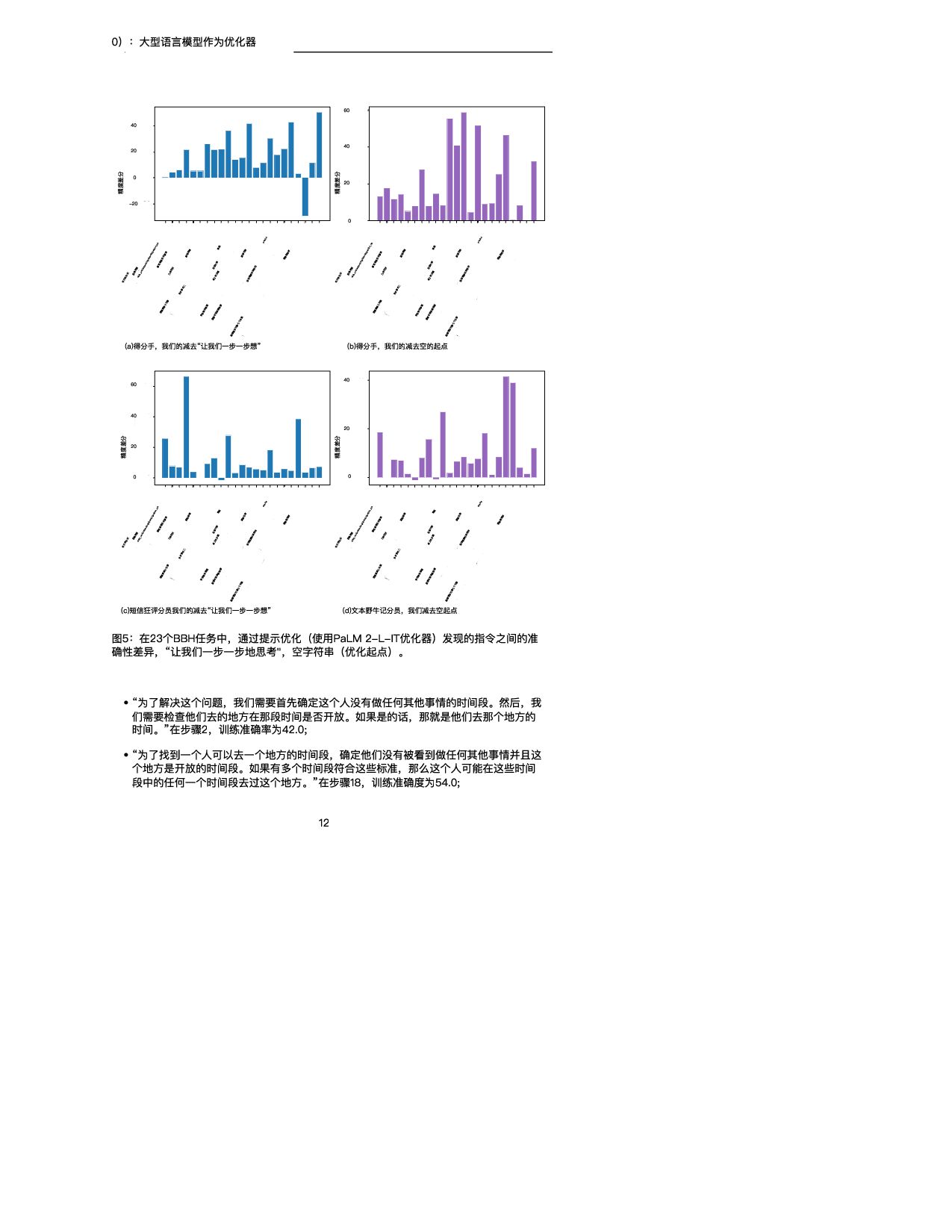
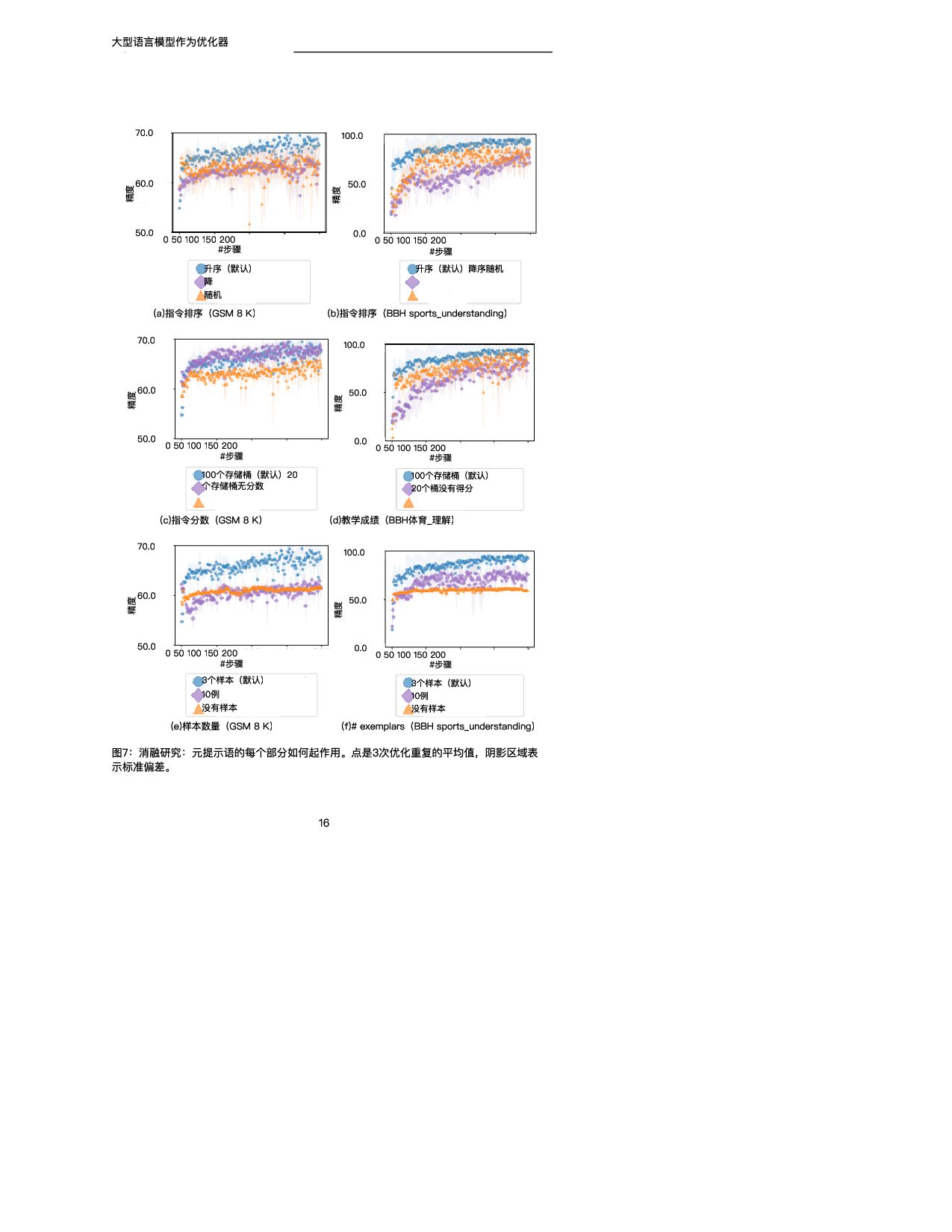
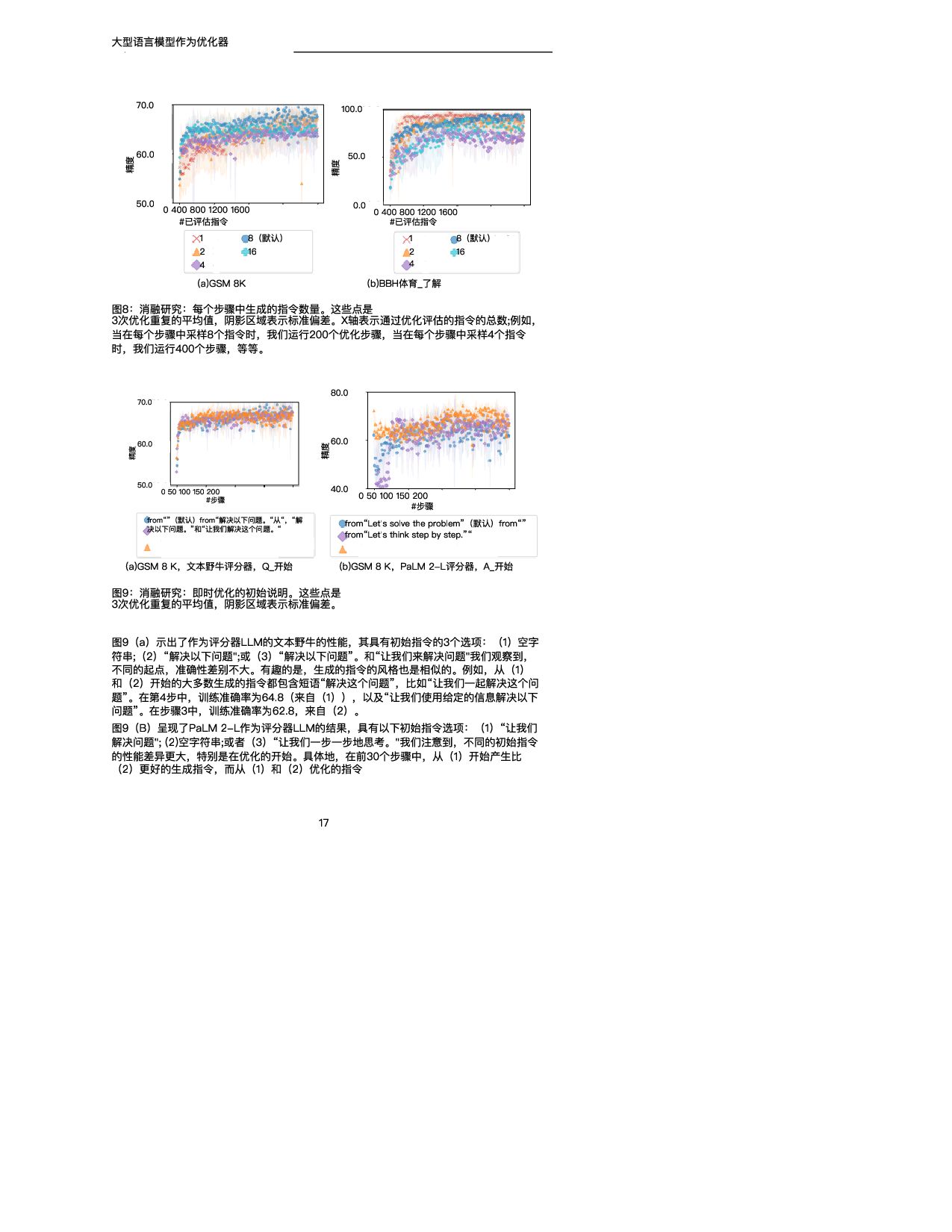
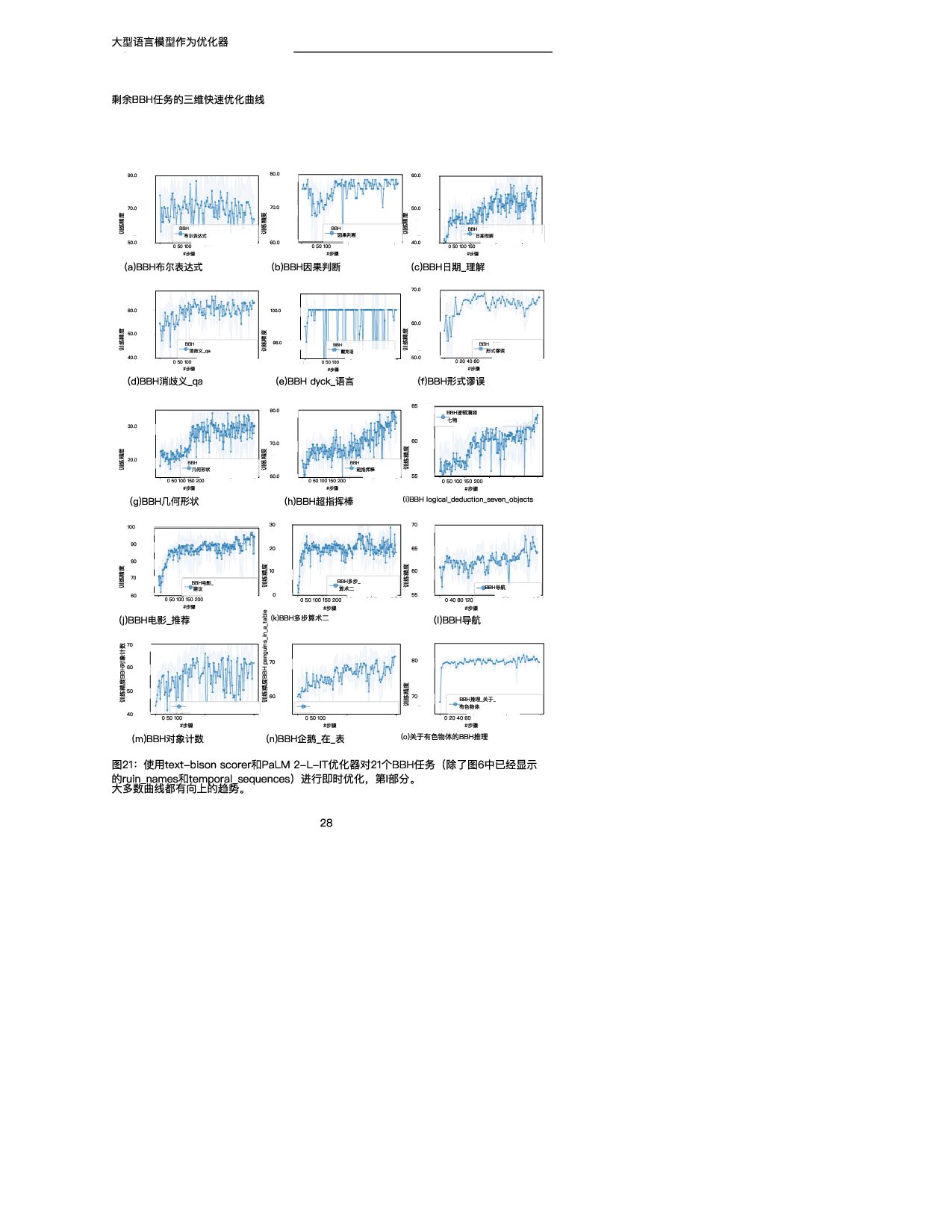
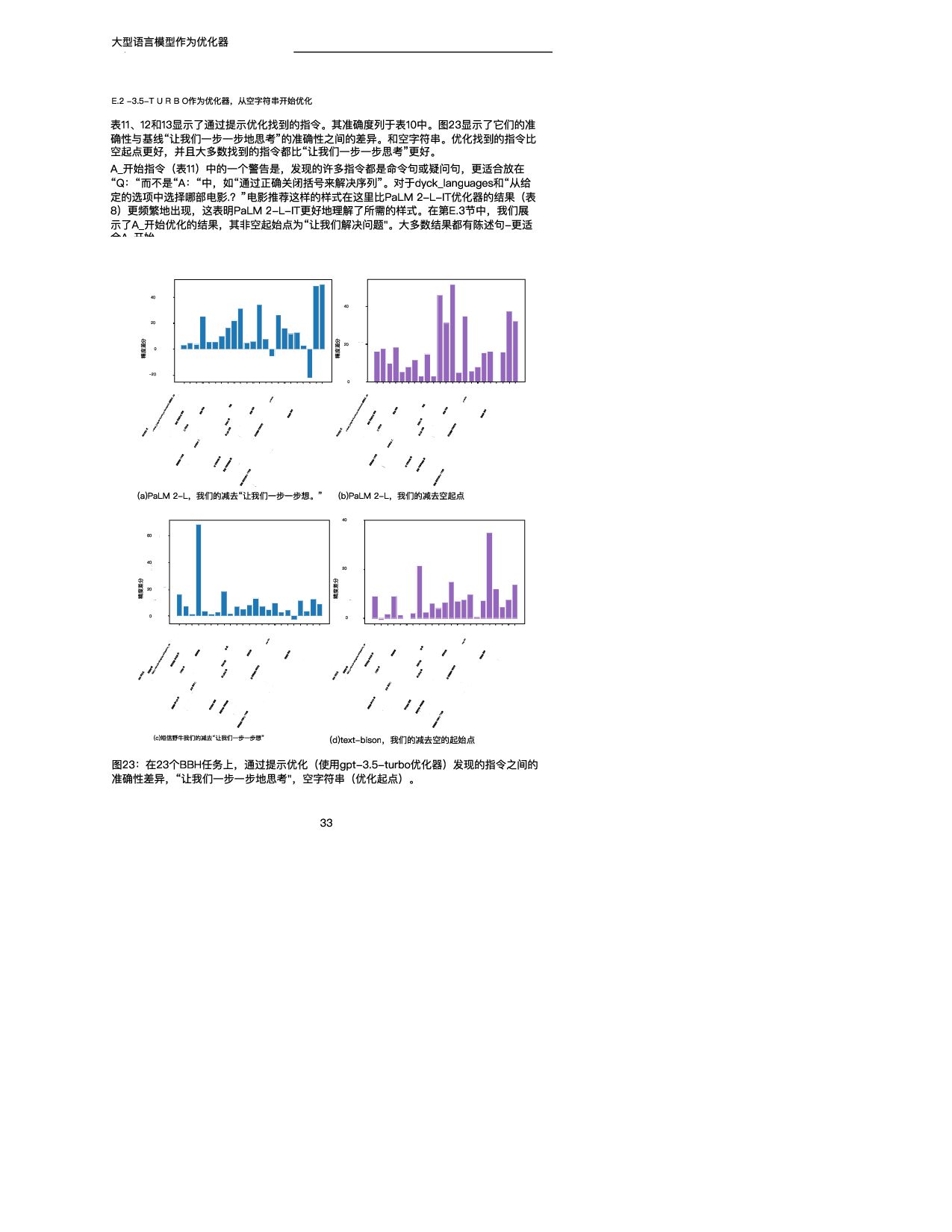
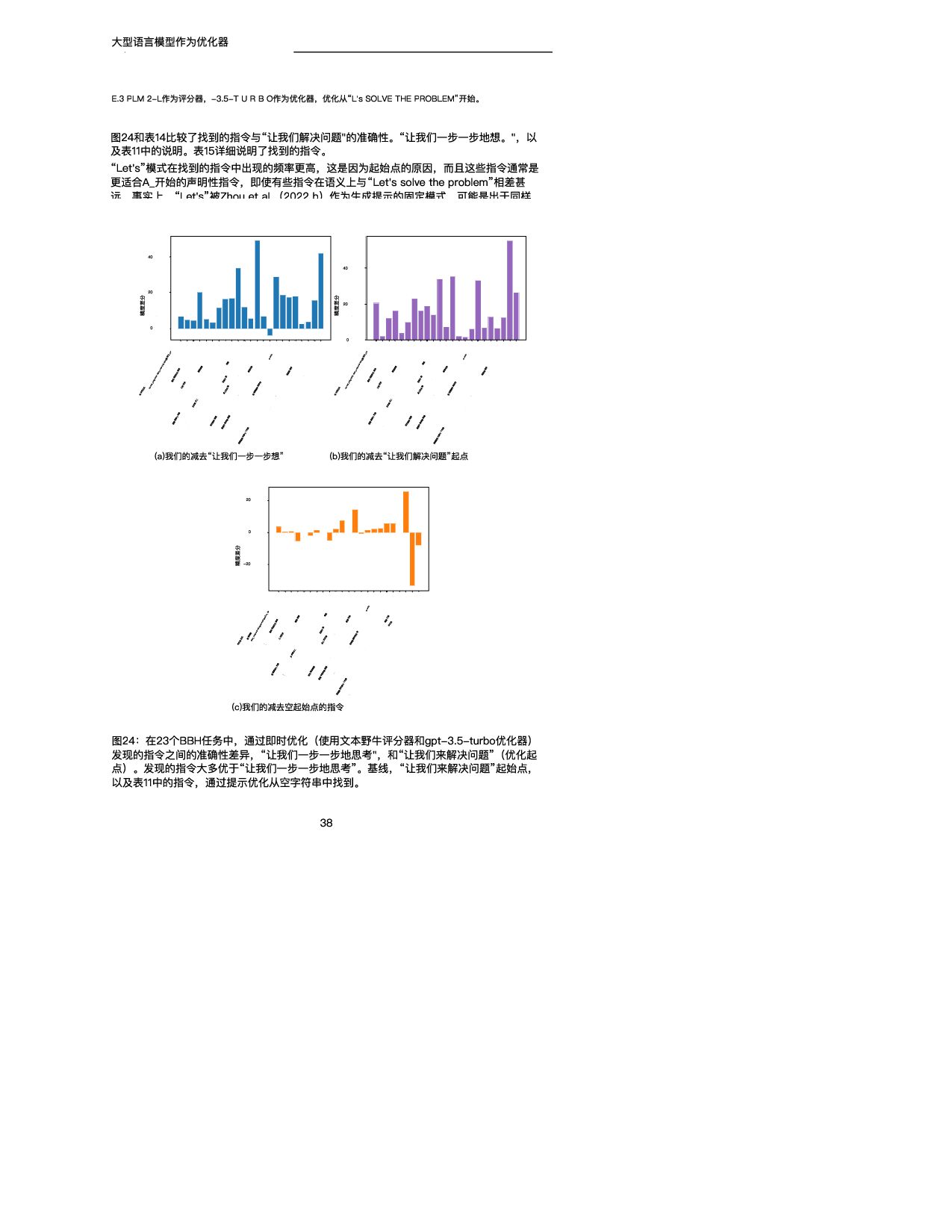
训练精度 GSM 8K (scorer:text-bison) (a)PaLM 2-L-IT优化器 0 20 40 60 80 #步骤 20.0 40.0 60.0 