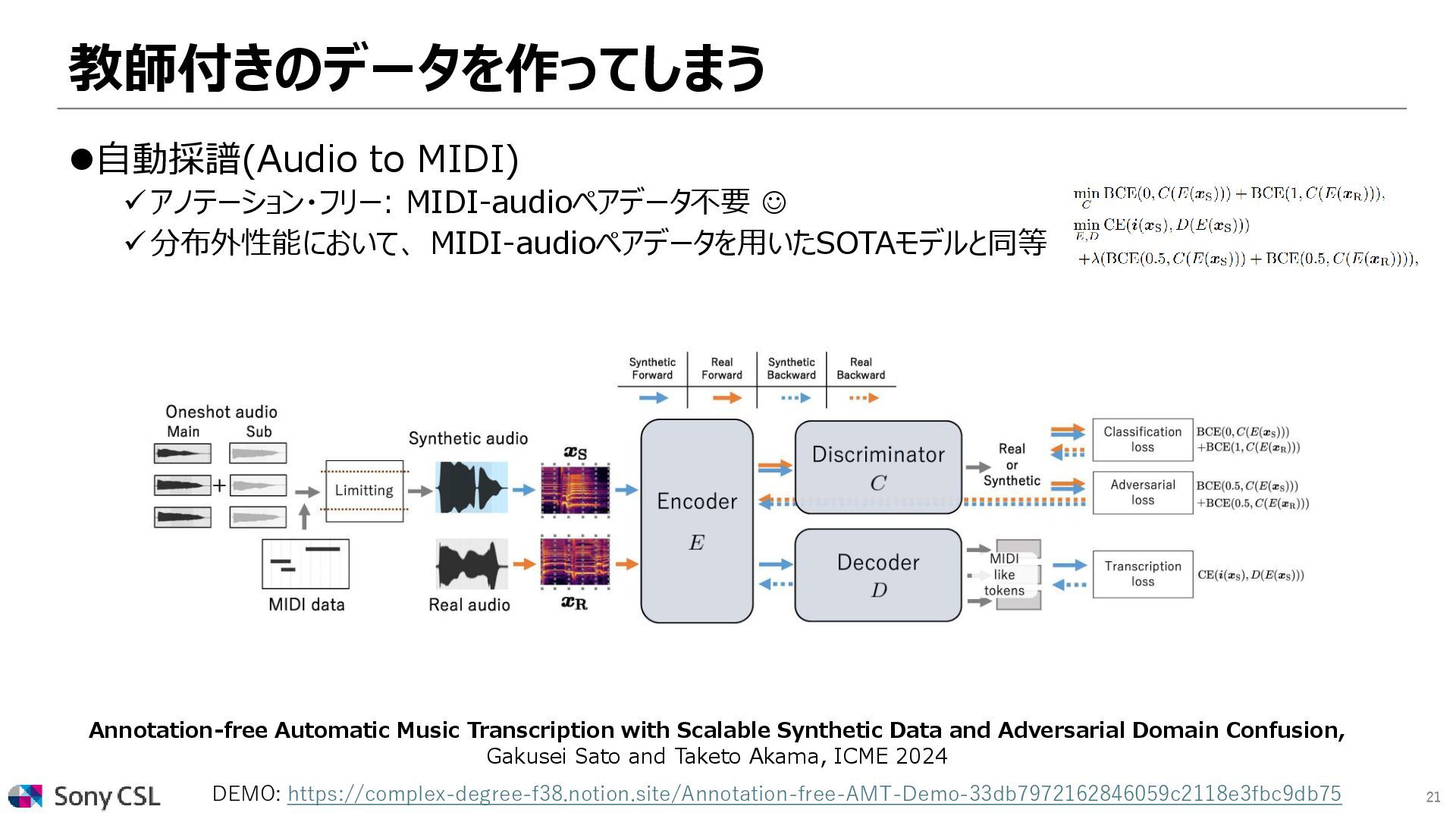
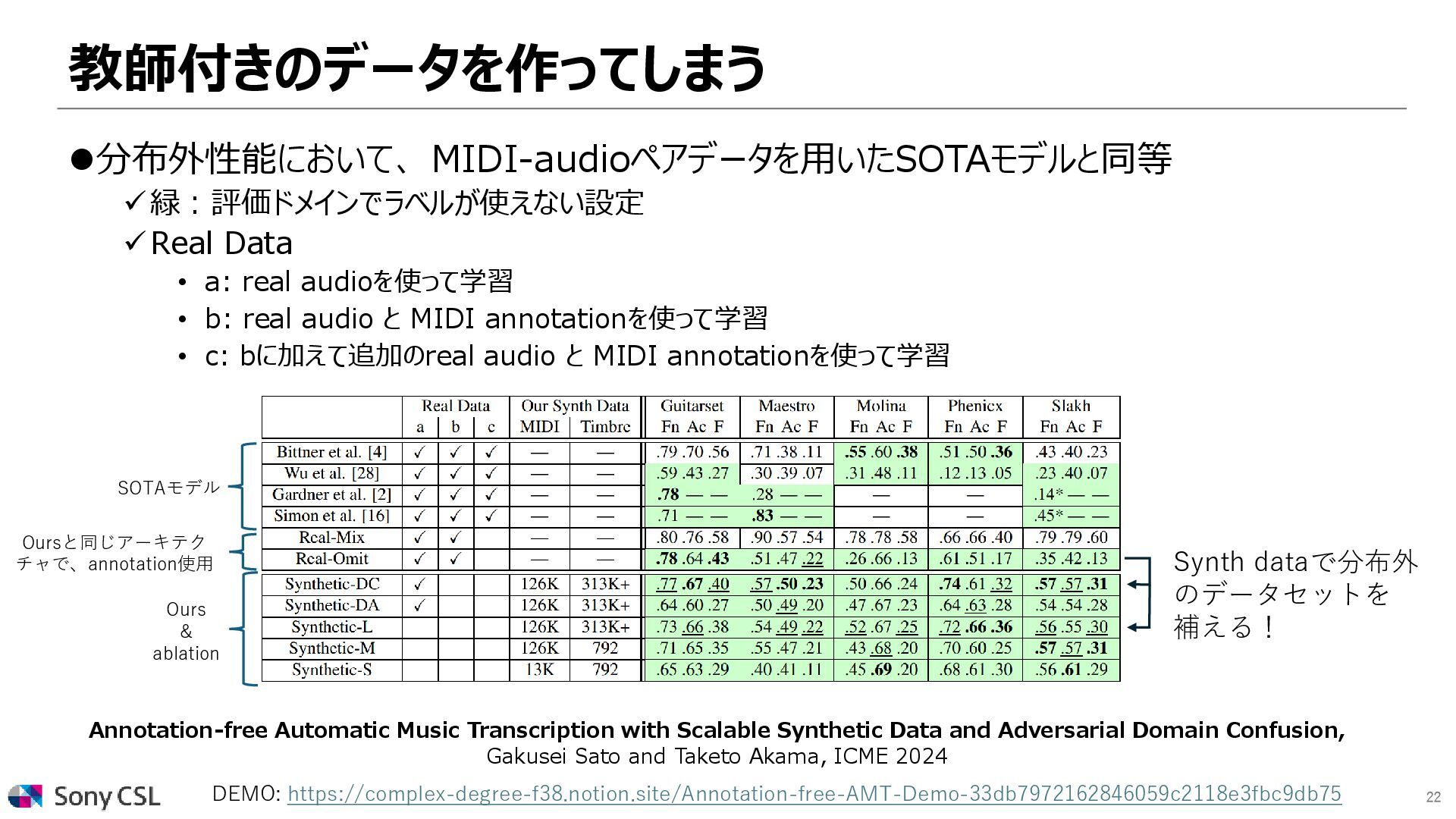
Annotation-free Automatic Music Transcription with Scalable Synthetic Data and Adversarial Domain Confusion, Gakusei Sato and Taketo Akama, ICME 2024 DEMO: https://complex-degree-f38.notion.site/Annotation-free-AMT-Demo-33db7972162846059c2118e3fbc9db75
• ユーザーの教育 • 自律的な改善 Music Proofreading with RefinPaint: Where and How to Modify Compositions given Context, Pedro