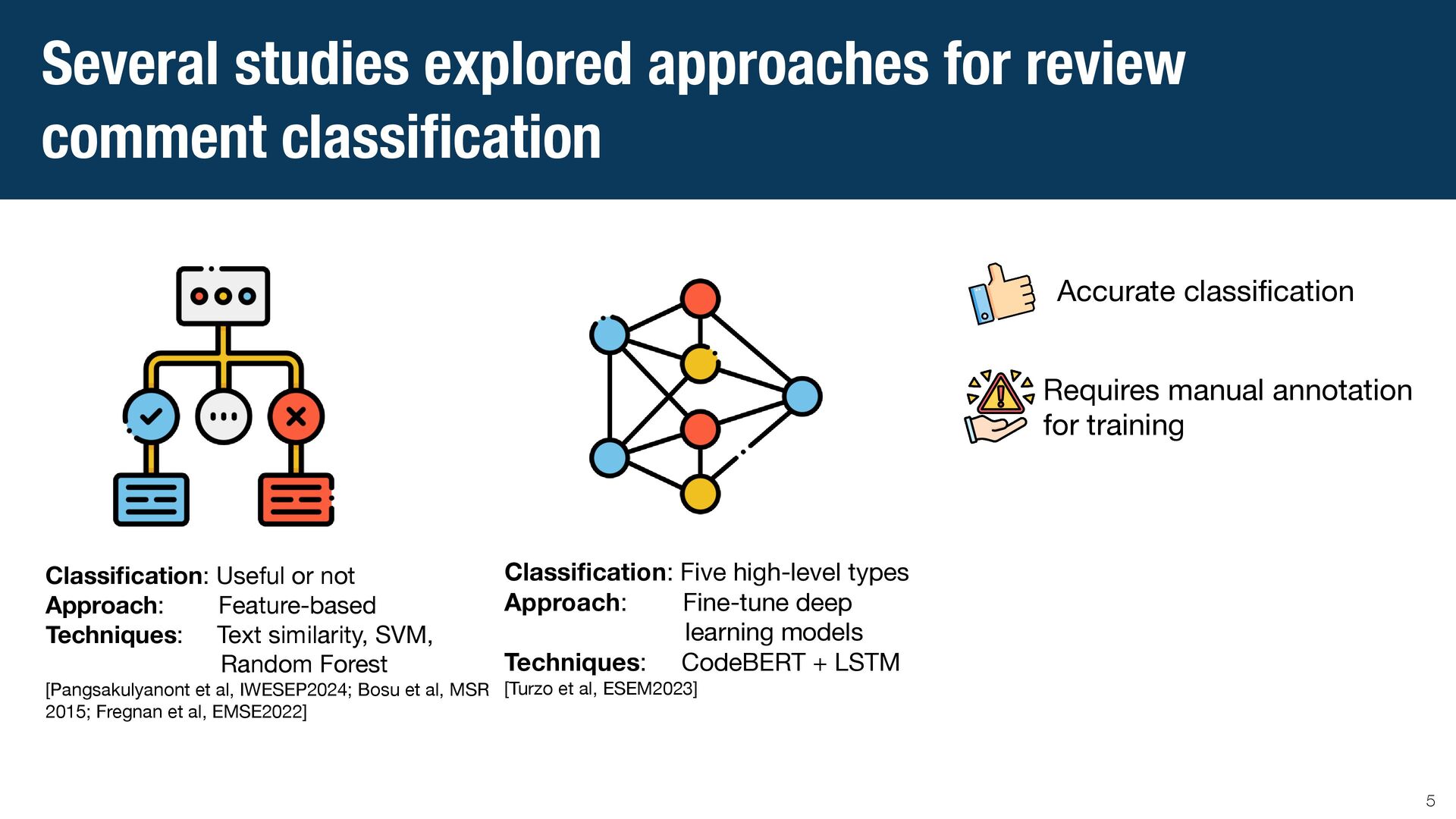{kind=link}
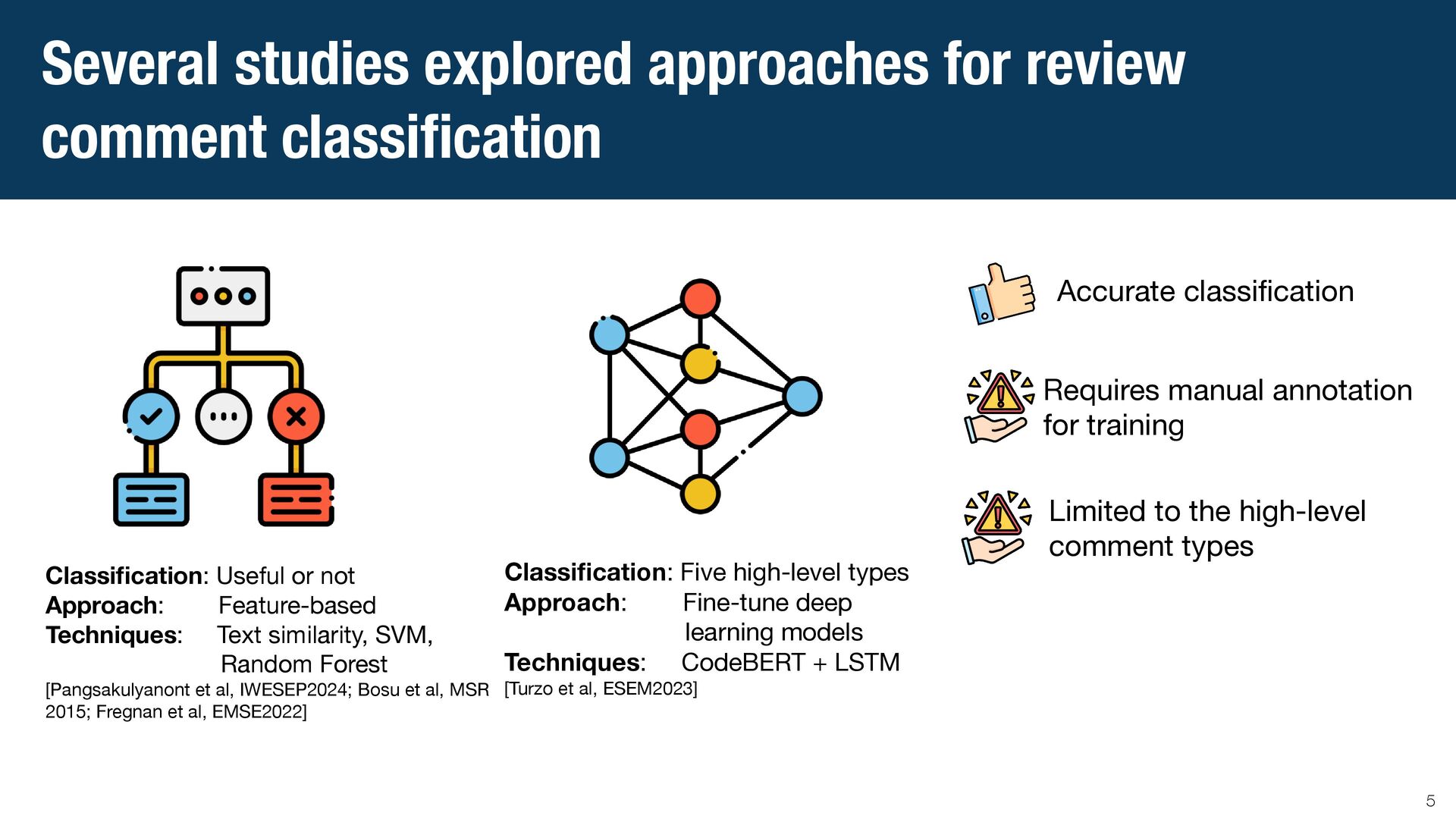{kind=link}
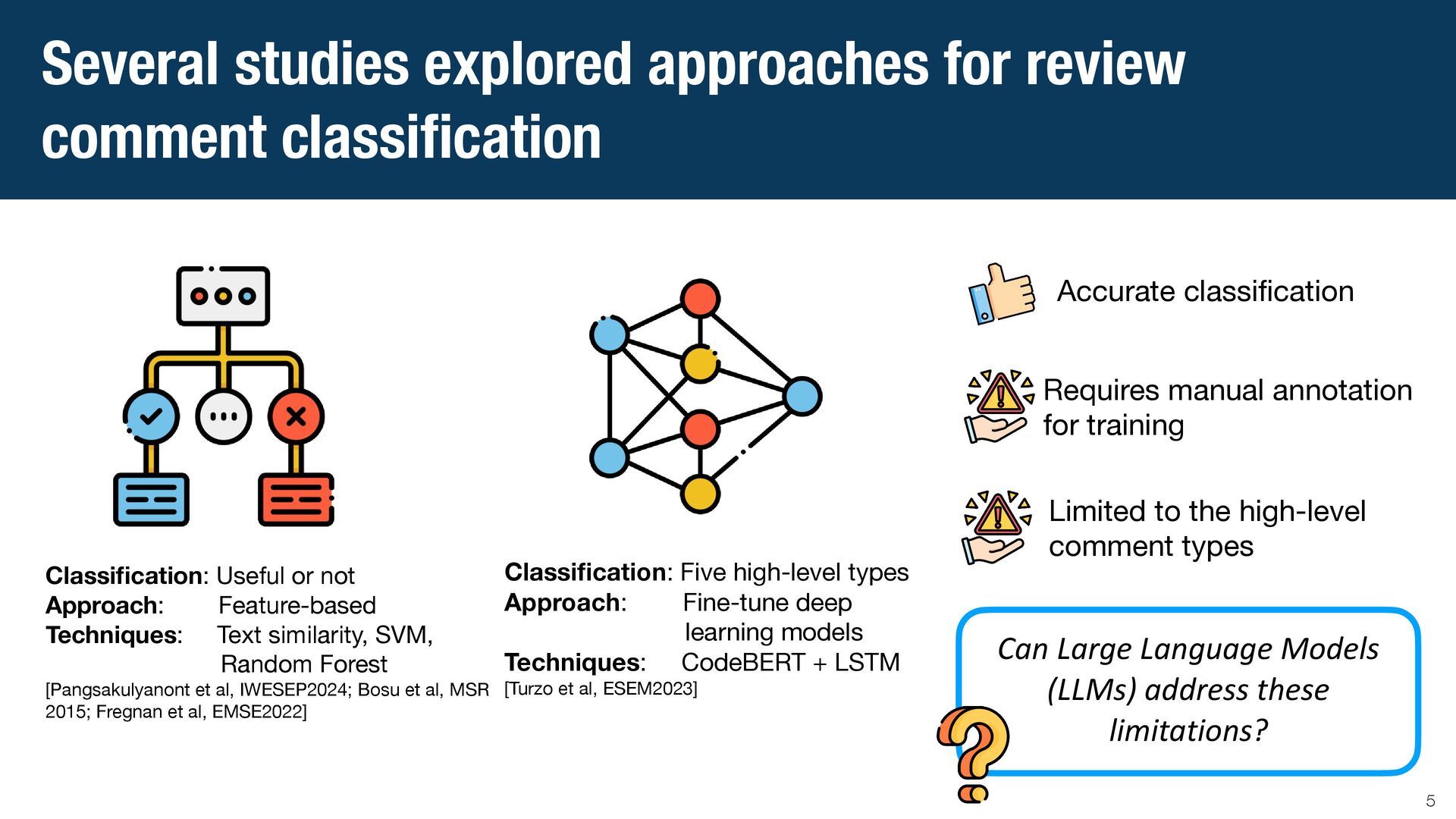{kind=link}
{kind=link}
{kind=link}
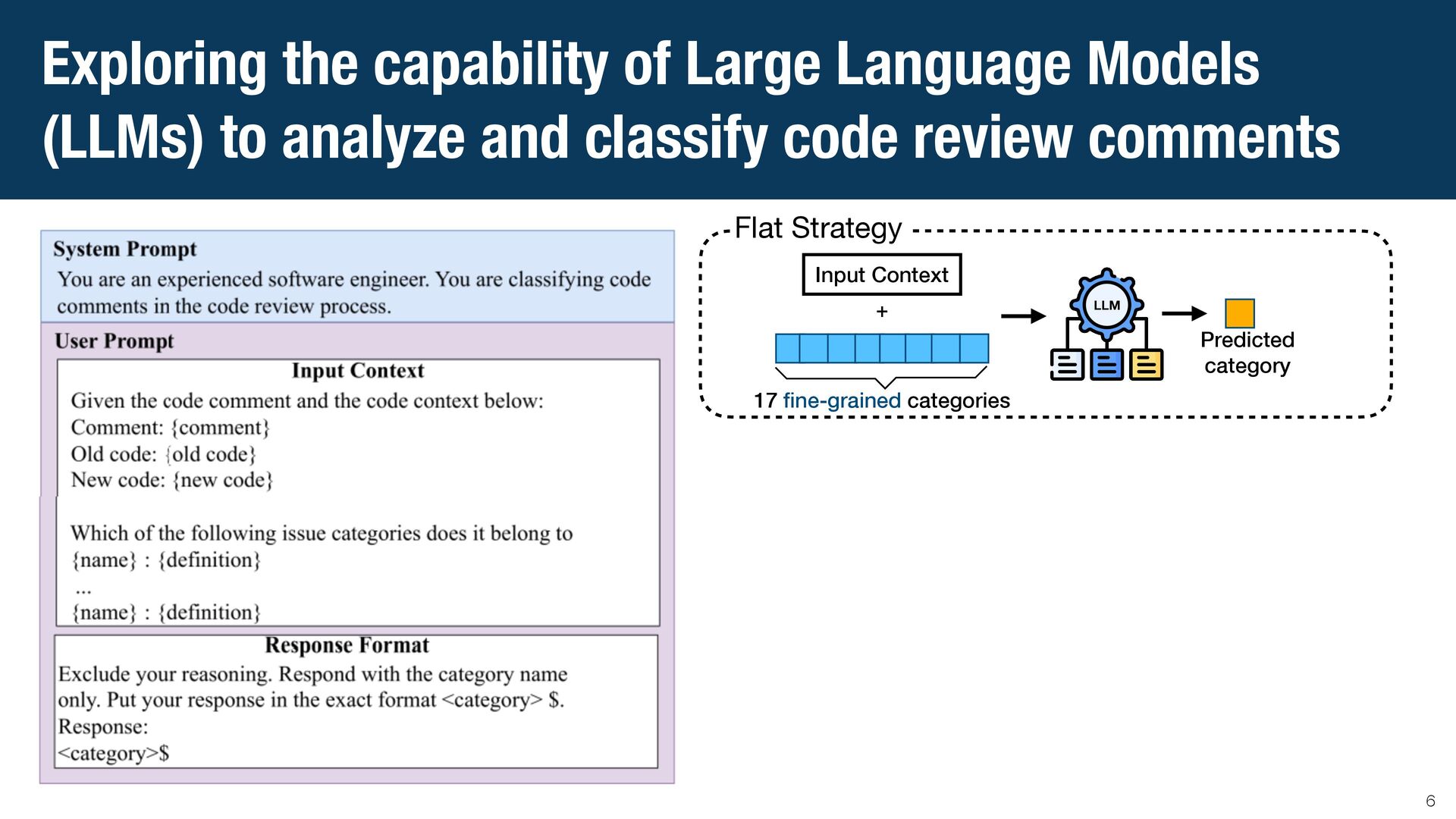{kind=link}
