Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ACL読み会2025@名大:Completing A Systematic Review in...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
RyokoTokuhisa
September 22, 2025
99
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ACL読み会2025@名大:Completing A Systematic Review in Hours instead of Months with Interactive AI Agents
RyokoTokuhisa
September 22, 2025
Featured
See All Featured
The Invisible Side of Design
smashingmag
302
52k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Visualization
eitanlees
152
17k
Thoughts on Productivity
jonyablonski
76
5.2k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Believing is Seeing
oripsolob
1
150
Paper Plane (Part 1)
katiecoart
PRO
0
9k
Rails Girls Zürich Keynote
gr2m
96
14k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
How to Ace a Technical Interview
jacobian
281
24k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
44k
Transcript
読んだ人: 愛知工業大学 情報科学部 徳久良子 https://github.com/OSU-NLP-Group/InsightAgent https://aclanthology.org/2025.acl-long.1523.pdf
自己紹介 1 2001年4月 豊田中央研究所 入所 2021年4月 東北大学准教授(クロスアポイントメント) 2024年4月 愛知工業大学情報科学部情報科学科着任 9月
理化学研究所客員研究員 専門:自然言語処理・対話システム 学会活動: 人工知能学会対話システムシンポジウム実行委員 言語処理学会理事(若手担当) https://aitech.ac.jp/~nlplab/
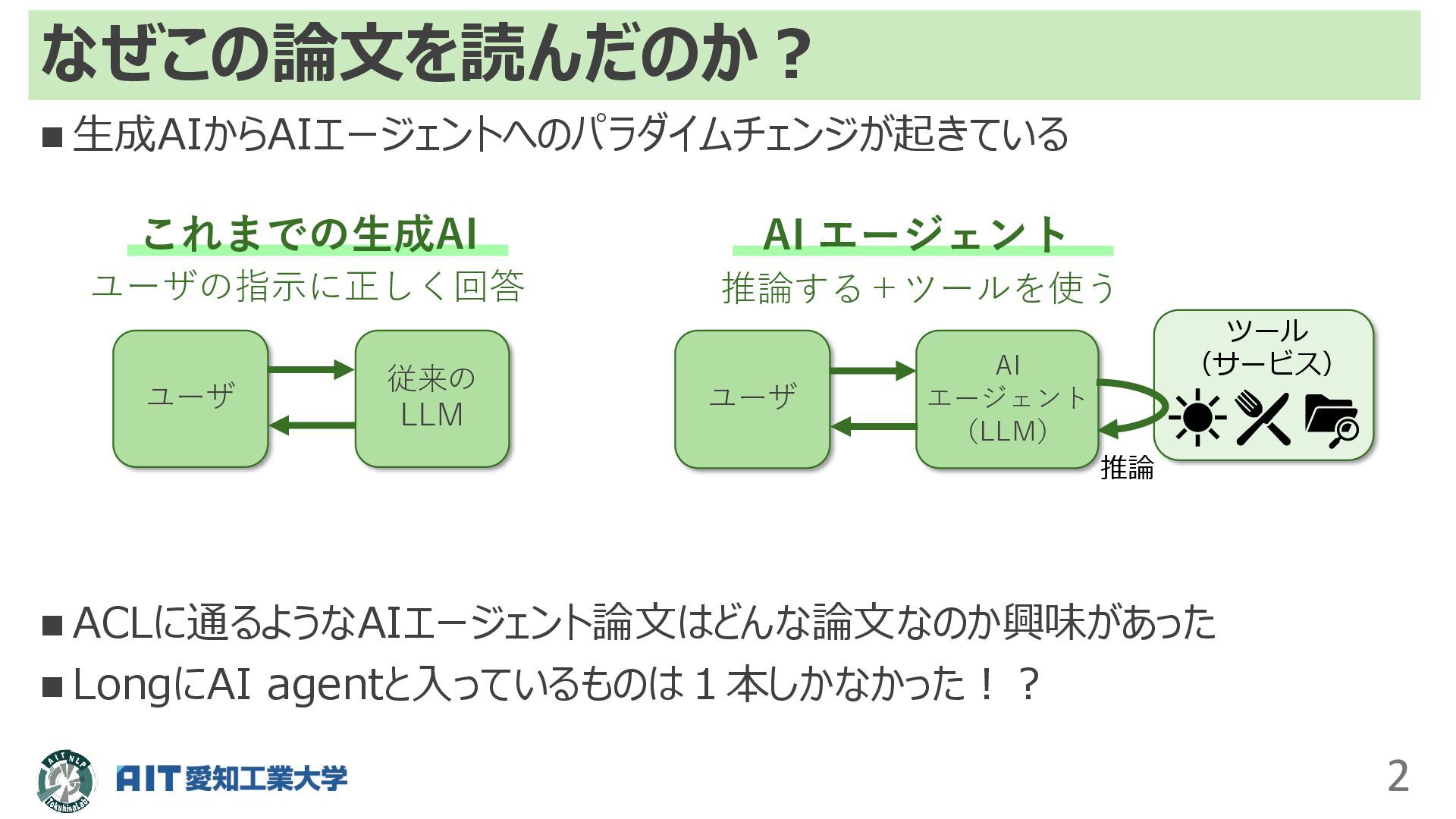
なぜこの論文を読んだのか? 2 ユーザ 従来の LLM これまでの生成AI ユーザの指示に正しく回答 ユーザ AI エージェント
(LLM) AI エージェント 推論する+ツールを使う ツール (サービス) 推論 ◼ 生成AIからAIエージェントへのパラダイムチェンジが起きている ◼ ACLに通るようなAIエージェント論文はどんな論文なのか興味があった ◼ LongにAI agentと入っているものは1本しかなかった!?
Abstract(1/2) 3 • システマティックレビュー(SR)は重要だが 専門的な知識が必要とされるので多大な労力 が必要となる • LLMに基づく人間中心型のインタラクティブ AIエージェントInsightAgentを提案する
Abstract(2/2) 4 • InsightAgentは文献を意味に基づいて分割→分野ごと にエージェントが配置されて各分野を集中的に処理す ることで、SRの性能を上げる • InsightAgentは処理を可視化することでユーザがリア ルタイムなフィードバックをしやすくしている点もポ イント
• (SRの経験を持つ)医療専門家9名による評価の結果、 SRの性能が27.2%向上した
Introduction(1/4) 5 • システマティックレビュー(SR)はヘルスケ アのようなエビデンスを必要とする分野では 特に重要 • 1990年代は50以下だったSRが、2022年には 約36000になっている •
以前として多くの労力がかかっていて、完成 までに数ヶ月かかるものもある
Introduction(2/4) 6 • システマティックレビュー(SR)のKey steps: • Research questionの定式化 • 文献コーパスの収集
• 最後のレビューに加えるかどうかの判定* • 要約* • 知見を統合* • 最終的なレポートにまとめる • 初期の情報検索についてはNLP技術でサポート済み • *がボトルネックになっている • 現状SRは主に*のrecord screeningに焦点を当てて いるが、リコールにばらつきがあって現場での利用 は限定的 • 知見の統合ではChatCiteやAutoSurveyなどのツール も出ているが、重要な詳細を見逃してしまったり出 典を追従できないなど課題がある
