al. 2022. Chain-of-thought Prompting Elicits Reasoning in Large Language Models. In Proceedings of the NeurIPS 2022. [3] Xuezhi Wang, Jason Wei, Dale Schuurmans, et al. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. In Proceedings of the ICLR 2023. [4] 高野・齋藤・石原『Kaggleではじめる大規模言語モデル入門』講談社( 2026) [5] https://github.com/huggingface/transformers [6] https://github.com/huggingface/trl [7] https://github.com/huggingface/sentence-transformers [8] Edward J. Hu, Yelong Shen, Phillip Wallis, et al. 2022. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the ICLR 2022. [9] Tim Dettmers, Mike Lewis, Younes Belkada, et al. 2022. LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale. In Proceedings of the NeurIPS 2022. [10] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, et al. 2023. QLoRA: Efficient Finetuning of Quantized LLMs. In Proceedings of the NeurIPS 2023. [11] https://github.com/bitsandbytes-foundation/bitsandbytes [12] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, et al. 2023. GPTQ: Accurate Quantization for Generative Pre- trained Transformers. In Proceedings of the ICLR 2023. [13] https://github.com/ModelCloud/GPTQModel [14] https://github.com/vllm-project/llm-compressor [15] Ji Lin, Jiaming Tang, Haotian Tang, et al. 2024. AWQ: Activation-aware Weight Quantization for On-device LLM Compression and Acceleration. GetMobile: Mobile Computing and Communications, 28(4):12–17. 引用