80.0 训练精度 GSM 8K (评分器和优化器: PaLM 2-L) (b)预先训练的PaLM 2-L优化器 图4:使用(a)文本野牛评分器和PaLM 2-L-IT优化器以及(b)预训练的PaLM 2-L作为 评分器和优化器对GSM 8 K进行即时优化。 表4总结了在具有不同评分器和优化器LLM的GSM 8 K上发现的顶级指令。我们注意到: • 不同的优化器LLM发现的指令的风格有很大的不同:PaLM 2-L-IT和text-bison的指令 是简洁的,而GPT的指令是长而详细的。 • 虽然一些顶级指令包含“逐步”短语,但大多数其他指令在不同的语义含义下实现了可比 或更好的准确性。 5.2.2 BBH 在BBH上,默认情况下,优化从空字符串作为初始指令开始。当评分器是PaLM 2-L时,指 令被放置在A_开始,当评分器是文本野牛时,指令被放置在Q_开始。对于每个任务,我们利 用20%的示例子集进行快速优化,其余示例用于测试。我们在附录E中展示了关于指令位置 和初始化的更多变体的实验结果。 图5显示了所有23个BBH任务与“让我们一步一步思考”指令相比的每项任务准确性差异。 (Kojima等人,2022)和空指令,我们在附录E的表7中给出了具体的精度。我们表明, OPRO发现的指令优于“让我们一步一步地思考”。在几乎所有的任务上都有很大的优势:我 们的指令在PaLM 2-L评分器的19/23任务上超过5%,在文本-野牛评分器的15/23任务上超 过5%。