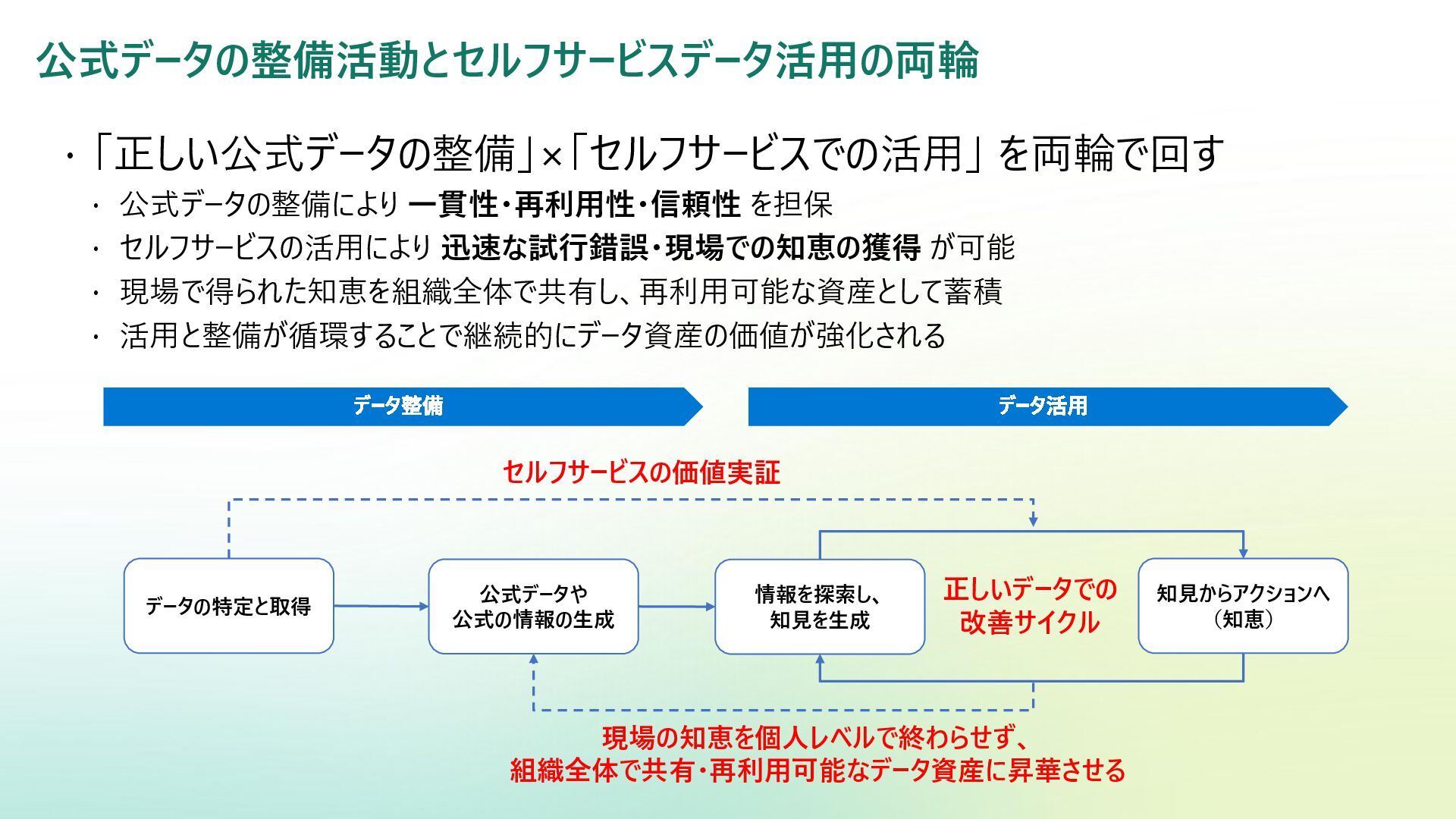
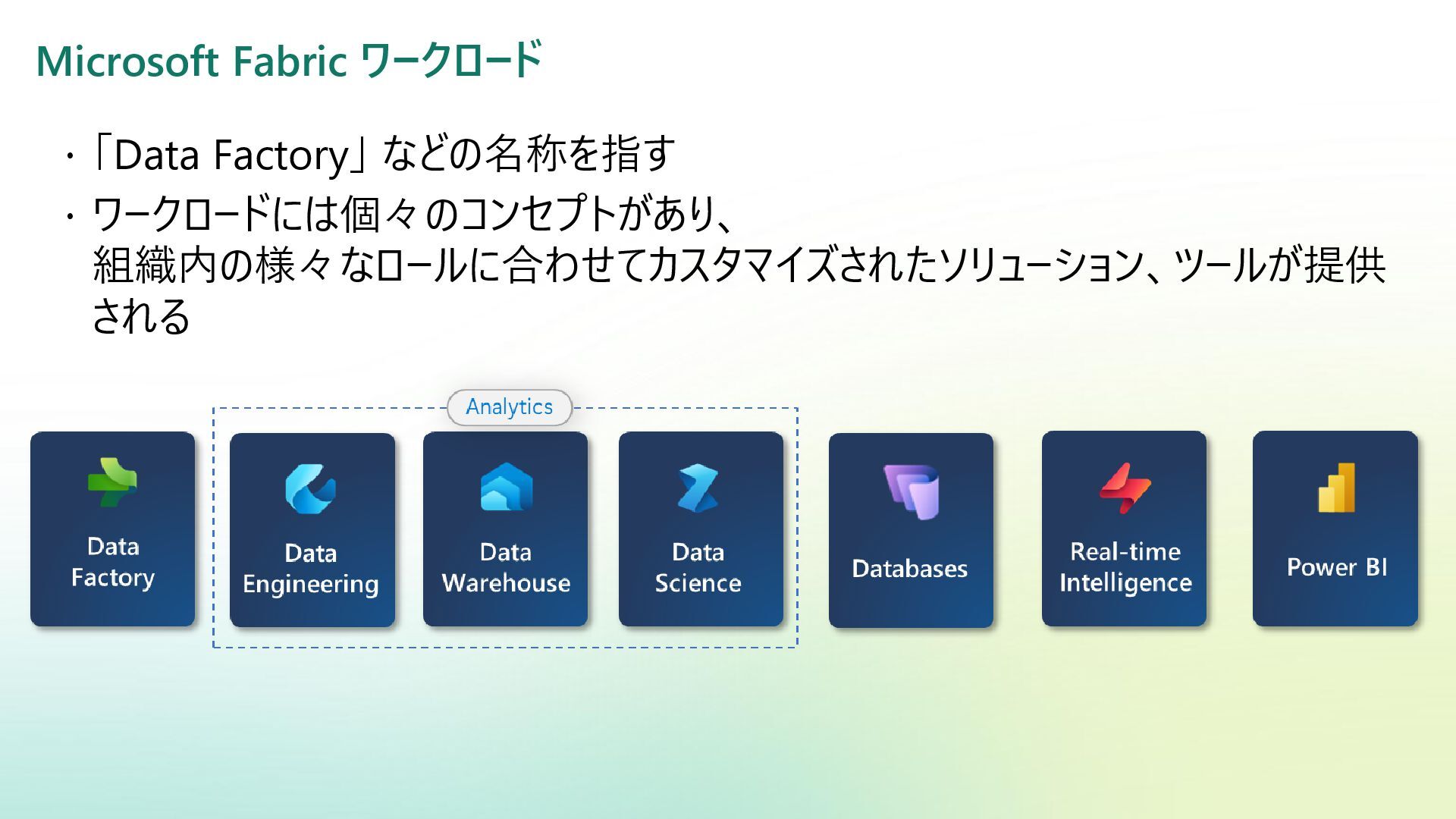
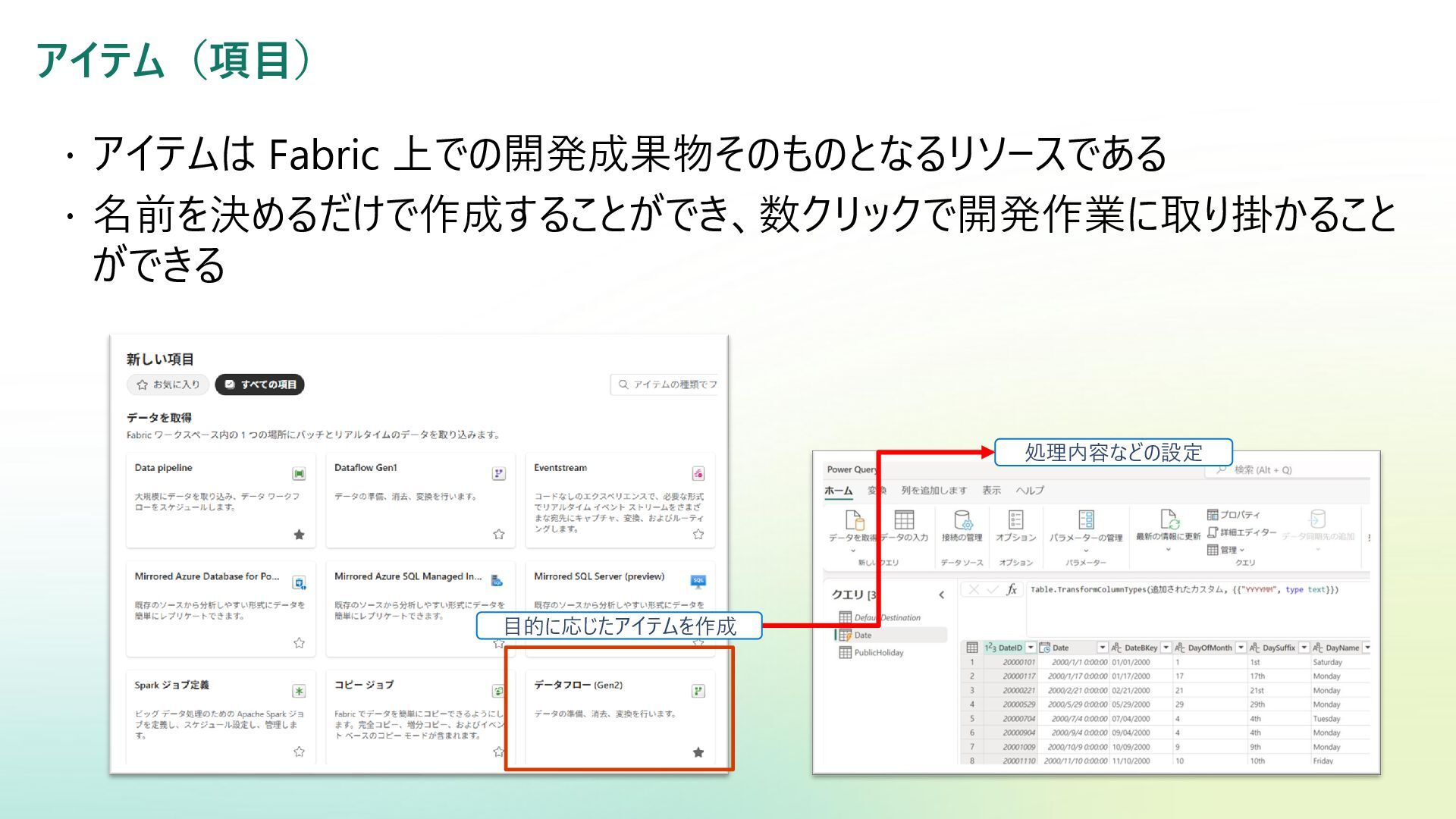
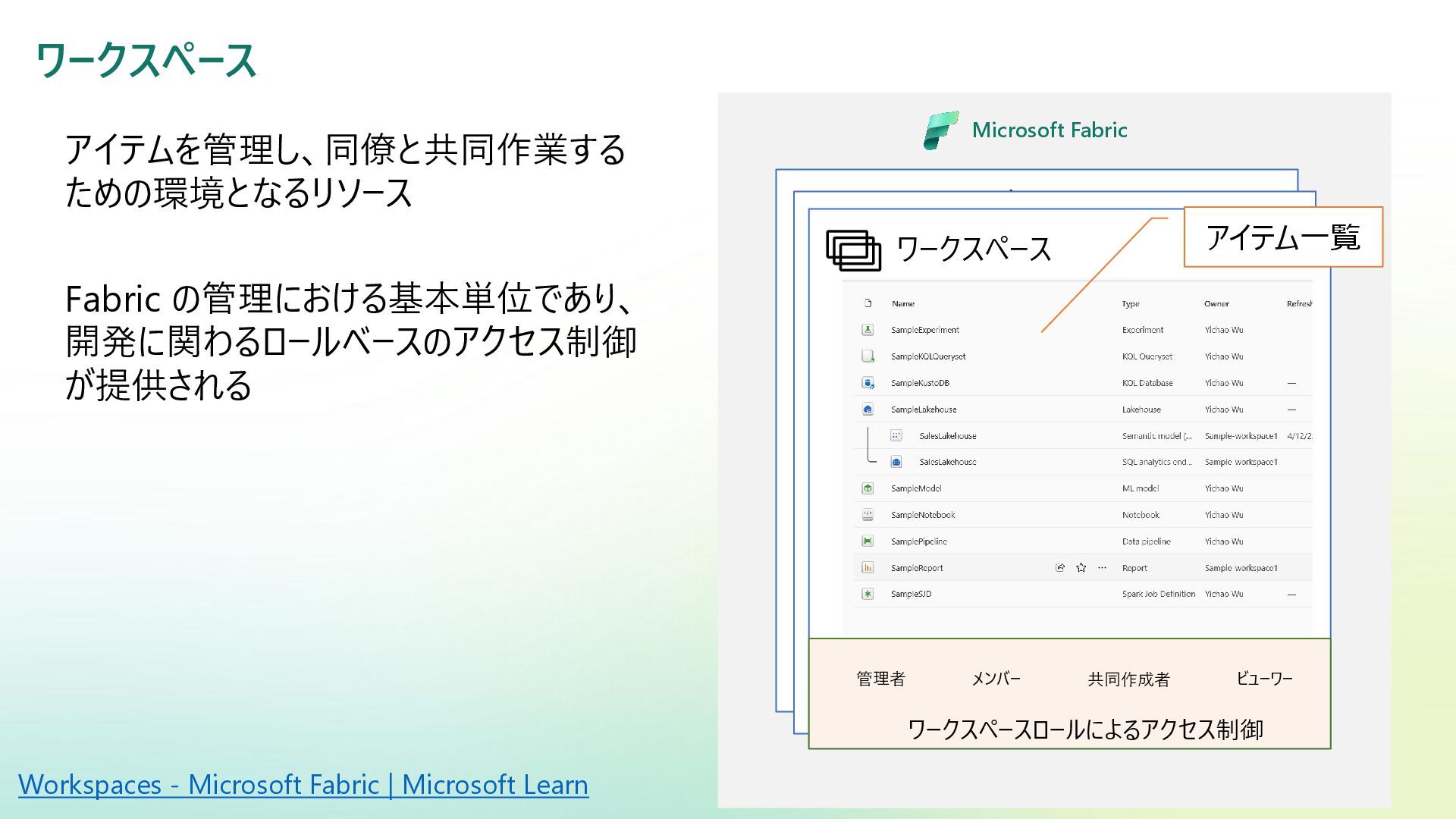
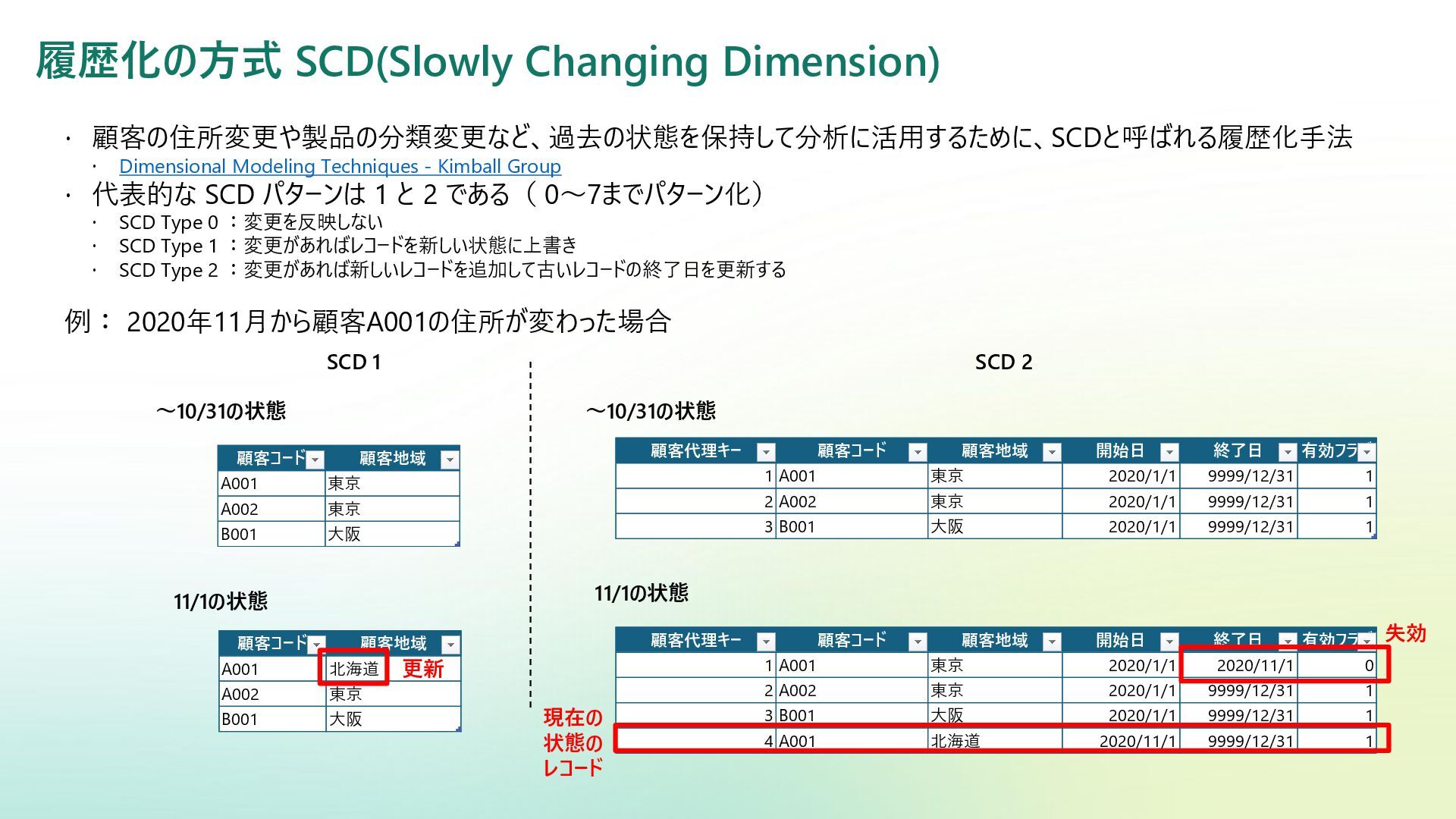