Introduction(3/4) 7 • 人間中心のフレームワークを提案する。これは、言語的な エージェント(Su2024)に以下の2点を加えたものである • 視覚的に表示することによりリアルタイムにユーザが フィードバックできるようにした • インタラクションを通じてユーザの専門知識を入れられ
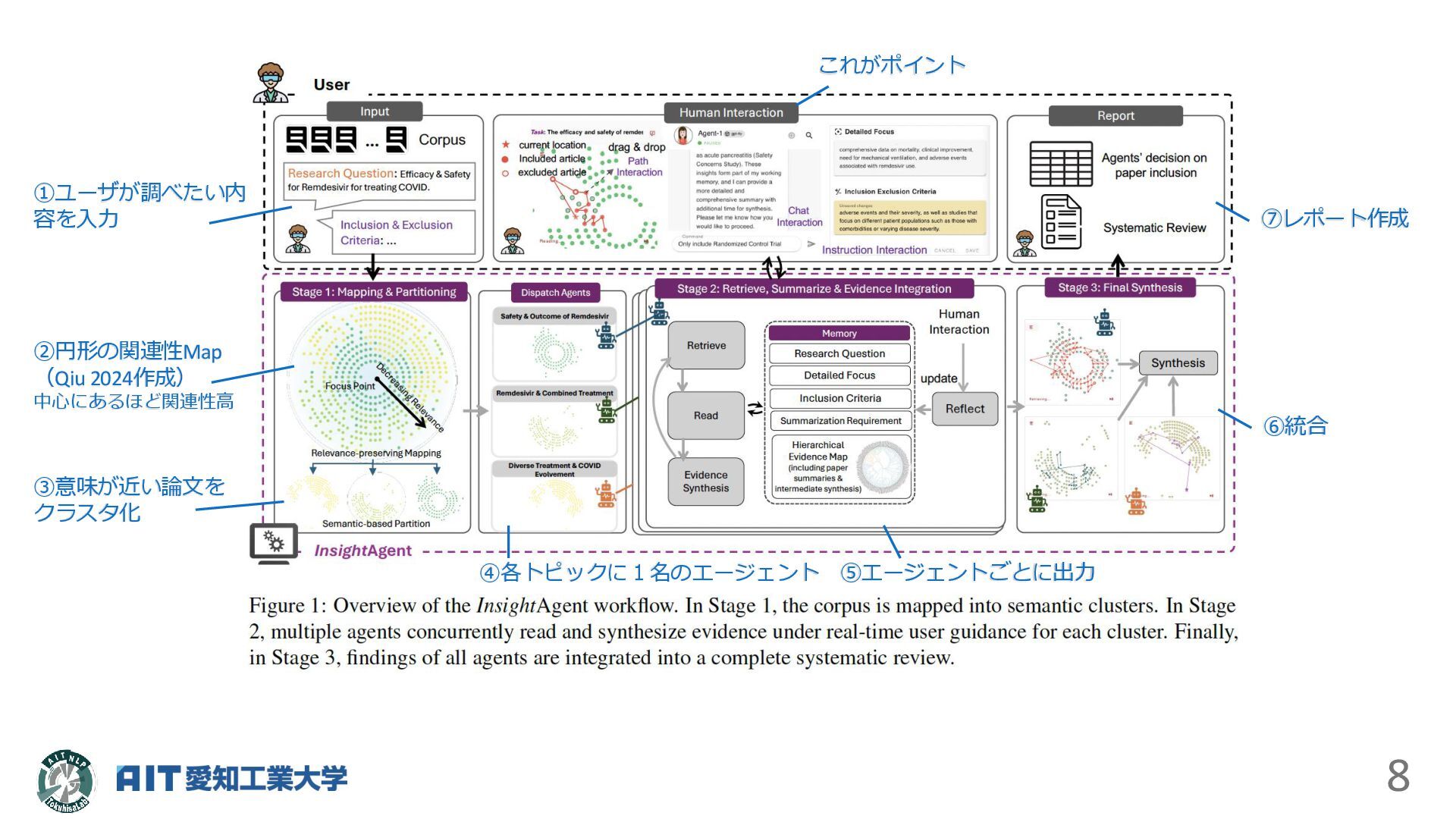
るようにした • Figure1の説明は次のページ • それぞれの知見がどの論文に書いてあったかを辿れるように している点もポイント(要所要所で主張されている)
8 ②円形の関連性Map (Qiu 2024作成) 中心にあるほど関連性高 ③意味が近い論文を クラスタ化 ①ユーザが調べたい内 容を入力 ④各トピックに1名のエージェント
⑤エージェントごとに出力 ⑥統合 ⑦レポート作成 これがポイント
Introduction(4/4) 9 • 可視化によって各エージェントの読解の軌跡を直感的に把握 で切るので、さまざまな形で介入し、エージェントのFocus を調整可能 • 既存の15件のSRを対象に9名の専門家と医学生の協力を得て 実験。 •
InsightAgentのマルチエージェント設計によりAutoSurveyよ り15.6%精度高 • 論文の同定確率はF1で47%、レビューの生成精度は27.2%、 ユーザ満足度は34.4%向上。平均で1.5時間でレビュー作成。 人間が執筆したレビューの79.7%の品質だった。
Related Work(1/2) 10 • LLMを活用したサーベイに関する研究がある • AutoSurvey • ChatCite •
LitLLM • ただし、いずれも完全自動でユーザのインタラクションがで きない • 人間が関与しない自律エージェントは、その意思決定プロセ スに対して一貫性や透明性を担保することが難しい →これをInsightAgentで解決
Related Work(2/2) 11 • Visual Analytics for Information-seeking and Decision
Making • 主に2つの目的で利用されている • 意味づけと解釈可能性 • 検索、分類、意思決定 • Sensemaking and Interpretability • ハイパーグラフで表現するとか、二次元レイアウトとか • Retrieval Classification and Decision-Making • インタラクティブな可視化によって、文書検索とか情報検索の RecallとPrecisionが向上することが知られている 知見としては前からあって、ちゃんと適用したところがえらい(?)