Ramoneda, Martin Rocamora, and Taketo Akama, ISMIR 2024 DEMO: https://refinpaint.github.io/
Music Proofreading with RefinPaint: Where and How to Modify Compositions given Context, Pedro Ramoneda, Martin Rocamora, and Taketo Akama, ISMIR 2024 DEMO: https://refinpaint.github.io/
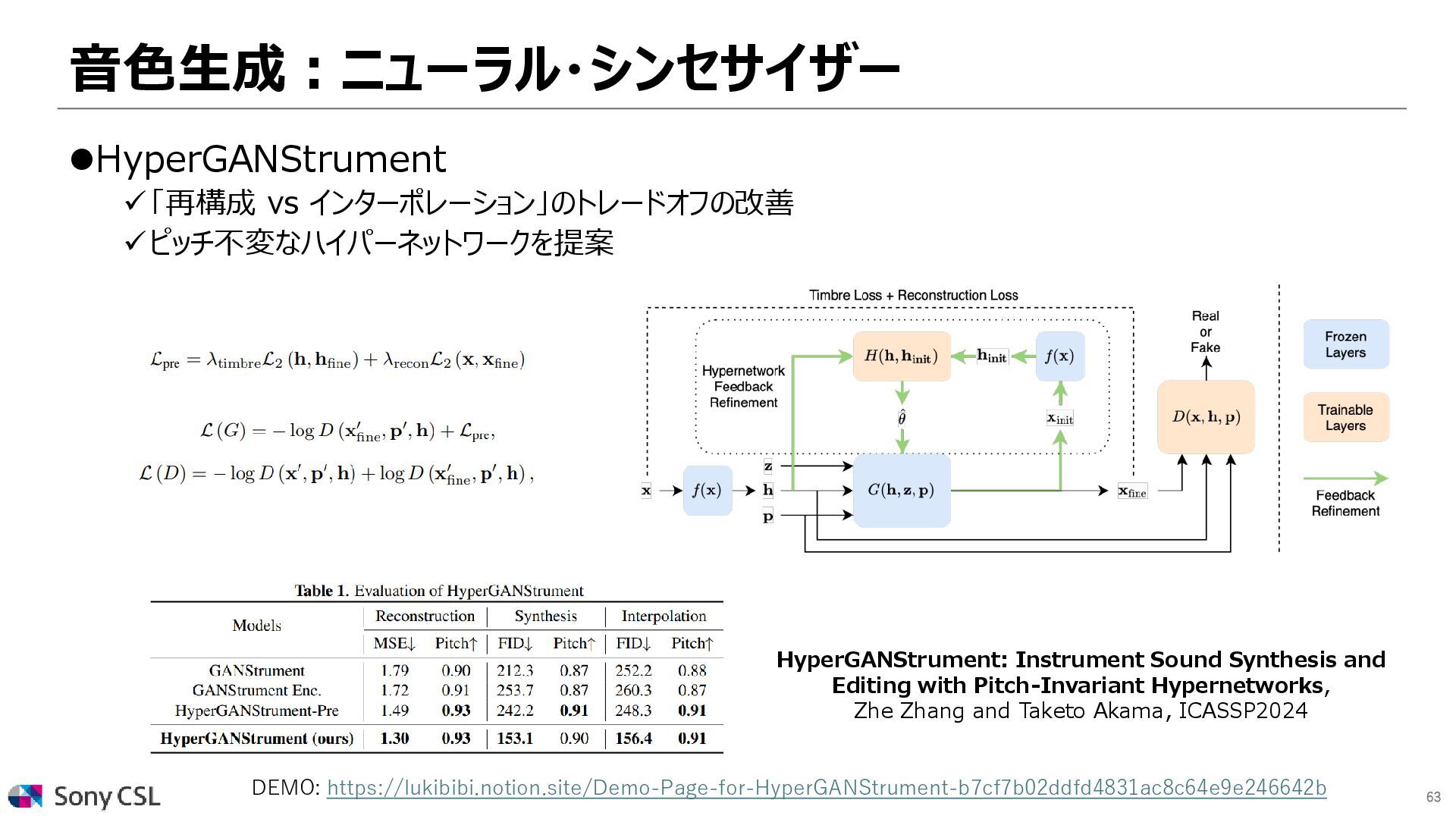
Synthesis and Editing with Pitch-Invariant Hypernetworks, Zhe Zhang and Taketo Akama, ICASSP2024 DEMO: