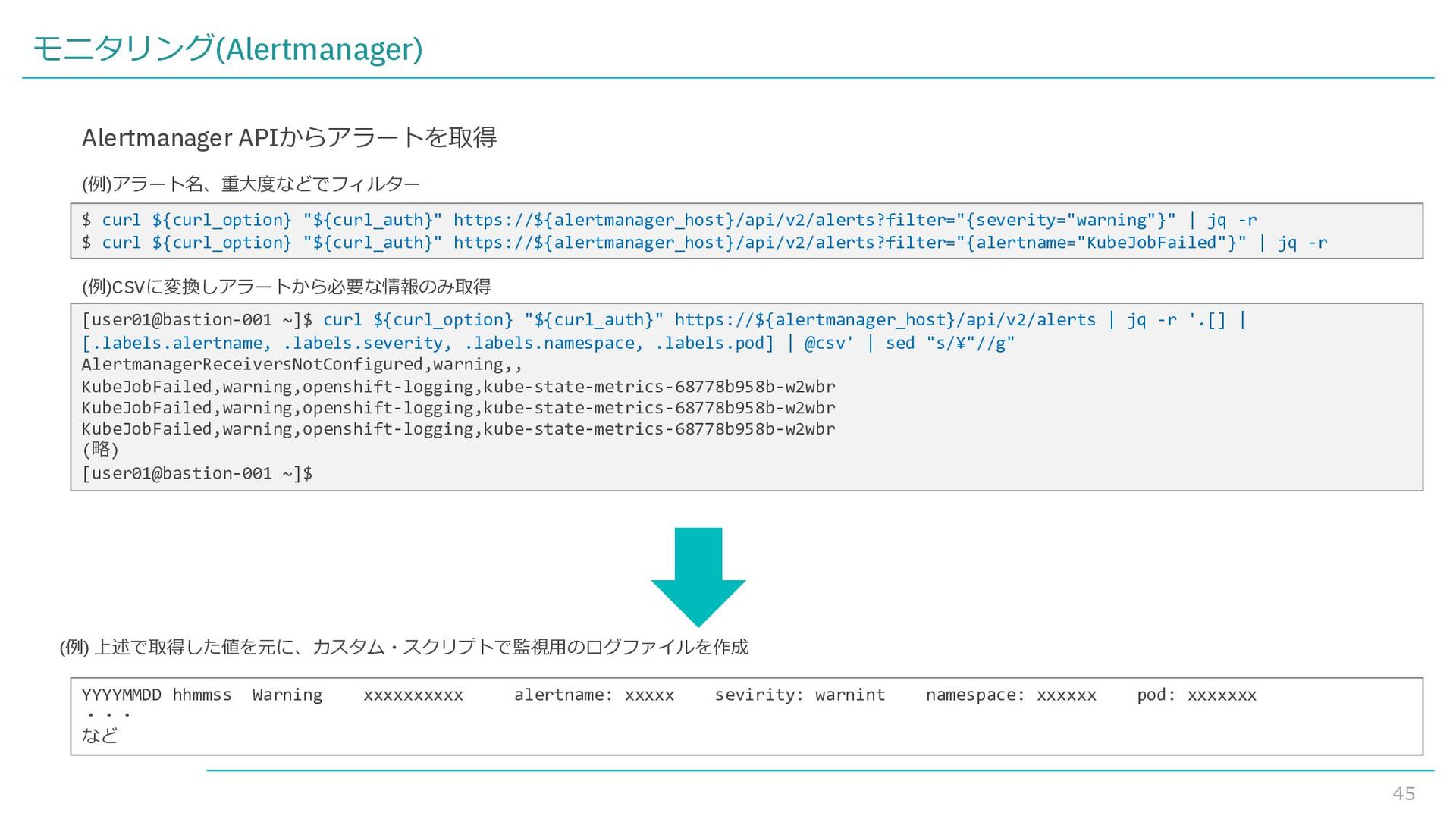
in 1.509 seconds."",""ibm_threadId"":""0000002d"",""ibm_datetime"":""2022-04- 11T17:20:09.038+0000"",""ibm_messageId"":""CWWKF0008I"",""module"":""com.ibm.ws.kernel.feature.internal.FeatureManager"",""loglevel"":""INFO"",""ibm_sequ ence"":""1649697609038_000000000002D""}" "2022-04-11T17:20:09.039474+00:00","liberty-test","mylibertyapp-ibm-websphe-0","{""type"":""liberty_message"",""host"":""mylibertyapp-ibm-websphe- 0.mylibertyapp-ibm-websphe.liberty- test.svc.cluster.local"",""ibm_userDir"":""¥/opt¥/ibm¥/wlp¥/usr¥/"",""ibm_serverName"":""defaultServer"",""message"":""CWWKF0011I: