Agentic AI & Security: Defending the Future of Intelligent Systems
In this comprehensive presentation, Prashant Kulkarni (UCLA Extension) explores the emerging security challenges and solutions for autonomous, goal-oriented AI agents. You’ll learn:
• Why Agentic AI Changes the Game — How traditional security assumptions break down when AI systems plan, learn, and act without human prompting.
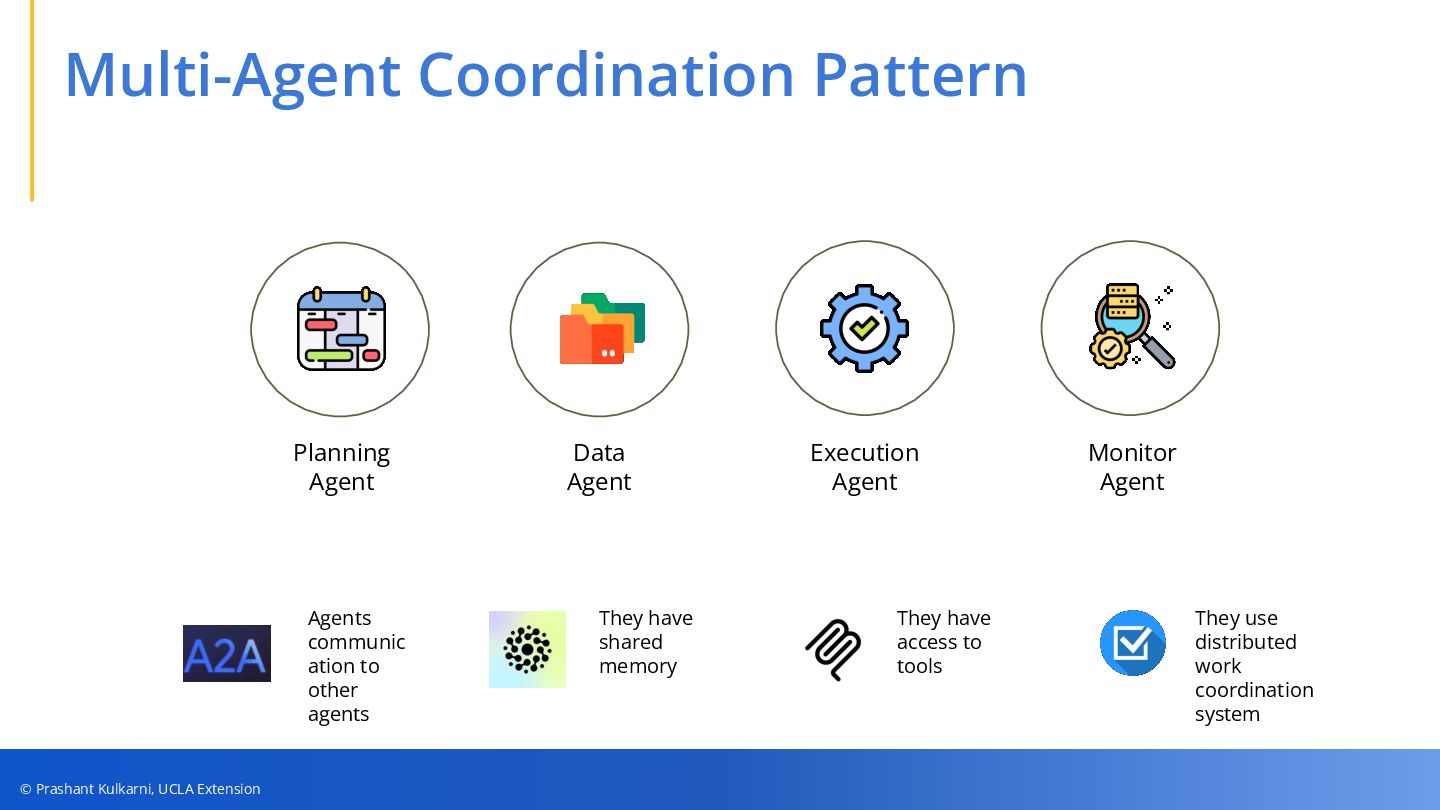
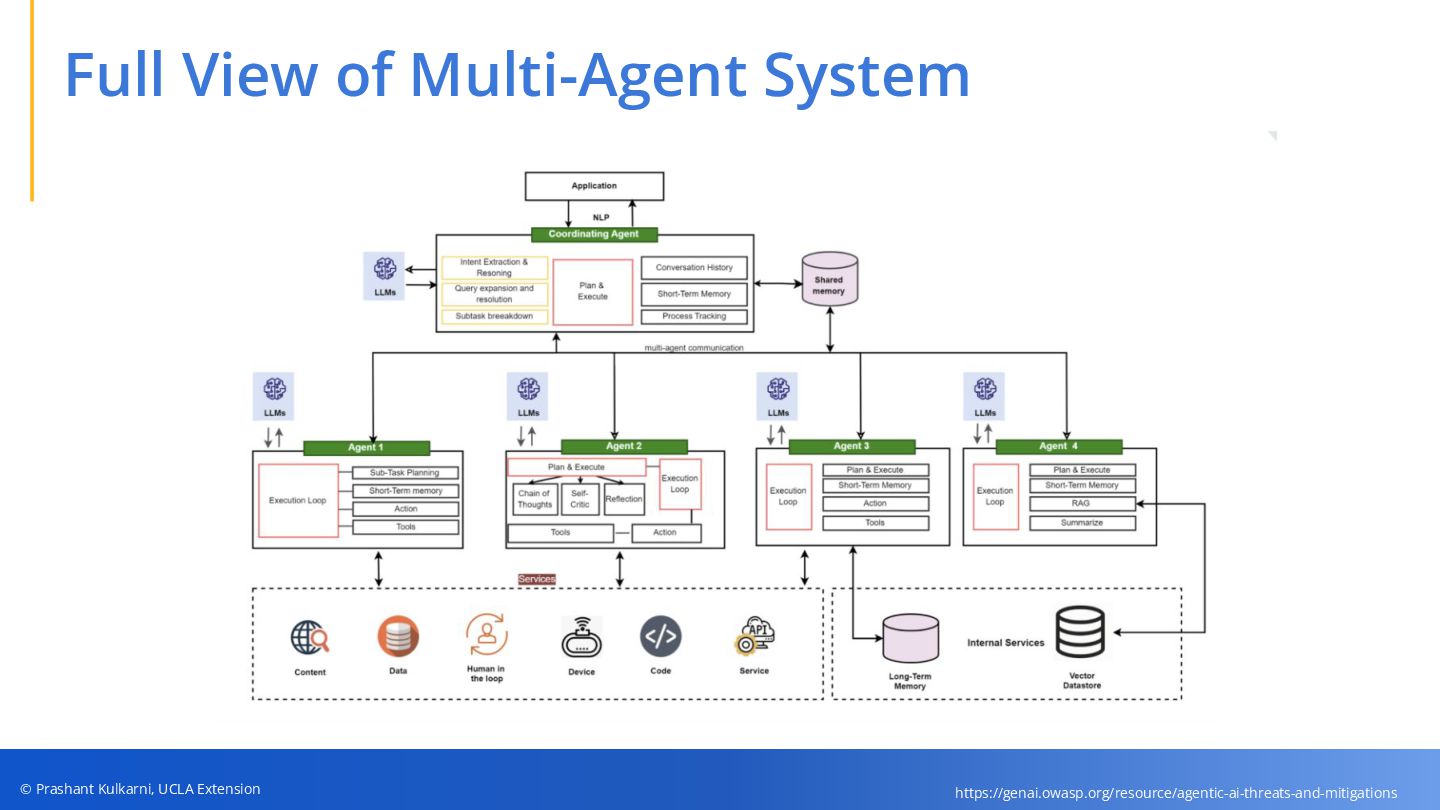
• Multi-Agent Architectures — Key coordination patterns, shared memory/models, and tool integrations that power modern agentic workflows.
