You can write good code. So can I. But can we write correct code together? The hardest problem facing the ordinary developer of today is not in algorithms or frameworks. Bugs are commonly found between the lines. Projects contain rules that must be adhered to everywhere but are specified nowhere. They are conventions, tribal knowledge, and best practices. Let's learn how Rust makes it easier to write code that agrees and is consistent across files, crates, and persons. This is the story of how I stopped stepping on everyone's toes and learned to love the borrow checker.
Speaker: Zac Burns
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![let mutex = Mutex :: new(entity); [drink]](https://files.speakerdeck.com/presentations/c1d85aa2eac042a996907c5b40f11cfa/slide_38.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
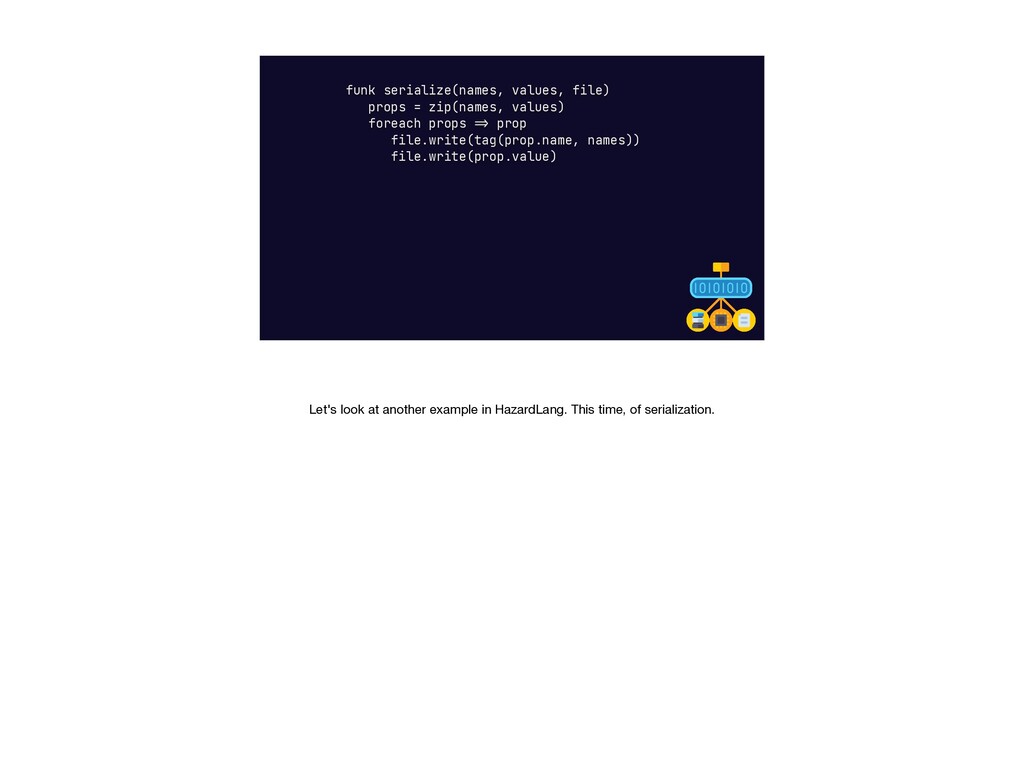{kind=link}
