Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
古典的な時系列解析フレームワークの理論とその実装 / theory-and-implement...
Search
369_ru
November 26, 2022
Science
1.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
古典的な時系列解析フレームワークの理論とその実装 / theory-and-implementation-of-classical-time-series-analysis-frameworks
古典的な時系列解析フレームワークであるBox-jenkins法を、時系列解析の数学的な準備をした後、実装を通して説明します。
369_ru
November 26, 2022
Other Decks in Science
See All in Science
機械学習 - ニューラルネットワーク入門
trycycle
PRO
0
1.1k
SHINOMIYA Nariyoshi
genomethica
0
150
Van Dare naar Durf
voginip
0
230
Utiliser Bitcoin sans Internet
rlifchitz
0
160
Cross-Media Technologies, Information Science and Human-Information Interaction
signer
PRO
3
32k
CVPR2026_VGGTとその仲間たち
mickey_0226
0
830
Non-Gaussian, nonlinear causal discovery with hidden variables and application
sshimizu2006
0
140
Bear-safety-running
akirun_run
0
160
SpatialRDDパッケージによる空間回帰不連続デザイン
saltcooky12
0
250
フィードフォワードニューラルネットワークを用いた記号入出力制御系に対する制御器設計 / Controller Design for Augmented Systems with Symbolic Inputs and Outputs Using Feedforward Neural Network
konakalab
0
140
見上公一.pdf
genomethica
0
150
データベース03: 関係データモデル
trycycle
PRO
1
550
Featured
See All Featured
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
200
Being A Developer After 40
akosma
91
590k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Code Review Best Practice
trishagee
74
20k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Deep Space Network (abreviated)