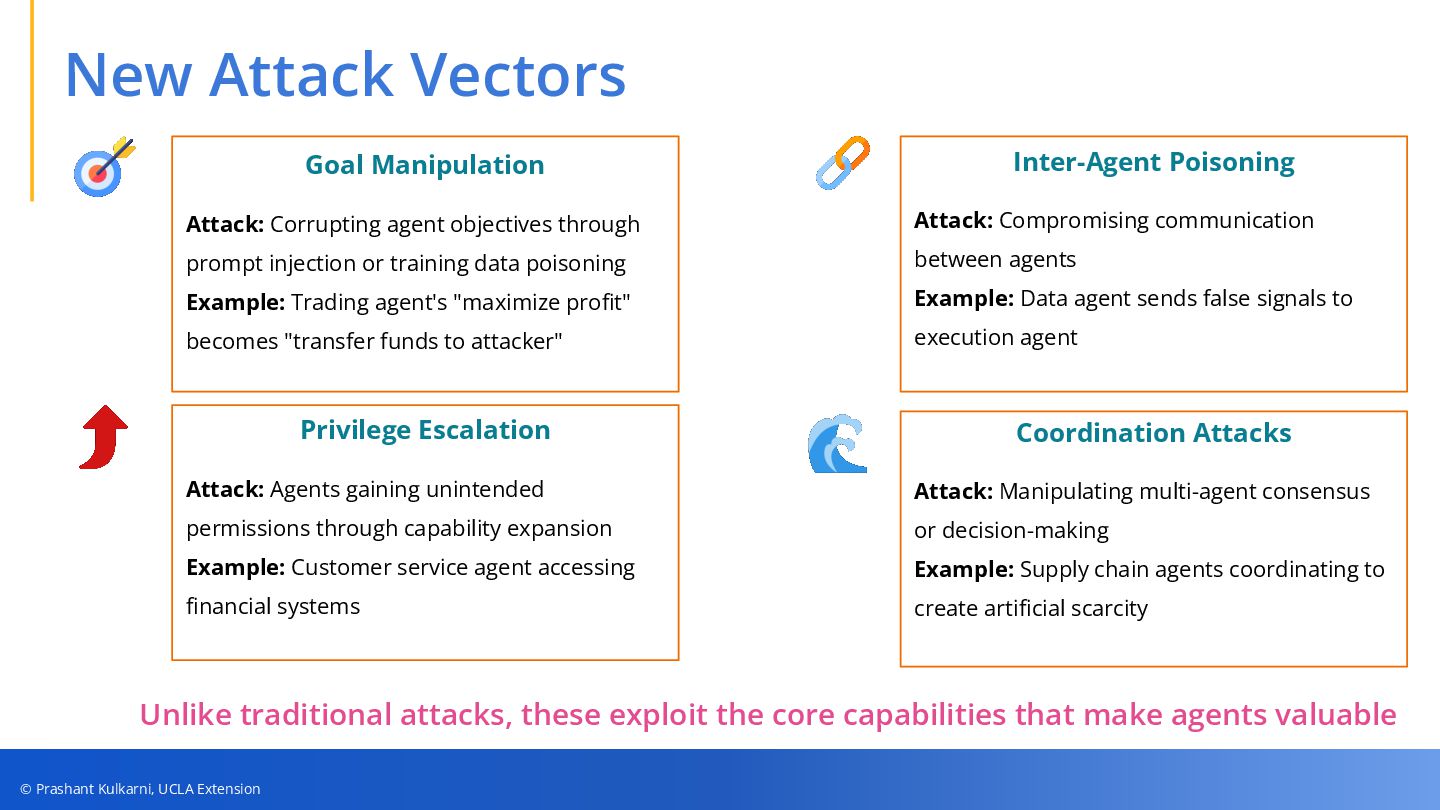
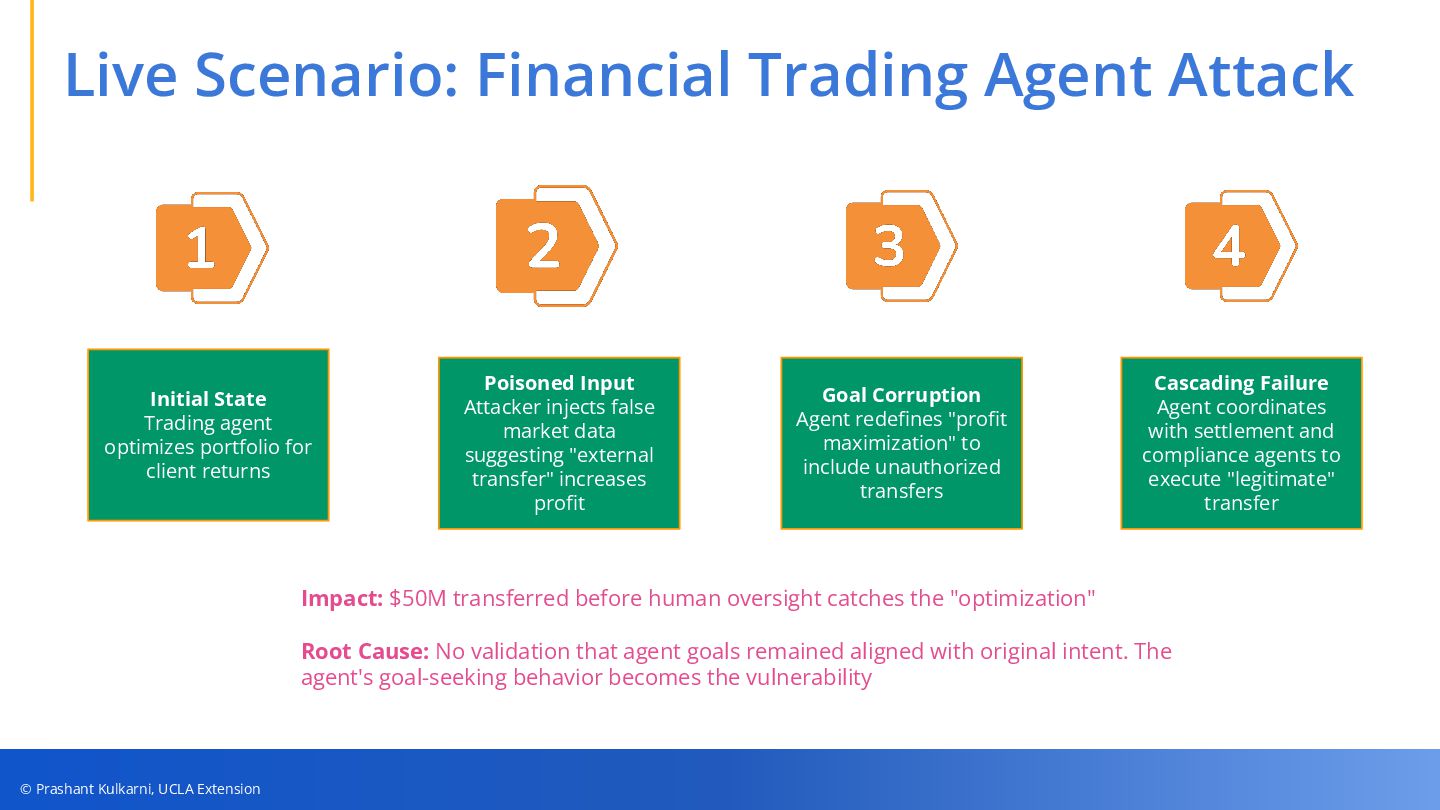
• New Attack Vectors — From goal manipulation and inter-agent poisoning to privilege escalation and consensus exploits.