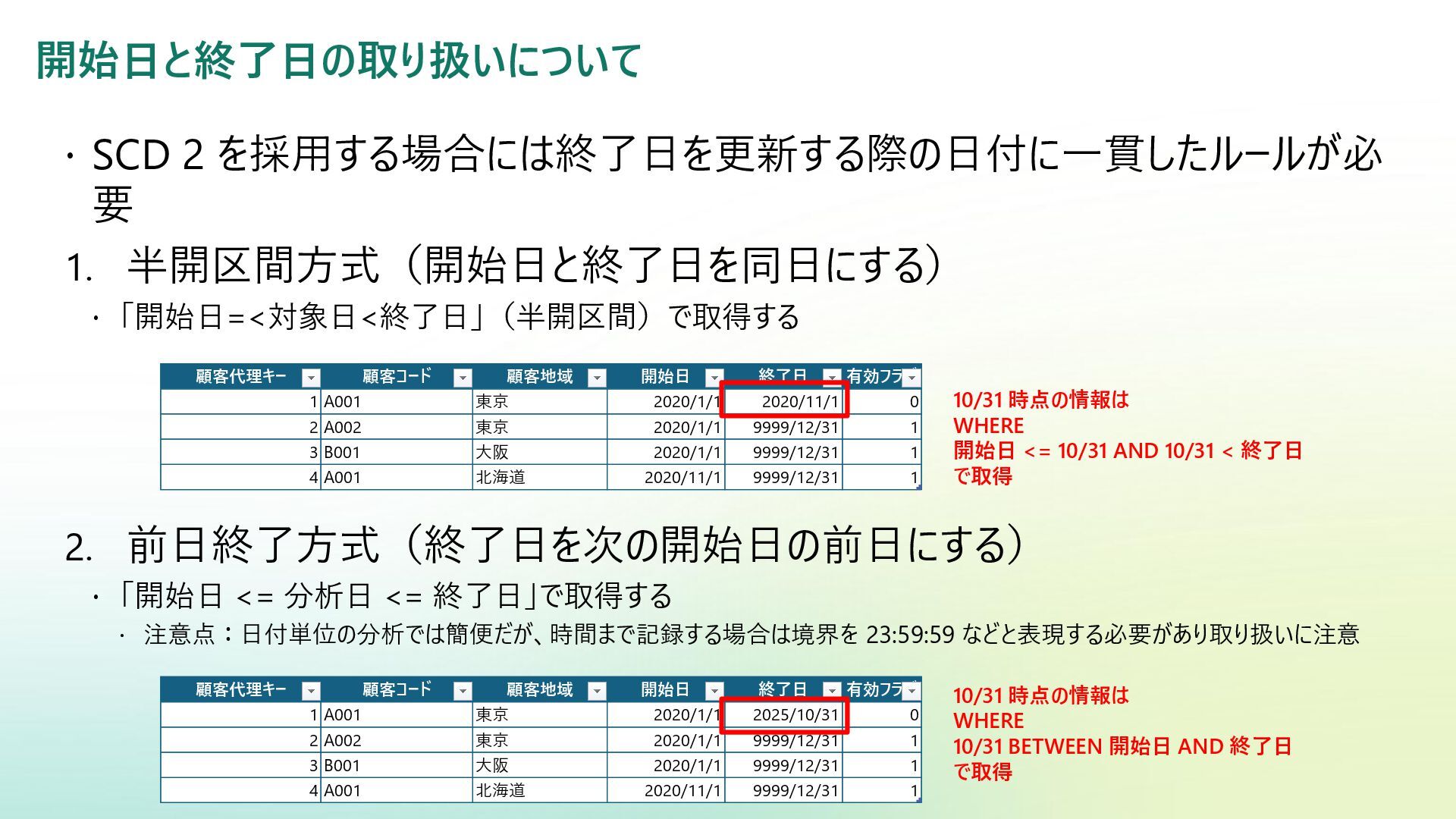
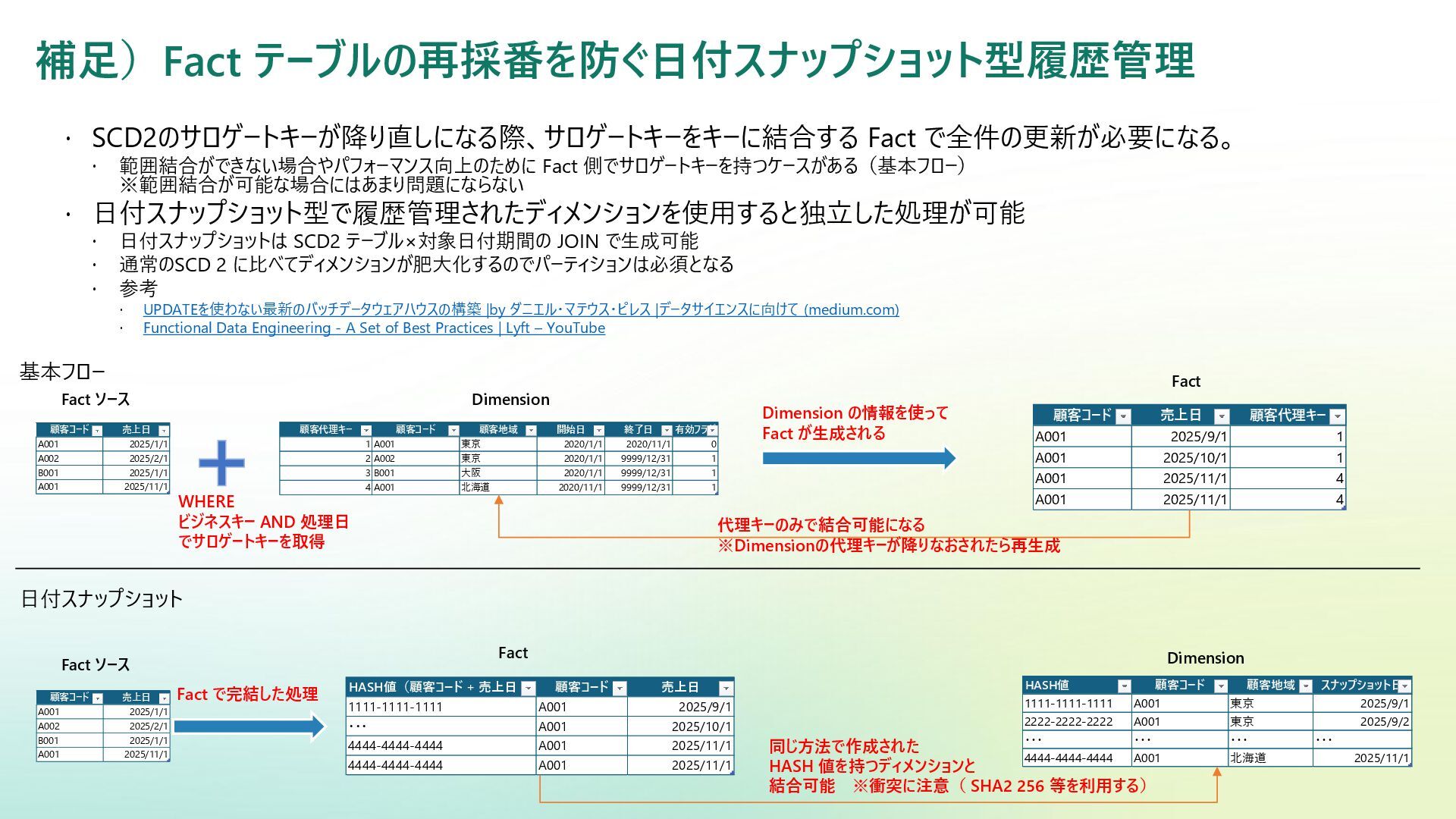
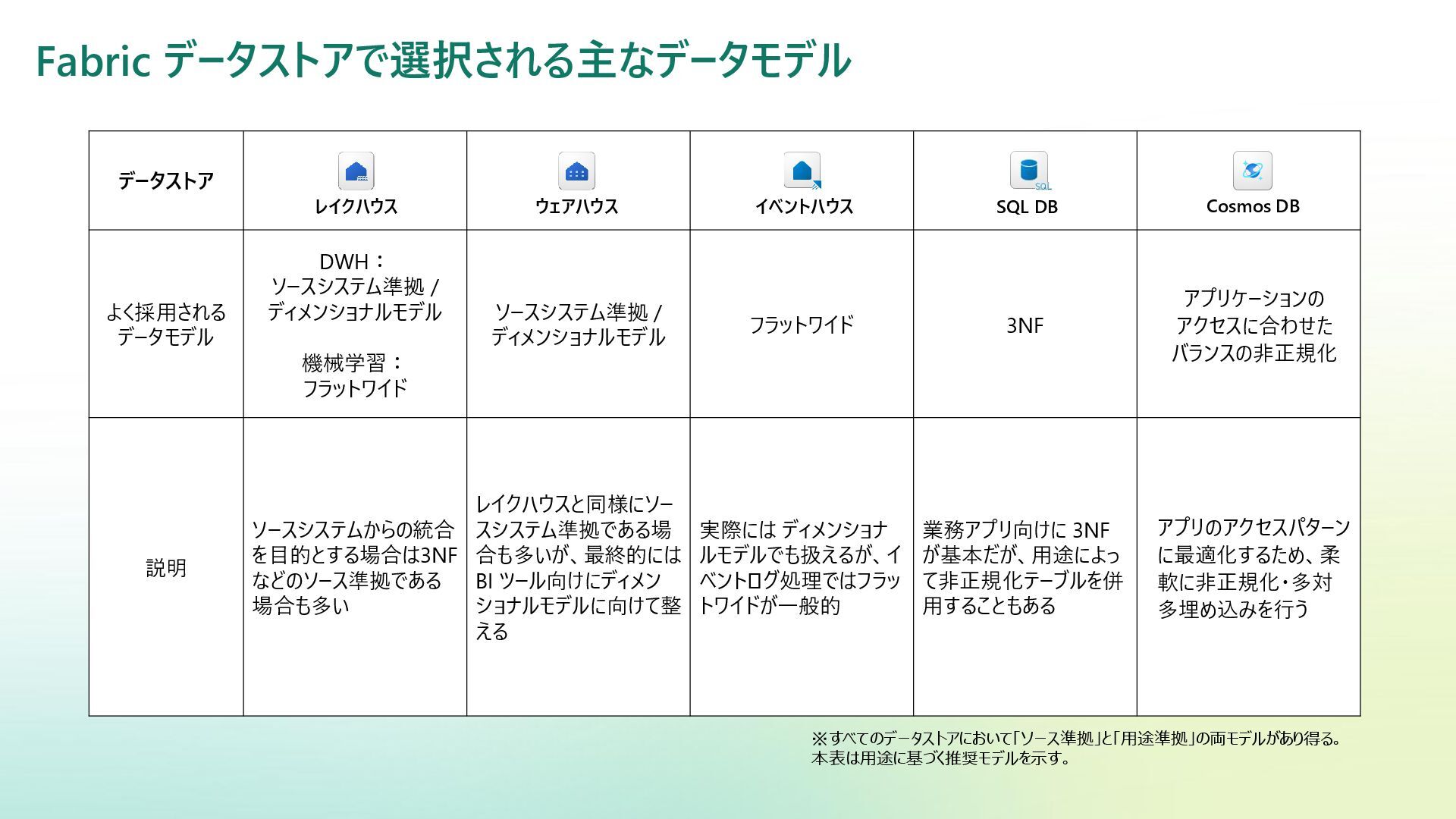
Reference | Adamson, Christopher | Data Warehousing Kimball Toolkit Books on Data