Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Amazon S3 Vectors とハイブリット検索を実現してみる
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
ryu-ki
August 23, 2025
3.7k
16
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Amazon S3 Vectors とハイブリット検索を実現してみる
ryu-ki
August 23, 2025
More Decks by ryu-ki
See All by ryu-ki
AgentCore Harness × AgentCore Browser × Live View
ryuki0947
1
47
VPCとも向き合いたい2026(年度)
ryuki0947
0
290
Strands Agents × AWS DevOps Agent 〜自作エージェントに組み込んでみた〜
ryuki0947
0
85
AI-DLCを試してみて困ったことを共有したい
ryuki0947
0
420
Claude Codeに要件をヒアリングしてもらった体験がかなり良かった(2026年版)
ryuki0947
0
480
Qiita 週1投稿を1年間完走した感想
ryuki0947
0
60
AWS × LINE で始める FinOps ~Terraform を添えて~
ryuki0947
0
160
A2A のトレース事情 〜親子エージェントの動きをLangfuseで可視化してみる〜
ryuki0947
1
620
A2A においてエージェント同士はどのようにやりとりしているのか
ryuki0947
0
360
Featured
See All Featured
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Amusing Abliteration
ianozsvald
1
240
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.2k
Crafting Experiences
bethany
1
230
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
730
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Technical Leadership for Architectural Decision Making
baasie
3
440
Transcript
Amazon S3 Vectors と ハイブリット検索を実現してみる 2025/08/23(土) JAWS-UG新潟 × Python機械学習勉強会in新潟 生成AI祭り
はじめに ┃本日お話しすること 2 RAGにおける検索手法について Amazon S3 Vectorsについて ・全文検索 ・ベクトル検索 ・ハイブリッド検索
・概要 ・ハイブリッド検索の実現方法
RAGにおける検索手法 3 ┃全文検索 ‐ キーワードベースの検索手法 ‐ 単語の出現頻度や重要度をもとに検索 ┃ベクトル検索 ‐ テキストをベクトルに変換し、意味的な類似度で検索
┃ハイブリッド検索 ‐ 全文検索とベクトル検索を組み合わせた手法 ‐ RRFなどの手法がある
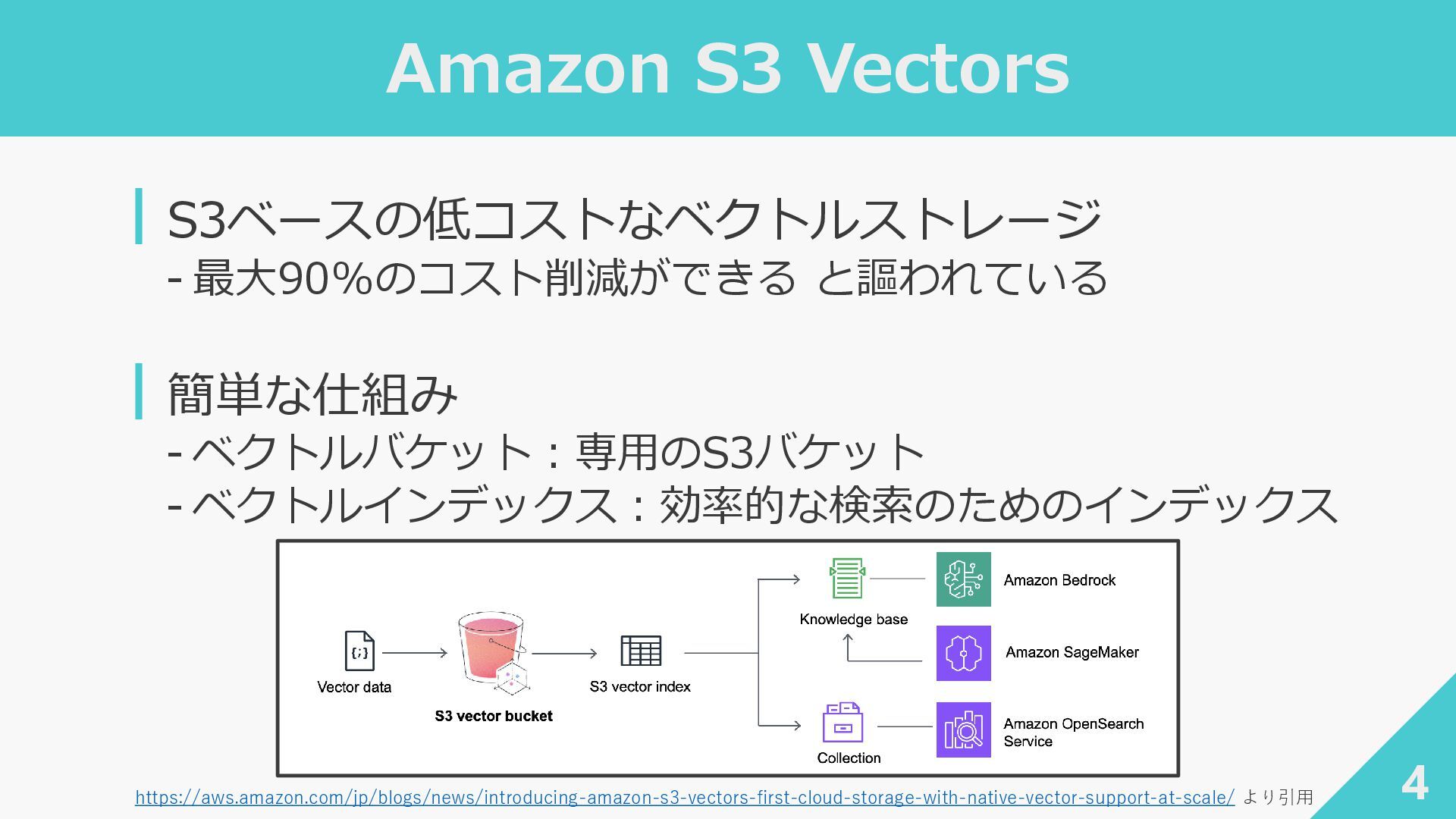
Amazon S3 Vectors 4 ┃S3ベースの低コストなベクトルストレージ ‐ 最大90%のコスト削減ができる と謳われている ┃簡単な仕組み ‐
ベクトルバケット:専用のS3バケット ‐ ベクトルインデックス:効率的な検索のためのインデックス https://aws.amazon.com/jp/blogs/news/introducing-amazon-s3-vectors-first-cloud-storage-with-native-vector-support-at-scale/ より引用
5 とても良いサービスだが…
Amazon S3 Vectors 6 ┃ナレッジベースと連携した際、ハイブリッド検索に 対応していない ‐ ベクトル検索に特化 出来ないと言われると 多少無理してもやってみたい…
勉強にもなりそうなのでやってみよー!