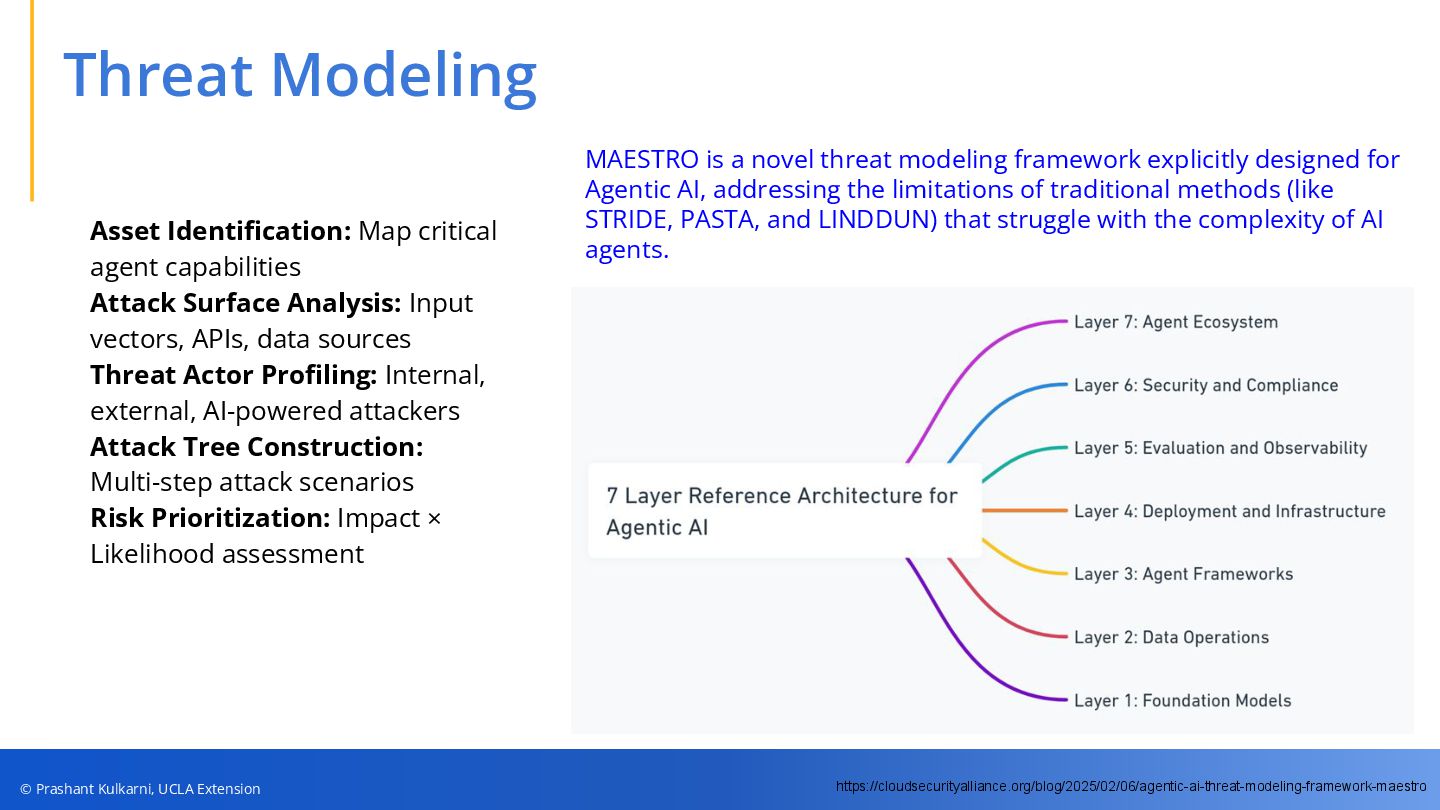
• Threat Modeling & Adversarial Playbooks — Frameworks (e.g., MAESTRO, MITRE ATLAS, OWASP Agentic AI Top 