The defaultServer server is ready to run a smarter planet. The defaultServer server started in 2.445 seconds."",""ibm_threadId"":""0000002d"",""ibm_datetime"":""2022-04- 11T17:20:09.039+0000"",""ibm_messageId"":""CWWKF0011I"",""module"":""com.ibm.ws.kernel.feature.internal.FeatureManager"",""loglevel"":""AUDIT"",""ibm_seq uence"":""1649697609039_000000000002E""}" "2022-04-11T17:20:20.272646+00:00","liberty-test","mylibertyapp-ibm-websphe-0","{""type"":""liberty_accesslog"",""host"":""mylibertyapp-ibm-websphe- 0.mylibertyapp-ibm-websphe.liberty- test.svc.cluster.local"",""ibm_userDir"":""¥/opt¥/ibm¥/wlp¥/usr¥/"",""ibm_serverName"":""defaultServer"",""ibm_remoteHost"":""10.131.2.1"",""ibm_requestP rotocol"":""HTTP¥/1.1"",""ibm_requestHost"":""10.131.2.83"",""ibm_bytesReceived"":13283,""ibm_requestMethod"":""GET"",""ibm_requestPort"":""9080"",""ibm_ elapsedTime"":1291,""ibm_responseCode"":200,""ibm_uriPath"":""¥/"",""ibm_userAgent"":""kube-probe¥/1.19"",""ibm_datetime"":""2022-04- 11T17:20:20.272+0000"",""ibm_sequence"":""1649697620271_0000000000003""}" "2022-04-11T17:20:06.461657+00:00","liberty-test","mylibertyapp-ibm-websphe-0","" "2022-04-11T17:20:07.453593+00:00","liberty-test","mylibertyapp-ibm-websphe-0","{""type"":""liberty_message"",""host"":""mylibertyapp-ibm-websphe- 