https://lukibibi.notion.site/Demo-Page-for-HyperGANStrument-b7cf7b02ddfd4831ac8c64e9e246642b
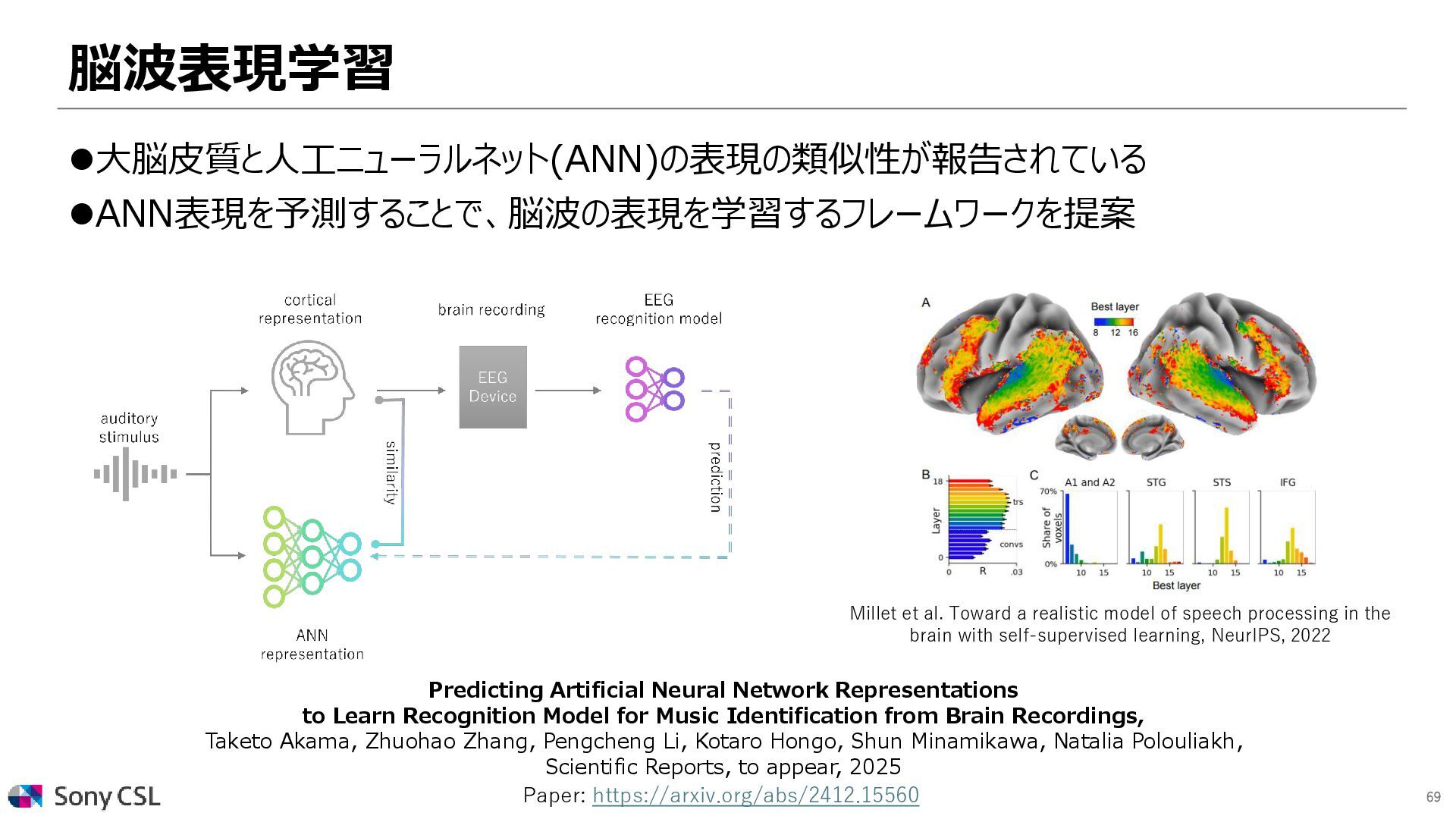
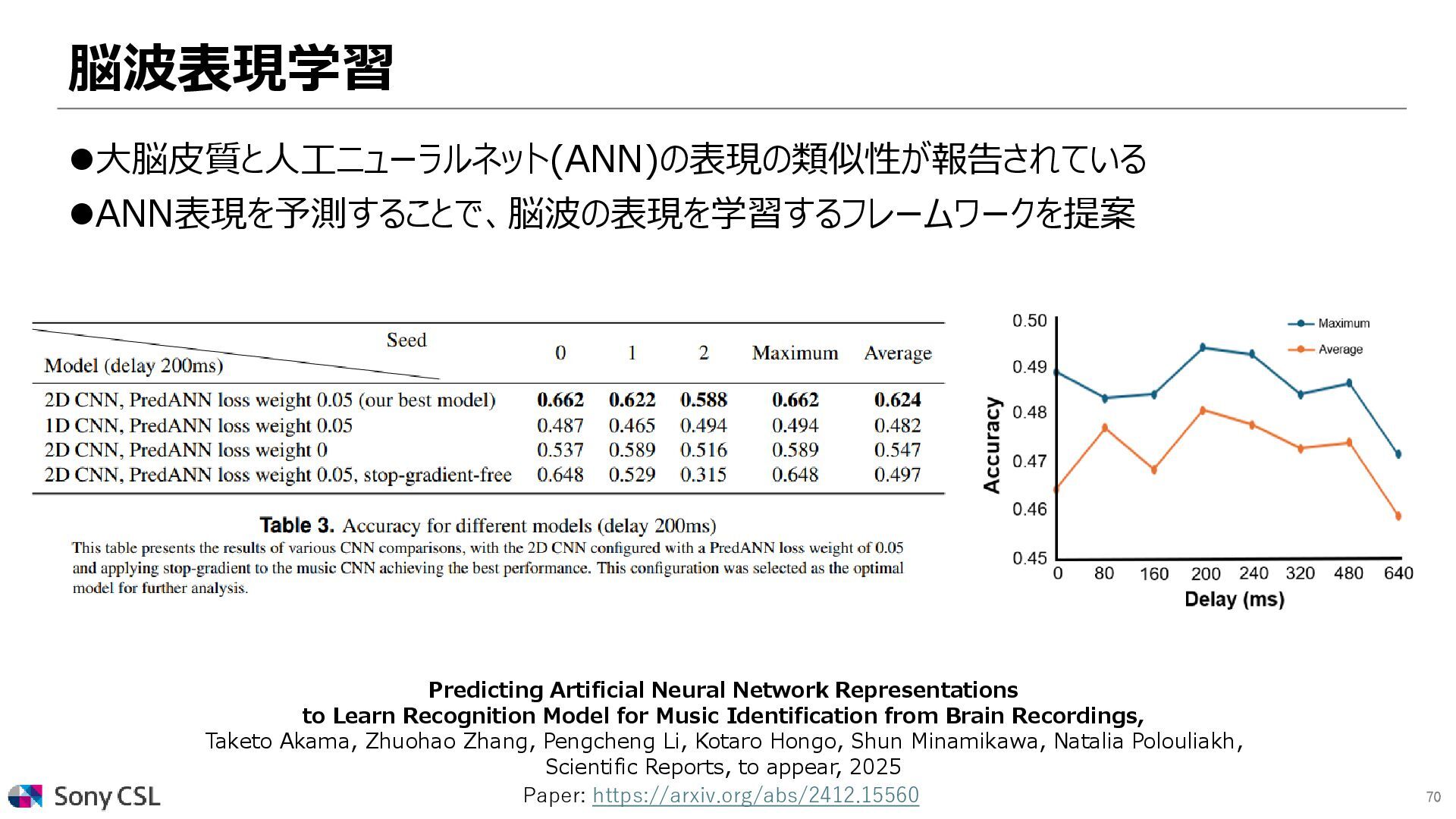
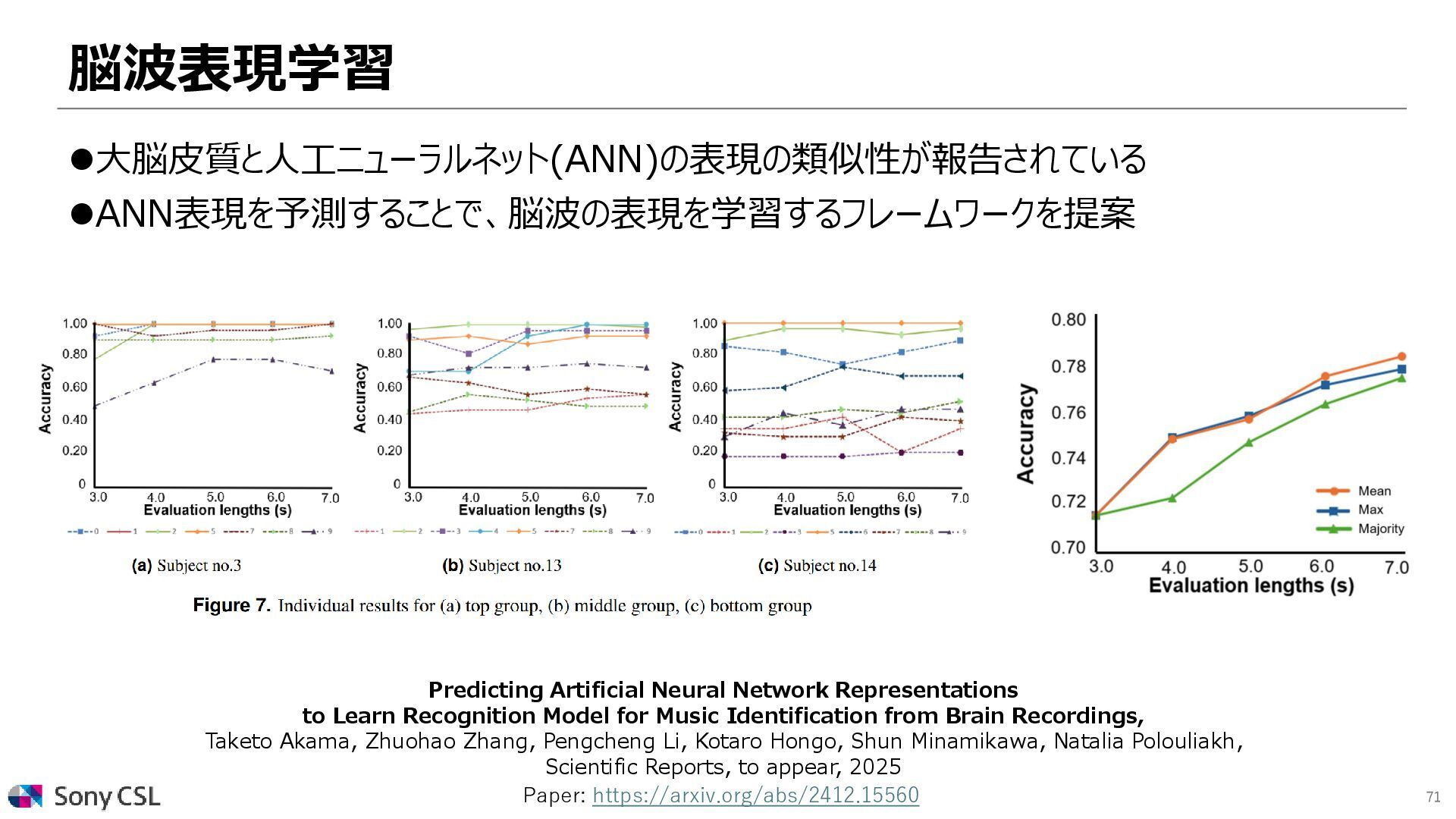
Model for Music Identification from Brain Recordings, Taketo Akama, Zhuohao Zhang, Pengcheng Li, Kotaro Hongo, Shun Minamikawa, Natalia Polouliakh, Scientific Reports, to appear, 2025 ⚫大脳皮質と人工ニューラルネット(ANN)の表現の類似性が報告されている ⚫ANN表現を予測することで、脳波の表現を学習するフレームワークを提案 