Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
10年動くアプリケーションに Embedded SRE を導入した話
Search
Ryo Nakamine
September 23, 2023
670
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
10年動くアプリケーションに Embedded SRE を導入した話
Tech BASE Okinawa 2023 で発表した資料です。
https://techbaseokinawa.com/
Ryo Nakamine
September 23, 2023
More Decks by Ryo Nakamine
See All by Ryo Nakamine
少人数SREで信頼性を配るためのセルフサービスとガードレール設計
rnakamine
3
700
Ruby on Rails におけるOpenTelemetry の活用
rnakamine
3
3.8k
Building a ServiceMap with Service Graph Connector
rnakamine
1
2k
EBILABを支えるクラウド・サーバーレス活用事例とこれから
rnakamine
1
99
Laravel NOVAを使ってみた
rnakamine
0
76
Featured
See All Featured
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
How Software Deployment tools have changed in the past 20 years
geshan
0
34k
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
250
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Un-Boring Meetings
codingconduct
0
330
Scaling GitHub
holman
464
140k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
320
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
180
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Into the Great Unknown - MozCon
thekraken
41
2.6k
sira's awesome portfolio website redesign presentation
elsirapls
0
290
Transcript
1 10年動くアプリケーションに Embedded SRE を導⼊した話 仲嶺 良 / GMO Pepabo,
inc. Tech BASE OKINAWA 2023 2023.09.23
2 ⾃⼰紹介 技術部 プラットフォームグループ 2021年 中途⼊社 仲嶺 良 Nakamine Ryo SRE
として minne の SLI / SLO の策定‧運⽤、それ に基づいたパフォーマンス改善や Kubernetes を⽤ いたコンテナプラットフォームの運⽤‧改善を担当 • naryo と呼ばれています • 沖縄県宜野湾市出⾝ • X ( 旧 Twitter ) : @r_nakamine
