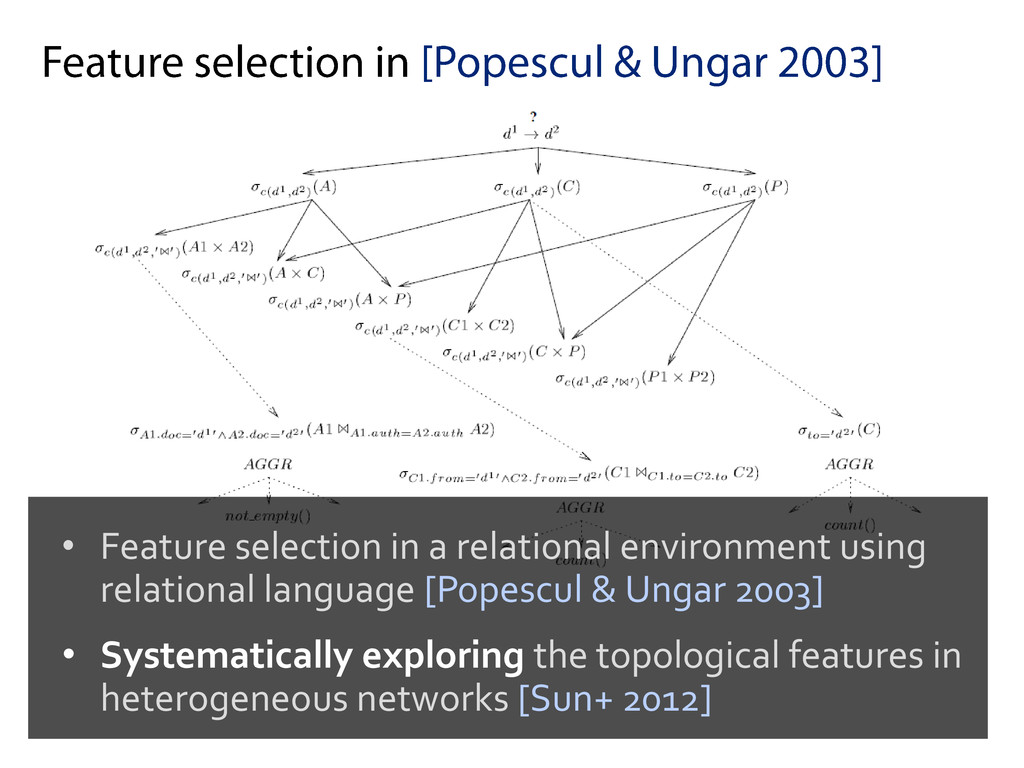
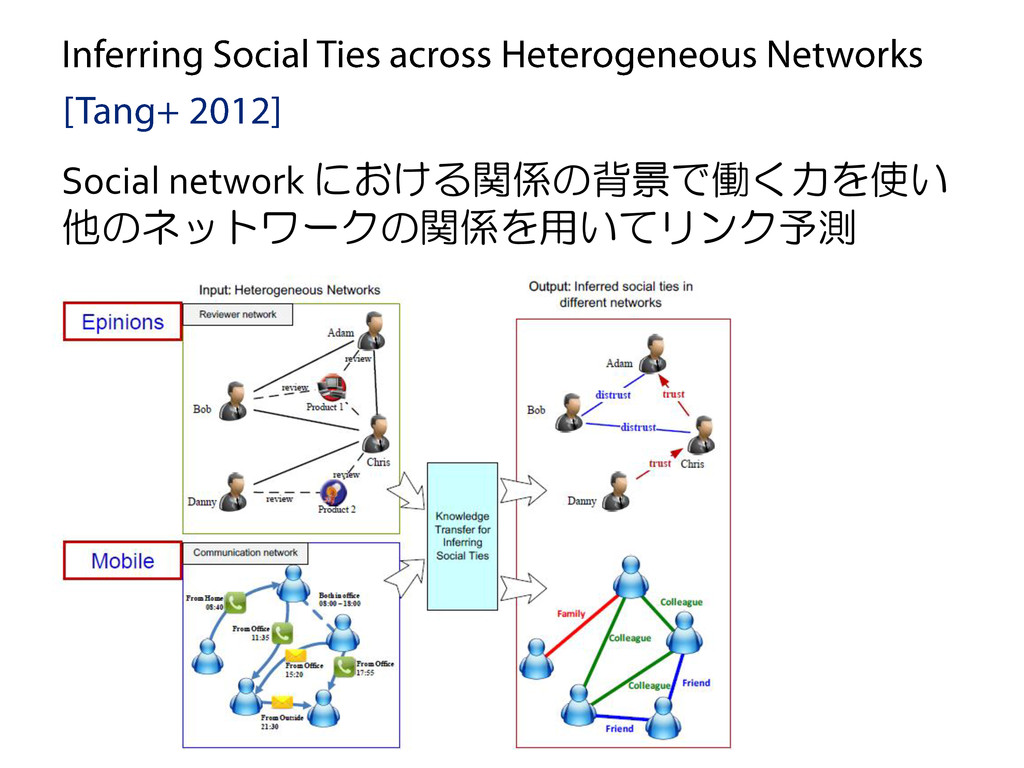
Prediction in Heterogeneous Information Networks [Sun+ 2012] 2. Inferring Social Ties across Heterogeneous Networks [Tang+ 2012] 3. 他 (※ Rights to all the images belong to their respective owners)
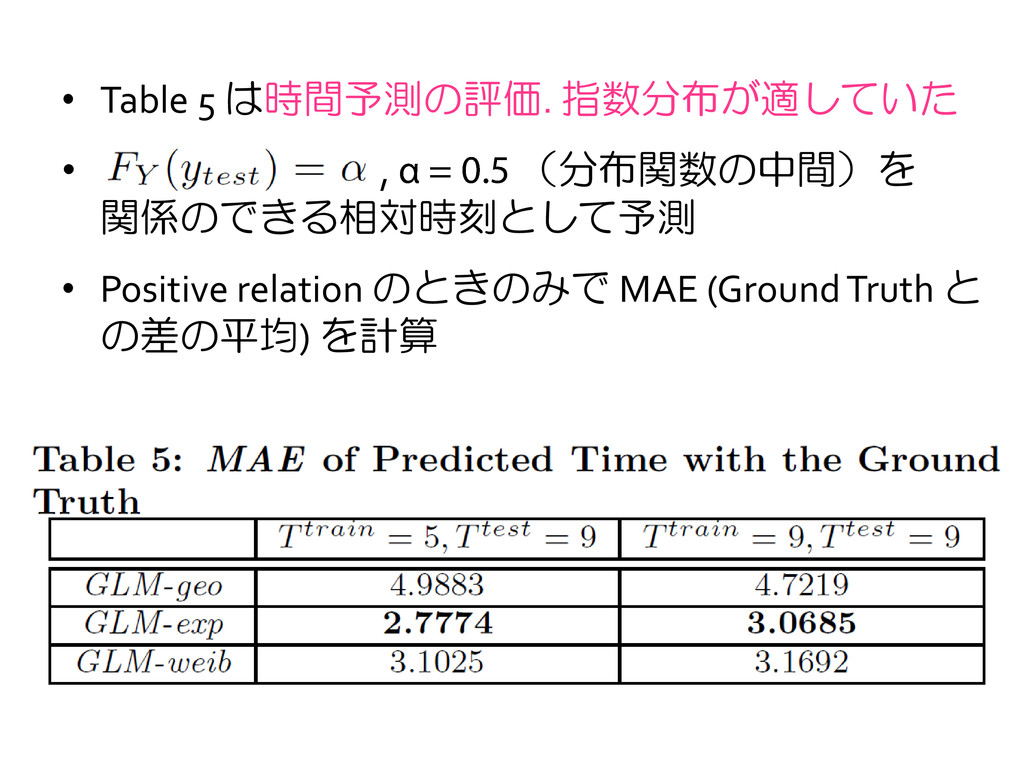
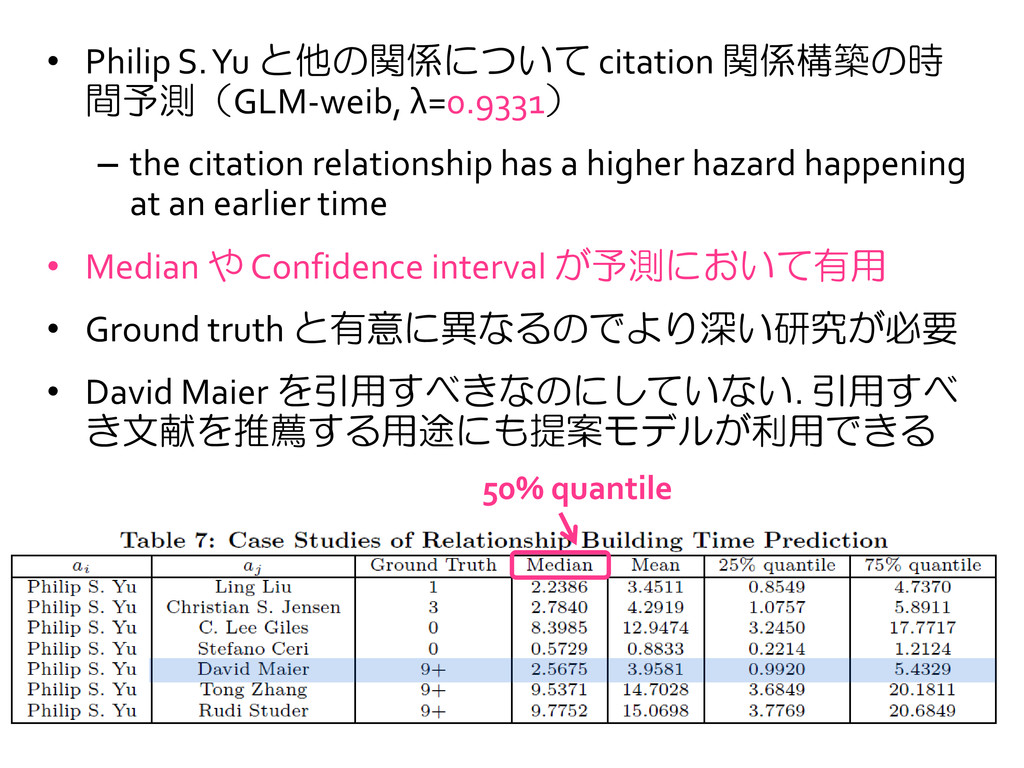
the citation relationship has a higher hazard happening at an earlier time • Median や Confidence interval が予測において有用 • Ground truth と有意に異なるのでより深い研究が必要 • David Maier を引用すべきなのにしていない. 引用すべ き文献を推薦する用途にも提案モデルが利用できる 50% quantile