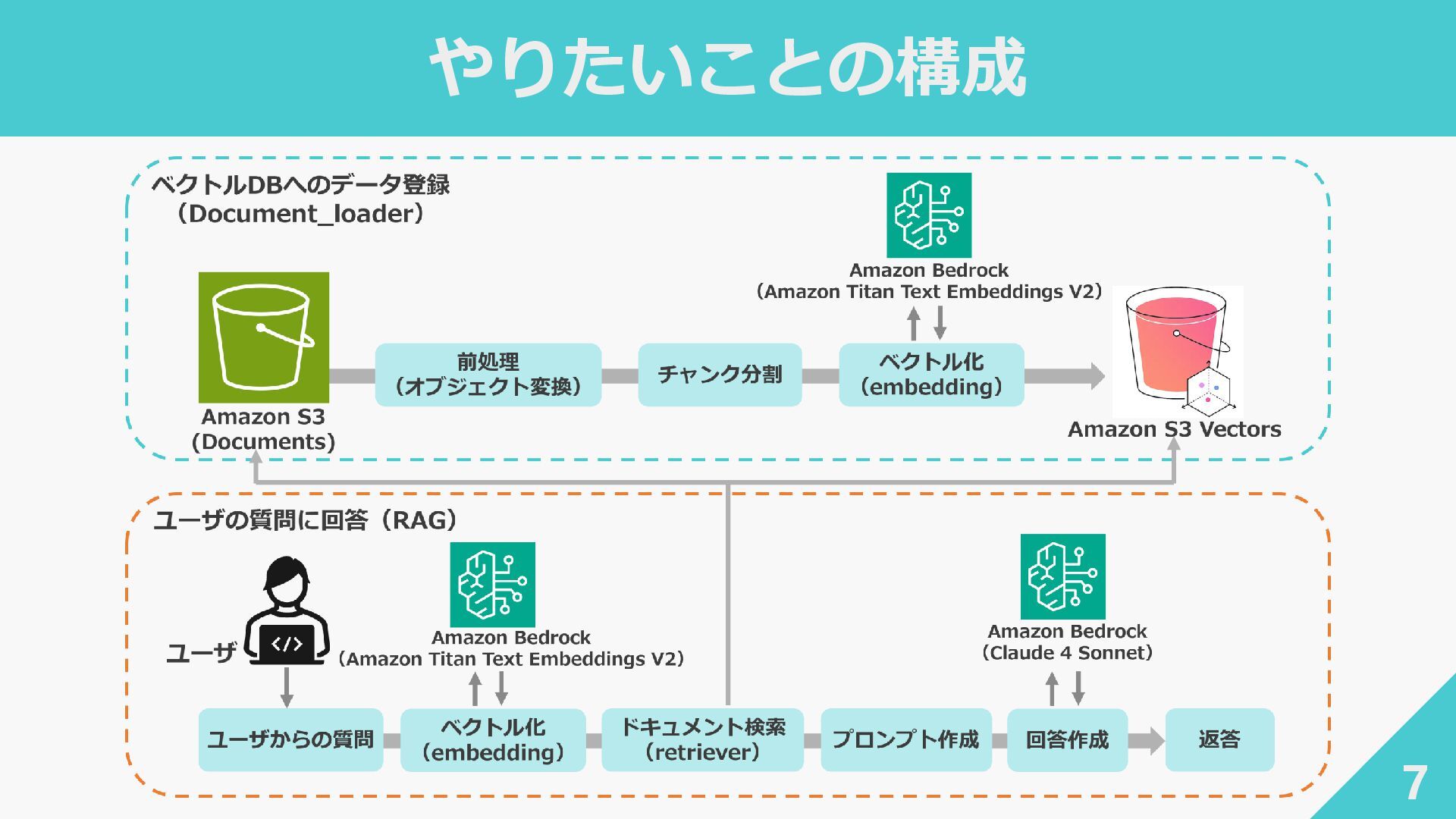
やりたいことの構成 7
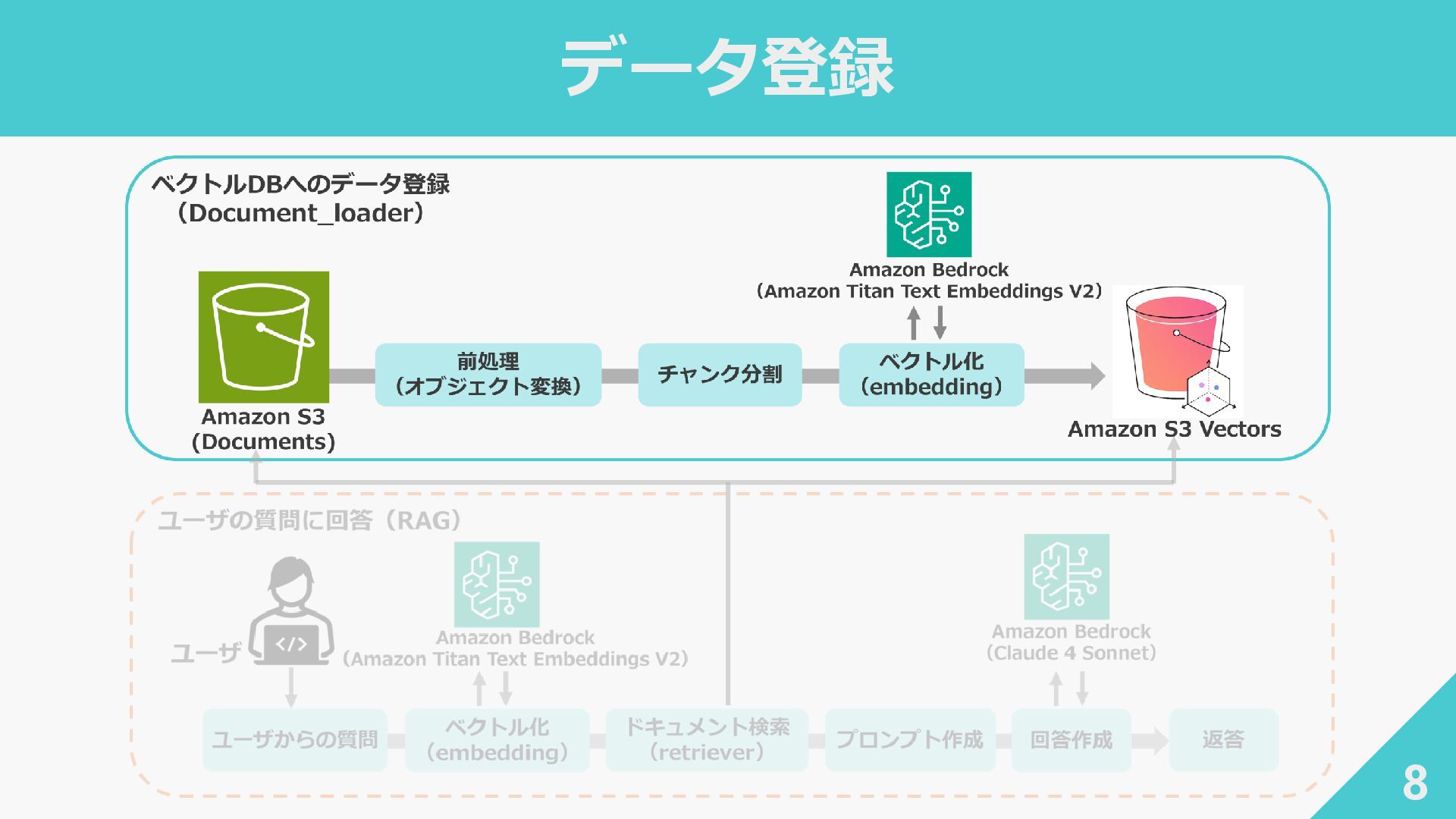
データ登録 8
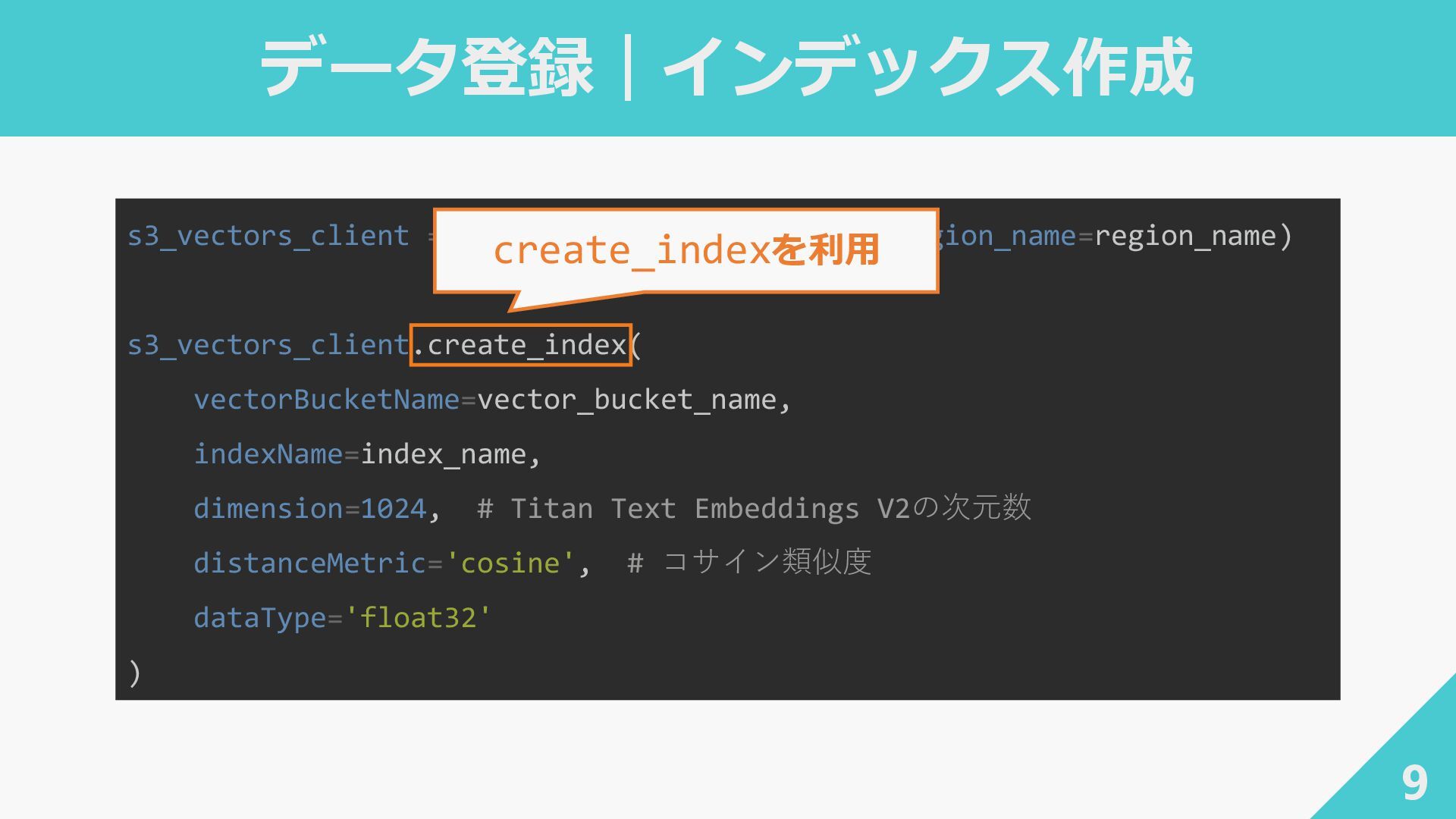
データ登録|インデックス作成 9 s3_vectors_client = boto3.client('s3vectors', region_name=region_name) s3_vectors_client.create_index( vectorBucketName=vector_bucket_name, indexName=index_name, dimension=1024,
# Titan Text Embeddings V2の次元数 distanceMetric='cosine', # コサイン類似度 dataType='float32' ) create_indexを利用
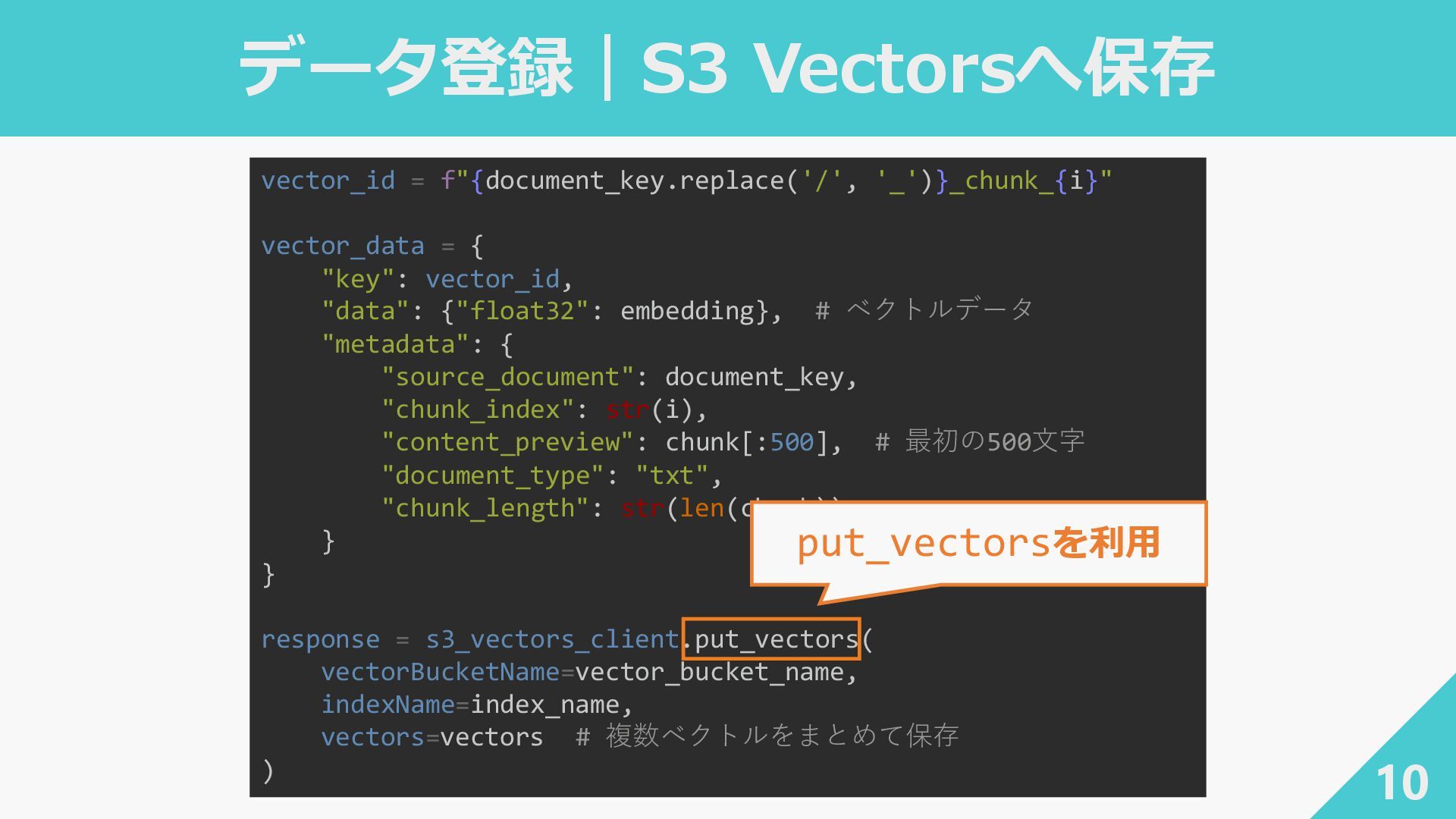
データ登録|S3 Vectorsへ保存 10 vector_id = f"{document_key.replace('/', '_')}_chunk_{i}" vector_data = {