GMO ペパボについて 3 https://pepabo.com
4 https://pepabo.com
minne について ライフスタイルに合わせたこだわりの作品を購⼊‧販売できる • 作家‧ブランド数 88 万件 • 登録作品数 1679
万点突破 • アプリDL数 1453 万件以上 • 累計流通額 1,000 億円突破 作品数 No.1 国内最⼤ のハンドメイドマーケット (※) 5 ※ハンドメイド作品の販売を主軸とするハンドメイドマーケット運営会社 2社の IR 資料公表数値及びサイト公表数値を比較。 2022年2月末時点、GMO ペパボ調べ。
minne について 6 https://minne.com/handmade-market
minne について 7
8 10年動く minne のアプリケーションに Embedded SRE を導⼊するにあたって、まず何から始めたか、サービス の成⻑に伴ってどのように信頼性の維持‧向上に向けた 取り組みを実践していったかについて、いくつかの事例 を交えながらお話します。
今⽇話すこと
9 アジェンダ 1. Embedded SRE について 2. minne に Embedded
SRE を導⼊した背景 3. SRE を実践した取り組み事例 3.1. まず始めたこと 3.2. 信頼性向上に向けた取り組み 3.3. 運⽤改善に向けた取り組み 4. まとめ
1. Embedded SRE について 10
そもそも SRE とは? 11
Embedded SRE について • SRE とは Site Reliability Engineer(ing) の略で、サービスの信頼性
( Reliability ) を維持‧向上させるための開発‧運⽤⽅法またはチームを指す • ソフトウェア‧エンジニアリングを⽤いて、システムの管理や運⽤における課題解 決、⾃動化を⾏うのが⽬的 そもそも SRE とは? 12
Embedded SRE について • SRE とは Site Reliability Engineer(ing) の略で、サービスの信頼性
( Reliability ) を維持‧向上させるための開発‧運⽤⽅法またはチームを指す • ソフトウェア‧エンジニアリングを⽤いて、システムの管理や運⽤における課題解 決、⾃動化を⾏うのが⽬的 そもそも SRE とは? 13
Embedded SRE について • サービスが⼀定の期間にわたって期待通りのパフォーマンスを維持し、サービスの 機能を正確かつ効果的に提供する指標 信頼性 14 エラー率 受信したリクエストを
正常に処理できなかっ た⽐率 レインテンシー リクエストに対するレ スポンスを返すまでに かかった時間 可⽤性 サービスが利⽤できる 時間の⽐率
Embedded SRE について • 信頼性こそあらゆるプロダクトの基本的な機能 • 誰も使えないシステムは、有益なものではありえない • 信頼性が⾼いほど、ユーザーは期待通りに サービスを利⽤することができる
なぜ信頼性が⼤事なのか 15 参考: SRE サイトリライアビリティエンジニアリング https://www.oreilly.co.jp/books/9784873117911
Embedded SRE 16
Embedded SRE について SRE が 開発チームの⼀員 となって、SRE のプラクティスを浸透させていく役割 • 開発チームと密接に連携し、コミュニケーションを測ることができる