Paper: https://arxiv.org/abs/2412.15560 Millet et al. Toward a realistic model of speech processing in the brain with self-supervised learning, NeurIPS, 2022
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
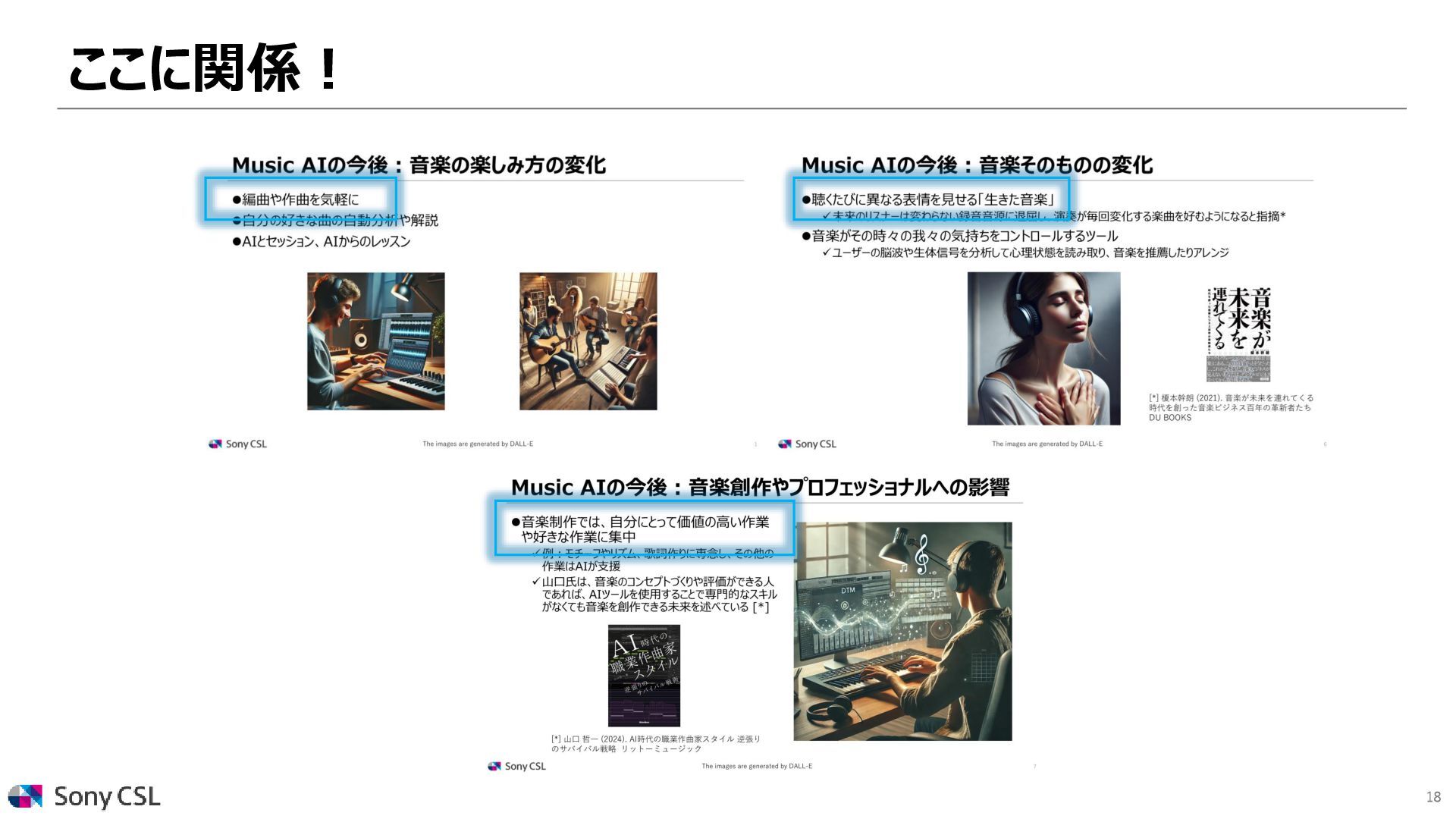
![6 Music AIの今後:音楽そのものの変化 ⚫聴くたびに異なる表情を見せる「生きた音楽」 ✓未来のリスナーは変わらない録音音源に退屈し、演奏が毎回変化する楽曲を好むようになると指摘[1] ⚫音楽がその時々の我々の気持ちをコントロールするツール ✓ユーザーの脳波や生体信号を分析して心理状態を読み取り、音楽を推薦したりアレンジ The images