"key": vector_id, "data": {"float32": embedding}, # ベクトルデータ "metadata": { "source_document": document_key, "chunk_index": str(i), "content_preview": chunk[:500], # 最初の500文字 "document_type": "txt", "chunk_length": str(len(chunk)) } } response = s3_vectors_client.put_vectors( vectorBucketName=vector_bucket_name, indexName=index_name, vectors=vectors # 複数ベクトルをまとめて保存 ) put_vectorsを利用
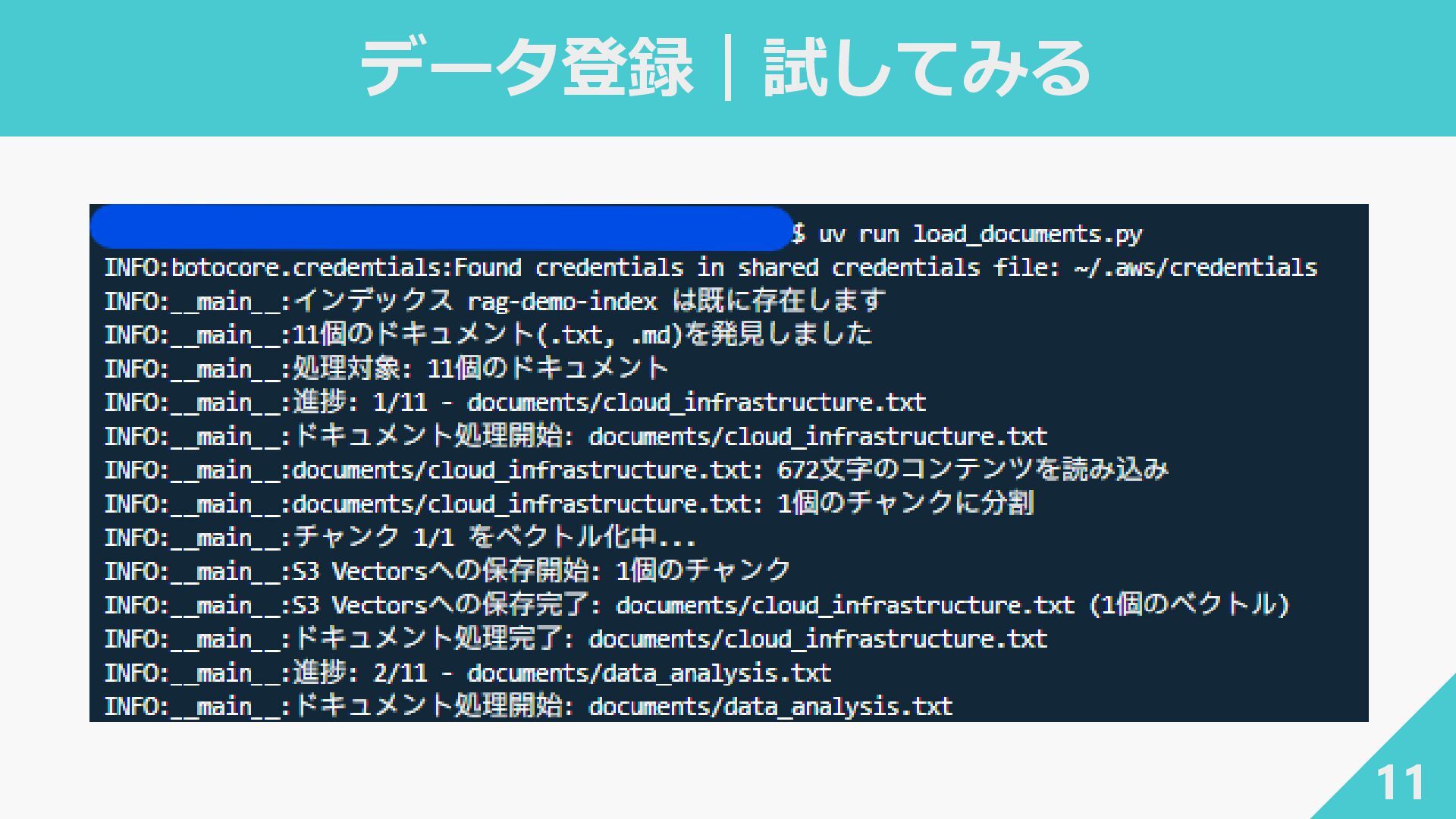
データ登録|試してみる 11
質問回答|ドキュメント検索 12
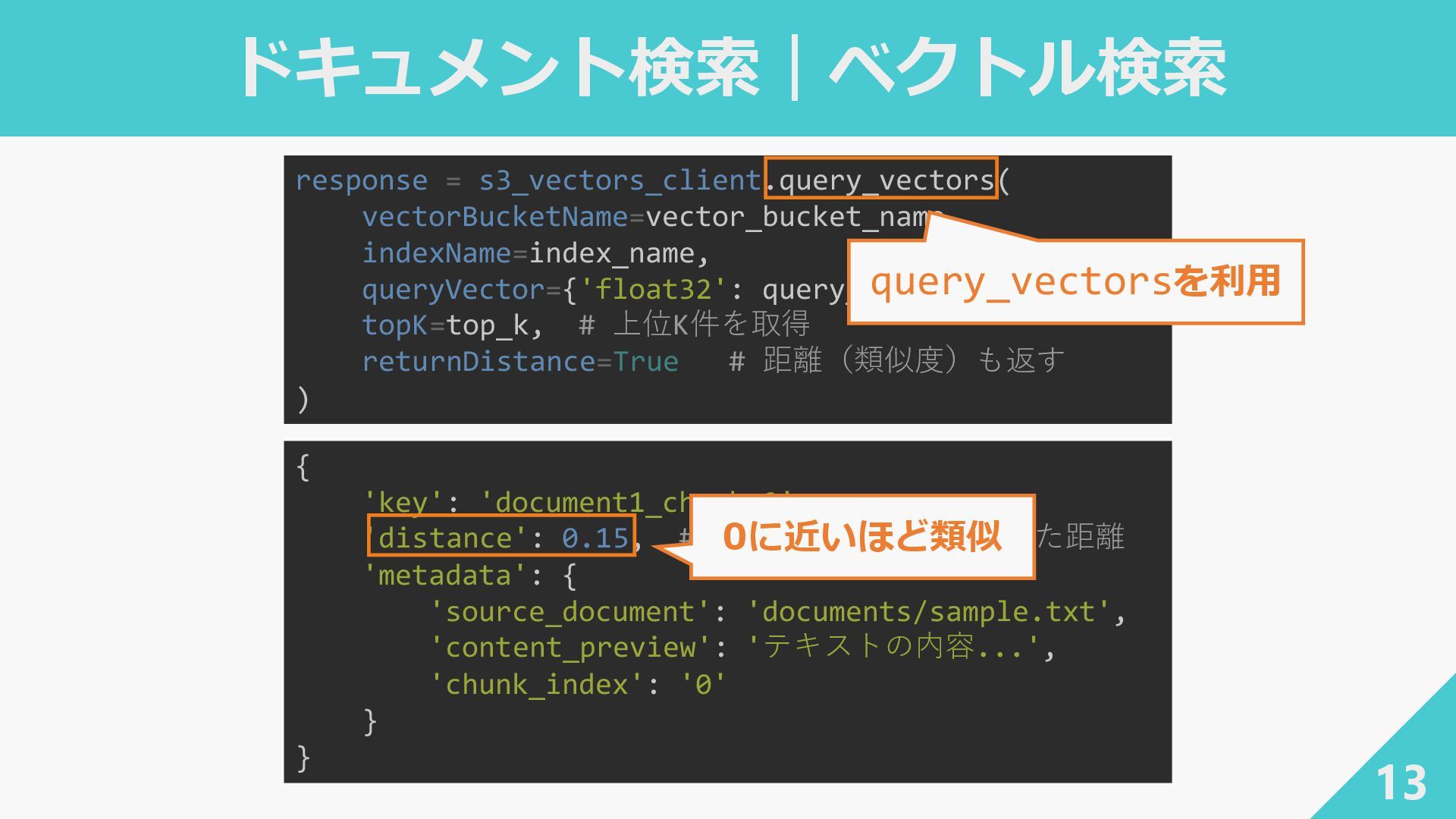
ドキュメント検索|ベクトル検索 13 response = s3_vectors_client.query_vectors( vectorBucketName=vector_bucket_name, indexName=index_name, queryVector={'float32': query_vector}, topK=top_k,