• SRE が開発チーム内にいることで、問題が発⽣した際の特定と解決がスムーズかつ 迅速に⾏える 詳しくは How SRE teams are organized, and how to get started Embedded SRE 17
18 2. Embedded SRE を導⼊した背景
Embedded SRE を導⼊した背景 • 事業部のアプリケーションエンジニアが⽚⼿間でインフラを管理していた ◦ 退職者も出たことからインフラの管理まで⼿が回らなくなった • オンコール体制の不備 •
10年近く動くインフラに精通してる⼈がいなかった ⼈⼿が⾜りない問題 19
Embedded SRE を導⼊した背景 • SLI / SLO は策定されているも、上⼿く運⽤できていなかった ◦ SLI
の悪化が直接ユーザーに影響していなかったりする • インフラの運⽤に⼿間がかかっていた ◦ Kubernetes クラスタのアップデート ◦ 各 VM インスタンスの管理 ◦ AWS EC2 のメンテナンス ◦ その他いろいろ... SREのプラクティスがあまり浸透されていない 20
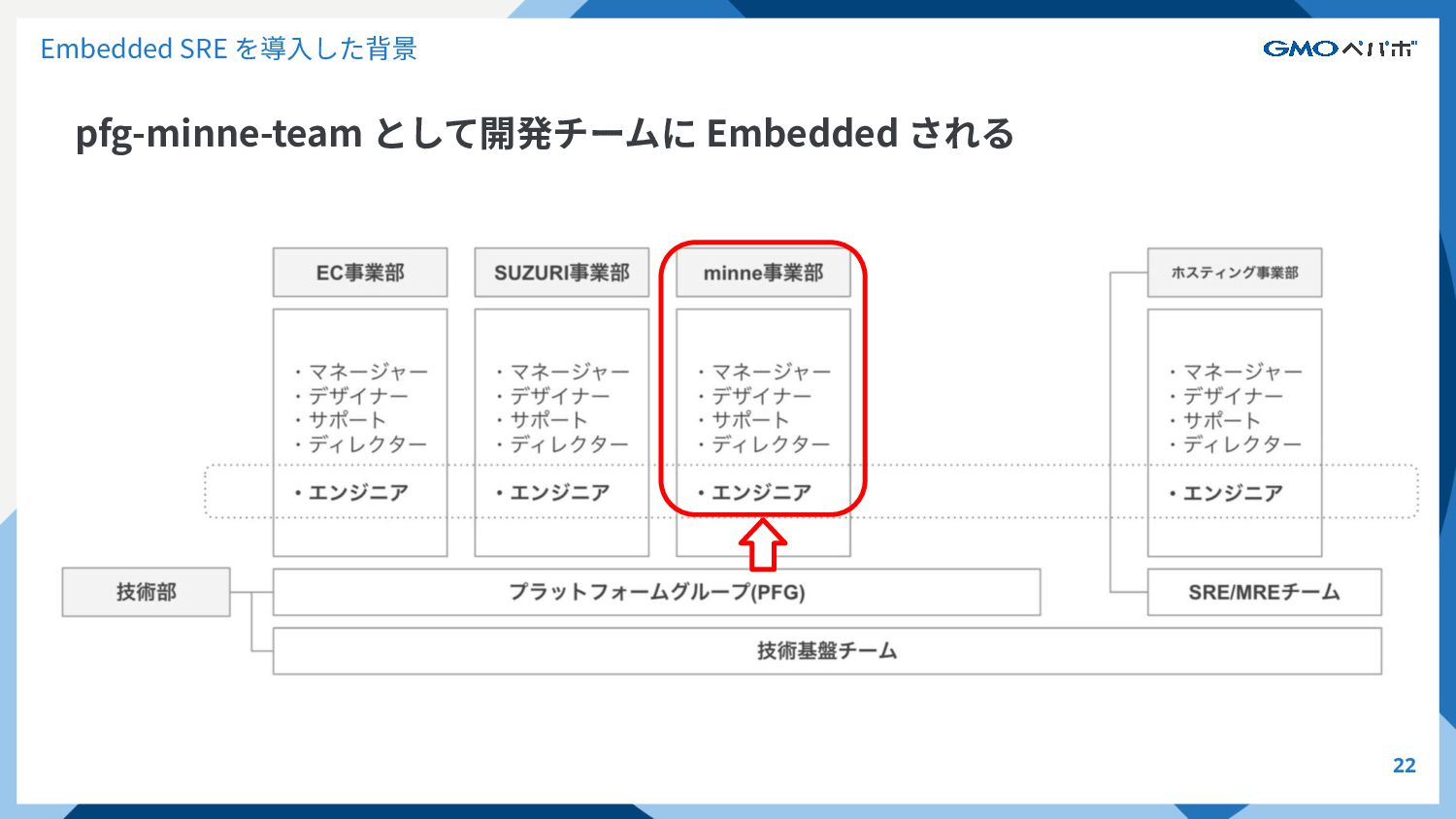
Embedded SRE を導⼊した背景 pfg-minne-team として開発チームに Embedded される 21
Embedded SRE を導⼊した背景 pfg-minne-team として開発チームに Embedded される 22
Embedded SRE を導⼊した背景 • モニタリング基盤を整えたり、⾃動化を取り⼊れたりするのは積極的に⾏うが、 インフラの運⽤に関わることは SRE チームにおまかせ!というわけじゃない • 事業部のアプリケーションエンジニアと
⼀緒になって SRE のプラクティスを浸透 させていくことが⽬的 SRE は開発チームのインフラ運⽤担当ではない 23
24 1. セクションタイトル 3. SRE を実践した取り組み事例
minne のインフラ構成をざっくり解説 25
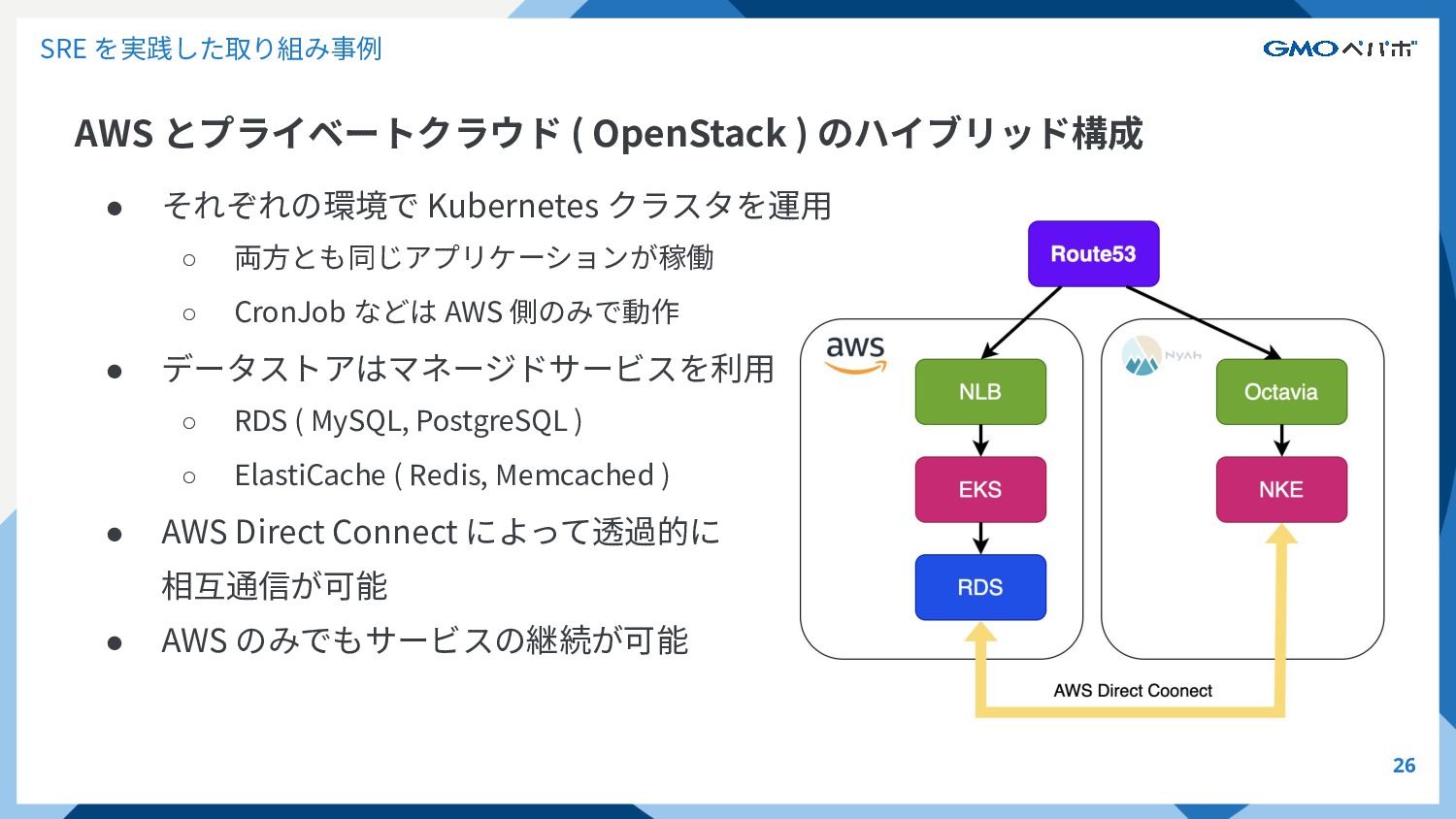
SRE を実践した取り組み事例 AWS とプライベートクラウド ( OpenStack ) のハイブリッド構成 26 •
それぞれの環境で Kubernetes クラスタを運⽤ ◦ 両⽅とも同じアプリケーションが稼働 ◦ CronJob などは AWS 側のみで動作 • データストアはマネージドサービスを利⽤ ◦ RDS ( MySQL, PostgreSQL ) ◦ ElastiCache ( Redis, Memcached ) • AWS Direct Connect によって透過的に 相互通信が可能 • AWS のみでもサービスの継続が可能
SRE を実践した取り組み事例 AWS とプライベートクラウド ( OpenStack ) のハイブリッド構成 27 https://speakerdeck.com/tnmt/pepabo-infra-past-and-future
https://speakerdeck.com/buty4649/hybrid-cloud-with-a ws-directconnect
まず始めたこと 28
SRE を実践した取り組み事例 • サービスに対する理解 ◦ 開発チームの⼀員となって仕事をする上でまずはサービスに対する理解やサービスの特性 を把握する必要がある • インフラ全体の構成把握のために構成図やドキュメントの整備 •