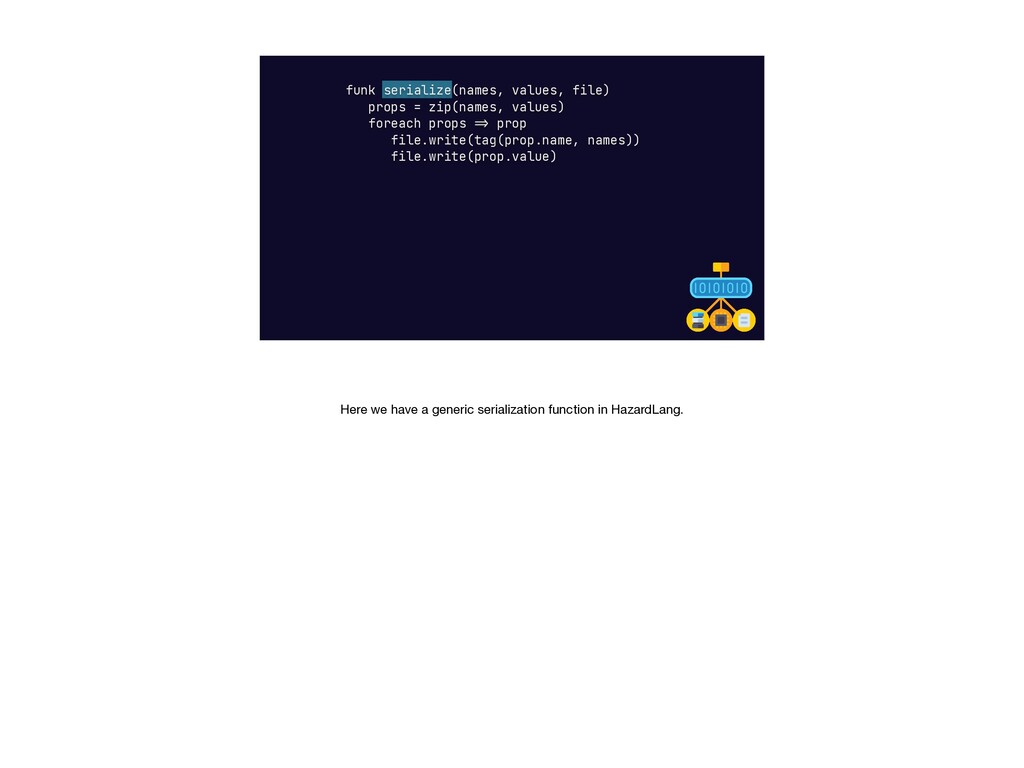{kind=link}
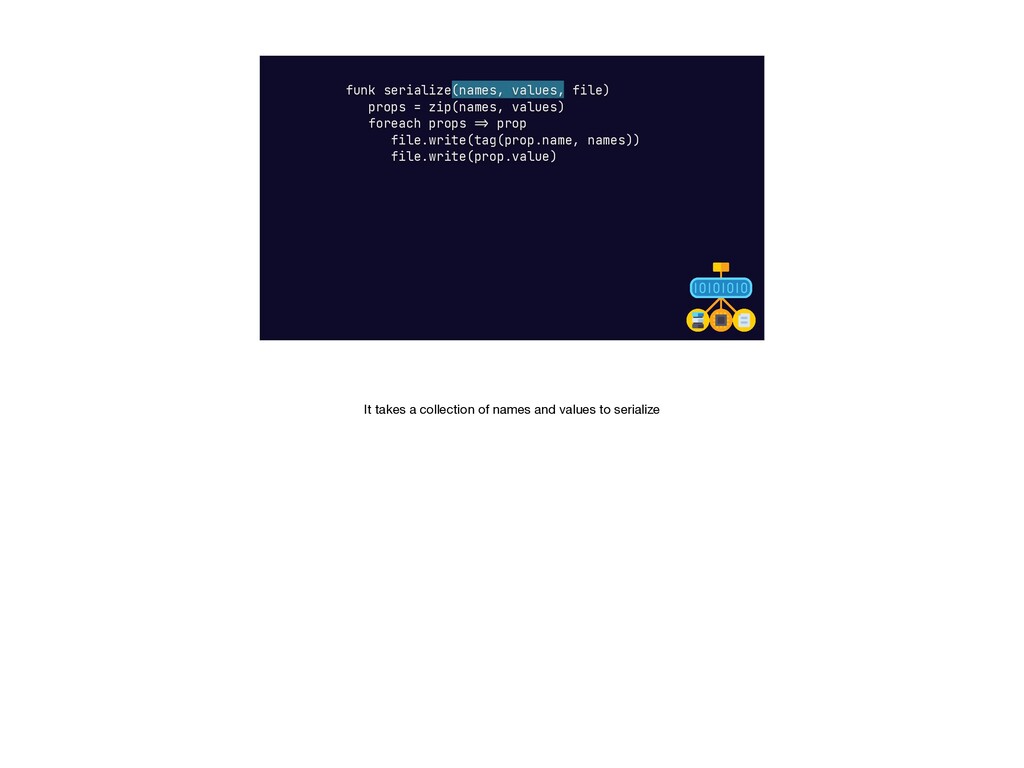{kind=link}
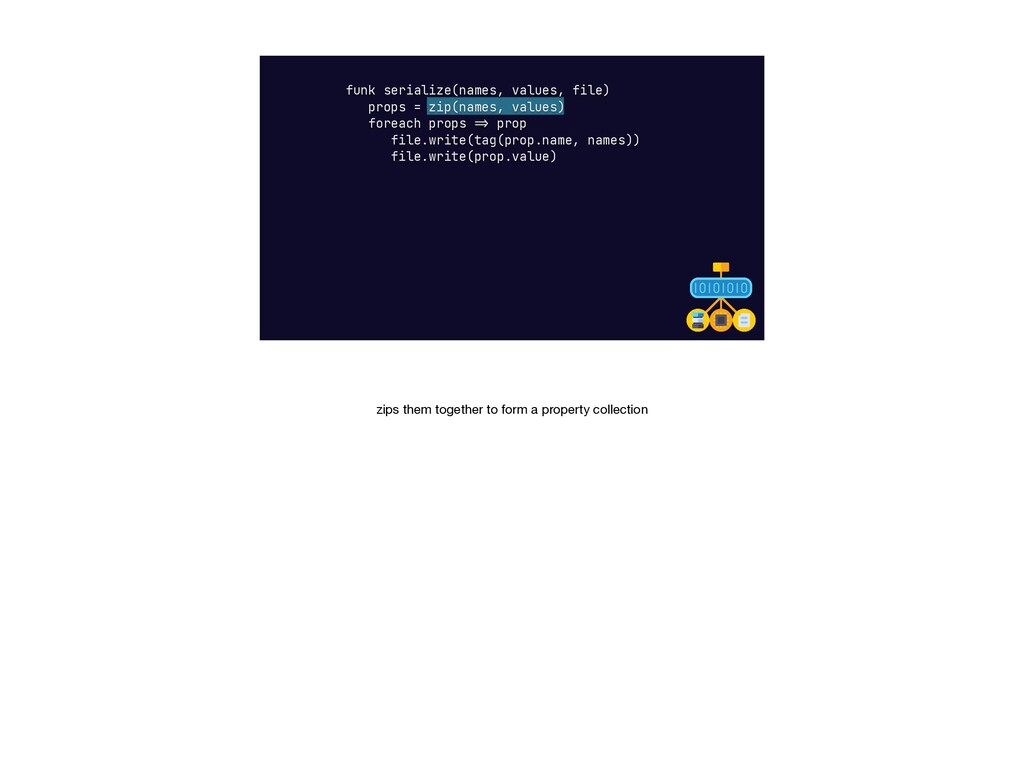{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![funk writeCustomer(customer, file) schema = [“name”, “date”] file.write(tag(“name”, schema)) file.write(customer.name)](https://files.speakerdeck.com/presentations/c1d85aa2eac042a996907c5b40f11cfa/slide_57.jpg){kind=link}