Warehousing and Business Intelligence 日本語版の書籍が一部あり:データウェアハウス・ツールキット | ラルフ キンボール, Kimball,Ralph, 康秀, 藤本, 和美, 岡田, 学, 下平, 磨瑳也, 伊藤, 喜一, 小畑 |本 | 通販 | Amazon アジャイルデータモデリング 組織にデータ分析を広めるためのテーブル設計ガイド (KS情報科学専門書) | ローレ ンス・コル, ジム・スタグニット, 株式会社風音屋, 打出 紘基, 佐々木 江亜, 土川 稔生, 濱田 大樹, 妹尾 拡 樹, ゆずたそ, 株式会社風音屋 |本 | 通販 | Amazon SCD dbt snapshot から学ぶ Slowly Changing Dimension - Gunosyデータ分析ブログ Slowly Changing Dimensions Are Not Always as Easy as 1, 2, 3 - Kimball Group デザインのヒント #152 緩やかに変化するディメンションタイプ 0、4、5、6、7 - Kimball Group
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
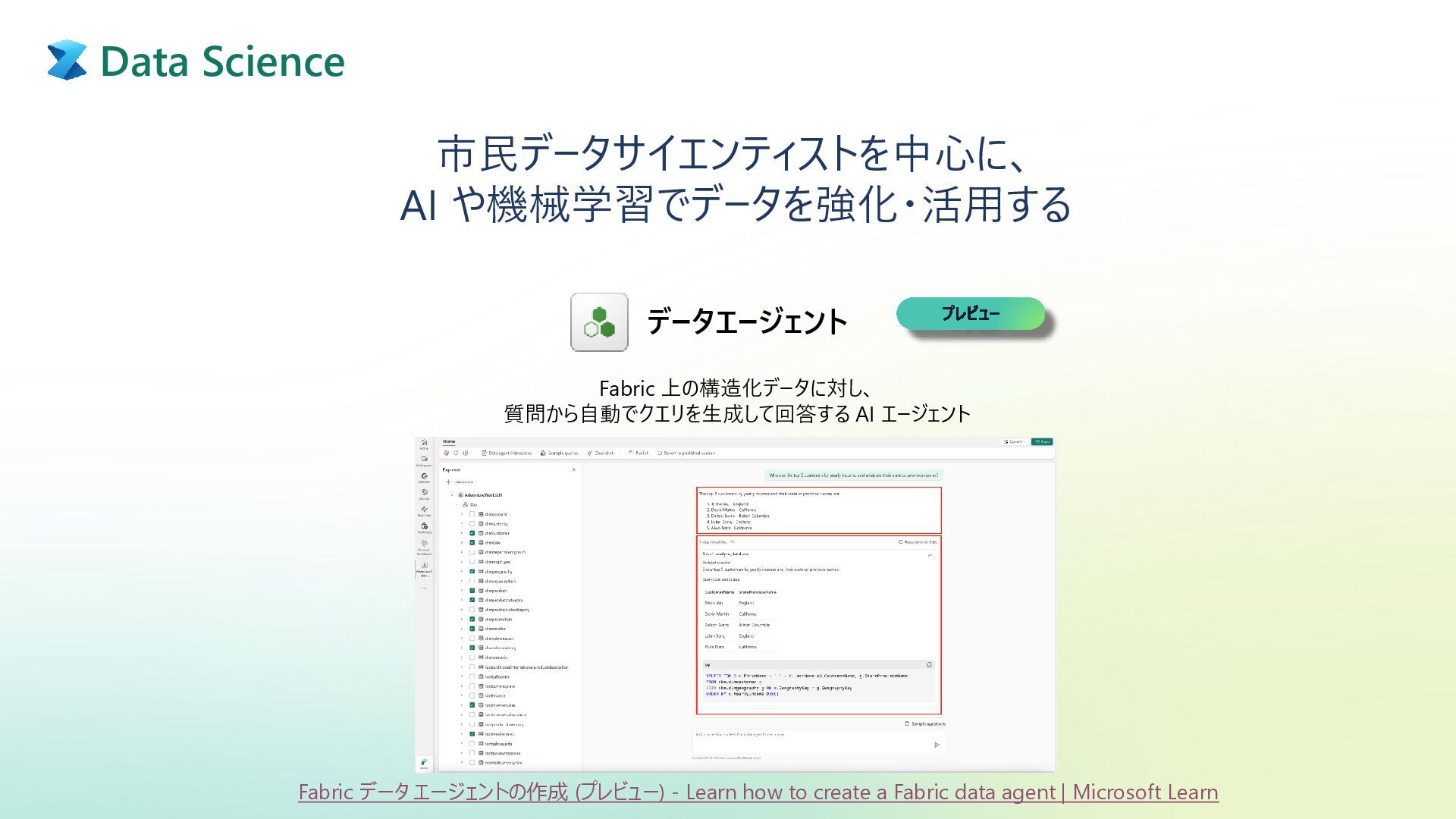{kind=link}