tonyrice
0
170
Facilitating Awesome Meetings
lara
57
7k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.8k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.5k
Highjacked: Video Game Concept Design
rkendrick25
PRO
1
390
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Transcript
古典的な時系列解析 フレームワークの 理論 とその実装 369_ru(さぶろく)
時系列解析とは何か 時系列解析とは、時系列データを取り扱う際に用いられる分析(手法) のことです。 時系列データは時系列データではないデータ(トランザクションデータ) とは異なり、従来の統計的な手法で分析することはできません。 従って、時系列データを扱う際は、トランザクションデータと区別して分 析する必要があります。
時系列解析におけるフレームワークについて 時系列解析のフレームワークには、 Box-Jenkins法と状態空間モデルがあります。 Box-Jenkins法は古典的な手法ではあるのですが、 分析をするための手順・規則が整備されているので、自動化しやすいと といった利点があります。 状態空間モデルは、非常に表現の幅が広く、人間の直感をそのままモデ ル化できるといった利点があります。 今回は、タイトルの通り、古典的なフレームワークであるBox-Jenkins法 の理論と実装について話します。
分析
理論に入る前の準備 「それでは、Box-Jenkins法について紹介していきましょ う!」と言いたいところなのですが、理論をある程度理 解するための準備をします。 具体的には、 ・定常性 ・MAモデル, ARモデル, ARMAモデルやそれに準ずるモデル ・単位根過程,
和分過程 について話します。
定常性 ・定義:(弱)定常性 時系列データがこのような性質を持つと平均と自己共分散が 時間(t)に依存しないので、複数時点のデータを取ってきて、そのデータ の平均や自己共分散を求めれば、特定時点での平均や特定時点間の 自己共分散を求めることができるようになります。
MAモデル ・定義:MA(q)モデル このようなモデル式を持つモデルをMA(q)モデルと言い、y_tはq 時点前までの誤差項で説明された式になっています。ここで、 誤差項ε_tは定常性を持つので、MA(q)モデルは定常性をもった モデルになります。
ARモデル ・定義:AR(p)モデル このようなモデル式を持つモデルをAR(p)モデルと言います。 p時点前までのデータで説明された式になっていて、ARモデル はMAモデルとは異なり定常であるとは限りません。 そこで、ARモデルが定常性を持つ条件を次のページで紹介します。
ARモデルの定常条件 AR(p)モデルが定常性を持つ条件は、次のAR特性方程式のzに関する すべての解の絶対値が1より大きくなることです。 ・AR特性方程式 例えば、AR(1)モデルだと解の絶対値が1より大きくなる時、係数の 絶対値は1より小さくなるので、係数の絶対値が1より小さくなる とき、定常であると言えるでしょう。
