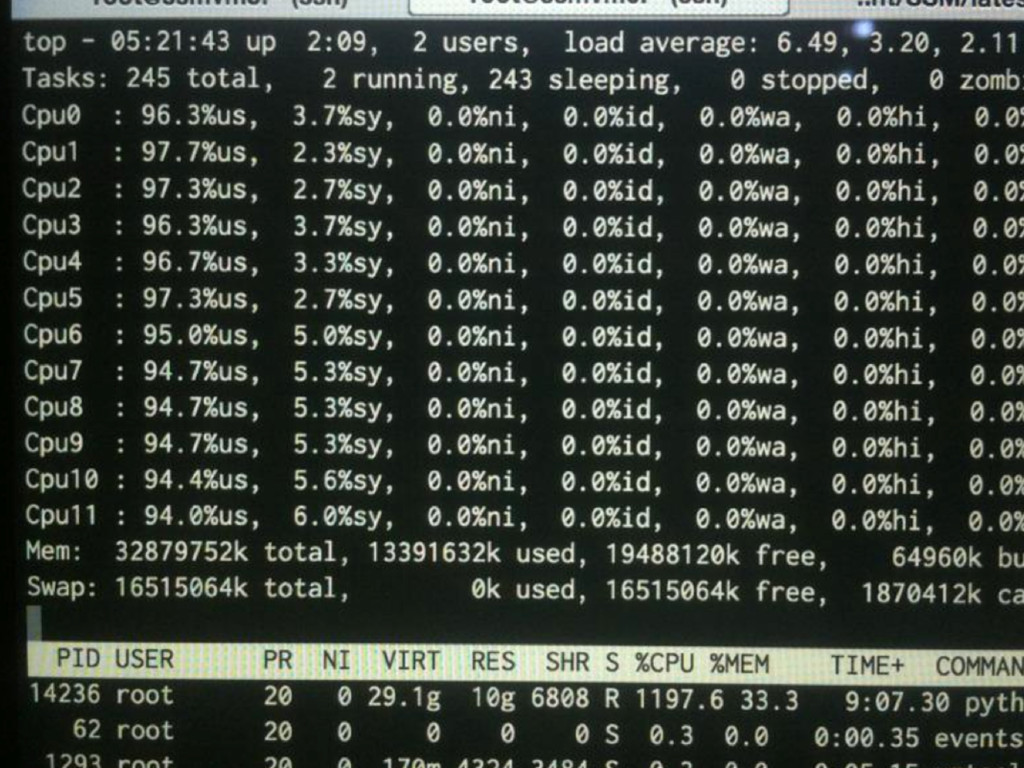
use case. • Multi-thread - no true parallelization. • Bottleneck is CPU not I/O bound • Multi-process - One single process already consuming lots of CPU. Lots of context switching.
raise LinAlgError("SVD did not