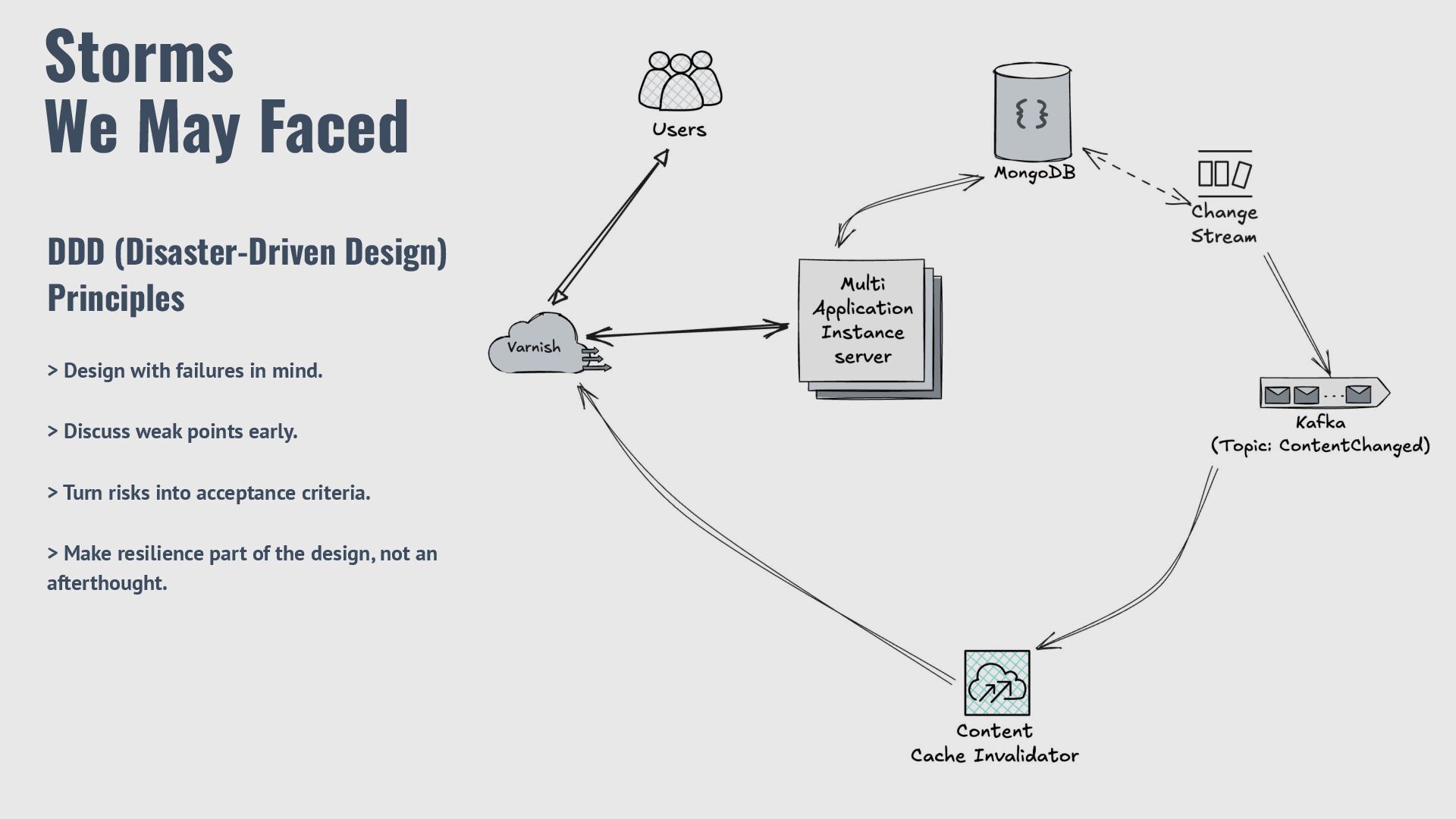
Are Modern Applications So Fragile? > Resilience ≠ Just Keeping Things Running > Why Is It Often Overlooked? > Storms We May Face > Being Prepared for the Storm > Planned Flexibility + Learning from Mistakes
a small update created a very large impact. A policy control module had not been fully tested before the rollout, because it only failed under very specific conditions. Once triggered, it caused Google’s global infrastructure to return many ‘503’ errors. Thousands of users, business processes, and applications were affected, including production systems.
on their own. Databases, message queues, third-party APIs… They are all part of a chain. But a chain is only as strong as its weakest link. And when that link breaks, the whole system breaks.
