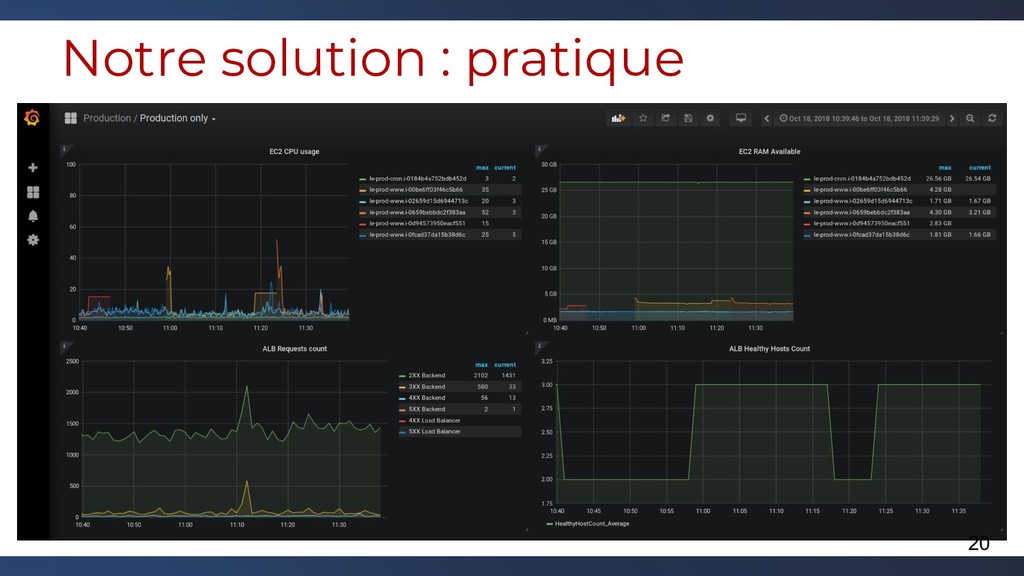
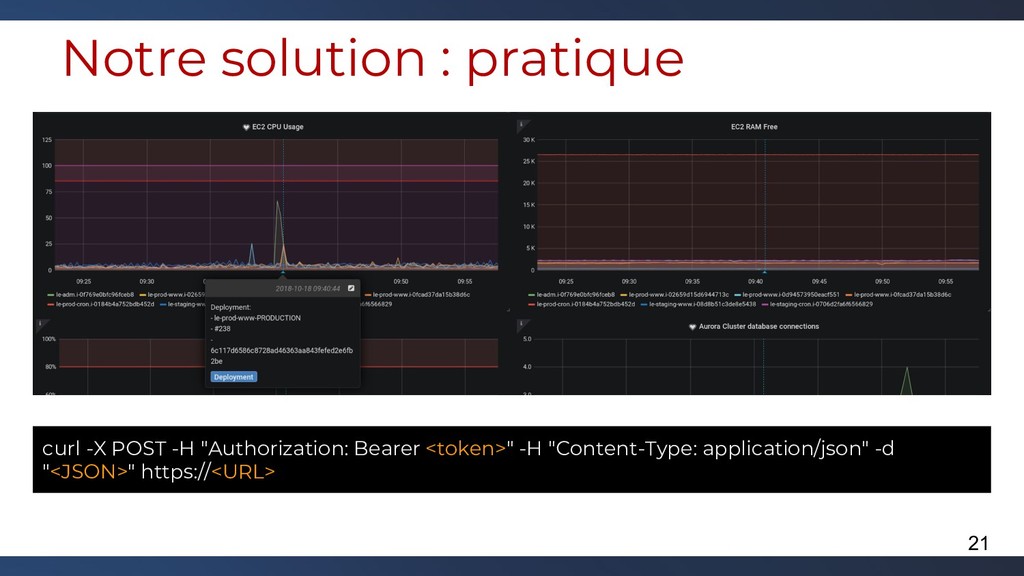
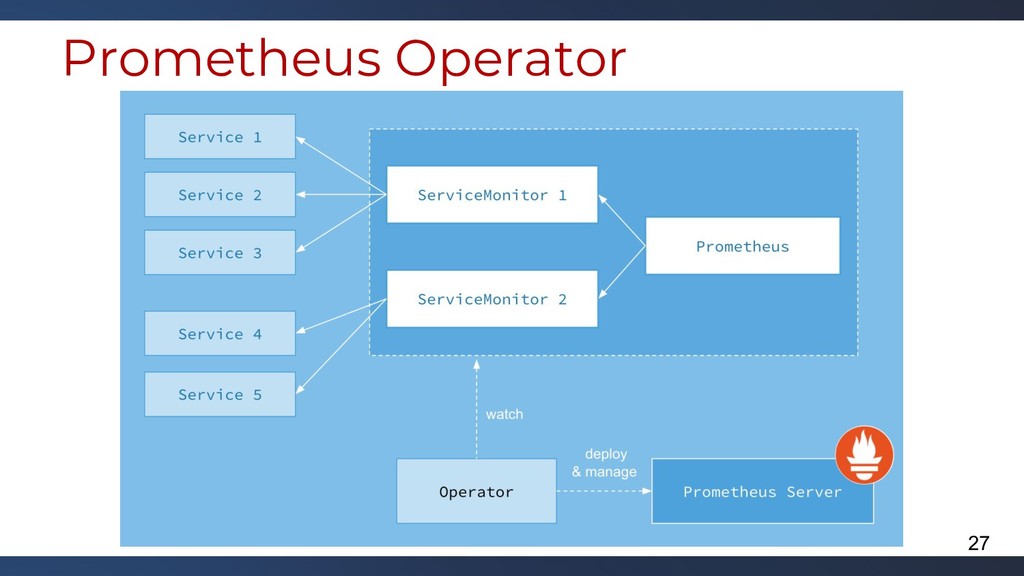
Le monitoring par des outils comme Zabbix peut être à la fois très puissant mais peut aussi rapidement lever des faux positifs et nécessiter du développement sur de l'infrastructure