Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
メールの分類をLLMをつかってやってみた
Search
ramo798
May 23, 2024
96
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
メールの分類をLLMをつかってやってみた
https://meguro-lt.connpass.com/event/305703/
ramo798
May 23, 2024
More Decks by ramo798
See All by ramo798
APIサーバのレスポンス速度をふわっと把握したかった
ramo798
0
470
Featured
See All Featured
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
230
Marketing to machines
jonoalderson
1
5.5k
HDC tutorial
michielstock
2
720
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
350
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.7k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
160
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
750
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
250
A Modern Web Designer's Workflow
chriscoyier
698
190k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
250
Transcript
メールの分類を LLMをつかってやってみた ramo
自己紹介 ramo 仕事→ URIHOというサービス開発。 好きなフレームワーク→ remix, sveltekit マイブーム→ cloudflare workers
最近matzさんとツーショット撮りました
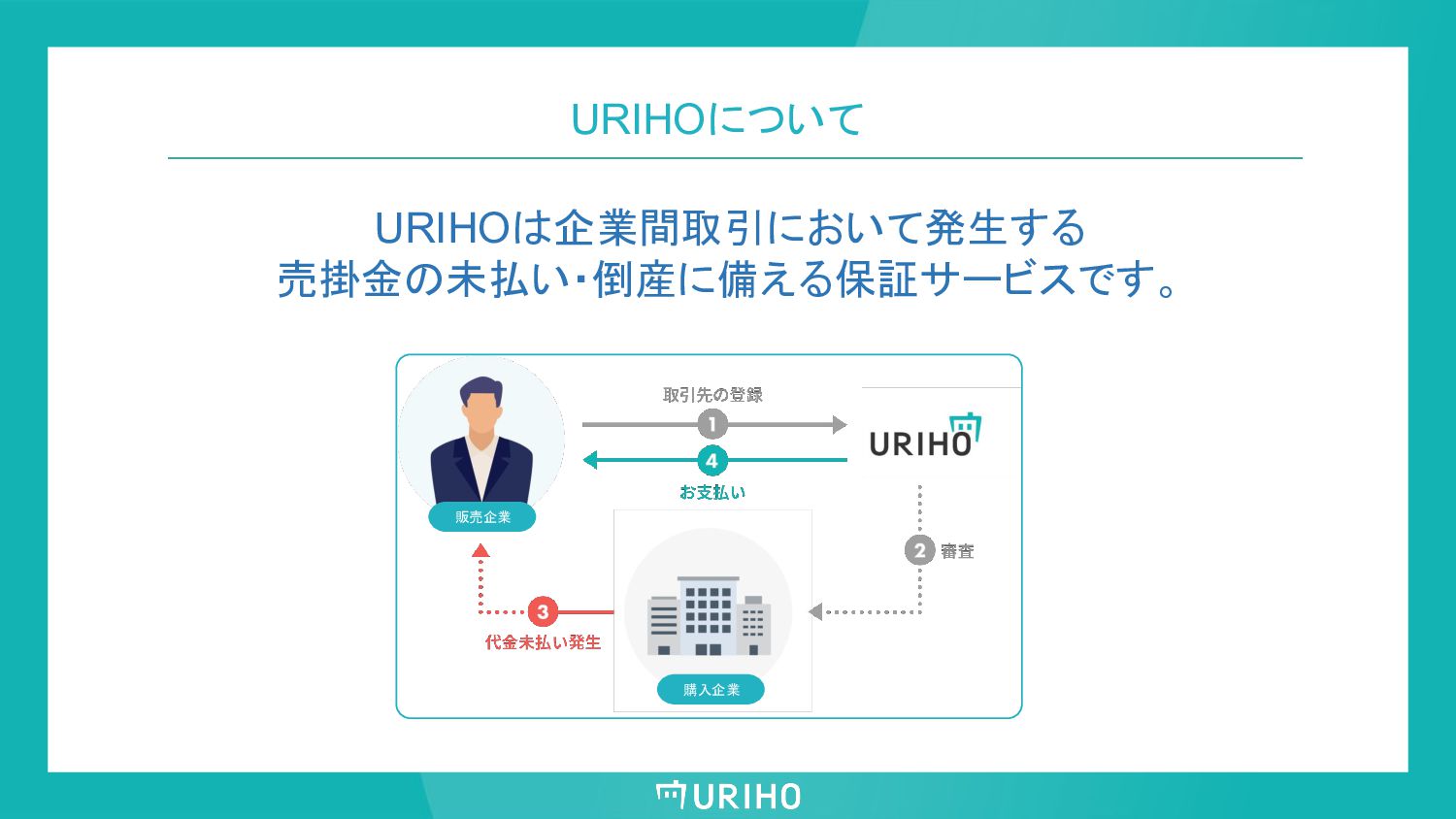
URIHOについて 販売企業 URIHOは企業間取引において発生する 売掛金の未払い・倒産に備える保証サービスです。 購入企業
やりたいこと 問い合わせメールの分類を行って よくある質問ページを拡充したい!
やったこと 1600件の問い合わせメールのうち 1000件を手動で分類 ↓ 分類モデルを作成し、残り600件の分類を自動化 内容の傾向の把握
技術的にやったこと LLMのBERTをファインチューニングして 分類モデルを作成しました その結果、少量のデータでもそれなりの精度になった
技術的にやったこと ・「cl-tohoku/bert-base-japanese-v3」というBERTモデ ルを使用 ・Hugging Faceのtransformersライブラリを使用する ・AutoModelForSequenceClassificationというクラスを使 用して分類問題を解けるようにファインチューニング
やったこと tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-v3") encoding = tokenizer(df_email['Content'].tolist(), padding=True, truncation=True, return_tensors="pt",
max_length=256) model = AutoModelForSequenceClassification.from_pretrained("cl-tohoku/bert-base-japanese-v3", num_labels=len(df_email['question_id'].unique())) # 訓練用のデータの準備等(省略) model.train()
結果 分類の種類 「よくある質問ページに書いてあること」 「サービスの説明をしてください」 「広告」 「その他」
結果 分類の種類 「よくある質問ページに書いてあること」 「サービスの説明をしてください」 「広告」 「その他」 → 90%の精度で分類可能に!
結果 分類の種類 「よくある質問ページに書いてあること」 ↓ よくある質問ページの大分類(5択) + それ以外 でタグ付けを行って学習
結果 分類の種類 「よくある質問ページに書いてあること」 ↓ よくある質問ページの大分類(5択) + それ以外 でタグ付けを行って学習 ↓ 約81%の精度
結果 90%の精度で分類可能に!
その他手法 ・Sentence Transformer + lightGBM →55% ・BoW + SVM →37%
・TF-IDF + SVM →40%
まとめ ・LLMを使うと少数のデータでもそれなりの精度がでる ・Hugging Faceでなんでもできる!
以上です。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![やったこと tokenizer = AutoTokenizer.from_pretrained("cl-tohoku/bert-base-japanese-v3") encoding = tokenizer(df_email['Content'].tolist(), padding=True, truncation=True, return_tensors="pt",](https://files.speakerdeck.com/presentations/94588132ea5643c7b0cd987f64b06305/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}