converge") numpy.linalg.linalg.LinAlgError: SVD did not converge • SVD does not converge. • Moore-Penrose pseudo-inverse make use of SVD. By definition, you can always find SVD. • Numpy has low iteration limit hard-coded into its source code. • Will raise SVD did not converge if failed to converge within this iteration limit. • Refer file dlapack_lite.c
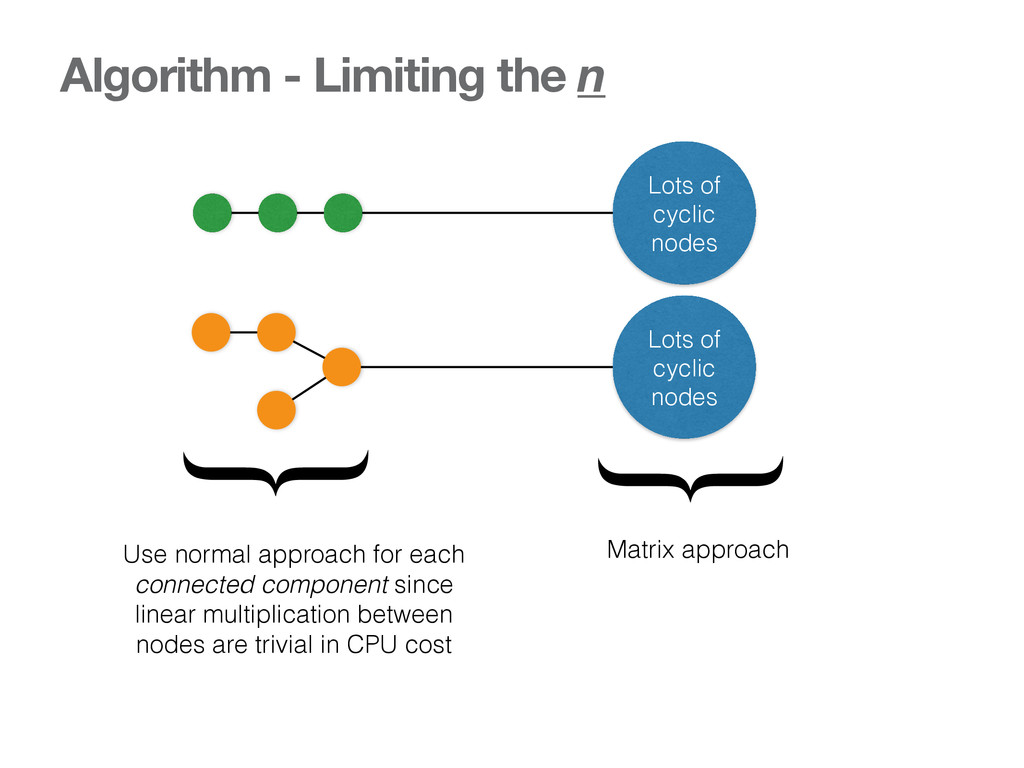
hard and cpu intensive • If we can’t invent algo that can do the calculation in O(1), try to limit the n • Because matrix inversion becomes slower as n becoms larger