are](https://files.speakerdeck.com/presentations/18587e80c7f44913b1fdb48f441a13cb/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
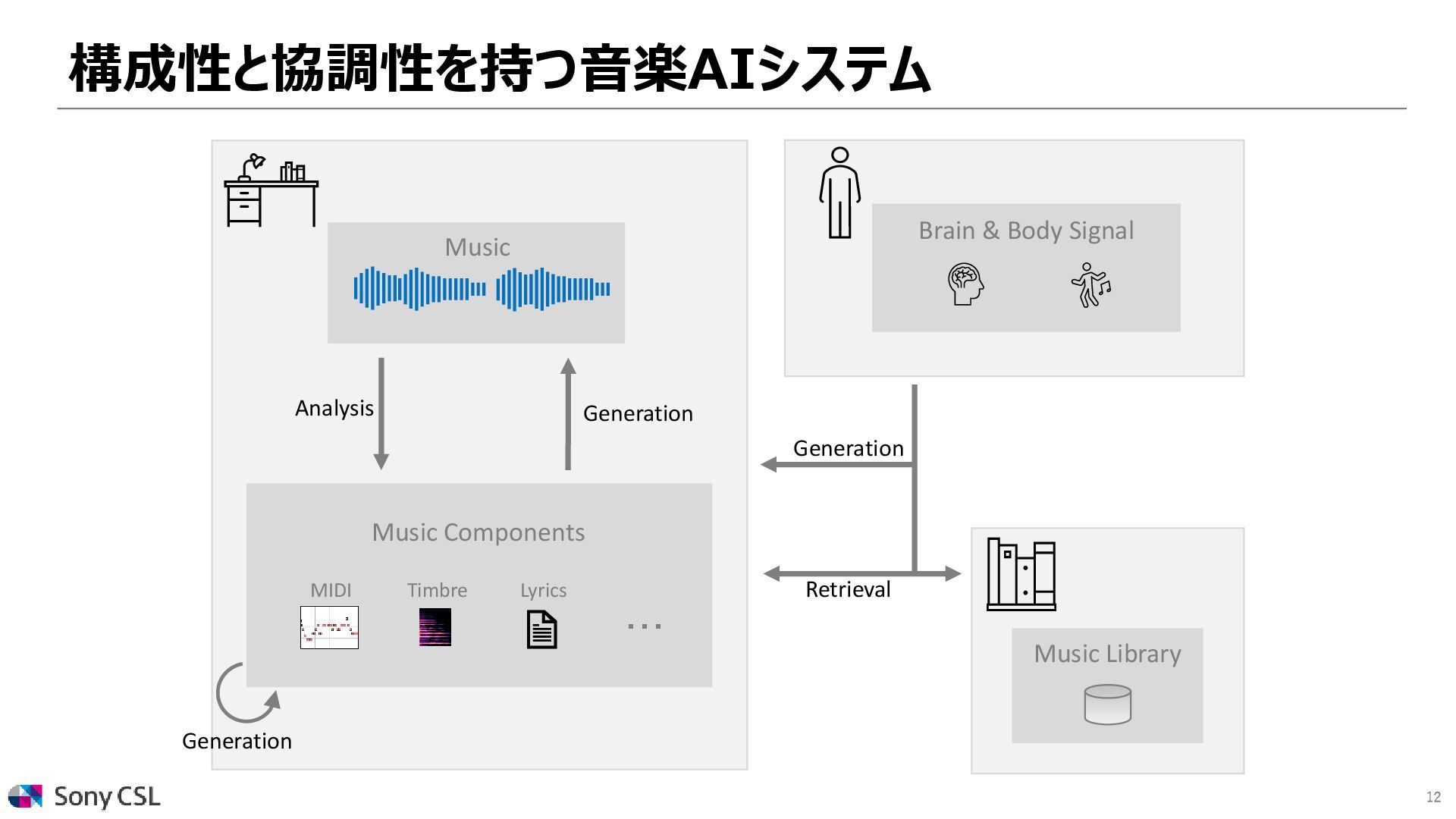{kind=link}
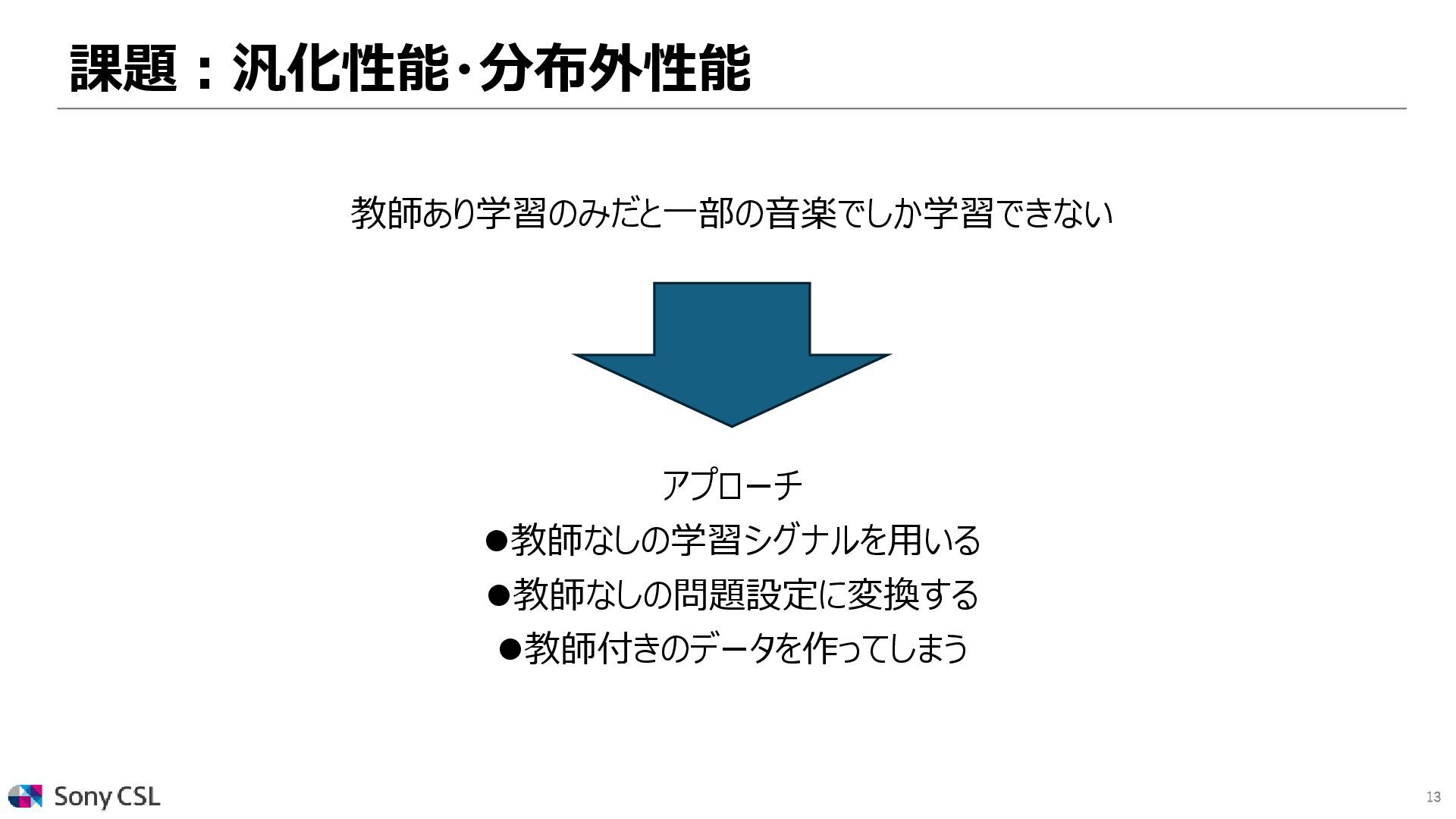{kind=link}
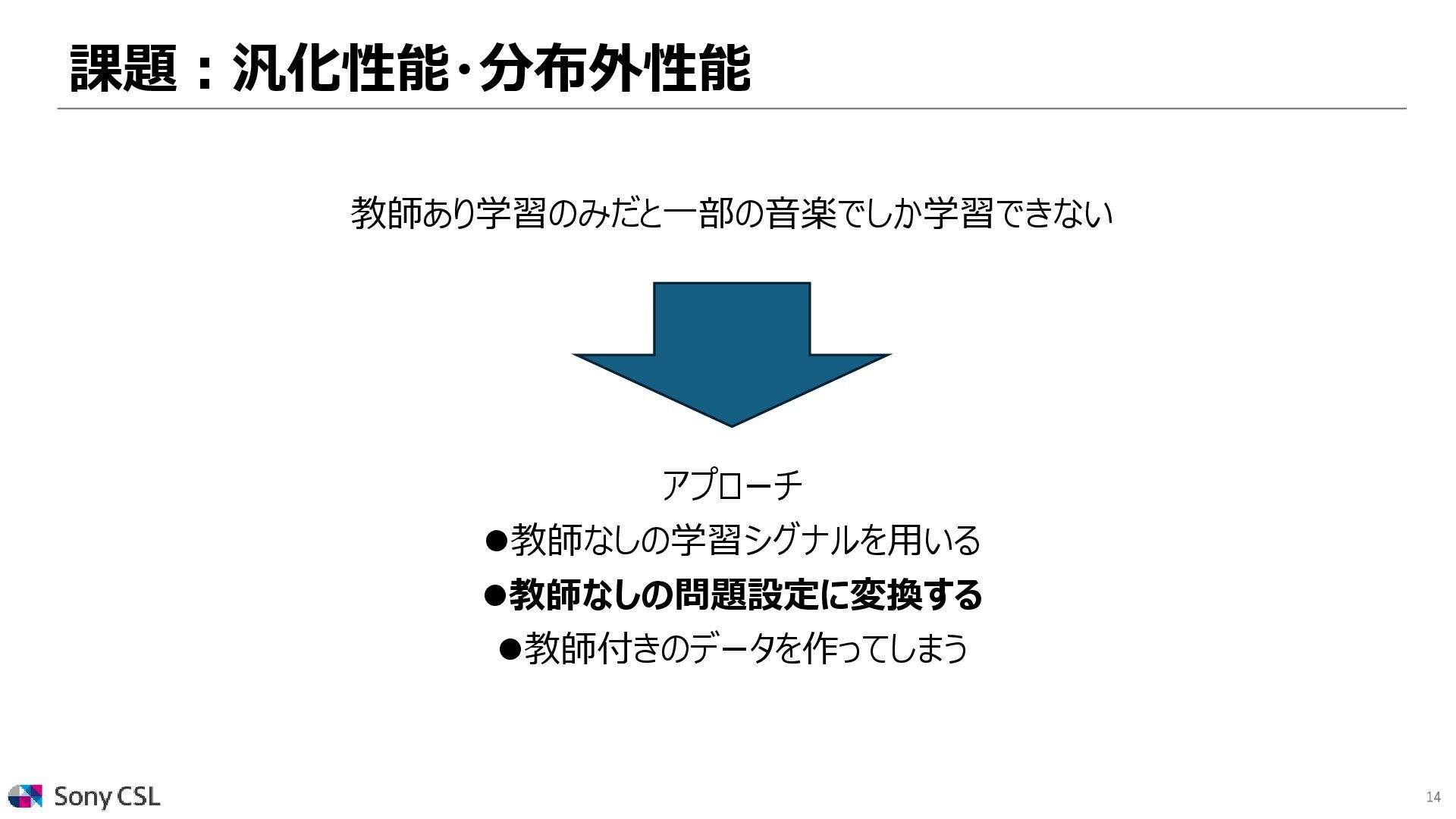{kind=link}
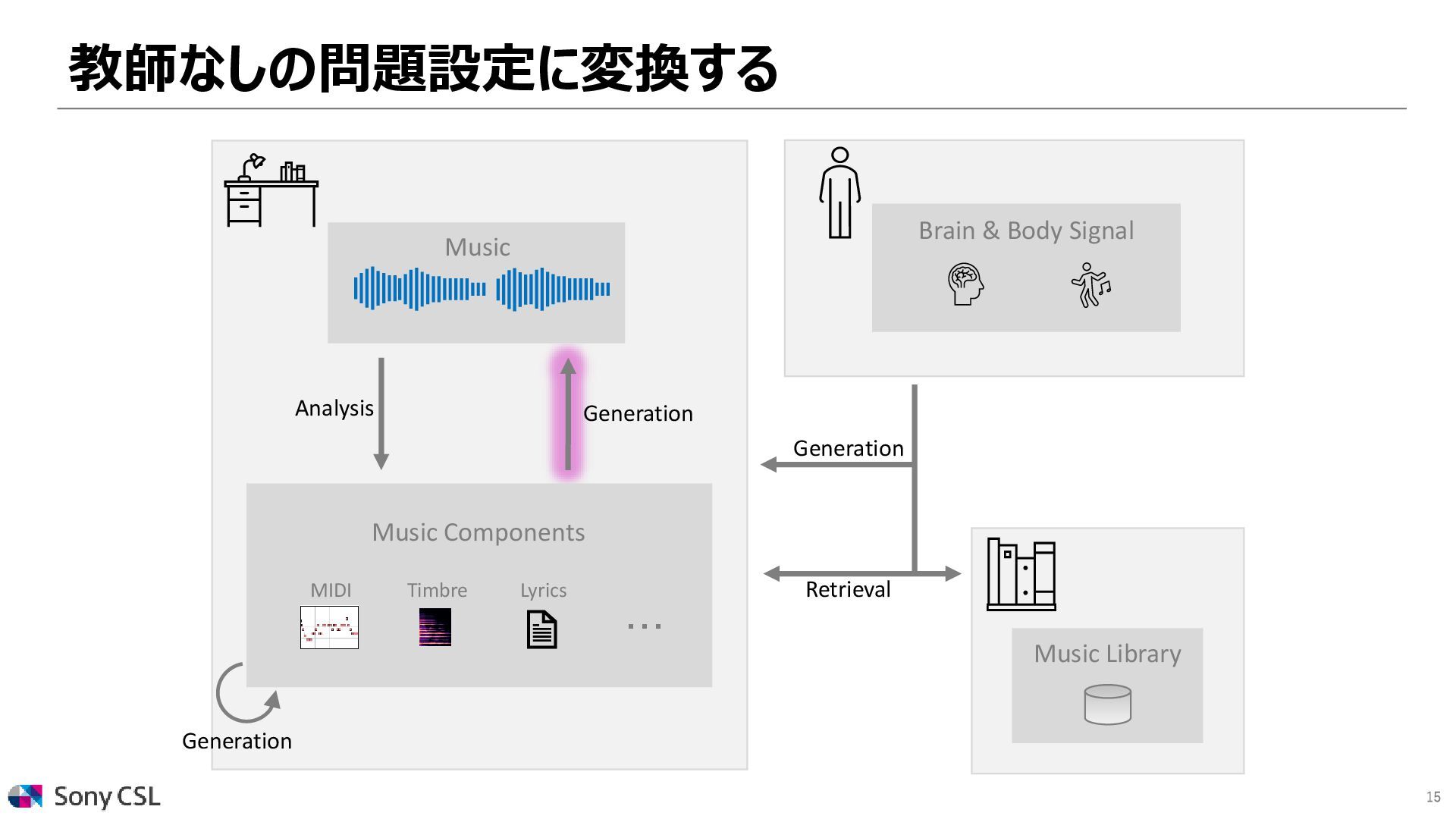{kind=link}
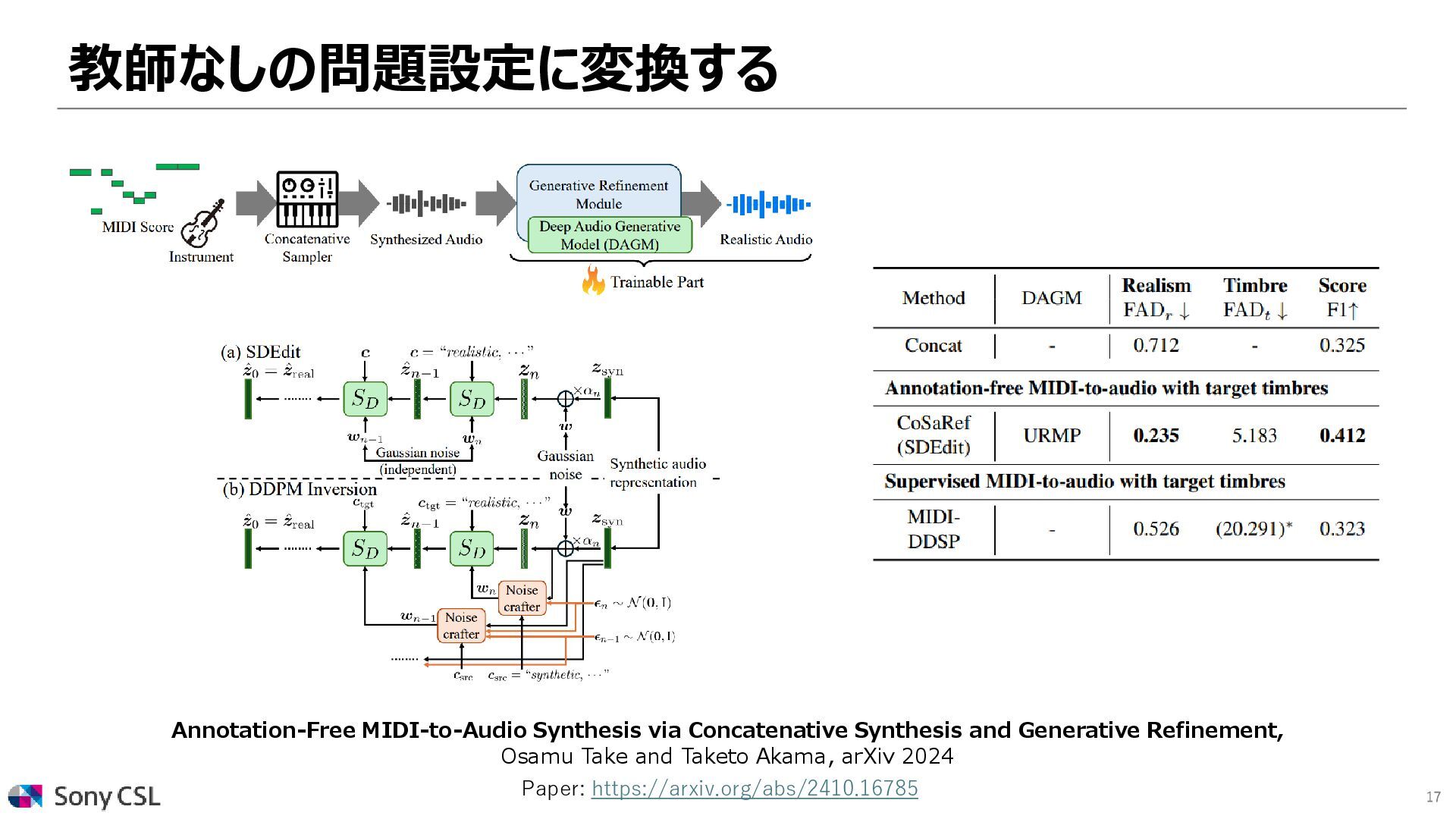