# 上位K件を取得 returnDistance=True # 距離(類似度)も返す ) query_vectorsを利用 { 'key': 'document1_chunk_0', 'distance': 0.15, # ← S3 Vectorsが計算した距離 'metadata': { 'source_document': 'documents/sample.txt', 'content_preview': 'テキストの内容...', 'chunk_index': '0' } } 0に近いほど類似
ドキュメント検索|全文検索 14 ┃BM25 というアルゴリズムを採用 ‐ 単語の重要度・文書長の調整 で検索スコアを計算 𝑡:クエリ中の単語(term) 𝑓(𝑡,𝐷):文書 𝐷
における単語 𝑡 の出現回数(TF) |𝐷|:文書 𝐷 の長さ(単語数) avgdl:コレクション全体の文書長の平均 𝑘1 :TFの効果の強さを調整するパラメータ 𝑏:文書長の補正をするパラメータ 𝐼𝐷𝐹(𝑡):逆文書頻度
ドキュメント検索|全文検索 15 ┃TF(Term Frequency) ‐ 1文書内の単語の出現回数 ‐ 出現回数が多ければその単語は重要である可能性が高い ┃IDF(Inversed Document
Frequency) ‐ 全文書のうち、ある単語が出現する文書数(単語の珍しさ) ‐ 多くの文書に出現する単語は、1つの文書の特徴語に なる可能性は低い
ドキュメント検索|全文検索 16 def calculate_score(query_terms: List[str], doc_index: int) -> float: doc_tokens
= tokenized_docs[doc_index] doc_length = document_lengths[doc_index] term_frequencies = Counter(doc_tokens) score = 0.0 for term in query_terms: tf = term_frequencies.get(term, 0) # 単語の出現回数 idf = calculate_idf(term) numerator = tf * (k1 + 1) denominator = tf + k1 * (1 - b + b * (doc_length / avg_doc_length)) score += idf * (numerator / denominator) scoreを降順にソートし、上位k件を取得
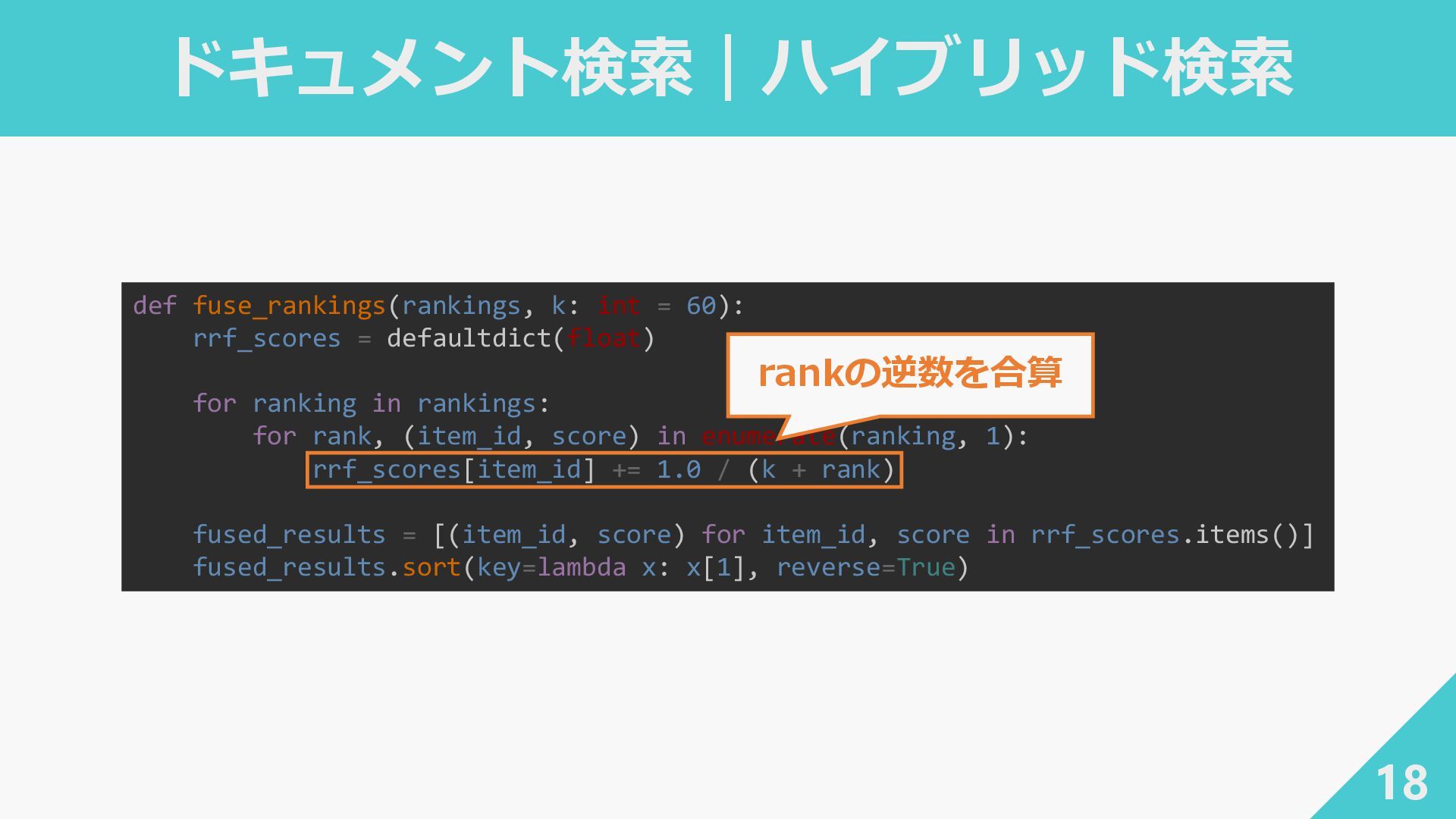