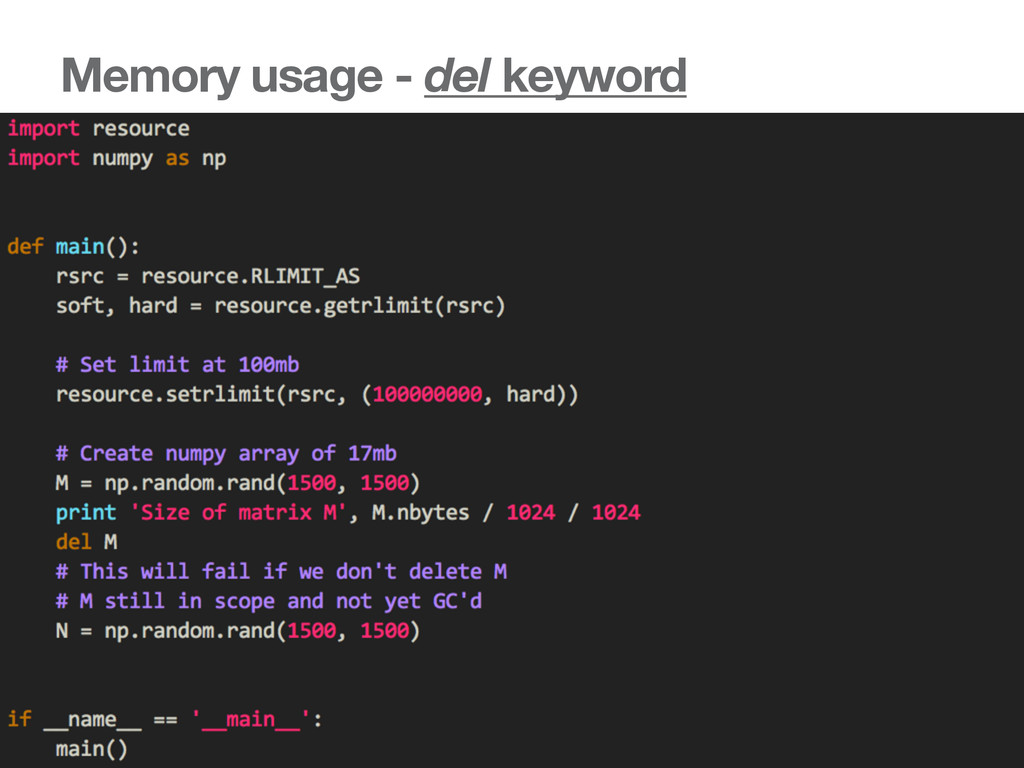
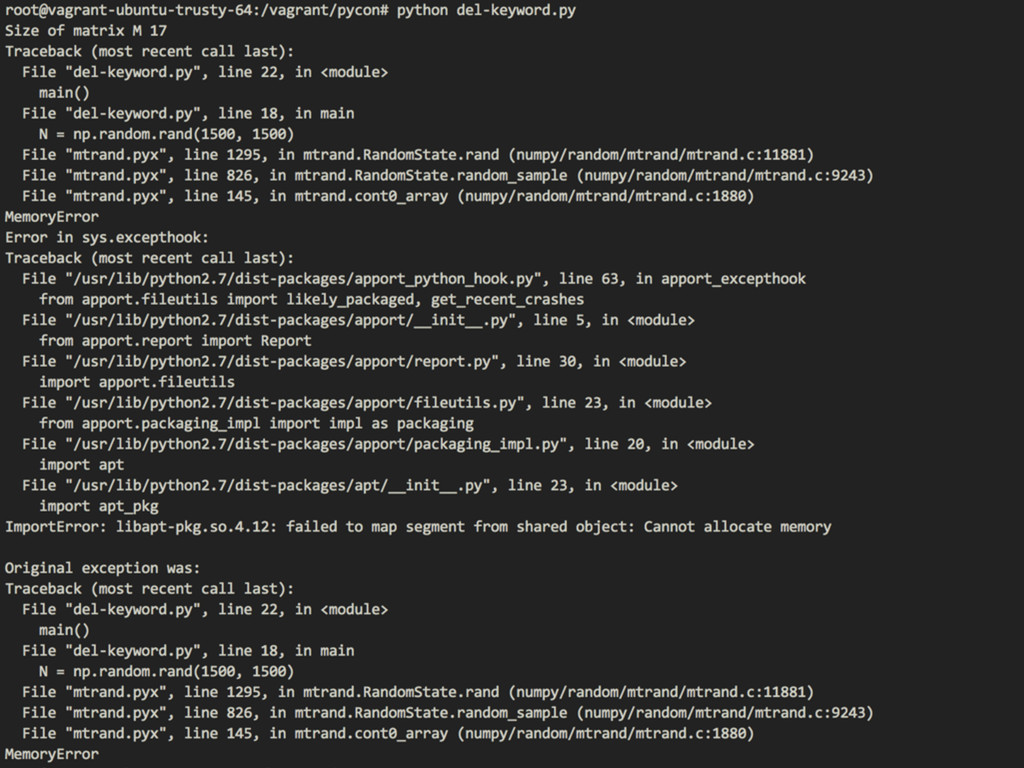
Reducing CPU utilization n x n n depends on the total companies/shareholders. Assuming n is 50,000. 50,000 x 50,000 x 8 bytes = 160Gb of memory usage just to hold data into memory. A =