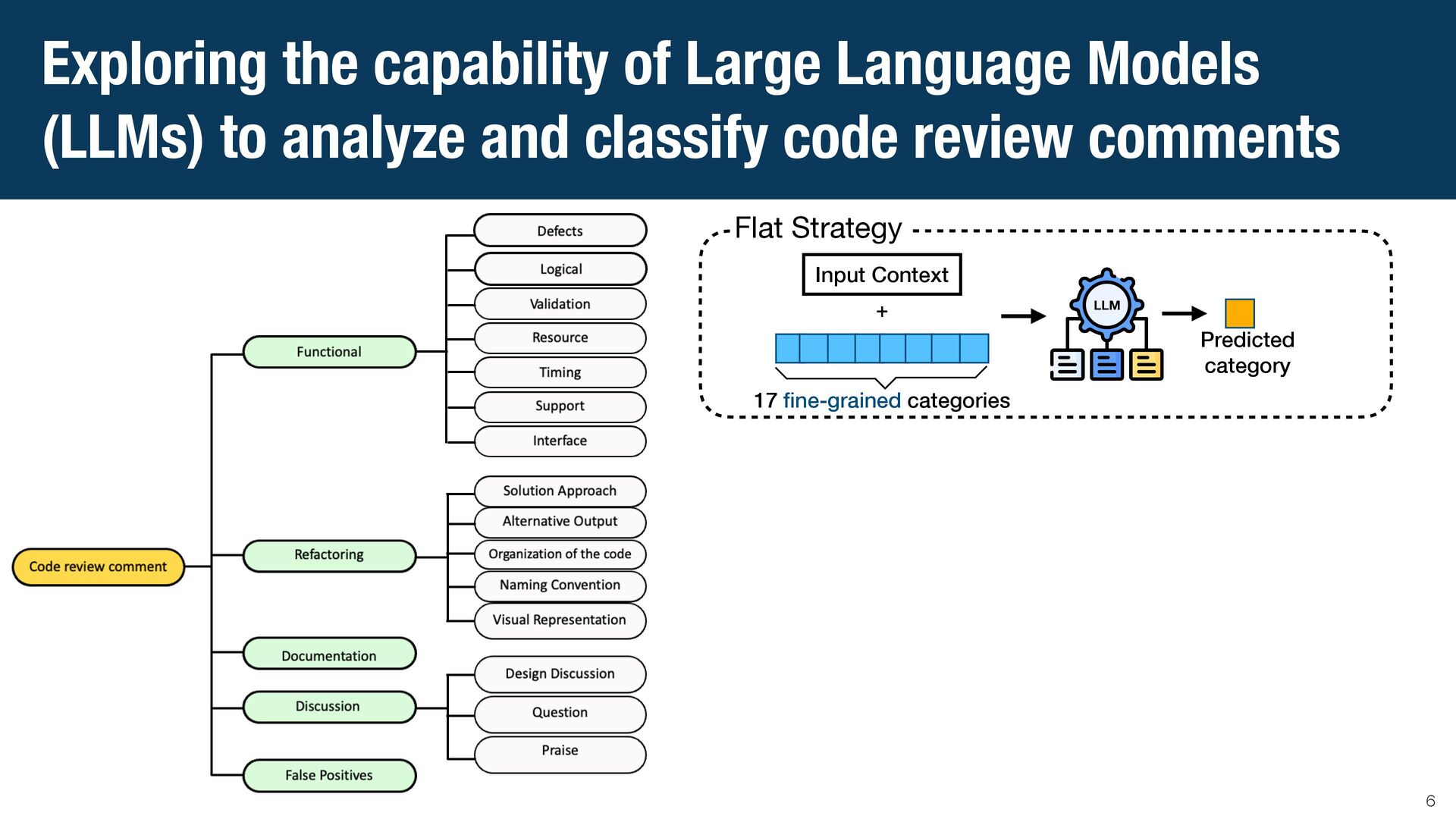{kind=link}
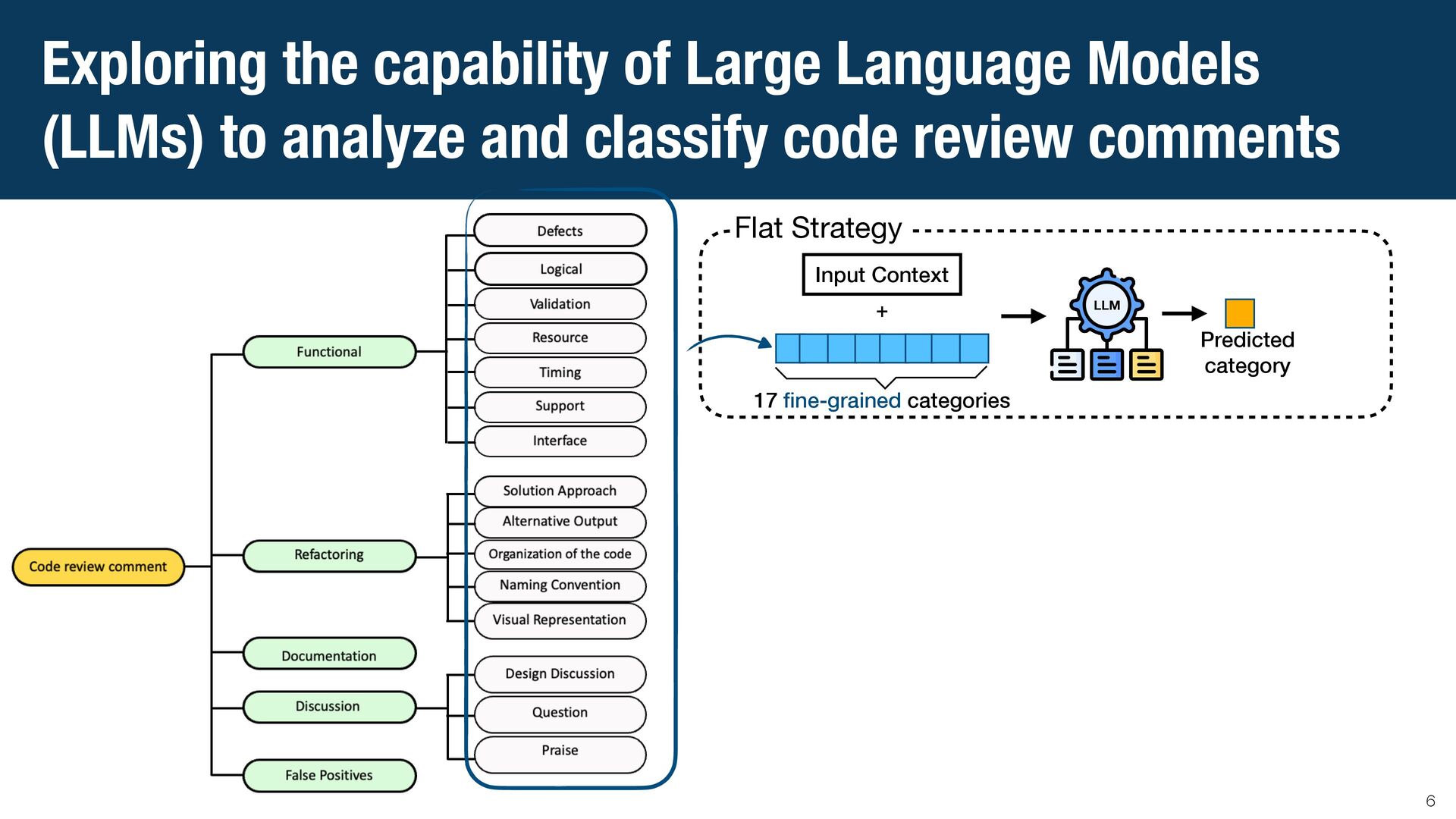{kind=link}
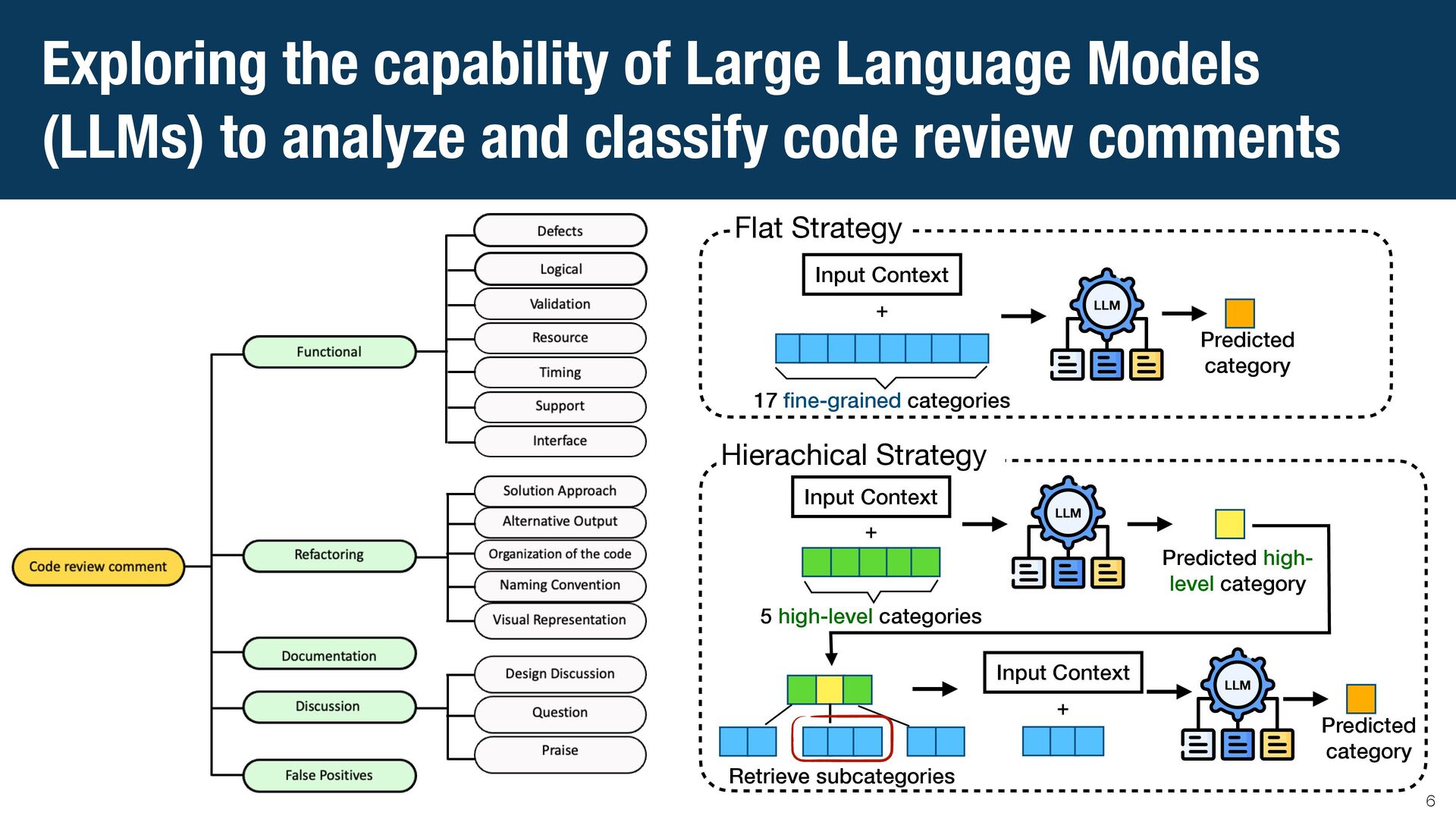{kind=link}
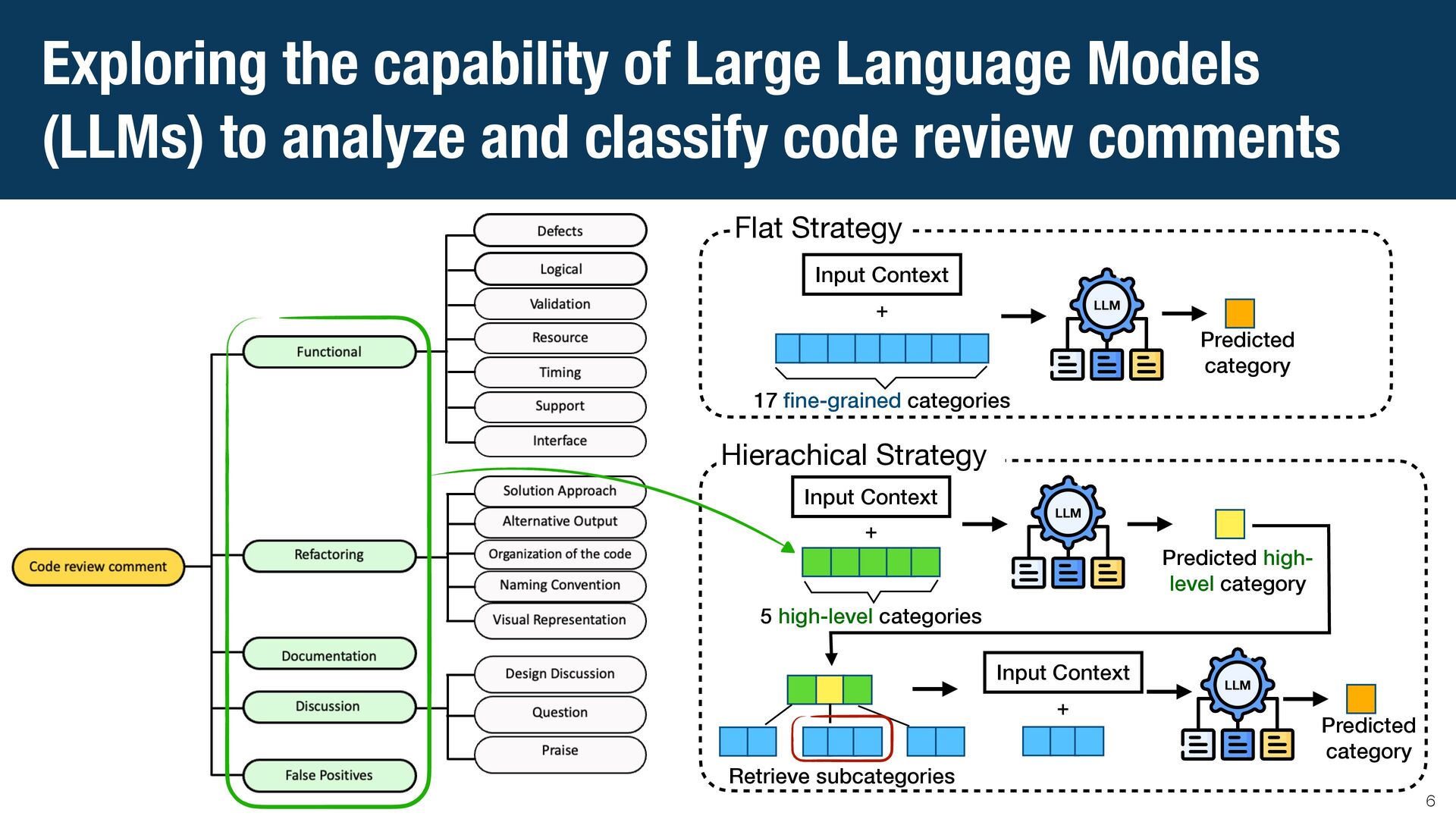{kind=link}
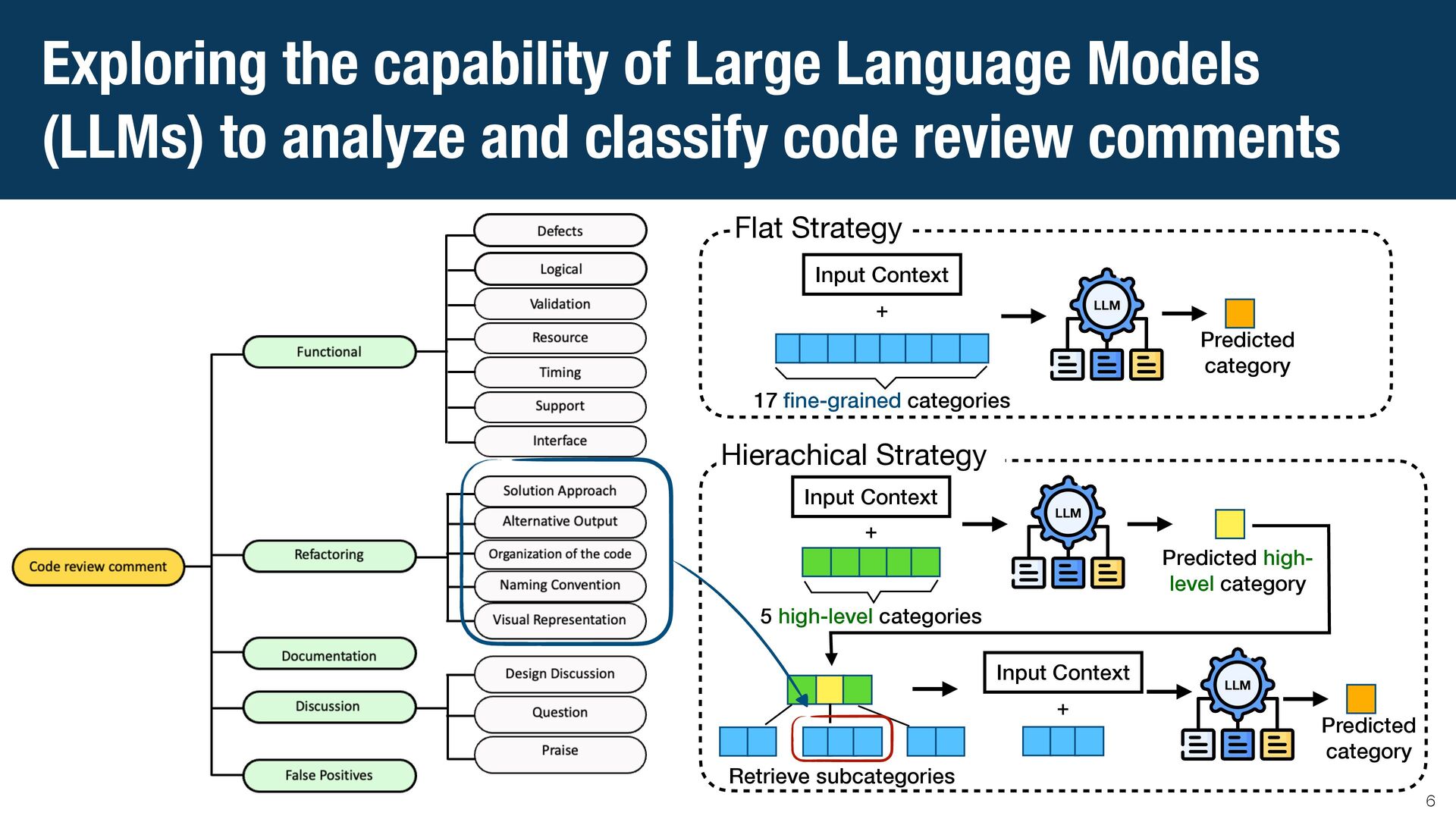{kind=link}