0.mylibertyapp-ibm-websphe.liberty- test.svc.cluster.local"",""ibm_userDir"":""¥/opt¥/ibm¥/wlp¥/usr¥/"",""ibm_serverName"":""defaultServer"",""message"":""CWWKG0093A: Processing configuration drop-ins resource: ¥/opt¥/ibm¥/wlp¥/usr¥/servers¥/defaultServer¥/configDropins¥/defaults¥/keystore.xml"",""ibm_threadId"":""00000024"",""ibm_datetime"":""2022-04- 11T17:20:07.451+0000"",""ibm_messageId"":""CWWKG0093A"",""module"":""com.ibm.ws.config.xml.internal.ServerXMLConfiguration"",""loglevel"":""AUDIT"",""ibm _sequence"":""1649697607451_0000000000002""}" Elasticsearch APIからログを取得するスクリプトの出⼒例 (例) 上述で取得した値を元に、監視、または保管⽤のログファイルを作成 (要件に応じてカスタマイズしたログファイル)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![24 モニタリング(ocコマンド) [root@bastion-01 ~]# oc get co NAME VERSION AVAILABLE](https://files.speakerdeck.com/presentations/bb7563d5f6084ab9b54484a18618c1f1/slide_23.jpg){kind=link}
![25 モニタリング(ocコマンド) [root@bastion-01 ~]# oc adm top node NAME CPU(cores)](https://files.speakerdeck.com/presentations/bb7563d5f6084ab9b54484a18618c1f1/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
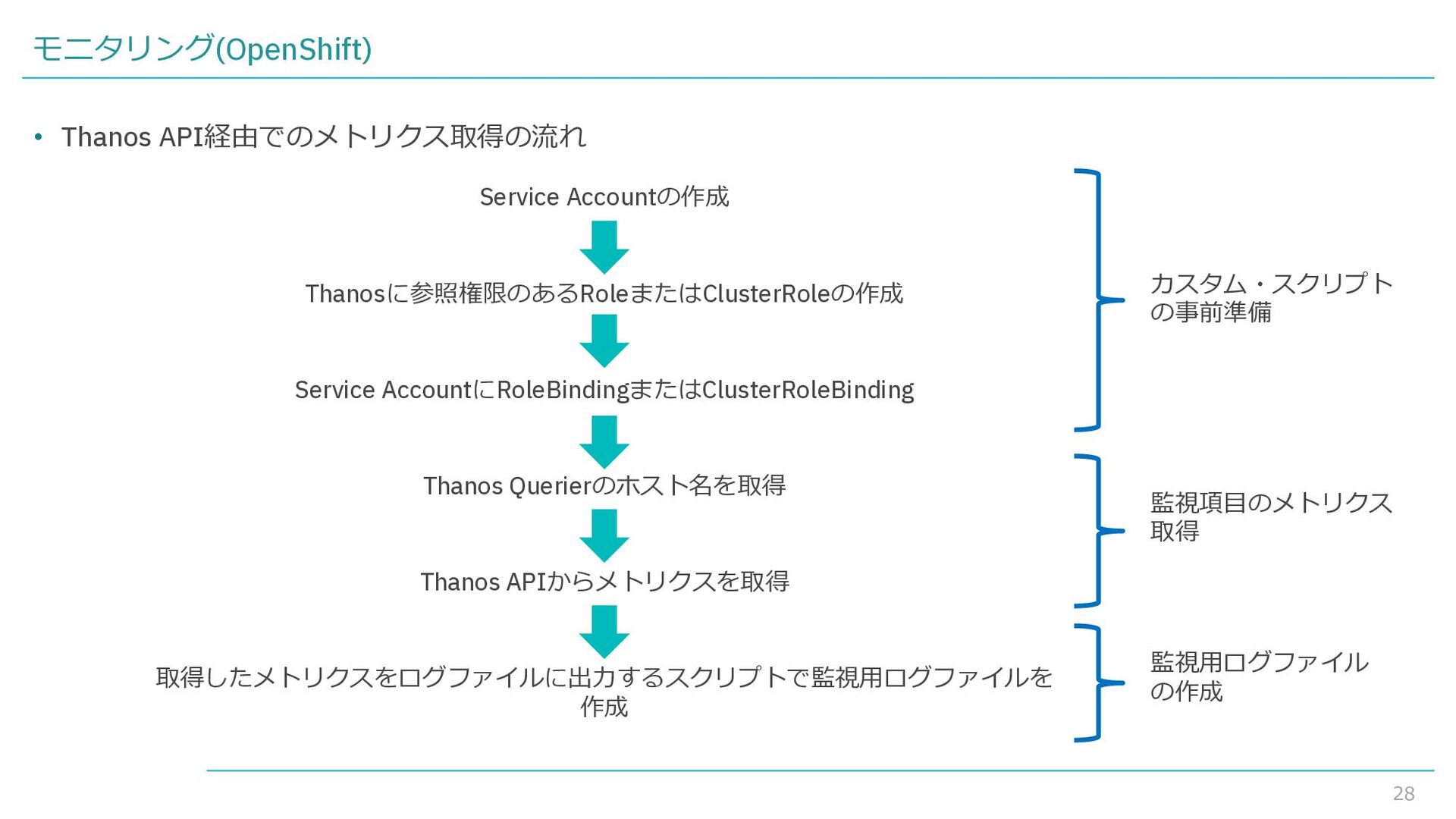{kind=link}