et al. 2024. Optimize Weight Rounding via Signed Gradient Descent for the Quantization of LLMs. In Findings of the EMNLP 2024. [18] https://github.com/intel/auto-round [19] Jianping Gou, Baosheng Yu, Stephen J. Maybank, et al. 2021. Knowledge Distillation: A Survey. International Journal of Computer Vision, 129(6):1789–1819. [20] https://medium.com/my-musings-with-llms/understanding-kv-cache-and-paged-attention-in-llms-a-deep-dive-into-efficient-inference-62fa372432ce [21] Tri Dao, Daniel Y. Fu, Stefano Ermon, et al. 2022. FLASHATTENTION: Fast and Memory-efficient Exact Attention with IO-awareness. In Proceedings of the NeurIPS 2022. [22] Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, et al. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. In Proceedings of the SOSP 2023. [23] https://github.com/vllm-project/vllm [24] https://www.kaggle.com/competitions/lmsys-chatbot-arena [25] https://huggingface.co/unsloth/gemma-2-9b-it-bnb-4bit [26] https://www.kaggle.com/code/emiz6413/training-gemma-2-9b-4-bit-qlora-fine-tuning [27] https://www.kaggle.com/competitions/map-charting-student-math-misunderstandings/overview [28] https://huggingface.co/Qwen/Qwen3-8B [29] https://www.kaggle.com/code/sinchir0/lb-0-942-infer-fullft-qwen3-8b-by-sfttrainer [30] https://www.kaggle.com/competitions/pii-detection-removal-from-educational-data [31] https://www.kaggle.com/competitions/pii-detection-removal-from-educational-data/discussion/472221
{kind=link}
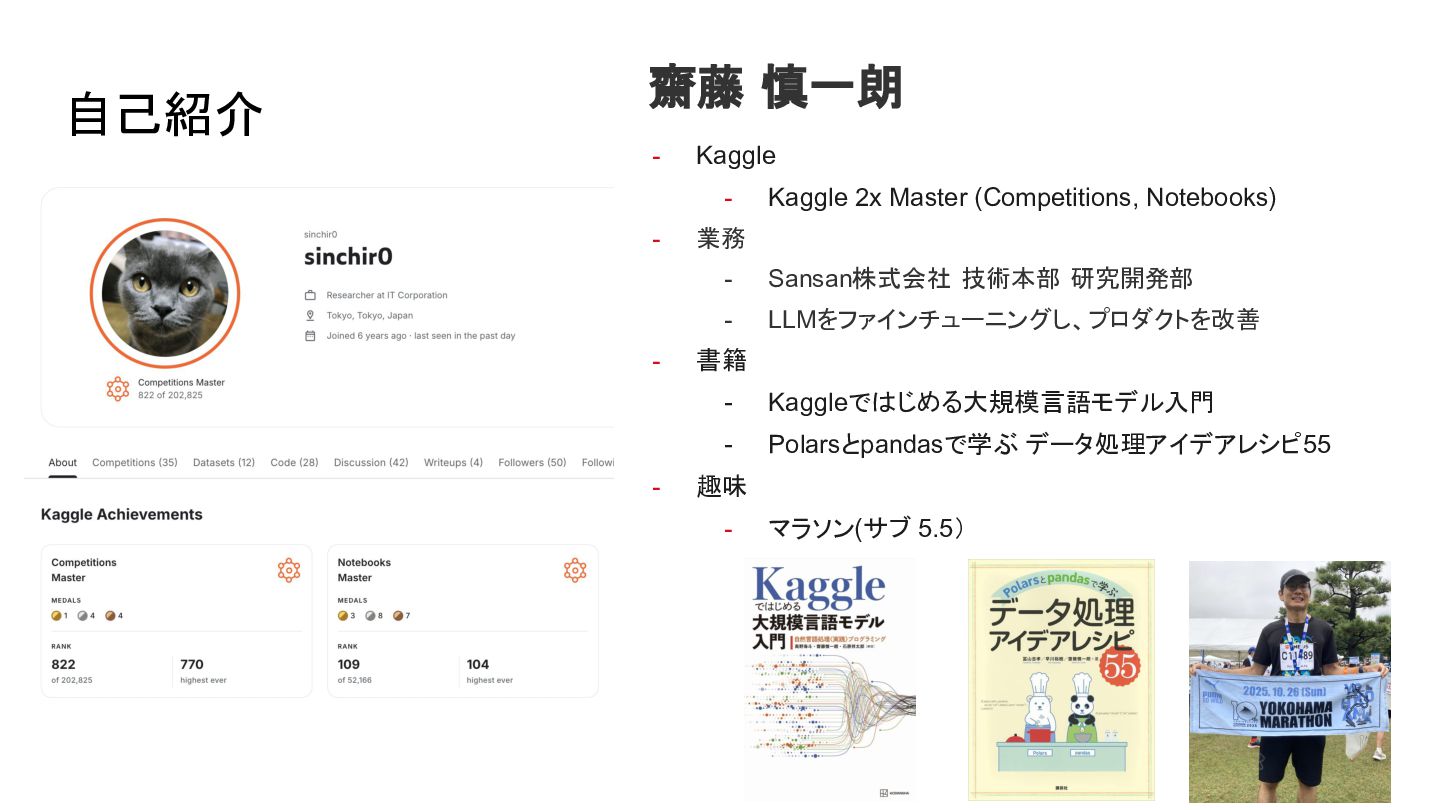{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![- 性能改善の代表的手法として、プロンプトエンジニアリング、RAG、ファインチュー ニングが存在する。 - プロンプトエンジニアリングを基点として、LLMが知っている必要がある知識をRAG で補い、LLMがどのように振る舞うかをファインチューニングで補う。 性能改善の全体感 LLM の性能向上の指針([1]より引用)](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_8.jpg){kind=link}
{kind=link}
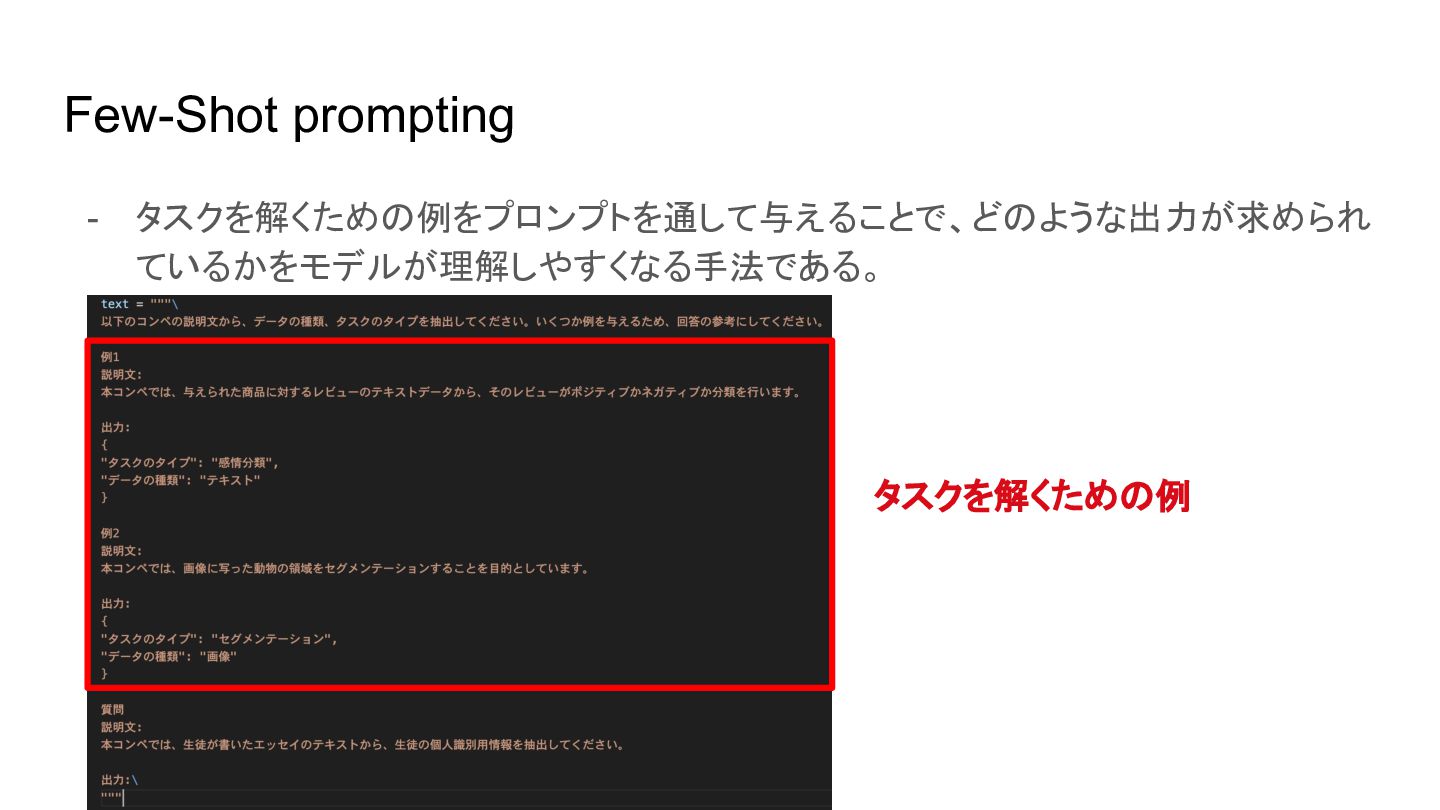{kind=link}
![Chain of Thought(CoT) - 通常の回答に加え、中間の推論過程も生成させることで、LLMの推論能力を向上 させる手法である。 Few-Shot CoT の概要図([2]より引用)](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_11.jpg){kind=link}
![Self-Consistency - 多様な推論を複数回繰り返すことで、より一貫性のある信頼性の高い結果を得る 手法である。 Self-Consistency の概要図([3]より引用)](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_12.jpg){kind=link}
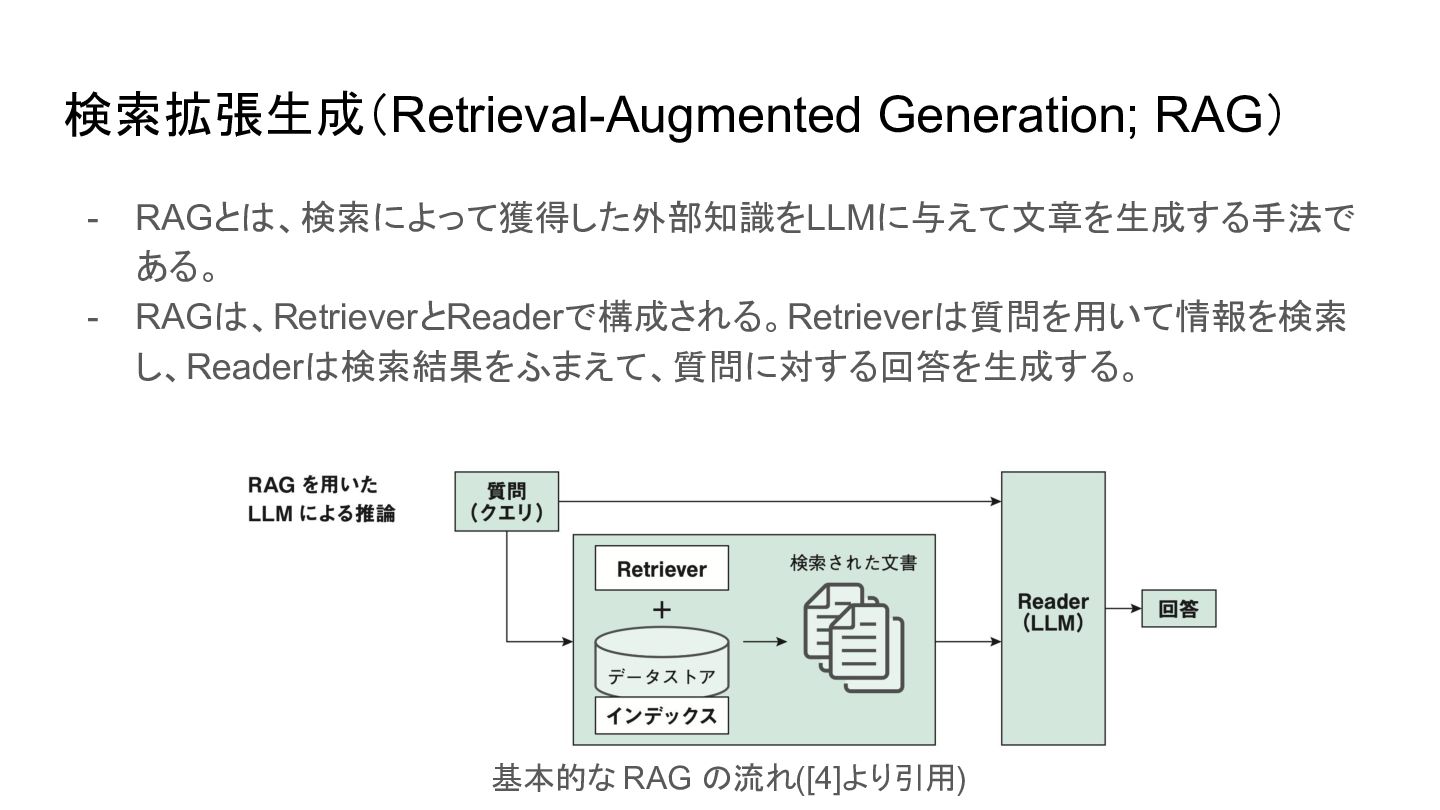{kind=link}