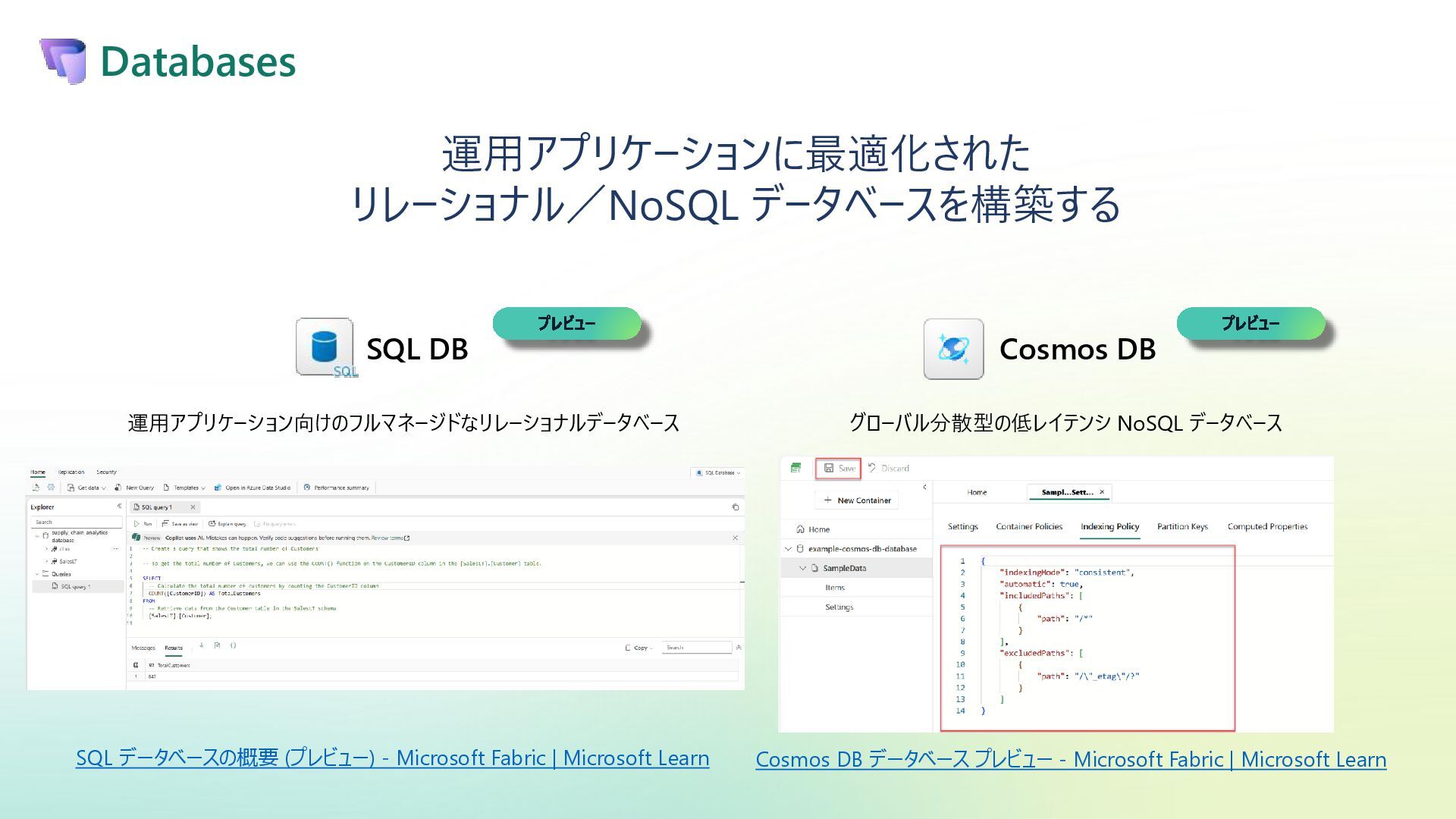{kind=link}
{kind=link}
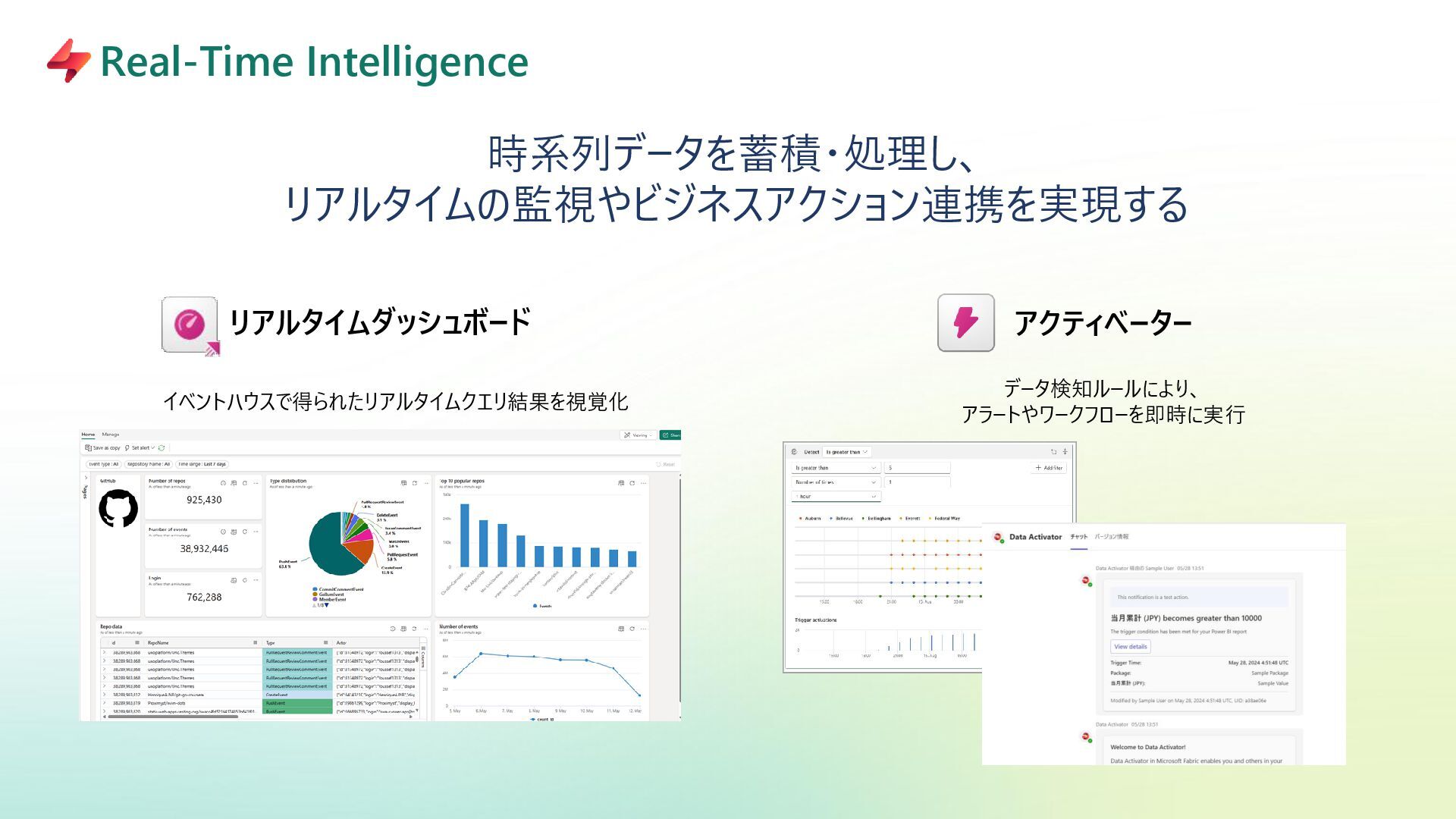{kind=link}
{kind=link}
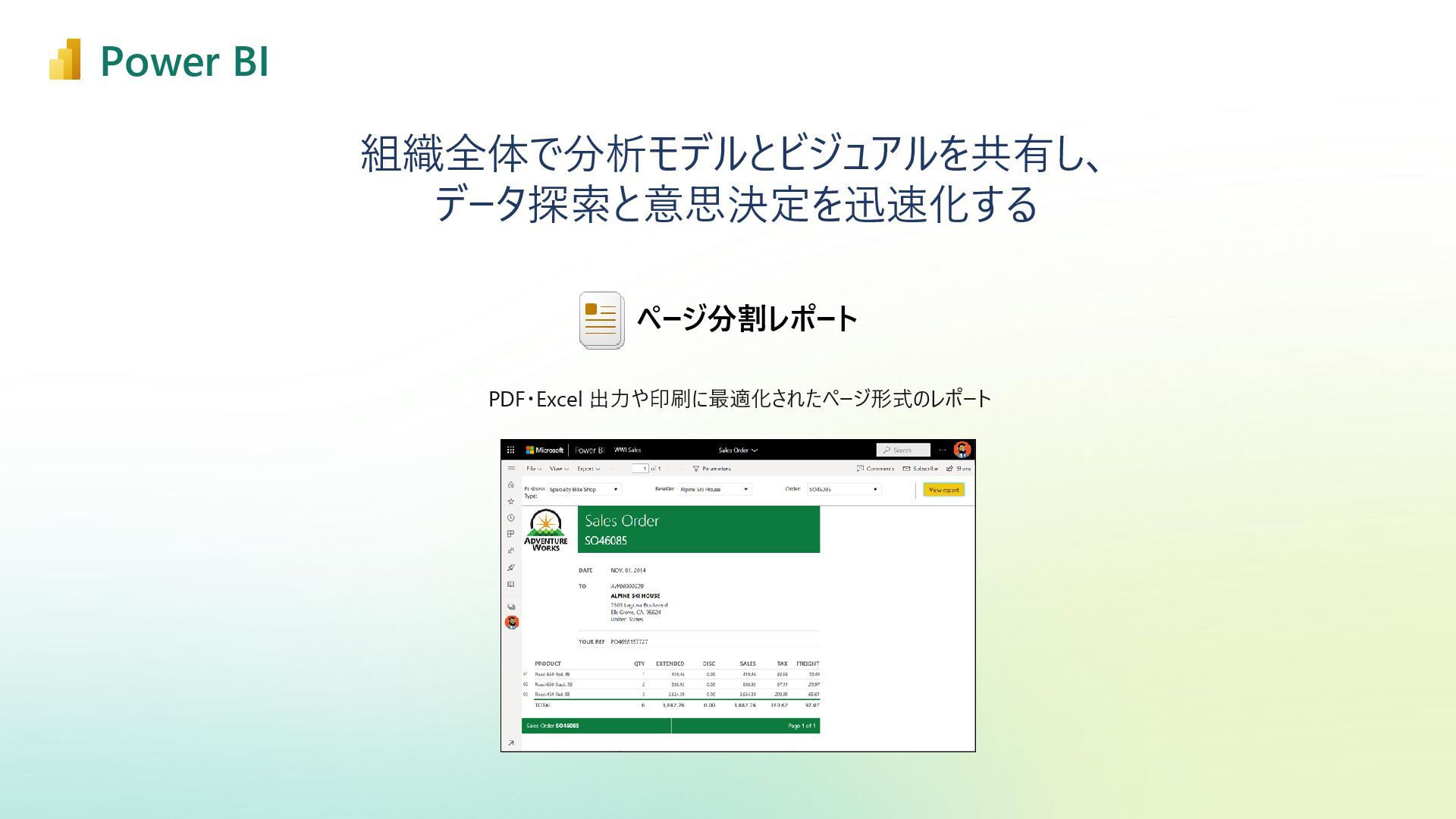{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