![29 モニタリング(OpenShift) [user01@bastion-001 ~]$ oc project liberty-test Already on project](https://files.speakerdeck.com/presentations/bb7563d5f6084ab9b54484a18618c1f1/slide_28.jpg){kind=link}
![30 モニタリング(OpenShift) Service Accountの作成、Roleの付与 [user01@bastion-001 ~]$ token=$(oc serviceaccounts get-token script-user)](https://files.speakerdeck.com/presentations/bb7563d5f6084ab9b54484a18618c1f1/slide_29.jpg){kind=link}
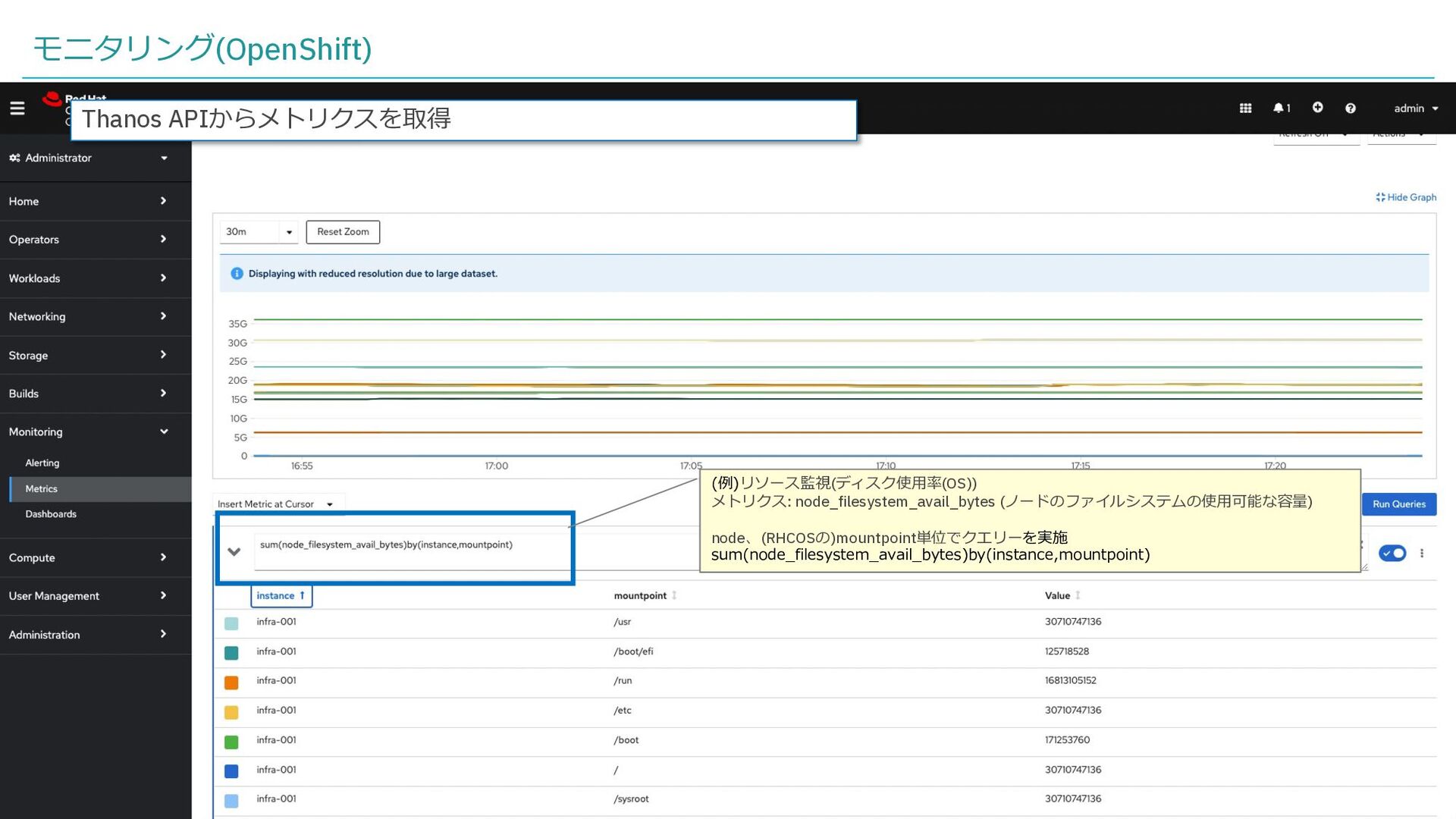{kind=link}
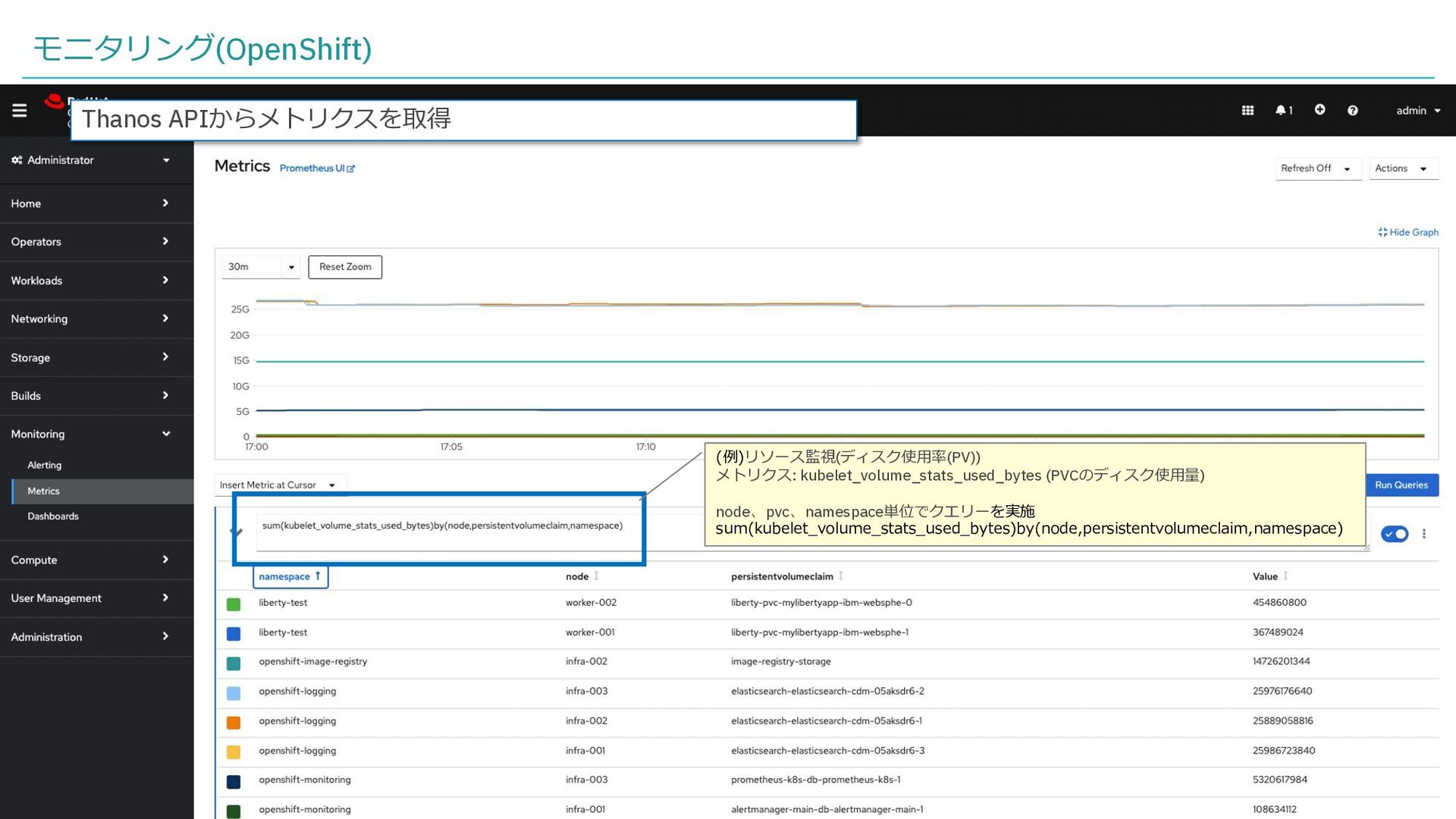{kind=link}