![- ファインチューニングとは、個々のタスクに特化するようモデルを微調整する手法で ある。 - ファインチューニングを実現可能なライブラリには、Transformers[5]、TRL[6]、 Sentence Transformers[7]などが存在する。 - タスクと、ライブラリの実装の対応は次の表のようになる。 ファインチューニング](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_14.jpg){kind=link}
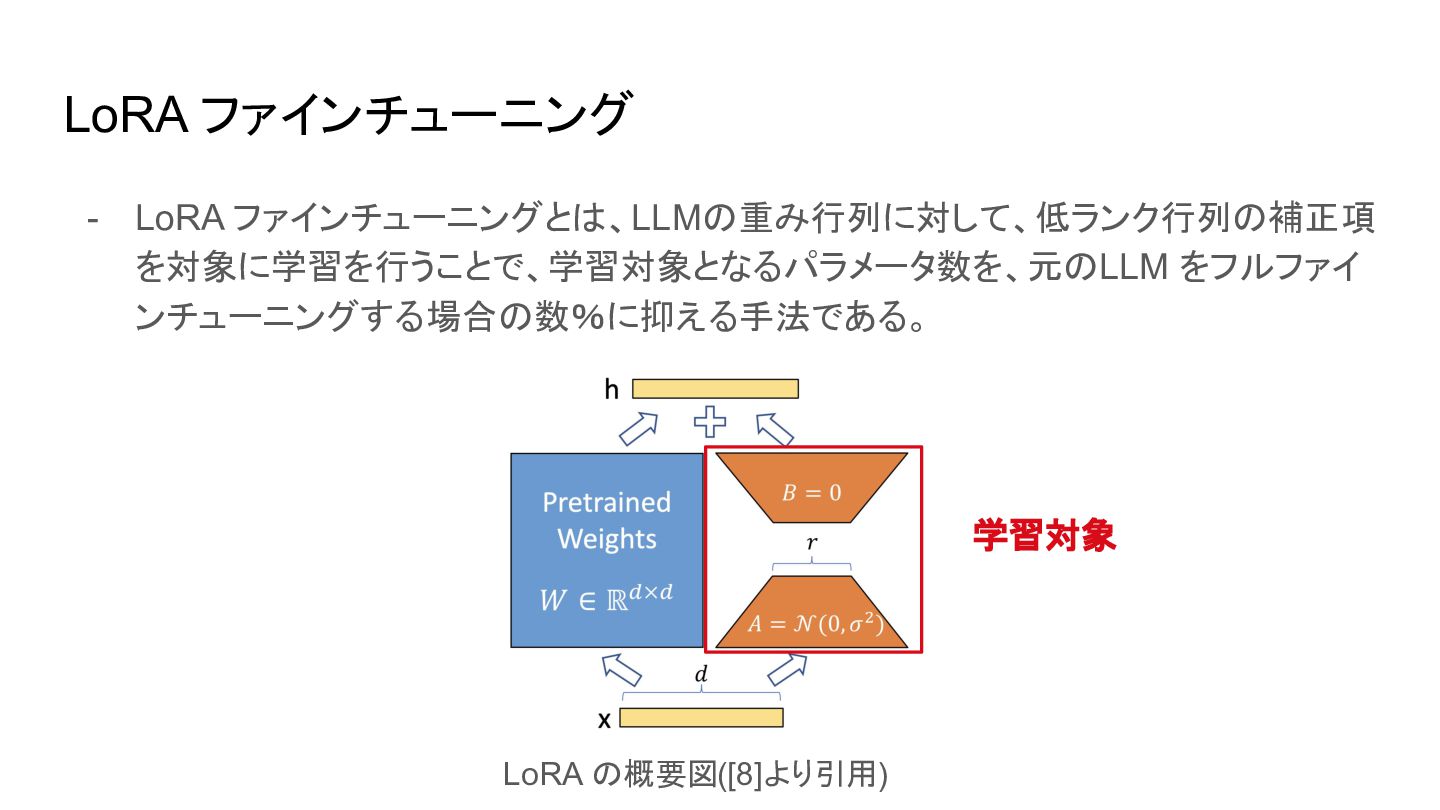{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![量子化の主な手法 手法 実現するためのライブラリ例 説明 LLM.int8()[9], NF4[10] bitsandbytes[11] LLM.int8()は、活性の外れ値はそのままの値を保持 し、通常の値は8bit量子化を行う。 NF4は、bitsandbytesで利用される、量子化に適した](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_22.jpg){kind=link}
![QLoRAファインチューニング - QLoRAファインチューニングとは、LoRAファインチューニングを行う際に、LLM(図 ではPretrained Weights)を量子化し、メモリ使用量を削減する手法である。 学習対象 LoRA の概要図([8]より引用) 量子化](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_23.jpg){kind=link}
![知識蒸留 - 知識蒸留とは、大きくて高い性能を持つ教師モデル(Teacher Model)の出力を利 用して、小さくて同等な性能を持つ生徒モデル(Student Model)を学習することで、 性能を保ったままモデルのサイズを大幅に削減する手法である。 知識蒸留の概要図([19]より引用)](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_24.jpg){kind=link}
{kind=link}
![KVキャッシュ - Attention の計算を効率的に実装できる仕組みである。Attentionの計算時に、すで に計算したことがあるKeyとValue をキャッシュし、必要な場面で呼び出すことで高 速化できる。 KVキャッシュのイメージ図([20]より引用)](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_26.jpg){kind=link}
![- Flash Attentionとは、GPUの記憶領域のうち、高速に計算できる領域(SRAM)を 使ってAttentionの計算を行えるようにした仕組みである。 Flash Attention FlashAttentionの概要図([21]より引用)](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_27.jpg){kind=link}