![funk writeCustomer(customer, file) schema = [“name”, “date”] file.write(tag(“name”, schema)) file.write(customer.name)](https://files.speakerdeck.com/presentations/c1d85aa2eac042a996907c5b40f11cfa/slide_58.jpg){kind=link}
![funk writeCustomer(customer, file) schema = [“name”, “date”] file.write(tag(“name”, schema)) file.write(customer.name)](https://files.speakerdeck.com/presentations/c1d85aa2eac042a996907c5b40f11cfa/slide_59.jpg){kind=link}
![funk writeCustomer(customer, file) schema = [“name”, “date”] file.write(tag(“name”, schema)) file.write(customer.name)](https://files.speakerdeck.com/presentations/c1d85aa2eac042a996907c5b40f11cfa/slide_60.jpg){kind=link}
![funk writeCustomer(customer, file) schema = [“name”, “date”] file.write(tag(“name”, schema)) file.write(customer.name)](https://files.speakerdeck.com/presentations/c1d85aa2eac042a996907c5b40f11cfa/slide_61.jpg){kind=link}
{kind=link}
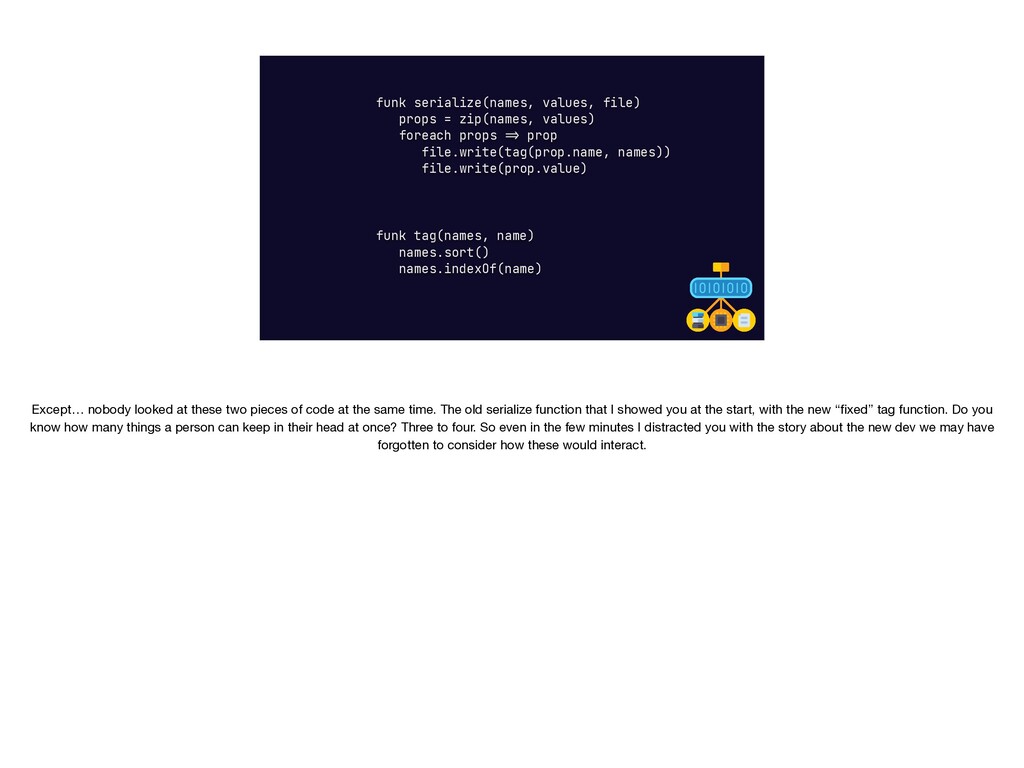{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
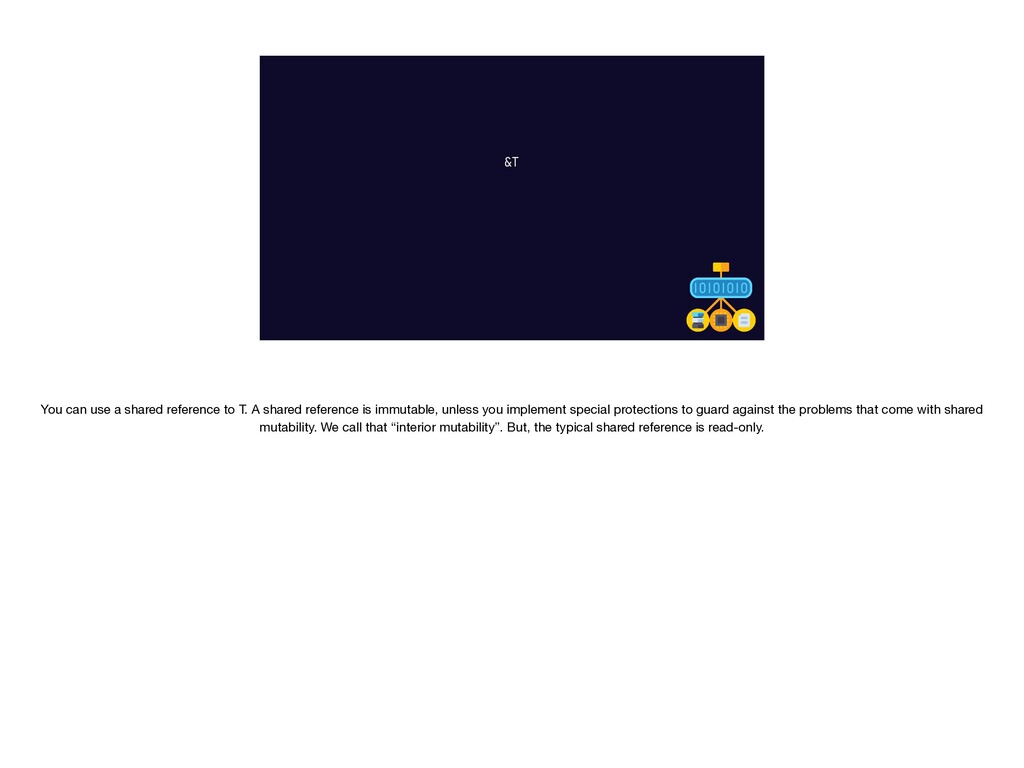{kind=link}
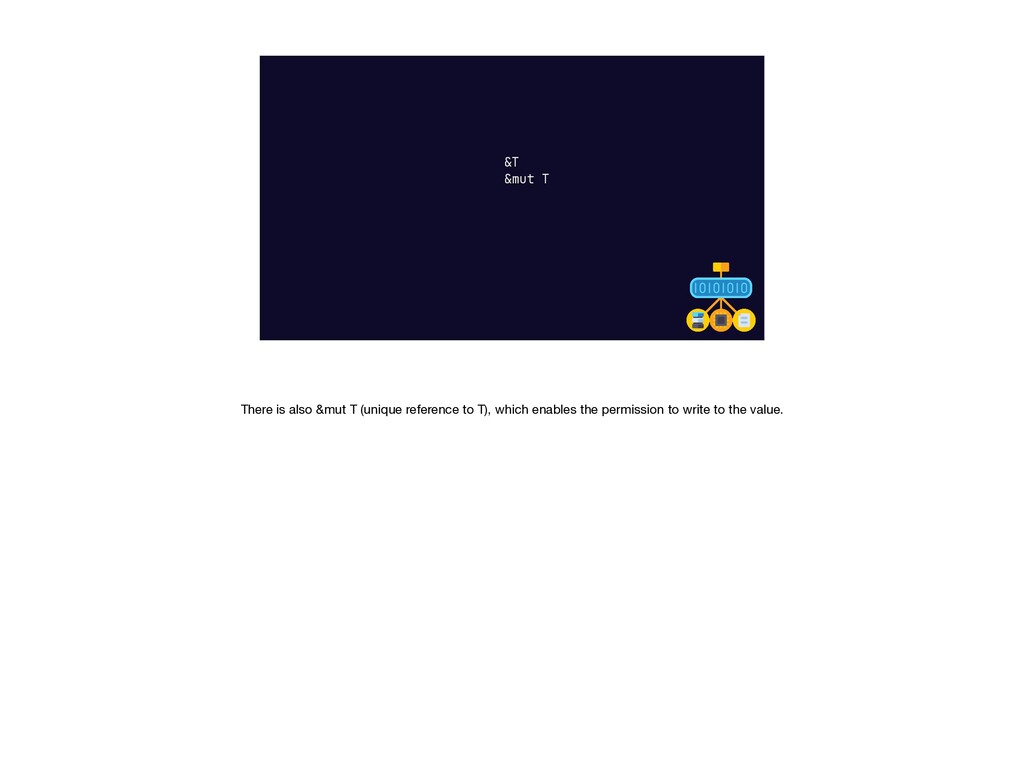{kind=link}
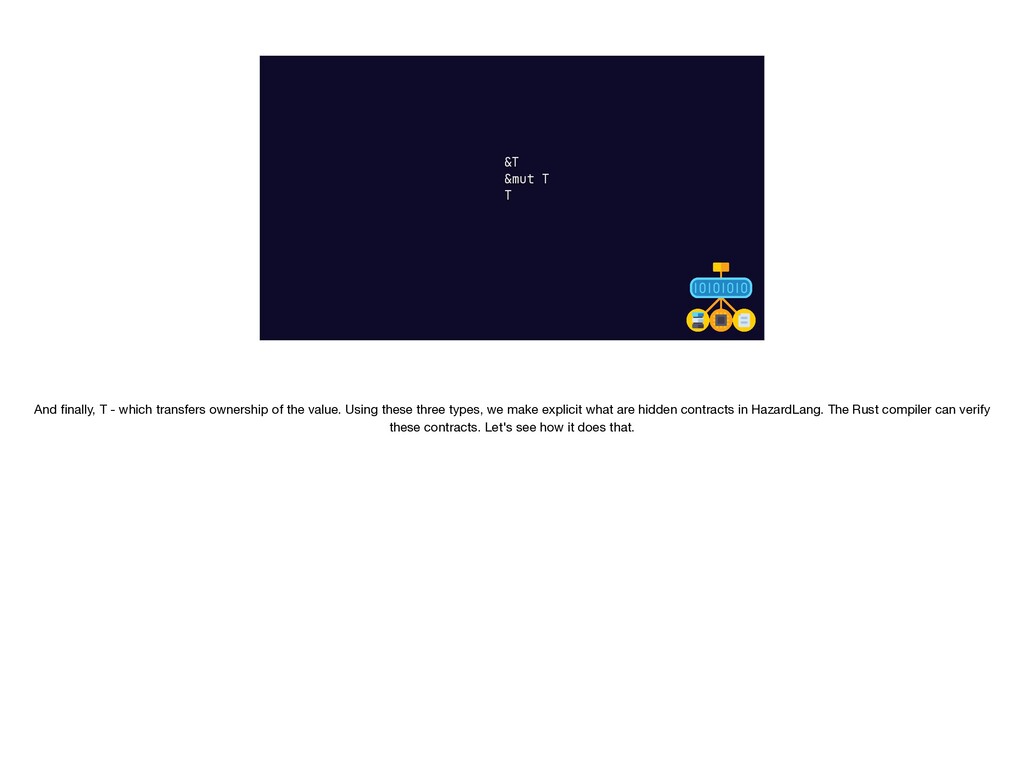{kind=link}
{kind=link}
{kind=link}
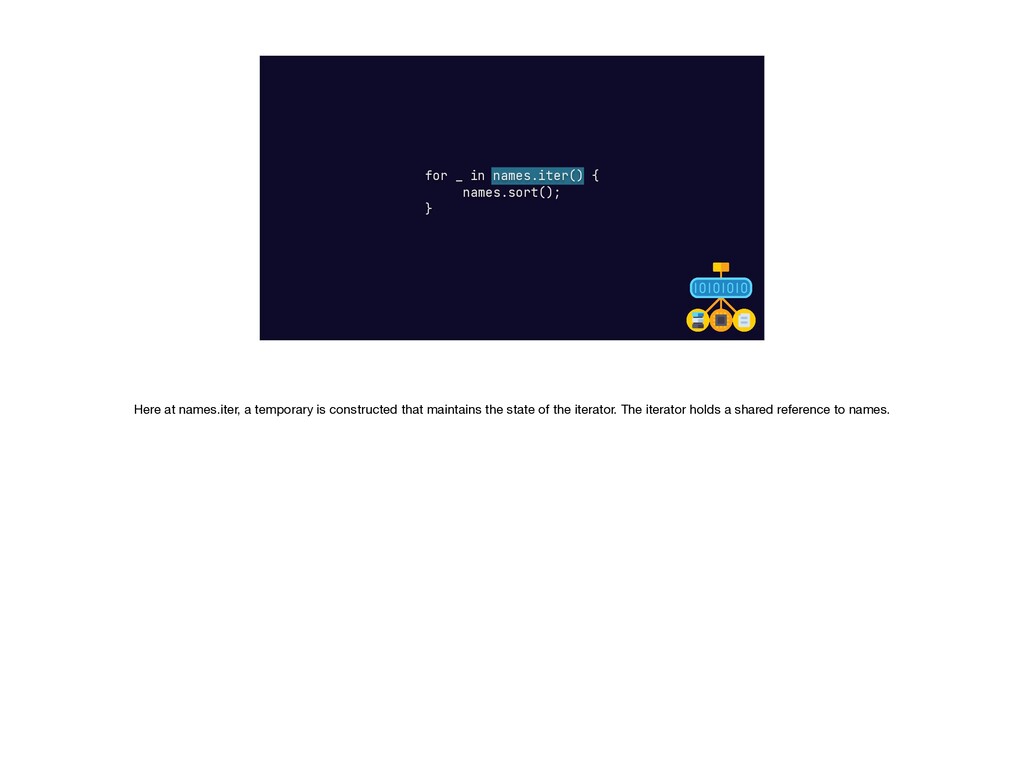{kind=link}
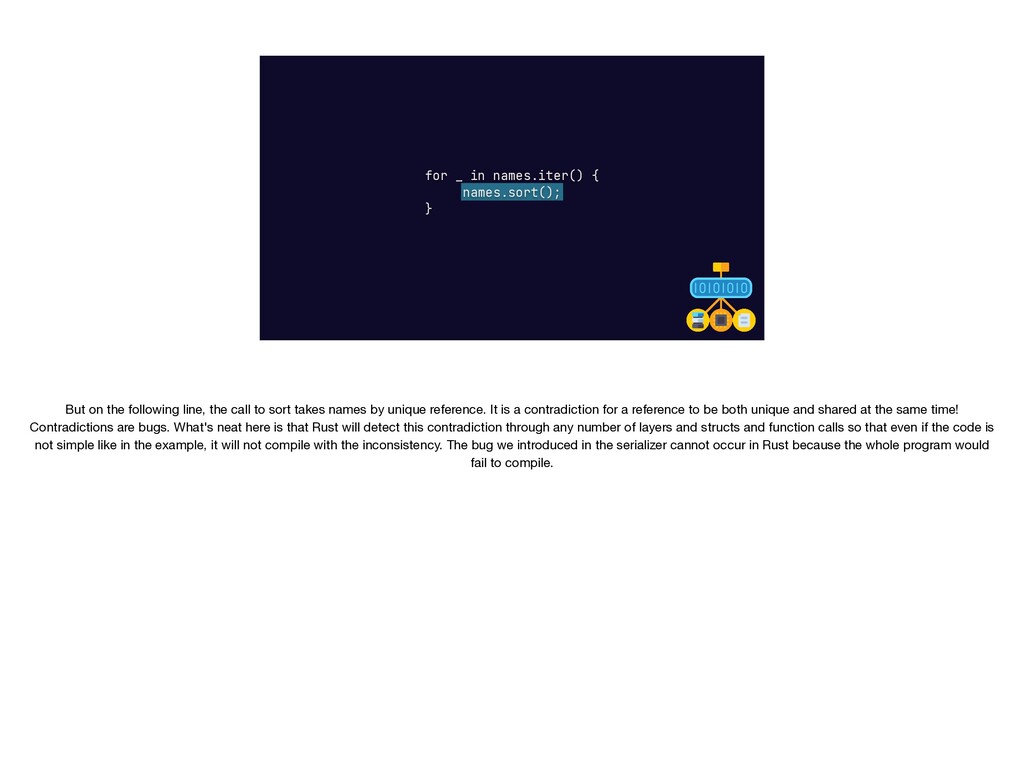{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