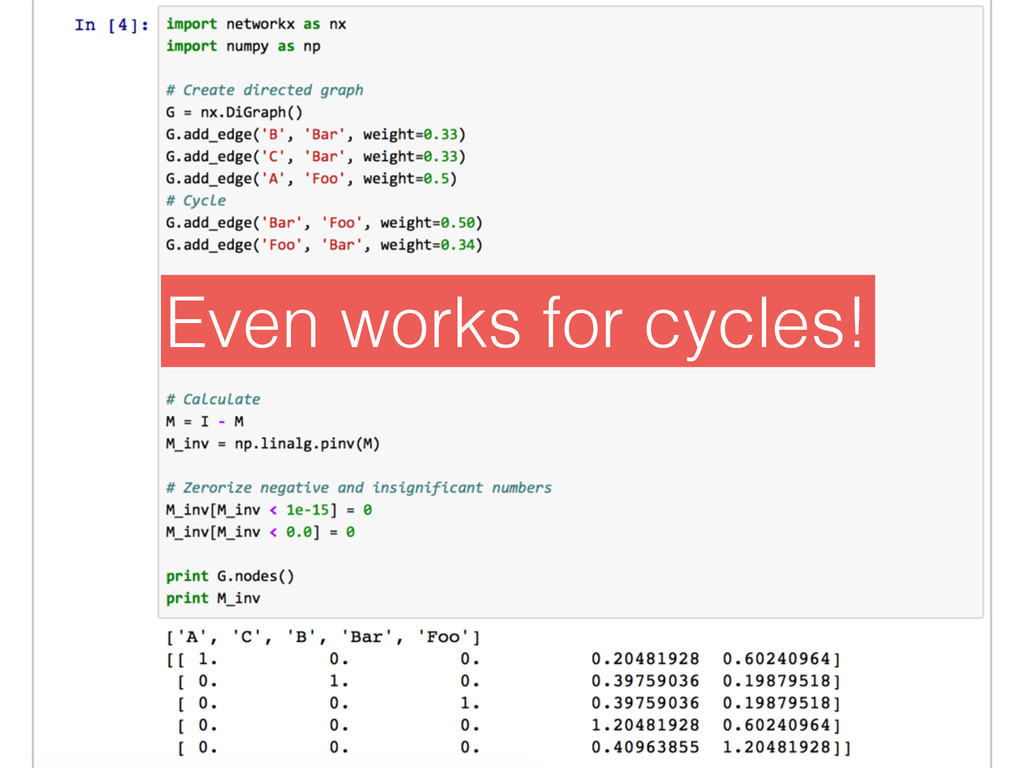
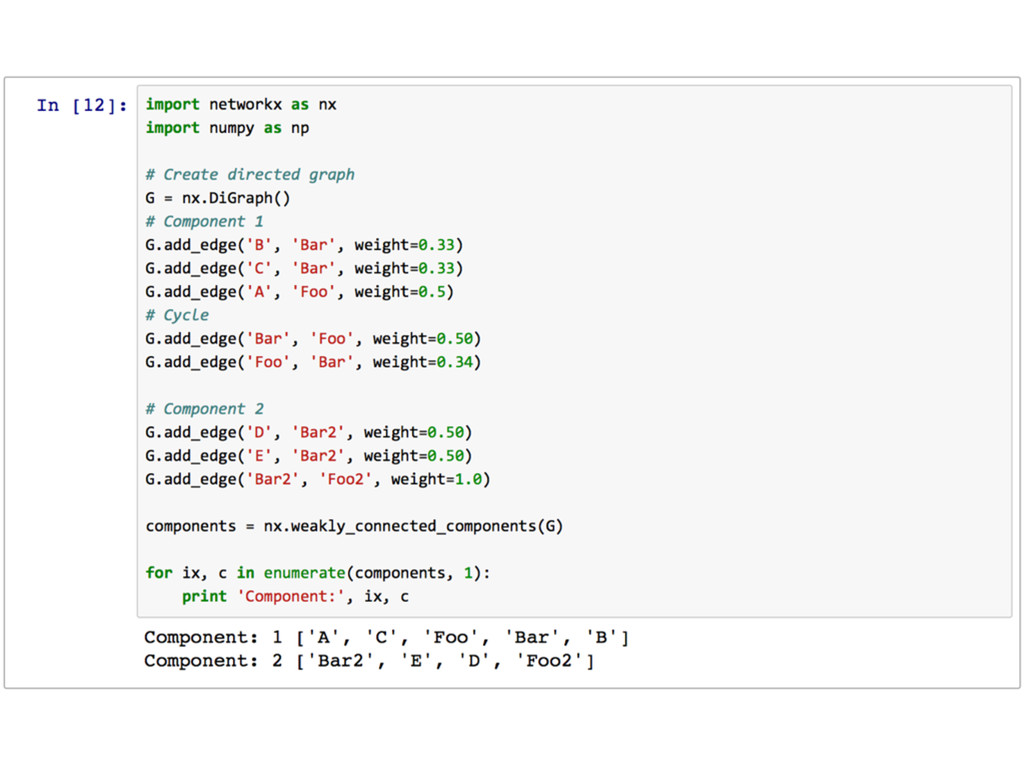
Matrix approach } Use normal approach for each connected component since linear multiplication between nodes are trivial in CPU cost Lots of cyclic