1 Developer Advocate with the UrbanCode Development Team. Focus on architecture, scalability, and performance in a client facing capacity to help design, plan, scale, and implement UrbanCode Deploy and Release.
clients to more rapidly deliver mobile, cloud, big data and traditional applications with high quality and low risk IBM UrbanCode Deploy automates the deployment of applications, databases and configurations into development, test and production environments, helping to drive down cost, speed time to market with reduced risk. IBM UrbanCode Release is an intelligent collaboration release management solution that replaces error-prone manual spreadsheets and streamlines release activities for application and infrastructure changes. https://www.ibmdw.net/urbancode/ Drive down cost Remove manual effort and wasted resource time with push button deployment processes Speed time to market Simple, graphical process designer, with built-in actions to quickly create deployment automation Reduce risk Robust configuration management, coordinated release processes, audits, and traceability
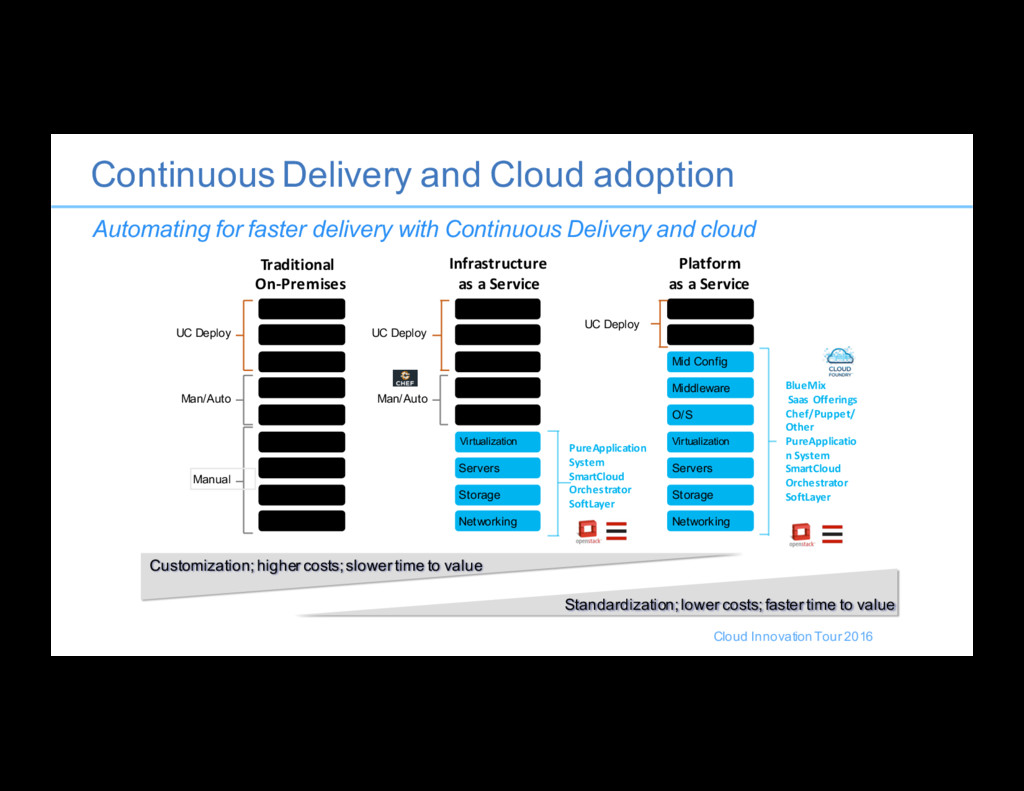