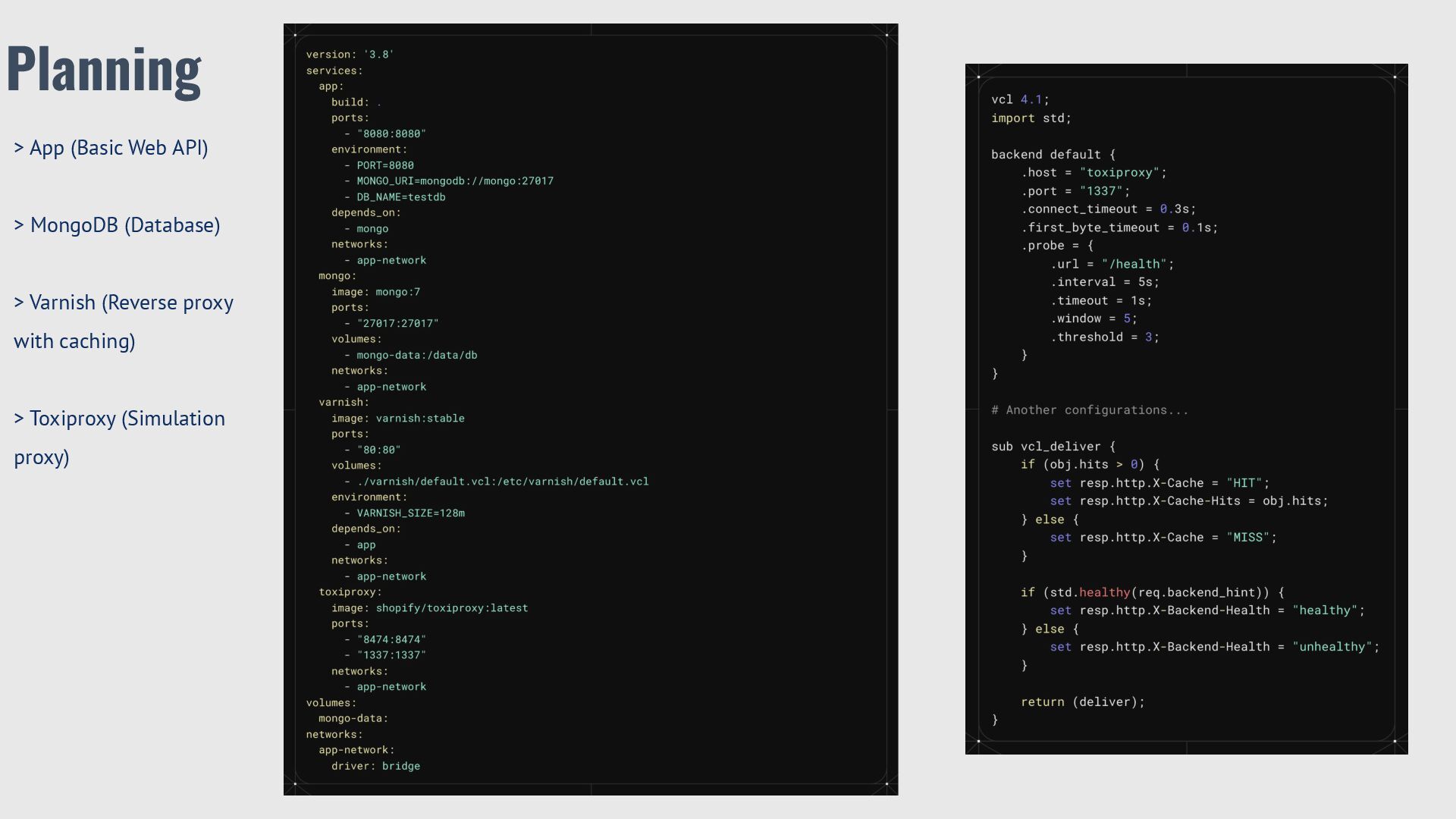
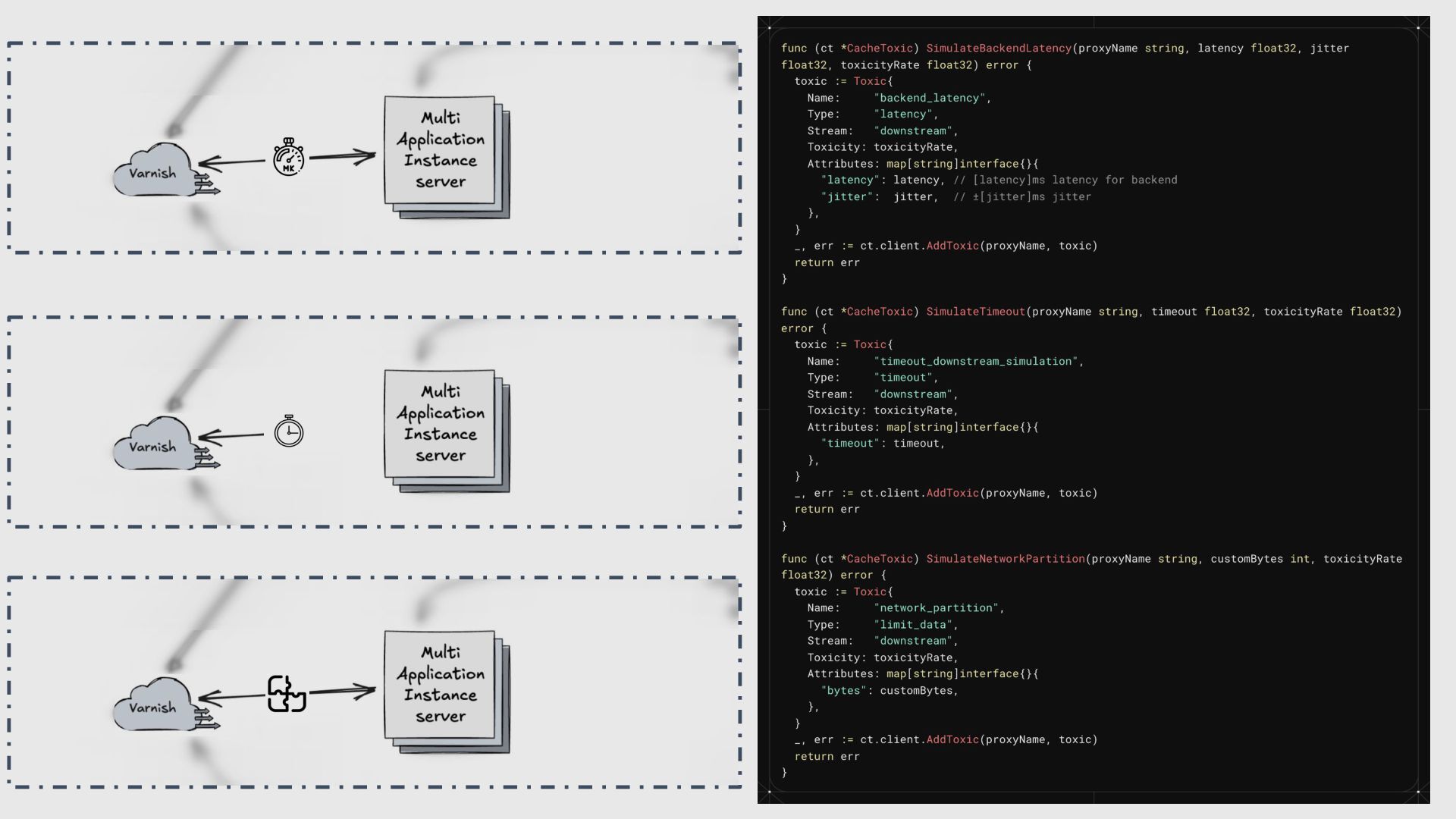
Stability Every part of a system can fail. Don’t believe that databases, APIs, or queues will always work. Inject Chaos in a Controlled Way Create test situations like network delays, database timeouts, or API errors before going to production. Observe, Measure, and Learn Watch how the system reacts, collect data, and use it to improve resilience. Automate Recovery and Build for Self-Healing Use tools like failover, retries with backoff, and circuit breakers to recover automatically. Balance Experiments with User Impact Run chaos tests in safe environments so users are not harmed by experiments.