ARMAモデル ・定義:ARMA(p, q)モデル このようなモデル式を持つモデルをARMA(p, q)モデルと言います。 これは、AR(p)モデルとMA(q)モデルを組み合わせたモデルになってい ます。 ARMA(p, q)が定常性を持つかどうかは、AR(p)の項について定常条件を 満たすかどうか確かめれば良いです。
単位根過程 ・定義: 単位根過程 単位根過程をそのまま分析することもできるのですが、この資料内に おいては、単位根過程の差分を取って定常過程に直してから、時系 列モデルを当てはめます。
和分過程 ・定義:和分過程 I(d)過程にARMA(p, q)モデルを当てはめる時、そのようなモデル をARIMA(p,d,q)モデルと言います。 また、このような過程を単位根を持つ過程と呼ぶこともあります。
季節性ARIMAモデル(SARIMAモデル) 時系列データには気温など、季節に依存するデータもあります。 例えば、「先月は寒かったから、今月もある程度寒くなるだろう。」や 「去年の〇月は暑かったから、今年の〇月も暑いだろう。」など、先 月と今月や、去年と今年などで相関関係をモデル化することができます。 このように、ARIMAモデルに季節成分を取り入れたモデルをSARIMAモデルと 言います。 一周期がsであるデータにおいて、ARIMAの次数(p, d, q)と、
季節性の次数(P, D, Q)を合わせてSARIMA(p, d, q)(P, D, Q)[s]と表記します。
単位根検定 時系列データが定常である方が分析がしやすいです。 データが定常であるということは、データが単位根を持たないとも捉え られます。 そこで、帰無仮説、対立仮説を単位根を持つ・持たないとした検定を 考えます。 この検定において、単位根過程を持つという仮説が採択されなけれ ば、データは定常であるということになります。 このような検定を単位根検定と言います。 今回はADF検定といった単位根検定について説明します。
ADF検定 ADF検定は拡張DF検定と呼ばれることもあります。 DF検定はAR(1)モデルに対して、単位根を持つかどうか判断するための検定です。 これをAR(p)モデルに拡張したモデルがADF検定になります。今回は簡単に DF検定を説明しま す。 この検定において、帰無仮説が棄却されたとき、単位根を持つと言えるわけです。 棄却域を求めるためには更に準備が必要なので、今回は省略します。
Box-Jenkins法の流れ 1.データを分析しやすい形に変換 2.データにARIMAモデルやそれに準ずるモデルの適用 3.推定されたモデルを評価 4.推定されたモデルを用いて予測 このようなステップを踏むことで、信用できる時系列モデルを作ることが できます。 これらを実装を通して見ていきましょう。
例:イギリスの交通事故死傷者数のモデル化 使用するデータは、馬場(2018)で使用しているイギリスの交通事故負傷者数の データSeatbeltsを使用します。 変数は ・front: 前席における死傷者数 ・PetrolPrice: ガソリンの値段 ・law: 前席においてシートベルトを装着することを