![Paged Attention[22] - バッチ推論におけるKVキャッシュの無駄を改善する仕組みである。 - KVキャッシュは、バッチ推論を前提としていないため、バッチ推論時に無駄が存在 する。 - 例えば、生成予定のトークン数が 512であり、実際に生成したトークン数が](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_28.jpg){kind=link}
![vLLM - Paged Attentionなどの高速化の仕組みを簡単に利用できるようにした推論エンジ ンである。 vLLMのロゴ([23]より引用)](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![- 実例 - unsloth/gemma-2-9b-it-bnb-4bit[25]をQLoRAファインチューニングする手法を用いたノートブック [26]が公開された。本手法にて、当時のリーダーボードの上位 5%以内に入ることができた。 - 高い性能を出せた理由は、 Gemma 2](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_33.jpg){kind=link}
{kind=link}
![- 実例 - vLLMを用いることで、Qwen/Qwen3-8B[28]の推論を、約16,000行のテストデータに対して、約 10 分で完了した。[30] - 参考として、同じデータを Transformersを用いて推論する場合は約 40分かかった。](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[1] https://developers.openai.com/api/docs/guides/optimizing-llm-accuracy [2] Jason Wei, Xuezhi Wang, Dale Schuurmans, et](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_40.jpg){kind=link}
![引用 [16] https://github.com/mit-han-lab/llm-awq [17] Wenhua Cheng, Weiwei Zhang, Haihao Shen,](https://files.speakerdeck.com/presentations/f75d7bda6870433da3a2659a2fda6fbd/slide_41.jpg){kind=link}