ドキュメント検索|ハイブリッド検索 17 ┃RRF(Reciprocal Rank Fusion) ‐ 複数のランキング結果を統合する方法 𝑑:文書 𝑚:ランキングの本数(例:BM25とベクトル検索なら2) rank
𝑖 (𝑑):文書 𝑑 がランキング 𝑖 で何位に出てきたか 𝑘:上位だけを重視するための調整パラメータ
ドキュメント検索|ハイブリッド検索 18 def fuse_rankings(rankings, k: int = 60): rrf_scores =
defaultdict(float) for ranking in rankings: for rank, (item_id, score) in enumerate(ranking, 1): rrf_scores[item_id] += 1.0 / (k + rank) fused_results = [(item_id, score) for item_id, score in rrf_scores.items()] fused_results.sort(key=lambda x: x[1], reverse=True) rankの逆数を合算
19 実行してみる
質問回答|実行結果 20 文書検索 回答生成
まとめ ┃本日お話ししたこと 21 RAGにおける検索手法について Amazon S3 Vectorsについて ・全文検索 ・ベクトル検索 ・ハイブリッド検索
・概要 ・ハイブリッド検索の実現方法
まとめ ┃本日お話ししたこと 22 RAGにおける検索手法について Amazon S3 Vectorsについて 全文検索:キーワードに着目 ベクトル検索:ベクトル(類似度)に着目 ハイブリッド検索:これらの組み合わせ
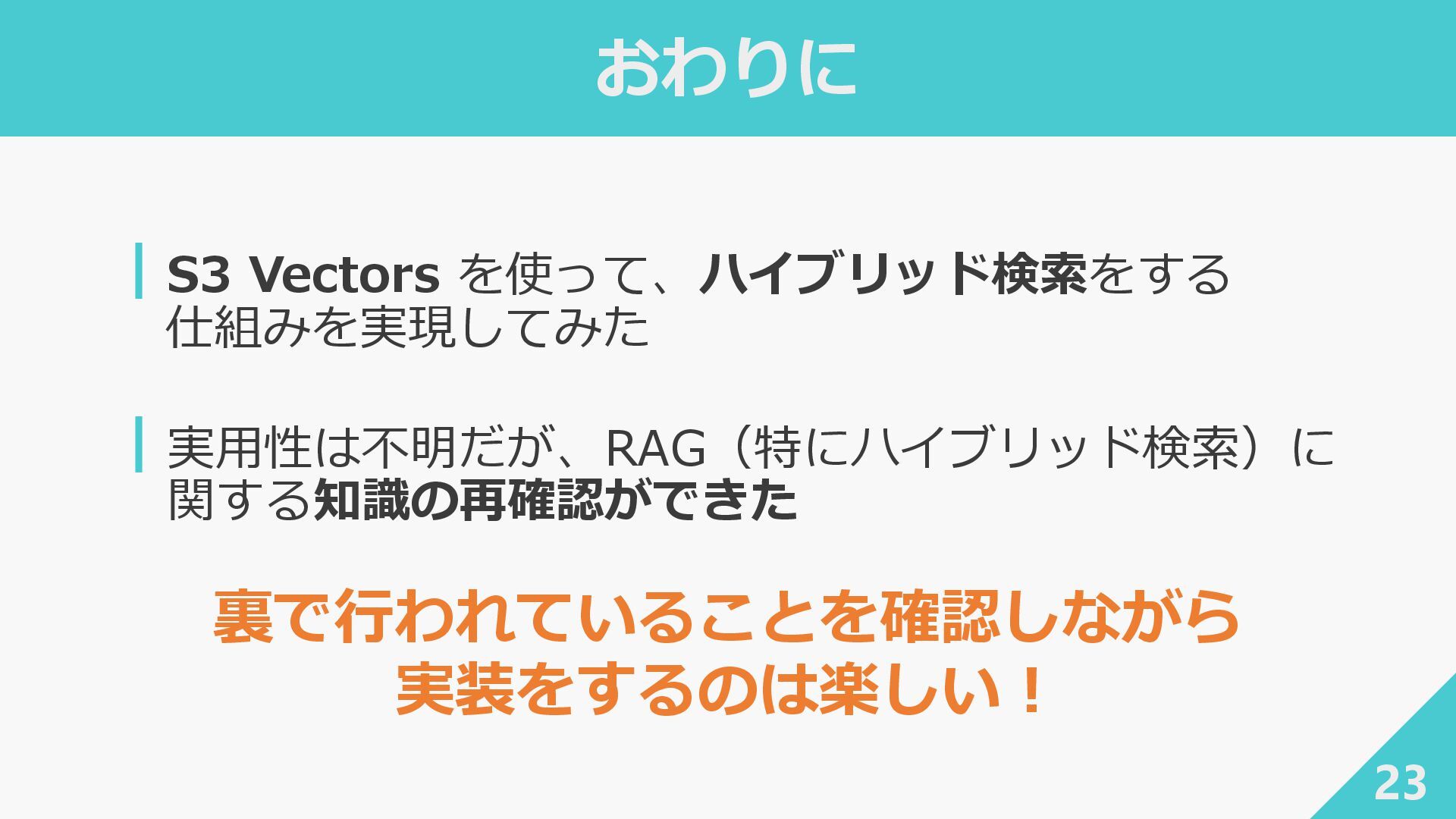
低コストでベクトルデータを扱うことができる RAGをより試しやすくなった
おわりに 23 ┃S3 Vectors を使って、ハイブリッド検索をする 仕組みを実現してみた ┃実用性は不明だが、RAG(特にハイブリッド検索)に 関する知識の再確認ができた 裏で行われていることを確認しながら 実装をするのは楽しい!
参考 24 ┃Amazon S3 Vectors ‐ https://aws.amazon.com/jp/s3/features/vectors/ ┃Amazon S3 Vectors
の紹介:ネイティブベクトルを大規模にサポートする 最初のクラウドストレージ (プレビュー) | Amazon Web Services ブログ ‐ https://aws.amazon.com/jp/blogs/news/introducing-amazon-s3-vectors-first-cloud- storage-with-native-vector-support-at-scale/ ┃S3Vectors - Boto3 1.40.15 documentation ‐ https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3vecto rs.html ┃BM25 ‐ https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/okapi_trec3.pdf ┃RFF ‐ https://dl.acm.org/doi/10.1145/1571941.1572114
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![ドキュメント検索|全文検索 16 def calculate_score(query_terms: List[str], doc_index: int) -> float: doc_tokens](https://files.speakerdeck.com/presentations/18be2cef1cb349649d20a1a39e460278/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}