です。 また、実行環境は R:version 4.2.1 RStudio: Version 2022.07.1+554 です。
1.データを分析しやすい形に変換 データの差分をとって定常にしましょう。まず、データが定常かどうか を確かめるために、単位根検定を行います。 ADF検定を行うためのコードと結果の一部は以下です。 有意水準が1,5,10%のいずれでも単位根を持つという帰無仮説は棄 却されないことがわかります。
差分を取る回数 データが単位根を持つということはわかりましたが、何回差分を取れば 定常になるかどうかはわかりません。 そこで以下のコードを書けば、差分を取る回数がわかります。 定常にするために必要な差分を取る回数は1回なので、このデータ は単位根過程であることがわかります。
また、データの対数をとると、分析をする際にうまくいくことがありま す。 データの対数を取るコードは以下です。 そして、このデータに対して差分を取りましょう。対数を取ったデータに 対して差分を取るコードは以下です。 対数変換
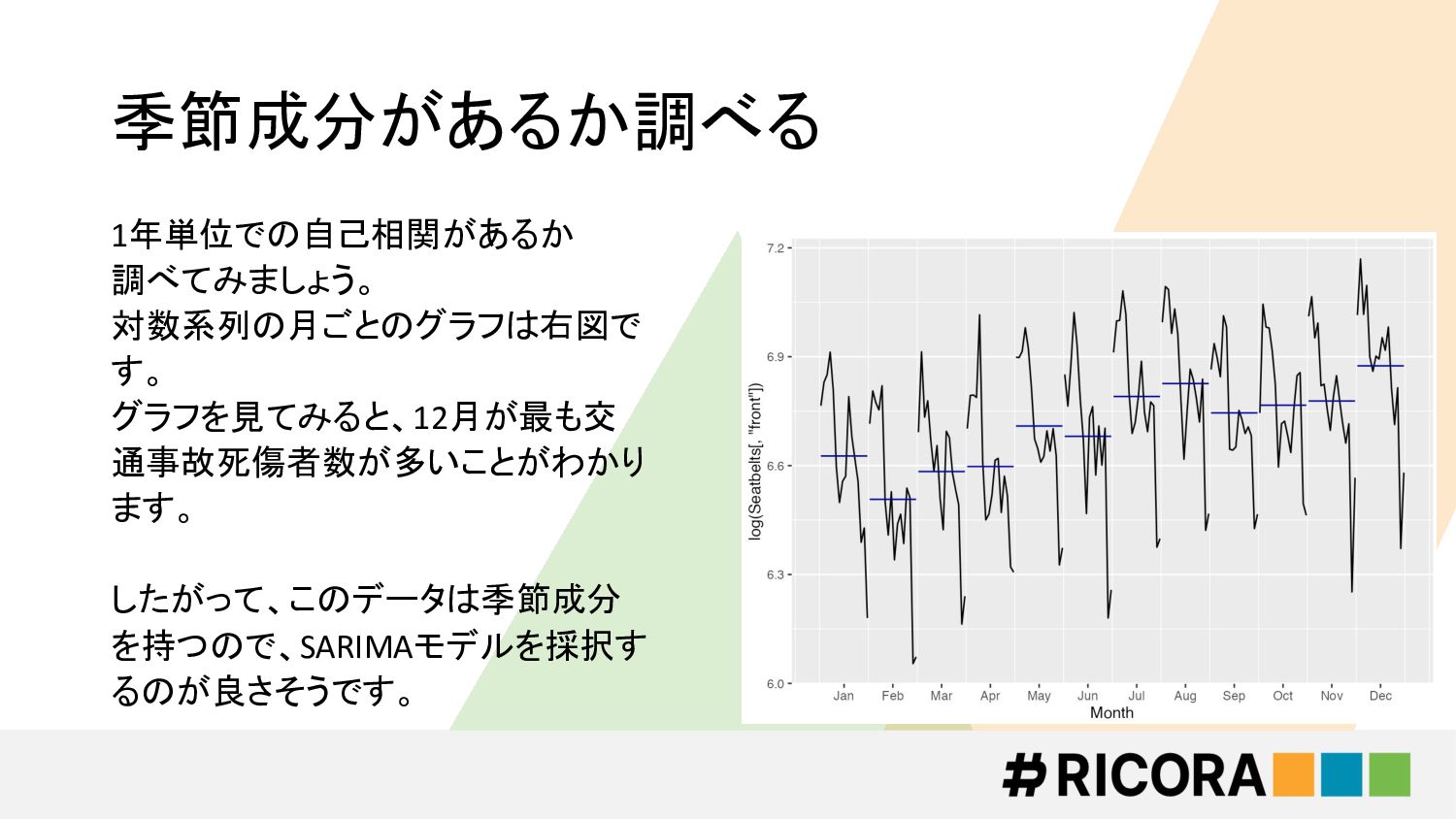
季節成分があるか調べる 1年単位での自己相関があるか 調べてみましょう。 対数系列の月ごとのグラフは右図で す。 グラフを見てみると、12月が最も交 通事故死傷者数が多いことがわかり ます。 したがって、このデータは季節成分 を持つので、SARIMAモデルを採択す
るのが良さそうです。
訓練データとテストデータに分ける 予測性能の評価のためにデータを訓練データとテストデータに分割します。 分割するコードは以下です。 Seatbelts_logはSeatbeltsの”front”と”PetrolPrice”を対数変換したデータになっ ています。 また、予測性能の評価のために説明変数だけ切り出しておきます。
2.データにARMAモデルやそれに準ずるモデルの 適用 先ほどまでのデータ変換において、季節成分を含めたモデルになる ので、データにはSARIMAモデルを当てはめることになります。 その際、SARIMA(p, d, q)(P, D, Q)の次数を決める必要がありますが、 データに適した次数を持つモデルを選びたいです。
その際、モデルを選ぶための規準を情報量規準と言い、モデルを選 ぶための操作をモデル選択と言います。
モデル選択 今回、モデル選択のために使う情 報量規準はAICです。 モデルの次数をひたすら変え て、その度にAICを計算してモ デルを比較するわけですが、 それは面倒です。 そこで、Rのforecastパッケージの auto.arima関数を使いましょう。 コードは右のようになります。
今回はSARIMA(2, 1, 3)(2, 0, 0)[12]が 選ばれました。
3.推定されたモデルの評価 作ったモデルの評価をしましょう。 その際に確認することは、 ・モデルが定常条件を満たすか ・残差は自己相関がないかどうか ・残差が正規分布に従うかどうか の3つになります。
定常性のチェック auto.arima関数を使う際に、定常性のチェックはできているのですが、 一応選ばれたモデルが定常性を持つかどうかAR特性方程式を解くこ とで確かめましょう。 コードは以下のようになり、解の絶対値がすべて1より大きいので定常 性を持つことがわかります。