![33 モニタリング(OpenShift) Thanos APIからメトリクスを取得 [user01@bastion-001 ~]$ curl_auth="Authorization: Bearer $(oc whoami](https://files.speakerdeck.com/presentations/bb7563d5f6084ab9b54484a18618c1f1/slide_32.jpg){kind=link}
{kind=link}
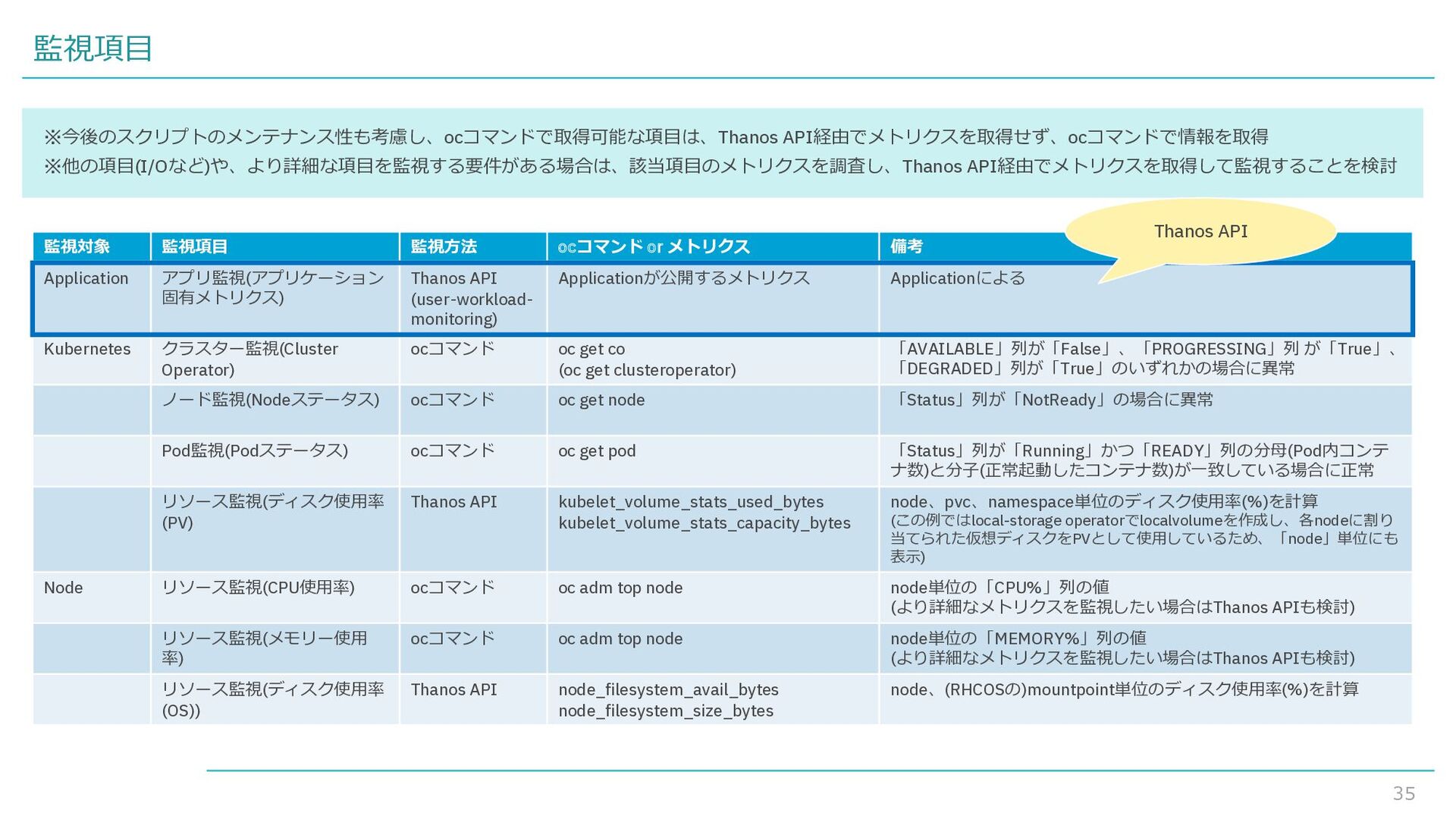{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![43 モニタリング(Alertmanager) Alertmanagerのホスト名の取得 [user01@bastion-001 ~]$ alertmanager_host=$(oc get route -n openshift-monitoring](https://files.speakerdeck.com/presentations/bb7563d5f6084ab9b54484a18618c1f1/slide_42.jpg){kind=link}
![44 モニタリング(Alertmanager) Alertmanager APIからアラートを取得 [user01@bastion-001 ~]$ curl_auth="Authorization: Bearer $(oc