Infrastructure as Code の整備 まず始めたこと 29
SRE を実践した取り組み事例 インフラ全体の構成把握 30 • 10年動いているサービスなので、それなりにたくさんの仕組みで動いている ◦ もう使われてないのもいくつか... • とりあえず、開発チームに聞いてまわる
• 過去の issue や Slack の履歴を追って歴史を把握する
SRE を実践した取り組み事例 インフラ全体の構成把握 31 • 10年動いているサービスなので、それなりにたくさんの仕組みで動いている ◦ もう使われてないのもいくつか... • とりあえず、開発チームに聞いてまわる
• 過去の issue や Slack の履歴を追って歴史を把握する ➡ わかったことはドキュメントに残したり、構成図に起こしていった
SRE を実践した取り組み事例 Infrastructure as Code の整備 32 Infrastructure as Code
がなぜ重要か • インフラのプロビジョニング、構成管理が効率的に⾏える • 開発、テスト、本番環境間での不⼀致が減少し、システムの可⽤性が向上する • バージョン管理され、変更の履歴を追跡できる • ⾃動化を取り⼊れることで運⽤コストを⼤幅に削減
SRE を実践した取り組み事例 Infrastructure as Code の整備 33 • 各アプリケーション⾃体は Kubernetes
のマニフェストで管理 ◦ ArgoCD を⽤いて GitOps で運⽤している • インフラリソースの管理は Terraform、 独⾃の構成管理ツール • プロビジョニングツールは Puppet • Codenize Tools ◦ Route53 は Roadworker で管理 ◦ IAM は Miam で管理 ◦ MySQL は Gratan で管理
SRE を実践した取り組み事例 Infrastructure as Code の整備 34 いくつかの課題があった • インフラの状態とコードに⼤きな差分がある
◦ これ適⽤して⼤丈夫?的なやつがたくさんあった • 全てのリソースがコードで管理されていない • 独⾃ツール⾃体のメンテナンスが⽌まってしまっている
• まずはインフラの状態とコードの差分が合うようにひたすら頑張る • インフラリソースに関しては全て Terraform で管理するようにする ◦ 社内の独⾃ツールや Coodnize Tools
で管理されたリソースは全て Terraform へ移⾏ ▪ ドキュメントが充実している ▪ 開発が活発(新しいリソースもすぐ対応されている) ▪ 複数のツールで管理したくない • 差分が出てもそのままの状態にならないように Github Actions を⽤いて ⾃動で Plan / Apply される仕組みを作った ◦ Pull Request を⽴てたら⾃動で Plan を実⾏ ◦ main ( master ) ブランチに Merge されたら Apply を実⾏ ◦ Cron で毎⽇ Plan を実⾏させ、差分が出たら Slack 通知させている SRE を実践した取り組み事例 Infrastructure as Code の整備 35
信頼性向上に向けた取り組み 36
SRE を実践した取り組み事例 • 信頼性こそあらゆるプロダクトの基本的な機能 • 誰も使えないシステムは、有益なものではありえない • 信頼性が⾼いほど、ユーザーは期待通りに サービスを利⽤することができる なぜ信頼性が⼤事なのか(再掲)