{kind=link}
![7 Experimental Design Manually annotated data [Turzo and Bosu; EMSE2023]](https://files.speakerdeck.com/presentations/a992f5fb4c4e40e1b172f7502755eb99/slide_29.jpg){kind=link}
![7 Experimental Design Manually annotated data [Turzo and Bosu; EMSE2023]](https://files.speakerdeck.com/presentations/a992f5fb4c4e40e1b172f7502755eb99/slide_30.jpg){kind=link}
![7 Experimental Design Manually annotated data [Turzo and Bosu; EMSE2023]](https://files.speakerdeck.com/presentations/a992f5fb4c4e40e1b172f7502755eb99/slide_31.jpg){kind=link}
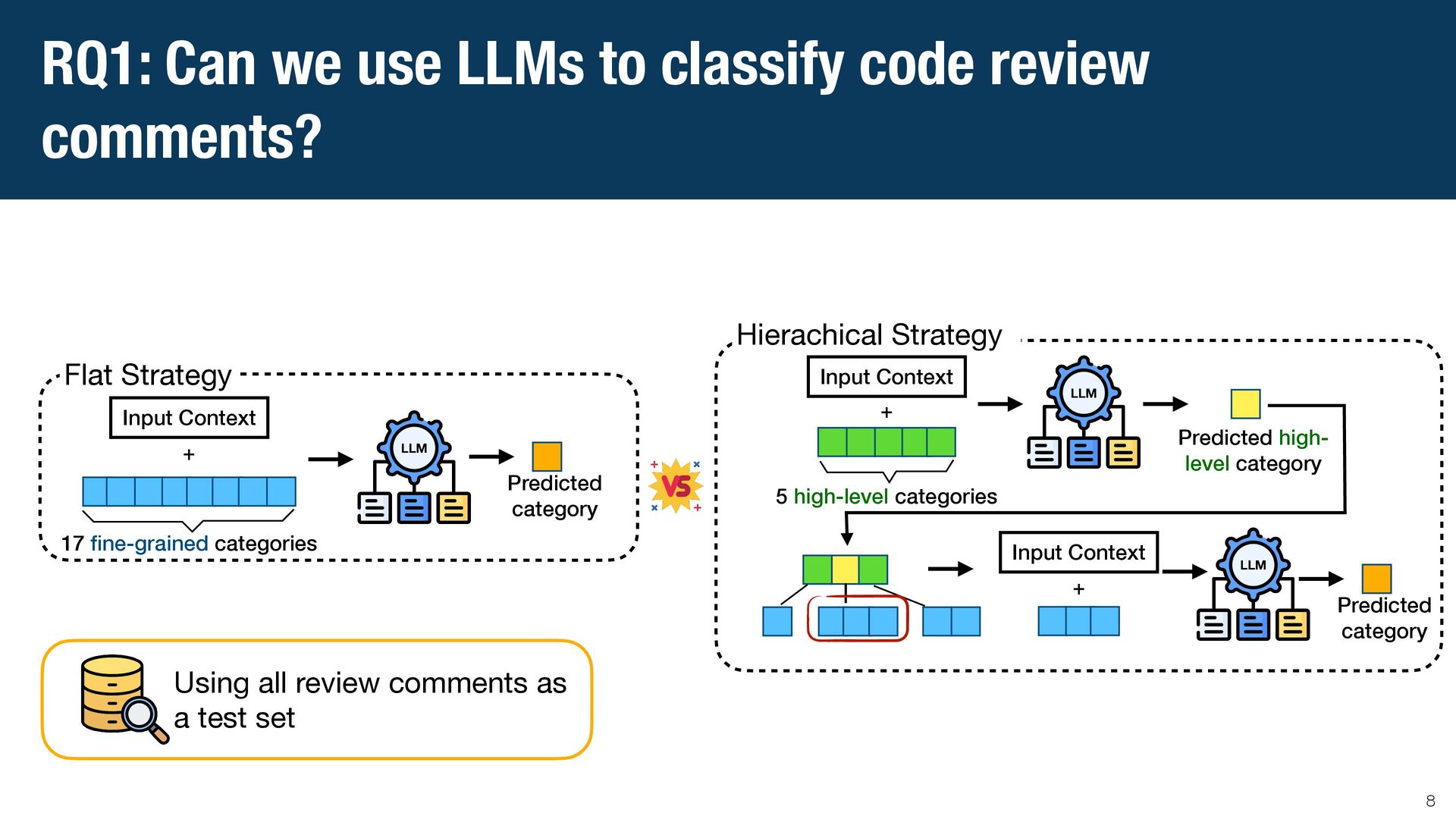{kind=link}
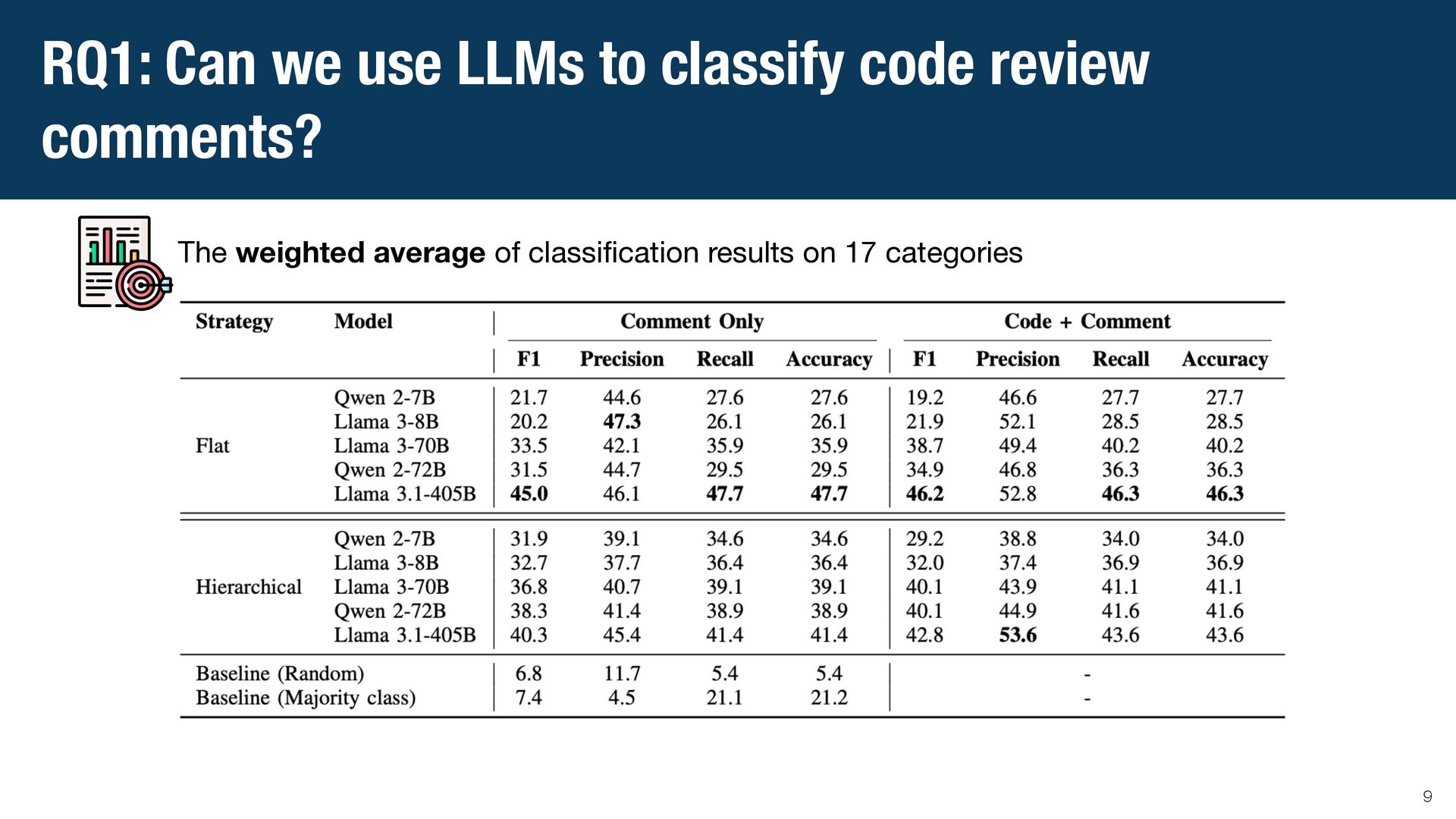{kind=link}
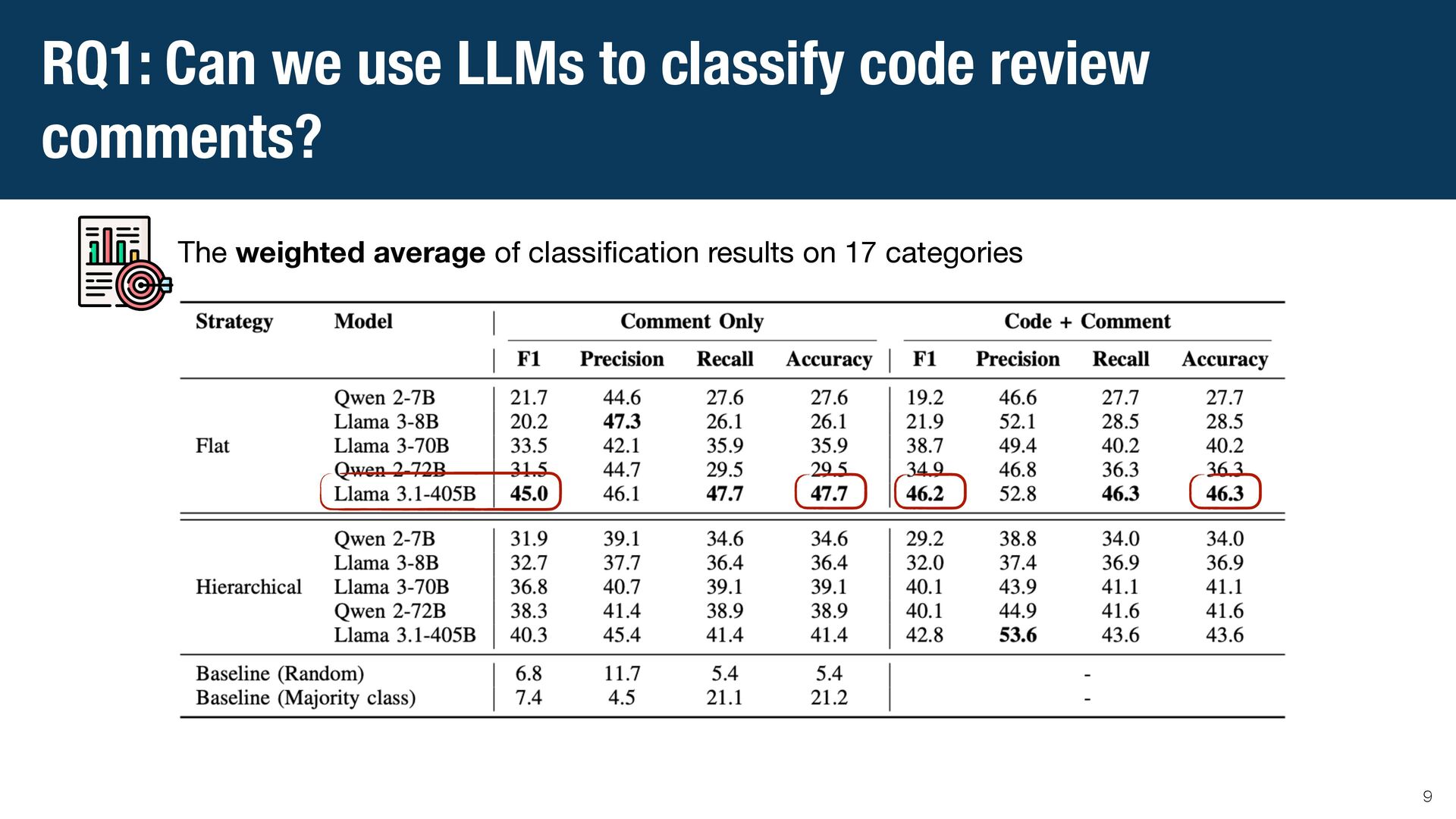{kind=link}