我们的即时优化算法在大多数任务中也将空起点的指令提高了5%以上:PaLM 2-L 评分器为20/23,文本野牛评分器为15/23。 与GSM 8K类似,我们观察到几乎所有BBH任务的优化曲线都呈上升趋势,如图6所示。有 关其他BBH任务的更多曲线,请参见附录D中的图21和22。 接下来,我们展示通过优化过程发现的指令的一些示例。在任务ruin_names上,从空指令 (训练精度为640)开始 使用t t bi 和P LM 2 L IT优化器 生成以下指 • “在幽默地编辑艺术家或电影名称时,请考虑以下内容:“在第1步,训练准确率为72.0; • “当对艺术家或电影名称进行幽默编辑时,您可以更改一个或多个字母,甚至通过添加听 起来相似的新词来创建双关语。在步骤18,训练精度为80.0; • “我们可以通过改变字母来创建声音相似但含义不同的新词,从而对艺术家/电影名称进 行幽默的编辑。例如,警察可以改为礼貌,深渊可以改为脚趾深渊,辛德勒的名单可以 改为辛德勒的迷失。在第38步,训练精度为82.0。 尽管上述指令在语义上是相似的,但优化器LLM的解释提供了显著的准确性改进。我们在第 5.2.3节中进一步强调了这一观察结果。 下面是对temporal_sequences执行提示优化时生成的一些指令,从空指令开始(训练精度 为 ) 11
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![大型语言模型作为优化器 表2:优化器LLM的线性回归:在达到全局最优值之前探索的步骤数和唯一(w,b)对的数 量的平均值±标准差。w和b都从[10,20]中的5个随机起点开始。我们为所有型号使用温度 1.0。每个设置运行5次。起始点在优化器LLM之间是相同的,但在5次运行之间是不同的,并 且按以下方式分组:在起始区域内,在起始区域外部且靠近起始区域,以及在起始区域外部 且远离起始区域 粗体数字表示每种设置中三种LLM中最好的 wb步骤数探索的唯一(w,b)对的数量 text-bison gpt-3.5-turbo](https://files.speakerdeck.com/presentations/2dfac75144a44cdda5de2cc221492f7f/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}