37 参考: SRE サイトリライアビリティエンジニアリング https://www.oreilly.co.jp/books/9784873117911
• SLI ( Service Level Indicator ) ◦ サービスの信頼性や性能などの側⾯を測定する指標 ◦
サービスがユーザーにとってどれほど機能しているかを定量的に表す ◦ 例 ) ▪ リクエストのレイテンシー:サービスがリクエストに応答するまでの時間 ▪ 成功率:全リクエスト中で成功したリクエストの割合 • SLO ( Service Level Objective ) ◦ SLIの値が満たすべき⽬標の値または範囲 ◦ サービスの品質や信頼性の⽬標を定め、これが満たされない場合には何かしらのアクショ ンを起こす SRE を実践した取り組み事例 SLI の再定義 38
SRE を実践した取り組み事例 SLI の再定義 39 現状の SLI に課題があった • SLI
/ SLO は策定されているも、上⼿く運⽤できていなかった ◦ SLI の悪化が直接ユーザーに影響していなかったりする • 全リクエストのレイテンシーと可⽤性を⽤いていた ◦ ユーザーが期待する信頼性を表しているとは⾔えない
SRE を実践した取り組み事例 SLI の再定義 40 現状の SLI に課題があった • SLI
/ SLO は策定されているも、上⼿く運⽤できていなかった ◦ SLI の悪化が直接ユーザーに影響していなかったりする • 全リクエストのレイテンシーと可⽤性を⽤いていた ◦ ユーザーが期待する信頼性を表しているとは⾔えない ➡ ユーザーへの影響が⼤きい機能別の SLI を再定義した
SRE を実践した取り組み事例 SLI の再定義 41 SLI / SLO の再定義を⾏い、事業部の責任者‧エンジニアから合意のもと決定した •
CUJ ( Critical User Journey )を⽤いて SLI を再定義 ◦ CUJ とは ユーザーがサービスを利⽤する過程で経験する⼀連のアクションやタスクの シーケンスを指す • minne の場合、登場⼈物が 作家‧購⼊者 となり、それぞれのユーザーが⽬的を達 成するための重要な機能をいくつかピックアップし、それに対して SLI を設定した • ここでは主に機能別のレイテンシー‧成功率を SLI として定義 • SLO は現状のレイテンシー‧成功率から少しストレッチした値を設定
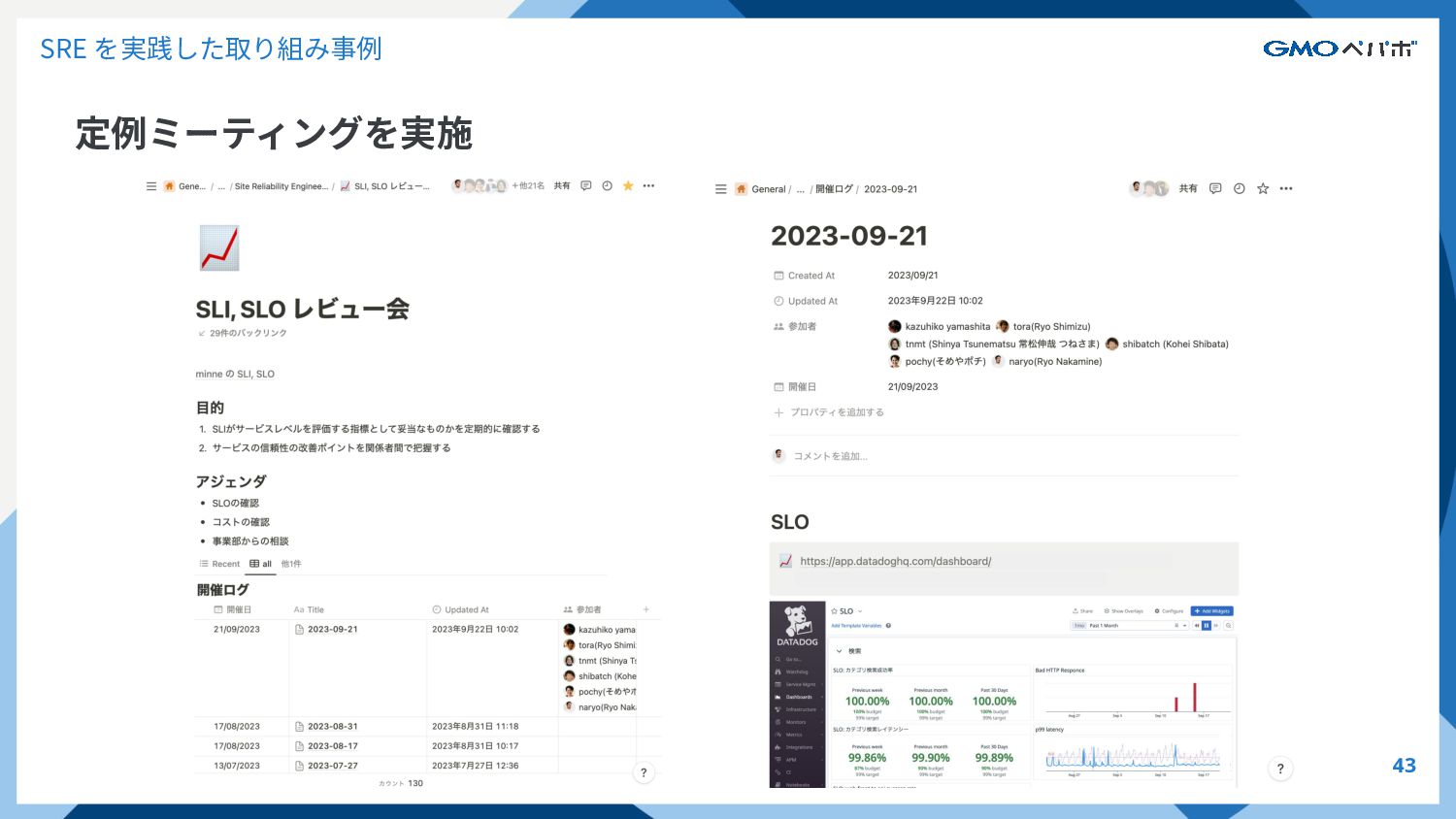
SRE を実践した取り組み事例 定例ミーティングを実施 事業部のエンジニア(エンジニアリング責任者も含む)とSREチームで運⽤に 関する定例のミーティングを実施している(主に週次で開催) • SLOの達成状況の確認 ◦ SLO 違反が⾒られた場合はアクションと期限を決める
◦ 悪化が著しい場合は、リリースを中⽌し改善に取り組む ▪ エラーバジェットを活⽤する • コストの確認 ◦ 意図しないコスト増が起きてないか ◦ コストに関する相談 • 事業部の困りごとの共有 42
SRE を実践した取り組み事例 定例ミーティングを実施 43
SRE を実践した取り組み事例 パフォーマンス改善に向けた取り組み 44 • 各 Kubernetes クラスターや AWS のマネージドサービス、アプリケーションにそれ
ぞれ監視ツールを導⼊し、オブザーバビリティをある程度確保できるようにしている基盤を 整備 • アプリケーション‧インフラ両⽅の軸からパフォーマンス悪化の原因を調査し、改 善に向けた取り組みを実施している