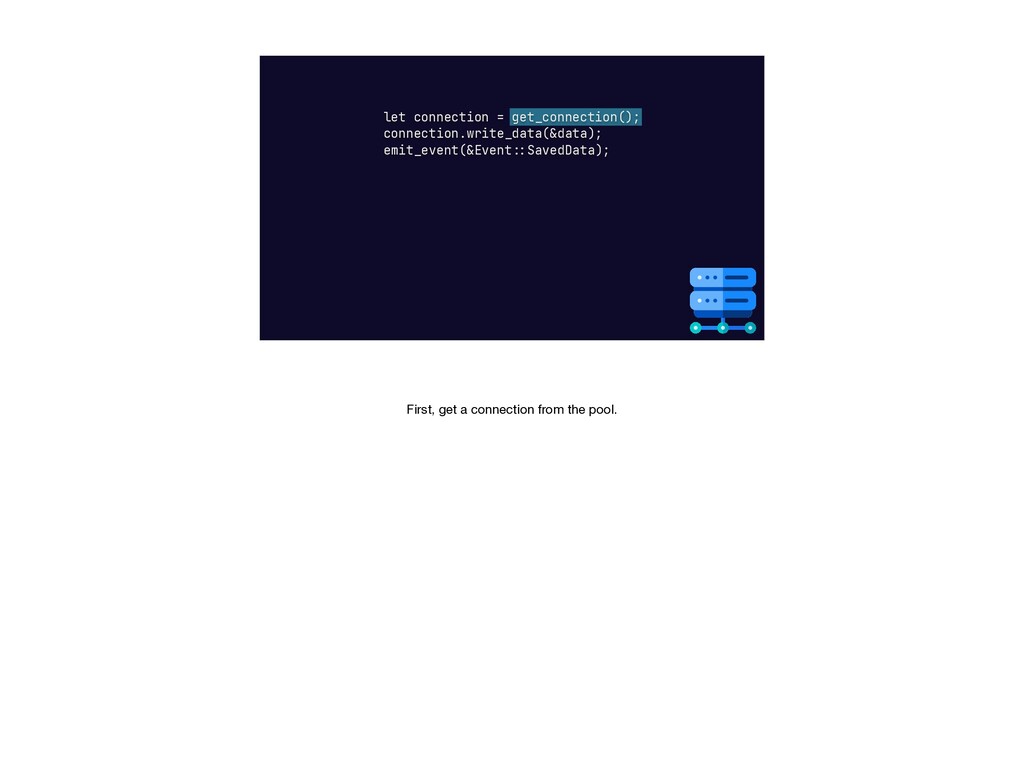{kind=link}
{kind=link}
{kind=link}
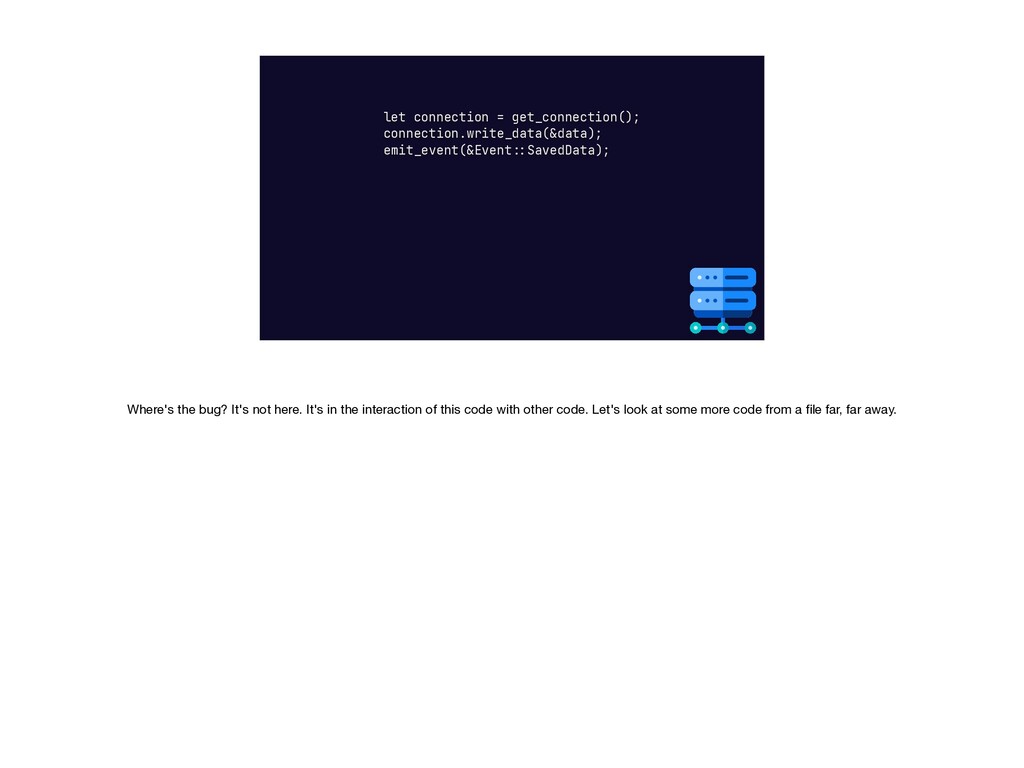{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
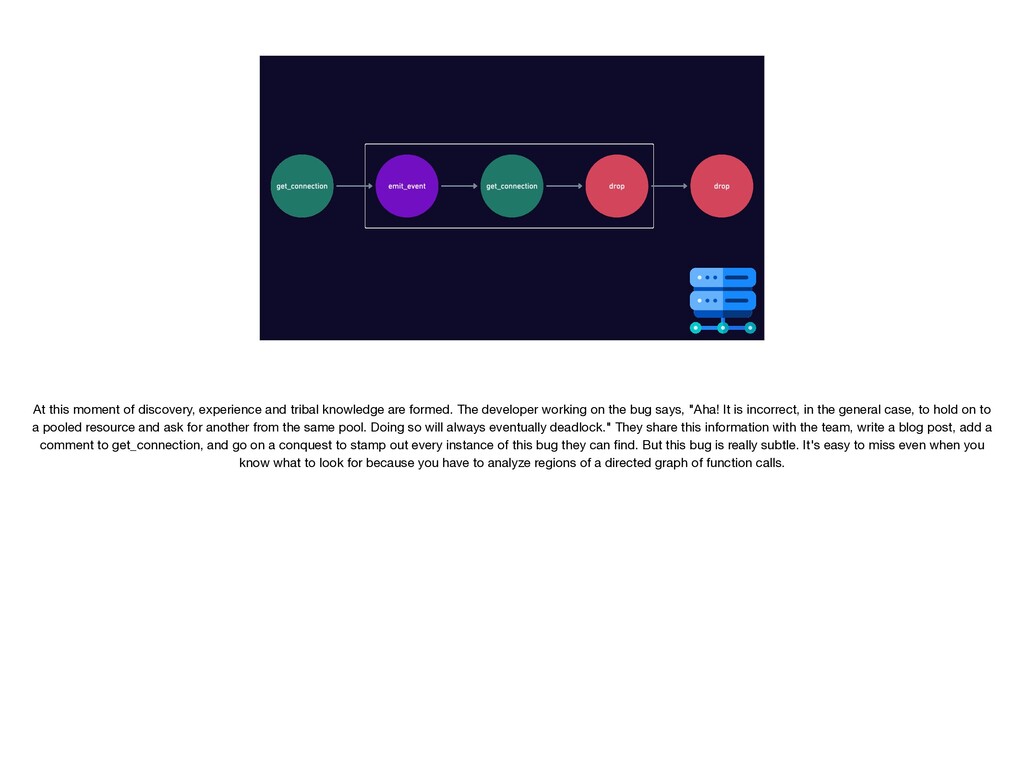{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
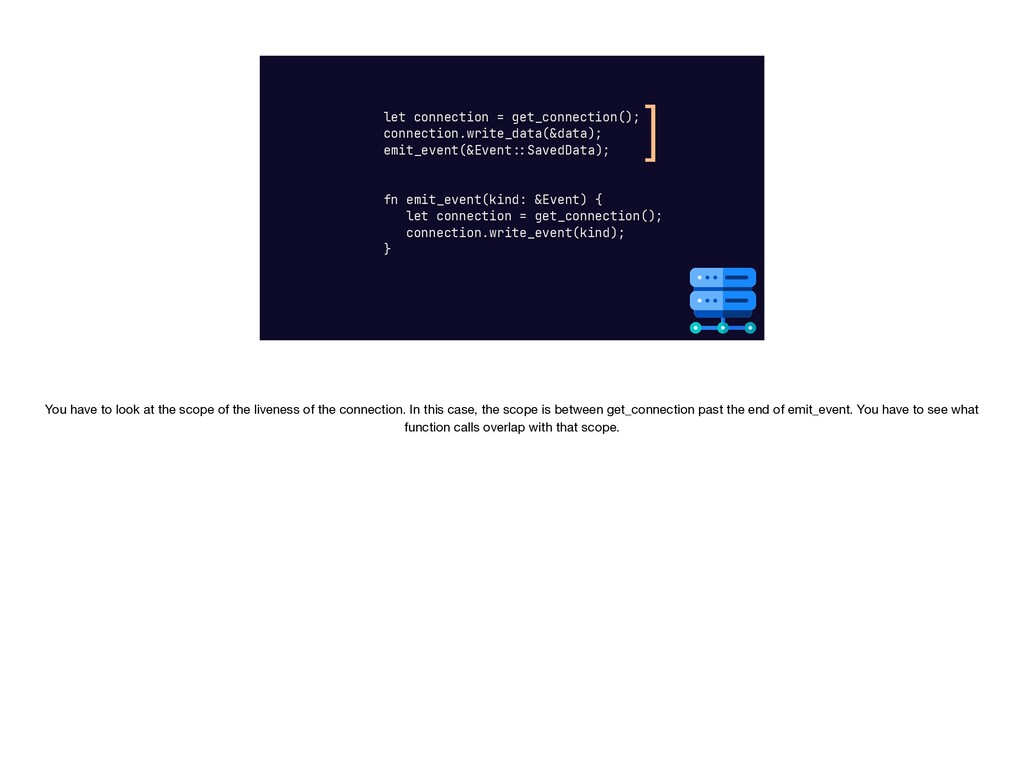
{kind=link}
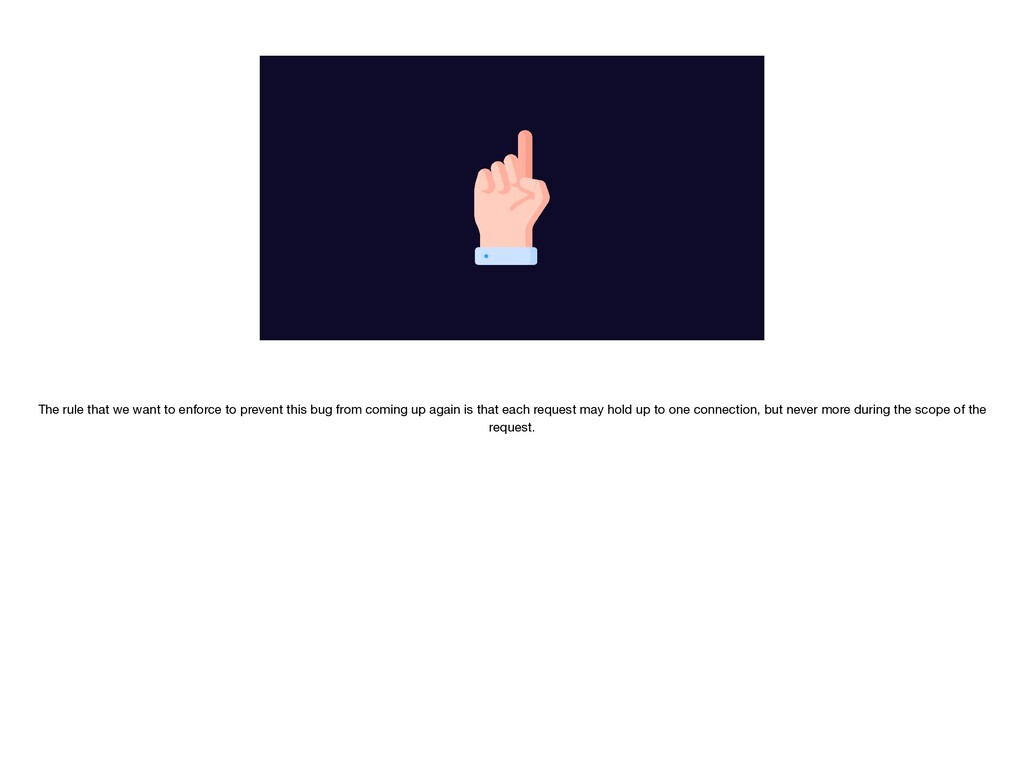
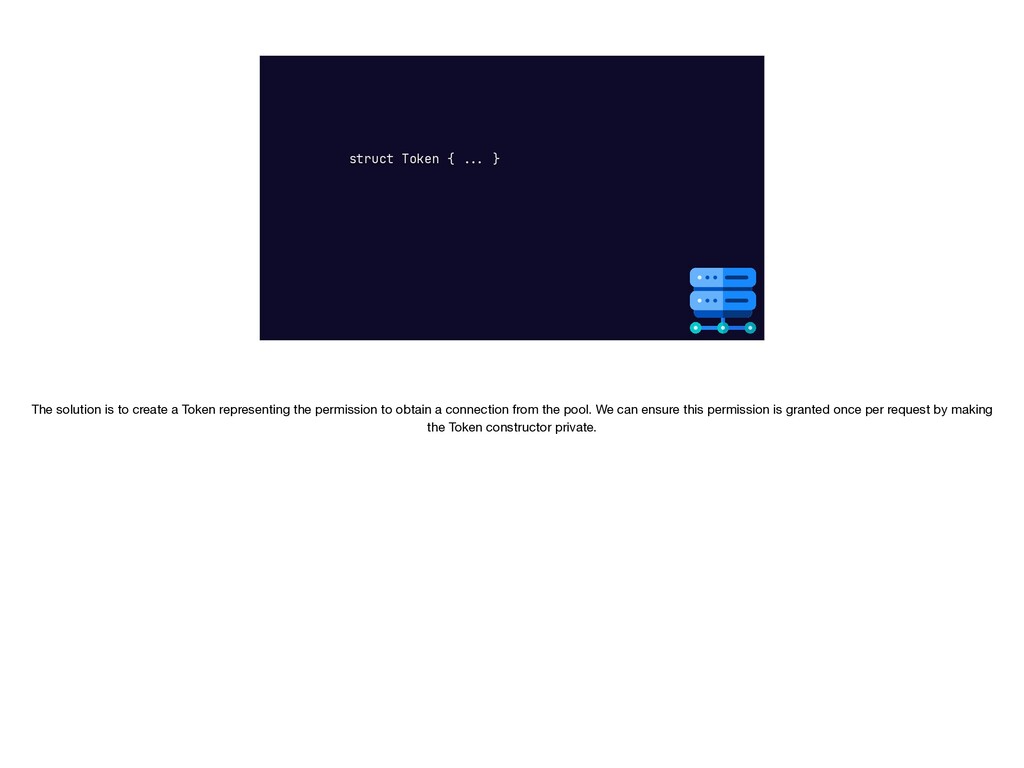{kind=link}
{kind=link}
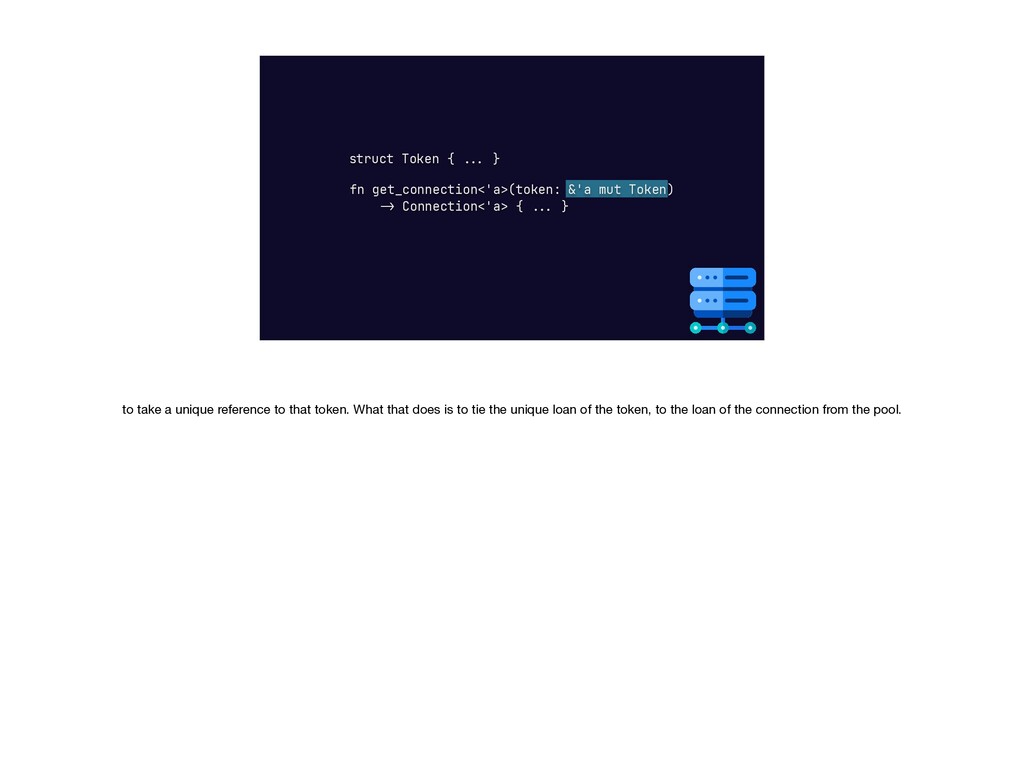{kind=link}