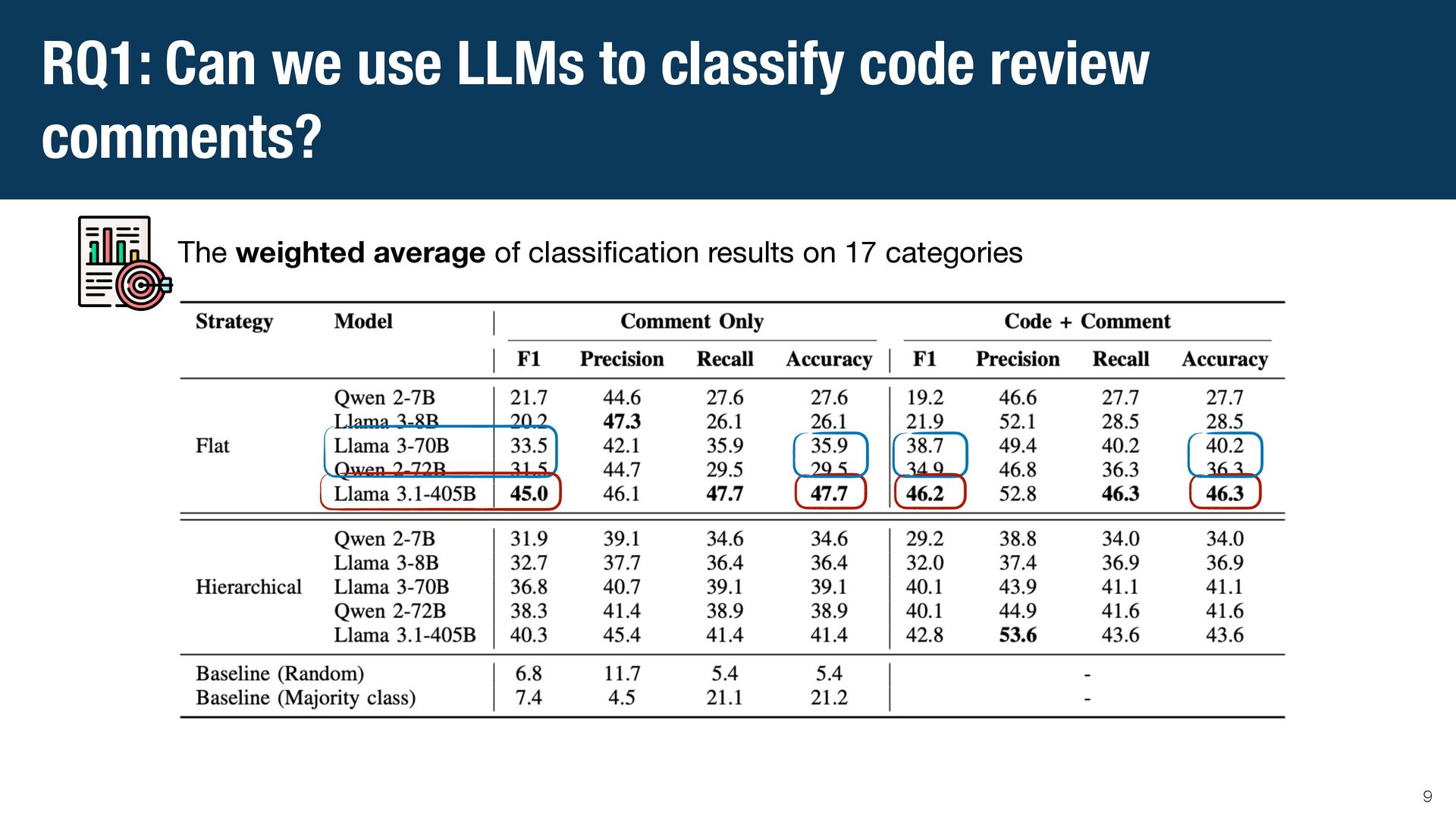{kind=link}
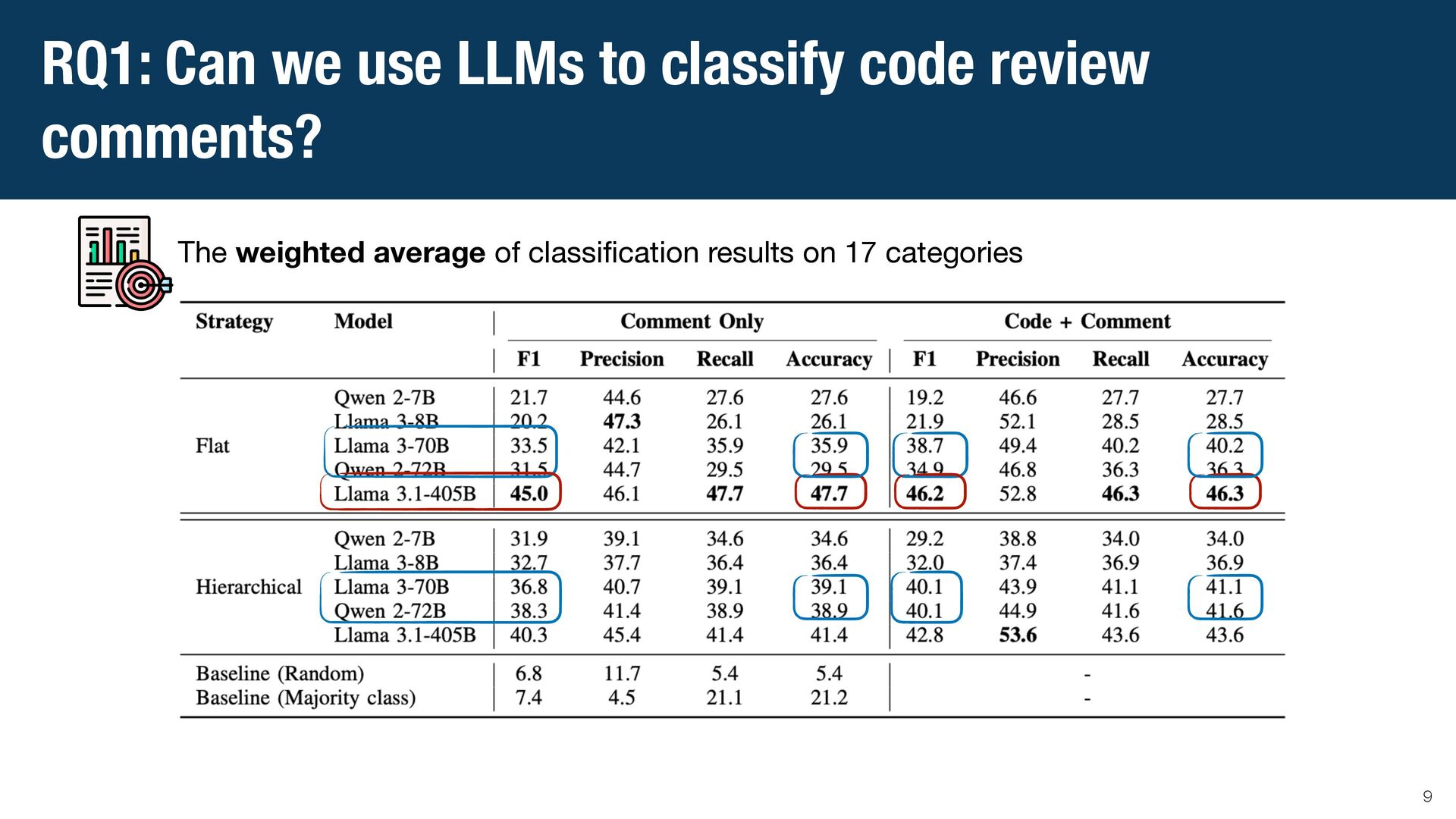{kind=link}
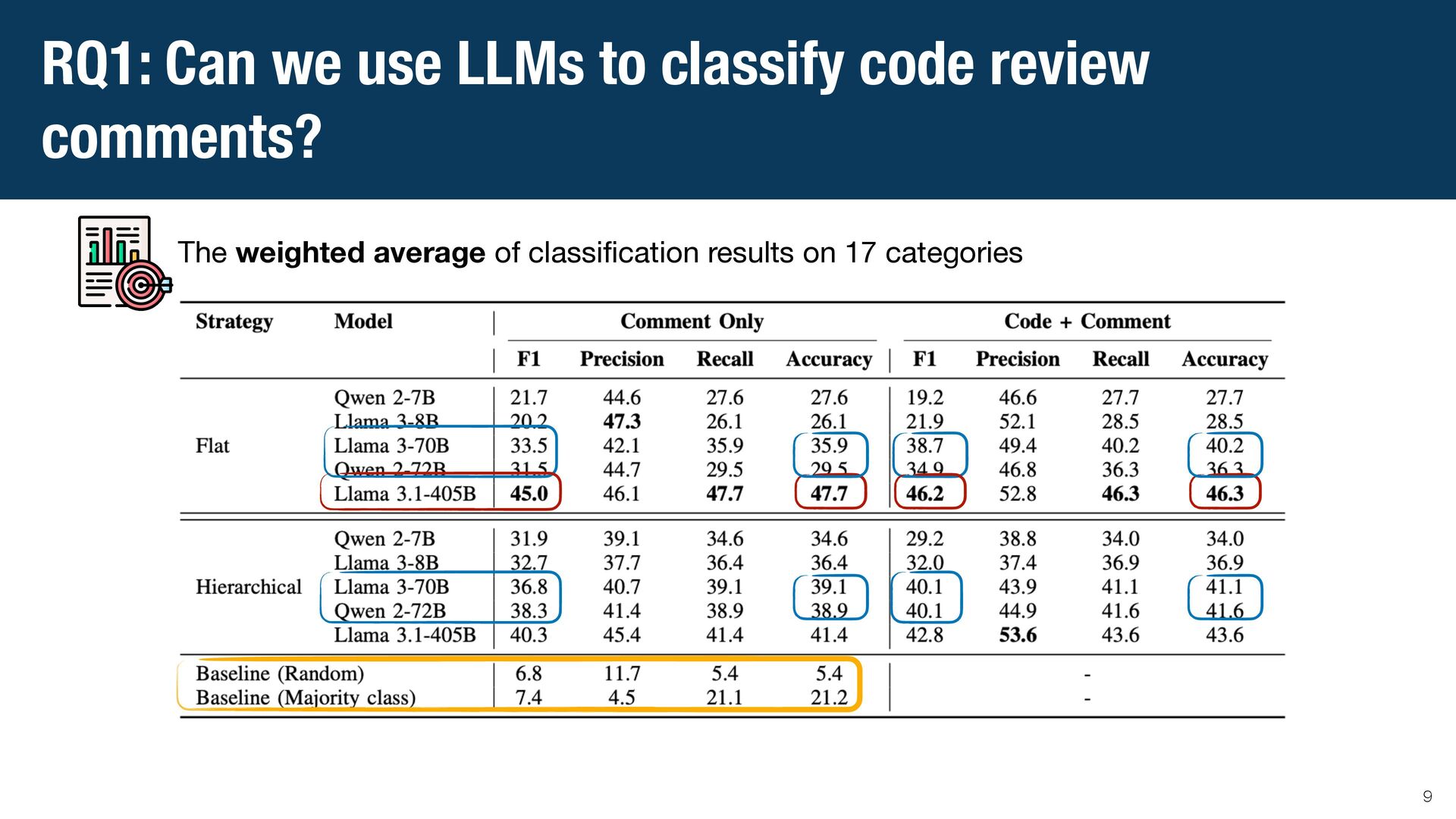{kind=link}
{kind=link}
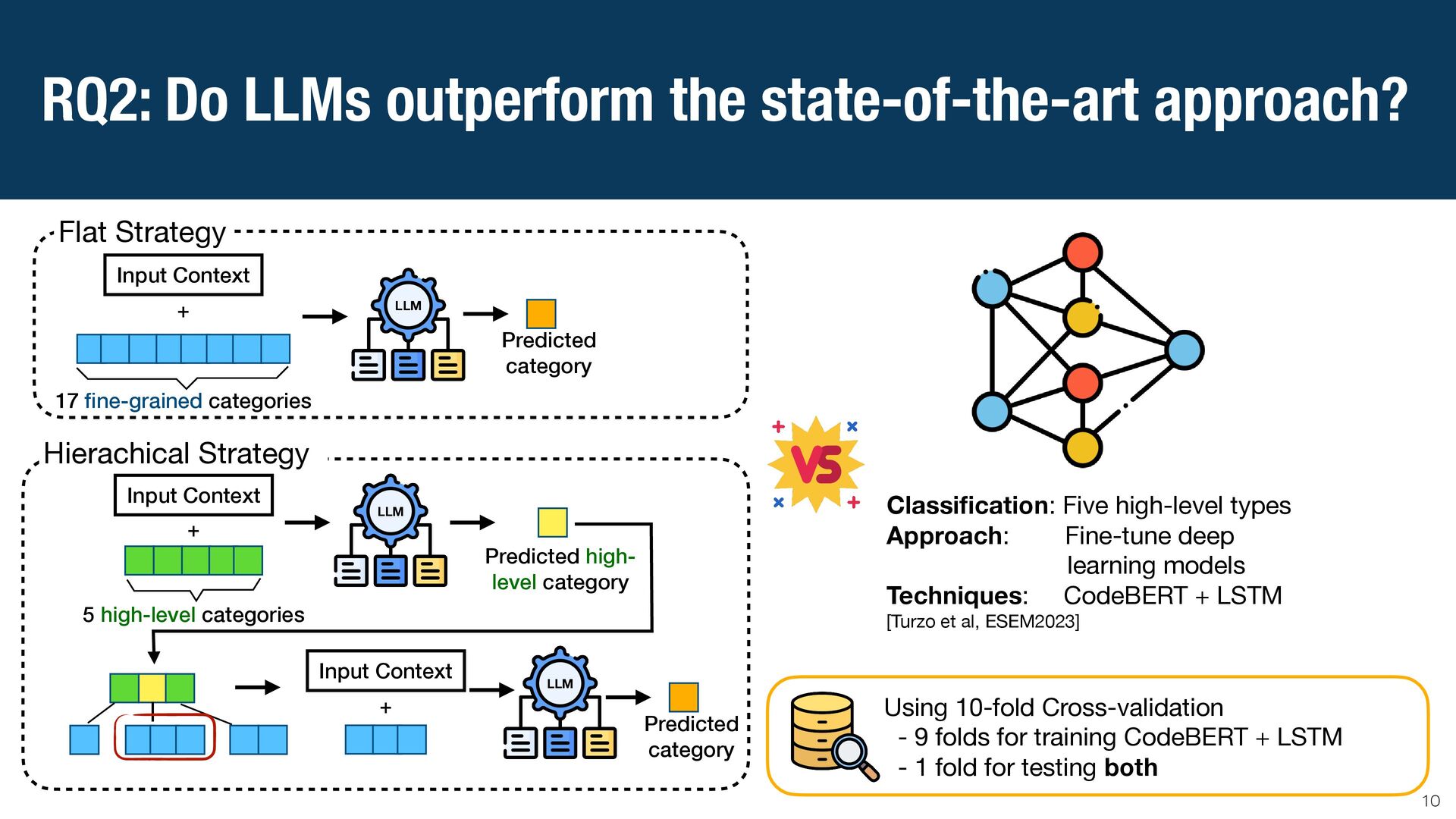{kind=link}