whoami](https://files.speakerdeck.com/presentations/bb7563d5f6084ab9b54484a18618c1f1/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
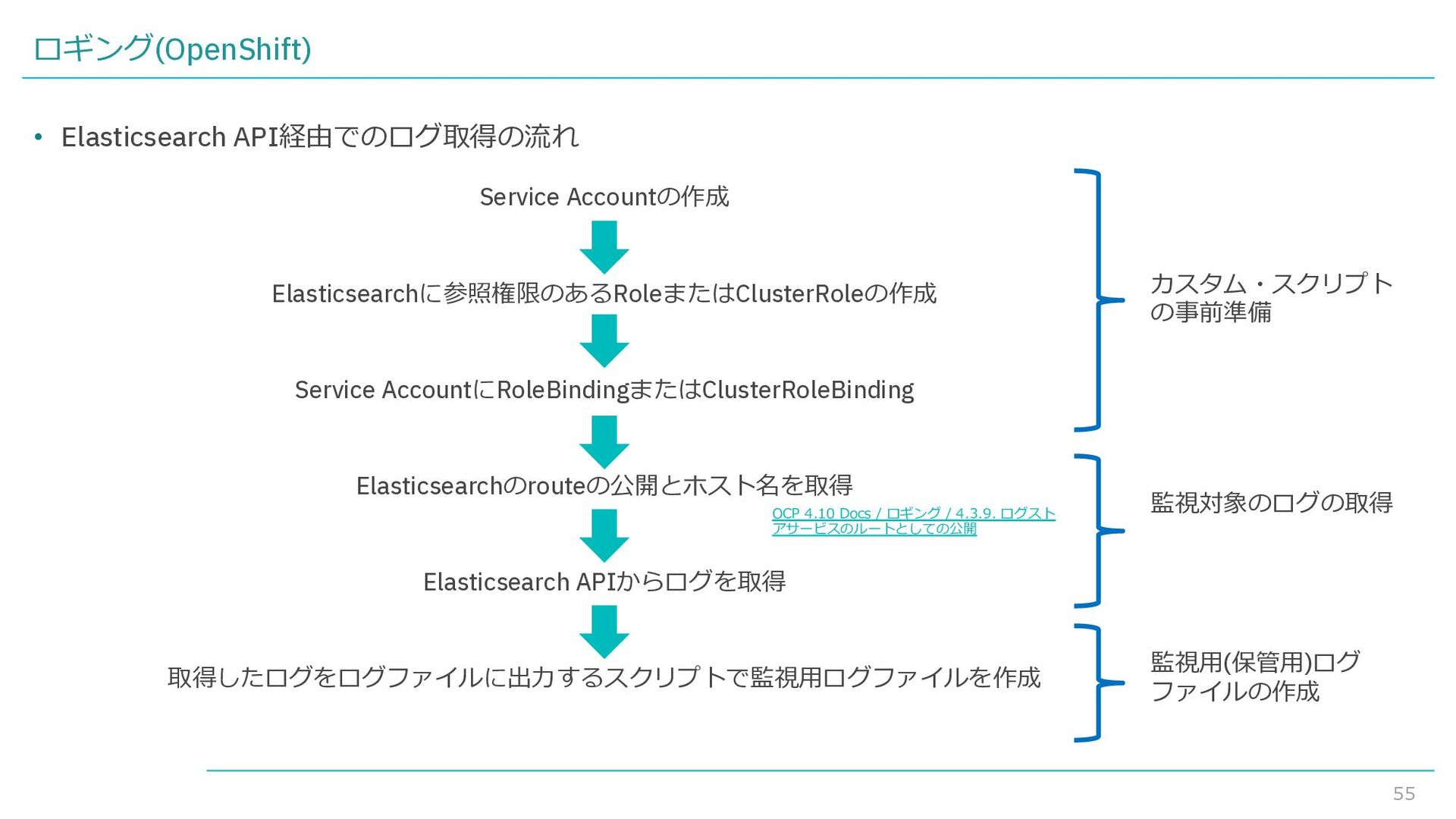{kind=link}
![56 ロギング(OpenShift) Elasticsearchのrouteの公開とホスト名を取得 [user01@bastion-001 ~]$ elasticsearch_host=$(oc get route elasticsearch -n](https://files.speakerdeck.com/presentations/bb7563d5f6084ab9b54484a18618c1f1/slide_55.jpg){kind=link}
{kind=link}
{kind=link}
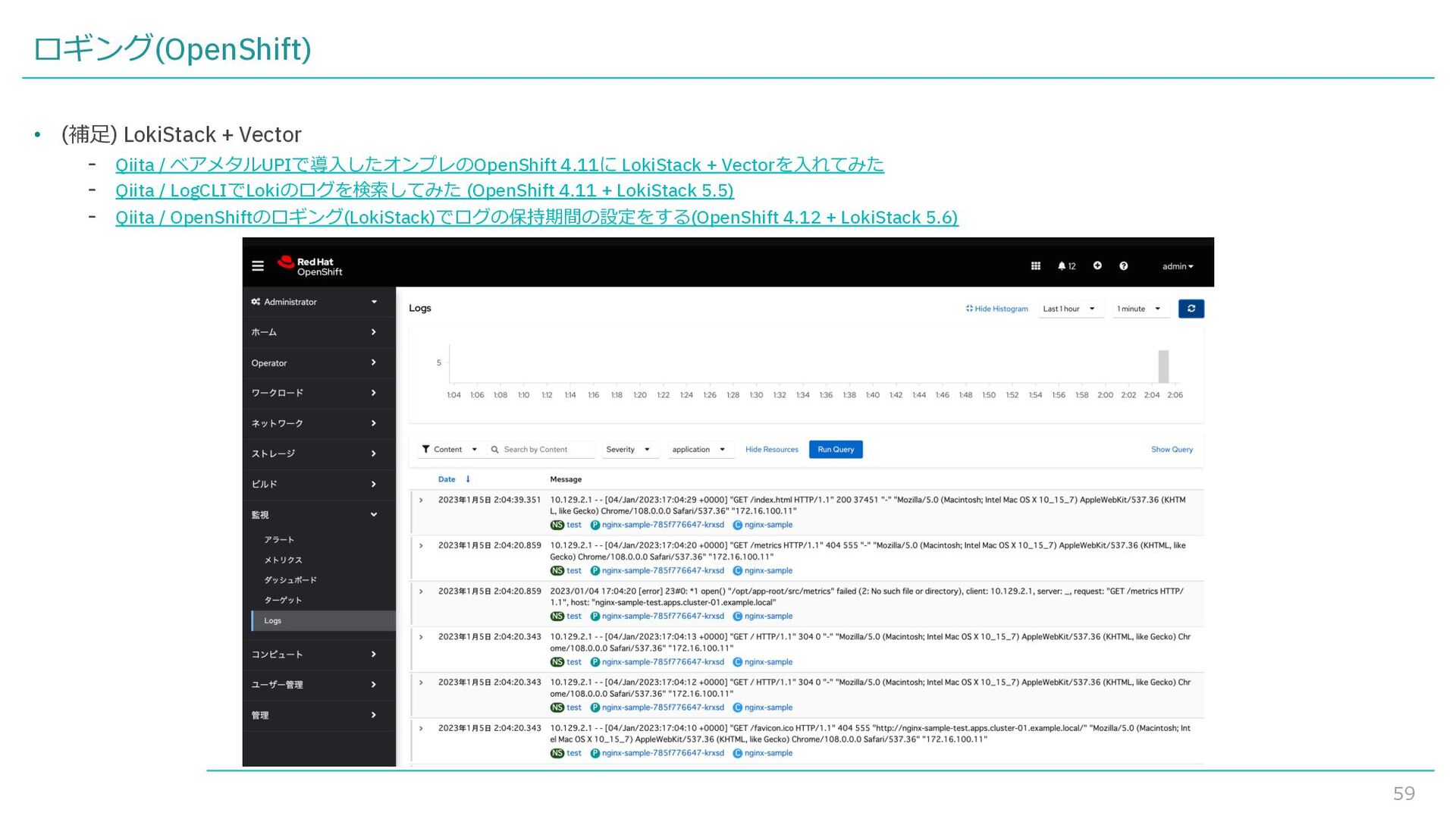{kind=link}
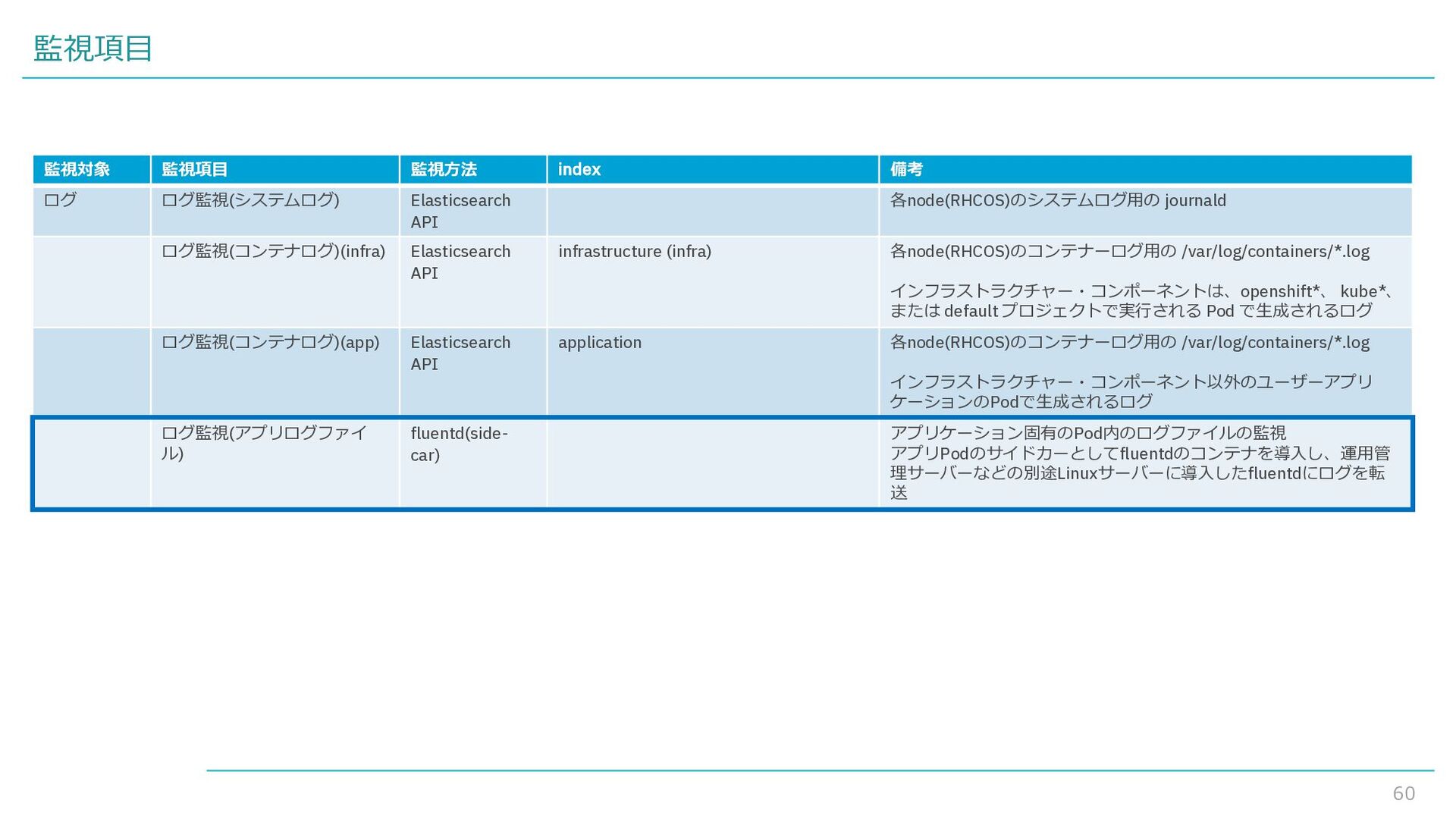{kind=link}
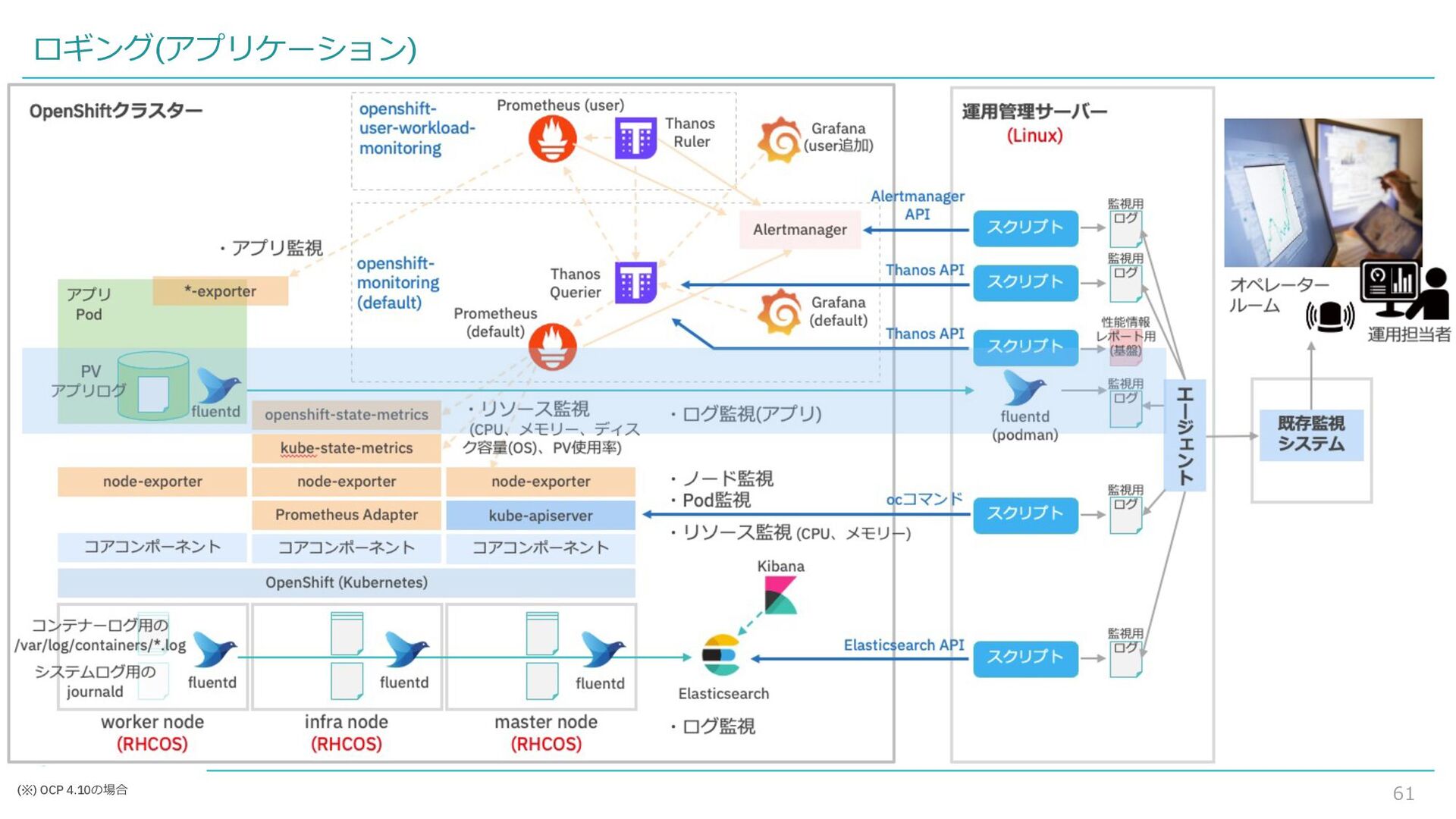{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}