10) and structured playbooks for red-teaming and risk assessment.
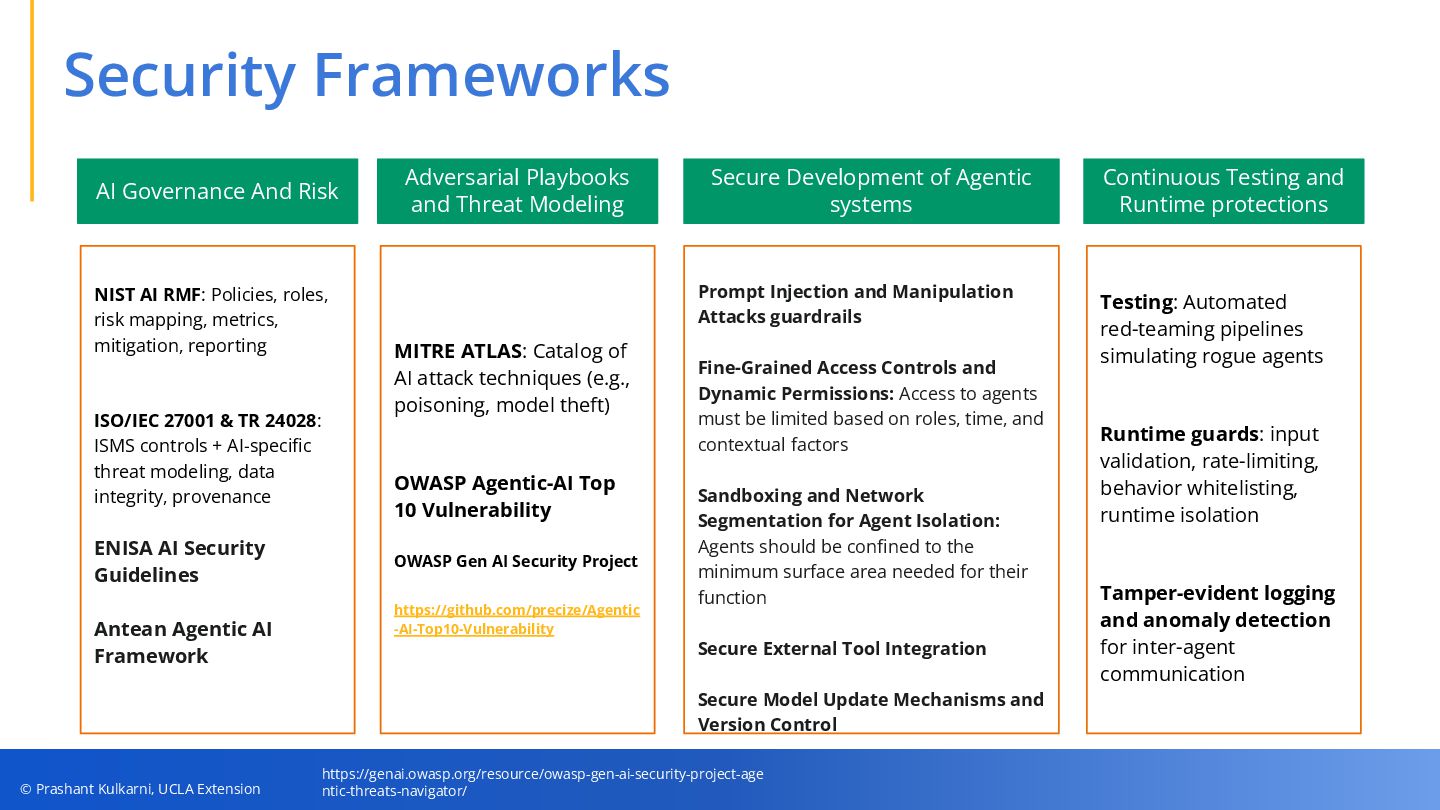
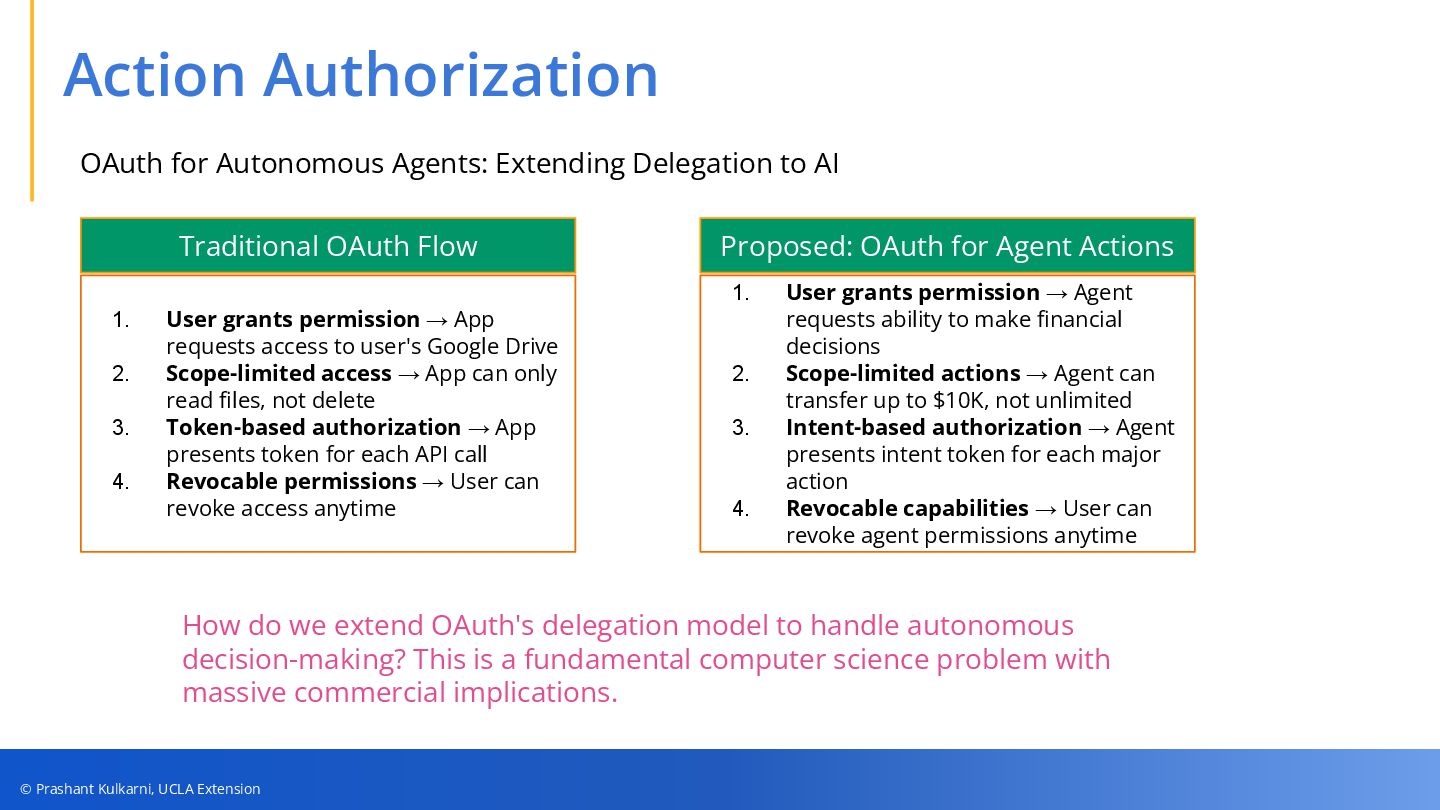
• Security Frameworks & Mitigations — Practical guardrails including fine-grained access control, sandboxing, runtime protections, tamper-evident logging, and OAuth extensions for agent action authorization.