éphémère comme le sont les infrastructures Cloud. Pour résoudre ces problématiques, des outils Open Source existent et permettent, lorsqu'ils sont combinés entre eux, de retrouver à peu près tout ce que l'on veut avec un détail assez précis.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
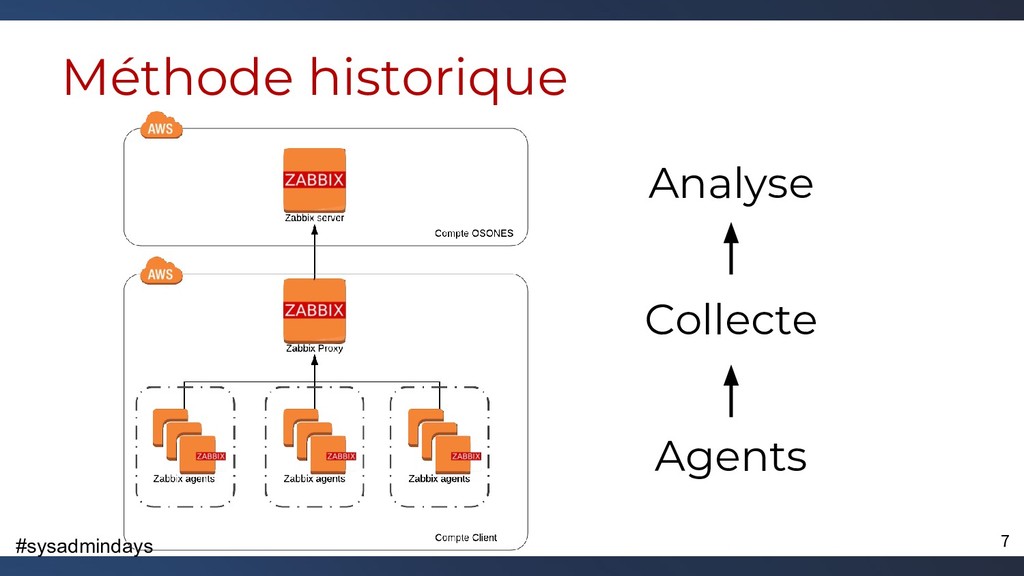{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
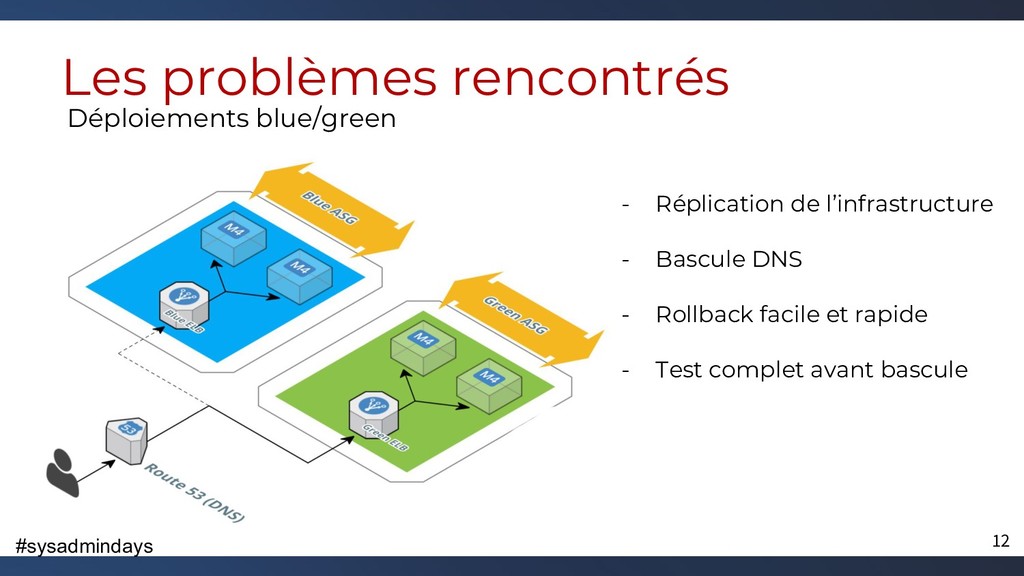{kind=link}
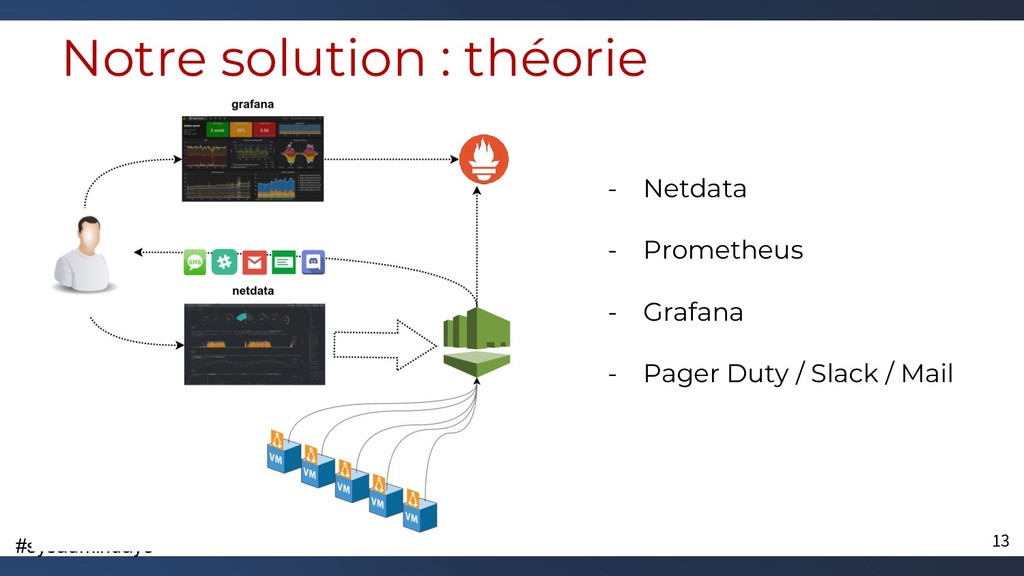{kind=link}
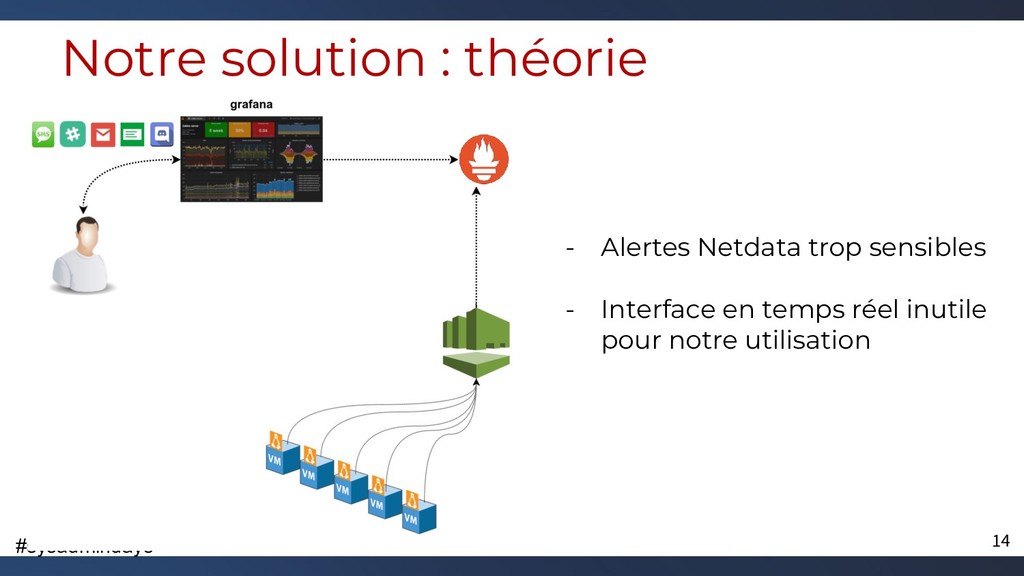{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}