InsightAgent(1/6) 12 • この節ではInsight Agentについて説明する • 人間中心というところがポイント • 次の3つのステージで実現 1.
コーパスのマッピングと分割 2. レコードのスクリーニングと証拠の統合 3. 最終的な統合
InsightAgent(2/6) 13 • ステージ1:Corpus Mapping& Partitioning • Corpus Mapping •
論文を点で表示。中央に行けば行くほど近い • どこに配置されるかは右記の2つで決まる:(1)元の Research Questionが近いと中央に、(2)他の論文との近さ • Corpus Partitioning • K-meansでクラスタリングして意味的に異なるクラスタごと に分割する • コーパス分割によってノイズが減る+各エージェントの作業 負荷も軽減される
InsightAgent(3/6) 14 • ステージ2:Reading and Evidence Synthesis • 各エージェントが割り当てられた論文の要約を作成する •
Agent Setup and Record Screening • エージェントはコーパスのResearch Question、包含・除外の基準(例: Study type)、要約要件(望ましい詳細度など)を設定する • 各ステップで、エージェントは関連性保持マップの中で現在の文書に隣接 する領域から読んでいく。基本的には内側から外側にスクリーニング開始。 • 全てのエージェントの動作に一貫性を与えるために、近接8件を読む • 短期的な読解戦略に関しては動的に更新される
InsightAgent(4/6) 15 ステージ2: Reading and Evidence Synthesisの続き • Summary Generation
& Memory Mechanism • エージェントは各論文について、元のResearch Questionとどのように関 係するかを要約し、local memoryに記憶していく • 重複や矛盾を発見したら、これまでの結果を削除するのはなく統合・更新 していく • 重要なのは、各エージェントの結果は最終的に統合されるまで独立である ということ • Transparent Evidence Integration • ある結論がどのようにして導き出されたかをわかるように、全ての要約の 