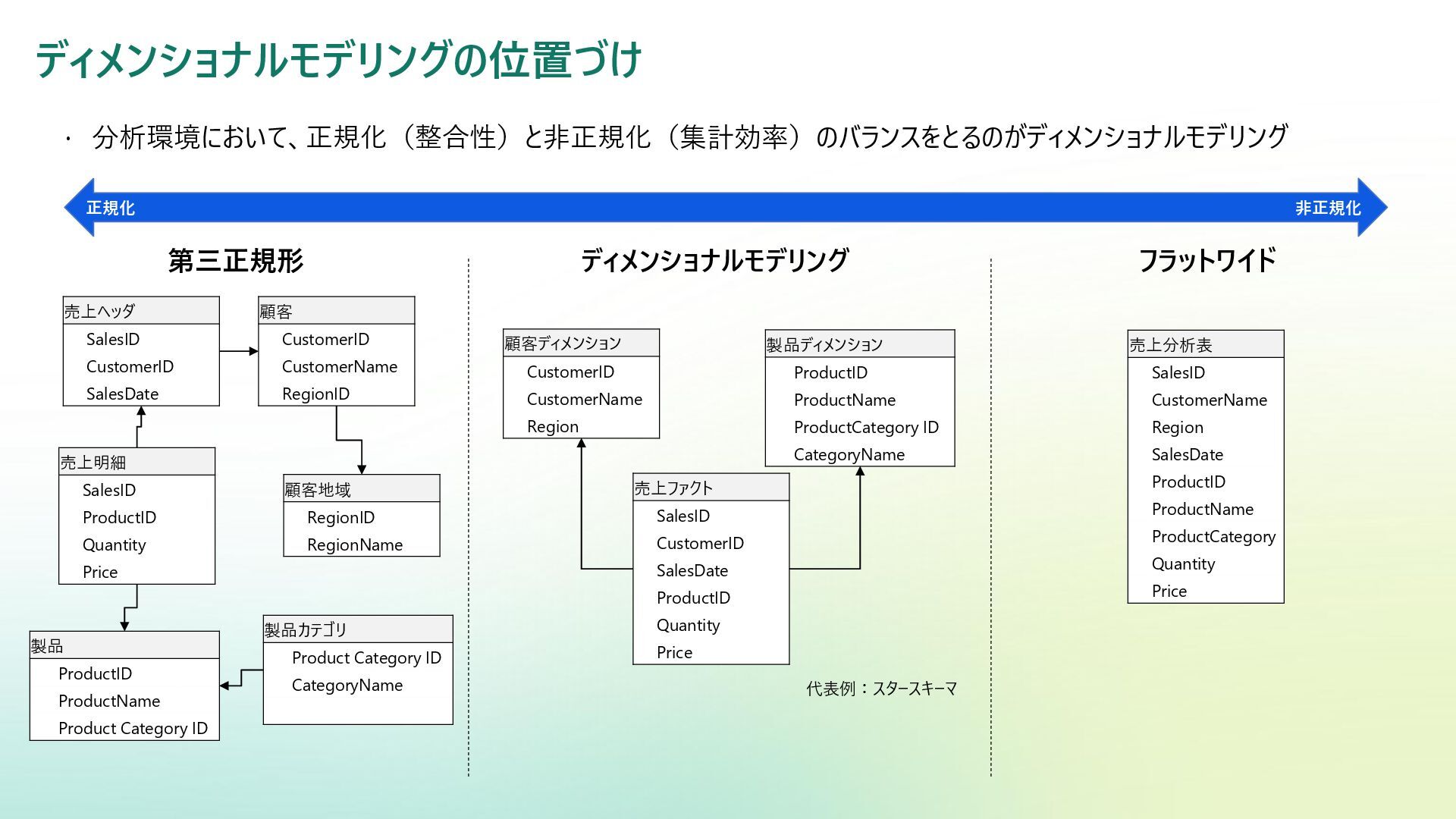{kind=link}
{kind=link}
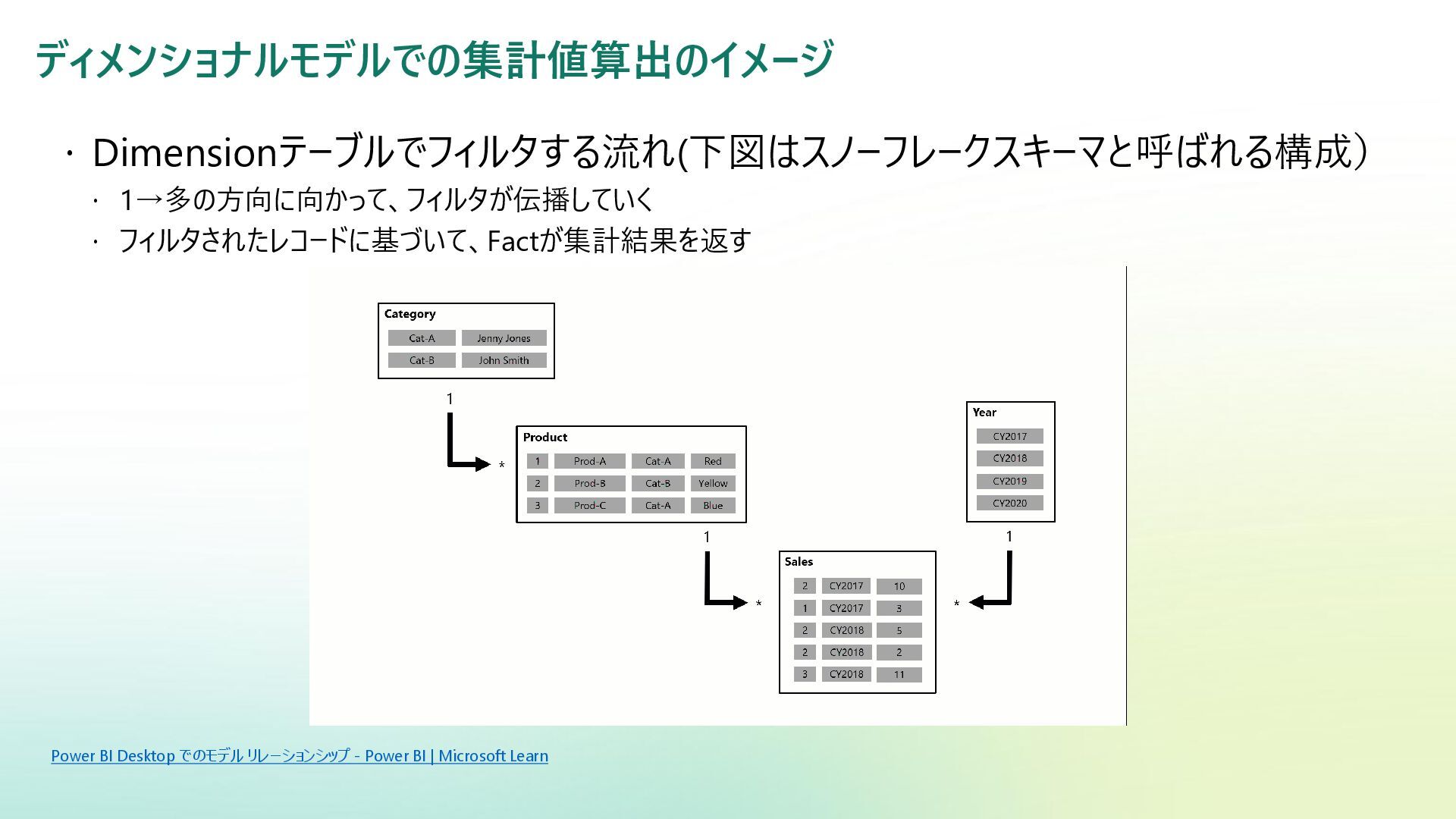{kind=link}
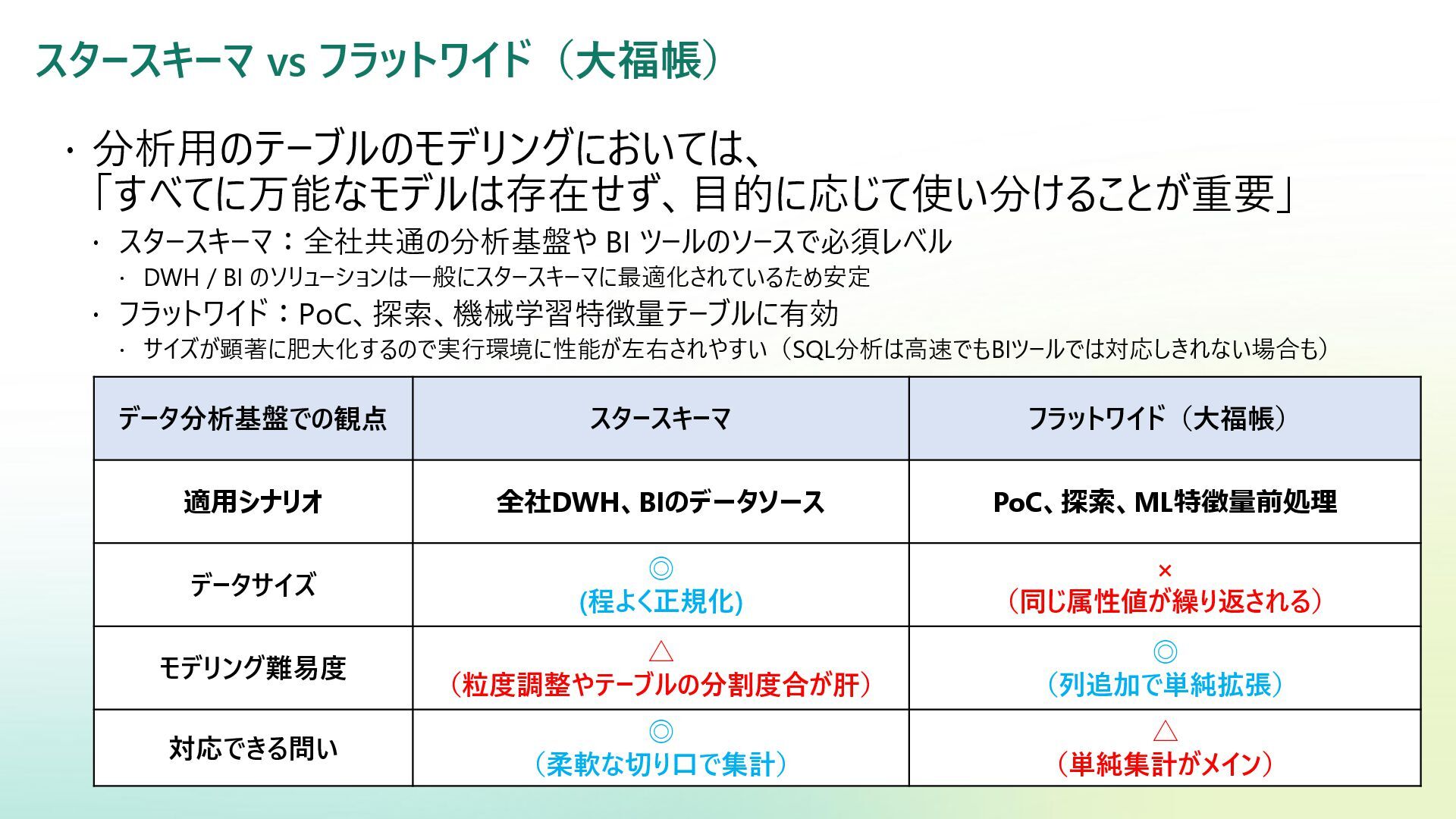{kind=link}