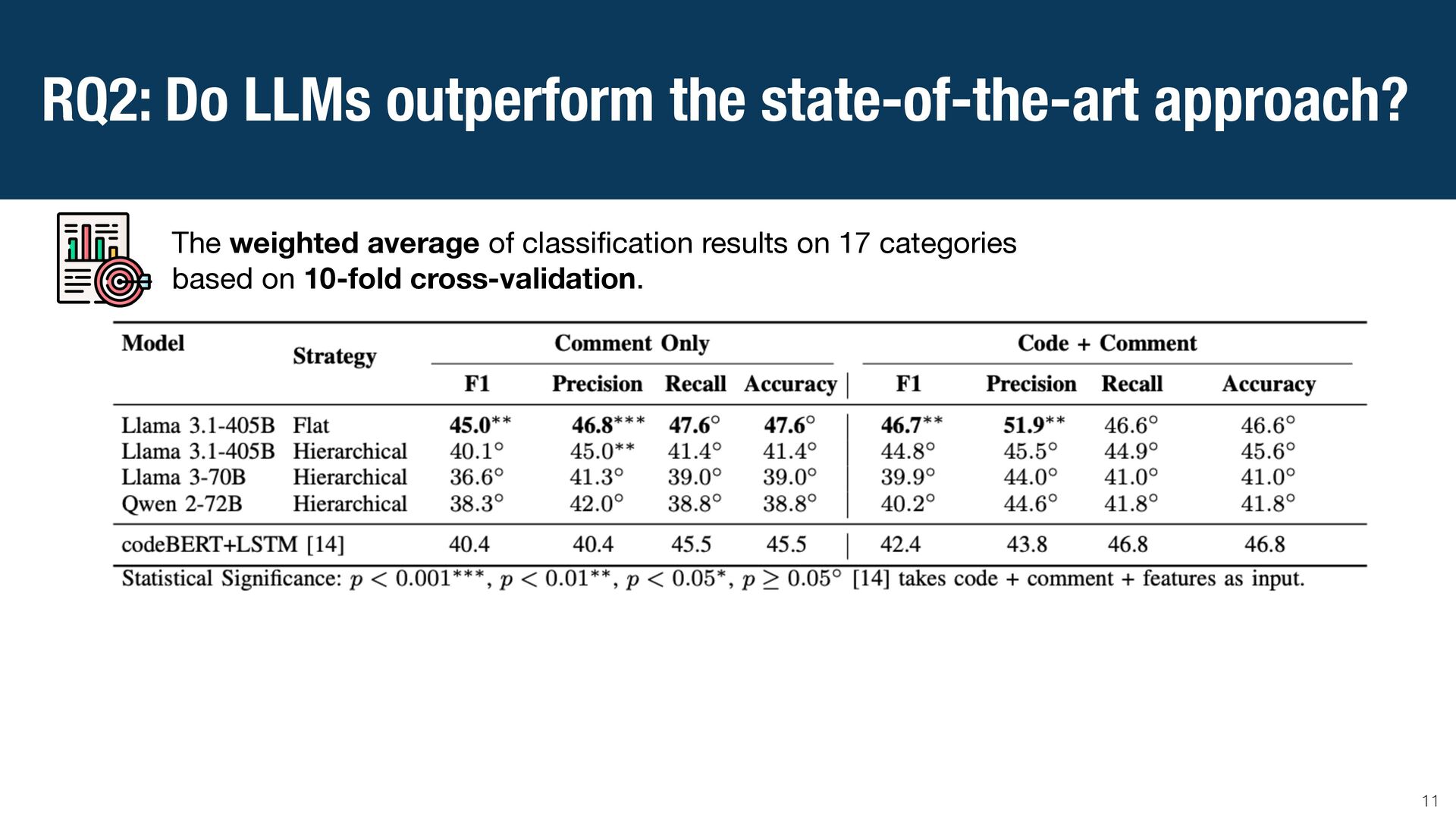{kind=link}
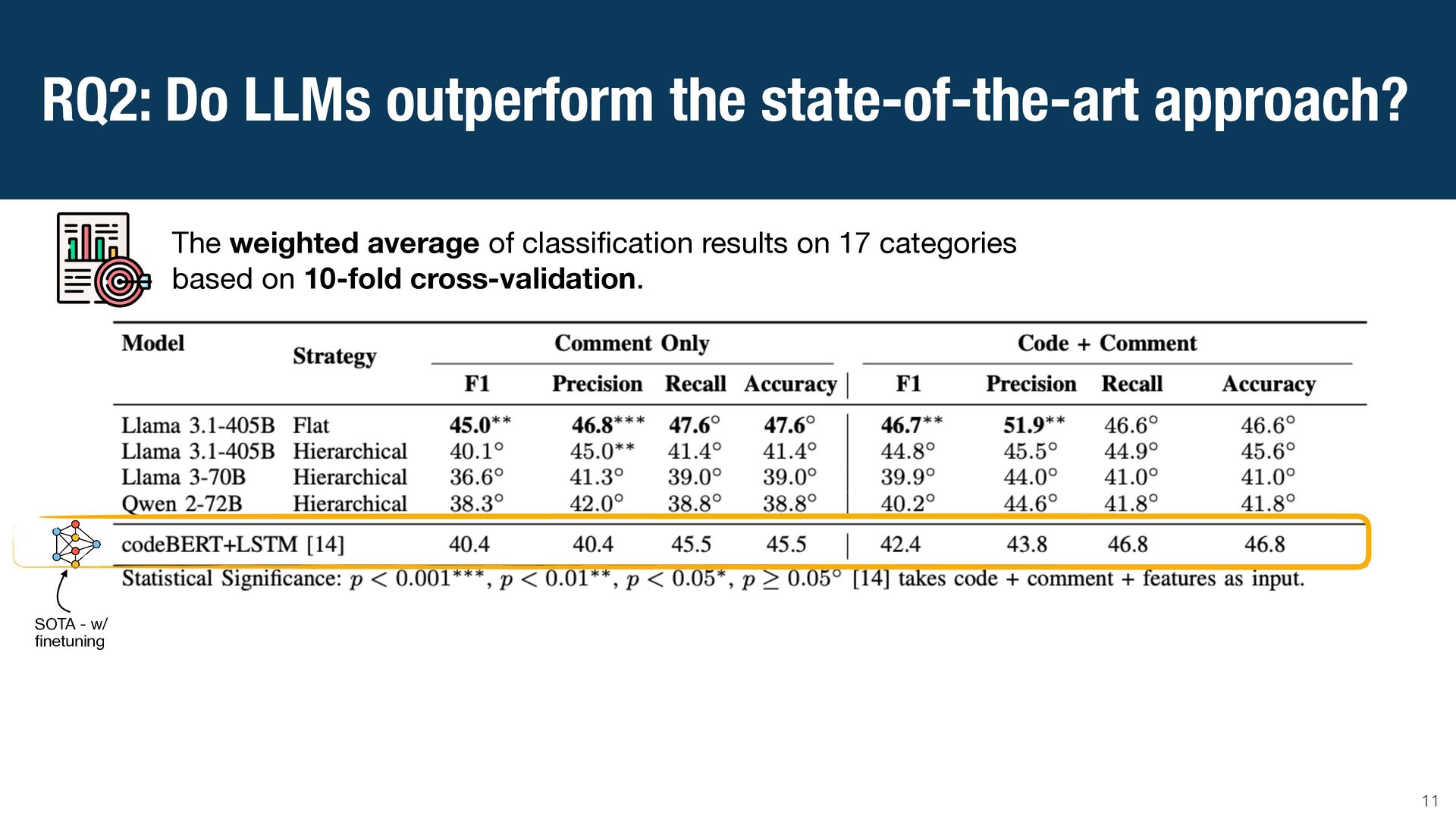{kind=link}
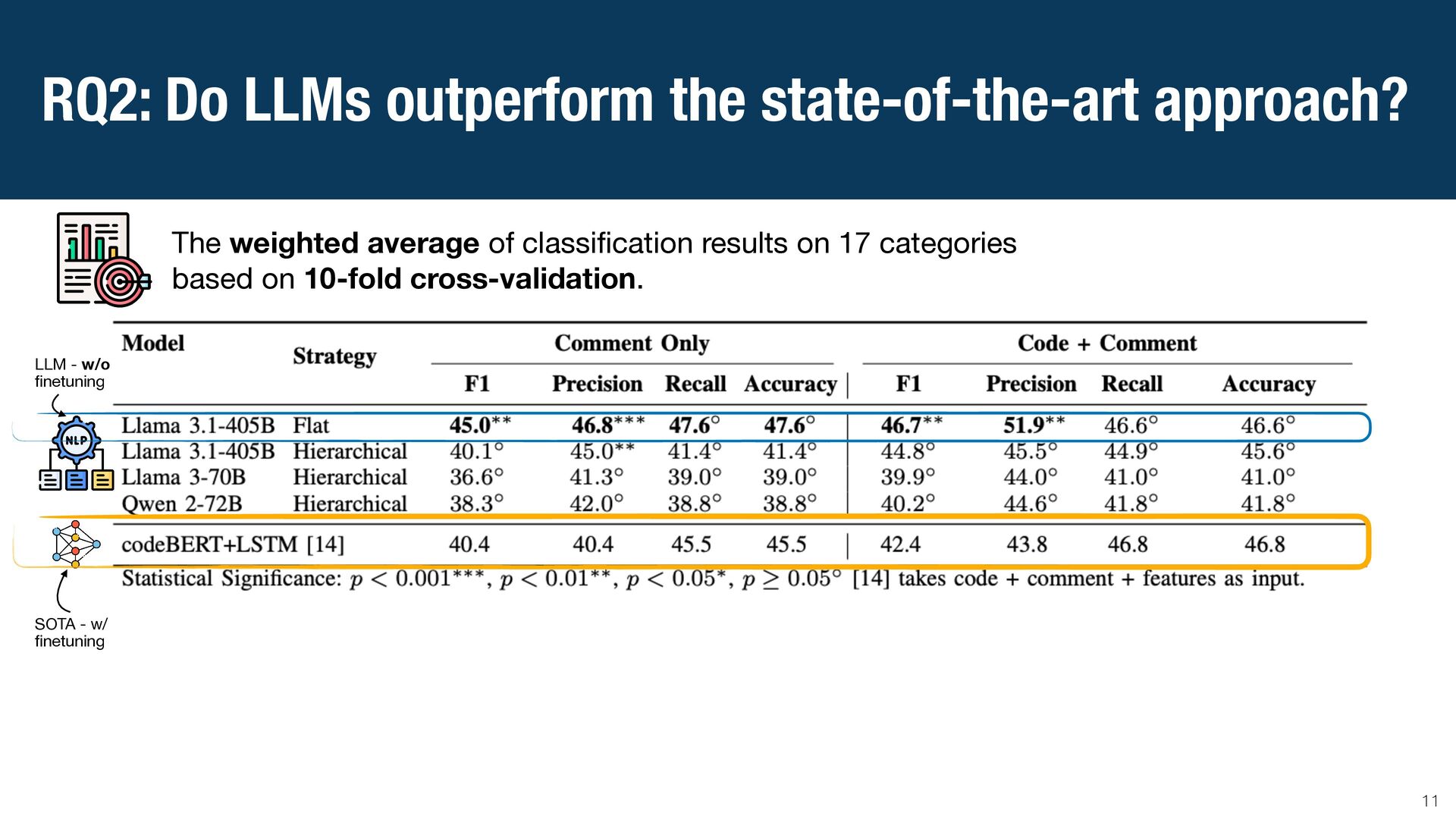{kind=link}
{kind=link}
{kind=link}
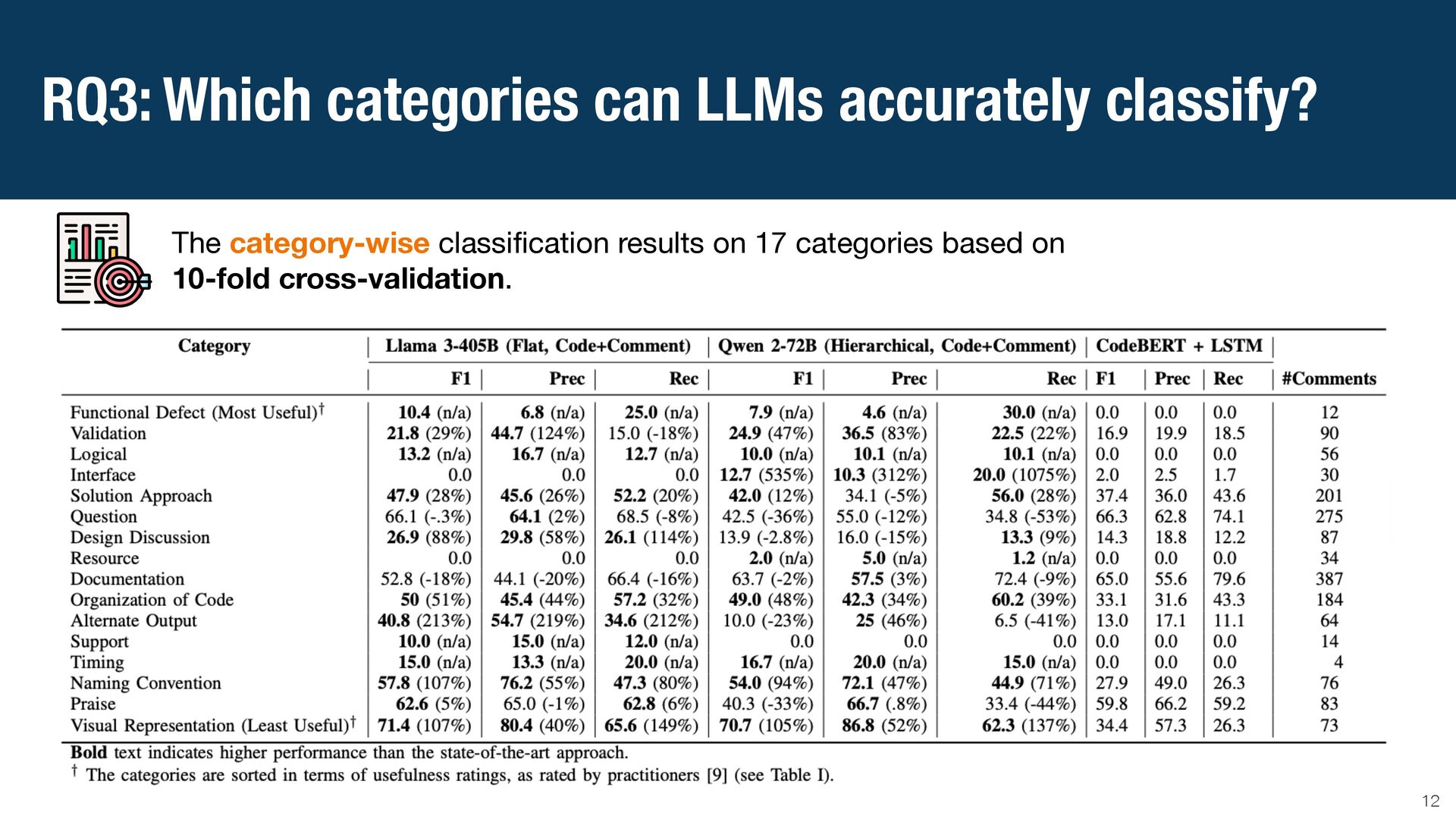{kind=link}