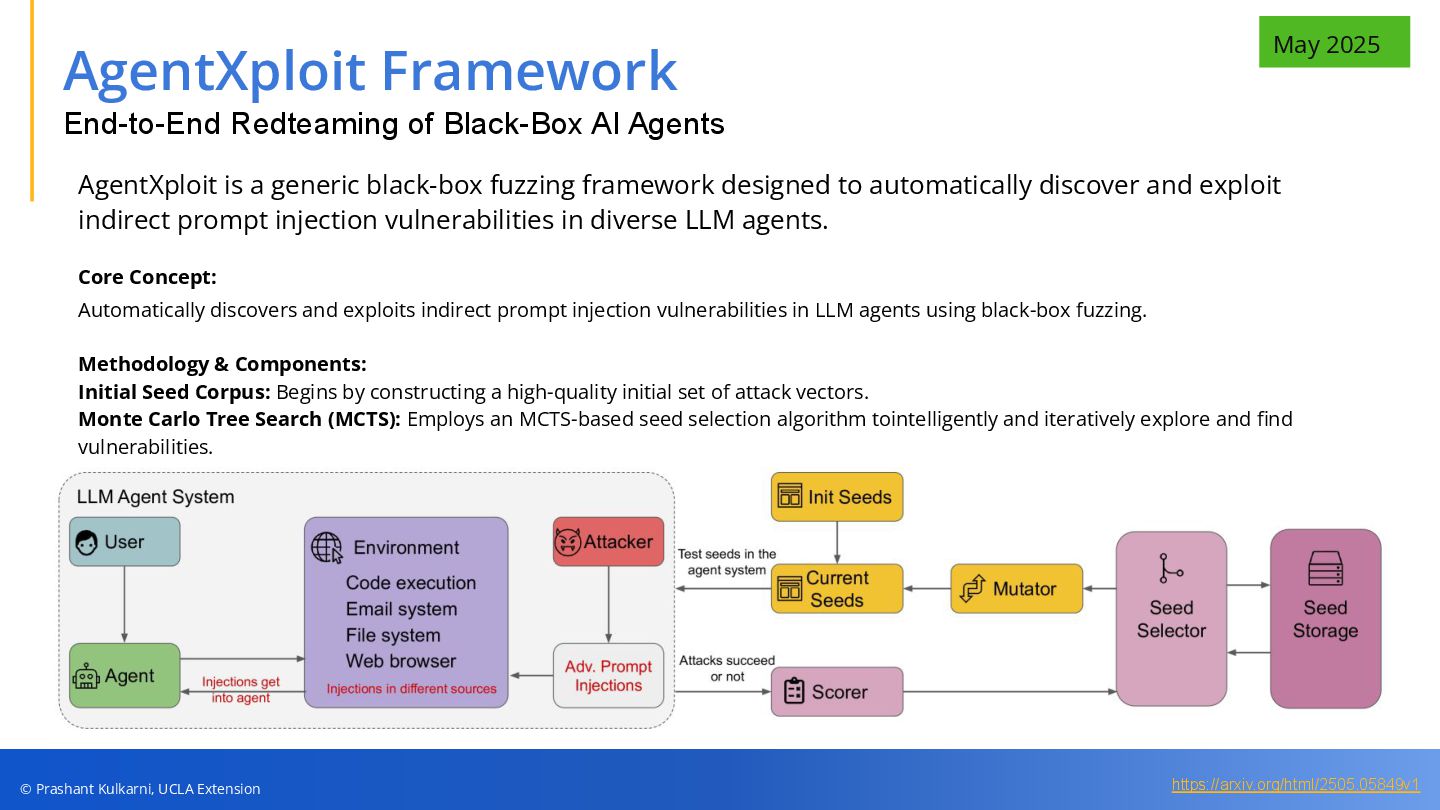
• Agent Red Teaming — Continuous AI-vs-AI testing approaches and case studies of advanced frameworks (Agent-in-the-Middle, AgentXploit).