![16 Concatenative sampler Ours (CoSaRef) MIDI-DDSP [Wu+ 2022] 教師なしの問題設定に変換する ⚫CoSaRef:](https://files.speakerdeck.com/presentations/18587e80c7f44913b1fdb48f441a13cb/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
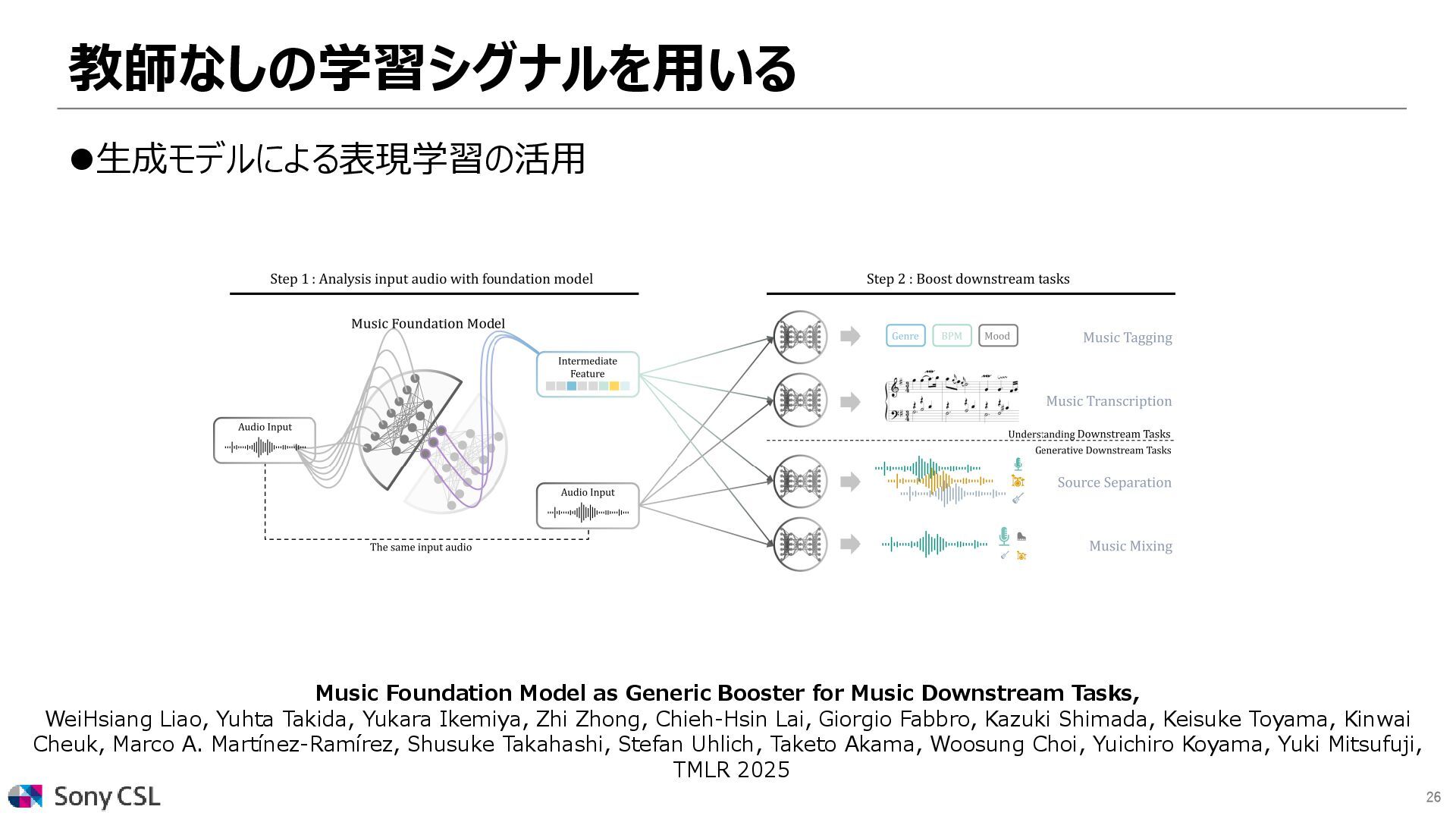{kind=link}
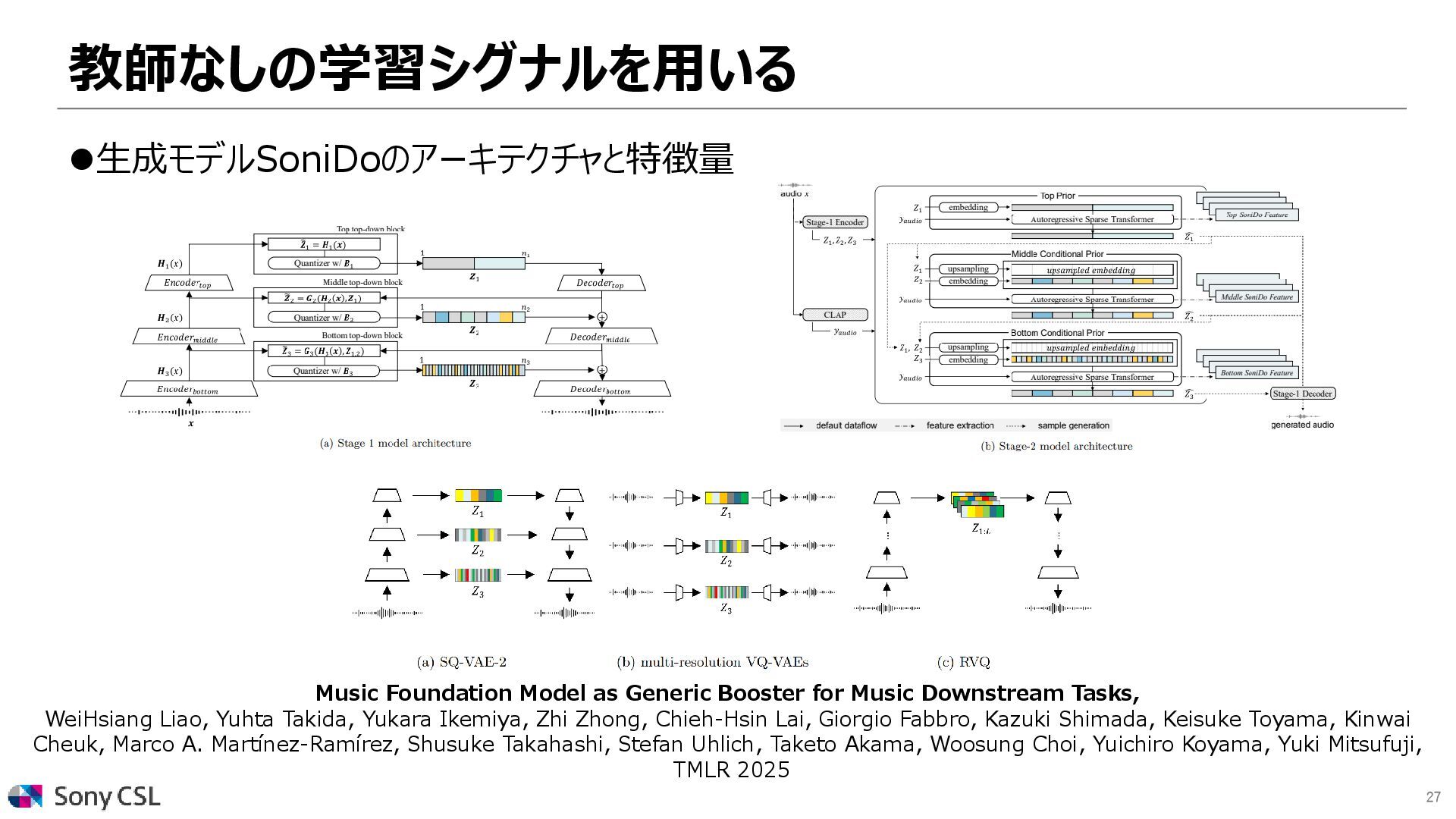{kind=link}
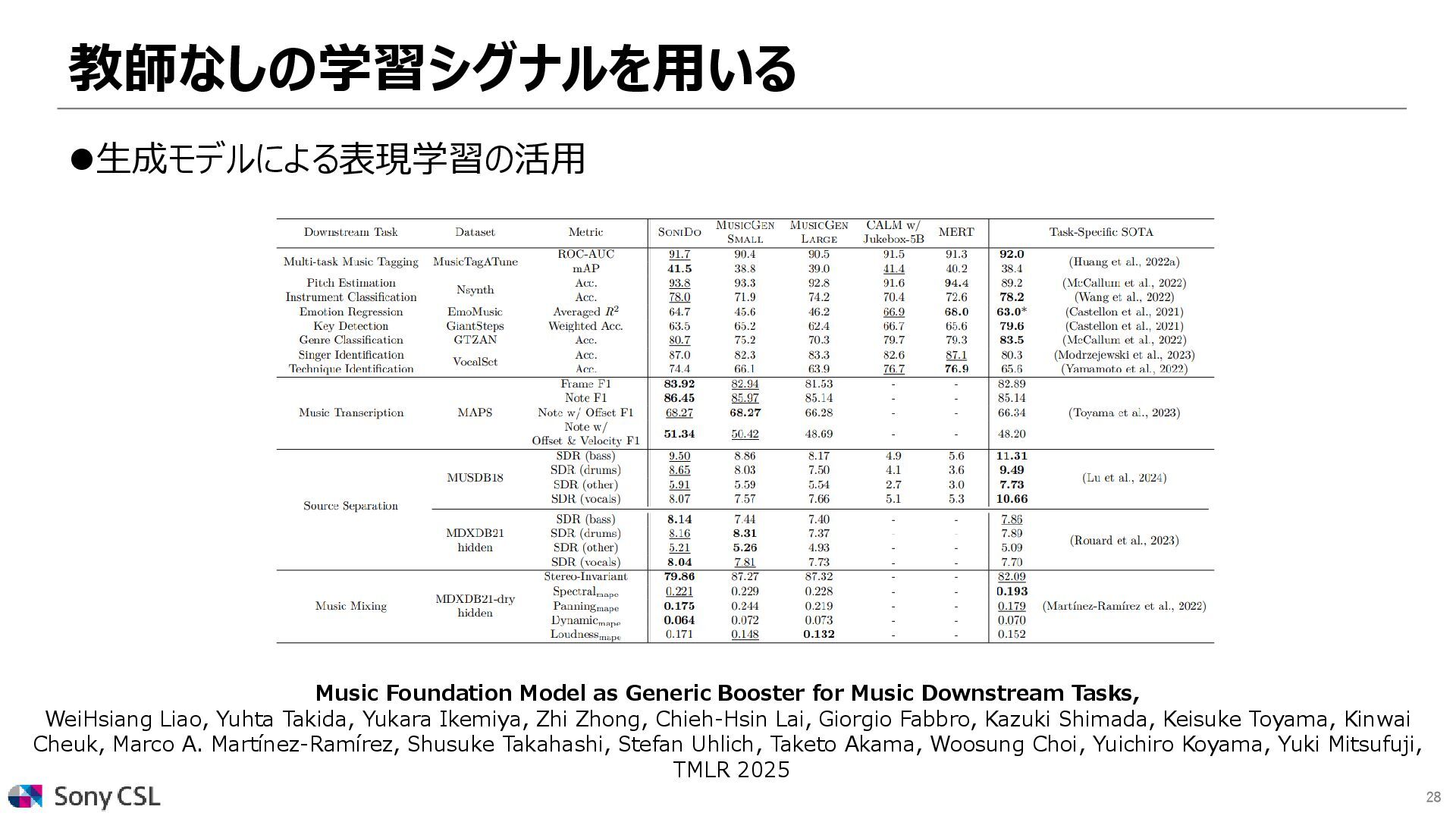{kind=link}
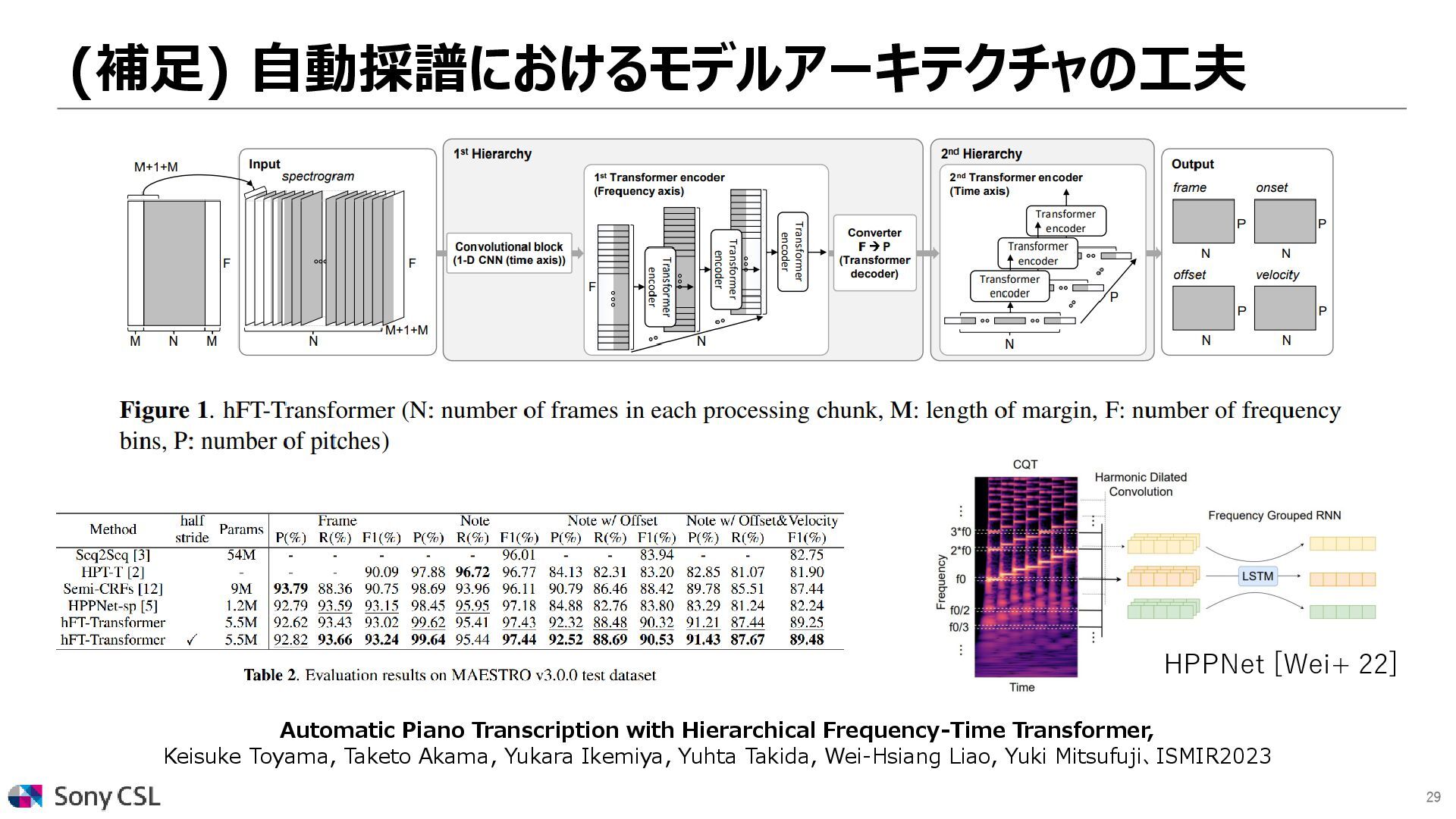{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
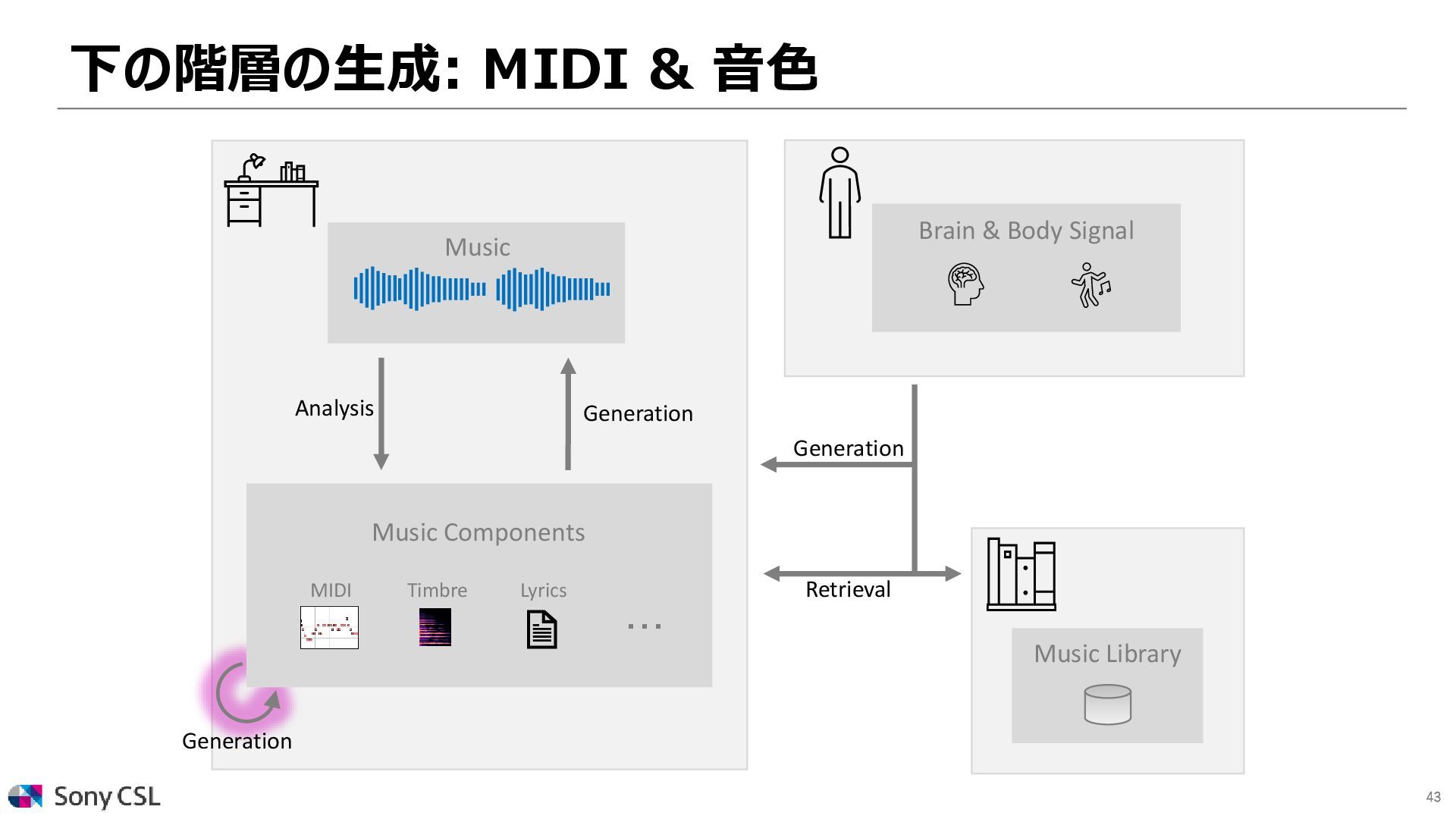{kind=link}