for faster delivery with Continuous Delivery and cloud Networking Networking Storage Storage Servers Servers Virtualisation Virtualization O/S O/S Middleware Middleware Mid Config Mid Config Data Data Applications Applications Traditional On-Premises Infrastructure as a Service Manual Customization; higher costs; slower time to value Standardization; lower costs; faster time to value Man/Auto UC Deploy UC Deploy Man/Auto Networking Storage Servers Virtualization O/S Middleware Mid Config Data Applications Platform as a Service PureApplication System SmartCloud Orchestrator SoftLayer UC Deploy BlueMix Saas Offerings Chef/Puppet/ Other PureApplicatio n System SmartCloud Orchestrator SoftLayer
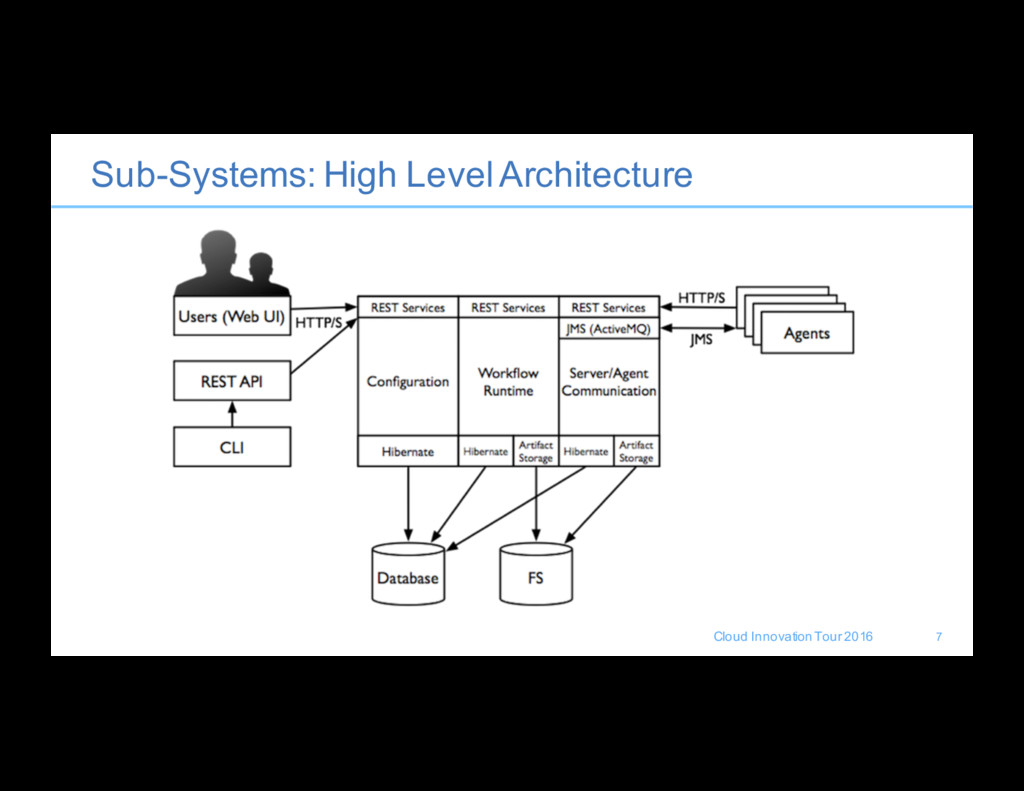
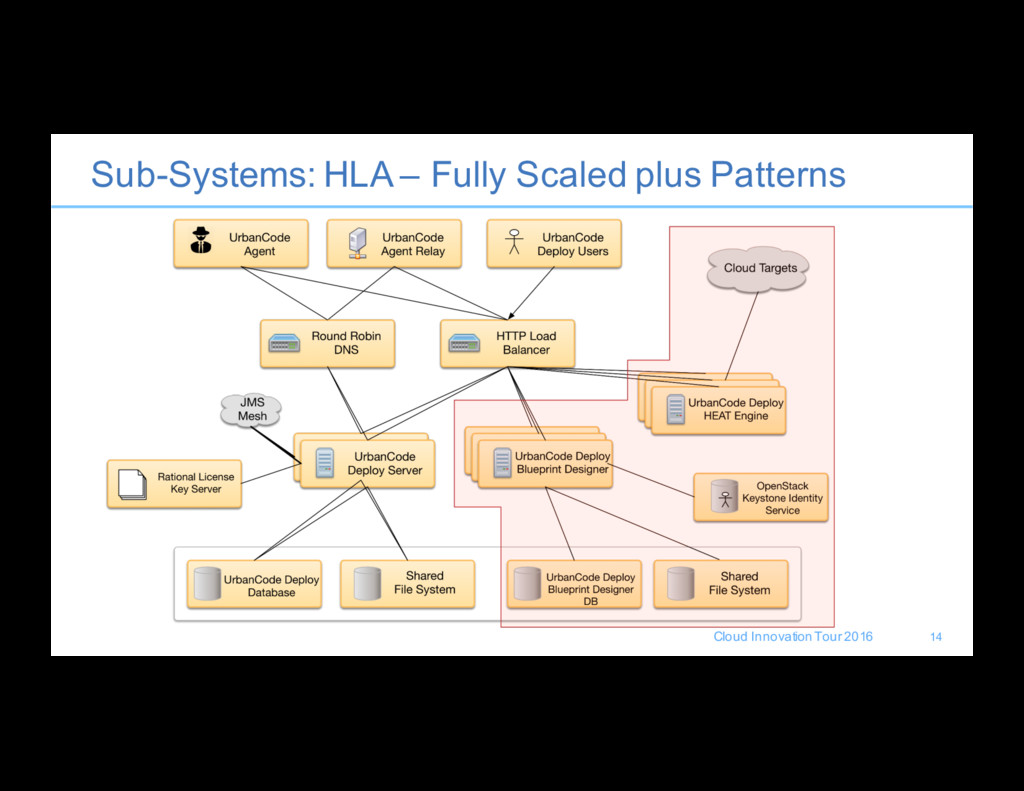
backup and plan for disaster recovery? • What are the bottlenecks to scaling the solution? • How do I guarantee availability of my server and agents? • What are some best practices in topology-design based on business requirements and constraints? • How do I manage large-scale and very large-scale deployments? • How do I know when I need to scale and where my breaking points are? • How do I plan for upgrades, downtime, and coordinate with the enterprise on a release process? 8
( delivered ~quarterly from IBM) cannot be done online • Full backup recommended process involves downtime and complete backups • Any database maintenance • UrbanCode Deploy console can be put in maintenance mode to stop any new deployments or any artifact imports from starting to bleed traffic from the server 9