統合などをdependency graphとして記録 • 異なるエージェントからの結果は色分けして表示されるので、議論がある ようなところは後から人が精査できる
InsightAgent(5/6) 16 ステージ2: Reading and Evidence Synthesisの続き • ユーザの介入:3種類の介入を許している •
Path Navigation: 関連している論文で見逃されているものを追加 • Chat Navigation: 対話で介入 • Instruct Navigation: エージェントへのインストラクション書き換え • ユーザからインタラク ションされると”反省 フェーズ(reflection)” に入って、これまでの読解 を見直し
InsightAgent(6/6) 17 • ユーザが作ったテンプレートに沿って、複数のエージェ ントの結果をまとめたレポートを作成 • テンプレートには、Introduction, Study Designなどが含 まれる
• Citation_numberで元の文献に辿れるようになっている
Experiments(1/6) 18 関連する論文をどの程度取ってこれるかについての評価 • 補足 • 評価対象とした全てのSystematic Reviewが100件未 満の論文をまとめるものなので、実用的な基準に基 づいてBM25とAutoSurveyはトップ100に制限した
• ChatCiteは検索機能は持たずユーザが指定した論文 を要約するシステムなので評価対象からは外されて いる • InsightAgent auto は全自動、何もついていないの は人手介入あり • 人手介入ありのInsightAgentは精度高い
Experiments(2/6) 19 • 補足 • 生成したSystematic reviewを専門家が評価 • InsightAgentは従来手法より高精度 •
この表はOverallのスコアで、詳細な結果は図2にある
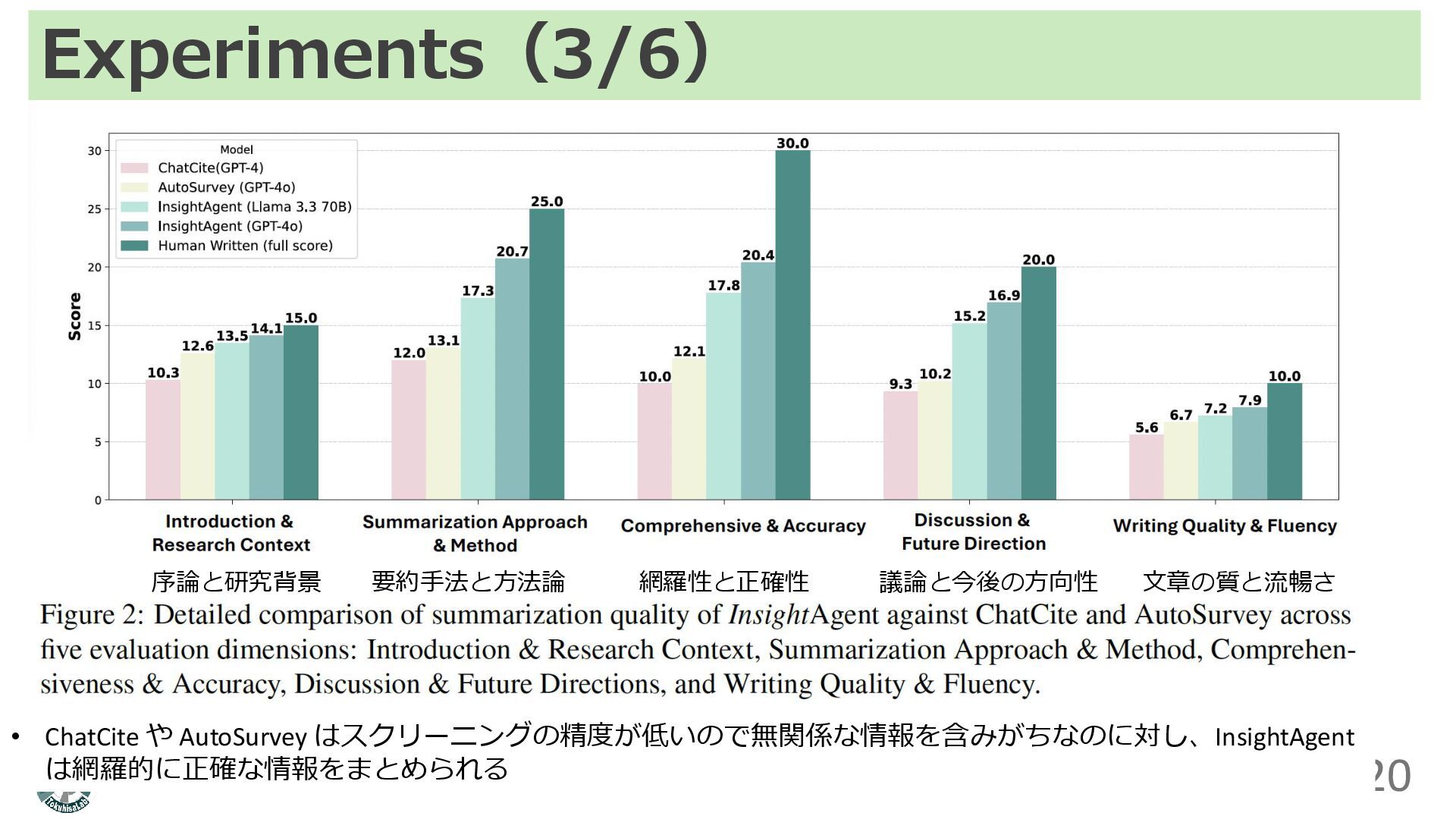
Experiments(3/6) 20 序論と研究背景 要約手法と方法論 網羅性と正確性 議論と今後の方向性 文章の質と流暢さ • ChatCite や
AutoSurvey はスクリーニングの精度が低いので無関係な情報を含みがちなのに対し、InsightAgent は網羅的に正確な情報をまとめられる