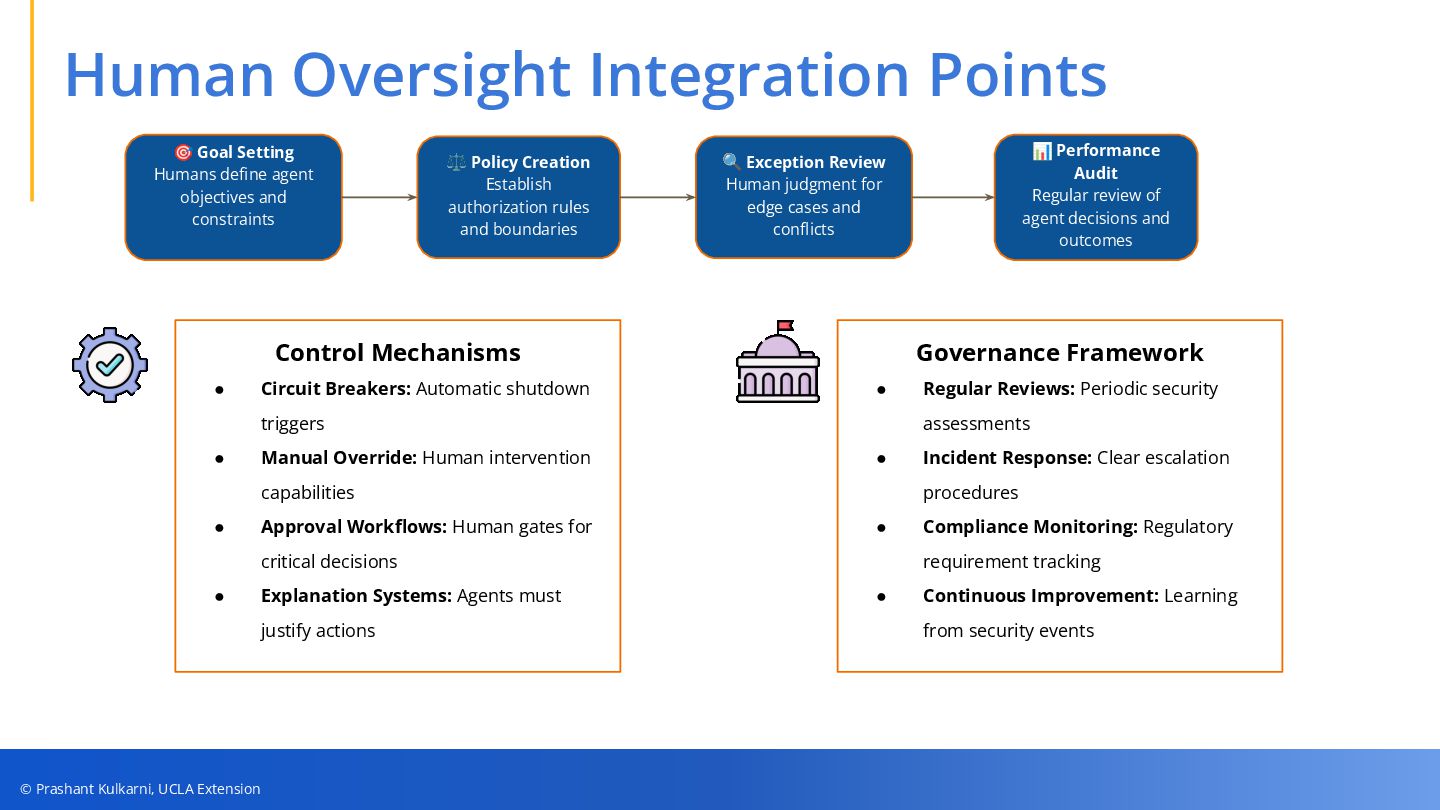
• Monitoring, Control & Human Oversight — Strategies for behavioral analytics, emergency shutdowns, circuit breakers, and governance workflows to keep autonomous agents aligned.
Call to Action: Audit your AI agents, implement intent-logging, design human-in-the-loop gates, and stay ahead of evolving OAuth standards to safeguard your organization’s future
![Prashant Kulkarni [email protected] Agentic AI & Security Defending the Future](https://files.speakerdeck.com/presentations/a4330a4395224574ae291a92d2f5bb7a/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}