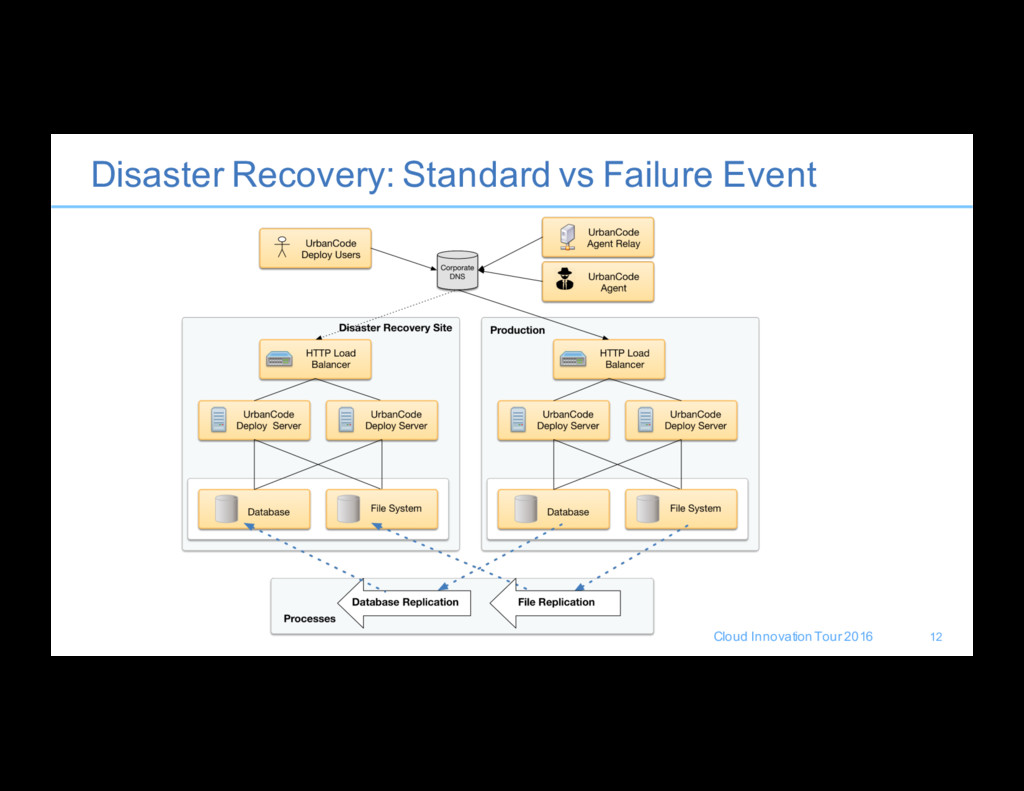
The documentation provides some basic guidance to get started • Simplify your process to cover both backup and disaster recovery • What do we need to recover – Database – Configuration Files – CodeStation – [+ Patterns] Plus OpenStack components KeyStone and HEAT Engine • Complete backups should be done regularly • Can use Console “Maintenance Mode” to bleed transactions off the server for taking the server down and online backup windows • Incremental backup should be happening continuously( <15m interval) 10
• A global DNS/Load Balancer solution is generally used to cut over to failover servers manually during a failure • Understand your SLA for fail over, this will effect how involved your process must be to support it. • Data to restore or host is generally built by extending our backup solution to include replication to the cold standby solution. • Licensing must be part of your plan, the products does not function without a license. IBM Support can assist you in generating a duplicate copy of your production licenses to host with the disaster recovery server at no additional cost. • Ensure that we understand how to fall back to production, reverse replication process and play forward to catch up database/filesystems 11