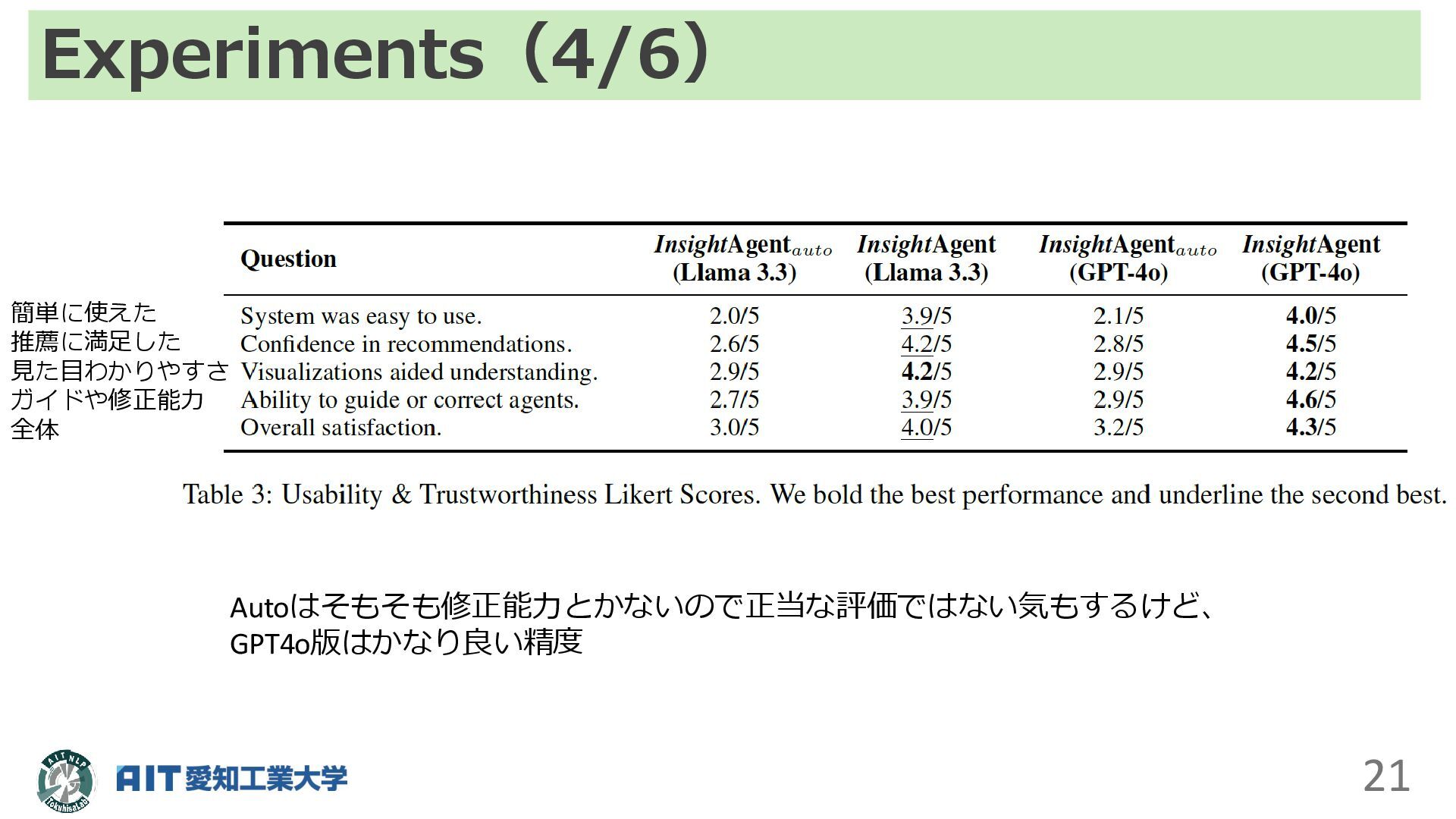
Experiments(4/6) 21 簡単に使えた 推薦に満足した 見た目わかりやすさ ガイドや修正能力 全体 Autoはそもそも修正能力とかないので正当な評価ではない気もするけど、 GPT4o版はかなり良い精度
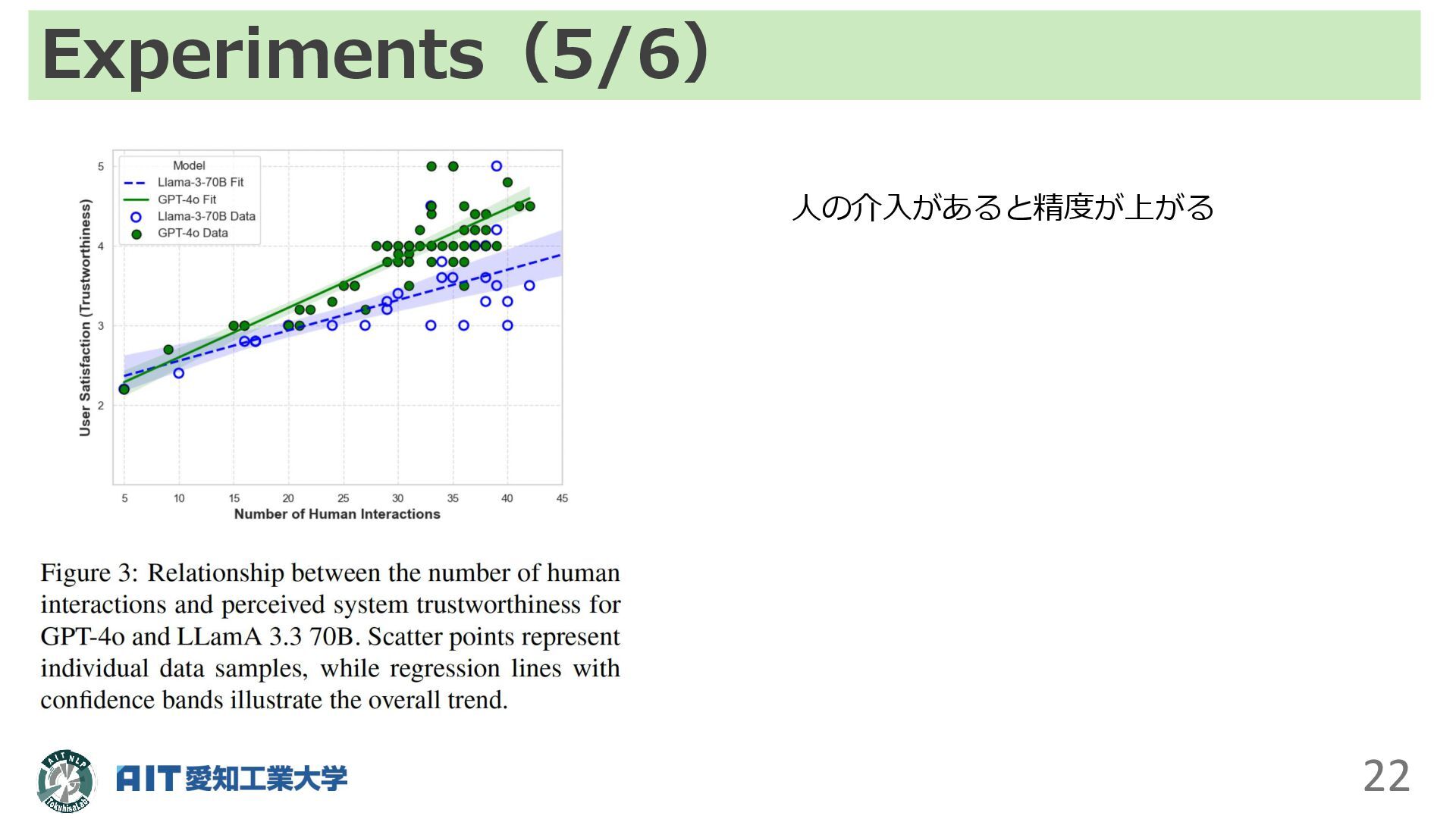
Experiments(5/6) 22 人の介入があると精度が上がる
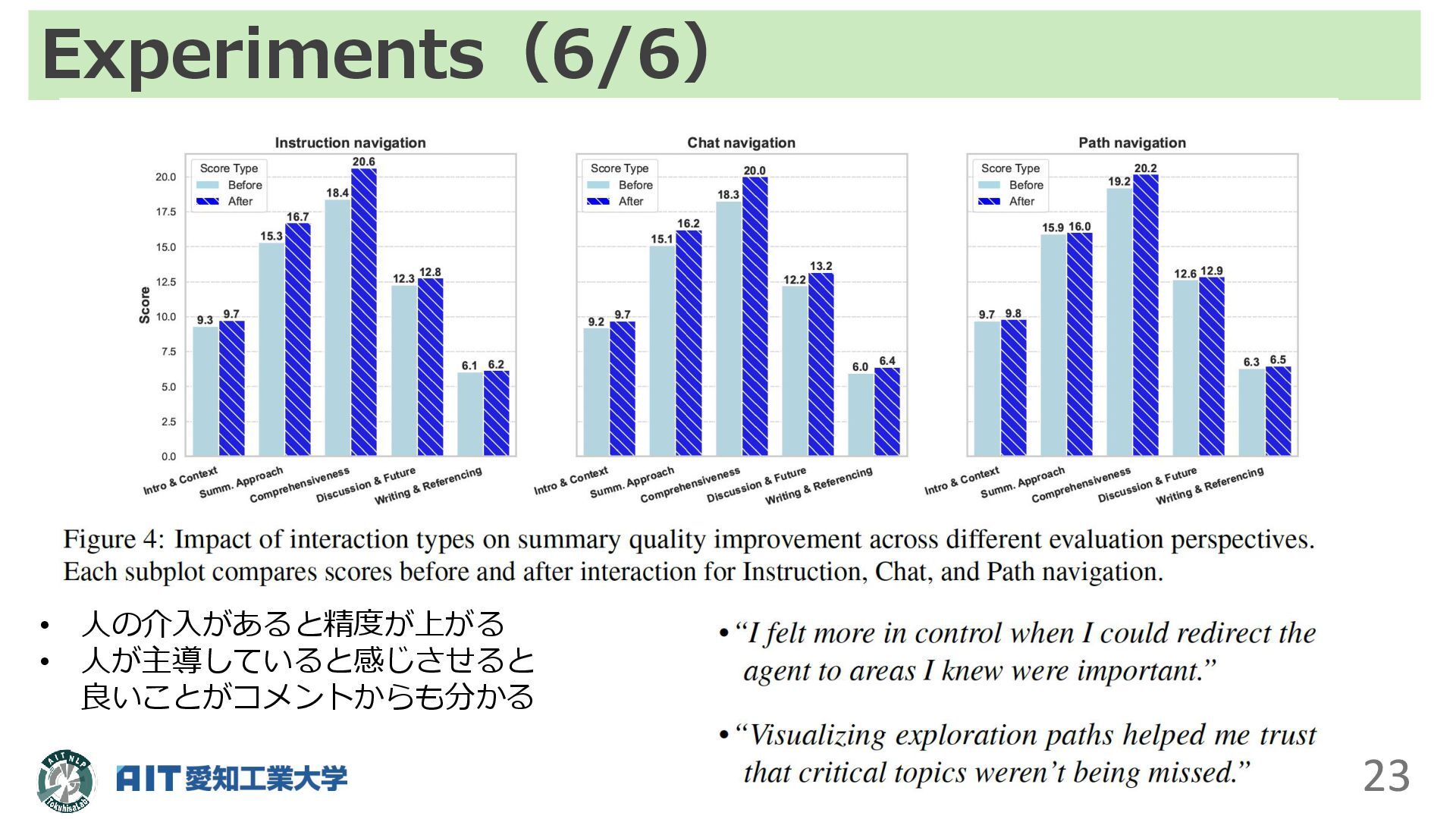
Experiments(6/6) 23 • 人の介入があると精度が上がる • 人が主導していると感じさせると 良いことがコメントからも分かる
まとめ ◼ ACLの「AI Agent論文」とはどのような論文なのかを読んでみました ◼ 一言で言うと:システマティックレビューをエージェントを使ってやるという論文 ◼ 人の介入を許す設計にした点がポイント 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}