triangle of quality, time, and cost, time usually becomes the main priority. Invisible Dependencies These dependencies run in the background, so the risk is often overlooked. Testing Gap Between Staging and Production Most resilience tests are done in staging, and the “real-world chaos” in production is missed. Short-Term Thinking The “quick fix” approach often leads to bigger problems in the future. Comfort of Ready-to-Use Frameworks We often believe the framework solves everything without simulating real scenarios.
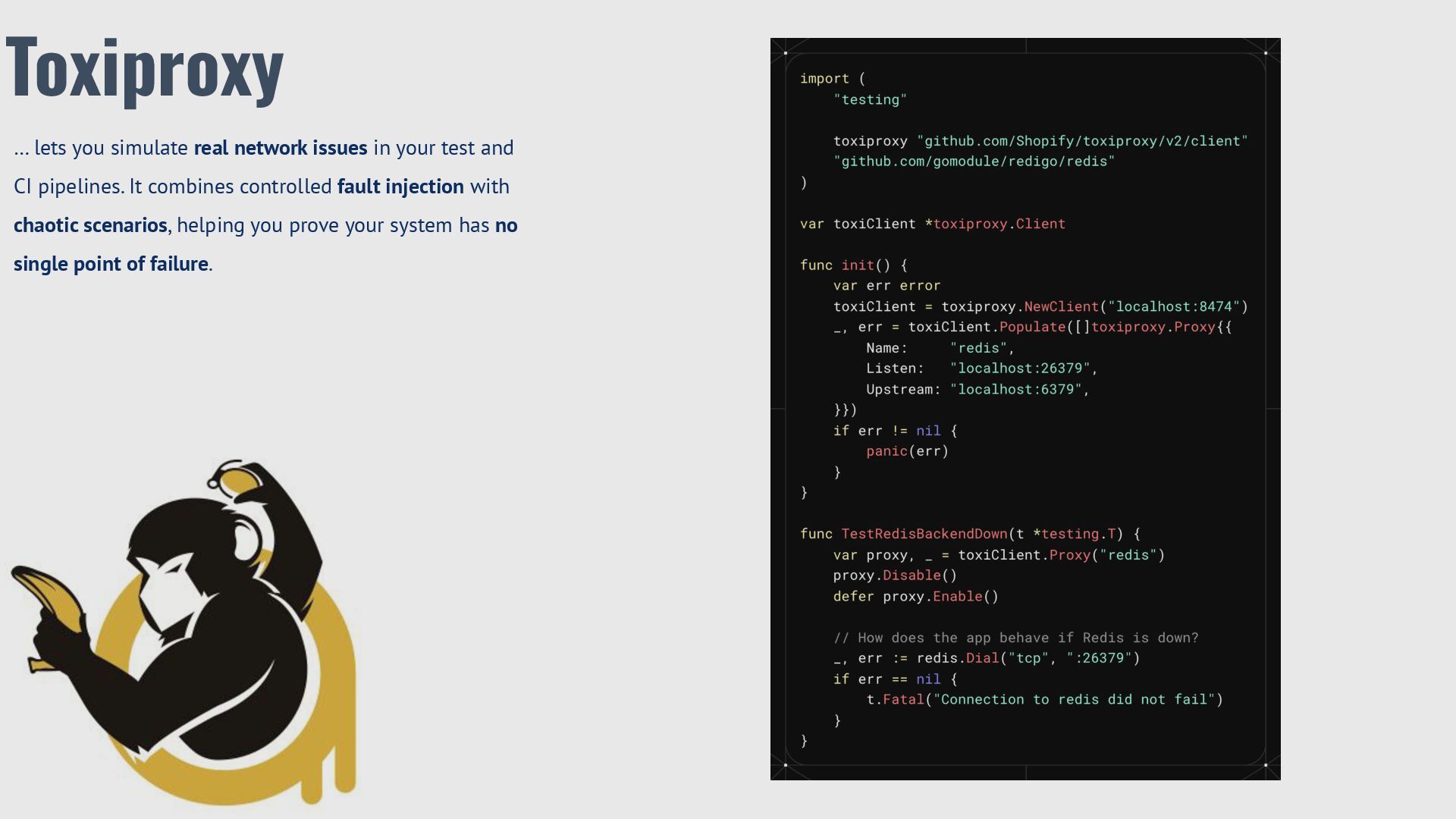
and CI pipelines. It combines