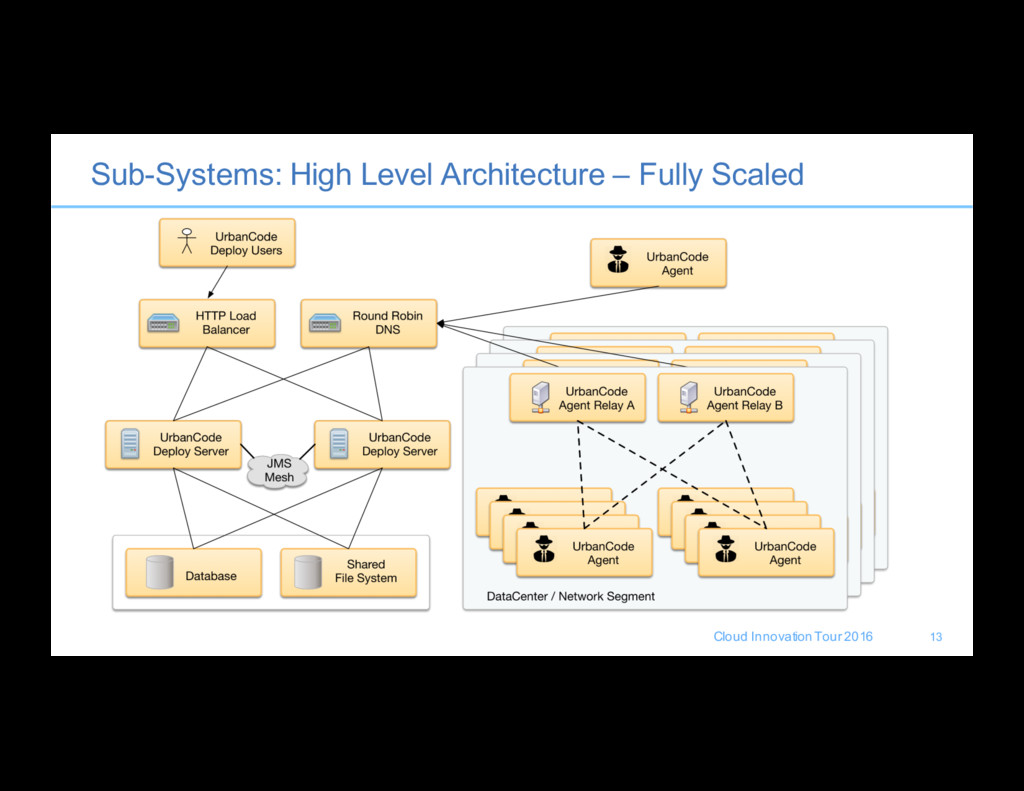
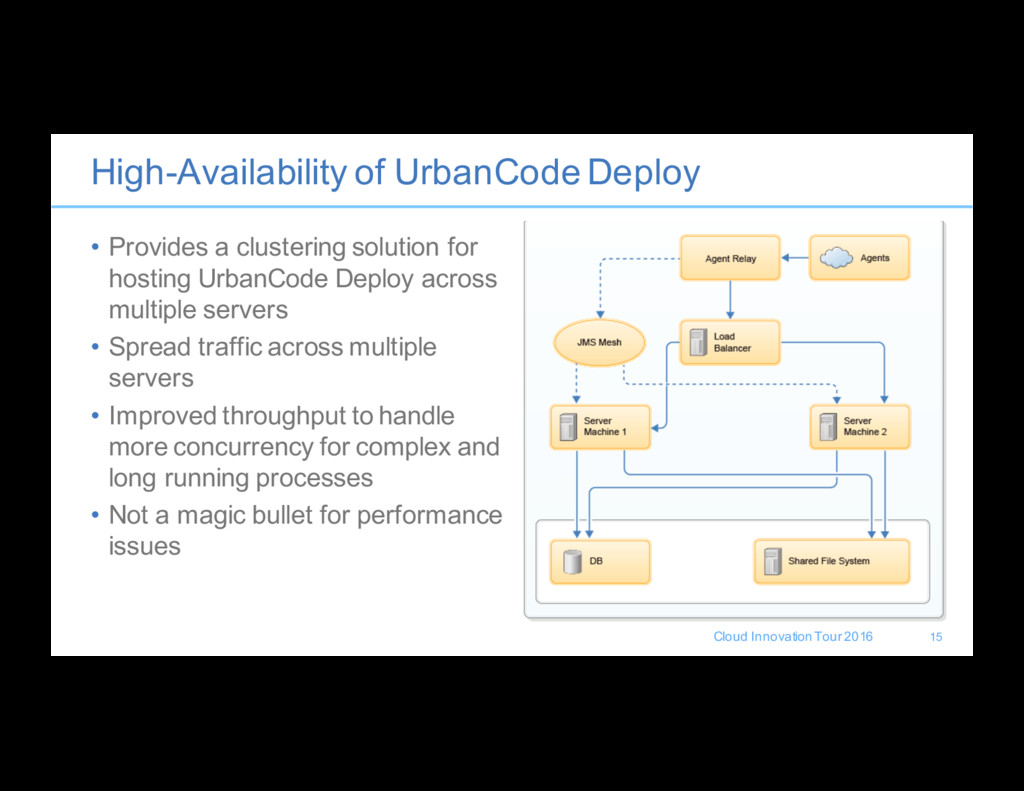
a clustering solution for hosting UrbanCode Deploy across multiple servers • Spread traffic across multiple servers • Improved throughput to handle more concurrency for complex and long running processes • Not a magic bullet for performance issues 15
Shared connectivity to the same database means we will be putting more load on a single database/server/instance so plan accordingly • Shared file system connectivity and latency, means that things like it is easy to saturate a single network card while moving only a few large files across the network. • Spanning data centers is possible but recommend that you co-locate servers, coordination overhead needs to be taken into consideration. • Agent Relays should also be configured for failover where resiliency is required. 16
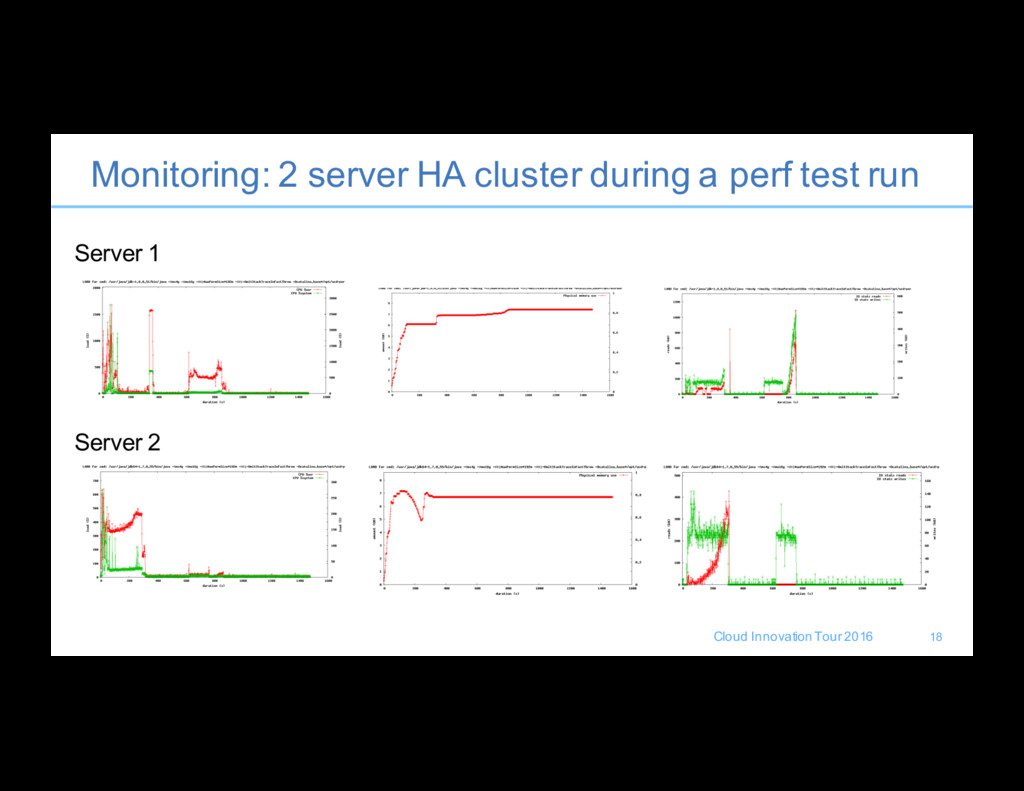
Memory, Disk I/O, Network I/O • Agent Relay(s) CPU, Memory, Disk I/O, Network I/O • Network Storage System I/O to UCD Servers • Database Services Resource and Space Utilization • Notification is important to ensure you find out when there are issues – CPU > 50% for 5 minutes – Disk < 50G • Goal here is to provide a high-level water mark to ensure that the UrbanCode operations team is aware of any infrastructure level issues before they get reported ( proactive versus reactive ) 17