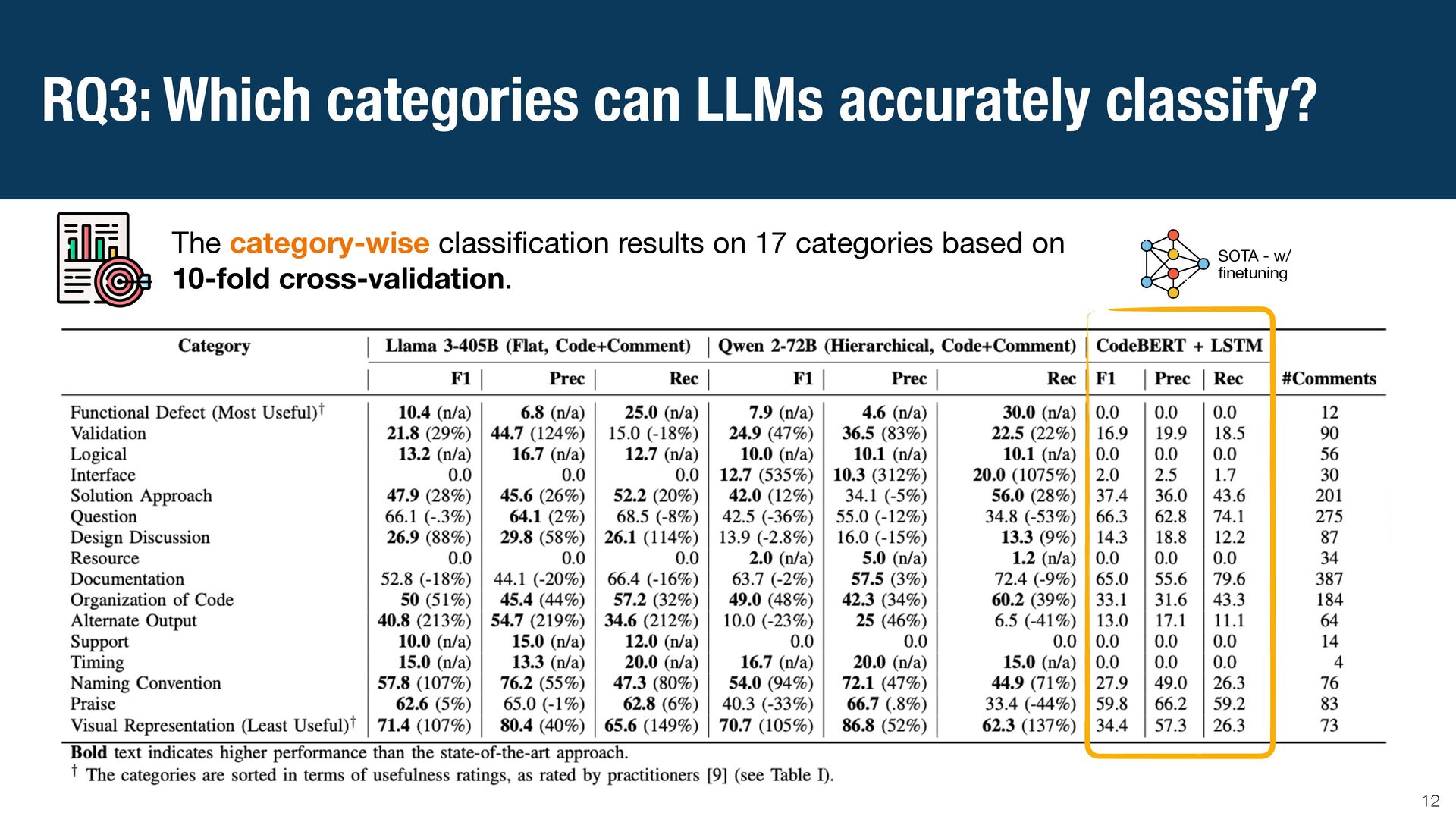{kind=link}
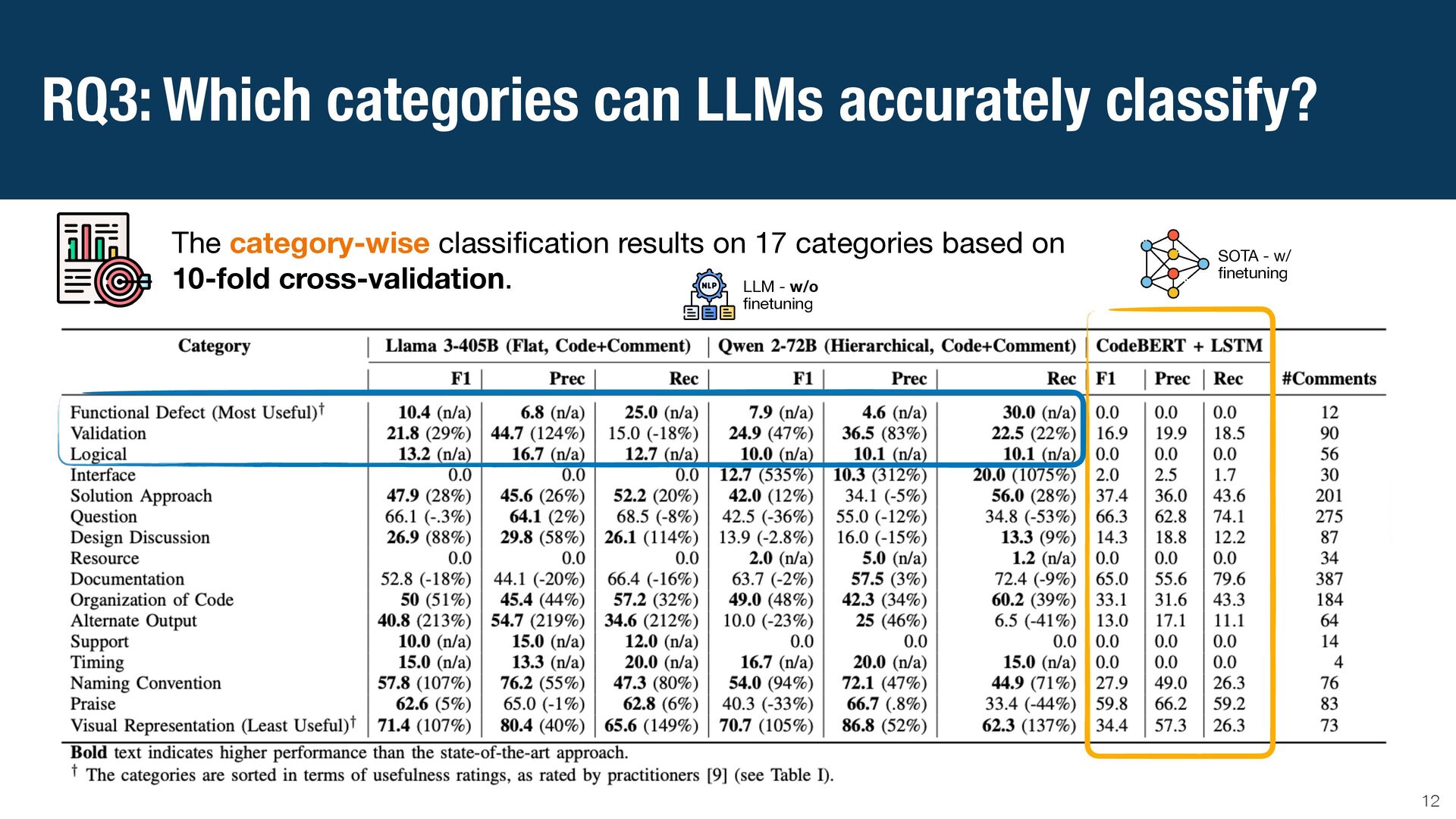{kind=link}
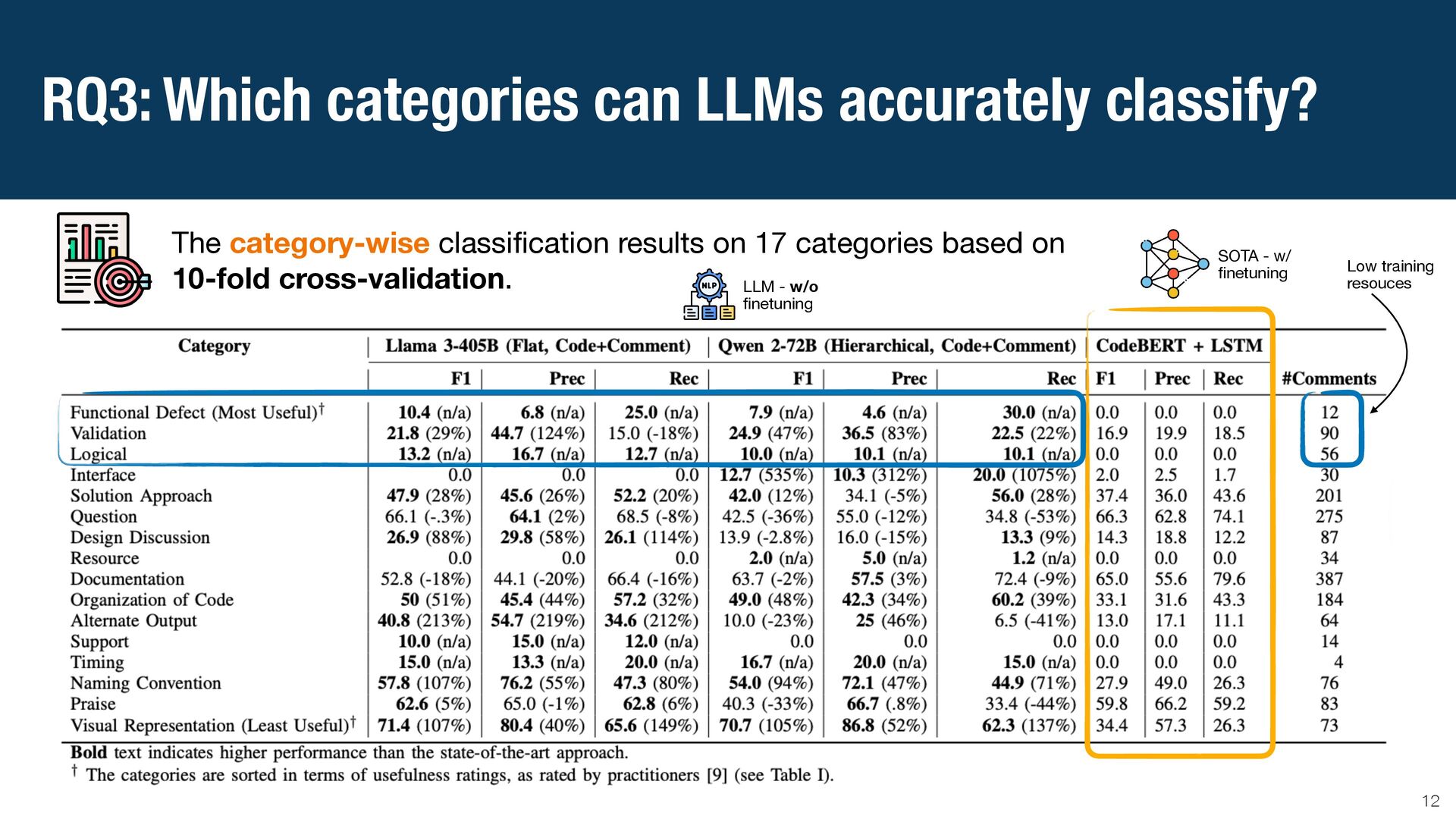{kind=link}
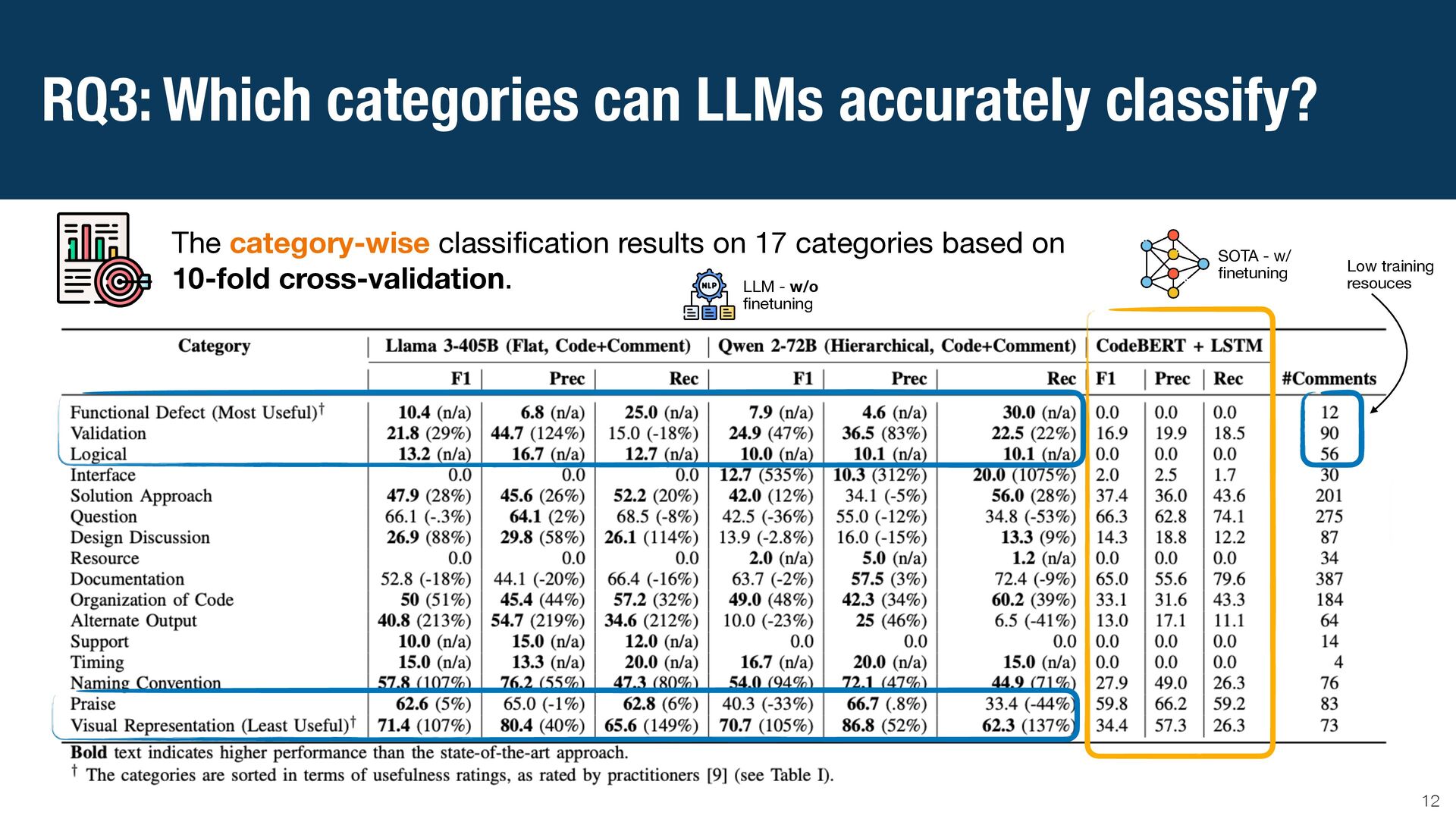{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}