When working with databases larger than 10TB that will be heavily read, it is necessary to find different options to improve efficiency, performance and maintainability. In the archives of the European Space Agency, where PostgreSQL is widely used, we have investigated different distributed flavours being postgres-XL the solution that so far is meeting our requirements better. The results of the tests performed will be presented with the conclusions drawn from this research.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
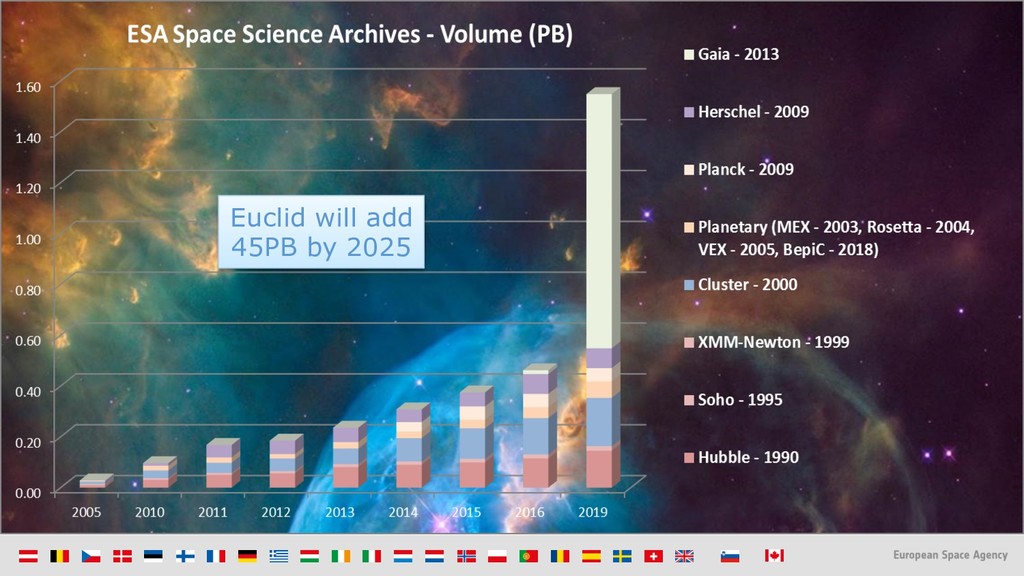{kind=link}
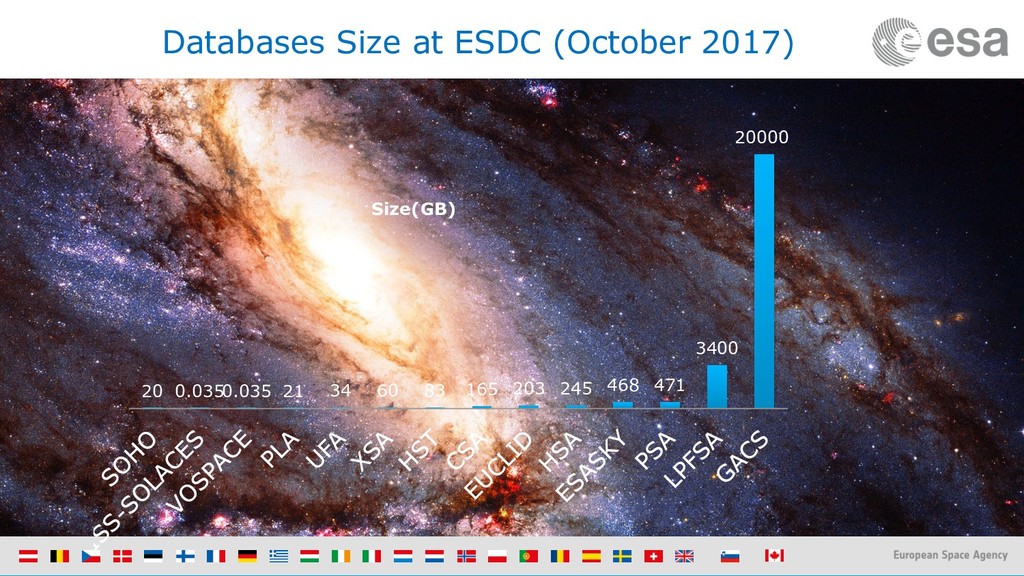{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