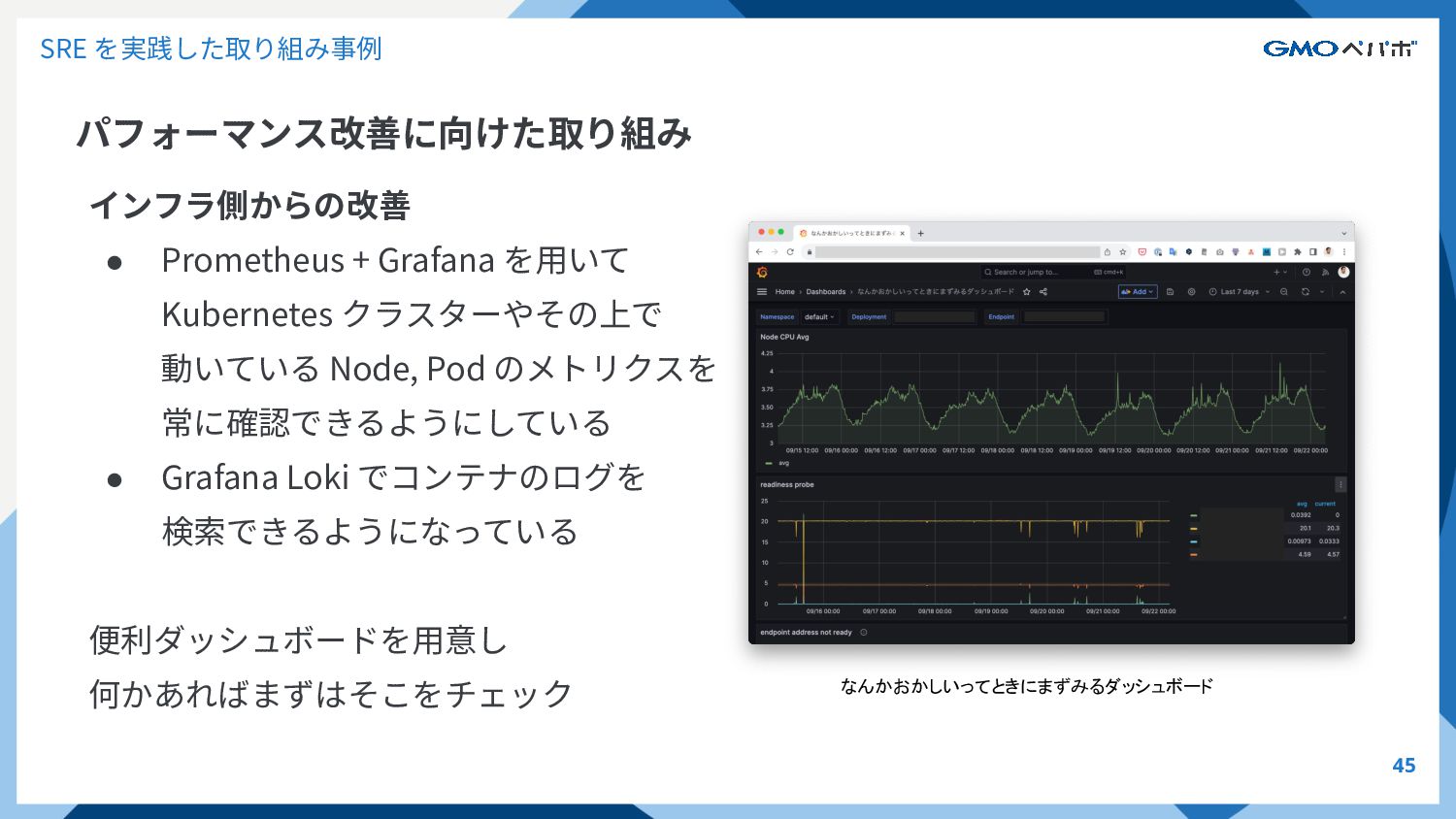
SRE を実践した取り組み事例 パフォーマンス改善に向けた取り組み 45 インフラ側からの改善 • Prometheus + Grafana を⽤いて
Kubernetes クラスターやその上で 動いている Node, Pod のメトリクスを 常に確認できるようにしている • Grafana Loki でコンテナのログを 検索できるようになっている 便利ダッシュボードを⽤意し 何かあればまずはそこをチェック なんかおかしいってときにまずみるダッシュボード
インフラ側からの改善 • プライベートクラウド側で稼働している Kubernetes クラスターのみで ピーク時にアプリケーションの全エンドポイントのレイテンシーが悪化する 事象が発⽣ • Kubernetes の
Node でピーク時の CPU Steal 増加によるノイジーネイバーが原因 SRE を実践した取り組み事例 パフォーマンス改善に向けた取り組み 46
SRE を実践した取り組み事例 パフォーマンス改善に向けた取り組み 47 インフラ側からの改善 • プライベートクラウド側で稼働している Kubernetes クラスターのみで ピーク時にアプリケーションの全エンドポイントのレイテンシーが悪化する
事象が発⽣ • Kubernetes の Node でピーク時の CPU Steal 増加によるノイジーネイバーが原因 ➡ 同僚の @pyama が開発した独⾃のスケジューラーを導⼊し、Kubernetes の Node が 動いている VM で Load Averageが閾値を超えている かつ Steal が発⽣している 場合、 別の物理サーバーに⾃動で live-migration させることによって、⼤幅に改善できた
SRE を実践した取り組み事例 パフォーマンス改善に向けた取り組み 48 https://speakerdeck.com/pyama86/dynamic-vm-scheduling-in-openstack
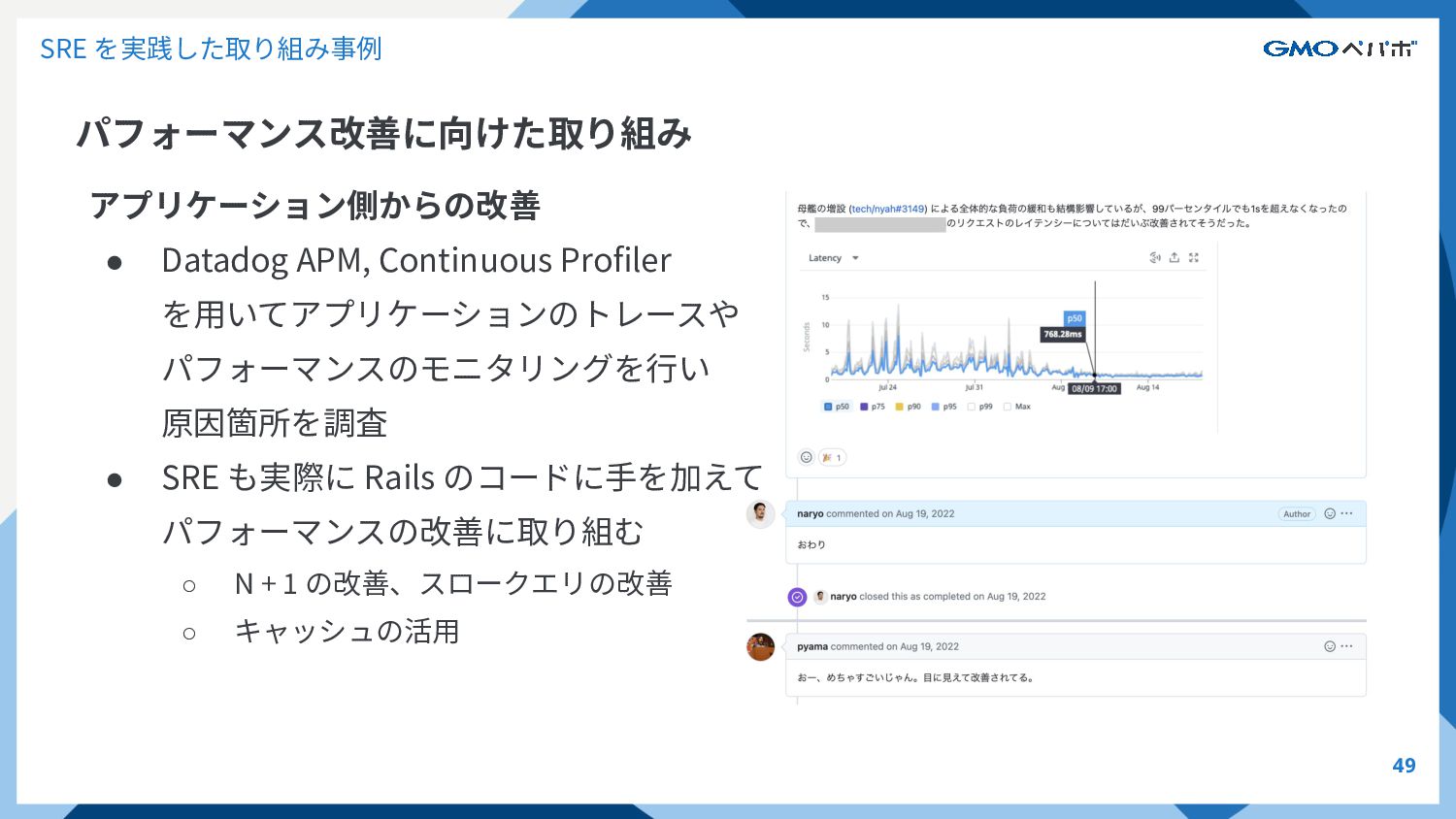
SRE を実践した取り組み事例 パフォーマンス改善に向けた取り組み 49 アプリケーション側からの改善 • Datadog APM, Continuous Profiler
を⽤いてアプリケーションのトレースや パフォーマンスのモニタリングを⾏い 原因箇所を調査 • SRE も実際に Rails のコードに⼿を加えて パフォーマンスの改善に取り組む ◦ N + 1 の改善、スロークエリの改善 ◦ キャッシュの活⽤
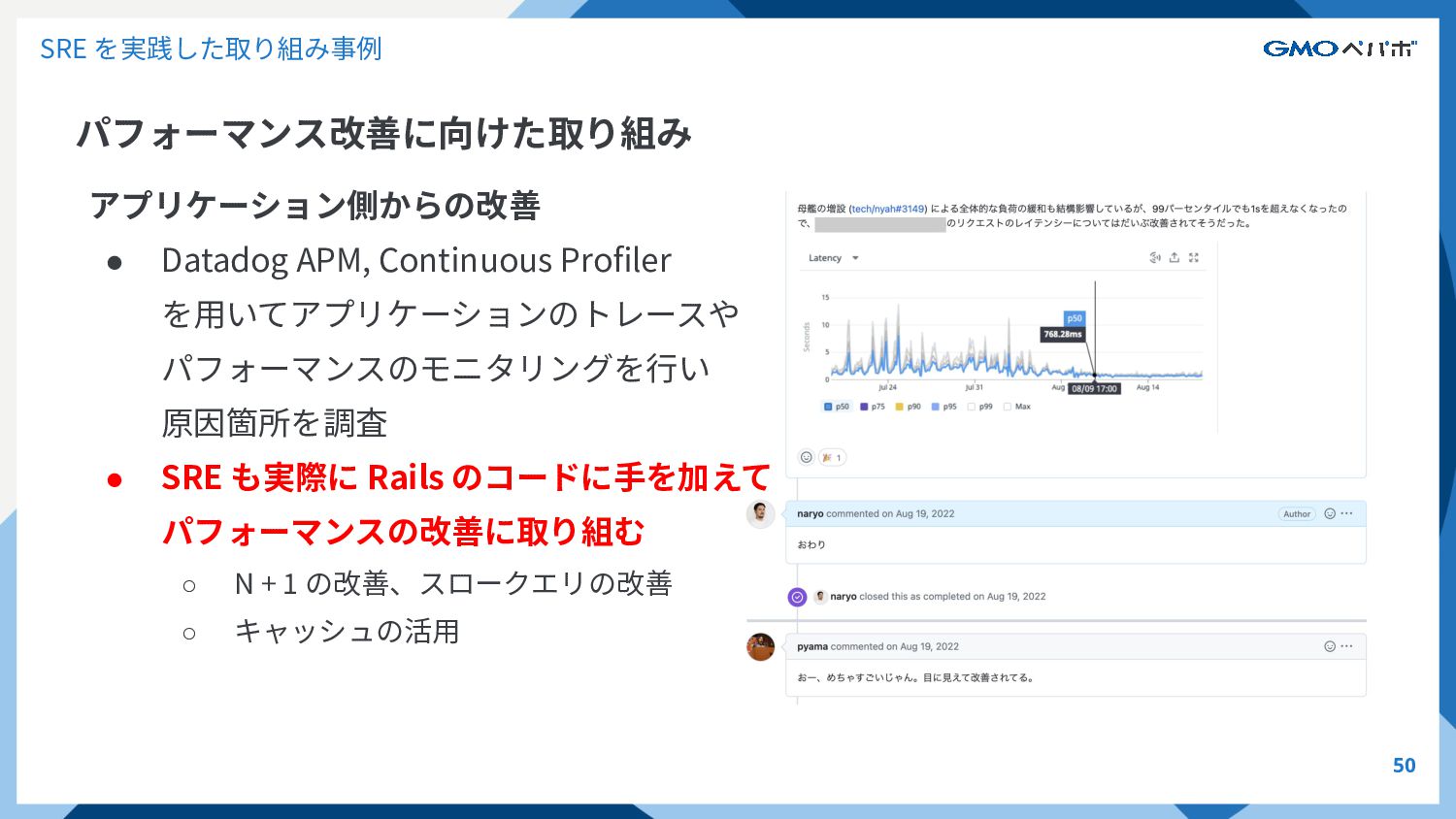
SRE を実践した取り組み事例 パフォーマンス改善に向けた取り組み 50 アプリケーション側からの改善 • Datadog APM, Continuous Profiler
を⽤いてアプリケーションのトレースや パフォーマンスのモニタリングを⾏い 原因箇所を調査 • SRE も実際に Rails のコードに⼿を加えて パフォーマンスの改善に取り組む ◦ N + 1 の改善、スロークエリの改善 ◦ キャッシュの活⽤
SRE を実践した取り組み事例 パフォーマンス改善に向けた取り組み 51 1. 最初に APM を確認
SRE を実践した取り組み事例 パフォーマンス改善に向けた取り組み 52 1. 最初に APM を確認 ⬇ 2.