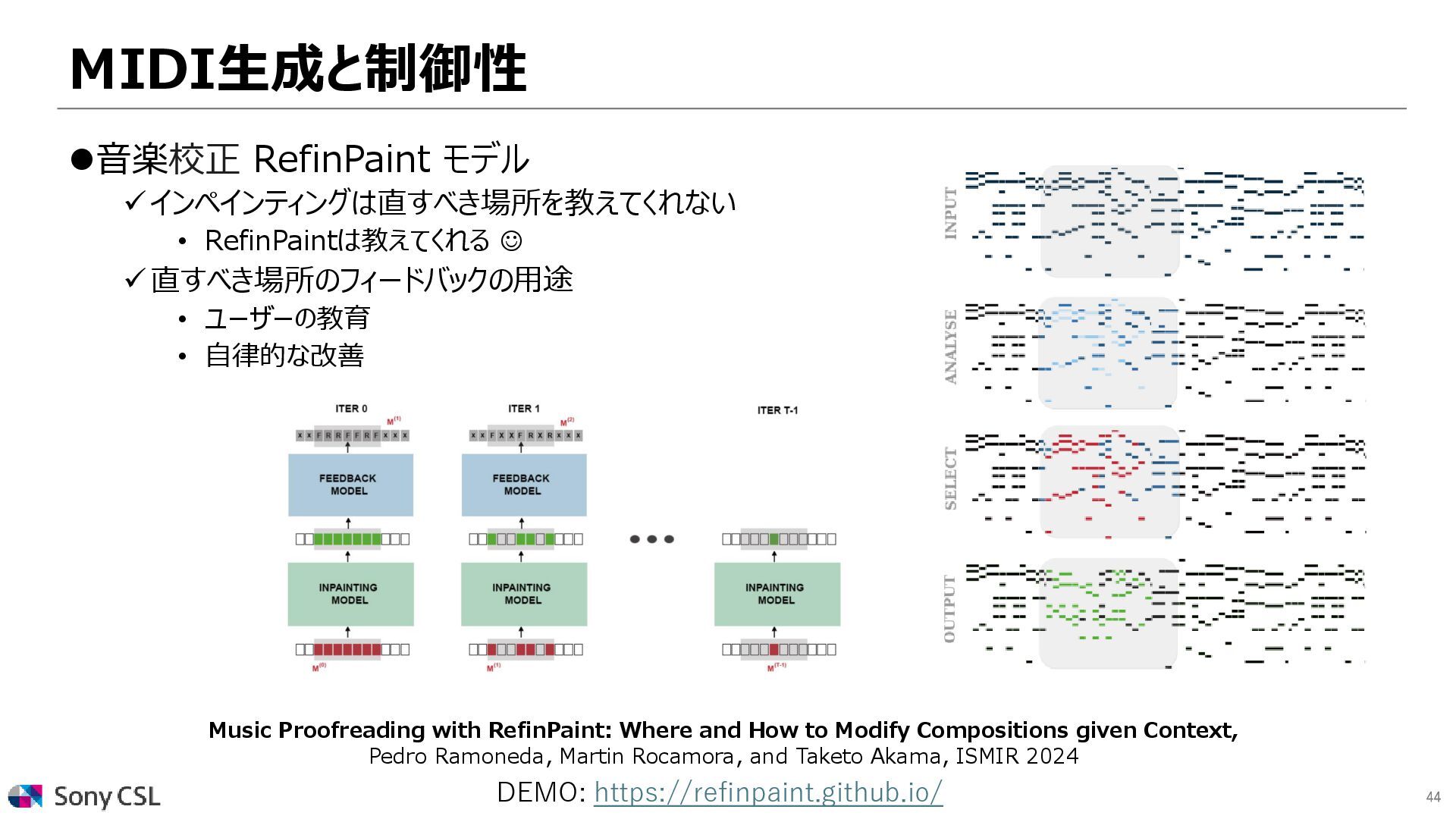{kind=link}
{kind=link}
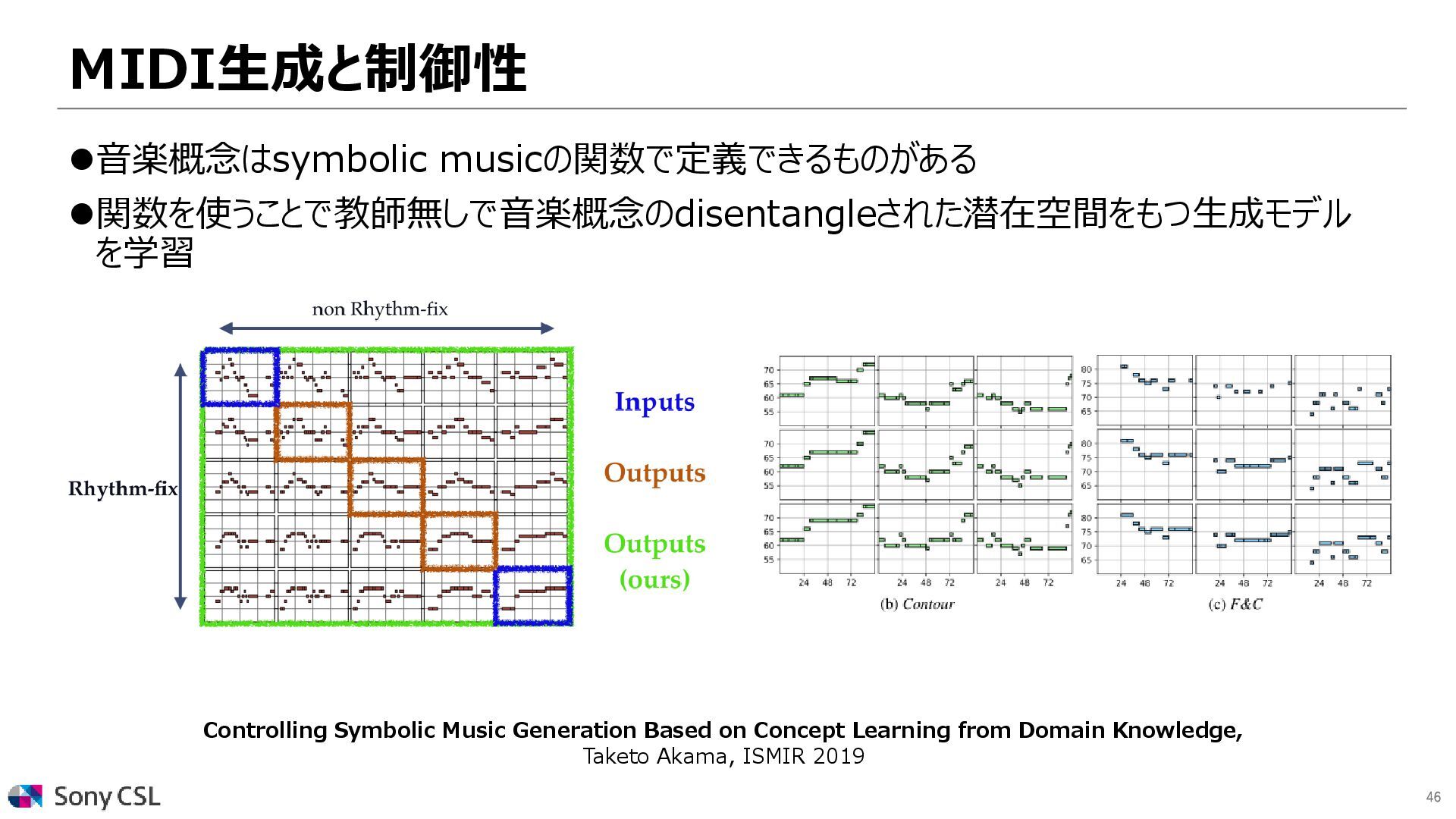{kind=link}
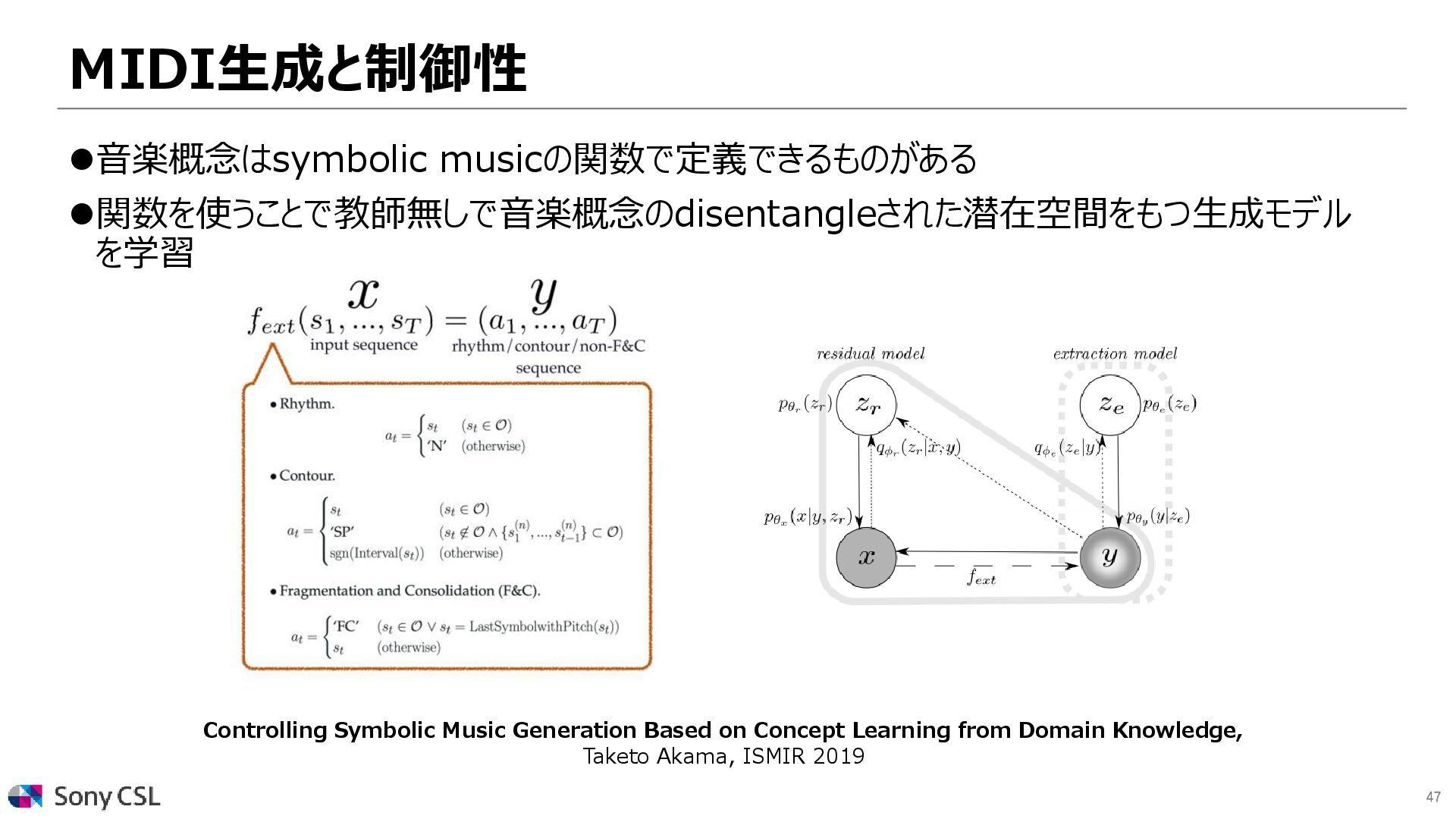{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
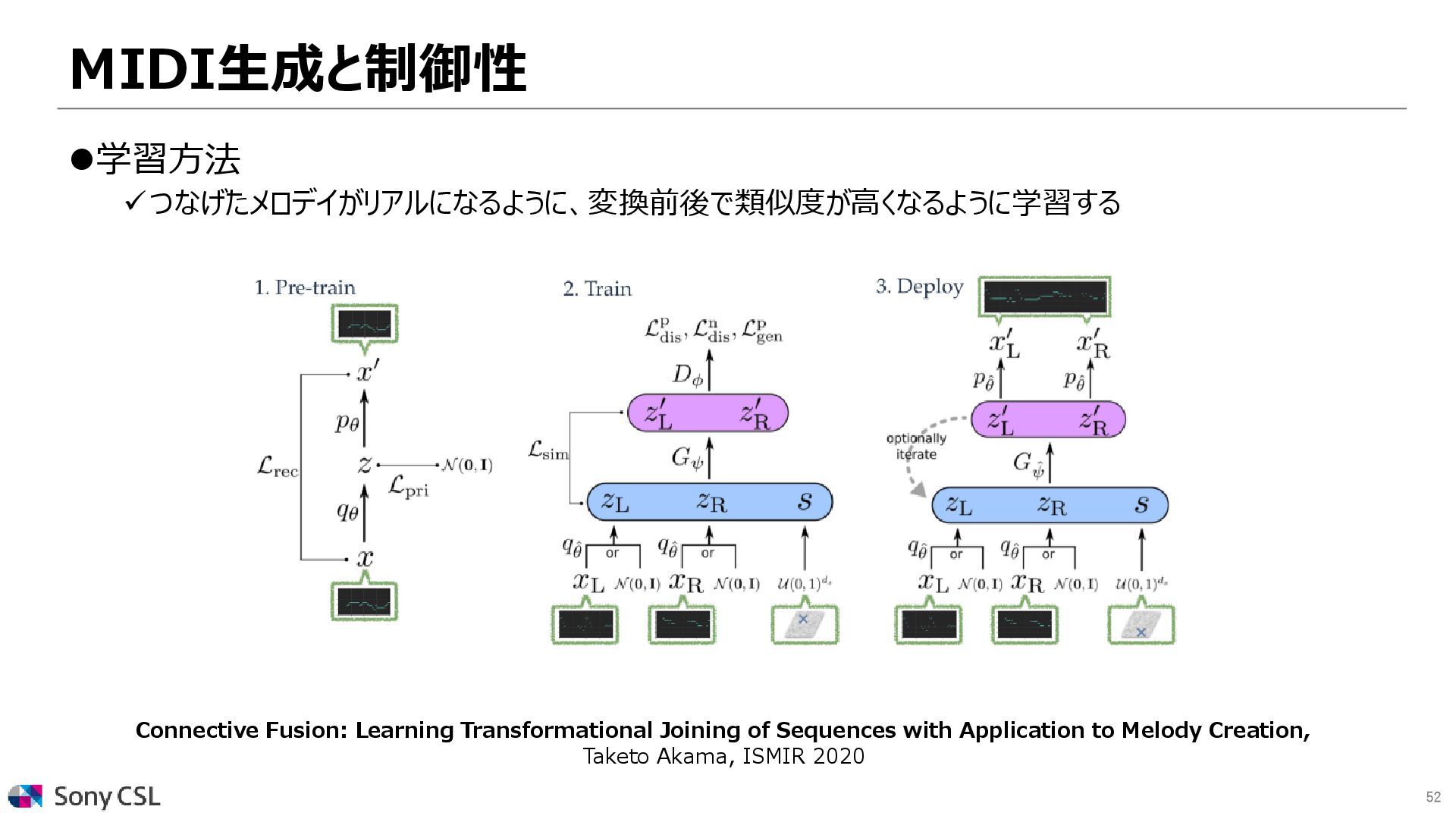{kind=link}
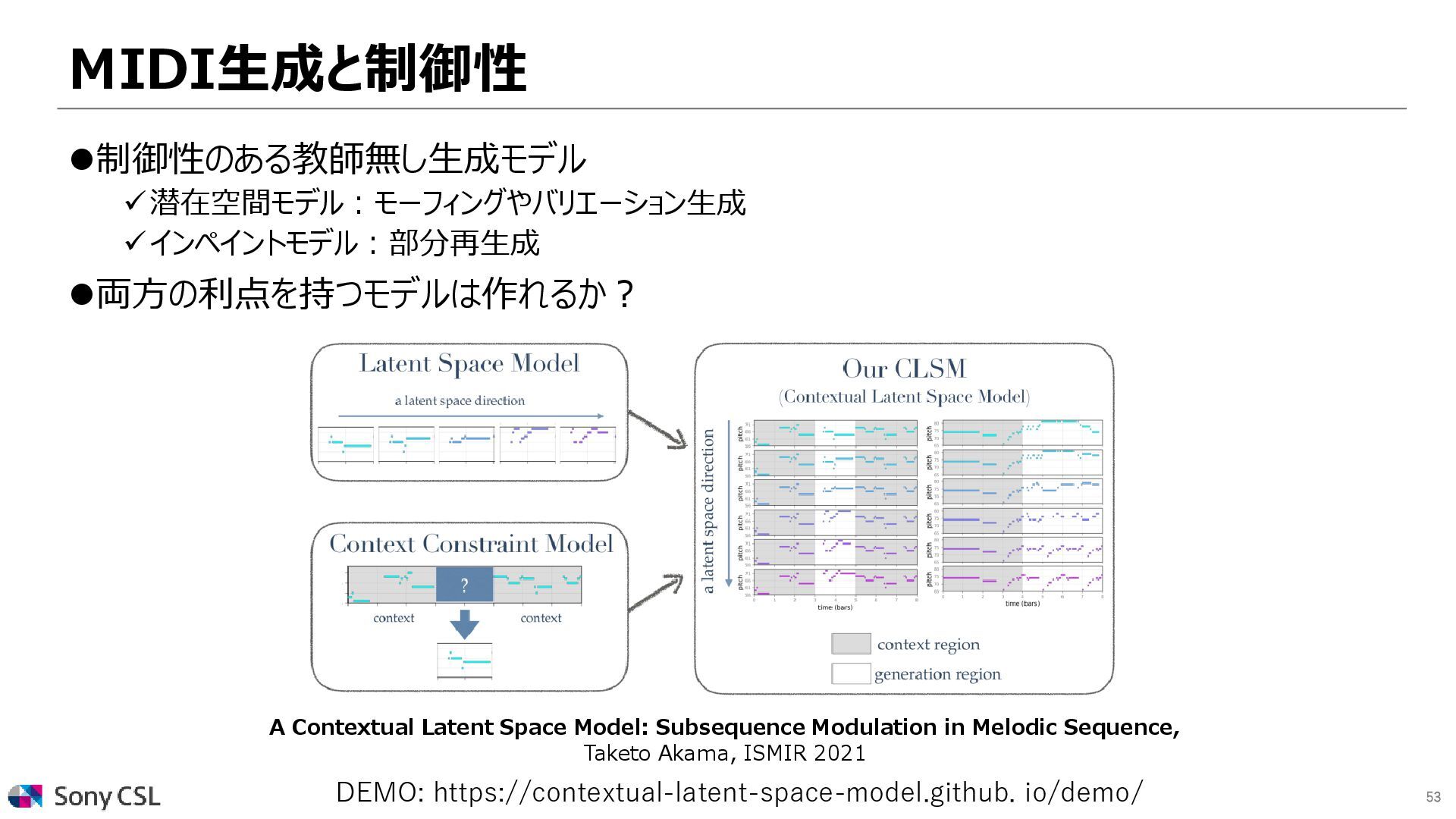{kind=link}
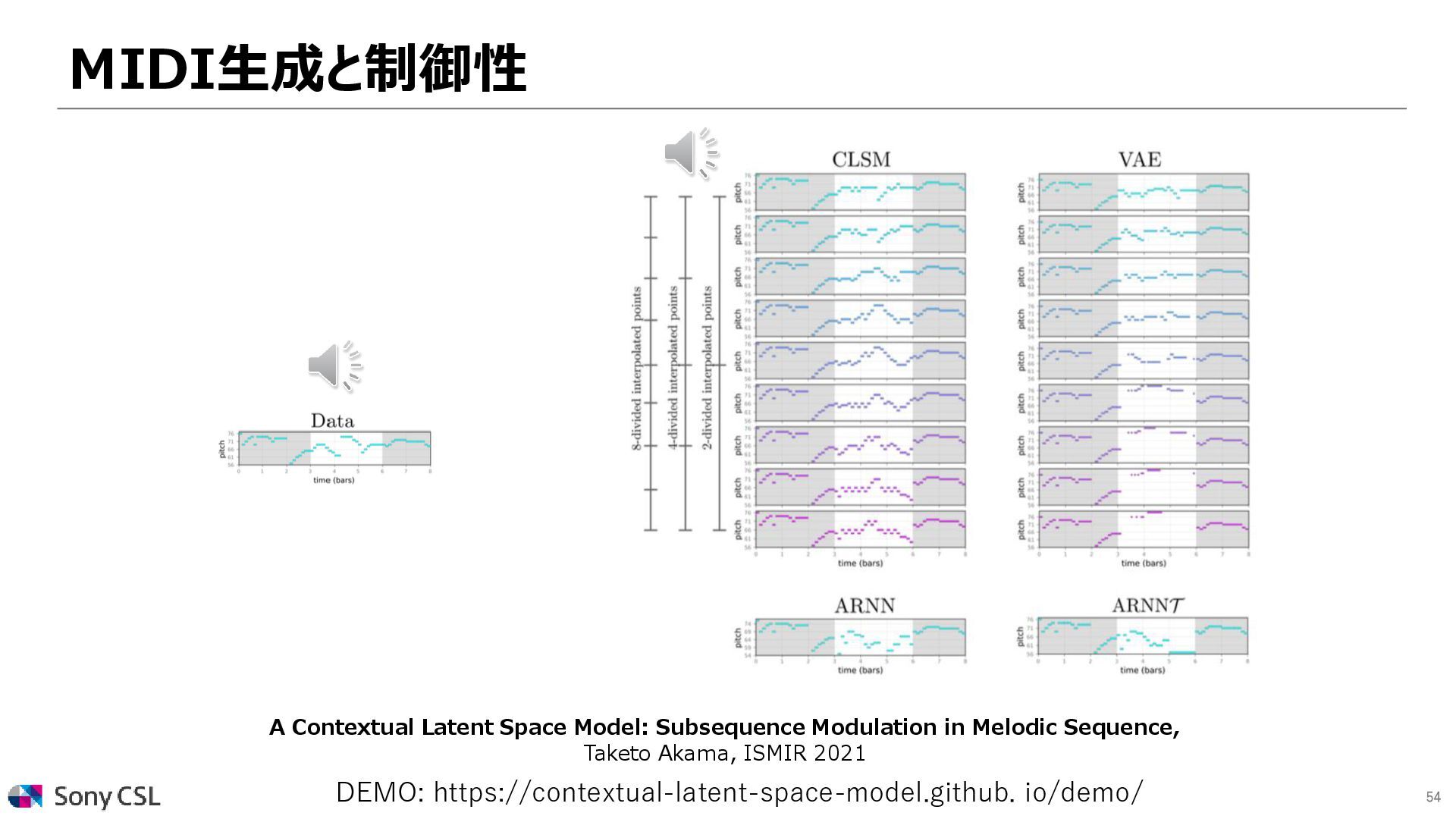{kind=link}
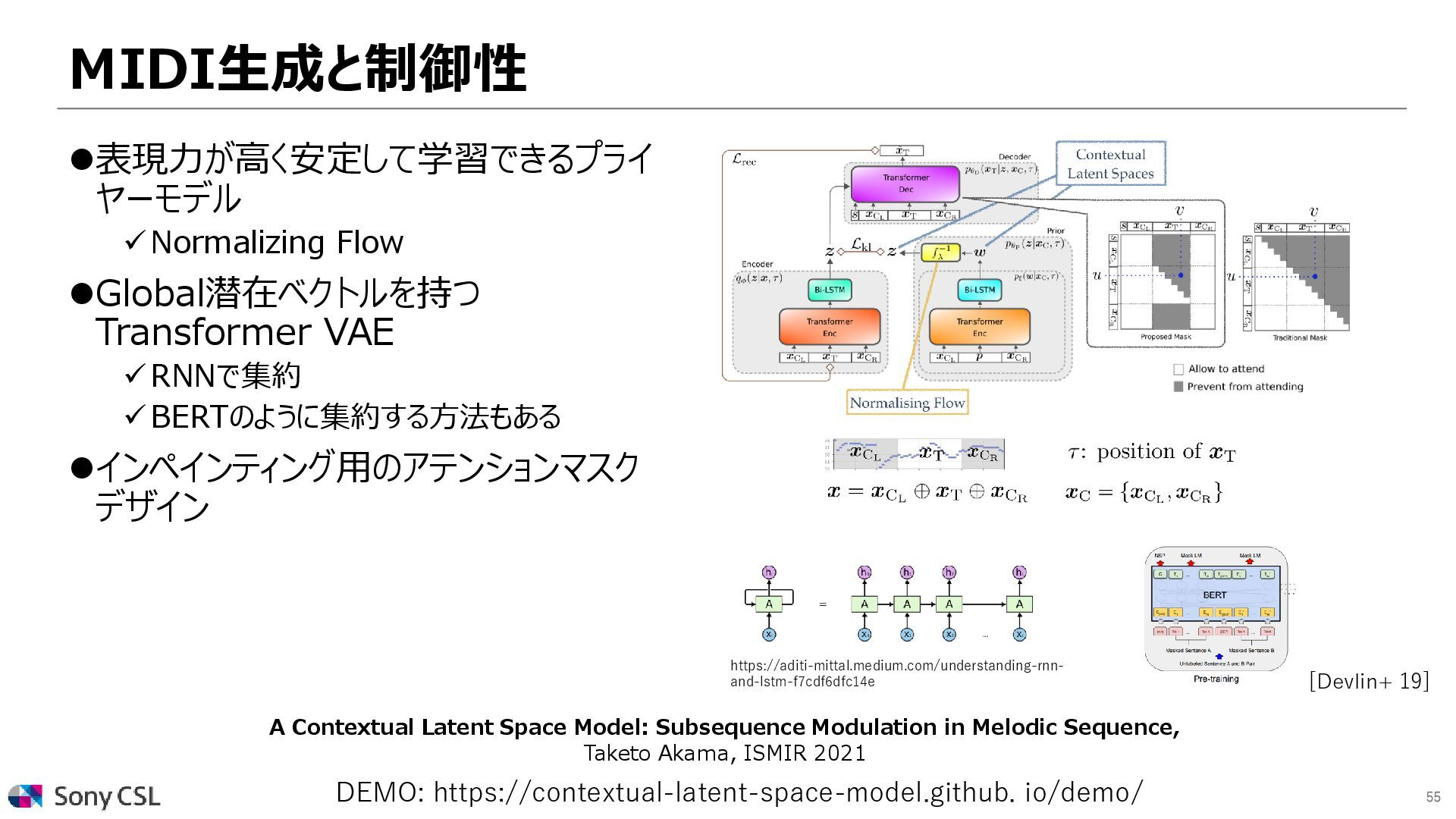{kind=link}
{kind=link}