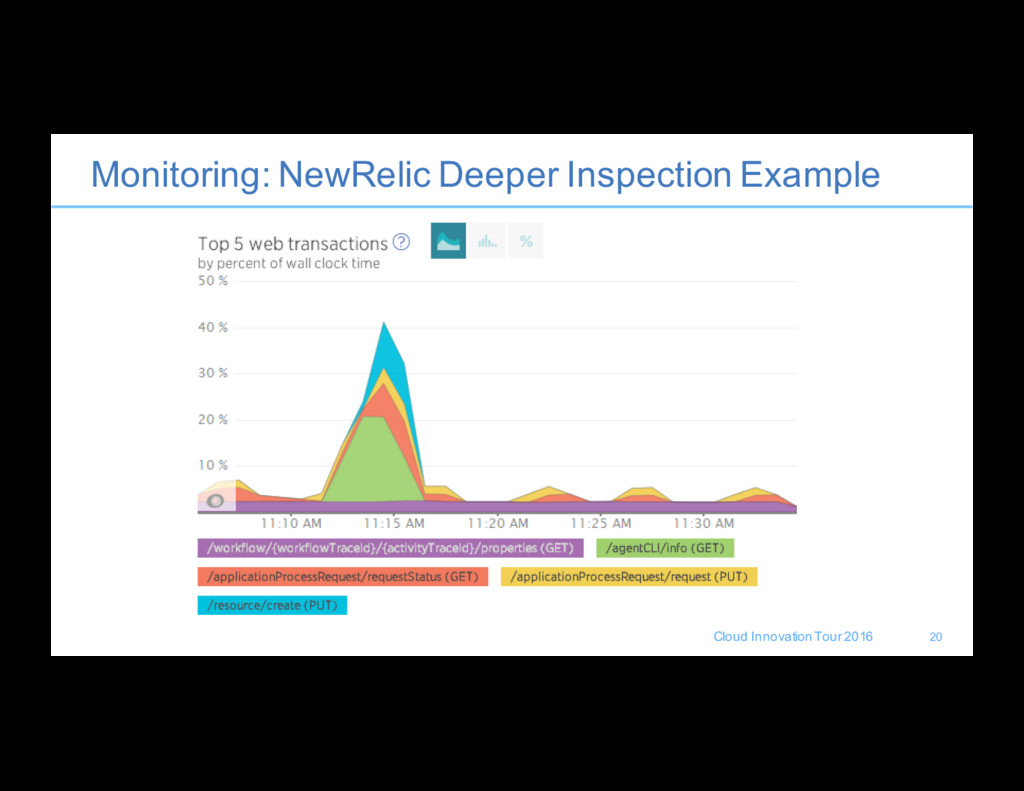
can be used to provide a deeper level of inspection of what is going on in the applications • UrbanCode level tracing can be enabled for specific issues, but debugging and tracing features will affect product performance. • Application Level: Want to look at the “Application” specific data so we can see time spent in the web, app, and database tiers of the applications • Database level monitoring: temporary space, buffer pools, expensive queries, large tables, missing indexes • Example monitoring tools IBM APM Suite, NewRelic, DynaTrace, 19
customer is a snowflake here as this depends so much on what your environment looks like • One major reason for monitoring is for you to develop a baseline of what is “normal” for your deployment • Internal UrbanCode Performance team formed in 2015 to help facilitate our focus on improving • Performance tests are built using API to build out, monitor, and validate • Suite being used as part of the UrbanCode Deploy’s internal build/release process to help identify any changes positive or negative 21