クエリに対して Explain を発⾏して実⾏計画を確認
SRE を実践した取り組み事例 パフォーマンス改善に向けた取り組み 53 1. 最初に APM を確認 ⬇ 2.
クエリに対して Explain を発⾏して実⾏計画を確認 ⬇ 3. 該当コードの修正 DB に index を追加したり、キャッシュを活⽤したり、etc...
SRE を実践した取り組み事例 プログレッシブデリバリーの導⼊ 54 新しい機能や変更をユーザーに段階的に展開する仕組みを実践 • Feature Flag ◦ 新機能は
Feature Flag を⽤いて隠され、特定のユーザーだけに展開 ▪ 新機能のパフォーマンスやユーザーの反応をテストすることができる ◦ Unleash (※1) を使って実現 • Canary Release • 新しいバージョンを最初に数%のユーザーにリリースし、問題がないことを確 認できたら、徐々に割合を広げてリリースしていく • Argo Rollouts (※2) を使って実現 ※1 Unleash https://docs.getunleash.io/ ※2 Argo Rollouts https://argoproj.github.io/rollouts/
運⽤改善に向けた取り組み 55
SRE を実践した取り組み事例 ソフトウェアを⽤いて⾃動化を積極的に取り⼊れることで以下の効果が期待される • 安全で効率的なリリースプロセスを確⽴することで、新機能の導⼊やバグの修正が スムーズに⾏え、信頼性が向上する • ⾃動化により、⼈的エラーを減少させ、⼀貫性と効率性を向上させ、信頼性が向上 する •
適切なキャパシティプランニングを⾏うことで、リソースの過不⾜を防ぎ、パ フォーマンスの安定性を確保できる 運⽤改善に向けた取り組みが信頼性にどう影響するか 56
SRE を実践した取り組み事例 デプロイフローの改善 アプリケーションのデプロイフローの課題 • Kubernetes のデプロイは ArgoCD を⽤いて GitOps
で運⽤ • 1つリポジトリで複数サービスのマニフェストを管理 ◦ サービスをデプロイする際は、直接マニフェストを書き換えてコンテナのイメージタグを 変更する必要がある • 1つのサービスでデプロイが進⾏中のとき、他のサービスのデプロイや、 Kubernetes のリソースの変更ができないといった問題が発⽣ 57
SRE を実践した取り組み事例 デプロイフローの改善 58 アプリケーションのデプロイフローの課題 • Kubernetes のデプロイは ArgoCD を⽤いて
GitOps で運⽤ • 1つリポジトリで複数サービスのマニフェストを管理 ◦ サービスをデプロイする際は、直接マニフェストを書き換えてコンテナのイメージタグを 変更する必要がある • 1つのサービスでデプロイが進⾏中のとき、他のサービスのデプロイや、 Kubernetes のリソースの変更ができないといった問題が発⽣ ➡ 開発速度に影響が出ていて、⽣産性の低下に繋がっていた
SRE を実践した取り組み事例 デプロイフローの改善 59 ArgoCD Image Updator を導⼊ • ArgoCD
で管理されている Kubernetes のワークロードのイメージを⾃動で更新 • 新しいイメージがコンテナレジストリに Push されると、それを⾃動で検知し、タ グを書き換えてくれるため、マニフェストの更新が不要 • ロールバックも ArgoCD からコントロールできるので、問題があってもすぐ戻せる
SRE を実践した取り組み事例 デプロイフローの改善 60 ArgoCD Image Updator を導⼊ • ArgoCD
で管理されている Kubernetes のワークロードのイメージを⾃動で更新 • 新しいイメージがコンテナレジストリに Push されると、それを⾃動で検知し、タ グを書き換えてくれるため、マニフェストの更新が不要 • ロールバックも ArgoCD からコントロールできるので、問題があってもすぐ戻せる ➡ 他のサービスのデプロイを意識せずに、ガンガンリリースできるようになった
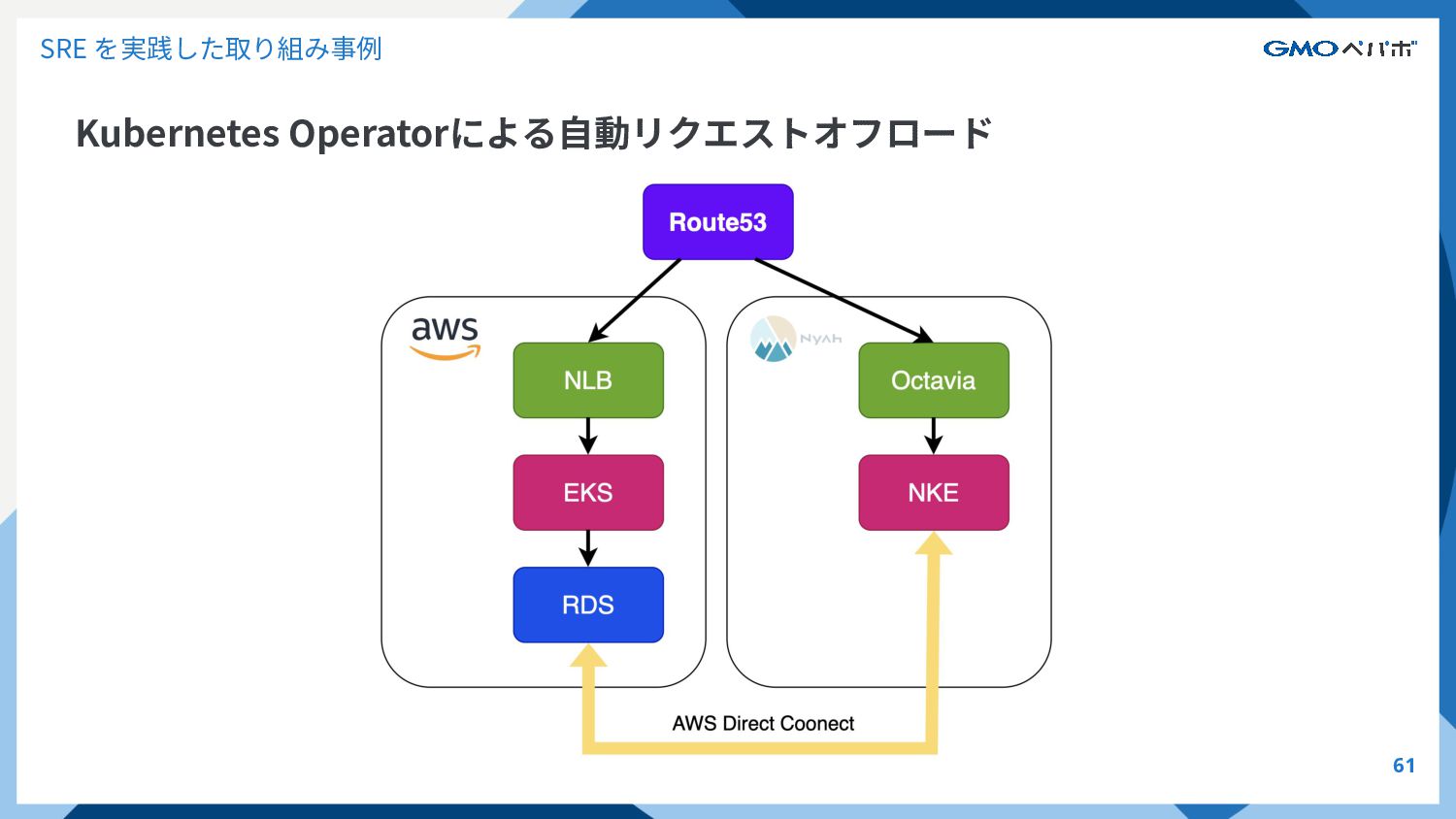
SRE を実践した取り組み事例 Kubernetes Operatorによる⾃動リクエストオフロード 61
SRE を実践した取り組み事例 Kubernetes Operatorによる⾃動リクエストオフロード 62 • AWS へのリクエストオフロードを⼈⼒で対応 ◦ 主にピークタイム前後の夜間や休⽇に実施