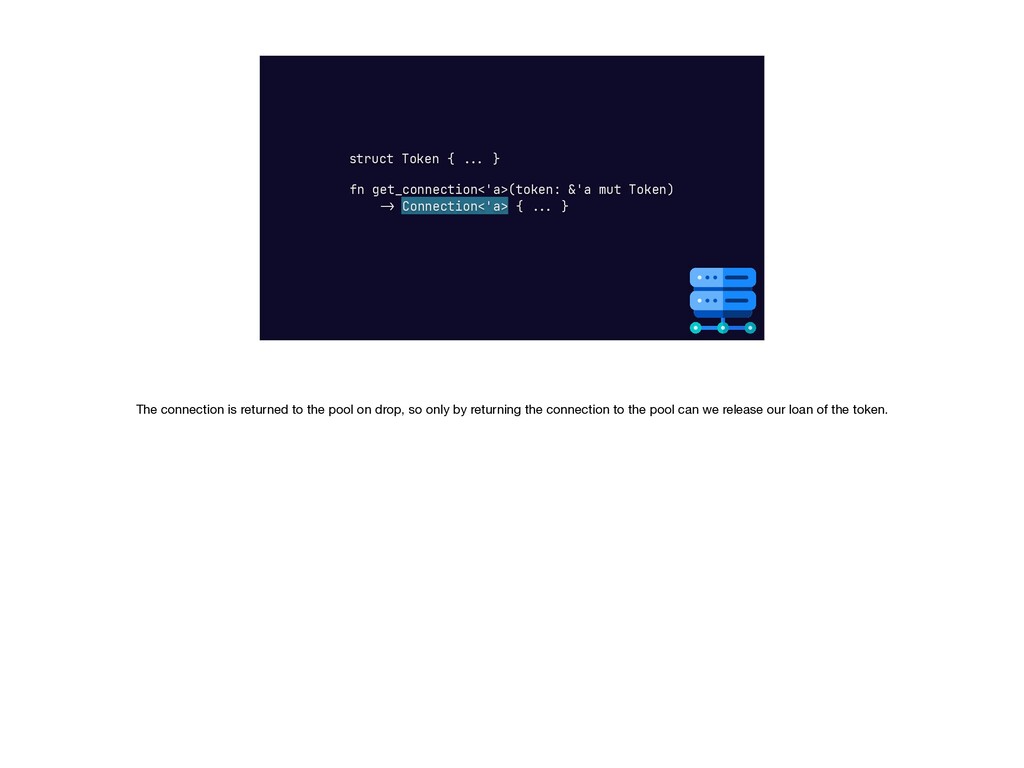{kind=link}
{kind=link}
{kind=link}
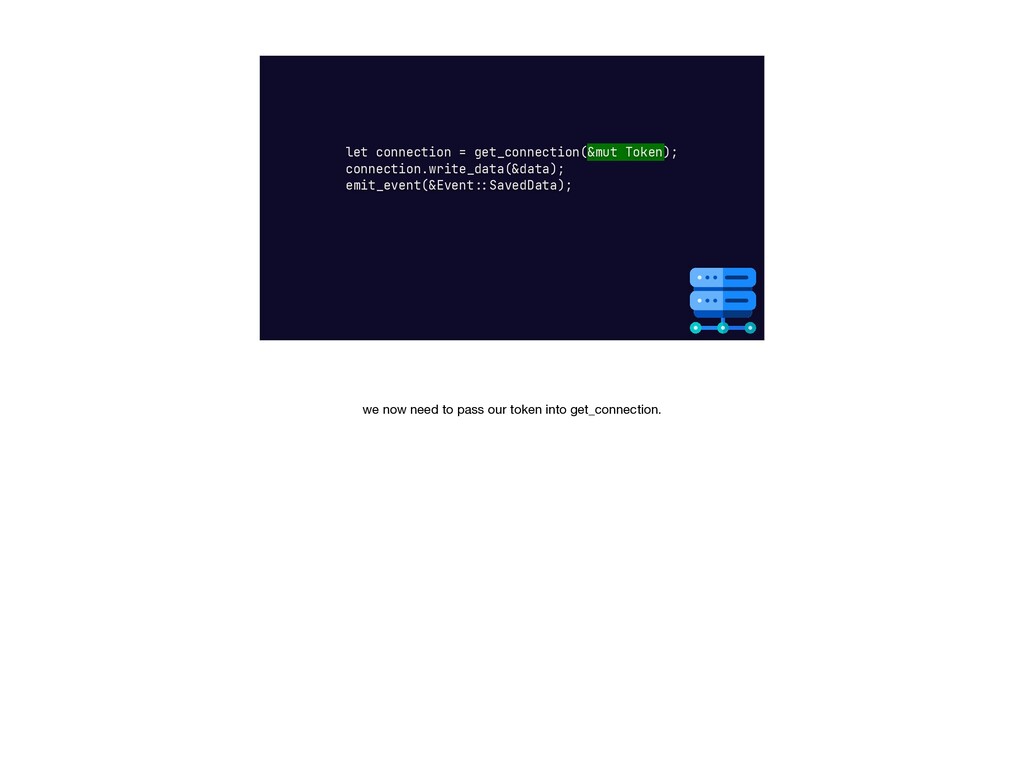{kind=link}
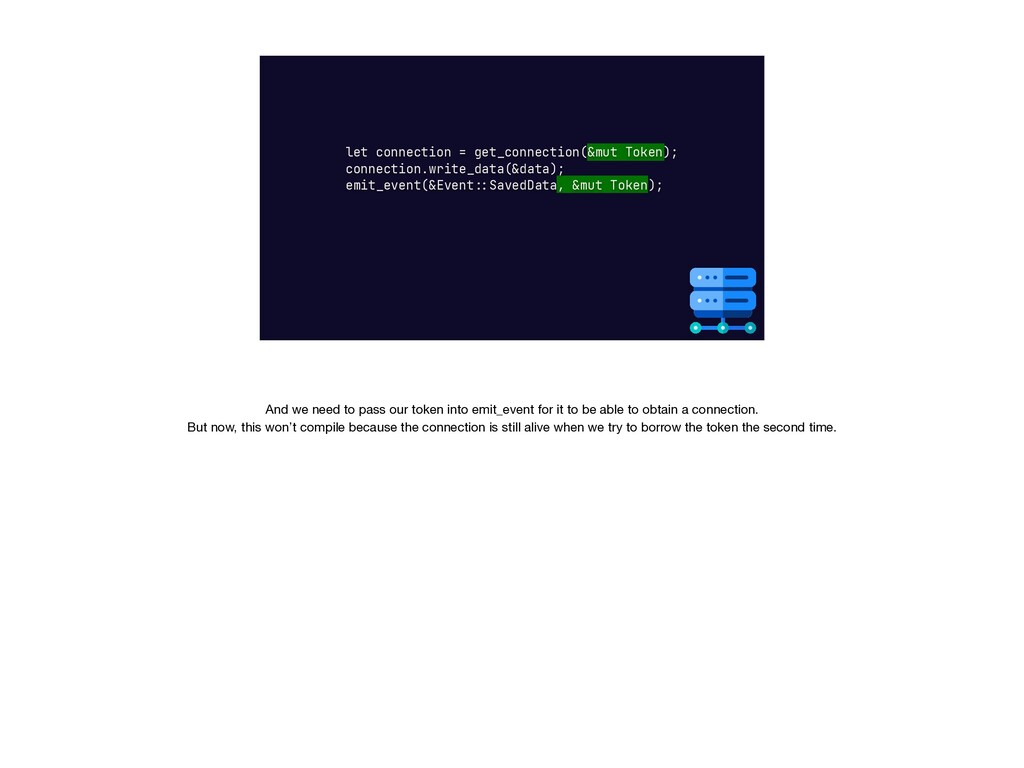{kind=link}
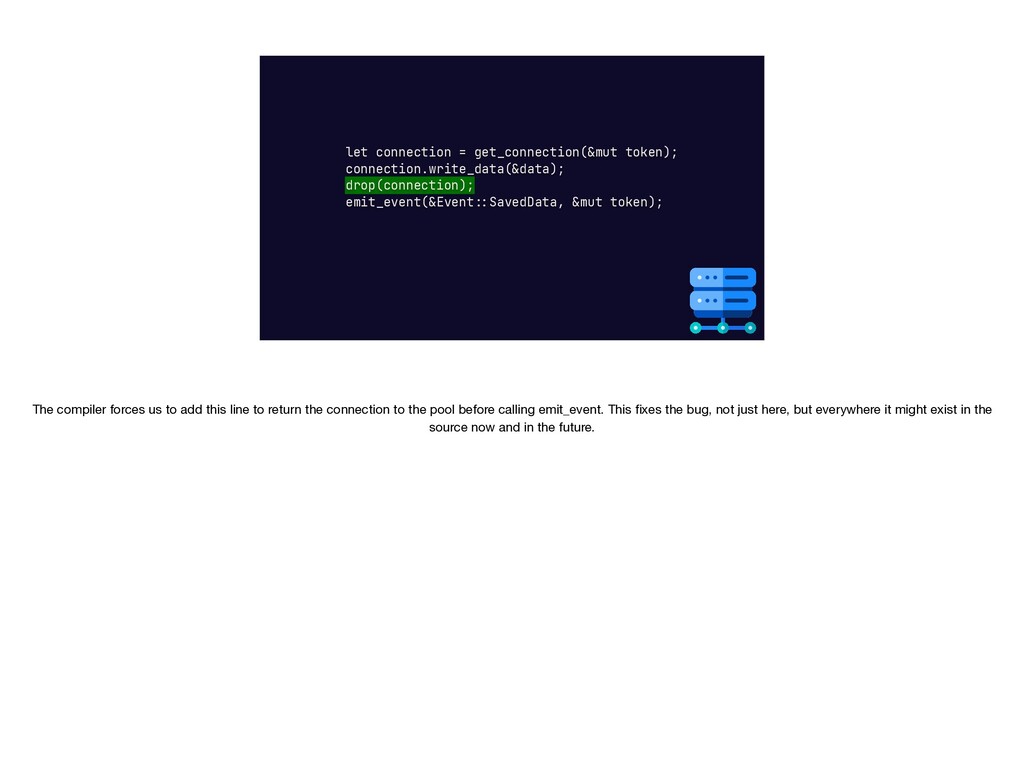{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] edgeandnode.com If you liked the idea of solving social](https://files.speakerdeck.com/presentations/c1d85aa2eac042a996907c5b40f11cfa/slide_121.jpg){kind=link}