Prediction in Heterogeneous Information Networks [Sun+ 2012] 2. Inferring Social Ties across Heterogeneous Networks [Tang+ 2012] 3. 他 (※ Rights to all the images belong to their respective owners)
outlier links Guo-Jun Qi, Charu C. Aggarwal, Thomas S. Huang – Social media (Flicker) を clustering するために Tri-partite graph (tags, multimedia objs, users) 上の random filed model (HRF) を提案 • mTrust: discerning multi-faceted trust in a connected world Jiliang Tang, Huiji Gao, Huan Liu – Trust Relationship の表現と, その強さの推定 (Reting prediction な ど) について Product review (Epinion, Ciao) のドメインで研究 • Beyond 100 million entities: large-scale blocking-based resolution for heterogeneous data George Papadakis, Ekaterini Ioannou, Claudia Niederée, Themis Palpanas, Wolfgang Nejdl • Pairwise cross-domain factor model for heterogeneous transfer ranking Bo Long, Yi Chang, Anlei Dong, Jianzhang He 感想: 門外漢から見るとクロールしたものを使う研究が多く、 実験結果を再現することが困難なものが多いという 印象を受けた. メタデータいっぱい持つ会社様に期待したい.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![コメント・誤りの指摘など歓迎します @smly (OR [email protected]) マデ](https://files.speakerdeck.com/presentations/4f7fcb5260b5460021000609/slide_47.jpg){kind=link}