nodes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
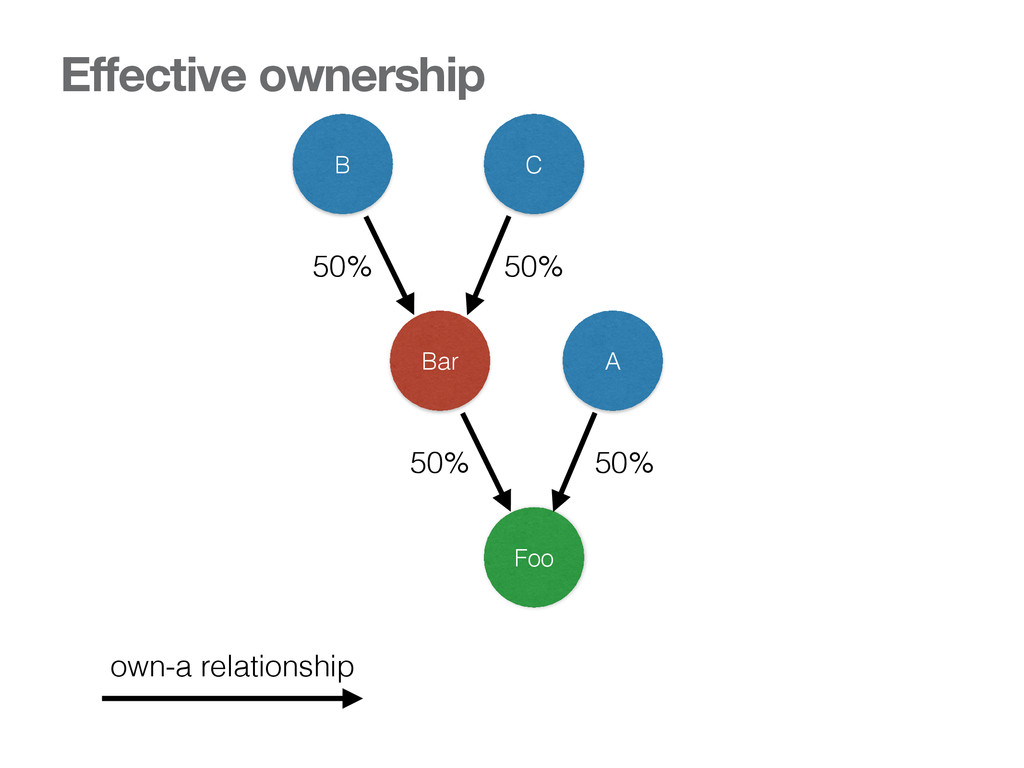{kind=link}
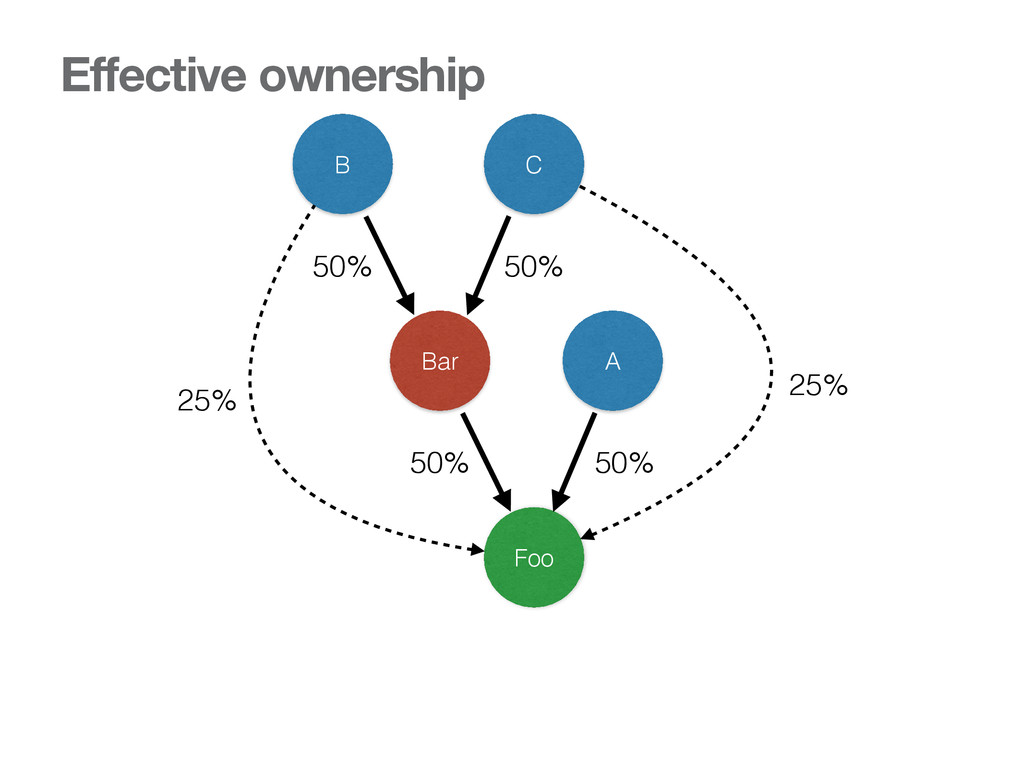{kind=link}
{kind=link}
{kind=link}
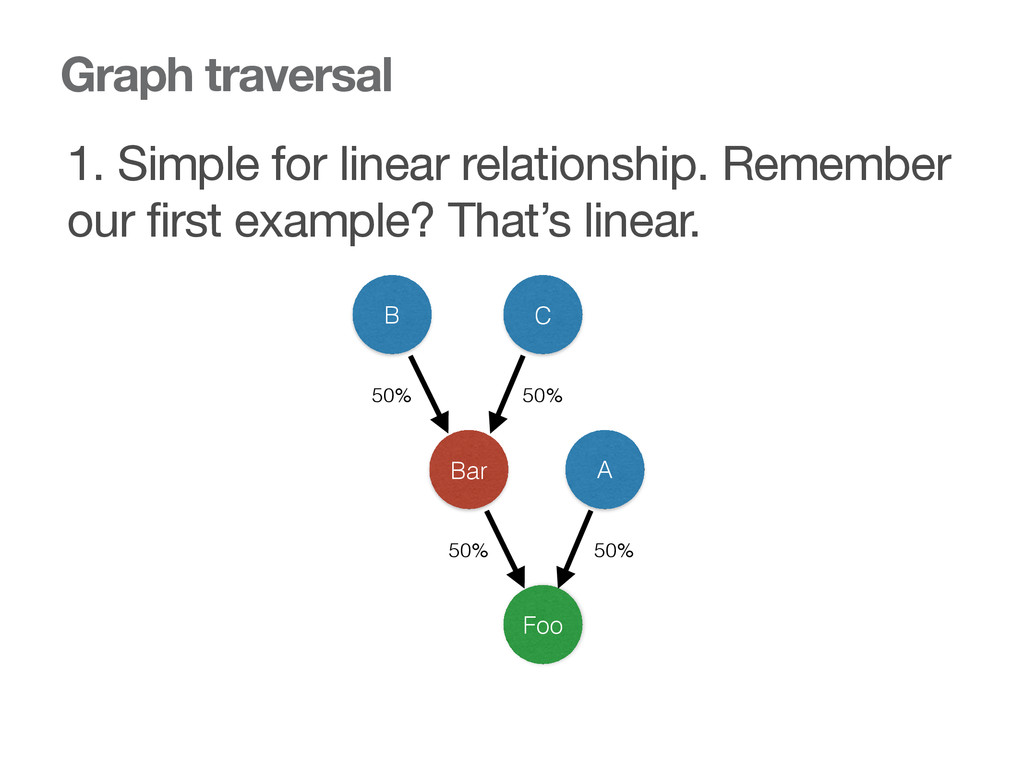{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}