• 専⾨性が⾼く、特定の⼈しか判断‧作業が⾏えず運⽤がスケールしない • 無駄に AWS リソースを利⽤してしまう場合がある • リクエスト量の⾒積もりを誤って、正常にリクエストが処理できずサービス障害を 引き起こす場合も
SRE を実践した取り組み事例 Kubernetes Operatorによる⾃動リクエストオフロード 63 • 同僚の @akichan によって開発された Rebalancer
(※) という Kubernetes Operator によって リクエストの⾃動オフロードが可能になった ◦ 運⽤作業がほぼ 0 に ◦ アイドルタイムに無駄に使⽤していた AWS のコストが削減できた • Prometheus でリクエスト数を監視し、⾃動で AWS、プライベートクラウド の加重を変更 • Kubernetes Operator にすることで、クラウドベンダー依存を少なくできた ※ https://github.com/ch1aki/rebalancer
SRE を実践した取り組み事例 Kubernetes Operatorによる⾃動リクエストオフロード 64 https://speakerdeck.com/ch1aki/k8s-operatordeyun-yong-fu-dan-jian-and-hai buritudokuraudonokosutozui-shi-hua-wositahua
SRE を実践した取り組み事例 CI の整備による⾃動化への取り組み 65 Kubernetes クラスターのマニフェストを管理しているリポジトリの CI を整備すること で、運⽤の効率化を計る
• OSS である kustomize-diff (※1) + ghput (※2) を CI に導⼊し、マニフェストのレ ビューコストを削減 ◦ ref: kustomize buildを実⾏して得たmanifestの差分ををPull Request上で確認する • Pluto (※3) を導⼊し、Kubernetes マニフェストの apiVersion の「⾮推奨」、「削 除」を⾃動で検知 ◦ Kubernetes クラスターのバージョンアップに備えて事前に対応が可能に ※1 https://github.com/dtaniwaki/git-kustomize-diff ※2 https://github.com/k1LoW/ghput ※3 https://github.com/FairwindsOps/pluto
SRE を実践した取り組み事例 VM で稼働しているサーバーの廃⽌ VM で稼働しているサーバーを全てコンテナ化 or マネージドサービスを積極的に 活⽤することによって、運⽤コストを削減 •
Load Balancer は OpenStack Octavia, AWS Network Load Balancerへ移⾏ • WAF は SiteGuard Server Edition (※) をコンテナ化し Kubernetes で運⽤ • アプリケーションから外部へ接続する際に利⽤する Proxy サーバーは AWS NAT Gateway へ移⾏ ◦ 以前から課題だった SPOF 問題も解決され、可⽤性の向上にも繋がった ※ SiteGuard Server Edittion https://siteguard.jp-secure.com/ 66
SRE を実践した取り組み事例 コスト最適化に向けた取り組み サービスの成⻑によって増加しがちなインフラのコスト最適化も積極的に実施 • 不要なリソース削減、オーバースペックなインスタンスの最適化 • Reserverd Instance によって割引価格でマネージドサービスを利⽤する
• EC2 スポットインスタンスを積極的に活⽤ • AWS Graviton インスタンス ( ARM ベースのプロセッサ ) への移⾏ ◦ MySQL 8.0にアップグレードしたことで、AWS RDS for MySQL で Gravition インスタンス が使⽤可能になり、⼤幅なコスト削減が⾒込まれる 67
4. まとめ 68
本⽇のまとめ • 信頼性を維持する⼿法の⼀つとして開発チームに Embedded SRE を導⼊し SRE の プラクティスの浸透を⾏なった •
SRE チームがインフラの運⽤を担当するのではなく、開発チームと⼀緒になって運 ⽤の最適化を⽬指していった • ソフトウェアを⽤いることで、運⽤作業に対して積極的に⾃動化を取り⼊れ、運⽤ の効率化を測り、信頼性の向上に繋げていった 69
70 Thank you!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}