• HW Sizing Recommendations • Part of the Performance Team work is to work on break the system – Number of Agents ( 10-15K Agents internally our maximum testing ) – Number of Applications – Components per Applications – Component Version Sizes – Concurrency • Practical limitations with setting up this many agents, we are scaling out to SoftLayer from our physical lab in Cleveland to do this • How many servers do you need to get here? 22
State? • Understanding what your target is will drive the decisions • Who will manage workflow changes? – Central vs self-directed teams • What are your governance points? – Preparing for continuous delivery means these will need to be automated eventually • How to handle inter-Application dependencies? – Release management strategy affects how you design your automated deployment processes 23
• Naming Conventions • Organization • Re-use via Component and Application Templates • Design of Applications and Components – provide a logical representation of path to production – Number of Components to Applications • CodeStation usage for smart staging and staying on top of cleanup • Resource organization, limited use of top level Resources, common standards here help at scale ( /<Business Unit>/<App>/<Env>/… ) 24
Environment that is a clone of your Production server including, database, files ( CodeStation, process logs), and a similar configuration ( HA vs non-HA) • Having a pseudo-production environment is crucial to being able for a few key scenarios – Validating Production updates/upgrades – Workflow development – User Training – Destructive Configuration/Integration Testing ( Security, API testing, plugin development ) • Can generally be built using a combination of the existing backup and/or Disaster Recovery process to re-create production at a point in time. 25
you should use them J • Roughly estimate 1 Agent Relay for every ~1000 Agents • Implementing Agent Relays is part of a best practice deployment • Minimizes concurrent connections to the server • When using CodeStation you can see immediate benefits from implementing Artifact Caching and/or Artifact Staging to minimize the re-download of the same files from the server during deployments. 26
• Component Cleanup Settings – Think smart staging, not permanent storage – To archive or not – System / Component /Environment values • Audit Cleanup – Cleanup audit table by date via System Settings – 6.2.1 – Add *beta* support for regular process request cleanup • Resources – Cleaning up offline agents – Removing unused items from retired or completed projects 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}