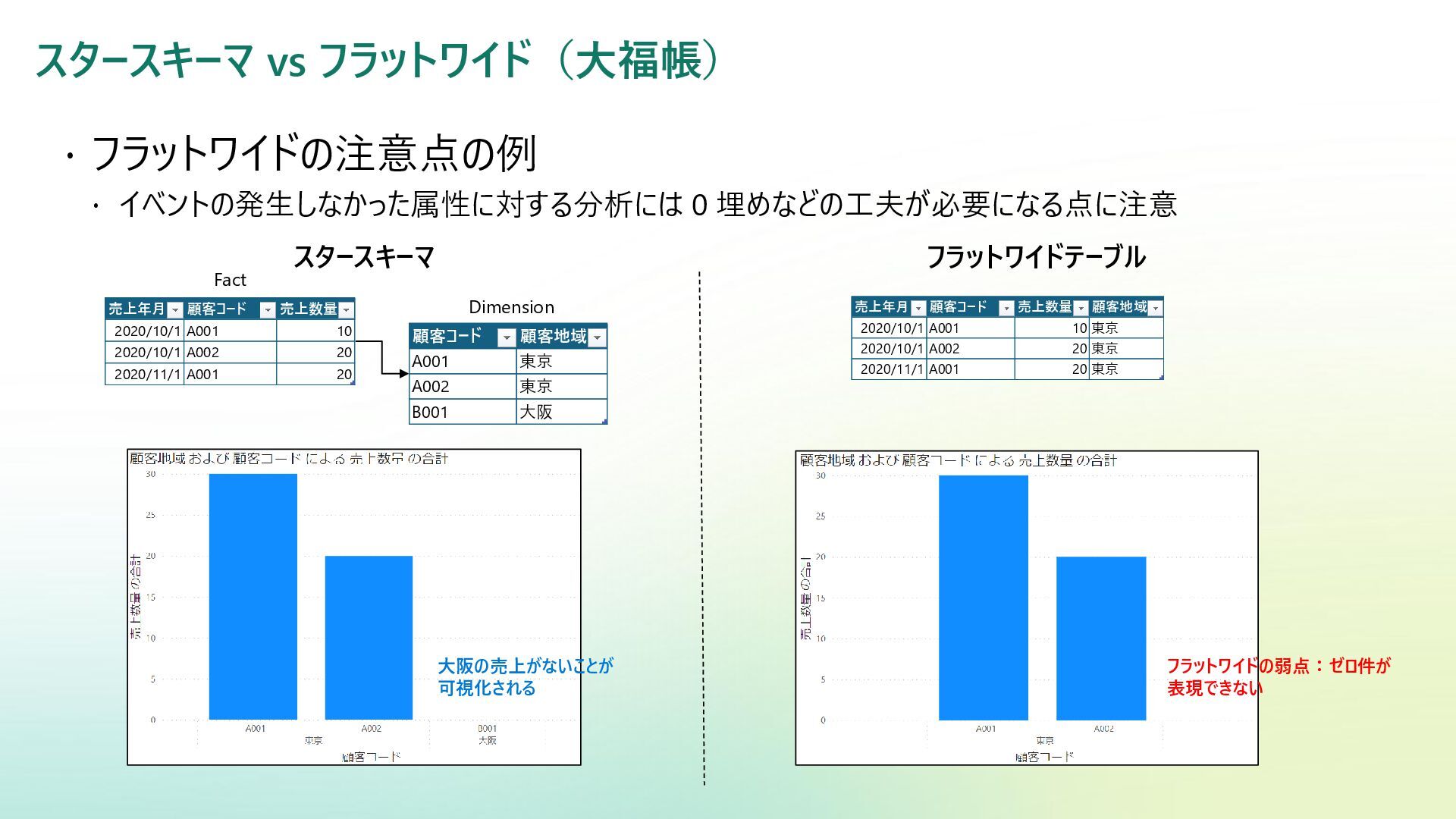{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
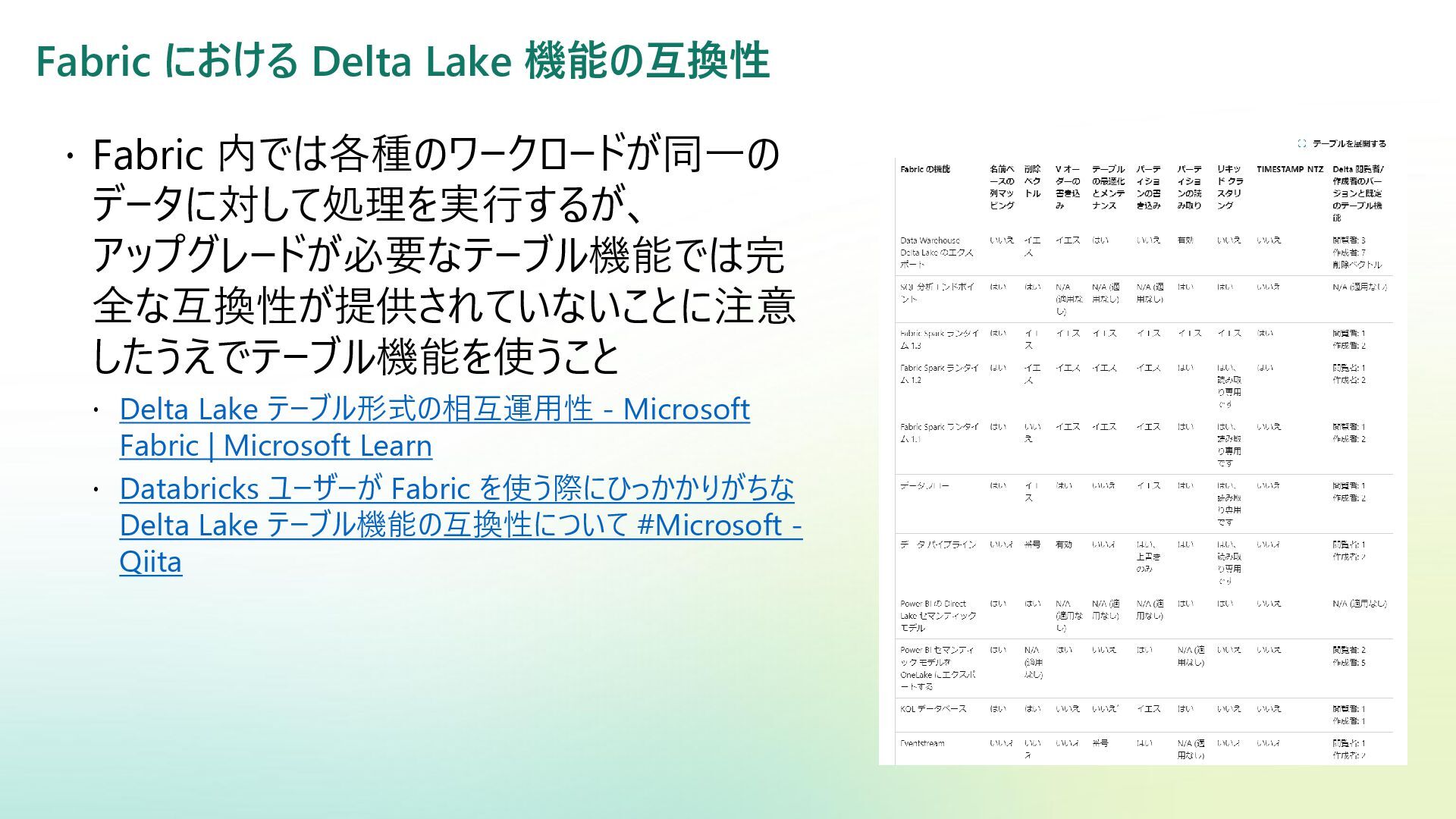{kind=link}
{kind=link}
{kind=link}
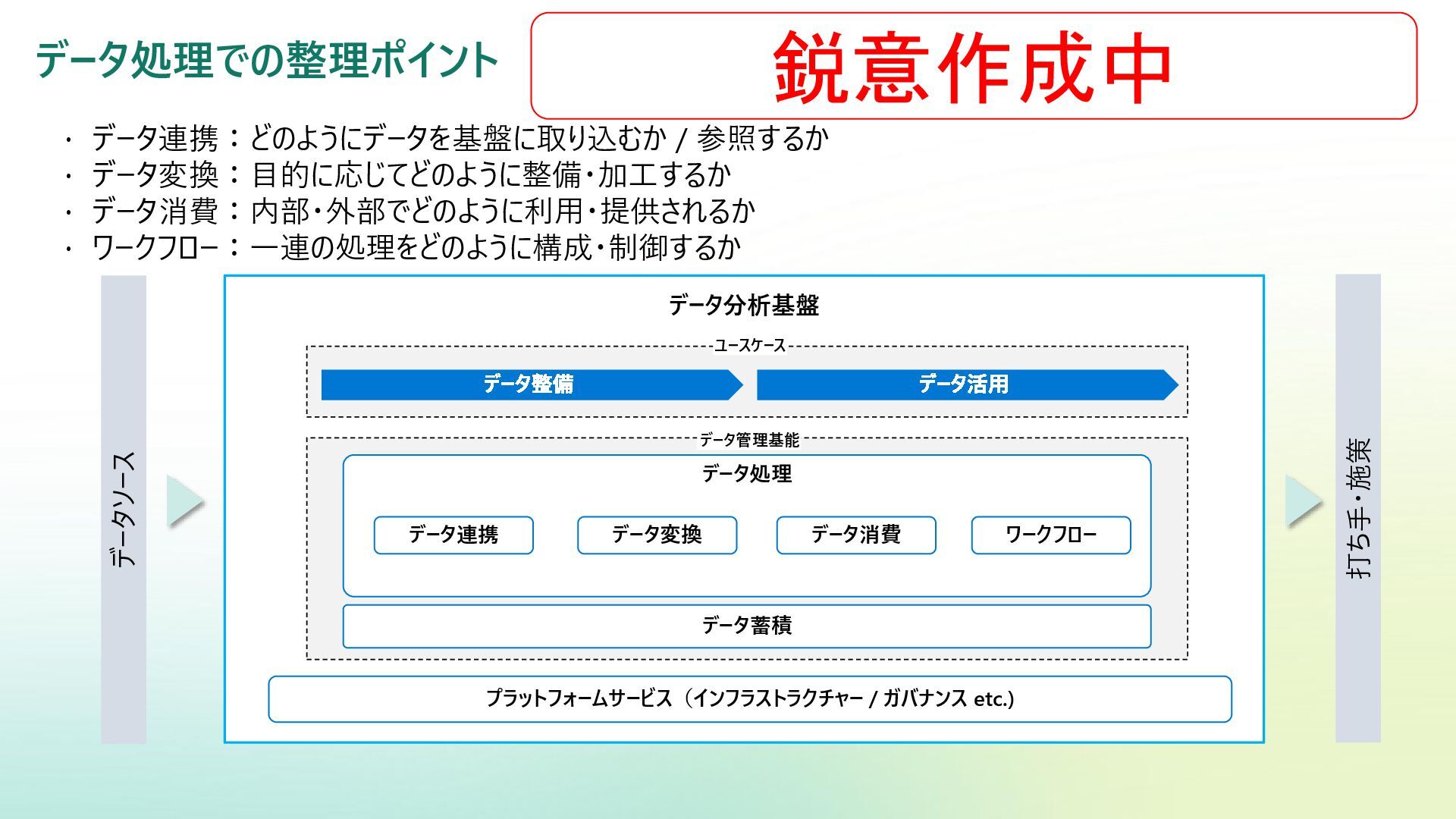{kind=link}