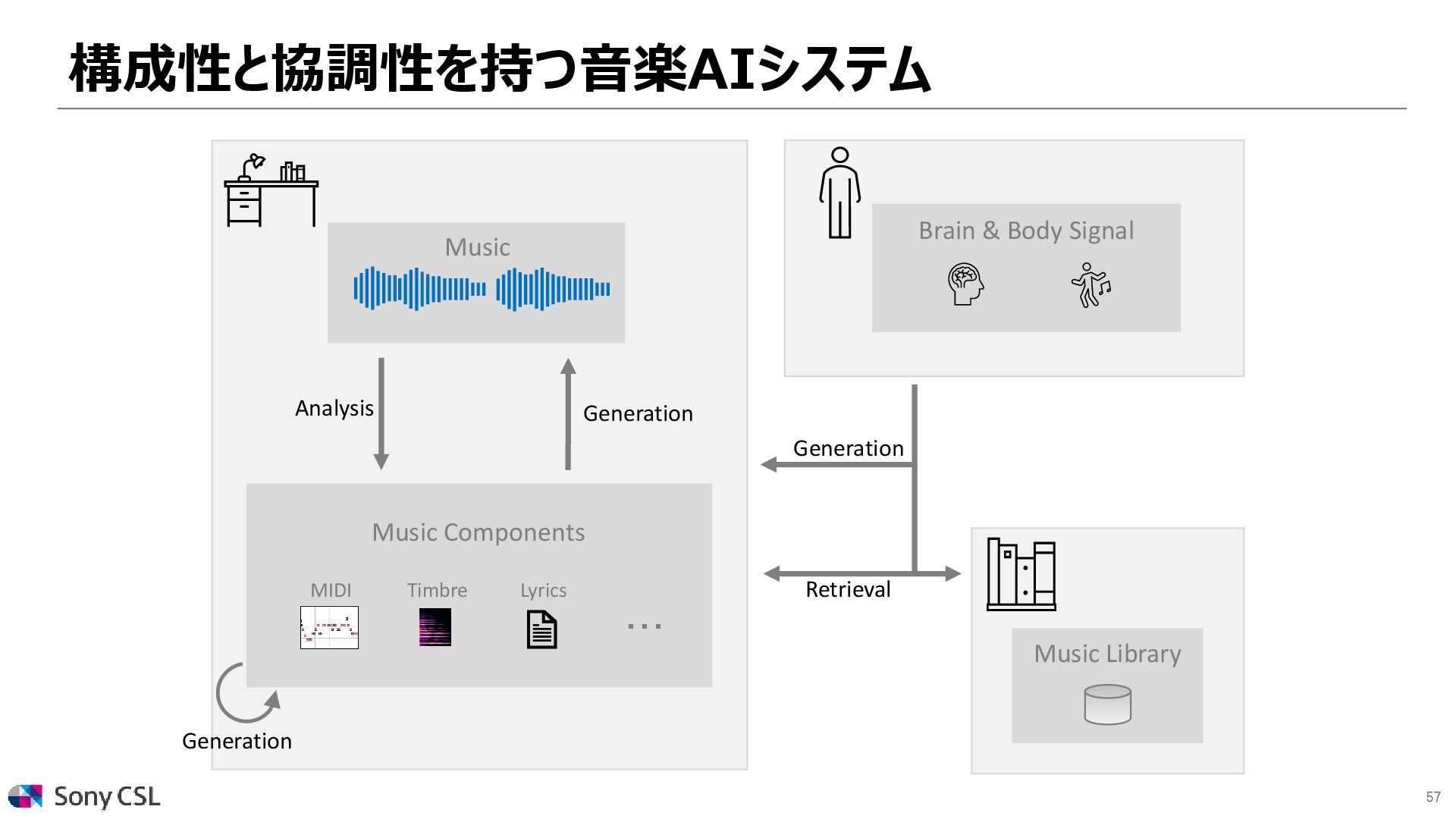{kind=link}
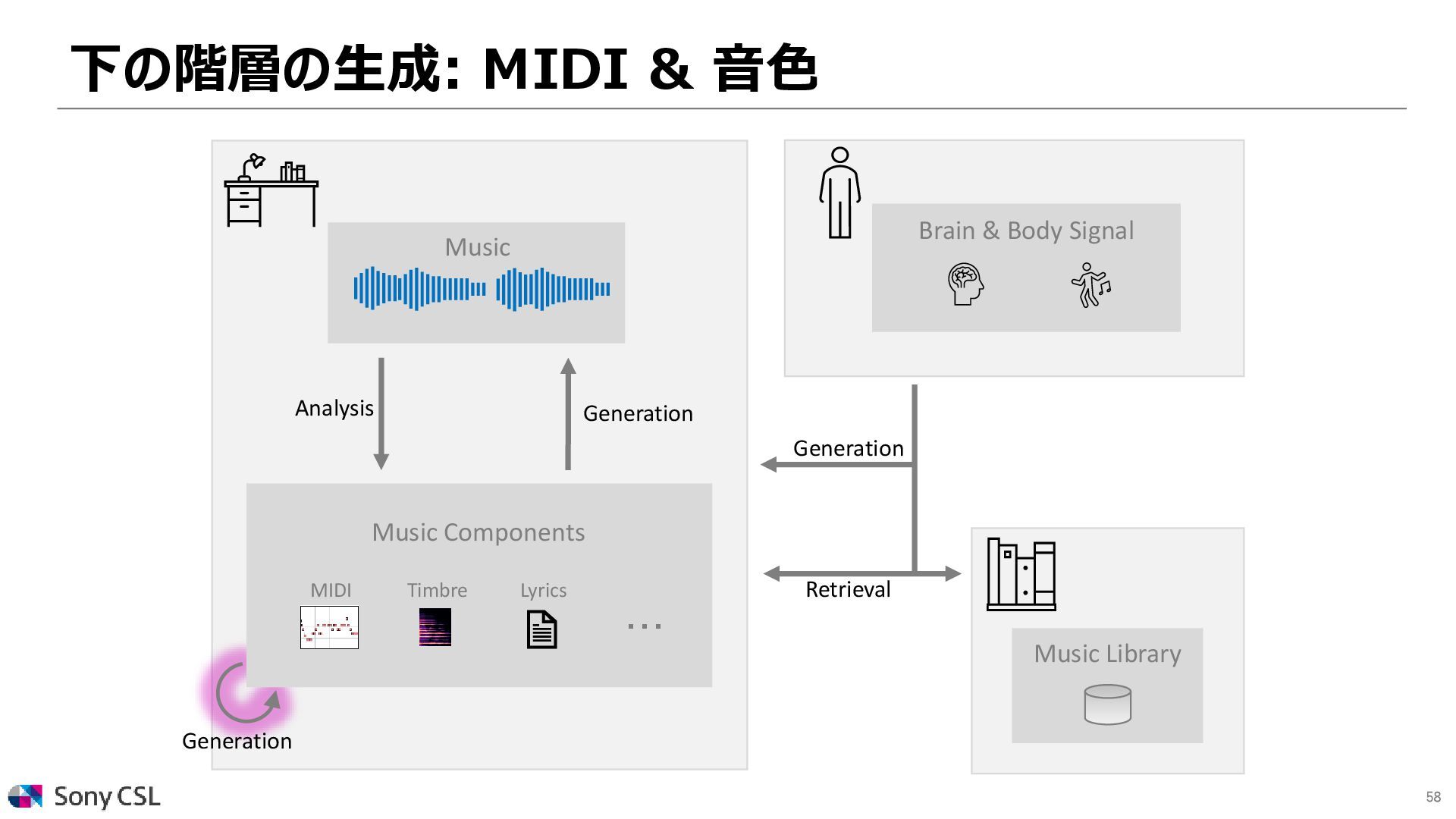{kind=link}
{kind=link}
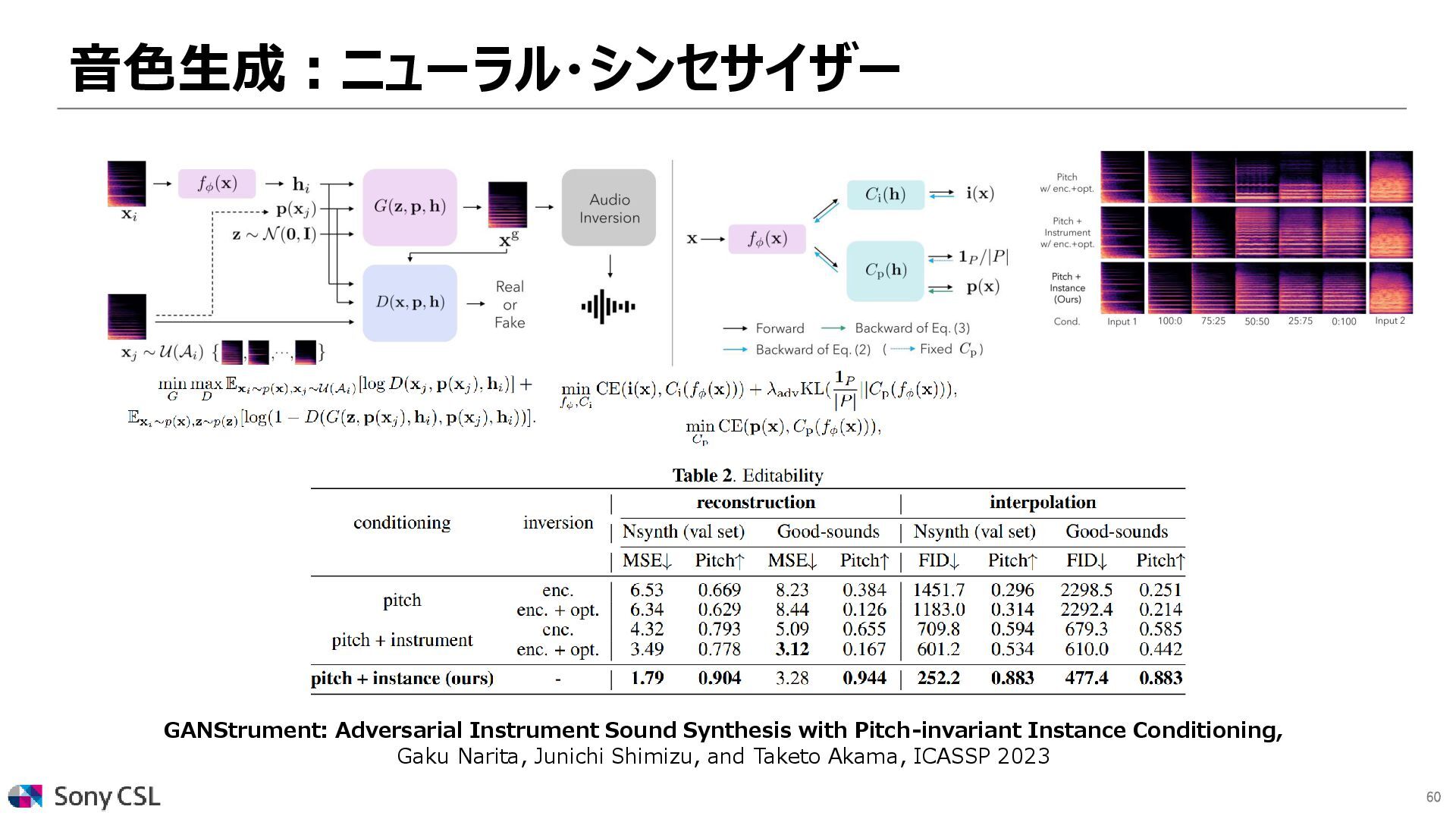{kind=link}
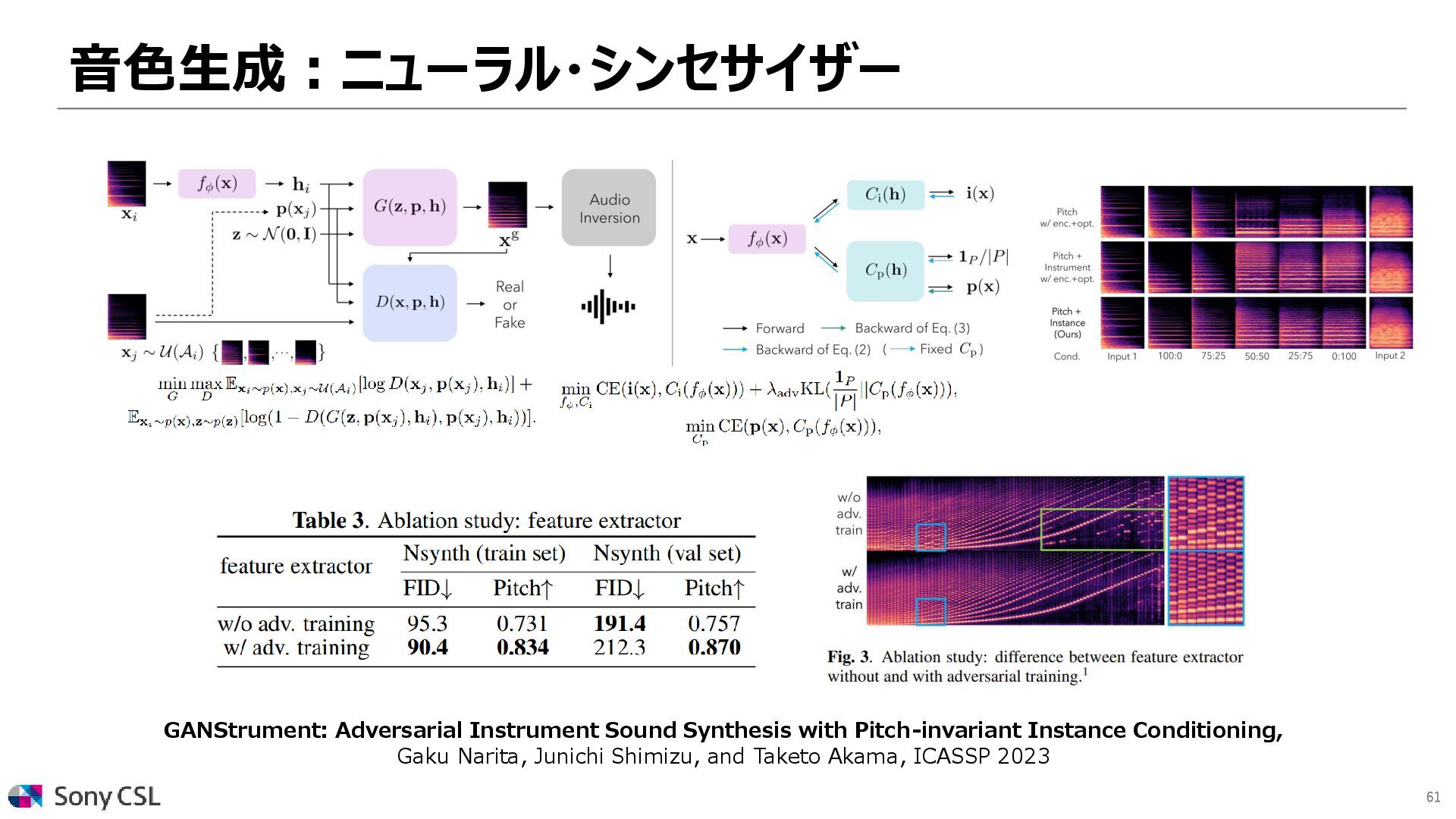{kind=link}
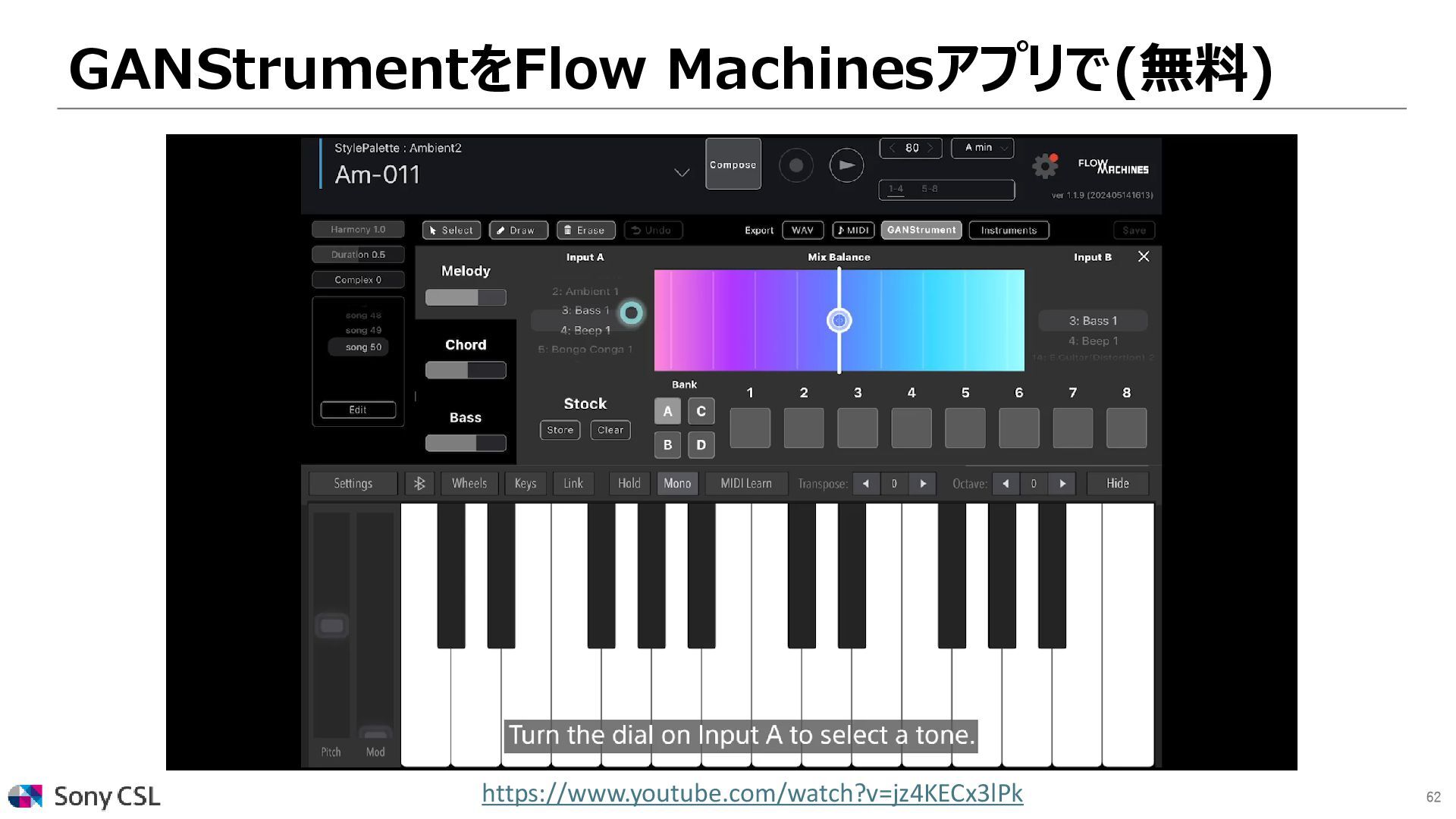{kind=link}
{kind=link}
{kind=link}
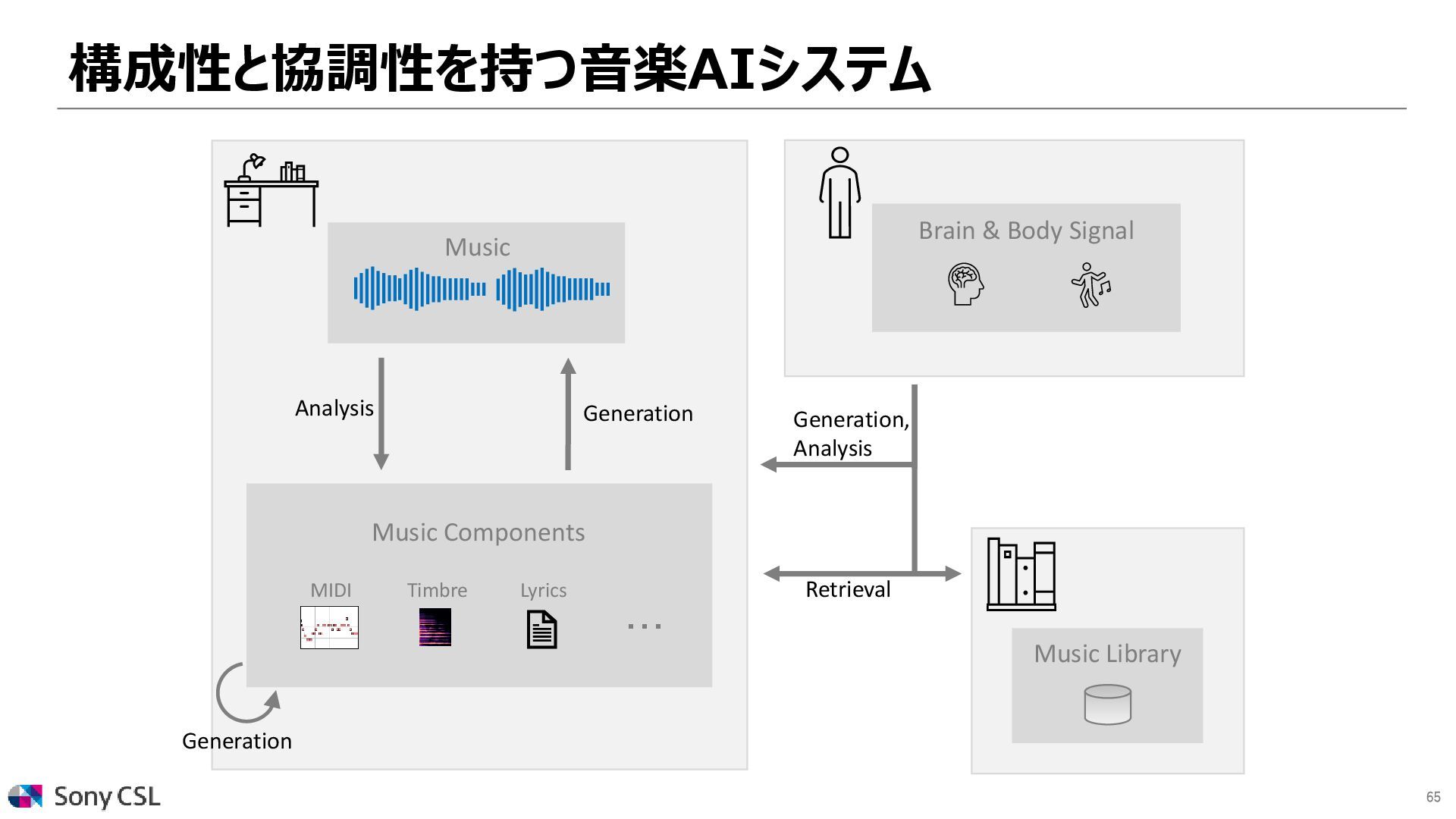{kind=link}
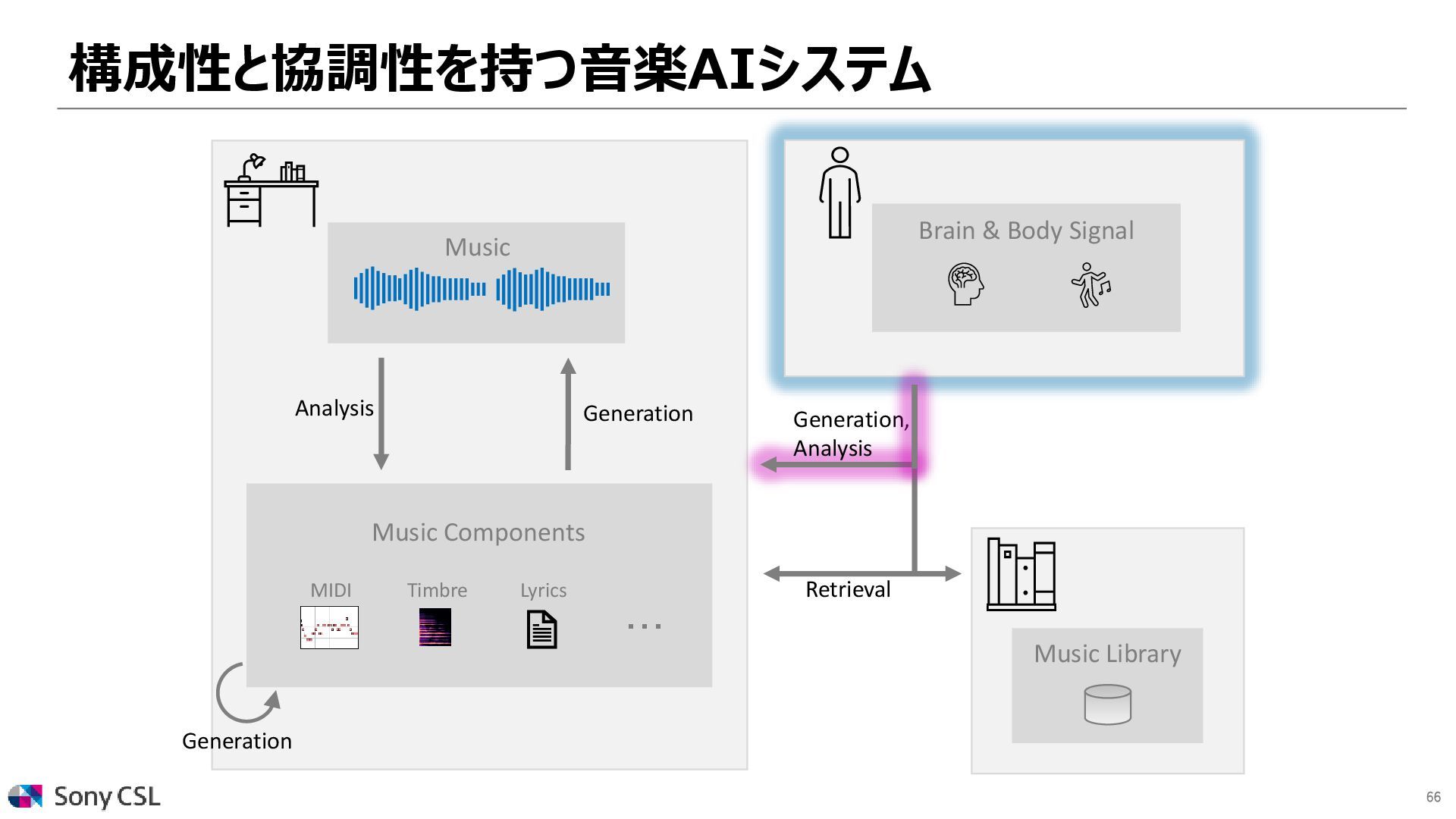{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}