残差の自己相関のチェック 残差に自己相関がある場合は、 まだ自己相関構造を作れる余地が あるということなので、正しく モデルが作れていません。 そこで、残差に自己相関があるか どうかを確かめる検定である Ljung-Boxの検定を行います。 コードと結果は右のように なります。
Ljung-Box検定の帰無仮説は「自己相関を持た ない」なので、p-value > 0.05より有意な自己相 関はみられないという結果が得られます。
残差の正規性チェック 残差が正規分布に従っている仮定でモデルを組んでいたので、当てはめ残 差が正規分布に従うことも確認します。 正規性の検定として、Jarque-Bera検定を行います。 この検定において、帰無仮説は「正規分布に従う」です。 コードと結果は以下になっていて、これも有意に正規性を持たないとは言えな いことがわかります。
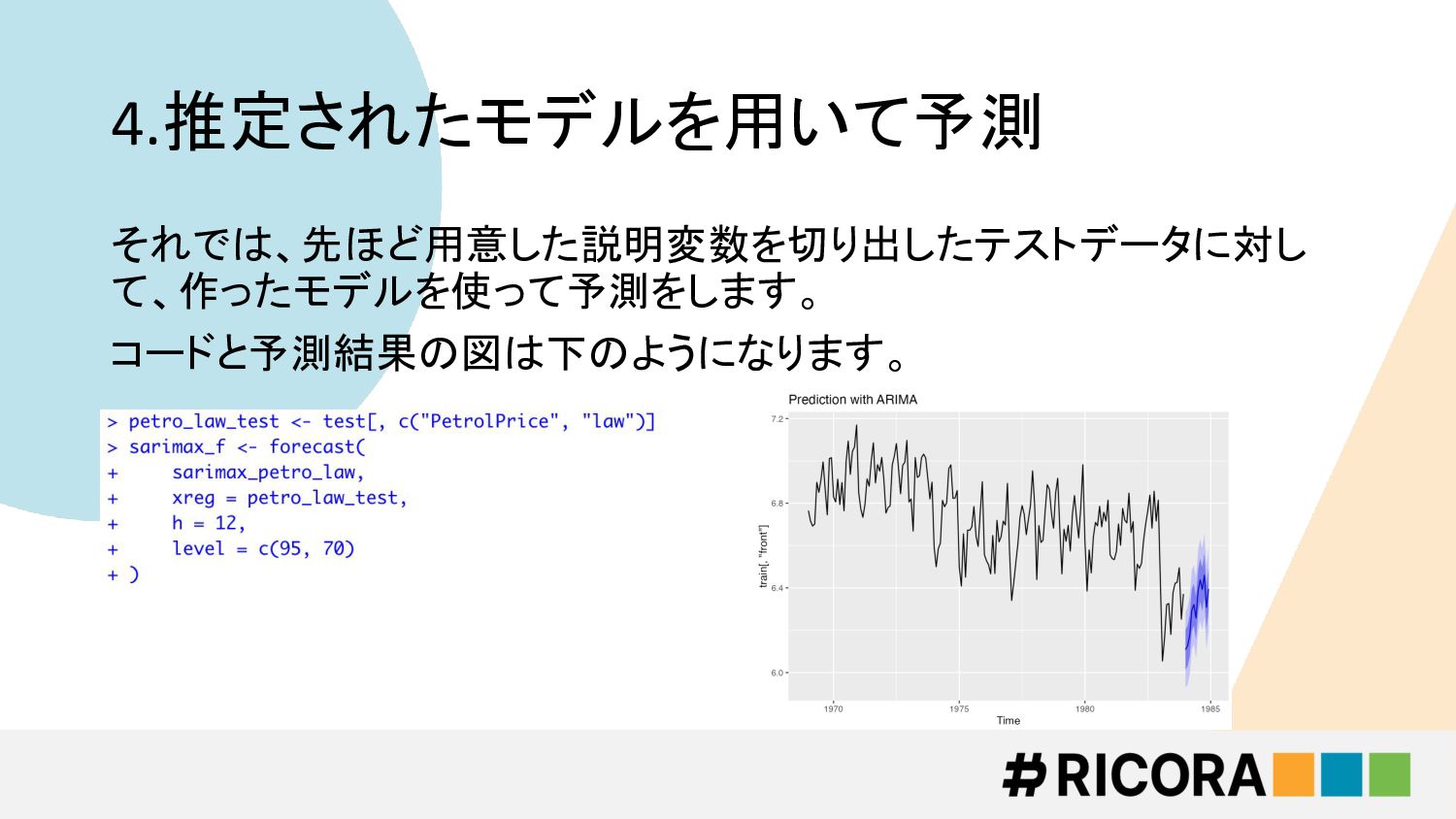
4.推定されたモデルを用いて予測 それでは、先ほど用意した説明変数を切り出したテストデータに対し て、作ったモデルを使って予測をします。 コードと予測結果の図は下のようになります。
ナイーブ予測との比較 最後にナイーブ予測と同定されたモデルのRMSEを用いた精度の比較を行います。 ナイーブ予測とは、「複雑な技術を使わずに出すことができる予測」です。 例えば、 ・過去の平均値を予測値として出す ・前時点の値を予測値として出す 作ったモデルがこのナイーブ予測よりも精度が上回ることを確認します。 もし、下回る、または同等であった場合、モデルを作る意味がなかったということになり ます。このようなことはしばしば起こるので予測精度を出す際に必ず比較しましょう。
RMSE ・定義:RMSE(Root Mean Square Error) RMSEが小さいほど、予測精度が高いモデルと言えます。 この指標を使って予測精度の比較を行いましょう。
予測精度の比較 forecastパッケージのaccuracy関数を使うことでRMSEなどを自動で計 算してくれます。 作ったモデルとナイーブ予測との比較は以下で、ナイーブ予測より優 れていることが確認できます。
最後に ナイーブ予測との比較まで行って、時系列解析におけるモデルの作成は終了で す。 データを定常にするために、差分を取っていますが、取りすぎるとデータの重要な 部分が抜け落ちしてしまうので、取りすぎには注意が必要です。 今回のスライドでは、一部の数理的な説明や省略した作業もあります。 詳しく知りたい方やこの分野に興味を持った方は、参考文献に載せた書籍を参照 してください。
参考文献 ・馬場真哉(2018)『時系列分析と状態空間モデルの基礎 RとStanで 学ぶ理論と実装』プレアデス出版 ・沖本竜義(2010)『経済・ファイナンスデータの計量時系列分析』朝倉 書店 ・Hamilton, J.(1994)『Time Series Analysis』Princeton
University Press.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}