controlled fault injection with chaotic scenarios, helping you prove your system has no single point of failure. Toxiproxy
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
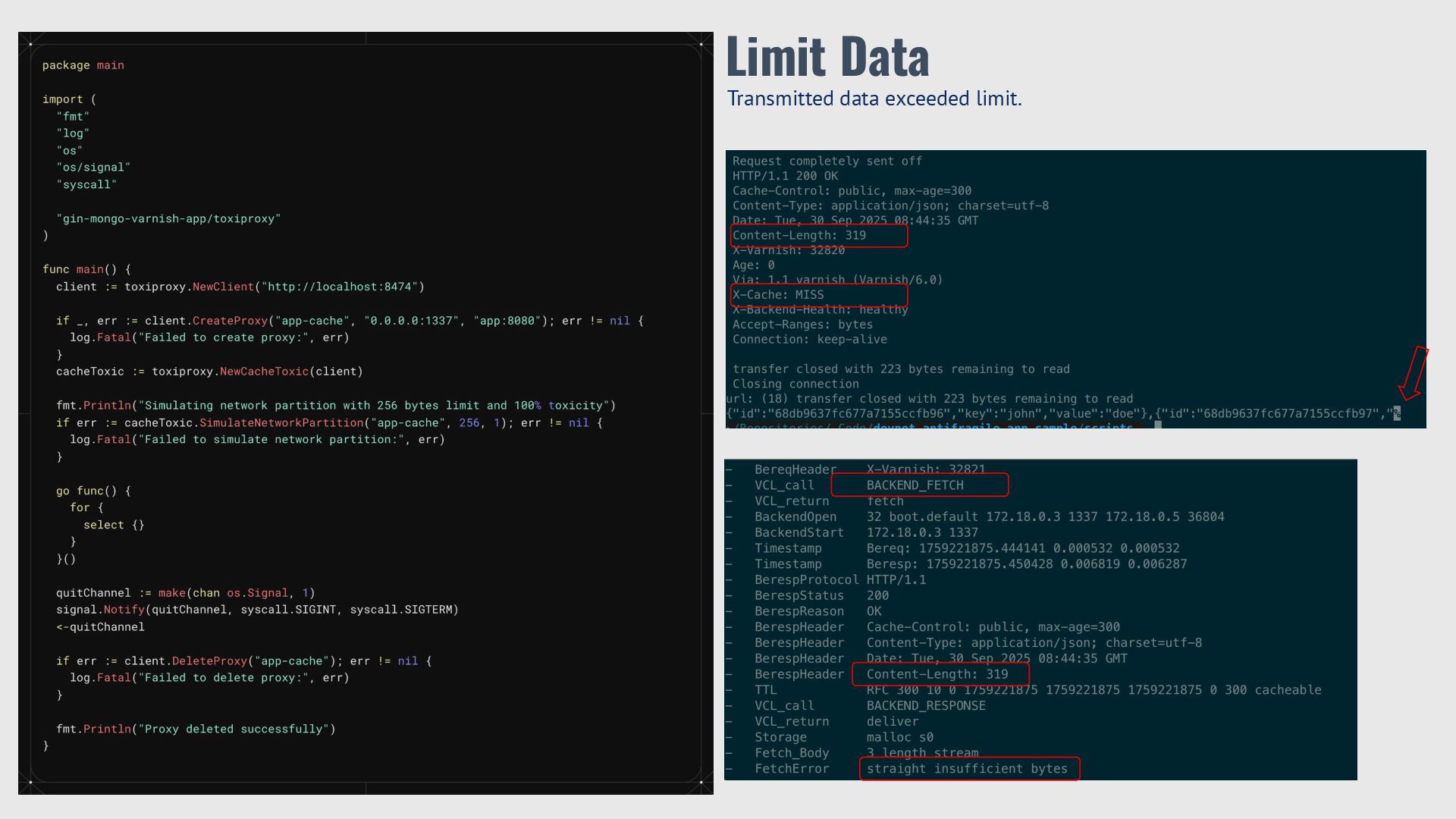{kind=link}
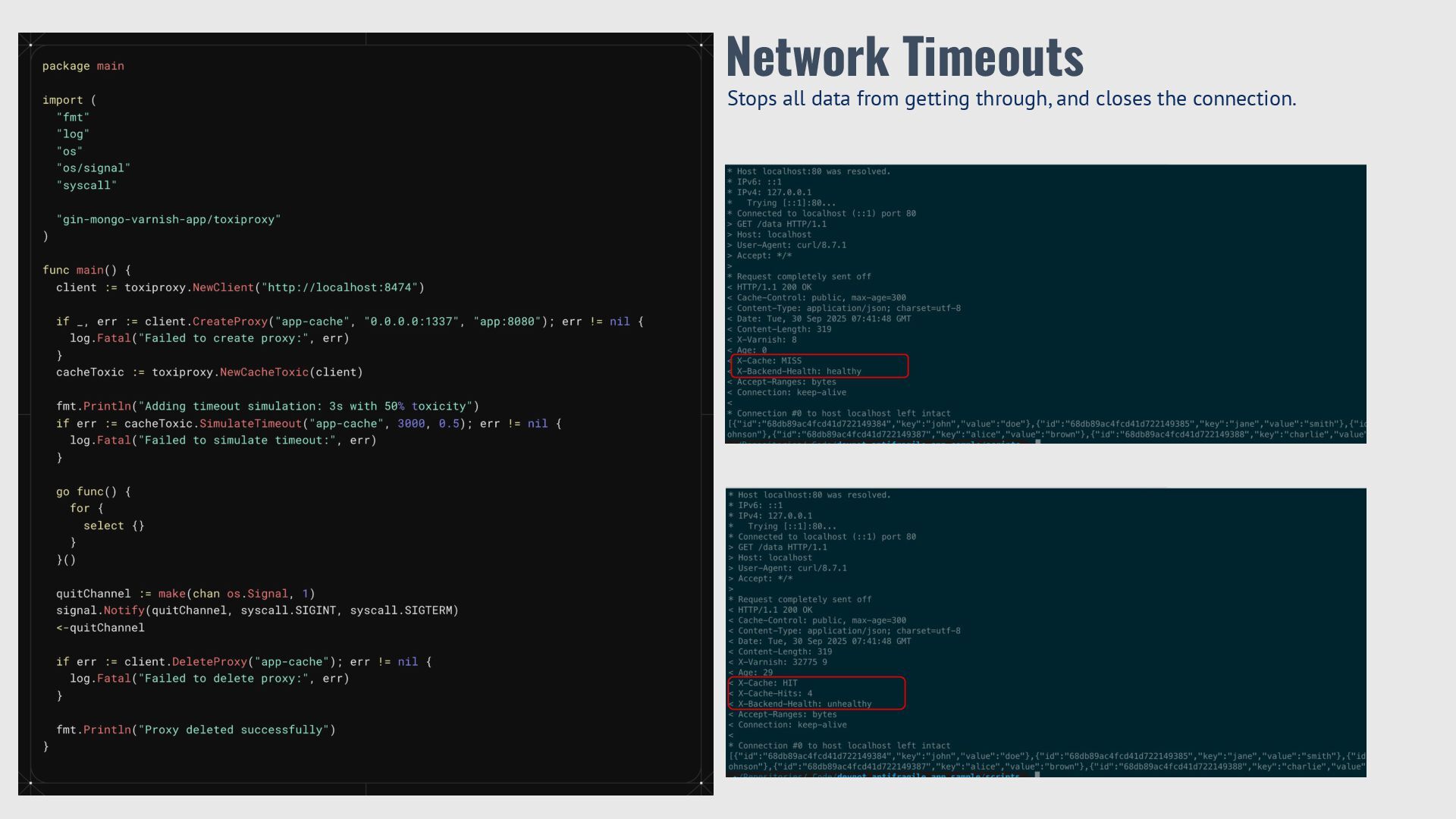{kind=link}
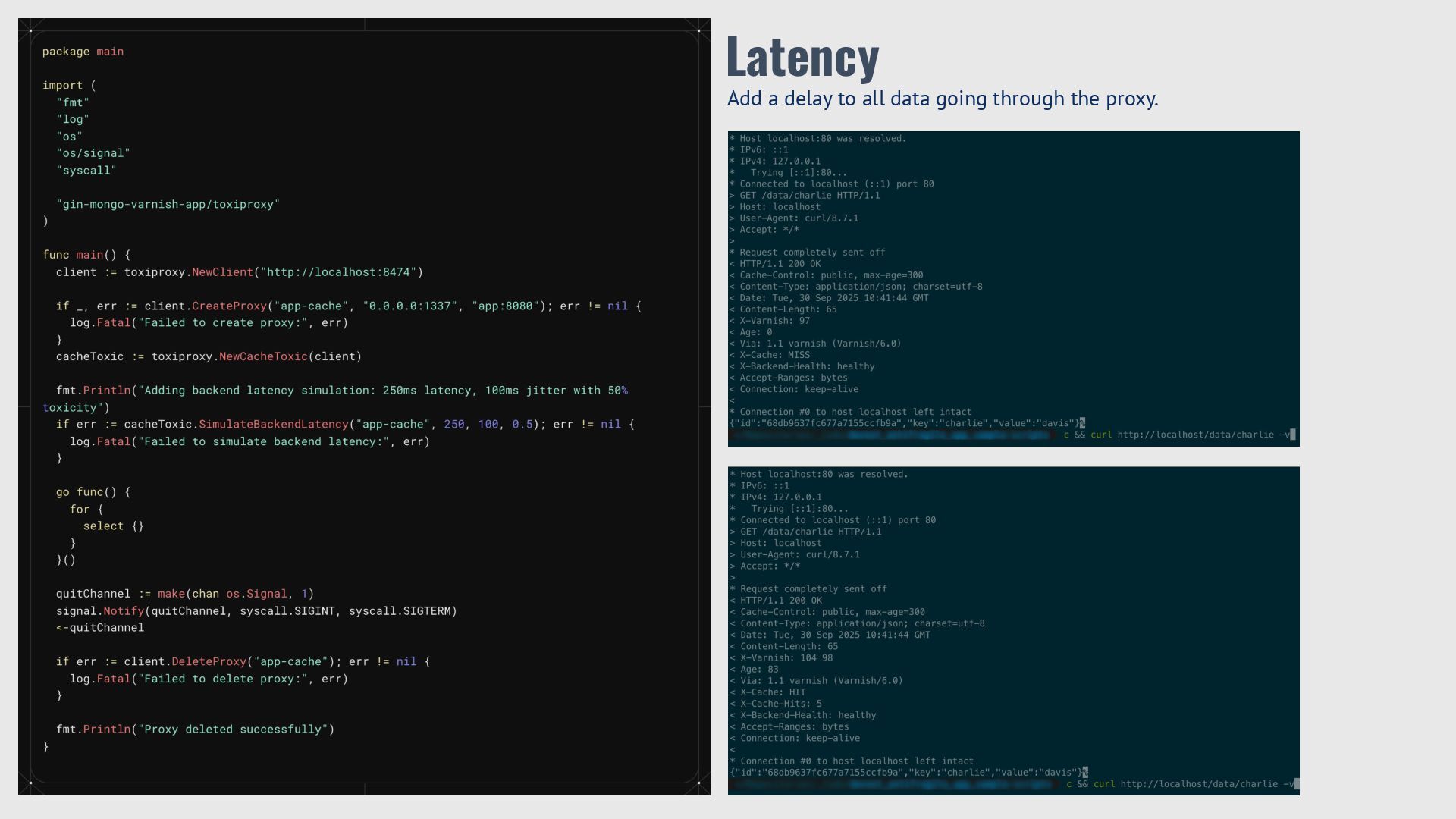{kind=link}
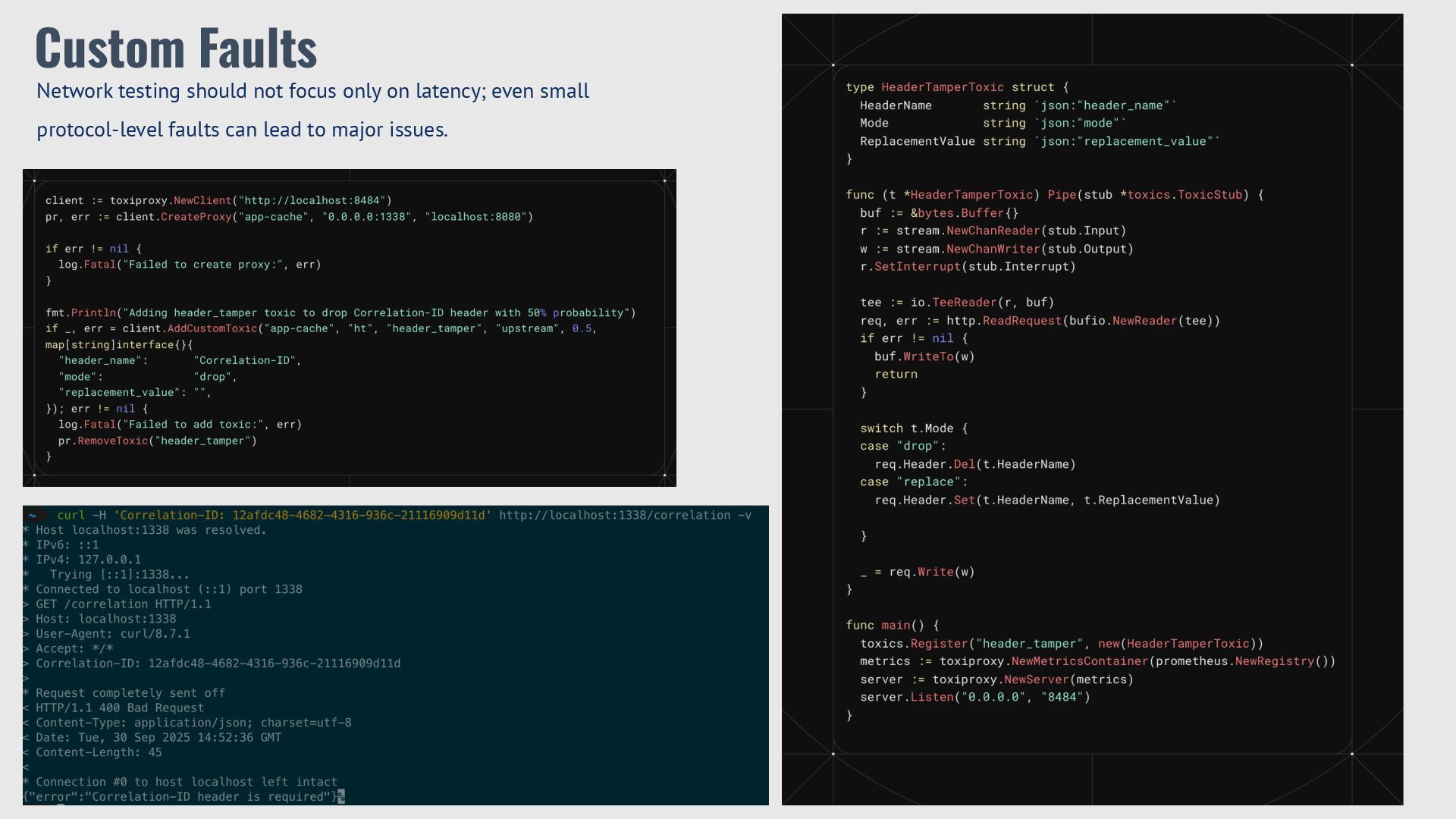{kind=link}
{kind=link}