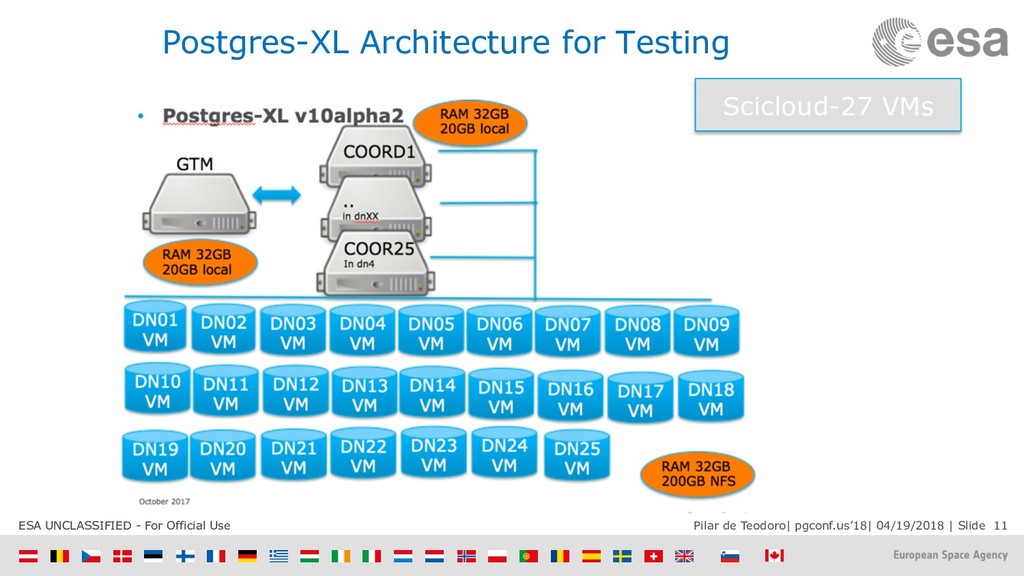{kind=link}
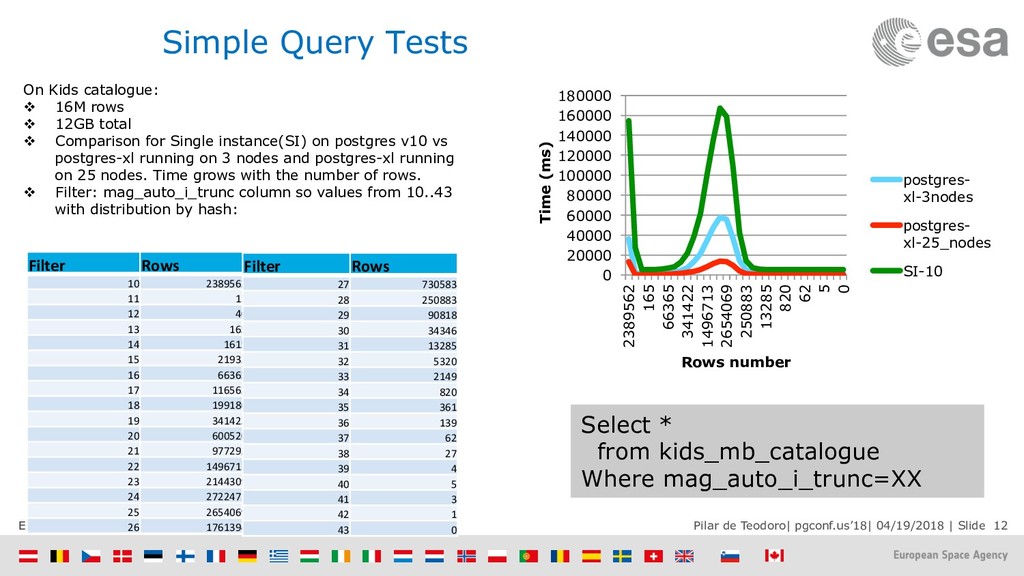{kind=link}
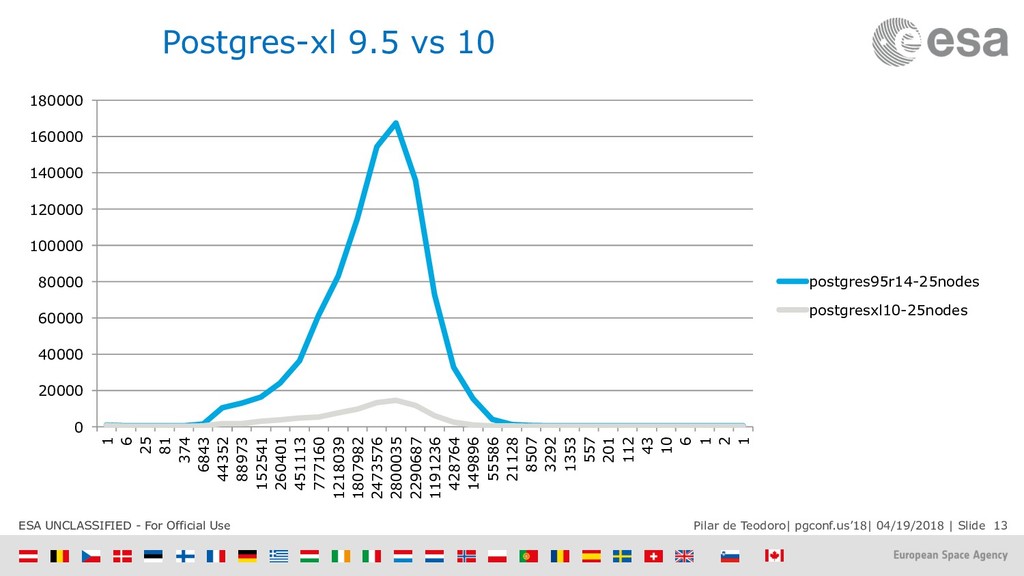{kind=link}
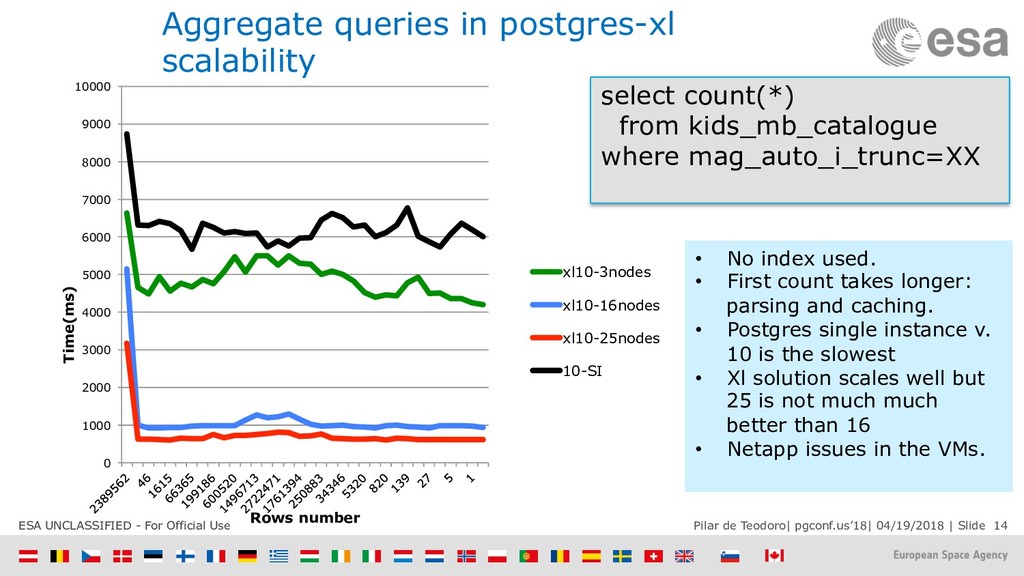{kind=link}
{kind=link}
{kind=link}
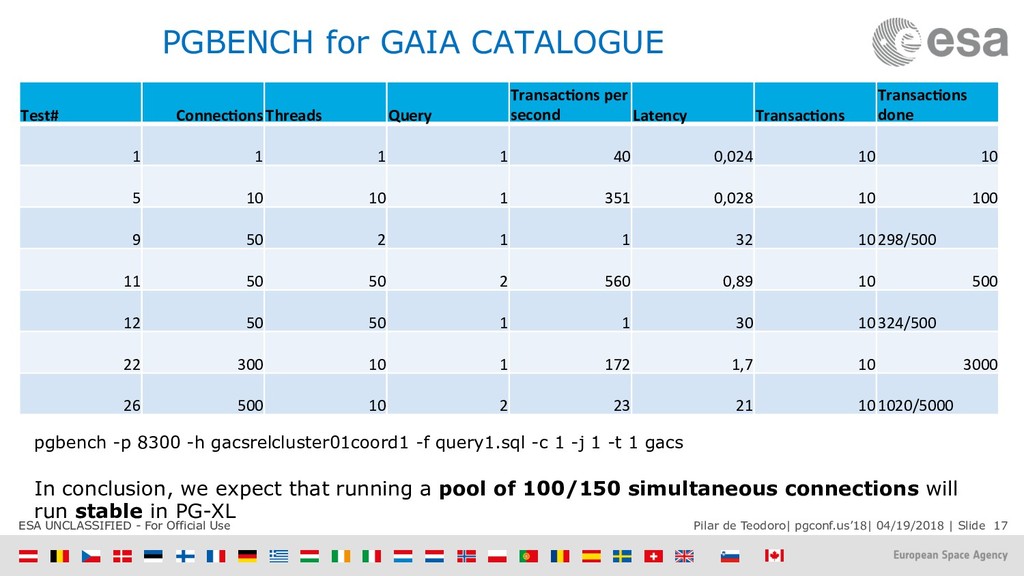{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}